Semantic Partial Grounding via LLMs
Grounding is a critical step in classical planning, yet it often becomes a computational bottleneck due to the exponential growth in grounded actions and atoms as task size increases. Recent advances in partial grounding have addressed this challenge…
Authors: Giuseppe Canonaco, Alberto Pozanco, Daniel Borrajo
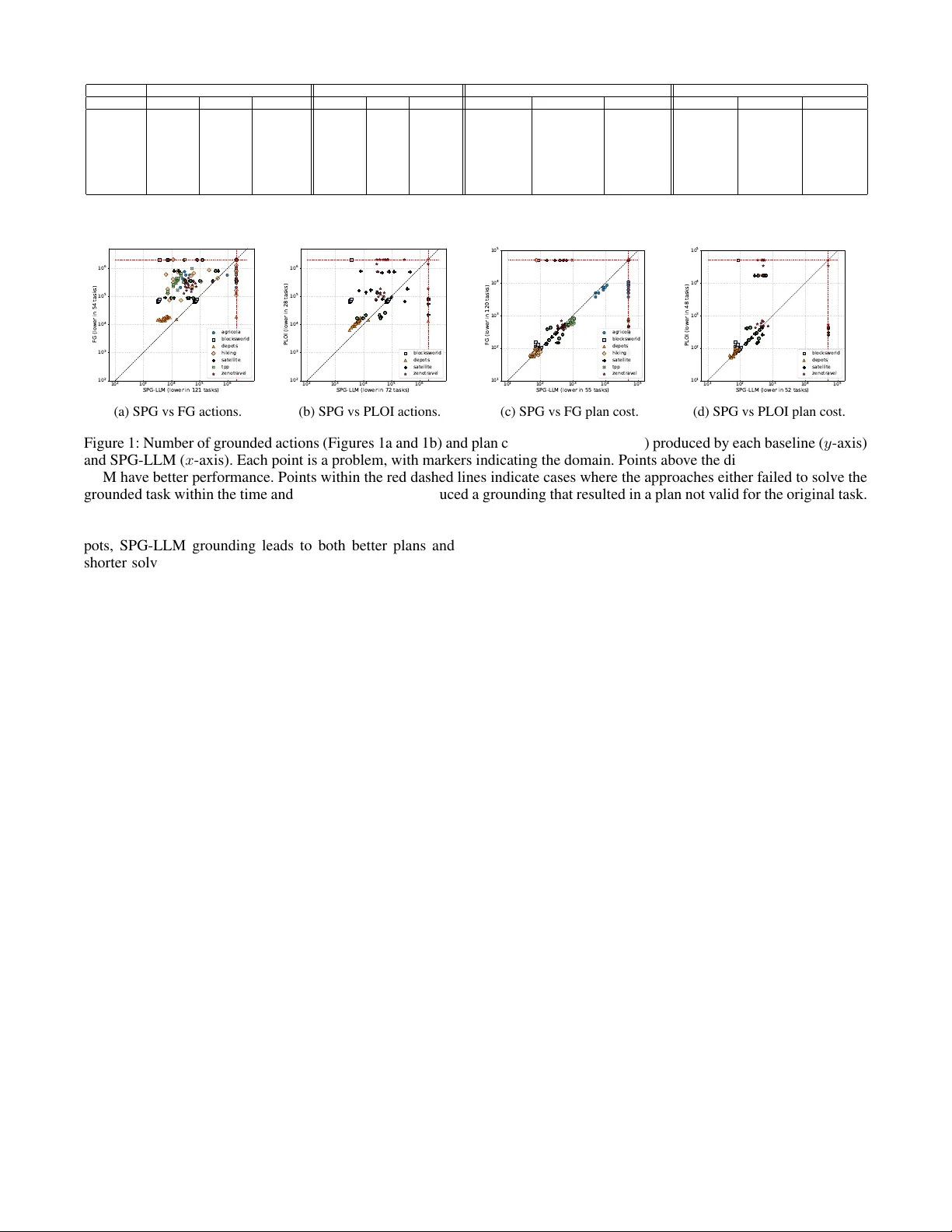
Semantic Partial Gr ounding via LLMs Giuseppe Canonaco * 1 , Alberto Pozanco * 1 , Daniel Borrajo 1 1 JPMorgan Chase & Co. AI Research giuseppe.canonaco@jpmorgan.com, alberto.pozancolancho@jpmor gan.com, daniel.borrajo@jpmchase.com Abstract Grounding is a critical step in classical planning, yet it often becomes a computational bottleneck due to the exponential growth in grounded actions and atoms as task size increases. Recent advances in partial grounding ha ve addressed this challenge by incrementally grounding only the most promis- ing operators, guided by predicti ve models. Howe ver , these approaches primarily rely on relational features or learned embeddings and do not leverage the textual and structural cues present in PDDL descriptions. W e propose SPG-LLM, which uses LLMs to analyze the domain and problem files to heuristically identify potentially irrelev ant objects, actions, and predicates prior to grounding, significantly reducing the size of the grounded task. Across seven hard-to-ground benchmarks, SPG-LLM achie ves faster grounding—often by orders of magnitude—while delivering comparable or better plan costs in some domains. 1 Introduction Domain-independent planning requires the world to be de- scribed using an appropriate representation language. In classical planning, a common such language is the Planning Domain Definition Language (PDDL) (Haslum et al. 2019), a first-order logic-based language designed to standardize research in planning. W ith some notable exceptions (Corr ˆ ea et al. 2020), most current planners ground the first-order representation of the problem into a propositional encoding as a preprocessing step. While this enables efficient implementation of heuris- tic and search algorithms, grounding can become impracti- cal for large planning problems, as the size of the grounded task grows e xponentially with the number of parameters in the predicates and actions of the planning domain. In order to retain the advantages of grounded representations while mitigating the grounding bottleneck, recent literature has proposed addressing large planning instances through par- tial gr ounding . This technique inv olves grounding only the parts of the planning task that are deemed necessary to find a plan, rather than grounding the entire task. The approach is sound—if a plan is found for the partially grounded task, it is a v alid plan for the original task—b ut incomplete, as the partially grounded task is only solvable if the operators in at least one plan hav e been grounded. * These authors contributed equally . Most partial grounding approaches train predictiv e mod- els that determine when an operator will be needed to solv e a planning task. In Gnad et al. (2019), the authors use small planning tasks as a training set to e xtract relational rules as features, and then apply simple machine learning models to predict whether an operator should be grounded. These predictiv e models are trained of fline for each domain, rely- ing only on the initial and goal descriptions to estimate the likelihood that a plan will include a giv en operator . In con- trast, Areces et al. (2023) also utilize intermediate informa- tion from the relax ed planning graph and employ small lan- guage models (word embeddings) as predictors. Instead of prioritizing certain operators during grounding, Silver et al. (2021) introduce a con volutional graph neural network ar- chitecture to predict the subset of objects suf ficient for solv- ing a planning problem. This approach of fers two main ad- vantages over Gnad et al. (2019) and Areces et al. (2023). First, by operating at the task level, it allows the planner’ s grounding step to be treated as a black box, whereas the other methods require modifications to the planner’ s ground- ing process. Second, by operating at the object lev el rather than over grounded action instances, it enjoys a computa- tional advantage, as the object set is typically far smaller than the combinatorial space of grounded actions. In this paper , we also adopt a task-lev el approach and lev erage recent adv ances in Large Language Models (LLMs) to identify not only potentially irrelev ant objects, but also actions and predicates before grounding. LLMs hav e been successfully used to prune the state space in robotic tasks (P ´ erez-Dattari et al. 2025). W e argue that many planning tasks specified in PDDL contain enough detail to provide rich semantic information, which LLMs can lev er- age to heuristically identify the sub-components of the task that are relev ant for finding a plan. Although this approach does not offer guarantees of completeness or soundness, it can be effecti ve in practice for grounding and solving large planning tasks that possess semantic structure e xposed in the PDDL files. For instance, in the context of a cooking domain we may hav e a very deep and wide taxonomy of ingredients like: seafood , meat , ve getable , and dairy , with many objects of each type. W e will have plenty of dif ferent actions like: chop ; slice ; boil ; mix ; and r oast . Howe ver , when it comes to finding the plan to accomplish a certain goal represent- ing a recipe like cooking a T agliatelle alla Bolognese , we may take advantage of the common knowledge exposed in the goal and preemptively remove from the problem all the objects that are under the seafood category , as well as all the r oast actions. This will result in less actions to be grounded because of the fe wer amount of objects and action schemas present in the problem. The remainder of the paper is organized as follo ws. First, we formalize planning tasks and explain ho w they are de- scribed and grounded. Next, we present SPG-LLM, our se- mantic partial grounding approach designed to reduce the number of objects, predicates, and actions in a planning task. W e then ev aluate SPG-LLM against sev eral baselines for grounding and solving planning tasks across different do- mains. Finally , we conclude by discussing the main findings and outlining potential directions for future research. 2 Background A STRIPS planning task is a tuple Π = ⟨P , O , A , s 0 , G ⟩ , where P is a set of pr edicates , O is a set of objects , A is a set of action schemas , s 0 is the initial state , and G is a goal condition . Predicates p ∈ P have an associated arity . If p is an n -ary predicate and t = ⟨ t 1 , . . . , t n ⟩ is a tuple of objects from O , then p ( t ) is an atom . By gr ounding the variables in an atom p ( t ) —that is, substituting them with ob- jects from O —we obtain a gr ound atom . A state , such as s 0 , is the set of ground atoms that are true at that moment. Sim- ilarly , the goal condition G is the set of ground atoms that must be true in a goal state. An action schema a [∆] ∈ A is a tuple ⟨ P R E ( a [∆]) , A D D ( a [∆]) , D E L ( a [∆]) , C O S T ( a [∆]) ⟩ , which specifies the precondition , the add list , delete list , and cost of a [∆] . The cost is a non-negati ve real number R 0 , while the other three components are finite sets of atoms defined over P . Here, ∆ refers to the set of free variables present in any atom within these components. By gr ound- ing an action schema a [∆] —substituting its free variables ∆ with objects from O —we obtain a gr ound action a , or simply an action . An action a is applicable in a state s if P R E ( a ) ⊆ s . W e define the result of applying an ac- tion in a state as γ ( s, a ) = ( s \ D E L ( a )) ∪ A D D ( a ) . A sequence of actions π = ( a 1 , . . . , a n ) is applicable in a state s 0 if there are states ( s 1 . . . . , s n ) such that a i is ap- plicable in s i − 1 and s i = γ ( s i − 1 , a i ) . The resulting state after applying a sequence of actions is Γ( s, π ) = s n , and C O S T ( π ) = P n i C O S T ( a i ) denotes the cost of π . The solu- tion to a planning task Π is a plan , i.e., a sequence of actions π such that G ⊆ Γ( s 0 , π ) . Planning tasks are described in PDDL (Haslum et al. 2019) by dividing the task definition into two files. The do- main , denoted as D , specifies the set of object types, the predicates P , and the action schemas A . The problem , de- noted as P , defines the set of objects O for the task, the initial state s 0 , and the goal condition G . 3 Proposed A ppr oach In this section, we will focus on ho w to prune P , A , and O with the aim of speeding up the grounding phase, a notorious Algorithm 1: SPG-LLM 1: Input: D , P , Φ the prompt template, and K the maxi- mum number of attempts 2: Output: D ′ , P ′ 3: φ = format( Φ , D , P ) 4: D ′ , P ′ = LLM( φ ) 5: if validate ( D ′ , P ′ , D , P , Φ , φ ) then 6: retur n D ′ , P ′ 7: end if 8: f or k=1 to K-1 do 9: D ′ , P ′ = LLM( φ ) 10: if v alidate ( D ′ , P ′ , D , P , Φ , φ ) then 11: retur n D ′ , P ′ 12: end if 13: end for 14: retur n ∅ , ∅ bottleneck for planning engines. W e will do so by le veraging the semantics intrinsic to the domain and problem files. This semantic analysis is performed by an LLM, which lev erages cues in the PDDL domain and problem descrip- tions to heuristically identify and propose pruning of objects, predicates, and actions that are unlikely to be required for the goal. It is important to note that pruning an object from O requires a consistent update to the initial state, specifi- cally by removing all atoms that inv olve the pruned object. This approach works at the task lev el, prior to grounding, hence it is complementary to the partial grounding solu- tions of Areces et al. (2023) and Gnad et al. (2019), as well as to deterministic approaches to eliminate irrele vant facts and operators from grounded tasks (Nebel, Dimopoulos, and K oehler 1997; Haslum, Helmert, and Jonsson 2013; T orralba and Kissmann 2015). In Algorithm 1, we have reported the pseudo-code d e- scribing our solution called Semantic P artial Gr ounding via LLM (SPG-LLM). In Line 3, we format the prompt to feed the LLM with the domain and problem descriptions. This is done by substituting the mentioned domain and problem descriptions placeholders in the prompt template with their actual descriptions via the format function. Once the prompt is ready , in Line 4, we call the LLM. Soon after , in Line 5, we v alidate the pruned domain and problem. This v alidation is performed at 3 different le vels: syntactic, computational, and semantic. Syntactic v alidation identifies errors related to output formatting and PDDL syntax compliance. Computa- tional validation assesses whether a plan can be generated within a predefined time bound. This is done to verify that the reformulated task is solv able. Semantic v alidation veri- fies that the relationships P ′ ⊆ P , A ′ ⊆ A , O ′ ⊆ O (this entails s ′ 0 ⊆ s 0 ), and G ′ ≡ G are correctly maintained. This serves only as a soundness proxy to ensure that the LLM is not hallucinating objects or actions, rather than pro viding a soundness guarantee. Plans that solve the reformulated task may still not be valid solutions for the original task. If valida- tion fails, the prompt template is populated with the original task description ( D and P ), the LLM-generated output ( D ′ and P ′ ), and a description of the identified error to f acilitate correction in subsequent LLM interactions. The formatted prompt is stored into the v ariable φ . If no errors are detected during v alidation, as indicated in Line 6, the process termi- nates. Otherwise, the procedure is retried up to K − 1 addi- tional times. The prompt template Φ employed to leverage common knowledge from LLMs for task simplification is presented in Appendix A. 4 Evaluation Experimental Setting Benchmark. T o ev aluate the performance of SPG-LLM, we selected a div erse set of planning domains: Agricola , Blocksworld , Depots , Hiking , Satellite , TPP , and Zeno- travel . These domains are the same as those used by Areces et al. (2023). For each domain, we e valuate the v arious ap- proaches on a fixed set of 25 randomly selected tasks from their ev aluation set. This evaluation set comprises hard to ground planning problems specifically designed to assess the effecti veness of partial grounding techniques. W e chose this benchmark over other hard-to-ground benchmarks (Lauer et al. 2021) because we wanted the tasks to be challeng- ing, yet sufficiently small to allo w grounding and solving within reasonable time and memory limits using standard planners. This selection enables us to assess not only the grounding capabilities of SPG-LLM, but also how its task reductions impact the performance of state-of-the-art plan- ners when solving these tasks. Appr oaches. W e compare SPG-LLM against Full Grounding (FG) (Helmert 2009) and Planning with Learned Object Importance (PLOI) (Silver et al. 2021). FG serv es as a simple baseline, instantiating all facts and operators that are delete-free reachable from the initial state (Hoffmann 2003). PLOI leverages a graph neural network to prioritize the objects to be included in the problem. The approach of Silver et al. (2021) was selected over those proposed by Gnad et al. (2019) and Areces et al. (2023), as it operates at the task lev el, thus being the most closely related tech- nique to our work in the literature. PLOI was trained with the following parameters ov er 3 random seeds per domain: 200 iterations, 120 seconds timeout, 100 training problems, with incremental planning to generate the proposed pruned problem, and the first iteration of LAMA (Richter and W estphal 2010) to collect training data. W e restrict our ev aluation of PLOI to domains containing predicates of arity two or less, reflecting a current limitation of the method. SPG-LLM has been run with K = 1 and GPT -5-2025-08-07 ( verbosity=”medium” and r easoning effort=”medium” ) as LLM model. Metrics. W e report the following metrics, where lower values indicate better performance: grounding time (in sec- onds) and the number of grounded actions; solving time (in seconds), and the plan cost for the best plan found by LAMA within the specified limits. Using optimal planners was not feasible in the context of these problems due to their size. W e verify that all the plans generated by solving the differ - ent reformulated tasks are sound wrt. the original task by using V AL (Howe y , Long, and Fox 2004). Reproducibility . SPG-LLM and PLOI have been run on mac OS Sequoia using an 8 cores Apple M2 processor and 24 GB of RAM to generate the reformulated (pruned) tasks. All the tasks have then been solved running LAMA on an Intel Xeon E5-2666 v3 CPU @ 2.90GHz x 8 processors with a 8GB memory bound and a time limit of 1800s. Results Grounding Results. Our first analysis aim to understand whether SPG-LLM improves grounding by generating a lower number of operators and reducing the grounding time. Figures 1a and 1b present the number of actions grounded by SPG-LLM in tasks that are both solvable and sound, in com- parison to FG and PLOI, respectively . SPG-LLM outper- forms both baselines by grounding fewer operators in most tasks, achie ving reductions of up to two orders of magnitude. Although consistent across domains, we can identify some peculiar patterns that are worth discussing. In Blocksworld, we may see two groups of results: one of them lying on the bisector , and the other above it. This is due to the fact that SPG-LLM lea ves all the problem files unchanged and re- mov es a superfluous action, move-b-to-b , from the domain in 10 out of 25 tasks. This action schema moves one clear block onto another, but it is superfluous because the same effect can be achiev ed using the other two action schemas: first moving clear blocks to the table, and then from the table onto clear blocks. Another pattern that can be clearly noticed is the fact that, in Depots, SPG-LLM is able to provide a smaller improvement w .r .t. other domains like Satellite. This is due to the fact that in Depots our approach can remo ve a smaller proportion of objects w .r .t. Satellite where there are more irrelev ant objects. Overall, the reduction in grounded operators achieved by SPG-LLM is reflected in the ground- ing times shown in T able 1, where SPG-LLM is the fastest approach across the commonly solv ed tasks in all domains. These benefits come with a trade-off, as SPG-LLM produces 36 tasks out of the 175 in the benchmark that cannot be solved to yield valid plans for the original task. The num- ber of in v alid tasks varies by domain; for e xample, in Agri- cola, SPG-LLM generates only 8 tasks where sound plans can be computed, while in Blocksw orld, all tasks grounded by SPG-LLM are valid. Solving Results. Our second analysis aims to asses the impact on performance the reformulated tasks have com- pared to solving the original task. Regarding coverage, FG is able to generate valid plans for the original task within the time and memory limits in 161 out of 175 tasks, com- pared to 139 out of 175 tasks for SPG-LLM, and 90 out of 100 tasks for PLOI. Figures 1c and 1d sho w the lowest plan cost achie ved by LAMA when solving tasks generated by SPG-LLM, compared to those generated by FG and PLOI, respectiv ely . In this case, the results vary depending on the domain. In domains such as Agricola, Satellite, and Zeno- trav el, FG and SPG-LLM produce plans of similar qual- ity . Ho we ver , in Agricola, SPG-LLM’ s grounding appears to negati vely impact search time, while search times are com- parable in Satellite and significantly faster for SPG-LLM’ s reformulated tasks in Zenotravel. In Blocksworld and De- Grounded Actions Grounding Time Plan Cost Solving Time Domain (#T asks) FG PLOI SPG FG PLOI SPG FG PLOI SPG FG PLOI SPG Agricola (8) 678 k ± 324 k - 146 k ± 329 k 103 . 0 ± 51 . 2 - 22 . 0 ± 51 . 5 7752 . 1 ± 2216 . 7 - 7752 . 5 ± 2217 . 4 156 . 7 ± 84 . 3 - 251 . 3 ± 555 . 3 Blocksworld (24) 72 k ± 5 k 72 k ± 5 k 46 k ± 34 k 7 . 8 ± 0 . 6 7 . 7 ± 0 . 6 4 . 8 ± 3 . 6 94 . 9 ± 17 . 4 95 . 2 ± 17 . 3 82 . 5 ± 10 . 5 704 . 7 ± 522 . 2 693 . 2 ± 507 . 3 396 . 2 ± 516 . 1 Depots (24) 16 k ± 1 k 11 k ± 2 k 6 k ± 2 k 2 . 2 ± 0 . 3 1 . 5 ± 0 . 3 0 . 8 ± 0 . 3 74 . 1 ± 15 . 3 71 . 6 ± 14 . 7 66 . 5 ± 11 . 3 192 . 0 ± 349 . 2 338 . 1 ± 472 . 0 158 . 2 ± 271 . 2 Hiking (15) 420 k ± 263 k - 69 k ± 116 k 67 . 3 ± 43 . 8 - 10 . 1 ± 18 . 2 69 . 9 ± 5 . 1 - 76 . 4 ± 12 . 0 288 . 8 ± 438 . 7 - 337 . 0 ± 445 . 4 Satellite (17) 327 k ± 262 k 142 k ± 224 k 91 k ± 135 k 20 . 4 ± 16 . 2 4 . 7 ± 3 . 7 5 . 3 ± 8 . 1 283 . 2 ± 124 . 6 2220 . 3 ± 5548 . 4 291 . 8 ± 123 . 5 244 . 5 ± 358 . 0 136 . 3 ± 220 . 9 179 . 3 ± 410 . 1 TPP (22) 385 k ± 199 k - 17 k ± 9 k 42 . 0 ± 21 . 6 - 1 . 9 ± 0 . 9 623 . 9 ± 124 . 3 - 850 . 0 ± 168 . 0 695 . 7 ± 440 . 8 - 27 . 8 ± 40 . 1 Zenotravel (12) 243 k ± 110 k 377 k ± 506 k 48 k ± 17 k 19 . 1 ± 8 . 9 8 . 4 ± 2 . 8 3 . 1 ± 1 . 2 457 . 0 ± 91 . 1 7389 . 6 ± 13090 . 9 493 . 2 ± 102 . 5 1154 . 2 ± 503 . 8 719 . 0 ± 660 . 0 371 . 3 ± 353 . 1 T able 1: Results of the three approaches across commonly solved tasks in the benchmark. Best performance in bold. 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 SPG-LLM (lower in 121 tasks) 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 FG (lower in 54 tasks) agricola blocksworld depots hiking satellite tpp zenotravel (a) SPG vs FG actions. 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 SPG-LLM (lower in 72 tasks) 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 PL OI (lower in 28 tasks) blocksworld depots satellite zenotravel (b) SPG vs PLOI actions. 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 SPG-LLM (lower in 55 tasks) 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 FG (lower in 120 tasks) agricola blocksworld depots hiking satellite tpp zenotravel (c) SPG vs FG plan cost. 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 SPG-LLM (lower in 52 tasks) 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 PL OI (lower in 48 tasks) blocksworld depots satellite zenotravel (d) SPG vs PLOI plan cost. Figure 1: Number of grounded actions (Figures 1a and 1b) and plan cost (Figures 1c and 1d) produced by each baseline ( y -axis) and SPG-LLM ( x -axis). Each point is a problem, with markers indicating the domain. Points abov e the diagonal indicate SPG- LLM hav e better performance. Points within the red dashed lines indicate cases where the approaches either failed to solve the grounded task within the time and memory limits, or produced a grounding that resulted in a plan not valid for the original task. pots, SPG-LLM grounding leads to both better plans and shorter solving times. SPG-LLM enables the generation of lower -cost plans because, with a smaller task, LAMA can perform more iterations using algorithms that may find solu- tions closer to optimal. Finally , in Hiking and TPP , FG yields lower -cost plans, but finding them in Hiking is faster , and in TPP , solving the SPG-LLM grounding can be up to two orders of magnitude faster . It is also noteworthy that SPG- LLM grounding enables LAMA to find plans for 10 tasks that cannot be solved using the standard FG grounding. T aking a more qualitati ve perspective, we analyzed prob- lems in Zenotrav el and found that our approach identifies the zoom action schema as irrele vant, since it is simply a faster variant of fly that consumes more fuel. Additionally , SPG-LLM simplifies the problems by removing objects. For one of the instances, it remov es 3 persons, namely person 5 , person 14 , and person 33 that are not in volved in the goal, hence they do not need to be transported. It also reduces the number of aircraft objects from 24 to 11, and the fuel lev- els from 7 to 2. All these changes may result in longer plans because fe wer resources are av ailable, requiring actions lik e r efuel to be used more frequently . Howe ver , this grounding in Zenotrav el enables, on av erage, a reduction of one order of magnitude in both grounding and solving time, while only increasing the av erage plan cost from 457 . 0 to 493 . 2 . 5 Conclusions and Future W ork In this paper , we introduced SPG-LLM, a pre-grounding, task-lev el approach that uses an LLM to analyze the PDDL domain and problem files and heuristically prune objects, ac- tion schemas, and predicates, followed by syntactic, compu- tational, and semantic checks. Across seven hard-to-ground benchmarks, SPG-LLM consistently reduces the number of grounded operators and achieves the fastest grounding times relativ e to FG and PLOI on commonly solved tasks. This happens with domain-dependent trade-offs in plan cost and ov erall coverage. In future work we would like to enhance SPG-LLM by improving the validation checks, incorporating soundness checks for a subset of the plans allowed in the reformu- lated task. This should lead to an increase in the number of reformulated tasks for which planners can generate plans that are valid in the original task. W e also plan to inv esti- gate the generation of explanations (Chakraborti, Sreedha- ran, and Kambhampati 2020) based on the task reformula- tions suggested by SPG-LLM, to better understand the rea- soning behind pruning specific objects or actions. Finally , we would like to experiment with real-world domains that hav e richer semantics, such as the one described in the in- troduction. In these domains, we anticipate e ven greater per - formance improv ements. Disclaimer This paper was prepared for informational purposes by the Artificial Intelligence Research group of JPMorgan Chase & Co. and its affiliates (”JP Morgan”) and is not a product of the Research Department of JP Morgan. JP Morgan makes no representation and warranty whatsoe ver and disclaims all liability , for the completeness, accuracy or reliability of the information contained herein. This document is not intended as in vestment research or inv estment advice, or a recommen- dation, offer or solicitation for the purchase or sale of any se- curity , financial instrument, financial product or service, or to be used in an y way for ev aluating the merits of participat- ing in an y transaction, and shall not constitute a solicitation under any jurisdiction or to any person, if such solicitation under such jurisdiction or to such person would be unlawful. © 2024 JPMorgan Chase & Co. All rights reserv ed. References Areces, F .; Ocampo, B.; Areces, C.; Domınguez, M.; and Gnad, D. 2023. P artial grounding in planning using small language models. In ICAPS 2023 W orkshop on Knowledg e Engineering for Planning and Scheduling . Chakraborti, T .; Sreedharan, S.; and Kambhampati, S. 2020. The emerging landscape of e xplainable automated planning & decision making. In 29th International Joint Conference on Artificial Intelligence, IJCAI 2020 , 4803–4811. Interna- tional Joint Conferences on Artificial Intelligence. Corr ˆ ea, A. B.; Pommerening, F .; Helmert, M.; and Frances, G. 2020. Lifted successor generation using query optimiza- tion techniques. In Pr oceedings of the International Con- fer ence on Automated Planning and Sc heduling , volume 30, 80–89. Gnad, D.; T orralba, A.; Dom ´ ınguez, M.; Areces, C.; and Bustos, F . 2019. Learning ho w to ground a plan–partial grounding in classical planning. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , volume 33, 7602– 7609. Haslum, P .; Helmert, M.; and Jonsson, A. 2013. Safe, strong, and tractable relev ance analysis for planning. In Pr oceed- ings of the International Confer ence on A utomated Planning and Scheduling , v olume 23, 317–321. Haslum, P .; Lipovetzky , N.; Magazzeni, D.; Muise, C.; Brachman, R.; Rossi, F .; and Stone, P . 2019. An intr oduc- tion to the planning domain definition language , volume 13. Springer . Helmert, M. 2009. Concise finite-domain representations for PDDL planning tasks. Artificial Intelligence , 173(5-6): 503–535. Hoffmann, J. 2003. The Metric-FF Planning System: T rans- lating“Ignoring Delete Lists”to Numeric State V ariables. Journal of artificial intellig ence r esear ch , 20: 291–341. Howe y , R.; Long, D.; and Fox, M. 2004. V AL: Automatic plan validation, continuous effects and mixed initiativ e plan- ning using PDDL. In 16th IEEE International Conference on T ools with Artificial Intelligence , 294–301. IEEE. Lauer , P .; T orralba, A.; Fi ˇ ser , D.; H ¨ oller , D.; Wichlacz, J.; and Hoffmann, J. 2021. Polynomial-time in PDDL input size: Making the delete relaxation feasible for lifted plan- ning. In ICAPS 2021 W orkshop on Heuristics and Searc h for Domain-independent Planning . Nebel, B.; Dimopoulos, Y .; and K oehler , J. 1997. Ignoring irrelev ant facts and operators in plan generation. In Eur o- pean Confer ence on Planning , 338–350. Springer . P ´ erez-Dattari, R.; Li, Z.; Bab u ˇ ska, R.; Kober , J.; and Della Santina, C. 2025. Scalable T ask Planning via Large Language Models and Structured W orld Representations. Advanced Robotics Resear ch , e202500002. Richter , S.; and W estphal, M. 2010. The LAMA planner: Guiding cost-based anytime planning with landmarks. Jour - nal of Artificial Intelligence Resear ch , 39: 127–177. Silver , T .; Chitnis, R.; Curtis, A.; T enenbaum, J. B.; Lozano- P ´ erez, T .; and Kaelbling, L. P . 2021. Planning with learned object importance in large problem instances using graph neural networks. In Pr oceedings of the AAAI confer ence on artificial intelligence , v olume 35, 11962–11971. T orralba, A.; and Kissmann, P . 2015. Focusing on what re- ally matters: Irrelev ance pruning in merge-and-shrink. In Pr oceedings of the International Symposium on Combinato- rial Sear ch , v olume 6, 122–130. A Prompt T emplate The template prompt Φ , presented in Listing 1, is structured in the following way . The first part instructs the LLM about what it has to do. Then we provide an example to further clarify the task it has to accomplish. The example is re- mov ed for conciseness. Howe ver , in a nutshell, it reports an example of a domain and problem we want to prune. The pruned domain with the rationale that allowed the pruning. The pruned problem with what we kept and the reason why we kept it, and analogously for what we removed. Finally , the domain and problem the LLM is supposed to work on. Listing 1: Prompt T emplate You are a PDDL expert and you will help me out simplifying a planning task according to the goal we have to achieve in the planning task itself. The simplification will revolve around objects removal from the problem.pddl file and actions and predicates from the domain.pddl file. The objects removal can be done analyzing the hierarchy of objects types and then selecting the objects (or types of objects) to be removed because not necessary in the achievement of the goal. The predicates that can be removed are as well the ones that are not necessary to achieve the goal. Be careful about the interplay between actions, predicates, and goal to understand what can be removed and what not. The goal cannot be modified. So all the objects and predicates present in the goal cannot be removed. Let me further elucidate with an example: Domain Original Problem New Domain: Reason: Simplified Problem: Removed: Kept: This is the domain we are going to operate on: This is the problem: Please output only the modified files ready to be fed to a planner.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment