LLMTailor: A Layer-wise Tailoring Tool for Efficient Checkpointing of Large Language Models
Checkpointing is essential for fault tolerance in training large language models (LLMs). However, existing methods, regardless of their I/O strategies, periodically store the entire model and optimizer states, incurring substantial storage overhead a…
Authors: Minqiu Sun, Xin Huang, Luanzheng Guo
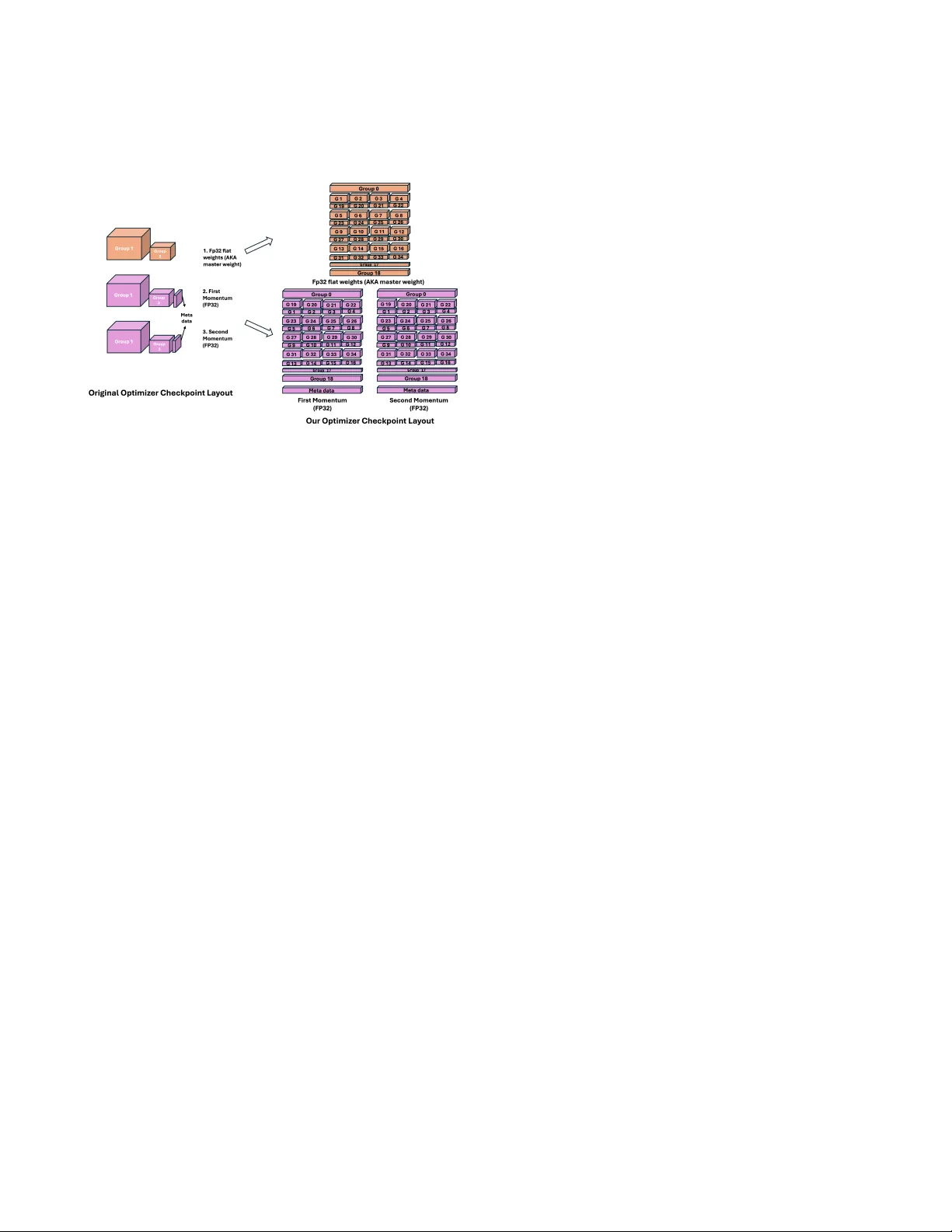
LLMT ailor: A Layer-wise T ailoring T ool for Eicient Checkpointing of Large Language Mo dels Minqiu Sun University of Delaware Newark, United States mqsun@udel.edu Xin Huang RIKEN Center for Computational Science Kobe, Japan xin.huang@a.riken.jp Luanzheng Guo Pacic Northwest National Laboratory Richland, United States lenny .guo@pnnl.gov Nathan R. T allent Pacic Northwest National Laboratory Richland, United States Nathan.T allent@pnnl.gov Kento Sato RIKEN Center for Computational Science Kobe, Japan kento.sato@riken.jp Dong Dai University of Delaware Newark, United States dai@udel.edu Abstract Checkpointing is essential for fault tolerance in training large lan- guage models (LLMs). However , existing methods, regardless of their I/O strategies, periodically store the entire model and opti- mizer states, incurring substantial storage overhead and r esource contention. Recent studies rev eal that updates across LLM lay ers are highly non-uniform. Across training steps, some layers may undergo more signicant changes, while others r emain relatively stable or even unchanged. This suggests that selectively che ck- pointing only layers with signicant updates could reduce over- head without harming training. Implementing such selective strate- gies requires ne-grained control over both weights and optimizer states, which no current tool provides. T o address this gap, we pro- pose LLMTailor , a checkpoint-merging framework that lters and assembles layers from dier ent checkpoints to form a composite checkpoint. Our evaluation indicates that LLMT ailor can work with dierent selective checkpointing strategies and eectively reduce checkpoint size (e.g., 4.3 times smaller for Llama3.1-8B) and che ck- point time ( e.g., 2.8 times faster for Qwen2.5-7B) while maintaining model quality . CCS Concepts • Computer systems organization → Dependable and fault- tolerant systems and networks ; A vailability ; • Computing methodologies → Articial intelligence . Ke ywords Checkpoint, Large Language Model, I/O optimization A CM Reference Format: Minqiu Sun, Xin Huang, Luanzheng Guo, Nathan R. Tallent, Kento Sato, and Dong Dai. 2025. LLMT ailor: A Layer-wise T ailoring T ool for Ecient Checkpointing of Large Language Models . In W orkshops of the International This work is licensed under a Creative Commons Attribution 4.0 International License. SC W orkshops ’25, St Louis, MO , USA © 2025 Copyright held by the owner/author(s). ACM ISBN 979-8-4007-1871-7/2025/11 https://doi.org/10.1145/3731599.3767515 Conference for High Performance Computing, Networking, Storage and A naly- sis (SC W orkshops ’25), November 16–21, 2025, St Louis, MO, USA. ACM, New Y ork, NY, USA, 9 pages. https://doi.org/10.1145/3731599.3767515 1 Introduction Originally de veloped in high-performance computing (HPC) to pro- tect long-running scientic simulations, checkpointing has become the primary safeguar d against failures in large-scale , high-cost LLM training. By periodically writing the complete model state, which includes weights, optimizer parameters, and other metadata, to per- sistent storage, the system can reload the most recent snapshot after a failure and resume training with minimal loss of progr ess [9]. Since current checkpointing uniformly saves all LLM layers, it introduces signicant I/O overhead. As training scales up, the checkpoint-related overhead can account for 12% of total training time and can rise to as much as 43% [ 18 ]. W e believe this ‘saving the entire LLM states’ approach might not be ecient, as many studies show that layers in LLMs are not updated at the same pace. Many recent works have highlighted the imbalances across lay- ers of LLMs. Jawahar et al. [14] show that dierent layers of large language models enco de distinct types of linguistic information. Phang et al. [ 23 ] observe that the lower and higher layers of ne- tuned RoBERT a and ALBERT mo dels are dissimilar . Zhou et al. [ 33 ] propose the 𝑃 𝐿 _ 𝐴 𝑙 𝑝ℎ𝑎 _ 𝐻 𝑖 𝑙 𝑙 metric, demonstrating that dierent layers train at dierent spee ds when using optimizers such as SGD and Adam. Colle ctively , these ndings indicate that the existing checkpointing mechanisms, which indiscriminately save the com- plete model, are not optimal. It is then natural to e xplore the idea of keeping only part of the model during training. For e xample, check- pointing half of the layers at a time, and merging 2 checkpoints into a complete one. Clearly , doing so requires reconstructing a com- plete training state from multiple partial checkpoints, which in turn demands ne-grained manipulation of individual layers, including both weights and optimizer states. T o our knowledge, no existing tool oers this capability . The closest one, MergeKit [ 10 ], merges the checkpoints only on weights and omits optimizers, making the recovery of training impossible. This is clearly not acceptable for checkpointing, as it is designed for training. SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Minqiu Sun, Xin Huang, Luanzheng Guo, Nathan R. T allent, Kento Sato, and Dong Dai In this study , we develop LLMTailor , a tool that merges both weights and optimizer shar ds to generate a fully resumable “Franken- stein” che ckpoint, which can be used to continue training. With LLMT ailor , we can investigate the feasibility and overhead of partial checkpointing during training. T o validate our design, we conduct extensive experiments to de- termine whether 1) partial checkpointing with LLMT ailor reduces storage and checkpoint time, 2) the checkpoint made by LLMT ailor will negatively impact the model quality; On Llama-3.1-8B, LLM- T ailor reduces total checkpoint size by 4.3 times; on Q wen-2.5-7B, we reduce the ratio of checkpoint time to end-to-end training time by 2.8 times. In another simple use case, we reduce the checkpoint size by half while maintaining model accuracy . The contributions of this study are threefold: (1) W e present LLMT ailor , an eective to ol that assembles a resumable “Frankenstein” checkpoint from parts of multiple checkpoints while maintaining the model p erformance. (2) W e demonstrate that partial checkp ointing with LLMT ailor can substantially lower storage requirements and che ckpoint time in LLM training. (3) W e show that LLMT ailor incurs only a small amount of overhead when resuming training from a merged checkp oint. The rest of the paper is organized as follows. In §2 we discuss relevant backgrounds of LLMs. In §4 we describ e the architecture of LLMT ailor in detail. W e present the extensive experimental results in §5. §6 discusses the closely related work. In §7 we present our conclusions and discuss future work. 2 Background and Motivation Large language models (LLMs) have demonstrated r emarkable power in various domains [ 5 – 7 , 21 ]. LLM training, like other neural networks, involves a forward pass, loss computation, a backward pass, and parameter update. Here , we revie w the key fundamentals that motivate our layer-wise checkpointing: (i) the structural com- ponents of LLMs, (ii) the organization of optimizers, and (iii) the distributed frameworks such as DeepSpeed used for scaling. 2.1 Structure of LLMs Figure 1 uses the Llama3-8B model as an example [ 2 ]: tokens are rst embedde d from a number to a vector , then propagated through 32 consecutive transformer layers. Then, after layer normalization to eliminate internal covariate shift, the hidden representations are projected back to the vocabulary space to produce logits in the lm_head layer; nally , a softmax yields output probabilities. Note that not all models include a separate lm_head ; in smaller models, this layer is often weight-tied to embed_tokens to reduce parameter count [24]. Each transformer block contains two lay er-normalization sub- layers that stabilize activation statistics. Between them, the self- attention module performs dynamic context aggregation, the den- ing operation of the Transformer architecture. The feed-forward network (FFN) then applies a non-linear transformation to each token representation: it expands the hidden dimension, activates it (e .g., with SwiGLU), and projects it back to the original size, thereby enriching the model’s ability to capture complex patterns. In the Figure 1: The layer-wise structure in a Llama3.1-8B model. right panel of the gure, each box represents a trainable layer; collectively , these layers comprise the large language model. 2.2 Structure of Optimizers The parameters are continuously updated to minimize the training loss, and this update process is applied by an optimizer , such as stochastic gradient descent (SGD) and Adam. T oday , optimizers in training LLMs are often from the Adam family rather than plain SGD , due to their strong ability to accelerate and stabilize conver- gence during LLM training. As Equation 1 shows, Adam maintains two running momentum estimates by continuously accumulating gradients into two auxiliary tensors 𝑚 and 𝑣 (the rst- and second- order momentum). So, the optimizer has double the parameter size as the model weights due to the two momentum terms. 𝑊 𝑖 ( 𝑡 ) ← 𝑊 𝑖 ( 𝑡 − 1 ) − 𝑙 𝑟 ( 𝑡 ) · 𝑚 √ 𝑣 + 𝜖 . (1) Figure 2 sketches the layout of the optimizer le in a checkpoint. During the update stage, all mo del parameters are attened into two parameter groups, disregarding the model’s hierarchical or sub- layer structure , to improve computational eciency . T o preserve adequate optimization control, each group is assigned its own hy- perparameters (e.g., learning rate, w eight decay). Grouping at this coarse granularity rather than per tensor strikes a practical balance between eciency and exibility . In Figure 2, the tw o groups are divided by dierent weight decay . This choice is because AdamW decouples weight decay from the loss gradient; it is standard to apply decay only to weights, while excluding biases and normal- ization parameters. Shrinking the latter can harm stability without oering meaningful regularization. Accordingly , one group con- tains all biases and normalization parameters ( with zero weight decay), and the other contains the remaining weights ( with nonzero weight decay). Checkpointing safeguards training continuity by periodically snapshotting every comp onent whose state evolves during opti- mization. The most obvious target is the model itself. In addition, the LLMT ailor: A Layer-wise T ailoring T ool for Eicient Checkp ointing of Large Language Models SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Figure 2: The AdamW optimizer use d in a Llama3.1-8B model. Adam optimizer relies on accumulated gradient moments to ensure precise and stable updates; omitting these optimizer states from the checkpoint can lead to large spikes or noisy up dates when training resumes. In addition to the momentum terms, the le contains an FP32 master weight tensor of the same size. This duplication is required for mixed-precision training: forward and backward prop- agation run in FP16/BF16 to exploit tensor-core throughput and reduce memory-bandwidth demands, while FP32 master weights and FP32 momentum estimates are retained for numerical stabil- ity . Consequently , including some remaining conguration les, a single checkpoint must store at least 7 × the size of the FP16/BF16 model itself. 2.3 Distributed LLM training under Deepspeed Since LLMs have now grown to unprecedented scales, this foot- print makes distributed frameworks such as DeepSpe ed’s ZeRO vital to LLM training. It can shard optimizer states, gradients, and parameters across data-parallel processes, dramatically reducing the per-GP U memory footprint [ 27 , 28 ]. For e xample, in the ZeRO3 stage, each rank holds only a shard of the mo del parameters and opti- mizer states. During for ward/backward passes, ZeRO-3 all-gathers the neede d parameter shards just-in-time for a layer , computes them, and then re-shards them. In distributed training checkpoint systems, optimizer states are saved as shards: each GP U writes only its own shard to reduce ov erhead. In contrast, to ensure that it can be used for reasoning at any time, the mo del weights are typically stor ed as a single consolidated le. During recovery , e very optimizer shard is loaded onto its corresponding GP U , ensuring that the training state is restored correctly . 3 Brief Introduction about Mergekit Mergekit [ 10 ] is a lightweight command-line toolkit that lets users compose new language-model checkpoints from two or more e xist- ing ones with only a short Y AML recipe. Internally , it loads each source model, matches tensors by name, and applies a user-selecte d merge rule. T o use it, users rst sele ct a merge method, such as linear blending, SLERP , passthrough copy , or LoRA-fusion . Next, users ne ed to write a recip e Y AML that lists source models and species layer-selection rules. And then run the CLI to emit a new model assembled according to these rules. After that, the resulting Frankenstein model can be loaded directly by standard PyT orch or Hugging Face runtimes. In practice, users most often apply it to tasks like model capability fusion and domain adaptation. Although mergekit supports several merging strategies, layer- wise checkpoint merging relies on the passthrough method, which splits and recombines source models by layer . Because MergeKit works only with weight les and therefore avoids both back propa- gation and retraining, it cannot support full che ckpoint merging for the following reasons: (1) Optimizer states are ignored. Mergekit merges only model weights, omitting optimizer les that ar e essential for resum- ing training. (2) A uxiliary layers are excluded. It manipulates transformer layers only , leaving out large auxiliary layers such as token embeddings and the prediction head. (3) Conguration les are not handled. Mergekit does not pro- vide support for merging or editing checkpoint conguration les. Given the popularity and practicality of MergeKit, w e want to adopt its Y AML-driven interface and extend its functionality to handle full checkpoints, including optimizer states, auxiliar y lay ers, and conguration metadata. 4 Design and Implementation In this se ction, we introduce LLMTailor , which constructs resumable training checkpoints by composing model layers (and associated optimizer states) from multiple checkpoints without changing the way mergekit is used. The ke y design insights behind LLMT ailor are detailed below . 4.1 Construct Separable Optimizers in Checkpoint Because MergeKit cannot merge optimizer states from dierent checkpoints, our LLMT ailor extends it to enable this functionality . The main challenge arises from the optimizer’s intrinsic structure: unlike model weights, which follow a layer-wise hierarchy , opti- mizer les store attened tensors that ar e dicult to split or merge. The only natural partition p oint in these les is the parameter group. W e therefore reconstruct the parameter groups to mirror the model’s layer-wise organization while preserving the original weight-decay settings. Sp ecically , each transformer layer is divided into two gr oups: one containing tensors exempt fr om weight decay and the other containing the remaining tensors. Since auxiliary lay- ers contain exclusively either weight-decay or non-w eight-decay parameters, they are assigned to a single parameter group. Since the or dering of such parameter gr oups is consistent across dierent LLMs, knowing only the total numb er of transformer layers and whether weight tying is applied by reading the conguration le is sucient to determine the parameter group index of each layer in the optimizer le. A s a result, the number of parameter groups increases fr om two to 2 𝐿 + 𝑥 , where 𝐿 is the number of transformer SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Minqiu Sun, Xin Huang, Luanzheng Guo, Nathan R. T allent, Kento Sato, and Dong Dai layers, 𝑥 is the number of auxiliary layers. Figure 3 illustrates the transformation of a 16-layer , 2-group model into a 35-group model. Figure 3: Reconstruct the parameter groups in the optimizer before training. The checkpoint’s structure must match the mo del in GP U mem- ory during training or before failure; otherwise, the checkpoint is unusable. As a result, we perform this r egrouping before training begins. During training, the master weights are automatically or- ganized into the same 35 groups, ensuring that the optimizer le stored in each checkpoint has a uniform, group-aligned structure. Next, we merge and assemble a new checkpoint by tracking the in- dices of the two parameter groups associate d with each transformer layer . This redesign renders the optimizer les separable, while pre- serving the original weight decay conguration. Because neither parameters nor hyperparameters are altered, the training procedure and nal results remain unchanged; the only additional cost is a small amount of computational overhead. This helps solidify the basis for tailoring checkpoints. 4.2 Merge Optimizers Supporting arbitrary assembly of layers from multiple checkpoints, especially in the optimizer les, is a key objective. Since MergeKit already handles weight merging, w e focus here on our implemen- tation of the optimizer le. LLMT ailor rst parses a Y AML specication that lists the base model, the source lay ers with their corresponding checkpoints, and the target positions of those layers in the new model. The xed parameter-group structure lets us locate each lay er and its associ- ated groups. Figure 3 illustrates the default or dering of parameter groups: the rst group stor es the normalization layer , followed by the non-weight-decay segments of the transformer layers, then the embedding layer and the optional lm_head , and nally the weight- decay segments of each transformer layer . When a transformer layer is selected, LLMT ailor automatically indexes and copies all its parameter groups, inserting them into the user-dene d position in the new model. Unlike the unie d mo del-weight le, each parameter group is uni- formly sharded across GPUs, and the corresponding checkpoints are stored in separate les because of distribute d training. The largest overhead in LLMT ailor is the I/O overhead of loading up to 𝑁 × ( 𝐿 + 3 ) optimizer les and writing up to 𝑁 les, where 𝑁 rep- resents the total number of GP Us. T o ensure the correctness of the resumed checkpoint, we keep the order of loading and writing. In addition, we leverage multiprocessing to accelerate this process. W e employ Python’s ProcessPoolExecutor to parallelize shard loading across multiple CP U cores, enabling concurrent decompression and deserialization of large ZeRO-3 optimizer les, which signicantly reduces overall I/O latency . 4.3 Split Auxiliary Layers Since mergekit focuses solely on model weight merging, it retains the base model’s norm , embed_token , and lm_head for vocabulary compatibility . Howe ver , the latter two contain the entire vocabulary and thus occupy far more space than individual transformer blocks. W e therefore adjust the merge plan to split and merge these auxil- iary modules explicitly . In LLMT ailor , the only extra requirement is that users list these three modules in the Y AML recipe. 4.4 Manipulate Conguration Files Metadata and conguration les record user-congured arguments, training state history , the current training step, and the current learning rate. Thus, these les must be copied from the most r ecent checkpoint to assemble a new "Frankenstein" checkp oint while preserving training continuity and eectiveness. LLMT ailor also provides an autonomous copy of these conguration les in the latest checkpoint that we create. 5 Experiments In this section, we describ e the experimental setup, models, datasets, baselines, and give 2 use case for our LLMT ailor . 5.1 Experimental Setting W e conducted all real-world experiments on an 8-GP U cluster fea- turing NVIDIA A100 80GB GP Us and two AMD EPY C 7713 CP Us. The le system that we use is a Lustre le system mounted via an InniBand network. The use d software versions are CUDA 12.8, DeepSpeed v0.17.2, and PyT orch 2.7.1. T o address GP U memory constraints and train larger models, we employed DeepSpee d ZERO Stage-3 optimization, with the default optimizer b eing AdamW [ 16 ]. W e evaluate LLMT ailor using p opular op en-source LLMs, namely Llama-3.2-1B, Llama-3.1-8B [ 2 ], and Qwen-2.5-7B [ 26 ]. All experi- ments employ a sequence length of 2048. T o quantify the reduction in checkpoint overhead in post-training, we test LLMT ailor on two representative tasks: continual pre-training (CPT) [ 12 ] and supervise d ne-tuning (SFT) [ 4 ]. Because post-training typically adapts a general-purpose LLM to sp ecialized knowledge or capabil- ities, we select two medical datasets: (i) PubMed-Summarization, a plain-text corpus for CPT [ 3 ], and (ii) MedQA [ 15 ], a structured question-answering dataset for SFT . Each task is trained for one epoch. For PubMe d-Summarization, we use a micro-batch size of 4 with 2 gradient-accumulation steps; for Me dQ A, we use a micro- batch size of 2 with 2 gradient-accumulation steps. T o assess model quality after recovery , we evaluate it on ve benchmarks spanning three categories: medical expertise, general knowledge, and reasoning. Our goal is not to improve absolute LLMT ailor: A Layer-wise T ailoring T ool for Eicient Checkp ointing of Large Language Models SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Model Final train loss Final eval loss Qwen2.5-7B (After SFT) 1.58 1.60 Parity merge (start from 400) 1.58 1.60 (a) Qwen2.5-7B in a SFT task. Model Final train loss Final eval loss Llama3.1-8B (After CPT) 1.58 1.58 Filtered Layers (start from 1000) 1.58 1.58 (b) Llama3.1-8B in a CPT task. T able 1: Comparison of training loss between original checkp oint and new che ckpoint created by parity . T ask Model MMLU MMLU_med Me dMCQ A MedQA PubMedQA SFT Qwen2.5-7B 73.14 89.00 60.75 64.02 75.20 parity-400 72.89 87.00 60.58 64.10 76.20 CPT Llama3.1-8B 60.00 75.00 53.10 55.15 77.20 parity-1000 60.03 72.00 53.12 54.36 76.60 T able 2: Zero-shot Benchmark Evaluation Results of resumed training in use case 1. (Question- Answer , higher is better) scores but to verify that LLMT ailor does not degrade performance in the post-training context. Conse quently , we do not perform dataset deduplication before evaluation. Since no prior w ork has explored partial checkpointing, and partial checkpointing mecha- nisms can also be combined with prior work on I/O optimization and in-memory techniques, as the approaches are not mutually exclusive, we establish our baseline using the default checkpointing mechanism provided by the transformers library . Specically , we adopt xed checkpoint inter vals of every 50 steps for the SFT task and every 100 steps for the CPT task, and then compare the time and storage overhead of our method against this baseline. 5.2 Use Case 1: Merge Che ckpoints by Parity The rst use case that we decide to test is to merge the odd layers and the embed_token layer from the previous checkpoint, and the even layers and the lm_head layer from the current checkp oint. Considering the layer-wise structure of LLM is sequential, in order to avoid the split of the front and back layers of the checkp oint, we use this method to reconstruct a new one for resuming. Check- pointing only half of the complete checkpoint each time can r educe the storage overhead by almost half. T able 3 lists the exact size of each checkpoint. Model T yp e T otal CKPT size (G) The proportion of checkpoint time(%) Llama3.1-8B T otal 1799.52 4.99 Parity 899.76 3.03 Qwen2.5-7B T otal 1811.52 20.63 Parity 905.76 12.76 T able 3: Comparison between complete checkp oint and par- tial checkpoint in parity che ckpoint In T able 3, the proportion of checkp oint time means the ratio of checkpointing time and the end-to-end training time. These results suggest that in this use case, we can reduce the storage o verhead by approximately 50% and checkpointing time overhead by 40%. W e then resume training using the new checkp oints generate d by our LLMT ailor framework. T able 1 compares the resumed training process with that of the original model. The results show that both the training loss and the evaluation loss at the nal step match those of the original training traje ctory . This demonstrates the correctness of the checkpoint merging in this use case. T o assess the quality of the model after recovery and continue d training, we evaluate the nal, fully trained models on ve bench- marks spanning three domains: medical expertise, general knowl- edge, and reasoning. T able 2 reports these results, where higher scores indicate better performance. The top results for each bench- mark are highlighted. Here, the absolute score might not be the most important thing. Instead, it is crucial to verify that the Franken- stein model does not signicantly degrade performance compared to the original model, which never e xperiences any failures or re- coveries. Results show that our method can preserve model quality after recovering from the merged checkpoints. Therefore, it oers the possibility that future che ckpointing systems could incorp o- rate more precise mechanisms that allow for a slight trade-o in model performance to better balance overall mo del quality with the reduction in overhead. 5.3 Use Case 2: Merge Che ckpoints by Filtering Previous work sho ws that the rst several lay ers and the last two layers of the model have a greater impact on model reasoning [ 11 ]. Based on that, we decide to checkp oint by ltering only the rst and the last 2 layers each time, and checkpoint half of the other layers less often 𝑒 𝑣 𝑒 𝑟 𝑦 5 × 𝑜 𝑟 𝑖 𝑔𝑖𝑛𝑎𝑙 _ 𝑖𝑛𝑡 𝑒 𝑟 𝑣 𝑎𝑙 -to- to reduce more overhead. T able 6 lists the exact size of each checkpoint. Here, we also set the default checkpoint me chanism as a baseline and measure the pr oportion of time spent on checkpoints. In this scenario, we can reduce the checkpoint time ratio to up to 2.8 × for the Qwen2.5-7B mo del, and 4.3 × storage overhead for the Llama3.1- 8B model. W e compare the size of the checkp oint with the default checkpoint method. Then, we use the new checkpoint created by our LLMT ailor to resume training. T able 4 shows the results of their continued training compared to the original model. W e then resume training using the new checkp oints generate d by our LLMT ailor framework. T able 4 compares the resumed training process with that of the original model. Since lower loss indicates better performance, the results show that both the training loss SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Minqiu Sun, Xin Huang, Luanzheng Guo, Nathan R. T allent, Kento Sato, and Dong Dai Model Final train loss Final eval loss Qwen2.5-7B (After SFT) 1.58 1.60 Filtered Layers (start from 400) 1.60 1.62 (a) Qwen2.5-7B in an SFT task. Model Final train loss Final eval loss Llama3.1-8B (After CPT) 1.58 1.58 Filtered Layers (start from 1000) 1.59 1.59 (b) Llama3.1-8B in a CPT task. T able 4: Comparison of training loss between original checkp oint and new che ckpoint created by the impact of layers. T ask Model MMLU MMLU_med MedMCQA MedQ A PubMedQA SFT Qwen2.5-7B 73.14 89.00 60.75 64.02 75.20 lter-400 71.64 84.00 59.50 62.06 75.60 CPT Llama3.1-8B 60.00 75.00 53.10 55.15 77.20 lter-1000 62.06 77.00 53.45 54.91 78.00 T able 5: Zero-shot Benchmark Evaluation Results of resumed training in Use case2. (Question- Answer , higher is better) Model T yp e T otal CKPT size (G) The proportion of checkpoint time(%) Llama3.1-8B T otal 1799.52 4.99 Filtered 420 1.66 Qwen2.5-7B T otal 1811.52 20.63 Filtered 434.56 7.26 T able 6: Comparison between complete checkp oint and par- tial checkpoint in ltered che ckpoint and the evaluation loss at the nal step de crease slightly . This demonstrates that p erformance could degrade if we fo cus solely on reducing overhead at the expense of preserving the original functionality of checkpoints. In the benchmark evaluation, T able 5 presents the results, wher e higher scores indicate b etter performance, and the top score for each benchmark is highlighted. In the SFT task, the newly created Qwen2.5 checkpoint p erforms noticeably worse than the default checkpoint, whereas in the CPT task, the comp osite Llama3 model noticeably outperforms the default model. This suggests that the inherent robustness of LLMs can, to some extent, support our con- cept of partial checkpointing. These relatively strong results fr om the rule-based partial che ckpointing mechanism suggest that fu- ture systems employing more dynamic strategies in de ciding which components to checkpoint and when are likely to achieve even better performance and greater robustness. 5.4 Checkpoint Overhead W e evaluate LLMT ailor for splitting and merging dierent LLMs on both CPT and SFT tasks. The che ckpoints we merge are partial. For the baseline, the reported time corresponds only to resuming a checkpoint, whereas for the other checkpoints, the reported time also includes the additional overhead of running LLMT ailor . There- fore, in T able 7, we present the measured merging ov erhead from dierent perspectives. Unless otherwise sp ecied, checkpoints are loade d in a straight- forward manner; for example, layers(1 – 16) are loaded from checkpoint- 100, layers (17 – 32) from checkpoint-200, and so on. When we re- fer to “parity , ” however , checkp oints are loaded multiple times Model Name Checkp oint Size (G) T otal layers CKPTs included Time (s) Llama3-1B 17.29 18 Baseline: 1 0.80 2 117 parity (2) 233.6 8 60.4 18 62.5 Llama3-8B 112.47 35 Baseline: 1 16.8 2 332.4 parity (2) 1027.5 8 279.2 35 264.3 T able 7: Loading time for dierent che ckpoints in an interleaved fashion: rst, layer(1) from checkpoint-100 and layer(2) from checkpoint-200; then layer(3) from checkp oint-100 and layer(4) from checkp oint-200, and so forth. Even with only two checkpoints, this process still requires loading and discarding them N times, where N is the total number of layers. This approach incurs substantial overhead because the optimizer state can only be accessed after the checkpoint is fully loaded, with no possibility of lazy loading, as in the case of model weights. From this, we ob- serve that the time overhead in LLMT ailor is determine d by: i) the loaded checkpoint size; ii) the number of loade d checkpoints; iii) the method we load the layers; iv) the number of total layers. Compared with the total training time, which can span several hours or ev en days, this overhead is relatively small and thus acceptable. W e also observe that, although checkpoints must be loaded from N dierent les, each checkpoint contains only a single layer . As a result, the loading process is relatively fast. This observation suggests that the overhead of LLMT ailor could b e signicantly reduced once a layer-wise checkpointing system is adopted. 6 Related W ork 6.1 Checkpointing in Deep Learning. Checkpoint techniques have b een widely explored and utilized in many deep learning frameworks, such as Py T orch [ 22 ], T en- sorFlow [ 1 ]. Howev er , default checkpoint systems will introduce signicant overhead and stalls during the training stage, especially for large models. T o address this challenge, many works have pr o- posed dierent optimizations. Some works focus on optimizing the LLMT ailor: A Layer-wise T ailoring T ool for Eicient Checkp ointing of Large Language Models SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA checkpoint system, such as CheckFreq [ 20 ], which dynamically ad- justs the checkpointing frequency to reduce I/O; Check-N-Run [ 8 ] compresses checkpoints with lossy schemes to reduce both I/O and required storage; [ 18 , 25 ] recovers only checkpoints on GP Us that failed. Gemini [ 29 ] introduces in-memory checkpoint protection to avoid stalls and reduce recovery time by using high-bandwidth CP U memory , while Just-in- Time checkpointing [ 13 ] utilizes state redundancy in data parallel replicas of large deep learning jobs for ecient run-time checkpointing. In addition, Datastate-LLM [ 19 ] uses a lazy asynchronous multi-level approach, optimizing the pipeline of the checkpoint system to reduce overhead. Howev er , unlike all these metho ds, our approach fo cuses on identifying the non-uniform weight updates in LLM training and do lay er-wise checkpointing to reduce the overhead, so that we can further reduce checkpoint size while utilizing current optimizations. 6.2 Model Merging Researchers also disassemble and merge mo dels. For instance, mo del merging is widely studied as an eective training-free method to combine the capabilities of ne-tuned large language models [ 30 ]. Y adav et al. [ 31 ] further help solve conicts between dierent task vectors through norm-based sparsication and consensus on the signs of weights. Yu et al. [ 32 ] showed that LLMs are highly ro- bust to sparsifying task vectors and pr oposed DARE for merging LLMs with random sparsication. Recently , Online Merging Opti- mizers [ 17 ] online merge the gradients of the policy model with the delta parameters of the SFT mo del. Our experiments show that both the model and the optimizer in checkpoints can also benet from model merging. 7 Conclusion In this paper , we introduce LLMT ailor , a tool that enables eective and lightweight layer-wise checkpoints split-and-merge for large models. By performing layer-wise checkpointing, our use cases show the potential of reducing total checkpoint size and time by at least 60% compared with existing solutions, while preser ving nal model quality . Although our prototype can only manipulate local che ckpoints, the underlying design can be applied to other checkpointing frameworks, and the implementation of this is part of our future work. Acknowledgements W e sincerely thank the anonymous reviewers for their valuable feedback. This work was supporte d in part by the National Science Foundation (NSF) under grants CNS-2008265 and CCF-2412345. This eort was also supp orted in part by the U.S. Department of Energy (DOE) thr ough the Oce of Advanced Scientic Computing Research’s “Orchestration for Distributed & Data-Intensiv e Scien- tic Exploration” and the “Decentralized data mesh for autonomous materials synthesis” A T SCALE LDRD at Pacic Northwest National Laboratory . PNNL is operated by Battelle for the DOE under Con- tract DE- A C05-76RL01830. References [1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jere y Dean, Matthieu Devin, Sanjay Ghemawat, Georey Irving, Michael Isard, Man- junath Kudlur , Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray , Benoit Steiner , Paul Tucker , Vijay V asudevan, Pete W arden, Martin Wicke, Yuan Y u, and Xiaoqiang Zheng. 2016. TensorFlow: a system for large-scale machine learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (Savannah, GA, USA) (OSDI’16) . USENIX Association, USA, 265–283. [2] AI@Meta. 2024. Llama 3 Model Card. https://github.com/meta- llama/llama3/ blob/main/MODEL_CARD.md [3] Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, W alter Chang, and Nazli Goharian. 2018. A Discourse-A ware Attention Model for Abstractive Summarization of Long Documents. In Proce edings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 2 (Short Papers) . Association for Computational Linguistics, New Orleans, Louisiana, 615–621. doi:10.18653/ v1/N18- 2097 [4] Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 1 (Long and Short Pap ers) , Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. doi:10.18653/ v1/N19- 1423 [5] Chris Egersdoerfer , Philip Carns, Shane Snyder , Robert Ross, and Dong Dai. 2025. STELLAR: Storage Tuning Engine Leveraging LLM Autonomous Reasoning for High Performance Parallel File Systems. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’25) . [6] Chris Egersdo erfer , Arnav Sareen, Jean Luca Bez, Suren Byna, and Dong Dai. 2024. ION: Navigating the HPC I/O Optimization Journey using Large Language Models. In Proceedings of the 16th ACM Workshop on Hot T opics in Storage and File Systems . 86–92. [7] Chris Egersdoerfer , Arnav Sareen, Jean Luca Bez, Suren Byna, Dongkuan Xu, and Dong Dai. 2025. IOAgent: Democratizing Trustworthy HPC I/O Performance Diagnosis Capability via LLMs. In Proceedings of the 39th IEEE International Parallel & Distributed Processing Symposium (IPDPS) . [8] Assaf Eisenman, Kiran Kumar Matam, Steven Ingram, Dheevatsa Mudigere, Raghuraman Krishnamoorthi, Krishnakumar Nair , Misha Smelyanskiy , and Mu- rali Annavaram. 2022. Check-N-Run: a Checkpointing System for Training Deep Learning Recommendation Models. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22) . USENIX Association, Renton, W A, 929–943. https://www.usenix.org/confer ence/nsdi22/presentation/eisenman [9] Swapnil Gandhi and Christos Kozyrakis. 2025. MoEtion: Ecient and Reliable Sparse Checkpointing for Mixture-of-Experts Models at Scale. arXiv:2412.15411 [cs.DC] https://ar xiv .org/abs/2412.15411 [10] Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. 2024. Arcee’s MergeKit: A T o olkit for Merging Large Language Models. In Proce edings of the 2024 Conference on Empirical Methods in Natural Language Processing: Indus- try Track , Franck Dernoncourt, Daniel Preoţiuc-Pietro , and Anastasia Shimorina (Eds.). Association for Computational Linguistics, Miami, Florida, US, 477–485. doi:10.18653/v1/2024.emnlp- industry.36 [11] Andrey Gromov , Kushal Tirumala, Hassan Shap ourian, Paolo Glorioso, and Daniel A. Roberts. 2025. The Unreasonable Ineectiveness of the Deep er Layers. arXiv:2403.17887 [cs.CL] [12] Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats L. Richter, Quentin Anthony , Eugene Belilovsky, Irina Rish, and Timothée Lesort. 2023. Contin- ual Pre-T raining of Large Language Models: How to (re)warm your model? arXiv:2308.04014 [cs.CL] [13] T anmaey Gupta, Sanjeev Krishnan, Rituraj Kumar, Abhishek Vije ev , Bhargav Gulavani, Nipun K watra, Ramachandran Ramje e, and Muthian Sivathanu. 2024. Just-In- Time Checkpointing: Low Cost Error Recovery fr om Deep Learning T rain- ing Failures. In Proceedings of the Nineteenth European Conference on Computer Systems (Athens, Greece) (EuroSys ’24) . Association for Computing Machinery , New Y ork, NY, USA, 1110–1125. doi:10.1145/3627703.3650085 [14] Ganesh Jawahar , Benoît Sagot, and Djamé Seddah. 2019. What Does BERT Learn about the Structure of Language? . In Procee dings of the 57th Annual Meeting of the Association for Computational Linguistics , Anna Korhonen, David T raum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy , 3651–3657. doi:10.18653/v1/P19- 1356 [15] Di Jin, Eileen Pan, Nassim Oufattole, W ei-Hung W eng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale op en domain question answering dataset from medical exams. A pplied Sciences 11, 14 (2021), 6421. [16] Ilya Loshchilov and Frank Hutter . 2019. Decouple d W eight Decay Regularization. arXiv:1711.05101 [cs.LG] https://ar xiv .org/abs/1711.05101 [17] Keming Lu, Bow en Y u, Fei Huang, Y ang Fan, Runji Lin, and Chang Zhou. 2024. Online Merging Optimizers for Boosting Rewards and Mitigating T ax in Align- ment. arXiv:2405.17931 [cs.CL] SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Minqiu Sun, Xin Huang, Luanzheng Guo, Nathan R. T allent, Kento Sato, and Dong Dai [18] Kiwan Maeng, Shivam Bharuka, Isabel Gao, Mark C. Jer ey , Vikram Saraph, Bor- Yiing Su, Caroline Trippel, Jiyan Y ang, Mike Rabbat, Brandon Lucia, and Carole- Jean Wu. 2020. CPR: Understanding and Improving Failure T olerant Training for Deep Learning Recommendation with Partial Recovery . arXiv:2011.02999 [ cs.LG] https://arxiv .org/abs/2011.02999 [19] A vinash Maur ya, Robert Underwood, M. Mustafa Raque, Franck Capp ello, and Bogdan Nicolae. 2024. DataStates-LLM: Lazy Asynchronous Checkpointing for Large Language Models. In Proceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing (Pisa, Italy) (HPDC ’24) . Association for Computing Machinery, New Y ork, NY, USA, 227–239. doi:10. 1145/3625549.3658685 [20] Jayashree Mohan, Amar Phanishayee, and Vijay Chidambaram. 2021. CheckFreq: Frequent, Fine-Grained DNN Checkpointing. In 19th USENIX Conference on File and Storage T echnologies (F AST 21) . USENIX Association, 203–216. https: //www.usenix.org/confer ence/fast21/presentation/mohan [21] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar , Nick Barnes, and Ajmal Mian. 2025. A com- prehensive overview of large language models. A CM Transactions on Intelligent Systems and T echnology 16, 5 (2025), 1–72. [22] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer , James Bradbury , Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Y ang, Zach De Vito, Martin Raison, Alykhan T ejani, Sasank Chilamkurthy , Benoit Steiner , Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyT orch: an imperative style, high-performance deep learning library . Curran Associates Inc., Red Hook, N Y , USA. [23] Jason P hang, Haokun Liu, and Samuel R. Bowman. 2021. Fine- T uned Trans- formers Show Clusters of Similar Representations Across Lay ers. In Proceedings of the Fourth BlackboxNLP W orkshop on A nalyzing and Interpreting Neural Net- works for NLP , Jasmijn Bastings, Y onatan Belinkov , Emmanuel Dupoux, Mario Giulianelli, Dieuwke Hupkes, Yuval Pinter , and Hassan Sajjad (Eds.). Associa- tion for Computational Linguistics, Punta Cana, Dominican Republic, 529–538. doi:10.18653/v1/2021.blackboxnlp- 1.42 [24] Or Press and Lior W olf. 2017. Using the Output Embedding to Improve Language Models. arXiv:1608.05859 [cs.CL] https://ar xiv .org/abs/1608.05859 [25] Aurick Qiao, Br yon Aragam, Bingjing Zhang, and Eric Xing. 2019. Fault T ol- erance in Iterative-Convergent Machine Learning. In Procee dings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, V ol. 97) , Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 5220–5230. https://proceedings.mlr .press/v97/qiao19a.html [26] Qwen, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Y ang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, K eqin Bao, Kexin Y ang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi Tang, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang Fan, Yang Su, Yichang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. 2025. Qwen2.5 T echnical Report. arXiv:2412.15115 [cs.CL] https://ar xiv .org/abs/2412.15115 [27] Samyam Rajbhandari, Je Rasley , Olatunji Ruwase, and Y uxiong He. 2020. ZeRO: memory optimizations toward training trillion parameter models. In Proce edings of the International Conference for High Performance Computing, Networking, Storage and A nalysis (Atlanta, Georgia) (SC ’20) . IEEE Press, Article 20, 16 pages. [28] Je Rasley , Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deep- Speed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. In Proceedings of the 26th ACM SIGKDD International Con- ference on Knowledge Discovery & Data Mining (Virtual Event, CA, USA) (KDD ’20) . Association for Computing Machinery, New Y ork, N Y , USA, 3505–3506. doi:10.1145/3394486.3406703 [29] Zhuang W ang, Zhen Jia, Shuai Zheng, Zhen Zhang, Xinwei Fu, T . S. Eugene Ng, and Yida W ang. 2023. GEMINI: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints. In Procee dings of the 29th Symposium on Op erating Systems Principles (Koblenz, Germany) (SOSP ’23) . Association for Computing Machinery , New Y ork, NY, USA, 364–381. doi:10.1145/3600006.3613145 [30] Mitchell W ortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Y air Carmon, Simon Kornblith, and Ludwig Schmidt. 2022. Model soups: averaging weights of multiple ne-tuned models improves accuracy without increasing inference time. arXiv:2203.05482 [cs.LG] [31] Prateek Y adav , Der ek T am, Leshem Choshen, Colin Rael, and Mohit Bansal. 2023. TIES-MERGING: resolving interference when merging models. In Proceedings of the 37th International Conference on Neural Information Processing Systems (New Orleans, LA, USA) (NIPS ’23) . Curran Associates Inc., Red Hook, N Y , USA, Article 310, 23 pages. [32] Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Y ongbin Li. 2024. Language models are super mario: absorbing abilities from homologous mo dels as a free lunch. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24) . JMLR.org, Article 2382, 21 pages. [33] Y efan Zhou, Tianyu Pang, Keqin Liu, Charles H. Martin, Michael W . Mahoney , and Y aoqing Y ang. 2023. Temperatur e balancing, layer-wise weight analysis, and neural network training. In Proceedings of the 37th International Conference on Neural Information Processing Systems (New Orleans, LA, USA) (NIPS ’23) . Curran Associates Inc., Red Hook, NY, USA, Article 2775, 31 pages. A Overview of Contributions and Artifacts A.1 Paper’s Main Contributions 𝐶 1 W e present LLMT ailor , an ee ctive tool that assembles a resum- able checkpoint from parts of multiple checkpoints while maintaining the model performance. 𝐶 2 W e demonstrate that partial che ckpointing with LLMT ailor can substantially lower storage requirements and che ckpoint time in LLM training. 𝐶 3 W e show that LLMT ailor incurs only a small amount of overhead when resuming training from a merged checkpoint. A.2 Computational Artifacts 𝐴 1 https://doi.org/10.5281/zenodo.16909083 Artifact ID Contributions Related Supported Paper Elements 𝐴 1 𝐶 1 , 𝐶 2 , 𝐶 3 T ables 1-7 Figure 3 B Artifact Identication B.1 Computational Artifact 𝐴 1 Relation T o Contributions The artifact provides the implementation of the methods and ideas presented in the paper . Our LLMT ailor , included as the artifact, supports ne-grained manipulation of model and optimizer states across checkpoints, selective merging part of the checkpoints, and reconstruction of training state. It is also the key to realizing the proposed checkpoint strategies as it enables partial layer saving. Expected Results (1) Flexibility in Checkpoint Composition By using LLM- T ailor , we are able to assemble “Frankenstein” checkpoints. It selects and mixes layers from dierent che ckpoints and shows both functional correctness (the model runs and trains as expected) and practical utility (supporting adaptive failure recovery or analysis). (2) Reduced Checkp ointing Overhead The experiments will show that LLMT ailor enables selective, layer-level check- pointing which can reduce the size and time of saved check- points. Compared to traditional full-model checkp oints, the system achieves signicant I/O savings and reduced storage usage without sacricing recoverability . (3) Faithful Model Recovery and Continuity By merging layers and optimizer states fr om multiple checkpoints, use case 1 (merge by parity) demonstrates that training can be faithfully resumed from partial checkpoints. The outcome to expe ct is a recovery traje ctory that closely matches (or even exactly ov erlays) the trajector y from full che ckpointing baselines. While in use case 2 (lter layers), the recovered training will have a bias with the original checkpoint. LLMT ailor: A Layer-wise T ailoring T ool for Eicient Checkp ointing of Large Language Models SC W orkshops ’25, November 16–21, 2025, St Louis, MO, USA Expected Reproduction Time (in Minutes) The expected computational time of this artifact on GP U is 60 min. Artifact Setup (incl. Inputs) Hardware. One 8 × A100(40GB-memor y ) node. CP U: At least 64 cores. Memory: At least 200 GB. Storage: Depending on the model and training epochs, recom- mend at least at least 350 GB for a 7B model and 700 GB for 14B model. Soware. The used software are CUDA -12.8, DeepSpe ed-v0.17.2, Py T orch-2.7.1, transformers-4.55.0, pydantic-2.9.2, ash_attn-2.6.3. The used models ar e Llama-3.2-1B, Llama-3.1-8B, and Qwen-2.5-7B. (https://huggingface.co/meta-llama/Llama-3.2-1B), (https://huggingface.co/meta-llama/Llama-3.1-8B), (https://huggingface.co/Qwen/Qwen2.5-7B). Datasets / Inputs. W e use two medical datasets: (i) PubMe d-Summarization ( https://huggingface.co/datasets/ccdv- /pubmed-summarization) (ii) Me dQ A ( https://huggingface.co/datasets/Malikeh1375/medical- question-answering-datasets) Installation and Deployment. First, using anaconda to create an environment using python version 3.11. Then using git to clone our artifacts and using ’pip install -r requirements.txt’ to install our dependencies. The examples are in the folder ’/example ’ . Then, modifying the Y AML le to whatever you like. Next, modifying the conguration in the top of this start_merge .py le. ( e.g. CHECKPOIN T_P A TH). And nally , run these steps in example.ipynb . For the benchmark running tasks, we use the open sour ce project called lm-evaluation-harness ( https://github.com/Eleuther AI/lm- evaluation-harness). Please follow the instructions of this pr oject to install and use. Artifact Exe cution The workow consists of 3 tasks: (1) 𝑇 1 . Run an LLM training job that generates multiple check- points. Our package can b e used as a submodule within a partial checkpointing framework, and is fully compatible with checkpoints produced in this form. (2) 𝑇 2 . T o congure and start our program, the user should pro- vide: the path to the pre vious checkpoints, the output path for the new "Frankenstein" checkpoint, the number of GP Us, the failure step numb er , and the number of hidden layers in the training model. If partial checkpoints are used, the user may also provide the JSON le generate d by the partial checkpointing system. In this case, our tool will automati- cally generate a corresponding Y AML le. Other wise, the user can manually write a Y AML le specifying the layers to be merged. Finally , LLMT ailor will select layers from dif- ferent checkpoints and assemble them into a complete new checkpoint. (3) 𝑇 3 . Use the path of the newly generated checkpoint to re- sume training. Observe whether the loss curves align with those of uninterrupted training, thereby conrming recovery from failure . For the nal stage, evaluate the model perfor- mance on the benchmarks mentioned in the paper to validate correctness and consistency . Artifact Analysis (incl. Outputs) Running T ask 𝑇 1 will generate multiple checkpoints together with an optional JSON le that r ecords the partial checkpointing deci- sions. Dierent layers ar e checkpointed at dierent steps, and the detailed information is logged in the JSON les. By comparing the size of these checkpoints, one can verify that when only a subset of layers is saved, the resulting checkp oint is smaller than a full checkpoint. T ask 𝑇 2 produces a complete checkpoint folder . Users can con- rm correctness by comparing its size and le structure against a standard full checkpoint generated without selective saving. Executing T ask 𝑇 3 demonstrates recovery from a simulated fail- ure. Training should resume exactly at the failure step, and the reported loss and downstream performance metrics will conrm that recovery is almost consistent with uninterrupted training.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment