Surrogate models for Rock-Fluid Interaction: A Grid-Size-Invariant Approach
Modelling rock-fluid interaction requires solving a set of partial differential equations (PDEs) to predict the flow behaviour and the reactions of the fluid with the rock on the interfaces. Conventional high-fidelity numerical models require a high …
Authors: Nathalie C. Pinheiro, Donghu Guo, Hannah P. Menke
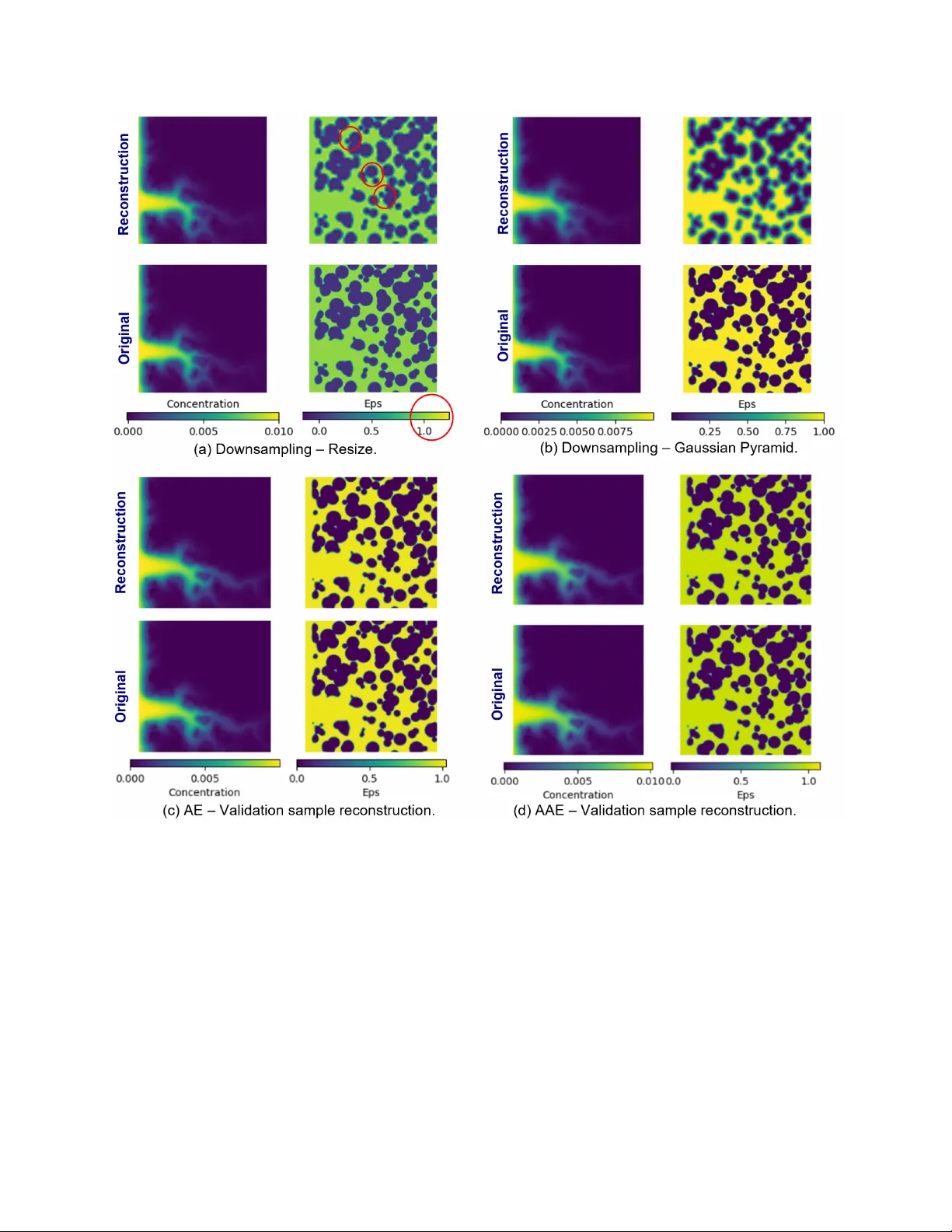
Surrogate models for Rock–Fluid Interaction: A Grid-Size-In v ariant Approach Nathalie C. Pinheiro a, ∗ , Donghu Guo a , Hannah P . Menke b , Aniket C. Joshi a,c , Claire E. Heaney a,d, ∗ , Ahmed H. ElSheikh b , Christopher C. Pain a,d,e a Applied Modelling and Computation Gr oup, Department of Earth Science and Engineering, Imperial Colleg e London, London, SW7 2AZ UK b Institute of GeoEner gy Engineering, Heriot-W att Univer sity, Edinbur gh, EH14 1AS UK c Department of Civil and En vir onmental Engineering, Imperial Colle ge London, London, SW7 2AZ UK d Centr e for AI-Physics Modelling, Imperial-X, White City Campus, Imperial Colle ge London, London, W12 7SL UK e Data Assimilation Lab ., Data Science Institute, Imperial Colle ge London, London, SW7 2AZ UK Abstract Modelling rock-fluid interaction requires solving a set of partial dif ferential equations (PDEs) to predict the flo w behaviour and the reactions of the fluid with the rock on the interfaces. Con ven- tional high-fidelity numerical models require a high resolution to obtain reliable results, resulting in huge computational expense. This restricts the applicability of these models for multi-query problems, such as uncertainty quantification and optimisation, which require running numerous scenarios. As a cheaper alternati ve to high-fidelity models, this work de velops eight surrogate mod- els for predicting the fluid flow in porous media. Four of these are reduced-order models (R OM) based on one neural network for compression and another for prediction. The other four are single neural networks with the property of grid-size in variance; a term which we use to refer to image- to-image models that are capable of inferring on computational domains that are larger than those used during training. In addition to the nov el grid-size-inv ariant frame work for surrogate models, we compare the predictiv e performance of UNet and UNet++ architectures, and demonstrate that UNet++ outperforms UNet for surrogate models. Furthermore, we sho w that the grid-size-in v ariant approach is a reliable way to reduce memory consumption during training, resulting in good cor- relation between predicted and ground-truth values and outperforming the R OMs analysed. The application analysed is particularly challenging because fluid-induced rock dissolution results in a non-static solid field and, consequently , it cannot be used to help in adjustments of the future prediction. K e ywor ds: Surrogate models, Reduced-order models, Grid-size in variance, Fluid flo w simulation, Adversarial training, UNet. ∗ Corresponding author Email addr esses: n.pinheiro23@imperial.ac.uk (Nathalie C. Pinheiro), c.heaney@imperial.ac.uk (Claire E. Heaney) 1. Introduction The concentration of carbon dioxide, CO 2 , in our atmosphere has increased since the mid-20th century , especially in recent decades. The impact of CO 2 on the greenhouse effect is well-known and an increase in the global temperature can be observed in the same period [1]. Attempts at mitigating this sharp increase can be seen through in vestments in rene wable energy and in Carbon Dioxide Remov al (CDR) or Carbon Capture and Storage (CCS). The first refers to human acti vi- ties to remove CO 2 from the atmosphere and durably store it in reserv oirs or in products [2]. In contrast, CCS considers CO 2 remov al at the source of emissions to storage in reservoirs, av oiding additional emissions. Both CDR and CCS are crucial to limit global warming and many projects hav e been studied or implemented in recent years [3]. Designing storage of CO 2 in geological reservoirs comprises numerous studies, such as predicting plume migration within the reserv oir and the dissolution of rocks induced by chemical reactions with CO 2 . As described in [4], high-resolution computational tools based on CFD require significant compu- tational resources and generate vast amounts of data. Although the y hav e seen great impro vements due to computational e volution o ver the last decades, using these algorithms to obtain a high accu- racy demands a refined mesh and, hence, a massiv e computational effort. As a result, researchers hav e recognised an opportunity to enhance the CFD simulations by combining them with machine learning techniques, as described in [5]. The main goal of this research is to dev elop a surrogate model framew ork for CO 2 injection, which can be extended to large datasets. In fact, a key moti- v ation for the current work is the ability of the methods to adapt to datasets with spatial domains modelled with many degrees of freedom, for example highly resolved 3D models. The surrogate models de veloped here can be broadly classified into two categories: (1) reduced-order models (R OMs) which combine one neural network for compression with another network for prediction and (2) a single neural network which has a grid-size-in variance property that allows inference ov er larger unseen domains. R OMs typically use tw o neural netw orks, one to compress the data from physical space to a lo wer- dimensional latent space and another to ev olve the latent variables in time. An autoencoder (AE) is well suited for compression, as it learns an identity map whilst having a bottleneck at its centre, forcing it to learn a reduced representation of the data [6, 7]. A key concept in machine learning is the con volution operation which computes element-wise products between a defined small grid of parameters [8], called a filter , and the data. The purpose of this operation is to capture spatial features contained within the data [9]. The combination of con volutional layers with AEs meant that Con volutional Autoencoders (CAEs) could be applied to larger images and that deeper CAEs could be trained successfully , as con volutional layers typically hav e fe wer trainable parameters than networks comprising purely of fully connected layers. One of the first reports of a CAE being used for dimensionality reduction in physical modelling occurs in Gonzalez and Balaje wicz [10]. Since then, con volutional autoencoders have been widely applied for dimensionality reduction due to their excellent performance in extracting the main features of the original dataset. Many studies hav e compared its performance with other algorithms used for finding low-dimensional spaces to approximate the high-fidelity CFD models, such as POD (Proper Orthogonal Decomposition). In general, the CAEs outperform POD [11, 12, 13], especially for advection-dominated flo ws [14]. For the predicion network of a R OM, the UNet has been reported to perform well. Primarily used for image segmentation, the UNet has been successfully applied in many other image-based 2 applications, such as predicting wind distrib ution [15], and surrogate modelling of fluid flo w , e.g., with applications including flo w past a cylinder and airfoil [16], turbulence [17], and flo w in porous media [18, 19, 20, 21, 22]. W e compare the performance of the UNet with an improv ed network called UNet++, a nested UNet architecture presented first in [23] and detailed in [24] for image segmentation in medical applications. Currently , UNet++ has prov ed to outperform the traditional UNet in various applications, such as segmentation in satellite images [25], fracture detection [26], and the creation of sketch images when combined with GANs [27]. A major challenge for R OMs is to produce stable and physically meaningful predictions over long periods of time. A pure data-driv en surrogate model often predicts well for shorter periods of time but di verges from expected values for long-term predictions. Although the reconstruction quality of images with autoencoders can be excellent, predicting the ev olution of latent v ariables in time often results in a loss of accuracy after a few timesteps. One reason is that the latent space is not regularised, and small v ariations can lead to very dif ferent reconstructions. Adversarial au- toencoders [28] are a reasonable alternati ve, as they provide a re gularisation of the latent space. W e will compare the performance of an Autoencoder with traditional training and an Adversarial Autoencoder for compression. Researchers ha ve worked on different methods to improv e pre- diction accuracy over long time periods, including learning operators rather than discretisations (neural dif ferential equations [29, 30]), physics-informed approaches [31, 32, 33, 34] and predict- ing for all time lev els simultaneously [35]. For models that are used to march forward in time, also kno wn as autoregressiv e surrogates, we can find in the literature approaches that consider some rollout of predictions during training to improv e how the temporal ev olution is captured. This ap- proach [36, 37, 38] is also referred to as unrolled training and, by minimising the modified loss, encourages the surrog ate’ s predictions to be close to the physics-based model for a number of time steps. Here, we adopted a similar strate gy for training that we call rollout training, described in Section 2.2.1. In addition to in vestigating whether adversarial training or rollout training approaches can help stabilise predictions or whether the UNet++ offers advantages in this regard, we also propose a nov el grid-size-in v ariant approach for image-to-image neural networks. T o achie ve grid-size in- v ariance, we use a particular architecture for our neural networks which enables the computational domain for prediction to be larger than the spatial e xtent of the samples used in training. Many of the CNNs cited abo ve hav e a mixture of con volutional and fully-connected layers. Howe ver , if all the layers are con volutional, which we refer to as a fully con volutional neural network, then such a network can be applied to images of different sizes since all the connections are local [39]. The research presented here le verages this property to train the network on smaller domains while inferring on larger domains. Grid-size in variance is particularly important giv en that memory re- sources are a limiting factor in many applications, especially during training. Recent dev elop- ments in this area include neural operators, which are point-based and therefore independent of any underlying grid [40, 41, 42], whereas the proposed grid-size-in variant frame work applies to grid-based and image-to-image netw orks. Furthermore, neural operators focus on obtaining a grid- independent model to work with any resolution, rather than being more memory-efficient. On the other hand, patch-based CNNs ha ve been proposed for problems dealing with large images, but the network performs both training and inference on the same patch-size [43, 44, 45]. They are memory-ef ficient for problems such as object classification or localisation, where the input image can be divided into patches, the patches are processed individually , and then the results are com- 3 bined. Howe ver , this strategy cannot be used in surrogate models where you want to predict the underlying physics. An approach similar to ours was proposed by Owerko et al. [46], b ut in the context of mobile infrastructure on demand. This article proposes a number of surrogate models for carbon storage in porous media and com- pares the model outputs to determine which methods produce the best results. The surrogate models de veloped here fall into tw o categories: (1) R OMs and (2) grid-size-in variant neural netw orks. For compression in the R OMs, adversarial training is in vestigated. For the prediction models (both in the R OMs and the grid-size-in variant networks), the performance of UNet and UNet++ is inv esti- gated. The surrogate models are trained on a 2D carbon storage dataset [47]. Although this dataset contains 2D-images with 256 × 256 pixels and represents flow in a porous medium, the proposed frame work is quite general and could be applied to other fluid flow applications as well as larger datasets that could come from highly resolv ed CFD simulations. For example, a similar framew ork with implicit time marching is being de veloped for inertial flo ws [48]. Besides the dev elopment of a grid-size in variant surrogate model for carbon injection, a second contribution of this work is an extensi ve in vestigation of eight surrogate models, highlighting per- formance improv ements when changing the framework, architecture or training strategy . Further- more, a particular challenge of the carbon storage application analysed here is that the dissolution of the rock caused by the chemical reactions with the fluid results in a non-static solid field. Con- sequently , it cannot be used as a special feature capable of helping in adjusting future predictions, such as some other surrogate models, which use the solid field as a mask for correcting predic- tions [49, 50, 51]. In the remainder of the text, we explain the methodology of the proposed models in Section 2; present the results in Section 3; and draw conclusions and discuss future w ork in Section 4. 2. Methodology This work compares dif ferent strategies for surrogate models. Four reduced-order surrogate mod- els are dev eloped, which couple an autoencoder for compression with another neural network for prediction. For compression, we compare traditional and adversarial training. For prediction, we compare UNet and UNet++ architectures. These reduced-order models are compared with four single neural netw orks that ha ve grid-size-in variant properties, which enables inference o ver lar ger (unseen) domains. 2.1. Reduced-or der models 2.1.1. Con volutional Autoencoder for Compr ession An autoencoder mimics the identity map and comprises two parts either side of a bottleneck [52]. This structure can be used to force the network to learn a compressed representation of the input. The first part, referred to as encoder , compresses the input into a latent-space representation, oper - ation represented by h enc : x 7→ ˆ x with h enc : R n → R m and m ≪ n . Then, the decoder , h d ec : ˆ x 7→ ˜ x with h d ec : R m → R n , uncompresses to reconstruct the input as a final output of the autoencoder . Therefore, the autoencoder can be written as the follo wing composition of tw o functions [6] repre- senting the encoder and decoder: h : x 7→ h dec ◦ h enc ( x ) . (1) 4 For a neural network with hidden layers, each layer corresponds to a linear transformation of the input x composed with an activ ation function to account for the non-linearities. Therefore, the encoder can also be re written as a composition of functions [6] as follows: h enc : ( x ; w enc ) 7→ h n L ( · ; W n L ) ◦ h n L − 1 ( · ; W n L − 1 ) ◦ · · · ◦ h 1 ( x ; W 1 ) , (2) where h i ( · ; W i ) denotes the function applied at layer i , and W i denotes the weights and biases at layer i , with w enc ≡ ( W 1 , . . . , W n L ) , and i = 1 , . . . , n L . Similarly , the decoder is also a composition of functions. For a con volutional autoencoder , each layer h i ( · ; W i ) applies a filter W i of size d h × d w through an input matrix X i , moving the filter with vertical stride s v and horizontal stride s h , such as the element µ i j of the output is gi ven by the equation: y jk = d h ∑ u = 1 d w ∑ v = 1 x j ′ k ′ · w uv + b with ( j ′ = j × s v + u k ′ = k × s h + v (3) where b is the bias term and w uv is the element of the filter W i that giv es the connection weight between elements of the input matrix X i and the elements of the output matrix Y i , see [7]. When training an autoencoder , a gradient based optimisation method is applied to minimise the loss between the output of the network and the original input, which process determines the weights of the neural network. In the results presented in this work, we used mean-square error as the loss function, gi ven by: L MSE = 1 n X − ˜ X 2 F = 1 n n ∑ k = 1 ( x k − ˜ x k ) 2 , (4) where n is the number of elements in the input matrix X and subscript F denotes the Frobenius norm. 2.1.2. Adversarial T r aining In this research, we compare the traditional training of an Autoencoder (AE) with an adversarial training forming an Adversarial Autoencoder (AAE). This strategy for training was first proposed for Generativ e Adversarial Networks (GANs) [53]. During adversarial training, one step in volv es updating the discriminator weights based on the loss when trying to distinguish between fake and real inputs. The other step is updating generator weights to fool the discriminator . In this case, the idea behind calculating the loss function is to maximise the probability of the discriminator making a mistake. This algorithm consists of a minimax two-player game [53], and the loss is gi ven by the cross-entropy function: min G max D L ( D , G ) = E x ∼ p x log D ( x ) + E z ∼ p z log ( 1 − D ( G ( z ))) . (5) For Adversarial Autoencoders, the training process aims to impose a specific prior distribution on the latent space of the autoencoder . In this case, the generator is the encoder , and the discriminator should compare its result with a sample with the dimensions of the latent space and with the prior distribution, p x , usually a normal distribution. The training for an AAE has an additional step, 5 where the weights of the encoder and decoder are updated to minimise the loss in reconstruction, according to equation (4). Then, the discriminator is updated, followed by the encoder acting as a generator , considering the minimax loss in equation (5). A more detailed mathematical description of the loss function and the backpropagation for the adversarial autoencoder can be found in [54]. 2.1.3. UNet and UNet++ for Pr ediction T o predict the spatio-temporal ev olution of the latent variables, we compare a UNet and a more complex network deri ved from it, the UNet++. Figure 1 illustrates their architectures, and we can observe that UNet++ has additional con volutional blocks, creating extra connections between en- coder and decoder layers. The hypothesis behind this architecture is that the extra blocks bring the semantic lev el of the encoder feature maps closer to that aw aiting in decoder, hence capturing fine-grained details [23]. In both UNet and UNet++, the network input consisted of three pre vious timesteps stacked along the field dimension, and the predictor generated one next timestep. Thus, the total input channels is 12 (3 timesteps for 4 fiels) and the number of output channels is 4. The diagram for UNet details the number of channels in each layer above the blocks, and shows how the spatial dimensions change in the vertical text next to each layer , considering training with 64 x 64 samples. For the UNet++ diagram, this numbers were omitted, but follo ws a similar logic: you hav e an encoder backbone (blocks from B 0 , 0 to B 4 , 0 ) where each block comprises one con volution in- creasing the number of channels and one con volution maintaining the number of channels; and the other blocks comprises one con volution decreasing the channels and a second con volution main- taining it. As in the Unet, the UNet++ also maintain the spatial dimensions in these con volutions, only changing it trough max pool operations (red arro ws) or up-con v (green arrows). Figure 1: Diagrams for the two different options of the prediction neural network compared. In the UNet++ diagram, each block B i , j corresponds to the sequence of operations highlighted in “Con v Block B1” in the UNet diagram. 2.2. Grid-size-in variant framework The grid-size-in v ariant framework relies on the ability of fully con volutional networks to capture spatial features and their applicability to arrays of any size due to the connections being local [39]. Considering these properties, a con volutional-based network can be trained with smaller domains 6 and used for inference over larger unseen domains. Thus, we refer to the ability of the neural network to be applied to a domain of any size as the grid-size-in variance property . Ne vertheless, the grid spacing must be the same as that used to generate the training data. The network architecture may assume different formats. Here, we compare UNet and UNet++ architectures with the same structure shown in Figure 1, both based on con volutional layers, and rely on the grid-size-in variance property for subsampling for training. It is notew orthy that the training subsamples need to be representativ e of the geometries and be- haviour considered. For instance, if the majority of the fluid flo ws in a free space and at some point it passes through an obstacle, we need to ensure that our training samples represent both flo w through free space and interaction of flo w with obstacles, whereas to learn complex beha viours such as vortices and turbulence, the subsample should be lar ge enough to capture the flo w patterns. 2.2.1. Rollout training In the con ventional approach for training, a surrogate model is trained to predict a single timestep. After that, the model is applied to predict multiple time steps autoregressi vely . Consequently , the following predictions carry the errors of the previous ones, accumulating these errors. As the model is trained to optimise only the next prediction, the accumulated error can increase quickly . T o reduce the accumulated error , we employ rollout training . In this strate gy , we iterate for a predetermined number of timesteps T inside the training loop, and measure the loss between the predicted and the true values altogether for the T timesteps. This is shown in the diagram of Figure 2. Therefore, the model is not only trained to predict the next timestep, but it should also consider the predictions ov er multiple timesteps. As the rollout training approach is more expensi ve in terms of memory and time consumption, we utilise the concept of curriculum learning to reduce the number of epochs required for con vergence. When using curriculum learning, the network is first trained with simpler samples, and then trained with the most complex cases [55, 56]. In our case, we first run a con ventional training (one timestep loss), then initialise the predictor with the obtained weights to retrain and adjust the weights to account for the beha viour ov er T timesteps. W ith this strategy , the rollout con ver ges to its best result after a fe w epochs. 2.3. Boundary conditions T o enforce a boundary condition during neural network training, we used a strategy that penalises errors at the boundaries: we compute the loss during training using mean squared error (MSE) in the whole spatial domain for prediction Ω , and add an extra term with a multiplier λ B C and the MSE only at the boundary ∂Ω . Therefore, the multiplier λ B C serves as a hyperparameter to be tuned to penalise more the loss in the boundaries. L T otal = L MSE | Ω + λ B C · L MSE | ∂Ω , (6) The domain Ω for the prediction in the R OM models is a 64 × 64 space, with images generated in latent space of compression network. For the grid-size-in variant framew ork, the domain Ω is the space of the original images (256 × 256). The models that are presented here considered ∂Ω as the outer 1-pixel boundary of the domain Ω . Initially λ B C = 0, that is, the training starts without any regularisation in the boundaries. Then, we change to λ B C = 0 . 5 and finally λ B C = 1, as a way of increasing the importance gi ven to the solution on the boundaries. The time for changing the 7 Figure 2: Rollout training: strategy used to improv e multiple timesteps inference in grid-size-in variant frame work. λ B C is empirical and depends on the number of epochs to reach the best model. F or R OMs, the predictor was trained ov er 1000 epochs, and λ B C was updated at epoch numbers 100 and 200. For the grid-size-in variant framework, the loss during training stops decreasing earlier , especially for UNet++ models. Thus, we updated λ B C at epoch numbers 50 and 100 for the UNet, and 15 and 65 for the UNet++. 3. Numerical results This section presents the results obtained from the surrogate models for a carbon storage scenario with rock-fluid interaction. T wo strategies are in vestigated: (1) a R OM-type approach in volving compression to latent space, prediction of latent variables and reconstruction to the ph ysical space; (2) prediction with a single grid-size-in variant neural network. 3.1. Governing equations and the carbon stor age dataset The rock-fluid interaction problem, which appears in carbon storage injection, is go verned by equa- tions that describe fluid flo w , transport, and reaction at the fluid-solid interface. Under isothermal conditions and in the absence of gravitational effects, fluid motion is governed by the incompress- ible Navier -Stokes equations [47]: ∇ · u = 0 , (7) ∂ u ∂ t + ∇ · ( u ⊗ u ) = − ∇ p + ν∇ 2 u , (8) where u (m / s) is the velocity , p (m 2 / s 2 ) is the kinematic pressure, and ν (m 2 / s) is the kinematic viscosity . 8 The transport is governed by the advection-dif fusion equation, which states that the concentra- tion c (kmol m − 3 ) of a species in the system, subject to the diffusion coefficient D (m 2 / s), should satisfy [47]: ∂ c ∂ t + ∇ · ( u c ) = ∇ · ( D ∇ c ) . (9) Finally , these equations are subject to continuity conditions at the fluid-solid interf ace based on the chemical reaction that occurs between the fluid and the solid. Using improved V olume-of-Solid (iV oS) to calculate the v olume-averaged surf ace reaction rate R at the interface, R = ε∇ · Φ R − ∇ · ( εΦ R ) , (10) where ε is the local porosity , and Φ R is an approximation for the reactiv e flux, assuming that the reacti ve surface can be approximated by its volume-a veraged v alue on the control v olume. Maes et al. [47] proposed the use of iV oS method abov e for reactiv e transport modelling in porous media. A more detailed explanation about the deriv ation of the interface reaction term can be found in [47], where the authors present a description of how they generated simulations with GeoChemFO AM. Their simulations show ho w CO 2 flo w ev olves in various porous media and prov okes rock dissolution, and were used to create a dataset used to train and v alidate the surrogate models presented here. The carbon storage dataset produced by Maes et al. [47] contains 2D images obtained from 32 sim- ulations of carbon dioxide injection in a carbonate reservoir , each simulation considering a dif ferent porosity . The porosity fields were created using a micromodel that has been benchmarked with an experimental in vestigation described in [57]. The simulations of CO 2 injection were generated in a solver called GeoChemFO AM, with a grid spacing of 25 µm in each direction. The snapshots were taken ev ery 4000 s, although each snapshot corresponded to thousands of numerical timesteps in the GeoChemFO AM simulation (the number varies according to the con ver gence criterion for outputting results). For each simulation, the dataset contains 100 timesteps of 256 × 256 images, representing four fields: concentration of CO 2 , porosity , and v elocities in the x - and y -directions. 3.2. Metrics W e compare the prediction methods using the Pearson Correlation Coefficient (PCC) as a metric. This coefficient measures the linear association between two variables (in this case, prediction array X and ground truth array Y ) and has a range of [ − 1 , 1 ] . The larger absolute values indicate a stronger relationship between the v ariables, with 0 indicating no relationship between the variables [58]. P CC ( X , Y ) = ∑ ( x i − x )( y i − y ) p ∑ ( x i − x ) 2 p ∑ ( y i − y ) 2 , (11) where x i and y i are the indi vidual elements for X and Y , and x and y are the mean values for X and Y , respecti vely . W e can observ e that the numerator is the cov ariance between X and Y , and the denominator is the product of the standard de viations of X and Y . 9 In case of prediction in a compressed space, this metric could be used to analyse only the perfor- mance of the prediction network, comparing the expected and predicted values in the compressed space, or the overall performance, comparing the results after reconstruction. Here, we sho w the results of the PCC after reconstruction. W e also compare the grid-size-in variant frameworks through the metrics of Structural Similarity Index Measure (SSIM), which was first introduced by W ang et al in 2004 in [59]. Since then, it has been a very popular metric for image quality , as it relies on the comparison of luminance, contrast and structure of both images, efficiently capturing human perception of the difference in images. As sho wn in [59], the similarity for each pixel in our prediction image x i and the corresponding pixel in our ground truth image y i can be expressed as SSI M ( x i , y i ) = ( 2 µ x µ y + C 1 )( 2 σ xy + C 2 ) ( µ 2 x + µ 2 y + C 1 )( σ 2 x + σ 2 y + C 2 ) , (12) where µ x and µ y are local means, and σ x and σ y are local v ariances of x i and y i , respecti vely; σ xy is a local cov ariance between x i and y i , and C 1 and C 2 are small constants to av oid division by zero. These local statistics are computed by applying a Gaussian filter for each pixel, and then the final SSIM is calculated as the mean of all SSI M ( x i , y i ) between both images. Finally , we propose a metric tailored for this carbon storage application and use it in comparisons of grid-size-in variant framew orks. This metric measures the difference in area occupied by CO 2 in original simulations (ground truth) and the area predicted in the proposed models. Thus, we define a threshold v alue in the middle of concentration range, C threshold , and compute this metric as the dif ference in percentage of number of pixels abo ve this threshold in ground truth concentration field Y n and in prediction ˜ Y n , that is, E area C O 2 = 100 A ( Y ) − A ( ˜ Y ) N , (13) where A ( Y ) = |{ n ∈ { 0 , 1 , . . . , N } : Y n > C threshold }| is the cardinality of the set of pixels whose v alue of concentration ( Y n ) e xceeds that of the threshold, and N is the total number of pixels for the concentration field. 3.3. Reduced-or der model surr ogates This framework utilises two nested neural networks: the first for compressing the input data and the second for predicting the future timestep in the latent space. As the size of the data used in the prediction netw ork is reduced, this approach is part of a set of surrogate frameworks called Reduced Order Models (R OM). The first step of compression is a pre-processing step where min-max scaling is applied to each of the four solution fields to limit the values of inputs to the range [ 0 , 1 ] . The compression network is based on a con volutional autoencoder (CAE), which consists of an encoder follo wed by a decoder . In our case, the encoder has two layers which reduce the size of the image, with connecting layers in between. The autoencoder (AE) is trained to minimise the difference between the reconstructed data (decoder output) and the original input data. The backpropagation procedure determines the weights of the neural network, finding v alues that minimise the error at each epoch of training. See 10 Figure 3 for a schematic diagram of the training process. After successful training of the AE, it has weights which result in the reconstructed data being similar to the original input data. In our in vestigation, we train two autoencoders, one as described abov e and a second with an adversarial autoencoder training approach (AAE) described in Section 2.1.2. Figure 3: W orkflo w for training the R OMs. The dashed box indicates the adversarial training extra steps, used only in Adversarial Autoencoder (AAE). After training the compression network, a prediction network is trained using latent space of compression. W e no w present results comparing the behaviour of the AE and AAE for compression. Both net- works reduce the size of the 2D solution fields by a factor of 4 in each dimension, resulting in a memory reduction ratio of 16 : 1. The reconstructed results of the AE and AAE applied to a v alida- tion sample are nearly indistinguishable from the original fields, as shown in Appendix A, where the details about the hyperparameter tuning and results are presented. The Mean Squared Error (MSE) obtained for the reconstruction of training data was 5 . 7 × 10 − 6 , and in validation data was 1 . 1 × 10 − 5 for the autoencoder . For the adversarial autoencoder , the MSE value was 3 . 8 × 10 − 5 in training data and 8 . 7 × 10 − 5 in v alidation data. After training the AE and AAE, the encoders are ready to generate datasets that will be used to train neural network for prediction. The encoder of the AE finishes with a sigmoid activ ation function, which ensures the output is in [ 0 , 1 ] . The AAE has no activ ation function at the end of the encoder , but the adversarial training regularises the latent space and pre vents the values from rising excessiv ely . Thus, no scaling of the latent v ariables from the autoencoders is needed before this data is used to train the prediction networks. This work compares some dif ferent netw orks for prediction, b ut always considers the four solution fields at three consecutiv e timesteps as the input and those four fields at the future timestep as the output. The training of the entire frame work de veloped is represented in Figure 3. When using this R OM framework to infer ev olution of the concentration, porosity and velocities, initial conditions are encoded to latent space before passing them to the prediction network. T ime marching is performed with the prediction network by predicting for a single timestep ( k + 1) from three previous timesteps ( k , k − 1 and k − 2). This prediction ( k + 1) is then used with two 11 pre vious timesteps ( k and k − 1) to produce the next timestep ( k + 2) and so on. This generates a sequence of solutions that are uncompressed by the decoder and to which in verse scaling is applied to obtain the predictions in the physical or original space as seen in Figure 4. The time marching or autoregressi ve calling of the prediction network is represented in the figure by the dashed lines. Figure 4: W orkflo w for inference using one of the reduced-order surrog ate models. The compression module produces an initial condition, the predictor uses the latent solution at three pre vious timesteps to generate a prediction for the next timestep, time marching is used to generate a sequence of predictions in latent space and, finally , the predictions are reconstructed to the original space. Figure 5(a) shows the results for predicting a sequence of 100 timesteps starting with one training sample taken from the carbon storage dataset. The figure compares the results with four different strategies for reduced-order surrogate models: for compression, we used a con volutional autoen- coder , both with traditional training (AE) and with an adversarial training strategy (AAE). Using the two compressed datasets generated with these compressors, we tested a prediction network based on a UNet and on a UNet++. As illustrated, the predictions for the training samples hav e good accurac y for all cases analysed, with models using a UNet slightly worse than others. For the cases with UNet++, it is dif ficult to discern the differences between the predictions with training samples and the ground truth, that is, the result of the original GeoChemFO AM simulation. The models can predict the formation of the main channel and its bifurcations in the right direction and generally preserve the physical characteristics of the system after 100 timesteps (starting with an initial condition taken from the training data). By contrast, when observing the predictions starting with initial conditions taken from the valida- tion dataset presented in Figure 5(b), we can observe some di ver gence from the ground truth. In general, the predictions maintain reliability for some timesteps of rollout inference, but then start di ver ging from the ground truth, resulting in the images shown after 100 timesteps. Some degra- dation in porosity , far from the channels where the carbon dioxide is percolating, especially for the models with UNet, is also observed. For the first model (UNet without adversarial training in compression) we observe bright spots in the picture, indicating that the predictions in these regions are outside the ground-truth scale. The e volution o ver time for each model can be better analysed in Figure 6, where each subplot sho ws the Pearson Correlation Coef ficient for a field and the dif ferent lines correspond to each model, as shown in the legend. Each line sho wn in the figure is an av erage of the metrics obtained 12 Figure 5: Surrogate model using compression - Autoregressi ve prediction after 100 timesteps in the carbon storage dataset, which contains four fields: concentration of CO2, porosity , and velocities in X- and Y -direction. Comparison of the results considering compression with an autoencoder or an adv ersarial autoencoder and prediction considering a UNet or a UNet++. for all the simulations used for training (24 simulations, av erage sho wn in 6a) or validation (8 simulations, average in 6b). As observed in Figure 5, the models with a UNet predictor have the worst performance. The UNet++ models performed similarly , with excellent performance on the training dataset, but lower accurac y on the validation data after rolling out for some timesteps. W ith the UNet, the model with Adversarial Autoencoder outperformed the model with traditional training. W ith UNet++, though, the AAE outperformed only for the first timesteps, then its metrics start dropping faster , and, after roughly 50 timesteps, traditional training outperformed the AAE. The figure also sho ws a comparison with a baseline model, which is a UNet++ trained on whole domain samples, that is, without any compression to reduce the data size. W e observe that the reduced-order models with UNet++ perform similarly to the baseline for concentration of CO 2 and porosity . Ho wev er , the baseline outperforms the models with compression in the prediction of the velocities. As mentioned before, this work focuses on applications in volving a large volume of data, where training and inference require substantial memory resources. The strategy of compressing or utilising the grid-size-in variant approach enables w orking with limited resources. As we will see in the next section, the grid-size-in variant approach performs similarly to this baseline whilst maintaining the improv ed computational performance. Depending on the application desired, one model may be preferable to another . For instance, a common objecti ve in modelling carbon dioxide flo w in porous media is to predict rock dissolution. This is obtained by analysing the v ariation in the porosity field relati ve to the original field immedi- 13 (a) A verage PCC per field for training simulations. (b) A verage PCC per field for validation simulations. Figure 6: Pearson correlation coefficient (PCC) for autoregressi ve prediction. Comparison of results obtained using compression with an autoencoder (dashed lines) or an adversarial autoencoder (solid lines) and prediction considering a UNet (blue lines) or a UNet++ (orange lines). The green line presents a base case of a UNet++ without R OM. For comparison, a shaded area is shown under P C C = 0 . 75, indicating the timestep where the model is losing accuracy . ately before injection starts. In this case, it is recommended to use any of the models with UNet++, as the y performed similarly and outperformed the others for the porosity field. In contrast, suppose the goal is to combine the surrogate model with a PDE solver to accelerate simulations. In this case, it is recommended to use surrogate models to predict a smaller windo w of timesteps, thereby keeping the metrics above a threshold and a voiding degradation of the velocity fields. For instance, if we choose a threshold of P C C = 0 . 75, the Pearson correlation remains above this value for up to 30 timesteps with AE+UNet, whereas AAE models remain above the threshold for roughly 50-60 timesteps. 3.4. Grid-Size-In variant Surr ogate models T o improve results whilst maintaining adaptability to large-domain datasets, we implemented the Grid-Size-In variant frame work proposed here for the carbon storage scenario, using a single net- work for prediction without prior compression. As mentioned in Section 2.2, a CNN-based network can capture spatial features and a fully con volutional NN can be applied to domains of any size. Consequently , the training may be performed on smaller representativ e domains, and the network 14 can predict ov er larger unseen domains. Here, we used 64 × 64 samples and inferred over the whole spatial domain of the dataset, i.e., 256 × 256. The samples were distributed uniformly in the spatial domain and were sampled across all timesteps av ailable for each simulation used in the training or the v alidation data. As in the case of the predictor for R OMs, for our single grid-size-in v ariant NN, we compared the results obtained with UNet and UNet++ architectures, using the same layers presented in Figure 1. Additionally , we compare the results of traditional training with the rollout training strategy , as explained in Section 2.2.1, considering T = 8 timesteps rolled out in the training loop. Figure 7 presents the results using a Grid-Size-In variant frame work for the autoregressi ve predic- tion of 100 timesteps for one training sample, which subsamples were used for training the network, and for one validation sample, which is an unseen case. As shown in the picture, the predictions yield reasonable results for all models, accurately detecting the formation of the main channel and maintaining the porosity field without any changes where the flow has not yet reached. Notably , UNet++ outperforms UNet models. W e also observe improv ements in both architectures when us- ing rollout training. For the validation simulation presented, the surrogates based on UNet predict a secondary channel forming upward after the autoregressi ve prediction of many timesteps, whereas the ground truth does not contain this channel. This ef fect was reduced with rollout training and disappeared with UNet++, showing that the complexity added in the architecture improv ed the re- sults. Overall, the models with rollout outperformed the corresponding ones without rollout, and the UNet++ outperformed the UNet. Figure 7: Surrogate model using grid-size in variance - Autoregressi ve prediction after 100 timesteps in the carbon storage dataset. Comparison of the results considering a UNet or a UNet++, both with traditional training and with rollout training. 15 T o analyse the general results with all the simulations av ailable, we calculated the temporal ev olu- tion for the Pearson Correlation Coef ficient (PCC) for each simulation (24 simulations were used for training and 8 remained for validation). Figure 8 illustrates the temporal e volution of the av- erage PCC per field of each grid-size-in variant model, as shown in the legend. For comparison, a UNet++ trained on the entire domain samples, used as a baseline model here, is also presented. It is worth noting that the model trained on the whole domain and using a UNet network performed slightly worse than the one with UNet++. This demonstrates that UNet++, as a more complex network, requires more samples to achie ve significant performance gains o ver UNet. (a) A verage PCC per field for training simulations. (b) A verage PCC per field for validation simulation. Figure 8: Pearson correlation coef ficient (PCC) for autoregressiv e prediction. Comparison of results obtained using the grid-size-in variant framework with a UNet or a UNet++ and considering traditional training and rollout training with T = 8 timesteps rolled during training. The comparison with the baseline model sho ws that the grid-size-in v ariant framew orks do not per- form as well as the baseline for the simulations used during training. Howe ver , the y outperform the baseline on unseen data, demonstrating that the grid-size-in variant method lev erages data augmen- tation enabled by domain subsampling and reduces model ov erfitting. This data augmentation also helped UNet++ to achieve a better performance, resulting in a significant advantage ov er UNet in the grid-size-in variant frame work. Among the Grid-Size-In variant models, the models performed similarly , but the models with roll- 16 out training slightly outperformed the ones without it. The Pearson correlation remains above a threshold of 0.75 for the 100-timestep prediction in all fields. Additionally , when observing images from the inference, our perception sometimes div erge from the results expected when comparing PCC values. Particularly , for the models with UNet++ the rollout does not seem to bring an impro vement in PCC metrics, b ut we can see some improv ements in the images. Therefore, we present in T able 1 the results of the Structural Similarity Index Mea- sure (SSIM), which captures the human perception when comparing images. The values of these metrics here represent the a verage value for all the testing simulations in the last timestep. The SSIM results highlight the adv antage of combining UNet++ with the rollout training strategy to enhance the model, in accordance with the perception when observing the resulting images of the fields. Using both metrics, the best model overall was UNet with rollout, closely followed by the others. T able 1: Pearson Correlation Coefficient (PCC) and Similarity (SSIM) metrics per field for different models using the Grid-Size-In variant frame work. Green values indicate the best performances. PCC SSIM Model C CO 2 Porosity V elocity-X V elocity-Y C CO 2 Porosity V elocity-X V elocity-Y UNet 0.89 0.96 0.83 0.76 0.79 0.89 0.93 0.94 UNet rollT8 0.93 0.97 0.88 0.81 0.81 0.91 0.94 0.95 UNet++ 0.90 0.97 0.82 0.78 0.80 0.91 0.92 0.94 UNet++ rollT8 0.90 0.96 0.83 0.75 0.81 0.90 0.93 0.95 T able 2 complements the metrics presented before. It shows the Mean Squared Error (MSE) ob- tained when comparing the scaled predicted fields after 100 timesteps and the ground truth values for the v alidation cases. It also shows the error in the prediction of the area occupied by CO 2 , calcu- lated following the equation 13. This metric was calculated in the concentration field scaled using min-max scaling, and we chose C threshold = 0 . 5. The v alues presented are the median, first quartile Q1 and third quartile Q3 for the cases used for validation. This metric also highlights the adv antage of using rollout training to reduce prediction errors that accumulate over multiple timesteps, and its lo w absolute values indicate that the proposed models maintain good statistics and are robust for multi-query problems, such as uncertainty quantification. Again, these metrics show that the UNet with rollout slightly outperformed other models. 3.5. General comparison of methods The T able 3 presents a comparison of the frame works presented here in terms of memory consump- tion for training and time to train and infer . For each frame work, the table depicts the total number of parameters in the prediction network, indicating the complexity of the network. Therefore, it is directly correlated with the time for training, also shown in the table. The time for training shown there considers the number of epochs necessary for a good con vergence of training/testing losses. In the case of rollout training models, as we initialised the training with the weights obtained with- out rollout, this means only a few epochs. All the simulations were run using one GPU NVIDIA GeForce R TX 4060. 17 T able 2: MSE and error in area occupied by CO 2 for different models using the Grid-Size-In variant frame work. Error Area CO 2 Model MSE Q1 Median Q3 UNet 0.0094 -2.3 -1.8 -1.3 UNet rollT8 0.0063 0.1 1.1 1.3 UNet++ 0.0078 1.8 2.1 2.8 UNet++ rollT8 0.0076 0.7 1.6 2.5 Concerning the “Time for inference” column, it refers to the time for autoregressi ve prediction of 97 timesteps, that is, using the first three timesteps of a simulation and predicting the total timesteps we hav e in our dataset. Additionally , it is worth highlighting that in “T ime for training”, we show the time for the models of each framew ork for which we showed the results in this paper . Ho wev er , the process of hy- perparameter tuning consumes a significant amount of time running other models. In this sense, adversarial training represents a disadvantage when compared to the hyperparameter tuning in a traditional autoencoder , as we can change three different learning rates to maintain the fooling game between the encoder and the discriminator . W e also tested different ratios of updates in these learning rates, as described in the Appendix A. T able 3: Comparison of methods in memory and time consumption. T ime for training in the R OM models presents the time for the compression network (C) and for the prediction network (P). Time for inference refers to the time for autoregressi ve prediction of 97 timesteps. Method T otal Parameters GPU-peak memory for training [GB] Time f or training [min] Time f or inference [sec] Whole Domain UNet 7.7M 1.809 191 < 1 UNet++ 9M 3.444 669 ∼ 1 . 5 R OMs AE + UNet 7.7M 0.263 399(C)+80(P) < 1 AE + UNet++ 9M 0.395 399(C)+266(P) ∼ 1 . 5 AAE + UNet 7.7M 0.263 534(C)+144(P) < 1 AAE + UNet++ 9M 0.395 534(C)+210(P) ∼ 1 . 5 Grid-Size In variant UNet 7.7M 0.263 194 < 1 UNet rollT8 7.7M 0.897 183 < 1 UNet++ 9M 0.393 222 ∼ 1 . 5 UNet++ rollT8 9M 1.542 142 ∼ 1 . 5 The comparison of GPU peak memory shows the adv antage of training the prediction model in a reduced-order space or using smaller subdomains based on the grid-size-in variant approach. This enables training models with large datasets using computational resources that can not af ford train- 18 ing models with the whole domain. Additionally , we can observe that the UNet++ requires approx- imately 1 . 5 × to 2 × the memory needed for the models with UNet. Finally , inference in these data-dri ven models is extremely fast and represents a gain of se veral orders of magnitude compared with a PDE-based approach. The time to produce each simulation in GeoCHemFO AM used to generate this dataset was approximately 3 hours using 24 CPUs of 3 GHz each [60]. 4. Conclusions This work compares different strategies for developing a machine-learning-based surrogate model for rock-fluid interaction prediction. The first group of frame works contains reduced-order models based on autoencoders for compression and a UNet or UNet++ for prediction. Then, we propose a grid-size-in variant approach and compare se veral models with this approach. The main findings are listed belo w . 1. Adversarial training for compression highly increases the complexity for training, but it brought a gain in comparison with the same autoencoder without adversarial training. Even if the generator stops fooling the discriminator after some epochs, the use of the adversarial training strategy to start the training helps to find a more regularised latent space for com- pression, and this improv es the predictions in the latent space. 2. When enough data to train a more complex network is av ailable, UNet++ resulted in better predictions than UNet. Although the UNet++ was first proposed for image segmentation, this work sho ws its strength for surrogate modelling. 3. The grid-size-in variant framew ork outperformed the Reduced Order Model approach for un- seen data, as observed in Pearson Correlation Coefficient comparisons and also in fields visualisation of the e volution of autore gressiv e prediction 4. Compression reduces memory and time consumption during predictor training and inference. Although it is necessary to train the compression network first and it requires the entire field’ s images, sampling in time can be used. The compression network should require less data than the predictor , as it only needs to learn spatial features, not the time ev olution. In contrast, the grid-size-in variant network only reduces memory during training, and uses the whole field’ s images during inference. 5. Rollout training helped to obtain surrogate models with better performance for long autore- gressi ve prediction. One of the ke y considerations when selecting methods for comparison was the feasibility of apply- ing them to large-domain datasets, particularly 3D datasets. Thus, the frameworks compared here considered reductions in memory during training to allo w the use with large datasets. As future work, we will apply the proposed methods to 3D datasets. Also, in the future, we will test the grid-size-in variant approach in a variety of fluid flow problems gov erned by different combinations of PDEs. As a data-dri ven method, we aim to demonstrate its applicability to potentially any fluid flow simulation, pro vided that we choose a subsample large enough to capture the flo w patterns. 19 Although this work focuses on carbon injection, the algorithms dev eloped here extend beyond the presented example, offering broader applicability to image-based modelling of time-ev olving systems. Finally , the surrogate will be combined with a PDE-based solver (potentially GeoChemFO AM, used to generate the original dataset). The surrogate will be used to predict for a number of timesteps in the simulation, whilst re verting to the PDE-solver if the metrics fall below a certain threshold. Thus, we can benefit from the gains in efficienc y provided by the surrogate and use the PDE-solver to guarantee the reliability of the prediction o ver a long-term run. Acknowledgments The authors would like to thank Petróleo Brasileiro S.A. (Petrobras) for sponsoring the doctoral research of Nathalie Carvalho Pinheiro. The authors would like to acknowledge the following EP- SRC and NERC grants: ECO-AI, “Enabling CO 2 capture and storage using AI” (EP/Y005732/1); the PREMIERE programme grant, AI-Respire, “ AI for personalised respiratory health and pol- lution (EP/Y018680/1); “ AI to enhance manufacturing, energy , and healthcare” (EP/T000414/1); SMAR TRES, “Smart assessment, management and optimisation of urban geothermal resources” (NE/X005607/1); AI4Urban-Health, “ AI Solutions to Urban Health Using a Place-Based Ap- proach” (APP55547); and W avE-Suite, “New Generation Modelling Suite for the Surviv ability of W a ve Energy Con vertors in Marine En vironments” (EP/V040235/1). Support from Imperial- X’ s Eric and W endy Schmidt Centre for AI in Science (a Schmidt Futures program) is gratefully ackno wledged. A ppendix A Compression tuning and results The network architectures presented in this work exhibit the same encoder and decoder layers for both Autoencoder and Adversarial Autoencoder; the unique difference lies in the presence of the discriminator , also known as the critic, which is an auxiliary netw ork used only during training. The result of adversarial training is finalising the training with dif ferent weights for the encoder and decoder , and this should guarantee that the distribution in the latent space is adherent to the distribution used in training, in this case, a Gaussian distrib ution. After testing different network architectures and extensiv e hyperparameter tuning, the encoder de- veloped in this research comprises fiv e layers. T wo of these consider a stride of 2 with a kernel size of 2 by 2, which reduces the size while also changing the number of channels. The remaining three layers, with a stride of 1 and a kernel size of 3 by 3, are interspersed among the other two, changing the number of channels in the layer without decreasing the dimension of the input. So, these layers can help to smooth the changes in the number of channels. F or the AAE, the discrim- inator comprises two con volutional layers. The total number of parameters is 854 , 728 for AE and 856 , 201 for AAE. The algorithms used for compression result in a reduction by a factor of 4 in each dimension of the 2D dataset, leading to a memory reduction with a ratio of 16 : 1. For the Autoencoder, the main tuning focused on comparing the best netw ork architectures, and the main hyperparameters used in the results presented here are shown in T able 4. W e also tested dif ferent sampling and data augmentation by flipping the images upside-down. 20 T able 4: Parameters for Compression AE. Hyperparameter V alue Learning Rate (LR) 0.001 Optimizer Adam Adam parameter β 1 0.9 Adam parameter β 2 0.999 Although the Adversarial Autoencoder has the advantage of regularising the latent space, it is much more challenging to tune its hyperparameters. W e started with the same network approv ed for the Autoencoder and adjusted the learning rates of the Autoencoder , the Discriminator, and the Encoder in adversarial mode to maintain the adversarial training for as long as possible. Howe ver , we did not af ford to maintain the adversarial game and reduce the loss for the Autoencoder to similar values to those obtained without adversarial training. Thus, the results presented here consider the adver- sarial training, b ut after 140 epochs, the encoder loss rocketed and the discriminator loss tended to zero, indicating that the encoder was unable to continue fooling the discriminator . Nonetheless, we continued the training, and the autoencoder loss decreased faster after that, achie ving similar v alues to those obtained without adv ersarial training. W e stopped the training when the loss of test- ing samples was no longer significantly reducing. Maintaining adversarial training for more than 100 epochs was only possible when considering some recommendations from previous works with AAEs or GANs, such as the use of Adam Optimiser with β 1 = 0 . 5, that is, reduce the exponential decay for the first momentum term (mean of the gradients) in Adam Optimizer when compared to its default v alue. This recommendation was highlighted in [61], where the authors comment that the default v alue of 0 . 9 has led to training oscillation and instability , while reducing it to 0 . 5 helped stabilise training. Additionally , we considered a lo wer update for the encoder in relation to the discriminator , as recommended in [62]. The results showed here considered a ratio of 2 : 1 between the discriminator and encoder updates. The T able 5 summarises the AAE parameters. T able 5: Parameters for Compression AAE. Hyperparameter V alue LR Autoencoder 0.0005 LR Discriminator 0.00025 LR Encoder (Generator) 0.0005 Discriminator/Encoder update ratio 2 : 1 Optimizer Adam Adam parameter β 1 0.5 Adam parameter β 2 0.999 Here, we present the results of the reconstruction using the compressor autoencoder (AE) and the adversarial autoencoder (AAE), and compare them with tw o other do wnsampling methods com- monly used in image processing with the same reduction ratio. The first one is the function cv .Resize, av ailable in the OpenCV library . It of fers various algorithm options. Here, we used do wnsampling with an interpolation based on the area relation and upsampling based on a bicubic 21 interpolation ov er a 4x4 pixel neighbourhood. The second image reduction method implemented for comparison is the use of Gaussian Pyramid do wnsampling and upsampling. They were im- plemented using the functions cv .pyrDo wn and cv .pyrUp. The concept behind this algorithm is to implement a con volution with a Gaussian kernel to obtain a do wnsampled image. Howe ver , when applying the Gaussian kernel to upsampling, it creates a blur effect in the reconstructed image. Another upsampling method could generate better results, called Laplacian Pyramid [63], b ut it re- quires storing extra information in its algorithm, so it is not feasible to be applied as a reduced-order modelling frame work. The reconstructed output of the compression AE and AAE in a validating sample is nearly in- distinguishable from the original fields, as can be seen in Figure 9. The av erage Mean Square Error obtained in the reconstruction of training data was 5 . 7 × 10 − 6 and in validation data w as 1 . 1 × 10 − 5 for the autoencoder . For the adversarial autoencoder , it was 3 . 8 × 10 − 5 in training data and 8 . 7 × 10 − 5 in v alidation data. References [1] IPCC. Climate Change 2021: The Physical Science Basis. Contribution of W orking Gr oup I to the Sixth Assessment Report of the Inter governmental P anel on Climate Chang e , v olume In Press. Cambridge Univ ersity Press, Cambridge, United Kingdom and New Y ork, NY , USA, 2021. doi: 10.1017/9781009157896. URL https://www.ipcc.ch/report/ar6/wg1/ . [2] IPCC. T echnical summary . In Climate Change 2022: Mitigation of Climate Change. Contri- bution of W orking Gr oup III to the Sixth Assessment Report of the Inter governmental P anel on Climate Change . Cambridge Univ ersity Press, Cambridge, United Kingdom and New Y ork, NY , USA, 2022. doi: 10.1017/9781009157926.002. URL https://www.ipcc.ch/report/ ar6/wg3/ . [3] IOGP Europe. Map of CO 2 storage projects in europe. https://iogpeurope.org/ resource/map- of- eu- ccus- projects/ , 2024. Poster (map) published online; accessed on 10 Sept 2025. [4] Bastian E. Rapp. Chapter 29 — Computational fluid dynamics. In Bastian E. Rapp, editor , Micr ofluidics (Second Edition) , Micro and Nano T echnologies, pages 653–666. Elsevier , Ox- ford, United Kingdom, second edition edition, 2023. ISBN 978-0-12-824022-9. doi: https:// doi.org/10.1016/B978- 0- 12- 824022- 9.00049- 8. URL https://www.sciencedirect.com/ science/article/pii/B9780128240229000498 . [5] Akshai Kumar Runchal and Madhukar M. Rao. CFD of the Futur e: Y ear 2025 and Beyond , pages 779–795. Springer Singapore, Singapore, 2020. ISBN 978-981-15-2670-1. doi: 10. 1007/978- 981- 15- 2670- 1_22. URL https://doi.org/10.1007/978- 981- 15- 2670- 1 . [6] Kookjin Lee and Ke vin Carlberg. Model reduction of dynamical systems on nonlinear mani- folds using deep con volutional autoencoders, 2019. [7] Stefanos Nikolopoulos, Ioannis Kalogeris, and V issarion Papadopoulos. Non-intrusiv e Sur- rogate Modeling for Parametrized T ime-dependent PDEs using Con volutional Autoencoders, 2021. 22 Figure 9: Comparison between downsampling methods common in image processing, the autoencoder used and the adversarial autoencoder used. [8] Rikiya Y amashita, Mizuho Nishio, Richard Kinh Gian, and Kaori T ogashi. Con volutional neural networks: an overvie w and application in radiology . Insights into Imaging , 9, 2018. ISSN 1869-4101. doi: 10.1007/s13244- 018- 0639- 9. URL https://doi.org/10.1007/ s13244- 018- 0639- 9 . [9] Iffat Zafar , Giounona Tzanidou, Richard Burton, Nimesh Patel, and Leonardo Araujo. Hands- On Con volutional Neural Networks with T ensorFlow: Solve computer vision pr oblems with modeling in T ensorFlow and Python . Packt Publishing, Birmingham, UK, 2018. ISBN 1789130336. 23 [10] Francisco J. Gonzalez and Maciej Balaje wicz. Deep con volutional recurrent autoencoders for learning lo w-dimensional feature dynamics of fluid systems. arXiv pr eprint , 1808.01346, 2018. [11] Romit Maulik, Bethany Lusch, and Prasanna Balaprakash. Reduced-order modeling of advection-dominated systems with recurrent neural networks and con volutional autoencoders. Physics of Fluids , 33(3), 2021. [12] T . Kadeethum, F . Ballarin, Y . Choi, D. O’Malley , H. Y oon, and N. Bouklas. Non-intrusive reduced order modeling of natural con vection in porous media using conv olutional autoen- coders: Comparison with linear subspace techniques. Advances in W ater Resour ces , 160: 104098, 2022. ISSN 0309-1708. doi: https://doi.org/10.1016/j.advw atres.2021.104098. URL https://www.sciencedirect.com/science/article/pii/S0309170821002499 . [13] Stefania Fresca, Luca Dede’, and Andrea Manzoni. A Comprehensiv e Deep Learning- Based Approach to Reduced Order Modeling of Nonlinear Time-Dependent Parametrized PDEs. J ournal of Scientific Computing , 87, 2021. ISSN 1573-7691. doi: 10.1007/ s10915- 021- 01462- 7. URL https://doi.org/10.1007/s10915- 021- 01462- 7 . [14] Claire E. Heaney , Zef W olffs, Jón Atli Tómasson, L yes Kahouadji, Pablo Salinas, André Nicolle, Ionel M. Na von, Omar K. Matar , Narakorn Srinil, and Christopher C. Pain. An AI- based non-intrusi ve reduced-order model for extended domains applied to multiphase flo w in pipes. Physics of Fluids , 34(5), May 2022. ISSN 1089-7666. doi: 10.1063/5.0088070. URL http://dx.doi.org/10.1063/5.0088070 . [15] Houzhi W ang, W ei Ma, Jianlei Niu, and Ruoyu Y ou. Ev aluating a deep learning-based surrogate model for predicting wind distribution in urban microclimate design. Building and En vir onment , 269:112426, 2025. ISSN 0360-1323. doi: https://doi.or g/10.1016/j. builden v .2024.112426. URL https://www.sciencedirect.com/science/article/pii/ S036013232401268X . [16] Quang T uyen Le and Chinchun Ooi. Surrogate modeling of fluid dynamics with a multigrid inspired neural network architecture. Machine Learning with Applications , 6:100176, 2021. ISSN 2666-8270. doi: https://doi.or g/10.1016/j.mlwa.2021.100176. URL https://www. sciencedirect.com/science/article/pii/S2666827021000888 . [17] Zhentao Pang, Kai Liu, Hualin Xiao, T ai Jin, Kun Luo, and Jianren Fan. A deep-learning super-resolution reconstruction model of turbulent reacting flo w . Computers & Fluids , 275: 106249, 2024. ISSN 0045-7930. doi: https://doi.org/10.1016/j.compfluid.2024.106249. URL https://www.sciencedirect.com/science/article/pii/S0045793024000811 . [18] Jiuyu Zhao, Jinsui W u, Han W ang, Y uxuan Xia, and Jianchao Cai. Single phase flo w simula- tion in porous media by physical-informed unet network based on lattice boltzmann method. J ournal of Hydr ology , 639:131501, 2024. ISSN 0022-1694. doi: https://doi.or g/10.1016/j. jhydrol.2024.131501. URL https://www.sciencedirect.com/science/article/pii/ S0022169424008977 . 24 [19] T areq Aljamou. Using U-Net for segmentation of fluid phases in porous media. Master’ s thesis, Norwe gian Univ ersity of Science and T echnology (NTNU), 2023. URL https:// ntnuopen.ntnu.no/ntnu- xmlui/handle/11250/3088500 . Accessed: 2025-08-12. [20] Zhihao Jiang, Pejman T ahmasebi, and Zhiqiang Mao. Deep residual U-net con volution neural networks with autoregressi ve strategy for fluid flo w predictions in large-scale geosystems. Ad- vances in W ater Resour ces , 150:103878, 2021. ISSN 0309-1708. doi: https://doi.org/10.1016/ j.advwatres.2021.103878. URL https://www.sciencedirect.com/science/article/ pii/S0309170821000336 . [21] Guang Y ang, Ran Xu, Y usong T ian, Songyuan Guo, Jingyi W u, and Xu Chu. Data- dri ven methods for flo w and transport in porous media: A re view . International Jour - nal of Heat and Mass T ransfer , 235:126149, 2024. ISSN 0017-9310. doi: https://doi. org/10.1016/j.ijheatmasstransfer .2024.126149. URL https://www.sciencedirect.com/ science/article/pii/S0017931024009797 . [22] Gege W en, Meng T ang, and Sally M. Benson. T ow ards a predictor for co2 plume migration using deep neural networks. International Journal of Greenhouse Gas Contr ol , 105:103223, 2021. ISSN 1750-5836. doi: https://doi.or g/10.1016/j.ijggc.2020.103223. URL https: //www.sciencedirect.com/science/article/pii/S1750583620306484 . [23] Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima T ajbakhsh, and Jianming Liang. Unet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support , pages 3–11. Springer , Switzerland, 2018. [24] Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima T ajbakhsh, and Jianming Liang. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmenta- tion. IEEE T ransactions on Medical Ima ging , 2019. [25] E. Bousias Alexakis and C. Armenakis. Evaluation of unet and unet++ architectures in high resolution image change detection applications. The International Ar chives of the Photogram- metry , Remote Sensing and Spatial Information Sciences , XLIII-B3-2020:1507–1514, 2020. doi: 10.5194/isprs- archi ves- XLIII- B3- 2020- 1507- 2020. URL https://isprs- archives. copernicus.org/articles/XLIII- B3- 2020/1507/2020/ . [26] Jimin P ark, Y ejin Kim, Sang Seob Kim, Kwang Y eom Kim, and T ae Sup Y un. Ef fect of injection rate and viscosity on stimulated fracture in granite: Extraction of fracture by con vo- lutional neural network and morphological analysis. Rock Mec hanics and Rock Engineering , 57-3:2159–2174, 2024. doi: 10.1007/s00603- 023- 03678- 5. URL https://doi.org/10. 1007/s00603- 023- 03678- 5 . [27] Humza Fazal Abbasi, Merium Fazal Abbasi, and Faizan Hamayat. Pix2pix++: An en- hanced gans based model for portrait to pencil sketch translation. In 2024 18th International Confer ence on Open Sour ce Systems and T echnologies (ICOSST) , pages 1–6, 2024. doi: 10.1109/ICOSST64562.2024.10871136. 25 [28] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly , Ian Goodfello w , and Brendan Frey . Ad- versarial autoencoders. arXiv pr eprint , 1511.05644, 2016. [29] Ricky T . Q. Chen, Y ulia Rubanov a, Jesse Bettencourt, and David Duvenaud. Neural Ordinary Dif ferential Equations, 2019. URL . [30] Patrick Kidger . On Neural Dif ferential Equations, 2022. URL 2202.02435 . [31] M. Raissi, P . Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning frame work for solving forward and in verse problems in volving nonlinear partial dif- ferential equations. Journal of Computational Physics , 378:686–707, 2019. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect.com/ science/article/pii/S0021999118307125 . [32] W enqian Chen, Qian W ang, Jan S. Hestha ven, and Chuhua Zhang. Physics-informed ma- chine learning for reduced-order modeling of nonlinear problems. Journal of Computational Physics , 446:110666, 2021. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2021.110666. URL https://www.sciencedirect.com/science/article/pii/S0021999121005611 . [33] Shengze Cai, Zhiping Mao, Zhicheng W ang, Minglang Y in, and Geor ge Em Karniadakis. Physics-informed neural networks (PINNs) for fluid mechanics: a revie w. Acta Mechanica Sinica , 37, 2021. ISSN 1614-3116. doi: 10.1007/s10409- 021- 01148- 1. URL https://doi. org/10.1007/s10409- 021- 01148- 1 . [34] Christopher J. Arthurs and Andrew P . King. Active training of physics-informed neu- ral networks to aggregate and interpolate parametric solutions to the navier -stokes equa- tions. J ournal of Computational Physics , 438:110364, 2021. ISSN 0021-9991. doi: https: //doi.org/10.1016/j.jcp.2021.110364. URL https://www.sciencedirect.com/science/ article/pii/S002199912100259X . [35] Gege W en, Zongyi Li, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M. Benson. U-FNO—An enhanced Fourier neural operator-based deep-learning model for multiphase flo w. Advances in W ater Resources , 163:104180, 2022. ISSN 0309-1708. doi: https://doi.org/ 10.1016/j.advwatres.2022.104180. URL https://www.sciencedirect.com/science/ article/pii/S0309170822000562 . [36] Bethany Lusch, J. Nathan Kutz, and Stev en L. Brunton. Deep learning for uni versal linear embeddings of nonlinear dynamics. Natur e Communications , 9(1):4950, 2018. ISSN 2041-1723. doi: 10.1038/s41467- 018- 07210- 0. URL https://doi.org/10.1038/ s41467- 018- 07210- 0 . [37] Georg Kohl, Li-W ei Chen, and Nils Thuerey . Benchmarking autoregressi ve conditional dif- fusion models for turbulent flo w simulation, 2024. URL 01745 . [38] Indranil Nayak, Ananda Chakrabarti, Mrinal Kumar , Fernando L. T eixeira, and Debdipta Goswami. T emporally-consistent koopman autoencoders for forecasting dynamical systems. 26 Scientific Reports , 15(1):22127, 2025. ISSN 2045-2322. doi: 10.1038/s41598- 025- 05222- 7. URL https://doi.org/10.1038/s41598- 025- 05222- 7 . [39] Jonathan Long, Ev an Shelhamer , and T rev or Darrell. Fully con volutional networks for se- mantic se gmentation. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 3431–3440, 2015. [40] Zong-Y i Li, Nikola B. K ov achki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhat- tacharya, Andrew M. Stuart, and Anima Anandkumar . Fourier neural operator for para- metric partial dif ferential equations. ArXiv , abs/2010.08895, 2020. URL https://api. semanticscholar.org/CorpusID:224705257 . [41] Nikola K ov achki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andre w Stuart, and Anima Anandkumar . Neural operator: learning maps between function spaces with applications to pdes. J. Mach. Learn. Res. , 24(1), January 2023. ISSN 1532-4435. [42] Zecheng Zhang, W ing T at Leung, and Hayden Schaef fer . Belnet: Basis enhanced learning, a mesh-free neural operator , 2022. URL . [43] S. Orhan and Y . Bastanlar . Training con volutional neural networks with image patches for object localisation. Electr onics Letters , 54(7):424–426, 2018. doi: 10.1049/el.2017.4725. URL https://doi.org/10.1049/el.2017.4725 . [44] Atharva Sharma, Xiuwen Liu, Xiaojun Y ang, and Di Shi. A patch-based con volutional neu- ral network for remote sensing image classification. Neural Networks , 95:19–28, 2017. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2017.07.017. URL https://www. sciencedirect.com/science/article/pii/S0893608017301806 . [45] T obias Goodwin-Allcock, T ing Gong, Robert Gray , Parashk ev Nachev , and Hui Zhang. Patch- cnn: T raining data-efficient deep learning for high-fidelity diffusion tensor estimation from minimal dif fusion protocols, 2023. URL . [46] Damian Owerko, Charilaos I. Kanatsoulis, and Alejandro Ribeiro. Solving lar ge-scale spatial problems with con volutional neural networks, 2024. URL 08191 . [47] Julien Maes, Cyprien Soulaine, and Hannah P . Menke. Impro ved volume-of-solid formula- tions for micro-continuum simulation of mineral dissolution at the pore-scale. F r ontiers in Earth Science , 10, 2022. doi: 10.3389/feart.2022.917931. [48] Donghu Guo, N. C. Pinheiro, C. E. Heaney , and C. C. Pain. Domain-Agnostic AI Surrog ates: Implicit Prediction for T ransient Flo w with Size and Geometry In variance. In pr eparation , 2026. [49] Shuaixian W ang, Haoran Xu, Y aokun Li, Jiwei Chen, and Guang T an. IE-NeRF: Exploring transient mask inpainting to enhance neural radiance fields in the wild. Neur ocomputing , 618: 129112, 2025. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2024.129112. URL https://www.sciencedirect.com/science/article/pii/S0925231224018836 . 27 [50] AmirPouya Hemmasian, Francis Ogoke, Parand Akbari, Jonathan Malen, Jack Beuth, and Amir Barati Farimani. Surrogate modeling of melt pool temperature field using deep learning. Additive Manufacturing Letters , 5:100123, 2023. ISSN 2772-3690. doi: https://doi.org/10. 1016/j.addlet.2023.100123. URL https://www.sciencedirect.com/science/article/ pii/S277236902300004X . [51] Haosu Zhou and Nan Li. Image-based artificial intelligence empowered surrogate model and shape morpher for real-time blank shape optimisation in the hot stamping process, 2022. URL https://arxiv.org/abs/2212.05885 . [52] T oby R. F . Phillips, Claire E. Heaney , Paul N. Smith, and Christopher C. Pain. An autoencoder-based reduced-order model for eigen value problems with application to neutron dif fusion. International J ournal for Numerical Methods in Engineering , 122(15):3780–3811, 2021. doi: https://doi.or g/10.1002/nme.6681. URL https://onlinelibrary.wiley.com/ doi/abs/10.1002/nme.6681 . [53] Ian J. Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-F arley , Sherjil Ozair , Aaron Courville, and Y oshua Bengio. Generativ e adversarial nets. In Pr oceedings of the 28th International Confer ence on Neural Information Pr ocessing Systems - V olume 2 , NIPS’14, page 2672–2680, Cambridge, MA, USA, 2014. MIT Press. [54] Benyamin Ghojogh, Ali Ghodsi, Fakhri Karray , and Mark Cro wley . Generati ve ad- versarial networks and adversarial autoencoders: T utorial and surve y . arXiv pr eprint arXiv:2111.13282 , 2021. [55] Y oshua Bengio, Jérôme Louradour , Ronan Collobert, and Jason W eston. Curriculum learn- ing. In Pr oceedings of the 26th Annual International Conference on Machine Learning , ICML ’09, page 41–48, Ne w Y ork, NY , USA, 2009. Association for Computing Machin- ery . ISBN 9781605585161. doi: 10.1145/1553374.1553380. URL https://doi.org/10. 1145/1553374.1553380 . [56] Petru Soviany , Radu T udor Ionescu, Paolo Rota, and Nicu Sebe. Curriculum learning: A surve y , 2022. URL . [57] Alexandros Patsoukis Dimou, Hannah P . Menke, and Julien Maes. Benchmarking the V iabil- ity of 3D Printed Micromodels for Single Phase Flo w Using Particle Image V elocimetry and Direct Numerical Simulations. T ransport in P or ous Media , 141, 2022. ISSN 1573-1634. doi: 10.1007/s11242- 021- 01718- 8. URL https://doi.org/10.1007/s11242- 021- 01718- 8 . [58] Sarah. Boslaugh. Statistics in a nutshell . In a nutshell. O’Reilly , Beijing, second edition. edition, 2012. ISBN 9781449361129. [59] Zhou W ang, A.C. Bovik, H.R. Sheikh, and E.P . Simoncelli. Image quality assessment: from error visibility to structural similarity . IEEE T ransactions on Image Pr ocessing , 13(4):600– 612, 2004. doi: 10.1109/TIP .2003.819861. [60] Marcos Cirne, Hannah Menke, Alhasan Abdellatif, Julien Maes, Florian Doster , and Ahmed H. Elsheikh. A deep-learning iterati ve stacked approach for prediction of reactiv e dissolution in porous media, 2025. URL . 28 [61] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep con volutional generati ve adversarial networks, 2016. URL 1511.06434 . [62] Jakub Langr and Vladimir Bok. GANs in action : deep learning with generative adversarial networks . Manning Publications, Shelter Island, New Y ork, 1st edition edition, 2019. ISBN 9781638354239. [63] P . Burt and E. Adelson. The Laplacian Pyramid as a Compact Image Code. IEEE T ransactions on Communications , 31(4):532–540, 1983. doi: 10.1109/TCOM.1983.1095851. 29
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment