Coarsening Bias from Variable Discretization in Causal Functionals
A class of causal effect functionals requires integration over conditional densities of continuous variables, as in mediation effects and nonparametric identification in causal graphical models. Estimating such densities and evaluating the resulting …
Authors: Xiaxian Ou, Razieh Nabi
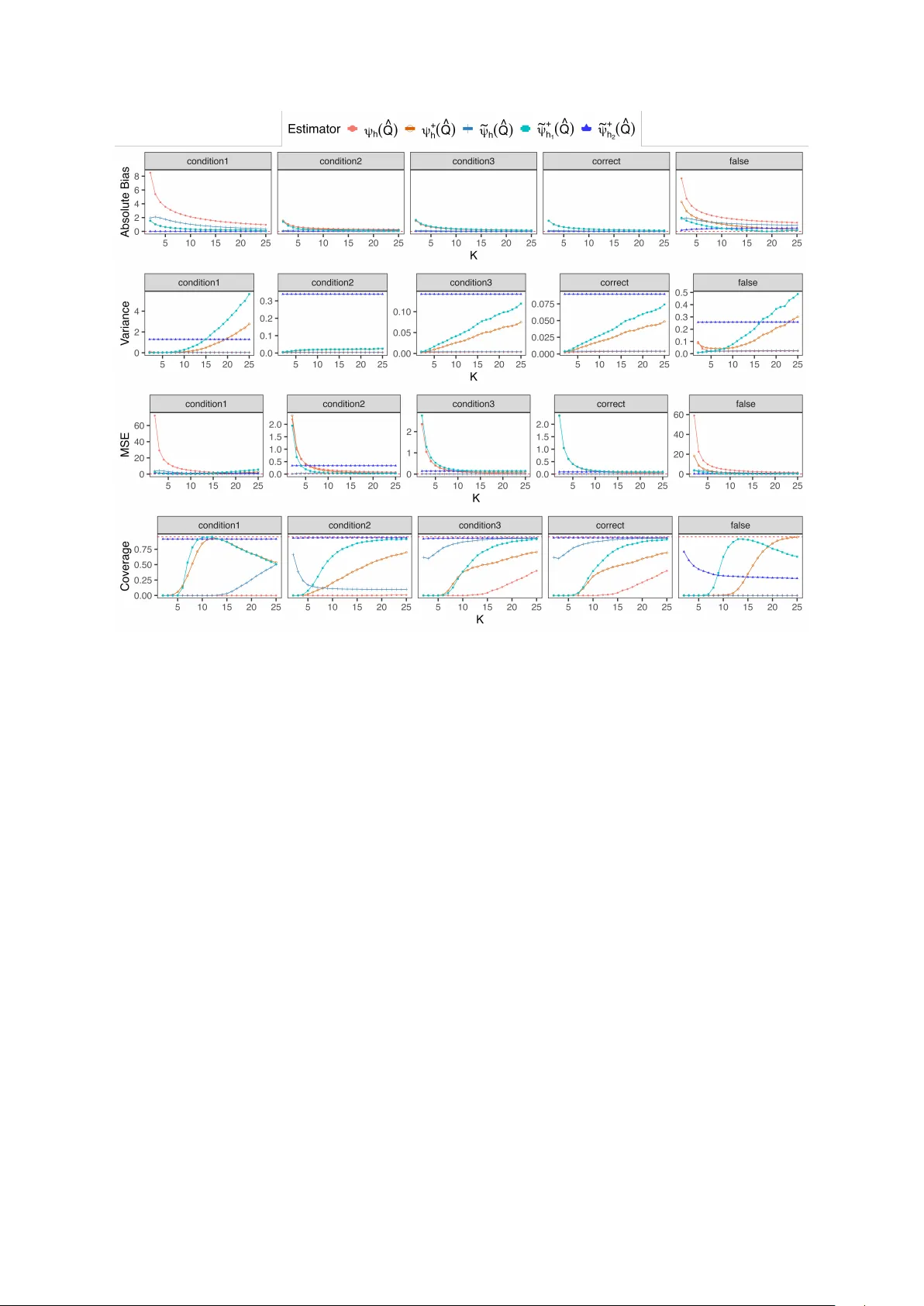
Coarsening Bias from V ariable Discretization in Causal F unctionals Xiaxian Ou and Razieh Nabi Departmen t of Biostatistics and Bioinformatics, Emory Univ ersit y , A tlan ta, GA, U.S.A. Abstract A class of causal effect functionals requires in tegration o v er conditional densities of con tin uous v ariables, as in mediation effects and nonparametric identification in causal graphical mo dels. Estimating such densities and ev aluating the resulting integrals can be statistically and computationally demanding. A common workaround is to discretize the v ariable and replace in tegrals with finite sums. Although conv enien t, discretization alters the p opulation-lev el functional and can induce non-negligible approximation bias, even under correct identification. Under smo othness conditions, we sho w that this coarsening bias is first order in the bin width and arises at the level of the target functional, distinct from statistical estimation error. W e prop ose a simple bias-reduced functional that ev aluates the outcome regression at within-bin conditional means, eliminating the leading term and yielding a second-order approximation error. W e derive plug-in and one-step estimators for the bias-reduced functional. Simulations demonstrate substantial bias reduction and near- nominal confidence in terv al cov erage, even under coarse binning. Our results provide a simple framew ork for con trolling the impact of v ariable discretization on parameter approximation and estimation. K eywor ds: Causal inference, Mediator discretization, Coarsening bias, F unctional appro ximation, Estimation bias. 1 In tro duction Sev eral causal parameters admit identification formulas that require av eraging an outcome regression o v er the distribution of mediating v ariables. This structure arises in mediation 1 analysis [ 1 , 2 ], path-specific effects [ 3 , 4 ], and nonparametric identification of causal effects in hidden-v ariable DA Gs [ 5 , 6 , 7 , 8 , 9 ]. When the mediator is contin uous or high-dimensional, as is common in biomedical and so cial science applications [ 10 , 11 , 12 ], ev aluating these identifying form ulas requires estimating conditional mediator densities and computing integrals with respect to them. Both tasks can b e statistically c hallenging, and Monte Carlo approximations may b e computationally in tensiv e and unstable in mo derate samples. A range of strategies hav e b een prop osed to address these challenges. One class of approaches directly mo dels the conditional mediator density and ev aluates the identifying integral nu- merically , using (semi/non-)parametric estimators [ 13 , 14 , 15 , 16 , 17 ]. These metho ds require correct sp ecification of the conditional densities to ac hiev e estimator consistency and can b e computationally demanding. Sequential regression approac hes a v oid explicit density estimation b y rewriting the iden tifying functional as iterated conditional exp ectations, thereby reducing the problem to estimation of a collection of regression functions [ 18 , 19 ]. How ev er, consistency of suc h estimators require correct sp ecification of all the nuisance regression comp onen ts. Alternativ ely , the identifying functional can often b e expressed using inv erse probability weigh ts inv olving treatmen t probabilities and mediator density ratios, which may b e rewritten via Bay es’ rule. Suc h weigh ting approac hes can suffer from instabilit y when treatment probabilities are small or p o orly estimated [ 20 , 21 , 22 ]. Influence-function based estimators, including one-step and targeted minimum loss estimators [ 23 , 24 ], provide a principled approach to estimation bias reduction and inference with flexible nuisance estimation, and can offer robustness to some forms of mo del missp ecification. How ever, such estimators are often av oided in practice due to metho dological complexit y . In practice, a simpler workaround is often adopted b y discretizing the mediator and replacing in tegrals with finite sums [ 25 , 26 , 27 ]. This a voids estimation of a contin uous conditional density and simplifies computation. Ho wev er, discretization changes the p opulation-level parameter. Ev en when the causal identification assumptions hold, the discretized functional is, in general, a different parameter from the original one. In many applied analyses, the bias induced by mediator discretization is either ov erlo oked or treated as secondary relative to computational considerations, and its impact on the target parameter is rarely quantified. Here, w e study the difference b etw een the original causal functional and its discretized analogue, 2 whic h we refer to as the coarsening bias. Our primary fo cus is not on first-order estimation bias arising from nuisance estimation, but rather on the p opulation-level approximation error induced b y mediator discretization itself. W e sho w that, under smo othness conditions, the naive discretized functional incurs a first-order bias prop ortional to the maximum bin width, driven by within-bin shifts in mediator means across treatmen t levels. W e then construct a bias-reduced coarsened functional that ev aluates the ou tcome regression at within-bin conditional means. A T a ylor expansion argument sho ws that this mo dification eliminates the leading first-order term, yielding a second-order remainder in the bin width. As for statistical estimation bias, we derive plug-in and one-step estimators and establish their asymptotic prop erties. Sim ulation studies demonstrate substan tial bias reduction and impro ved cov erage relativ e to naive discretization, ev en under coarse binning. More broadly , our results pro vide a formal foundation for con trolling the impact of discretization on parameter appro ximation and its estimate. 2 T arget estimands Let A denote a binary exp osure taking v alues in { a 0 , a 1 } , C observ ed co v ariates with supp ort C and marginal distribution P C , M a mediator, and Y the outcome. Define the outcome regression µ ( m, a, c ) = E ( Y | M = m, A = a, C = c ) , the conditional mediator density f M | A,C ( m | a, c ) = p ( M = m | A = a, C = c ) , and the prop ensity score π ( a | c ) = p ( A = a | C = c ) . Let Q = { µ, f M | A,C , π } collect the n uisance functions. The sp ecific causal functionals considered b elow may dep end only on subsets of Q . F or each c ∈ C , define θ ( Q )( c ) = Z µ ( m, a 1 , c ) f M | A,C ( m | a 0 , c ) dm . (1) The conditional functional θ ( Q )( c ) serv es as a building blo ck for several causal parameters. In particular, define ψ ( Q ) = Z θ ( Q )( c ) p ( c ) dc , γ ( Q ) = p ( a 0 ) E ( Y | a 0 ) + Z θ ( Q )( c ) π ( a 1 | c ) p ( c ) dc . (2) Under standard iden tification assumptions (see App endix B.1 ), these estimands corresp ond to the mediation functional E ( Y ( a 1 , M ( a 0 ))) and the fron t-do or functional E ( Y ( a 0 )) , resp ectiv ely , where Y ( a, m ) denotes the p otential outcome under A = a and M = m [ 1 , 28 , 8 , 29 ]. 3 Giv en n i.i.d. observ ations ( C i , A i , M i , Y i ) n i =1 and n uisance estimates collected in b Q , the plug-in estimators are ψ ( b Q ) = 1 n n X i =1 θ ( b Q )( C i ) , γ ( b Q ) = 1 n n X i =1 n I ( A i = a 0 ) Y i + θ ( b Q )( C i ) b π ( a 1 | C i ) o . (3) When M is contin uous, ev aluation of θ ( b Q )( c ) requires computing R b µ ( m, a 1 , c ) b f M | A,C ( m | a 0 , c ) dm , whic h ma y inv olv e n umerical in tegration or Monte Carlo appro ximation under a working mo del for the conditional densit y f M | A,C . In man y practical settings, this can b e statistically and com- putationally c hallenging. A common simplification is to coarsen the mediator by discretization. Next, w e formalize such coarsened functionals and analyze the resulting approximation errors. 3 Coarsened estimands F or clarity we present the dev elopmen t for a univ ariate mediator M ∈ R ; extensions to multi- v ariate mediators are discussed in App endix A . Let h : R → { 1 , . . . , K } b e a measurable discretization map that partitions the supp ort of M in to disjoin t bins B k = { m : h ( m ) = k } , k ∈ { 1 , . . . , K } . Let w k = sup m 1 ,m 2 ∈B k | m 1 − m 2 | denote the bin width and define f M = h ( M ) . The rule h ma y corresp ond, for instance, to thresholding M at a fixed or data-dep enden t cutoff, but more generally can enco de any measurable partition. F or each bin k , define µ k ( a, c ) = E ( Y | f M = k , A = a, C = c ) , g k ( a, c ) = p ( f M = k | A = a, C = c ) , and µ k,a 1 ( a, c ) = E ( µ ( M , a 1 , c ) | f M = k , A = a, C = c ) . The coarsened analogue of ( 1 ) is θ h ( Q )( c ) = K X k =1 µ k ( a 1 , c ) g k ( a 0 , c ) . (4) The coarsened v ersions of estimands in ( 2 ) , denoted by ψ h ( Q ) and γ h ( Q ) , are obtained b y replacing θ with θ h . W e primarily fo cus on θ since coarsening behavior propagates to ψ and γ through θ b y a veraging ov er C . Lemma 3.1. F or e ach c ∈ C , the c o arsening err or ∆ h ( Q )( c ) = θ h ( Q )( c ) − θ ( Q )( c ) satisfies ∆ h ( Q )( c ) = K X k =1 { µ k ( a 1 , c ) − µ k,a 1 ( a 0 , c ) } g k ( a 0 , c ) . (5) 4 If m 7→ µ ( m, a 1 , c ) is c ontinuously differ entiable on e ach B k and for e ach fixe d c ther e exists a finite c onstant L ( c ) < ∞ such that sup m ∈B k | µ ′ m ( m, a 1 , c ) | ≤ L ( c ) for al l k ∈ { 1 , . . . , K } and L ( C ) is squar e-inte gr able under P C , then | ∆ h ( Q )( c ) | = O w max ,K , wher e w max ,K : = max k ∈{ 1 ,...,K } w k is the maximum bin width. In p articular, if M has b ounde d supp ort and the K bins ar e chosen to have e qual width, then ∆ h ( Q )( c ) = O (1 /K ) . When one bin is muc h wider than the others, e.g., { 0 } v ersus (0 , M max ] , the w orst-case b ound based on w max ,K can be conserv ative; a sharper b ound uses the w eighted av erage P K k =1 w k g k ( a 0 , c ) . See a pro of in App endix B.2 . T o understand the magnitude of coarsening error in ( 5 ) and design coarsening bias corrections, w e take a closer lo ok at the difference b etw een µ k,a 1 ( a 0 , c ) and µ k ( a 1 , c ) . Assume µ is t wice contin uously differentiable on each B k , and define the within-bin mean m k ( a, c ) = E ( M | A = a, C = c, f M = k ) . (6) Under the conditions of Lemma 3.1 , a T a ylor expansion of µ ( M , a 1 , c ) around m k yields µ k ( a 1 , c ) − µ k,a 1 ( a 0 , c ) = µ ′ m ( m k ( a 1 , c ) , a 1 , c ) { m k ( a 1 , c ) − m k ( a 0 , c ) } + O ( w 2 k ) , (7) where µ ′ m is the deriv ative of µ w.r.t m ; see App endix B.2 . Equation ( 7 ) rev eals that the coarsening error in ( 5 ) scales linearly with the shift in within-bin mediator means b etw een treatment levels and the lo cal slop e of the outcome regression in M . The higher-order terms are prop ortional to the curv ature of µ and the within-bin spread of M ; under mild smo othness conditions, these remainder terms are of second order in the bin width. Therefore ∆ h ( Q )( c ) admits a first-order approximation with remainder O ( w 2 max ,K ) . In the follo wing remark, w e re-express the coarsening error via an exact cov ariance represen tation. Remark 3.2. ∆ h ( Q )( c ) admits an exact r epr esentation in terms of the within-bin c ovarianc e b etwe en (i) the c onditional outc ome surfac e µ ( M , a 1 , c ) and (ii) the tr e atment-induc e d density r atio r k ( M | c ) = p ( M | f M = k , A = a 0 , C = c ) /p ( M | f M = k , A = a 1 , C = c ) . The bias vanishes if within every bin, these two quantities ar e unc orr elate d under the distribution of M given ( f M = k , A = a 1 , C = c ) . This o c curs, for instanc e, if µ is lo c al ly c onstant in M within bins, or 5 if the c onditional distribution of M do es not differ b etwe en A = a 0 and A = a 1 inside e ach bin; se e App endix B.3 . The plug-in estimate of θ h ( Q )( c ) is θ h ( b Q )( c ) = K X k =1 b µ k ( a 1 , c ) b g k ( a 0 , c ) , (8) where b µ k ( a, c ) and b g k ( a, c ) estimate µ k ( a, c ) and g k ( a, c ) , e.g., via regressions of Y on ( f M , A, C ) and f M on ( A, C ) . The plug-in estimators ψ h ( b Q ) and γ h ( b Q ) are obtained by replacing θ ( b Q ) with θ h ( b Q ) in ( 3 ). W e decomp ose θ h ( b Q )( c ) − θ ( Q )( c ) as: n θ h ( b Q )( c ) − θ h ( Q )( c ) o | {z } estimation error + n θ h ( Q )( c ) − θ ( Q )( c ) o | {z } coarsening error . (9) Assume that for fixed h , the estimator θ h ( b Q ) satisfies ∥ θ h ( b Q ) − θ h ( Q ) ∥ L 2 ( P C ) = O p ( n − 1 / 2 ) , where ∥ g ∥ 2 L 2 ( P C ) = E ( g ( C ) 2 ) . Then, b y Lemma 3.1 , ∥ θ h ( b Q ) − θ ( Q ) ∥ L 2 ( P C ) = O p ( n − 1 / 2 ) + O ( w max ,K ) . Hence the asymptotic bias is driv en by the coarsening bias ∆ h ( Q ) , which is first order in the bin width. Let K = K n increase with n . If M has bounded supp ort and equal-width bins are used, then w max ,K n = O (1 /K n ) . If K n → ∞ and w max ,K n = o ( n − 1 / 2 ) (e.g., K n = o ( n 1 / 2 ) ), the coarsening bias is negligible relative to sampling error and θ h ( b Q ) is asymptotically equiv alent to θ in L 2 ( P C ) . 4 Debiased coarsened estimands W e introduce a simple correction that remov es the leading discretization bias by ev aluating the outcome regression µ ( ., a 1 , c ) at within-bin representativ es of the mediator under A = a 0 . Given 6 m k ( a, c ) in ( 6 ), define the debiased coarsened functional e θ h ( Q )( c ) = K X k =1 µ m k ( a 0 , c ) , a 1 , c g k ( a 0 , c ) . (10) The expansion is taken around m k ( a 0 , c ) because θ ( Q )( c ) a verages µ ( M , a 1 , c ) with resp ect to the distribution of M giv en A = a 0 . Th us ( 10 ) replaces the in-bin conditional exp ectation of µ ( M , a 1 , c ) under A = a 0 b y its ev aluation at the within-bin mean under the same distribution. The debiased coarsened causal parameters e ψ h ( Q ) and e γ h ( Q ) are obtained from ( 2 ) b y replacing θ with e θ h . Lemma 4.1. F or e ach c ∈ C , the c o arsening err or e ∆ h ( Q )( c ) = e θ h ( Q )( c ) − θ ( Q )( c ) satisfies e ∆ h ( Q )( c ) = K X k =1 { µ ( m k ( a 0 , c ) , a 1 , c ) − µ k,a 1 ( a 0 , c ) } g k ( a 0 , c ) . (11) If m 7→ µ ( m, a 1 , c ) is twic e c ontinuously differ entiable and R k ( c ) = µ m k ( a 0 , c ) , a 1 , c − µ k,a 1 ( a 0 , c ) , then | R k ( c ) | ≤ 1 2 sup m ∈B k | µ ′′ m ( m, a 1 , c ) | E ( M − m k ( a 0 , c )) 2 | a 0 , c, k . (12) If sup m ∈B k | µ ′′ m ( m, a 1 , c ) | ≤ L ( c ) , wher e L ( C ) is squar e-inte gr able under P C , then e ∆ h ( Q )( c ) = O ( w 2 max ,K ) . If M has b ounde d supp ort and the K bins ar e chosen to have e qual width, then ∆ h ( Q )( c ) = O (1 /K 2 ) . See App endix B.4 for a pro of. Giv en Lemma 4.1 , the first-order term in Lemma 3.1 is eliminated. The remaining error is prop ortional to the curv ature of µ ( m, a 1 , c ) and the within-bin v ariance of M , and is therefore second order in the bin width. The plug-in estimator of e θ h ( Q )( c ) is e θ h ( b Q )( c ) = K X k =1 b µ b m k ( a 0 , c ) , a 1 , c b g k ( a 0 , c ) , (13) where b m k ( a 0 , c ) = b E ( M | A = a 0 , C = c, f M = k ) . The estimators e ψ h ( b Q ) and e γ h ( b Q ) are obtained 7 b y replacing θ ( b Q ) with e θ h ( b Q ) in ( 3 ). W e decomp ose e θ h ( b Q )( c ) − θ ( Q )( c ) as n e θ h ( b Q )( c ) − e θ h ( Q )( c ) o | {z } estimation error + n e θ h ( Q )( c ) − θ ( Q )( c ) o | {z } coarsening error . (14) Assume that for fixed h , ∥ e θ h ( b Q ) − e θ h ( Q ) ∥ L 2 ( P C ) = O p ( n − 1 / 2 ) . Then, b y Lemma 4.1 , ∥ e θ h ( b Q ) − θ ( Q ) ∥ L 2 ( P C ) = O p ( n − 1 / 2 ) + O ( w 2 max ,K ) . F or fixed K , the asymptotic bias is driv en b y the coarsening error e ∆ h ( Q ) , whic h is second order in the bin width. Let K = K n increase with n . If M has bounded supp ort and equal-width bins are used, then w max ,K n = O (1 /K n ) , and hence e ∆ h ( Q )( c ) = O (1 /K 2 n ) . If K n → ∞ and w 2 max ,K n = o ( n − 1 / 2 ) (e.g., K n = o ( n 1 / 4 ) ), the coarsening bias is negligible relative to sampling error and e θ h ( b Q ) is asymptotically equiv alent to θ ( Q ) in L 2 ( P C ) . Compared to the naive coarsened functional θ h ( Q )( c ) , which incurs first-order bias of order O ( w max ,K ) , the debiased functional e θ h ( Q )( c ) achiev es a second-order approximation of order O ( w 2 max ,K ) under the stated smo othness conditions. Under equal-width binning, this corresp onds to O (1 /K ) versus O (1 /K 2 ) . 5 Smo othed debiased coarsened estimands Sections 3 and 4 analyzed the approximation error induced b y coarsening. W e now turn to statistical estimation. Throughout the previous sections w e assumed that, for fixed h , the estimation error of the plug-in estimator is O p ( n − 1 / 2 ) in L 2 ( P C ) . Such b ehavior typically requires sufficien tly fast conv ergence 8 of all nuisance estimators. When flexible machine learning metho ds are used to estimate µ , π , and g k , plug-in estimators can exhibit non-negligible first-order estimation bias. A standard v on Mises expansion sho ws that for a smo oth target parameter ψ ( Q ) , ψ ( b Q ) − ψ ( Q ) = − P { ϕ ( b Q ) } + R 2 ( b Q, Q ) , where ϕ ( Q ) is the canonical gradien t, efficien t influence function (EIF), and R 2 is a second-order remainder [ 23 ]. The leading term − P { ϕ ( b Q ) } represen ts first-order bias and dep ends directly on the qualit y of nuisance estimation. A chieving asymptotic linearity therefore requires sufficien tly fast nuisance conv ergence. Influence-function–based estimators, such as one-step and targeted minim um loss estimators, remo ve the first-order bias term and attain asymptotic linearit y under w eaker conditions. Ho wev er, to construct such estimators, the target parameter m ust b e pathwise differentiable in the nonparametric mo del. The debiased coarsened functional e θ h ( Q )( c ) fails this requirement when M is con tinuous, b ecause it inv olves p oin t ev aluation of µ ( m, a, c ) at m k ( a 0 , c ) . Poin t ev aluation is not a contin uous linear functional on L 2 ( P ) unless M is discrete, and therefore e ψ h and e γ h are not path wise differentiable in the nonparametric mo del. 5.1 Smo othed estimands and plug-ins T o restore pathwise differentiabilit y and enable influence-function–based estimation, we introduce a smo othed v ersion of the debiased functional. W e regularize the point ev aluation by replacing it with a lo calized a verage. Let K b e a symmetric k ernel and let b > 0 b e a bandwidth. Define K b ( u ) = b − 1 K ( u/b ) and the normalized weigh t ω b,k ( m | a 1 , c ) = K b ( m − m k ( a 0 , c )) E ( K b ( M − m k ( a 0 , c )) | A = a 1 , C = c ) . Define the lo calized mean µ b,k ( a 1 , c ) = E ( µ ( M , a 1 , c ) ω b,k ( M | a 1 , c ) | A = a 1 , C = c ) , and the smo othed debiased coarsened estimand e θ h,b ( Q )( c ) = K X k =1 µ b,k ( a 1 , c ) g k ( a 0 , c ) . (15) 9 As b → 0 , the k ernel K b concen trates at m k ( a 0 , c ) and e θ h,b ( Q )( c ) → e θ h ( Q )( c ) . The smo othed debiased coarsened parameters e ψ h,b ( Q ) and e γ h,b ( Q ) are obtained from ( 2 ) b y replacing θ with e θ h,b . Lemma 5.1. F or e ach c ∈ C , the smo othing err or e ∆ s h,b ( Q )( c ) = e θ h,b ( Q )( c ) − e θ h ( Q )( c ) satisfies e ∆ s h,b ( Q )( c ) = K X k =1 n µ b,k ( a 1 , c ) − µ ( m k ( a 0 , c ) , a 1 , c ) o g k ( a 0 , c ) . (16) Supp ose: (i) m 7→ µ ( m, a 1 , c ) is twic e c ontinuously differ entiable ne ar m k ( a 0 , c ) with sup m,c | µ ′′ m ( m, a 1 , c ) | < ∞ ; (ii) K is symmetric with R u K ( u ) du = 0 and R u 2 K ( u ) du < ∞ ; and (iii) f M | A,C ( · | a 1 , c ) is c ontinuous and b ounde d away fr om zer o ne ar m k ( a 0 , c ) . Then, as b → 0 , e ∆ s h,b ( Q )( c ) = O ( b 2 ) . Combining with L emma 4.1 , the total err or e ∆ h,b ( Q )( c ) = e θ h,b ( Q )( c ) − θ ( Q )( c ) satisfies e ∆ h,b ( Q )( c ) = O w 2 max ,K + b 2 . See a pro of in App endix B.5 . The plug-in estimator for e θ h,b ( Q )( c ) is e θ h,b ( b Q )( c ) = K X k =1 b µ b,k ( a 1 , c ) b g k ( a 0 , c ) , (17) where b µ b,k ( a 1 , c ) = b E ( b µ ( M , a 1 , c ) b ω b,k ( m | a 1 , c ) | a 1 , c ) . W e can decomp ose e θ h,b ( b Q )( c ) − θ ( Q )( c ) as n e θ h,b ( b Q )( c ) − e θ h,b ( Q )( c ) o | {z } estimation error + n e θ h,b ( Q )( c ) − θ ( Q )( c ) o | {z } total error . (18) Assume that for fixed h and b , ∥ e θ h,b ( b Q ) − e θ h,b ( Q ) ∥ L 2 ( P C ) = O p ( n − 1 / 2 ) . Then, b y Lemma 5.1 , ∥ e θ h,b ( b Q ) − θ ( Q ) ∥ L 2 ( P C ) = O p ( n − 1 / 2 ) + O ( w 2 max ,K + b 2 ) . Th us, for fixed K and b , the asymptotic bias is driven by e ∆ h,b ( Q )( c ) , whic h is second order in 10 the bin width and quadratic in the smoothing bandwidth. Let K = K n and b = b n dep end on n . Under equal-width binning, w max ,K n = O (1 /K n ) , so e ∆ h,b n ( Q )( c ) = e θ h,b n ( Q )( c ) − θ ( Q )( c ) = O (1 /K 2 n + b 2 n ) . If K n → ∞ , b n → 0 , and 1 /K 2 n + b 2 n = o ( n − 1 / 2 ) , for example K n = o ( n 1 / 4 ) and b n = o ( n 1 / 4 ) , then e θ h,b n ( b Q ) is asymptotically equiv alent to θ ( Q ) in L 2 ( P C ) . 5.2 Influence function based estimation As an example, consider the smo othed mediation functional e ψ h,b ( Q ) = Z e θ h,b ( Q )( c ) p ( c ) dc . T o present the influence function in a transparent form, we first treat the bin cen ters m k ( a 0 , c ) as fixed quan tities m ⋆ k ( a 0 , c ) (e.g., midp oin ts or pre-sp ecified represen tatives). Theorem 5.2. The nonp ar ametric efficient influenc e function for e ψ h,b ( Q ) when m k ( a 0 , k ) is fixe d, is e ϕ fixe d h,b ( Q )( O ) = K X k =1 I ( A = a 1 ) π ( a 1 | C ) g k ( a 0 , C ) n Y ω b,k ( M | a 1 , C ) − µ b,k ( a 1 , C ) o + K X k =1 I ( A = a 0 ) π ( a 0 | C ) µ b,k ( a 1 , C ) n I ( f M = k ) − g k ( a 0 , C ) o + n e θ h,b ( Q )( C ) − e ψ h,b ( Q ) o . See a pro of in App endix B.6 . Let b Q collect all nuisance estimates. The one-step estimator of e ψ h,b ( Q ) , when m k ( a 0 , k ) is fixed, is e ψ one-step h,b ( b Q ) = e ψ fixed h,b ( b Q ) + 1 n n X i =1 e ϕ fixed h,b ( b Q )( O i ) , 11 where e ϕ fixed h,b ( b Q )( O i ) is the ev aluation of the influence function at b Q and O i , and e ψ fixed h,b ( b Q )= 1 n n X i =1 K X k =1 b µ fixed b,k ( a 1 , C i ) b g k ( a 0 , C i ) , b µ fixed b,k ( a 1 , c )= b E h b µ ( M , a 1 , c ) ω b,k ( M | a 1 , c ) | A = a 1 , C = c i . Under sufficien t regularity conditions, n − 1 / 4 rates of the n uisance estimators, and cross-fitting, the one-step estimator is asymptotically linear with asymptotic v ariance of E ( e ϕ fixed h,b ( Q )( O ) 2 ) . When m k ( a 0 , c ) is estimated from the data, additional influence function contributions arise. The con tribution of the nuisance m k to the EIF, denoted b y e ϕ ω h,b ( Q )( O ) , is e ϕ ω h,b ( Q )( O ) = K X k =1 α k ( C ) I ( A = a 0 ) I ( f M = k ) π ( a 0 | C ) M − m k ( a 0 , C ) , (19) where α k ( c ) : = ∂ ∂ m µ b,k ( a 1 , c ) . The full EIF for e ψ h,b ( Q ) is th us giv en b y e ϕ h,b ( Q )( O ) = e ϕ fixed h,b ( Q )( O )+ e ϕ ω h,b ( Q )( O ) . See a pro of in App endix B.6 . 6 Sim ulation studies W e study estimation of the mediation functional ψ ( Q ) = E ( Y ( a 1 , M ( a 0 ))) , corresp onding to ( 2 ) , with a 1 = 1 and a 0 = 0 throughout. Our goals are tw ofold: (i) T o quantify the p opulation-lev el coarsening bias of the discretized estimand θ h ( Q )( c ) and verify the first-order scaling derived in Lemma 3.1 ; (ii) T o ev aluate the finite-sample p erformance of the coarsened estimator ψ h ( b Q ) and the prop osed debiased estimator e ψ h ( b Q ) , including plug-in and one-step v ariants. All sim ulations are conducted under the following data-generating pro cess (DGP). The baseline co v ariate C tak es v alues in {− 2 , − 1 , 0 , 1 , 2 } with probability mass (0 . 15 , 0 . 20 , 0 . 18 , 0 . 30 , 0 . 17) resp ectiv ely; A | C ∼ Bernoulli expit(0 . 5 C ) , M | A, C ∼ N − 0 . 6 C + 2 A + 0 . 5 AC , 1 , Y | M , A, C ∼ N µ ( M , A, C ) , 1 , where µ ( M , A, C ) = 0 . 8 C + 1 . 5 A + 0 . 75 AM + 0 . 20 M C 2 + 0 . 1 M 3 + 0 . 55 AC , nonlinear in M , 12 T able 1: Coarsening error ∆ h ( Q )( c ) for equal-frequency discretizations with K = 2 and K = 6 . C = -2 C = -1 C = 0 C = 1 C = 2 K = 2 1.103 0.871 0.876 1.522 3.390 K = 6 0.195 0.149 0.216 0.550 1.562 ensuring nonzero curv ature and hence non negligible second order terms in the T a ylor expansions b ehind Lemmas 3.1 and 4.1 . Sim ulation #1: Population coarsening error. W e first isolate the population-level discretization bias ∆ h ( Q )( c ) = θ h ( Q )( c ) − θ ( Q )( c ) as c haracterized in Lemma 3.1 . T o approximate the theoretical quantities app earing in ∆ h ( Q )( c ) , w e generate a large Mon te Carlo sample of size n = 1 , 000 , 000 from the DGP . No nuisance estimation is in volv ed in this exp eriment. Instead, we exploit the known parametric forms to compute: g k ( a, c ) , m k ( a, c ) , µ k ( a, c ) . W e consider equal-frequency discretizations of M with K = 2 and K = 6 bins. T able 1 rep orts ∆ h ( Q )( c ) across lev els of C . F or all cov ariate v alues, the magnitude of the coarsening error decreases substantially as K increases. This pattern is consistent with the theoretical scaling ∆ h ( Q )( c ) = O (1 /K ) under equal-width binning and b ounded supp ort, as established in Lemma 3.1 . Imp ortantly , even at K = 6 , the bias remains non-negligible for some v alues of C , illustrating that coarse discretization can alter the target parameter. Equation ( 7 ) sho ws that the leading term of ∆ h ( Q )( c ) is prop ortional to µ ′ m ( m k ( a 1 , c ) , a 1 , c ) { m k ( a 1 , c ) − m k ( a 0 , c ) } . Figure 1 plots the within-bin shifts m k ( a 1 , c ) − m k ( a 0 , c ) for discretizations with K = 2 and K = 6 . Increasing K reduces these shifts across bins and cov ariate strata, thereby atten uating the dominant first-order comp onent of the discretization bias. The empirical b ehavior aligns closely with the T a ylor expansion derived in Lemma 3.1 . Remark 3.2 expresses the coarsening bias as a within-bin cov ariance b etw een µ ( M , a 1 , c ) and the ratio r k ( M | c ) . Figure 2 illustrates this at C = 0 . With finer discretization, the co v ariance magnitude drops substan tially , giving a complementary view of the reduced coarsening error. T ogether, these results empirically v alidate the O (1 /K ) first-order b ehavior predicted b y Lemma 3.1 . 13 Figure 1: Within-bin differences in conditional mediator means, m k ( a 1 , c ) − m k ( a 0 , c ) , under discretizations with K = 2 (red) and K = 6 (blue). Each horizontal segmen t represen ts one mediator bin, with bin indices shown on the upp er axis for K = 2 and on the lo wer axis for K = 6 . Panels corresp ond to differen t v alues of the cov ariate C . Figure 2: Within-bin cov ariance b et ween µ ( M , a 1 , C ) and r k ( M | C ) at C = 0 , as formalized in Remark 3.2 . Finer discretization reduces the magnitude of this co v ariance. 14 Sim ulation #2: Finite-sample p erformance. W e now turn to statistical estimation. W e generate datasets with sample sizes n ∈ { 500 , 5 , 000 , 50 , 000 } , using 1,000 Mon te Carlo replications for eac h n . W e consider equal-frequency discretizations of the mediator using a broad range of bin coun ts K . F or each discretization lev el K , we compare: the coarsened plug-in estimator ψ h ( b Q ) , the debiased coarsened plug-in estimator e ψ h ( b Q ) , and their corresp onding one-step estimators. All n uisance functions are estimated using correctly sp ecified generalized linear mo dels. The within-bin means m k ( a 0 , c ) and bin probabilities g k ( a, c ) are computed under the truncated normal distribution implied b y the DGP . Figure 3 displa ys the bias of ψ h ( b Q ) and e ψ h ( b Q ) as functions of n for sev eral v alues of K . T w o distinct phenomena are evident: (i) Increasing n reduces Mon te Carlo v ariability , and (ii) for fixed K , the bias of ψ h ( b Q ) does not v anish as n increases. The p ersistence of bias reflects p opulation coarsening error, not estimation error. In con trast, e ψ h ( b Q ) exhibits dramatically reduced bias across all sample sizes, consisten t with the second-order scaling e ∆ h ( Q )( c ) = O (1 /K 2 ) from Lemma 4.1 . Because bias patterns are qualitativ ely similar across sample sizes, w e fo cus on n = 5 , 000 . Figure 4 summarizes absolute bias, v ariance, mean squared error (MSE), and cov erage of 95% confidence in terv als (CIs) as functions of K . The coarsened plug-in estimator ψ h ( b Q ) exhibits substantial bias and p o or cov erage for small K . P erformance improv es gradually as K increases, reflecting the O (1 /K ) deca y of discretization bias. In contrast, the debiased estimator e ψ h ( b Q ) ac hiev es near-zero bias even for relativ ely small K , smaller MSE, and co v erage close to the nominal lev el across a broad range of discretization lev els. V ariance is only mo destly affected by the debiasing step. These findings demonstrate that ev aluating µ at the within-bin mean m k ( a 0 , c ) effectiv ely remov es the leading discretization bias without inducing meaningful v ariance inflation. One-step estimators are often used to reduce estimation bias b y incorp orating influence-function corrections. Define the generalized prop ensity score g ( a | m, c ) = p ( A = a | M = m, C = c ) . The 15 one-step estimators for ψ ( Q ) and ψ h ( Q ) , denoted ψ + ( b Q ) and ψ + h ( b Q ) are ψ + ( b Q ) = 1 n n X i =1 " I ( A i = a ) b π ( a 0 | C i ) b g ( a 0 | M i , C i ) b g ( a 1 | M i , C i ) Y − b µ ( M i , a 1 , C i ) (20) + I ( A i = a 0 ) ˆ π ( a 0 | C i ) b µ ( M i , a 1 , C i ) − θ ( b Q )( C i ) + θ ( b Q )( C i ) # , ψ + h ( b Q ) = 1 n n X i =1 " I ( A i = a ) b π ( a | C i ) b g k ( a 0 , C i ) b g k ( a 1 , C i ) Y − b µ k ( a 1 , C i ) (21) + I ( A i = a 0 ) b π ( a 0 | C i ) b µ k ( a 1 , C i ) − θ h ( b Q )( C i ) + θ h ( b Q )( C i ) # . The estimator in ( 21 ) is consisten t for ψ h ( Q ) if either (i) b π and b g k , (ii) b π and b µ k , or (iii) b g k and b µ k are consisten t. Note that ψ + h ( b Q ) still targets the coarsened functional ψ h ( Q ) rather than the original parameter ψ ( Q ) . T o remedy this limitation, we compare: (i) ψ + h ( b Q ) , the one-step estimator for ψ h ( Q ) , (ii) e ψ + h 1 ( b Q ) , a naiv e deriv ative-based correction that replaces b µ k b y b µ ( m k ( a 0 , c ) , a 1 , c ) and θ h ( b Q )( c ) with e θ h ( b Q )( c ) in ( 21 ) , (iii) e ψ + h 2 ( b Q ) , the one-step estimator that replaces θ ( b Q )( c ) with e θ h ( b Q )( c ) in ( 20 ), (iv) the coarsened plug-in estimator ψ h ( b Q ) , (v) the debiased plug-in estimator e ψ h ( b Q ) . Figure 5 presents results under correct sp ecification and a range of missp ecification for nuisance mo dels. Details of the missp ecification configurations is pro vided in App endix C . The one-step estimator ψ + h ( b Q ) yields mo dest improv emen ts in bias and cov erage relative to ψ h ( b Q ) , but do es not eliminate discretization bias, since the target remains ψ h ( Q ) . The first deriv ative estimator e ψ + h 1 ( b Q ) b eha v es similarly and do es not meaningfully reduce discretization bias. In contrast, e ψ + h 2 ( b Q ) achiev es uniformly lo w bias and near-nominal cov erage across scenarios. Notably , the debiased plug-in estimator e ψ h ( b Q ) p erforms comparably to e ψ + h 2 ( b Q ) , with only minor differences in bias and co verage. Ov erall, these findings demonstrate that discretization bias arises at the level of the target functional and therefore cannot b e eliminated by influence-function correction alone. Correcting the functional through the prop osed debiased coarsened construction is essential for v alid inference. The resulting debiased plug-in estimator achiev es substantial bias reduction while retaining computational simplicit y and strong empirical p erformance. 16 Figure 3: Bias of the coarsened plug-in estimator ψ h ( b Q ) and the debiased plug-in estimator e ψ h ( b Q ) as functions of sample size for sev eral discretization lev els K . F or fixed K , the bias of ψ h ( b Q ) p ersists as n increases, reflecting p opulation coarsening error, whereas e ψ h ( b Q ) exhibits substan tially reduced bias across sample sizes. Figure 4: The p erformance of the coarsened plug-in estimator ψ h ( b Q ) and the debiased estimator e ψ h ( b Q ) as functions of the n umber of mediator bins K for sample size n = 5 , 000 . 17 Figure 5: Comparison of plug-in and one-step estimators under nuisance-model missp ecification for n = 5 , 000 . “Correct” indicates all nuisance mo dels are correctly sp ecified, whereas “F alse” indicates all nuisance mo dels are missp ecified. Conditions 1–3 corresp ond to missp ecification of { µ, µ k } , { g , g k } , an d π , resp ectiv ely . Performance is summarized in terms of bias, v ariance, MSE, and 95% confidence in terv al cov erage. 7 A real data application W e apply our proposed estimation framew ork to data from the B_PR OUD study , an observ ational in vestigation assessing the impact of Mobile Stroke Unit (MSU) dispatch on p ost-stroke outcomes in Berlin [ 30 ] conducted b et ween F ebruary 2017 and May 2019. It can b e used to ev aluate the effect of additional MSU care on 3-mon th functional outcomes among patients for whom an MSU w as received. W e analyzed 768 patients eligible for rep erfusion therap y , of whom 588 (76.6%) receiv ed MSU care ( A = 1 ) and 180 (23.4%) received conv entional emergency services ( A = 0 ). The outcome Y is the 3-month mo dified Rankin Scale (mRS), an ordinal measure ranging from 0 (no symptoms) to 6 (death). In our study , we treat mRS as contin uous. The full mediator M is defined as the time from am bulance dispatc h to thrombolysis and is set to zero for patien ts who did not receive 18 Figure 6: Comparison of plug-in estimators γ h ( b Q ) , e γ h ( b Q ) and γ s ( b Q ) in B_PROUD study for estimating γ ( Q ) = E [ Y ( a 0 )] throm b olytic therap y . W e adjust for tw o baseline contin uous cov ariates: systolic blo o d pressure and strok e severit y . Missing data are handled using m ultiple imputation. This dataset was previously analyzed by [ 27 ] emplo ying a front-door approach to estimate the causal effect of MSU dispatc h on 3-mon th mRS using a three-category mediator. Subsequently , [ 8 ] considered both contin uous and binary v ersions of the mediator, exploring different cutoffs and implemen ting one-step and TMLE estimators of the fron t-do or functional. In this analysis, w e compare three estimators of the fron t-do or functional γ ( Q ) for E ( Y ( a 0 )) in ( 2 ) with a 0 = 0 : (i) the coarsened plug-in estimator γ h ( b Q ) , (ii) the debiased plug-in estimator e γ h ( b Q ) , and (iii) the plug-in estimator γ s ( b Q ) based on sequen tial regression, which av oids explicit estimation of the mediator densit y by rewriting θ ( Q )( c ) as θ ( Q )( c ) = E ( ˜ Y | a 0 , c ) , where e Y = E ( Y | a 1 , m, c ) . (22) All nuisance functions w ere estimated using super learner with candidates including glm.interaction , glmnet , random forests (1000 trees), xgboost , and dbarts . Figure 6 presen ts p oint estimates along with 95% CIs obtained via b o otstrapping. In terms of p oin t estimates, the debiased estimator e γ h ( b Q ) and the sequen tial estimator γ s ( b Q ) are closer to eac h other than either is to the coarsened estimator γ h ( b Q ) . When K = 2 , the CIs of the three estimators exhibit limited o verlap, and γ h ( b Q ) (2.074; 95% CI: 1.931–2.217) app ears somewhat 19 Figure 7: Estimated within-bin differences in conditional mediator means, b m k ( a 1 , C i ) − b m k ( a 0 , C i ) , under discretizations with K = 2 . The red line denotes zero and the blue dashed lines indicate the median of within-bin differences. farther from the debiased estimator e γ h ( b Q ) (2.182; 95% CI: 2.015–2.382) and the sequential estimator γ s ( b Q ) (2.157; 95% CI: 1.984–2.340). F or K = 3 , 4 , and 5 , the CIs largely ov erlap. In particular, the estimate of e γ h ( b Q ) with K = 5 (2.144; 95% CI: 2.010–2.340) is nearly identical to the estimate of γ s ( b Q ) , indicating substan tial agreement under finer discretization. The coarsened estimator e γ h ( b Q ) do es not p erform as p o orly as migh t b e anticipated. This pattern is in terpretable up on examining the within-bin mediator mean shifts across treatmen t lev els, as illustrated in Figure 7 . F or K = 2 , the estimated shifts in the tw o bins cluster around opp osite signs-one predominan tly p ositive and the other predominantly negativ e. As indicated in ( 5 ) , the coarsening bias dep ends on b oth the mediator shifts within bins and the lo cal deriv ative structure of µ ( m, a 1 , c ) . When mediator shifts differ in sign across bins, their weigh ted contributions ma y partially offset.This cancellation effect pro vides a plausible explanation for the relativ ely small empirical deviation of the coarsened estimator compared with the other estimators in this dataset. Ho wev er, such offsets dep ends on sp ecific features of the data structure and cannot b e alw ays guaran teed in practice. Therefore, although the coarsened plug-in estimator ma y p erform well in certain empirical settings, relying on it without bias correction remains p otentially risky . In con trast, the prop osed debiased estimator offers a more reliable alternative, mitigating first-order coarsening bias without imp osing restrictive assumptions on the mediator–outcome relationship. 20 8 Discussion W e study the bias induced by discretizing a contin uous mediator in causal functionals. Even under correct identification and consistent nuisance estimation, naive discretization alters the target parameter and introduces a first-order approximation error that scales with the bin width. Ev aluating the outcome regression at within-bin means under the appropriate treatment- reference distribution remov es this leading term and reduces the error to second order under standard smo othness conditions. A key distinction is b etw een functional appro ximation error and statistical estimation error. Influence-function–based estimators address the latter but do not correct discretization bias when the estimand itself has b een mo dified. Correcting the functional is therefore essential; once this is done, standard semiparametric to ols can b e applied to con trol estimation error and conduct v alid inference. F rom a practical p ersp ective, discretization is frequen tly used to simplify computation or av oid direct conditional d ensit y estimation. Our results sho w that the resulting approximation error can be formally characterized and reduced through a simple within-bin correction that preserv es computational tractabilit y . Although we fo cus on mediation and fron t-do or functionals, the underlying argument applies more broadly to causal parameters that integrate a regression surface against a conditional distribution, provided suitable smo othness conditions hold. 21 References [1] Judea P earl. Direct and indirect effects. In Pr o c e e dings of the Sevente enth Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UAI-01) , pages 411–420. Morgan Kaufmann, San F rancisco, 2001. [2] T yler V anderW eele and Stijn V ansteelandt. Mediation analysis with m ultiple mediators. Epidemiolo gic metho ds , 2(1):95–115, 2014. [3] Chen A vin, Ily a Shpitser, and Judea Pearl. Iden tifiabilit y of path-sp ecific effects. In Pr o c e e dings of the IJCAI , pages 357–363, 12 2005. [4] Ily a Shpitser. Counterfactual graphical mo dels for longitudinal mediation analysis with unobserv ed confounding. Co gnitive scienc e , 37(6):1011–1035, 2013. [5] Jin Tian and Judea P earl. A general identification condition for causal effects. In Eighte enth National Confer enc e on A rtificial Intel ligenc e , pages 567–573, 2002. [6] Thomas S Richardson, Robin J Ev ans, James M Robins, and Ilya Shpitser. Nested mark o v prop erties for acyclic directed mixed graphs. The A nnals of Statistics , 51(1):334–361, 2023. [7] Rohit Bhattac harya, Razieh Nabi, and Ily a Shpitser. Semiparametric inference for causal effects in graphical mo dels with hidden v ariables. Journal of Machine L e arning R ese ar ch , 23:1–76, 2022. [8] Anna Guo, Da vid Benk eser, and Razieh Nabi. Flexible nonparametric inference for causal effects under the fron t-do or mo del. arXiv pr eprint arXiv:2312.10234 , 2023. [9] Anna Guo, David Benkeser, and Razieh Nabi. Causal inference with the" napkin graph". arXiv pr eprint arXiv:2512.19861 , 2025. [10] Y asmmyn D Salinas, Zuoheng W ang, and Andrew T DeW an. Discov ery and mediation analysis of cross-phenotype asso ciations b etw een asthma and b o dy mass index in 12q13. 2. A meric an Journal of Epidemiolo gy , 190(1):85–94, 2021. [11] Jiasheng Huang, Y ehua Li, Angelique G Brellenthin, Duc k-ch ul Lee, Xuemei Sui, and Stev en N Blair. Causal mediation analysis b et ween resistance exercise and reduced risk of 22 cardio v ascular disease based on the aerobics center longitudinal study . Journal of A pplie d Statistics , 49(14):3750–3767, 2022. [12] Ali Hemade and P ascale Salameh. Revisiting the ob esity–anaemia paradox: Inflammation and iron homeostasis in the bmi–haemoglobin relationship. Endo crinolo gy, Diab etes & Metab olism , 8(5):e70110, 2025. [13] Ze-w ei Ma and W ei-nan Zeng. A multiple mediator mo del: Po wer analysis based on monte carlo sim ulation. A meric an Journal of Applie d Psycholo gy , 3(3):72–79, 2014. [14] Dustin Tingley , T epp ei Y amamoto, Kentaro Hirose, Luk e Keele, and Kosuk e Imai. Mediation: R pac kage for causal mediation analysis. Journal of statistic al softwar e , 59:1–38, 2014. [15] Katrina L Devic k, Linda V aleri, Jarvis Chen, Alejandro Jara, Marie-Abèle Bind, and Bren t A Coull. The role of b o dy mass index at diagnosis of colorectal cancer on black–white disparities in surviv al: a density regression mediation approac h. Biostatistics , 23(2):449–466, 2022. [16] An tonio R Linero. Sim ulation-based estimators of analytically intractable causal effects. Biometrics , 78(3):1001–1017, 2022. [17] Yi Li, May a B Math ur, Daniel H Solomon, Paul M Ridker, Rob ert J Glynn, and Kazuki Y oshida. Effect measure mo dification by co v ariates in mediation: extending regression-based causal mediation analysis. Epidemiolo gy , 34(5):661–672, 2023. [18] R uyi Liu, Liangyuan Hu, F rancis Perry Wilson, Josh ua L W arren, and F an Li. A bay esian approac h to the g-form ula via iterative conditional regression. Statistics in Me dicine , 44(13-14):e70123, 2025. [19] Zeyi W ang, Lars v an der Laan, May a Petersen, Thomas Gerds, Ka jsa K vist, and Mark v an der Laan. T argeted maximum likelihoo d based estimation for longitudinal mediation analysis. Journal of Causal Infer enc e , 13(1):20230013, 2025. [20] Guanglei Hong. Ratio of mediator probabilit y w eighting for estimating natural direct and indirect effects. arXiv pr eprint arXiv:2506.03284 , 2025. [21] Xiang Zhou. Semiparametric estimation for causal mediation analysis with m ultiple causally 23 ordered mediators. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 84(3):794–821, 2022. [22] Chang Liu and AmirEmad Ghassami. T wo-stage nuisance function estimation for causal mediation analysis. arXiv pr eprint arXiv:2404.00735 , 2024. [23] Aad W V an der V aart. A symptotic statistics , volume 3. Cambridge universit y press, 2000. [24] Mark J v an der Laan and Daniel Rubin. T argeted maximum likelihoo d learning. The International Journal of Biostatistics , 2(1), 2006. [25] Mu-Chi Chung, Hui-T sung Hsu, Y an-Chiao Mao, Chin-Ching W u, Chih-T e Ho, Chiu-Shong Liu, and Chi-Jung Ch ung. Asso ciation and mediation analyses among multiple metals exp osure, plasma folate, and communit y-based impaired estimated glomerular filtration rate in cen tral taiwan. Envir onmental He alth , 21(1):44, 2022. [26] Osv aldo F Morera, Mosi I Dane’el, Brandt A Smith, Alisha H Redelfs, Sarah L Ruiz, Kristopher J Preac her, and Leah D Whigham. Discretizing contin uous v ariables in n utrition and ob esity research: a practice that needs to b e cut short. Nutrition & Diab etes , 13(1):20, 2023. [27] Marco Piccininni, T obias Kurth, Heinrich J A udeb ert, and Jessica L Rohmann. The effect of mobile stroke unit care on functional outcomes: an application of the front-door formula. Epidemiolo gy , 34(5):712–720, 2023. [28] Judea P earl. Causal diagrams for empirical research. Biometrika , 82(4):669–688, 1995. [29] Anna Guo and Razieh Nabi. A v erage causal effect estimation in dags with hidden v ariables: Bey ond back-door and front-door criteria. arXiv pr eprint arXiv:2409.03962 , 2024. [30] Martin Ebinger, Peter Harmel, Christian H Nolte, Ulrike Grittner, Bob Siegerink, and Heinric h J Audebert. Berlin prehospital or usual deliv ery of acute strok e care–study proto col. International Journal of Str oke , 12(6):653–658, 2017. 24 Coarsening Bias from V ariable Discretization in Causal F unctionals (Supplementary Material) This Supplemen tary Material is organized as follows. App endix A presents extensions to settings with m ultiple mediators. App endix B contains all technical pro ofs. App endix C pro vides additional details for the sim ulation studies. A Extensions to m ultiple mediators W e discuss the extensions with t w o (sets of ) mediators. Let M 1 and M 2 denote tw o ordered con tinuous or m ulti-dimensional mediators. Define the outcome regression µ ( m 1 , m 2 , a, c ) = E ( Y | M 1 = m 1 , M 2 = m 2 , A = a, C = c ) , the conditional mediator density f M 1 | A,C ( m 1 | a, c ) = p ( M 1 = m 1 | A = a, C = c ) and f M 2 | M 1 ,A,C ( m 2 | m 1 , a, c ) = p ( M 2 = m 2 | M 1 = m 1 , A = a, C = c ) . Let Q = { µ, f M 1 | A,C , f M 2 | M 1 ,A,C } collects the n uisance functions. Let ( a y , a 1 , a 2 ) ∈ { 0 , 1 } 3 , and for eac h c ∈ C , θ ( Q )( c ) = Z Z µ ( m 2 , m 1 , a y , c ) f M 2 | M 1 ,A,C ( m 2 | m 1 , a 2 , c ) f M 1 | A,C ( m 1 | a 1 , c ) dm 2 dm 1 . (23) Similarly , for i = 1 , 2 , let h i : R 7→ { 1 , . . . , K i } denote the measu rable discretization maps that partitions the supp ort of M i in to K i disjoin t bins: B i,k i = { m i : h i ( m i ) = k i } , k i ∈ { 1 , . . . , K i } . Let w i,k i = sup m i, 1 ,m i, 2 ∈B i,k i | m i, 1 − m i, 2 | denote the bin width and define the coarsened mediator f M i = h ( M i ) . F or each bin k i ∈ { 1 , . . . , K i } , define g k 1 ( a 1 , c ) = p ( f M 1 = k 1 | A = a 1 , C = c ) , g k 1 ,k 2 ( a 2 , c ) = p ( f M 2 = k 2 | f M 1 = k 1 , A = a 2 , C = c ) , and µ k 1 ,k 2 ( a y , c ) = E ( Y | f M 2 = k 2 , f M 1 = k 1 , A = a y , C = c ) . The coarsened analogue of ( 23 ) is: θ h ( Q )( c ) = K 1 X k 1 =1 K 2 X k 2 =1 µ k 1 ,k 2 ( a y , c ) g k 1 ,k 2 ( a 2 , c ) g k 1 ( a 1 , c ) . (24) T o introduce the similar correction as one mediator in main draft, we first define g k 2 ( m 1 , a 2 , c ) = p ( f M 2 = k 2 | M 1 = m 1 , A = a 2 , C = c ) , µ k 2 ,a y ( m 1 , a 2 , c ) = E ( µ ( M 1 , M 2 , a y , C ) | f M 2 = k 2 , M 1 = m 1 , A = a 2 , C = c ) , η k 2 ,a y ( m 1 , a 2 , c ) = µ k 2 ,a y ( m 1 , a 2 , c ) p ( f M 2 = k 2 | M 1 = m 1 , A = a 2 , C = c ) , 25 µ η ,k 1 ,k 2 ,a 2 ,a y ( a 1 , c ) = E η k 2 ,a y ( M 1 , a 2 , C ) | f M 1 = k 1 , A = a 1 , C = c . Then, the conditional functional θ ( Q )( c ) could b e written as θ ( Q )( c ) = K 1 X k 1 =1 K 2 X k 2 =1 Z n Z µ ( m 1 , m 2 , a y , c ) p ( m 2 | f M 2 = k 2 , m 1 , a 2 , c ) dm 2 o × p ( f M 2 = k 2 | m 1 , a 2 , c ) p ( m 1 | f M 1 = k 1 , a 1 , c ) dm 1 × p ( f M 1 = k 1 | a 1 , c ) = K 1 X k 1 =1 K 2 X k 2 =1 µ η ,k 1 ,k 2 ,a 2 ,a y ( a 1 , c ) g k 1 ( a 1 , c ) . (25) Define the within-bin mean m 1 ,k 1 ( a 1 , c ) = E [ M 1 | f M 1 = k 1 , A = a 1 , C = c ] , m 2 ,k 2 ( m 1 , a 2 , c ) = E [ M 2 | f M 2 = k 2 , M 1 = m 1 , A = a 2 , C = c ] . Th us, we define the debiased coarsened functional as e θ h ( Q )( c ) = K 1 X k 1 =1 K 2 X k 2 =1 µ m 1 ,k 1 ( a 1 , c ) , m 2 ,k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c , a y , c g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c g k 1 ( a 1 , c ) . (26) F or each c ∈ C , the coarsening error e ∆ h ( Q )( c ) = e θ h ( Q )( c ) − θ ( Q )( c ) satisfies e ∆ h ( Q )( c ) = K 1 X k 1 =1 K 2 X k 2 =1 µ m 1 ,k 1 ( a 1 , c ) , m 2 ,k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c , a y , c g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c − µ η ,k 1 ,k 2 ,a 2 ,a y ( a 1 , c ) g k 1 ( a 1 , c ) . (27) Assume µ ( m 1 , m 2 , a 1 , c ) is t wice con tin uously differentiable on eac h B i,k i . Inside each bin B 2 ,k 2 , apply a second-order T aylor expansion of µ ( m 1 , m 2 , a 1 , c ) around m 2 ,k 2 ( m 1 , a 2 , c ) : µ ( m 1 , M 2 , a y , c ) = µ ( m 1 , m 2 ,k 2 ( m 1 , a 2 , c ) , a y , c ) + µ ′ m 2 ( m 1 , m 2 ,k 2 ( m 1 , a 2 , c ) , a y , c )( M 2 − m 2 ,k 2 ( m 1 , a 2 , c ) + 1 2 µ ′′ m 2 ( m 1 , M ∗ 2 , a y , c )( M 2 − m 2 ,k 2 ( m 1 , a 2 , c )) 2 , (28) for some M ∗ 2 ∈ B 2 ,k 2 . 26 Assume η k 2 ,a y ( m 1 , a 2 , c ) is t wice contin uously differentiable on each B 1 ,k 1 . Inside each bin B 1 ,k 1 for M 1 , apply a second-order T aylor expansion of η k 2 ,a y ( M 1 , a 2 , c ) around m 1 ,k 1 ( a 1 , c ) : η k 2 ,a y ( M 1 , a 2 , c ) = η k 2 ,a y ( m 1 ,k 1 ( a 1 , c ) , a 2 , c ) + ( η k 2 ,a y ) ′ m 1 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) + 1 2 ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) 2 . (29) for some M ∗ 1 ∈ B 1 ,k 1 . T ake conditional exp ectation sequentially : µ η ,k 1 ,k 2 ,a 2 ,a y ( a 1 , c ) = E η k 2 ,a y ( M 1 , a 2 , c ) | f M 1 = k 1 , A = a 1 , C = c 29 = η k 2 ,a y ( m 1 ,k 1 ( a 1 , c ) , a 2 , c ) + 1 2 E ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) 2 f M 1 = k 1 , A = a 1 , C = c = µ k 2 ,a y ( m 1 ,k 1 ( a 1 , c ) , a 2 , c ) g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c + 1 2 E ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) 2 f M 1 = k 1 , A = a 1 , C = c = E µ ( m 1 ,k 1 ( a 1 , c ) , M 2 , a y , c ) | f M 2 = k 2 , m 1 ,k 1 ( a 1 , c ) , A = a 2 , C = c g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c + 1 2 E ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) 2 f M 1 = k 1 , A = a 1 , C = c 28 = n µ m 1 ,k 1 ( a 1 , c ) , m 2 ,k 2 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c ) , a y , c + 1 2 E µ ′′ m 2 ( m 1 ,k 1 ( a 1 , c ) , M ∗ 2 , a y , c )( M 2 − m 2 ,k 2 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c )) 2 | f M 2 = k 2 , m 1 ,k 1 ( a 1 , c ) , A = a 2 , C = c o × g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c + 1 2 E ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) 2 f M 1 = k 1 , A = a 1 , C = c . Th us R k 1 ,k 2 ( c ) = m 1 ,k 1 ( a 1 , c ) , m 2 ,k 2 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c ) , a y , c g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c − µ η ,k 1 ,k 2 ,a 2 ,a y ( a 1 , c ) = − 1 2 E µ ′′ m 2 ( m 1 ,k 1 ( a 1 , c ) , M ∗ 2 , a y , c )( M 2 − m 2 ,k 2 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c )) 2 | f M 2 = k 2 , m 1 ,k 1 ( a 1 , c ) , A = a 2 , C = c × g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c − 1 2 E ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c )( M 1 − m 1 ,k 1 ( a 1 , c )) 2 f M 1 = k 1 , A = a 1 , C = c . Giv en | g k 2 m 1 ,k 1 ( a 1 , c ) , a 2 , c | < 1 , the monotonicity and linearity of expectations, taking 27 absolute v alues, we obtain the following upp er b ound on | R k 1 ,k 2 ( c ) | : | R k 1 ,k 2 ( c ) | ≤ 1 2 E | µ ′′ m 2 ( m 1 ,k 1 ( a 1 , c ) , M ∗ 2 , a y , c ) | ( M 2 − m 2 ,k 2 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c )) 2 | f M 2 = k 2 , m 1 ,k 1 ( a 1 , c ) , A = a 2 , C = c + 1 2 E | ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c ) | ( M 1 − m 1 ,k 1 ( a 1 , c )) 2 f M 1 = k 1 , A = a 1 , C = c ≤ 1 2 sup m 2 ∈B 2 ,k 2 ( c ) | µ ′′ m 2 ( m 1 ,k 1 ( a 1 , c ) , m 2 , a y , c ) | E ( M 2 − m 2 ,k 2 ( m 1 ,k 1 ( a 1 , c ) , a 2 , c )) 2 | f M 2 = k 2 , m 1 ,k 1 ( a 1 , c ) , A = a 2 , C = c + 1 2 sup m 1 ∈B 1 ,k 1 ( c ) | ( η k 2 ,a y ) ′′ m 1 ( M ∗ 1 , a 2 , c ) | E ( M 1 − m 1 ,k 1 ( a 1 , c )) 2 | f M 1 = k 1 , A = a 1 , C = c . F or any ( a 1 , a 2 , c ) , the conditional la w p ( m 1 | f M 1 = k 1 , A = a 1 , C = c ) is supp orted on B 1 ,k 1 ( c ) and p ( m 2 | f M 2 = k 2 , M 1 = m 1 ,k 1 ( a 1 , c ) , A = a 2 , C = c ) is supp orted on B 2 ,k 2 ( c ) , hence V ar ( M 1 | k 1 , a 1 , c ) ≤ (sup m 1 , 1 ,m 1 , 2 ∈B 1 ,k 1 ( c ) | m 1 , 1 − m 1 , 2 | ) 2 4 = w 1 ,k 1 ( c ) 2 4 V ar ( M 2 | k 2 , m 1 ,k 1 ( a 1 , c ) , a 2 , c ) ≤ (sup m 2 , 1 ,m 2 , 2 ∈B 2 ,k 2 ( c ) | m 2 , 1 − m 2 , 2 | ) 2 4 = w 2 ,k 2 ( c ) 2 4 . Therefore, e ∆ h ( Q )( c ) = O ( w max , 1 ,K 1 ( c ) 2 + w max , 2 ,K 2 ( c ) 2 ) . B Pro ofs B.1 Iden tification pro ofs F or the identification of mediation functional E ( Y ( a 1 , M ( a 0 ))) and the front-do or functional E ( Y ( a 0 )) , w e first introduce general assumptions that apply throughout. F or any a and m , we assume (A) Consistency , whic h indicates that observed outcome and mediators match their coun terfac- tuals when treatmen t and mediator v alues are set at observed v alues; i.e. Y ( a, m ) = Y if A = a and M = m , and M ( a ) = m if A = a . (B) Positivity , which states that P ( A = 1 | C = c ) > 0 when P ( C = c ) > 0 , and P ( A = 1 | M = m, C = c ) > 0 when P ( M = m, C = c ) > 0 . T o identify the mediation functional E ( Y ( a 1 , M ( a 0 ))) , w e additionally need: (C1) Conditional ignor ability , which assumes the absence of unmeasured confounders b et w een the treatment-mediator, treatment-outcome and mediator-outcome pairs; i.e. for an y 28 a, a 0 , a 1 and m : (i) Y ( a 1 , m ) , M ( a 0 ) ⊥ ⊥ A | C ; (ii) Y ( a 1 , m ) ⊥ ⊥ M ( a ) | A, C . Under (A)–(C1), the mediation functional is iden tified as E ( Y ( a 1 , M ( a 0 ))) = Z Z E ( Y ( a 1 , m ) | M ( a 0 ) = m, C = c ) p ( M ( a 0 ) = m | C = c ) p ( C = c ) dm dc = Z Z E ( Y ( a 1 , m ) | M ( a 0 ) = m, A = a 1 , C = c ) p ( M = m | A = a 0 , C = c ) p ( C = c ) dm dc = Z Z E ( Y ( a 1 , m ) | M ( a 1 ) = m, A = a 1 , C = c ) p ( M = m | A = a 0 , C = c ) p ( C = c ) dm dc = Z Z E ( Y | M = m, A = a 1 , C = c ) p ( M = m | A = a 0 , C = c ) p ( C = c ) dm dc (30) T o identify the front-door functional E ( Y ( a 0 )) , in addition to (A) and (B), w e require: (C2) Conditional ignor ability , which assumes the absence of unmeasured confounders b et w een the treatment-mediator, and mediator-outcome pairs; i.e. (i) M ( a 0 ) ⊥ ⊥ A | C ; (ii) Y ( m ) ⊥ ⊥ M | A, C ; (iii) Y ( m ) ⊥ ⊥ M ( a 0 ) | C . (D) No dir e ct effe ct , whic h assumes that M blo c ks all directed paths from A to Y , i.e., Y ( a, m )= Y ( m ) for any a and m . Under (A), (B), (C2) and (D), the fron t-do or functional is identified as E ( Y ( a 0 )) = Z Z E ( Y ( a 0 ) | M ( a 0 ) = m, C = c ) p ( M ( a 0 ) = m | C = c ) p ( C = c ) dm dc = Z Z E ( Y ( a 0 , m ) | M ( a 0 ) = m, C = c ) p ( M ( a 0 ) = m | A = a 0 , C = c ) p ( C = c ) dm dc = Z Z E ( Y ( m ) | M ( a 0 ) = m, C = c ) p ( M = m | A = a 0 , C = c ) p ( C = c ) dm dc = Z Z E ( Y ( m ) | C = c ) p ( M = m | A = a 0 , C = c ) p ( C = c ) dm dc = Z Z X a ∈{ 0 , 1 } E ( Y | M = m, A = a, C = c ) p ( A = a | C = c ) p ( M = m | A = a 0 , C = c ) p ( C = c ) dm dc = p ( A = a 0 ) E ( Y | A = a 0 ) + Z Z E ( Y | M = m, A = a 1 , C = c ) p ( M = m | A = a 0 , C = c ) p ( A = a 1 , C = c ) dm dc . (31) 29 B.2 Lemma 3.1 Giv en our notations, we can rewrite θ ( Q )( C ) in ( 1 ) as: θ ( Q )( C )= K X k =1 Z µ ( m, a 1 , c ) p ( m | f M = k , a 0 , c ) dm g k ( a 0 , c )= K X k =1 µ k,a 1 ( a 0 , c ) g k ( a 0 , c ) , (32) By definition of the coarsened estimand, θ h ( Q )( c ) = K X k =1 µ k ( a 1 , c ) g k ( a 0 , c ) . Therefore, ∆ h ( Q )( c ) = θ h ( Q )( c ) − θ ( Q )( c ) (33) = K X k =1 µ k ( a 1 , c ) g k ( a 0 , c ) − K X k =1 µ k,a 1 ( a 0 , c ) g k ( a 0 , c ) (34) = K X k =1 n µ k ( a 1 , c ) − µ k,a 1 ( a 0 , c ) o g k ( a 0 , c ) , (35) whic h prov es ( 5 ). F urther, supp ose that sup m ∈B k ( c ) | µ ′ m ( m, a 1 , c ) | ≤ L ( c ) for some square-integrable function under P C . Then from ( 5 ), ∆ h ( Q )( c ) ≤ K X k =1 µ k ( a 1 , c ) − µ k,a 1 ( a 0 , c ) g k ( a 0 , c ) (36) ≤ L ( c ) K X k =1 m k ( a 1 , c ) − m k ( a 0 , c ) g k ( a 0 , c ) . (37) Since b oth conditional means m k ( a 1 , c ) and m k ( a 0 , c ) lie in the same bin B k ( c ) , their difference is b ounded b y the bin width, m k ( a 1 , c ) − m k ( a 0 , c ) ≤ w k ( c ) , so ∆ h ( Q )( c ) ≤ L ( c ) K X k =1 w k ( c ) g k ( a 0 , c ) . (38) 30 The w eights g k ( a 0 , c ) form a probability distribution ov er k , hence P K k =1 w k ( c ) g k ( a 0 , c ) is a w eighted a verage of the bin widths and is b ounded by the maximum bin width, K X k =1 w k ( c ) g k ( a 0 , c ) ≤ max k w k ( c ) = : w max ,K ( c ) . Therefore ∆ h ( Q )( c ) = O w max ,K ( c ) . When the mediator has b ounded support and the K bins are chosen to ha v e equal width, w max ,K ( c ) = O (1 /K ) , so ∆ h ( Q )( c ) = O (1 /K ) . T o prov e ( 7 ), we assume µ is twice contin uously differen tiable and define the within-bin mean m k ( a, c ) = E ( M | A = a, C = c, f M = k ) . (39) Applying a first-order T aylor expansion of µ ( M , a 1 , c ) around m k ( a, c ) yields µ ( M , a 1 , c ) ≈ µ ( m k ( a, c ) , a 1 , c ) + µ ′ m ( m k ( a, c ) , a 1 , c ) ( M − m k ( a, c )) , where µ ′ m denotes the partial deriv ative of µ with resp ect to m . T aking exp ectations w.r.t. p ( m | f M = k , a, c ) sho ws that E ( µ ( M , a 1 , c ) | f M = k , a, c ) ≈ µ ( m k ( a, c ) , a 1 , c ) up to second-order remainder terms. Hence, µ k ( a 1 , c ) − µ k,a 1 ( a 0 , c ) can b e appro ximated by µ k ( a 1 , c ) − µ k,a 1 ( a 0 , c ) ≈ µ ( m k ( a 1 , c ) , a 1 , c ) − µ ( m k ( a 0 , c ) , a 1 , c ) ≈ µ ′ m ( m k ( a 1 , c ) , a 1 , c ) m k ( a 1 , c ) − m k ( a 0 , c ) , (40) where the second line follo ws another first-order T aylor expansion of µ around m k ( a 1 , c ) . B.3 Remark 3.2 F or each bin index k and co v ariate v alue c , define p k,a ( m | c ) = p ( m | f M = k , A = a, C = c ) , r k ( m | c ) = p k,a 0 ( m | c ) p k,a 1 ( m | c ) . (41) 31 W e can write µ k,a 1 ( a 0 , c ) − µ k ( a 1 , c ) = Z µ ( m, a 1 , c ) p k,a 0 ( m | c ) dm − Z µ ( m, a 1 , c ) p k,a 1 ( m | c ) dm = Z µ ( m, a 1 , c ) n r k ( m | c ) − 1 o p k,a 1 ( m | c ) dm = E p k,a 1 µ ( M , a 1 , c ) r k ( M | c ) − 1 = E p k,a 1 µ ( M , a 1 , c ) − E p k,a 1 µ ( M , a 1 , c ) r k ( M | c ) − 1 = Co v p k,a 1 µ ( M , a 1 , c ) , r k ( M | c ) , since E p k,a 1 r k ( M | c ) = 1 . B.4 Lemma 4.1 In the pro of of Lemma 3.1 , we show ed θ ( Q )( c ) = P K k =1 µ k,a 1 ( a 0 , c ) g k ( a 0 , c ) . By definition of the debiased coarsened functional, e θ h ( Q )( c ) = P K k =1 µ m k ( a 0 , c ) , a 1 , c g k ( a 0 , c ) . Subtracting the t wo displa ys yields ( 11 ). W e now b ound R k ( c ) for a fixed bin index k . Inside each bin B k , apply a second-order T a ylor expansion of µ ( M , a 1 , c ) around m k ( a 0 , c ) : µ ( M , a 1 , c ) = µ ( m k ( a 0 , c ) , a 1 , c ) + µ ′ m ( m k ( a 0 , c ) , a 1 , c )( M − m k ( a 0 , c )) + 1 2 µ ′′ m ( M ∗ , a 1 , c )( M − m k ( a 0 , c )) 2 , for some M ∗ ∈ B k (b y the mean-v alue form of the remainder). T aking the conditional exp ectation under ( f M = k , A = a 0 , C = c ) gives E ( µ ( M , a 1 , c ) | k , a 0 , c ) = µ ( m k ( a 0 , c ) , a 1 , c ) + 1 2 E µ ′′ m ( M ∗ , a 1 , c )( M − m k ( a 0 , c )) 2 | k , a 0 , c . Th us R k ( c ) = µ ( m k ( a 0 , c ) , a 1 , c ) − µ k,a 1 ( a 0 , c ) = − 1 2 E µ ′′ m ( M ∗ , a 1 , c )( M − m k ( a 0 , c )) 2 | k , a 0 , c . T aking absolute v alues and given the monotonicit y and linearity of exp ectations, we obtain the follo wing upp er b ound on | R k ( c ) | : | R k ( c ) | ≤ 1 2 E | µ ′′ m ( M ∗ , a 1 , c ) | ( M − m k ( a 0 , c )) 2 | k , a 0 , c ≤ 1 2 sup m ∈B k ( c ) | µ ′′ m ( m, a 1 , c ) | E ( M − m k ( a 0 , c )) 2 | k , a 0 , c . 32 Finally , since the conditional la w of M giv en ( A = a 0 , C = c, f M = k ) is supp orted on B k , its range is at most w k , and hence E ( M − m k ( a 0 , c )) 2 | A = a 0 , C = c, f M = k = V ar( M | A = a 0 , C = c, f M = k ) ≤ (sup m 1 ,m 2 ∈B k | m 1 − m 2 | ) 2 4 = w 2 k / 4 Com bining with sup m ∈B k | µ ′′ m ( m, a 1 , c ) | ≤ L ( c ) yields | R k ( c ) | ≤ L ( c ) w 2 k / 8 . F urthermore, using the fact that P K k =1 g k ( a 0 , c ) = 1 , w e obtain | e ∆ h ( Q )( c ) | ≤ K X k =1 | R k ( c ) | g k ( a 0 , c ) ≤ L ( c ) 8 K X k =1 w 2 k g k ( a 0 , c ) ≤ L ( c ) 8 w 2 max ,K , whic h implies e ∆ h ( Q )( c ) = O ( w 2 max ,K ) . B.5 Lemma 5.1 By definition: e θ h,b ( Q )( c ) = K X k =1 µ b,k ( a 1 , c ) g k ( a 0 , c ) , e θ h ( Q )( c ) = K X k =1 µ m k ( a 0 , c ) , a 1 , c g k ( a 0 , c ) , so e ∆ s h,b ( Q )( c ) = e θ h,b ( Q )( c ) − e θ h ( Q )( c ) = K X k =1 n µ b,k ( a 1 , c ) − µ m k ( a 0 , c ) , a 1 , c o g k ( a 0 , c ) , whic h establishes the first display . It remains to show that eac h term in braces is of order b 2 uniformly in k , c under the stated conditions. Fix k and c , µ b,k ( a 1 , c ) = E n µ ( m, a 1 , c ) ω b,k ( M | a 1 , c ) | A = a 1 , C = c o = E n µ ( m, a 1 , c ) K b ( M − m k ( a 0 , c )) | A = a 1 , C = c o E n K b ( M − m k ( a 0 , c )) | A = a 1 , C = c o = N b D b , 33 where N b = Z µ ( m, a 1 , c ) K b ( m − m k ( a 0 , c )) f M | A,C ( m | a 1 , c ) dm, D b = Z K b ( m − m k ( a 0 , c )) f M | A,C ( m | a 1 , c ) dm. Mak e the change of v ariables m = m k ( a 0 , c ) + bu , so that dm = b du and K b ( m − m k ( a 0 , c )) = 1 b K m − m k ( a 0 ,c ) b = 1 b K ( u ) . Then N b = Z µ ( m k ( a 0 , c ) + bu, a 1 , c ) K b m k ( a 0 , c ) + bu − m k ( a 0 , c ) f M | A,C ( m k ( a 0 , c ) + bu | a 1 , c ) b du = Z µ ( m k ( a 0 , c ) + bu, a 1 , c ) f M | A,C ( m k ( a 0 , c ) + bu | a 1 , c ) K ( u ) du, D b = Z f M | A,C ( m k ( a 0 , c ) + bu | a 1 , c ) K ( u ) du. By assumption (i), µ ( · ) is t wice contin uously differen tiable in a neighborho o d of m k ( a 0 , c ) and its second deriv ative is uniformly b ounded; similarly , assumption (iii) ensures that f M | A,C ( · ) is con tinuous and b ounded aw a y from zero in a neighborho o d of m k ( a 0 , c ) . Applying a second order T aylor expansion around m k ( a 0 , c ) , µ ( m k ( a 0 , c ) + bu, a 1 , c ) = µ ( m k ( a 0 , c ) , a 1 , c ) + µ ′ m ( m k ( a 0 , c ) , a 1 , c ) bu + 1 2 µ ′′ m ( f M 1 , a 1 , c ) b 2 u 2 , f M | A,C ( m k ( a 0 , c ) + bu | a 1 , c ) = f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + f ′ ( m k ( a 0 , c ) | a 1 , c ) bu + 1 2 f ′′ ( f M 2 | a 1 , c ) b 2 u 2 , for some f M 1 , f M 2 b et w een m k ( a 0 , c ) and m k ( a 0 , c ) + bu . Multiplying these expansions and using that the second deriv atives are uniformly b ounded yields µ ( m k ( a 0 , c ) + bu, a 1 , c ) f M | A,C ( m k ( a 0 , c ) + bu | a 1 , c ) = µ ( m k ( a 0 , c ) , a 1 , c ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + n µ ′ m ( m k ( a 0 , c ) , a 1 , c ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + µ ( m k ( a 0 , c ) , a 1 , c ) f ′ ( m k ( a 0 , c ) | a 1 , c ) o bu + O ( b 2 u 2 ) , where the O ( b 2 u 2 ) term is uniform in u on the support of K . 34 Substituting in to the expression for N b and using assumption (ii) on the k ernel, Z K ( u ) du = 1 , Z u K ( u ) du = 0 , Z u 2 K ( u ) du < ∞ , w e obtain N b = Z h µ ( m k ( a 0 , c ) , a 1 , c ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + n µ ′ m ( m k ( a 0 , c ) , a 1 , c ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + µ ( m k ( a 0 , c ) , a 1 , c ) f ′ ( m k ( a 0 , c ) | a 1 , c ) o bu + O ( b 2 u 2 ) i K ( u ) du = µ ( m k ( a 0 , c ) , a 1 , c ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + O ( b 2 ) , since the term prop ortional to bu in tegrates to zero by symmetry of K , and the O ( b 2 u 2 ) term in tegrates to O ( b 2 ) b ecause R u 2 K ( u ) du < ∞ . A similar argumen t for D b giv es D b = Z h f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + f ′ ( m k ( a 0 , c ) | a 1 , c ) bu + O ( b 2 u 2 ) i K ( u ) du = f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + O ( b 2 ) . Assumption (iii) ensures that f M | A,C ( m k ( a 0 , c ) | a 1 , c ) is b ounded a wa y from zero, so for b small enough D b is also b ounded a wa y from zero and we can write µ b,k ( a 1 , c ) = N b D b = µ ( m k ( a 0 , c ) , a 1 , c ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + O ( b 2 ) f M | A,C ( m k ( a 0 , c ) | a 1 , c ) + O ( b 2 ) = µ ( m k ( a 0 , c ) , a 1 , c ) + O ( b 2 ) , where the O ( b 2 ) term is uniform in k and c under the stated uniform b oundedness conditions. Therefore, for eac h k , µ b,k ( a 1 , c ) − µ m k ( a 0 , c ) , a 1 , c = O ( b 2 ) . 35 Plugging this in to the expression for e ∆ s h,b ( Q )( c ) and using that P K k =1 g k ( a 0 , c ) = 1 yields e ∆ s h,b ( Q )( c ) ≤ K X k =1 µ b,k ( a 1 , c ) − µ m k ( a 0 , c ) , a 1 , c g k ( a 0 , c ) ≤ C ∗ b 2 K X k =1 g k ( a 0 , c ) = C ∗ b 2 , for some constant C ∗ < ∞ not dep ending on b . Hence e ∆ s h,b ( Q )( c ) = O ( b 2 ) as b → 0 , as claimed. F urthermore, we can write e ∆ h,b ( Q )( c ) : = e θ h,b ( Q )( c ) − θ ( Q )( c ) = e θ h ( Q )( c ) − θ ( Q )( c ) | {z } coarsening error + e θ h,b ( Q )( c ) − e θ h ( Q )( c ) | {z } smoothing error = O w 2 max ,K + b 2 . B.6 Theorem 5.2 W e derive the EIF for the smo othed mediation functional e ψ h,b ( Q ) = E K X k =1 µ b,k ( a 1 , C ) g k ( a 0 , C ) , (42) where µ b,k ( a 1 , c ) = E h Y ω b,k ( M | a 1 , c ) A = a 1 , C = c i , g k ( a 0 , c ) = p ( f M = k | A = a 0 , C = c ) . (43) Recall that ω b,k ( m | a 1 , c ) = K b m − m k ( a 0 , c ) E K b M − m k ( a 0 , c ) | A = a 1 , C = c , K b ( u ) = b − 1 K ( u/b ) . (44) The functional e ψ h,b ( Q ) dep ends on Q in tw o distinct w a ys: (i) through the conditional laws defining g k ( a 0 , c ) and µ b,k ( a 1 , c ) , (ii) through the nuisance center m k ( a 0 , c ) that app ears inside the w eight ω b,k . Along a regular parametric submo del Q ε with score S , the pathwise deriv ative decomp oses in to 36 t wo con tributions, d dε e ψ h,b ( Q ε ) ε =0 = d dε e ψ h,b Q ε ; { m k } ε =0 | {z } v ary Q holding { m k } fixed + K X k =1 ∂ e ψ h,b ∂ m k Q d dε m k ( Q ε ) ε =0 | {z } chain rule through m k . W e compute these tw o contributions separately . P art (I): Deriv ative with resp ect to the conditional laws (holding m k fixed). In this first step we treat the function m 7→ ω b,k ( m | a 1 , c ) as fixed, so that µ b,k ( a 1 , c ) = E { Y ω b,k ( M | a 1 , c ) | A = a 1 , C = c } is a standard regression functional; the dep endence of the normalization in ( 44 ) on the conditional law is accounted for when w e later add the c hain-rule correction through m k . Let Z k ≡ Z k ( O ) : = Y ω b,k ( M | a 1 , C ) . Then µ b,k ( a 1 , c ) = E ( Z k | A = a 1 , C = c ) . F or fixed ω b,k , the EIF for the regression functional c 7→ E ( Z k | A = a 1 , C = c ) is D fix µ b,k ( O ) = I ( A = a 1 ) π ( a 1 | C ) Z k − µ b,k ( a 1 , C ) . = I ( A = a 1 ) π ( a 1 | C ) Y ω b,k ( M | a 1 , C ) − µ b,k ( a 1 , C ) . (45) This corresponds to the deriv ative of e ψ h,b ( Q ) with respect to the conditional distribution argument in the m ultiv ariate chain rule. F or g k ( a 0 , c ) = E ( I ( f M = k ) | A = a 0 , C = c ) , the EIF is D g k ( O ) = I ( A = a 0 ) π ( a 0 | C ) I ( f M = k ) − g k ( a 0 , C ) . (46) Since e θ h,b ( C ) = P k g k ( a 0 , C ) µ b,k ( a 1 , C ) is a pro duct of tw o regression functionals, its deriv ative with resp ect to the conditional laws follo ws from the usual pro duct rule applied p oint wise in C . The EIF for e ψ h,b ( Q ) = E ( e θ h,b ( Q )( C )) under fixed ω b,k is e ϕ fixed h,b ( Q ) = K X k =1 g k ( a 0 , C ) D fix µ b,k ( O ) + K X k =1 µ b,k ( a 1 , C ) D g k ( O ) + e θ h,b ( Q )( C ) − e ψ h,b ( Q ) . (47) 37 Substituting ( 45 ) and ( 46 ) yields the explicit display ed form ula. P art (I I): Deriv ative with resp ect to the nuisance cen ters m k ( a 0 , c ) . No w consider the actual w eight in ( 44 ), whic h dep ends on the unkno wn cen ter m k ( a 0 , c ) = E ( M | A = a 0 , C = c, f M = k ) and on the normalizing denominator E n K b M − m k ( a 0 , c ) | A = a 1 , C = c o . This induces an additional EIF comp onen t through the path wise deriv ative of µ b,k ( a 1 , c ) with resp ect to the cen ter m k ( a 0 , c ) . The EIF for the conditional mean m k ( a 0 , C ) = E ( M | A = a 0 , C, f M = k ) is D m k ( O ) = I ( A = a 0 ) I ( f M = k ) π ( a 0 | C ) g k ( a 0 , C ) M − m k ( a 0 , C ) . (48) T o compute the second term in the multiv ariate chain rule, we differen tiate µ b,k ( a 1 , c ) with respect to its second argument m k ( a 0 , c ) while holding the conditional law of ( Y , M ) | ( A = a 1 , C = c ) fixed. W riting µ b,k ( a 1 , c ) = N k ( c ) /D k ( c ) with N k ( c ) = E n Y K b M − m k ( a 0 , c ) | A = a 1 , C = c o , D k ( c ) = E n K b M − m k ( a 0 , c ) | A = a 1 , C = c o , and applying the quotient rule yields (assuming the usual regularity conditions that justify differen tiation under the conditional exp ectation) α k ( c ) : = ∂ ∂ m µ b,k ( a 1 , c ) = − E h { Y − µ b,k ( a 1 , c ) } K ′ b M − m k ( a 0 , c ) | A = a 1 , C = c i E h K b M − m k ( a 0 , c ) | A = a 1 , C = c i . (49) 38 By the m ultiv ariate chain rule, the contribution of the nuisance m k to the EIF is e ϕ ω h,b ( Q )( O ) = K X k =1 g k ( a 0 , C ) α k ( C ) D m k ( O ) . (50) Substituting ( 48 ) into ( 50 ) simplifies this term to e ϕ ω h,b ( Q )( O ) = K X k =1 α k ( C ) I ( A = a 0 ) I ( f M = k ) π ( a 0 | C ) M − m k ( a 0 , C ) . (51) Com bining the deriv ative with resp ect to the conditional laws and the deriv ativ e with resp ect to the n uisance centers yields the full efficient influence function e ϕ h,b ( Q )( O ) = e ϕ fixed h,b ( Q )( O ) + e ϕ ω h,b ( Q )( O ) , (52) where e ϕ fixed h,b ( Q )( O ) is giv en in ( 47 ) and e ϕ ω h,b ( Q )( O ) is giv en in ( 51 ). C Details in sim ulations In this section, w e presen t a detailed explanation of the missp ecification scenarios implemented in Simulation #2. F or eac h of the estimators, the corresp onding collection of nuisance functions Q is giv en as follows: (i) ψ h ( b Q ) : { µ k , g k } ; (ii) e ψ h ( b Q ) : { µ, m k , g k } ; (iii) ψ + h ( b Q ) : { µ k , g k , π } ; (iv) e ψ + h 1 ( b Q ) : { µ, m k , g k , π } ; (v) e ψ + h 2 ( b Q ) : { µ, m k , g k , g , π } . T able 2 presents the sp ecification and missp ecification configurations of the n uisance functions. The plug-in estimator ψ h ( b Q ) coincides with the sp ecification under Condition 3 as well as the fully correctly sp ecified setting; the same holds for e ψ h ( b Q ) . Under the DGP describ ed in Section 6 , correctly sp ecified n uisance functions can b e consistently estimated using GLMs. Missp ecification is in tro duced b y constructing mo dels with nonlinear and irrelev ant functional forms, including exp onen tial, cosine, in verse, and higher-order p olynomial terms. 39 T able 2: Missp ecification scenarios for n uisance functions in Simulation #2. A chec k mark ( ✓ ) indicates correct sp ecification, while a cross mark ( ✗ ) denotes model missp ecification. F unction Condition 1 Condition 2 Condition 3 Correct F alse m k ✓ ✓ ✓ ✓ ✗ µ ✗ ✓ ✓ ✓ ✗ µ k ✗ ✓ ✓ ✓ ✗ g ✓ ✗ ✓ ✓ ✗ g k ✓ ✗ ✓ ✓ ✗ π ✓ ✓ ✗ ✓ ✗ 40
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment