Complexity of Classical Acceleration for $\ell_1$-Regularized PageRank
We study the degree-weighted work required to compute $\ell_1$-regularized PageRank using the standard one-gradient-per-iteration accelerated proximal-gradient method (FISTA). For non-accelerated local methods, the best known worst-case work scales a…
Authors: Kimon Fountoulakis, David Martínez-Rubio
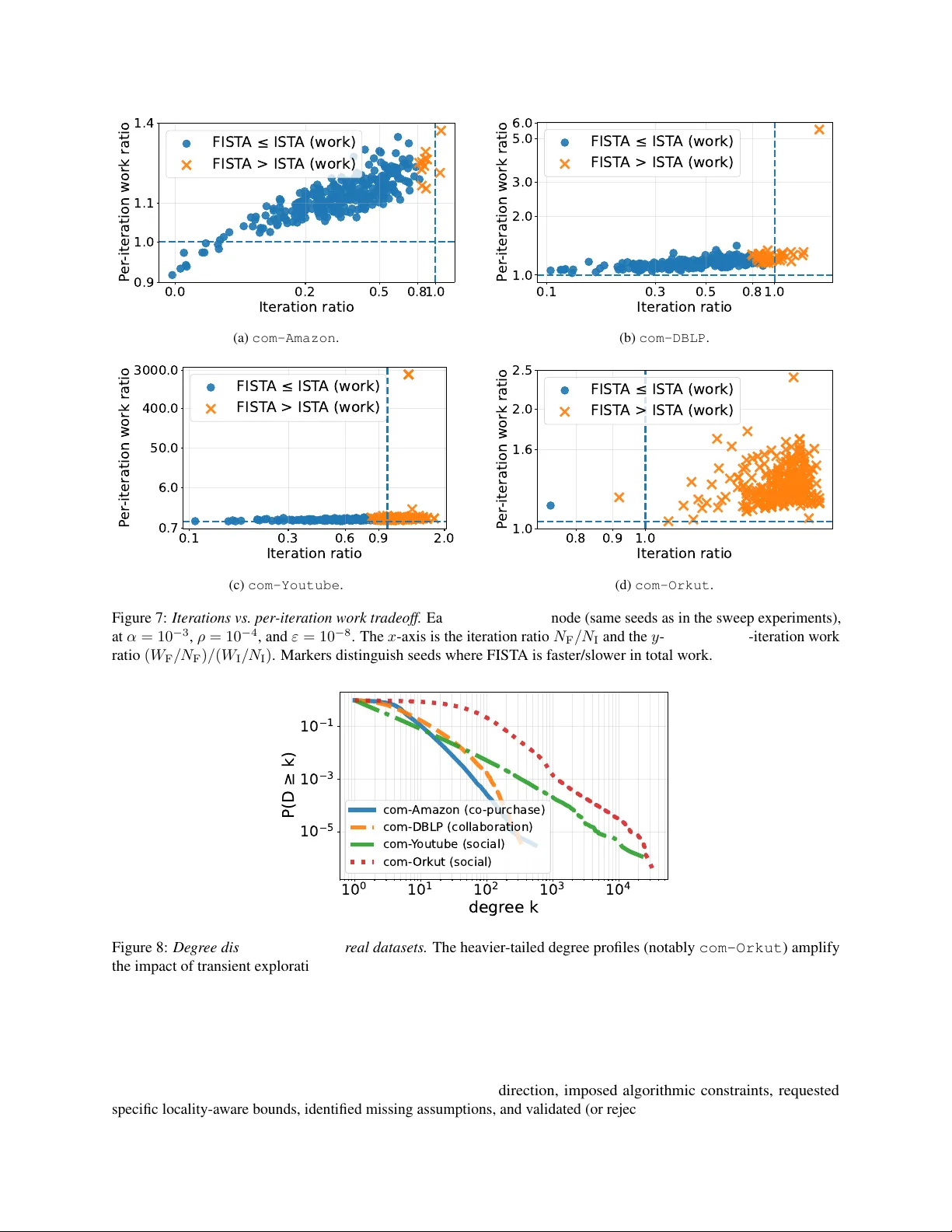
Comple xity of Classical Acceleration for ℓ 1 -Re gularized P ageRank Kimon Fountoulakis * Uni versity of W aterloo, Canada kimon.fountoulakis@uwaterloo.ca David Martínez-Rubio * IMDEA Software Institute, Madrid, Spain david.martinezrubio@imdea.org February 25, 2026 Abstract W e study the degree-weighted work required to compute ℓ 1 -regularized PageRank using the standard one-gradient- per-iteration accelerated proximal-gradient method (FIST A). For non-accelerated local methods, the best known worst-case work scales as e O (( αρ ) − 1 ) , where α is the teleportation parameter and ρ is the ℓ 1 -regularization parameter . A natural question is whether FIST A can improve the dependence on α from 1 /α to 1 / √ α while preserving the 1 /ρ locality scaling. The challenge is that acceleration can break locality by transiently activ ating nodes that are zero at optimality , thereby increasing the cost of gradient evaluations. W e analyze FIST A on a slightly over - regularized objecti ve and sho w that, under a checkable confinement condition, all spurious activ ations remain inside a boundary set B . This yields a bound consisting of an accelerated ( ρ √ α ) − 1 log( α/ε ) term plus a boundary ov erhead p v ol( B ) / ( ρα 3 / 2 ) . W e provide graph-structural conditions that imply such confinement. Experiments on synthetic and real graphs show the resulting speedup and slo wdo wn re gimes under the degree-weighted w ork model. 1 Intr oduction Personalized PageRank (PPR) is a diffusion primiti ve for exploring large graphs from a seed: starting from a node or distribution s , the diffusion returns a nonnegati ve score vector that concentrates near s and is widely used for local graph clustering and ranking [ A CL06 ; Gle15 ]. A central algorithmic requirement in this setting is locality : the running time should scale with the size of the region around the target cluster , rather than with the total number of nodes or edges in the ambient graph. A useful tool to obtain locality is adding ℓ 1 regularization, which induces sparsity at the solution. In the ℓ 1 - regularized PageRank formulation [ GM14 ; FRS+19 ], one solves a strongly con v ex objective whose minimizer is sparse and nonnegati v e 1 . Concretely , for teleportation parameter α ∈ (0 , 1] and sparsity parameter ρ > 0 , we consider problems of the form min x ∈ R n 1 2 x ⊤ Qx − α ⟨ D − 1 / 2 s, x ⟩ | {z } smooth PageRank quadratic + αρ ∥ D 1 / 2 x ∥ 1 | {z } ℓ 1 sparsity penalty , where D is the degree matrix and Q is a symmetric, scaled and shifted, Laplacian matrix, see Section 3 . Let x ⋆ denote the unique minimizer and let S ⋆ := supp( x ⋆ ) be its support. For the abo ve problem, the primiti v es of first-order methods can be implemented locally: if an iterate is supported on a set S , e v aluating its gradient and performing a proximal gradient step only requires accessing edges incident to S . This motiv ates the degree-weighted work model [ FRS+19 ], in which we charge one unit of work per neighbor access. Thus scanning the neighborhood of a verte x i costs d i work, and the cost of a set S of non-zero nodes is v ol( S ) := P i ∈ S d i . The total work of an algorithm is the cumulativ e number of neighbor accesses with repetition performed ov er its ex ecution. Motivation. Accelerated first-order methods are worst-case optimal in gradient ev aluations for smooth con ve x problems [ Nes04 ; BT09 ], but for our objectiv e, the cost per gradient depends on which nodes are active. Thus, sparsity gov erns the total work: IST A is prov ably local, acti v ating only the optimal support S ⋆ [ FRS+19 ], whereas FIST A * Equal contribution. 1 This is a trivial corollary of [ FRS+19 ], obtained by observing that the proximal-gradient iterates are nondecreasing when starting from zero. 1 forms extrapolated points y k that can transiently create nonzeros outside S ⋆ . Even a fe w such spurious acti v ations can dramatically increase work (e.g., by touching high-degree nodes), so f aster con v er gence in iterations does not imply less total work. W e quantify this tradeoff and v alidate it empirically . Our approach. W e analyze FIST A under a degree-weighted work model that separates the work spent on the optimal support S ⋆ and the cumulati ve work spent on transient coordinates outside that set. W e bound the latter using two key ideas: (A) bounding transient activ ations from coordinates with a large complementary gap at x ⋆ from the KKT conditions and (B) bounding the number of coordinates with small complementary gaps, by arguing that they belong to the support of an already sparse, slightly less regularized solution. T otal w ork bound and sufficient conditions. Under a verifiable confinement condition ensuring that all spurious activ ations remain within a boundary set B , we obtain a work bound of the form e O 1 ρ √ α log α ε + p v ol( B ) ρα 3 / 2 ! . The first term is the accelerated cost of con verging to the optimal support; the second term is an explicit overhead capturing the cumulativ e cost for exploring spurious nodes. W e also gi ve graph-structural sufficient conditions: a no-percolation criterion that makes the confinement hypothesis explicit and checkable. When this criterion holds with the target optimal support S ⋆ as the core set, it guarantees that momentum-induced acti v ations cannot percolate arbitrarily far into the graph: for all iterations k , the iterates remain supported in S ⋆ ∪ ∂ S ⋆ . In particular , any acti v ation outside S ⋆ is confined to the vertex boundary B := ∂ S ⋆ , so the locality overhead in our work bound is gov erned by the boundary volume v ol( B ) = vol( ∂ S ⋆ ) . This makes the second term directly interpretable as the cost of probing only the immediate neighborhood of the target support. Experiments. Finally , experiments on synthetic instances and SNAP [ LK14 ] graphs corroborate the predicted speedup/slowdo wn regimes under de gree-weighted work: acceleration helps when boundary exploration is limited, and it can hurt when transient boundary activ ations dominate. Contributions. Our main contributions can be summarized as follo ws. • F r om KKT slack to cumulative spurious work. W e pro ve that an y activ ation of an inacti v e coordinate (that is, which is zero at the solution) implies a quantitative “jump” in per-iteration work, controlled by its KKT slack (complementarity gap). W e combine this fact with FIST A ’ s geometric contraction to bound the total degree-weighted work spent on such spurious activ ations. • A void tiny margins via over-r e gularization. The smallest KKT slack can be arbitrarily small, see Section C , which would make our work bound meaningless. T o fix this, we analyze a slightly more regularized problem and use regularization-path monotonicity [ HFM21 ] to treat “nearly active” nodes as part of the true solution, and charge e xtra work only to nodes that remain clearly inacti ve. • A worst-case work bound for classic FIST A. Under a boundary confinement condition (spurious activ ations stay within a boundary set B ), we obtain an explicit w ork bound with an accelerated term e O (( ρ √ α ) − 1 log( α/ε )) plus a boundary ov erhead quantified by v ol( B ) (cf. Theorem 4.3 ). • Graph-structur al confinement guarantees and de gree-based non-activation. W e giv e a sufficient no-percolation condition for boundary confinement, and we characterize (in Section B ) when high-de gree inacti v e nodes prov ably nev er acti v ate under o ver -re gularization. 2 Related work Personalized PageRank (PPR) and related dif fusion vectors are widely used primiti v es for ranking and network analysis beyond web search (see, e.g., the surv ey [ Gle15 ]). A foundational locality result is due to Andersen, Chung, and Lang [ A CL06 ], who introduced the Approximate Personalized PageRank (APPR) “push” procedure and showed that one can compute an ε -approximate PPR vector in time ˜ O (1 / ( αε )) independent of the graph size. This establishes that diffusion solutions can be computed locally and used for local graph partitioning. V ariational f ormulations and w orst-case locality f or non-accelerated methods. The v ariational perspecti ve of Gleich and Mahoney [ GM14 ] and Fountoulakis et al. [ FRS+19 ] shows that a standard local clustering guarantee (in the spirit of APPR) can be obtained by solving an ℓ 1 -regularized P ageRank objecti ve. Fountoulakis et al. [ FRS+19 ] show 2 that proximal-gradient/IST A iterations can be implemented locally on undirected graphs, with total work ˜ O (( αρ ) − 1 ) to reach a prescribed accuracy , where ρ is the regularization parameter . This gi ves a worst-case, graph-size-independent work bound for non-accelerated optimization. What is missing is an analogous worst-case bound for accelerated proximal-gradient methods. A related line studies statistical and regularization-path properties of local dif fusion objectiv es. For instance, Ha, Fountoulakis, and Mahoney [ HFM21 ] dev elop statistical guarantees for local graph clustering and analyze properties of the ℓ 1 -regularized PageRank solution path, which is a structural tool (e.g., monotonicity along the regularization path) that we le v erage when reasoning about ov er -regularization in our paper . The COL T’22 open pr oblem on acceleration and its solutions/attempts. Fountoulakis and Y ang [ FY22 ] posed the COL T’22 open problem of whether one can obtain a prov able accelerated algorithm for ℓ 1 -regularized P ageRank with work e O (( ρ √ α ) − 1 ) , improving the α -dependence by a factor of 1 / √ α ov er IST A while preserving locality . They emphasized that existing IST A analyses do not cover acceleration and that it w as unclear whether worst-case work might ev en degrade under acceleration. The first affirmati ve solution is due to Martínez-Rubio, W irth, and Pokutta [ MWP23 ], who design accelerated algorithms that retain sparse updates. Their method ASPR uses an expanding-subspace (outer- inner) scheme: it grows a set of “good” coordinates and runs an accelerated projected gradient subroutine on the restricted feasible set. This yields a worst-case bound of O ( | S ⋆ | f v ol( S ⋆ ) α − 1 / 2 log(1 /ε ) + | S ⋆ | v ol( S ⋆ )) , where S ⋆ is the support of the optimal solution and f v ol( S ⋆ ) is the number of edges of the subgraph formed only by nodes in S ⋆ . Compared to O (v ol( S ⋆ ) α − 1 log(1 /ε )) = e O (1 / ( ρα )) of IST A, the solution improves the α -dependence with a different sparsity dependence than IST A. In this work, we provide a support-sensitive, de gree-weighted work analysis of the classic one-gradient-per -iteration FIST A method. Our contribution is algorithmically orthogonal, and the bound establishes a new trade-off under checkable conditions. Zhou et al. [ ZSB+24 ] study locality for accelerated linear-system solvers via a “locally ev olving set process” and obtain an accelerated guarantee under an additional run-dependent residual-reduction assumption, which they note is empirically reasonable but not yet theoretically justified. In contrast, our bounds for standard FIST A are checkable, and we quantify when classical acceleration reduces total degree-weighted work and when boundary e xploration can dominate. Support identification, strict complementarity . Our complementarity-gap vie wpoint connects to the constraint- identification literature: under strict-complementarity-type conditions, proximal and proximal-gradient methods identify the optimal support in finitely many iterations [ BM94 ; NSH19 ; SJN+19 ], and acceleration can delay identification via oscillations [ BI20 ] (see also related strict-complementarity analyses for Frank-W olfe [ W ol70 ; GM86 ; Gar20 ]). T o the best of our kno wledge, these identification results are iteration-complexity statements under unit-cost gradient/prox steps, and they do not quantify a locality-a ware total work measure for accelerated methods. 3 Pr eliminaries and notation W e assume undirected and unweighted graphs, and we use [ n ] := { 1 , . . . , n } . ∥ · ∥ 2 denotes the Euclidean norm and ∥ · ∥ 1 denotes the ℓ 1 norm. For a set S ⊆ [ n ] we write | S | for its cardinality . If the indices in S represent node indices of a graph, we use v ol( S ) := P i ∈ S d i for the graph volume, where d i is the number of neighbors of node i , that is, its degree. W e assume d i > 0 for all vertices. W e say a dif ferentiable function f is L -smooth if ∇ f is L -Lipschitz with respect to ∥ · ∥ 2 , that is ∥∇ f ( x ) − ∇ f ( y ) ∥ 2 ≤ L ∥ x − y ∥ 2 . W e denote by µ > 0 the strong-con ve xity parameter of a strongly-con ve x function F with respect to ∥ · ∥ 2 . In such a case F has a unique minimizer x ⋆ . For one such problem, define the optimal support and its complement as S ⋆ := supp( x ⋆ ) and I ⋆ := [ n ] \ S ⋆ . The main objecti ve that we consider in this work is the personalized PageRank quadratic objecti ve, and its ℓ 1 regularized v ersion. For a parameter α > 0 , called the teleportation parameter , and an initial distrib ution of nodes s (i.e., ⟨ 1 , s ⟩ = 1 , s ≥ 0 ), the unregularized PageRank objecti ve is f ( x ) := 1 2 ⟨ x, Qx ⟩ − α ⟨ D − 1 / 2 s, x ⟩ for Q = αI + 1 − α 2 L , where L := I − D − 1 / 2 AD − 1 / 2 is the symmetric normalized Laplacian matrix, which is known to satisfy 0 ≼ L ≼ 2 I [ BC14 ]. Thus, αI ≼ Q ≼ I , which implies the objectiv e is α -strongly con v ex and 1 -smooth. W e will assume the seed is a single node v , that is s = e v . This is the case for clustering applications, where one seeks to find a cluster of nodes near v that hav e high intraconnecti vity and lo w connecti vity to the rest of the graph [ A CL06 ; Gle15 ]. A common objective for obtaining sparse PageRank solutions is the ℓ 1 -Regularized Personalized PageRank problem (RPPR), which comes with the sparsity guarantee v ol( S ⋆ ) ≤ 1 /ρ , cf. [ FRS+19 , Theorem 2], where ρ > 0 is a 3 regularization weight on the objecti v e: min x ∈ R n F ρ ( x ) := min x ∈ R n f ( x ) + g ( x ) = min x ∈ R n f ( x ) + αρ ∥ D 1 / 2 x ∥ 1 . (RPPR) where g ( x ) := αρ ∥ D 1 / 2 x ∥ 1 . This is the central problem we study in this work. It is worth noticing some properties of (RPPR) . The initial gap from x 0 = 0 is ∆ 0 := F (0) − F ( x ⋆ ) ≤ α/ 2 , cf. Lemma A.1 , and so by strong conv exity , the initial distance to x ⋆ satisfies ∥ 0 − x ⋆ ∥ 2 ≤ p 2∆ 0 /µ ≤ 1 . Finally , the minimizer x ⋆ ( ρ ) of F ρ is coordinatewise nonne gati v e and the optimality conditions are, cf. [ FRS+19 ]: ∇ i f x ⋆ ( ρ ) ∈ ( {− αρ √ d i } , x ⋆ i ( ρ ) > 0 , [ − αρ √ d i , 0] , x ⋆ i ( ρ ) = 0 . (1) 3.1 The FIST A Algorithm W e introduce here the classical accelerated proximal-gradient method (FIST A) [ BT09 ] and the properties we use later . W e present the method for a composite objective F ( x ) := f ( x ) + g ( x ) where f is L -smooth and F is µ -strongly con v ex with respect to ∥ · ∥ 2 . For (RPPR) , we have L = 1 and µ = α (since αI ≼ Q ≼ I ), so the standard choice is step size η = 1 /L = 1 and momentum parameter β = √ L/µ − 1 √ L/µ +1 = 1 − √ α 1+ √ α . The iterates of the FIST A algorithm initialized with x − 1 = x 0 = 0 are, for k ≥ 0 : y k = x k + β ( x k − x k − 1 ) , x k +1 = pro x η g y k − η ∇ f ( y k ) . (FIST A) The proximal operator is defined as pro x η g ( x ) := arg min y { η g ( y ) + 1 2 ∥ y − x ∥ 2 2 } . For the RPPR regularizer g ( x ) = αρ ∥ D 1 / 2 x ∥ 1 the prox is separable and yields: x k +1 ,i = sign( y k,i − η ∇ i f ( y k )) max n y k,i − η ∇ i f ( y k ) − η αρ p d i , 0 o . (2) Definition 3.1 W e measur e runtime via a de gr ee-weighted work model. F or an iterate pair ( y k , x k +1 ) we define the per-iter ation work as w ork k := vol(supp( y k )) + v ol(supp( x k +1 )) . (3) F or IST A, y k = x k ; for FIST A, y k = x k + β ( x k − x k − 1 ) . The total work to reac h the stopping tar get is the sum of w ork k over the iterations tak en 2 . 4 FIST A ’ s work analysis in RPPR under ℓ 1 ov er -regularization W e analyze the work of (FIST A) on (RPPR) . In this setting, fe wer iterations do not automatically mean less work. Although FIST A improves the iteration complexity of IST A, its extrapolated points y k can transiently acti v ate coordinates that are zero at the optimizer , increasing the cost of computing the gradient at each iteration. Our analysis splits the work into a core cost and a spurious-exploration ov erhead. W e fix a core set S that we are willing to pay for at every iteration, and we charge any additional work to the spurious activ e sets outside S , namely e A k := supp( x k +1 ) ∩ S c . W e sho w that the additional work is in v ersely proportional to the minimum KKT margin. T o a void v acuous bounds when KKT margins are tin y , we choose S = supp( x ⋆ ( ρ )) , while our target is F 2 ρ . By the RPPR sparsity guarantee, this implies v ol( S ) ≤ 1 /ρ (cf. Section 3 ). The remainder of the section bounds the cumulati v e ov erhead P k v ol( e A k ) via complementarity slacks, confinement condition, and FIST A ’ s iteration complexity . 2 Since each FIST A iteration computes a single gradient at y k , one could alternatively take work k := vol(supp( y k )) . Our definition ( 3 ) is a con venient symmetric upper bound (it also cov ers ev aluations at x k +1 , e.g., for stopping diagnostics), and it matches the quantities controlled in our proofs up to an absolute constant. 4 4.1 Over -regularization A direct locality analysis of accelerated proximal-gradient methods naturally runs into a margin issue. In the arguments that follo w , spurious acti v ations will be controlled by KKT slacks at the optimum. For RPPR, howe ver , the smallest slack ov er inacti ve coordinates can be arbitrarily small (see Section C ), so any bound that depends on the minimum slack would be vacuous. T o obtain a work bound that remains meaningful, we will slightly over -re gularize the objecti v e, and we will relate the support of the solutions for F 2 ρ and F ρ . For these tw o problems, we introduce the notation: g A ( x ) := αρ ∥ D 1 / 2 x ∥ 1 and g B ( x ) := 2 αρ ∥ D 1 / 2 x ∥ 1 , and the corresponding minimizers x ⋆ A ∈ arg min x f ( x ) + g A ( x ) , x ⋆ B ∈ arg min x f ( x ) + g B ( x ) , with supports S A := supp( x ⋆ A ) , S B := supp( x ⋆ B ) , I B := [ n ] \ S B . W e run standard (FIST A) on the ov er -regularized (B) problem, and we treat S A as a region where coordinates are potentially active at every iteration, e v en if some are inactiv e for x ⋆ B . This choice does not entail large w ork, since the guarantee is v ol( S A ) ≤ 1 /ρ , cf. v ol( S B ) ≤ 1 / (2 ρ ) . W e also hav e to account for the work of nodes that are activ e outside from S A . Define the spurious activ e set at step k by e A k := supp( x k +1 ) ∩ S c A . Under the de gree-weighted work model, such activ ations are the only mechanism by which FIST A can incur additional locality overhead be yond the cost of working inside S A . Then, after N iterations, the total degree-weighted work is O N vol( S A ) + N − 1 X k =0 v ol( e A k ) ! . (4) The first term corresponds to the cost of running N proximal-gradient steps while remaining in S A , since computing the gradient and applying the prox map costs work proportional to the volume of the acti ve set. The second term is the cumulativ e o verhead from transient acti v ations outside S A . Our goal is to bound (4) . The next subsection provides the tools for controlling the second term. In particular , the complementarity-slack lemma ( Lemma 4.1 ) will sho w that ev ery spurious activ ation forces a quantitativ e de viation in the forward-gradient map relati ve to x ⋆ B , and the split of Lemma 4.2 will ensure that any index outside S A has a uniform slack lower bound under the (B) problem. These ingredients remov e dependence on tiny mar gins and allow us to sum the spurious volumes o ver iterations using FIST A ’ s geometric contraction, leading to our w ork bound. 4.2 Complementarity slack and spurious activations W e now make precise how momentum-induced activ ations outside the optimal support can be con v erted into a quantitativ e cost that we can later sum ov er iterations. The main idea is: for a coordinate that is zero at the optimum of the (B) problem, the KKT conditions specify a nontrivial interv al in which its (signed) gradient must lie. The distance to the edge of that interv al is a measure of ho w safely inactive the coordinate is. If FIST A ne v ertheless acti v ates such a coordinate at some extrapolated point, then something must have mo v ed by at least that safety mar gin. This is the mechanism that will let us bound the cumulativ e work spent on spurious supports. Fix the (B) problem and let x ⋆ := x ⋆ B . F or e very inactive coordinate i ∈ I B , define its degree-normalized complementarity (KKT) slack by γ i := λ i − |∇ f ( x ⋆ ) i | √ d i = λ i + ∇ i f ( x ⋆ ) √ d i ≥ 0 , where λ i := 2 αρ p d i . (5) The quantity γ i is the (degree-normalized) gap between the soft-threshold le vel λ i and the magnitude of the optimal gradient at coordinate i . In other words, it measures how far coordinate i is from becoming activ e at the optimum. Define the gradient map and the set of spurious nodes by u ( x ) := x − η ∇ f ( x ) , A ( y ) := supp pro x η g B u ( y ) ∩ I B for any x ∈ R n , y ∈ R n . Here u ( · ) is the standard forward step used by proximal-gradient methods, and A ( y ) is the subset of (B)-inactive indices that become nonzero after applying the prox map at the point y . The set A ( y k ) is exactly what creates the extra per-iteration cost due to spurious e xploration with respect to an ideal local acceleration complexity of ˜ O (1 / ( ρ √ α )) . W e no w formalize the connection between a spurious activ ation and a nontrivial de viation in the forward step. This is the basic bridge from optimality structure to the work bound. 5 Lemma 4.1 [ ↓ ] F ix y ∈ R n . F or every i ∈ A ( y ) , | u ( y ) i − u ( x ⋆ ) i | > η γ i √ d i . Lemma 4.1 is what allows us to turn spurious activ ations into a summable error budget that is compatible with FIST A ’ s con v ergence rate, gi v en that the distance to optimizer bounds ∥ u ( y k ) − u ( x ⋆ ) ∥ and contracts with time. Recall that the margin for the (B) problem can be written as γ ( B ) i := 2 ρα + ∇ i f ( x ⋆ B ) √ d i for i ∈ I B . (6) W e no w sho w that the margin of coordinates that are not in S A is large enough. Lemma 4.2 [ ↓ ] Let I B := [ n ] \ S B be the inactive set for pr oblem (B), and define I small B := n i ∈ I B : γ ( B ) i < ρα o , I large B := n i ∈ I B : γ ( B ) i ≥ ρα o . Then I small B ⊆ S A . Next, we compute a bound on the work v ol( e A k ) which is proportional to the in v erse minimum margin of the coordinates in v olved, and this quantity is no more than 1 / ( ρα ) by the lemma above. 4.3 W ork bound and sufficient conditions W e no w deri ve a bound on the work. Recall the decomposition ( 4 ) , the uniform bound for the margin of coordinates in e A k in the previous section, together with Cauchy-Schwarz and the distance contraction of ∥ y k − x ⋆ B ∥ 2 that we show in Corollary A.3 , makes the series P k v ol( e A k ) summable and leads to the overhead term in the theorem belo w . Theorem 4.3 [ ↓ ] F or the (B) pr oblem with objective F B ( x ) = f ( x ) + g B ( x ) , run (FIST A) . Let B be a set such that e A k ⊆ B for all k ≥ 0 , Then, we reac h F B ( x N ) − F B ( x ⋆ B ) ≤ ε after a total degr ee-weighted work of at most W ork( N ε ) ≤ O 1 ρ √ α log α ε + p v ol( B ) ρα 3 / 2 ! . The bound in Theorem 4.3 separates the cost of con v erging on S A , from the extra cost of transient exploration. The first term is the baseline accelerated contrib ution: FIST A needs N ε = O ( √ α ) − 1 log( α/ε ) iterations, and each iteration costs at most a constant times v ol( S A ) ≤ 1 /ρ , yielding O (( ρ √ α ) − 1 log( α/ε )) . The second term bounds the entire cumulative volume of the spurious sets e A k . The factor ρ − 1 α − 3 / 2 reflects the combination of (i) the uniform margin ρα obtained from Lemma 4.2 and (ii) the geometric contraction of the iterates, which sums to O ( α − 1 / 2 ) . W e used hypothesis e A k ⊆ B as an explicit locality requirement. W e no w give a checkable graph-structural sufficient condition that implies such confinement, with B identified as a verte x boundary . Theorem 4.4 [ ↓ ] Consider the (B) pr oblem objective F 2 ρ in (RPPR) , and let S be a set such that S B ⊆ S . Define ∂ S as the vertex boundary of S and Ext( S ) := V \ ( S ∪ ∂ S ) . Assume ther e e xists ξ ∈ [0 , 1] such that for all i ∈ Ext( S ) , |N ( { i } ) ∩ ∂ S | d i ≤ αρ 2(1 − α ) 2 d i d min ∂ S , (7) wher e d min ∂ S := min j ∈ ∂ S d j . Then the iterates of (FIST A) satisfy , for all k ≥ 0 : supp( x k ) ⊆ S ∪ ∂ S. Theorem 4.4 provides a mechanism by which spurious activ ations can be ruled out in the exterior of a candidate region. Condition ( 7 ) controls ho w an e xterior node is connected to the current active region by upper-bounding the fraction of its incident edges that connect to the boundary ∂ S . This condition is fav orable for FIST A: it rules out “percolation” of extrapolated iterates into the exterior . Ne vertheless, our synthetic experiments in Section 5 still e xhibit regimes where FIST A is slower . Remark 4.5 If S = S A in Theor em 4.4 , then supp( x k ) ⊆ S A ∪ ∂ S A for all k ≥ 0 . So any spurious activation happens in B := ∂ S A , that is, the confinement hypothesis in Theor em 4.3 holds with B = ∂ S A , and the overhead term in the work bound is governed by the boundary volume v ol( ∂ S A ) . Remark 4.6 In Section B , we pr ove a complementary pr opery showing that nodes of high-enough de gr ee do not every get activated, whic h implies in fact the v ol( B ) term in Theor em 4.3 can be r educed to the volume of nodes in B with de gr ee below a threshold given by the amount in Section B . 6 = 3 2 0 = 4 0 0 = 6 0 0 = 8 0 0 = 1 0 0 0 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 edge density Figure 1: Adjacency density . For each boundary size |B | we visualize the adjacency matrix via a binned edge-density heatmap (bin size 20 ), where each pixel shows the fraction of possible edges between a pair of bins (log-scaled; colormap magma with white below 10 − 4 ). Dashed lines mark the core | boundary | exterior block boundaries. The plots sho w the clique (upper -left block), the boundary circulant band, the nearly dense exterior block, and the sparse cross-region interfaces. 5 Experiments This section ev aluates when FIST A reduces (and when it can increase) the total de gree-weighted w ork for ℓ 1 -regularized PageRank, reflecting the tradeof f in Theorem 4.3 . W e present two sets of experiments. First, we consider a controlled synthetic core-boundary-e xterior graph f amily . Details on parameter tuning are gi ven in Section D . Second, we compare IST A and FIST A on real data: SN AP [ LK14 ] graphs. In our experiments, we did not over -re gularize the problem. For synthetic experiments the no-percolation assumption is satisfied. W e use a three-block node partition V = S ∪ B ∪ Ext , where S (the core) contains the seed. The induced subgraph on S is a clique, while B (the boundary) and Ext (the exterior) are each internally connected. Cross-re gion connecti vity is sparse: the core connects to B with a fix ed per-core fan-out, and each exterior node has one neighbor in B . This yields a clear block structure in the adjacency matrix and lets us vary the boundary size/v olume v ol( B ) while keeping the core fixed. Figure 1 visualizes an example of this construction. W e pro vide details in Section D 3 . 5.1 Synthetic boundary-volume sweep experiment 30K 40K 50K 60K 70K 80K v o l ( ) 72K 75K 78K 80K 82K 85K T otal work IST A FIST A Figure 2: W ork vs. v ol( B ) . W ork by IST A and FIST A against vol( B ) . This section provides synthetic e xperiments illustrating ho w the boundary volume can dominate the running time of accelerated proximal-gradient methods. In particular , the experiment isolates the mechanism behind the p v ol( B ) -term in the work bound in Theorem 4.3 , and shows empirically that, as v ol( B ) increases, the accelerated method can become slo wer than its non-accelerated counterpart. W e use the core-boundary-exterior synthetic construction from Sec- tion 5 , and vary only the boundary size |B | (and hence v ol( B ) ), keeping the core, exterior , and all degree/connecti vity parameters fixed. On each instance of the sweep we solve the ℓ 1 -regularized PageRank objectiv e ( RPPR ) with α = 0 . 20 and ρ = 10 − 4 , comparing IST A and FIST A un- der the common initialization, parameter choices, stopping protocol, and degree-weighted w ork accounting described in Section 5 . W e set ε = 10 − 6 . Figure 2 plots the work to reach the common stopping target as a func- tion of v ol( B ) . The ke y trend is that FIST A becomes increasingly expensi v e as v ol( B ) gro ws. For sufficiently large v ol( B ) it becomes slower than IST A. This is exactly the beha vior suggested by the bound in Theorem 4.3 (and in particular by the p v ol( B ) / ( ρα 3 / 2 ) term): as the boundary volume gro ws, the potential cost of spurious e xploration in the boundary gro ws as well. 5.2 Sweeps in ρ , α and ε at fixed boundary size W e fix |B | = 600 , and we run three sweeps (summarized in Figure 3 ): (i) an ρ -sweep, reported for both a dense-core (clique) instance and a sparse-core variant (connected, 20% of clique edges) to confirm that the observed ρ -dependence 3 Code that reproduces all experiments is a vailable at https:// github .com/ watcl- lab/ accelerated_l1_P ag eRank_experiments . 7 is not an artifact of the symmetric clique core; (ii) an α -sweep with ρ = 10 − 4 ; and (iii) an ε -sweep at fixed α = 0 . 20 (complete details in Section E ). The ρ sweeps ( Figures 3a and 3b ) show that work decreases as ρ increases and collapses to 0 beyond the tri vial- solution threshold; across the sweep, IST A and FIST A e xhibit qualitati vely similar 1 /ρ -type scaling, consistent with the ρ -dependence in Theorem 4.3 for fixed α and fixed boundary size. The α sweep ( Figure 3c ) shows increasing work as α decreases, and FIST A can be slo wer than IST A ov er a substantial small- α range, consistent with the interpretation of Theorem 4.3 . Finally , the ε sweep ( Figure 3d ) sho ws increasing w ork as the tolerance decreases. FIST A is faster for small ε , consistent with the interpretation of Theorem 4.3 . 1 0 4 1 0 3 1 0 2 0 1 10 100 1.0K 10K T otal work IST A FIST A (a) Dense cor e (clique). 1 0 3 1 0 2 0 1 10 100 1.0K 10K T otal work IST A FIST A (b) Sparse cor e . 1 0 2 1 0 1 1 0 0 100 1.0K 10K 100K T otal work IST A FIST A (c) α sweep 1 0 1 0 1 0 7 1 0 4 1 0 1 0 200K 400K T otal work IST A FIST A (d) ε sweep Figure 3: Sweeps at fixed |B | = 600 . Figure 3a shows the ρ -sweep with a dense core (clique) on a fresh randomized graph per ρ ; Figure 3b shows the ρ -sweep with a sparse core (connected, 20% of clique edges) on a fresh randomized graph per ρ . Figure 3c sweeps α at a fixed residual tolerance ε = 10 − 6 on a single instance constructed to satisfy ξ > 0 and the no-percolation condition at the smallest swept v alue, with parameters selected by an inexpensiv e auto-tuning step ( Section E ). Figure 3d sweeps the tolerance ε at fixed α = 0 . 20 on the baseline unweighted instance. 5.3 Real-data benchmarks on SNAP graphs Our synthetic experiments use a deliberate core-boundary-exterior construction in order to satisfy the no-percolation assumption. The real-data benchmarks in this subsection are at the opposite end of the spectrum: heterogeneous SN AP [ LK14 ] networks whose connecti vity and de gree profiles are not engineered to fit the synthetic template. W e include these datasets to illustrate both a positi ve and a negati v e real example for acceleration. On com-Amazon , com-DBLP , and com-Youtube we typically observe a consistent work reduction with FIST A, whereas com-Orkut exhibits a setting where FIST A can be slower due to costly exploration be yond the optimal support. 4 . W ork vs. parameter α . W e sweep α ov er a log-spaced grid in [10 − 3 , 0 . 9] while fixing ρ = 10 − 4 and ε = 10 − 8 5 ; results are in Figure 4 . On com-Amazon , com-DBLP , and com-Youtube , FIST A consistently reduces work relativ e to IST A across the full α range. On com-Orkut , howe ver , FIST A can be slo wer than IST A for small α before becoming competitiv e again at moderate and lar ge α , illustrating that acceleration can lose under our work metric. W ork vs. KKT tolerance ε . W e next fix α = 0 . 20 and ρ = 10 − 4 and sweep the tolerance ε ov er a log-spaced grid in [10 − 8 , 10 − 2 ] ; results are in Figure 5 . Tightening the tolerance (smaller ε ) increases work for both methods, and FIST A typically achiev es the same tolerance with less total work on these datasets, though the gap can be small (notably on com-Orkut ) for intermediate tolerances. W ork vs. sparsity parameter ρ . Finally , we fix α = 0 . 20 and ε = 10 − 8 and sweep ρ ov er a log-spaced grid in [10 − 6 , 10 − 2 ] ; results are shown in Figure 6 . As ρ increases (stronger regularization), the solutions become more localized and the work decreases sharply . Across all four graphs, FIST A generally impro v es upon IST A by a modest constant factor for these settings. Additional diagnostics. Because total work conflates iteration count and per-iteration cost, aggre gate curv es alone do not explain why the IST A–FIST A ranking differs across datasets. In Section F we separate these two factors and we report degree-tail summaries. In particular , the diagnostics sho w that com-Orkut ’ s slowdo wns are dri ven by costly transient exploration, i.e., small sets of high-degree acti v ations inflate the per -iteration work and can of fset (or e v en rev erse) the iteration sa vings of acceleration ( Figures 7 and 8 ). 4 For each dataset we sample 300 seed nodes uniformly at random from the non-isolated vertices; the same seed set is reused for both IST A and FIST A and across all sweeps. In the sweep plots below , solid lines are means o ver the 300 seeds and the shaded bands show the interquartile range (25%-75%). 5 Note that ε = 10 − 8 is different from the value used in the synthetic e xperiments, which was ε = 10 − 6 . This is because we observed that the latter setting was too large for the real data to produce meaningful plots. 8 1 0 3 1 0 2 1 0 1 1 0 0 10K 1.0M W ork to r each tol. IST A FIST A (a) com-Amazon . 1 0 3 1 0 2 1 0 1 1 0 0 1.0K 10K 100K 1.0M IST A FIST A (b) com-DBLP . 1 0 3 1 0 2 1 0 1 1 0 0 1.0K 100K IST A FIST A (c) com-Youtube . 1 0 3 1 0 2 1 0 1 1 0 0 1.0K 10K 100K IST A FIST A (d) com-Orkut . Figure 4: Real graphs: work vs. α . W ork to reach tolerance 10 − 8 as a function of α , with ρ = 10 − 4 fixed. Curves show mean ov er 300 random seeds; shaded bands are interquartile ranges. 1 0 7 1 0 5 1 0 3 100 1.0K 10K W ork to r each tol. IST A FIST A (a) com-Amazon . 1 0 7 1 0 5 1 0 3 100 1.0K 10K 100K IST A FIST A (b) com-DBLP . 1 0 7 1 0 5 1 0 3 1.0K 10K 100K IST A FIST A (c) com-Youtube . 1 0 7 1 0 5 1 0 3 100 1.0K 10K 100K IST A FIST A (d) com-Orkut . Figure 5: Real graphs: work vs. KKT tolerance. W ork to reach ε , with α = 0 . 20 and ρ = 10 − 4 fixed. Curves show mean ov er 300 random seeds; shaded bands are interquartile ranges. 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1.0K 10K 100K 1.0M W ork to r each tol. IST A FIST A (a) com-Amazon . 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1.0K 10K 100K 1.0M IST A FIST A (b) com-DBLP . 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1.0K 100K IST A FIST A (c) com-Youtube . 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1.0K 10K 100K 1.0M IST A FIST A (d) com-Orkut . Figure 6: Real graphs: work vs. ρ . W ork to reach 10 − 8 as a function of ρ , with α = 0 . 20 fixed. Curves show mean ov er 300 random seeds; shaded bands are interquartile ranges. 6 Conclusion, limitations and futur e work W e analyzed the classical one-gradient-per-iteration accelerated proximal-gradient method (FIST A) for ℓ 1 -regularized PageRank under a degree-weighted locality work model. Under a verifiable confinement assumption, the resulting complexity decomposes into acceleration together with an explicit ov erhead that quantifies momentum-induced transient exploration. The main limitation is that the bound is informativ e when spurious activ ations remain confined to a boundary set of moderate v olume. Several directions remain open. For e xample, establishing lo wer bounds in the degree-weighted work model. Additional work could sharpen confinement diagnostics and deri ve more instance-adapti v e predictions, as well as extend the frame work to other acceleration schemes. 9 Acknowledgements K. Fountoulakis would lik e to ackno wledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC). Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), [RGPIN-2019-04067, DGECR-2019-00147]. D. Martínez-Rubio was partially funded by grant PID2024-160448NA-I00 and by La Caixa Junior Leader Fellowship 2025. Refer ences [A CL06] Reid Andersen, Fan R. K. Chung, and Ke vin J. Lang. Local Graph Partitioning using PageRank V ectors . In: 47th Annual IEEE Symposium on F oundations of Computer Science (FOCS 2006), 21-24 October 2006, Berkele y , California, USA, Pr oceedings . IEEE Computer Society, 2006, pp. 475–486 (cit. on pp. 1 – 3 ). [BC14] Stev e E. Butler and Fan R. K. Chung. Spectral Graph Theory . In: Handbook of Linear Algebra . Ed. by Leslie Hogben. 2nd. Boca Raton, FL, USA: CRC Press, 2014, pp. 47-1–47-14. I S B N : 9781466507289 (cit. on p. 3 ). [Bec17] Amir Beck. F ir st-Or der Methods in Optimization . V ol. 25. MOS-SIAM Series on Optimization. Philadel- phia, P A, USA: Society for Industrial and Applied Mathematics (SIAM), 2017. I S B N : 9781611974980 (cit. on p. 12 ). [BI20] Gilles Bareilles and Franck Iutzeler. On the interplay between acceleration and identification for the proximal gradient algorithm . In: Computational Optimization and Applications 77 (2020), pp. 351–378 (cit. on p. 3 ). [BM94] James V . Burke and Jor ge J. Moré. Exposing Constraints . In: SIAM J . Optim. 4.3 (1994) (cit. on p. 3 ). [BT09] Amir Beck and Marc T eboulle. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear In v erse Problems . In: SIAM J. Ima ging Sci. 2.1 (2009) (cit. on pp. 1 , 4 ). [FRS+19] Kimon Fountoulakis, Farbod Roosta-Khorasani, Julian Shun, Xiang Cheng, and Michael W Mahoney. V ariational perspectiv e on local graph clustering . In: Mathematical Pr ogramming 174.1 (2019), pp. 553– 573 (cit. on pp. 1 – 4 , 12 , 14 ). [FY22] Kimon Fountoulakis and Shenghao Y ang. Open Problem: Running time complexity of accelerated ℓ 1 - regularized P ageRank . In: Pr oceedings of Thirty F ifth Confer ence on Learning Theory . V ol. 178. Proceed- ings of Machine Learning Research. PMLR, 2022, pp. 5630–5632 (cit. on p. 3 ). [Gar20] Dan Garber. Revisiting Frank-W olfe for Polytopes: Strict Complementarity and Sparsity . In: Advances in Neural Information Pr ocessing Systems 33: Annual Confer ence on Neural Information Pr ocessing Systems 2020, NeurIPS 2020 . Ed. by Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-T ien Lin. 2020 (cit. on p. 3 ). [Gle15] David F . Gleich. PageRank Beyond the W eb . In: SIAM Revie w 57.3 (2015), pp. 321–363 (cit. on pp. 1 – 3 ). [GM14] David Gleich and Michael Mahoney. Anti-dif ferentiating approximation algorithms:A case study with min-cuts, spectral, and flo w . In: Pr oceedings of the 31st International Confer ence on Mac hine Learning . V ol. 32. Proceedings of Machine Learning Research 2. PMLR, 2014, pp. 1018–1025 (cit. on pp. 1 , 2 ). [GM86] Jacques Guélat and Patrice Marcotte. Some comments on W olfe’ s ’away step’ . In: Math. Pr ogr am. 35 (1986), pp. 110–119 (cit. on p. 3 ). [HFM21] W ooseok Ha, Kimon Fountoulakis, and Michael W . Mahoney. Statistical guarantees for local graph clustering . In: Journal of Mac hine Learning Resear ch 22.148 (2021), pp. 1–54 (cit. on pp. 2 , 3 , 12 ). [LK14] Jure Lesko vec and Andrej Krevl. SN AP Datasets: Stanford Larg e Network Dataset Collection . http : // snap.stanfor d.edu/ data . June 2014 (cit. on pp. 2 , 7 , 8 ). [MWP23] David Martínez-Rubio, Elias W irth, and Sebastian Pokutta. Accelerated and Sparse Algorithms for Approximate Personalized PageRank and Beyond . In: Pr oceedings of Thirty Sixth Confer ence on Learning Theory . V ol. 195. Proceedings of Machine Learning Research. PMLR, 2023, pp. 2852–2876 (cit. on p. 3 ). 10 [Nes04] Y urii Nesterov . Introductory Lectur es on Con ve x Optimization: A Basic Course . V ol. 87. Applied Opti- mization. Springer, 2004. I S B N : 978-1-4020-7553-7 (cit. on p. 1 ). [NSH19] Julie Nutini, Mark Schmidt, and W arren Hare. Activ e-Set Complexity of Proximal Gradient: How Long Does It T ake to Find the Sparsity P attern? In: Optimization Letters 13 (2019), pp. 645–655 (cit. on p. 3 ). [SJN+19] Y ifan Sun, Halyun Jeong, Julie Nutini, and Mark Schmidt. Are we there yet? Manifold identification of gradient-related proximal methods . In: Proceedings of the T wenty-Second International Confer ence on Artificial Intelligence and Statistics . V ol. 89. Proceedings of Machine Learning Research. PMLR, 2019, pp. 1110–1119 (cit. on p. 3 ). [W ol70] Philip W olfe. Con v er gence Theory in Nonlinear Programming . In: Inte ger and Nonlinear Pr ogr amming . Ed. by J. Abadie. Amsterdam, Netherlands: North-Holland Publishing Compan y, 1970, pp. 1–36. I S B N : 9780444100009 (cit. on p. 3 ). [ZSB+24] Baojian Zhou, Y ifan Sun, Reza Babanezhad Harikandeh, Xingzhi Guo, Deqing Y ang, and Y anghua Xiao. Iterativ e Methods via Locally Ev olving Set Process . In: Advances in Neural Information Pr ocessing Systems . V ol. 37. Curran Associates, Inc., 2024, pp. 141528–141586 (cit. on p. 3 ). 11 A Pr oofs Lemma A.1 (Initial gap) Assume the seed is a single node v so s = e v and initialize x 0 = 0 . Then F ρ (0) = 0 and ∆ 0 = F ρ (0) − F ρ ( x ⋆ ) = − F ρ ( x ⋆ ) ≤ α 2 d v ≤ α 2 . Proof W e ha ve F ρ ( x ) ≥ f ( x ) and thus F ρ ( x ⋆ ) ≥ min x f ( x ) . The unconstrained minimizer of the quadratic f is x ⋆ f = Q − 1 f b and min f = − 1 2 b ⊤ Q − 1 f b . Because Q ⪰ αI , we ha ve Q − 1 f = Q − 1 ⪯ 1 α I , and therefore b ⊤ Q − 1 f b ≤ 1 α b ⊤ b = 1 α α 2 ∥ D − 1 / 2 s ∥ 2 2 = αs ⊤ D − 1 s. For s = e v , we hav e s ⊤ D − 1 s = 1 /d v , which yields min f ≥ − α 2 d v , and hence − F ρ ( x ⋆ ) ≤ − min f ≤ α 2 d v . W e no w state the classical guarantee on the function-v alue con v er gence on FIST A. Fact A.2 (FIST A con ver gence rate) Assume f is L -smooth and F is µ -str ongly con ve x with respect to ∥ · ∥ 2 . Run (FIST A) with η = 1 /L and β := √ L/µ − 1 √ L/µ +1 ∈ [0 , 1) . Then F ( x k ) − F ( x ⋆ ) ≤ 2 ( F ( x 0 ) − F ( x ⋆ )) 1 − r µ L k for all k ≥ 1 . See [ Bec17 , Section 10.7.7] and take into account that µ 2 ∥ x 0 − x ⋆ ∥ 2 2 ≤ F ( x 0 ) − F ( x ⋆ ) by strong con v exity . W e note that the con v ergence guarantee abo ve, along with strong con vexity , yields bounds on the distance to the minimizer x ⋆ . As a corollary , we can bound the distance to optimizer of the iterates along the whole computation path. Corollary A.3 (FIST A iterates) In the setting of Fact A.2 , we have: ∥ y 0 − x ⋆ ∥ 2 2 ≤ 4∆ 0 µ and ∥ y k − x ⋆ ∥ 2 2 ≤ M 1 − r µ L k − 1 for all k ≥ 1 , for M := 8∆ 0 µ (1 + β ) 2 (1 − p µ/L ) + β 2 . Using the bounds on ∆ 0 and µ in Section 3 , one obtains that for (RPPR) it is M ≤ 20 and ∆ 0 /µ ≤ 1 / 2 . Thus ∥ y k − x ⋆ ∥ 2 ≤ √ 20 for all k ≥ 0 . Proof Let q := 1 − p µ/L . Strong con v exity gi ves F ( x ) − F ( x ⋆ ) ≥ µ 2 ∥ x − x ⋆ ∥ 2 2 , hence, by Fact A.2 : ∥ x k − x ⋆ ∥ 2 2 ≤ 2 µ ( F ( x k ) − F ( x ⋆ )) ≤ 4∆ 0 µ q k , which already yields the result for k = 0 , using y 0 = x 0 . For k ≥ 1 , write y k − x ⋆ = (1 + β )( x k − x ⋆ ) − β ( x k − 1 − x ⋆ ) and use ∥ a − b ∥ 2 2 ≤ 2 ∥ a ∥ 2 2 + 2 ∥ b ∥ 2 2 to obtain ∥ y k − x ⋆ ∥ 2 2 ≤ 2(1 + β ) 2 ∥ x k − x ⋆ ∥ 2 2 + 2 β 2 ∥ x k − 1 − x ⋆ ∥ 2 2 . Substitute the bounds on ∥ x k − x ⋆ ∥ 2 2 and ∥ x k − 1 − x ⋆ ∥ 2 2 . Proof of Lemma 4.1 . Fix i ∈ A ( y ) ⊆ I ⋆ . Then x ⋆ i = 0 , and we hav e | u ( y ) i − u ( x ⋆ ) i | 1 ≥ || u ( y ) i | − | u ( x ⋆ ) i || ≥ | u ( y ) i | − | u ( x ⋆ ) i | 2 > η λ i − η ( λ i − γ i p d i ) = η γ i p d i . where we used the rev erse triangle inequality in 1 . In 2 we used that i ∈ A ( y ) means pro x η g ( u ( y )) i = 0 and so | u ( y ) i | > η λ i . And also that by definition, we have | u ( x ⋆ ) i | = η |∇ f ( x ⋆ ) i | = η ( λ i − γ i √ d i ) by the definition of γ i . The following Lemma A.4 is pro v ed, for example, as Lemma 4 in Ha, F ountoulakis, and Mahoney [ HFM21 ] (see also the discussion of regularization paths in F ountoulakis et al. [ FRS+19 ]). 12 Lemma A.4 (Monotonicity of the ℓ 1 -regularized P ageRank path) F or the family (RPPR) , let x ⋆ ( ρ ) := arg min x F ρ ( x ) , for any ρ > 0 . The solution path is monotone: if ρ ′ > ρ ≥ 0 , then x ⋆ ( ρ ′ ) ≤ x ⋆ ( ρ ) coor dinate wise. Lemma A.5 (Monotonicity of proximal gradient steps f or P ageRank) If z ≥ z ′ ≥ 0 , then pro x g c z − 1 L ∇ f ( z ) ≥ prox g c z ′ − 1 L ∇ f ( z ′ ) (componentwise). Proof Using the definition of the forw ard-gradient map u ( z ) := z − 1 L ∇ f ( z ) , and that, for PageRank, ∇ f ( z ) = Qz − b with b = αD − 1 / 2 s , we hav e u ( z ) = z − 1 L ( Qz − b ) = I − 1 L Q z + 1 L b. Since Q is an M -matrix (positi ve semidefinite and of f-diagonal entries are nonpositiv e) and Q ≼ LI (by L -smoothness), the matrix I − 1 L Q is entrywise nonnegativ e. Therefore u ( · ) is monotone componentwise: z ≥ z ′ ⇒ u ( z ) ≥ u ( z ′ ) . Next, for g c ( x ) = cα ∥ D 1 / 2 x ∥ 1 , the proximal map is separable and monotone componentwise, since pro x g c ( w ) i = sign( w i ) max {| w i | − cα p d i , 0 } . Composing these two monotone maps yields the claim. Proof of Lemma 4.2 . Fix any i ∈ I small B ⊆ I B . Then x ⋆ B ,i = 0 . Recall that u ( z ) := z − ∇ f ( z ) (here η = 1 ). By the definition (6) of the (B)-margin at coordinate i and the fact that x ⋆ B ,i = 0 , we hav e γ ( B ) i < ρα ⇐ ⇒ 2 ρα + ∇ i f ( x ⋆ B ) √ d i < ρα ⇐ ⇒ ∇ i f ( x ⋆ B ) √ d i < − ρα ⇐ ⇒ ∇ i f ( x ⋆ B ) < − ρα p d i ⇐ ⇒ −∇ i f ( x ⋆ B ) > ρα p d i ⇐ ⇒ u ( x ⋆ B ) i > ρα p d i . Therefore, applying the coordinate formula for the prox of g A (cf. (2) ) giv es pro x g A ( u ( x ⋆ B )) i = sign( u ( x ⋆ B ) i ) max {| u ( x ⋆ B ) i | − ρα p d i , 0 } > 0 . Next, since ρ B = 2 ρ > ρ A = ρ , path monotonicity Lemma A.4 yields x ⋆ A ≥ x ⋆ B componentwise. Applying Lemma A.5 with c = 1 (i.e., g A ), z = x ⋆ A , and z ′ = x ⋆ B , we obtain pro x g A ( u ( x ⋆ A )) ≥ pro x g A ( u ( x ⋆ B )) (componentwise). Finally , x ⋆ A is a fixed point of the proximal-gradient map for the (A) problem, so x ⋆ A = pro x g A ( u ( x ⋆ A )) . Hence x ⋆ A,i = pro x g A ( u ( x ⋆ A )) i ≥ pro x g A ( u ( x ⋆ B )) i > 0 , which implies i ∈ supp( x ⋆ A ) = S A . Therefore I small B ⊆ S A . Proof of Theor em 4.3 . Recall that e A k = supp( x k +1 ) ∩ S c A and that we assume e A k ⊆ B for all k ≥ 0 . By Lemma 4.2 , any inde x in e A k is (B)-inacti ve with mar gin at least ρα ; concretely , γ ( B ) i ≥ ρα for all i ∈ e A k . Let B ′ be the subset of B such that γ ( B ) i ≥ ρα for all i ∈ B ′ . Thus, e A k ⊆ B ′ . 13 W e first bound the total spurious work: ∞ X k =0 X i ∈ e A k d i = ∞ X k =0 X i ∈ e A k √ d i γ ( B ) i ! γ ( B ) i p d i ≤ ∞ X k =0 s X i ∈B ′ d i ( γ ( B ) i ) 2 s X i ∈ e A k ( γ ( B ) i ) 2 d i (Cauchy-Schwarz, and e A k ⊆ B ′ ) ≤ ∞ X k =0 s X i ∈B ′ d i ρ 2 α 2 s X i ∈ e A k | u ( y k ) i − u ( x ⋆ B ) i | 2 (since γ ( B ) i ≥ ρα, Lemma 4 . 1 ) ≤ ∞ X k =0 p v ol( B ) ρα ∥ u ( y k ) − u ( x ⋆ B ) ∥ 2 ( because B ′ ⊆ B ) ≤ ∞ X k =0 p v ol( B ) ρα ( ∥ y k − x ⋆ B ∥ 2 + η ∥∇ f ( y k ) − ∇ f ( x ⋆ B ) ∥ 2 ) ≤ ∞ X k =0 p v ol( B ) ρα (1 + η L ) ∥ y k − x ⋆ B ∥ 2 . (by smoothness) (8) For RPPR we use η = 1 and L = 1 , hence (1 + η L ) = 2 . Using Corollary A.3 and writing q := 1 − p µ/L = 1 − √ α , we hav e ∥ y k − x ⋆ B ∥ 2 ≤ O (1) q k/ 2 , so the series in ( 8 ) sums to O ((1 − q ) − 1 ) = O ( α − 1 / 2 ) . Therefore, ∞ X k =0 v ol( e A k ) = O p v ol( B ) ρα 3 / 2 ! . Next, we bound the core w ork. By the sparsity guarantee for RPPR [ FRS+19 , Theorem 2], v ol( S A ) ≤ 1 /ρ . Thus, after N iterations, the total work is bounded by W ork( N ) = O N vol( S A ) + N − 1 X k =0 v ol( e A k ) ! = O N ρ + p v ol( B ) ρα 3 / 2 ! . Finally , by Fact A.2 , to ensure F B ( x N ) − F B ( x ⋆ B ) ≤ ε it suffices to take N ≥ N ε := log(∆ 0 /ε ) log 1 / (1 − p µ/L ) = O 1 √ α log α ε , using L = 1 , µ = α , and ∆ 0 ≤ α/ 2 from Section 3 . Substituting N = N ε yields the stated bound. Proof of Theorem 4.4 . W e pro ve by induction that supp( x k ) ⊆ S ∪ ∂ S for all k ≥ 0 . The base case is trivial, since x 0 = 0 , so supp( x 0 ) = ∅ ⊆ S ∪ ∂ S . Now assume supp( x k − 1 ) ⊆ S ∪ ∂ S and supp( x k ) ⊆ S ∪ ∂ S for some k ≥ 0 (with x − 1 = x 0 = 0 cov ering k = 0 ). Then supp( y k ) ⊆ supp( x k ) ∪ supp( x k − 1 ) ⊆ S ∪ ∂ S . Fix any i ∈ Ext( S ) . Since i / ∈ S ∪ ∂ S and supp( y k ) ⊆ S ∪ ∂ S , we hav e y k,i = 0 . Also i = v (the seed lies in S ), hence ( D − 1 / 2 s ) i = 0 . For RPPR, ∇ f ( y ) = Qy − αD − 1 / 2 s , so with η = 1 we have u ( y ) = y − ∇ f ( y ) = ( I − Q ) y + αD − 1 / 2 s. Using Q = 1+ α 2 I − 1 − α 2 D − 1 / 2 AD − 1 / 2 , we get ( I − Q ) = 1 − α 2 I + D − 1 / 2 AD − 1 / 2 . Therefore, for our fixed i ∈ Ext( S ) , u ( y k ) i = 1 − α 2 X j ∼ i y k,j p d i d j = 1 − α 2 X j ∈N ( { i } ) ∩ ∂ S y k,j p d i d j , 14 because i has no neighbors in S (by definition of Ext( S ) ) and y k has no support outside S ∪ ∂ S . T aking absolute values and using d j ≥ d min ∂ S for j ∈ ∂ S giv es | u ( y k ) i | ≤ 1 − α 2 √ d i X j ∈N ( { i } ) ∩ ∂ S | y k,j | p d j 1 ≤ 1 − α 2 √ d i · p |N ( { i } ) ∩ ∂ S | √ d min ∂ S · ∥ y k ∥ 2 2 ≤ α 4 ρ p d i ( ∥ y k − x ⋆ ∥ 2 + ∥ x ⋆ ∥ 2 ) 3 ≤ 2 αρ p d i . where 1 uses Cauch y-Schwarz and 2 uses the triangular inequality and our no-percolation assumption (7) . Finally 3 uses the bound ∥ y k − x ⋆ ∥ 2 ≤ √ 20 from Corollary A.3 and ∥ x ⋆ ∥ 2 ≤ 1 from the preliminaries Section 3 and bound the resulting constants to an integer number . For the (B) problem, the shrinkage threshold is λ i = 2 αρ √ d i , so we sho wed | u ( y k ) i | ≤ λ i and thus the proximal update keeps x k +1 ,i = 0 (cf. the coordinate formula (2) ). Since this holds for every i ∈ Ext( S ) , we conclude supp( x k +1 ) ⊆ S ∪ ∂ S . This completes the induction. B High-degr ee nodes do not activ ate W e provide an extra property of (FIST A) . Nodes of high-enough degree can never be acti v ated by the accelerated iterates when we over -regularize. The proof argues that (FIST A) on problem (B) with a large margin pre vents high-degree nodes and large mar gins are guaranteed for coordinates outside from S A . Proposition B.1 (Lar ge-degree nodes do not acti vate) Run (FIST A) on problem (B) F 2 ρ and let i such that that the minimizer of pr oblem (A) F ρ satisfies x ⋆ A,i = 0 . If d i ≥ LR αρ 2 , then (FIST A) does not activate node i , that is x k,i = y k,i = 0 for all k ≥ 0 . Using that in our PageRank problem (RPPR) , it is L ≤ 1 and R ≤ 20 , we conclude that nodes satisfying d i ≥ 1600 α − 2 ρ − 2 will not get activ ated. Proof Fix i such that x ⋆ A,i = 0 . By path monotonicity Lemma A.4 and nonneg ativity of the minimizers, ∆ x := x ⋆ A − x ⋆ B ≥ 0 and ∆ x i = 0 . Recall ∇ f ( x ) = Qx − b , where b ≥ 0 and Q ij ≤ 0 for i = j . Since x ⋆ A , x ⋆ B ≥ 0 and x ⋆ A,i = x ⋆ B ,i = 0 , we hav e ∇ i f ( x ⋆ A ) ≤ 0 , ∇ i f ( x ⋆ B ) ≤ 0 , and ∇ i f ( x ⋆ B ) − ∇ i f ( x ⋆ A ) = − ( Q ∆ x ) i = − X j = i Q ij ∆ x j ≥ 0 . Hence |∇ i f ( x ⋆ B ) | ≤ |∇ i f ( x ⋆ A ) | ≤ α ρ p d i , where the last inequality holds by the KKT conditions for problem (A) ( ρ -regularization), W e now prov e x k,i = 0 for all k by induction. The base case holds since x − 1 = x 0 = 0 . Assume x k,i = x k − 1 ,i = 0 . Then y k,i = 0 and by L -smoothness, |∇ i f ( y k ) | ≤ |∇ i f ( x ⋆ B ) | + ∥∇ f ( y k ) − ∇ f ( x ⋆ B ) ∥ 2 ≤ αρ p d i + L ∥ y k − x ⋆ B ∥ 2 . Using ∥ y k − x ⋆ B ∥ 2 ≤ R and d i ≥ LR αρ 2 , we obtain |∇ i f ( y k ) | ≤ 2 α ρ p d i . (9) 15 Let w k = y k − η ∇ f ( y k ) . Since y k,i = 0 , | w k,i | = η |∇ i f ( y k ) | . The proximal map of g ( x ) = αρ ∥ D 1 / 2 x ∥ 1 is weighted soft-thresholding, so by ( 9 ), x k +1 ,i = sign( w k,i ) max {| w k,i | − 2 η αρ p d i , 0 } = 0 . This closes the induction and prov es x k,i = 0 for all k ≥ 0 . C Bad instances wher e the margin γ can be very small W e now record two explicit graph families showing that the degree-normalized strict-complementarity margin (the one that naturally interfaces with our degree-weighted work model in (4) ) can be made arbitrarily small (and e ven γ = 0 ) by choosing ρ near a breakpoint of the regularization path where an inacti ve KKT inequality becomes tight. This moti v ates our theory for linking a problem (B) with the sparsity pattern of a slightly less regularized one (A), so that no requirement in the minimum margin is made (since we split the coordinates into lo w-margin ones which are included in the support of the (A) solution and then the high-margin ones). Concretely , let x ⋆ be the minimizer and I ⋆ := { i : x ⋆ i = 0 } . Define the coordinate wise degree-normalized KKT slack γ i := λ i − |∇ i f ( x ⋆ ) | √ d i ( i ∈ I ⋆ ) , λ i := ρα p d i , and the global margin γ := min i ∈ I ⋆ γ i . C.1 Star graph (seed at the center) Let G be a star on m + 1 nodes with center node c of degree d c = m and leav es ℓ of degree 1 . Let the seed be s = e c . Lemma C.1 (Star graph breakpoint: γ can be 0 ) F ix α ∈ (0 , 1] and m ≥ 1 and define ρ 0 := 1 − α 2 m . F or any ρ ∈ [ ρ 0 , 1 /m ) , the unique minimizer has support S ⋆ = { c } , with x ⋆ c = 2 α (1 − ρm ) (1 + α ) √ m . Mor eover , for any leaf ℓ (recall d ℓ = 1 ), with λ ℓ = αρ √ d ℓ = αρ , the de gr ee-normalized slac k equals γ ℓ := λ ℓ − |∇ ℓ f ( x ⋆ ) | √ d ℓ = λ ℓ − |∇ ℓ f ( x ⋆ ) | = 2 α 1 + α ( ρ − ρ 0 ) , and thus at the br eakpoint ρ = ρ 0 one has γ = 0 . Proof Recall that f ( x ) = 1 2 x ⊤ Qx − α ⟨ D − 1 / 2 s, x ⟩ , hence ∇ f ( x ) = Qx − αD − 1 / 2 s, and Q = αI + 1 − α 2 I − D − 1 / 2 AD − 1 / 2 = 1 + α 2 I − 1 − α 2 D − 1 / 2 AD − 1 / 2 . On the star with seed s = e c , we ha v e D − 1 / 2 s = e c / √ m , and for each leaf ℓ , ( D − 1 / 2 AD − 1 / 2 ) ℓc = 1 / √ m. Therefore Q cc = 1 + α 2 , Q ℓc = Q cℓ = − 1 − α 2 √ m . 16 Assume x ⋆ = x ⋆ c e c with x ⋆ c > 0 . For the ℓ 1 -regularized P ageRank objectiv e F ρ ( x ) = f ( x ) + αρ ∥ D 1 / 2 x ∥ 1 + I R ≥ 0 ( x ) , the coordinatewise KKT conditions (cf. (1) ) giv e, at an activ e coordinate, ∇ c f ( x ⋆ ) = − αρ √ d c = − αρ √ m. Using ∇ c f ( x ⋆ ) = ( Qx ⋆ ) c − α / √ m = Q cc x ⋆ c − α / √ m , we obtain 0 = ∇ c f ( x ⋆ ) + αρ √ m = Q cc x ⋆ c − α √ m + α ρ √ m = 1 + α 2 x ⋆ c − α √ m + α ρ √ m, which yields x ⋆ c = 2 α (1 − ρm ) (1 + α ) √ m , and this is positiv e exactly when ρ < 1 /m . Now fix any leaf ℓ . Since x ⋆ ℓ = 0 , the KKT condition requires ∇ ℓ f ( x ⋆ ) ∈ [ − αρ √ d ℓ , 0] = [ − α ρ, 0] . Here ∇ ℓ f ( x ⋆ ) = ( Qx ⋆ ) ℓ = Q ℓc x ⋆ c = − 1 − α 2 √ m x ⋆ c ≤ 0 , so the inactiv e condition is equi v alent to |∇ ℓ f ( x ⋆ ) | = 1 − α 2 √ m x ⋆ c ≤ αρ. Substituting the expression for x ⋆ c and cancelling α > 0 gives 1 − α 2 √ m · 2 α (1 − ρm ) (1 + α ) √ m ≤ αρ ⇐ ⇒ (1 − α )(1 − ρm ) (1 + α ) m ≤ ρ ⇐ ⇒ ρ ≥ 1 − α 2 m = ρ 0 . Hence for ρ ∈ [ ρ 0 , 1 /m ) , the point x ⋆ = x ⋆ c e c satisfies all KKT conditions. Since F ρ is α -strongly conv ex, these KKT conditions certify that x ⋆ is the unique minimizer and S ⋆ = { c } . Finally , for any leaf ℓ (with d ℓ = 1 ) the degree-normalized slack is γ ℓ = λ ℓ − |∇ ℓ f ( x ⋆ ) | √ d ℓ = αρ − 1 − α 2 √ m x ⋆ c = αρ − 1 − α 2 √ m · 2 α (1 − ρm ) (1 + α ) √ m = 2 α 1 + α ( ρ − ρ 0 ) , so at ρ = ρ 0 we indeed hav e γ = 0 . C.2 Path graph (seed at an endpoint) Let G = P m +1 be the path on nodes 1 , 2 , . . . , m + 1 with edges ( i, i + 1) . Let s = e 1 (seed at endpoint 1 ). Assume m ≥ 2 , so that d 1 = d m +1 = 1 and d i = 2 for 2 ≤ i ≤ m . Consider candidates of the form x = x 1 e 1 . Lemma C.2 (Path graph br eakpoint: γ can be 0 ) Fix α ∈ (0 , 1] and m ≥ 2 and define ρ 0 := 1 − α 3 + α . F or any ρ ∈ [ ρ 0 , 1) , the unique minimizer has support S ⋆ = { 1 } , with x ⋆ 1 = 2 α (1 − ρ ) 1 + α . Mor eover , the degree-normalized KKT slack at node 2 (wher e d 2 = 2 ), with λ 2 = αρ √ d 2 = αρ √ 2 , equals γ 2 := λ 2 − |∇ 2 f ( x ⋆ ) | √ d 2 = α (3 + α ) 2(1 + α ) ( ρ − ρ 0 ) . In particular , at the br eakpoint ρ = ρ 0 one has γ = 0 . 17 Proof Recall that f ( x ) = 1 2 x ⊤ Qx − α ⟨ D − 1 / 2 s, x ⟩ , hence ∇ f ( x ) = Qx − αD − 1 / 2 s, Q = 1 + α 2 I − 1 − α 2 D − 1 / 2 AD − 1 / 2 . Since s = e 1 and d 1 = 1 , we hav e D − 1 / 2 s = e 1 . Also, for the edge (1 , 2) we hav e ( D − 1 / 2 AD − 1 / 2 ) 21 = 1 / √ d 2 d 1 = 1 / √ 2 , so Q 11 = 1 + α 2 , Q 21 = Q 12 = − 1 − α 2 √ 2 . Assume x ⋆ = x ⋆ 1 e 1 with x ⋆ 1 > 0 . For the ℓ 1 -regularized PageRank objectiv e F ρ ( x ) = f ( x ) + αρ ∥ D 1 / 2 x ∥ 1 + I R ≥ 0 ( x ) , the activ e KKT condition at node 1 is ∇ 1 f ( x ⋆ ) = − αρ p d 1 = − αρ. But ∇ 1 f ( x ⋆ ) = ( Qx ⋆ ) 1 − α = Q 11 x ⋆ 1 − α , hence 0 = ∇ 1 f ( x ⋆ ) + αρ = Q 11 x ⋆ 1 − α + αρ = 1 + α 2 x ⋆ 1 − α + αρ, which yields x ⋆ 1 = 2 α (1 − ρ ) 1 + α , and this is positiv e if f ρ < 1 . No w consider node 2 (which is inactiv e under our candidate). Since ( D − 1 / 2 s ) 2 = 0 and x ⋆ is supported only on node 1 , ∇ 2 f ( x ⋆ ) = ( Qx ⋆ ) 2 = Q 21 x ⋆ 1 = − 1 − α 2 √ 2 x ⋆ 1 ≤ 0 , so |∇ 2 f ( x ⋆ ) | = 1 − α 2 √ 2 x ⋆ 1 . The inactiv e KKT condition at node 2 requires |∇ 2 f ( x ⋆ ) | ≤ α ρ √ d 2 = αρ √ 2 . Substituting x ⋆ 1 giv es 1 − α 2 √ 2 · 2 α (1 − ρ ) 1 + α ≤ αρ √ 2 ⇐ ⇒ (1 − α )(1 − ρ ) 1 + α ≤ 2 ρ ⇐ ⇒ ρ ≥ 1 − α 3 + α = ρ 0 . For nodes i ≥ 3 , we ha v e ( Qx ⋆ ) i = Q i 1 x ⋆ 1 = 0 because node 1 is adjacent only to node 2 , and also ( D − 1 / 2 s ) i = 0 , hence ∇ i f ( x ⋆ ) = 0 , which satisfies the inacti ve KKT interv al [ − αρ √ d i , 0] . Therefore, for an y ρ ∈ [ ρ 0 , 1) , the point x ⋆ = x ⋆ 1 e 1 satisfies all KKT conditions. Since F ρ is α -strongly con v ex, this certifies that x ⋆ is the unique minimizer and S ⋆ = { 1 } . Finally , the degree-normalized slack at node 2 is γ 2 = λ 2 − |∇ 2 f ( x ⋆ ) | √ d 2 = αρ √ 2 − 1 − α 2 √ 2 x ⋆ 1 √ 2 = αρ − 1 − α 4 x ⋆ 1 = αρ − 1 − α 4 · 2 α (1 − ρ ) 1 + α = α 2(1 + α ) (3 + α ) ρ − (1 − α ) = α (3 + α ) 2(1 + α ) ( ρ − ρ 0 ) , and at ρ = ρ 0 this slack is 0 , so γ = 0 . D Experimental setting details This section collects the common e xperimental ingredients used throughout the synthetic e xperiments in Sections 5.1 and 5.2 . All experiments solve the ℓ 1 -regularized PageRank objecti ve (RPPR) and report runtime using the degree- weighted work metric in (3) . When we refer to the no-percolation diagnostic, we mean the inequality from Theorem 4.4 . Synthetic graph family: core-boundary-exterior construction. Each synthetic instance is an undirected graph with a three-way partition of the node set V = S ∪ B ∪ Ext , where S is a core (containing the seed), B is a boundary region, and Ext is an exterior . The construction is deterministic. Given sizes | S | , |B | , and | Ext | , edges are added according to the following rules: 18 • Cor e clique. The induced subgraph on S is a complete graph (a clique). • Cor e-boundary connectivity . Let the core nodes be ordered as S = { 0 , 1 , . . . , | S | − 1 } and let the boundary nodes be stored in an ordered list ( b 0 , b 1 , . . . , b |B|− 1 ) . Each core node has c bnd boundary per core neighbors in B . For each core node u ∈ S and each j ∈ { 0 , 1 , . . . , c bnd − 1 } we add the edge ( u, b ( u · c bnd + j ) mo d |B | ) . When |B | ≥ c bnd (as in our sweeps), this gives c bnd distinct boundary neighbors per core node. Each core node has fixed de gree d u = ( | S | − 1) + c bnd for |B | > 0 . • Boundary internal connectivity . The boundary induces a circulant graph with an e ven de gree parameter deg B , capped at |B | − 1 , and adjusted to be even. • Exterior internal connectivity . The exterior induces a circulant graph with degree deg Ext , with deg Ext < | Ext | . • Boundary-exterior connectivity . Each exterior node has exactly one neighbor in B , using the same rule as above, so the number of boundary-exterior edges equals | Ext | . This construction yields a dense core, an internally connected boundary band, and a highly connected exterior , with sparse cross-region interfaces. When we visualize adjacency matrices, this produces a clear block structure (core | boundary | exterior) and a boundary re gion whose size/volume can be v aried independently of the core neighborhood. Optimization objective and parameters. On each graph instance we solve the ℓ 1 -regularized P ageRank objectiv e (RPPR) with a single-node seed s = e v . Unless otherwise specified, the seed node v is a fixed core v ertex (in the code, v = 0 ). Each experiment specifies a teleportation parameter α ∈ (0 , 1] and a sparsity parameter ρ > 0 . When using FIST A we set the momentum parameter to the standard strongly-con v ex choice β := 1 − √ α 1+ √ α (for PageRank, L = 1 and µ = α ). Both IST A and FIST A are initialized at x − 1 = x 0 = 0 . Stopping criterion. All experiments compare IST A and FIST A under the same KKT surrogate based on the proximal-gradient fixed point. With unit step size, define the prox-gradient map T α,ρ ( x ) := pro x g x − ∇ f ( x ) , r ( x ) := ∥ x − T α,ρ ( x ) ∥ ∞ . A point x ⋆ is optimal for (RPPR) if and only if x ⋆ = T α,ρ ( x ⋆ ) , i.e., r ( x ⋆ ) = 0 . W e therefore declare conv er gence when the fixed-point residual satisfies r ( x k ) ≤ ε , where ε > 0 is the prescribed tolerance. This termination rule is applied identically to IST A and FIST A. In the work-vs- ε sweeps, the x -axis parameter is this residual tolerance ε ; for the other sweeps, ε is held fixed (and we impose a single large global iteration cap, e.g. 50 , 000 , for all runs). Degree-weighted work model. W e measure runtime via a degree-weighted work model (3) . For an iterate pair ( y k , x k +1 ) we define the per-iteration work as w ork k := vol(supp( y k )) + vol(supp( x k +1 )) . For IST A, y k = x k ; for FIST A, y k = x k + β ( x k − x k − 1 ) . The work to reach the stopping target is the sum of w ork k ov er the iterations taken. No-percolation diagnostic. The no-percolation assumption (7) is satisfied for all our synthetic experiments. Conceptually , this condition is fav orable for accelerated methods: it rules out “percolation” of extrapolated iterates into the exterior , so FIST A is not penalized by acti v ating a lar ge, highly connected ambient re gion. Ne vertheless, our sweeps still e xhibit regimes where FIST A does not impro ve work (and can be slo wer than IST A), showing that even when exterior e xploration is prov ably suppressed, acceleration can lose due to transient boundary acti v ations. Default synthetic parameters. Unless a sweep varies them, the synthetic experiments use the baseline block sizes and degrees | S | = 60 , | Ext | = 1000 , c bnd = 20 , deg B = 82 , deg Ext = 998 , and a fixed seed v ∈ S (node 0 in the implementation). The specific sweep parameter(s) are described in the corresponding experiment sections. Per -point graph generation and how to read sweep plots. Our theory giv es instance-wise guarantees (each bound applies to ev ery graph in the family), and the synthetic family itself is specified by coarse structural parameters (block sizes and target degrees), not a single fixed adjacency matrix. Accordingly , in several sweeps we intentionally re generate the synthetic instance at each x -axis v alue. In these cases, each dot should be interpreted as one representati v e draw from the family at that parameter value, i.e., a snapshot of what can happen empirically under the same coarse structure. This design a v oids conclusions that are artifacts of one particular synthetic realization and is aligned with the worst-case nature of the theory . E Full details f or the fixed-boundary sweeps experiments W e provide full details for the experiments in Section 5.2 . W e follow the synthetic construction, algorithmic choices, and work-metric con ventions from Section D , and fix the boundary size to |B | = 600 . W e sweep ρ (with fresh graphs 19 per point), and we additionally sweep α and the fixed-point residual tolerance ε with ρ = 10 − 4 fixed (and all other baseline parameters fixed). This experiment complements the boundary-volume sweep of Section 5.1 by holding the boundary size fixed ( |B | = 600 ) and varying only the regularization strength ρ . The aim is to isolate the ρ -dependence suggested by Theorem 4.3 (both terms scale as 1 /ρ when α and the boundary are fixed), and to check whether IST A and FIST A respond similarly as ρ increases, since their worst-case theoretical running time depends on ρ in the same way . W e run two versions of the ρ -sweep, both using a randomized graph per ρ : • Dense-core sweep. The core subgraph is a clique, see Section D . • Sparse-cor e sweep. The core subgraph is sparsified by retaining a fixed fraction of its edges while enforcing that the core remains connected (implemented by sampling a random spanning tree and then adding random core-core edges up to the target density). In the sparse variant used here we keep 20% of the clique edges. W e perform experiments on the sparsified-core variant to v erify that the observed ρ -dependence is not an artifact of the highly symmetric clique core: sparsifying reduces and heterogenizes core/seed degrees. For both v ariants, we sweep ρ ov er a log-spaced grid chosen so that the no-percolation inequality holds for all sampled v alues. The next e xperiment sweeps α , while keeping all other parameters fixed. Sweeping α to smaller values mak es the no-percolation condition more stringent. Rather than reweighting edges, we keep the graph unweighted and use an α -sweep-specific graph family in which the exterior is a complete graph on | Ext | nodes, and only a prescribed number m of exterior nodes have a single boundary neighbor (the remaining exterior nodes ha ve no boundary neighbor). W e choose | Ext | so that the no-percolation inequality holds at the smallest swept value α min ; since the left-hand side decreases with α , this implies no-percolation for all α ≥ α min in the sweep. The α sweep in our code additionally includes an auto-tuning step that selects a single unweighted instance from this family before running the sweep. Concretely , the tuner searches over: (i) the core-boundary fanout c bnd (boundary neighbors per core node), (ii) the boundary internal circulant de gree, and (iii) the number m of exterior -to-boundary edges (one boundary neighbor for each of the first m exterior nodes), with | Ext | set to the smallest value that enforces no-percolation at α min . For each candidate, it e v aluates performance on a calibration grid of 12 log-spaced α values in [ α min , 0 . 9] and chooses the candidate that maximizes the fraction of calibration points where FIST A incurs lar ger work than IST A. This is meant to illustrate that acceleration can be counterproductive on some valid instances e v en when iteration complexity impro ves. For the ε sweep, we keep α = 0 . 20 fixed and vary the fixed-point residual tolerance over a log-spaced grid ε ∈ [ 10 − 12 , 10 − 1 ] . W e use the original baseline instance (no auto-tuning and no graph modification). F Additional r eal-data diagnostics In this section we interpret the results of the experiments on real data from Section 5.3 . Diagnosing slowdowns: iterations vs. per -iteration work. The work metric counts degree-weighted support volumes touched by both the extrapolated point y k and the proximal update, so FIST A can lose either by taking more iterations than IST A or by having a lar ger per-it eration locality cost. T o separate these effects, for each seed (at α = 10 − 3 , ρ = 10 − 4 , ε = 10 − 8 ) we plot iteration ratio = N F N I vs. per-iter ratio = ( W F / N F ) ( W I / N I ) , where N I , N F are iteration counts and W I , W F are total works. Since W F W I = N F N I · ( W F / N F ) ( W I / N I ) , points with both ratios abov e 1 correspond to clear slowdo wns. Figure 7 shows that on com-Orkut at α = 10 − 3 , FIST A is frequently slo wer because it often incurs both a larger iteration count and a larger per-iteration w ork cost, whereas on the other datasets FIST A typically reduces iterations while paying a moderate per-iteration locality overhead. Degree heter ogeneity . Because our work metric is de gree-weighted, transient acti v ations of e v en a small number of high-degree nodes can dominate the locality cost. Figure 8 plots the empirical degree complementary CDF for the four datasets and highlights the substantially heavier tail of com-Orkut (and, to a lesser extent, com-Youtube ), which is consistent with the larger v ariability and the small- α slowdo wns observ ed in Figures 4 and 7 . 20 0.0 0.2 0.5 0.8 1.0 Iteration ratio 0.9 1.0 1.1 1.4 P er -iteration work ratio FIST A IST A (work) FIST A > IST A (work) (a) com-Amazon . 0.1 0.3 0.5 0.8 1.0 Iteration ratio 1.0 2.0 3.0 5.0 6.0 P er -iteration work ratio FIST A IST A (work) FIST A > IST A (work) (b) com-DBLP . 0.1 0.3 0.6 0.9 2.0 Iteration ratio 0.7 6.0 50.0 400.0 3000.0 P er -iteration work ratio FIST A IST A (work) FIST A > IST A (work) (c) com-Youtube . 0.8 0.9 1.0 Iteration ratio 1.0 1.6 2.0 2.5 P er -iteration work ratio FIST A IST A (work) FIST A > IST A (work) (d) com-Orkut . Figure 7: Iterations vs. per-iter ation work tradeof f . Each point is a seed node (same seeds as in the sweep experiments), at α = 10 − 3 , ρ = 10 − 4 , and ε = 10 − 8 . The x -axis is the iteration ratio N F / N I and the y -axis is the per-iteration work ratio ( W F / N F ) / ( W I / N I ) . Markers distinguish seeds where FIST A is faster/slo wer in total work. 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 degr ee k 1 0 5 1 0 3 1 0 1 P(D k) com- Amazon (co -pur chase) com-DBLP (collaboration) com- Y outube (social) com- Ork ut (social) Figure 8: De gr ee distributions on the r eal datasets. The hea vier-tailed de gree profiles (notably com-Orkut ) amplify the impact of transient exploration. G AI-assisted dev elopment and pr ompt traceability This paper was dev eloped with the assistance of an interacti ve large-language-model (LLM) workflo w . The LLM was used as a proof-synthesis and re writing aid: it generated candidate lemmas, algebraic manipulations, and L A T E X skeletons, while the human author(s) provided the research direction, imposed algorithmic constraints, requested specific locality-aware bounds, identified missing assumptions, and validated (or rejected) intermediate arguments. The 21 final statements and proofs appearing in the paper were human-checked and edited for correctness and presentation. G.1 Prompt clusters and ho w they map to r esults in the paper The interacti ve prompting that led to the final results naturally grouped into a small number of “prompt clusters. ” Below we summarize each cluster , the key human supervision intervention(s), and the resulting manuscript artifacts (with cross-references). W e use GPT -5.2 Pro (extended thinking) for all results and experiments. (P1) “Standard accelerated algorithm only; avoid expensi ve subpr oblems. ” The initial constraint was to analyze classic one-gradient-per-iteration acceleration (FIST A) rather than outer-inner schemes or methods that solve expensi ve auxiliary subproblems. This constraint fixed the algorithmic object of study and ruled out approaches akin to expanding- subspace or repeated restricted solves. It directly shaped the scope of the main runtime result Theorem 4.3 and the fact that all bounds are expressed in the de gree-weighted work model. (P2) “Use the margin/KKT slack idea. ” This idea was suggested by GPT , but we found it useful and, therefore, retained it in the final results. A ke y prompt requested a self-contained ar gument based on a margin parameter . This produced the degree-normalized slack definition (5) and its operational meaning: an inactiv e coordinate can become acti ve at an extrapolated point only if its forward-gradient map deviates from the optimum by an amount proportional to its slack. The corresponding quantitative statement is Lemma 4.1 , which is the main bridge from optimality structure to spurious activ ations. (P3) “T ransient support is the bottleneck; bound the sum of supports/volumes. ” A crucial human intervention was to point out that it is not enough to argue e ventual identification: one must control the cumulative de gree-weighted work over the entire transient. This prompted the transition from pointwise identification to a global summation argument: Cauchy-Schwarz con verts “acti v ation implies a jump” (from Lemma 4.1 ) into a bound on P k v ol( A k ) , and geometric contraction of FIST A controls the resulting series. This is the backbone of the spurious-work bound in the proof of Theorem 4.3 (see in particular the deriv ation around (8) ). (P4) “A void vacuous bounds when the minimum margin is tiny; use over -regularization. ” Another human- directed prompt asked how to proceed when the minimum slack can be arbitrarily small, which would make an y bound that depends on min i ∈ I ⋆ γ i meaningless. Thus the idea for analyzing a more re gularized problem (“(B)”) b ut treating nearly-activ e nodes as part of the target support of the less-regularized problem (“(A)”) was suggested to the LLM. Concretely , this yielded the split in Lemma 4.2 , which uses regularization-path monotonicity (cf. Lemma A.4 ) to show that “small (B)-mar gin” nodes must lie in S A and should not be char ged as spurious. This is a ke y input to the work bound Theorem 4.3 . (P5) “T ur n the work bound into a running-time bound using v ol( S ⋆ ) ≤ 1 /ρ . ” A prompt e xplicitly requested that the final complexity be stated in the degree-weighted work model and use the kno wn sparsity guarantee v ol( S ⋆ ) ≤ 1 /ρ . This guided the decomposition (4) into “work on the tar get support” plus “spurious work, ” and it is the reason the first term in Theorem 4.3 scales as e O (( ρ √ α ) − 1 ) (up to logarithms). (P6) “Give a checkable confinement condition so spurious activations stay local. ” After the spurious-work summation bound was obtained, a prompt requested a graph-checkable assumption guaranteeing that all spurious activ ations remain confined to a boundary set. This produced the e xposure/no-percolation-style sufficient condi tion formalized as Theorem 4.4 , which is referenced immediately after Theorem 4.3 to justify the boundary-set hypothesis e A k ⊆ B . (P7) “Identify explicit bad instances where γ can be very small (or 0 ). ” T o stress-test the margin-based reasoning, a sequence of prompts asked for explicit graphs where the slack is smaller than √ ρ and even o ( √ ρ ) . This led to the breakpoint constructions recorded in Section C , including the star graph ( Lemma C.1 ) and the path graph ( Lemma C.2 ). These examples motiv ate why the paper a voids global dependence on γ and instead relies on the ov er-re gularization/two-tier strate gy ( Lemma 4.2 ) together with confinement ( Theorem 4.4 ). (P8) “High-degree non-activation under over -regularization. ” A later prompt suggested to use the overre gu- larization idea to rule out spurious acti v ations of very high-degree nodes. This yielded the explicit degree cutoff condition in Proposition B.1 , which provides an additional structural non-acti v ation guarantee that complements the boundary-confinement approach. (P9) “Experiments. ” All code was generated by the LLM. Howe v er , the authors hea vily supervised the process. G.2 How much human supervision was r equir ed? The dev elopment required human-in-the-loop supervision. Across roughly two dozen interactive turns, the human prompts performed tasks that the LLM did not do reliably on its own: 22 • Problem framing and constraints. The human author fixed the algorithmic scope (standard FIST A; no expensi v e subproblems) and demanded a locality-a ware work bound rather than a standard iteration bound (dri ving Theorem 4.3 ). • Identifying the real bottleneck. A key correction was the insistence that bounding ev entual identification is insufficient; one must bound the sum of transient supports/volumes (leading to the summation argument in the proof of Theorem 4.3 ). • Stress-testing with counter examples. The human prompts requested explicit worst cases (star and path) and used them to diagnose when naiv e γ -based bounds become vacuous (motiv ating Section C and the ov er-re gularization strategy used in Lemma 4.2 ). • Assumption checking and proof repair . When an intermediate proof relied on an unproven positivity/sign as- sumption, the human author demanded either a proof or a repair; this resulted in a revised subgradient/KKT -based certificate (ultimately not needed for the core theorems, but an important correctness checkpoint). • L A T E X integration/debugging . Compile errors and presentation issues (e.g., list/itemization mistakes) were identified via human compilation and corrected in subsequent iterations. Overall, the LLM contributed most ef fecti vely as a rapid generator of candidate proofs and algebraic manipulations, while the human supervision was essential for (i) setting the right target statement, (ii) insisting on the correct work metric, (iii) enforcing locality constraints, (i v) catching missing assumptions, and (v) selecting which generated material belonged in the final paper . 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment