MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline
Song generation aims to produce full songs with vocals and accompaniment from lyrics and text descriptions, yet end-to-end models remain data- and compute-intensive and provide limited editability. We advocate a compositional alternative that decompo…
Authors: Fang-Duo Tsai, Yi-An Lai, Fei-Yueh Chen
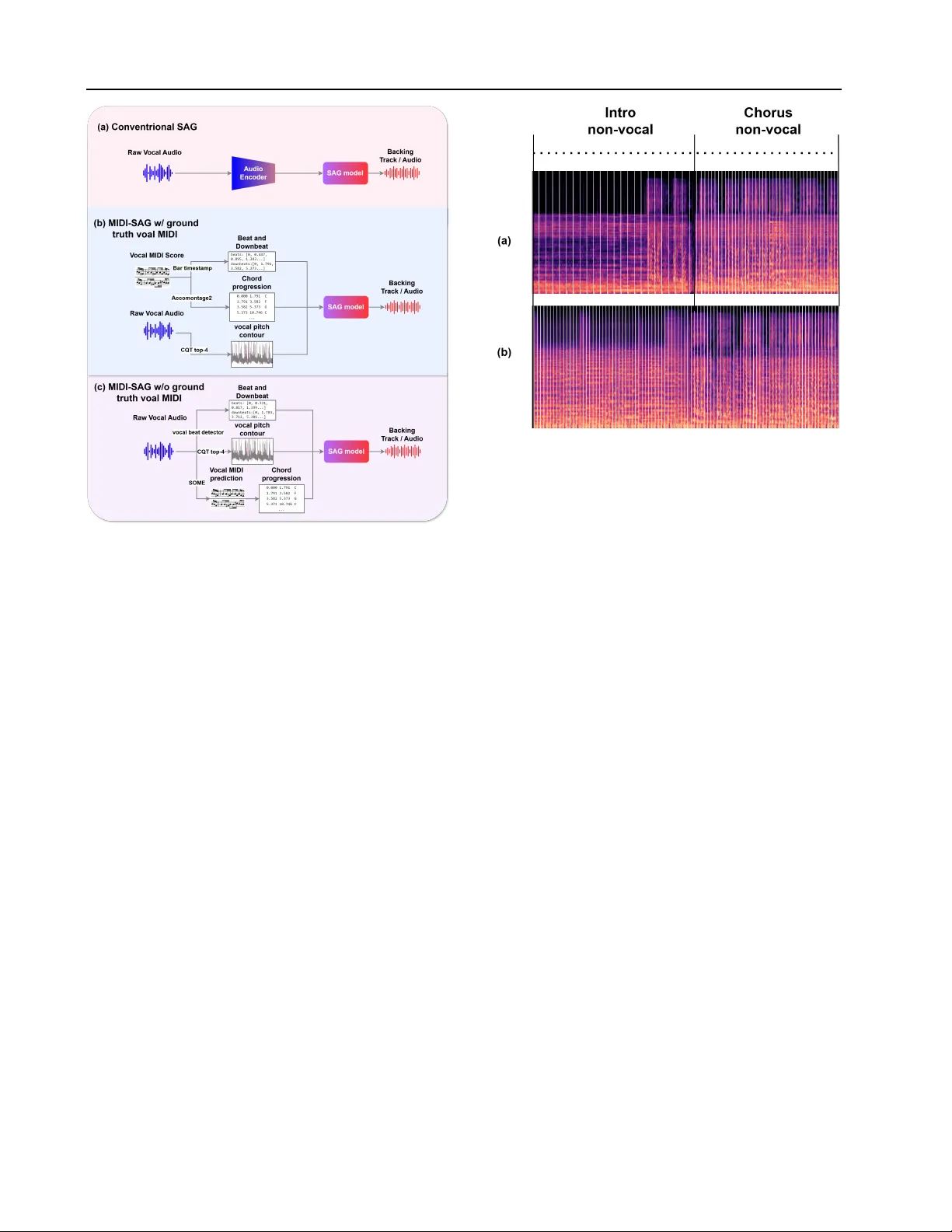
MIDI-Inf ormed Singing Accompaniment Generation in a Compositional Song Pipeline Fang-Duo Tsai 1 2 Y i-An Lai 1 Fei-Y ueh Chen 3 Hsueh-W ei Fu 1 Li Chai 4 W ei-Jaw Lee 1 2 Hao-Chung Cheng 1 Y i-Hsuan Y ang 1 2 Abstract Song generation aims to produce full songs with vocals and accompaniment from lyrics and te xt descriptions, yet end-to-end models remain data- and compute-intensive and provide limited ed- itability . W e advocate a compositional alternati ve that decomposes the task into melody composi- tion, singing voice synthesis, and singing accom- paniment generation. Central to our approach is MIDI-informed singing accompaniment g enera- tion (MIDI-SA G), which conditions accompani- ment on the symbolic vocal-melody MIDI to im- prov e rhythmic and harmonic alignment between singing and instrumentation. Moreover , beyond con ventional SA G settings that assume continu- ously sung vocals, compositional song genera- tion features intermittent vocals; we address this by combining explicit rhythmic/harmonic con- trols with audio continuation to keep the back- ing track consistent across vocal and non-vocal regions. W ith lightweight ne wly trained compo- nents requiring only 2.5k hours of audio on a single R TX 3090, our pipeline approaches the per - ceptual quality of recent open-source end-to-end baselines in se veral metrics. W e provide audio de- mos and will open-source our model at https: //composerflow.github.io/web/ . 1. Intr oduction T raditional song production is a collaborati ve, multi-stage workflo w—spanning songwriting, arrangement, recording, and mixing—that relies on specialized e xpertise and itera- tiv e feedback within a Digital Audio W orkstation. While this process offers high fidelity and granular editability , it is remarkably resource-intensi ve; changes at an y stage often trigger a laborious cascade of downstream rew ork. This ten- 1 National T aiwan Uni versity 2 T aiwan AI Labs 3 Univ ersity of Rochester 4 Independent researcher. Correspondence to: Fang-Duo Tsai < fundwotsai2001@gmail.com > . Pr eprint. F ebruary 26, 2026. sion between control and cost highlights a critical need for computational systems that can automate production while retaining the modular editability of con ventional pipelines. Recent advances in large generativ e models hav e led to commercial systems (e.g., Suno ( 2025 )) and emerging open- source models ( Y uan et al. , 2025 ; Liu et al. , 2025b ; Ning et al. , 2025 ; Gong et al. , 2025 ; Y ang et al. , 2025b ; Lei et al. , 2025 ; Liu et al. , 2025a ; Y ang et al. , 2026 ) that demonstrate high-quality , con venient song generation. Unlike the tra- ditional studio workflo w , these models typically adopt a monolithic, end-to-end approach, mapping lyrics and text directly to audio. Howe ver , this paradigm has significant hurdles: (i) the lack of interpretable intermediates makes refining specific musical elements difficult; (ii) the mapping is notoriously data- and compute-hungry; and (iii) the black- box nature often leads to rhythmic/harmonic misalignment or raises concerns regarding v oice identity and rights. A compelling, yet currently under -explored, alternati ve to monolithic systems is the compositional approach, which utilizes a sequence of specialized modules to construct the final audio. By decomposing the pipeline into three discrete sub-tasks—melody composition, singing voice synthesis (SVS), and singing accompaniment generation (SA G)—we introduce two critical intermediate representations: the vo- cal MIDI score and the synthesized singing audio . This modularity mirrors the professional D A W workflow , of fer- ing granular editability (e.g., refining a melody via MIDI) and significantly lower training costs for each component compared to massiv e, all-in-one architectures. While the compositional concept is established, na ¨ ıvely chaining off-the-shelf components often results in systemic decoherence, manifesting as beat misalignment, harmonic drift, and artifacts at vocal-silent transitions. W e identify two primary gaps in the current literature: (i) a lack of rigorous empirical benchmarks comparing the resource effi- ciency and performance of compositional pipelines against end-to-end architectures, and (ii) a tendency to treat com- ponents in isolation , which neglects critical interdependen- cies. 1 W e argue that achie ving optimal data efficienc y and 1 For example, V ersBand ( Zhang et al. , 2025c ) proposed a 1 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline perceptual quality requires more than simple concatenation; components must be co-designed to ensure the intermediate representations (e.g., MIDI) ef fectiv ely bridge the sub-tasks. Our core technical contribution is the introduction of MIDI- informed singing accompaniment generation ( MIDI-SA G ), a novel cross-stage conditioning mechanism. While ex- isting audio-SA G methods (e.g., ( Donahue et al. , 2023 ; Chen et al. , 2024 ; T rinh et al. , 2024 ; Zhang et al. , 2025c )) rely solely on raw vocal audio, we exploit the symbolic vocal MIDI score M from the preceding stage as an ex- plicit conditioning signal. 2 This approach significantly bol- sters rhythmic consistency , as we can more easily trace the beats and downbeats from the MIDI input than from the vocal audio. Moreov er , we enhance harmonic consis- tency by integrating a melody harmonization module ( Y i et al. , 2022 ) to deri ve chord progressions from the MIDI. This dual-conditioning—symbolic melody and explicit chords—provides the generator with a structural roadmap unav ailable in traditional audio-only frameworks. Furthermore, we address the challenge of structural com- pleteness . While con ventional SA G models often assume continuous vocal input, real-world song generation requires coherent instrumentation during v ocal-silent segments, such as intros, bridges, and outros. Although end-to-end models handle these transitions implicitly , compositional pipelines risk disjointedness when the primary conditioning signal vanishes. W e resolve this by combining global rhythmic and chordal constraints with the inpainting and outpainting capabilities of latent diffusion ( Tsai et al. , 2025 ). This ap- proach ensures structural integrity and stylistic consistenc y across the entire track, effectiv ely bridging the g aps between intermittent vocal se gments. While our compositional framew ork is model-agnostic, our implementation lev erages CSL-L2M ( Chai & W ang , 2025 ) for melody composition while we train the SVS and MIDI- SA G modules in-house (see Figure 1 ). The SVS compo- nent utilizes a FastSpeech-based architecture ( Ren et al. , 2020 ) trained on 10 hours of data from two licensed pro- fessional singers. For MIDI-SA G, we curate 2.5k hours of pop recordings, and adapt MuseControlLite ( Tsai et al. , 2025 ) to introduce time-varying controls into Stable Audio Open ( Ev ans et al. , 2025 ). Notably , the entire pipeline was trained on a single R TX 3090 GPU. This highlights a sig- framew ork with four separate components—L yricBand, Melody- Band, V ocalBand, and AccompBand—that is similar to our com- positional pipeline. Ho wev er, V ersBand only generates audio of 10 seconds, not long-form audio. Specifically , their AccompBand follows the con ventional SA G setting and uses vocal audio directly as input, not exploring MIDI-based representations of v ocal, and the case of intermittent vocal seen in long-form music. 2 Even without ground-truth v ocal MIDI, MIDI-informed SAG remains applicable: we can e xtract a v ocal-MIDI representation directly from the input vocal audio. W e tackle this in Section 3.4 . System T raining Data (hrs) GPUs Used for T raining Y uE 650K 16 × H800 DiffRh ythm 60K 8 × Ascend 910B A CE-Step 100K 120 × A100 SongBloom 100K 16 × A100 J AM 54K 8 × H100 Lev o 110K 8 × A100 Ours 2.5K 1 × 3090 T able 1. Comparison of the proposed compositional pipeline with existing open-source, end-to-end song generation models. See T able 10 in the appendix for more details. nificant reduction in computational ov erhead compared to massiv e open-source baselines (see T able 1 ), while provid- ing promising empricial results, editable intermediates, and the use of licensed singing voices. Our contributions are three-fold: (i) MIDI-SA G, condition- ing SA G on the vocal MIDI score; (ii) structural complete- ness, supporting intermittent vocals for consistent backing; and (iii) a modular , data-efficient compositional pipeline trained on a single consumer GPU and validated through extensi ve objectiv e and subjectiv e ev aluations against state- of-the-art end-to-end baselines. Audio samples, including mid-pipeline editability demos, are av ailable on our demo page. W e will open-source our model, code, and dataset metadata upon publication. 2. Related W ork Musical audio generation has ev olved rapidly , with text- to-music (TTM) models ( Agostinelli et al. , 2023 ; Copet et al. , 2024 ; Liu et al. , 2024 ; Fei et al. , 2024 ; Nov ack et al. , 2025 ; Y ang et al. , 2025a ; Zhang et al. , 2025a ; Ev ans et al. , 2025 ; Niu et al. , 2026 ) focusing primarily on instrumental synthesis. In contrast, lyrics-to-song generation produces in- tegrated vocal and instrumental audio. Following early work like Jukebox ( Dhariwal et al. , 2020 ), and commercial sys- tems like Suno ( 2025 ), a proliferation of open-source models has emerged, including autoregressi ve framew orks ( Y uan et al. , 2025 ; Lei et al. , 2025 ; Y ang et al. , 2026 ), and diffusion- based architectures ( Ning et al. , 2025 ; Jiang et al. , 2025 ; Gong et al. , 2025 ; Y ang et al. , 2025b ). Despite their high fidelity , these end-to-end approaches suffer from prohibitive computational costs (cf. T able 1 ) and monolithic architec- tures that lack transparenc y and user control, moti vating our compositional alternativ e. Prior to end-to-end models, research addressed sub-tasks in isolation, including lyrics-to-melody generation ( Y u et al. , 2021 ; Sheng et al. , 2021 ; Ju et al. , 2021 ), SVS ( Lu et al. , 2020 ; Chen et al. , 2020 ; Liu et al. , 2022 ), and SA G ( Don- ahue et al. , 2023 ). Howe ver , these works often lack a uni- 2 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline F igure 1. Overvie w of the compositional song generation pipeline. The system sequentially maps lyrics to a full song through: (1) Melody Composition (CSL-L2M), (2) SVS (FastSpeech-based), (3) Melody Harmoniz ation (AccoMontage2), and (4) the proposed MIDI-SA G, which adapts MuseControlLite to incorporate symbolic and acoustic conditioning for final accompaniment synthesis. fied framew ork for full-scale song generation. For instance, Melodist ( Hong et al. , 2024 ) focuses on integrating SVS and SA G but relies on pre-supplied melodies, while Song- Composer ( Ding et al. , 2025 ) targets the upstream lyrics- to-melody task. While V ersBand ( Zhang et al. , 2025c ) im- plements a complete compositional pipeline, it is limited to short-form (10-second) clips. Existing audio-SAG models ( Donahue et al. , 2023 ; Chen et al. , 2024 ; Trinh et al. , 2024 ; Zhang et al. , 2025b ; c ) rely exclusi vely on raw vocal audio, assuming no access to sym- bolic MIDI. By neglecting the symbolic prior, audio-only models struggle to maintain harmonic and rhythmic preci- sion, especially during complex performances. Furthermore, we address the challenges of long-range structural coher- ence/completeness required for full-length songs, which remains largely unaddressed in e xisting SA G literature. 3. Compositional Song Generation Framework Formally , we define a compositional pipeline P for song generation as a sequence of modular mappings { T 1 , T 2 , T 3 } . Giv en a user -provided lyric sequence L and a text descrip- tion D , the pipeline generates the final song waveform A through a chain of intermediate representations. { L, D } T 1 − → M T 2 − → V T 3 ( D,M ,C,V ) − − − − − − − − − → A , (1) where T 1 (melody composition) maps { L, D } to a sym- bolic vocal MIDI score M , specifying the pitch and du- ration of each syllable; T 2 (SVS) maps M and L to the vocal-only audio wa veform V characterized by intermittent vocal segments and silences; and T 3 represents the proposed MIDI-informed accompaniment generator . Unlike traidi- tional audio-SA G, which maps V directly to A , the the proposed MIDI-SA G exploits the data coupling within the pipeline to learn the more robust mapping { D , M , V } → A . Moreov er , for stronger harmonic coherence, we introduce an auxiliary sub-task “melody harmonization” ( T 4 ). This module maps the symbolic vocal melody M to a structured chord progression sequence C (i.e., T 4 : M → C ), which serves as an explicit harmonic constraint for the accom- paniment. Consequently , our MIDI-SAG actually learns { D , M , C , V } → A . By conditioning on C , the generator mov es beyond simple v ocal-following to a more proacti vely structured orchestration, where the instrumental arrange- ment is grounded in a musically consistent harmonic frame- work deri ved from the source melody . Figure 1 provides a model o vervie w . W e outline each mod- ule below , focusing more on the MIDI-SA G part. 3.1. Melody Composition ( T 1 ) & Singing Synthesis ( T 2 ) W e assume the user provides full-song, sentence-le vel lyrics L with structural markers (e.g., intro, verse, chorus). No- tably , our pipeline does not require sentence-lev el times- tamps as needed in some recent end-to-end models (e.g., DiffRh ythm ( Ning et al. , 2025 )). The melody composition module ( T 1 ) maps L to the symbolic MIDI representation M . While the mapping between lyrics and melody is non- deterministic and weakly correlated, we lev erage established generativ e models for this stage ( Chai & W ang , 2025 ). W e emphasize that in end-to-end models, melody compo- sition is performed implicitly , offering no interpretable or editable intermediate representation. In contrast, we treat M as an e xplicit, structur ed prior serving as the foundational 3 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline F igure 2. Architectural comparison of SA G variants: (a) Con ven- tional audio-SA G; (b) the proposed MIDI-SA G with ground-truth vocal MIDI score (Section 3.2 ); (c) the MIDI-SAG variant that uses automatically extracted MIDI representation (Section 3.4 ). coordinate system for all downstream modules ( T 2 , T 3 , T 4 ). SVS ( T 2 ) is integrated into our pipeline to mitigate the unnatural v ocal timbres and high word error rates frequently observed in end-to-end models ( Liu et al. , 2025a ). It also allows for the use of licensed voices. W e can use any high- fidelity SVS model to render the vocal wa veform V from { L, M } . Importantly , the symbolic melody M acts as a structural anchor , explicitly defining instrumental passages (e.g., intros, bridges) where V must remain silent, ensuring synchronization with the global temporal song structure. 3.2. MIDI-informed Accompaniment Generation ( T 3 ) Giv en the synthesized vocal V , the SA G module generates the complementary accompaniment to produce the final mix A . This task requires precise temporal synchronization of beat and downbeat structures, alongside harmonic alignment between the vocal melody and the underlying instrumental progression. Existing audio-based SA G models attempt to learn these complex dependencies in an end-to-end fash- ion (Figure 2 (a)); ho wev er , this approach necessitates mas- siv e datasets—often e xceeding 40k hours ( Donahue et al. , 2023 )—to implicitly learn musical structure. Our prelimi- nary studies indicate that under resource-constrained condi- tions (e.g., 2.5k hours of data and a single GPU), audio-only F igure 3. Comparison of rhythmic stability . White stripes represent the predicted beat positions from the generated accompaniment. While (a) audio-SA G loses rhythmic consistency in non-vocal seg- ments, (b) MIDI-SA G maintains stable beat and coherent content. conditioning fails to achie ve suf ficient coherence. MIDI-SA G leverages the pipeline’ s inherent data coupling by using time-varying structural priors from M to guide accompaniment generation (Figure 2 (b)). This strategy pro- vides two distinct adv antages o ver audio-only SAG methods. First, it ensures rhythmic precision by utilizing the unam- biguous beat and downbeat timings inherent in the symbolic melody , bypassing the noise and estimation errors typical of raw audio analysis. Second, it provides explicit harmonic guidance by integrating a chord progression C deri ved from M via an off-the-shelf harmonization module ( Y i et al. , 2022 ) as a conditioning signal. This dual-conditioning on M and C establishes a consistent musical roadmap for both vocal and instrumental sections, significantly reducing har- monic drift and rhythmic misalignment. 3.3. Proposed T echniques f or Structural Completeness Importantly , MIDI-SA G ensures structural completeness across the entire song architecture. While latent diffusion models inherently support inpainting for smooth transitions, our framework provides explicit rhythmic and harmonic constraints e ven during instrumental passages where vo- cal audio is absent. Con ventional SA G models, lacking this symbolic guidance, often struggle to maintain coher - ence during v ocal silences. In contrast, MIDI-SA G treats these segments as constrained generation tasks, ensuring a musically consistent accompaniment reg ardless of vocal presence. See Figure 3 for an examplar instrumental intro. In particular , to effecti vely handle se gments without v ocal 4 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline guidance and ensure coherence across full-length songs, we introduce the following tw o core strategies. Section-anchor ed slicing is designed to maintain structural integrity across the discrete segments, or windows , required by our latent diffusion backbones. Rather than slicing audio at arbitrary time interv als, we align each generation windo w with song section boundaries. By anchoring a window at the start of a functional section (e.g., verse, chorus, bridge), the model learns to synthesize transitions that respect the song’ s architectural layout, using the preceding section’ s audio as a reference for the current generation. Backwar d continuation addresses the “cold start” problem during instrumental intros, where the absence of vocal pitch signals leads to impov erished conditioning. During training, if a target window begins with an intro, we replace the reference audio with a subsequent verse section with a 50% probability . This strategy encourages the model to maintain stylistic and harmonic consistency across the entire track, effecti vely allowing the tonal characteristics of the main song body to inform the preceding instrumental sections. 3.4. MIDI-SA G without Ground-truth V ocal MIDI Finally , we extend the applicability of MIDI-SA G to gen- eral vocal-to-accompaniment scenarios where ground-truth symbolic data is una vailable. In this setting, the structural conditions ( M , C ) must be estimated directly from the vocal input V (Figure 2 (c)). W e utilize SOME ( open vpi , 2023 ) for MIDI extraction and a custom-trained singing beat detector following He ydari & Duan ( 2022 ) for rhythmic alignment. T o ensure stability across the entire song, we address a key limitation of beat detectors: their tendency to produce random activ ations during vocal silence, which misleads Dynamic Bayesian Network post-processing ( B ¨ ock et al. , 2016 ). W e integrate Silero V AD ( Silero T eam , 2024 ) to iso- late vocal-present se gments for direct beat detection, while for silent se gments, we interpolate timestamps using a BPM inferred from neighboring re gions. This robust estimation pipeline allo ws MIDI-SA G to work well even when the symbolic prior is not part of the original input, significantly broadening its utility for real-world audio-only applications. 4. System Implementation Our pipeline integrates two fixed, pre-trained models for symbolic generation (Figure 1 ), CSL-L2M ( Chai & W ang , 2025 ) for melody composition ( T 1 ), and AccoMontage2 ( Y i et al. , 2022 ) for harmonization ( T 4 ) (see Appendix A.1.1 – A.1.2 for details). W e freeze T 1 and T 4 to focus training exclusi vely on the SVS and MIDI-SAG modules. While these specific architectures were selected for prototyping, the framew ork is model-agnostic. Howe ver , due to CSL- L2M’ s language support, our implementation focuses on T able 2. Conditioning signals used during training and inference for MIDI-SA G. Featur e T raining Inference V ocal pitch V ocal CQT top- 4 ( Hou et al. , 2025 ) V ocal CQT top-4 ( Hou et al. , 2025 ) Rhythm Allin1 ( Kim & Nam , 2023 ) From generated vocal MIDI Chord Chord detec- tion ( Park et al. , 2019 ) Accomontage2 ( Y i et al. , 2022 ) Structure Allin1 ( Kim & Nam , 2023 ) User-pro vided Ke y Ke y CNN ( Schreiber & M ¨ uller , 2019 ) User-pro vided or from vocal MIDI Ref. audio Mask one struc- ture; others as ref- erence From previous song- structure segment Mandarin SVS and pop MIDI-SA G. For SVS ( T 2 ), we train FastSpeech ( Ren et al. , 2020 ) from scratch using a 10-hour internal corpus from two licensed singers (male/female) with aligned MIDI, phonemes, and melspectrograms. The model was trained for 24 hours on a single NVIDIA R TX 3090. See Appendix A.1.3 for details. W e implement MIDI-SA G ( T 3 ) by fine-tuning Stable Au- dio Open (SA O) ( Evans et al. , 2025 ), a latent diffusion TTM model naturally optimized for instrumental genera- tion. Our approach utilizes MuseControlLite ( Tsai et al. , 2025 ) adapters to inject time-v arying controls, which are temporally interpolated and concatenated along the cross- attention feature dimension. W e fine-tune the system on 2.5k hours of Mandarin pop using the same 3090 GPU for 9 days (see Appendix A.1.4 for details). T o adapt SA O for full-scale song generation, we extend the continuation strategy of Tsai et al. ( 2025 ) to bypass the 47s context limit and, unlike the original cross-attention-only fine-tuning, we additionally unfreeze selected self-attention blocks. This allows the backbone to learn smoother structural transitions (see T able 9 in the appendix for empirical data). T o overcome the challenges of low-resource, long-form generation, we employ a more extensi ve set of global and time-varying controls than the original MuseControlLite. As sho wn in T able 2 , we address the discrepanc y between training (where ground-truth accompaniment is av ailable) and inference (where signals must be deri ved from v ocals audio or symbolic melody). Our preliminary experiments (cf. T able 7 ) confirmed that excluding chord or rhythm conditions led to unstable harmony and poor temporal align- ment. Specifically , we resolve the failure of standard beat trackers on dry vocals by deri ving rhythm directly from the T 1 MIDI at inference time. T o ensure structural coherence, 5 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline all conditioning boundaries are aligned with do wnbeats or song section transitions. See Appendix A.1.5 for details. 4.1. Inference Pr ocess of the Pr oposed Pipeline At inference, the system translates user-pro vided lyrics and structure tags into a full song (Figure 1 ). The melody com- position module ( T 1 ) first generates a symbolic vocal score, which is fed to the SVS model ( T 2 ) to synthesize the singing voice. Since the realized vocal pitch may naturally de viate from quantized MIDI, we extract the pitch contour directly from the SVS output to serve as a precise conditioning signal for the accompaniment. Simultaneously , the harmonization model ( T 4 ) deriv es a chord progression from the T 1 MIDI. T o generate the full backing track, we employ a non-linear sequential approach to bypass the 47s generation limit. W e first synthesize the verse without audio conditioning, then generate the intr o using the verse as a “backward refer- ence” (cf. Section 3.3 ). Subsequent segments are generated section-by-section, each conditioned on the previously syn- thesized audio window , until the outr o . Finally , the com- pleted accompaniment is mix ed with the singing v oice via summation and peak normalization. 5. Experimental Setup Our e valuation consists of three parts. Experiment 1 bench- marks our MIDI-SA G (without ground-truth MIDI) against existing audio-SAG baselines for the standard 10-second accompaniment generation task. W e restrict this compar- ison to 10-second segments containing continuous vocals to maintain parity with existing models, which do not inher- ently support longer durations or intermittent v ocal silence (see T able 3 ). W e select FastSA G ( Chen et al. , 2024 ) and AnyAccomp ( Zhang et al. , 2025b ) as the baselines, e xclud- ing SingSong ( Donahue et al. , 2023 ) and V ersBand ( Zhang et al. , 2025c ) as their checkpoints are not av ailable. For ev aluation, we employ Accompaniment Prompt Ad- herence ( AP A ) ( Grachten & Nistal , 2025 ), a measure for ev aluating music accompaniment that is the higher the bet- ter . W e use the MUSDB18 ( Rafii et al. , 2017 ) test set as the ev aluation dataset and its training set as the reference. For fairness, all audio is segmented into 10-second chunks. Experiment 2 considers an extended 47-second accompa- niment generation task to inv estigate the performance gap between audio-SA G and MIDI-SAG using a shared model backbone (Figure 2 ). Specifically , we implement an ablated version of our SA O-based model that relies exclusi vely on the reference audio as its conditioning signal, discarding all symbolic inputs. W e then compare this pure audio-SAG baseline against the proposed MIDI-SAG using a test set of 200 clips randomly selected from the MUSDB18 ( Rafii et al. , 2017 ) test set. All models e valuated here are trained T able 3. Result of Experiment 1, comparing our MIDI-SA G and existing SA G baselines. F or fairness, we use only vocal audio input (i.e., without ground-truth vocal MIDI) here. AnyAccomp FastSAG Our MIDI-SA G w/o ground truth vocal MIDI Base generation length 10s 10s 47s Potential of ev en longer generation ✗ ✗ ✓ T ext control capability ✗ ✗ ✓ Training data (hrs) 8k 3k 2.5k AP A ( Grachten & Nistal , 2025 ) ↑ 0.457 0.000 0.595 T able 4. Result of Experiment 2, comparing the performance of audio-only and MIDI-informed SA G for 47s accompaniment generation using the same Stable Audio Open (SA O) backbone. Method Rhythm F1 Key acc. Audio-SA G (Figure 2 (a)) 0.64 0.55 MIDI-SA G w/ ground-truth MIDI (Figure 2 (b)) 0.91 0.93 MIDI-SA G w/o ground truth MIDI (Figure 2 (c)) 0.77 0.91 with 40k steps with a batchsize of 64, using MuseControl- Lite to learn the time-varying condition. T o quantify performance, we focus on rhythm and tonal con- sistency . Following Wu et al. ( 2024a ), we use the Rhythm F1 score to ev aluate alignment between v ocals and accom- paniment; a detected beat is considered correct if it falls within 70ms of the ground truth. Additionally , we measure Key Accuracy , where a prediction is deemed correct only if both the pitch class and mode (major/minor) match the reference. These metrics allow us to isolate the contribution of symbolic MIDI controls to the structural and harmonic stability of the generated output. Experiment 3 ev aluates the full compositional pipeline on generating complete tracks of 90–120 seconds. This ex- periment assesses the system’ s ability to maintain structural and harmonic coherence over extended durations where vocals may be sparse or absent. W e benchmark against sev eral representativ e baselines: Suno v4.5 ( Suno , 2025 ), DiffRh ythm 1.2-base ( Ning et al. , 2025 ), A CE-Step ( Gong et al. , 2025 ), and Le vo ( Lei et al. , 2025 ). 3 Evaluat ion is con- ducted on a 200-sample test set generated via GPT -5, with prompts specifying lyrics (v erse, chorus, outro) and stylistic metadata. T o handle the heterogeneous input requirements of the baselines—ranging from tag-style descriptions in LeV o to timestamped lyrics in DiffRhythm—we reformat the GPT -generated metadata for each model while maintain- ing semantic consistency across all systems. W e employ both objectiv e and subjecti ve measures for this experiment. T o mitigate listener fatigue during subjectiv e ev aluation, we target a standardized intro–verse–chorus–outro structure 3 W e exclude SongGen ( Liu et al. , 2025b ) (30s limit), Song- Bloom ( Y ang et al. , 2025b ) (requires style prompts), and J AM ( Liu et al. , 2025a ) (requires phoneme-level timing) to ensure a fair , reference-free comparison across a common sequence length. 6 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline rather than full-length commercial tracks. For objecti ve ev aluation of song generation, we use a com- prehensiv e set of metrics targeting four ke y musical dimen- sions. Lyrics alignment is measured via phoneme error rate ( PER ) for singing intelligibility . Style alignment is assessed using CLAP embeddings to verify consistency with the provided text prompts. T o reflect human-like judgments of aesthetics and pr oduction quality , we use A udiobox- Aesthetics ( Tjandra et al. , 2025 ) and SongEval ( Y ao et al. , 2025 ). Finally , contr ollability is quantified through Rhythm F1 , K ey Accuracy , and Chord F1 , all computed between the reference and generated audio. Detailed definitions and configurations for these metrics are in Appendix A.2 . For subjecti ve e v aluation of song generation, we conducted a mean opinion score (MOS) listening test with 33 anony- mous participants recruited online. The cohort comprised a diverse group of self-reported music experts and non- experts. Each participant listened to 10 generated samples (representing 5 models across 2 unique prompt-lyric pairs) and rated them on a 5-point Likert scale where 1 signifies poor quality and 5 represents e xcellence. W e assessed the samples across fi ve key dimensions: Overall Preference to measure general aesthetic appeal; L yrics Adherence to verify the alignment between vocal content and input text; Musicality to judge melodic and harmonic coherence; V oice Naturalness to e valuate the human-like quality of the singing; and Song Structure Clarity to determine how well the arrangement follows the prescribed lyrical format. 6. Experimental Results 6.1. Experiment 1: Short-form (10s) SA G This experiment v alidates the fundamental accompaniment generation capabilities of our MIDI-SAG against existing baselines. As shown in T able 3 , our model achiev es the highest AP A score among all ev aluated methods, demon- strating superior alignment with the vocal track. Informal listening (visit the demo page for examples) suggests that our model provides comparable musical quality with Any- Accomp ( Zhang et al. , 2025b ), despite being trained on a smaller dataset—a testament to the ef ficiency of symbolic conditioning. In contrast, F astSA G ( Chen et al. , 2024 ) f ailed to produce meaningful accompaniment, likely due to its sen- sitivity to source separation artif acts present in the training vocals. These results confirm that integrating symbolic con- trols via MuseControlLite adapters ef fectiv ely adapts the SA O backbone for the SA G task. Importantly , as highlighted in T able 3 , our model is the only one capable of incorporat- ing both text-based stylistic controls and generating audio beyond the standard 10-second limit. These features are essential for a unified song-generation pipeline that requires both structural flexibility and long-form coherence. 6.2. Experiment 2: Long-form (47s) SA G This experiment compares the performance of audio-only and MIDI-informed SA G—representing the three v ariants depicted in Figure 2 —for 47s accompaniment generation us- ing a shared SA O backbone. As sho wn in T able 4 , condition- ing directly on vocal audio leads to misaligned rhythm and harmony when training resources and data are limited. In contrast, MIDI-SA G maintains strong harmonic consistenc y regardless of whether ground-truth v ocal MIDI is av ailable. A ke y challenge arises when vocal MIDI is absent, as stan- dard beat detectors cannot accurately predict timestamps during silent vocal se gments. By inferring beat timestamps from adjacent v ocal-present regions, our model maintains structural continuity , though it experiences a 0.14 reduction in Rhythm F1 compared to the ground-truth MIDI setting. Despite this, the MIDI-informed approach still outperforms raw vocal conditioning by a margin of 0.13, demonstrat- ing that symbolic guidance is significantly more robust for long-form generation than pure audio conditioning. 6.3. Experiment 3: Long-Form Song Generation This final experiment compares the proposed compositional song generation pipeline (using ground-truth MIDI from T 1 for MIDI-SA G) against prev ailing end-to-end approaches. T able 5 presents the CLAP scores and PER for all ev al- uated models. W e see that our model attains compara- ble CLAP scores as A CE-Step and DiffRhythm, whereas the closed-source commercial system Suno has the highest CLAP , demonstrating superior text–audio alignment. Our model achie ves the lowest PER, slightly outperforming both A CE-Step and Suno. W e attribute this to the use of an dedi- cated SVS model capable of generating clear and temporally well-aligned vocals in our compositional approach. T able 5 further details performance across specialized ev al- uation framew orks. According to Audiobox-Aesthetics, DiffRh ythm scores the highest o verall, with other mod- els follo wing in a closely grouped cluster . Con versely , SongEval identifies Suno as the strongest performer across all internal dimensions, noting a high correlation between its v arious aesthetic metrics. Our model is slightly weak er than DiffRh ythm but surpasses A CE-Step and LeV o. T able 6 shows the subjecti ve e valuation result. Consistent with the SongEval metrics, Suno outperforms all systems, highlighting a sizable gap between closed- and open-source models. Among open-source baselines, our system ranks abov e DiffRhythm and LeV o in Overall Pr efer ence , but trails ACE-Step. For Lyrics Adher ence , our scores are on par with A CE-Step and exceed other open-source models; this partially di ver ges from the objectiv e Alignment metric. W e hypothesize that participants’ adherence judgments are influenced by perceptual factors be yond phonetic accuracy , ev en though our SVS inherently ensures strong vocal-lyric 7 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline T able 5. Objective e valuation results of Experiment 3 for song generation. Audiobox and SongEval metrics are the higher the better . Model A udiobox SongEval CLAP ↑ PER ↓ CE CU PC PQ Coherence Musicality Memorability Clarity Naturalness Suno v4.5 ( Suno , 2025 ) 0.210 0.290 7.339 7.766 5.333 8.036 4.198 4.011 4.174 4.034 3.939 A CE-Step ( Gong et al. , 2025 ) 0.184 0.238 7.209 7.642 5.820 7.948 3.449 3.214 3.203 3.216 3.162 DiffRhythm ( Ning et al. , 2025 ) 0.187 0.325 7.530 7.791 6.336 8.189 3.740 3.419 3.595 3.512 3.354 LeV o ( Lei et al. , 2025 ) 0.081 0.617 7.565 7.674 4.993 8.295 3.392 3.272 3.198 3.265 3.155 Ours 0.184 0.213 7.590 7.712 6.294 8.240 3.653 3.397 3.442 3.440 3.260 T able 6. Subjectiv e e valuation results of Experiment 3 for song generation (mean ± confidence interval); higher values indicate better performance. Bold denotes the highest value, and underlin- ing indicates the second highest. Model Overall Preference L yrics Adherence Musicality V oice Naturalness Structure Clarity Suno v4.5 4.297 ± 0.194 4.375 ± 0.188 4.344 ± 0.201 4.188 ± 0.195 4.297 ± 0.184 A CE-Step 2.953 ± 0.249 3.656 ± 0.244 3.172 ± 0.271 2.672 ± 0.280 3.266 ± 0.252 DiffRhythm 2.469 ± 0.231 2.922 ± 0.192 2.859 ± 0.235 2.703 ± 0.238 2.688 ± 0.239 LeV o 2.297 ± 0.275 2.188 ± 0.239 2.641 ± 0.256 2.484 ± 0.262 2.531 ± 0.235 Ours 2.656 ± 0.287 3.672 ± 0.243 2.703 ± 0.242 3.109 ± 0.270 2.516 ± 0.262 T able 7. Ablation study on conditions for MIDI-SAG. Setting Chord F1 Key Acc Rhythm F1 w/ all conditions 0.9006 0.79 0.8339 w/o chord 0.3908 0.21 0.7870 w/o key 0.9027 0.78 0.8535 w/o rhythm 0.8914 0.79 0.4279 w/o structure 0.8957 0.79 0.8317 w/o audio 0.9027 0.84 0.8442 w/o vocal pitch contour 0.5930 0.69 0.4319 alignment. In Musicality and Song Structure Clarity , our model surpasses LeV o b ut falls short of the remaining sys- tems. Notably , we obtain the best V oice Naturalness among open-source methods, underscoring the benefit of utilizing a specialized SVS module within the compositional pipeline. 6.4. Ablation Study on Conditioning Signals T able 7 presents an ablation study clarifying the contrib ution of each conditioning signal to MIDI-SAG controllability . W e observe that the scores are highest when the model is conditioned only on non-audio inputs. In this setting, the model is freed from reconciling with ambiguous ref- erence audio, allowing it to strictly follow the remaining time-v arying conditions. Howe ver , this simplification can in- troduce acoustic abruptness detectable by listeners, whereas the reference audio helps smooth transitions. Further analysis rev eals redundancy in harmonic conditions: removing the key condition has a negligible impact, whereas removing the chord condition greatly lowers both Chord F1 and K ey Accuracy . This suggests the model deriv es the ke y implicitly from the chord progression. Conv ersely , excluding the vocal pitch contour leads to a performance drop across all metrics, indicating that SA G relies heavily on this condition for temporal and harmonic grounding. 7. Discussion Our experiments demonstrate the effecti veness of the pro- posed compositional pipeline, yet the inherent risk of error propagation across sequential stages warrants discussion. W e hav e addressed this through targeted implementation strategies at each interf ace. For instance, to ensure singing quality , we implement a register -check mechanism that val- idates the generated melody against the trained range of the SVS model before synthesis (see A.1.3 ). For SA G, the model is exposed to conditions extracted from real-world recordings during training; since these extracted signals can be noisy , the SAG is forced to learn a robust interpretation of its inputs. Consequently , we observ e that our system is re- silient to minor errors from preceding stages, as the model’ s training prepares it for imperfect conditioning signals. While current generations target 90–120s structural forms, this is not a fundamental constraint but a deliberate focus to ev aluate structural coherence within a low-resource training setting. Although our system currently trails large-scale models like Suno in some aspects, our modular foundation can be further enhanced by scaling data and parameters in future work, offering a transparent and editable path for long-form song generation. 8. Conclusion This paper presents a compositional pipeline and a MIDI- informed SA G approach, demonstrating that a modular ar- rangement of lightweight components can achiev e high- quality song generation with fewer resources than end-to- end models. By integrating symbolic controls into a fine- tuned text-to-music backbone, our system enables the edit- ing of intermediate MIDI data and pro vides separate vocal and backing tracks for greater fle xibility . The modular de- sign ensures the framew ork can incorporate advancing SVS or accompaniment modules as the y become av ailable. Our ev aluations confirm that this approach yields results com- parable to state-of-the-art open-source systems, suggesting that structural integrity and user controllability in music AI can be achieved without the need for massive datasets or 8 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline excessi ve computational power . References Agostinelli, A., Denk, T . I., Borsos, Z., Engel, J., V erzetti, M., Caillon, A., Huang, Q., Jansen, A., Roberts, A., T agliasacchi, M., et al. MusicLM: Generating music from text. arXiv preprint , 2023. B ¨ ock, S., Krebs, F ., and W idmer , G. Joint beat and downbeat tracking with recurrent neural networks. In ISMIR , pp. 255–261. New Y ork City , 2016. Chai, L. and W ang, D. CSL-L2M: Controllable song-lev el lyric-to-melody generation based on conditional trans- former with fine-grained lyric and musical controls. In Pr oceedings of the AAAI Conference on Artificial Intelli- gence , v olume 39, pp. 23541–23549, 2025. Chen, J., T an, X., Luan, J., Qin, T ., and Liu, T .-Y . Hi- fisinger: T owards high-fidelity neural singing v oice syn- thesis. arXiv pr eprint arXiv:2009.01776 , 2020. Chen, J., Xue, W ., T an, X., Y e, Z., Liu, Q., and Guo, Y . FastSA G: tow ards fast non-autore gressiv e singing accom- paniment generation. arXiv preprint , 2024. Chu, Y ., Xu, J., Y ang, Q., W ei, H., W ei, X., Guo, Z., Leng, Y ., Lv , Y ., He, J., Lin, J., et al. Qwen2-audio technical report. arXiv pr eprint arXiv:2407.10759 , 2024. Copet, J., Kreuk, F ., Gat, I., Remez, T ., Kant, D., Synnaeve, G., Adi, Y ., and D ´ efossez, A. Simple and controllable music generation. Advances in Neural Information Pr o- cessing Systems , 36, 2024. Dhariwal, P ., Jun, H., Payne, C., Kim, J. W ., Radford, A., and Sutske ver , I. Jukebox: A generativ e model for music. arXiv pr eprint arXiv:2005.00341 , 2020. Ding, S., Liu, Z., Dong, X., Zhang, P ., Qian, R., Huang, J., He, C., Lin, D., and W ang, J. SongComposer: A lar ge language model for lyric and melody generation in song composition. In Annual Meeting of the Association for Computational Linguistics (A CL) , 2025. Donahue, C., Caillon, A., Roberts, A., Manilow , E., Es- ling, P ., Agostinelli, A., V erzetti, M., Simon, I., Pietquin, O., Zeghidour , N., et al. SingSong: Generating mu- sical accompaniments from singing. arXiv pr eprint arXiv:2301.12662 , 2023. Evans, Z., P arker , J. D., Carr , C., Zukowski, Z., T aylor , J., and Pons, J. Stable Audio Open. In IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2025. Fei, Z., Fan, M., Y u, C., and Huang, J. FLUX that plays music. arXiv pr eprint arXiv:2409.00587 , 2024. Goel, A., Ghosh, S., Kim, J., Kumar , S., Kong, Z., Lee, S.-g., Y ang, C.-H. H., Duraiswami, R., Manocha, D., V alle, R., et al. Audio Flamingo 3: Adv ancing audio intelligence with fully open large audio language models. arXiv pr eprint arXiv:2507.08128 , 2025. Gong, J., Zhao, S., W ang, S., Xu, S., and Guo, J. Ace-step: A step to wards music generation foundation model. arXiv pr eprint arXiv:2506.00045 , 2025. Grachten, M. and Nistal, J. Accompaniment prompt ad- herence: A measure for ev aluating music accompani- ment systems. In ICASSP 2025-2025 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 1–5. IEEE, 2025. Heydari, M. and Duan, Z. Singing beat tracking with self-supervised front-end and linear transformers. arXiv pr eprint arXiv:2208.14578 , 2022. Heydari, M., Cwitko witz, F ., and Duan, Z. Beatnet: Crnn and particle filtering for online joint beat downbeat and meter tracking. arXiv pr eprint arXiv:2108.03576 , 2021. Hong, Z., Huang, R., Cheng, X., W ang, Y ., Li, R., Y ou, F ., Zhao, Z., and Zhang, Z. T ext-to-Song: T ow ards con- trollable music generation incorporating vocals and ac- companiment. In Annual Meeting of the Association for Computational Linguistics (A CL) , 2024. Hou, S., Liu, S., Y uan, R., Xue, W ., Shan, Y ., Zhao, M., and Zhang, C. Editing music with melody and text: Us- ing ControlNet for diffusion transformer . In IEEE In- ternational Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2025. Jiang, Y ., Chen, H., Ning, Z., Y ao, J., Han, Z., Wu, D., Meng, M., Luan, J., Fu, Z., and Xie, L. Diffrhythm 2: Efficient and high fidelity song generation via block flo w matching. arXiv pr eprint arXiv:2510.22950 , 2025. Ju, Z., Lu, P ., T an, X., W ang, R., Zhang, C., W u, S., Zhang, K., Li, X., Qin, T ., and Liu, T .-Y . T eleMelody: L yric- to-melody generation with a template-based two-stage method. In Conference on Empirical Methods in Natural Language Pr ocessing , 2021. Kim, T . and Nam, J. All-in-one metrical and functional struc- ture analysis with neighborhood attentions on demixed audio. In IEEE W orkshop on Applications of Signal Pro- cessing to Audio and Acoustics (W ASP AA) , 2023. Lei, S., Xu, Y ., Lin, Z., Zhang, H., T an, W ., Chen, H., Y u, J., Zhang, Y ., Y ang, C., Zhu, H., et al. Levo: High-quality song generation with multi-preference alignment. arXiv pr eprint arXiv:2506.07520 , 2025. 9 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline Liu, H., Y uan, Y ., Liu, X., Mei, X., Kong, Q., Tian, Q., W ang, Y ., W ang, W ., W ang, Y ., and Plumbley , M. D. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM T ransactions on Audio, Speec h, and Language Pr ocessing , 32:2871–2883, 2024. Liu, J., Li, C., Ren, Y ., Chen, F ., and Zhao, Z. DiffSinger: Singing voice synthesis via shallo w diffusion mechanism. In Pr oceedings of the AAAI conference on artificial intel- ligence , v olume 36, pp. 11020–11028, 2022. Liu, R., Hung, C.-Y ., Majumder , N., Gautreaux, T ., Bagherzadeh, A. A., Li, C., Herremans, D., and Poria, S. J AM: A tiny flow-based song generator with fine-grained controllability and aesthetic alignment. arXiv pr eprint arXiv:2507.20880 , 2025a. Liu, Z., Ding, S., Zhang, Z., Dong, X., Zhang, P ., Zang, Y ., Cao, Y ., Lin, D., and W ang, J. SongGen: A single stage auto-regressi ve transformer for text-to-song generation. arXiv pr eprint arXiv:2502.13128 , 2025b. Lu, P ., W u, J., Luan, J., T an, X., and Zhou, L. XiaoiceSing: A high-quality and integrated singing voice synthesis system. arXiv pr eprint arXiv:2006.06261 , 2020. Music Information Retriev al Evaluation eXchange (MIREX). MIREX 2018: Automatic lyrics-to-audio alignment. https://music- ir.org/mirex/ wiki/2018:Automatic_Lyrics- to- Audio_ Alignment , 2018. Accessed: 2025-11-21. Ning, Z., Chen, H., Jiang, Y ., Hao, C., Ma, G., W ang, S., Y ao, J., and Xie, L. Diffrhythm: Blazingly f ast and embar - rassingly simple end-to-end full-length song generation with latent dif fusion. arXiv pr eprint arXiv:2503.01183 , 2025. Niu, X., Cheuk, K. W ., Zhang, J., Murata, N., Lai, C.-H., Mancusi, M., Choi, W ., Fabbro, G., Liao, W .-H., Martin, C. P ., and Mitsufuji, Y . SteerMusic: Enhanced musical consistency for zero-shot text-guided and personalized music editing. In Pr oceedings of the AAAI Conference on Artificial Intelligence , 2026. Nov ack, Z., Zhu, G., Casebeer , J., McAuley , J., Ber g- Kirkpatrick, T ., and Bryan, N. J. Presto! distilling steps and layers for accelerating music generation. In Interna- tional Confer ence on Learning Repr esentations (ICLR) , 2025. open vpi. SOME: Singing-Oriented MIDI Extractor , 2023. URL https://github.com/openvpi/SOME/ releases/tag/v0.0.1 . Git commit 02936ec. Park, J., Choi, K., Jeon, S., Kim, D., and Park, J. A bi- directional transformer for musical chord recognition. In International Society for Music Information Retrieval Confer ence , pp. 620–627, 2019. Radford, A., Kim, J. W ., Xu, T ., Brockman, G., McLeav ey , C., and Sutske ver , I. Robust speech recognition via large- scale weak supervision, 2022. Rafii, Z., Liutkus, A., St ¨ oter , F .-R., Mimilakis, S. I., and Bittner , R. The musdb18 corpus for music separation. 2017. Ren, Y ., Hu, C., T an, X., Qin, T ., Zhao, S., Zhao, Z., and Liu, T .-Y . FastSpeech 2: Fast and high-quality end-to-end text to speech. arXiv preprint , 2020. Schreiber , H. and M ¨ uller , M. Musical tempo and key estima- tion using con volutional neural networks with directional filters. In Pr oceedings of the Sound and Music Computing Confer ence (SMC) , pp. 47–54, 2019. Sheng, Z., Song, K., T an, X., Ren, Y ., Y e, W ., Zhang, S., and Qin, T . SongMASS: Automatic song writing with pre- training and alignment constraint. In Pr oceedings of the AAAI Conference on Artificial Intelligence , volume 35, pp. 13798–13805, 2021. Silero T eam. Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier . https://github.com/snakers4/ silero- vad , 2024. Accessed: 2026-01-27. Suno, I. Introducing v4.5. https://suno.com/blog/ introducing- v4- 5 , May 2025. Accessed: 2025-09- 24. Tjandra, A., Wu, Y .-C., Guo, B., Hoffman, J., Ellis, B., Vyas, A., Shi, B., Chen, S., Le, M., Zacharov , N., W ood, C., Lee, A., and Hsu, W .-N. Meta Audiobox Aesthetics: Unified automatic quality assessment for speech, music, and sound, 2025. URL 2502.05139 . T rinh, Q.-H., Nguyen, M.-V ., Mau, T .-H. N., T ran, K., and Do, T . Sing-On-Y our-Beat: Simple text- controllable accompaniment generations. arXiv preprint arXiv:2411.01661 , 2024. Tsai, F .-D., W u, S.-L., Lee, W ., Y ang, S.-P ., Chen, B.-R., Cheng, H.-C., and Y ang, Y .-H. MuseControlLite: Multi- functional music generation with lightweight condition- ers. In International Conference on Mac hine Learning , 2025. W ang, J.-C., Lu, W .-T ., and W on, M. Mel-band ro- former for music source separation. arXiv preprint arXiv:2310.01809 , 2023. 10 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline W u, S.-L. and Y ang, Y .-H. Musemorphose: Full-song and fine-grained piano music style transfer with one trans- former v ae. IEEE/A CM T ransactions on A udio, Speech, and Language Pr ocessing , 31:1953–1967, 2023. W u, S.-L., Donahue, C., W atanabe, S., and Bryan, N. J. Mu- sic controlnet: Multiple time-v arying controls for music generation. IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , 32:2692–2703, 2024a. W u, Y ., Chen, K., Zhang, T ., Hui, Y ., Nezhurina, M., Berg-Kirkpatrick, T ., and Dubnov , S. Lar ge-scale con- trastiv e language-audio pretraining with feature fusion and keyw ord-to-caption augmentation, 2024b. Y amamoto, R., Song, E., and Kim, J.-M. Parallel W ave- GAN: A fast w av eform generation model based on gen- erativ e adversarial netw orks with multi-resolution spec- trogram. In IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2020. Y ang, C., Chen, H., W ang, S., Zhu, H., and Li, H. TVC- MusicGen: T ime-varying structure control for back- ground music generation via self-supervised training. In INTERSPEECH , 2025a. Y ang, C., W ang, S., Chen, H., T an, W ., Y u, J., and Li, H. SongBloom: Coherent song generation via interleaved autoregressi ve sketching and diffusion refinement. arXiv pr eprint arXiv:2506.07634 , 2025b. Y ang, D., Xie, Y ., Y in, Y ., W ang, Z., Y i, X., Zhu, G., W eng, X., Xiong, Z., Ma, Y ., Cong, D., et al. Heartmula: A family of open sourced music foundation models. arXiv pr eprint arXiv:2601.10547 , 2026. Y ao, J., Ma, G., Xue, H., Chen, H., Hao, C., Jiang, Y ., Liu, H., Y uan, R., Xu, J., Xue, W ., Liu, H., and Xie, L. SongEval: A benchmark dataset for song aesthetics ev aluation, 2025. Y i, L., Hu, H., Zhao, J., and Xia, G. Accomontage2: A com- plete harmonization and accompaniment arrangement system. arXiv pr eprint arXiv:2209.00353 , 2022. Y u, Y ., Sriv astav a, A., and Canales, S. Conditional LSTM- GAN for melody generation from lyrics. ACM T ransac- tions on Multimedia Computing, Communications, and Applications (TOMM) , 17(1):1–20, 2021. Y uan, R., Lin, H., Guo, S., Zhang, G., Pan, J., Zang, Y ., Liu, H., Liang, Y ., Ma, W ., Du, X., et al. Y uE: Scaling open foundation models for long-form music generation. arXiv pr eprint arXiv:2503.08638 , 2025. Zhang, C., Ma, Y ., Chen, Q., W ang, W ., Zhao, S., Pan, Z., W ang, H., Ni, C., Nguyen, T . H., Zhou, K., Jiang, Y ., T an, C., Gao, Z., Du, Z., and Ma, B. InspireMusic: Integrating super resolution and large language model for high-fidelity long-form music generation. arXiv pr eprint arXiv:2503.00084 , 2025a. Zhang, J., Zhang, Y ., Zhang, X., and W u, Z. An yaccomp: Generalizable accompaniment generation via quantized melodic bottleneck. arXiv pr eprint arXiv:2509.14052 , 2025b. Zhang, Y ., Guo, W ., Pan, C., Zhu, Z., Li, R., Lu, J., Huang, R., Zhang, R., Hong, Z., Jiang, Z., et al. V ersatile frame- work for song generation with prompt-based control. arXiv pr eprint arXiv:2504.19062 , 2025c. 11 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline A. A ppendix A.1. Implementation Details A . 1 . 1 . I M P L E M E N TA T I O N D E TA I L S O N L Y R I C S - T O - M E L O DY G E N E R AT I O N W e employ the CSL-L2M model ( Chai & W ang , 2025 ) to map Chinese lyrics to vocal MIDI scores. The architecture is a Transformer decoder utilizing an in-attention mechanism ( W u & Y ang , 2023 ) for fine-grained control. Generation is conditioned on global attrib utes (key and emotion), sentence-level structure tags, and twelve statistical musical attrib utes (e.g., pitch v ariance, note density , and syllable-to-note alignment) that strengthen lyric–melody coupling. While users can specify emotion and ke y manually , the statistical attributes are deri ved from a reference MIDI track. The model achie ves optimal performance when the reference track and target lyrics share similar section structures and w ord counts. T o facilitate generation without user-pro vided MIDI, we curated a reference bank of 1,000 attribute sets. For a giv en set of input lyrics, we select the most compatible candidate using a weighted penalty score P = 0 . 4 P sent + 0 . 4 P prof + 0 . 2 P struct , where lower scores indicate higher compatibility . Here, P sent penalizes discrepancies in total line count (optionally rejecting candidates with fe wer lines than the target); P prof is the mean absolute dif ference between per-line tok en counts—treating each visible Chinese character as one token—after padding the shorter sequence with its median and scaling by the maximum observed token count; and P struct compares section tags mapped to integers, counting position-wise mismatches and adding a penalty for extra sections, normalized by the longer sequence length. A . 1 . 2 . I M P L E M E N TA T I O N D E TA I L S O N M E L O D Y H A R M O N I Z A T I O N Since chord progressions serve as primary ti me-varying controls, the inference pipeline must supply compatible harmonic sequences. W e harmonize the vocal MIDI scores produced by CSL-L2M using AccoMontage2 ( Y i et al. , 2022 ). T o ensure a natural musical flow , we prepend a 4-bar instrumental intro; the chord sequence for this intro is generated by duplicating the chords from the first four bars of the melody . This harmonization stage provides the essential chordal grounding that allo ws the singing-accompaniment generator to produce coherent backing tracks. T o maintain user agency , the system supports manual overrides: if the automatically generated progression is unsatisfactory , users may provide their own chord sequences or perform partial edits on the generated results. A . 1 . 3 . I M P L E M E N TA T I O N D E TA I L S O N S I N G I N G V O I C E S Y N T H E S I S W e integrate a MIDI-conditioning embedding to align each phoneme with its corresponding pitch and duration in the MIDI score. T o ensure natural vocal quality , we perform a register-matching optimization before synthesis. Giv en the vocal MIDI track, we e valuate potential octa ve shifts ∆ ∈ {− 12 , 0 , +12 } against both male (lo wer) and female (higher) vocal profiles. The optimal configuration ( singer , ∆) is selected by maximizing the number of notes within the profile’ s comfortable tessitura while simultaneously minimizing the magnitude of the octav e shift | ∆ | . This ensures the generated vocals remain within a realistic performance range while preserving the melodic intent of the original MIDI as closely as possible. T o reconstruct the final wav eform audio, we fine-tuned a Parallel W aveGAN v ocoder ( Y amamoto et al. , 2020 ) specifically on our singing voice dataset. The training was conducted for one week on a single NVIDIA R TX 3090 GPU, optimizing the model to capture the nuances and high-frequency details characteristic of v ocal performances. A . 1 . 4 . I M P L E M E N TA T I O N D E TA I L S O N S I N G I N G A C C O M PA N I M E N T G E N E R A T I O N T o fine-tune the Stable Audio Open backbone, we curated a specialized dataset of Mandarin pop music following the pipeline illustrated in Figure 4 . The preparation in volv es source separation to isolate vocal and backing tracks ( W ang et al. , 2023 ) and automated audio captioning ( Goel et al. , 2025 ). T o provide the model with granular guidance, we extract a comprehensiv e set of time-varying conditioning signals, including chords ( Park et al. , 2019 ), local key ( Schreiber & M ¨ uller , 2019 ), rhythmic features and structural tags ( Kim & Nam , 2023 ), and vocal pitch contours ( Hou et al. , 2025 ). The source audio was retrieved from public web sources and is maintained exclusi vely as an internal dataset for academic research purposes, yet we commit to share the dataset metadata. W e fine-tuned the model on NVIDIA R TX 3090 GPUs using an effecti ve batch size of 108, training for a total of 9 days to ensure con vergence across the di verse conditioning signals. 12 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline F igur e 4. The data-preprocessing pipeline to curate data for fine-tuing Stable Audio Open to implement our MIDI-informed singing accompaniment generation (MIDI-SA G) model. A . 1 . 5 . C O N D I T I O N I N G S I G N A L S W e utilize an extensi ve set of controls, b uilding upon the framew ork of MuseControlLite ( Tsai et al. , 2025 ), to address the specific challenges of low-resource, long-form song generation. A key distinction in our approach lies in the source of these signals: during training, conditioning signals are e xtracted directly from the ground-truth accompaniment to ensure high precision. Con versely , at inference time, these conditions must be derived solely from the synthesized vocal audio or the symbolic vocal MIDI. This transition requires the model to be resilient to the slight v ariations inherent in predicted signals. The specific extraction methods and their roles in the pipeline are summarized in T able 2 and detailed below . V ocal pitch contour . T o capture melodic nuance, we first isolate the v ocal track using Mel-Band RoFormer ( W ang et al. , 2023 ). W e then extract prominent pitch information using the top-4 Constant-Q Transform (CQT) method proposed by Hou et al. ( 2025 ). During the training phase, this contour is deri ved from the ground-truth isolated vocals to provide a precise melodic anchor . At inference, the signal is extracted directly from the SVS-generated singing, allowing the accompaniment module to track the synthesized vocal performance with high fidelity . Rhythm. Our pilot study sho ws that existing beat tracking models do not work well on isolated v ocal audio. For example, BeatNet ( Heydari et al. , 2021 ) achieved a Rhythm F1 score of only 0.3449 in our ev aluation. Consequently , we adopt a dual-strategy approach. During training, we use All-In-One ( Kim & Nam , 2023 ) to extract beat and do wnbeat timestamps from the ground-truth backing tracks. These are conv erted into binary indicator sequences of shape ( T , 1) , where T represents the number of time frames (1 if an e vent occurs at a giv en frame, 0 otherwise). W e then apply a Gaussian filter to these sequences to produce smooth “rhythm activ ation” curves, which pro vide a more resilient conditioning signal. At inference time, as audio-based tracking remains unreliable for singing voices, we deri ve beat and downbeat timings directly from the quantized MIDI generated by the CSL-L2M model ( Chai & W ang , 2025 ), which outputs melodies in 4/4 time. This ensures that the generated accompaniment is nicely synchronized with the structural rhythmic grid of the vocal melody . Chord. Our preliminary experiments indicated that the SAG model generates unstable harmon y and weak progressions when depriv ed of explicit chordal conditioning. T o ensure harmonic stability , we implement a chromagram-based approach. During training, we apply a chord detector ( Park et al. , 2019 ) to the isolated backing tracks and encode the detected progressions as 12-bin chromagrams, representing pitch-class membership over time. At inference, these harmonic cues are supplied by the AccoMontage2 ( Y i et al. , 2022 )harmonization module. This ensures that the generated accompaniment adheres to a structured harmonic framew ork that is musically compatible with the synthesized vocal melody . Key . While chords pro vide immediate harmonic grounding, we include a section-le vel key condition to capture broader tonal context and global coherence. W e utilize a Ke y-CNN ( Schreiber & M ¨ uller , 2019 ) to estimate the ke y for each structural section individually . This approach reflects the musical reality that key modulations often coincide with section boundaries (e.g., a shift from verse to chorus), allo wing the model to anticipate and execute these transitions with greater accuracy . Structure. T o organize the song’ s narrati ve and energy flow , we extract section labels and timestamps using All-In- One ( Kim & Nam , 2023 ). W e retain a standardized set of labels—including intro, verse, chorus, bridge, solo, break, inst, and outro—while discarding truncated fragments at the audio boundaries. These section labels serve as a primary time-varying conditioning signal. Furthermore, we utilize a Large Audio Language Model (LALM), AudioFlamingo3 ( Goel et al. , 2025 ), 13 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline F igure 5. Augmenting Stable Audio Open for singing accompaniment and audio continuation. The architecture utilizes the MuseControl- Lite frame work to inte grate multi-modal conditioning signals, enabling precise singing-accompaniment alignment and seamless long-form audio continuation. to generate section-le vel text captions that provide high-lev el semantic guidance. T o prevent acoustic artifacts and ensure musical fluidity , we strictly align all conditioning boundaries with structural transitions or detected downbeats during both the training and inference phases. Reference audio. T o facilitate structural completeness, we employ reference audio conditioning similar to MuseCon- trolLite ( Tsai et al. , 2025 ). This allows the model to utilize inpainting and outpainting techniques for the generation of instrumental sections, ensuring stylistic consistency between synthesized and retrieved audio. Specifically , we apply a backwar d continuation technique (as detailed in Section 3.3 ). This reference mechanism provides the necessary acoustic anchor for the SAG to maintain a unified timbre and energy le vel across the transition between v ocal and purely instrumental passages. The comprehensi ve set of conditioning signals described abov e is integrated into the proposed SA G pipeline, as illustrated in Figure 5 . By combining symbolic (MIDI, chords, key), acoustic (pitch contour , rhythm activ ation), and semantic (captions) controls, the model gains a robust understanding of the multi-f aceted relationship between vocals and accompaniment. T o ev aluate the specific contribution of each signal, we conducted ablation studies (detailed in Section 6.4 ), which e xamine how the remov al of individual conditions impacts result. This systematic validation ensures that each control signal serves a functional purpose in mitigating the challenges of long-form song generation. A.2. Objective Ev aluation Metrics for Song Generation L yrics Alignment: W e employed Whisper ASR ( Radford et al. , 2022 ) to transcribe the generated vocals and compared the transcriptions with the ground-truth lyrics. Alignment quality is measured using the phoneme error rate (PER). W e first con vert both the predicted and reference texts into their phoneme representations. Then, PER is computed as PER = S + D + I N , where S , D , and I denote substitutions, deletions, and insertions, respectiv ely . A lower PER indicates better alignment. 14 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline T able 8. Inference latenc y per module. This table reports the time required to generate a full-length song (90–120 seconds) comprising an intr o–verse–c horus–outr o structure. For the singing-accompaniment stage, MuseControlLite ( Tsai et al. , 2025 ) is configured with 50 denoising steps. All measurements were conducted on a single NVIDIA R TX 3090 GPU. Module Time (s) L yrics-to-melody 10 Melody harmonization 0.2 Singing voice synthesis 3 singing accompaniment generation 40 T able 9. Ablation study demonstrating the ef fectiv eness of unfreezing self-attention layers for audio continuation. The smoothness value is proposed in ( Tsai et al. , 2025 ). FD ↓ KL ↓ CLAP ↑ Smoothness v alue ↑ MuseControlLite w/ audio condition 111.58 0.2160 0.3622 –0.2734 MuseControlLite w/ audio condition unfreeze self attention layers 109.62 0.1794 0.3961 –0.3529 T o verify the suitability of Whisper as an ev aluation proxy for singing voice, we benchmarked its performance on the C P O P dataset ( Music Information Retriev al Ev aluation eXchange (MIREX) , 2018 ), which consists of high-quality human vocal recordings. By comparing Whisper’ s transcriptions against the ground-truth lyrics, we obtained a PER of 0.059. This low error rate demonstrates that Whisper is highly effecti ve at recognizing singing voices and pro vides a sufficiently reliable metric for ev aluating lyric–audio alignment in our experiments. Furthermore, we observed a specific behavior in the Suno v4.5 baseline where short lyric inputs often triggered repetitive vocal lines. T o prev ent these repetitions from artificially inflating the PER and ensuring a fair comparison, we performed a deduplication step on the transcriptions, removing repeated lines before computing the PER scores. Style Alignment: W e utilized CLAP ( W u et al. , 2024b ) to compute the cosine similarity between audio embeddings of the generated music and embeddings of the text prompts, quantifying adherence to the intended global style. Aesthetics Ev aluation: W e used Audiobox-Aesthetics ( Tjandra et al. , 2025 ), to provide an automatic aesthetics assessment of the generated songs, capturing aspects such as clarity , richness, and technical fidelity . Specifically , Audiobox reports four sub-scores: Coherence (CE), Cultural Understanding (CU), Production Complexity (PC), and Production Quality (PQ). SongEval ( Y ao et al. , 2025 ) : A recently released ev aluation framework specifically designed for songs, used to measure structural clarity , memorability , musical coherence, and ov erall musicality . Controllability : T o ev aluate whether MIDI-SAG successfully aligns with the gi ven conditions, we extract rhythm, chord, and key features from the generated backing audio using the same procedure as in training. Specifically , we employ BeatNet ( Heydari et al. , 2021 ) instead of All-in-one ( Kim & Nam , 2023 ) to verify if the alignment remains consistent across different detection methods. Follo wing W u et al. ( 2024a ), we use the F1 score to ev aluate rhythm alignment, where the giv en timestamps and the detected timestamps are considered aligned if they dif fer by less than 70 milliseconds. For the chord condition, we also use the F1 score, computed between the chromagrams of the reference and generated audio. Key accuracy is defined as the percentage of matches in both pitch class and mode (major/minor). A.3. Additional Experimental Result T o ev aluate the computational efficienc y of our pipeline, we measured the inference latency for each component on a single NVIDIA R TX 3090 GPU. The results, summarized in T able 8 , detail the time required for each stage—from initial melody generation to final singing-accompaniment synthesis—for a standard full-length song. This breakdown highlights the real-world feasibility of our modular approach and demonstrates that the bottleneck remains the iterative denoising process in the SA G module, which we have optimized via the 50-step configuration. The results in T able 9 demonstrate that partially unfreezing the self-attention layers of the SA O backbone significantly enhances generation quality . This optimization allows the model to re-align its internal spatial-temporal representations to better accommodate the high-dimensional conditioning signals provided by the ne w adapters. By maintaining most of the backbone in a frozen state while selecti vely adapting the attention mechanism, the model retains its pre-trained acoustic 15 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline Stage Component Base model / source Upstream training (prior work) Our additional training (this work) 1 L yrics → V ocal MIDI CSL-L2M ( Chai & W ang , 2025 ) 300 hours lyrics–melody pairs; trained with 1 × V100 for 24 hours None 2 SVS (MIDI → vocals) FastSpeech ( Ren et al. , 2020 ) None 10 h licensed internal (2 singers); GPU: 1 × 3090 for 8 days; Method: trained from scratch 3 Backing generator backbone Stable Audio Open ( Evans et al. , 2025 ) GPU: 36224 A100 GPU hours 7.3k hours license data; None 3b MIDI-SA G conditioning module (adapter) MuseControlLite None 2.5k h Mandarin pop; GPU: 1 × 3090 for 9 days 4 Harmony / chord extraction or harmonization AccoMontage2 ( Y i et al. , 2022 ) (or other) None, it is based on template matching and dynamic programming None 5 Beat / tempo tracking (for silent spans) Heydari & Duan ( 2022 ) None 2.5k h Mandarin pop; GPU: 1 × 3090 for 12 hours T able 10. Component-level provenance and training effort. W e explicitly separate (i) upstr eam pretraining performed in prior work from (ii) incr emental training performed in this paper . priors while achieving the precision necessary for v ocal-accompaniment synchronization. W e also tested the vocal beat detector ( Heydari & Duan , 2022 ) on a 250 hr test set separated from the training set, the F1 score of the beat is 0.73. A.4. Our training data distribution Our training data primarily consists of Mandarin pop music, as our goal was to generate music from Chinese vocals (i.e., CSL-L2M ( Chai & W ang , 2025 ) and our fine-tuned FastSpeech ( Ren et al. , 2020 ) only support Mandarin). The genre distribution is based on tags predicted by Qwen2-Audio-7B-Instruct ( Chu et al. , 2024 ), and a single song may contain multiple genres, results are shown in Figure 7 . The results show that pop and electronic music are the most prominent genres in the training dataset. A.5. Regarding training r esources used in the compositional pipeline T able 10 shows the pretraining effort and the incremental training cost of each module. The total amount of training data used across all components is 10k hours. The o verall computational resource is dominated by the pretraining of Stable-Audio Open ( Evans et al. , 2025 ). A.6. Input examples of our compositional song pipeline The input of our compositional song pipeline is shown in 6 , it is basically same as other end-to-end song generation models, but our models supports using dif ferent text prompts to control different musical structures. 16 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline F igur e 6. The input lyrics are same as other end-to-end song generation models, which comes with structure tags, but we only support madarin, due to the constraint of CSL-L2M ( Chai & W ang , 2025 ). The text control of our method could be either a single global style prompt (e.g. ”airy pad swell, filtered noise, sparse off-beat hats; slo w LPF rise. ”) or different local style prompts for dif ferent segment. 17 MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline F igure 7. The genre distribution of the curated training dataset for training MIDI-SA G. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment