Scaling Vision Transformers: Evaluating DeepSpeed for Image-Centric Workloads
Vision Transformers (ViTs) have demonstrated remarkable potential in image processing tasks by utilizing self-attention mechanisms to capture global relationships within data. However, their scalability is hindered by significant computational and me…
Authors: Huy Trinh, Rebecca Ma, Zeqi Yu
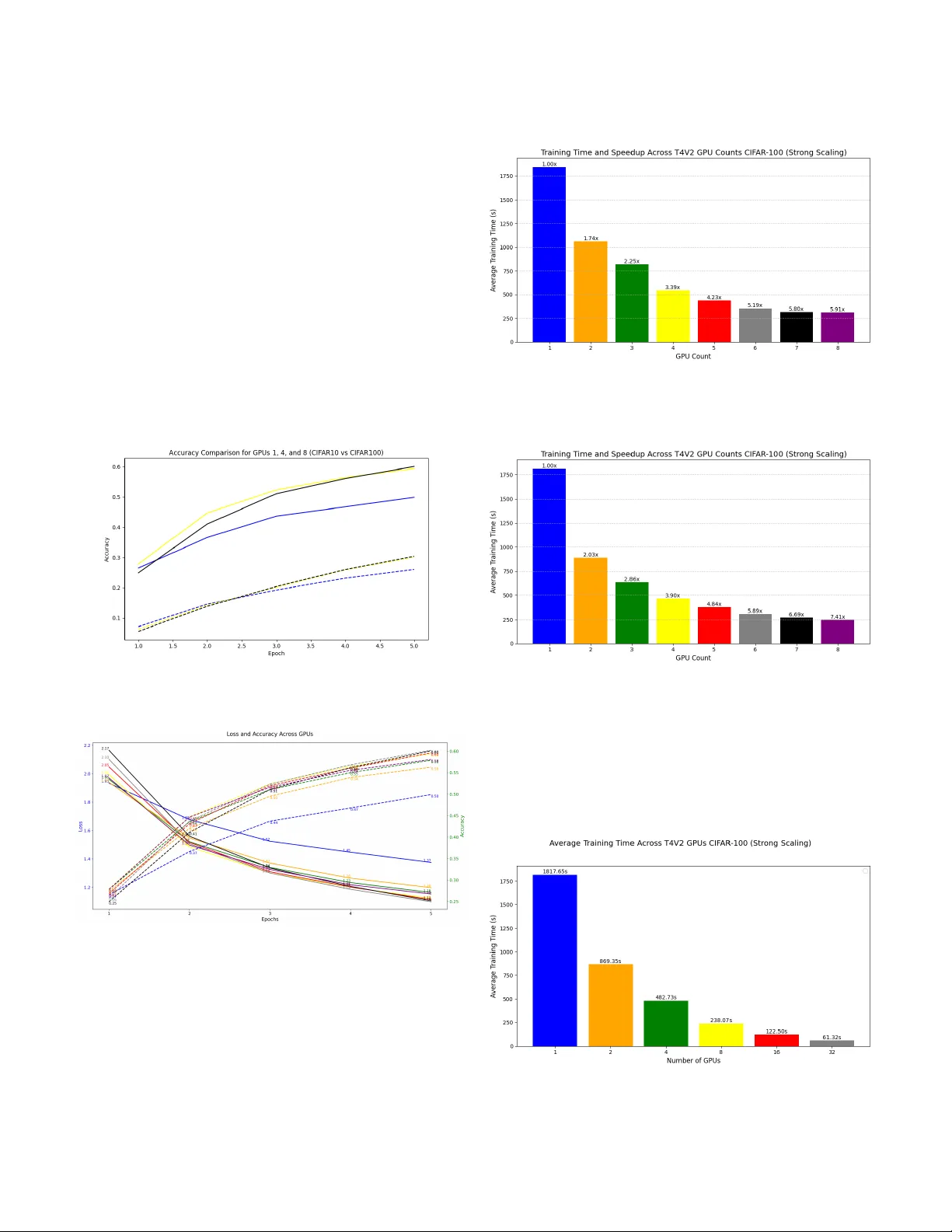
Scaling V ision T ransformers: Ev aluating DeepSpeed for Image-Centric W orkloads Huy T rinh Electrical & Computer Eng University of W aterloo h3trinh@uwaterloo.ca Rebecca Ma Electrical & Computer Eng University of W aterloo rebecca.ma@uwaterloo.ca Zeqi Y u Electrical & Computer Eng University of W aterloo zeqi.yu@uwaterloo.ca T ahsin Reza Electrical & Computer Eng University of W aterloo tahsin.reza@uwaterloo.ca Abstract —V ision T ransf ormers (V iTs) have demonstrated re- markable potential in image processing tasks by utilizing self- attention mechanisms to capture global relationships within data. Howev er , their scalability is hindered by significant computa- tional and memory demands, especially for large-scale models with many parameters. This study aims to leverage DeepSpeed, a highly efficient distributed training framework that is com- monly used for language models, to enhance the scalability and performance of V iTs. W e evaluate intra- and inter-node training efficiency across multiple GPU configurations on various datasets lik e CIF AR-10 and CIF AR-100, exploring the impact of distributed data parallelism on training speed, communication overhead, and overall scalability (strong and weak scaling). By systematically varying software parameters, such as batch size and gradient accumulation, we identify key factors influencing performance of distributed training. The experiments in this study provide a foundational basis for applying DeepSpeed to image-related tasks. Future work will extend these in vestigations to deepen our understanding of DeepSpeed’s limitations and explore strategies for optimizing distributed training pipelines for V ision T ransf ormers. Index T erms —Vision T ransformers, DeepSpeed, Distributed T raining, Scalability I . I N T RO D U C T I O N Deep Learning (DL) has transformed numerous fields over the past decade, from healthcare to autonomous systems to natural language processing (NLP) and computer vision (CV). Transformers is a deep learning architecture initially introduced for NLP in language models such as BER T and GPT to handle large-scale data, learn complex representations, and generalize across tasks [1]. Studies hav e shown that trans- formers can also be expanded to apply not only to language tasks but also to image tasks in the form of V ision Transform- ers (V iT) in applications including image classification and object detection [2]. Unlike traditional Conv olutional Neural Networks (CNNs) that rely on con volutional layers to extract features hierarchically from the data, transformers adopt the self-attention mechanism to gain a holistic view of the image. In V iTs shown in Figure 1, the image is first divided into smaller fix ed-size patches and then con verted into ”tokens” [3]. These ”tokens” are then linearly embedded into a sequence of feature vectors and fed to a standard Transformer encoder [3]. The ke y dif ferentiation between V iTs and traditional CNNs is their ability to model global relationships across an image through the self-attention mechanism. V iTs analyze interac- Fig. 1. V iT Model Overview [3] tions between all patches of the input data simultaneously , which captures long-range dependencies and provides a holis- tic understanding of the image. Howe ver , a downside of V iTs is the computation cost and memory requirements, especially as the model and data sizes grow (e.g., parameters scaling from millions to billions) [4]. DeepSpeed is a framew ork that provides memory-efficient data parallelism, lev eraging multiple machines/GPUs to train the model using less time [5]. Data parallelism replicates the model on each device and performs training on dif ferent batches of data in parallel, which is ef ficient because each machine is training on a portion of the original data. Pre vious work with DeepSpeed has resulted in impressiv e results compared to the state-of-art methods, such as training BER T -lar ge in 44 minutes using 1024 V100 GPUs and training GPT -2 with 1.5B parameters 3.75x faster than NVIDIA Megatron on Azure GPUs [5]. Howe ver , DeepSpeed has not been commonly applied to image-related tasks or V iTs. Therefore, this study aims to le verage DeepSpeed and data parallelism to in vestigate the scalability of V iTs. Our key contributions are as follows: • Adapt DeepSpeed for V ision Transformers and run inter- and intra-node training to observe scalability trends. • Experiment with distributed training (specifically data parallelism) and measure training speed and communi- cation ov erhead for increasing number of GPUs. • Evaluate how changes in software parameters (e.g., batch size, accumulation step) can affect the scalability of the system. I I . B AC K G RO U N D A N D R E L A T E D W O R K Distributed training is when multiple GPUs are used to train a single model. The three common types are Data Paral- lelism, Model Parallelism, and Pipeline Parallelism [6]. Data parallelism (DP) is commonly used when models fit within device memory , replicating model parameters across devices and distributing mini-batches among processes. Each process handles a subset of data, performs forward and backward propagation, and updates model parameters using a veraged gradients [6]. The a verage of the gradients is used to update the model weights on each device to ensure that all devices hav e the same set of training weights at the beginning of the next training step as shown in Figure II. This exchange of gra- dients between de vices is performed with an algorithm called AllReduce, executing a reduction operation on data distributed across multiple devices [6]. When models exceed device memory , model parallelism (MP) and pipeline parallelism (PP) are employed. PP horizontally partitions the model across devices and uses micro-batching to manage pipeline b ubbles [7]. Howe ver , PP introduces challenges, such as complexities in implementing tied weights and batch normalization, large batch size requirements af fecting con vergence, and memory inefficienc y [7]. T o combat memory challenges, Zero Redun- dancy Optimizer is one input parameter in DeepSpeed that eliminates memory redundancies by partitioning three model states (optimizer states, gradients, parameters) across data- parallel processes rather than replicating them [8]. There is also an extension to ZeRO called ZeR O-Infinity , where it takes advantage of GPU, CPU, and NVMe memory to allow models to scale on limited resources as we become limited by the GPU memory wall [8]. Ho wev er , due to resource and time constraints, our work will focus on data parallelism without ZeR O. Fig. 2. Data Parallelism Gradient Computation [6] There is a recent survey by Duan et al. [9] that inv estigates recent advancements in distrib uted systems for training LLMs like GPT and LLaMA, which demand extensi ve GPU clusters and significant computational resources. The paper revie ws in- nov ations in AI accelerators, networking, storage, and schedul- ing, alongside strategies for parallelism and optimizations in computation, communication, and memory usage. While it is a comprehensi ve survey on training language models, it shifts the focus on system reliability for long-duration training by exploring alternativ e computing approaches such as optical computing, which focuses more on hardware optimizations. Additional work in distributed training by Dash et al. [10] examines efficient strategies for training trillion-parameter LLMs using Frontier , the first exascale supercomputer for open science. It e valuates model and data parallel techniques, including tensor parallelism, pipeline parallelism, and sharded data parallelism, focusing on their impact on memory , com- munication latency , and computational efficiency . The study identifies optimized strategies through empirical analysis and hyperparameter tuning, achieving high throughput and strong scaling efficiencies (up to 89%) for large-scale models on thousands of GPUs. While these findings are significant for language models, there has not been work done in the V ision T ransformers space to ev aluate scalability and efficiency . I I I . S O L U T I O N D E S I G N W e use DeepSpeed [5] along with NCCL [11] and MPI (OpenMPI implementation) to run on the remote clusters. Mpirun initializes a distributed en vironment in which each process (one per GPU) can communicate between nodes. MPI provides the rank and world size (total number of processes) that are crucial for inter-nodes communications. On the other hand, Deepspeed’ s init distributed() initializes the training en- vironment within each process. When called, it sets up Pytorch distributed backend (NCCL in our case) to allow processes to communicate data across GPUs, le veraging MPI configuration. In summary , MPI handles the distribution and launching of processes across nodes while DeepSpeed, in conjunction with Pytorch’ s torch.distributed, manages the GPU-to-GPU communication and synchronization. torch.distributed.barrier() ensures that all processes synchronize at the end of each epoch, prev enting any processes from moving to the next epoch before others are complete. W e train on three remote clusters to cover both intra- and inter-node training: Nebula, T esla, and V ector . The configu- rations of the three clusters along with their corresponding GPUs are shown in Figure 3. Nodes are indicated in green and GPUs (within a node) are indicated in orange. On the Nebula and V ector machines, we use virtual en vironments from Anaconda. On the T esla machine, we install non-pip virtual environment first, and manually install pip later . All the installing steps along with the code can be found in our Github repository trinhgiahuy/Scalable V iT DT. It is important to note that due to resource limitations, the T esla cluster does not hav e homogeneous GPUs for all fiv e nodes, where machines 1, 2 and 4 have the same GPUs (R TX 3070) while machines 0 and 3 hav e weaker GPUs (GTX 1070 and T esla P4). W e begin with intra-node training to test the functionality of the pipeline before moving onto inter-node training. W e first implement the pipeline and test on the Nebula Clus- ter System from the ECE Linux computing facility ( ece- nebula07.eng .uwaterloo.ca ). The pipeline has 2 modes: intra- node and inter-node training. On the Nebula cluster , we can 2 Fig. 3. Remote Cluster Setup use midcard and dualcard partitions. The midcard partition comprises 1 node with 1 GPU while dualcard partition comprises 2 nodes with 2 GPUs. Due to resource constraints, only 1 node is av ailable in the dualcard partition. W e run the pipeline on 2 GPUs on the same node (share-memory system) first and compare it with single-node training. After the pipeline is functioning on Nebua, we deploy our imple- mentation to ECE GPU Ubuntu Servers, where we use 6 machines: eceubuntu0 as a controlling node and ecetesla[0-4] as compute nodes. W e use the V ision T ransformer architecture V iT b 16 [3] and train on the datasets summarized in T able I. Finally , we deploy our work on V aughan cluster from V ector Institute which has 54 nodes with 32 cores, 152GB memory , and 8 T esla T4 (16GB) GPUs. T ABLE I D AT A S ET S F O R E V A LU A T IO N Dataset No. of Classes No. of Images Resolution CIF AR-10 [12] 10 60,000 32x32 CIF AR-100 [12] 100 60,000 32x32 ImageNet-100 [13]* 100 100,000 224x224 *Due to time limitations, we could not train successfully on ImageNet, but the intention is to choose a dataset with higher resolution. I V . E V A L UA T I O N A. Evaluation Methodology The ev aluation process in v olves conducting a series of experiments and scaling the number of GPUs to observe the trends in training time, communication overhead, and accuracy . W e modify software parameters such as training batch size to monitor how the training performance changes across inter-node and intra-node setups. The key question is to assess whether DeepSpeed’ s data parallelism can effecti vely handle the computational demands of V iTs while maintaining efficienc y and scalability . Throughout the test, we fix the DeepSpeed configuration B across all experiments and change the train batch size and micr o batch per gpu accordingly . W e demonstrate strong and weak scaling by modifying this configuration file in relation to the data set size. Strong scaling is achiev ed by fixing the workload by using the entire dataset for increasing number of GPUs. W eak scaling is achiev ed by modifying the partition of the dataset proportional to the number of GPUs so each GPU would receive equal workload. For example, 1 GPU uses 10% of the dataset while 8 GPUs use 80% of the dataset (each GPU will only compute on 10% of the dataset as the number of GPUs scales). Since the training time should not vary between epochs for data parallelism, the model is trained for 5 epochs for all experiments and averaged when plotting the results (time in seconds) to dampen the effects of any outliers. B. Initial Scaling Results for Inter-node on T esla Fig. 4. T esla Strong Scaling Fig. 5. T esla W eak Scaling 3 Our first experiments uses T esla machines for inter-node training, as shown in Figure 4 and Figure 5. The results deviates from ideal strong or weak scaling, largely due to communication overhead between GPUs in the cluster . T wo T esla machines with weaker GPUs are limited to small batch sizes (e.g., 16), causing high synchronization costs due to frequent gradient averaging. Adding the fourth and fifth GPUs further increases training time because these weaker GPUs introduces computational bottlenecks, forcing other GPUs to wait during synchronization. This highlights the importance of GPU homogeneity for efficient scaling. C. Evaluating Communication Overhead on Nebula T o examine the impact of batch size on synchronization costs, we switched to Nebula machines with more powerful GPUs capable of handling larger batch sizes. As shown in Figure 6, synchronization costs (highlighted in red) decreases significantly with larger batch sizes, especially in the two-GPU setup. Small batch sizes (e.g., 16) results in disproportionately high synchronization costs, leading to poor scaling. Howe v er , improv ements plateau when the batch size increases from 128 to 256. One plausible explanation is that the GPU resources are already fully utilized, and larger batch sizes introduced a new bottleneck: the ov erhead of loading large batches from CPU to GPU memory [14]. Fig. 6. Nebula Strong Scaling vs Batch Sizes Figure 7 illustrates how accuracy changes with batch size. Initially , the accuracy improves with increasing batch size but declines when the batch size became too large, possibly due to overfitting. This suggests an optimal balance exists between batch size and model performance. Our findings suggest that a batch size of 64 or 128 offers a good trade-off between synchronization costs and memory us- age for training V ision T ransformer models with DeepSpeed. Additionally , gradient accumulation could be a promising pa- rameter for GPUs with memory limitations, enabling effecti ve larger batch sizes without frequent gradient averaging. Fig. 7. Nebula Accuracy vs Batch Sizes D. Scaling Results for Intra-node on V ector Fig. 8. CIF AR-10 Strong Scaling (Batch size 64) Fig. 9. CIF AR-10 W eak Scaling (Batch size 64) Figure 8 and Figure 9 shows the trend for strong and weak scaling for CIF AR-10 dataset on T4V2 GPUs on the V ector cluster . As expected, strong scaling shows a consistent decrease in training time as more resources/GPUs are allocated 4 for training. The scaling is best from 1 GPU to 2 GPUs, showing a reduction by almost half of the time. W eak scaling results are also as expected as we observe the times to remain constant for increasing GPUs. Similar results for the CIF AR-100 dataset are shown for strong and weak scaling as reported in Figure 16 and Figure 17 in the Appendix. This is e xpected since CIF AR-10 and CIF AR- 100 have the same number of samples and same image resolutions. Howev er , when comparing the accuracies of the two, it is expected that the CIF AR-100 performs worse in comparison since it has more classes and less data to train for each class. The accuracy comparisons between the two datasets are shown in Figure 10, where it is also observed that 4 GPUs and 8 GPUs has a better performance than 1 GPU for later epochs. This does not necessarily mean that more GPUs result in a higher accuracy , b ut it is an observation from our results. Figure 11 sho ws successful distributed training as loss decreases and accuracy increases for each epoch. Fig. 10. CIF AR-10 and CIF AR-100 Accuracies Fig. 11. Loss and Accuracy of Strong Scaling (Batch size 64) From the results from Nebula cluster , we found that the optimal batch size that produces the best results for distributed training for V iTs is 128. Howe ver , due to memory constraints in the V ector cluster, only batch size of 64 can be successfully obtained. All the results presented thus far are using batch size 64, b ut we also experimented with batch size 16 to compare the speedup for the CIF AR-100 dataset. Figure 12 and Figure 13 shows the speedup of batch sizes 16 and 64, respectiv ely . As expected, the speedup ratio is generally better for the larger batch size. Fig. 12. CIF AR-10 Strong Scaling Speedup (Batch size 16) Fig. 13. CIF AR-10 Strong Scaling Speedup (Batch size 64) E. Scaling Results for Inter-node on V ector W e also conduct Multi-Node Single-GPU experiments on the V ector cluster . Specifically , we use only 1 GPU per node and scale the total GPU count from 1 to 32 nodes. The training workload on CIF AR-100 is fixed, focusing on strong scaling. Fig. 14. Multi-node Single GPU Strong Scaling Result On CIF AR-100 (Batch size 64) 5 Figure 14 demonstrates the strong scaling of Multi-node Single GPU up to 32 nodes. Fig. 15. Multi-node Single-GPU vs Single-Node Multi-GPU Strong Scaling Result On CIF AR-100 (Batch size 64) Finally , we compare the strong scaling results between Multi-node Single-GPU (in bold colors) and Single-Node Multi-GPU (in light colors) using batch size of 64. Figure 15 shows that there are no significant dif ferences between using GPU intra-node and inter-node. V . C O N C L U S I O N A N D F U T U R E W O R K This study explored the use of DeepSpeed, a distrib uted training framew ork, to improve the scalability and perfor- mance of V ision T ransformers (V iTs) for image classification tasks. Our ev aluations, conducted across v arious GPU setups (e.g., Nebula, T esla, and V ector clusters) and datasets such as CIF AR-10 and CIF AR-100, rev ealed key insights into training speed, communication overhead, and demonstrated strong and weak scaling when using distributed data parallelism for both inter- and intra-node training. While the T esla inter -node training was unsuccessful due to non-homogeneous GPUs, the V ector inter-node training showed good scaling rseults, scaling to 32 nodes. Through intra-node training on Nebula and V ector clusters, we demonstrated the effect of software parameters like batch size on training efficiency . W e determined that batch sizes of 64 or 128 optimally minimize synchronization costs, achieving better speedup while ef fecti vely utilizing GPU memory . W e also sho wed that there is more communication ov erhead when scaling to multiple GPUs, which is important to keep in mind when managing the demands of lar ge-scale models. By optimizing software parameters and addressing hardware limitations, we can achieve efficient scaling and optimal training accuracy in V iTs. This study is only the beginning to in vestigating distributed training for V iTs and we hope to continue our work with some future improvements. Immediate future works include conducting further experi- ments to understand the limitations of DeepSpeed on V ision T ransformers. For instance, V iTs often have large intermediate activ ations due to high resolution images, which might strain memory more than token-based LLMs. T o extend our work, we can ev aluate each ZeR O stage to measure memory savings and overhead, as well as test performance with different optimizers such as SGD and LAMB [15]. W e could also benchmark the performance against other distributed training framew orks such as Megatron-LM or HuggingFace Accelerate when applied to V iTs. Finally , our work can be extended to V ision Language Model or scientific imaginary research, especially the scalabil- ity of processing very long sequence of images. DeepSpeed- Ulysses, which uses model sharding parallelism and ZeR O- 3 optimization, enables highly ef ficient LLM training with long sequence lengths [16]. The authors propose sequence parallelism as a solution to partition the input sequence along the sequence length dimension using all-to-all communication for attention computation [16]. W e will adapt this to our project by tokenizing image patches in the V ision Transformer model. Instead of token-based sequences, we would partition along the ”image patches dimension” and combine with recent advanced research of vision models such as Long-Sequence- Segmentation [17], SparseV iT [18], etc for further sequence parallelism scaling. W e would e valuate our work on medium and high resolution or multiple-channel images dataset (e.g., ”fastMRI” [19] in medical imaging, ”CoST AR” [20] for robotics, ”GTDB” [21] for genomics, etc). R E F E R E N C E S [1] A. V aswani et al., “ Attention Is All Y ou Need, ” arXiv , Jun. 12, 2017. https://arxiv .org/abs/1706.03762 [2] S. Jamil, M. J. Piran, and O.-J. Kwon, “ A Comprehensive Survey of Transformers for Computer V ision, ” arXi v .org, Nov . 11, 2022. https://arxiv .org/abs/2211.06004 [3] A. Dosovitskiy , L. Beyer , A. K olesnikov , D. W eissenborn, X. Zhai, T . Unterthiner , M. Dehghani, M. Minderer , G. Heigold, S. Gelly , J. Uszko- reit, and N. Houlsby , ”An image is worth 16x16 words: T ransformers for image recognition at scale, ” 2021. [4] Aminabadi, Reza Y azdani et al., “DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, ” arXiv .org, 2022. https://arxiv .org/abs/2207.00032 [5] DeepSpeed T eam, ”DeepSpeed: Extreme-scale model training for every- one, ” Sep. 2020. [Online]. A v ailable: https://www .microsoft.com/en- us/ research/blog/deepspeed- extreme- scale- model- training- for - everyone/. (accessed Dec. 10, 2024). [6] T . and, “Distributed Training and DeepSpeed, ” Tinkerd.net, Jun. 18, 2023. https://tinkerd.net/blog/machine-learning/distributed-training/ (ac- cessed Dec. 11, 2024). [7] S. Rajbhandari, J. Rasley , O. Ruwase, and Y . He, “ZeRO: Memory Optimizations T oward T raining T rillion Parameter Models, ” arXiv:1910.02054 [cs, stat], May 2020, A v ailable: https://arxiv .org/abs/1910.02054 [8] S. Rajbhandari, O. Ruwase, J. Rasley , S. Smith, and Y . He, “ZeR O- Infinity: Breaking the GPU Memory W all for Extreme Scale Deep Learning, ” arXiv .org, Apr . 15, 2021. https://arxiv .org/abs/2104.07857 [9] J. Duan et al., “Efficient Training of Large Language Mod- els on Distributed Infrastructures: A Surve y , ” arXi v .or g, 2024. https://arxiv .org/abs/2407.20018 [10] S. Dash et al., “Optimizing Distributed Training on Frontier for Large Language Models, ” arXiv (Cornell Univ ersity), Dec. 2023, doi: https://doi.org/10.48550/arxi v .2312.12705. [11] “NVIDIA Collectiv e Communications Library (NCCL), ” NVIDIA De- veloper , May 10, 2017. https://developer .nvidia.com/nccl [12] A. Krizhevsky , “CIF AR-10 and CIF AR-100 datasets, ” T oronto.edu, 2009. https://www .cs.toronto.edu/ kriz/cifar .html [13] “ImageNet, ” www .image-net.org. https://www .image-net.org/ [14] NVIDIA Corporation, “GPU Performance Background User’ s Guide, ” NVIDIA Dev eloper Documentation, [Online]. A vailable: https://docs.n vidia.com/deeplearning/performance/ dl- performance- gpu- background/index.html. (accessed Dec. 10, 2024). 6 [15] “1-bit LAMB: Communication Efficient Large-Scale Large-Batch T raining with LAMB’ s Conver gence Speed, ” DeepSpeed, Dec. 10, 2024. https://www .deepspeed.ai/tutorials/onebit-lamb/ (accessed Dec. 11, 2024). [16] S. A. Jacobs et al., “DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models, ” arXiv .org, 2023. https://arxiv .or g/abs/2309.14509 (accessed Dec. 11, 2024). [17] C. Xu, C.-T . Li, C. P . Lim, and D. Creighton, “HSVIT : Hor- izontally Scalable V ision Transformer , ” arXiv .org, Apr . 08, 2024. https://arxiv .org/abs/2404.05196 [18] X. Chen, Z. Liu, H. T ang, L. Yi, H. Zhao, and S. Han, “SP ARSE- VIT : Revisiting Activ ation sparsity for Efficient High-Resolution V ision T ransformer, ” arXiv .or g, Mar . 30, 2023. https://arxiv .org/abs/2303.17605 [19] J. Zbontar et al., “FastMRI: an open dataset and benchmarks for Accel- erated MRI, ” arXiv .org, Nov . 21, 2018. https://arxiv .org/abs/1811.08839 [20] A.Hundt, et al, ”The CoST AR Block Stacking Dataset: Learning with W orkspace Constraints, ” 2019. [21] W . Ohyama, M. Suzuki, S. Uchida. ”Detecting Mathematical Expres- sions in Scientific Document Images Using a U-Net T rained on a Di verse Dataset, ” in IEEE Access, vol. 7, pp. 144030-144042, 2019. A P P E N D I X A V E C T O R C L U S T E R R E S U L T S Fig. 16. CIF AR-100 Strong Scaling (Batch size 64) Fig. 17. CIF AR-100 W eak Scaling (Batch size 64) A P P E N D I X B D E E P S P E E D C O N FI G U R A T I O N C O D E 1 { 2 "train_batch_size" : 32, 3 "gradient_accumulation_steps" : 1, 4 "micro_batch_per_gpu" : 16, 5 "fp16" : { 6 "enabled" : false 7 }, 8 "zero_optimization" : { 9 "stage" : 0, 10 "offload_optimizer" : { 11 "device" : "none" 12 }, 13 "offload_param" : { 14 "device" : "none" 15 } 16 }, 17 "wall_clock_breakdown" : true , 18 "prescale_gradients" : false , 19 "pipeline" : { 20 "pipe_partitioned" : false 21 }, 22 "pin_memory" : true 23 } 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment