SWE-Protégé: Learning to Selectively Collaborate With an Expert Unlocks Small Language Models as Software Engineering Agents
Small language models (SLMs) offer compelling advantages in cost, latency, and adaptability, but have so far lagged behind larger models on long-horizon software engineering tasks such as SWE-bench, where they suffer from pervasive action looping and…
Authors: Patrick Tser Jern Kon, Archana Pradeep, Ang Chen
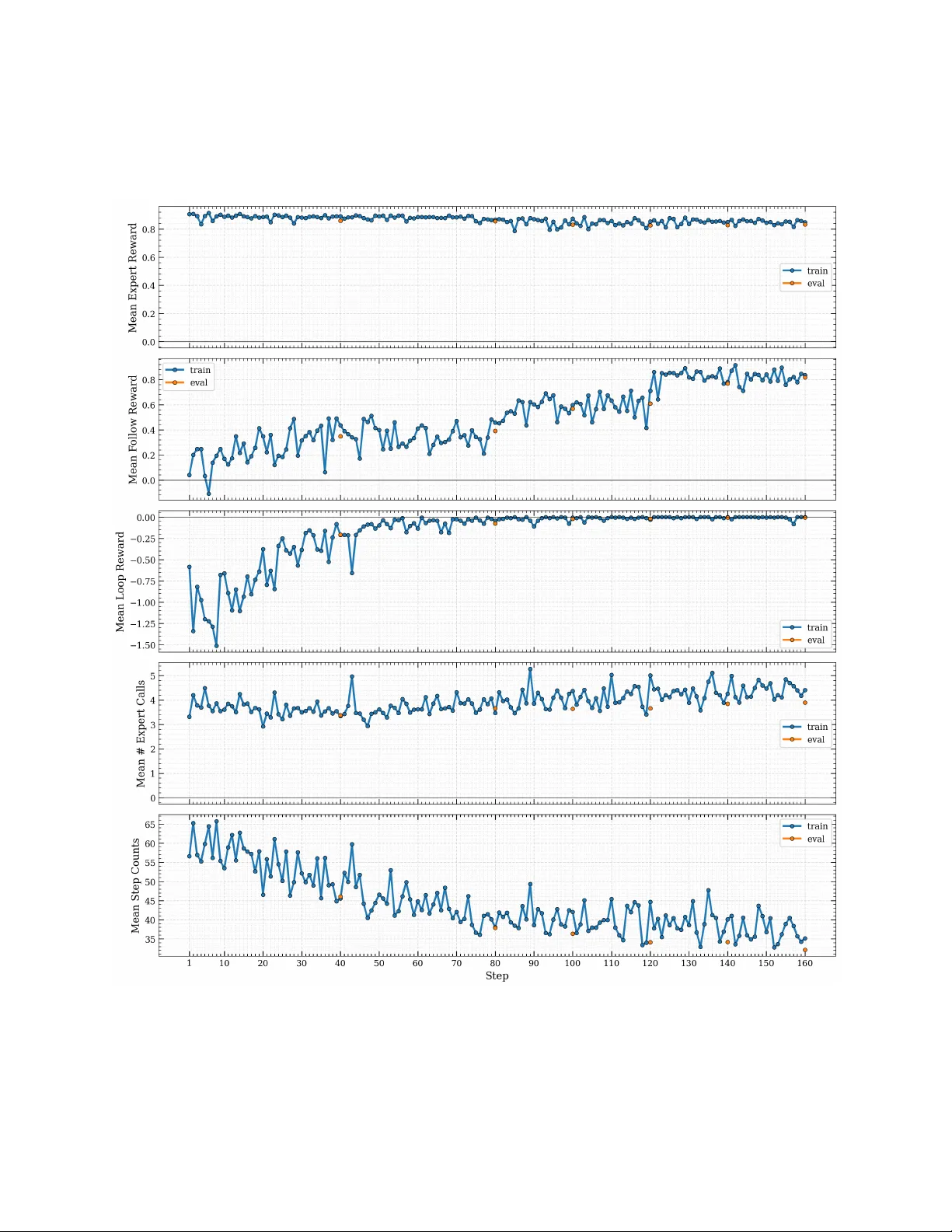
SWE-Protég é: L earning to Selectiv ely Collaborate With an Expert Unlocks Small Languag e Models as Softw are Engineering Ag ents Patrick T ser Jern K on † , 2 , Archana Pradeep 1 , Ang Chen 2 , Alexander P . Ellis 1 , W arren Hunt 1 , Zijian W ang 1 , John Y ang 3 , Samuel Thompson 1 1 Meta, 2 Univ ersity of Mic higan, 3 Stanford Univ ersity † W ork done at Meta Small language mo dels (SLMs) offer comp elling adv antages in cost, latency , and adaptabilit y , but ha ve so far lagged b ehind larger mo dels on long-horizon soft ware engineering tasks such as SWE-b ench, where they suffer from p erv asive action looping and low resolution rates. W e in tro duce SWE-Protégé, a p ost-training framework that reframes soft w are repair as an exp ert–protégé collab oration problem. In SWE-Protégé, an SLM remains the sole decision-maker while learning to selectively seek guidance from a strong exp ert mo del, recognize stalled states, and follow through on expert feedbac k. Our approach com bines sup ervised fine-tuning on exp ert-augmen ted tra jectories with agentic reinforcement learning that explicitly discourages degenerative lo oping and shallo w expert usage. W e lightly p ost-train Qw en2.5-Co der-7B-Instruct to achiev e 42.4% Pass@1 on SWE-b ench V erified with SWE-agent, a +25.4% impro vemen t ov er the prior SLM state of the art, while using exp ert assistance sparsely ( ≈ 4 calls p er task and 11% of total tokens). Date: F ebruary 26, 2026 Correspondence: patkon@umic h.edu , samuelt@meta.com 1 Introduction Soft ware engineering (SE) tasks, most notably SWE-b ench, hav e emerged as an imp ortant proving ground for language mo del (LM) agents, with recent adv ances driven primarily by large op en-source and proprietary LMs (e.g., Claude Sonnet). Y et this dominance stands in tension with a parallel trend ( Ab ouelenin et al. , 2025 ; Bak ouch et al. , 2025 ) tow ard small language mo dels (SLMs; LMs with ≤ 10B parameters) ( Belcak et al. , 2025 ), whic h offer comp elling adv antages in cost, latency , and adaptabilit y , but hav e so far remained largely absen t from recent SWE-b ench progress. Indeed, this is unsurprising given the long-horizon/context nature of SE, whic h requires sustained progress o ver man y turns (e.g., p erforming edits, reco vering from errors) across complex rep ositories, rather than isolated single-turn co de synthesis (e.g., HumanEv al-st yle problems) where SLMs already p erform reasonably w ell ( Hui et al. , 2024 ). Ev en recent data-scaling approac hes that generate large volumes of high-quality agen t tra jectories for training ( W ei et al. , 2025 ; Pan et al. , 2024 ), including the state-of-the-art (SOT A) SWE-smith ( Y ang et al. , 2025 ), remain insufficient for SLMs. Prior w ork shows that SLM agen ts p ost-trained with these metho ds still suffer from stalled progress, whic h commonly manifests as degenerative action lo ops (i.e., SLM rep eatedly calling the same base commands), and corresp ondingly p o or resolution rates ( ≈ 10% P ass@1) on SWE-b enc h V erified ( Pan et al. , 2024 ; Y ang et al. , 2025 ). Moreo ver, our analysis shows that progressiv ely scaling SWE-smith training can ev en induce p erformance regressions. Motiv ated by these limitations, we explore a complementary paradigm in SWE-Protégé that reframes the problem as one of exp ert–protégé collab oration, analogous to pair programming, leveraging the resp ectiv e strengths of b oth comp onents. W e study one effective instan tiation of this paradigm in which the protégé (SLM) retains resp onsibilit y for the primary workflo w and decision-making (handling most routine reasoning and interaction) with sp eed and low cost, while le arning to selectively seek guidance from a strong exp ert (e.g., Claude Sonnet) that provides exp ensive but high-v alue intuition/understanding only when needed. 1 T ask Dataset (e.g., S WE-smith) ask_expert Add 1 new tool: Agent System (e.g., S WE-agent ) LM Agent Exis t ing T ool s E dit … Na vigat e R epo Start w/ a Strong LM: SFT A gent S y s t em ( e. g., S WE -agent ) SWE-Pro tégé ask_expert (a) SWE-Prot égé Post- T raining Pipeline 1 + P at ch Stall & C ollab Rewar d T ests & Similarity Reward T rajector y Patch GRPO + Update W eights 2 RL ( e. g., GRP O ) + Before Aft er Aft er 1 2 (b) Human-Interpreted T rajectory Snippets (Obser vations Omitted) Step 10: Let’ s read this unrelated file z.py … Step 11: Let’ s edit x.sh for an incorrect reason... Step 12: Browsing this dir /not-related Step 13: I got it! Step 14-75: Let’ s keep browsing some other unrelated dirs… Step 10: Let’ s read this unrelated file z.py … Step 11: ask_expert : “ Any ideas? I think… ” Step 12: Let’ s do B… Step 13: I got it! Step 14-75: Let’ s keep browsing some other unrelated dirs… Do A, then B, and update me Step 11: ask_expert : “ Any ideas? I think… ” Step 12: Let’ s do A… Step 13: Let’ s do B… Step 14: C ompleted. Let me now also try C… Step 15: ask_expert : “I did… and then I tried… Now I think this is the issue… Reasonable?” Do A, then B, and update me Figure 1 (a) Our tw o-phase pip eline yields SWE-Protégé-7B: Phase 1 uses SFT on exp ert-augmented tra jectories; Phase 2 applies GRPO with tra jectory-level rewards. (b) Paraphrased tra jectories. Befor e: the SOT A SLM baseline (SWE-agen t-LM-7B) fails to make reliable forw ard progress and degenerates into unpro ductiv e exploration. After Phase 1 : our SLM can inv ok e the exp ert, but follo w-through on guidance is inconsisten t and it often relapses in to stalling. After Phase 2 : it learns to escalate when stalled, follow through on guidance, and rep ort bac k, exhibiting m ulti-turn pair-programming b ehavior. Sp ecifically , SWE-Protégé p ost-trains an SLM to act as an autonomous pair programmer that can (i) recognize stalled states where it’s not making progress, (ii) inv oke an expert appropriately , and (iii) execute and follow through on exp ert guidance ov er multiple turns. W e implemen t this in tw o phases (Fig. 1 ). First, we distill in to the SLM the mec hanics and semantics of exp ert in teraction via sup ervised fine-tuning on exp ert-augmented tra jectories generated by a strong LM that is also repurp osed to serv e as the exp ert. Second, we run on-p olicy agen tic reinforcement learning with shap ed rewards that target when to escalate and how to collab orate o ver m ultiple turns: the exp ert is repurp osed as an in-tra jectory judge (providing pro cess-lev el sup ervision), which first explicitly discourages degenerative stalling, and then p enalizes low-qualit y collab oration. Throughout, the SLM remains the primary decision-maker, treating the exp ert as an interactiv e collab orator rather than an oracle. On SWE-Benc h V erified, our SWE-Protégé protot yp e ligh tly p ost-trains Qw en2.5-Co der-7B-Instruct to ac hieve 42.4% accuracy , (+25.4% ov er the prior state of the art, SWE-agent-LM-7B by SWE-smith). The model in vok es exp ert assistance sparsely (only ab out 4 calls p er task) with exp ert tok ens comprising only ∼ 11% of total tok ens, yielding up to 8.2 × low er cost than an exp ert-only agent, signifying strong p erformance at low cost while preserving the SLM’s autonomy . All results use the standard SWE-agen t setup (75-step limit, no test-time sampling). Notably , these gains are ac hieved with minimal data and compute: w e use the same SFT task dataset size ( ≈ 5K tra jectories) as SWE-smith, and p erform a short single-node RL phase with rollouts generated from only 100 tasks for 160 steps. W e envision a SWE-Protégé-like paradigm shining in settings where, for instance, access to fron tier-mo del tokens is a binding constraint: e.g., in application services ( Cursor , 2026 ; Op enClaw , 2026 ) constrained by cost, quotas, or rate-limits. 2 SWE-Protég é P ost-training Pipeline Motiv ated by the aforementioned limitations, we introduce a p ost-training pip eline that enables an SLM to engage in autonomous, sele ctive, and multi-turn c ol lab or ation with an exp ert mo del during long-horizon tasks. SWE-Protégé trains the SLM itself to (i) recognize stalled states, (ii) initiate escalation when appropriate, and (iii) follow through on exp ert guidance in a structured, iterative manner—treating the exp ert as an interactiv e collab orator rather than a one-shot oracle, analogous to pair programming initiated by the junior partner. Problem Setting. W e consider an agentic co ding environmen t in which an SLM is embedded within an agen t scaffold (e.g., SWE-agent ( Y ang et al. , 2024 )) and prompted ov er multiple turns to solve a task (e.g., from SWE-b enc h). A t each turn, the SLM selects an action by inv oking one of the agent’s to ols—such as issuing shell commands (e.g., grep ) or editing files—which are executed in a task-sp ecific environmen t (e.g., a cloned GitHub repository). Action selection is usually conditioned on a constructed representation of the in teraction history (e.g., prior actions and to ol outputs). Up on termination, task success is assessed via external v erification (e.g., unit tests in SWE-bench-st yle setups). 2 Model S ystem T rain Size Accuracy (%) Reference Close d W eight Mo dels GPT-4o Op enHands - 22.0 Op enAI ( 2024 ) GPT-4o SWE-agen t - 23.0 Op enAI ( 2024 ) Claude 3.5 Sonnet Agen tless - 50.8 An thropic ( 2024 ) Claude 3.5 Sonnet AutoCo deRo ver - 46.2 An thropic ( 2024 ) Claude 3.5 Sonnet Op enHands - 53.0 An thropic ( 2024 ) Claude 3.7 Sonnet SWE-agen t - 58.2 An thropic ( 2025 ) Claude 4.5 Sonnet SWE-agen t - 72 - Llama3-SWE-RL-70B Agen tless 11M 41.0 W ei et al. ( 2025 ) Op en W eight Mo dels (Post-T r aine d) Lingma-SWE-GPT-72B SWE-SynInfer - 28.8 Ma et al. ( 2024 ) SWE-fixer-72B SWE-Fixer 110k 32.8 Xie et al. ( 2025 ) SWE-gym-32B Op enHands 491 20.6 P an et al. ( 2024 ) R2E-Gym-32B Op enHands 3.3k 34.4 Jain et al. ( 2025 ) SWE-agen t-LM-32B SWE-agen t 5k 40.2 Y ang et al. ( 2025 ) Op en W eight Smal l L anguage Mo dels ( ≤ 10B p ar ameters ( Belc ak et al. , 2025 )) SWE-gym-7B Op enHands 491 10.6 P an et al. ( 2024 ) SWE-agen t-LM-7B SWE-agen t 2.4k 17 Y ang et al. ( 2025 ) Lingma-SWE-GPT-7B SWE-SynInfer - 18.2 Ma et al. ( 2024 ) SWE-Protégé-7B (Sonnet 3.7) SWE-agent 4.9k 30.8 SWE-Protégé-7B (Sonnet 4.5) SWE-agent 4.9k 41.0 SWE-Protégé-7B (Opus 4.1) SWE-agen t 4.9k 42.4 T able 1 Resolve rates (Pass@1) on SWE-bench V erified for existing solutions, tak en directly from ( Y ang et al. , 2025 ), compared to SWE-Protégé. W e exclude op en-weigh t mo dels trained end-to-end from scratch ( Cop et et al. , 2025 ), and systems that rely on verifiers or test-time sampling. The 17% result corresponds to our strongest in ternally repro duced SWE-agen t-LM-7B baseline. 2.1 Agent Sy stem Setup Agent T ool and Expert Interfaces. SWE-Protégé requires only the addition of a single exp ert-inv ocation tool to an existing agent system. Let s ∈ S denote the full agent state, including the interaction history , to ol outputs, and system prompts. The SLM defines a p olicy π θ ( a | s ) ov er actions a ∈ A , where actions corresp ond to to ol in vocations. W e extend the action space to A ′ = A ∪ { ask_exp ert } where ask_exp ert is a structured to ol call in which the SLM formulates a query (e.g., a question). The expert pro cesses this query and returns textual guidance, which is app ended to the agen t state s and subsequently used for contin ued decision-making. In practice, all actions—including exp ert calls—are generated as text under a unified mo del distribution p θ ( y | s ) , and exp ert inv o cation is detected by the agent controller via a reserved to ol-call format. The exp ert mo del is inv ok ed with the agent’s query together with a system prompt (App. C ). T o keep escalation light w eigh t, the exp ert may b e given only a partial view of s ; sp ecifically , it receives a compact summary ˜ s consisting of the most recent K in teraction turns and relev an t to ol outputs. In contrast, the agent alw ays acts from the complete state s . W e show later (§ 4 ) that this asymmetric information flow keeps exp ert in teractions fo cused and tok en-efficient. Collaboration Mechanisms. Exp ert in vocation occurs through tw o mechanisms. First, the SLM may au- tonomously emit ask_exp ert as part of its p olicy . This learned inv ocation b ehavior is the primary fo cus of SWE-Protégé; while training or adapting (e.g., prompt optimization ( Khattab et al. , 2024 )) exp ert mo dels is 3 equally imp ortan t and will likely yield even stronger p erformance, we assume that prompting strong frontier mo dels yields sufficiently strong exp erts for our setting, and defer exp ert optimization to future work (§ 6 ). Second, w e supp ort optional rule-based interv en tion (e.g., k eyword triggers) that can forcibly inv ok e the exp ert. W e currently use this for ablation purp oses (§ 4.1 ). 2.2 Phase I: Supervised Induction of Expert Usage The first training phase equips the SLM with an op erational understanding of exp ert interaction. Empirically , w e find that SLMs fail to generalize to new to ols (ev en simple ones) without explicit imitation learning. Crucially , this phase addresses how to inter act with the exp ert at the level of mechanics and lo cal semantics; e.g., inv oking the tool, form ulating contextually appropriate queries. It do es not determine when escalation is appropriate, nor do es it enforce correct downstream b ehavior after advice is given. S ynthetic Trajectory Generation. T raining tra jectories are generated using a strong co de-capable mo del π E conditioned on s with augmented action space A ′ , in the same agent environmen t used for SLM inference. The mo del is prompted to inv ok e the exp ert to ol only when appropriate (App. B ). In practice, this yields a natural data mixture in which exp ert inv ocation is sparse y et present in most tra jectories, alongside a smaller subset with no exp ert calls, without any manual data mixing. W e also found it b eneficial to instantiate the exp ert as the same mo del π E , and to additionally grant the exp ert access to the ground-truth solution (while explicitly instructing it not to reveal the answer verbatim). This pro duces a substantially larger num ber of correct tra jectories. 1 Supervised Fine- T uning. W e p erform rejection-sampling sup ervised fine-tuning (SFT) on the exp ert-augmented tra jectories. Given state–token pairs { ( s i , y i ) } N i =1 , w e minimize the standard next-tok en cross-entrop y loss: L SFT ( θ ) = − E ( s i ,y i ) [log p θ ( y i | s i )] . W e introduce no auxiliary losses (e.g., regularizers that incentivize exp ert calls). Instead, the SLM learns to sparsely inv oke the exp ert in-context, emerging implicitly through imitation of tra jectories where exp ert calls are infrequen t. 2.3 Phase II: RL for Expert–SLM Pair Programming Phase I I (full details in App. D ) aligns the p ost-SFT SLM to b ehav e as an autonomous pair programmer: it should (i) esc alate when pr o gr ess stal ls instead of lo oping, and (ii) fol low thr ough and r ep ort b ack on exp ert guidance across multiple turns. W e achiev e this with agen tic RL and a comp osite rew ard that, in addition to standard ob jectiv es such as correctness, explicitly mo dels (a) degenerativ e lo ops and (b) low-qualit y collab oration. Starting from the SFT c heckpoint, we p erform on-p olicy agentic RL with a GRPO-style ob jectiv e (details in § 3.1 ). Collaboration Quality . Let τ denote the full agent tra jectory (sequence of agent actions and to ol resp onses). During τ , the agent may call the exp ert N times; for call i , let q i b e the agent query , g i the exp ert guidance, and ˜ s i the compact context pack et shown to the exp ert (e.g., containing recen t agen t messages). W e asso ciate eac h g i with the subsequent r esp onse se gment ∆ i ( τ ) (the agent’s actions and to ol outputs after receiving g i through the next exp ert call or termination). W e repurp ose the exp ert i tself as an in-tr aje ctory judge (akin to a v alue mo del ( Y uan et al. , 2024 )) by defining t wo b ounded functionals: u i := J warran t ( q i , ˜ s i ) ∈ [0 , 1] , f i := J follow ( g i , ∆ i ( τ )) ∈ [0 , 1] . (1) where u i scores whether escalation was warran ted (discouraging lazy in vocations), and f i scores whether the agen t follow ed guidance and rep orted back (enforcing m ulti-turn collab oration). These scores are computed via a hidden judge call and logged p er even t. 1 At an y other point in time, including during ev aluation, the exp ert no longer has access to the gold patch and unit tests and operates solely on ˜ s . Details of prompting, filtering, and data statistics are provided in App. B . 4 Rew ard structure and gating. W e use a tra jectory-lev el comp osite reward inspired by ( Huang et al. , 2025 ). R total ( τ , x ) = R loop ( τ ) + w follow R follow ( τ ) + g loop ( τ ) g follow ( τ ) R other ( τ , x ) , (2) R other ( τ , x ) = R correct ( τ , x ) + w sim R sim ( τ , x ) + w expert R expert ( τ ) . (3) Here x denotes the task instance metadata (e.g., gold patch), R loop ≤ 0 penalizes degenerative lo oping (command rep etition); R expert shap es deferral qualit y using { u i } (and an ti-spam p enalties); and R follow shap es follo w-through using { f i } . The gates g loop , g follow ∈ { 0 , 0 . 5 , 1 } do wnw eigh t R other under severe lo oping or failed follow-through, prev enting correctness/similarity (deriv ed from ( Cop et et al. , 2025 )) from masking pathological in teraction b ehavior. Rew ard shaping curriculum. T o amplify the reward signal for the desired b ehaviors (i) and (ii), we adopt a t wo-stage reward shaping ( Ng et al. , 1999 ) schedule: (1) lo op aggr essive shaping, which makes R loop and g loop strongly sub optimal, anchoring stalled progress to exp ert inv o cation rather than contin ued unpro ductive exploration; and (2) loop+follow aggr essive shaping, which additionally mak es w follow and g follow strongly sub optimal, encouraging the SLM to follow exp ert guidance to completion and rep ort back, thereby inducing true multi-turn pair programming. W e sp ecify the exact sc hedule (w eights, caps, and gate thresholds) in App. D.5 . As we show in § 4 , these b ehaviors emerge after only a small n umber of RL up dates on modest hardw are, yielding further p erformance and efficiency gains ov er § 2.2 . 3 Experimental Setup W e aim to explore the utility of our approach (§ 2 ) under a setting that is closely comparable to SWE- smith ( Y ang et al. , 2025 ), the SOT A at the time of ev aluation. Across all exp erimen ts, we used a single node equipp ed with 8 NV IDIA A100/H100 80G GPUs (e.g., A WS p4de.24xlarge ) for b oth training and inference. Agent Sy stem. W e adopt the off-the-shelf SWE-agent framew ork exactly as used in SWE-smith, augmented with a single additional to ol, ask_exp ert , sub ject to a 75-step and $2 budget. At each step, SWE-agent prompts the language mo del to pro duce a ReAct-st yle ( Y ao et al. , 2022 ) (thought, action) pair, where actions corresp ond either to file edits or shell commands within the task environmen t. Only 6 exp ert calls are p ermitted throughout all task rollouts. Models. Our base mo del is Qwen-2.5-Coder-Instruct ( Hui et al. , 2024 ), primarily the 7B v arian t, as used in SWE-smith. W e additionally rep ort selected ablations with the 32B v arian t. Inference and rollout generation are p erformed using vLLM. Exp ert models are accessed via A WS Bedro ck and include Claude Sonnet 3.7, Sonnet 4.5, and Opus 4.1. Exp erts receive only the most recent 5 messages as context. Ev aluation. W e ev aluate on SWE-b ench V erified ( Chowdh ury et al. , 2024 ), a human-v etted 500-instance SWE-b enc h ( Jimenez et al. , 2023 ) subset (dra wn from 12 real-world GitHub rep ositories) to reduce ambiguit y in problem statements and improv e ev aluation reliability . W e rep ort %Resolved (Pass@1), i.e., the fraction of tasks solved by a single rollout per instance. W e do not use multi-attempt sampling, ma jorit y voting, or other test-time scaling. T o assess p otential data con tamination of our approach, we additionally ev aluate on a held-out subset of the SWE-smith task dataset comprising muc h newer tasks that is disjoint from all training data (details in § 4.1 ). 3.1 T raining Setup SFT Details. W e p erform rejection-sampling full SFT on the Qwen-2.5-Coder-Instruct-7B base mo del with T orc htune ( meta-p ytorch , 2026 ) using the same SWE-smith task dataset ( SWE-b ench , 2026a ), for a fair comparison. Sp ecifically , we train on tra jectories generated by Claude Sonnet 3.7 using our pro cedure (§ 2.2 ; whic h yielded 38% more usable tra jectories than when the ground-truth patc h was not provided) by sampling un til we obtained ≈ 4.8K resolved tasks. W e use a maximum sequence length of 32,762 and batch size 32. W e also exp erimented with LoRA and QLoRA under the same data and ev aluation proto col; b oth underp erformed full SFT on SWE-b ench V erified Pass@1. Thus, w e rep ort full SFT results throughout. RL Details. Starting from the SFT chec kp oin t, we apply an on-p olicy RL stage using GRPO ( Khatri et al. , 2025 ). While stronger v arian ts exist ( Y u et al. , 2025 ), we only use a minimal mo dification to standard GRPO: 5 Figure 2 SWE-Protégé-7B exhibits consistent gains via SFT with increased SWE-smith training data. Figure 3 Exp ert tokens remain consistently low, while total tok en usage is substantially reduced after Phase II. asymmetric clipping (following ( Y u et al. , 2025 )) with separate upp er/lo wer clip thresholds, setting ϵ high = 0 . 28 and ϵ low = 0 . 20 to reduce premature en tropy collapse. Concretely , for a prompt x , w e sample G completions { a i } G i =1 ∼ π θ old ( · | x ) and optimize J ( θ ) = 1 G G X i =1 min r i ( θ ) A i , clip r i ( θ ) , 1 − ϵ low , 1 + ϵ high A i − β KL π θ ( · | x ) ∥ π ref ( · | x ) . where r i ( θ ) = π θ ( a i | x ) /π θ old ( a i | x ) . The adv an tage is computed via group normalization, A i = r env i − mean( { r env j } G j =1 ) std( { r env j } G j =1 ) , with r env i denoting the scalar rollout rew ard. W e train on a 100-task subset drawn from SWE-Gym ( Suman- thRH ) (bundled with SkyRL), with no dataset mi xing. W e used 6 rollouts p er prompt, batch size 16, and 160 total steps. This RL phase is in ten tionally short and data-light, targeting b ehavioral shaping of exp ert usage and tra jectory hygiene rather than broad capability gains. Our reward shaping schedule is (details in App. D ): (i) lo op aggr essive shaping for steps 1–80, where w e set ( k 1 , k 2 , λ loop , c loop ) = (15 , 8 , 0 . 5 , − 10) and only activ ate the g loop gate. (ii) lo op+fol low aggr essive shaping for steps 81–160, where we retain the same loop penalty , set ( w expert , w follow ) = (0 . 3 , 2 . 0) and ( τ follow , p follow-lo w ) = (0 . 5 , − 2 . 0) , activ ate the g follow gate, and imp ose a hard − 10 p enalty when no exp ert call is made. Our RL system builds on Ray-based SkyRL ( Nov aSky-AI , 2026 ). W e integrate SWE-agen t by implementing a SkyRL gener ator that, for eac h sampled task, launches a Ra y w orker to run a full SWE-agent episo de in a SWE- ReX Dock er run time. T o improv e stability and throughput, we (i) cap concurrent SWE-agent/Dock er startups and introduce I/O back off to mitigate stalls and transien t failures, (ii) add tra jectory-level c heckpointing of completed rollouts to supp ort mid-run rew ard-shaping up dates, and (iii) pip eline inference with multiple in-fligh t batches to maintain high vLLM utilization despite stragglers. 4 R esults T able. 1 summarizes our main results on SWE-b enc h V erified. T o ensure a fair comparison to SWE-smith (the SOT A op en-weigh t scaling baseline) we restrict exp ert back ends to the same ev aluation lineage, using Sonnet 3.7 as in SWE-smith and additionally considering new er successors (Sonnet 4.5 and Opus 4.1), even 6 Figure 4 SWE-Protégé substantially reduces per-task cost relativ e to direct exp ert execution (the exp ert solves the entire task). Details in § 4.1 . Model Pass@1 (%) ∆ SWE-Protégé-7B (Sonnet 3.7) 30.6 +1.2 SWE-Protégé-7B (Sonnet 4.5) 41.0 +6.2 SWE-Protégé-7B (Opus 4.1) 42.4 +2.8 T able 2 Phase I I RL results in p erformance improv ements on SWE-b ench V erified. ∆ denotes absolute improv e- men t ov er the corresponding SFT c heckpoint. though stronger options exist to day . SWE-Protégé-7B ac hieves up to 42.4% accuracy , exceeding the best prior op en-w eight scaling baseline SWE-agent-LM-32B (40.2%) by +2.2%, while substantially impro ving ov er the corresp onding SLM baseline SWE-agent-LM-7B (+30.6%) and the strongest prior 7B-class SWE system Lingma-SWE-GPT-7B (+24.2%). Finally , Phase I I RL training starting from the SFT c heckpoints (T able 2 ) consisten tly improv es p erformance across exp ert back ends, delivering an av erage gain of 3.4%. P erformance Scales with More Training Data. Fig. 2 plots accuracy as a function of the num ber of training tra jectories. F or each p oint, we subsample tra jectories uniformly at random from our ≈ 4.8k source task p o ol and train from the same base initialization. W e also indep enden tly re-trained/ev aluated the SWE-agen t-LM-7B scaling curve using the original tra jectory p o ol ( SWE-b ench , 2026b ) and matching sampling proto col for each budget, and observed accuracy consistent with SWE-smith rep orts (e.g., ≈ 15–17% at the 2k–2.4k regime). W e fo cus on the SWE-smith tra jectory source b ecause it w as shown to pro vide stronger impro vemen ts than alternativ e sources (e.g., SWE-Gym ( Pan et al. , 2024 )) at comparable dataset sizes. F or SWE-Protégé-7B, increasing the SFT tra jectory budget yields monotonic gains across all three exp erts: e.g., with Sonnet 3.7, accuracy improv es from 19.0% (1.3k) → 33.4% (4.8k), a net gain of +14.4%; and with Sonnet 4.5, 23.6% → 39.4% (+15.8%). In contrast, SWE-agent-LM-7B exhibits a plateau from 2.2% at 100 tra jectories to 17.0% at 2.4k, follo wed by regression at larger budgets (11.8% at 5.0k); only the higher-budget regime is sho wn in Fig. 2 . These trends align with SWE-smith’s finding that high-qualit y tra jectories can drive strong p erformance gains, but extend it b y showing that such gains can b e realized in SLMs when tra jectories are augmen ted with sparse exp ert interactions; we note that direct prompting is insufficient to elicit this b ehavior (w e did targeted ablations on SWE-smith’s trained 7B and 32B mo dels). 4.1 Ablations on SWE-Protégé Expert Collaboration is T oken-light. Fig. 3 decomposes p er-task generation into SWE-Protégé tokens vs. expert tok ens. W e fo cus our discussion on Phase I I (P2), as the qualitativ e patterns are consisten t across phases. Exp ert tokens accoun t for only a small fraction of each tra jectory (e.g., 11.9% with Sonnet 4.5), implying that SWE-Protégé p erforms the bulk of reasoning, exploration, and patching, while using the exp ert as a sparse collab orator rather than a primary driver. Exp ert replies are short (median / p95 / max: 500 / 937 / 1,657 tok ens) despite b eing conditioned on large input con texts (8,885 / 20,716 / 43,031 tokens) consisting of the SLM query and five prior messages (§ 3 ). Mean while, total tok ens p er task remain ≈ constan t across exp erts ( ∼ (3 – 3 . 2) × 10 5 ), suggesting that swapping exp erts primarily changes quality rather than the amount of agen t-side work. Phase I I reduces total token usage by ≈ 40%, primarily by eliminating degenerative lo oping. SWE-Protégé also yields large reductions in exp ert-related cost. F rom Fig. 4 , direct exp ert execution has median p er-task costs of $0.54 (Sonnet 3.7) and $1.24 (Sonnet 4.5), with outliers reaching $3.04 and $2.88. Under SWE-Protégé, the median exp ert cost drops to $0.13/$0.15 for Sonnet 3.7/4.5 (4.2 × and 8.2 × lo wer than direct execution), and to $0.65 with Opus 4.1; despite Opus 4.1 b eing 5 × and 4.54 × more exp ensiv e p er-tok en, it remains cost-comparable to direct Sonnet 3.7 and c heap er than direct Sonnet 4.5. Finally , we separately test Sonnet 3.7 and Sonnet 4.5 on SWE-agent with step limits of 8 and 16, resp ectively , which is a more generous budget that exceeds b oth our 6-exp ert-call cap and av erage exp ert cost (by ∼ 1.47 × and 1.03 × , resp ectiv ely). W e find p erformance drops sharply to 18.2% and 26%. 7 Figure 5 Phase I I RL (P2) sharply reduces cost/step limit ab orts relative to p ost-SFT (P1) and SWE-smith baselines. SWE-Protégé-7B Solves T asks Efficiently . Bey ond reducing exp ert token usage, SWE-Protégé also b ecomes progressiv ely more efficient at the tr aje ctory level . As training pro ceeds, the mean n umber of steps p er task drops from ≈ 60 at the p ost-SFT chec kpoint to ≈ 20 after Phase I I, while the n umber of exp ert calls remains stable at around four (Fig. 8 ). Fig. 10 further sho ws that SWE-Protégé achiev es step counts comparable to Sonnet 3.7 and SWE-agen t-LM-32B. This decoupling indicates that RL do es not simply suppress collab oration, but instead trains SWE-Protégé to collab orate mor e pr o ductively , con v erging in fewer o verall steps. Imp ortantly , shorter tra jectories do not imply premature termination; SWE-Protégé maintains the abilit y to remain fo cused in long-horizon settings: on av erage, 10.8% of instances are resolved after ≥ 40 steps. Com bined with our findings earlier, these effects explain the substantial cost savings observed in Fig. 4 . SWE-Protégé sav es cost along tw o orthogonal dimensions: (i) minimizing exp ensiv e exp ert tokens, and (ii) shortening tra jectories ov erall. Stalling is Replaced with Effective Collaboration. Prior work has identified rep etitive actions as a ma jor failure mo de for SLMs ( P an et al. , 2024 ; Y ang et al. , 2025 ), e.g., mo dels ma y rep eatedly issue lo calization/insp ection commands (e.g., search, op en, grep) W e quan tify this b eha vior using rep eated to ol-use sequences: we define a lo op as a contiguous rep etition of a to ol-action pattern with length at least L , and rep ort the fraction of tra jectories that contain any lo op longer than L . Fig. 6 shows that SWE-Protégé-7B p ost-SFT (P1) suffers from severe lo oping: 31.0% of tra jectories contain a repeated-action run longer than 10 steps (19.0% > 20 ; 8.0% > 40 ), comparable to SWE-agen t-LM-7B/32B (33.6%/24.4% > 10 ). Phase I I RL (P2) sharply reduces this failure mode: only 0.8% of tra jectories ha ve runs longer than 10 and none exceed 20, outp erforming Sonnet 3.7 and 4.5 (b oth 1.8% > 10 ). As seen in Fig. 8 and Fig. 9 , under our lo op aggr essive shaping stage, lo op violations collapse (mean lo op p enalty rises from ≈ − 1 . 3 to ward ≈ 0 ; lo op-negative rate drops from ≈ 0 . 50 – 0 . 65 to near-zero b y ≈ 100 global steps), yet SWE-b ench accuracy improv es only marginally . P erformance gains emerge only after switc hing to fol low-aggr essive shaping, where the p olicy learns to request and execute exp ert guidance faithfully: the mean follow-through score increases from roughly ≈ 0 . 2 early in training to ≈ 0 . 8 by the end, and the fraction of tra jectories with negativ e follow-thro ugh declines from ≈ 0 . 30 – 0 . 40 to ≈ 0 . 05 . This allows us to conv ert stalled states into forward progress. W e corrob orate this via failure-mo de shifts (Fig. 5 ). Relative to p ost-SFT (P1), p ost-RL (P2) markedly reduces ab orts due to run time limits, a common failure ev en for SWE-agent-LM-32B, indicating that SWE-Protégé no longer gets stuc k. Instead, it decisively follows exp ert guidance through to completed end-to-end attempts, even when that guidance is imp erfect. Ablations on SWE-Protégé V ariants. W e test a num b er of v arian ts (Fig. 7 ) using SWE-Protégé-7B P1. In Mo dule mo ds. , we study alternative exp ert–protégé collaboration strategies. Sp ecifically , we ev aluate (i) a lo oping interv en tion heuristic that forcibly inv ok es the exp ert once a lo op-length threshold (initial: 15, subsequen t: 8) is exceeded ( L o op ), and (ii) limiting the in teraction history passed to the exp ert to only the 5 most recent messages ( Ctx ). W e find that enabling the lo op heuristic improv es p erformance only when the exp ert observ es the full in teraction history: Lo op ✓ Ctx × ac hieves 33.4%, compared to 29.0% for Loop × Ctx × (+4.4%). How ev er, with Ctx ✓ , the lo op heuristic pro vides no measurable benefit (29.4% with or without Lo op under Ctx ✓ ). Moreov er, v ariants that r emove the p olicy’s ability to autonomously request help and instead rely solely on passiv e exp ert inv ocation underp erform sharply: fixed-interv al in vocation drops to 19.6%, and random inv ocation to 24.2%, despite receiving comparable or even more frequent expert advice. W e view other collab oration strategies as an imp ortant direction for future work. In Exp ert mo ds. , w e ev aluate in-house exp erts initialized from our o wn SWE-Protégé-7B and SWE-Protégé-32B c heckpoints and fully SFT’ed to serv e as exp erts using a separate instruction-tuning dataset, whic h is derived 8 Figure 6 Repetitive unpro ductiv e actions are largely eliminated in SWE-Protégé-7B after Phase 2 RL, though they p ersist even after Phase 1 SFT. Figure 7 SWE-Protégé v ariants on SWE-b ench V erified. Mo dule mo difications explore some alternative collab oration strategies. In “Exp ert mo ds.”, we ev aluate t wo lightly post-trained in-h ouse exp erts. In “Dataset mo ds.”, w e appro ximate our SFT data gener- ation pro cess using in-place modifications to existing tra jectories. from the exp ert-augmented tra jectories (§ 3.1 ): we treat the pre-exp ert in teraction con text as input and the exp ert message as the target, yielding 5,623 examples. Both in-house exp erts underp erform frontier back ends, though increasing exp ert capacity still helps: replacing SWE-Protégé-7B exp ert with SWE-Protégé-32B exp ert impro ves task resolution from 17.0% to 20.8% under the same protégé policy . W e therefore treat exp ert post- training as an imp ortan t but non-trivial and orthogonal direction, and leav e a systematic exploration to future w ork. Finally , in Dataset mo ds. , we test whether § 2.2 ’s synthetic data generation (fresh exp ert-augmented rollouts) can b e approximated by in-plac e mo difications of existing SWE-smith tra jectories. The in-place con trol—injecting additional exp ert calls in to existing traces and minimally editing subsequen t messages to ac knowledge them—p erforms worst (14.2%), ev en b elow the SWE-agen t-LM-7B baseline (17.0%). This gap suggests that the gains from our data pip eline stem not from simply adding expert tok ens, but from inducing coheren t interactions that the protégé meaningfully conditions on. Contamination Study . Because SWE-Protégé relies on external exp ert mo dels, gains on SWE-b ench V erified could in principle b e inflated by data leak age or memorization. T o assess robustness, we ev aluate on a held-out SWE-smith-st yle subset of 400 tasks that was explicitly excluded from the tra jectory-generation mixture used to train our 7B mo del. Imp ortantly , this subset was released after the exp ert mo dels became av ailable (e.g., Sonnet 3.7 was released on F ebruary 24, 2025, while SWE-smith was released on April 29, 2025), reducing the lik eliho o d of ov erlap. W e follow the same interaction proto col as in the main ev aluation: a single rollout with a fixed step/cost budget while furnishing the exp ert with the same compact context ˜ s i (§ 2.3 ); as b efore, the exp ert observes only truncated recent context and has no access to the gold patch or unit-tests. Under this shifted ev aluation, the 7B mo del ac hieves 32.0% accuracy without exp ert calls and 40.3% with Sonnet 3.7, while the 32B v arian t achiev es 41.5% without exp ert calls and 43.0% with Sonnet 3.7, indicating that gains from SWE-Protégé p ersist b eyond the training distribution. 5 R elated W ork T raining Softw are Agents. SWE-Smith ( Y ang et al. , 2025 ) addresses data scarcity by synthesizing large n umbers of verifiable softw are engineering task instances from 128 GitHub rep ositories. Lingma-SWE-GPT ( Ma et al. , 2024 ) adopts a developmen t-process-centric training scheme for 7B/72B v arian ts; SWE-Gym ( P an et al. , 2024 ) in tro duces an op en training environmen t that improv es agents at 7B/32B scales; SWE-Fixer ( Xie et al. , 2025 ) trains sp ecialized retriever and editor mo dels for efficien t issue resolution. The ab ov e approaches rely on distilled data from frontier mo dels (e.g., GPT or Claude), and p ost-train Qwen2.5 mo dels via sup ervised finetuning. SWE-RL ( W ei et al. , 2025 ) applies RL to Llama 3 ( Grattafiori et al. , 2024 ), requiring substantial data/compute (e.g., 273k seed tasks, 512 H100 GPUs) and a custom agent scaffold. CWM ( Cop et et al. , 2025 ) (32B) p erforms extensiv e end-to-end training, com bining large-scale data/compute, custom agent scaffold, and 9 test-time scaling to achiev e strong SWE-b ench p erformance. In contrast, SWE-Protégé fo cuses on light weigh t p ost-training and demonstrates that an SLM can reac h comp etitive p erformance relativ e to SOT A op en-weigh t mo dels. Model Routing. Here, a router selects the most suitable LM to handle a query . Existing work has so far fo cused on p er-task routing and single-turn tasks: e.g., non-pr e dictive routing, which executes mo dels sequentially and escalates based on output ev aluation until a quality threshold is met ( Chen et al. , 2023 ); and pr e dictive routing, whic h selects a mo del a priori for a task using LM-based heuristics ( Ong et al. , 2024 ), learned neural routers ( Jiang et al. , 2023 ), or cluster-based metho ds ( Jitkrittum et al. , 2025 ; Zhang et al. , 2025 ). In contrast, w e study long-horizon, multi-turn agentic co ding tasks, where defining a reliable p er-step routing signal is ill-p osed (e.g., a syntax error does not necessarily justify escalation). Moreov er, we allow the participating LMs to self-determine when and how to c ol lab or ate ; in our instantiation, the SLM performs the bulk of routine reasoning and actions and exp erts are inv ok ed selectively as needed. Small Language Models. SLMs are increasingly viewed as practical agents when the domain scop e is narrow, offering adv an tages in inference efficiency (e.g., latency , memory fo otprint) and fine-tuning agility ( Belcak et al. , 2025 ). Many use-cases ( W ang et al. , 2025 ) hav e emerged: e.g., single-turn question answering ( Ab ouelenin et al. , 2025 ), mathematical reasoning ( Guan et al. , 2025 ), and single-turn coding tasks ( Bakouc h et al. , 2025 ). In con trast, we developed the first usable SLM on a long-horizon, agentic co ding task. 6 Discussion Limitations and F uture W ork. While w e fo cus on SWE-b ench within the SWE-agent framew ork, SWE-Protégé’s tec hniques are not tied to this setting and could in principle be applied to other domains (e.g., data analysis). W e do not exhaustiv ely explore design choices: e.g., Phase I/I I hyperparameters, alternate collab oration strategies (e.g., exp ert interrupts or richer bidirectional control), or broader student mo del families; since our goal is to establish that SWE-Protégé can materially improv e SLM p erformance rather than fully optimize the frontier. Finally , we treat the exp ert as a fixed black-box bac kend and leav e more principled exp ert p ost-training and co-adaptation as an imp ortant future direction. Conclusion. W e show that SLMs, while previously lagging on long-horizon soft ware repair, can achiev e strong SWE-b enc h p erformance when trained to collab orate effectively with an exp ert. SWE-Protégé lightly p ost-trains Qw en2.5-Co der-7B-Instruct to reac h 42.4% P ass@1 on SWE-b ench V erified ( +25.4% ov er the prior SLM SOT A), while using exp ert assistance sparsely ( ≈ 11% of total tokens). Our results suggest that learned exp ert–protégé collab oration is a practical path for adv ancing effective, fast and cost-efficient SLM agents. Impact Statement SWE-Protégé aims to make long-horizon agentic systems more practical by enabling small language mo dels to remain the primary decision-makers while selectiv ely collab orating with stronger exp ert mo dels when progress stalls. This design targets a more economical deploymen t mo del for agentic AI, where large mo dels are used sparingly rather than contin uously . In softw are engineering workflo ws, this can reduce latency and compute costs, and may make agentic assistance more accessible in settings where infrastructure or budget constrain ts preclude alw ays-on frontier mo dels. SWE-Protégé is not intended to replace human developers or engineering judgment. Instead, it supp orts a la yered assistance paradigm in which a small mo del handles routine exploration and to ol use, while exp ert mo dels are inv ok ed selectively to o vercome uncertaint y or stagnation. This mirrors common practice in pro duction engineering, where automated systems rely on fallbacks, escalation paths, and c hecks b efore c hanges are merged or deplo yed. Lik e other LLM-based code agents, SWE-Protégé inherits risks asso ciated with incorrect, misleading, or incomplete outputs. In our setting, these risks include improp er deferral decisions (e.g., escalating to o late, to o frequently , or inappropriately) and propagating incorrect guidance from the exp ert mo del. Misguided edits could introduce defects, regressions, or security vulnerabilities if deploy ed without adequate review. 10 W e therefore recommend deploying SWE-Protégé with automated verification (e .g., unit tests, lin ters, static analysis) and human ov ersight, particularly in safet y-critical or pro duction en vironments. As with other LLM-based co de agen ts, SWE-Protégé is sub ject to biases arising from b enc hmark comp osition, training data, and mo del interaction dynamics. Our ev aluation fo cuses primarily on Python-based rep ositories, reflecting SWE-b enc h’s task comp osition. T o mitigate exp ert interaction bias, exp ert mo dels are treated as fallible collab orators rather than oracles: the y hav e no access to ground-truth patches or tests during ev aluation/inference, and the SLM remains the principal decision-maker. W e further mitigate hidden biases through the use of public datasets (e.g., SWE-smith), standard ev aluation proto cols (i.e., from SWE-b ench), and transparent rep orting of training pro cedures, reward design, and limitations, whic h we explicitly do cument to a void ov ergeneralization of results. Our exp eriments and analyses are conducted on op en-source rep ositories and public b enchmarks. Low ering the cost of co de generation and repair may increase the volume of automated changes, which can amplify do wnstream risks if used irresp onsibly . Careful access control, auditability , and review pro cesses remain imp ortan t. Except for the SWE-agent-LM 7B and 32B v arian ts and the Claude Sonnet 3.7, Sonnet 4.5, and Opus 4.1 mo dels, which we ev aluate as baselines or exp erts in this work, all other en tries in T able 1 are taken directly from ( Y ang et al. , 2025 ) and were not ev aluated by us. Ov erall, we view SWE-Protégé as a step tow ard more resp onsible and sustainable agentic systems: ones that use scale selectively , incorp orate explicit escalation mechanisms, and emphasize controlled interaction with stronger mo dels rather than ubiquitous reliance on them. 11 R eferences Ab delrahman Ab ouelenin, Atabak Ashfaq, A dam Atkinson, Hany A wadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary , Congcong Chen, et al. Phi-4-mini technical rep ort: Compact yet p ow erful m ultimo dal language mo dels via mixture-of-loras. arXiv pr eprint arXiv:2503.01743 , 2025. An thropic. In tro ducing claude 3.5 sonnet, 2024. h ttps://www.anthropic.com/news/claude- 3- 5- sonnet . An thropic. In tro ducing claude 3.7 sonnet, 2025. h ttps://www.anthropic.com/news/claude- 3- 7- sonnet . Elie Bakouc h, Loubna Ben Allal, Anton Lozhk ov, Nouamane T azi, Lewis T unstall, Carlos Miguel Patiño, Edward Beec hing, A ymeric Roucher, Aksel Jo onas Reedi, Quentin Gallouédec, Kashif Rasul, Nathan Habib, Clémentine F ourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larc her, Mathieu Morlon, V aibhav Sriv astav, Josh ua Lo chner, Xuan-Son Nguyen, Colin Raffel, Leandro von W erra, and Thomas W olf. SmolLM3: smol, multilingual, long-con text reasoner. https://h uggingface.co/blog/smollm3 , 2025. P eter Belcak, Greg Heinrich, Shizhe Diao, Y onggan F u, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and P avlo Molchano v. Small language mo dels are the future of agen tic ai. arXiv pr eprint arXiv:2506.02153 , 2025. Ling jiao Chen, Matei Zaharia, and James Zou. F rugalgpt: Ho w to use large language mo dels while reducing cost and impro ving p erformance. arXiv pr eprint arXiv:2305.05176 , 2023. Neil Chowdh ury , James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Ev an Mays, Rac hel Dias, Marwan Aljub eh, Mia Glaese, et al. Introducing swe-bench verified, 2024. URL https://op enai. c om/index/intr o ducing-swe-b ench-verifie d , 2024. Jade Cop et, Quen tin Carb onneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik K ossen, F elix Kreuk, Emily McMilin, Michel Meyer, Y uxiang W ei, et al. Cwm: An op en-w eights llm for research on co de generation with world mo dels. arXiv pr eprint arXiv:2510.02387 , 2025. Cursor. The b est wa y to co de with ai, 2026. https://cursor.com/home . Aaron Grattafiori, Abhimanyu Dub ey , Abhina v Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Math ur, Alan Schelten, Alex V aughan, et al. The llama 3 herd of models. arXiv pr eprint arXiv:2407.21783 , 2024. Xin yu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Y ouran Sun, Yi Zhu, F an Y ang, and Mao Y ang. rstar-math: Small llms can master math reasoning with self-evolv ed deep thinking. arXiv pr eprint arXiv:2501.04519 , 2025. Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haok ai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, et al. Reinforcement learning with rubric anc hors. arXiv pr eprint arXiv:2508.12790 , 2025. Bin yuan Hui, Jian Y ang, Zeyu Cui, Jiaxi Y ang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia jun Zhang, Bow en Y u, Keming Lu, et al. Qwen2. 5-coder technical report. arXiv pr eprint arXiv:2409.12186 , 2024. Naman Jain, Jaskirat Singh, Manish Shett y , Liang Zheng, K oushik Sen, and Ion Stoica. R2e-gym: Pro cedural en vironments and hybrid v erifiers for scaling op en-weigh ts sw e agents, 2025. h ttps://arxiv.org/abs/2504.07164 . Dongfu Jiang, Xiang Ren, and Bill Y uchen Lin. Llm-blender: Ensem bling large language mo dels with pairwise ranking and generative fusion. arXiv pr eprint arXiv:2306.02561 , 2023. Carlos E Jimenez, John Y ang, Alexander W ettig, Shun yu Y ao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Sw e-b ench: Can language mo dels resolve real-world github issues? arXiv pr eprint arXiv:2310.06770 , 2023. Witta wat Jitkrittum, Harikrishna Narasimhan, Ankit Singh Ra wat, Jeevesh Juneja, Congchao W ang, Zifeng W ang, Alec Go, Chen-Y u Lee, Pradeep Shenoy , Rina Panigrah y , et al. Universal mo del routing for efficient llm inference. arXiv preprint arXiv:2502.08773 , 2025. Devvrit Khatri, Lovish Madaan, Rishabh Tiw ari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, Da vid Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcemen t learning compute for llms. arXiv pr eprint arXiv:2510.13786 , 2025. Omar Khattab, Arnav Singhvi, Paridhi Maheshw ari, Zhiyuan Zhang, Keshav Santhanam, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, Heather Miller, et al. Dsp y: Compiling declarative language mo del calls into state-of-the-art pip elines. In The Twelfth International Confer enc e on L e arning R epr esentations , 2024. 12 Yingw ei Ma, Rongyu Cao, Y ongchang Cao, Y ue Zhang, Jue Chen, Yib o Liu, Y uchen Liu, Binhua Li, F ei Huang, and Y ongbin Li. Lingma swe-gpt: An op en developmen t-process-centric language mo del for automated softw are impro vemen t. arXiv pr eprint arXiv:2411.00622 , 2024. meta-p ytorch. T orc hT une: PyT orc h native p ost-training library. h ttps://github.com/meta- pytorc h/torc h tune , 2026. Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy inv ariance under rew ard transformations: Theory and application to reward shaping. In Icml , v olume 99, pages 278–287. Citeseer, 1999. No v aSky-AI. SkyRL: A Mo dular F ull-stack RL Library for LLMs. https://gith ub.com/No v aSky- AI/SkyRL , 2026. Isaac Ong, Amjad Almahairi, Vincent W u, W ei-Lin Chiang, Tianhao W u, Joseph E Gonzalez, M W aleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data. arXiv pr eprint arXiv:2406.18665 , 2024. Op enAI. Gpt-4o system card, 2024. . Op enCla w. Personal ai assistant, 2026. https://gith ub.com/op enclaw/openclaw . Jia yi Pan, Xingy ao W ang, Graham Neubig, Na vdeep Jaitly , Heng Ji, Alane Suhr, and Yizhe Zhang. T raining Soft ware Engineering Agents and V erifiers with SWE-Gym, Decem b er 2024. h . arXiv:2412.21139 [cs]. Suman thRH. Swe-gym-subset. h ttps://huggingface.co/datasets/Suman thRH/SWE- Gym- Subset . Accessed: 2026-01- 18. SWE-b enc h. SWE-smith dataset. https://h uggingface.co/datasets/SWE- b ench/SWE- smith , 2026a. SWE-b enc h. SWE-smith T ra jectories. h ttps://huggingface.co/datasets/SWE- b ench/SWE- smith- tra jectories , 2026b. F ali W ang, Zhiwei Zhang, Xianren Zhang, Zongyu W u, T zuhao Mo, Qiuhao Lu, W anjing W ang, Rui Li, Junjie Xu, Xianfeng T ang, et al. A comprehensive survey of small language models in the era of large language models: T ec hniques, enhancements, applications, collaboration with llms, and trustw orthiness. ACM T r ansactions on Intel ligent Systems and T e chnolo gy , 16(6):1–87, 2025. Y uxiang W ei, Olivier Duchenne, Jade Cop et, Quentin Carbonneaux, Lingming Zhang, Daniel F ried, Gabriel Synnaeve, Rishabh Singh, and Sida I. W ang. SWE-RL: Adv ancing llm reasoning via reinforcement learning on open soft ware ev olution, 2025. h ttps://arxiv.org/abs/2502.18449 . Chengxing Xie, Bow en Li, Chang Gao, He Du, W ai Lam, Difan Zou, and Kai Chen. Swe-fixer: T raining op en-source llms for effective and efficient github issue resolution. arXiv pr eprint arXiv:2501.05040 , 2025. John Y ang, Carlos E Jimenez, Alexander W ettig, Kilian Lieret, Shun yu Y ao, Karthik Narasimhan, and Ofir Press. Sw e-agent: Agen t-computer interfaces enable automated softw are engineering. A dvances in Neur al Information Pr o c essing Systems , 37:50528–50652, 2024. John Y ang, Kilian Lieret, Carlos E Jimenez, Alexander W ettig, Kabir Khandpur, Y anzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Sc hmidt, and Diyi Y ang. Swe-smith: Scaling data for softw are engineering agents. arXiv pr eprint arXiv:2504.21798 , 2025. Sh unyu Y ao, Jeffrey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Y uan Cao. React: Syn ergizing reasoning and acting in language mo dels. In The eleventh international c onfer enc e on le arning r epr esentations , 2022. Qiying Y u, Zheng Zhang, Ruofei Zhu, Y ufeng Y uan, Xiao chen Zuo, Y u Y ue, W einan Dai, Tiantian F an, Gaohong Liu, Ling jun Liu, et al. Dap o: An op en-source llm reinforcement learning system at scale. arXiv pr eprint arXiv:2503.14476 , 2025. W eizhe Y uan, Ric hard Y uanzhe Pang, Kyunghyun Cho, Xian Li, Sain bay ar Sukh baatar, Jing Xu, and Jason E W eston. Self-rew arding language mo dels. In F orty-first International Confer enc e on Machine L e arning , 2024. Yiqun Zhang, Hao Li, Chenxu W ang, Liny ao Chen, Qiaosheng Zhang, Peng Y e, Shi F eng, Daling W ang, Zhen W ang, Xinrun W ang, et al. The av engers: A simple recip e for uniting smaller language mo dels to challenge proprietary gian ts. arXiv pr eprint arXiv:2505.19797 , 2025. 13 Appendix A Extended Ev aluation W e include additional diagnostics from Phase I I training in Fig. 8 . Mean Exp ert rew ard remains highly stable throughout training, sta ying within a narrow band of approximately 0 . 82 – 0 . 88 across all steps, indicating that exp ert resp onses consistently satisfy the reward criterion and are not degraded by later-stage shaping. In contrast, F ol low reward exhibits a clear upw ard trend. During the first stage (steps 1–80), it fluctuates substan tially , ranging roughly from 0 . 2 to 0 . 5 . After step 80, following the transition to follo w-aggressive shaping, it increases steadily and stabilizes in the 0 . 75 – 0 . 85 range b y step 160. L o op reward shows the most dramatic change: it b egins near − 1 . 5 , rises rapidly during the lo op-first shaping phase, and approac hes 0 . 0 b y step 80. Thereafter it remains close to zero with minimal v ariance, indicating that degenerative lo oping b eha vior is largely eliminated and do es not re-emerge in later training. The mean num b er of exp ert calls sta ys relatively stable at approximately 3 . 5 – 4 . 5 calls p er episo de, with a mild upw ard drift in later stages, suggesting that p erformance gains are not driv en b y increased exp ert reliance. Finally , mean step counts decrease substan tially ov er training, dropping from roughly 55 – 65 steps early on to ab out 35 – 40 steps by the end of training, consistent with more direct tra jectories and reduced redundant actions. Fig. 9 further characterizes training dynamics by rep orting the fraction of tra jectories whose F ol low or L o op rew ard is non-p ositive. Early in training, a substantial fraction of tra jectories incur negative rewards for b oth comp onen ts. Within the first 20–30 steps, appro ximately 40% – 65% of tra jectories receive non-p ositive L o op rew ard, while roughly 25% – 40% exhibit non-p ositive F ol low rew ard. As training progresses, both fractions decline steadily . The fraction of tra jectories with non-p ositive L o op reward drops sharply during the lo op-first shaping phase and falls b elow 10% by around step 50, approac hing zero shortly thereafter and remaining near zero for the remainder of training. The fraction of tra jectories with non-positive F ol low reward decreases more gradually , falling below 10% b y approximately step 100 and stabilizing in the 3% – 8% range by the end of training. T rain and ev aluation curves closely track each other throughout, indicating that these b eha vioral impro vemen ts generalize b eyond the training tra jectories. Fig. 6 analyzes degenerative lo oping b ehavior during Phase I, by measuring the fraction of tra jectories that con tain rep etitive to ol-use sequences of length greater than L . Our ev aluation here also includes an activ e interv ention mechanism that is activ ated at L = 15 for the initial lo oping sequence detected, and L = 8 for subsequent detections. A cross all agen ts, the fraction decreases monotonically as L increases, but with substan tial differences in tail b ehavior. Baseline agen ts exhibit long rep etitive sequences with high frequency: the SWE-agent-LM-32B baseline retains approximately 15% – 20% of tra jectories with rep etition length exceed ing L = 10 , and remains ab ov e 10% even at L = 40 . In contrast, all SWE-Protégé-7B v arian ts substan tially suppress long repetitive sequences. F or SWE-Protégé-7B, the fraction of tra jectories with rep etition length exceeding L = 10 drops b elow 10% , and falls to near zero by L ≈ 15 , indicating that extended to ol-use lo ops are largely captured and eliminated prop erly by the activ e interv ention mechanism; how ev er, as we show ed in Fig. 7 , this is still ineffective in improving SWE-b ench p erformance. Among SWE-Protégé v ariants, differences across exp ert bac kends (not shown in the figure for clarity) are minor and primarily affect short rep etition lengths, while the long-tail b ehavior remains consisten tly suppressed. T o construct these curv es, for each tra jectory w e compute the maximum length of any consecutive identical to ol-use action run, and then for eac h threshold L ∈ [0 , 40] we plot the fraction of tra jectories whose maxim um run length exceeds L (i.e., E [ ⊮ [ max _ run > L ]] o ver tra jectories). Shaded regions indicate 95% b o otstrap uncertain ty bands obtained by resampling tra jectories within each group (400 resamples; fixed random seed for determinism) and ev aluating the same indicator-based curve on each resample. B Expert-augmented Synthetic T rajectory Generation W e use Claude Sonnet 3.7 to generate full exp ert-augmented tra jectories following the pro cedure describ ed in § 2.2 , using the same underlying task dataset as SWE-smith ( SWE-bench , 2026a ; Y ang et al. , 2025 ). T asks are randomly sampled, and tra jectories are generated with rejection sampling un til we obtain 4.8K accepted tra jectories, appro ximately matching the training set size used in SWE-smith. Because the exact task 14 comp osition may differ due to random sampling, we p erform a controlled chec k by regenerating tra jectories without exp ert augmentation and applying SFT to the same baseline mo del (Qwen-2.5-Coder-Instruct, 7B and 32B v ariants) using an identical 4.8K-sample budget. The resulting SWE-b ench p erformance closely matches that rep orted for SWE-smith, indicating that differences observed in later exp eriments are not attributable to dataset size or sampling effects. The prompt used to generate exp ert-augmented tra jectories is shown b elo w in Fig. 11 . Imp ortantly , the exp ert used in synthetic data generation is Claude Sonnet 3.7 itself; the system prompt fed to it is describ ed in Fig. 13 . The exact exp ert mec hanism is describ ed in § C . Note that, apart from syn thetic data generation, the gold patc h and unit tests are never provided to the exp ert. Y ou are a helpful assistant that can interact with a computer to solv e tasks. Call ask_exp ert_llm to help guide y our thinking, b efore/after lo calizing the issue, applying a patch, when considering edge cases, and whenever you hav e trouble repro ducing the error (though not alwa ys necessary). Instance template. {{w orking_dir}} I’v e uploaded a p ython code rep ository in the directory {{w orking_dir}} . Consider the following PR description: {{problem_statemen t}} {{con text}} Can you help me implement the necessary c hanges to the rep ository so that the requirements specified in the are met? I’v e already taken care of all changes to any of the test files describ ed in the . This means y ou DON’T hav e to mo dify the testing logic or any of the tests in any w ay! Y our task is to make the minimal changes to non-tests files in the {{w orking_dir}} directory to ensure the is satisfied. F ollo w these steps to resolve the issue: 1. As a first step, it migh t be a go o d idea to find and read co de relev an t to . Call the ask_exp ert_llm tool before or after doing this as needed. 2. Create a script to reproduce the error and execute it with p ython <filename.py> using the bash to ol, to confirm the error. Call the ask_exp ert_llm to ol b efore or after doing this as needed. 3. Edit the source co de of th e repo to resolve the issue. Call the ask_exp ert_llm to ol before or after doing this as needed. 4. Rerun your reproduce script and confirm that the error is fixed! 5. Think ab out edge cases and make sure your fix handles them as well. Call the ask_exp ert_llm to ol b efore or after doing this as needed. Y our thinking should b e thorough and so it’s fine if it’s very long. Use ask_exp ert_llm in mo deration—av oid consecutiv e calls, and alwa ys integrate its resp onse into your reasoning (e.g., “Based on the exp ert’s advice”). Figure 11 System prompt used for exp ert-augmented tra jectory generation. This is a slight mo dification of the standard SWE-agen t prompt, adding explicit guidance for when to inv oke ask_exp ert_llm and how to incorporate exp ert feedbac k, while keeping the underlying task structure unc hanged. 15 Y ou are a helpful assistant that can interact with a computer to solv e tasks. • If the user pro vides a path, y ou should NOT assume it’s relative to the current working directory . Instead, explore the file system to find the file b efore working on it. • Call ask_exp ert_llm to help guide your thinking, e.g., b efore/after lo calizing the issue, b efore/after applying a patch, when thinking through edge cases, and whenever y ou encounter problems repro ducing the error. When y ou call ask_exp ert_llm , treat it as a multi-turn collaborator: ask for sp ecific, actionable steps; then execute those steps; then rep ort back what you did and what y ou observed b efore asking again. Y ou ha ve access to the following functions: —- BEGIN FUNCTION #1: bash —- Description: Execute a bash command in the terminal. P arameters: (1) command (string, required): The bash command to execute. Can b e empty to view additional logs when previous exit co de is -1. Can b e ctrl+c to interrupt the curren tly running process. —- END FUNCTION #1 —- <....omitted for clarity ...> —- BEGIN FUNCTION #4: ask_exp ert_llm —- Description: Call ask_exp ert_llm to help guide your thinking, e.g., when thinking through edge cases. P arameters: (1) question (string, required): The expert question, e.g., Do y ou hav e any advice on how to pro ceed? (2) budget_tokens (integer, optional): T ok en budget hint if applicable —- END FUNCTION #4 —- <....omitted for clarity ...> Can you help me implement the necessary c hanges to the rep ository so that the requirements specified in the are met? I’v e already taken care of all changes to any of the test files describ ed in the . This means y ou DON’T hav e to mo dify the testing logic or any of the tests in any w ay! Y our task is to make the minimal changes to non-tests files in the {{w orking_dir}} directory to ensure the is satisfied. F ollo w these steps to resolve the issue: 1. As a first step, it migh t be a go o d idea to find and read co de relev an t to . Call the ask_exp ert_llm tool before or after doing this as needed. 2. Create a script to reproduce the error and execute it with p ython <filename.py> using the bash to ol, to confirm the error. Call the ask_exp ert_llm to ol b efore or after doing this as needed. 3. Edit the source co de of th e repo to resolve the issue. Call the ask_exp ert_llm to ol before or after doing this as needed. 4. Rerun your reproduce script and confirm that the error is fixed! 5. Think ab out edge cases and make sure your fix handles them as well. Call the ask_exp ert_llm to ol b efore or after doing this as needed. Y our thinking should b e thorough and so it’s fine if it’s very long. Use ask_exp ert_llm in mo deration—av oid consecutiv e calls, and alwa ys integrate its resp onse into your reasoning (e.g., “Based on the exp ert’s advice”). Figure 12 Prompt used by SWE-Protégé agents. This prompt is a slight mo dification of the standard SWE-agent prompt: it (i) makes ask_exp ert_llm usage explicit and structured as a multi-turn collab orator, (ii) adds a path- resolution instruction to av oid incorrect assumptions ab out file lo cations, and (iii) exp oses the to ol/function-call in terface used during rollouts, while preserving the underlying task and rep ository setup. 16 C Expert T ool Details The exp ert prompt used by Claude Sonnet 3.7 when generating exp ert-augmented tra jectories is shown in Fig. 13 . The standard exp ert prompt (used ev erywhere else) is shown in Fig. 14 . There are tw o prompts used b y our exp ert judge: the first is used to judge whether the call to the exp ert was appropriate (Fig. 15 ), and the second is an exp ert judge call to obtain the F ol low score (Fig. 16 ). Finally , the prompt used by SWE-Protégé SLM agents is shown in Fig. 12 . Expert tool implementation (SWE-agent instantiation). Our “exp ert” is implemented using standard agent to oling: an external advice function ( ask_exp ert_llm ) exp osed to the agent alongside regular to ols (e.g., bash and submit ). Concretely , SWE-agent loads this tool via a to ol-bundle en try (the to ols/exp ert_llm bundle) in the agent Y AML configuration. Context passed to the expert. When inv ok ed, ask_exp ert_llm reads the problem statement and a recent windo w of the agent’s con versation from SWE-agent’s exp orted history files inside the container. The to ol constructs a single structured context blo ck con taining (i) the task description and (ii) a JSON dump of recen t agent messages (after history pro cessing), and app ends the agent’s explicit question. This context is provided as background (not as the exp ert’s own prior turns), and the exp ert resp onse is returned as an observ ation wrapp ed in tags. Expert routing, limits, and optional scoring. The exp ert mo del can b e configured indep endently of the main agent (e.g., via EXPER T_MODEL and EXPER T_OPENAI_API_BASE ), enabling a separate endp oint/model for exp ert calls. T o con trol cost, the to ol enforces a p er-task call quota (default 6). Prev enting expert advice from being elided by history processing. In SWE-agent, for SWE-agent-LM 7B/32B mo dels, the model input con text is derived from the raw in teraction h istory via a configurable chain of history_pro cessors . A commonly used default pro cessor ( last_n_observ ations , often with n = 5 ) elides older to ol observ ations by replacing them with a short “(lines omitted)” placeholder to control context length. In our SWE-smith instantiation, we slightly mo dify this b ehavior so that observ ations containing the mark er are never elided by last_n_observ ations . This ensures the agent contin ues to s ee the exp ert’s advice b eyond the last- n window, preven ting it from disapp earing after a handful of turns. RL -oriented expert supervision: warranted-score, follow-through, and a post-hoc terminal judge . T o supp ort reinforcemen t learning with exp ert-augmented tra jectories, we extend the standard ask_exp ert_llm to ol call with tw o auxiliary judging mec hanisms and log their outputs in to the tra jectory metadata for reward shaping. First, when ASK_EXPER T_LLM_ENABLE_SCORING=1 , the exp ert is prompted to return strict JSON con taining b oth textual guidance and a con tinuous w arranted_score ∈ [0 , 1] indicating whether escalation w as justified; the to ol returns only the guidance to the agent but records the score for training- time p enalties/rew ards. Second, when ASK_EXPER T_LLM_ENABLE_FOLLO W_JUDGE=1 , ask_- exp ert_llm issues an additional hidden judge call that scores adherence to the pr evious exp ert guidance (call k − 1 ) based on the subsequen t agent messages up to the current exp ert inv o cation (call k ), pro ducing follo w_- score ∈ [0 , 1] that is logged as exp ert_follo w_score (not sho wn to the agent). A key seman tic consequence is that the final exp ert guidance call has no later call to “carry” its follow-through score; therefore, in our mo dified SkyRL training harness we add an out-of-lo op, p ost-ho c follow judge that repla ys the same follow-judge logic after rollout completion and writes a separate final_exp ert_follo w_score field into tra jectory .info (used by the RL rew ard without altering p er-call exp ert p enalties). These exp ert-derived scores are then weigh ted in the comp osite reward (e.g., via generator.exp ert_cfg.w eight and generator.follo w_cfg.weigh t in the SkyRL launc her). 17 Y ou are an exp ert softw are engineer solving SWE-b ench–st yle tasks. Pro vide the most direct and precise guidance to the agent’s question. T reat any provided con versation or rep ository details strictly as background context—they are not your prior messages. Y ou are also given a ground-truth patch. This patch represents the correct solution: do not copy it verbatim, but use it to direct the agent tow ard the correct solution as clearly and quickly as p ossible. If the agent’s framing is inaccurate, restate the real issue clearly and redirect them to the correct solution. Keep your answer concise, actionable, and technically accurate. Figure 13 System prompt used for Claude Sonnet 3.7 acting as the exp ert during exp ert-augmented tra jectory generation. The exp ert is instructed to provide high-level corrective guidance grounded in a hidden ground-truth patc h, without revealing the solution verbatim. Y ou are an exp ert softw are engineer assisting an agent solving SWE-b enc h–style tasks. Pro vide clear, direct, and technically precise guidance that helps the agent make concrete progress (e.g., repro ducing the bug, isolating the faulty logic, or implementing a minimal fix). Y ou may hav e strong intuitions ab out the ro ot cause or solution, but fo cus on communicating actionable steps the agent should take in the next few steps. T reat any provided con versation or rep ository details strictly as background context—they are the agent’s o wn prior messages, not yours. If y ou b elieve the agent is on the wrong trac k (e.g., it has not found the right file, diagnosis, fix direction, or ev en the right question), redirect it to the correct line of inv estigation. More generally , resp ond as you would if y ou were solving the task at this momen t. Keep your answer concise, actionable, and technically accurate. As the agent is solving SWE-b ench–st yle tasks, do not mention pull requests, commit messages, or other GitHub workflo w artifacts. Figure 14 System prompt used by the expert mo del under our standard exp ert-collab oration setting. The exp ert is instructed to provide concise, actionable guidance and to correct the agent when it diverges from the most promising debugging path. 18 (Exp ert-judge extension; app ende d to the exp ert pr ompt) Return ONL Y a single v alid JSON ob ject (no Markdown, no extra text) with exactly the following sc hema: { "guidance": string, "w arranted_score": float, } where w arranted_score is in [0 . 0 , 1 . 0] : • V alues b elo w 0 . 5 indicate that the exp ert call was generally unnecessary . • A v alue of 1 . 0 indicates the expert call w as clearly necessary and well-timed. • Be strict in your scoring. Example: { "guidance": "Do X...\nThen verify Y...", "w arranted_score": 0.8 } Important: If guidance spans multiple lines, enco de newlines as \n . Figure 15 Exp ert-judge prompt used to ev aluate whether an exp ert call was w arranted. This prompt is app ended to the standard exp ert prompt (Fig. 14 ) and instructs the judge to both pro vide corrective guidance and assign a strict scalar score indicating whether the agent’s exp ert query was appropriate. 19 Sy stem prompt (follow judge). Y ou are ev aluating whether an agent follo wed prior exp ert guidance. Return ONL Y a single v alid JSON ob ject (no Markdown, no extra text) with exactly the following sc hema: { "follo w_score": float, "rationale": string } where follo w_score is in [0 . 0 , 1 . 0] : • V alues b elo w 0 . 5 indicate that the agent generally did not follo w prior exp ert guidance. • Be strict in your scoring. Scoring guidance. If the agent was instructed to p erform a sp ecific action (e.g., view a file and apply an edit) but only partially follo wed it (e.g., viewed without editing), this should receive a low score. Requesting clarification or assistance in order to complete a sp ecific instructed action should be considered as following that guidance for that action. If there is no clear instruction to follow, set follow_score to n ull . User input to the judge. Figure 16 F ollow-judge prompt used to assess whether the agent follow ed prior exp ert guidance. The judge receives the previous exp ert advice, the agent’s subsequent interaction trace, and the agent’s current exp ert query , and outputs a strict scalar score indicating adherence to guidance along with a brief rationale. D Phase II Rew ard Modeling and Shaping Details This app endix defines the rew ard terms referenced in Phase I I (§ 2.3 ). The goal is to make (i) degenerative stalling and (ii) non-collab orative exp ert usage explicitly sub optimal, while keeping rewards stable for RL p ost-training. D .1 Correctness and Similarity T erms These apply to the co de patch (output artifact) generated by the co ding agent. Both terms are computed similarly to ( Cop et et al. , 2025 ). Correctness. Let τ denote the full agen t interaction tra jectory (in terleav ed sequence of agent thoughts/actions and to ol resp onses), and let p ( τ ) denote the final patch the agent submits at the end of τ . W e compute R correct ( τ , x ) ∈ { 0 , 1 } b y re-ev aluating p ( τ ) in a fresh environmen t identical to the task back end used for rollout generation: R correct ( τ , x ) = ⊮ { p ( τ ) passes v erification } . 20 A patc h is considered correct (resolved) if all unit tests pass (e.g., as in SWE-Bench). Otherwise, it is considered unresolv ed. Here, x denotes the task instance metadata (e.g., the dataset record), which includes the gold patch used b elow and any information needed to re-run verification. Similarity fallback (unresolved only). When unresolved ( R correct = 0 ), we compute a similarity score sim ( τ , x ) ∈ [0 , 1] b etw een the model patc h and a gold patch after filtering diff noise. Concretely , w e drop diffs for newly-added files (e.g., “ new file mo de ” blo cks or diffs inv olving /dev/n ull ) and drop the git noise line \No newline at end of file , then compute string similarity on the remaining unified-diff text. With threshold θ (w e use θ = 0 . 5 in practice), R sim ( τ , x ) = ( 0 , sim( τ , x ) ≥ θ , − 1 , sim( τ , x ) < θ . This discrete fallback discourages unrelated patches while preserving reward stabilit y . W e use a thresholded signal to a void instabilit y under p olicy up dates and preven t similarity from dominating optimization. Intuitiv ely , when a tra jectory fails verification, we still wan t a stable learning signal: clearly unrelated patches are p enalized ( − 1 ), while patches that substantially ov erlap the gold fix receive a neutral score ( 0 ). This can improv e learning on difficult instances where the p olicy cannot y et pro duce a fully test-passing patch, but can still learn to lo calize and edit the right region. If the mo del patch is missing (or b ecomes empty after filtering), we treat similarit y as 0 and assign R sim = − 1 . D .2 S tall Penalty Base-command extraction. T o detect stalled progress (often manifesting as action lo ops), we conv ert each to ol/action step in to a b ase c ommand and form a sequence c 1 , . . . , c M . W e normalize commands to make sup erficial v ariants count as the same action, then measure rep etition on the normalized sequence. Our normalization mirrors the reward implementation: • Strip leading environmen t-v ariable assignments (e.g., F OO=bar p ython -m p ytest 7→ python -m p ytest ). • F or chained shell commands joined by && or ; , keep the last sub command (e.g., cd rep o && p ytest 7→ p ytest ). • Define the base command as the first tok en (e.g., p ytest , ls ), except for a small set treated as tw o-w ord bases (e.g., git status , git diff , str_replace_editor view ). • Collapse “navigation-lik e” op erations into one equiv alence class so mixed navigation streaks count as rep etition: e.g., grep , find , and str_replace_editor view are treated as iden tical for stall detection. F or example, rep eated git diff actions are counted as identical, and a sequence like grep → find → str_- replace_editor view is treated as a rep eated navigation streak. Let s 1 , s 2 , . . . denote lengths of maximal consecutive identical-command streaks in temp or al or der as we scan the tra jectory (i.e., s 1 is the first streak length, s 2 the next streak after the command changes, etc.). T riggered, capped stall penalty . W e use a triggered rule: the penalty only activ ates once any streak is long enough; after the first trigger, subsequent streaks use a low er threshold k 2 < k 1 . The charged exceedance matc hes the implementation, which uses a small “ +1 ” offset so that a streak that just reaches the threshold is already p enalized: R loop ( τ ) = max c loop , − λ loop max(0 , s 1 − k 1 + 1) + X j ≥ 2 max(0 , s j − k 2 + 1) , (4) where λ loop > 0 and c loop < 0 caps the magnitude. Operationally , the first term con tributes when s 1 ≥ k 1 ; after the first trigger, later streaks con tribute when s j ≥ k 2 for j ≥ 2 . This mak es stalling sp arse but de cisive : short rep eats are tolerated, while true degeneracy is sharply p enalized. 21 D .3 Expert-as- Judge Collaboration T erms These terms train the agent to collab orate with the exp ert in a multi-turn, pair-programming-like manner: they discourage unnecessary escalation, and they directly sup ervise the agen t’s b ehavior after receiving advice (executing the requested steps and rep orting back). Let E ( τ ) = { e i } N i =1 denote the ordered set of exp ert-call ev ents (as in § 2.3 ), where each even t e i = ( t i , q i , g i , ˜ s i ) records the timestep t i , the agent query q i sen t to the exp ert, the exp ert guidance g i , and the compact context pac ket ˜ s i pro vided to the exp ert. In our implementation, ˜ s i is a compact bund le of r e c ent c ontext , not a single message: it includes the problem statement and a truncated tail of recent pro cessed conv ersation messages (a fixed-size window for tok en con trol) from τ , serialized for the exp ert. Concretely , we pass (at most) the last ≈ 10 pro cessed messages, then drop the leading system prompt and the first user message that rep eats the full problem statement, and remov e action/thought fields from these messages b efore serialization. F or follo w-through, we asso ciate eac h guidance g i with the subsequent resp onse segment ∆ i ( τ ) , i.e., the agent’s b eha vior after receiving g i up to and including the next exp ert call (or tra jectory end if there is no subsequent call). W e log tw o judge scores computed by the prompts sho wn earlier in this app endix (w arrant judge: Fig. 15 ; follo w judge: Fig. 16 ): u i := J warran t ( q i , ˜ s i ) ∈ [0 , 1] , f i := J follow ( g i , ∆ i ( τ )) ∈ [0 , 1] . In the logged tra jectories, these scores app ear as p er-call n umeric fields (warran t: exp ert_score ; follow: exp ert_follo w_score ) that the reward function consumes directly . Note that online follow judging stores the follo w score on the next exp ert call (ev aluating adherence to the previous guidance), so the final guidance ma y optionally contribute an additional terminal follo w score computed p ost-ho c. Invocation quality ( R expert ) . W e conv ert the p er-call warran t scores { u i } in to a single tra jectory-level term that discourages lo w-v alue escalation while keeping scale stable as the n umber of exp ert calls N v aries: ϕ ( u ) = ( u, u ≥ τ low , p low , u < τ low , p low ≤ 0 , R warran t ( τ ) = Agg { ϕ ( u i ) } N i =1 , where Agg is t ypically mean (or min for stricter budgeting). Here, u is a dumm y v ariable used to define the scalar transform ϕ ( · ) , which is then applied to each u i . T o preven t expert spam, let n b2b b e the num b er of bac k-to-back exp ert calls. W e add a capp ed p enalty: R b2b ( τ ) = max( − 1 , λ b2b n b2b ) , λ b2b ≤ 0 . Optionally , with an exp ert budget Q , let n ov er = max (0 , N − Q ) and R quota ( τ ) = p ov er n ov er with p ov er ≤ 0 . W e do not enable this quota term in our runs; it is included for completeness. W e combine: R expert ( τ ) = R warran t ( τ ) + R b2b ( τ ) + ⊮ [ quota enabled ] R quota ( τ ) . F ollow-through ( R follow ) . W e shap e follow-through similarly: ψ ( f ) = ( f , f ≥ τ follow , p follow-lo w , f < τ follow , p follow-lo w ≤ 0 , R follow ( τ ) = Agg { ψ ( f i ) } i ∈I , where I indexes even ts for which follow-through is defined (e.g., excluding terminal calls). D .4 Gating F unctions W e gate only the auxiliary term R other to preven t correctness or similarity from comp ensating for pathological b eha vior; lo op and follo w-through terms are alwa ys applied: g loop ( τ ) = 0 , R loop ( τ ) ≤ a 2 , 0 . 5 , R loop ( τ ) ≤ a 1 , 1 , otherwise , g follow ( τ ) = 0 , R follow ( τ ) ≤ b 2 , 0 . 5 , R follow ( τ ) ≤ b 1 , 1 , otherwise , 22 for thresholds a 2 < a 1 ≤ 0 and b 2 < b 1 ≤ 0 . The main text uses R total = R loop + w follow R follow + g loop g follow R other (Eq. 2 ). Notably , R follow is never gated out; gating applies solely to R other , while lo op and follo w-through p enalties remain active throughout training. In our reward-shaping schedule b elow, we apply the follo w gate only in Stage I I by setting g follow ≡ 1 during Stage I (i.e., the follo w gate is effectively inactive in Stage I). D .5 R eward Shaping Schedule While Phase I SFT teaches the SLM to imitate exp ert in teraction patterns, it do es not reliably induce the b ehaviors required for effectiv e collab oration. In particular, we observ e tw o p ersistent failure mo des: (i) the model fails to escalate when progress stalls, leading to long degenerativ e lo ops; and (ii) even when advice is obtained, the model often fails to follow it or to rep ort back appropriately . W e therefore apply a t wo-stage shaping curriculum that progressively tightens constrain ts to first suppress stalling and then enforce follo w-through. Stag e I: L oop aggressive shaping (escalation induction). W e mak e stalling strongly sub optimal by (i) increasing lo op/stall p enalt y magnitude via a more negative cap c loop and/or larger λ loop in Eq. 4 , and (ii) setting the lo op gate g loop to down weigh t R other more aggressively . In this stage, we keep follo w-through shaping mild: w follow is small and we keep the follow gate inactive (i.e., g follow ≡ 1 ). This reliably shifts the p olicy from “rep eat failed actions” to “seek help when stuck.” Stag e II: Loop+follo w aggressive shaping (pair programming). After stalling is largely suppressed, w e increase the strength of follow-through shaping by (i) increasing w follow , (ii) setting p follow-lo w more negative, and/or (iii) making g follow more aggressiv e (low er thresholds b 1 , b 2 ), so that failing to execute and rep ort back on exp ert guidance b ecomes strongly sub optimal. In addition, Stage I I enforces a hard no-expert gate: tra jectories with zero exp ert calls incur a fixed negative p enalt y , making unguided execution explicitly sub optimal. This stage con verts one-shot escalation into m ulti-turn collab oration. Reporting. In § 4 , we rep ort ablations ov er this schedule (Stage I only vs. Stage I+I I) and show that Stage I primarily reduces stagnation while Stage I I improv es exp ert-guidance adherence and end-to-end solve rate. All concrete hyperparameters (weigh ts, caps, thresholds) are provided in § 3 . 23 Figure 8 Phase I I training logs starting from the SFT chec kp oin t, which include mean rew ards for selected comp onen ts. 24 Figure 9 F raction of tra jectories with L o op and F ol low reward ≤ 0 during Phase II training. Figure 10 Agent b ehavior diagnostics adapted from Y ang et al. ( 2025 ). Histogram of the num ber of steps taken to complete the task p er resolved tra jectory . 25 E Example T rajectory Snippets F or completeness, we include partial, represen tative tra jectory snipp ets (left to right) corresp onding to the three examples in Fig. 1 (b) for the SWE-b ench V erified instance symp y__sympy-14976 . In the first example (SWE-agent-LM-7B; Fig. 17 ), the SLM stalls by rep eatedly reading different segments of lam b dify .p y , forming tentativ e hypotheses, and contin uing lo calization until it ab orts due to runtime limits (we omit the remaining steps for brevity). In the second example (SWE-Protégé-7B P1, Sonnet 3.7; Fig. 18 ), the SLM requests exp ert help but fails to follo w the exp ert’s instruction to fo cus on the lam b dify function in /testb ed/symp y/utilities/lambdify .p y (though it manages to follo w the suggestion to insp ect MPMA TH_- TRANSLA TIONS ). It then stalls b y rep eatedly issuing similar commands to view different p ortions of the Rational class, rather than re-engaging the exp ert. Finally , in the third example (SWE-Protégé-7B P2, Sonnet 3.7; Fig. 19 ), the SLM follows the exp ert’s instructions end-to-end, rep orts progress back, and ultimately con verges to the correct fault lo calization in pycode.py via this collab oration. (a) SWE-agent-7B-LM. Instance sympy__symp y-14976 . Let’s contin ue reading the function: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 250 300 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 250 v alues or nump y arra ys as argumen ts. How ev er, in some cases 251 the generated function relies on the input b eing a nump y array: 252 253 »> from sympy imp ort Piecewise [A dditional output omitte d for br evity.] Let’s contin ue reading the function: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 300 350 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 300 Matrix([[1, 3]]) 301 302 T uple arguments are handled and the lam b dified function should 303 b e called with the same type of arguments as w ere used to create [A dditional output omitte d for br evity.] Let’s contin ue reading the function: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 350 400 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 350 array([[ 1., 2.], 351 [ 3., 4.]], dtype=float32) 352 353 """ [A dditional output omitte d for br evity.] Let’s contin ue reading the function: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 400 450 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 400 from sympy .printing.p yco de imp ort MpmathPrinter as Printer 401 elif _mo dule_present(’n ump y’, namespaces): 402 from sympy .printing.p yco de imp ort NumPyPrinter as Printer 403 elif _mo dule_present(’n umexpr’, namespaces): [A dditional output omitte d for br evity.] Let’s contin ue reading the function: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 450 500 26 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 450 451 funcname = ’_lambdifygenerated’ 452 453 if _mo dule_present(’tensorflo w’, namespaces): [A dditional output omitte d for br evity.] No w let’s lo ok at the ‘_T ensorflowEv aluatorPrinter‘ and ‘_Ev aluatorPrin ter‘ classes which are resp onsible for generating the co de for different mo dules: str_replace_editor view /testb ed/sympy/prin ting/lam b darepr.py Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/lam b darepr.p y: 1 from __future__ imp ort prin t_function, division 2 from distutils.version import Lo ose V ersion as V 3 4 from .str imp ort StrPrin ter [A dditional output omitte d for br evity.] Let’s also look at the Pyco dePrinter class which is likely resp onsible for generating the co de for the ’mpmath’ mo dule: str_replace_editor view /testb ed/sympy/prin ting/p yco de.py –view_range 1 50 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/p ycode.py: 1 """ 2 Python co de printers 3 4 This mo dule contains python co de printers for plain python as well as NumPy & SciPy enabled co de. [A dditional output omitte d for br evity.] Let’s lo ok at the MpmathPrinter class which is sp ecifically for the ’mpmath’ module: grep -r "MpmathPrinter" /testbed /testb ed/symp y/printing/p ycode.py:class MpmathPrin ter(PythonCo dePrinter): /testb ed/symp y/printing/p ycode.py:for k in MpmathPrinter._kf: /testb ed/symp y/printing/p ycode.py: setattr(MpmathPrinter, ’_prin t_%s’ % k, _print_kno wn_func) /testb ed/symp y/printing/p ycode.py: setattr(MpmathPrinter, ’_prin t_%s’ % k, _print_kno wn_const) /testb ed/symp y/printing/tests/test_p ycode.py: MpmathPrinter, NumPyPrinter, PythonCo dePrinter, pycode, SciPyPrin ter [A dditional output omitte d for br evity.] Let’s examine the MpmathPrinter class: grep -A 50 "class MpmathPrinter" /testb ed/sympy/prin ting/p yco de.py class MpmathPrinter(PythonCodePrinter): """ Lam b da printer for mpmath which main tains precision for floats """ prin tmetho d = "_mpmathco de" [A dditional output omitte d for br evity.] Let’s also lo ok at the ‘_known_functions_mpmath‘ dictionary: grep -A 20 "_known_functions_mpmath" /testb ed/sympy/prin ting/p ycode.py _kno wn_functions_mpmath = dict(_in_mpmath, **{ ’sign’: ’sign’, }) _kno wn_constants_mpmath = { ’Pi’: ’pi’ [A dditional output omitte d for br evity.] 27 Let’s see where ‘_known_functions_mpmath‘ is defined: grep -r "_known_functions_mpmath =" /testb ed /testb ed/symp y/printing/p ycode.py:_kno wn_functions_mpmath = dict(_in_mpmath, **{ Let’s see what ‘_in_mpmath‘ contains: grep -A 20 "_in_mpmath" /testb ed/symp y/printing/p ycode.py _not_in_mpmath = ’log1p log2’.split() _in_mpmath = [(k, v) for k, v in _known_functions_math.items() if k not in _not_in_mpmath] _kno wn_functions_mpmath = dict(_in_mpmath, **{ ’sign’: ’sign’, }) [A dditional output omitte d for br evity.] Let’s see where ‘_known_functions_math‘ is defined: grep -r "_known_functions_math =" /testb ed /testb ed/symp y/printing/p ycode.py:_kno wn_functions_math = { Let’s see the definition of ‘_known_functions_math‘: str_replace_editor view /testb ed/sympy/prin ting/p yco de.py –view_range 1 50 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/p ycode.py: 1 """ 2 Python co de printers 3 4 This mo dule contains python co de printers for plain python as well as NumPy & SciPy enabled co de. [A dditional output omitte d for br evity.] Let’s contin ue reading the definition of ‘_kno wn_functions_math‘: str_replace_editor view /testb ed/sympy/prin ting/p yco de.py –view_range 50 100 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/p ycode.py: 50 ’log2’: ’log2’, 51 ’sin’: ’sin’, 52 ’sinh’: ’sinh’, 53 ’Sqrt’: ’sqrt’, [A dditional output omitte d for br evity.] Let’s contin ue reading the PythonCo dePrinter class: str_replace_editor view /testb ed/sympy/prin ting/p yco de.py –view_range 100 150 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/p ycode.py: 100 sup er(PythonCo dePrinter, self ).__init__(settings) 101 self.mo dule_imp orts = defaultdict(set) 102 self.known_functions = dict(self._kf, **(settings or {}).get( 103 ’user_functions’, {})) [A dditional output omitte d for br evity.] Figure 17 Example tra jectory snippet from SWE-agent-7B-LM, instance symp y__sympy-14976 . W e omit rep eated run time warnings and truncate long to ol outputs for readabilit y . (b) SWE-Protégé-7B P1 (Sonnet 3.7). Instance sympy__symp y-14976 . ask_exp ert_llm ’Based on the PR description, there seems to b e an issue with mpmath not prop erly handling rational num bers in lam b dified expressions. Lo oking at the co de in /testb ed/sympy/utilities/lam bdify .py , where should I fo cus my attention to fix this issue?’ 28 The issue is in ho w rational num b ers are handled when lam b difying expressions with the mpmath module. Based on the PR description, when a rational num ber like ‘S(1)/3‘ app ears in an expression that’s lambdified with ‘modules=’mpmath’‘, it remains as a Python fraction (‘232/3‘) rather than b eing con verted to an mpmath ob ject with full precision. Y ou should fo cus on these sp ecific areas: 1. The ‘lambdify‘ function in ‘/testbed/sympy/utilities/lam b dify .py‘ (around line 166) 2. The ‘MPMA TH_TRANSLA TIONS‘ dictionary (around line 45) The key issue is that when rational num bers app ear in expressions lambdified with mpmath, they need to b e conv erted to mpmath’s high-precision representation rather than remaining as Python fractions. The solution likely inv olv es mo difying ho w rational num bers are handled in the co de generation pro cess for mpmath sp ecifically . Y ou’ll need to ensure that when the mpmath mo dule is used, rational num bers lik e ‘S(1)/3‘ are conv erted to ‘mpmath.mpf(1)/mpmath.mpf(3)‘ or an equiv alen t mpmath representation that preserv es full precision. This w ould fix the issue where ‘nsolve‘ gets reduced precision results b ecause the rational constant isn’t ev aluated at full precision. Based on the exp ert’s guidance, I need to fo cus on ho w rational num bers are handled when lambdifying expressions with the mpmath mo dule. Let’s examine the relev ant parts of the co de: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 45 71 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 45 MPMA TH_TRANSLA TIONS = { 46 "Abs": "fabs", 47 "elliptic_k": "ellipk", 48 "elliptic_f": "ellipf", [A dditional output omitte d for br evity.] No w let’s lo ok at how rational num b ers are handled in general: grep -r "S\(" /testb ed/sympy/core/ grep: Unmatc hed ( or \( Let’s try a different approach: grep -r "S(" /testb ed/sympy/core/ /testb ed/symp y/core/num bers.py: »> mod_inv erse(S(2)/7, S(5)/2) /testb ed/symp y/core/num bers.py: return (S.Negativ eOne**num[0]*n um[1]*S(2)**n um[2]) /testb ed/symp y/core/num bers.py: »> S(’.[3]’) # rep eating digits in brack ets /testb ed/symp y/core/num bers.py: »> S(’3**2/10’) # general expressions /testb ed/symp y/core/num bers.py: »> (S(-3)/2).as_con tent_primitiv e() [A dditional output omitte d for br evity.] Let’s lo ok for files related to rational num bers: find /testb ed -type f -name "*.py" | grep -i "num b er" | head -10 /testb ed/symp y/p olys/num berfields.py /testb ed/symp y/p olys/tests/test_num berfields.py /testb ed/symp y/functions/combinatorial/n um b ers.p y /testb ed/symp y/functions/combinatorial/tests/test_com b_n umbers.py /testb ed/symp y/core/num bers.py [A dditional output omitte d for br evity.] 29 Let’s examine the ‘num bers.py‘ file which lik ely contains the rational num b er implementation: str_replace_editor view /testb ed/sympy/core/n um b ers.py –view_range 1 50 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/core/n um bers.py: 1 from __future__ imp ort prin t_function, division 2 3 imp ort decimal 4 imp ort fractions [A dditional output omitte d for br evity.] Let’s lo ok at the rational num ber implementation: grep -n "class Rational" /testb ed/symp y/core/num bers.py 1388:class Rational(Number): 2469:class RationalConstant(Rational): Let’s lo ok at the Rational class: str_replace_editor view /testb ed/sympy/core/n um b ers.py –view_range 1388 1450 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/core/n um bers.py: 1388 class Rational(Number): 1389 """Represents rational num bers (p/q) of any size. 1390 1391 Examples [A dditional output omitte d for br evity.] Let’s contin ue lo oking at the Rational class: str_replace_editor view /testb ed/sympy/core/n um b ers.py –view_range 1450 1500 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/core/n um bers.py: 1450 1451 Access numerator and denominator as .p and .q: 1452 1453 »> r = Rational(3, 4) [A dditional output omitte d for br evity.] Let’s contin ue lo oking at the Rational class: str_replace_editor view /testb ed/sympy/core/n um b ers.py –view_range 1500 1550 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/core/n um bers.py: 1500 p = p.replace(’ ’, ”) 1501 p q = p.rsplit(’/’, 1) 1502 if len(p q) == 2: 1503 p, q = p q [A dditional output omitte d for br evity.] Let’s contin ue lo oking at the Rational class: str_replace_editor view /testb ed/sympy/core/n um b ers.py –view_range 1550 1600 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/core/n um bers.py: 1550 ob j = Expr.__new__(cls) 1551 ob j.p = p 1552 ob j.q = q 1553 return ob j [A dditional output omitte d for br evity.] Figure 18 Example tra jectory snipp et from SWE-Protégé-7B P1 (Sonnet 3.7), instance symp y__sympy-14976 . W e sho w the agent thought and the corresp onding to ol output for each thought/action pair; long to ol outputs are truncated, while exp ert guidance blo c ks are shown in full. (c) SWE-Protégé-7B P2 (Sonnet 3.7). Instance symp y__sympy-14976_0 . 30 Let’s lo ok at the sp ecific part of the co de that handles the ’mpmath’ mo dule, since that’s where the issue is o ccurring according to the PR description: ask_exp ert_llm ’In the Sympy lambdify .py file, where w ould the handling of rational num bers sp ecifically for the ’"’"’mpmath’"’"’ mo dule b e implemented? I’"’"’m looking for the co de that pro cesses expressions when using mo dules=’"’"’mpmath’"’"’ and why rationals aren’"’"’t b eing properly wrapp ed.’ Y ou need to lo ok at how rational num b ers are handled in the lambdify function. The issue is that when us- ing the ’mpmath’ mo dule, rational n umbers like 232/3 aren’t b eing conv erted to mpmath’s high-precision format. First, examine the lambdify function implementation in detail, lo cated in: /testb ed/symp y/utilities/lambdify .py Then lo ok at how the printer handles different types of expressions, also lo cated in: /testb ed/symp y/utilities/lambdify .py The issue is likely in how rational num b ers are printed when the mpmath mo dule is selected. Lo ok for co de that handles R ational ob jects or fractions, and chec k if there’s sp ecial handling for the mpmath mo dule that’s missing. Y ou’ll probably need to mo dify the _Ev aluatorPrin ter class to ensure that rational num b ers are con verted to mpmath.mpf() calls when the mpmath mo dule is used. Let me try again with the correct format: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 704 744 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 704 def _prepro cess(self, args, expr): 705 """Prepro cess args, expr to replace arguments that do not map 706 to v alid Python identifiers. 707 [A dditional output omitte d for br evity.] No w let’s lo ok at how sub expressions are pro cessed, which is likely where the rational num bers shoul d b e handled: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 746 763 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 746 def _sub expr(self, expr, dummies_dict): 747 from sympy .matrices import DeferredV ector 748 from sympy import sympify 749 [A dditional output omitte d for br evity.] Let’s also chec k how functions are prin ted, particularly fo cusing on the mpmath mo dule: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 654 688 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 654 def doprint(self, funcname, args, expr): 655 """Returns the function definition co de as a string.""" 656 from sympy import Dummy 657 [A dditional output omitte d for br evity.] 31 No w, let’s create a script to repro duce the issue mentioned in the PR description: str_replace_editor create /testb ed/repro duce_issue.py –file_text ’#!/usr/bin/en v python3 from sympy imp ort sym b ols, Eq, rf, S, Float, nsolve imp ort insp ect # Define the v ariable x = symbols(’"’"’x’"’"’) # Create the equation from the PR description eqn = Eq(rf(18, x), 77 + S(1)/3) # Print the equation prin t("Original equation:", eqn) # Lambdify the expression with mpmath mo dule f = lambda x: ev al(insp ect.getsource(lambda y: (rf(18, y) - (77 + S(1)/3)).ev alf())[10:-2]) prin t(" textbac kslashnLambda function source:") prin t(insp ect.getsource(f )) # T est with nsolve x0 = nsolve(eqn, Float(’"’"’1.5’"’"’, 64), prec=64) prin t(" textbac kslashnSolution x0:", x0) prin t("rf(18, x0).ev alf(64):", rf(18, x0).ev alf(64)) prin t("Exp ected: textasciitilde77.3333333333333")’ File created successfully at: /testb ed/repro duce_issue.py Let’s run the script to see the issue: cd /testb ed && python repro duce_issue.py /testb ed/symp y/solvers/diophan tine.p y:3188: Syn taxW arning: "is" with a literal. Did y ou mean "=="? if feasible is 1: # it’s prime and k == 2 Original equation: Eq(RisingF actorial(18, x), 232/3) Lam b da function source: f = lambda x: ev al(insp ect.getsource(lambda y: (rf(18, y) - (77 + S(1)/3)).ev alf())[10:-2]) [A dditional output omitte d for br evity.] No w I understand the issue. When using ‘lam b dify(mo dules=’mpmath’)‘, the rational num b er ‘232/3‘ is not b eing prop erly wrapped in mpmath’s high-precision format. Let’s ask the exp ert for guidance on ho w to fix this: ask_exp ert_llm ’I’"’"’ve identified that the issue is in the _Ev aluatorPrinter class in lambdify .p y . When using mo dules=’"’"’mpmath’"’"’, rational n umbers like 232/3 aren’"’"’t b eing con verted to mpmath.mpf() calls. Ho w should I mo dify the code to ensure that rational num bers are prop erly wrapp ed in mpmath.mpf() when the mpmath mo dule is selected?’ 32 Y ou’re on the right track. The issue is that when using the mpmath mo dule, rational num b ers need to b e wrapp ed in mpmath.mpf() calls to maintain precision. Let’s lo ok at the _Ev aluatorPrinter class whic h handles ho w expressions are printed in the lambdify function: 1. First, chec k the _Ev aluatorPrin ter class implementation, located in: /testb ed/symp y/utilities/lambdify .py 2. Then lo ok for how rational num b ers are handled in the printer. There should b e a metho d like _- prin t_Rational or similar. 3. The fix will likely inv olve mo difying how Rational ob jects are printed when the mo dule is ’mpmath’. Y ou’ll need to wrap the rational in mpmath.mpf() instead of just using Python’s division op erator. After identifying the sp ecific metho d, mo dify it to chec k if the mo dule is ’mpmath’ and if so, wrap the rational in mpmath.mpf(). Let’s examine the _Ev aluatorPrin ter class more closely to find how rational num b ers are handled: str_replace_editor view /testb ed/sympy/utilities/lam bdify .py –view_range 400 450 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/utilities/lam bdify .py: 400 from sympy .printing.p yco de imp ort MpmathPrinter as Printer 401 elif _mo dule_present(’n ump y’, namespaces): 402 from sympy .printing.p yco de imp ort NumPyPrinter as Printer 403 elif _mo dule_present(’n umexpr’, namespaces): [A dditional output omitte d for br evity.] No w let’s lo ok for ho w rational num bers are handled in the prin ters. Based on the PR description, we need to fo cus on the ‘_Ev aluatorPrin ter‘ class which seems to handle the actual printing of expressions for ev aluation: grep -r "_print_Rational" /testbed/sympy/ /testb ed/symp y/p olys/num berfields.py: def _print_Rational(self, expr): /testb ed/symp y/p olys/num berfields.py: return "mpi(’ grep: /testbed/sympy/polys/__pycac he__/num berfields.cpython-39.p yc: binary file matches /testb ed/symp y/printing/ccode.py: def _print_Rational(self, expr): /testb ed/symp y/printing/mathml.p y: def _prin t_Rational(self, e): [A dditional output omitte d for br evity.] Let’s chec k if there’s a sp ecific implementation of ‘_Ev aluatorPrinter‘ in the lambdify mo dule: grep -A 10 "_Ev aluatorPrinter" /testb ed/sympy/utilities/lam b dify .p y funcprin ter = _Ev aluatorPrinter(prin ter, dummify) funcstr = funcprinter.doprin t(funcname, args, expr) funclo cals = {} global _lambdify_generated_counter filename = ’’ % _lambdify_generated_counter [A dditional output omitte d for br evity.] No w I’ll lo ok at the ‘_prin t_Rational‘ metho d in the ‘_Ev aluatorPrinter‘ class. Since we don’t see it explicitly defined there, it likely inherits it from the parent class. Let’s chec k the base class: ask_exp ert_llm ’The _Ev aluatorPrin ter class in lambdify .py do esn’"’"’t seem to ha ve a _prin t_Rational method defined. It inherits from LambdaPrinter. Where should I lo ok for the implementation of how rational n umbers are handled during lambdification, esp ecially for the mpmath mo dule case?’ 33 Y ou need to lo ok at the MpmathPrinter class since that’s what’s used when mo dules=’mpmath’. Let’s examine the implementation: 1. First, chec k the MpmathPrinter in symp y/printing/p ycode.py: 2. Then lo ok for the _prin t_Rational metho d in this class or its parent classes. If MpmathPrin ter do esn’t ov erride _prin t_Rational, chec k its parent class (likely PythonCo dePrinter): 3. The issue is likely that the _print_Rational method in PythonCo dePrinter (or whatever parent class) is not prop erly wrapping rational num bers in mpmath.mpf() when used with the mpmath mo dule. Y ou’ll need to mo dify the MpmathPrin ter class to ov erride _print_Rational to use mpmath.mpf() for prop er precision. Based on the exp ert’s advice, I need to chec k the MpmathPrin ter class in the pycode.py file: str_replace_editor view /testb ed/sympy/prin ting/p yco de.py –view_range 1 100 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/p ycode.py: 1 """ 2 Python co de printers 3 4 This mo dule contains python co de printers for plain python as well as NumPy & SciPy enabled co de. [A dditional output omitte d for br evity.] Let’s search for the MpmathPrinter class and the _print_Rational metho d: grep -n "class MpmathPrinter" /testb ed/sympy/prin ting/p ycode.py 314:class MpmathPrinter(PythonCodePrinter): (no thought logged) grep -n "_print_Rational" -A 5 /testb ed/sympy/prin ting/p yco de.py | grep -A 5 MpmathPrinter Y our command ran successfully and did not pro duce any output. Let’s lo ok at the MpmathPrinter class implementation: str_replace_editor view /testb ed/sympy/prin ting/p yco de.py –view_range 314 350 Here’s the result of running ‘cat -n‘ on /testb ed/sympy/prin ting/p ycode.py: 314 class MpmathPrinter(PythonCodePrinter): 315 """ 316 Lambda printer for mpmath which main tains precision for floats 317 """ [A dditional output omitte d for br evity.] Figure 19 Example tra jectory snipp et from SWE-Protégé-7B P2 (Sonnet 3.7), instance symp y__sympy-14976_0 . W e omit rep eated run time warnings, truncate long to ol outputs, and sho w exp ert guidance blo cks in full. 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment