Language Models Exhibit Inconsistent Biases Towards Algorithmic Agents and Human Experts
Large language models are increasingly used in decision-making tasks that require them to process information from a variety of sources, including both human experts and other algorithmic agents. How do LLMs weigh the information provided by these di…
Authors: Jessica Y. Bo, Lillio Mok, Ashton Anderson
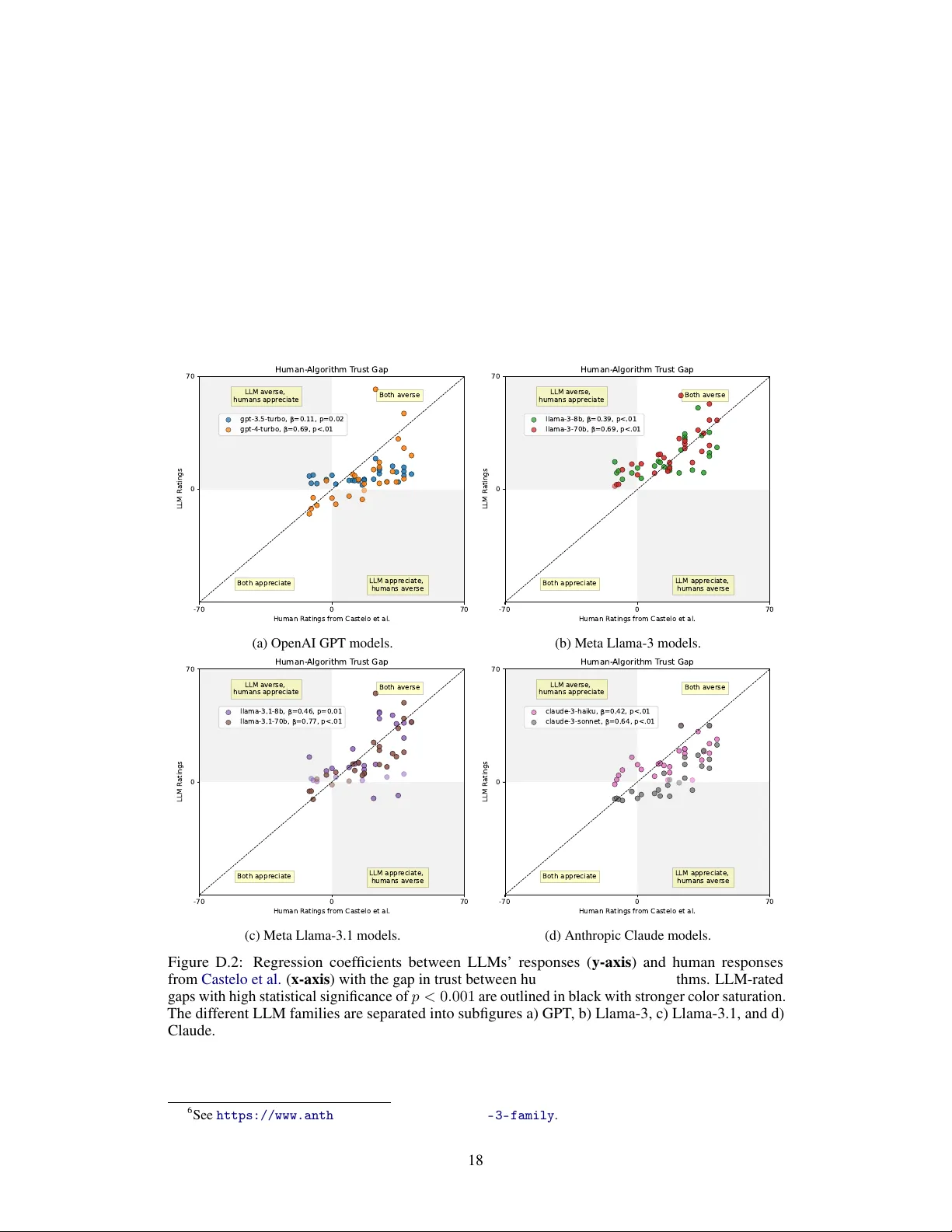
Language Models Exhibit Inconsistent Biases T owards Algorithmic Agents and Human Experts Jessica Y . Bo ∗ Computer Science Univ ersity of T oronto jbo@cs.toronto.edu Lillio Mok ∗ † Computer Science Univ ersity of T oronto lillio@cs.toronto.edu Ashton Anderson Computer Science Univ ersity of T oronto ashton@cs.toronto.edu Abstract Large language models are increasingly used in decision-making tasks that require them to process information from a variety of sources, including both human e xperts and other algorithmic agents. How do LLMs weigh the information pro vided by these dif ferent sources? W e consider the well-studied phenomenon of algorithm av ersion, in which human decision-makers e xhibit bias against predictions from algorithms. Drawing upon e xperimental paradigms from beha vioural economics, we ev aluate ho w eight different LLMs deleg ate decision-making tasks when the delegatee is framed as a human expert or an algorithmic agent. T o be inclusiv e of different e v aluation formats, we conduct our study with two task presentations: stated pr efer ences , modeled through direct queries about trust tow ards either agent, and r evealed pr efer ences , modeled through pro viding in-context examples of the performance of both agents. When prompted to rate the trustworthiness of human experts and algorithms across di verse tasks, LLMs giv e higher ratings to the human expert, which correlates with prior results from human respondents. Howe ver , when shown the performance of a human expert and an algorithm and asked to place an incenti vized bet between the two, LLMs disproportionately choose the algorithm, ev en when it performs demonstrably worse. These discrepant results suggest that LLMs may encode inconsistent biases to wards humans and algorithms, which need to be carefully considered when they are deployed in high-stakes scenarios. Furthermore, we discuss the sensitivity of LLMs to task presentation formats that should be broadly scrutinized in e valuation rob ustness for AI safety . 1 Introduction The rapid development of capable large language models (LLMs) has led to their inclusion in important decision-making settings ranging from healthcare [ Meskó and T opol , 2023 ] to finance [ Liu et al. , 2021 ]. While it is well-documented that the social and cognitive biases embedded within the learned representations of LLMs can af fect their output quality [ Bai et al. , 2024 , Ferrara , 2023 , Zhang et al. , 2023b , Gross , 2023 ], it is also important to inv estigate whether LLMs encode biases tow ards the source of information the y receive in decision-making scenarios. For instance, recent dev elopments in multi-agent systems in v olving multiple LLMs [ Huang et al. , 2024 ], or LLMs and other algorithms [ Schick et al. , 2023 ], giv e rise to scenarios where LLMs are used in tasks inv olving other algorithmic agents. Howev er , people often display algorithm aversion and disproportionately distrust algorithmic advice [ Dietv orst et al. , 2015 , Mok et al. , 2023 , Castelo et al. , 2019 , Mahmud et al. , 2022 ]. Thus, do LLMs trained on human data also display these biases; and if so, under which contexts do the y show up? ∗ Equal authorship contribution. † Now at T oyota Research Institute. Second Conference of the International Association for Safe and Ethical Artificial Intelligence (IASEAI’26). W ithin the realm of decision-making with algorithms, we consider tw o particular task framings of how LLMs can impart their influences: 1) through directly answering queries on their ‘stated’ trust to wards either algorithms or human e xperts, and 2) through making a ‘re vealed’ reliance decision based on in-context e xamples provided of the performance of the algorithm and human expert. It is important to understand ho w algorithm av ersion can manifest under dif ferent e valuation methods of eliciting the LLM’ s judgment. For e xample, a hiring manager consulting ChatGPT on whether she should lay off employees in fa vor of automated tools can be influenced by stated opinions to wards algorithms in the LLM’ s responses, while a medical AI choosing treatment autonomously can directly impact a patient’ s health by being biased to wards deferring to a doctor or a specialized algorithm. In both cases, either indirectly or directly , biases of the LLM can influence the outcomes of decision-making in volving algorithms. Furthermore, in the field of economics, it is well-known that people often have diver ging stated and rev ealed preferences, and much ef fort goes into understanding how , when, and why [ Glaeser et al. , 2000 ]. While we refrain from promoting over -anthropomorphized parallels between LLMs and human behaviour , prior empirical ev aluations hav e indicated that LLMs e xpress different attitudes or biases when prompted explicitly versus implicitly [ Bai et al. , 2024 , Zhao et al. , 2025 ]. These twin problems of inconsistent stated and re vealed prefer ences and algorithm aversion form a critical challenge in the adoption of LLMs to help decision-making. Do LLMs inherit our propensity to distrust algorithmic advice ev en when it is beneficial to us, and is this consistent between both the stated and revealed preferences embedded in their generated outputs? W ith respect to LLM ev aluations, we translate probing stated and re vealed preferences to answering dir ect queries and delegating based on in-context perf ormance of agents framed as human e xperts and algorithms. These two e valuation setups also motiv ate a broader in v estigation into how discrepant task formats can rev eal different underlying biases of LLMs. Thus, to incorporate LLMs into decision-making processes in a trustworthy and transparent manner [ Liao and V aughan , 2023 ], we need a deeper understanding of the preferences they state and of the rev ealed preferences in their choices. W e ask the following research questions: • RQ1 : Do LLMs display algorithm a version when answering dir ect queries about human experts and algorithmic agents (‘stated’ preferences)? • RQ2 : Do LLMs display algorithm av ersion when delegating based on in-context perfor - mance of human experts and algorithmic agents (‘re vealed’ preferences)? • RQ3 : Do LLMs’ stated and rev ealed preferences tow ards algorithmic agents align? W e adapt two ke y human studies from economics and behavioral science research to wards ev aluating the above RQs in LLMs: Castelo et al. [ 2019 ], which probes people’ s stated attitudes tow ards algorithmic decision-makers across a div erse set of objectiv e and subjectiv e tasks (“Study 1” for RQ1 ); and Dietvorst et al. [ 2015 ], the original paper demonstrating rev ealed algorithm av ersion when people are asked to bet on human and algorithmic predictions (“Study 2” for RQ2 ). W e then contrast the results between the two studies on a subset of overlapping tasks to answer RQ3 . W e perform these experiments with prompted con versations with eight LLMs from OpenAI, Meta, and Anthropic, which are among the most prev alent, high-performing, and scrutinized LLMs at the time of experimentation 3 [ Ray , 2023 , Singh , 2023 , Ferrara , 2023 ]. Statement of Contrib utions. W e find that LLMs generate opposing biases to wards algorithms in different task framings, when prompted to provide direct ratings of the agents vs. delegating an agent based on in-context information. For RQ1 , LLMs output consistently lower ratings of trust tow ards algorithms and rate human experts as more trustworthy across a range of tasks. Howe ver , for RQ2 , LLM-generated decisions re veal a bias to wards dele gating predictions to algorithmic agents, ev en when the performance from human experts is stronger . Therefore, RQ3 suggests a potential discrepancy between the two e valuation formats. The size of the models is a predictor of this pattern, with smaller models being more prone to e xhibit the stated-revealed preference discrepancy and to bet on the suboptimal algorithm. These findings sho w that LLM-generated text should be treated firstly as containing discrepant biases to wards algorithms based on the ev aluation format, and secondly as potentially overly appreciativ e of algorithmic advice — despite stating a preference for human advice. 3 Our results were collected in mid-2024. T o keep pace with the rapidly ev olving landscape of state-of-the-art LLMs, we repeat the experiment in January 2026 with six ne wer LLMs, and discuss the results in Appendix F . 2 2 Related W ork This study draws from several bodies of related work. First, studies show people tend to exhibit algorithm a version , where the y trust predictions made by an algorithm less than those made by other humans, ev en when the algorithm outperform the human expert [ Mahmud et al. , 2022 , Jussupow et al. , 2020 ]. In behavioral settings, people avoid betting on algorithms after seeing them make mistakes [ Dietvorst et al. , 2015 ], and prefer human advice when they have less control over the decision-making process [ Dietvorst et al. , 2018 ]. When asked for explicit ratings, people also say they trust algorithms less across a wide range of tasks [ Castelo et al. , 2019 ], especially for high-stakes scenarios [ Lee , 2018 ]. Understanding algorithm av ersion is therefore increasingly important for many domains in which algorithmic aids can impro ve on human performance [ Zhang et al. , 2022 ], especially when modern algorithms lik e LLMs can themselv es interf ace with other algorithmic agents [ Park et al. , 2023 , Liu et al. , 2023b ]. Because LLMs are trained on vast amounts of human data, there is reason to suspect that they may also inherit an aversion to algorithms [ Ziems et al. , 2023 , Aher et al. , 2023 , Binz and Schulz , 2023 ]. Furthermore, our period of study ov erlaps with a shift in the public’ s trust towards algorithms, coinciding with the rise of highly capable AI [ Chacon , 2025 , Cheng et al. , 2025 ], b ut the extent to which these ne w perspectiv es are now embedded in LLMs is not known. W e ev aluate LLMs as if they are the decision-maker in terms of choosing who, between the human expert and the algorithmic agent, the task should be dele gated to. W ith re gards to stated and revealed preferences , people’ s self-reports of who and what the y trust are often paradoxically misaligned [ Sofianos , 2022 ]. Experiments in behavioral economics illustrate that stated attitudes, collected through questionnaires, do not predict re vealed behaviors [ Glaeser et al. , 2000 ]. Thus, it is critical that both stated and revealed preferences are both considered when making high-stakes, consequential decisions. For instance, the treatments that physicians say they prefer may not align with what they actually prescribe [ Mark and Swait , 2004 ], consumer food choices are modeled better when using both stated and re vealed preferences [ Brooks and Lusk , 2010 ], and house buyers may want lar ger lots but in practice b uy smaller spaces [ Earnhart , 2002 ]. While LLMs do not embody beliefs and preferences in the same manner as people, they are increasingly placed in similar decision-making positions [ Eigner and Händler , 2024 , Ferrag et al. , 2025 ]. Therefore, we design experimental setups that v ary in the task presentation format (explicit queries vs. implicit in-context information), hence appr oximating ho w stated and rev ealed preferences are elicited in humans. Prior work in LLM evaluation has measured the presence of biases in generated text, such as for gender [ Gross , 2023 ], race [ Caliskan et al. , 2017 ], and culture [ T ao et al. , 2023 ]. AI safety research has focused on aligning LLMs with explicitly stated preferences against harmful biases [ Shen et al. , 2023 , Zou et al. , 2023 , Bai et al. , 2022 ]. Howe ver , ev en de-biased LLMs are found to encode implicit biases, demonstrating a disconnect between LLMs’ sanitized outputs and their internal representation [ Bai et al. , 2024 ]. As LLMs become in volv ed as collaborators and overseers [ Bowman et al. , 2022 ] of both human and other algorithms in complex tasks, these bodies of research therefore illustrate the need to understand ho w outward, stated preferences dif fer from revealed actions embedded in LLM-generated choices. For instance, while LLMs exhibit human-lik e behaviors in trust [ Xie et al. , 2024 ] and risk av ersion [ Jia et al. , 2024 ], their trust towards other artificial agents remains unkno wn. Thus, to probe explicitly ‘stated’ preferences for algorithms (Study 1; Section 3.1 ), we follow Castelo et al. [ 2019 ] in surve ying trust tow ards algorithms and humans across 27 tasks. T o measure implicitly ‘rev ealed’ preferences for algorithms (Study 2; Section 3.2 ), we adapt Dietvorst et al. [ 2015 ]’ s experiment that measures incentivized bets on humans and algorithms. 3 Methods T o in vestigate whether LLMs exhibit algorithm av ersion and to assess the alignment between their stated and re vealed preferences, we conducted tw o complementary studies. Study 1 examines ho w LLMs directly rate their lev el of trust in human experts v ersus algorithms, and Study 2 analyzes ho w they simulate decision-making when presented with in-conte xt predictions from human experts and algorithms. W e then compare the trends in the stated and revealed preferences against each other . Across both studies, we gather results from eight open- and closed-source LLMs, split into four families: GPT ( gpt-3.5-turbo , gpt-4-turbo ) [ Achiam et al. , 2023 ], Llama-3 Instruct vari- ants ( Llama-3-8b , Llama-3-70b ), Llama-3.1 Instruct v ariants ( llama-3.1-8b , llama-3.1-70b ) [ T ouvron et al. , 2023 ], and Claude ( claude-3-haiku-20240307 , claude-3-sonnet-20240229 ) 3 [ Anthropic , 2024 ]. Within each group, we test one “smaller” model and one “larger” model. The OpenAI and Anthropic models were accessed through their respecti ve APIs, while Meta models were accessed through the Huggingface Serverless Inference API. Hyperparameters ( temperatur e of 0.3 and top-p of 0.99) were set such that responses were syntactically correct, had adequate v ariance, and also adhered to existing w ork [ Achiam et al. , 2023 , W ang et al. , 2023 ]. The results presented in the main body of this paper were collected in mid-2024, approximately 1.5 years before publication. For transparency , we present a set of updated results on newer LLMs in Appendix F and discuss what implications the new results pose to the longe vity of LLM e valuations in subsection 4.4 . 3.1 Study 1: Asking Direct Queries (Stated) T o probe ho w LLMs directly state their trust, we adapt the methodology of Castelo et al. ’ s Study 1, which analyzed people’ s percei ved trust in human experts vs. algorithmic agents to perform a variety of tasks. W e use a set of 27 tasks for this study , 26 of which are from the original experiment and one of which is added based on its use in our Study 2 (originally used by Dietvorst et al. ). The full list of tasks can be found in T able C.1 in Appendix C , which includes both objectiv e tasks like estimating air traf fic and subjectiv e tasks like r ecommending music . W e prompt each LLM n = 100 times per task to rate their trust in relying on a human expert and an algorithm to perform the task from 1 (no trust) to 100 (high trust). The humans are framed as experts relev ant to the task, for example, pilot for piloting a plane . No performance information is provided for either agent. W e con verted the experimental method from between-subjects to within-subjects, allowing the LLM- as-subject to provide a trust score for both the human and algorithm in the same trial. This decision was taken to match the procedure of Study 2, to allo w better comparison across the stated and revealed trials. If an LLM ga ve equiv alent ratings for the human expert and an algorithm, we treated this as a ‘neutral’ outcome. Sample prompts and responses can be found in Appendix A , follo wing the original experiment’ s wording as much as possible. T o av oid ordering effects [ Zhao et al. , 2021 ], we randomized the order of the tasks and the sequence in which the agents were presented. 3.2 Study 2: Pro viding In-Context Information (Re vealed) T o examine ho w LLMs make task dele gation decisions based on performance information giv en for each agent, we adapted the experimental setup from Dietvorst et al. ’ s study on algorithm av ersion. In their between-subjects experiment, participants made bets on either agent based on recei ving dif ferent permutations of human and algorithmic advice. In our adaption of their study , the LLMs-as-subject are giv en: the task description, 10 samples of a human expert’ s predictions, 10 samples of an algorithm’ s predictions, the corresponding binary outcome of each sample, and a monetary incentiv e (i.e. a bet ) to delegate the best prediction agent for a future unseen sample. For example, in the heart disease diagnosis task, each LLM was shown the 10 predictions made by a cardiologist and an algorithm, along with the actual outcomes, and then asked to bet $100 on the better-performing agent. This adaptation of Dietvorst et al. mirrors classification tasks in the in-context learning literature [ Liu et al. , 2023a ], with the LLM’ s goal here being to choose the more accurate predictor . W e conducted this study by prompting each LLM n = 200 times ( 100 per condition). W e further manipulated the accuracy of the human and algorithmic agents, such that they either hav e the accuracy of 90% (the “stronger” agent) or 50% (the “weaker” agent). The assignment of strong and weak agents was randomized, creating two conditions: a) a strong algorithm with a weak human, and b) a strong human with a weak algorithm. Note that we only use the framings of “strong" and “weak" to clarify our writing, and these descriptors are never gi ven to the LLM. Again, we randomized the order in which the human and the algorithm were presented. An example prompt can be found in Appendix B . Due to the increased trials for Study 2, we used a subset of six tasks from the 27 tasks of Study 1, which are highlighted in bold in the Appendix’ s T able C.1 . In addition to the student performance and airport traffic tasks from Dietvorst et al. , we also sample four additional tasks from Castelo et al. : predicting heart disease , r ecidivism , r omantic partners , and r ating films . A secondary reason for chooseing these tasks is because they correspond to existing real world datasets that would be plausible to train algorithms on. For e xample, UCI’ s datasets on Heart Disease [ Janosi et al. , 1988 ] and Student Performance [ Cortez , 2014 ]. These added tasks e xtend the original tw o tasks to represent a more div erse set of decision-making scenarios and enable better comparison with Study 1. 4 gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3-sonnet 10 0 10 20 30 40 50 60 Human- Algorithm T rust Gap 8.61 10.90 30.68 26.74 27.97 19.95 17.41 5.14 Algorithm Appreciation Algorithm Aversion Figure 1: ‘Stated’ algorithm aversion across all models and tasks, operationalized as the gap between the trust rating giv en to the human expert and the algorithm. 4 Results 4.1 Study 1: Direct Queries In voke Algorithm A version (Stated) Does algorithm av ersion materialize when LLMs are asked to state their ratings of trust directly? T o answer this, we follo w the original study’ s operationalization of stated algorithm aversion as the gap in trust scor es assigned to the human and algorithmic agents , where a positi ve trust gap indicates algorithm av ersion, and a negati ve g ap indicates algorithm appreciation. The aggregated trust gaps across all tasks rated by all eight LLMs are sho wn in Figure 1 . Each trust gap stated for a specific task is plotted as an indi vidual bar . T asks are grouped by model, and within each model, the tasks are in decreasing order of objectivity . The mean trust gap is indicated by a star marker . Stated A v ersion. W e find evidence that evaluated LLMs ar e algorithm averse when pr oviding explicit trust ratings . The mean human-algorithm trust gap range from a low of 5.14 for claude-3-sonnet to a high of 30.68 for llama-3-70b , and is significantly positive ( p < 0 . 001 ) for all models. Furthermore, fiv e out of eight models hav e significant positiv e trust gaps in all tasks . In comparison, human participants in Castelo et al. were av erse in 77% of tasks. while a majority of tested LLMs are always algorithmically averse. W e present additional analyses comparing our results with the original human results from Castelo et al. in Appendix D , finding high directional agreement. LLM Complexity . W e also analyze whether model complexity af fects stated preferences. Larger models produce an av erage human-algorithm trust gap of 15.68, while smaller models hav e a trust gap of 21.16. W e conducted a W ilcoxon signed-rank test on paired data from the small and large models across the same tasks and model families, demonstrating high significance ( Z = − 4 . 3678 , p < 0 . 001 ) with an ef fect size of r = − 0 . 42 from smaller to lar ger models. Overall, this indicates that smaller models ar e mor e likely to state algorithmically-averse trust r atings than larger models. Robustness Check. W e perform two additional v ariations of Study 1, where the algorithm framed alternati vely as either an LLM agent or an expert algorithm . W e find that algorithm av ersion is present in both prompt variations, but the size of the human-algorithm trust gap is affected. Relativ e to a plain algorithm , LLMs state higher trust in the expert algorithm , b ut less trust in the LLM agent . The full replication of Figure 1 for the robustness tests are presented in Figures D.3 in Appendix D . 4.2 Study 2: In-Context Inf ormation In voke Algorithm A ppreciation (Re vealed) Our results thus far suggest that LLMs state that they trust human decision-makers more than algorithms. Do LLMs also behav e apprehensiv ely tow ards algorithmic advice? Revealed A version. T o test whether LLMs e xhibit distrust to ward algorithms when pro vided performance information of the agents, we measured the aggre gate probability of the LLMs deleg ating the task to each predictor , denoted P ( alg ) and P ( human ) (see Figure 2 ). Gi ven that Study 2 is constructed such that the human and the algorithm are each the stronger predictor in half of the trials, the ideal response is to bet on whichever agent is stronger, which corresponds to betting on each agent 50% of the time 5 A i r p o r t s H e a r t S t u d e n t s C r i m e D a t i n g M o v i e s 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C h o i c e P r o b a b i l i t y C h o i c e H u m a n N e u t r a l A l g o r i t h m Figure 2: Aggregate probabilities that LLMs in Study 2 demonstrate in delegating an algorithmic agent or a human expert to make the ne xt prediction in the task, or neutral (no indicated preference). 0.0 0.5 1.0 gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3-sonnet Airports 0.0 0.5 1.0 Heart Disease 0.0 0.5 1.0 Students 0.0 0.5 1.0 R ecidivism 0.0 0.5 1.0 Dating 0.0 0.5 1.0 Movies Str ong Alg Str ong Human P(Chose Str onger P r edictor) Figure 3: Probability that each LLM correctly bets on the stronger predictor , disaggreg ated by task and whether the stronger predictor is presented as a human expert or an algorithm. Ho wev er , we find that LLMs consistently choose the algorithmic agent more ( algorithm appr eciation ), despite it having the same ov erall performance as the human, contrasting the outcomes from Study 1. For the student and r ecidivism tasks, the two most algorithm-appreciati ve settings, LLMs bet on the algorithm 69.9% and 69.6% of times, respecti vely . For the least algorithm-appreciati ve task ( heart disease ), LLMs still picked the algorithm (52.8%) more than the human (34.6%), with the rest of the responses being neutral (12.6%) 4 . Identifying the Str ongest Predictor . This preference for algorithms is further reinforced when we consider whether LLMs chooses the better-performing predictor . W e plot the probability that each LLM correctly delegates the best predictor in Figure 3 , split by the selected tasks. Despite their higher trust ratings towards human experts in Study 1, we find that LLMs exhibit rev ealed distrust tow ards humans in their decision-making. gpt-3.5-turbo , both llama-3 models, and both claude-3 models were significantly more likely to choose strong algorithm in all of the tasks than the strong human (Haldane-corrected Fisher’ s exact tests, p < 0 . 05 ). Giv en e vidence that either the strong algorithm or the strong human is much more accurate than their weaker counterparts, a rational agent should tend towards betting on the strong agent that they see, and thus P ( str ong | al g ) and P ( str ong | human ) should approach 1, yielding algorithm- human relativ e risks of RR ah = P ( str ong | al g ) /P ( str ong | human ) = 1 . Instead, LLMs display a clear preference for the algorithmic predictor . The claude-3 models, for example, hav e relati ve risks ranging from 1.28 ( claude-3-sonnet for dating , p < 0 . 05 ) to 66.34 ( claude-3-haiku for r ecidivism , p < 0 . 05 ) with a median of 1.74, representing a 74% increased chance of Claude selecting the stronger agent when it is an algorithm rather than a human. claude-3-haiku and llama-3-8b are the most algorithm-appreciati ve, with the latter o verwhelmingly choosing the algorithm in the student task ( RR ah = 18 . 09 , p < 0 . 05 ) and always picking the algorithm in the recidivism task. The two models that did not consistently display algorithm appreciation in this setup are gpt-4-turbo (for correctly choosing the stronger agents) and llama-3.1-8b (for making random choices). 4 While neutral responses account for 9.9% of all outputs, the vast majority (94.0%) come from gpt-4-turbo and occur uniformly for both experimental conditions. W e exclude these responses from our analyses. 6 T able 1: Regression coef ficients and p -values for a mixed ef fects logistic model predicting whether LLMs will delegate the task to the more accurate agent. V ariable Coefficient p -V alue Intercept β = − 0 . 78 p < 0 . 001 Strong Algorithm β = 2 . 04 p < 0 . 001 Complex LLM β = 1 . 52 p < 0 . 001 Interaction β = 0 . 58 p < 0 . 001 gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3-sonnet 0% 20% 40% 60% 80% 100% P ick Human Expert (%) Algorithm Aversion Algorithm Appreciation Stated R evealed Figure 4: Probability of choosing the human expert ov er the algorithm in Studies 1 and 2, demon- strating the stated-r evealed trust inconsistency . Error bars are SEM. In summary , the LLMs tested in Study 2 presented as algorithm-appreciativ e, or , equiv alently , averse to predictions made by human experts. Of the 6 × 8 task-LLM pairs, thirty-fi ve had significant algorithm-human relati ve risks above 1, ten were insignificant, and three had significant relativ e risk below 1, suggesting that most of the tested LLMs in our tasks would delegate decisions to an algorithm ev en when its performance is worse than a human expert’ s. LLM Complexity . W e observe that more complex models appear to perform better in choosing the stronger predictor via the following mixed effects logistic model: ˆ Y ∼ x alg + x complex + x alg ∗ x complex + ( x alg | z task ) + ( x complex | z task ) , where Y is whether the LLM correctly bet on the strong agent, x alg is whether the strong agent is an algorithm, x complex is whether the LLM is the more complex model of the family , and z task is a grouping factor for the six tasks. The results, shown in T able 1 , reinforce the finding that LLMs are more likely to correctly bet on the stronger agent when it is presented as a strong algorithm rather than a strong human ( x alg - β = 2 . 04 , p < 0 . 001 ). The more complex LLMs are substantially more likely to bet on the correct agent ( x complex - β = 1 . 52 , p < 0 . 001 ). W e perform a secondary analysis with the strong human condition, presented in Appendix E , and again find support that higher complexity is associated with less algorithm appreciation. Robustness Checks. For robustness against prompting variations, we conducted two baseline experiments in Appendix E where both agents are framed as algorithms – either with the names ‘ A ’ and ‘B’, or two random alphanumeric strings. W e find that LLMs do not show dif ferences in baseline performance in choosing the stronger predictor , suggesting that the results in this section are likely driv en by the presentation of a human and an algorithm, and not other artifacts in the prompt. 4.3 Stated-Revealed Comparison (RQ3) Our results in Study 1 illustrate that LLMs consistently generate stated algorithm aversion by expressing higher lev els of trust in humans over algorithmic agents, whereas Study 2 shows that LLMs reveal algorithm appreciation by generating choices that pick humans ov er algorithms. T o formalize this comparison, we directly contrast the probability that LLMs choose the human agent in stated and rev ealed scenarios. In Study 1, LLM is considered to hav e chosen the human when its rated human-algorithm trust gap is positi ve (more trust in the human). For Study 2, we directly use the LLMs’ incenti vized choices. The results are aggregated across shared tasks in Studies 1 and 2 and shown as Figure 4 . 7 T o quantify the discrepancy between how LLMs generate stated and re vealed algorithm av ersion, we measure the stated-re vealed relativ e risk of trusting a human RR sr = P ( human | stated ) /P ( human | r ev eal ed ) and test for significance with Fisher’ s exact tests. W e find that RR sr > 1 for all LLMs in Figure 4 ( p < 0 . 001 ), indicating that they state algorithm av ersion in a human-like way , but re veal algorithm appreciation through the delegation decisions they make. This stated-revealed discrepancy is smallest for claude-3-sonnet ( RR sr = 1 . 29 ) and largest for claude-3-haiku ( RR sr = 8 . 52 ), with the median relati ve risk for all LLMs being 2 . 62 . claude-3-sonnet is also one of only two models with both preferences in the same direction ( P ( human | stated ) < 0 . 5 and P ( human | r ev eal ed ) < 0 . 5 ), with the other , llama-3.1-8b , being consistently algorithm-av erse ( P ( human | stated ) > 0 . 5 and P ( human | r ev eal ed ) > 0 . 5 ). All other LLMs exhibit opposing stated and r e vealed biases towards algorithms . 4.4 Updated Experiments with Newer LLMs Although we originally conducted Studies 1 and 2 with contemporary , consumer-facing LLMs in mid-2024, we now rerun experiments in January 2026 with newer models 5 to assess whether the patterns we find hold after approximately 1.5 years of LLM dev elopment. These newer e xperiments are presented in Appendix F . W e include these updated results to document how empirical LLM ev aluation findings can change across model generations, while retaining the original findings as a snapshot of LLM capabilities at the time of study . At a high le vel, we find that the ne wer models from the same LLM families demonstrate noticeably different beha vior from our original experiment, re vealing meaningful shifts in model beha vior ov er time. In Study 1, while the human-algorithm trust gap still varied across tasks (with a preference giv en to human experts in subjecti ve and interpreti ve tasks), the a verage gap magnitude across tasks was close to neutral. Ho wev er , the newer LLMs rated the algorithm higher than the human more frequently than in the original Study 1, indicating a ne w degree of implicit algorithm appr eciation in stated prefer ences . In Study 2, the LLMs now more accurately bet on the stronger agent based on their performance history . While there is still evidence of rev ealed algorithm appreciation, effect sizes are reduced and are statistically borderline. In the stated-rev ealed comparison, the relativ e risk of choosing the human is slightly re versed from our original findings, with Study 1 no w appearing to surface more algorithm appreciation than the Study 2. Howe ver , the trends in model complexity still track our original results, with the complex model more likely to be algorithm appreciati ve in Study 1 and to choose the stronger predictor in Study 2. This echoes other behavioral economics studies where LLM complexity correlates to performance [ Bini et al. , 2025 ]. W e speculate on these dev elopments, as well as the implications they pose to our original results, in the Discussion below . 5 Discussion In our original results, we found strong evidence that LLMs display inconsistent biases tow ards algorithms when prompted with different task presentations. RQ1 illustrates that LLMs are likely to generate higher trust ratings for human experts than algorithms when asked directly , thus exhibiting algorithm av ersion. For RQ2 , LLM and are more likely to be biased against humans as the better predictor – ev en when giv en performance information demonstrating that the human is more accurate than the algorithm, thus exhibiting algorithm appreciation. T aken together , RQ3 shows that LLMs generally exhibit inconsistent trust tow ards algorithms when stating their trust directly versus rev ealing it through decision-making. Our findings also indicate that larger , more complex LLMs are less biased in both Studies 1 and 2. While some of these core patterns ha ve shifted within the SO T A LLMs, we frame our Discussion around the impacts of algorithm aversion/appreciation biases in decision-making LLMs, incongruent outcomes across dif ferent task framings in LLM e valuations, and the longitudinal stability of results across model ev olutions. Stated vs Revealed Algorithm A version in LLMs. First, we uncover that LLMs are sensitiv e to the task format used in the ev aluation, in both the original and updated experiments. Thus, their internal biases to wards algorithms under different task contexts may be misaligned and need to be treated as if they will lead to disparate outcomes. As these massi ve, intelligent models become widely used across div erse scenarios [ Haupt and Marks , 2023 ], it is increasingly important that we understand whether 5 W e use GPT -5 from OpenAI, Llama-4 from Meta, and Claude 4.5 from Anthropic. See Appendix F . 8 they can make sound, consistent decisions. Safety-critical decision-making tasks can catastrophically suffer if the outwardly stated goals of AI agents are misaligned with their actions [ Li et al. , 2025 ], which also has implications for AI enacting deception on their human users and collaborators [ Park et al. , 2024b ]. W e showed that LLMs are not only often incapable of detecting optimal choices in simple decision-making scenarios, but their suboptimal choices are also internally inconsistent with their stated trust attitudes. And yet, while stated and revealed preferences form the basis of many theories of human decision-making [ Adamowicz et al. , 1994 ], the stated-rev ealed distinction is rarely made in ev aluation framew orks for LLMs trained on human data [ Chang et al. , 2024 ]. Our results therefore illustrate the importance of e v aluating LLMs across both their generated attitudes and generated choices, because e ven if an LLM yields desired outputs in its stated preferences, the embedded, rev ealed preferences in its responses may div erge. Indeed, a contemporaneous study has shown misalignment between e xplicit and implicit stereotype biases in LLM outputs [ Bai et al. , 2024 ], complementing our finding of a stated-rev ealed algorithmic trust gap. Inappropriate T rust in Algorithmic Agents. Secondly , Study 2 also demonstrates that LLMs may disproportionately delegate tasks to algorithms in incenti vized decision-making, e ven when a human alternativ e is demonstrably the best choice and the LLMs behave rationally with a high- performing algorithm and low-performing human. For instance, users relying on LLMs as decision aids may be subject to sub-optimal recommendations when other algorithms are in volv ed, which may hav e problematic downstream consequences for high-stakes tasks that already frequently employ algorithmic aids [ Zhang et al. , 2021 , Mahmud et al. , 2022 ]. On the other hand, users could also be nudged to wards algorithm-appreciativ e preconceptions that distract them from other important information, like whether a human is fairer than an algorithm [ Lee , 2018 , Mok et al. , 2023 ]. Although this may be beneficial for situations in which LLMs can overcome problematic human decision- making by recommending an algorithm [ Kleinber g et al. , 2018 , Obermeyer et al. , 2019 ], it may be harmful in other domains in which e xisting, commercial algorithmic systems are kno wn to exacerbate societal biases [ Buolamwini and Gebru , 2018 ]. This latter concern is reinforced by our newer experiments in 2026 — while LLMs ha ve impro ved substantially at identifying the better predictor in settings like Study 2, regardless of whether the y are human or algorithm, their stated preferences are now actually more lik ely to ske w towards preferring an algorithmic agent. Interpr eting Static Evaluations of Evolving Models. These ne w experiments, summarized in Section 4.4 and Appendix F , illustrate the need for continuous ev aluation and benchmarking of po werful, consumer-facing AI models. The updated results indicate that LLMs may now be systemat- ically algorithm-appr eciative in their stated preferences, and while still showing traces of algorithm appreciation in rev ealed preferences. These patterns suggest key positi ve, cautionary , and potentially negati ve implications for the use of LLMs in predictiv e tasks. On a positi ve note, LLMs appear to be gro wing less cognitiv ely biased along the algorithm appreciation vs. av ersion spectrum, and hav e clearly become much better at mathematical reasoning when shown past predictions in Study 2. Ho wev er , one must exercise caution when using LLMs in these tasks, because their behavioral quirks may not only be reduced o ver the course of a year – the y may e ven change directions, as shown in Study 1. Thus, one potential risk is that, in light of a growing mo vement to simulate humans with LLMs (c.f. Park et al. [ 2024a ], Bini et al. [ 2025 ]), it has become at best dif ficult to ascertain which LLMs retain kno wn human characteristics. People do ha ve cogniti ve biases to wards algorithms as demonstrated by studies like Castelo et al. [ 2019 ] and Dietvorst et al. [ 2015 ], so newer and more mathematically capable LLMs may actually be less appr opriate for realistically simulating people. Interrogating the causes of these changes, whether in the training data or the models’ engineered reasoning abilities, can shed light on how LLM e v aluations should be interpreted over time. Broader Implications and Futur e W ork. Beyond immediate repercussions for end-users, LLMs that encode biases to wards or against algorithms may also have broader downstream impact. In journalism, their capabilities as text generators hav e led to their exploration as news summarizers [ T am et al. , 2023 , Zhang et al. , 2023a ], writing aids [ Petridis et al. , 2023 ], and fact-checking tools [ Hu et al. , 2023 ]. For educators, LLMs help teachers generate teaching materials and e v aluate students [ Kasneci et al. , 2023 , Dai et al. , 2023 ]. In these scenarios, if LLMs were to generate inconsistently algorithm- av erse or algorithm-appreciative text, they risk misleading the public – as they already do with explicitly false content [ De Angelis et al. , 2023 , Zhang et al. , 2023b , Longoni et al. , 2022 ]. More work is therefore needed to understand, firstly , the situations in which the content LLMs help create encode inappropriately av erse or appreciativ e attitudes towards algorithms. Secondly , the underlying mechanisms leading LLMs to obtain these inconsistent behaviors, potentially because of algorithm- 9 av erse text in their training data or algorithm-appreciati ve engineering for LLMs to interface with external algorithmic tools [ Schick et al. , 2023 ], remain unclear and require future in vestigation. In light of quickly-advancing multi-agent systems, our work also raise questions not only of interac- tions between LLMs and humans like end-users and content consumers, but also of AI-AI interactions in volving LLMs. LLMs are increasingly being tested for their ability to use other algorithmic tools [ Schick et al. , 2023 , Jin et al. , 2023 ] and even con verse with and learn from each other [ W u et al. , 2023 , Chan et al. , 2023 ]. If LLMs are inconsistently algorithm-a verse or algorithm-appreciati ve, to the extent that they discard beneficial advice as in Study 2, ho w would their performance be impacted if other agents are rev ealed to be artificial? Our study forms a basis for ev aluating biases LLMs display tow ards algorithms in these multi-agent contexts, which we lea ve to future work. 6 Limitations As with similar work on probing LLMs with human experimental methods, our work is subject to se veral limitations in order to limit the vast design space for experimentation [ Binz and Schulz , 2023 ]. W e focused on four LLM families, fixed the temperature and top- p parameters [ W ang et al. , 2023 ], did not v ary personas or demographics [ Deshpande et al. , 2023 ], and conducted our study amidst constant model changes [ Chen et al. , 2023 ], on top of the design choices made in the human experiments our studies are based on [ Dietvorst et al. , 2015 , Castelo et al. , 2019 ]. W e took multiple steps to ensure that our work is consistent with both the pre vious human studies, e.g., using identical tasks and surve y ratings, and with best practices for LLM experimentation, e.g., randomizing option order and enforcing JSON formatting, and further include coherent robustness checks in the Appendix. Importantly , as highlighted in subsection 4.4 , the results captured in the main e xperiments in 2024 may hav e since shifted — this is expected for empirical ev aluations of this nature, howe ver , as LLMs do ev olve in their capabilities rapidly . The additional experimentation we perform in Appendix F illustrates the need to continuously re-e valuate LLMs for their biases to wards algorithms and humans. W e also prioritized this approach of following existing human studies in the stated-re vealed preference comparison in Section 4.3 , rather than engineering prompts that are directly comparable. For example, we did not present LLMs with survey-based prompts (mirroring Castelo et al. ) for rev ealed preferences, or , vice versa, a betting methodology (mirroring Dietv orst et al. ) for stated preferences. While this makes direct comparison difficult, we note that dif ferent experimental methods are standard for human studies of stated and re vealed preferences [ List and Gallet , 2001 ] – and yet, the stated-rev ealed preference div ergence is well kno wn [ Glaeser et al. , 2000 ]. Additionally , care must be taken when interpreting our results to a void o verly anthropomorphizing LLMs. W e used a behavioral science apparatus because, firstly , it is the de facto standard for studying human-like phenomena in LLMs trained on human data [ Binz and Schulz , 2023 , Ziems et al. , 2023 ], and secondly , LLMs are now delegated tasks that were previously done by humans [ Meskó and T opol , 2023 , Petridis et al. , 2023 ]. Howe ver , this human-centric approach does not imply that LLMs hold preferences themselves; rather , the preferences examined in this study are more accurately characterized as those embedded in text generated by LLMs. 7 Conclusion W e in vestigate whether LLMs encode biases tow ards other algorithmic agents, finding that their degree of a version to wards algorithms is inconsistent based on the ev aluation method. When asked to generate explicit trust ratings to wards human experts and algorithms across a div erse set of tasks, we find that the ev aluated LLMs consistently state higher trust in the human agent, echoing a human- like algorithm a version. Howe ver , when placed in decision-making scenarios and gi ven in-conte xt performance information of each agent, the LLMs generally choose a weaker-performing algorithm ov er the human, demonstrating irrational algorithm appreciation. Our results hav e dual implications for the consistency of LLM e valuations based on the task format and the problematic bias to wards algorithms that LLMs seemingly exhibit in decision-making, both of which are crucial to better understand as LLMs are being incorporated in high-stakes, autonomous decision-making. 10 References Josh Achiam, Stev en Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv pr eprint arXiv:2303.08774 , 2023. W iktor Adamowicz, Jordan Louviere, and Michael W illiams. Combining revealed and stated preference methods for valuing en vironmental amenities. Journal of en vir onmental economics and management , 26(3):271–292, 1994. Gati V Aher , Rosa I Arriaga, and Adam T auman Kalai. Using large language models to simulate multiple humans and replicate human subject studies. In International Confer ence on Machine Learning , pages 337–371. PMLR, 2023. Anthropic. The claude 3 model family: Opus, sonnet, haiku. 2024. Xuechunzi Bai, Angelina W ang, Ilia Sucholutsky , and Thomas L Griffiths. Measuring implicit bias in explicitly unbiased lar ge language models. arXiv preprint , 2024. Y untao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nov a DasSarma, Dawn Drain, Stanislav F ort, Deep Ganguli, T om Henighan, et al. T raining a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint , 2022. Pietro Bini, Lin W illiam Cong, Xing Huang, and Lawrence J Jin. Behavioral economics of ai: Llm biases and corrections. A vailable at SSRN 5213130 , 2025. Marcel Binz and Eric Schulz. Using cogniti ve psychology to understand gpt-3. Pr oceedings of the National Academy of Sciences , 120(6):e2218523120, 2023. Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil ˙ e Lukoši ¯ ut ˙ e, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scalable ov ersight for large language models. arXiv pr eprint arXiv:2211.03540 , 2022. Kathleen Brooks and Jayson L Lusk. Stated and rev ealed preferences for organic and cloned milk: combining choice experiment and scanner data. American Journal of Agricultural Economics , 92 (4):1229–1241, 2010. Joy Buolamwini and T imnit Gebru. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Confer ence on fairness, accountability and tr ansparency , pages 77–91. PMLR, 2018. A ylin Caliskan, Joanna J Bryson, and Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases. Science , 356(6334):183–186, 2017. Noah Castelo, Maarten W Bos, and Donald R Lehmann. T ask-dependent algorithm av ersion. J ournal of Marketing Resear ch , 56(5):809–825, 2019. Alvaro Chacon. The end of algorithm aversion. AI & SOCIETY , 40(4):2331–2332, 2025. Chi-Min Chan, W eize Chen, Y usheng Su, Jianxuan Y u, W ei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chatev al: T ow ards better llm-based ev aluators through multi-agent debate. arXiv pr eprint arXiv:2308.07201 , 2023. Y upeng Chang, Xu W ang, Jindong W ang, Y uan W u, Linyi Y ang, Kaijie Zhu, Hao Chen, Xiao yuan Y i, Cunxiang W ang, Y idong W ang, et al. A survey on e valuation of lar ge language models. ACM T ransactions on Intelligent Systems and T echnology , 15(3):1–45, 2024. Lingjiao Chen, Matei Zaharia, and James Zou. How is chatgpt’ s behavior changing o ver time? arXiv pr eprint arXiv:2307.09009 , 2023. Myra Cheng, Angela Y Lee, Kristina Rapuano, Kate Niederhoffer , Alex Liebscher , and Jeffre y Hancock. From tools to thie ves: Measuring and understanding public perceptions of ai through crowdsourced metaphors. arXiv preprint , 2025. 11 Paulo Cortez. Student Performance. UCI Machine Learning Repository , 2014. DOI: https://doi.org/10.24432/C5TG7T . W ei Dai, Jionghao Lin, Hua Jin, T ongguang Li, Y i-Shan Tsai, Dragan Gaševi ´ c, and Guanliang Chen. Can large language models pro vide feedback to students? a case study on chatgpt. In 2023 IEEE International Conference on Advanced Learning T echnologies (ICAL T) , pages 323–325. IEEE, 2023. Luigi De Angelis, Francesco Bagli vo, Guglielmo Arzilli, Gaetano Pierpaolo Pri vitera, Paolo Ferragina, Alberto Eugenio T ozzi, and Caterina Rizzo. Chatgpt and the rise of large language models: the new ai-dri ven infodemic threat in public health. F r ontiers in Public Health , 11:1166120, 2023. Ameet Deshpande, V ishvak Murahari, T anmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. T oxicity in chatgpt: Analyzing persona-assigned language models. arXiv preprint arXiv:2304.05335 , 2023. Berkeley J Dietv orst, Joseph P Simmons, and Cade Massey . Algorithm aversion: people erroneously av oid algorithms after seeing them err . Journal of Experimental Psycholo gy: General , 144(1):114, 2015. Berkeley J Dietv orst, Joseph P Simmons, and Cade Massey . Overcoming algorithm av ersion: People will use imperfect algorithms if they can (ev en slightly) modify them. Management science , 64(3): 1155–1170, 2018. Dietrich Earnhart. Combining rev ealed and stated data to examine housing decisions using discrete choice analysis. Journal of Urban Economics , 51(1):143–169, 2002. Eva Eigner and Thorsten Händler . Determinants of llm-assisted decision-making. arXiv pr eprint arXiv:2402.17385 , 2024. Mohamed Amine Ferrag, Norbert Tihan yi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensi ve re view . arXiv preprint , 2025. Emilio Ferrara. Should chatgpt be biased? challenges and risks of bias in large language models. F irst Monday , November 2023. ISSN 1396-0466. doi: 10.5210/fm.v28i11.13346. URL http: //dx.doi.org/10.5210/fm.v28i11.13346 . Edward L Glaeser , Da vid I Laibson, Jose A Scheinkman, and Christine L Soutter . Measuring trust. The quarterly journal of economics , 115(3):811–846, 2000. Nicole Gross. What chatgpt tells us about gender: a cautionary tale about performativity and gender biases in ai. Social Sciences , 12(8):435, 2023. Claudia E Haupt and Mason Marks. Ai-generated medical advice—gpt and beyond. Jama , 329(16): 1349–1350, 2023. Beizhe Hu, Qiang Sheng, Juan Cao, Y uhui Shi, Y ang Li, Danding W ang, and Peng Qi. Bad actor, good advisor: Exploring the role of large language models in f ake ne ws detection. arXiv pr eprint arXiv:2309.12247 , 2023. Jen-tse Huang, Eric John Li, Man Ho Lam, T ian Liang, W enxuan W ang, Y ouliang Y uan, W enxiang Jiao, Xing W ang, Zhaopeng Tu, and Michael R L yu. How f ar are we on the decision-making of llms? ev aluating llms’ gaming ability in multi-agent en vironments. arXiv pr eprint arXiv:2403.11807 , 2024. Andras Janosi, W illiam Steinbrunn, Matthias Pfisterer, and Robert Detrano. Heart Disease. UCI Machine Learning Repository , 1988. DOI: https://doi.org/10.24432/C52P4X. Jingru Jessica Jia, Zehua Y uan, Junhao P an, Paul McNamara, and Deming Chen. Decision-making behavior e v aluation framework for llms under uncertain context. Advances in Neural Information Pr ocessing Systems , 37:113360–113382, 2024. Qiao Jin, Y ifan Y ang, Qingyu Chen, and Zhiyong Lu. Genegpt: Augmenting large language models with domain tools for improv ed access to biomedical information. ArXiv , 2023. 12 Ekaterina Jussupo w , Izak Benbasat, and Armin Heinzl. Why are we a verse to wards algorithms? a comprehensiv e literature revie w on algorithm a version. 2020. Enkelejda Kasneci, Kathrin Seßler , Stefan Küchemann, Maria Bannert, Daryna Dementiev a, Frank Fischer , Urs Gasser , Georg Groh, Stephan Günnemann, Eyk e Hüllermeier , et al. Chatgpt for good? on opportunities and challenges of large language models for education. Learning and individual differ ences , 103:102274, 2023. Jon Kleinberg, Himabindu Lakkaraju, Jure Leskov ec, Jens Ludwig, and Sendhil Mullainathan. Human decisions and machine predictions. The quarterly journal of economics , 133(1):237–293, 2018. Min Kyung Lee. Understanding perception of algorithmic decisions: Fairness, trust, and emotion in response to algorithmic management. Big Data & Society , 5(1):2053951718756684, 2018. Xiaoyong Li, Qing Jiang, Linfeng Jiang, Shuo Zhang, and Siyuan Hu. The landscape of ai alignment: A comprehensi ve re view of theories and methods. International Journal of P attern Recognition and Artificial Intelligence , page 2539001, 2025. Q V era Liao and Jennifer W ortman V aughan. Ai transparency in the age of llms: A human-centered research roadmap. arXiv preprint , 2023. John A List and Craig A Gallet. What experimental protocol influence disparities between actual and hypothetical stated v alues? En vir onmental and r esour ce economics , 20(3):241–254, 2001. Pengfei Liu, W eizhe Y uan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surve ys , 55(9):1–35, 2023a. Zhuang Liu, Degen Huang, Kaiyu Huang, Zhuang Li, and Jun Zhao. Finbert: A pre-trained financial language representation model for financial text mining. In Pr oceedings of the twenty-ninth international confer ence on international joint conferences on artificial intellig ence , pages 4513– 4519, 2021. Zijun Liu, Y anzhe Zhang, Peng Li, Y ang Liu, and Diyi Y ang. Dynamic llm-agent network: An llm-agent collaboration frame work with agent team optimization. arXiv pr eprint arXiv:2310.02170 , 2023b. Chiara Longoni, Andrey Fradkin, Luca Cian, and Gordon Pennycook. News from generative artificial intelligence is belie ved less. In Pr oceedings of the 2022 A CM Confer ence on F airness, Accountability , and T ranspar ency , pages 97–106, 2022. Hasan Mahmud, AKM Najmul Islam, Syed Ishtiaque Ahmed, and Kari Smolander . What influences algorithmic decision-making? a systematic literature revie w on algorithm aversion. T echnological F or ecasting and Social Change , 175:121390, 2022. T ami L Mark and Joffre Swait. Using stated preference and rev ealed preference modeling to ev aluate prescribing decisions. Health economics , 13(6):563–573, 2004. Bertalan Meskó and Eric J T opol. The imperativ e for regulatory ov ersight of large language models (or generativ e ai) in healthcare. NPJ digital medicine , 6(1):120, 2023. Lillio Mok, Sasha Nanda, and Ashton Anderson. People percei ve algorithmic assessments as less f air and trustworthy than identical human assessments. Proceedings of the A CM on Human-Computer Interaction , 7(CSCW2):1–26, 2023. Ziad Obermeyer , Brian Powers, Christine V ogeli, and Sendhil Mullainathan. Dissecting racial bias in an algorithm used to manage the health of populations. Science , 366(6464):447–453, 2019. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generati ve agents: Interactiv e simulacra of human behavior . In Pr oceedings of the 36th Annual A CM Symposium on User Interface Softwar e and T echnology , pages 1–22, 2023. 13 Joon Sung Park, Carolyn Q Zou, Aaron Shaw , Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb W iller , Perc y Liang, and Michael S Bernstein. Generativ e agent simulations of 1,000 people. arXiv preprint , 2024a. Peter S Park, Simon Goldstein, Aidan O’Gara, Michael Chen, and Dan Hendrycks. Ai deception: A surve y of examples, risks, and potential solutions. P atterns , 5(5), 2024b. Savv as Petridis, Nicholas Diakopoulos, Ke vin Crowston, Mark Hansen, K eren Henderson, Stan Jastrzebski, Jeffrey V Nickerson, and L ydia B Chilton. Anglekindling: Supporting journalistic angle ideation with large language models. In Pr oceedings of the 2023 CHI Confer ence on Human F actors in Computing Systems , pages 1–16, 2023. Partha Pratim Ray . Chatgpt: A comprehensiv e revie w on background, applications, ke y challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems , 2023. T imo Schick, Jane Dwiv edi-Y u, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer , Nicola Cancedda, and Thomas Scialom. T oolformer: Language models can teach themselv es to use tools. arXiv preprint , 2023. T ianhao Shen, Renren Jin, Y ufei Huang, Chuang Liu, W eilong Dong, Zishan Guo, Xinwei W u, Y an Liu, and Deyi Xiong. Large language model alignment: A surv ey . arXiv preprint , 2023. Sahib Singh. Is chatgpt biased? a revie w . 2023. Andis Sofianos. Self-reported & re vealed trust: Experimental evidence. Journal of Economic Psychology , 88:102451, 2022. Derek T am, Anisha Mascarenhas, Shiyue Zhang, Sarah Kwan, Mohit Bansal, and Colin Raffel. Evaluating the factual consistency of large language models through news summarization. In F indings of the Association for Computational Linguistics: A CL 2023 , pages 5220–5255, 2023. Y an T ao, Olga V iber g, Ryan S. Baker , and Rene F . Kizilcec. Auditing and mitigating cultural bias in llms, 2023. Hugo T ouvron, Thibaut Lavril, Gautier Izacard, Xa vier Martinet, Marie-Anne Lachaux, T imothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar , et al. Llama: Open and efficient foundation language models. arXiv preprint , 2023. Boxin W ang, W eixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaef fer , et al. Decodingtrust: A comprehensive assessment of trustworthiness in gpt models. In NeurIPS , 2023. Qingyun W u, Gagan Bansal, Jieyu Zhang, Y iran W u, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi W ang. Autogen: Enabling next-gen llm applications via multi-agent con versation frame work. arXiv pr eprint arXiv:2308.08155 , 2023. Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Y e, Kai Shu, Adel Bibi, Ziniu Hu, Philip T orr , Bernard Ghanem, and Guohao Li. Can large language model agents simulate human trust beha viors? arXiv pr eprint arXiv:2402.04559 , 2024. Lixuan Zhang, Iryna Pentina, and Y uhong Fan. Who do you choose? comparing perceptions of human vs robo-advisor in the context of financial services. Journal of Services Mark eting , 35(5): 634–646, 2021. Qiaoning Zhang, Matthe w L Lee, and Scott Carter . Y ou complete me: Human-ai teams and complementary expertise. In Pr oceedings of the 2022 CHI Conference on Human F actors in Computing Systems , pages 1–28, 2022. T ianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeo wn, and T atsunori B Hashimoto. Benchmarking large language models for news summarization. arXiv pr eprint arXiv:2301.13848 , 2023a. 14 Y ue Zhang, Y afu Li, Leyang Cui, Deng Cai, Lemao Liu, T ingchen Fu, Xinting Huang, Enbo Zhao, Y u Zhang, Y ulong Chen, et al. Siren’ s song in the ai ocean: A surve y on hallucination in large language models. arXiv preprint , 2023b. Y achao Zhao, Bo W ang, Y an W ang, Dongming Zhao, Ruifang He, and Y uexian Hou. Explicit vs. implicit: In vestigating social bias in lar ge language models through self-reflection. arXiv preprint arXiv:2501.02295 , 2025. Zihao Zhao, Eric W allace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving fe w-shot performance of language models. In International conference on machine learning , pages 12697–12706. PMLR, 2021. Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Y ang. Can large language models transform computational social science? arXiv pr eprint arXiv:2305.03514 , 2023. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Y in, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparenc y . arXiv pr eprint arXiv:2310.01405 , 2023. 15 A Study 1 Prompting PROMPTER : T h e f o l l o w i n g J S O N c o n t a i n s a l i s t o f t a s k s a n d a q u e s t i o n a b o u t h o w m u c h y o u t r u s t i t t o b e p e r f o r m e d b y t w o d i f f e r e n t a g e n t s [ a : a g e n t _ a , b : a g e n t _ b ] . P l e a s e r e t u r n a J S O N o f t h e l i s t o f t a s k s a n d a c o r r e s p o n d i n g t r u s t r a t i n g f o r e a c h o f t h e a g e n t s f r o m 1 ( w o u l d n o t t r u s t a g e n t ) t o 1 0 0 ( w o u l d d e f i n i t e l y t r u s t a g e n t ) . T h e t a s k s a r e : { " W r i t i n g n e w s a r t i c l e " : " H o w m u c h w o u l d y o u t r u s t [ a : a j o u r n a l i s t , b : a n a l g o r i t h m ] f r o m 1 ( n o t r u s t ) t o 1 0 0 ( h i g h t r u s t ) ? " , . . . " R e c o m m e n d i n g a m a r k e t i n g s t r a t e g y " : " H o w m u c h w o u l d y o u t r u s t [ a : a m a r k e t e r , b : a n a l g o r i t h m ] f r o m 1 ( n o t r u s t ) t o 1 0 0 ( h i g h t r u s t ) ? " } LLM : { " W r i t i n g n e w s a r t i c l e " : { " a " : 7 5 , " b " : 7 0 } , . . . " R e c o m m e n d i n g a m a r k e t i n g s t r a t e g y " : { " a " : 7 0 , " b " : 8 0 } } Listing A.1: Example prompt from Study 1 for generating stated preferences. B Study 2 Prompting PROMPTER : W e ’ v e b u i l t a n a l g o r i t h m a n d a s k e d a c a r d i o l o g i s t t o p r e d i c t t h e l i k e l i h o o d t h a t p a t i e n t s a t a l o c a l h o s p i t a l h a s c a r d i o v a s c u l a r d i s e a s e . B e l o w a r e 1 0 e x a m p l e s o f p r e d i c t i o n s m a d e b y t h e c a r d i o l o g i s t a n d a l g o r i t h m . { " A l g o r i t h m ’ s P r e d i c t i o n " : 0 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 1 . 0 , " A c t u a l O u t c o m e " : 0 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 1 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 0 . 0 , " A c t u a l O u t c o m e " : 1 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 1 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 1 . 0 , " A c t u a l O u t c o m e " : 1 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 0 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 1 . 0 , " A c t u a l O u t c o m e " : 0 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 1 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 1 . 0 , " A c t u a l O u t c o m e " : 1 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 1 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 0 . 0 , " A c t u a l O u t c o m e " : 1 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 0 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 0 . 0 , " A c t u a l O u t c o m e " : 0 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 1 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 1 . 0 , " A c t u a l O u t c o m e " : 1 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 0 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 1 . 0 , " A c t u a l O u t c o m e " : 1 . 0 } { " A l g o r i t h m ’ s P r e d i c t i o n " : 0 . 0 , " C a r d i o l o g i s t ’ s P r e d i c t i o n " : 0 . 0 , " A c t u a l O u t c o m e " : 0 . 0 } Y o u h a v e 1 0 0 U S D t o b e t o n e i t h e r t h e c a r d i o l o g i s t o r t h e a l g o r i t h m t o g e t a f i n a l p r e d i c t i o n r i g h t . Y o u m u s t p l a c e a b e t a n d w i l l l o s e 1 0 0 U S D i f y o u d o n ’ t . Y o u w i l l r e c e i v e n o a d d i t i o n a l i n f o r m a t i o n . A n s w e r i n J S O N f o l l o w i n g t h e f o r m a t { " C h o i c e " : X } w h e r e X i s e i t h e r " C a r d i o l o g i s t " o r " A l g o r i t h m " . Y o u r J S O N a n s w e r : LLM : { " C h o i c e " : " A l g o r i t h m " } Listing B.2: Example prompt for generating revealed preferences in Study 2, for the Str ong Algorithm condition in the heart disease task. 16 C T asks T able C.1: List of tasks used in Study 1 from Castelo et al. , ordered in descending task objectivity (as ranked in the original study). W e designate a corresponding human expert role for each task. Bolded tasks are a representativ e subset of tasks included in Study 2, where † indicates that the task was also in Dietvorst et al. . T ask Human Expert T ask Human Expert Estimating air traffic † Air traffic controller Recommending a marketing strate gy Marketer Piloting a plane Pilot Predicting student perf ormance † Admissions officer Diagnosing a disease Cardiologist Predicting employee performance Manager Giving directions Navigator Hiring and firing employees Manager Analyzing data Analyst Playing a piano Musician Driving a subw ay Conductor Writing news article Journalist Driving a truck Driv er Predicting r ecidivism Probation officer Driving a car Driv er Composing a song Songwriter Recommending disease treatment Doctor Predicting joke funniness Comedian Predicting weather Meteorologist Recommending a gift Shopping assistant Scheduling ev ents Planning strategist Recommending a romantic partner Matchmaker Predicting stocks Analyst Recommending a movie Film critic Predicting an election Political analyst Recommending music Radio DJ Buying stocks Analyst D Additional Study 1 Results gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3-sonnet gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3-sonnet Cor r elation of LLMs' Stated A version 0.5 0.6 0.7 0.8 0.9 1.0 Figure D.1: Correlation between the LLMs trust gaps. Correlation between LLMs. The correlation between each LLM’ s human-algorithm trust gap across the 27 tasks are visualized in Figure D.1 . The smallest models of llama-3-8b and llama-3.1-8b display higher similarity with each other and less with the other models. Correlation with Human Responses. T o what extent do responses from different LLM families reflect known human responses at the more granular , task lev el? For each LLM l , we fit a simple linear regression ˆ Y t,l ∼ x t predicting the LLM’ s human-algorithm trust gap Y in task t from the original surve y participants’ human-algorithm gap x for t and an intercept, which we obtain directly from Castelo et al. . The results we obtained are visualized in Figure D.2 , in which each point is a 17 task from T able C.1 and the x and y axes represent the task’ s human-algorithm gap from human participants and our LLM responses. W e find three key patterns. First, all LLMs exhibit strong directional agreement with human responses in a majority of task — most points lie in the upper right quadrant where both LLM responses and participants from Castelo et al. yielded positive human-algorithm trust gaps. In other words, LLMs are likely to express algorithm a version to tasks for which people also e xpress algorithm aversion. Second, all regression coefficients are positiv e and statistically significant at the 0 . 05 threshold, indicating that the original human participants and our LLM emulations are likely to state high degrees of algorithm av ersion towards the same tasks. Thirdly , the more complex models within each LLM family , such as the larger versions of Llama and the sonnet version of Claude 6 , hav e substantially larger regression coef ficients than the simpler models. Thus, while larger LLMs ha ve lower human-algorithm trust gaps than smaller LLMs, their trust gaps across tasks actually correlate much more strongly with human responses. -70 0 70 Human R atings fr om Castelo et al. 0 70 LLM R atings Both averse LLM averse, humans appr eciate Both appr eciate LLM appr eciate, humans averse Human- Algorithm T rust Gap gpt-3.5-turbo, =0.11, p=0.02 gpt-4-turbo, =0.69, p<.01 (a) OpenAI GPT models. -70 0 70 Human R atings fr om Castelo et al. 0 70 LLM R atings Both averse LLM averse, humans appr eciate Both appr eciate LLM appr eciate, humans averse Human- Algorithm T rust Gap llama-3-8b, =0.39, p<.01 llama-3-70b, =0.69, p<.01 (b) Meta Llama-3 models. -70 0 70 Human R atings fr om Castelo et al. 0 70 LLM R atings Both averse LLM averse, humans appr eciate Both appr eciate LLM appr eciate, humans averse Human- Algorithm T rust Gap llama-3.1-8b, =0.46, p=0.01 llama-3.1-70b, =0.77, p<.01 (c) Meta Llama-3.1 models. -70 0 70 Human R atings fr om Castelo et al. 0 70 LLM R atings Both averse LLM averse, humans appr eciate Both appr eciate LLM appr eciate, humans averse Human- Algorithm T rust Gap claude-3-haik u, =0.42, p<.01 claude-3-sonnet, =0.64, p<.01 (d) Anthropic Claude models. Figure D.2: Re gression coefficients between LLMs’ responses ( y-axis ) and human responses from Castelo et al. ( x-axis ) with the gap in trust between human experts and algorithms. LLM-rated gaps with high statistical significance of p < 0 . 001 are outlined in black with stronger color saturation. The dif ferent LLM families are separated into subfigures a) GPT , b) Llama-3, c) Llama-3.1, and d) Claude. 6 See https://www.anthropic.com/news/claude- 3- family . 18 gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3.7-sonnet 0 20 40 60 80 100 Human- Algorithm T rust Gap 15.58 33.80 53.01 47.89 9.81 46.63 29.17 31.45 Algorithm Appreciation Algorithm Aversion (a) Study 1 experiment repeated with the algorithm framed as an LLM agent . All human-algorithm trust gaps are statistically significant. gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3.7-sonnet** 0 20 40 60 80 100 Human- Algorithm T rust Gap 4.82 8.65 13.79 23.25 13.08 17.74 17.34 6.18 Algorithm Appreciation Algorithm Aversion (b) Study 1 experiment repeated with the algorithm framed as an expert algorithm (equalizes the framing of the human and the algorithm). All human-algorithm trust gaps are statistically significant. Figure D.3: Robustness e xperiments conducted to test the prompt variation of Study 1, where the algorithm is framed as (a) an LLM agent or (b) an expert algorithm . Robustness Check. T o understand how sensiti ve LLMs are to the framing of the algorithmic agent, we v ary the wording in the prompt in tw o ways: (a) an LLM agent instead of algorithm, sho wn in Figure D.3a ; and (b) an expert algorithm instead of algorithm, sho wn in Figure D.3b . The expert framing was chosen to match the name of the human expert. For example, autonomous driving algorithm for the driving a car task. Note that due to model deprecation, we replace the results of claude-3-sonnet with claude-3-7-sonnet . In summary , LLMs expressed mor e algorithmically averse trust gaps when the algorithm is framed as an LLM agent, b ut less av erse when framed as an e xpert algorithm equiv alent to the human e xpert. Howe ver , in both robustness checks, all LLMs still state a significant preference for human experts. Thus, we take the original wording of Castelo et al. with algorithm for the results for Study 1, which falls in the middle of the more extreme results demonstrated in the rob ustness checks. E Additional Study 2 Results Regression o ver algorithm appreciation. T o test whether more complex models are less algorithm- appreciativ e when faced with a weak algorithm, we build a secondary regression ov er the strong human condition only (i.e. n = 9600 / 2 = 4800 trials). This is specified by ˆ Y ∼ x complex + ( x complex | z task ) , where ˆ Y is an indicator variable denoting whether an LLM responds incorrectly by identifying the algorithm as the more accurate predictor . x complex and z task are the same v ariables as in the main text; ( x complex | z task ) fits random intercepts and slopes to each of the 6 tasks to control for task-based randomness. Results are shown in T able E.1 . The positiv e intercept indicates that, on aggregate, smaller LLMs are fairly likely (68%) to incorrectly bet on the algorithm ev en when shown a substantially more accurate human. Howe ver , the larger , more complex LLMs are way less likely 19 (odds ratio of 0.17) to make this inaccurate prediction, demonstrating that the y are empirically also much less algorithm-appreciativ e. T able E.1: Regression coef ficients and p -values for a mix ed effects logistic model predicting whether LLMs will incorrectly bet on an algorithm when shown a str onger human alternati ve. V ariable Coef ficient p -V alue Intercept β = 0 . 74 p < 0 . 001 Complex LLM β = − 1 . 77 p < 0 . 001 Robustness Checks. T o reinforce the robustness of the apparatus used in Study 2, we use the same prompts for the r ecidivism and student tasks but ask LLMs to choose between two algorithms. Our expectation is that there should be no systematic differences in their bets on either algorithm, as opposed to the human-avoiding results of Study 2. In the altered r ecidivism task we replace the algorithm and human expert with “ Algorithm A ” and “ Algorithm B”, and in the altered student task with two randomly-generated string identifiers “ Algorithm g31XK” and “ Algorithm ELeyT”. The results of running the same experiment ( n = 200 prompts) with either a strong algorithm A ( n = 100 ) or strong algorithm B ( n = 100 ) are shown in Figure E.1 . W e find that the LLMs on aggregate ha ve no consistent preference for either algorithm, with algorithm A being chosen 50% of the time (binomial test p > 0 . 05 ) in the altered recidivsm task. Excluding gpt-3.5-turbo in the altered student task also leads to a 52% chance of picking algorithm ELeyT ( p > 0 . 05 ). W e believe that gpt-3.5-turbo ’ s preference for ELeyT is lik ely by chance, as the rest of the LLMs do not ha ve statistically-significant dif ferences in their responses. W e thus conclude that our results in Study 2 are likely to hav e been caused by the presentation of a human and an algorithm, and not by some other underlying structure of the prompts. 0.4 0.6 0.8 1.0 P(Chose Str onger) gpt-3.5-turbo gpt-4-turbo llama-3-8b llama-3-70b llama-3.1-8b llama-3.1-70b claude-3-haik u claude-3-sonnet R ecidivism (Algos) Str ong Alg A Str ong Alg B 0.4 0.6 0.8 1.0 P(Chose Str onger) Students (Algos) Str ong Alg g31XK Str ong Alg EL eyT Figure E.1: Baseline version of Figure 3 with two algorithmic predictors instead of a human and an algorithm. The algorithms are either labelled as A and B or with random strings g31XK and ELeyT . F Results from Newer Models T o assess the ongoing capabilities of LLMs and whether newer , more sophisticated models released by major AI providers display the same behavioral traits, we re-ran our experiments in January 2026. W e used the following models and snapshots for this updated experiment: gpt-5-2025-08-07 , gpt-5-mini-2025-08-07 , claude-sonnet-4-5-20250929 , claude-haiku-4-5-20251001 , llama-4-maverick-17b-128e-instruct , and llama-4-scout-17b-16e-instruct . Study 1: Stated. In replicating the Stated experiment, we find that only gpt-5 has a significant human-algorithm trust g ap by a one-sample t-test ( p = . 04 ) in the direction of algorithm appreciation; all other models a verage across tasks to ha ve no significant gaps. See Figure F .1 for a recreation of Figure 1 . While the gaps between the raw trust ratings are largely neutral, we find that the winrate of choosing the algorithm is now significantly higher than chance by a binomial test with p < 0 . 001 for all models (see a visualization via the stated bars in Figure F .3 ). While the underlying cause of this change cannot be pinpointed within the scope of our study , we suggest that it may be a combination 20 gpt-5-mini gpt-5 llama-4-scout llama-4-maverick claude-4-haik u claude-4-sonnet 20 10 0 10 20 30 40 50 Human- Algorithm T rust Gap 0.49 -4.14 -1.71 -3.62 -0.68 -3.29 Algorithm Appreciation Algorithm Aversion Figure F .1: Replication of the Study 1 results in Figure 1 with ne wer models from OpenAI, Anthropic, and Meta in 2026. of underlying changes to the models’ reasoning abilities and the shift in training data representing people’ s views to wards algorithms and AI, which has been gro wing in fa vourability in recent years [ Cheng et al. , 2025 ]. The relativ e complexity of the models still correlates with their degree of algorithm av ersion. Similar to what we find in the main results, the smaller models are more likely to be algorithmically averse by a W ilcoxon signed-rank test ( Z = − 4 . 97 , p < 0 . 001 ) with an effect size of r = − 0 . 55 from smaller to larger models. Study 2: Revealed. W e ran Study 2 with the updated models and found noticeable differences in the rev ealed preferences of the LLMs from their 2024 versions. W e recreate Figure 2 in Figure F .2 using contemporary LLMs, from which it is evident that the algorithm-appreciative behavior across the LLM families appear more infrequently than before. This is reinforced by the new re gression results presented in T able F .1 , which uses the same specification as in Study 2 but on the responses from the newer models. The coefficient for the strong algorithm , i.e. x alg , is positiv e at β = 1 . 46 but falls just abov e the 0 . 05 significance threshold, suggesting that algorithm appreciation is likely still detectable across many trials. Furthermore, LLM complexity is again correlated with the probability of correctly betting on the stronger predictor ( β = 0 . 66 , p = 0 . 02 ), reinforcing the capabilities of larger models. Howe ver , the clear difference is that the intercept ( β = 2 . 65 ) represents a clear shift from that of the first regression ( β = − 0 . 78 ), suggesting that as a whole LLMs ha ve improv ed between mid 2024 and January 2026 at the mathematical task of inferring the more accurate predictor from demonstrated examples. A i r p o r t s H e a r t S t u d e n t s C r i m e D a t i n g M o v i e s 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C h o i c e P r o b a b i l i t y C h o i c e H u m a n N e u t r a l A l g o r i t h m Figure F .2: Updated Figure 2 with ne wer models from OpenAI, Anthropic, and Meta in 2026. 21 T able F .1: Updated regression from T able 1 using responses from newer models in 2026. V ariable Coefficient p -V alue Intercept β = 2 . 65 p < 0 . 001 Strong Algorithm β = 1 . 46 p = 0 . 06 Complex LLM β = 0 . 66 p = 0 . 02 Interaction β = 0 . 67 p = 0 . 33 Stated-Revealed Comparison. Figure F .3 compares the updated Study 1 and 2 results for the stated- rev ealed algorithm av ersion gap. Overall, models are stating much mor e pr efer ence and r evealing slightly less pr efer ence to wards algorithms as compared to before. These shifts have resulted in the stated-r evealed relative risk of trusting a human RR sr = P ( human | stated ) /P ( human | r ev eal ed ) to shift to wards stating algorithm appreciation relati vely more than re vealing, which is opposite to the effect we found pre viously . W e find that RR sr < 1 for all models, most with p < 0 . 01 except claude-4-haiku and llama-4-scout . Nonetheless, tracking pre vious results in Section 4.3 , the less complex model in each family has a greater RR sr than the more complex model, indicating that model complexity may be correlated with more stated algorithm appreciation. gpt-5-mini gpt-5 llama-4-scout llama-4-maverick claude-4-haik u claude-4-sonnet 0% 20% 40% 60% 80% 100% P ick Human Expert (%) Algorithm Aversion Algorithm Appreciation Stated R evealed Figure F .3: Replication of the stated-re vealed comparison results in Figure 4 with ne wer models. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment