DualWeaver: Synergistic Feature Weaving Surrogates for Multivariate Forecasting with Univariate Time Series Foundation Models
Time-series foundation models (TSFMs) have achieved strong univariate forecasting through large-scale pre-training, yet effectively extending this success to multivariate forecasting remains challenging. To address this, we propose DualWeaver, a nove…
Authors: Jinpeng Li, Zhongyi Pei, Huaze Xue
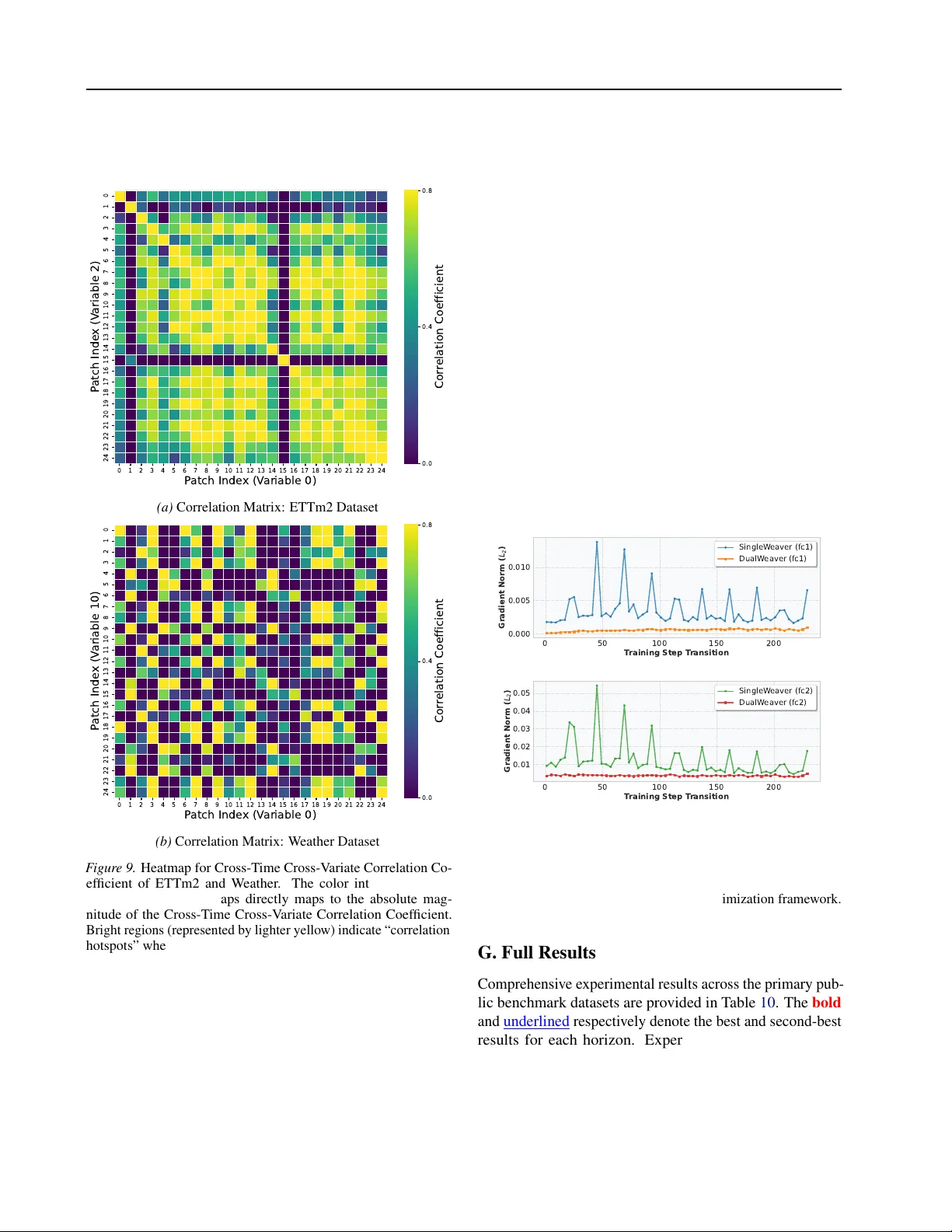
DualW ea ver: Synergistic F eatur e W ea ving Surr ogates f or Multivariate F or ecasting with Univariate T ime Series F oundation Models Jinpeng Li * 1 Zhongyi Pei * 1 Huaze Xue 1 Bojian Zheng 2 Chen W ang 1 Jianmin W ang 1 Abstract T ime-series foundation models (TSFMs) ha ve achiev ed strong univ ariate forecasting through large-scale pre-training, yet effecti vely extend- ing this success to multiv ariate forecasting re- mains challenging. T o address this, we pro- pose DualW eaver , a nov el framework that adapts univ ariate TSFMs (Uni-TSFMs) for multi vari- ate forecasting by using a pair of learnable, structurally symmetric surrogate series. Gener- ated by a shared auxiliary feature-fusion mod- ule that captures cross-variable dependencies, these surrogates are mapped to TSFM-compatible series via the forecasting objectiv e. The sym- metric structure enables parameter-free recon- struction of final predictions directly from the surrogates, without additional parametric decod- ing. A theoretically grounded re gularization term is further introduced to enhance rob ustness against adaptation collapse. Extensiv e experi- ments on div erse real-world datasets show that DualW eaver outperforms state-of-the-art multi- variate forecasters in both accuracy and stabil- ity . W e release the code at https://github. com/li- jinpeng/DualWeaver . 1. Introduction Deep learning models hav e achiev ed remarkable success in div erse domains such as natural language processing (NLP) ( Otter et al. , 2020 ), computer vision (CV) ( V oulodimos et al. , 2018 ), and recommendation systems ( Da’u & Salim , 2020 ). Their ability to capture complex dependencies has also made them highly effecti ve for time series analysis, surpassing traditional statistical methods ( W u et al. , 2022 ; Zeng et al. , 2023 ; Liu et al. , 2023b ). In particular , Transformer models hav e been successfully adapted for time series ( Liu et al. , 2023a ; Nie et al. , 2022 ; W ang et al. , 2024b ). Their attention mechanism enables selectiv e focus on different parts of the 1 School of Software, BNRist, Tsinghua Univ ersity . 2 T encent. Correspondence to: Zhongyi Pei < peizhyi@tsinghua.edu.cn > . Pr eprint. F ebruary 26, 2026. input sequence, enabling flexible discovery of both temporal and cross-variable dependencies. Howe ver , the potential of deep learning for time series fore- casting is often limited by data sparsity . This challenge has been partially addressed by the emergence of lar ge univ ari- ate time series foundation models (Uni-TSFMs) ( Ansari et al. , 2024 ; Liu et al. , 2024d ; 2025 ). Pre-trained on massiv e datasets, these models exhibit strong zero-shot forecasting capabilities. They can be ef fecti vely adapted to downstream tasks by fine-tuning (updating a subset or all parameters), lev eraging broad temporal kno wledge while remaining ro- bust with limited data ( Y e et al. , 2024 ; Liang et al. , 2024 ). A ke y limitation of Uni-TSFMs, howe ver , emerges in mul- tiv ariate forecasting. In practice, variables from the same source are often inherently correlated, suggesting that mod- eling these dependencies should yield better performance than uni variate (channel-independent) forecasting (we use channel interchangeably with v ariable, follo wing previous work). Ne vertheless, due to the architectural constraints for univ ariate temporal dynamics, Uni-TSFMs fundamentally ov erlook these crucial cross-variable dependencies ( Mar - coni , 2025 ; Feng et al. , 2024 ; Benechehab et al. , 2025 ). Sev eral recent studies ha ve focused on modeling multi- variate time series with TSFMs ( Ekambaram et al. , 2024 ; Liu et al. , 2024b ; Benechehab et al. , 2025 ). Channel- independent fine-tuning serves as a primary method for adapting TSFMs to specific target scenarios, whereas cross- variable dependencies are ignored. As a novel paradigm, AdaPTS ( Benechehab et al. , 2025 ) introduces additional modules to capture cross-variable dependencies for a giv en vanilla or finetuned Uni-TSFM. It employs encoder - decoder adaptation , in which the encoder first transforms original variables into a sequence of latent v ariables and the decoder generates final predictions based on these latent variables’ predictions. Howe ver , a key challenge remains: much of the adaptation capacity is consumed by reconstruct- ing the real predictions from the latent v ariables, rather than by learning prediction-friendly cross-variable dependencies. T o address this, we propose the DualW eav er framework, which lev erages a pair of dual surrogates to explicitly model cross-variable dependencies without relying on para- 1 DualW eaver: Syner gistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM metric reconstructions. Comparisons of the three paradigms are illustrated in Figure 1 . (a) Channel-independent (b) Encoder-Decoder (c) Dual-tuned Surrogates F igur e 1. The paradigms adapting Uni-TSFM for multiv ariate forecasting. (a) Channel-independent: each variable is processed separately by Uni-TSFMs, ignoring cross-v ariable dependencies. (b) Encoder-Decoder: an encoder maps original variables to latent representations, whose predictions are then decoded back; the decoding may mislead the adaptation. (c) Dual-tuned Surrogates (ours): a shared feature-fusion module generates dual surrogates that capture dependencies under distinct optimization directions, reducing ov erfitting and making adaptation more robust. A key design of DualW eaver is its shared feature-fusion module, which learns to fuse information across variables and outputs a pair of surrogate series. These surrogates, as more robust representations of the joint signal, simplify the problem for a Uni-TSFM, enabling accurate and stable re- construction of the final multiv ariate forecasts. The primary contributions of this w ork are: • W e propose a novel adaptation paradigm for Uni- TSFMs, DualW eaver , that employs dual surrogates generated by a shared feature-fusion module to capture cross-variable dependencies and enable robust multi- variate forecasting with gi ven Uni-TSFMs. • W e provide a theoretical analysis of the error bound, which motiv ates the design of a novel regularization term. This term is explicitly formulated to stabilize training and enhance the robustness of the adapted model. • Through extensi ve experiments on di verse benchmarks, we demonstrate that DualW eav er consistently outper- forms state-of-the-art multi variate forecasters in both accuracy and rob ustness. DualW eaver thus establishes a novel paradigm that ef fec- tiv ely unlocks the potential of large pre-trained Uni-TSFMs for complex multiv ariate forecasting, directly addressing the core challenge of adapting po werful TSFMs with minimal cost while preserving their inherent strengths. 2. Related W ork 2.1. Time Series F oundation Models The field of time series forecasting is increasingly lev eraging foundation models (FMs) to achie ve more capable predic- tors ( Ansari et al. , 2024 ; Marconi , 2025 ; Liang et al. , 2024 ). These models are pre-trained on large datasets, which helps address the widespread issue of data sparsity . Address- ing the multiv ariate setting is particularly challenging for TSFMs, primarily due to increased data sparsity and the high complexity of model architecture. T o the best of our knowledge, only a few TSFMs nativ ely support multiv ariate analysis. Moirai ( W oo et al. , 2024 ) in- curs a computational cost due to the simultaneous flattening of all channels, resulting in quadratic memory complex- ity with respect to the number of channels. GTT ( Feng et al. , 2024 ) employs shared-weight attention mechanisms to capture both temporal and cross-v ariable dependencies. Chronos-2 ( Ansari et al. , 2025 ) achie ves unified modeling of both univ ariate and multiv ariate time series through a general-purpose architecture that sequentially applies atten- tion across both the temporal and variate dimensions. Although these TSFMs can achiev e good performance on some multiv ariate forecasting benchmarks, they are typi- cally designed to rely on a specific architecture to handle the compl exity of multi variate time series, which limits their scalability to dynamic patterns in real-world multiv ariate scenarios. Simultaneously , the potential of Uni-TSFMs for multiv ariate forecasting remains underexplored. De- veloping extensible frame works to effecti vely harness the Uni-TSFMs’ powerful uni variate forecasting capabilities for multi variate tasks represents a promising and important research direction. 2.2. Multivariate F orecasting Adapters Fine-tuning is the predominant approach for adapting TSFMs to do wnstream tasks. Ho we ver , when applied to Uni- TSFMs for multiv ariate forecasting, standard fine-tuning fails to capture cross-variable dependencies essential for accurate predictions. T o bridge this gap, recent studies have introduced specialized adaptation mechanisms. For instance, TTM ( Ekambaram et al. , 2024 ) employs channel mixing within a fine-tuned decoder head, leaving the pre-trained backbone restricted to channel-independent learning. Gen- P-T uning ( Liu et al. , 2024b ) utilizes summary “prompts” as prefix sequences, yet this shallow adaptation is inherently constrained by the frozen model’ s attention mechanism and a fixed prompt space. AdaPTS ( Benechehab et al. , 2025 ) wraps a Uni-TSFM in a trainable encoder-decoder struc- ture to model variable interactions. Ho wev er , its ablation study sho ws a decoder-only variant matches the full model’ s performance, suggesting the encoder fails to fully distill 2 DualW eaver: Syner gistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM cross-variable dependencies. In contrast, DualW eaver proactiv ely transforms the multi- vari ate into a pair of learnable, highly predictable surrogates via a shared feature-fusion module. Unlike the late-stage mixing of TTM or the prefix-based prompting of Gen-P- T uning, our framew ork integrates deep cross-variable depen- dencies before foundation model processing. Crucially , Du- alW eaver enables non-parametric reconstruction, focusing the entire adaptation on lev eraging variable dependencies instead of being distracted by a parametric decoder . 3. DualW eav er Framework 3.1. Overview The proposed DualW eaver frame work for adapting Uni- TSFMs for multiv ariate forecasting is presented in Figure 2 . W e denote the input multiv ariate time series data by X ∈ R L × C , where L is the lookback window size in fore- casting, and C is the number of variables. The prediction of multi variate time series data is denoted by ˆ Y ∈ R H × C , where H is the future steps for prediction, and Y ∈ R H × C denotes the ground truth. Specifically , we use ˆ Y ori to indi- cate the original prediction of a gi ven TSFM M and ˆ Y our to denote the prediction of our work. Our goal is to reduce the generalization error of a gi ven TSFM M on multi variate test sets while keeping M frozen. DualW eaver captures cross-variable dependencies via a length-agnostic feature-fusion module f ( · ) : R T × C → R T × C , where T denotes an arbitrary sequence length (e.g., the lookback window L or the ground truth horizon H ). While f ( · ) preserves the dimensionality of the input se- quence, it transforms the original features into a fused rep- resentation space. W e utilize the feature-fusion module to construct a pair of dual-tuned surrogates, a positi vely-tuned surrogate and a negati vely-tuned surrogate, each of which is a specific instance of the proposed surrogate’ s hypothesis space, i.e., S = α 1 f ( X ) + α 2 X . For the positively-tuned surrogate, we define it by S α = f ( X ) + w α ⊙ X (1) where w α ∈ R C are linear channel-wise weights. Similarly , we define the negati vely-tuned surrogate by S β = f ( X ) − w β ⊙ X (2) where w β ∈ R C are also linear channel-wise weights. The surrogates are vie wed as the input and ground truth of mul- tiv ariate forecasting. During adaptation, f ( · ) , w α , and w β are optimized, while the giv en TSFM M (vanilla or fine- tuned) remains frozen. The dual-tuned surrogates are designed to capture comple- mentary aspects of cross-v ariable dependencies. From the viewpoint of function approximation, the dual surrogates define two distinct optimization directions in the feature space. A geometric interpretation is pro vided in Appendix A.4.1 . The final prediction is deri ved via non-parametric reconstruction: ˆ Y our = 1 w α + w β ⊙ ( ˆ S α − ˆ S β ) (3) where ˆ S denotes the prediction of the surrogates by M . Nu- merical stability is inherently guaranteed as the regulariza- tion term Ω (Eq. 12 ) approaches infinity if ( w α + w β ) → 0 , naturally pre venting the denominator from v anishing during optimization. Facilitating non-parametric reconstruction di- rectly enables DualW eaver to learn cross-v ariable dependen- cies via its shared feature-fusion module robustly . Unlike encoder-decoder methods such as AdaPTS ( Benechehab et al. , 2025 ), which consume adaptation capacity to restore original v ariables, our frame work prioritizes an ef ficient rep- resentation of these dependencies. This mechanism further mitigates ov erfitting by introducing distinct optimization directions, as evidenced by training stability in Appendix F . 3.2. Theoretical Analysis In practice, multiple variables from the same source of- ten exhibit inherent correlations, which underpin the ar gu- ment that channel-dependent forecasting should outperform channel-independent forecasting ( W ang et al. , 2024c ; Liu et al. , 2024c ). In this section, we propose a condition for this argument by analyzing the theoretical error bound of DualW eaver compared with uni variate forecasting. Accord- ing to Eq. 3 , the ground truths for the dual-tuned surrogates are, ˜ S α = f ( Y ) + w α ⊙ Y (4) ˜ S β = f ( Y ) − w β ⊙ Y (5) Then we can define the dif ference between ˆ Y our and the ground truth on the i -th channel: ˆ Y i our − Y i = ˆ S i α − ˆ S i β w i α + w i β − ˜ S i α − ˜ S i β w i α + w i β (6) = 1 w i α + w i β [( ˆ S i α − ˜ S i α ) − ( ˆ S i β − ˜ S i β )] (7) The MSE of the DualW eaver frame work on the i -th channel 3 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM - Feature-Fusion M odule capturing cross- variable dependencies Fused Features Dual Guidance on M ing of Dependencies Dual-Tuned Surrog ates Surrogate Predictions Prediction Recons truction is neutralized through the surrogate pre dictions Positively-Tuned Surrogate Negatively-Tuned Surrogate Univariate TSFM Optimized Task by Surrogates Dependency Insight s Original Forecast ing Task without Considering Variab les' Dependencies Symmetric Structure F igur e 2. The overvie w of the DualW eaver framework. A shared feature-fusion module first extracts cross-variable dependencies to generate a pair of dual-tuned surrogates ( S α , S β ). These surrogates are independently processed by a frozen Uni-TSFM, after which the final multiv ariate predictions are derived via non-parametric reconstruction to neutralize the shared fusion part. can be defined as follows: E i our = E [ ˆ Y i our − Y i 2 ] (8) = E [( 1 w i α + w i β [( ˆ S i α − ˜ S i α ) − ( ˆ S i β − ˜ S i β )]) 2 ] (9) ≤ 1 ( w i α + w i β ) 2 E [( ˆ S i α − ˜ S i α + ˆ S i β − ˜ S i β ) 2 ] (10) ≤ 2 ( w i α + w i β ) 2 E [( ˆ S i α − ˜ S i α ) 2 + ( ˆ S i β − ˜ S i β ) 2 ] (11) where E [( ˆ S i α − ˜ S i α ) 2 ] and E [( ˆ S i β − ˜ S i β ) 2 ] are, respectiv ely , the MSE of the positively-tuned surrogate S α and the negati vely-tuned surrogate S β on i -th channel. Therefore, we define the theoretical error bound for the i -th channel as: Ω i = 2 ( w i α + w i β ) 2 ( E i α + E i β ) (12) where E i α and E i β denote the MSE of the surrogates in Du- alW eaver on the i -th channel. Then the suf ficient condition for DualW eaver to ha ve a lower error bound than that of the original channel-independent forecasting is as follows: Ω i ≤ E i ori , i ∈ { 1 , 2 , ..., C } (13) where C denotes the number of input channel and E i ori de- notes the MSE of the original channel-independent forecast- ing on the i -th channel. As an easily achievable boundary case, let E α and E β be equal to E ori , and w i α + w i β = 2 for i ∈ { 1 , 2 , ..., C } , the condition will be satisfied. Incor- porating this lo wer error bound condition of Eq. 13 as a regularization term ensures adaptation robustness, effec- tiv ely av erting the catastrophic div ergence and e xponential error growth empirically observ ed in Section 4.4.1 . 3.3. Multivariate F eature-Fusion Module W e define the multiv ariate feature-fusion module by f ( · ) : R T × C → R T × C , which transforms the original multiv ari- ate into a fused feature space. For instance, we employ a multi-layer perceptron (MLP) architecture to capture cross- variable dependencies at each timestamp. Specifically , the MLP-based feature-fusion module processes the multi vari- ate input at each time step t as follows: f ( X ) t MLP = W 2 × σ W 1 × X t + b 1 + b 2 (14) where W 1 ∈ R D × C and W 2 ∈ R C × D are weights, D denotes the dimension of hidden layer , b 1 ∈ R D and b 2 ∈ R C are biases, and σ is the acti v ation function. It learns nonlinear timestamp-specific relationships across variables. Prior works hav e shown that di verse multiv ariate dependen- cies benefit from distinct modeling strategies ( Shao et al. , 2025 ). Accordingly , DualW eav er is purposefully designed as an extensible framew ork to accommodate such v ariabil- ity . This e xtensibility is fundamentally rooted in the archi- tectural substitutability of DualW eaver , which allo ws the feature-fusion module f ( · ) to be seamlessly replaced by alternati ve multiv ariate backbones, such as CNN-, GNN-, or T ransformer-based models. T o further demonstrate this ar- chitectural versatility , we provide additional ev aluations of an alternati ve module design, a CNN-based implementation, in Appendix C . 4 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM 3.4. Adaptation Process W ith the dual surrogates, the forecasting task is transformed from the original feature space into the surrogate space, as shown in Eq. 1 and 2 , capturing variables’ dependencies through the feature-fusion module f ( · ) . By initializing f ( · ) to zero, the frame work ensures that the optimization process starts directly from the foundation model’ s original predic- tiv e state. This stability-preserving initialization allo ws the model to refine representations incrementally without noti- cably distorting the original series, thereby preserving the foundation model’ s inherent temporal stability and effec- tiv ely shielding it from overfitting. During the adaptation, the primary loss functions are the MSE of the predictions on the dual surrogates: L α = 1 C C X i =1 L i α = 1 C C X i =1 MSE ( ˆ S i α , ˜ S i α ) (15) L β = 1 C C X i =1 L i β = 1 C C X i =1 MSE ( ˆ S i β , ˜ S i β ) (16) where ˆ S i α = M ( S i α ) and ˆ S i β = M ( S i β ) denote the predic- tions of TSFM M on the i -th channel in surrogate space. Only the feature-fusion module f ( · ) and the weights of linear combination in the surrogates, w α and w β , are opti- mized in the adaptation process. As demonstrated in Section 3.2 , a lo wer error bound condition is also used as a regular - ization term in the optimization: L bound = 1 C C X i =1 MAX (Ω i , MSE ( ˆ Y i ori , Y i )) (17) The total optimization objectiv e is formulated as follows: L total = L α + L β 2 + λ L bound (18) where λ is a hyperparameter used to re gulate the influence of the theoretical error bound. T o minimize the complexity of hyperparameter tuning and present the univ ersality of the model, we adopt λ = 1 as a natural weight, thus assigning equal priority to empirical loss minimization and maintain- ing the theoretical safety boundary . Once the adaptation con verges, a rob ust prediction of the test set of the original multiv ariate time series can be derived through Eq. 3 . 4. Experiments In this section, we conduct a comprehensi ve ev aluation of the proposed DualW eav er’ s performance across multiple publicly av ailable datasets. The empirical results demon- strate that DualW eav er consistently achiev es state-of-the-art performance across all ev aluated datasets (Section 4.2.1 ). Furthermore, DualW eav er e xhibits enhanced robustness against the injection of irrelev ant noisy sequences (Sec- tion 4.2.3 ) and demonstrates superior computational effi- ciency (Section 4.3 ). Finally , we present an ablation study to validate our framew ork’ s design, specifically highlight- ing the rob ustness afforded by our theoretical error bound condition (Section 4.4.1 ) and its exceptional scalability in high-dimensional settings (Section 4.4.2 ). 4.1. Setup W e ev aluate the performance of DualW eaver in multiv ari- ate forecasting, lev eraging two state-of-the-art Uni-TSFMs: Sundial ( Liu et al. , 2025 ) and T imerXL ( Liu et al. , 2024d ). Benchmarks are conducted on core datasets, including the ETT (4 subsets) and W eather , and are supplemented by ex- tended analyses on additional datasets, such as Electricity ( Zhou et al. , 2021 ; W u et al. , 2021 ). Our ev aluation encom- passes a comprehensi ve suite of baselines: (a) zero-shot and fully fine-tuned (SFT) configurations of the original Uni- TSFMs; (b) the state-of-the-art encoder-decoder method AdaPTS; and (c) leading nativ e multiv ariate forecasters, in- cluding T imePro ( Ma et al. , 2025 ), SimpleTM ( Chen et al. , 2025 ), T imeMixer ( W ang et al. , 2024a ), and iT ransformer ( Liu et al. , 2024c ). All experiments are conducted on 8 NVIDIA H20 GPUs. In line with previous works, we em- ploy the mean squared error (MSE) and the mean absolute error (MAE) as e valuation metrics. Detailed experimental configurations are provided in Appendix A . 4.2. Main Results 4 . 2 . 1 . F O R E C A S T I N G P E R F O R M A N C E The experimental results on the public datasets are pre- sented in T able 1 . DualW eav er consistently achie ves state- of-the-art performance across all datasets, outperforming both existing encoder-decoder paradigms (AdaPTS) and nativ e end-to-end multiv ariate forecasters. Our empirical evidence demonstrates that DualW eaver serv es as a potent framew ork for unlocking the potential of Uni-TSFMs, sig- nificantly improving their multiv ariate forecasting perfor - mance. Specifically , DualW eav er yields notable reductions in error over v anilla Uni-TSFMs: for TimerXL, the av erage MSE and MAE decrease by 8.95% and 6.07% , respecti vely; for Sundial, the improvements reach 6.74% and 4.47% , re- spectiv ely . Furthermore, DualW eav er outperforms full fine- tuning, reducing MSE and MAE by 3.91% and 1.55% for T imerXL, while achieving 2.67% and 1.12% for Sundial. 4 . 2 . 2 . C O M PA R I S O N W I T H M U L T I V A R I A T E T S F M Nati ve multiv ariate TSFMs, such as Chronos-2 ( Ansari et al. , 2025 ), are explicitly architected to capture complex cross- variable dependencies. Ho we ver , this modeling capability 5 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM T able 1. Multiv ariate forecasting results on public datasets with forecasting horizons ∈ { 96 , 192 , 336 , 720 } . A veraged results are reported here, and full results are provided in T able 10 with the best in bold and the second underlined . 1 st Count represents the number of wins achiev ed by a method under all prediction lengths and datasets. Results for TimePro, SimpleTM, TimeMix er , and iTransformers are reported in ( Ma et al. , 2025 ) and ( Chen et al. , 2025 ). Extended ev aluations on additional datasets are provided in Appendix D . Methods DualW eaver AdaPTS SFT V anilla TimePr o SimpleTM TimeMixer iT rans. (Ours) (2025) (2025) (2025) (2024) (2024c) Metric MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE TimerXL ETTh1 0.406 0.419 0.411 0.433 0.427 0.428 0.419 0.427 0.438 0.438 0.422 0.428 0.458 0.445 0.454 0.447 ETTh2 0.340 0.386 0.348 0.399 0.349 0.389 0.359 0.396 0.377 0.403 0.353 0.391 0.384 0.407 0.383 0.407 ETTm1 0.338 0.379 0.347 0.392 0.377 0.390 0.397 0.409 0.391 0.400 0.381 0.396 0.385 0.399 0.407 0.410 ETTm2 0.260 0.318 0.268 0.336 0.261 0.320 0.288 0.347 0.281 0.326 0.275 0.322 0.278 0.325 0.288 0.332 W eather 0.225 0.271 0.227 0.284 0.228 0.275 0.255 0.302 0.252 0.276 0.243 0.271 0.245 0.276 0.258 0.278 Sundial ETTh1 0.395 0.419 0.412 0.434 0.411 0.431 0.419 0.439 0.438 0.438 0.422 0.428 0.458 0.445 0.454 0.447 ETTh2 0.333 0.385 0.347 0.398 0.336 0.387 0.337 0.389 0.377 0.403 0.353 0.391 0.384 0.407 0.383 0.407 ETTm1 0.319 0.364 0.329 0.377 0.341 0.374 0.340 0.379 0.391 0.400 0.381 0.396 0.385 0.399 0.407 0.410 ETTm2 0.239 0.304 0.268 0.347 0.243 0.304 0.288 0.347 0.281 0.326 0.275 0.322 0.278 0.325 0.288 0.332 W eather 0.209 0.255 0.212 0.275 0.210 0.254 0.238 0.274 0.252 0.276 0.243 0.271 0.245 0.276 0.258 0.278 1 st 33 32 3 0 3 3 0 0 0 0 1 5 0 0 0 0 necessitates high computation demands; specifically , by computing attention across the variable dimension, their complexity scales quadratically in the form of O ( V 2 ) , where V denotes v ariable count ( Ansari et al. , 2025 ). In contrast, Uni-TSFMs like Sundial utilize channel-independent mod- eling, maintaining a fa vorable linear comple xity of O ( V ) . T o ensure an equitable comparison, we ev aluate Sundial (128M) and Chronos-2 (119M), both of which possess a comparable parameter scale. W e report the optimal perfor - mance (the better of V anilla or SFT) for each baseline to rep- resent their strongest predicti ve capabilities. As illustrated in Figure 3 , Chronos-2 le verages its nati ve multi variate mod- eling to outperform the Sundial on most ETT subsets. Cru- cially , after integration with the DualW eaver framew ork, Sundial approaches Chronos-2’ s performance on ETTh and surpasses it on ETTm subsets. The results demonstrate that DualW eaver ef fectively bridges the g ap between univ ariate and multiv ariate modeling, allowing computationally effi- cient Uni-TSFMs to achiev e superior accuracy without the quadratic complexity of nati ve multi variate architectures. Notably , Sundial significantly outperforms Chronos-2 on the W eather dataset; a comprehensiv e analysis re garding the influence of cross-variable correlation on this performance div ergence is provided in Section 4.2.3 . 4 . 2 . 3 . R O B U S T NE S S T O I R R E L E V A N T D I M E N S I O N S T o in vestigate the performance diver gence in Section 4.2.2 regarding the superior performance of the channel- independent Sundial over the nati ve multi v ariate Chronos-2 on the W eather dataset, we employ the Cross-T ime Cross- V ariate Correlation Coefficient ( Liu et al. , 2024a ). The ETTh1 ETTh2 ETTm1 ETTm2 weather Datasets 0.20 0.25 0.30 0.35 0.40 For ecasting Err or (MSE) 0.41 1 0.336 0.340 0.243 0.210 0.392 0.331 0.333 0.244 0.248 0.395 0.333 0.319 0.239 0.209 Sundial Chronos-2 DualW eaver + Sundial F igur e 3. Performance comparison between Sundial (128M) and Chronos-2 (119M). While Chronos-2 benefits from cross-variable interactions in certain scenarios, DualW eaver enables the adapted Sundial to approach or exceed such performance. metric ef fectiv ely characterizes the dynamic dependencies among variables across series, with details and comprehen- siv e results pro vided in Appendix E . As sho wn in T able 2 , the av erage correlation for the W eather dataset is remarkably low compared to the ETT series. This sparse correlation poses a significant challenge for models that rely on deep coupling of both time and variable dimensions. T able 2. Cross-Time Cross-V ariate Correlation Coefficient Measurement ETTh1 ETTh2 ETTm1 ETTm2 W eather correlations 0.0238 0.0334 0.0314 0.0420 0.0007 Nativ e multiv ariate TSFMs and e xisting adapters attempt to extract predicti ve features through intensiv e modeling 6 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM that deeply modifies the input X based on percei ved cross- variable relationships. Howe ver , in scenarios with weak cross-variable dependencies, this structural ov er-coupling forces such models to learn spurious relationships from irrel- ev ant features, leading to significant generalization failure. Instead, as shown in Eq. 1 and Eq. 2 , DualW eaver em- ploys a residual-like surrogate mechanism that integrates multiv ariate insights as a supplement to the original series. Under weak-correlation conditions, this increment can adap- tiv ely decrease to av oid excessi ve alteration of X . This design ensures that the model maintains a remarkably sta- ble error profile e ven when cross-v ariable correlations are sparse, whereas deep-coupling baselines e xhibit progressi ve performance degradation as noise increases. T o empirically e v aluate method robustness under weak cross-variable dependencies, we inject v arying numbers of non-informativ e noise sequences sampled from a standard normal distribution N (0 , 1) into the ETTh1 dataset. As il- lustrated in Figure 4 , while the prediction errors of Chronos- 2 and AdaPTS grow progressi vely as the number of noise channels increases, DualW eav er maintains a remarkably sta- ble error profile. These results underscore DualW eav er’ s superior generalization capability and its effecti veness in handling real-world en vironments characterized by varying lev els of variable correlation. 0 2 4 6 8 10 Number of Additional Noise Channels 0.345 0.350 0.355 0.360 0.365 0.370 0.375 F orecasting Error (MSE) DualW eaver: Stable prediction despite correlation decay Baselines: Error increases as correlations weaken AdaPTS Chronos-2 DualW eaver 0.000 0.005 0.010 0.015 0.020 0.025 0.030 Correlation Coefficient Correlation Coefficient F igure 4. Predicti ve stability under increasing noise. DualW eaver remains robust to additional noise, outperforming baselines that degrade progressi vely . Done with forecasting horizon at 96. 4 . 2 . 4 . P R E D I C TA B I L I T Y I N T H E S U R R O G A T E S P A C E DualW eaver enhances Uni-TSFMs for multiv ariate fore- casting by projecting multi variate inputs into a highly pre- dictable surrogate space. T o quantify this enhancement, we compare the forecasting errors of the original ETTh1 time series with those of our surrogates, both using the same frozen T imerXL foundation model. Figure 5 illustrates the resulting error distributions after adaptation con ver gence, with each data point representing the local error mean com- puted o ver a 100-timestep rolling windo w to enhance clarity . Empirically , the surrogates exhibit significantly lower er - ror profiles, achieving av erage reductions of 85.44% in MSE and 61.58% in MAE. These substantial improv ements provide concrete e vidence that our surrogate mechanism ef- fectiv ely simplifies complex multiv ariate signals into more tractable representations, thereby ef fectiv ely aligning the robust temporal modeling of Uni-TSFMs with the require- ments of multiv ariate forecasting. 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 Mean Squared Error (MSE) 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 Mean Absolute Error (MAE) Error Reduction: MSE: 85.44% MAE: 61.58% Original Space S u r r o g a t e S p a c e ( ) S u r r o g a t e S p a c e ( ) F igure 5. Predictability enhancement in the surrogate space. Dual- W eaver transforms comple x multiv ariate signals into predictable surrogates, yielding an av erage reduction of 85.44% in MSE and 61.58% in MAE compared to the original input space. 4.3. Computational Efficiency This section compares the training ef ficiency and memory consumption of DualW eaver with those of AdaPTS. Bench- marks were performed on the ETTh1 dataset across varying hidden dimensions. As illustrated in Figure 6 , our proposed DualW eaver maintains low training time cost and memory footprint across v arying hidden dimensions. At the same time, AdaPTS exhibits near-linear gro wth in both metrics as the number of hidden dimensions increases. This scala- bility limitation stems from AdaPTS’ s architectural design: it projects input features to match the hidden dimension size before processing them through the foundation model, causing computational costs to scale directly with hidden dimension size. Consequently , practitioners must trade of f efficienc y against modeling capacity , significantly limiting practical deployment. In contrast, DualW eav er preserv es dimensionality alignment between input features and the foundation model’ s e xpected inputs. This design princi- ple ensures that computational ef ficiency remains nearly constant as the number of hidden dimensions increases. 4.4. Ablation Study 4 . 4 . 1 . R O B U S T NE S S F RO M E R RO R B O U N D C O N D I T I O N T o validate the theoretical error bound guarantee provided by Eq. 13 , we examine the impact of the proposed regu- larization on con ver gence stability . Figure 7 contrasts the validation error trajectories on ETTh1 using T imerXL with and without this constraint, illustrating its role in ensuring 7 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM 32 64 96 128 160 192 Hidden Layer Dimension 10 20 30 40 50 60 T raining T ime (s/epoch) 32 64 96 128 160 192 7.50 7.75 8.00 8.25 DualW eaver Detail DualW eaver (T ime) AdaPTS (T ime) DualW eaver (Mem) AdaPTS (Mem) 10 20 30 40 50 60 70 80 Max Memory Usage (GB) 7.00 7.25 7.50 7.75 F igure 6. T raining ef ficiency and scalability comparison by train- ing time per epoch (s) and peak memory consumption (GB) on the ETTh1 dataset using T imerXL. While AdaPTS exhibits lin- ear growth in computational costs, DualW eav er maintains a near- constant resource footprint across varying hidden dimensions. robust adaptation. The empirical results rev eal a stark div er- gence in training stability . Under error -b ound regularization, DualW eaver exhibits a remarkably stable v alidation MSE. In contrast, the unregularized v ariant, while initially matching the stable performance during the first 10 epochs, under goes a catastrophic collapse thereafter . Specifically , the valida- tion error enters an e xponential growth re gime, increasing by over 4 orders of magnitude. The proposed regularization effecti vely serves as a safety boundary , preserving the in- tegrity of the surrogate space and ensuring rob ust adaptation ev en during extended exploration. 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15 16 17 18 19 20 Epoch 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 V alidation Pr ediction Err or (MSE) Exponential Growth Prediction error increased by 4 orders of magnitude 1 2 3 4 5 6 7 8 9 10 0.68 0.70 Regularization maintains error within 0.67-0.68 range Stable Phase: Epochs 1-10 W ithout Regularization W ith Regularization F igure 7. Impact of the re gularization on training stability . Without the theoretical constraint (Eq. 13 ), the model experiences catas- trophic div ergence after epoch 10, with validation error increasing by four orders of magnitude. Using our proposed regularization ensures consistent stability and performance. 4 . 4 . 2 . D I M E N S I O N A L S C A L A B I L I T Y T o further ev aluate the robustness of DualW eav er when handling higher-dimensional data, we conducted scalability experiments on the ECL dataset. Featuring 321 variables, this dataset provides a rigorous benchmark for assessing model performance in large-scale multiv ariate scenarios. By selecting the first N variables ( N ∈ { 5 , 10 , 20 , ..., 321 } ), we constructed subsets of varying dimensions to observe the performance gains of DualW eav er and AdaPTS when adapting the T imerXL foundation model. The experimental results are illustrated in Figure 8 . At low v ariable counts ( N ≤ 20 ), both adaptation paradigms yield comparable and significant improvements in accuracy ov er the foundation model. Howe ver , as N increases, the marginal utility of AdaPTS progressiv ely decreases. This performance de gradation stems from its underlying encoder - decoder architecture; as dimensionality scales, a substantial portion of the adaptation capacity is consumed by recon- structing the original v ariables from latent representations, rather than by distilling critical cross-variable dependencies. In contrast, DualW eaver maintains a remarkably consis- tent performance gain across the entire range of v ariable scales. This resilience is attrib uted to our dual-surrogate mechanism, which lev erages a shared feature-fusion module to optimize directly within the surrogate space. Eliminat- ing parametric reconstruction enables DualW eav er to focus solely on capturing cross-v ariable dependencies, thereby contributing to its e xceptional scalability and stable perfor- mance in high-dimensional settings. 0 50 100 150 200 250 300 350 Number of V ariables 0 5 10 15 Performance Gain (%) 13.3% 8.8% 5.9% 1.1% 1 1.3% 1 1.4% 10.9% 10.8% DualW eaver stabilizes at high dimensions AdaPTS DualW eaver F igure 8. Dimensionality Scalability on ECL Dataset. Comparison of performance gains (MSE reduction) achiev ed by DualW eaver and AdaPTS on TimerXL as the number of v ariables N increases. While AdaPTS exhibits sensitivity to increasing dimensionality with declining returns, DualW eaver demonstrates superior rob ust- ness and stable predictiv e gains e ven as N reaches 321. 5. Conclusion In this paper , we introduce DualW eav er , a novel frame work that enables multiv ariate forecasting with Uni-TSFMs. It employs an innov ativ e dual-surrogate paradigm: a learn- able feature-fusion module extracts cross-variable depen- dencies to generate a pair of highly predictable surrogate series, enabling non-parametric reconstruction of final pre- dictions. Unlike encoder -decoder approaches, DualW eaver eliminates capacity loss through costless, direct surrogate mapping. Supported by theoretical error-bound analysis and a novel regularization term for stable adaptation, the framew ork demonstrates state-of-the-art accuracy , superior computational ef ficiency , and robustness against noise and high-dimensional data in extensi ve experiments. 8 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM Impact Statement This paper presents a nov el framework to address the effi- ciency and rob ustness challenges of TSFM in multi variate forecasting via an innov ative dual-surrog ate paradigm. By achieving state-of-the-art accurac y with superior compu- tational efficiency and inherent robustness to noise, our method provides both a practical tool for real-world appli- cations and a v aluable conceptual adv ance—the learnable feature-fusion module and costless surrogate mapping—for the broader deep learning research community . This work is strictly focused on the scientific and engineering problem of forecasting methodology . W e foresee no direct ethical risks arising from the frame work itself and are committed to its responsible dev elopment and application. References Ansari, A. F ., Stella, L., T urkmen, C., Zhang, X., Mercado, P ., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P ., Kapoor , S., Zschiegner , J., Maddix, D. C., W ang, H., Mahoney , M. W ., T orkkola, K., W ilson, A. G., Bohlke- Schneider , M., and W ang, Y . Chronos: Learning the Lan- guage of T ime Series, Nov ember 2024. URL http:// . [cs]. Ansari, A. F ., Shchur, O., K ¨ uken, J., Auer , A., Han, B., Mercado, P ., Rangapuram, S. S., Shen, H., Stella, L., Zhang, X., Goswami, M., Kapoor , S., Maddix, D. C., Guerron, P ., Hu, T ., Y in, J., Erickson, N., Desai, P . M., W ang, H., Rangwala, H., Karypis, G., W ang, Y ., and Bohlke-Schneider , M. Chronos-2: From uni v ariate to univ ersal forecasting, 2025. URL https://arxiv. org/abs/2510.15821 . Benechehab, A., Feofano v , V ., Paolo, G., Thomas, A., Fil- ippone, M., and K ´ egl, B. AdaPTS: Adapting Uni variate Foundation Models to Probabilistic Multi variate T ime Se- ries F orecasting, February 2025. URL http://arxiv. org/abs/2502.10235 . arXi v:2502.10235 [stat]. Chen, H., Luong, V ., Mukherjee, L., and Singh, V . Sim- pleTM: A simple baseline for multiv ariate time series forecasting. In The Thirteenth International Confer- ence on Learning Repr esentations , 2025. URL https: //openreview.net/forum?id=oANkBaVci5 . Da’u, A. and Salim, N. Recommendation system based on deep learning methods: a systematic re view and ne w directions. Artificial Intelligence Revie w , 53(4):2709– 2748, 2020. Ekambaram, V ., Jati, A., Dayama, P ., Mukherjee, S., Nguyen, N. H., Gifford, W . M., Reddy , C., and Kalagnanam, J. T iny time mixers (ttms): F ast pre-trained models for enhanced zero/few-shot forecasting of mul- tiv ariate time series, 2024. URL https://arxiv. org/abs/2401.03955 . Feng, C., Huang, L., and Krompass, D. Only the curv e shape matters: T raining foundation models for zero-shot multiv ariate time series forecasting through next curve shape prediction, 2024. URL abs/2402.07570 . Goswami, M., Szafer , K., Choudhry , A., Cai, Y ., Li, S., and Dubrawski, A. MOMENT : A family of open time-series foundation models. In F orty-first International Confer- ence on Machine Learning, ICML 2024, V ienna, Austria, J uly 21-27, 2024 . OpenRe view .net, 2024. URL https: //openreview.net/forum?id=FVvf69a5rx . Hu, E. J., Shen, Y ., W allis, P ., Allen-Zhu, Z., Li, Y ., W ang, S., W ang, L., and Chen, W . Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv. org/abs/2106.09685 . Lai, G., Chang, W .-C., Y ang, Y ., and Liu, H. Modeling long- and short-term temporal patterns with deep neural networks, 2018. URL 1703.07015 . Liang, Y ., W en, H., Nie, Y ., Jiang, Y ., Jin, M., Song, D., Pan, S., and W en, Q. Foundation models for time series analysis: A tutorial and surve y . In Pr oceedings of the 30th A CM SIGKDD Confer ence on Knowledge Discovery and Data Mining , KDD ’24, pp. 6555–6565. A CM, August 2024. doi: 10.1145/3637528.3671451. URL http: //dx.doi.org/10.1145/3637528.3671451 . Liu, J., Liu, C., W oo, G., W ang, Y ., Hooi, B., Xiong, C., and Sahoo, D. Unitst: Effecti vely modeling inter-series and intra-series dependencies for multi variate time se- ries forecasting, 2024a. URL abs/2406.04975 . Liu, M., Chen, A. H., and Chen, G. H. Generalized Prompt T uning: Adapting Frozen Univ ariate Time Series F oun- dation Models for Multiv ariate Healthcare Time Series, Nov ember 2024b. URL 2411.12824 . arXi v:2411.12824 [cs]. Liu, Y ., Hu, T ., Zhang, H., W u, H., W ang, S., Ma, L., and Long, M. itransformer: Inv erted transformers are effecti ve for time series forecasting. arXiv pr eprint arXiv:2310.06625 , 2023a. Liu, Y ., Li, C., W ang, J., and Long, M. K oopa: Learning non- stationary time series dynamics with koopman predictors. Advances in neur al information pr ocessing systems , 36: 12271–12290, 2023b. 9 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM Liu, Y ., Hu, T ., Zhang, H., W u, H., W ang, S., Ma, L., and Long, M. itransformer: Inv erted transformers are ef fectiv e for time series forecasting, 2024c. URL https: //arxiv.org/abs/2310.06625 . Liu, Y ., Qin, G., Huang, X., W ang, J., and Long, M. Timer - xl: Long-conte xt transformers for unified time series fore- casting, 2024d. URL 2410.04803 . Liu, Y ., Qin, G., Shi, Z., Chen, Z., Y ang, C., Huang, X., W ang, J., and Long, M. Sundial: A f amily of highly capable time series foundation models. arXiv preprint arXiv:2502.00816 , 2025. Loshchilov , I. and Hutter , F . SGDR: stochastic gradi- ent descent with warm restarts. In 5th International Confer ence on Learning Representations, ICLR 2017, T oulon, F rance, April 24-26, 2017, Conference T rac k Pr oceedings . OpenRevie w .net, 2017. URL https: //openreview.net/forum?id=Skq89Scxx . Loshchilov , I. and Hutter, F . Decoupled weight decay regu- larization. In 7th International Confer ence on Learning Repr esentations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenRe view .net, 2019. URL https: //openreview.net/forum?id=Bkg6RiCqY7 . Ma, X., Ni, Z., Xiao, S., and Chen, X. Timepro: Ef- ficient multi variate long-term time series forecasting with variable- and time-aware hyper-state, 2025. URL https://arxiv.org/abs/2505.20774 . Marconi, B. A. T ime series foundation models for mul- tiv ariate financial time series forecasting, 2025. URL https://arxiv.org/abs/2507.07296 . Nie, Y ., Nguyen, N. H., Sinthong, P ., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. arXiv pr eprint arXiv:2211.14730 , 2022. Otter , D. W ., Medina, J. R., and Kalita, J. K. A survey of the usages of deep learning for natural language process- ing. IEEE transactions on neur al networks and learning systems , 32(2):604–624, 2020. Shao, Z., W ang, F ., Xu, Y ., W ei, W ., Y u, C., Zhang, Z., Y ao, D., Sun, T ., Jin, G., Cao, X., Cong, G., Jensen, C. S., and Cheng, X. Exploring Progress in Multi variate T ime Series Forecasting: Comprehensi ve Benchmark- ing and Heterogeneity Analysis. IEEE T ransactions on Knowledge and Data Engineering , 37(1):291–305, January 2025. ISSN 1558-2191. doi: 10.1109/TKDE. 2024.3484454. URL https://ieeexplore.ieee. org/abstract/document/10726722 . V oulodimos, A., Doulamis, N., Doulamis, A., and Protopa- padakis, E. Deep learning for computer vision: A brief revie w . Computational intellig ence and neur oscience , 2018(1):7068349, 2018. W ang, S., W u, H., Shi, X., Hu, T ., Luo, H., Ma, L., Zhang, J. Y ., and Zhou, J. Timemix er: Decomposable multiscale mixing for time series forecasting. In The T welfth Inter- national Confer ence on Learning Repr esentations, ICLR 2024, V ienna, Austria, May 7-11, 2024 . OpenRe view .net, 2024a. URL https://openreview.net/forum? id=7oLshfEIC2 . W ang, Y ., W u, H., Dong, J., Liu, Y ., Long, M., and W ang, J. Deep T ime Series Models: A Comprehensiv e Survey and Benchmark, July 2024b. URL abs/2407.13278 . arXi v:2407.13278 [cs]. W ang, Y ., W u, H., Dong, J., Qin, G., Zhang, H., Liu, Y ., Qiu, Y ., W ang, J., and Long, M. T imexer: Empowering transformers for time series forecasting with e xogenous variables. Advances in Neural Information Processing Systems , 37:469–498, 2024c. W oo, G., Liu, C., Kumar , A., Xiong, C., Sav arese, S., and Sahoo, D. Unified training of univ ersal time series fore- casting transformers, 2024. URL https://arxiv. org/abs/2402.02592 . W u, H., Xu, J., W ang, J., and Long, M. Autoformer: Decom- position transformers with auto-correlation for long-term series forecasting. Advances in neural information pr o- cessing systems , 34:22419–22430, 2021. W u, H., Hu, T ., Liu, Y ., Zhou, H., W ang, J., and Long, M. T imesnet: T emporal 2d-v ariation modeling for general time series analysis. arXiv preprint , 2022. Y e, J., Zhang, W ., Y i, K., Y u, Y ., Li, Z., Li, J., and Tsung, F . A survey of time series foundation models: Generaliz- ing time series representation with large language model. arXiv pr eprint arXiv:2405.02358 , 2024. Zeng, A., Chen, M., Zhang, L., and Xu, Q. Are transformers effecti ve for time series forecasting? In Pr oceedings of the AAAI confer ence on artificial intelligence , v olume 37, pp. 11121–11128, 2023. Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., and Zhang, W . Informer: Beyond ef ficient transformer for long sequence time-series forecasting. In Pr oceedings of the AAAI confer ence on artificial intelligence , v olume 35, pp. 11106–11115, 2021. 10 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM A. Implementation Details A.1. Datasets A . 1 . 1 . D A TA S E T D E S C R I P T I O N S W e conduct experiments on six public datasets to ev aluate the performance of the proposed DualW eav er , including: (1) ETT ( Zhou et al. , 2021 ) contains seven factors of electricity transformer from July 2016 to July 2018. There are four subsets where ETTh1 and ETTh2 are recorded ev ery hour , and ETTm1 and ETTm2 are recorded every 15 minutes. (2) W eather 1 includes 21 meteorological factors collected e very 10 minutes from the W eather Station of the Max Planck Biogeochemistry Institute in 2020. (3) Electricity ( W u et al. , 2021 ) records the hourly electricity consumption data of 321 clients. T o ensure fair benchmarking against baseline methods, we strictly adhere to the identical training-v alidation-test split strategy used across all baseline datasets. The details of the datasets are pro vided in T able 3 . Dim denotes the v ari- able number of each dataset. Dataset Size denotes the total number of time points in the (train, v alidation, test) split, respectiv ely . Frequency represents the sampling interval of time points. T able 3. Detailed dataset descriptions. Dataset Dim Dataset Size Frequency ETTh1 7 (8545, 2881, 2881) Hourly ETTh2 7 (8545, 2881, 2881) Hourly ETTm1 7 (34465, 11521, 11521) 15min ETTm2 7 (34465, 11521, 11521) 15min W eather 21 (36792, 5271, 10540) 10min ECL 321 (18317, 2633, 5261) Hourly A . 1 . 2 . D A TA P R E P RO C E S S I N G T o ensure experimental consistenc y and align with estab- lished research benchmarks, we standardized all experimen- tal datasets during preprocessing. Specifically , we applied StandardScaler to normalize feature scales to ensure consis- tency across all baseline methods and the proposed Dual- W eaver method. A.2. T raining Configurations All e xperiments were implemented in PyT orch and executed on 8 NVIDIA H20 (96GB) GPUs. W e used distributed data parallelism via torchrun to accelerate both training and 1 https://www .bgc-jena.mpg.de/wetter/ inference. W e adopted the AdamW optimizer ( Loshchilov & Hutter , 2019 ) with h yperparameters β 1 = 0 . 9 , β 2 = 0 . 95 , and weight decay = 1 × 10 − 3 , coupled with a cosine an- nealing learning rate scheduler ( Loshchilov & Hutter , 2017 ) configured with T max = 10 and η min = 1 × 10 − 8 . All models underwent 10 training epochs with early stopping (patience = 3 ). For adapter -based methods (including Dual- W eaver and AdaPTS), we froze all Uni-TSFM parameters. Multi variate forecasting experiments used a fix ed batch size of 32, with gradient accumulation and micro-batching to maintain equiv alent batch processing while preventing out- of-memory errors. In contrast, univ ariate fine-tuning utilized a fixed batch size of 256 with sequential variable loading. Across all configurations, we preserved complete test set integrity by omitting the “drop last” strate gy . W e adopted a context length of 2880 for Uni-TSFMs, consis- tent with the configurations used in Sundial ( Liu et al. , 2025 ). This extended conte xt length is crucial for fully activ ating the inherent long-term dependency modeling capabilities of foundation models. F or the multi variate forecasters (T ime- Pro, SimpleTM, T imeMixer , and iT ransformer), we directly report their published results as presented in their original papers, maintaining the input length of 96 as specified in their established experimental protocols. For all experiments, we use a grid search to optimize hyperparameters. For all adapter -based methods (Du- alW eaver and AdaPTS), we search o ver learning rates { 10 − 1 , 10 − 2 , 10 − 3 , 10 − 4 } . F or full fine-tuning, we utilize reduced learning rates { 5 × 10 − 5 , 10 − 5 , 5 × 10 − 6 , 10 − 6 } to mitigate the risk of overfitting. For AdaPTS, we adopt its representati ve v ariant, LinearAE, as the baseline. Here, the hidden dimension ( d hidden ) is defined by the output chan- nels of the first linear projection layer in both AdaPTS and DualW eaver , which characterizes the models’ capability to embed multiv ariate features into a latent space. The hidden layer dimension for both AdaPTS and our proposed Dual- W eaver is configured according to the widely adopted bench- mark setting established by TimesNet ( W u et al. , 2022 ). This dimension is dynamically adjusted based on the number of variables ( V ) in each dataset, balancing model capacity and computational efficienc y . The calculation is defined by: d hidden = min n max n 2 ⌈ log 2 V ⌉ , 32 o , 512 o (19) This design ensures a baseline model complexity that scales with the intrinsic dimensionality of the data while prev ent- ing the hidden layer from becoming impractically small or excessi vely large. A.3. Adaptation Pipeline T o ensure a fair comparison, our adaptation process strictly follows the stage-wise adaptation paradigm established by 11 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM the baseline AdaPTS ( Benechehab et al. , 2025 ). Specifically , the Uni-TSFM is first optimized via methods such as full fine-tuning, linear probing ( Goswami et al. , 2024 ), or LoRA ( Hu et al. , 2021 ); in this work, we adopt full fine-tuning as the primary strategy . Following this initial stage, all parameters of the Uni-TSFM backbone are frozen, while only those within the DualW eaver frame work are trained. A.4. Design and Implementation A . 4 . 1 . G E O M E T R I C I N T E R P R E T A T I O N O F D UA L S U R RO G ATE S The dual surrogates can be understood as constructing a pair of learnable tangent vectors on the representation manifold M repr . At the base point f ( X ) , we define two adaptive exploration directions: v α = w α ⊙ X , v β = w β ⊙ X , where the channel-wise weights w α , w β ∈ R C are initial- ized to 1 and optimized during adaptation. Initialization : Setting w α = w β = 1 establishes a symmet- ric, unbiased starting point, assuming a preliminary align- ment between the raw input space and the tangent space of the representation manifold. Optimization : The learning process calibrates these tangent vectors to the specific local geometry of the tar get domain. Crucially , w α and w β are learned independently . This de- sign allows the model to disco ver that the most informativ e directions for feature enhancement ( v α ) and suppression ( v β ) are not necessarily symmetric around f ( X ) . It captures the anisotropic nature of the local data distribution—the manifold may curve more sharply or contain more signal in certain directions. Theoretical Advantage : Thus, the dual surrogates S α = f ( X ) + v α and S β = f ( X ) − v β do not merely perform fixed affine transformations. Instead, they implement a data-driv en, structured exploration of the neighborhood of the representation manifold, guided by the adapted tangent vectors v α and v β . This provides a principled and ef fi- cient mechanism for domain adaptation that is both flexible (due to learning) and regularized (by the tangent space con- straint). A . 4 . 2 . U N I - T S F M S For the Uni-TSFMs Sundial and T imerXL, we use their original model architectures and the of ficially released pre- trained weights from the Huggingface platform 2 to ensure experimental reproducibility . 2 https://huggingface.co A . 4 . 3 . M U LT I V A R I A T E F E AT U R E - F U S IO N M O D U L E The DualW eaver framework incorporates a learnable feature-fusion module f ( · ) : R T × C → R T × C to capture cross-variable dependencies in multi variate time series data. This module is implemented as a multi-layer perceptron (MLP), which consists of two fully-connected layers: the first layer projects the input features to a hidden dimen- sion, follo wed by a SiLU activ ation and dropout (with a rate of 0.1) for nonlinear transformation; the second layer then projects the features back to the original dimensional- ity . The weights of the final linear layer are initialized to zero, ensuring that the optimization process begins from the Uni-TSFM’ s original predictions. B. DualW eav er on V anilla Uni-TSFMs The non-intrusi ve architecture of DualW eav er enables seam- less compatibility with div erse Uni-TSFM implementations. Lev eraging this flexibility , we conduct an extended perfor- mance assessment of DualW eav er applied to v anilla Uni- TSFMs. As illustrated in T able 4 , DualW eav er consistently outperforms AdaPTS across the vast majority of e valuation metrics when integrated with v anilla Uni-TSFMs. Notably , on the Sundial model, DualW eav er achie ves a substantial performance margin o ver the AdaPTS baseline. Specifi- cally , compared to zero-shot forecasting, our framew ork yields a 3.70% reduction in MSE and a 2.26% reduction in MAE. These results underscore the superior generalizability of the dual-surrogate mechanism, demonstrating its ability to ef fectively unlock the multiv ariate potential of frozen foundation models without the parametric reconstruction ov erhead typical of prior encoder-decoder architectures. T able 4. Multi variate forecasting results on vanilla Uni-TSFMs with forecasting horizons ∈ { 96 , 192 , 336 , 720 } . A veraged results are reported here with the best in bold . Methods DualW eav er AdaPTS V anilla Metric MSE MAE MSE MAE MSE MAE TimerXL ETTh1 0.409 0.418 0.407 0.429 0.419 0.427 ETTh2 0.341 0.386 0.344 0.397 0.359 0.396 ETTm1 0.368 0.397 0.360 0.400 0.397 0.409 ETTm2 0.276 0.335 0.273 0.344 0.288 0.347 W eather 0.245 0.289 0.244 0.304 0.255 0.302 Sundial ETTh1 0.403 0.426 0.412 0.435 0.419 0.439 ETTh2 0.332 0.385 0.347 0.399 0.337 0.389 ETTm1 0.329 0.373 0.349 0.397 0.340 0.379 ETTm2 0.256 0.321 0.268 0.344 0.261 0.323 W eather 0.230 0.271 0.226 0.289 0.238 0.274 12 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM C. Extensibility As shown in benchmarks like BasicTS+ ( Shao et al. , 2025 ), the strength of cross-v ariable correlations varies signifi- cantly across datasets. Models such as DLinear ( Zeng et al. , 2023 ), which rely on simple linear architectures, tend to perform well on datasets with weak dependencies, while more complex GNN-based approaches excel when strong cross-variable relationships are present. T o accommodate such div ersity in real-world data, the feature-fusion module in DualW eaver is designed to be highly extensible. As long as the output shape matches the input multi variate sequence, the feature-fusion module can be replaced with an y neural network architecture—such as CNNs, GNNs, or Transform- ers—enabling the model to adapt to varying correlation strengths without altering the ov erall framew ork. In this section, we define a CNN-based feature-fusion mod- ule that employs 1D con volutional layers applied along all the dimensions, treating the variables as channels of con vo- lution: f ( X ) j,t CNN = C X i =1 ( X i ⊛ W j,i ) t + b j (20) where i is the index of the input channel, j is the index of the output channel, ⊛ is the con volution operation, X i ∈ R L is the time series of the i -th v ariable, W j,i ∈ R K is the kernel weight matrices for the i -th input channel and the j th output channel, and b j ∈ R is the j th bias for the output. Here, for simplicity , we present the CNN-based module using only one con volutional layer . In experiments, the CNN-based variant emplo ys two 1D con volutional blocks (kernel size 5, stride 1, replicate padding) where the initial con volution expands the input dimensionality to a configurable hidden dimension, followed by layer normalization, SiLU activ a- tion, and dropout (p=0.1). The CNN-based feature-fusion module uses con volutional layers to capture cross-v ariable dependencies within a specified time window automatically , lev eraging parameter sharing and locality to reduce compu- tational cost. W e ev aluate the multiv ariate forecasting performance of the CNN-based DualW eaver across five benchmark datasets. Follo wing the experimental protocols detailed in Appendix A , our empirical results (T able 5 ) demonstrate that this vari- ant consistently achie ves substantial precision gains across all ev aluated scenarios. Specifically , DualW eav er yields av- erage reductions in MSE and MAE of 8.70% and 5.99% for T imerXL, and 6.68% and 4.47% for Sundial, respecti vely . Furthermore, the inherent extensibility of the feature-fusion module underscores the frame work’ s versatility and broad applicability across div erse real-world tasks. T able 5. Multiv ariate forecasting results of CNN-variant Dual- W eaver with forecasting horizons ∈ { 96 , 192 , 336 , 720 } . A ver - aged results are reported here with the best in bold . Methods W eaverCNN AdaPTS V anilla Metric MSE MAE MSE MAE MSE MAE TimerXL ETTh1 0.406 0.419 0.411 0.433 0.419 0.427 ETTh2 0.342 0.386 0.348 0.39 0.359 0.396 ETTm1 0.336 0.388 0.347 0.392 0.397 0.409 ETTm2 0.260 0.318 0.268 0.336 0.288 0.347 W eather 0.228 0.273 0.227 0.284 0.255 0.302 Sundial ETTh1 0.395 0.419 0.412 0.434 0.419 0.439 ETTh2 0.333 0.385 0.347 0.398 0.337 0.389 ETTm1 0.320 0.364 0.329 0.333 0.340 0.379 ETTm2 0.239 0.304 0.268 0.307 0.261 0.323 W eather 0.209 0.255 0.212 0.275 0.238 0.274 D. Ev aluation on Additional Datasets T o further v alidate the generalizability of DualW eaver in enhancing Uni-TSFMs for multiv ariate forecasting, we e v al- uate its performance using TimerXL across se veral addi- tional datasets. This expanded ev aluation encompasses the Exchange ( W u et al. , 2021 ), Solar -Energy ( Lai et al. , 2018 ), and IEAC (Industrial Equipment Air Conditioning Dataset)—a real-world industrial dataset collected from a production en vironment. Exchange collects the panel data of daily exchange rates from 8 countries from 1990 to 2016. Solar-Ener gy records solar po wer production from 137 PV plants in 2006, sampled at 10-minute interv als. IEAC is from an HV A C (Heating, V entilation, and Air Condition- ing) system, which comprises fiv e critical parameters: (1) HV A C1 (System Operating Mode): A discrete v ariable in- dicating the current operational state/phases. (2) HV A C2 (Compression Po wer): A continuous v ariable representing the power le vel of the upstream air sources, set by system demand (higher values = greater air source pressure). (3) HV A C3 (Distrib ution Duct Pressure): A continuous v ariable directly reflecting the pressure within the distrib ution lines, primarily driven by HV A C2. (4) HV A C4 (User Pressure): A continuous variable denoting the pressure at do wnstream user systems, influenced by HV AC3 and internal system regulation. (5) HV A C5 (User Flow Rate): A continuous variable indicating the flow rate to downstream user sys- tems, af fected by HV AC3 and internal system regulation. Ke y relationships show a causal chain: HV AC2 determines HV A C3, which subsequently influences both downstream HV A C4 and HV AC5, subject to the HV A C system’ s activ e control. HV A C1 governs system state while performance is regulated via continuous monitoring of pressures (HV A C3 and HV A C4) and flow (HV A C5). The detailed dataset splits are summarized in T able 6 . Given the limited scale of the Ex- 13 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM change dataset, we employ a reduced context length of 512 time points and shorter forecast horizons of { 24 , 36 , 48 , 60 } steps. This configuration ensures sufficient training and testing samples while maintaining statistical reliability . Sev- eral additional multi variate public datasets, such as T raffic (PEMS 3 ), were excluded from e valuation because they are already included in the pre-training datasets used for these Uni-TSFMs. T able 6. Detailed additional dataset descriptions. Dataset Dim Dataset Size Fr equency Exchange 8 (5120, 665, 1422) Daily Solar-Ener gy 137 (36601, 5161, 10417) 10 min IEA C 5 (70000, 10000, 20000) 5s Performance results for the Exchange, Solar-Energy , and IEA C datasets are summarized in T able 7 . DualW eav er achiev es state-of-the-art (SO T A) performance in fiv e out of the six e valuated metrics, with AdaPTS marginally outper - forming it only on the MAE metric for the Solar -Energy dataset. The rob ust forecasting performance across these additional real-world datasets underscores DualW eav er’ s superior generalization capabilities and its potential for de- ployment in di verse industrial en vironments. T able 7. Multi variate forecasting on additional datasets with forecasting horizons ∈ { 24 , 36 , 48 , 60 } for Exchange and ∈ { 96 , 192 , 336 , 720 } for others. A veraged results are reported here with the best in bold . Methods DualW eaver AdaPTS SFT V anilla Metric MSE MAE MSE MAE MSE MAE MSE MAE Exchange 0.055 0.158 0.057 0.163 0.057 0.160 0.064 0.168 Solar-Ener gy 0.354 0.365 0.376 0.359 0.403 0.361 0.517 0.492 IEA C 0.750 0.439 0.754 0.441 0.767 0.479 0.930 0.562 E. Multivariate Corr elations The Cross-Time Cross-V ariate Correlation Coefficient ( Liu et al. , 2024a ) quantifies dynamic relationships between variates across asynchronous periods. By computing co- variance between standardized subsequences from dif ferent vari ates in offset time windo ws, this metric captures delayed dependencies that traditional synchronous correlation coef fi- cients cannot rev eal, providing a precise characterization of asynchronous cross-variate interactions essential for model- ing complex multi variate correlations. According to it, we measure the multiv ariate correlations as follows: R ( i,j ) ( t, t ′ , P ) = 1 P P X k =0 x ( i ) t + k − µ ( i ) σ ( i ) · x ( j ) t ′ + k − µ ( j ) σ ( j ) (21) 3 http://pems.dot.ca.gov/ where P = { 32 , 64 , 96 , 128 } is the patch size to measure correlations, µ ( · ) and σ ( · ) are the mean and standard de via- tion of corresponding time series patches. T able 8 presents av eraged results under different patch sizes across fiv e benchmark datasets. W e use several patch lengths to ensure measurement reliability . Notably , ETT series datasets exhibit significantly stronger correlations. In con- trast, the W eather dataset shows consistently weak correla- tions ( < 0 . 0011 ) across all patch sizes. Figure 9 visualizes the Cross-T ime Cross-V ariate Correlation Coefficients for the first 25 patches (patch size=96) of two variables selected from the public datasets ETTm2 and W eather . T able 8. Cross-Time Cross-V ariate Correlation Coefficients Dataset Patch Size P 32 64 96 128 A vg ETTh1 0.0134 0.0116 0.0598 0.0105 0.0238 ETTh2 0.0087 0.0080 0.1094 0.0075 0.0334 ETTm1 0.0306 0.0179 0.0624 0.0148 0.0314 ETTm2 0.0143 0.0101 0.1347 0.0090 0.0420 W eather 0.0007 0.0011 0.0009 0.0002 0.0007 In Section 4.2.3 , we ev aluate the robustness of DualW eav er against irrele vant dimensions. By injecting non-informativ e noise sequences into the ETTh1 dataset, we simulate scenar - ios where cross-variable correlations progressiv ely weaken. Empirical results demonstrate that while the forecasting performance of AdaPTS and Chronos-2 degrades as the number of noise channels increases, DualW eaver maintains a remarkably stable error profile, showcasing its superior resilience to spurious features. T able 9 provides detailed Cross-T ime Cross-V ariate Correlation Coefficient measure- ments for ETTh1 under increasing noise injection. T able 9. Cross-variable correlation decay under synthetic noise injection. Noise Patch Size P Channels 32 64 96 128 A vg 0 0.0134 0.0116 0.0598 0.0105 0.0238 1 0.0105 0.0087 0.0461 0.0080 0.0183 2 0.0078 0.0073 0.0364 0.0065 0.0145 3 0.0068 0.0057 0.0294 0.0052 0.0118 4 0.0055 0.0049 0.0246 0.0044 0.0098 5 0.0046 0.0039 0.0199 0.0038 0.0081 6 0.0039 0.0037 0.0174 0.0033 0.0071 7 0.0033 0.0030 0.0145 0.0028 0.0059 8 0.0027 0.0026 0.0131 0.0024 0.0052 9 0.0027 0.0022 0.0113 0.0022 0.0046 10 0.0023 0.0022 0.0098 0.0023 0.0042 14 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 P atch Inde x (V ariable 0) 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 P atch Inde x (V ariable 2) 0.0 0.4 0.8 Cor r elation Coefficient (a) Correlation Matrix: ETTm2 Dataset 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 P atch Inde x (V ariable 0) 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 P atch Inde x (V ariable 10) 0.0 0.4 0.8 Cor r elation Coefficient (b) Correlation Matrix: W eather Dataset F igure 9. Heatmap for Cross-T ime Cross-V ariate Correlation Co- efficient of ETTm2 and W eather . The color intensity (bright- ness) within the heatmaps directly maps to the absolute mag- nitude of the Cross-T ime Cross-V ariate Correlation Coefficient. Bright re gions (represented by lighter yello w) indicate “correlation hotspots” where the coefficient approaches 0.8, signifying potent synchronous or asynchronous dependencies between the specific variable patches. Con versely , dark regions (represented by deep purple) denote “null zones” where the correlation is near zero, indi- cating that the variables e volve independently without identifiable inter-series relationships in those temporal windo ws. F . T raining Stability From Dual-Surr ogate The dual-surrogate mechanism in DualW eaver bolsters training stability by lev eraging complementary optimiza- tion directions. T o isolate this effect, we introduce Sin- gleW eaver , a baseline formulated with only a single surro- gate: S single = f ( X ) + w α ⊙ X . This ablation baseline enables a direct comparison of optimization stability be- tween single-surrogate and dual-surrogate strategies. W e monitor the stability of gradient updates in the fully connected layers (fc1 and fc2) of the feature-fusion module. Specifically , we compute the Euclidean distance (i.e., the L 2 norm of the difference) between the weight gradients of consecutiv e training steps ( t and t + 1 ) to characterize the magnitude of instantaneous gradient fluctuations. Figure 10 presents the visualized results, with v alues aggregated ev ery four steps to enhance clarity . The results demonstrate that while DualW eaver maintains a remarkably smooth gradient transition, the SingleW eaver suffers from frequent, high- magnitude spikes. This contrast underscores that our dual- tuned approach ef fectiv ely mitigates optimization instability during adaptation. 0 50 100 150 200 T raining Step T ransition 0.000 0.005 0.010 G r a d i e n t N o r m ( L 2 ) SingleW eaver (fc1) DualW eaver (fc1) 0 50 100 150 200 T raining Step T ransition 0.01 0.02 0.03 0.04 0.05 G r a d i e n t N o r m ( L 2 ) SingleW eaver (fc2) DualW eaver (fc2) F igure 10. Comparison of gradient dynamics and training stability . W e visualize the L 2 norm of weight gradient differences between consecutiv e steps ( ∇ W t +1 − ∇ W t ) for the fully-connected layers of the feature-fusion module. DualW eaver maintains a remarkably smooth, consistent gradient transition, underscoring the superior numerical stability of our dual-surrogate optimization framework. G. Full Results Comprehensi ve experimental results across the primary pub- lic benchmark datasets are pro vided in T able 10 . The bold and underlined respecti vely denote the best and second-best results for each horizon. Experimental results for T ime- Pro, SimpleTM, T imeMixer , and iT ransformer are officially reported in ( Ma et al. , 2025 ) and ( Chen et al. , 2025 ). 15 DualW eaver: Synergistic Featur e W eaving Surr ogates for Multi variate For ecasting with Uni-TSFM T able 10. Multiv ariate forecasting results on public datasets with forecasting horizons ∈ { 96 , 192 , 336 , 720 } . Methods DualW eaver AdaPTS SFT V anilla TimePr o SimpleTM T imeMixer iT rans. (Ours) (2025) (2025) (2025) (2024) (2024) Metirc MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE ETTh1 96 0.352 0.380 0.351 0.387 0.360 0.384 0.366 0.392 0.375 0.398 0.366 0.392 0.381 0.401 0.386 0.405 192 0.401 0.410 0.401 0.421 0.411 0.415 0.415 0.419 0.427 0.429 0.422 0.421 0.440 0.433 0.441 0.436 336 0.434 0.431 0.437 0.445 0.452 0.438 0.450 0.439 0.472 0.450 0.440 0.438 0.501 0.462 0.487 0.458 720 0.437 0.456 0.456 0.479 0.486 0.474 0.446 0.457 0.476 0.474 0.463 0.462 0.501 0.482 0.503 0.491 A vg 0.406 0.419 0.411 0.433 0.427 0.428 0.419 0.427 0.438 0.438 0.422 0.428 0.458 0.445 0.454 0.447 ETTh2 96 0.274 0.336 0.280 0.349 0.280 0.338 0.287 0.345 0.293 0.345 0.281 0.338 0.292 0.343 0.297 0.349 192 0.334 0.378 0.341 0.389 0.339 0.378 0.347 0.385 0.367 0.394 0.355 0.387 0.374 0.395 0.380 0.400 336 0.371 0.404 0.376 0.416 0.377 0.406 0.387 0.412 0.419 0.431 0.365 0.401 0.428 0.433 0.428 0.432 720 0.383 0.426 0.395 0.440 0.401 0.433 0.413 0.440 0.427 0.445 0.413 0.436 0.454 0.458 0.427 0.445 A vg 0.340 0.386 0.348 0.399 0.349 0.389 0.359 0.396 0.377 0.403 0.353 0.391 0.384 0.407 0.383 0.407 TimerXL ETTm1 96 0.272 0.330 0.273 0.338 0.285 0.334 0.307 0.355 0.326 0.364 0.321 0.361 0.328 0.363 0.334 0.368 192 0.306 0.356 0.318 0.371 0.331 0.363 0.356 0.386 0.367 0.383 0.360 0.380 0.364 0.384 0.377 0.391 336 0.343 0.386 0.355 0.401 0.384 0.398 0.411 0.419 0.402 0.409 0.390 0.404 0.390 0.404 0.426 0.420 720 0.430 0.444 0.442 0.460 0.507 0.466 0.514 0.477 0.469 0.446 0.454 0.438 0.458 0.445 0.491 0.459 A vg 0.338 0.379 0.347 0.392 0.377 0.390 0.397 0.409 0.391 0.400 0.381 0.396 0.385 0.399 0.407 0.410 ETTm2 96 0.158 0.246 0.166 0.268 0.161 0.248 0.191 0.279 0.178 0.260 0.173 0.257 0.176 0.259 0.180 0.264 192 0.219 0.291 0.228 0.311 0.219 0.292 0.244 0.317 0.242 0.303 0.238 0.299 0.242 0.303 0.250 0.309 336 0.281 0.335 0.290 0.352 0.280 0.336 0.299 0.357 0.303 0.342 0.296 0.338 0.304 0.342 0.311 0.348 720 0.382 0.398 0.389 0.414 0.385 0.403 0.416 0.434 0.400 0.399 0.393 0.395 0.393 0.397 0.412 0.407 A vg 0.260 0.318 0.268 0.336 0.261 0.320 0.288 0.347 0.281 0.326 0.275 0.322 0.278 0.325 0.288 0.332 W eather 96 0.146 0.199 0.151 0.220 0.149 0.204 0.169 0.225 0.166 0.207 0.162 0.207 0.165 0.212 0.174 0.214 192 0.192 0.246 0.194 0.259 0.194 0.250 0.212 0.267 0.216 0.254 0.208 0.248 0.209 0.253 0.221 0.254 336 0.242 0.289 0.244 0.308 0.243 0.292 0.270 0.318 0.273 0.296 0.263 0.290 0.264 0.293 0.278 0.296 720 0.322 0.348 0.318 0.350 0.326 0.354 0.367 0.393 0.351 0.346 0.340 0.341 0.342 0.345 0.358 0.347 A vg 0.225 0.271 0.227 0.284 0.228 0.275 0.254 0.301 0.251 0.276 0.243 0.271 0.245 0.276 0.258 0.278 ETTh1 96 0.340 0.379 0.344 0.385 0.349 0.385 0.354 0.390 0.375 0.398 0.366 0.392 0.381 0.401 0.386 0.405 192 0.381 0.406 0.384 0.410 0.391 0.413 0.400 0.423 0.427 0.429 0.422 0.421 0.440 0.433 0.441 0.436 336 0.405 0.422 0.433 0.445 0.420 0.433 0.430 0.445 0.472 0.450 0.440 0.438 0.501 0.462 0.487 0.458 720 0.455 0.470 0.487 0.494 0.484 0.493 0.493 0.499 0.476 0.474 0.463 0.462 0.501 0.482 0.503 0.491 A vg 0.395 0.419 0.412 0.434 0.411 0.431 0.419 0.439 0.438 0.438 0.422 0.428 0.458 0.445 0.454 0.447 ETTh2 96 0.268 0.330 0.273 0.340 0.271 0.331 0.274 0.335 0.293 0.345 0.281 0.338 0.292 0.343 0.297 0.349 192 0.325 0.375 0.334 0.385 0.329 0.377 0.331 0.379 0.367 0.394 0.355 0.387 0.374 0.395 0.380 0.400 336 0.351 0.399 0.361 0.408 0.358 0.403 0.358 0.404 0.419 0.431 0.365 0.401 0.428 0.433 0.428 0.432 720 0.388 0.436 0.421 0.458 0.387 0.437 0.387 0.438 0.427 0.445 0.413 0.436 0.454 0.458 0.427 0.445 A vg 0.333 0.385 0.347 0.398 0.336 0.387 0.337 0.389 0.377 0.403 0.353 0.391 0.384 0.407 0.383 0.407 Sundial ETTm1 96 0.261 0.324 0.268 0.334 0.288 0.333 0.285 0.337 0.326 0.364 0.321 0.361 0.328 0.363 0.334 0.368 192 0.307 0.355 0.313 0.365 0.334 0.366 0.325 0.369 0.367 0.383 0.360 0.380 0.364 0.384 0.377 0.391 336 0.333 0.374 0.342 0.387 0.354 0.385 0.353 0.391 0.402 0.409 0.390 0.404 0.390 0.404 0.426 0.420 720 0.375 0.403 0.393 0.424 0.387 0.411 0.395 0.420 0.469 0.446 0.454 0.438 0.458 0.445 0.491 0.459 A vg 0.319 0.364 0.329 0.377 0.341 0.374 0.340 0.379 0.391 0.400 0.381 0.396 0.385 0.399 0.407 0.410 ETTm2 96 0.153 0.240 0.163 0.267 0.155 0.240 0.173 0.259 0.178 0.260 0.173 0.257 0.176 0.259 0.180 0.264 192 0.207 0.282 0.231 0.325 0.212 0.283 0.231 0.303 0.242 0.303 0.238 0.299 0.242 0.303 0.250 0.309 336 0.259 0.320 0.294 0.371 0.265 0.320 0.284 0.340 0.303 0.342 0.296 0.338 0.304 0.342 0.311 0.348 720 0.336 0.373 0.383 0.426 0.341 0.372 0.355 0.391 0.400 0.399 0.393 0.395 0.393 0.397 0.412 0.407 A vg 0.239 0.304 0.268 0.347 0.243 0.304 0.261 0.323 0.281 0.326 0.275 0.322 0.278 0.325 0.288 0.332 W eather 96 0.137 0.187 0.139 0.206 0.138 0.187 0.160 0.208 0.166 0.207 0.162 0.207 0.165 0.212 0.174 0.214 192 0.180 0.233 0.184 0.254 0.181 0.233 0.209 0.255 0.216 0.254 0.208 0.248 0.209 0.253 0.221 0.254 336 0.228 0.275 0.233 0.297 0.229 0.273 0.258 0.292 0.273 0.296 0.263 0.290 0.264 0.293 0.278 0.296 720 0.292 0.323 0.292 0.342 0.293 0.322 0.326 0.339 0.351 0.346 0.340 0.341 0.342 0.345 0.358 0.347 A vg 0.209 0.255 0.212 0.275 0.210 0.254 0.238 0.274 0.251 0.276 0.243 0.271 0.245 0.276 0.258 0.278 1 st 33 32 3 0 3 3 0 0 0 0 1 5 0 0 0 0 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment