Cell-Free Massive MIMO-Assisted SWIPT Using Stacked Intelligent Metasurfaces
This study explores a next-generation multiple access (NGMA) framework for cell-free massive MIMO (CF-mMIMO) systems enhanced by stacked intelligent metasurfaces (SIMs), aiming to improve simultaneous wireless information and power transfer (SWIPT) p…
Authors: Thien Duc Hua, Mohammadali Mohammadi, Hien Quoc Ngo
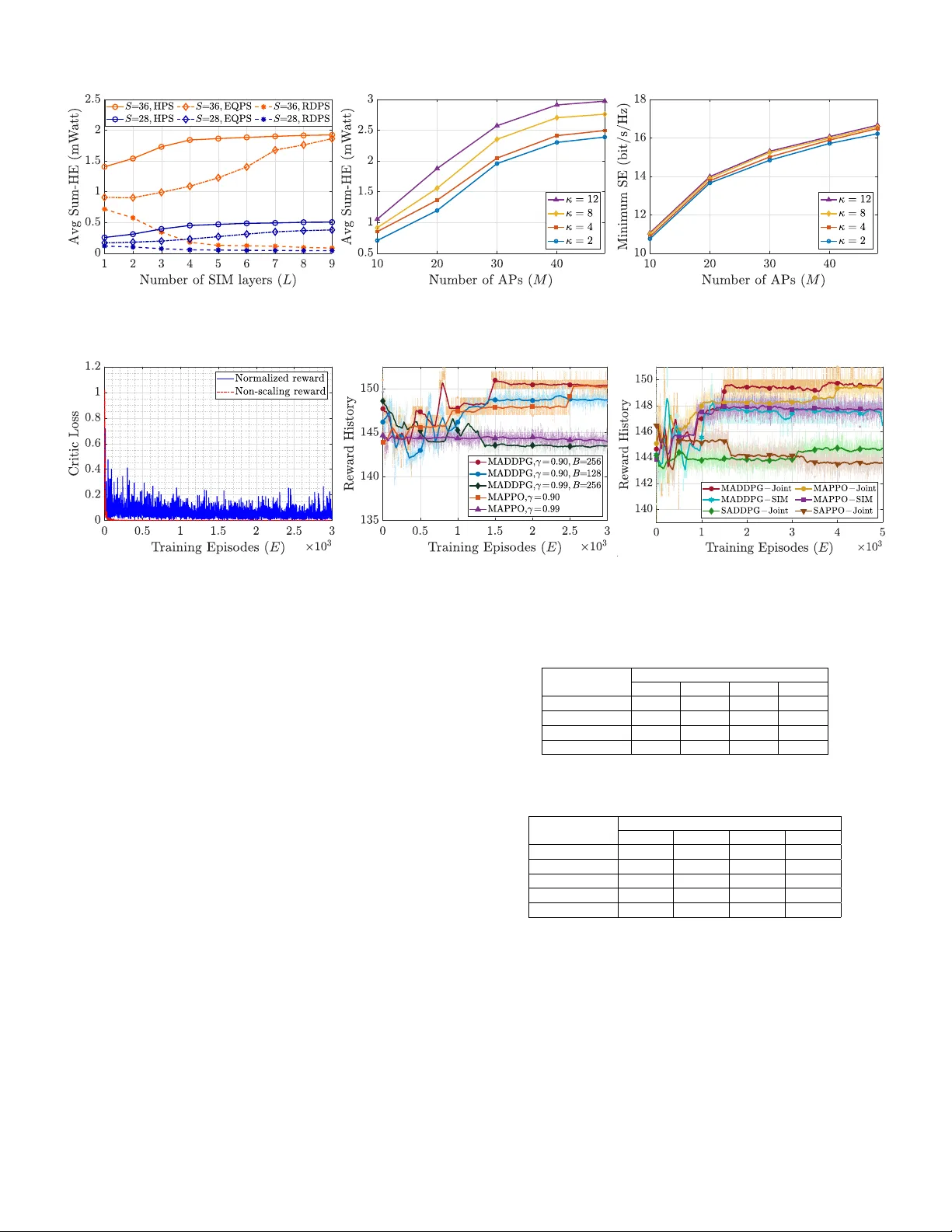
. 1 Cell-F ree Massiv e MIMO-Assisted SWIPT Using Stac k ed In telligen t Metasurfaces Thien Duc Hua, Graduate Studen t Mem b er, IEEE,, Mohammadali Mohammadi, Senior Member, IEEE, Hien Quo c Ngo, F ello w, IEEE, and Michail Matthaiou, F ello w, IEEE Abstract—This study explores a next-generation multiple access (NGMA) framew ork for cell-free massiv e MIMO (CF- mMIMO) systems enhanced by stac ked in telligent metasurfaces (SIMs), aiming to improv e simultaneous wireless information and p ow er transfer (SWIPT) p erformance. A fundamental challenge lies in optimally selecting the op erating mo des of access p oints (APs) to join tly maximize the received energy and satisfy sp ectral eciency (SE) quality-of-service constraints. Practical system impairments, including a non-linear harvested energy mo del, pilot con tamination (PC), channel estimation errors, and reliance on long-term statistical channel state information (CSI), are considered. W e deriv e closed-form expressions for b oth the ac hiev able SE and the av erage sum harvested energy (sum-HE). A mixed-integer non-conv ex optimization problem is form ulated to jointly optimize the SIM phase shifts, APs mo de selection, and pow er allo cation to maximize a verage sum-HE under SE and a v erage harv ested energy constraints. T o solve this problem, w e prop ose a centralized training, decen tralized execution (CTDE) framew ork based on deep reinforcement learning (DRL), whic h ecien tly handles high-dimensional decision spaces. A Marko- vian environmen t and a normalized joint reward function are in tro duced to enhance the training stability across on-p olicy and o-p olicy DRL algorithms. Additionally , w e provide a tw o- phase con vex-based solution as a theoretical robust performance. Numerical results demonstrate that the prop osed DRL-based CTDE framew ork achiev es SWIPT p erformance comparable to con v exication-based solution, while signican tly outperforming baselines. Index T erms—Cell-free massiv e multiple-input m ultiple- output (CF-mMIMO), simultaneous wireless information and p ow er transfer (SWIPT), stack ed in telligen t metasurfaces (SIMs). I. Introduction The surging demand for reliable wireless connectivity and ecien t energy harv esting (HE) in Internet of Thing devices has made sim ultaneous wireless information and p ow er transfer (SWIPT) a k ey research fo cus. Subsequen tly , n umerous studies hav e underscored its integration with cell- free massive multiple input m ultiple output (CF-mMIMO) that could signican tly impro v e both the b oth HE and This work w as supp orted by the U.K. Engineering and Physical Sciences Research Council (EPSRC) grant (EP/X04047X/2) for TI- T AN T elecoms Hub. The work of T. D. Hua and M. Matthaiou was supp orted by the European Researc h Council (ERC) under the European Union’s Horizon 2020 Researc h and Innov ation Programme (grant agreemen t No. 101001331). The authors are with the Centre for Wireless Innov ation (CWI), Queen’s Universit y Belfast, BT3 9DT Belfast, U.K. (email:{dhua01, m.mohammadi, hien.ngo, m.matthaiou}@qub.ac.uk). Parts of this paper appeared at the 2025 IEEE ICC [1]. sp ectral eciency (SE) [2], [3]. A ccording to [4], [5], while adv anced mMIMO is eective at enhancing netw ork capacit y , it is often unsustainable due to their excessive energy consumption. F urthermore, the implementation of b oth massive MIMO and millimeter-wa v e comm unications is hindered by the need for expensive hardware comp onents, suc h as numerous radio frequency (RF) chains and high- resolution digital-to-analog conv erters. These limitations highligh t an urgent need for a nov el CF-mMIMO SWIPT top ology , based on next-generation multiple access tec h- niques (NGMA), that integrates adv anced technologies to enable ecien t and energy-sa ving op eration. Notably , a pio- neering work by Huang et al. demonstrated the integration of single-lay er diagonal recongurable intelligen t surfaces (RISs) within an access p oint (AP)’s antenna radome to directly con trol its signal radiation c haracteristics [6]. While this represents a signican t step forward, the inheren t struc- ture of RISs imp oses limitations relating to the conned degrees of freedom (DoF) for signal manipulation because of their limiting ability to adjust the beam pattern eectiv ely . T o address these c hallenges, w e turn to stac ked intelligen t metasurfaces (SIMs), an emerging technology that oers a sup erior architecture. Unlike RISs, the m ulti-lay ered structure of a SIM provides additional spatial DoF for signal manipulation compared to RISs. Additionally , SIMs directly manipulate the electromagnetic wa ve (EM) through a net work of recongurable la y ers, leading to the capabilit y of p erforming complex signal pro cessing tasks [7]. This abilit y to perform analog computations drastically reduces the need for complex baseband digital preco ding, whic h in turn low ers hardw are costs and energy consumption [8]. F rom a practical standp oints, SIMs emerge as a highly promising and practical candidate for implementing NGMA arc hitectures in CF-mMIMO SWIPT systems. A. Literature Review 1) RIS-assisted CF-mMIMO: Shi et al. [13] pro vided a comprehensive ov erview of opp ortunities and challenges in this domain and prop osed ecient resource allo cation algorithms for wireless energy transfer. Chien et al. [14] analytically inv estigated CF-mMIMO systems with RISs for transmission to a zone of receivers and prop osed a low- complexit y sub-optimal phase shift (PS) conguration to minimize NMSE, thereb y enhancing SE. Y ang et al. [15] applied alternativ e optimization (AO) to maximize the . 2 T ABLE I: Con trasting our contributions to the SIM-assisted CF-mMIMO literature Con tributions This pap er [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] SIM ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ CF-mMIMO ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ SWIPT ✓ ✓ ✓ ✓ Statistical Design ✓ ✓ ✓ CTCE DRL ✓ ✓ CTDE DRL ✓ max sum-rate (MSR) metric in RIS-aided CF-mMIMO SWIPT. Y ang et al. [16] emplo y ed particle-swarm-based optimization to jointly maximize sum-HE and SE metrics via PS optimization. 2) SIM-assisted CF-mMIMO: Li et al. [17] maximized SE metrics by optimizing SIM’s PS using the AO technique. Li et al. [18] studied the holographic cell-free systems in the presence of SIMs with hardw are impairments. Shi et al. [19] inv estigated tw o-stage pilot allo cation and MSR sub-problems using an A O metho d in uplink SIM-aided CF-mMIMO system. Shi et al. [20] prop osed a three-phase sc heme that combines heuristic search, A O, and pro jected gradien t descent (GD) for interference minimization, AP p ow er transmission, and SIM’s PSs for the MSR problem under instantaneous CSI-based design. 3) SIMs v ersus RISs: In recen t years, SIM-related studies ha v e progressed tow ard physics-based inv estigations that explicitly mo del electromagnetic eects, suc h as in ter- la y er reections and mutual coupling, thereby rev ealing the ph ysical mechanisms that impact the passive b eamforming capabilit y of practical SIMs. Li et al. [18] inv estigated the substan tial impact of SIMs’ physical prop erties, including the n um ber of metasurfaces p er SIM, inter-la yer distance, hardw are quality factors on to the ac hiev able rates Nerini et al. [21] prop osed a ph ysically consisten t SIM-assisted single- input single-output transmission to illustrate the eect of m utual coupling on the SIM p erformance. Y ah ya et al. [22] prop osed a tractable T-parameter-based model that simpli- es the coupling-aw are analysis of cascaded metasurfaces. Li et al. [23] inv estigated SIM-based b eamforming for m ulti- altitude satellite netw orks, rev ealing that incorp orating m utual coupling in to the b eamforming design can eectively comp ensate for the reduced throughput. The numerical ndings demonstrated that it is crucial to account for ph ysical and hardw are impairmen ts in SIM-assisted wireless systems. B. Research Gap and Summarized Contributions It is well-established that SIMs hold great promise in extending co v erage and mitigating blo ckage eects, but their in tegration into CF-mMIMO systems with SWIPT remains underexplored. In addition, existing studies primar- ily rely on traditional optimization frameworks such as AO, GD, and successiv e conv ex approximation (SCA). Although these metho ds oer adv antages in analytical tractability , they share a common limitation of p o or scalability . Sp ecif- ically , A O is prone to lo cal optima, SCA dep ends on complex con vex approximations, and all en tail considerable computational ov erhead [24]. Deep reinforcement learning (DRL) oers a comp elling alternativ e by inherently capturing non-con vex problem c haracteristics without requiring handcrafted conv exica- tion. Conv entional DRL frameworks typically employ a cen tralized training and cen tralized execution (CTCE) strategy , in which a single agent, equipp ed with a deep neural netw ork (DNN) actor handles all decision-making for the en tire netw ork [25]–[27]. In this strategy , the single agen t observ es a global state, computes a global joint action, and optimizes its p olicy through a centralized bac kpropagation pro cess. Once trained, this single agent m ust also execute the global p olicy in real-time. Figure 1 illustrates a SIM-assisted CF-mMIMO SWIPT system op erating under the CTCE framework, where a DNN- equipp ed central pro cessing unit (CPU) is resp onsible for training and subsequen tly determining all signal pro cessing, p o w er allo cation, active and passive b eamforming for all APs. Consequently , as the CF-mMIMO netw orks scale up, the single-pro cessing CPU faces an exp onentially growing dimensionalit y of optimizing v ariables, leading to increased computational complexit y , comm unication and fronthaul o v erhead. These factors constitute critical b ottlenec ks for learning large-scale CF-mMIMO deploymen ts. T o ov ercome the scalability limitations of CTCE, w e hereafter prop ose a centralized training, decen tralized ex- ecution (CTDE) framework tailored for SIM-assisted CF- mMIMO SWIPT systems, as shown in Fig. 2. Compared to the CTCE strategy , CTDE equips each AP with its o wn DNN-based actor and decouples the learning and execution phases. This elab orates in telligen t distributing optimization, where each AP makes optimization decisions based on its lo cal observ ations and a low er-dimensional action space, instead of relying on a single centralized p olicy that must jointly output all AP decisions. The distributed learning strategy signican tly reduces the input–output dimensionalit y of each actor net w ork, whic h in turn reduces the DNN ’s size and p er-step computational cost, making b oth training and inference more scalable in large-scale CF- mMIMO deplo ymen ts. At the same time, CTDE improv es the learning b ehavior b ecause it mitigates the curse of di- mensionalit y inheren t in fully cen tralized DRL as the p olicy gradien t v ariance and critic estimation errors t ypically grow when the state and action spaces b ecome excessively high- . 3 dimensional. The CTDE strategy tends to yield more stable up dates and eective learning conv ergence, while ensuring high scalability and low fron thaul latency for large-scale net w orks, ecien tly handling the growing complexity of CF-mMIMO SWIPT systems. T o this end, we fo cus on a CF-mMIMO SWIPT sys- tem serving tw o distinct user groups: information-deco ding receiv ers (IRs) and energy-harvesting receivers (ERs). T o optimize resource utilization, we adopt the metho dology from [28], categorizing APs in to information-APs (I-APs) and energy-APs (E-APs). Eac h AP’s signal transmission is enhanced b y integrating a SIM within its antenna radome. W e emplo y the protectiv e partial zero-forcing (PPZF) preco der to safeguard transmissions to IRs from interference b y applying partial ZF at I-APs and protectiv e maximum ratio transmission (PMR T) at E-APs [29]. The primary con tribution of this work is enabling autonomous decision- making through a CTDE DRL framework, which lev erages DNNs at b oth the individual APs and a central CPU. Our main contributions can b e summarized as follows: • W e explore a statistical CSI-based SIM-assisted CF- mMIMO SWIPT system, which accounts for channel estimation errors, pilot contamination (PC), and non- linear energy harvesting (NLEH) eects. Under these conditions, we deriv e closed-form expressions for the ergo dic SE of the IRs and the av erage HE of the ERs. Using these expressions, we formulate a mixed- in teger non-con v ex optimization problem to jointly determine the AP op eration mo de, p ow er allo cation, and SIMs’ PS conguration, aiming to maximize the a v erage total HE at the ERs, while meeting minimum SWIPT quality-of-service (QoS) requirements. • The optimization problem is reformulated as a Marko- vian environmen t, enabling the APs to interact with it and jointly optimize solutions via a reward-driv en feedbac k mechanism. A reward normalization step is then introduced to enhance learning stability , reduce h yp erparameter sensitivity , and low er p olicy gradient v ariance, ultimately improving DRL conv ergence. • T o serv e as a robust comparison b enchmark, we dev elop a tw o-stage conv ex-based optimization framework. In the rst stage, we heuristically optimize the SIMs’ PS. In the second stage, we employ a conv ex-based metho d to jointly address the remaining subproblem, whic h entails APs mo de selection and transmit p ow er allo cation. • Through extensiv e numerical simulations, we v alidate the eectiveness of integrating SIMs in to the CF- mMIMO SWIPT framew ork. A comprehensive p er- formance comparison is carried out among v arious CTDE and CTCE learning strategies, and the conv ex- based b enchmark, highlighting trade-os in solution robustness, computational complexit y , and real-time adaptabilit y . A comparison of our con tributions against the SIM- orien ted literature is presented in T able I. Notation: W e use b old lo w er (capital) case letters to denote vectors (matrices). The sup erscript ( · ) † stands for the Hermitian transp ose; I N denotes an N × N iden tity matrix; 0 N × K denotes the matrix with all elements zero; [ A ] i,j denotes the ( i, j ) th en try of A ; tr( · ) and diag( · ) denote the trace and diagonal op erators, resp ectively; ∥ · ∥ F denotes the F rob enius norm; mo d ( · , · ) is the modulus op eration; ⌈·⌉ denotes the ceil function; ¯ x and ˜ x denote the line-of-sigh t (LoS) and non-line-of-sight (NLoS) terms of a complex-v alued Gaussian distributed vector x ; a circularly symmetric complex Gaussian v ariable with v ariance σ 2 is denoted by C N (0 , σ 2 ) . Finally , E {·} denotes statistical exp ectation. I I. System Mo del Consider a SIM-assisted CF-mMIMO SWIPT system where M APs simultaneously serve K I single-an tenna IRs and K E single-an tenna ERs o v er the same frequency band. W e assume p erfect synchronization among the distributed APs. 1 F or notational simplicity , we dene the sets K , K I , K E , M , L , and S to resp ectively collect the indices of the total receivers, IRs, ERs, APs, SIMs, and reectiv e elements p er metasurface. W e mo del AP m with a uniform linear ar- ra y (ULA) of N active antennas that uniformly illuminates its attached SIM as in [11], [31]. Each SIM comprises L metasurfaces, where each metasurface comprises S reectiv e elemen ts. W e denote the attached L -la y er SIM at AP- m as Φ mℓ ∈ C S × S ≜ diag( e j θ mℓ 1 , . . . , e j θ mℓ s , . . . , e j θ mℓ S ) , where θ mℓ s ∈ [0 , 2 π ] is the PS elemen t. Remark 1. W e denote a coupling-aw are PS of metasurface ( m, ℓ ) as ( m, ℓ ) as ˜ Φ mℓ ≜ Φ mℓ I S − Φ mℓ S m,ℓ − 1 cap- tures multiport prop erties including mutual coupling and m ultiple reections [32]. By inserting a carefully designed imp edance matching or decoupling net work b etw een the SIM elemen ts and their loads, the o-diagonal coupling terms can b e canceled [33], [34]. This technique makes the o v erall response of the comp ensated SIM approximately diagonal. F or analytical tractability , we assume negligible m utual coupling in the propagation manipulated through the SIMs, mathematically sp eaking S m,ℓ ≈ 0 S × S , th us ˜ Φ mℓ = Φ m,ℓ , ∀ m ∈ M , ℓ ∈ L . This serves as a mo del for a coupling-compensated SIM, allowing system performance b ounds to b e derived. A. Channel Model W e assume a blo ck fading channel that remains inv ari- an t and frequency-at during each coherence in terv al τ c , 1 Synchronization among the APs is important from a practical point of view. According to [30], the CPU can estimate residual p er-AP synchronization errors using uplink pilots. Ov er one coherence blo ck of duration T C , carrier frequency oset ∆ f m induces a phase rotation ∆ ϕ m ≈ 2 π ∆ f m T C . Subsequently , a practical verication step is to estimate ∆ f m and determine that the phase misalignment ov er T C is within a small tolerance such that the p erformance gap to the perfect sync hronization b ound is negligible. This is feasible since ∆ f m is pilot-aided and can b e estimated with negligible ov erhead b eyond the existing UL training. . 4 CPU IR 𝑘 𝑖 ER 𝑘 𝑒 SIM - assisted AP 𝑚 𝑁 ant enna s Fig. 1: The CTCE CF-mMIMO-assisted SWIPT using SIMs. C P U CPU I R 𝑘 ER 𝑘 ER 𝑘 SIM-assisted AP 𝑚 𝑁 antennas IR 𝑘 Fig. 2: The CTDE CF-mMIMO-assisted SWIPT using SIMs. including τ samples for UL channel estimation training and the rest for downlink (DL) transmission. F or a general in terpretation, let k ∈ K b e the index of the receivers and i ∈ { I , E } b e the index corresp onding to wireless information transmission (WIT) and WPT op erations. In eac h coherence interv al, the instantaneous c hannel from AP m to receiver k is mathematically expressed as g i mk ≜ F † m z i mk , where F m ∈ C S × N and z i mk ∈ C S × 1 denote the propagations from the ULA to the SIM and from the last SIM lay er of AP m to receiv er k , resp ectively . Mathematically sp eaking: F m ≜ Φ mL H mL · · · Φ mℓ H mℓ · · · Φ m 1 H m 1 , (1) where H m 1 ∈ C S × N and H mℓ ∈ C S × S are the EM-wa ve propagation matrices from AP m to the rst SIM lay er and from the ( ℓ − 1) -th lay er to the ℓ -th lay er, ∀ ℓ > 1 , resp ectively . According to Rayleigh-Sommerfeld diraction theory [9], the co ecient from the ˘ s -th elemen t of the ( ℓ − 1) - th lay er to the s -th element of the ℓ -th lay er is formulated as [ H mℓ ] s, ˘ s = λ 2 cos( χ mℓ s, ˘ s ) 4 d ℓ s, ˘ s 1 2 π d ℓ s, ˘ s − j λ exp j 2 π d ℓ s, ˘ s λ , (2) where λ is the wa velength, χ mℓ s, ˘ s is the angle b etw een the propagation and normal directions of the ( ℓ − 1) -th lay er, while d ℓ s, ˘ s is the geometric distance from the ˘ s -th element of the ( ℓ − 1) -th lay er to the s -th element of the ℓ -th lay er, i.e., d ℓ s, ˘ s = r d PS q ( s z − ˘ s z ) 2 + ( s y − ˘ s y ) 2 2 + d 2 SIM , (3) where d PS and d SIM are the spacings b etw een tw o adjacent elemen ts and metasurfaces, resp ectively; the indices of the elemen ts s z and s y along the z - and y -axes can be computed as s z ≜ ⌈ s/ √ S ⌉ and s y = mod ( s − 1 , √ S ) + 1 , resp ectively . W e note that the propagation co ecien t from the n -th transmit antenna to the s -th element of the rst SIM lay er [ H m, 1 ] s,n is formulated by (2). The Ricean instantaneous c hannel from the last SIM lay er of AP m to receiver k is mo deled as z i mk ≜ q ¯ β i mk √ κ ¯ z i mk + ˜ z i mk , (4) where ¯ β i mk ≜ β i mk / (1 + κ ) , with β i mk represen ting the large- scale fading co ecient (LSFC), κ is the Ricean factor, ˜ z i mk is the NLoS comp onent, whose s -th element is distributed as [ ˜ z i mk ] s ∼ C N (0 , 1) , ∀ m ∈ M , ∀ k ∈ K . In addition, ¯ z i mk is the LoS comp onent whose s -th element is given by ¯ z i mk s = exp ζ s z sin χ L s,k + ζ s y sin ε L s,k cos χ L s,k , (5) where ζ ≜ j 2 π d PS /λ , sin ε L s,k cos χ L s,k = ( n z − k z ) /d L n,k , sin χ L s,k = ( | n z − k z | ) / d L n,k , where d L n,k is the geometric distance from receiv er k to element n of the last SIM lay er, while χ L n,k and ε L n,k are the elev ation and azim uth angle b et w een the propagation direction and the O xy and O y z surfaces, resp ectively . T o facilitate subsequent deriv ations, w e present the channel statistics in the following remark. Remark 2. By leveraging the second-order moment of the c hannel comp onents, we obtain E {∥ g i mk ∥ 2 } = κ ¯ β i mk tr F m F † m ( ¯ z i mk ) † ¯ z i mk + ¯ β i mk tr F m F † m , while g i mk is distributed as g i mk ∼ C N ¯ g i mk , ¯ β i mk F † m F m , where ¯ g i mk ≜ q ¯ β i mk κ F † m ¯ z i mk [29, Lemma 1]. B. Uplink Channel Estimation In the training phase, all IRs and ERs transmit their pilot sequences of length τ symbols to the APs. W e consider the general case where shared pilot sequences are used and denote P k ⊂ K as the set of receiv ers k ′ , including k , that are assigned with the same pilot sequence as the receiver k . In this regard, i k ∈ { 1 , . . . , τ } denotes the index of the pilot sequence used by receiv er k . The pilot sequences φ i k ∈ C τ × 1 , with ∥ φ i k ∥ 2 = 1 , are mutually orthogonal so that φ † i k ′ φ i k = 1 if i k ′ ∈ P k and φ † i k ′ φ i k = 0 , otherwise. Then, the signal received at AP m can b e expressed as Y i p,m = √ τ ρ u g i mk φ † i k + X k ′ ∈K \ k g i mk ′ φ † i k ′ + N p,m , (6) where ρ u is the normalized UL signal-to-noise ratio (SNR), while N p,m ∈ C N × τ is the receiver noise matrix containing indep enden t and iden tically distributed (i.i.d.) C N (0 , σ 2 n ) random v ariables (R V s). Similar to [29], to estimate g i mk , w e rst project Y i p,m on to the i k -th pilot sequence, and then apply the linear minim um mean-squared error (MMSE) . 5 estimation technique. The corresp onding c hannel estimate is ˆ g i mk = E { g i mk } + C g i mk y i mk C y i mk y i mk − 1 y i mk − E { y i mk } = q ¯ β i mk κ F † m ¯ z i mk + A mk × √ τ ρ u X k ′ ∈P k q ¯ β i mk ′ F † m ˜ z i mk ′ + ˜ n p,mk , (7) where y i mk = Y i p,m φ i k , ˜ n p,mk ≜ N p,m φ i k ∼ C N ( 0 , σ 2 n I N ) , and A mk = √ τ ρ u ¯ β i mk F † m F m τ ρ u X k ′ ∈P k ¯ β i mk ′ F † m F m + σ 2 n I N − 1 . Th us, the statistical distribution of ˆ g i mk follo ws ˆ g i mk ∼ C N ¯ g i mk , Σ ˆ g i mk , where Σ ˆ g i mk ≜ √ τ ρ u ¯ β i mk F † m F m A mk . Moreo v er, we obtain E {∥ ˆ g i mk ∥ 2 } ≜ κ ¯ β i mk tr( F m F † m ¯ z i mk ( ¯ z i mk ) † ) + γ i mk , (8) where γ i mk = τ ρ u ( ¯ β i mk ) 2 tr( F m F † m ) 2 τ ρ u P k ′ ∈P k ¯ β i mk ′ tr( F m F † m ) + N σ 2 n . (9) Subsequen tly , the exp ectation of the norm square of the estimate error ˜ g i mk ≜ g i mk − ˆ g i mk is E {∥ ˜ g i mk ∥ 2 } = ¯ β i mk tr( F m F † m ) − γ i mk . 2 C. Downlink Wireless Information and P ow er T ransmission W e dene the binary v ariable a m as the operation indicator, where a m = 1 ( a m = 0 ) if the m -th AP op erates as an I-AP (E-AP). Let x I ,k i ( x E ,k e ) denote the information (energy) sym b ol transmitted to IR k i (ER k e ) that satises E {| x I ,k i | 2 } = E {| x E ,k e | 2 } = 1 and η I mk i ( η E mk e ) denote the p ow er control co ecients asso ciated with AP m and IR k i (ER k e ). Hence, the signal transmitted from the m -th AP can b e expressed as x m = X k i ∈K I q a m ρ d η I mk i w I ,mk i x I ,k i + X k e ∈K E q (1 − a m ) ρ d η E mk e w E ,mk e x E ,k e , (10) where ρ d = ˜ ρ d /σ 2 n is the normalized DL SNR; w I ,mk i ∈ C N × 1 ( w E ,mk e ∈ C N × 1 ) represen ts the preco ding v ector for IR k i (ER k e ) with E w I ,mk i 2 = E w E ,mk e 2 = 1 ; η I mk i and η E mk e are the p ow er con trol co ecients at AP m , c hosen to satisfy the pow er transmission constraint a m E x I ,m 2 + (1 − a m ) E x E ,m 2 ≤ ρ d . (11) Then, the IR and ER resp ectively receive 2 Pilot contamination interacts with SIM phase-shift optimization through the channel estimation qualit y . P articularly , the MMSE estimation variance term dep ends on the SIM conguration via the quadratic form tr( F m F † m ) . As a result, the receivers sharing the same pilot con tribute to the denominator of the term γ i mk , scaled by their large-scale fading and the SIMs phase-shift. Hence, optimizing the SIM phase shifts not only shap es the downlink b eamforming gain, but also implicitly alters the eectiv e pilot con tamination lev el during the uplink training phase. y I ,k i = X k ′ i ∈K I X m ∈M q a m ρ d η I mk ′ i ( g I mk i ) † w I ,mk ′ i x I ,k ′ i + X k e ∈K E X m ∈M q (1 − a m ) ρ d η E mk e ( g I mk i ) † w E ,mk e x E ,k e + n d,k i , y E ,k e = X k ′ e ∈K E X m ∈M q (1 − a m ) ρ d η E mk ′ e ( g E mk e ) † w E ,mk ′ e x E ,k ′ e + X k i ∈K I X m ∈M q a m ρ d η I mk i ( g E mk e ) † w I ,mk i x I ,k i + n d,k e , resp ectiv ely , where n d,k i , n d,k e ∼ C N (0 , 1) are the additive noise terms. D. Protective P artial Zero F orcing Preco ding A ccording to [28], [35], w e employ the PPZF preco ding sc heme, whic h strategically com bines distinct b eamforming tec hniques for the tw o AP mo des. A t the I-APs, zero-forcing (ZF) is used to eliminate inter-user interference among the information receiv ers. A t the E-APs, the goal is to use PMR T, as it is optimal for wireless pow er transfer, esp ecially in large-an tenna systems. How ever, conv entional MR T from the E-APs would cause signicant interference to the IRs. T o address this, PPZF implements a crucial mo dication: the PMR T preco der is pro jected into the or- thogonal complement of the IRs’ collective c hannel matrix. This mo died sc heme forces the energy signals in to the null space of the IRs. As a result, if the channel estimation is p erfect, the information transmission to IRs is fully protected from the energy signals directed at the ERs. Let ˆ G I m = ˆ g I mk i ∈ C N ×K I and ˆ G E m = ˆ g I mk ∈ C N ×K E b e the matrices of the estimated channels b etw een AP m and all IUs, and all EUs, resp ectively . By in v oking [29], the ZF and PMR T preco ders at AP m for IR k i and ER k e are given b y w ZF I ,mk i = ( α ZF mk i ) − 1 ˆ G I m ˆ G I m † ˆ G I m − 1 e I k i , (13a) w PMRT E ,mk e = ( α PMRT mk e ) − 1 B m ˆ G E m e I k e , (13b) where e I k i ( e E k e ) denotes the k i ( k e ) -th column of I K i ( I K e ) ; B m denotes the projection matrix onto the orthogonal complemen t of ˆ G I m so that g I H mK B m = 0 . Th us, B m can b e computed as B m = I N − ˆ G I m ˆ G I m † ˆ G I m − 1 ˆ G I m † , (14) and E { B m } = E { B † m B m } = E { B m B † m } = I N , ∀ m ∈ M , whic h w as mathematically prov en in [36]. Note that in (13), α ZF mk i and α PMRT mk e are normalization factors, given b y α ZF mk i ≜ E n ˆ G I m ˆ G I m † ˆ G I m − 1 e I k i 2 o − 1 2 = h E n ˆ G I m † ˆ G I m − 1 oi k i ,k i − 1 2 , α PMRT mk e ≜ E B m ˆ G E m e E k e 2 − 1 2 = h E n ˆ G E m † ˆ G E m o i k e k e − 1 2 . Note that ˆ G I m † ˆ G I m follo ws a non-cen tral Wishart dis- tribution with the non-iden tical cov ariance matrices of the row v ectors of ˆ G I m . Thus, it is c hallenging to obtain the exact closed-form expressions for α ZF mk i and α PMRT mk e . . 6 T ABLE I I: Summary of Notations Notation Description τ c , τ Coherence interv al length and UL training duration (in symbols) ρ d , ρ u Normalized downlink and UL SNR σ 2 n A WGN p ow er φ i k Pilot sequence used by receiver k g i mk Actual channel vector for receiver k at AP m ˆ g i mk Estimated channel vector for receiver k at AP m ˜ g i mk Estimated channel error for receiver k at AP m F m Cascade channel from AP m through SIM Φ m,ℓ Diagonal PS matrix of the ℓ -th SIM la y er at AP m θ s m,ℓ PS of the s -th element on the ℓ -th la y er at AP m H m,ℓ Propagation matrix between lay ers ( ℓ − 1) and ℓ Θ Set of all SIM PS congurations z i mk Channel vector from the last SIM la yer of AP m to receiver k ¯ z i mk ( ˜ z i mk ) Line-of-sight (non line-of-sight) comp onent of the channel z i mk β i mk Large-scale fading coecient b etween AP m and receiver k κ Ricean fading factor x m T ransmitted signal from the AP m x I ,m ( x E ,m ) T ransmitted signal from I-AP (E-AP) m y I ,k i ( y E ,k e ) Received signal at IR k i (ER k e ) n d,k i ( n d,k e ) Additiv e noise at the IR k i (ER k e ) w ZF I ,mk i ZF preco der at AP m for IR k i w PMRT E ,mk e PMR T preco der for ER k e ξ, χ, ϕ, Ω Circuit parameters for the NLEH model SINR k i Eective SINR at IR k i SE k i Ac hiev able sp ectral eciency (SE) at IR k i Q k e A verage harvested energy (HE) at ER k e E { E NL k e } A verage non-linear harvested energy at ER k e Γ k e Minimum EH QoS requirement for ER k e S k i Minimum SE QoS requirement for IR k i a m Binary op eration mode indicator for AP m η I mk i ( η E mk e ) Po wer control co ecient for IR k i (ER k e ) at AP m T o render the problem more tractable, we deplo y a tight appro ximation which relies on the law of large n umbers (via the T cheb yshev’s theorem) when N → ∞ . By using T cheb yshev’s theorem [37], w e obtain 1 N E ˆ G I m † ˆ G I m − 1 − 1 N E E n ˆ G I m † ˆ G I m o − 1 a.s. − − − − → N →∞ 0 . (16) By using the ab ov e asymptotic result, we can obtain the follo wing tight approximations α ZF mk i ≈ ( ˆ W I , ◦ m ) − 1 k i ,k i − 1 2 , (17) where ˆ W I , ◦ m = κ ( D I m ) 1 / 2 ( ¯ Z I m ) † F m F † m ¯ Z I m ( D I m ) 1 / 2 + D I m , (18) with ¯ Z I m ≜ { z I mk i } , ∀ k i ∈ K I ; D I m ∈ R K I × K I is diagonal with [ D I m ] k i ,k i ≜ ¯ β I mk i . The detailed proof of (17) is pro vided in App endix A. F ollo wing a similar metho dology to the deriv ation of (17), we can derive α PMRT mk e as α PMRT mk e ≈ ˆ W E , ◦ m k e ,k e − 1 2 , (19) where ˆ W E , ◦ m = κ ( D E m ) 1 / 2 ( ¯ Z E m ) † F m F † m ¯ Z E m ( D E m ) 1 / 2 + D E m , (20) with ¯ Z E m ≜ { ¯ z E mk e } , ∀ k e ∈ K E ; D E m ∈ R K E × K E are diagonal matrices with [ D E m ] k e ,k e ≜ ¯ β E mk e . T o this end, the summary of notations used in the pap er is listed in T able I I. Remark 3. The approximation (17) is obtained from the asymptotic result (16), whic h is very tigh t in the massive MIMO regime where the num ber of antennas p er AP is signican tly larger than the n umber of served IRs, i.e., N ≫ K I [38]. In this regime, the random ˆ G I m † ˆ G I m − 1 matrix con v erges asymptotically to its deterministic mean. I I I. Performance Analysis and Problem F orm ulation A. Ergo dic Do wnlink Sp ectral Eciency with PPZF Applying the use-and-then-forget technique [38], the signal received at IR k i can b e expressed as y I ,k i = DS k i x I ,k i + BU k i x I ,k i + X k ′ i ∈K I \ k i IUI k i k i ′ x I ,k ′ i + X k e ∈K E EUI k i k e x E ,k e + n k i , ∀ k i ∈ K I , (21) where DS k i , BU k i , IUI k i k i ′ , and EUI k i k e represen t the desired signal, the b eamforming gain uncertaint y , the in ter- ference caused by the k ′ i -th IR, and the interference caused b y the k e -th ER, resp ectively , given b y DS k i ≜ X m ∈M q a m ρ d η I mk i E ( g I mk i ) † w ZF I ,mk i , (22a) BU k i ≜ X m ∈M q a m ρ d η I mk i ( g I mk i ) † w ZF I ,mk i − E ( g I mk i ) † w ZF I ,mk i , (22b) IUI k i k i ′ ≜ X m ∈M q a m ρ d η I mk ′ i ( g I mk i ) † w ZF I ,mk ′ i , (22c) EUI k i k e ≜ X m ∈M q (1 − a m ) ρ d η E mk e ( g I mk i ) † w PMRT E ,mk e . (22d) Th us, the DL SE in [bit/s/Hz] for IR k i is SE k = 1 − τ τ c log 2 1 + SINR k i Θ , a η I , η E , (23) while SINR k i is the eective SINR at IR k i , given by SINR k i = | DS k i | 2 E {| BU k i | 2 } + IT + 1 , (24) where IT ≜ P k ′ i ∈K I \ k i E {| IUI k i k i ′ | 2 } + P k e ∈K E E {| EUI k i k e | 2 } . Prop osition 1. The SE of IR k i is given by (23), where SINR k i = P m ∈M α ZF mk i q a m ρ d η I mk i 2 PC k i + Ω k i + 1 , (25) while PC k i = P k ′ i ∈P k \ k i P m ∈M α ZF mk ′ i q a m ρ d η I mk ′ i 2 , and Ω k i = X k ′ i ∈K I X m ∈M a m ρ d η I mk ′ i ¯ e mk i + X k e ∈K E X m ∈M (1 − a m ) ρ d η E mk e ¯ e mk i , (26) with ¯ e mk i = ¯ β I mk i tr( F m F † m ) − γ I mk i . Pro of. See App endix B. . 7 B. A v erage Non-Linear Harvested Energy with PPZF W e use the NLEH model [29], [39], [40] to c haracterize the HE at ER k e . Subsequently , the total HE at ER k e ∈ K E is given by E NL k e ≜ Λ E k e − ϕ Ω (1 − Ω) − 1 , where ϕ is the maxim um output DC p ow er, Ω ≜ 1 / (1 + exp( ξ χ )) is a constan t to guaran tee a zero input/output resp onse, ξ and χ are circuit constants, and E k e denotes the received RF energy at ER k e , ∀ k e ∈ K E . W e obtain the energy at the output of the circuit as a logistic function of the received input RF signal at ER k e , i.e. Λ( E k e ) = ϕ 1 + exp − ξ E k e − χ − 1 . T o this end, the av erage of the total HE at ER k e is formulated as E E NL k e = E Λ E k e − ϕ Ω 1 − Ω ≈ Λ Q k e − ϕ Ω 1 − Ω , (27) where Q k e ≜ ( τ c − τ ) σ 2 n ρ d × X m ∈M (1 − a m ) η E mk e E n g E mk e † w PMRT E ,mk e 2 o + X k ′ e ∈K E \ k e X m ∈M (1 − a m ) η E mk ′ e E n g E mk e † w PMRT E ,mk ′ e 2 o + X k i ∈K I X m ∈M a m η I mk i E n g E mk e † w ZF I ,mk i 2 o + 1 ρ d . (28) Remark 4. The appro ximation E { Λ ( E k e ) } ≈ Λ ( E {E k e } ) = Λ ( Q k e ) is applied on (27). The approximation relies on a rst-order T a ylor expansion of the NLEH logistic func- tion around the mean received energy Q k e , neglecting higher-order terms. This approximation is tight when the uctuation of the receiv ed energy E k e is small [40]. In addition, the Λ( · ) function has conv exity and conca vit y ends of the logistic curve, which represents the low-pow er and saturation regimes, resp ectively . In extreme cases, the appro ximation may strictly serv e as a low er b ound (in the lo w-p o w er regime) or an upp er b ound (in the saturation regime) for the actual a v erage harvested energy . Prop osition 2. With PMR T preco ding, the av erage HE at ER k e ∈ K E is given by (27), where Q k e is given by Q k e = ( τ c − τ ) σ 2 n ρ d h 1 /ρ d + X m ∈M (1 − a m ) η E mk e ¯ d mk e + X m ∈M X k ′ e ∈P k \ k e (1 − a m ) η E mk ′ e ¯ e m,k e k ′ e + X m ∈M X k ′ e / ∈P k \ k e (1 − a m ) η E mk ′ e ¯ f m,k e k ′ e + X m ∈M X k i ∈K I a m η I mk i (1 / N ) ¯ h m,k e i , (29) while ¯ d mk e = α PMRT mk e 2 h ¯ β E mk e tr F m F † m − γ E mk e × κ ¯ β E mk e tr F m F † m ¯ z E mk e ( ¯ z E mk e ) † γ E mk e + ¯ a m,k e i , ¯ e m,k e k ′ e = α PMRT mk e 2 × h ¯ b m,k e k ′ e + κ ¯ β E mk ′ e tr F m F † m ¯ z E mk ′ e ( ¯ z E mk ′ e ) † + γ E mk ′ e × ¯ β E mk e tr F m F † m − γ E mk e i , ∀ k ′ e ∈ P k \ k e , ¯ f m,k e k ′ e = α PMRT mk e 2 × h κ ¯ β E mk e tr F m F † m ¯ z E mk e ( ¯ z E mk e ) † + ¯ β E mk e tr F m F † m × κ ¯ β E mk ′ e tr F m F † m ¯ z E mk ′ e ( ¯ z E mk ′ e ) † + γ E mk ′ e i , ∀ k ′ e / ∈ P k \ k e , and ¯ h m,k e = κ ¯ β E mk e tr F m F † m ¯ z E mk e ( ¯ z E mk e ) † + ¯ β E mk e tr F m F † m , where ¯ a mk e = tr Σ ˆ g E mk e 2 + tr Σ ˆ g E mk e Σ ˆ g E mk e + ( ¯ g E mk e ) † ¯ g E mk e 2 + 2( ¯ g E mk e ) † ¯ g E mk e tr Σ ˆ g E mk e + 2( ¯ g E mk e ) † Σ ˆ g E mk e ¯ g E mk e , ¯ b m,k e k ′ e = | ( ¯ g E mk e ) † ¯ g E mk ′ e | 2 + 2 ( ¯ β E mk ′ e ) 2 / ( ¯ β E mk e ) 2 ( ¯ g E mk e ) † ¯ g i mk ′ tr Σ ˆ g i mk + ( ¯ β E mk ′ e ) 4 / ( ¯ β E mk e ) 4 tr Σ ˆ g E mk e 2 + tr Σ ˆ g E mk e Σ ˆ g E mk e + 2 ( ¯ β E mk ′ e ) 2 / ( ¯ β E mk e ) 2 ( ¯ g E mk e ) † Σ ˆ g E mk e ¯ g E mk ′ e , ∀ m ∈ M . Pro of. See App endix C. C. Problem F ormulation W e formulate an optimization problem that maximizes the av erage sum-HE, sub ject to the minimum HE QoS Γ k e , the minimum SE QoS S k i , and the p ow er budget for each AP . Our ob jective is to optimally determine the AP mode selection a, pow er control coecients, η I = η I mk i , ∀ m ∈ M , ∀ k i ∈ K I and η E = η E mk e , ∀ m ∈ M , k e ∈ K E , and the PS matrices of M SIM-attached APs Θ ≜ { Φ m,ℓ , ∀ m ∈ M , ℓ ∈ L} . The optimization problem can b e mathematically expressed as max a , η I , η E , Θ X k e ∈K E E E NL k e (30a) s.t. E E NL k e ≥ Γ k e , ∀ k e ∈ K E , (30b) SE k i ≥ S k i , ∀ k i ∈ K I , (30c) a m X k i ∈K I η I mk i + (1 − a m ) X k e ∈K E η E mk e ≤ 1 , ∀ m ∈ M , (30d) a m ∈ { 0 , 1 } , ∀ m ∈ M , (30e) θ ℓ s ∈ [0 , 2 π ] , ∀ s ∈ S , (30f ) where Γ k e and T k i are the QoS requiremen ts for WPT and WIT op erations, resp ectively , while (30d) is the p ow er constrain t at each AP , obtained from (11). Problem (30) is an immensely complex problem due to its mixed-integer and non-con v ex nature. T o solv e this problem, we rst present an autonomous DRL-based solution, follo w ed by a robust . 8 t w o-stage optimization approach that leverages structured con v ex approximations. IV. CTDE MADRL Strategy In this section, w e prop ose a scalable and autonomous learning-based framew ork to solve the non-con v ex optimiza- tion problem dened in ( P 1) . While DRL-based approac hes ha v e shown promise in solving mixed-in teger problems without requiring manual conv exication, the CTCE strat- egy faces a critical scalability b ottleneck in our prop osed system. In particular, the joint optimization of SIMs’ phase shifts and p ow er allo cation creates a global action space with a dimension of M × ( L × S + K + 1) , which gro ws exp onentially with the num b er of APs ( M ) . The high- dimensional action space complicates the learning pro cess and impedes conv ergence. T o address this, we decentralize the action space across the APs, thereb y reducing the dimensionalit y for each individual actor to a more man- ageable lo cal action space of size ( L × S + K + 1) . This distributed learning approach remov es the dimensionality b ottleneck and facilitates eective con v ergence in large- scale netw orks. T o further enhance learning eciency and guaran tee that the agen ts produce feasible outputs, we in tro duce tw o crucial mechanisms: a constraint-satised normalization pro cess to handle the mixed-in teger and b ounded constraints (30 d ) and (30 f ) , and max-min reward scaling to guide the agen ts to sim ultaneously maximize (30) and satisfy (30 a ) , (30 b ) . As a result, these techniques enable the CTDE framew ork to stabilize the learning process, then instan taneously determine optimal and feasible solutions in dynamic large-scale CF-mMIMO SWIPT systems. A. Marko vian-Based Problem T ransformation W e b egin b y transforming the system prop osed in Section II in to a Mark ovian en vironmen t tailored for agents, whic h are the M resource-equipp ed APs. Let t ∈ T denote the time step of the learning interv al. A t each time step t , agen t m observes its lo cal LSFC to all the receivers, which can b e mathematically presented as ϑ m [ t ] ≜ Σ NL [ t − 1] , β ( m, :)[ t ] , (31) where Σ NL [ t − 1] ≜ P k e ∈K E E E NL k e is the sum-HE metric of the previous step and β ( m, :) ≜ { ¯ β i mk } , ∀ m ∈ M is the LSF C observ ed b y agent m . Then, eac h agent m determines its local joint action containing its op eration mo de a m , p ow er allo cation η I ( m, :) ≜ { η I mk i , ∀ k i ∈ K I } , and η E ( m, : ) ≜ { η E mk e , ∀ k e ∈ K E } , and L × S SIM’s PS matrix Φ m ≜ { δ ℓ s , ∀ ℓ ∈ L , ∀ s ∈ S } . How ever, the ranges of v alues of the optimization v ariables are distinct compared to each other. Th us, an execution normalization pro cess should b e carried out appropriately . B. Constraint-Satised Normalization Pro cess W e rst introduce ˘ Π m [ t ] ∈ R 1+ K + L × S ∈ [0 , 1] output after activ ation pro cess from agent m , given by ˘ Π m [ t ] ≜ v ec[˘ a m , ϱ I m , ϱ E m , ∆ m ] , (32) where ϱ I m ≜ { ϱ I mk i , ∀ k i ∈ K I } , ϱ E m ≜ { ϱ E mk e , ∀ k e ∈ K E } , ∆ m ≜ { δ ℓ s , ∀ ℓ ∈ L , ∀ s ∈ S } . W e rst apply a step function to discretize the contin uous v ariable ˘ a m in to a binary decision, where a m = 1 if ˘ a m ≥ 0 . 5 . Then, we implement a normalization step θ ℓ s ≜ 2 π δ ℓ s , thus the constraint (30f) is satised. In addition, in order to satisfy the constraint (30d), we implemen t softmax normalization for each pow er allo cation of AP m . Mathematically sp eaking, η I mk i = exp( ϱ I mk i ) exp X k ′ i ∈ K I ϱ I mk ′ i − 1 , and , η E mk e = exp( ϱ E mk e ) exp X k ′ e ∈ K E ϱ E mk ′ e − 1 , ∀ m ∈ M . (33) Ev en tually , the constraint-satised action of the agent m is mathematically expressed as Π m [ t ] ≜ v ec a m , η I ( m, :) , η E ( m, :) , Φ m . (34) C. Normalized Join t Reward F unction Building up on the closed-form expressions deriv ed in Prop osition 1 and 2, we observe a direct and constructive inuence of F m , ∀ m ∈ M on the ov erall SWIPT p erfor- mance. Particularly , the F rob enius norm of the equiv alen t SIM channel, ∥ F m ∥ F pla ys a critical role in enhancing b oth signal fo cusing and energy delivery . Thus, we incor- p orate the F robenius norm of the SIM-assisted EM wa ve propagation, ∥ F m ∥ F , in to the reward structure alongside with the maximum ob jective and QoS constraints in (30). Mathematically sp eaking r [ t ] ≜ λ r ˜ ∆ HE [ t ] + (1 − λ r ) ˜ Q [ t ] − λ SE , (35) where ∆ HE [ t ] ≜ Σ NL [ t ] − Σ NL [ t − 1] , Q [ t ] ≜ P m ∈M ∥ F m ∥ F , λ r ∈ [0 , 1] is the trade-o parameter to balancing the WPT impro v emen t against SIMs’ EM wa ve b eamforming, λ SE is a p enalty for violating (30c), ˜ ∆ HE [ t ] and ˜ Q [ t ] are the normalized v alues using dynamic min-max tracking. T o handle scaling disparity b etw een tw o distinct v alues, we up date the normalization b ounds at eac h t using: ˜ ∆ HE [ t ] = ∆ HE [ t ] − min ∆ HE max ∆ HE − min ∆ HE , ˜ Q [ t ] = Q [ t ] − min Q max Q − min Q . (36) T o preven t bias v alues and c hanging scales, the min- max thresholds are track ed from the previous step, i.e., min x [ t ] ≜ min(min x [ t − 1] , min x ) and max x [ t ] ≜ min(max x [ t − 1] , max x ) , where x ∈ { ∆ HE , Q } . T o this end, the normalization join t rew ard function serv es a dual purp ose: it stabilizes the learning pattern for impro ved cen tralized learning con v ergence and encourages eac h agent to adaptively execute Θ to enhance SWIPT metrics ov er the learning time. Remark 5. While an y RL en vironmen t must satisfy the Mark o vian prop erty , an inecient designed environmen t ma y not b e equally eective for b oth o-p olicy and on- p olicy trainings, as n umerically shown in [26, Section IV.C]. Ho w ev er, as m ultiple v ariables in the reward (35) are . 9 T ABLE I I I: Complexity comparison across DRL training comp onents T raining Comp onents O-policy MADRL O-p olicy SADRL On-p olicy MADRL On-policy SADRL T otal Neurons M · P A, MA + P C, MA P A, SA + P C, SA M · P A, MA + P C, MA P A, SA + P C, SA Actor F orw ard P ass O ( M · L A, MA · d lo · d la ) O ( L A, SA · d go · d ga ) O ( M · L A, MA · d lo · d la ) O ( L A, SA · d go · d ga ) Critic F orward Pass O ( L C, MA · ( d go + d ga ) 2 ) O ( L C, SA · ( d go + d ga ) 2 ) O ( L C, MA · ( d go + d ga ) 2 ) O ( L C, SA · ( d go + d ga ) 2 ) Critic Propagation O ( P C, MA ) O ( P C, SA ) O ( P C, MA ) O ( P C, SA ) Actor Propagation O ( M · P A, MA ) O ( P A, SA ) O ( M · P A, MA ) O ( P A, SA ) Replay Buer Sampling O ( B e · ( d go + d ga )) O ( B e · ( d go + d ga )) 0 0 T arget Netw ork Update O ( P C, MA + M · P A, MA ) O ( P C, SA + P A, SA ) 0 0 Adv an tage Estimation 0 0 O ( T · d go ) O ( T · d go ) PPO Clipping + Ratio 0 0 O ( T · d la ) O ( T · d ga ) Optimal decision-making post training O ( L A, MA · d lo · d la ) O ( L A, SA · d go · d ga ) O ( L A, MA · d lo · d la ) O ( L A, SA · d go · d ga ) Abbreviations: actor (A), batch size ( B e ), critic (C), global/lo cal action (ga/la), global/local observation (go/lo), m ulti/single-agent (MA/SA) normalized within predened ranges, the resulting reward signal becomes more stable across episo des, contributing to reduced v ariance in p olicy gradient up dates and improv ed con v ergence b ehavior. Consequently , our prop osed Marko- vian environmen t eectively supp orts long-term learning and stability within any centralized training with the CTDE framework. In this framework, each of the M agents indep endently observes its lo cal state (31) and selects its action (32) in a decen tralized manner. During training, a centralized critic lev erages global information, including the joint state and joint actions of all agents. This design enables agen ts to coop eratively learn policies that maximize a global reward, while resp ecting constrain ts in (30). D. Complexity Analysis In this subsection, w e analyze and compare the mo del complexit y of on-p olicy and o-p olicy MADRL and single- agen t SADRL. F or o-p olicy methods, the replay buer stores exp eriences E ≜ [ s [ t ] , a [ t ] , r [ t ] , s [ t + 1]] with a buer length B and batc h size B e . W e denote d lo ≜ 1 + K , d go ≜ 1 + M K , d la ≜ 1 + K + LS , d ga ≜ M d la , the dimensions of the global observ ation, lo cal observ ation, global action, and lo cal action, resp ectively . Utilizing fully- connected DNNs, we denote b y P A, · and P C, · the num ber of neurons in the actor and critic netw orks, resp ectively . T able I I I provides a comprehensive complexity comparison across all DRL frameworks. V. T w o-Phrase Robust Join t AP Mo de Selection and P o w er Control Design In this section, w e introduce a robust optimization sc heme based on the conv ex optimization metho d to serve as a comparison b enchmark for ev aluating our prop osed CTDE autonomous learning framework. W e selected the com bined heuristic and SCA approach for its tractabilit y , strong theoretical con v ergence guaran tees, and seamless in tegration with standard conv ex optimization solvers like CVX and MOSEK. How ever, applying them necessitates extensiv e conv ex reformulations and approximations, which results in high computational complexit y , esp ecially as the net w ork scales. Therefore, a direct comparison is essen tial to ev aluate the p erformance-complexity trade-o, assessing whether the signican t reduction in computational o v erhead oered by the MADRL-based CTDE framework justies an y p otential p erformance gap against the con v ex-based solution. W e provide a step-by-step pro cedure to conv exify the constraints in (30), and a comprehensive numerical comparison betw een the conv ex-based solution and the DRL-based approach is presented in Section VI-C. A. Heuristic Phase Shift Design (HPS) F rom the closed-form in Prop osition 2, w e notice that the SIM’s PS directly aects the trace v alue of the SIM-aected c hannel with its Hermitian, which serv es as a dominant term in the expression. Thus, we heuristically optimize the PSs b y solving the problem: max Θ m f ( Θ ) = tr( F m F † m ) . (37) Algorithm 1 provides the lay er-by-la yer heuristic scheme while the complexit y of the heuristic sc heme is O ( M C S L 2 ) . Notably , the eectiveness of the heuristic searc h is prop or- tional to the heuristic iteration C , as a higher C allows for extensiv e explorations of the solution space. Thus, C serv es as a trade-o parameter b etw een computational eciency and optimization p erformance. B. Joint AP-mo de Selection and Po wer Allo cation (JAPP A) Once the SIM’s PS are optimally determined, the joint AP-mo de selection and p ow er allo cation problem is then solv ed using a SCA metho d. F or subsequen t con vexify steps, w e rst reformulate the constrain t (30b). T o expand the logistic function Λ Q k e , w e in troduce Q k e ≥ Ξ( ˜ Γ k e ) , where ˜ Γ k e = (1 − Ω)Γ k e + ϕ Ω , where Ξ( ˜ Γ k e ) = χ − 1 ξ ϕ − ˜ Γ k e ˜ Γ k e , whic h is the inv erse function of the logistic function. Then, w e dene ϵ = { ϵ k e ≥ 0 , k e ∈ K E } where ϵ k e is an auxiliary v ariable for ˜ Γ k e , w e obtain: ˜ ϵ k e ≜ (1 − Ω) ϵ k e + ϕ Ω . Subsequen tly , we transform the binary constraint (30e) in to con tin uous counterpart [36] a m ∈ { 0 , 1 } ≡ a m − a 2 m ≥ 0 , a m ∈ [0 , 1] . (38) T o accelerate the conv ergence sp eed, we relax (38) in to the ob jectiv e, and then transform the non-conv ex a 2 m . Herein, w e use the concav e low er b ound, x 2 ≥ x 0 (2 x − x 0 ) , in whic h we resp ectiv ely replace a 2 m , a ( n ) m , a m b y x 2 , x 0 , x , and . 10 Algorithm 1 Lay er-b y-lay er heuristic search for L -la y er SIM 1: Initiate SIM with sto chastic Φ m,ℓ in range of [0 , 2 π ) , ∀ ℓ ∈ L , ∀ m ∈ M 2: for m = 1 to M : 3: for ℓ = 1 to L : 4: for it = 1 to C : 5: Generate Φ mℓ and compute f ( it ) according to (37) 6: Store Φ mℓ ( it ) , ob j( it ) and its index 7: Search the maximum ob j( it ∗ ) v alue and its index it ∗ 8: Assign it ∗ -th Φ mℓ as optimal ( Φ mℓ ) ∗ 9: Mov e to ℓ + 1 lay er until the last lay er 10: Mo v e to m + 1 AP until the last AP 11: return ( Θ m ) ∗ ≜ { ( Φ mℓ ) ∗ , ∀ m ∈ M , ℓ ∈ L} . sup erscript ( n ) denotes the v alue of the inv olving v ariable pro duced after ( n − 1) iterations ( n ≥ 1 ) [41]. Given xed Θ conguration after the rst heuristic phrase, we reform ulate (30) as max a , η I , η E , e X k e ∈K E ϵ k e − λ pen X m ∈M a m − a ( n ) m 2 a m − a ( n ) m (39a) s.t. Q k e ≥ Ξ( ˜ e k e ) , ∀ k e ∈ K E , (39b) SE k i ≥ S k i , ∀ k i ∈ K I , (39c) ϵ k e ≥ Γ k e , ∀ k e ∈ K E , (39d) X k i ∈K I η I mk i ≤ a ( n ) m 2 a m − a ( n ) m , ∀ m ∈ M , (39e) X k e ∈K E η E mk e ≤ 1 − a 2 m , ∀ m ∈ M , (39f ) 0 ≤ a m ≤ 1 , ∀ m ∈ M . (39g) W e rst notice that the non-conv ex nature of (39b) is due to the pro duct of the tw o v ariables, i.e. a m η I mk i and a m η E mk e , and the in v erse function Ξ( ˜ Γ k e ) . T o address the non-con v ex terms, we use the upp er b ound of Ξ(˜ ϵ k e ) as Ξ(˜ ϵ k e ) ≤ χ − 1 ξ ln ϕ − ˜ ϵ k e ˜ ϵ ( n ) k e − ˜ ϵ k e − ˜ ϵ ( n ) k e ˜ ϵ ( n ) k e ≜ ˜ Ξ(˜ ϵ k e ) , (40) where ˜ ϵ ( n ) k e is the ( n − 1) -th iteration of ˜ ϵ k e T o this end, we recast the constraint (39b) as ( τ c − τ ) σ 2 n ρ d X m ∈M η E mk e ¯ d mk e + X k ′ e ∈P k \ k e η E mk ′ e ¯ e m,k e k ′ e + X k ′ e / ∈P k \ k e η E mk ′ e ¯ f m,k e k ′ e + ( τ c − τ ) σ 2 n ρ d X m ∈M a m Z mk e + ( τ c − τ ) σ 2 n ≥ ˜ Ξ(˜ ϵ k e ) , (41) where Z mk e = X k i ∈K I η I mk i (1 / N ) ¯ h m,k e − η E mk e ¯ d m,k e − X k ′ e ∈P k \ k e η E mk ′ e ¯ e m,k e k ′ e − X k ′ e / ∈P k \ k e η E mk ′ e ¯ f m,k e k ′ e . (42) Using 4 xy = ( x + y ) 2 − ( x − y ) 2 , we further recast (41) as 4( τ c − τ ) σ 2 n ρ d X m ∈M η E mk e ¯ d mk e + X k ′ e ∈P k \ k e η E mk ′ e ¯ e m,k e k ′ e + X k ′ e / ∈P k \ k e η E mk ′ e ¯ f m,k e k ′ e + ( τ c − τ ) σ 2 n ρ d X m ∈M ( a m + Z mk e ) 2 + 4( τ c − τ ) σ 2 n ≥ 4 ˜ Ξ(˜ ϵ k e ) + ( τ c − τ ) σ 2 n ρ d X m ∈M ( a m − Z mk e ) 2 . (43) The abov e inequalit y is still non-conv ex, due to the presence of ( a m + Z mk e ) 2 . Therefore, using SCA, w e get 4( τ c − τ ) σ 2 n ρ d X m ∈M η E mk e ¯ d mk e + X k ′ e ∈P k \ k e η E mk ′ e ¯ e m,k e k ′ e + X k ′ e / ∈P k \ k e η E mk ′ e ¯ f m,k e k ′ e + 4( τ c − τ ) σ 2 n + ( τ c − τ ) σ 2 n ρ d × X m ∈M a ( n ) m + Z ( n ) mk e 2 a m + Z mk e − a ( n ) m − Z ( n ) mk e ≥ 4 ˜ Ξ(˜ ϵ k e ) + ( τ c − τ ) σ 2 n ρ d X m ∈M ( a m − Z mk e ) 2 , (44) where we used x 2 ≥ x 0 (2 x − x 0 ) and replaced x and x 0 b y a m + Z mj and a ( n ) m + Z ( n ) mj , resp ec tiv ely . T o this end, (39c) is equiv alent to ρ d q 2 k i T k i ≥ ρ d X k ′ i ∈P k \ k i q 2 k ′ i + ρ d X m ∈M X k ′ i ∈K I a m η I mk ′ i ¯ e mk i + ρ d X m ∈M X k e ∈K E η E mk e ¯ e mk i − ρ d X m ∈M X k e ∈K E a m η E mk e ¯ e mk i + 1 ≥ ρ d X k ′ i ∈P k \ k i q 2 k ′ i + ρ d X m ∈M X k ′ i ∈K I a m η I mk ′ i ¯ e mk i + ρ d X m ∈M X k e ∈K E a m ω m ¯ e mk i + 1 , (45) where we hav e replaced q k i ≜ P m ∈M α ZF mk i q a m η I mk i , ∀ k i ∈ K I , ω m ≜ η I m − η E m , η I m ≜ P k ′ i ∈K I η I mk ′ i , and η E m ≜ P k e ∈K E η E mk e . T o conv exify q k i , we dene its ( n − 1 )- th iteration, i.e., q ( n ) k i ≜ P m ∈M α ZF mk i q a ( n ) m η I ( n ) mk i , then apply x 2 ≥ x 0 (2 x − x 0 ) for x ≜ q k i and x 0 ≜ q ( n ) k i to obtain ρ d q ( n ) k i T k i 2 q k i − q ( n ) k i ≥ 1 + ρ d X k ′ i ∈P k \ k i q 2 k ′ i + ρ d X m ∈M a m ω m ¯ e mk i + ρ d X m ∈M η E m ¯ e mk i . (46) The abov e inequalit y is still non-conv ex due to a m ω m in the righ t-hand side, thus w e use 4 a m ω m = ( a m + ω m ) 2 − ( a m − ω m ) 2 and then utilize x 2 ≥ x 0 (2 x − x 0 ) , for x ≜ a m − ω m and x 0 ≜ a ( n ) m − ω ( n ) m to get the following conv ex constrain t 4 ρ d q ( n ) k i T k i 2 q k i − q ( n ) k i + ρ d X m ∈M ¯ e mk i a ( n ) m − ω ( n ) m × 2 a m − ω m − a ( n ) m − ω ( n ) m ≥ 4 + 4 ρ d X k ′ i ∈P k \ k i q k ′ i + ρ d X m ∈M ¯ e mk i ( a m + ω m ) 2 + 4 ρ d X m ∈M η E m ¯ e mk i . (47) The optimization problem (39) is now recast as . 11 Algorithm 2 Joint AP mode op eration and p ow er allo cation 1: Initialize: n = 0 , λ pen > 1 , random initial p oint e x (0) ∈ b F . 2: rep eat 3: Up date n = n + 1 4: Solv e (48) to obtain its optimal solution e x ∗ 5: Up date e x ( n ) = e x ∗ 6: until con v ergence max a , η I , η E , e X k e ∈K E ϵ k e − λ pen X m ∈M a m − a ( n ) m 2 a m − a ( n ) m (48a) s.t. (44) , ∀ k e ∈ K E , (48b) (47) , ∀ k i ∈ K I , (48c) (39d) − (39g) . (48d) Problem (48) is conv ex, and th us it can b e solved using CVX. In Algorithm 2, w e outline the main steps to solv e problem (48), where e x ≜ { a , η I , η E , e } and b F ≜ { (48b) , (48c) , (48d) } are con v ex feasible sets. Starting from a random p oint e x ∈ b F , we solv e (48) to obtain its optimal solution e x ∗ , and use e x ∗ as an initial p oint in the next iteration. The pro of of this conv ergence prop ert y follo ws similar steps as the pro of in [42, Prop osition 2], and hence, is omitted. Complexit y analysis: The relaxed optimization prob- lem (48) each requires a computational complexit y of O ( p A l + A q ( A v + A l + A q )( A v ) 2 ) , p er iteration [41], where A v represen ts the n um ber of real-v alued scalar v ariables, while A l and A q denote the num b er of linear and quadratic constrain ts, resp ectively . F or ease of presentation, if we let K E = K I , w e ha ve A v = M ( K e + K i + 1) + K e , A l = 2 M + K e , and A q = M + K e + K i . VI. Numerical Results W e present numerical results to ev aluate the p erfor- mance of the SIM-assisted CF-mMIMO SWIPT system. W e consider that the APs, K i = 3 IRs and K e = 4 ERs, are randomly distributed in a square of 0 . 1 × 0 . 1 km 2 . The heigh ts of the SIM-attac hed APs and the receiv ers are 15 m, and 1.65 m, respectively . W e set τ c = 200 , σ 2 n = − 92 dBm, ρ d = 1 W and ρ u = 0 . 2 W. In addition, we set the NLEH mo del’s parameters as ξ = 150 , χ = 0 . 024 , and = 0 . 024 W [29], [40]. The LSFCs are generated following the three-slope propagation model from [38]. Shado w fading follo ws a log-normal distribution with a standard deviation of 8 dB. W e denote the num b er of symbols for the UL c hannel estimation phase as τ = K I + K I − PRF , where PRF ≜ PRF I + PRF E is the pilot reuse factor, which is clearly explained in [40]. Considering the vulnerability of information transmission to PC [43], w e assume that τ > K I and then assign the rst K I out of the τ orthogonal pilot sequences to the K I IRs as a priority (i.e., PRF I = 0 ), with the remaining ( τ − K I ) pilot sequences then allo cated to the ERs. W e denote the SIM’s PS b enchmarks that adopt sto chastic PS, equal PS, and heuristic PS p er lay er T ABLE IV: V alues of H mℓ v ersus v arious SIM thic knesses 10 λ 8 λ 6 λ 5 λ 4 λ 3 λ S = 40 0.9985 0.9993 0.9961 1.0351 1.0113 1.1653 S = 36 0.9966 0.9986 0.9979 0.9989 0.9996 1.1128 S = 32 0.9956 0.9982 0.9992 0.9976 0.9906 1.1222 S = 28 0.9954 0.9981 0.9992 0.9976 0.9882 1.0952 as RDPS, EQPS [44], and HPS [1], resp ectively . W e also incorp orate the lo w-complexity random AP mo de operation with equal p ow er allo cation (RAPEP A) as a b enc hmark to ev aluate the eectiv eness of the prop osed optimiza- tion algorithms. T o ensure a fair comparison b etw een the prop osed JAPP A and RAPEP A, the n um b er of I-APs and E-APs in RAPEP A is set to be aligned with the output of JAPP A in each netw ork realization. Mathe- matically , let M JAPP A I and M JAPP A E denote the num b er of APs designated as I-APs and E-APs b y the JAPP A sc heme, resp ectiv ely , where M = M JAPP A I + M JAPP A E . W e denote the num b er of I-APs and E-APs designated b y the RAPEP A sc heme as M RAPEP A I and M RAPEP A E , which sto c hastically sample from a discrete uniform distribution as M RAPEP A I ∼ U M JAPP A I − δ, M JAPP A I + δ and M RAPEP A E ≜ M − M RAPEP A I , where δ is a small in teger threshold to allo w sligh t v ariations in the assignmen t. The p ow er allo cation in RAPEP A is then set equally for all M . A. Impact of SIM Settings on SWIPT CF-mMIMO P erfor- mance In this section, w e analyze the impact of SIM parameters on the minim um SE and sum-HE p erformance in a SIM- assisted CF-mMIMO SWIPT system. The eectiveness of EM wa ve manipulation b y SIMs is go v erned by multiple fac- tors, including the metasurface thic kness T SIM , the n um ber of lay ers ( L ), the num b er of reectiv e elements p er lay er ( N ), and the geometric design of the SIMs. Giv en that these parameters directly inuence SWIPT p erformance, their optimal settings must be carefully ev aluated based on our prop osed CF-mMIMO SWIPT framework [7], [18]. T o ensure our mo del remains physically consistent with the passiv e nature of the SIM-assisted propagation, w e strictly enforce the sp ectral norm constraint ∥ H mℓ ∥ < 1 for every settings of the SIMs. This condition reects the ph ysical principle that the received signal energy cannot exceed the transmitted signal energy [21]. W e set up the lay out of the PS elements p er metasurface as S y × S z where S z = 4 . The spacing b etw een adjacent an tennas or elements is λ/ 2 . T able IV presents the v alues of H mℓ < 1 for the dierent SIM thicknesses considered. F or instance, as T SIM = 3 λ and S = 40 mak e H mℓ > 1 for any l ∈ L , w e exclude that parameter’s v alue in the n umerical simulations. Figure 3 and 4 show case the impact of SIMs thickness on the CF-mMIMO SWIPT p erformance. In particular, T SIM directly aects the adjacent metasurface spacing d ℓ s, ˘ s ≜ T SIM /L , which provides additional DoF for the EM w a v e manipulation. As the d ℓ s, ˘ s expands, the propagation deteriorates due to the rank deciency of the propagation matrix F m . Under the RDPS scheme, the minimum SE and sum-HE degrade b y 16 % and 76 %, respectively , as . 12 Fig. 3: Minimum SE v ersus T SIM ( S = 36 , M = 10 , N = 20 , PRF I = 0 , PRF I = 3 ). Fig. 4: Sum-HE versus T SIM ( S = 36 , M = 10 , N = 20 , PRF I = 0 , PRF I = 3 ). Fig. 5: Minimum SE v ersus S ( T SIM = 4 λ , M = 10 , PRF I = 0 , PRF I = 3 ). L increases. In contrast, the sub-optimal EQPS scheme ac hiev es approximately 16 % and 105 % gains in WIT and WPT p erformance, resp ectively , as L increases. This can b e explain that the randomly congured RDPS acts as a destructiv e propagating medium. With eac h additional la y er, the signal undergo es further detrimental scattering and attenuation, destro ying coherent b eamforming gain. Con v ersely , EQPS b enc hmark shows impro ved performance as L increases since equal phase shifts conguration pre- serv es constructive forw ard signal propagation and leverages the array gain of the stack ed architecture. The numerical results highligh t the critical role of T SIM , but without an appropriate PS conguration, propagation attenuation o ccurs regardless of the c hosen thickness settings. Figures 5 and 6 show the impact of SIM PSs conguration sc hemes on minim um SE and sum-HE metrics. Under ph ysical constraints, an insucient n um ber of elements p er lay er, N , leads to rank deciency in the propagation c hannel, degrading SWIPT p erformance. F or L = 5 and S = 36 , the HPS scheme yields minimum SE and sum- HE v alues that are 1 . 05 and 1 . 52 times greater than those ac hiev ed by the EQPS sc heme, resp ectively . By leveraging heuristic PS search, w e can eectively reduce the num b er of SIM lay ers and PS elements while main taining optimal DoF, thereb y minimizing propagation attenuation and lo w ering computational and hardw are requiremen ts. It is clear that SIMs with m ultiple lay ers outp erform RISs in terms of SE and HE metrics. Figure 7 shows the impact of the Ricean factor on the a v erage sum-HE in the SWIPT scenario. When M = 10 , the a v erage sum‑HE increases from approximately 0.7 m W for κ = 2 to ab out 1.05 m W for κ = 12 , corresp onding to a tw o-fold improv ement. As the num b er of deplo y ed APs grows, this upw ard trend p ersists, with higher Ricean factors consistently yielding larger harvested energy and pro viding gains on the order of 30% when κ magnitude increases from 2 to 12. These results indicate that the harv ested energy at the receiv ers is highly sensitive to the Ricean factor ( κ ), whic h aligns with the strong dep endence of the rectied p ow er on the received signal amplitude. This increase is primarily due to the more pronounced LoS comp onent asso ciated with higher κ v alues. Figure 8 illustrates the impact of the Ricean factor on the achiev able minim um SE. F or denser AP deploymen t, the b enet of larger κ b ecomes sligh tly more pronounced. A t M = 48 , the minim um SE increases from around 16.2 to 16.6 bit/s/Hz when κ gro ws from 2 to 12, which corresp onds to a gain of almost 3%. Thus, the minim um SE exhibits an upw ard trend as the Ricean factor increases, but the sensitivit y is more mo derate than that of the sum‑HE metric. B. Numerical Ev aluation for DRL F ramew orks W e adopt the preliminaries of deep deterministic p olicy gradien t (DDPG) [45] and pro ximal policy optimization (PPO) [46] as represen tativ e algorithms for the o-p olicy and on-p olicy learning strategies, resp ectiv ely . W e deter- mine the hyper-parameters for the training pro cess that t the b est with our studied systems through a trial- and-error process. The critic netw ork is made up of t w o hidden lay ers (with 1028 and 512 no des), while the actor net w ork includes three hidden la y ers (with 1028, 512, and 256 no des). The learning rates for the actor and critic net w ork are 1e-4 and 5e-3, resp ectively . W e train b oth DDPG and PPO mechanisms for 5,000 episo des and 300 steps p er episo de. F or the DDPG method, we set the batc h size B e = 128 , discount factor ¯ γ = 0 . 99 , and buer length 1 e 6 . F or the PPO metho d, PPO clipping 0 . 15 and generalized adv antage estimation rate 0 . 995 are applied to ensure learning stability and accurate action’s v alue. The episo dic exploration rate and the up date of the target netw ork are 1 e − 4 . Additionally , ReLu activ ation is implemen ted for all hidden lay ers and critic’s output lay er, while T anh activ ation is applied for the actor’s output lay er. Ev en tually , gradient clipping 0 . 5 is set to prev en t gradient explosion and unstable training. Figure 9 illustrates the impact of the normalized reward function on the critic loss patterns, which directly reects the stability of the long-term return during the learning progress. In this regard, we simply set the baseline step rew ard r base [ t ] = λ r ∆ HE + (1 − λ r ) Q [ t ] − λ SE without the max-min normalization pro cedure in (36). Without rew ard scaling, the critic’s loss sho w ed large uctuations during the initial episo des b ecause the long-term target returns had high v ariance. Without stable backpropagation, the critic . 13 Fig. 6: Sum-HE v ersus S ( T SIM = 4 λ , M = 10 , PRF I = 0 , PRF I = 3 ). Fig. 7: The impact of Ricean factors on the sum-HE ( M N = 480 , S = 36 , L = 2 , PRF I = 0 , PRF I = 3 ). Fig. 8: The impact of Ricean factors on the minim um SE ( M N = 480 , S = 36 , L = 2 , PRF I = 0 , PRF I = 3 ). Fig. 9: Impact of reward structures onto the critic loss patterns ( S k i = 12 , M = 20 , LRC = 1 e − 4 , LRA = 5 e − 5 ). Fig. 10: The impact of hyperparameters on the learning pattern ( S k i = 12 , M = 20 , LRC = 1 e − 4 , LRA = 5 e − 5 ). Fig. 11: The impact of joint lo cal actions on the reward ( S k i = 12 , M = 20 , LRC = 1 e − 4 , LRA = 5 e − 5 , ¯ γ = 0 . 9 , B = 256 ). loss with non-scaling reward quic kly collapses to near zero, indicating that the agen t fails to learn entirely b ecause the feedbac k signal b ecomes numerically problematic. By appropriately scaling the reward to a suitable range, the returns and adv an tage computations are kept within a consisten t stable regime leading to conv ergent learning b ehavior. Figure 10 illustrates the impact of the batc h size B , used in DDPG, and the expected long-term reward discount factor ¯ γ , used in b oth DDPG and PPO frameworks. While ¯ γ go v erns the trade-o b etw een short-term and long-term rew ards, B inuences the stabilit y and eciency of gradien t up dates during learning. W e rst observe that the learning b ehavior in the initial phase of DDPG tends to b e less stable compared to PPO. This instabilit y can b e attributed to the sto chastic nature of exp erience replay and the Ornstein- Uhlen b ec k exploration strategy , whic h aim to explore the solution space b efore transitioning to exploitation. In con trast, PPO exhibits more stable learning in the early stages due to their use of latest tra jectory tuples, whic h constrains abrupt p olicy changes and promotes smo other con v ergence. F or MADDPG and MAPPO schemes, a high discoun t factor of ¯ γ = 0 . 99 ma y not b e ideal for episo dic accum ulated reward structures, even with large sampling batc hes. Although this setting can initially ac hieve the highest rew ard in early episo des, it tends to make the T ABLE V: T raining time of the learning-based solutions (sec- onds p er episo de) Benchmarks Number of APs ( M ) 10 20 30 40 MAPPO 35.09 54.88 61.78 74.26 MADDPG 31.24 34.19 37.97 45.26 SAPPO 23.58 24.46 26.19 28.30 SADDPG 21.38 22.39 23.47 24.03 T ABLE VI: Inference/execution time b etw een learning-based and conv ex-based solutions (seconds) Benchmarks Number of APs ( M ) 10 20 30 40 JAPP A 193.17 356.23 582.41 826.12 MAPPO 0.021 0.026 0.033 0.036 MADDPG 0.021 0.022 0.027 0.033 SAPPO 0.073 0.074 0.077 0.080 SADDPG 0.060 0.061 0.065 0.066 learned p olicies excessively prioritize distant future returns. This can result in p o or gradients and cause the p olicies to con v erge tow ards sub-optimal solutions T o this end, tw o scenarios for ev aluating the CTDE franew ork are considered: (i) eac h AP optimizes its full local action as dened in (32), namely -Join t A ction, and (ii) each AP only optimizes the SIM congurations, while RAPEP A is executed by the backhaul CPU (-SIM). Figure 11 provides the numerical results of -Join t Action and -SIM for the CTDE and CTCE strategies. F or both on- and o-p olicy . 14 Iterations 0 200 400 600 800 1000 Ob jective V alue -200 -150 -100 -50 0 M = 40 M = 30 M = 20 Fig. 12: The conv ergence pattern of the JAPP A solution ( N = 480 / M , S = 36 , L = 2 , S k i = 10 [bit/s/Hz], K = 3 , J = 4 ). mec hanisms, the MA framew ork reac hes its optimal p olicies after 3,000 episo des, while the SA counterparts require 4,000 episo des to reach the phase of reward exploitation since single agent suers from limited observ ability , making it c hallenging to explore the join t action space eectiv ely and th us requiring more episo des to conv erge to stable p olicies. In addition, the reward increasing trend is insignicant for b oth CTCE mechanisms. This adv an tage can b e attributed to the signicantly large dimensions of d go and d ga spaces in the SA setting, which ma y hinder the learning eciency due to the curse of dimensionality and the absence of co ordinated learning signals. As a result, SAPPO struggles due to limited exp erience reuse, high p olicy v ariance, and p o or visibility in large dimensions, while SADDPG slightly b enets from stabilized learning through experience replay , making it more resilient to complexit y . Moreov er, -Joint A ction ac hieves approximately tw o-fold improv ement in episo de-accumulated reward compared to -SIM, a v eraged across CTDE settings. How ever, optimizing only -SIM yields more stable con v ergence and consistently satises sum-HE under the SE constraint. This demonstrates that optimizing SIMs’ PS is crucial, as it noticeably enhances p erformance in CF-mMIMO SWIPT systems. T able V compares the av erage training time p er episo de for the learning-based frameworks as the num b er of APs scales. W e observ e that the CTCE schemes, i.e., SADDPG and SAPPO, exhibit faster training times compared to their CTDE counterparts, MADDPG and MAPPO. This is b ecause the CTCE framework trains a single pair of global actor-critic netw orks, whereas MA frameworks correspond- ingly update M actor netw orks, in tro ducing signicant computational ov erhead from managing multiple optimiz- ers and gradient backpropagations. Among the CTDE framew orks, MAPPO requires signicantly longer training time than MADDPG due to its on-p olicy nature, which in v olv es computationally in tensive calculations for GAE factor and entrop y regularization, while the deterministic single-gradien t updates of the o-p olicy MADDPG require a simpler back-propagation pro cess [26]. T able VI illustrates the online inference (execution) time of the trained DRL mo dels against the con v ex-based JAPP A b enchmark. The main adv antages of the learning- based solutions compared to their conv ex-based counter- parts are their abilit y to make instantaneous decisions after obtaining the optimal parameterized models. The latency in JAPP A arises from its nature to iterate ov er all high-dimensional SCA lo ops un til conv ergence. In addition, while SA schemes exhibit faster training times, the MA sc hemes achiev e sup erior inference speed due to the parallel distributed execution inherent to the CTDE strategy , where M APs p erform inference on their lo cal ( L × S + K + 1) - dimensional solutions, simultaneously enabled by smaller input and action dimensions p er actor netw ork, as describ ed in details in Section IV. C. Performance Comparison Across Optimization Metho ds In this subsection, w e present numerical results compar- ing the DRL-based and con v ex-based solutions for enhanc- ing CF-mMIMO SWIPT p erformance under the physical SIM settings describ ed in Section VI-A. After training, the learned p olicies are directly used to determine the optimal solutions, and the p erformance is av eraged ov er multiple net w ork realizations. W e choose to n umerically ev aluate MADDPG and SADDPG as represen tativ es of the CTDE and CTCE strategies, resp ectively , giv en the comparable SWIPT p erformance observed b etw een the DDPG and PPO mec hanisms. Figure 12 shows the con v ergence b ehavior of the JAPP A solution across scalable netw ork setups. F or a fair compar- isons b etw een conv ex-based and learning-based solutions, w e initialize the same random seed (100) in b oth PYTHON and MA TLAB simulations so that the system parameters are iden tically generated b efore the optimization b ench- marks b egin. The p enalty term to satisfy the binary AP mo de selection constraints is initialized as λ pen = 10 . In general, JAPP A is able to provide near-optimal solutions with maximum achiev able HE gain p er ER for all expanding scenarios. W e observ e that with a larger n um ber of deplo yed APs, the con vex-based solutions con verge faster due to an increasing num b er of serving E-APs to achiev e the maxim um sum-HE gains while the minimum SE threshold is satised. Conv ersely , a smaller num ber of APs ( M = 20 ) decreases the computational complexity p er iteration but induces longer execution time to allo cate adequate num b er of E-APs p er scenario setup. Overall, the con vex-based baseline is robust, though its scalabilit y can b ecome a b ottlenec k in larger deploymen ts. Figure 13 sho ws ho w dieren t optimization schemes aect sum-HE under v arying SE QoS lev els. Joint optimization enables op eration in the upp er region of the logistic har- v esting curv e (27), whereas RAPEP A underp erforms due to p o or AP-receiver matching. As SE k i increases, more I- APs are assigned, reducing sum-HE. How ever, integrating JAPP A with a 5-lay er SIM yields an extra 12 m W gain . 15 Fig. 13: A verage sum-HE versus S k i ( S = 36 , M = 30 ). Fig. 14: Minimum SE versus M ( Γ k e = 0 . 01 m W, S k i = 15 bit/s/Hz). Fig. 15: A v erage sum-HE versus M ( Γ k e = 0 . 01 m W, S k i = 15 bit/s/Hz). ev en at S k i = 18 bit/s/Hz. In con trast, MADDPG and SADDPG struggle b eyond S k i ≥ 18 due to their sensitivit y to p enalty terms λ SE , which destabilize reward signals and hinder training. Figure 14 illustrates the performance of the prop osed so- lutions versus M in terms of the minim um SE metric. Under a practical QoS requirement of SE k i = 12 bit/s/Hz, the DRL-based MADDPG and SADDPG demonstrate strong univ ersal approximation capabilit y , with sligh tly lo w er min- SE v alues compared to the JAPP A. This can b e attributed to the DRL agents fo cusing smo othly on maximizing the sum-HE, as reward stability is enhanced by not violating the SE constrain t λ SE to o frequently during training. Nev ertheless, MADDPG outp erforms SADDPG with a signican t SE gain of 15 . 38% , v alidating the eectiveness of the prop osed CTDE framew ork. Although JAPP A-HPS incurs the highest computational cost, it achiev es a 125% impro v emen t ov er RAPEP A-EQPS, which represen ts the lo w est-complexit y b enchmark. Figure 15 illustrates the WPT p erformance across v arious M v alues. A slight drop in sum-HE app ears for M ≥ 40 due to few er antennas per AP , though this eect is minor compared to [28], [29] thanks to SIM-based EM wa ve b eamforming. P erformance gains from SIMs grow with more la y ers: at M = 30 , the v e-la yer JAPP A-EQPS outperforms the tw o-lay er version by 35.9%. The o-p olicy CTDE also p erforms well, closely tracking the conv ex b enchmark and surpassing the cen tralized SADDPG by 30.77%. With a target S k i = 12 bit/s/Hz, DRL-based metho ds eectively manage p enalty rewards, ensuring stable exploration and episo dic optimization. VI I. Conclusion W e prop osed the CF-mMIMO SWIPT systems enhanced with SIMs, supp orted by extensiv e ev aluation of v arious DRL-based algorithms. Closed-form expressions for the ergo dic SE and av erage HE were deriv ed to characterize the system p erformance. T o address the high-dimensionalit y of the join t optimization problem and the non-con v ex nature of SWIPT formulations, we introduced a Marko vian envi- ronmen t with pre-pro cessing approaches and a normalized join t reward function to satisfy the non-con v ex constrain ts while enhance the distributed learning mechanisms. A t wo- phase conv ex-based optimization scheme was also dev elop ed to serve as a traceability and robust b enc hmark for as- sessing DRL eectiveness. Through numerical ev aluations, w e inv estigated b oth the limitations of conv entional cen- tralized, whether heuristic, SCA- or DRL-based, optimiza- tion schemes and the adv antages of the prop osed CTDE framew ork in mitigating these drawbac ks. Sp ecically , the DRL-based CTDE metho ds demonstrates sup erior ability to globally determine optimized sum-HE without relying on complex conv ex approximations p ost-training and eec- tiv ely av oid sub-optimal conv ergence caused by the curse of dimensionality inherent in fully centralized DRL-based optimization. F uture w ork will extend the prop osed CTDE-MADRL framew ork to near-eld SWIPT, where near-eld propa- gation leads to strongly geometry-dep enden t channel re- sp onses [47]. This extension primarily aects the channel mo deling and the Marko vian environmen t design, while the o v erall CTDE-MADRL algorithm remains applicable. In con trast, for full-duplex SWIPT, additional self-interference and cross-link in terference terms arise in b oth UL and DL. As a result, the asso ciated optimization becomes signican tly more challenging, motiv ating the developmen t of interference-a w are problem formulations and enhanced learning-based solution designs. Another imp ortant direc- tion for future research is to incorp orate the eects of c hannel aging in to the prop osed system mo del and to further v alidate the learning b ehavior and robustness of the CTDE framework under suc h CSI mismatch. App endix A Pro of of (17) Giv en ˆ W I , ◦ m = E ˆ G I m † ˆ G I m , where ˆ G I m ∈ C N × K I ≜ ˆ g I mk i , ∀ k i ∈ K I , with ˆ g I mk i ∈ C N × 1 distributed as ˆ g I mk i ∼ C N ¯ g I mk i , Σ ˆ g I mk i , we derive ˆ W I , ◦ m k i ,k i as = E ¯ g I mk i + ˜ ˆ g I mk i 2 ( a ) = E ¯ g I mk i 2 + √ τ ρ u ¯ β i mk F † m F m A mki ( b ) ≈ κ ¯ β I mk i ( z I mk i ) † F m F † m z I mk ′ i + ¯ β I mk i , (49) where ˜ ˆ g I mk i ∼ C N 0 , Σ ˆ g I mk i is the NLoS comp onent of ˆ g I mk i , (a) exploits the indep endence prop erty b etw een the . 16 LoS and NLoS comp onents, and (b) is obtained due to the negligible noise p ow er σ 2 n (in W atts) in the second term of the denominator of A mk i . Then, D I m ∈ R K I × K I in (18) is dened with the ( k i , k i ) -th element D I m k i ,k i ≜ ¯ β I mk i . App endix B Pro of of Prop osition 1 W e note that the deriv ations for DS k i , BU k i and EUI k i k e in (24) follow a similar pro cedure as in [1], [41]. Due to the consideration of PPZF preco ding, the computation of (22c) adopts dierent approach. T o this end, w e obtain X k ′ i ∈K I \ k i E | IUI k i k i ′ | 2 (50) = X k ′ i ∈K I \ k i E X m ∈M q ρ d a m η I mk ′ i ( ˆ g I mk i ) † w ZF I ,mk ′ i 2 + X k ′ i ∈K I \ k i E X m ∈M q ρ d a m η I mk ′ i ( ˜ g I mk i ) † w ZF I ,mk ′ i 2 ( a ) = X k ′ i ∈P k \ k i X m ∈M α ZF mk ′ i q a m ρ d η I mk ′ i 2 + X k ′ i ∈K I \ k i X m ∈M a m ρ d η I mk ′ i ¯ β I mk i tr( F m F † m ) − γ I mk i , where in (a), the rst term follows from that the ZF suppresses interference tow ards all the IRs except for ones sharing the same pilot, while the second term exploits [1, App endix B]. Then, we hav e E | BU k i | 2 = X m ∈M a m ρ d η I mk i E n ˆ g I mk i + ˜ g I mk i † w ZF I ,mk i 2 o − E n ˆ g I mk i + ˜ g I mk i † w ZF I ,mk i 2 o = X m ∈M a m ρ d η I mk i ¯ β I mk i tr( F m F † m ) − α ZF mk i . (51) Subsequen tly , exploiting the orthogonality b etw een g I mk i and normalized w PMRT E ,mk e due to PPZF preco ding, w e further obtain X k e ∈K E E {| EUI k i k e | 2 } = X k e ∈K E X m ∈M a m ρ d η E mk e × ¯ β I mk i tr( F m F † m ) − γ I mk i . (52) T o this end, by substituting the nal results for, (50), (51), and (52) into (24), we get the desired result in (25). App endix C Pro of of Prop osition 2 The proof of Proposition 2 applies a similar methodology as in App endix B, with the dierence lying in the analysis of the exp ectation terms in (28). F ollo wing the algebraic manipulation steps in [1, App endix C], we obtain the rst term in (27) as E g E mk e † w PMRT E ,mk e 2 = E ˆ g I mk i + ˜ g I mk i † w PMRT E ,mk e 2 = ˆ W E , ◦ m k e k e − 1 E ( ˆ g E mk e ) † B m ˆ g E mk e 2 + α PMRT mk e − 1 E tr ˆ g E mk e ( ˆ g E mk e ) † B † m ˜ g E mk e ( ˜ g E mk e ) † B m ( a ) = α PMRT mk e − 1 h ¯ a m,k e + κ ¯ β E mk e tr F m F † m ¯ z E mk e ( ¯ z E mk e ) † + γ E mk e × ¯ β E mk e tr F m F † m − γ E mk e i , (53) where the second term in (a) exploits the indep endent prop ert y b etw een ˆ g E mk e , ˜ g E mk e . Under the asymptotic ap- pro ximation of E { B m } , for ∀ k ′ e ∈ P k \ k e , we obtain E g E mk e † w PMRT E ,mk ′ e 2 = α PMRT mk e − 1 h ¯ b m,k e k ′ e + κ ¯ β E mk ′ e tr F m F † m ¯ z E mk ′ e ( ¯ z E mk ′ e ) † + γ E mk e × ¯ β E mk e tr F m F † m − γ E mk e i , (54) while, ∀ k ′ e / ∈ P k \ k e , we hav e E g E mk e † w PMRT E ,mk ′ e 2 ( b ) = α PMRT mk e − 1 × h κ ¯ β E mk e tr F m F † m ¯ z E mk e ( ¯ z E mk e ) † + ¯ β E mk e tr F m F † m × κ ¯ β E mk ′ e tr F m F † m ¯ z E mk ′ e ( ¯ z E mk ′ e ) † + γ E mk ′ e i , (55) where (b) exploits the indep endence betw een the orthogonal c hannels from AP m to ER- k e and ER- k ′ e where k e k e / ∈ P k . 3) Given the statistical indep endence, b etw een g E mk e and normalized w ZF I ,mk i for ER k e and IR k i , resp ectively , the third term in (27) is obtained as E g E mk e † E w ZF I ,mk i w ZF I ,mk i g E mk e = 1 N ¯ β E mk e tr F m F † m + κ ¯ β E mk e tr F m F † m ¯ z E mk e ( ¯ z E mk e ) † . (56) By substituting the nal results for (53), (54), (55), and (56) into (28), after some manipulations, we get the result in (29). References [1] T. D. Hua, M. Mohammadi, H. Q. Ngo, and M. Matthaiou, “SWIPT in cell-free massive MIMO using stack ed intelligen t metasurfaces,” in Proc. IEEE ICC, Jun. 2025. [2] M. Mohammadi, L.-N. T ran, Z. Mobini, H. Q. Ngo, and M. Matthaiou, “Cell-free massive MIMO-assisted SWIPT for IoT netw orks,” IEEE T rans. Wireless Commun., v ol. 24, no. 10, pp. 8598–8614, May 2025. [3] M. Chakrab orty , E. Sharma, H. A. Sura w eera, and H. Q. Ngo, “Analysis and optimization of RIS-assisted cell-free massive MIMO NOMA systems,” IEEE T rans. Wireless Commun., vol. 73, no. 4, pp. 2631–2647, Apr. 2025. [4] H. Q. Ngo, G. Interdonato, E. G. Larsson, G. Caire, and J. G. Andrews, “Ultradense cell-free massive MIMO for 6G: T echnical ov erview and op en questions,” Pro c. IEEE, vol. 112, no. 7, pp. 805–831, Jul. 2024. [5] Z. Y u et al., “Detection and multiparameter estimation for NLoS targets: An RIS-assisted framework,” IEEE T rans. Signal Process., vol. 73, pp. 1470–1484, Mar. 2025. [6] Y. Huang, L. Zh u, and R. Zhang, “Integrating in telligent reect- ing surface in to base station: Architecture, channel mo del, and passive reection design,” IEEE T rans. Commun., v ol. 71, no. 8, pp. 5005–5020, A ug. 2023. [7] J. An et al., “Stack ed intelligent metasurface-aided MIMO transceiver design,” IEEE Wireless Comm un. Lett., vol. 31, no. 4, pp. 123–131, A ug. 2024. [8] X. Jia et al., “Stac ked in telligen t metasurface enabled near-eld multiuser b eamfocusing in the wa v e domain,” in Pro c. IEEE VTC, Jul. 2024, pp. 1–5. [9] J. An et al., “Stack ed intelligent metasurfaces for ecient holo- graphic MIMO communications in 6G,” IEEE J. Sel. Areas Commun., v ol. 41, no. 8, pp. 2380–2396, Aug. 2023. [10] N. S. Pero vić and L.-N. T ran, “Mutual information optimization for SIM-based holographic MIMO systems,” IEEE Commun. Lett., vol. 28, no. 11, pp. 2583–2587, Nov. 2024. . 17 [11] S. Li et al., “T ransmit b eamforming design for ISAC with stack ed intelligen t metasurfaces,” IEEE T rans. V eh. T echnol., vol. 74, no. 4, pp. 6767–6772, Apr. 2025. [12] A. Abdallah et al., “Multi-agent DRL for distributed co deb o ok design in RIS-aided cell-free massive MIMO netw orks,” IEEE T rans. Commun., vol. 73, no. 5, pp. 3283–3297, May 2025. [13] E. Shi et al., “Wireless energy transfer in RIS-aided cell-free massive MIMO systems: Opp ortunities and challenges,” IEEE Commun. Mag., vol. 60, no. 3, pp. 26–32, Mar. 2022. [14] T. V. Chien, H. Q. Ngo, S. Chatzinotas, M. Di Renzo, and B. Ottersten, “Recongurable intelligen t surface-assisted cell-free massive MIMO systems ov er spatially-correlated c hannels,” IEEE T rans. Wireless Comm un., v ol. 21, no. 7, pp. 5106–5128, Jul. 2022. [15] Z. Y ang and Y. Zhang, “Beamforming optimization for RIS-aided SWIPT in cell-free MIMO netw orks,” China Commun., v ol. 18, no. 9, pp. 175–191, Sept. 2021. [16] K. Y ang et al., “On the p erformance of RIS-aided CF-IoE-SWIPT netw ork ov er correlated Rician fading channels,” IEEE Wireless Commun. Lett., vol. 13, no. 10, pp. 2692–2696, Oct. 2024. [17] Y. Hu et al., “Joint b eamforming and p ower allo cation design for stack ed intelligen t metasurfaces-aided cell-free massive MIMO systems,” IEEE T rans. V eh. T ec hnol., vol. 74, no. 3, pp. 5235– 5240, Mar. 2025. [18] Q. Li, M. El-Ha jjar, C. Xu, J. An, C. Y uen, and L. Hanzo, “Stack ed intelligen t metasurfaces for holographic MIMO-aided cell-free netw orks,” IEEE T rans. Commun., vol. 72, no. 11, pp. 7139–7151, Nov. 2024. [19] E. Shi et al., “Uplink p erformance of stack ed intelligent metasurface-enhanced cell-free massive MIMO systems,” IEEE T rans. Commun., vol. 24, no. 5, pp. 3731–3746, F eb. 2025. [20] ——, “Join t AP-UE asso ciation and precoding for SIM-aided cell- free massive MIMO systems,” IEEE T rans. Commun., vol. 24, no. 6, pp. 5352–5367, Jun. 2025. [21] M. Nerini and B. Clerckx, “Physically consistent mo deling of stack ed intelligen t metasurfaces implemented with beyond diag- onal RIS,” IEEE Commun. Lett., v ol. 28, no. 7, pp. 1693–1697, Jul. 2024. [22] H. Y ah y a, M. Nerini, B. Clerc kx, and M. Debbah, “T-parameters- based mo deling for stack ed intelligent metasurfaces: T ractable and physically consisten t model,” IEEE Wireless Commun. Lett., vol. 14, no. 7, pp. 2149–2153, Jul. 2025. [23] Q. Li, M. El-Ha jjar, K. Cao, C. Xu, H. Haas, and L. Hanzo, “Holographic metasurface-based beamforming for multi-altitude LEO satellite netw orks,” IEEE T rans. Wireless Comm un., vol. 24, no. 4, pp. 3103–3116, Apr. 2025. [24] H. Zhou et al., “A survey on mo del-based, heuristic, and machine learning optimization approaches in RIS-aided wireless net works,” IEEE Comm un. Surveys T uts., v ol. 26, no. 2, pp. 781–823, Dec. 2023. [25] T. D. Hua, M. Mohammadi, H. Q. Ngo, and M. Matthaiou, “Cell- free massive MIMO SWIPT with b eyond diagonal recongurable intelligen t surfaces,” IEEE T rans. Commun., vol. 73, no. 12, pp. 13 340–13 356, A ug. 2025. [26] T. D. Hua et al., “Learning-based recongurable-intelligen t- surface-aided rate-splitting multiple access netw orks,” IEEE In- ternet Things J., vol. 10, no. 20, pp. 17 603–17 619, Oct. 2023. [27] Q. T. Do et al., “Multi-UA V aided energy-a w are transmissions in mm W ave communication netw ork: A ction-branc hing QMIX netw ork,” J. Netw. Comp. App., v ol. 230, p. 103948, Oct. 2024. [28] M. Mohammadi, L.-N. T ran, Z. Mobini, H. Q. Ngo, and M. Matthaiou, “Cell-free massive MIMO and SWIPT: Access point operation mode selection and p ow er con trol,” in Proc. IEEE GLOBECOM, Dec. 2023, pp. 661–666. [29] T. D. Hua, M. Mohammadi, H. Q. Ngo, and M. Matthaiou, “Cell- free massive MIMO SWIPT with b eyond diagonal recongurable intelligen t surfaces,” in Pro c. IEEE WCNC, Apr. 2024, pp. 1–6. [30] S. Mukherjee and S. K. Mohammed, “Information rate performance of massive MU-MIMO uplink with constan t en v elope pilot-based frequency synchronization,” 2016, submitted on 20 May 2016. [Online]. A v ailable: [31] J. An et al., “Stack ed intelligen t metasurfaces for multiuser beamforming in the wa ve domain,” in Proc. IEEE ICC, Jun. 2023, pp. 2834–2839. [32] M. Nerini, S. Shen, H. Li, M. Di Renzo, and B. Clerckx, “A uni- versal framew ork for multiport netw ork analysis of recongurable intelligen t surfaces,” IEEE T rans. Wireless Commun., vol. 23, no. 10, pp. 14 575–14 590, Oct. 2024. [33] M. T. Ivrlač and J. A. Nossek, “T ow ard a circuit theory of communication,” IEEE T rans. Circuits Syst., vol. 57, no. 7, pp. 1663–1683, Jul. 2010. [34] D. Semmler, J. A. Nossek, M. Joham, B. Bö ck, and W. Utschic k, “Decoupling netw orks and super-quadratic gains for RIS systems with m utual coupling,” IEEE T rans. Wireless Commun., v ol. 25, pp. 1624–1639, Jan. 2026. [35] G. Interdonato, M. Karlsson, E. Björnson, and E. G. Larsson, “Local partial zero-forcing preco ding for cell-free massiv e MIMO,” IEEE T rans. Wireless Commun., vol. 19, no. 7, pp. 4758–4774, Jul. 2020. [36] M. Elatoure, M. Mohammadi, H. Q. Ngo, P . J. Smith, and M. Matthaiou, “Protecting massive MIMO-radar co existence: Precoding design and p ow er control,” IEEE Op en J. Commun. Society , vol. 5, pp. 276–293, Jan. 2024. [37] H. Cramer, Random V ariables and Probabilit y Distributions. Cambridge, U.K.: Cambridge Universit y Press, 1970. [38] H. Q. Ngo, A. Ashikhmin, H. Y ang, E. G. Larsson, and T. L. Marzetta, “Cell-free massive MIMO versus small cells,” IEEE T rans. Wireless Commun., vol. 16, no. 3, pp. 1834–1850, Mar. 2017. [39] E. Boshko vska et al., “Practical non-linear energy harvesting model and resource allo cation for SWIPT systems,” IEEE Wire- less Commun. Lett., v ol. 19, no. 12, pp. 2082–2085, Sept. 2015. [40] M. Mohammadi, H. Q. Ngo, and M. Matthaiou, “Phase-shift and transmit p ow er optimization for RIS-aided massive MIMO SWIPT IoT netw orks,” IEEE T rans. Commun., vol. 73, no. 1, pp. 631–647, Jan. 2025. [41] M. Mohammadi, T. T. V u, H. Q. Ngo, and M. Matthaiou, “Netw ork-assisted full-duplex cell-free massive MIMO: Sp ectral and energy eciencies,” IEEE J. Sel. Areas Commun., vol. 41, no. 9, pp. 2833–2851, Sept. 2023. [42] T. T. V u et al., “Sp ectral and energy eciency maximization for conten t-centric C-RANs with edge caching,” IEEE T rans. Commun., v ol. 66, no. 12, pp. 6628–6642, Dec. 2018. [43] M. Mohammadi, Z. Mobini, H. Q. Ngo, and M. Matthaiou, “Next- generation multiple access with cell-free massive MIMO,” Pro c. IEEE, vol. 112, no. 9, pp. 1372–1420, Sept. 2024. [44] T. V. Chien and H. Q. Ngo, Massive MIMO Channels. Antennas and Propagation for 5G and Beyond, Jul. 2024. [45] T. P . Lillicrap, J. J. Hun t, A. Pritzel, N. Heess, T. Erez, Y. T assa, D. Silver, and D. Wierstra, “Contin uous control with deep reinforcement learning,” Jul. 2019. [Online]. A v ailable: [46] J. Sch ulman, F. W olski, P . Dhariwal, A. Radford, and O. Klimov, “Proximal p olicy optimization algorithms,” Aug. 2017. [Online]. A v ailable: [47] Q. Li, M. El-Hajjar, Y. Sun, and L. Hanzo, “P erformance analysis of recongurable holographic surfaces in the near-eld scenario of cell-free netw orks under hardware impairments,” IEEE T rans. Wireless Commun., vol. 23, no. 9, pp. 11 972–11 984, Apr. 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment