Extending $μ$P: Spectral Conditions for Feature Learning Across Optimizers
Several variations of adaptive first-order and second-order optimization methods have been proposed to accelerate and scale the training of large language models. The performance of these optimization routines is highly sensitive to the choice of hyp…
Authors: Akshita Gupta, Marieme Ngom, Sam Foreman
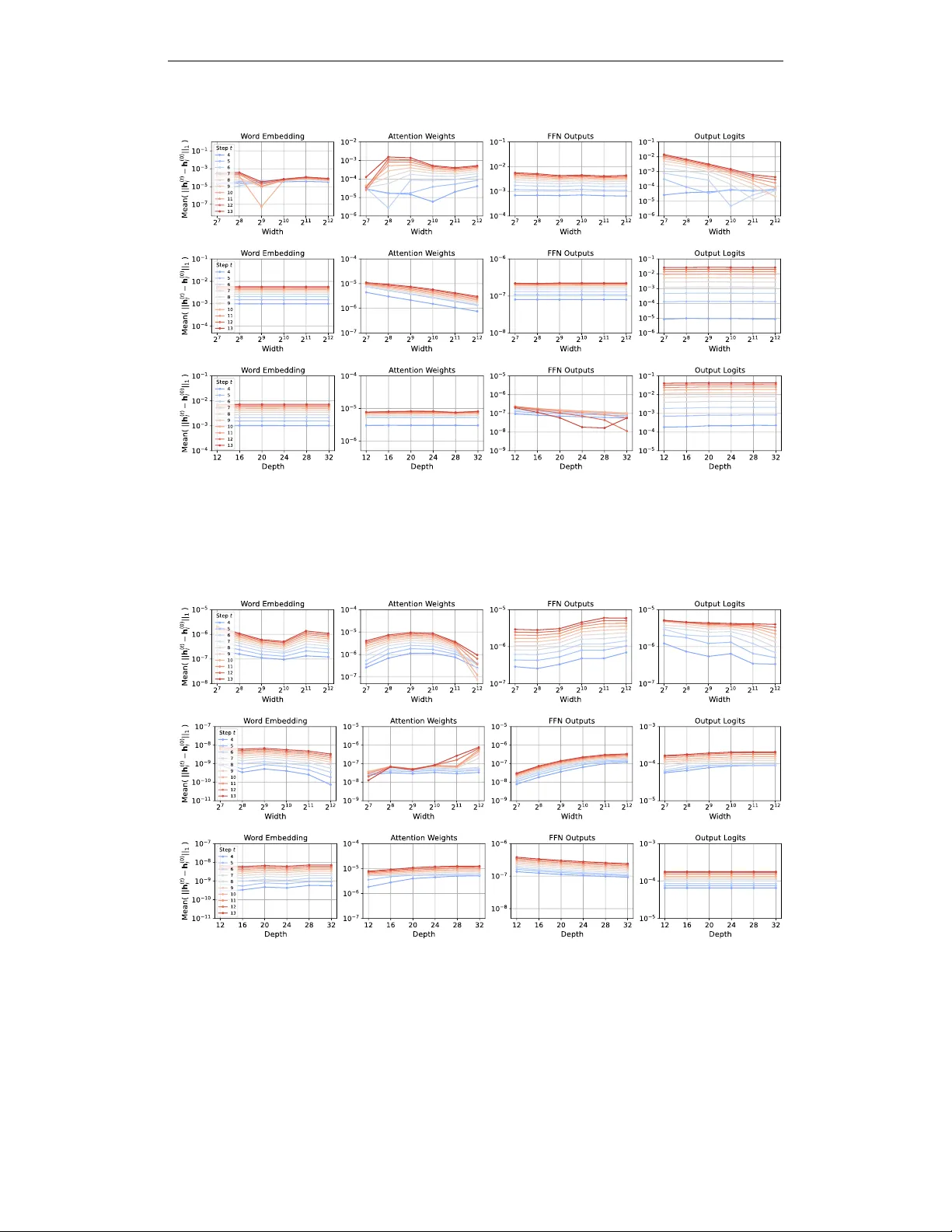
Preprint E X T E N D I N G µ P : S P E C T R A L C O N D I T I O N S F O R F E A T U R E L E A R N I N G A C R O S S O P T I M I Z E R S Akshita Gupta Purdue Univ ersity gupta417@purdue.edu Marieme Ngom Argonne National Laboratory mngom@anl.gov Sam For eman Argonne National Laboratory foremans@anl.gov V enkatram V ishwanath Argonne National Laboratory venkat@anl.gov A B S T R AC T Sev eral variations of adaptive first-order and second-order optimization methods hav e been proposed to accelerate and scale the training of large language mod- els. The performance of these optimization routines is highly sensiti ve to the choice of h yperparameters (HPs), which are computationally expensi ve to tune for large-scale models. Maximal update parameterization ( µ P ) is a set of scal- ing rules which aims to make the optimal HPs independent of the model size, thereby allowing the HPs tuned on a smaller (computationally cheaper) model to be transferred to train a larger , target model. Despite promising results for SGD and Adam, deri ving µ P for other optimizers is challenging because the underlying tensor programming approach is difficult to grasp. Building on recent work that introduced spectral conditions as an alternative to tensor programs, we propose a nov el frame work to deriv e µ P for a broader class of optimizers, including AdamW , ADOPT , LAMB, Sophia, Shampoo and Muon. W e implement our µ P deriv ations on multiple benchmark models and demonstrate zero-shot learning rate transfer across increasing model width for the abov e optimizers. Further , we pro vide em- pirical insights into depth-scaling parameterization for these optimizers. 1 I N T R O D U C T I O N Large language models (LLMs) have achiev ed remarkable progress in generati ve AI, yet their per- formance and reproducibility depend on man y interacting factors. A ke y aspect of training LLMs is the optimization routine, which can become unstable as models grow in size and complexity . T o im- prov e stability and efficiency , se veral modifications to existing optimizers have been proposed. For example, LAMB (Y ou et al., 2019) proposes a layer-wise adaptiv e optimization routine to reduce the computational time required for training deep neural networks o ver lar ge mini-batches, while Sophia (Liu et al., 2023) is a light-weight second-order method which achiev es faster conv ergence than Adam and is more robust to non-conv ex landscapes. Muon is another recent optimizer designed explicitly for scaling with model size (Jordan et al., 2024; Liu et al., 2025; Bernstein, 2025). Although these recent algorithms demonstrate strong performance, the computational overhead of hyperparameter (HP) tuning poses a fundamental scalability bottleneck for training LLMs. T o ad- dress this challenge, practitioners hav e heuristically tuned HPs on smaller models to guide the search for optimal configurations in larger models. Recent works (Y ang et al., 2021; Y ang & Hu, 2020) hav e formalized this approach by proposing a zero-shot HP transfer algorithm based on maximal update parameterization ( µ P), which stabilizes feature learning across different model widths. µ P is im- plemented by carefully scaling the weights and HPs proportional to the model width, with scaling factors tailored to the specific architecture and optimization algorithm. Under µ P , feature learning is stable throughout the training process and HPs are stable across increasing model width. For the abov e reasons, se veral recent works have deriv ed and incorporated µ P for different models (Zheng et al., 2025; Th ´ erien et al.) and optimization algorithms (Blake et al., 2025b; Ishikawa & Karakida). Fig. 1 demonstrates the increased training stability and predictability after µ P is incorporated in Sophia. Fig. 1 (left) sho ws that the relati ve mean of different feature v ectors remains stable across increasing model width, thereby ensuring maximal (weights not decreasing to 0 ) and 1 Preprint stable (weights not diver ging) feature learning under µ P . Fig. 1 (middle) demonstrates zero-shot learning rate transfer across model widths where the best validation loss is obtained at learning rate 0 . 1 for all widths. Finally , Fig. 1 (right) demonstrates the “wider is always better” property where the training loss improv es consistently with increasing model width under µ P . While µ P delivers strong results, it is tedious to implement in existing large codebases and difficult to understand in practice. T o address this, authors in (Y ang et al., 2023a) proposed simpler spectral scaling conditions on the weight matrices that lead to the same width-independent and maximal feature learning properties of µ P . This work focuses on using the more tractable spectral conditions to deriv e µ P for a wide range of optimizers. Despite being more intuiti ve, using spectral conditions to deri ve µ P is not tri vial and the analysis for each adapti ve optimizer is different and requires a careful study of the order-of-magnitude of the coef ficient terms that scale the gradients. Our contributions are as follows: (1) we propose a general frame work to deri ve µ P using a novel spectral scaling approach; (2) we use the proposed framework to analytically derive µ P for se veral adaptiv e first and second-order optimizers (AdamW , ADOPT , LAMB, Sophia, Shampoo, Muon); (3) we implement µ P for the abo ve optimizers and v alidate our implementation by demonstrating zero- shot HP transfer (specifically of the optimal learning rate) across model width on benchmark LLMs (NanoGPT (Karpathy, 2022); Llama2 (T ouvron et al., 2023) ); and (4) we provide an empirical study of zero-shot HP transfer across model depth for these optimizers to motiv ate future work. Figure 1: µ P for Sophia (trained on Llama2) - Coordinate check plots for the word embedding and output logits layers (left); Zero-shot learning rate transfer across increasing model width (middle); Decreasing training loss with increasing model width (right). 2 P R E L I M I NA R I E S The l p − norm of a vector x ∈ R n is defined as || x || p := ( P n i =1 | x i | p ) 1 /p . F or a matrix A ∈ R n × n , A α = P i λ α e i u i u T i where ( λ e i , u i ) are the i − th eigen pair . The spectral norm of a matrix A ∈ R m × n is defined as || A || ∗ := max x ∈ R n \{ 0 } || Ax || 2 || x || 2 , and the Frobenius norm is defined as || A || F := q P m i =1 P n j =1 | A i,j | 2 (Strang, 2012; Meyer, 2023). If r denotes the rank of matrix A , then || A || ∗ ≤ || A || F ≤ √ r || A || ∗ . If a matrix A ∈ R m × n can be written as an outer product of some vectors u ∈ R m and v ∈ R n , that is, A = uv T then matrix A is a rank one matrix and || A || ∗ = || A || F = || u || 2 · || v || 2 . (1) For an y symmetric matrix, the spectral norm is equal to the absolute value of the maximum eigen value. Therefore, for p ∈ R , for a symmetric rank one matrix A = uu T ∈ R n × n , || A p || ∗ = || A || p ∗ . (2) A sequence of random vectors { x i ∈ R n } ∞ i =1 is said to ha ve Θ( n α ) -sized coordinates if there exists constants A, B such that An α ≤ q || x i || 2 2 n ≤ B n α for all i , and for sufficiently lar ge n . 3 B A C K G R O U N D In Sections 3, 4 and Appendix A, µ P is derived for a linear MLP trained with a batch size of 1 , similar to the model used in (Y ang et al., 2023a). Let us consider an MLP with L layers. Let 2 Preprint x ∈ R n 0 denote the input v ector and W l ∈ R n l × n l − 1 denote the weight matrix for the l − th layer of the model. Then the feature vector h l ∈ R n l for the input x is giv en as h l ( x ) = W l h l − 1 ( x ) , ∀ l = 1 , 2 , . . . , L (3) where h 0 ( x ) = x . Let L = g ( h L ( x ) , y ) denote the loss, where g : R n 0 × R n L → R is a loss function, y ∈ R n L is the target vector corresponding to the input x and h L ( x ) ∈ R n L is the output vector returned by the MLP . After one step of training, the change in the weight matrices is typically a function, Ψ( · ) , of the history of the gradients. Then, the change in weights from time instant t to t + 1 can be written using the following generic update rule, W ( t +1) l = W ( t ) l − η ( t +1) Ψ( {∇ W ( i ) l L} t i =1 ) (4) where η ( t +1) is the learning rate at time instant t + 1 . W e specify the forms of Ψ( · ) for dif ferent optimizers in T able 1. T o reduce cumbersome notation, we omit time indices in the remaining sections unless their inclusion is necessary for clarity . This will not affect the deriv ation of µ P as it is sufficient to analyze a single step of rule (4) to determine the correct scaling laws (Y ang et al., 2021; Blake et al., 2025a). Using eqs. (3) and (4) the change in weights and feature v ectors for an y layer l , after one training step can be written as ∆ W l = − η Ψ( {∇ W l L} ) and ∆ h l ( x ) = ∆ W l h l − 1 ( x ) + ∆ W l ∆ h l − 1 ( x ) + W l ∆ h l − 1 ( x ) . Optimizer Ψ ( · ) AdamW / ADOPT ˆ m ( t ) √ ˆ v ( t ) + ϵ + λ W ( t ) l Sophia clip m ( t ) max { γ h ( t ) , ϵ } , 1 + λ W ( t ) l LAMB ϕ ( || W ( t ) l || F ) || r ( t ) l + λ W ( t ) l || F r ( t ) l + λ W ( t ) l Shampoo ( L ( t ) ) − 1 / 4 ∇ W ( t ) l L ( R ( t ) ) − 1 / 4 Muon q n l n l − 1 O ( t ) l T able 1: V alues of Ψ( · ) for dif ferent optimizers. Auxiliary variables are defined in Section 4 and Appendix A. 3 . 1 M A X I M A L U P D A T E P A R A M E T R I Z A T I O N ( µ P ) Authors in (Y ang & Hu, 2020; Y ang et al., 2021) proposed µ P to ensure that overparameterized models do not learn trivial features, or that the feature values do not blo w up with increasing model width. In practice, µ P is implemented via the abc -parameterization (Y ang & Hu, 2020) which en- sures that the MLP weights, their initial variance and the learning rate are appropriately scaled with respect to the model width. In Y ang & Hu (2020), the abc -parameterization was introduced for MLPs where the hidden layers ha ve the same width, that is, n l − 1 = n l = n for l = 2 , . . . , L − 1 . For simplicity , it was assumed that the inputs and outputs are scalars. Then, for each layer , the set of parameters { a l , b l } L l =1 ∪ { c } comprise the abc -parameterization to 1. Initialize and scale weight matrices at ev ery layer as W l = n − a l [ w ( i,j ) l ] , where w ( i,j ) l ∼ N (0 , n − 2 b l σ 2 ) 2. Scale the learning rate such that ∆ W l = − η n − c Ψ( {∇ W l L} ) where the scale of initial v ariance, σ 2 , and the learning rate, η , is assumed to be width-independent. As emphasized in Section 1, the theoretical principles behind µ P can be difficult to grasp. Recog- nizing these challenges, (Y ang et al., 2023a) provided the follo wing equiv alent conditions for µ P || h l ( x ) || 2 = Θ( √ n l ) and || ∆ h l || 2 = Θ( √ n l ) , for l = 1 , 2 , . . . , L − 1 . (C.1.) The abov e conditions concisely represent the requirements of µ P . 3 Preprint 3 . 2 S P E C T R A L C O N D I T I O N S F O R F E A T U R E L E A R N I N G In (Y ang et al., 2023a), the authors futher argued that conditions (C.1.) can be ensured by the following spectr al scaling conditions on the weight matrices and their one step update, || W l || ∗ = Θ r n l n l − 1 and || ∆ W l || ∗ = Θ r n l n l − 1 , for l = 1 , 2 , . . . , L. (C.2.) The abov e spectral scaling conditions hold for an y optimizer , and in the next section we present a framew ork to deriv e µ P for any arbitrary optimizer using conditions (C.2.). 3 . 3 T H E O RY T O P R AC T I C E While the µ P scalings in T able 2 are deriv ed for the model described in the beginning of Section 3, empirical results in Fig. 2 and Fig. 3 show that the deri vations also hold for more practical, comple x models. This section lists the assumptions required for the deriv ed scalings to hold in practice . W e first need to justify that deri ving µ P based on one time step analysis recursively yields the same scaling in the following time steps. This holds if the order of magnitude of the norms remain the same after the updates are performed, and this is formalized in Assumption 1. Note that violating Assumption 1 will require e xact cancellation which is rare to observe in practice and can be easily av oided by adding small randomness to the learning rate (Y ang et al., 2023a). Assumption 1 The weight updates do not cancel initial quantities. || W l + ∆ W l || ∗ = Θ( || W l || ∗ + || ∆ W l || ∗ ) || h l ( x ) + ∆ h l ( x ) || 2 = Θ( || h l ( x ) || 2 + || ∆ h l ( x ) || 2 ) . In practice, nonlinear acti v ation functions, ϕ ( · ) , act on incoming feature vectors from the previous layer , thereby changing (3) to h l ( x ) = W l ϕ ( h l − 1 ( x )) . Our analysis directly translates to acti vation functions that preserv e the order of magnitude of the inputs, as formalized in Assumption 2, and this phenomenon is observed for most commonly used acti vations which are designed to pre vent the out- puts from div erging or v anishing to 0 . Additionally , Assumption 2 also holds for most transformer layers where the activ ation functions are preceded by layer normalization, because the normalization maps the vectors to nonne gativ e constants. Assumption 2 If a nonlinear activation function ϕ ( · ) is added to each layer of the MLP , then || ϕ ( h l ( x )) || 2 = Θ( || h l ( x ) || 2 ) . Finally , we require mild assumptions on the batch size, as stated in Assumption 3. Mathematically , Assumption 3 is required to ensure that the sub-multiplicative property of norms doesn’t result in a loose bound for the deri vations in Section 4 to hold in practice. Intuitiv ely , Assumption 3 holds if the update matrix ∆ W l has a lo w rank even for lar ge batch sizes. W e refer the reader to (Y ang et al., 2023a, Figure 1) for empirical observations of lo w-rank behavior of update matrices. Assumption 3 The batch size, B , is fixed and independent of the width, that is, B = Θ(1) . If i denotes the index of a tr aining sample in the batch then, ∥ ∆ W l h l ( x i ) ∥ 2 = Θ 1 B ∆ W ( i ) l h l ( x i ) 2 . Remark 1 W e note that Assumption 3 constitutes a limitation of µ P as it implies a fixed batch size acr oss model width. This is often suboptimal, as the critical batch size typically incr eases with model size (McCandlish et al., 2018; Kaplan et al., 2020). In practice , however , this can be mitigated by first tuning the smaller pr oxy model with a fixed batch size B . When transferring to larger models, one can incr ease the batch size to impro ve parallelization efficiency , pr ovided the learning r ate is adjusted accor dingly . Standar d heuristics for this adjustment include the linear scaling rule (Goyal et al., 2017) or squar e r oot scaling (Krizhevsk y, 2014; Hoffer et al., 2017). 4 Preprint 4 D E R I V I N G µ P U S I N G S P E C T R A L S C A L I N G C O N D I T I O N S As discussed in Section 3.1, deriving µ P for a particular model and optimizer boils do wn to deter- mining the scaling parameters in abc -parameterization, or an equiv alent form. W e propose a frame- work which only utilizes the spectral scaling conditions (C.2.) to derive the abc -parameterization. The typical approach to deri ve µ P is to determine the proper scaling factors for a one step gradient update, and then argue recursiv ely that for stable input vectors under µ P , the output vectors are also stable, independent of the time (Assumption 1). 4 . 1 G E N E R I C F R A M E WO R K Scaling of Model W eights and Initial V ariance: The scaling factors for the model weights and their initial variance, that is, akin to parameters { a l , b l } L l =1 in the abc -parameterization, can be computed by satisfying the condition on || W l || ∗ in (C.2.). More rigorously , let us define the model weights as W l = σ l ˜ W l ∈ R n l × n l − 1 where the elements of ˜ W l are sampled from some initial distribution with scaled variance, n − 2 b l σ 2 . For ease of theoretical analysis, we fix b l = 0 for all layers. Then, || W l || ∗ = σ l || ˜ W l || ∗ . Since || ˜ W l || ∗ is a random matrix with unit variance, existing results in random matrix theory can be le veraged to deduce the scaling of the spectral norm in terms of matrix dimensions (Rudelson & V ershynin, 2010) V ershynin (2018). Then, σ l can be computed by equating σ l || ˜ W l || ∗ = Θ p n l /n l − 1 . Scaling of Learning Rate: The scaling f actor for the learning rate, akin to parameter c in abc -parameterization, is computed by satisfying the condition on || ∆ W l || ∗ in (C.2.). This implies that the generic update rule in eq. (4) should be equated as, || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 || Ψ ( ∇ W l L ) || ∗ = Θ r n l n l − 1 , (5) where the scaling constants c 1 and c 2 are determined based on the exact nature of Ψ( · ) . Input W eights Output W eights Hidden W eights Init. V ar . 1 ( 1 n l − 1 ) 1 ( 1 n 2 l − 1 ) 1 ( 1 n l − 1 ) Multiplier 1 √ n l − 1 (1) 1 n l − 1 (1) 1 √ n l − 1 (1) AdamW / ADOPT 1 (1) 1 n l − 1 ( 1 n l − 1 ) 1 n l − 1 ( 1 n l − 1 ) Sophia LR 1 ( − ) 1 n l − 1 ( − ) 1 n l − 1 ( − ) LAMB LR 1 ( − ) 1 ( − ) 1 ( − ) Shampoo LR √ n l ( − ) 1 √ n l − 1 ( − ) q n l n l − 1 ( − ) Muon LR (designed for hidden layers only) N A N A 1 ( − ) T able 2: Comparison of µ P from spectral conditions (black) vs. tensor programs (Y ang et al., 2021, T able 3) (red). Discussion: Observe that the scaling of model weights and initial v ariance is only dependent on the model architecture, not the optimization routine. Therefore, in the rest of this work we use the linear MLP described in Section 3 as our fixed model architecture and assume that the weights are initialized using standard normal distribution. Since the spectral norm of a random matrix with unit variance scales ≈ ( √ n l + √ n l − 1 ) , the appropriate scaling factor is computed to be σ l = Θ 1 √ n l − 1 min 1 , q n l n l − 1 (Y ang et al., 2023a). Note that the initial v ariance is fix ed as 1 for the ease of theoretical analysis. In practice, to increase numerical stability , the variance can be set to σ 2 l while the weight multiplier can be fixed to 1 , for normal distrib ution. Further , observ e that eq. (5) computes separate scaling factors for the input and output dimensions of the weight matrices, that is, using spectral scaling conditions to deri ve µ P allows us to collec- tiv ely analyze the dif ferent types of layers (input, output and hidden layers). W e recommend first 5 Preprint determining the scaling factors c 1 and c 2 by removing additional HPs, such as weight-decay , epsilon for numerical stability etc., from the update rule because they typically do not hav e a comparable order of magnitude to other terms. In case of lo w-precision training (Blake et al., 2025a), these HPs can be scaled after c 1 and c 2 hav e been computed, as demonstrated at the end of Section 4.2. Finally , we want to highlight that while there is no difference in the correctness and rigor of using either a tensor programming approach or the proposed spectral scaling approach, the latter is more intuitiv e and therefore, makes it easier to adopt and reason about µ P for a wide class of optimizers. Additionally , the rich literature on spectral norms and their properties can be lev eraged to analyze different adapti ve optimization routines, as will be demonstrated in the following sections. In Section 4.2, we first demonstrate ho w to utilize the above frame work by deri ving µ P for AdamW , and corroborate our results with the µ P scalings reported in literature (Y ang et al., 2021). W e then deriv e µ P for optimizers - ADOPT , LAMB, Sophia, Shampoo and Muon, which have shown promis- ing results for training LLMs. Our results are summarized in T able 2 and in Result 4.1. Figs. 2 and 3 demonstrate zero-shot learning rate transfer across model widths for different optimizers, under the deriv ed µ P scalings. Figure 2: (NanoGPT) Mean validation loss for increas- ing model width and different learning rates across four op- timizers: ADOPT (top left), LAMB (top right), Sophia (bottom left), and Shampoo (bottom right). The plots demonstrate zero-shot learn- ing rate transfer under µ P (T a- ble 2). Result: Under standing assumptions, for a linear MLP with L layers, if the weight matrices W l = σ l ˜ W l , l = 1 , 2 , . . . L are initialized as ˜ W i,j ∼ N (0 , 1) , then the spectral conditions (C.2.) are satisfied for AdamW , ADOPT and Sophia if σ l = Θ 1 √ n l − 1 min 1 , r n l n l − 1 ; η = Θ 1 n l − 1 , for LAMB and Muon if σ l = Θ 1 √ n l − 1 min 1 , r n l n l − 1 ; η = Θ (1) , and for Shampoo if σ l = Θ 1 √ n l − 1 min 1 , r n l n l − 1 ; η = Θ r n l n l − 1 , where n l − 1 = 1 for input weights and n l = 1 for output weights. Remark 2 F or a linear MLP tr ained with a batch size of 1 , the gradient matrix is a rank one matrix because it can be written as an outer pr oduct of two vectors, ∇ W l L = ∇ h l L · h T l − 1 . Ther efore , ||∇ W l L|| ∗ = ||∇ W l L|| F fr om pr operty (1). (See discussion in (Y ang et al., 2023a, p. 9)) Remark 3 F or a linear MLP tr ained with a batch size of 1 , it can be shown using first or der T aylor series e xpansion that ||∇ W l L|| ∗ = Θ( q n l − 1 n l ) (Y ang et al., 2023a, p. 9). Further , since ∇ W l L is 6 Preprint a r ank one matrix, ||∇ W l L|| ∗ = ||∇ h l L|| 2 || h l − 1 || 2 = ||∇ h l L|| 2 Θ( √ n l − 1 ) , using pr operty (1) and condition (C.1.). Then, ||∇ h l L|| 2 = Θ(1 / √ n l ) . Figure 3: (Llama2) V alidation loss for increasing model width and different learning rates across three optimizers: AdamW (left), ADOPT (middle), and LAMB (right). The plots demonstrate zero-shot learning rate transfer under µ P (T able 2). 4 . 2 µ P F O R A D A M W Recall the update rule for AdamW (Loshchilov & Hutter, 2017), W ( t +1) l = W ( t ) l − η ( t +1) ˆ m ( t ) √ ˆ v ( t ) + ϵ + λ W ( t ) l (AdamW) where ˆ m ( t ) = m ( t ) (1 − β t 1 ) = 1 (1 − β t 1 ) h β 1 m ( t − 1) + (1 − β 1 ) ∇ W ( t ) l L i ; m (0) = 0 ˆ v ( t ) = v ( t ) (1 − β t 2 ) = 1 (1 − β t 2 ) h β 2 v ( t − 1) + (1 − β 2 )( ∇ W ( t ) l L ) 2 i ; v (0) = 0 From the spectral scaling condition in eq. (5), we need to find c 1 , c 2 ∈ R such that || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 ˆ m √ ˆ v + ϵ + λ W l ∗ = Θ r n l n l − 1 . (6) Similar to pre vious w orks, we first analyze AdamW for β 1 = β 2 = ϵ = 0 . Then, the above update rule reduces to signSGD (Bernstein et al., 2018). Additionally , since the gradient term dominates the weight decay term, we ignore the latter because we are only concerned with an order-of-magnitude calculation. Therefore, (6) reduces to || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 || sign ( ∇ W l L ) || ∗ ≈ η ( n l ) − c 1 ( n l − 1 ) − c 2 || sign ( ∇ W l L ) || F where the last equation follo ws from Remark 2. From the definition of the Frobenius norm, we hav e || 1 n l × n l − 1 || 2 F = P n l i =1 P n l − 1 j = i 1 = n l n l − 1 . This giv es || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 Θ √ n l n l − 1 = Θ n 1 / 2 − c 1 l n 1 / 2 − c 2 l − 1 . (7) By fixing c 1 = 0 and c 2 = 1 , the spectral scaling condition in eq.(5) is satisfied. Therefore, the learning rate for AdamW should be scaled by a factor of 1 /n l − 1 . Observe that this scaling is consistent with the µ P derived using the tensor programming approach (Y ang et al., 2021, T able 3), and this equiv alence is highlighted in T able 2. Fig. 4 further v alidates our deriv ation via the coordinate check plots and the “wider is better” phenomenon observed in the plot on the right. Since the update rule of ADOPT is similar to AdamW , we discuss µ P for ADOPT in Appendix A. Scaling of Momentum, Adaptive Noise, and W eight Decay terms: T ypically , HPs like β 1 and β 2 are width-independent and have Θ(1) order of magnitude. Thus, these parameters are not dominant when analyzing the momentum terms and do not require separate scaling rules. Similarly , the adapti ve noise term ϵ requires no scaling if it is fixed at a very small value. Howe ver , empirical studies sho w that ϵ may affect the performance of µ P under certain training regimes (Blake et al., 2025a; Dey et al., 2025). In such cases the scaling law for ϵ can 7 Preprint be derived as follows. From (AdamW), we observe that for the above scaling law to hold, the spectral norm of ϵ should hav e the same order of magnitude as the spectral norm of √ ˆ v . No w , || √ ˆ v || ∗ = ||∇ W l L|| ∗ = Θ( p n l − 1 /n l ) and || ϵ 1 n l × n l − 1 || ∗ ≈ ϵ || 1 n l × n l − 1 || F = ϵ Θ( √ n l n l − 1 ) . Therefore, a factor of 1 n l scales ϵ to the appropriate order of magnitude. On the other hand, for the deri ved µ P scaling to hold for (AdamW), the spectral norm of the weight decay term, || λ W l || ∗ , must ha ve the same order of magnitude as the spectral norm of the gradient term, which is Θ( √ n l n l − 1 ) . Since, || λ W l || ∗ = λ || W l || ∗ = λ Θ( p n l /n l − 1 ) , where the last equal- ity follo ws from condition (C.2.), then λ should be scaled by a f actor of n l − 1 . The above results are consistent with T able 1 in (Dey et al., 2025). 4 . 3 µ P F O R L A M B Recall the update rule for LAMB (Y ou et al., 2019), W ( t +1) l = W ( t ) l − η ( t +1) ϕ ( || W ( t ) l || F ) || r ( t ) l + λ W ( t ) l || F r ( t ) l + λ W ( t ) l (LAMB) where r ( t ) l = ˆ m ( t ) √ ˆ v ( t ) + ϵ . In (LAMB), the gradient in each layer of the model is scaled by terms of orders || W l || F || r l + λ W l || F . From condition (C.2.), we kno w || W l || F ≈ || W l || ∗ = Θ q n l n l − 1 . Observe that the term in the denominator is the update rule for (AdamW) and we can use the result in (7) to determine its order of magnitude. Therefore, || r l + λ W l || F = Θ √ n l n l − 1 and || W l || F || r l + λ W l || F = Θ 1 n l − 1 . (8) Then, from the spectral scaling condition in eq. (5), we need to find c 1 , c 2 ∈ R such that || ∆ W || ∗ ≈ η ( n l ) − c 1 ( n l − 1 ) − c 2 Θ 1 n l − 1 || r l + λ W l || F = η ( n l ) − c 1 ( n l − 1 ) − c 2 Θ 1 n l − 1 Θ √ n l n l − 1 = η ( n l ) − c 1 ( n l − 1 ) − c 2 Θ r n l n l − 1 where the second equality follows using the same reasoning as for AdamW . Then condition (5) holds if c 1 = c 2 = 0 .Note that by in voking result (7) from AdamW’ s analysis to determine the order of magnitude of || r l + λ W l || F in (8), we implicitly assume that the HPs λ and ϵ have been appropriately scaled follo wing the analysis in Section 4.2. Therefore, the HPs in (LAMB) follow the same scaling rule as (AdamW). Insight 1 The above derivation sug gests that the update rule for LAMB is implicitly independent of width scaling . Intuitively , this r esult holds because the layerwise gradient scaling in (LAMB) causes the effective learning r ate to be differ ent for each layer . 4 . 4 µ P F O R S O P H I A Recall the update rule for Sophia (Liu et al., 2023), W ( t +1) l = W ( t ) l − η ( t +1) clip m ( t ) max { γ h ( t ) , ϵ } , 1 − η ( t ) λ W ( t ) l (Sophia) where h ( t ) is a momentum-based estimate of the diagonal vector of the Hessian at time t . From the spectral scaling condition in (5), we need to find c 1 , c 2 ∈ R such that || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 clip m ( t ) max { γ h ( t ) , ϵ } , 1 − λ W ( t ) l ∗ = Θ r n l n l − 1 . For analysis, we consider β 1 = β 2 = ϵ = 0 , and since the weight decay term is usually very small, the abov e weight update simplifies to 8 Preprint Figure 4: (Llama2 model) AdamW optimizer - Coordinate check plots under standard parame- terization (top left) and under µ P (bottom left) for the word embedding and output logits layers; Decreasing training loss with increasing model width under µ P (right). || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 clip ∇ W l L γ ∇ 2 W l L , 1 ! ∗ ≈ η ( n l ) − c 1 ( n l − 1 ) − c 2 clip ∇ W l L γ |∇ 2 W l L| , 1 ! F where we take the modulus in the denominator because Sophia a voids negati ve diagonal terms in the Hessian (thereby av oiding con vergence to a saddle point; see discussion in (Liu et al., 2023, pg. 6)). Observe that the clip ( · , 1) bounds the coordinate-wise weight updates as, | [∆ W l ] i, j | ≤ 1 . Therefore, we can compute an upper bound for the Frobenius norm and get || ∆ W l || ∗ ≤ η ( n l ) − c 1 ( n l − 1 ) − c 2 1 γ Θ( √ n l n l − 1 ) . Then, eq. (5) is satisfied by fixing c 1 = 0 and c 2 = 1 , resulting in the same µ P scaling as AdamW . Note that the momentum terms β 1 and β 2 do not require any additional scaling because they hav e Θ(1) , width-indepedent order of magnitude, where as the HPs λ and ϵ follow the same scaling as the HPs of AdamW because Sophia and AdamW hav e the same µ P scaling. Insight 2 W e pr ovide an intuitive explanation for this result. Sophia uses signSGD as the default method to handle ne gative Hessian terms (to avoid con ver gence to a saddle point), ther eby mirr oring the analysis for AdamW for suc h cases. Additionally , when γ = 1 , all the elements in the weight update are clipped to 1 , and the upper bound holds exactly . Thus, we get the same scaling as AdamW . In pr actice, the authors sugg est to choose γ such that 10% − 50% of the par ameters ar e not clipped. Ther efor e, for each term which is not clipped, the above bound incurs an error of less than 1 . However , as demonstrated in our simulations (F ig. 2), for the typical values of γ used in practice, the µ P scaling derived based on the above calculation works well. Fig. 1 further validates the µ P deriv ation for Sophia via stable coordinate check plots (Fig. 1 (left)) and a consistently improving training loss across model widths (Fig. 1 (right)). 4 . 5 µ P F O R S H A M P O O Recall the update rule for Shampoo (Gupta et al., 2018), W ( t +1) l = W ( t ) l − η ( t +1) L ( t ) l − 1 / 4 ∇ W l L R ( t ) l − 1 / 4 (Shampoo) where for some δ > 0 , L ( t ) l = L ( t − 1) l + ∇ W l L · ∇ W l L T ; L (0) l = δ I ∈ R n l × n l R ( t ) l = R ( t − 1) l + ∇ W l L T · ∇ W l L ; R (0) l = δ I ∈ R n l − 1 × n l − 1 From the spectral scaling condition in (5), we need to find c 1 , c 2 ∈ R such that || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 L ( t ) l − 1 / 4 ∇ W l L R ( t ) l − 1 / 4 ∗ = Θ r n l n l − 1 . 9 Preprint For one-step analysis, let δ = 0 . Then the above condition reduces to || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 ∇ W l L · ∇ W l L T − 1 / 4 ∇ W l L ∇ W l L T · ∇ W l L − 1 / 4 ∗ (1) ≤ η ( n l ) − c 1 ( n l − 1 ) − c 2 ∇ W l L · ∇ W l L T − 1 / 4 ∗ ∥∇ W l L∥ ∗ ∇ W l L T · ∇ W l L − 1 / 4 ∗ (2) = η Θ ( n l ) − c 1 − 1 2 ( n l − 1 ) − c 2 + 1 2 ∇ h l L · h T l − 1 h l − 1 · ∇ h l L T − 1 / 4 ∗ h l − 1 · ∇ h l L T ∇ h l L · h T l − 1 − 1 / 4 ∗ (3) = η Θ ( n l ) − c 1 − 1 2 ( n l − 1 ) − c 2 + 1 2 Θ( n − 1 / 4 l − 1 ) ∇ h l L · ∇ h l L T − 1 / 4 ∗ Θ( n 1 / 4 l ) h l − 1 · h T l − 1 − 1 / 4 ∗ (4) = η Θ ( n l ) − c 1 − 1 4 ( n l − 1 ) − c 2 + 1 4 ||∇ h l L|| − 1 / 2 2 || h l − 1 || − 1 / 2 2 (5) = η Θ ( n l ) − c 1 − 1 4 ( n l − 1 ) − c 2 + 1 4 Θ( n 1 / 4 l )Θ( n − 1 / 4 l − 1 ) = η Θ ( n l ) − c 1 ( n l − 1 ) − c 2 where (1) follo ws from sub-multiplicati ve property of matrix norms, (2) follo ws from Remark 3, (3) and (5) follow from condition (C.1.) and Remark 3, (4) follows from property (1) and property (2). Therefore, condition (5) is satisfied by fixing c 1 = − 1 / 2 and c 2 = 1 / 2 . Note that the δ HP in (Shampoo) is akin to the momentum HPs in (AdamW) and have a Θ(1) order of magnitude. Therefore, δ doesn’t contribute to the calculations of L l and R l , and it doesn’t require any further scaling. Muon: Muon was first introduced in (Jordan et al., 2024) and empirical results hav e demonstrated its scalability for LLMs (Liu et al., 2025). (Jordan et al., 2024) also showed the equi valence between Muon and Shampoo if the preconditioner accumulation is remov ed from (Shampoo). Therefore, the original v ersion of Muon (Jordan et al., 2024) follows the same µ P scaling as Shampoo. Howe ver , a more recent version of Muon (Bernstein, 2025) incorporates width-independent scaling of the learning rate explicitly in the update rule itself (T able 1). W e analyze this version of Muon in Appendix A and sho w that no further scaling is required for stable feature learning. This conclusion is added to Result 4.1. 5 N U M E R I C A L R E S U L T S W e test and validate our deriv ations on the NanoGPT model (Karpathy (2022)) and the Llama2 model (T ouvron et al. (2023)). As demonstrated in Figs. 2 and 3, our simulation results v alidate the µ P deriv ations in T able 2 across the dif ferent optimizers. Extensive numerical results, including training settings, HP values, depth scaling studies, and v alidation loss v alues for the different opti- mizers and model sizes can be found in Appendix B. The simulations on NanoGPT were performed using four A 100 GPUs of the Argonne Leadership Computing Facility’ s Polaris supercomputer (Leadership Computing Facility (b)), while the simulations on Llama2 were performed using 12 Intel Data Center GPU Max Series on the Aurora supercomputer (Leadership Computing Facility (a)). 6 C O N C L U S I O N W e hav e proposed a novel framework to derive µ P using spectral scaling conditions, which are more intuitiv e and easier to work with than the prev alent tensor programs. Using the proposed framew ork, we hav e deriv ed µ P for a wide range of adaptiv e, first and second-order optimizers including, AdamW , ADOPT , LAMB, Sophia, Shampoo and Muon. W e have implemented µ P for the abo ve optimizers on two benchmark LLMs, and v alidated our implementation by demonstrating zero-shot learning rate transfer . Motiv ated by our depth-scaling simulations (Appendix B), we aim to dev elop a sound theoretical framew ork for depth-scaling parameterization in the future. 10 Preprint A C K N OW L E D G M E N T S This research used resources of the Argonne Leadership Computing Facility , a U.S. Department of Ener gy (DOE) Of fice of Science user facility at Argonne National Laboratory and is based on research supported by the U.S. DOE Office of Science-Advanced Scientific Computing Research Program, under Contract No. DE-A C02-06CH11357. Gov ernment License. The submitted manuscript has been created by UChicago Argonne, LLC, Operator of Argonne National Laboratory (“ Argonne”). Argonne, a U.S. Department of Energy Office of Science laboratory , is operated under Contract No. DE-A C02-06CH11357. The U.S. Gov ernment retains for itself, and others acting on its behalf, a paid-up none xclusiv e, irrev ocable worldwide license in said article to reproduce, prepare deri vati ve works, distrib ute copies to the pub- lic, and perform publicly and display publicly , by or on behalf of the Go vernment. The Department of Ener gy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan. http://energy .gov/do wnloads/doe- public-access-plan. R E F E R E N C E S Jeremy Bernstein. Deriving muon. https://jeremybernste.in/writing/ deriving- muon , 2025. Jeremy Bernstein, Y u-Xiang W ang, Kamyar Azizzadenesheli, and Animashree Anandkumar . signsgd: Compressed optimisation for non-con vex problems. In International confer ence on ma- chine learning , pp. 560–569. PMLR, 2018. URL https://doi.org/10.48550/arXiv. 1802.04434 . Charlie Blake, Constantin Eichenberg, Josef Dean, Lukas Balles, Luke Y uri Prince, Bj ¨ orn Deis- eroth, Andres Felipe Cruz-Salinas, Carlo Luschi, Samuel W einbach, and Douglas Orr . u- $ \ mu$p: The unit-scaled maximal update parametrization. In The Thirteenth International Con- fer ence on Learning Representations , 2025a. URL https://openreview.net/forum? id=P7KRIiLM8T . Charlie Blake, Constantin Eichenberg, Josef Dean, Lukas Balles, Luke Y uri Prince, Bj ¨ orn Deiseroth, Andres Felipe Cruz-Salinas, Carlo Luschi, Samuel W einbach, and Douglas Orr . u- \ µ p: The unit- scaled maximal update parametrization. In The Thirteenth International Confer ence on Learning Repr esentations , 2025b. Nolan Dey , Bin Claire Zhang, Lorenzo Noci, Mufan Li, Blake Bordelon, Shane Ber gsma, Cengiz Pehlev an, Boris Hanin, and Joel Hestness. Don’t be lazy: Completep enables compute-efficient deep transformers. arXiv pr eprint arXiv:2505.01618 , 2025. URL https://doi.org/10. 48550/arXiv.2505.01618 . Priya Goyal, Piotr Doll ´ ar , Ross Girshick, Pieter Noordhuis, Lukasz W esolowski, Aapo Kyrola, An- drew T ulloch, Y angqing Jia, and Kaiming He. Accurate, large minibatch sgd: T raining imagenet in 1 hour . arXiv pr eprint arXiv:1706.02677 , 2017. V ineet Gupta, T omer Koren, and Y oram Singer . Shampoo: Preconditioned stochastic tensor opti- mization. In International Confer ence on Machine Learning , pp. 1842–1850. PMLR, 2018. URL https://doi.org/10.48550/arXiv.1802.09568 . Elad Hof fer , Itay Hubara, and Daniel Soudry . T rain longer , generalize better: closing the generaliza- tion gap in lar ge batch training of neural networks. In Advances in Neur al Information Pr ocessing Systems , pp. 1731–1741, 2017. Roger A Horn and Charles R Johnson. Matrix analysis . Cambridge univ ersity press, 2012. Satoki Ishikawa and Ryo Karakida. On the parameterization of second-order optimization effecti ve tow ards the infinite width. In The T welfth International Conference on Learning Repr esentations . Keller Jordan, Y uchen Jin, Vlado Boza, Jiacheng Y ou, Franz Cesista, Lak er Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. Cited on , pp. 10, 2024. URL https://kellerjordan.github.io/posts/muon/ . 11 Preprint Jared Kaplan, Sam McCandlish, T om Henighan, T om B Brown, Benjamin Chess, Re won Child, Scott Gray , Alec Radford, Jeffrey W u, and Dario Amodei. Scaling laws for neural language models. arXiv preprint , 2020. Andrej Karpathy . NanoGPT. https://github.com/karpathy/nanoGPT , 2022. Alex Krizhe vsky . One weird trick for parallelizing con volutional neural networks. arXiv preprint arXiv:1404.5997 , 2014. Argonne Leadership Computing Facility . Aurora. https://www.alcf.anl.gov/aurora , a. Argonne Leadership Computing F acility . Polaris. https://www.alcf.anl.gov/polaris , b. Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and T engyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. arXiv pr eprint arXiv:2305.14342 , 2023. URL https://doi.org/10.48550/arXiv.2305.14342 . Jingyuan Liu, Jianlin Su, Xingcheng Y ao, Zhejun Jiang, Guokun Lai, Y ulun Du, Y idao Qin, W eixin Xu, Enzhe Lu, Junjie Y an, et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982 , 2025. URL https://doi.org/10.48550/arXiv.2502.16982 . Ilya Loshchilov and Frank Hutter . Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 , 2017. URL https://doi.org/10.48550/arXiv.1711.05101 . Sam McCandlish, Jayesh Narang, Dario Amodei, and Jared Kaplan. An empirical model of lar ge- batch training. arXiv preprint , 2018. Carl D Meyer . Matrix analysis and applied linear algebra . SIAM, 2023. Mark Rudelson and Roman V ershynin. Non-asymptotic theory of random matrices: extreme singu- lar v alues. In Pr oceedings of the International Congr ess of Mathematicians 2010 (ICM 2010) (In 4 V olumes) V ol. I: Plenary Lectur es and Cer emonies V ols. II–IV : In vited Lectur es , pp. 1576–1602. W orld Scientific, 2010. Gilbert Strang. Linear algebra and its applications . 2012. Shohei T aniguchi, Keno Harada, Gouki Minegishi, Y uta Oshima, Seong Cheol Jeong, Go Naga- hara, T omoshi Iiyama, Masahiro Suzuki, Y usuke Iwasa wa, and Y utaka Matsuo. Adopt: Modified adam can con ver ge with any β 2 with the optimal rate. Advances in Neural Information Pr ocess- ing Systems , 37:72438–72474, 2024. URL https://doi.org/10.48550/arXiv.2411. 02853 . Benjamin Th ´ erien, Charles- ´ Etienne Joseph, Boris Knyaze v , Edouard Oyallon, Irina Rish, and Eu- gene Belilovsky . µ lo: Compute-ef ficient meta-generalization of learned optimizers. In OPT 2024: Optimization for Machine Learning . URL https://doi.org/10.48550/arXiv. 2406.00153 . Hugo T ouvron, Louis Martin, K evin Stone, Peter Albert, Amjad Almahairi, Y asmine Babaei, Niko- lay Bashlykov , Soumya Batra, Prajjwal Bharga va, Shruti Bhosale, et al. Llama 2: Open founda- tion and fine-tuned chat models. arXiv preprint , 2023. Roman V ershynin. High-dimensional pr obability: An introduction with applications in data science , volume 47. Cambridge uni versity press, 2018. Greg Y ang and Edward J Hu. Feature learning in infinite-width neural networks. arXiv pr eprint arXiv:2011.14522 , 2020. URL https://doi.org/10.48550/arXiv.2011.14522 . Greg Y ang, Edward Hu, Igor Bab uschkin, Szymon Sidor, Xiaodong Liu, Da vid F arhi, Nick Ryder, Jakub Pachocki, W eizhu Chen, and Jianfeng Gao. T uning large neural networks via zero-shot hyperparameter transfer . Advances in Neural Information Pr ocessing Systems , 34:17084–17097, 2021. URL https://doi.org/10.48550/arXiv.2203.03466 . 12 Preprint Greg Y ang, James B Simon, and Jeremy Bernstein. A spectral condition for feature learning. arXiv pr eprint arXiv:2310.17813 , 2023a. URL https://doi.org/10.48550/arXiv.2310. 17813 . Greg Y ang, Dingli Y u, Chen Zhu, and Soufiane Hayou. T ensor programs vi: Feature learning in infinite-depth neural networks. arXiv pr eprint arXiv:2310.02244 , 2023b. URL https://doi. org/10.48550/arXiv.2310.02244 . Y ang Y ou, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar , Srinadh Bhojanapalli, Xiaodan Song, James Demmel, Kurt Keutzer , and Cho-Jui Hsieh. Lar ge batch optimization for deep learning: Training bert in 76 minutes. arXiv pr eprint arXiv:1904.00962 , 2019. URL https: //doi.org/10.48550/arXiv.1904.00962 . Chenyu Zheng, Xin yu Zhang, Rongzhen W ang, W ei Huang, Zhi Tian, W eilin Huang, Jun Zhu, and Chongxuan Li. Scaling diffusion transformers efficiently via µ p. arXiv preprint arXiv:2505.15270 , 2025. A D E R I V I N G µ P A . 1 µ P F O R A D O P T Recall that the update rule for ADOPT is the same as AdamW . The key difference lies in the se- quence in which the terms ˆ m ( t ) and ˆ v ( t ) are updated (T aniguchi et al. (2024)). From a theoretical perspectiv e, this does not change the order of magnitude of the gradient function Ψ( {∇ W l L} ) from that of AdamW , and hence, the parameterization deriv ed for AdamW also holds for ADOPT . A . 2 µ P F O R S H A M P O O ( D E T A I L E D ) W e present a more detailed deriv ation for Shampoo in this section. Recall the update rule for Shampoo (Gupta et al., 2018), W ( t +1) l = W ( t ) l − η ( t +1) L ( t ) l − 1 / 4 ∇ W l L R ( t ) l − 1 / 4 (Shampoo) where for some δ > 0 , L ( t ) l = L ( t − 1) l + ∇ W l L · ∇ W l L T ; L (0) l = δ I ∈ R n l × n l R ( t ) l = R ( t − 1) l + ∇ W l L T · ∇ W l L ; R (0) l = δ I ∈ R n l − 1 × n l − 1 From the spectral scaling condition in (5), we need to find c 1 , c 2 ∈ R such that || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 L ( t ) l − 1 / 4 ∇ W l L R ( t ) l − 1 / 4 ∗ = Θ r n l n l − 1 . 13 Preprint For one-step analysis, let δ = 0 . Then the above condition reduces to || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 ∇ W l L · ∇ W l L T − 1 / 4 ∇ W l L ∇ W l L T · ∇ W l L − 1 / 4 ∗ (1) ≤ η ( n l ) − c 1 ( n l − 1 ) − c 2 ∇ W l L · ∇ W l L T − 1 / 4 ∗ ∥∇ W l L∥ ∗ ∇ W l L T · ∇ W l L − 1 / 4 ∗ (2) = η ( n l ) − c 1 ( n l − 1 ) − c 2 Θ r n l − 1 n l ∇ W l L · ∇ W l L T − 1 / 4 ∗ ∇ W l L T · ∇ W l L − 1 / 4 ∗ = η Θ ( n l ) − c 1 − 1 2 ( n l − 1 ) − c 2 + 1 2 ∇ h l L · h T l − 1 h l − 1 · ∇ h l L T − 1 / 4 ∗ h l − 1 · ∇ h l L T ∇ h l L · h T l − 1 − 1 / 4 ∗ = η Θ ( n l ) − c 1 − 1 2 ( n l − 1 ) − c 2 + 1 2 || h l − 1 || 2 2 ∇ h l L · ∇ h l L T − 1 / 4 ∗ ||∇ h l L|| 2 2 h l − 1 · h T l − 1 − 1 / 4 ∗ = η Θ ( n l ) − c 1 − 1 2 ( n l − 1 ) − c 2 + 1 2 || h l − 1 || − 1 / 2 2 ∇ h l L · ∇ h l L T − 1 / 4 ∗ ||∇ h l L|| − 1 / 2 2 h l − 1 · h T l − 1 − 1 / 4 ∗ (3) = η Θ ( n l ) − c 1 − 1 2 ( n l − 1 ) − c 2 + 1 2 Θ( n − 1 / 4 l − 1 ) ∇ h l L · ∇ h l L T − 1 / 4 ∗ Θ( n 1 / 4 l ) h l − 1 · h T l − 1 − 1 / 4 ∗ = η Θ ( n l ) − c 1 − 1 4 ( n l − 1 ) − c 2 + 1 4 ∇ h l L · ∇ h l L T − 1 / 4 ∗ h l − 1 · h T l − 1 − 1 / 4 ∗ (4) = η Θ ( n l ) − c 1 − 1 4 ( n l − 1 ) − c 2 + 1 4 ||∇ h l L|| − 1 / 2 2 || h l − 1 || − 1 / 2 2 (5) = η Θ ( n l ) − c 1 − 1 4 ( n l − 1 ) − c 2 + 1 4 Θ( n 1 / 4 l )Θ( n − 1 / 4 l − 1 ) = η Θ ( n l ) − c 1 ( n l − 1 ) − c 2 where (1) follows from sub-multiplicative property of matrix norms, (2) follo ws from Remark 3, (3) and (5) follow from condition (C.1.) and Remark 3, (4) follows from property (1) and property (2). Therefore, condition (5) is satisfied by fixing c 1 = − 1 / 2 and c 2 = 1 / 2 . A . 3 µ P F O R M U O N Muon is one of the first optimizers to implicitly adopt a width-independent update rule by scaling the learning rate with a factor of q n l n l − 1 . Therefore, intuitiv ely , we do not expect any further scaling of the learning rate under µ P . This conjecture is v alidated through the following analysis on the most recent version of Muon. Recall the update rule for Muon (Bernstein, 2025; Jordan et al., 2024), W ( t +1) l = W ( t ) l − η ( t +1) r n l n l − 1 O ( t ) l (Muon) where O ( t ) l = NewtonSchulz ( B ( t ) l ) B ( t ) l = µ B ( t − 1) l + ∇ W ( t ) l L ; B (0) l = 0 From the spectral scaling condition in eq. (5), we need to find c 1 , c 2 ∈ R such that || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 r n l n l − 1 O l ∗ = Θ r n l n l − 1 (9) 14 Preprint In this analysis we are working directly with an orthogonal matrix O ( t ) l ∈ R n l × n l − 1 and the spectral norm of an orthogonal matrix is 1 because the modulus of all its eigen v alues is 1 Horn & Johnson (2012). || ∆ W l || ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 r n l n l − 1 O ( t ) l ∗ = η ( n l ) − c 1 ( n l − 1 ) − c 2 r n l n l − 1 . Then condition (5) holds if c 1 = c 2 = 0 . Fig. 5 demonstrates the zero-shot learning rate transfer as well as the ”wider is better” phenomenon for Muon. Note that the initial implementation of Muon did not incorporate the scaling factor q n l n l − 1 in the update rule, but the proven equiv alence between Muon and Shampoo leads to Muon ha ving the same µ P scaling as Shampoo (Jordan et al., 2024). Figure 5: µ P for Muon (trained on Llama2) - Coordinate check plots for the word embedding and output logits layers (left); Zero-shot learning rate transfer across increasing model width (middle); Decreasing training loss with increasing model width (right). B S I M U L A T I O N S Consistent with existing literature, we first verify µ P for ADOPT , Sophia, LAMB and Shampoo optimizers by implementing the deriv ed parameterization scheme (T able 2) in the NanoGPT code- base Karpathy (2022). Although prior w orks hav e already implemented µ P for AdamW , we present the results again for completeness. T able 3 lists some of the settings for our experimental setup to test µ P on NanoGPT . Further , we demonstrate the effecti veness for AdamW , ADOPT , LAMB and Sophia on the Llama2 model, the experimental setup for which is listed in T able 15. W e also present simulation results for depth-scaling parameterization for the abov e optimizers on NanoGPT , using the implementation suggested in Y ang et al. (2023b) and Dey et al. (2025). Note that deri ving proper depth-scaling parameterization for dif ferent optimizers is an ongoing work, and we only present preliminary results on the NanoGPT codebase in Section B.2 to moti vate further theoretical analysis. T able 4 lists some of the settings for our e xperimental setup to test the depth- scaling parameterization. The remainder of this section documents the simulation results for AdamW (Subsection B.2.1 and Subsection B.3.1), ADOPT (Subsection B.2.2 and Subsection B.3.2), Sophia (Subsection B.2.3 and Subsection B.3.4), LAMB (Subsection B.2.4 and Subsection B.3.3) and Shampoo (Subsection B.2.5) optimizers. For each optimizer we first present the coordinate check plots under standard pa- rameterization, µ P and depth-scaling parameterization. These plots serve as a quick implementation check to monitor whether the weights blow-up, diminish to zero or remain stable with increasing model size (see discussion in (Y ang et al., 2021, Section D.1, pg. 27)). W e then provide tables and plots listing the validation loss for different learning rates, and increasing model width and model 15 Preprint depth. The values in the tables for NanoGPT are the a verage loss values observed over multiple runs. While we do not document the standard de viations in the tables, they are highlighted in the plots. Note that since we are using an early stopping criterion for simulations performed on NanoGPT , we rely more on the observ ations gained from the validation loss data than the training loss data. Similar validation loss tables are documented for simulations performed on Llama2. B . 1 D I S C U S S I O N S Overall, it is observed that the implementation of µ P following T able 2 is quite stable with increasing model width. This is illustrated in the coordinate check plots for all the optimizers (Figs. 6 - 10 and Figs. 14 - 17 ). Under standard parameterization, the top row of the coordinate check plots shows that the relative mean of the feature v ectors blo w-up with increasing model width. W ith the incorporation of µ P in the codebase, the relativ e mean values of the feature vectors stabilize with increasing model width (middle row of coordinate check plots). It is interesting to note that since the theoretical underpinnings for µ P hold in infinite width (Y ang & Hu (2020)), the model width has to be “large enough” for the coordinate check plots to stabilize. This is especially observed in the coordinate check plots for LAMB (Fig. 9 and Fig. 16) where the mean values of the feature vectors initially increase, but gradually stabilize with increasing model width. This phenomenon is also observed in Fig. 2 which demonstrate the zero-shot learning rate transfer across model width on the NanoGPT model. In the minimum validation loss tables for ADOPT (T able 7) and LAMB (T able 11) the optimal value of the learning rate gradually stabilizes after a width of 256, whereas for AdamW (T able 5) and Sophia (T able 9) the optimal learning rate stabilizes after a width of 128. These inconsistencies across optimizers also suggest that introducing a “base model width” for µ P scalings will introduce another HP . Therefore, we fix the value of the base model width to 1 in our implementation. In comparison to NanoGPT , the width scaling plots (Fig. 3) for Llama2 sho w that the model is “lar ge enough” for the optimal learning rate to stabilize from the smallest model width of 128 . This is perhaps because for width of 128 , the total number of parameters in Llama2 is significantly higher than the total number of parameters in NanoGPT . The second set of simulations empirically ev aluate the performance of the depth-scaling parameteri- zation in existing works (Y ang et al. (2023b); Dey et al. (2025)). The coordinate check plots (bottom row) for depth-scaling demonstrate that the feature vectors are stable with increasing model depth. In the coordinate check plots for ADOPT and LAMB (Figs. 7 and 9) the feature vectors stabilize after a depth of 16, while for AdamW , Sophia and Shampoo (Figs. 6, 8 and 10) the feature vectors are stable for shallow depths too. This phenomenon is similar to our observations for µ P , because the depth-scaling parameterization is also deri ved for an infinite depth limit (Y ang et al. (2023b)). Therefore, to prevent tuning an additional “base model depth” HP , we fix its v alue to 1 in our simula- tion setup. Howev er , the loss plots in Figs. 11, 12 and 13 do not consistently demonstrate zero-shot learning rate transfer across increasing model depths. While the v alidation loss tables for AdamW (T able 6) and Sophia (T able 10) demonstrate that the optimal value of the learning rate stabilizes for deep models, the same is not observed for ADOPT (T able 8), LAMB (T able 12) and Shampoo (T able 14), where the value of the optimal learning rate oscillates as the depth is increased. These results suggest that deriving depth-scaling parameterization for different optimizers needs a more thorough theoretical analysis. Additionally , performing simulations on a finer grid of learning rates can also giv e further insights into the depth-scaling behavior . B . 2 µ P O N N A N O G P T B . 2 . 1 A DA M W O P T I M I Z E R 16 Preprint T able 3: Hyperparameter v alues and training settings to test µ P on NanoGPT model. Architecture NanoGPT Karpathy (2022) W idth 128 (scaled to 2048) Depth 8 Number of heads 2 T otal parameters 1.59 M (scaled to 403 M) Dataset T iny Shakespeare V ocab size 65 T okens per iteration 8192 Batch size 2 Stopping criteria Early stopping if validation loss doesnot impro ve in last 150 iterations Optimizers AdamW / ADOPT / LAMB / Sophia / Shampoo Hyperparameter search range η ∈ [2 × 10 − 1 , 2 × 10 − 5 ] T able 4: Hyperparameter v alues and training settings to test depth-scaling parameterization on NanoGPT model. Architecture NanoGPT Karpathy (2022) W idth 256 Depth 2 (scaled to 64) T otal parameters 1.6 M (scaled to 50.56 M) Dataset T iny Shakespeare V ocab size 65 T okens per iteration 8192 Batch size 2 Stopping criteria Early stopping if validation loss doesnot impro ve in last 150 iterations Optimizers AdamW / ADOPT / LAMB / Sophia / Shampoo Hyperparameter search range η ∈ [2 × 10 − 1 , 2 × 10 − 5 ] Figure 6: Coordinate check plots for AdamW under standard parameterization (top row), µ P (middle row); depth scaling (bottom ro w) for NanoGPT model. 17 Preprint T able 5: Mean v alidation loss for increasing model width and different learning rates for AdamW on NanoGPT model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 2 × 10 − 1 2.54111195 2.54770319 2.50132585 2.53559383 2.45719266 2 × 10 − 2 2.57009896 2.56583707 2.57900651 2.53385917 2.51431378 2 × 10 − 3 2.63474766 2.6022807 2.64679337 2.63449661 2.55710355 2 × 10 − 4 3.38827054 3.5544157 3.38896998 3.44941664 3.44561863 2 × 10 − 5 4.09221347 4.08871428 4.05257797 4.08837303 4.08405908 T able 6: Mean v alidation loss for increasing model depth and different learning rates for AdamW on NanoGPT model. The minimum loss for each depth is highlighted in green. LR / Depth 2 4 8 16 32 64 2 × 10 − 1 2.53525917 2.55192765 2.53510944 2.50357556 2.51294963 2.53008548 5 × 10 − 2 2.52700798 2.49422677 2.50334986 2.29428236 2.45176029 2.36860998 2 × 10 − 2 2.55682977 2.52176666 2.56583563 2.30422862 2.45500112 2.5650301 2 × 10 − 3 2.59745781 2.63078475 2.60228316 2.61588136 2.64065663 2.65051214 2 × 10 − 4 3.41396125 3.41677833 3.55441554 3.45801504 3.43285489 3.47577778 2 × 10 − 5 4.09297959 4.05970796 4.08871428 4.08113146 4.06712834 4.10902596 B . 2 . 2 A D O P T O P T I M I Z E R Figure 7: Coordinate check plots for ADOPT optimizer under SP (top ro w); µ P (middle row); depth scaling (bottom row) for NanoGPT model. 18 Preprint T able 7: Mean v alidation loss for increasing model width and different learning rates for ADOPT on NanoGPT model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 2 × 10 − 1 2.55120134 2.54616404 2.54178079 2.5524296 2.54457998 7 × 10 − 2 2.48560476 2.44316975 2.37087123 2.50733534 2.50883015 2 × 10 − 2 2.43175697 2.58847451 2.57006375 2.54323697 2.53191725 2 × 10 − 3 2.63016931 2.6073552 2.65681744 2.66118956 2.55337548 2 × 10 − 4 3.528404 3.49065232 3.49065232 3.42789133 3.43255997 2 × 10 − 5 4.09183598 4.08832375 4.0521698 4.08806594 4.08391444 T able 8: Mean v alidation loss for increasing model depth and different learning rates for ADOPT on NanoGPT model. The minimum loss for each depth is highlighted in green. LR / Depth 2 4 8 16 32 64 2 × 10 − 1 2.56129368 2.51452438 2.54788987 2.51456078 2.52271922 2.55469418 9 × 10 − 2 2.48695572 2.47477563 2.53124801 2.48145302 2.50687472 2.54724765 2 × 10 − 2 2.56718413 2.50419029 2.58847276 2.44447954 2.54996069 2.52524622 2 × 10 − 3 2.67992798 2.62949713 2.6073552 2.60433618 2.61753988 2.6286815 2 × 10 − 4 3.41052596 3.46538957 3.56757394 3.47856442 3.43608022 3.56190586 2 × 10 − 5 4.09267759 4.05929391 4.08832375 4.08074443 4.06675259 4.10877307 B . 2 . 3 S O P H I A O P T I M I Z E R Figure 8: Coordinate check plots for Sophia optimizer under SP (top row); µ P (middle row); depth scaling (bottom row) for NanoGPT model. 19 Preprint T able 9: Mean v alidation loss for increasing model width and different learning rates for Sophia on NanoGPT model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 2 × 10 − 1 3.0969398 2.57144117 2.56875261 2.62573036 2.57240287 2 × 10 − 2 2.27450609 2.27830847 2.31632638 2.53347905 1.98427689 2 × 10 − 3 2.5456597 2.61430057 2.5594302 2.54869485 2.65462987 2 × 10 − 4 3.35409013 3.54614369 3.36089802 3.35862382 3.36431138 2 × 10 − 5 4.08766381 4.08859126 4.06069756 4.08811712 4.08371623 T able 10: Mean v alidation loss for increasing model depth and different learning rates for Sophia on NanoGPT model. The minimum loss for each depth is highlighted in green. LR / Depth 2 4 8 16 32 64 2 × 10 − 1 2.5213503 3.01081316 3.22649105 3.34855215 3.24310446 3.12229093 2 × 10 − 2 2.4717048 2.27232289 2.24736114 2.47475751 2.46061246 1.93401444 2 × 10 − 3 2.54103192 2.58136233 2.61035593 2.610612 2.45068415 2.55488427 2 × 10 − 4 3.40887721 3.52765425 3.54587563 3.40669481 3.33997742 3.47574107 2 × 10 − 5 4.09267314 4.06576761 4.08859126 4.08140405 4.066552 4.10874732 B . 2 . 4 L A M B O P T I M I Z E R Figure 9: Coordinate check plots for LAMB optimizer under SP (top ro w); µ P (middle ro w); depth scaling (bottom row) for NanoGPT model. 20 Preprint T able 11: Mean v alidation loss for increasing model width and different learning rates for LAMB on NanoGPT model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 2 × 10 − 1 3.3306915 2.91992474 2.75658234 2.84724092 2.84511503 2 × 10 − 2 2.27427769 2.55330944 2.53250345 2.50694895 2.51612274 2 × 10 − 3 2.46762419 2.42723028 2.47571055 2.49152549 2.46575729 2 × 10 − 4 3.69672974 3.70961714 3.66877778 3.2370429 3.37923479 2 × 10 − 5 4.16929531 4.1694754 4.1684103 4.1674579 4.16771809 T able 12: Mean v alidation loss for increasing model depth and different learning rates for LAMB on NanoGPT model. The minimum loss for each depth is highlighted in green. LR / Depth 2 4 8 16 32 64 2 × 10 − 1 2.76534136 2.85949779 2.88115621 3.26932732 3.24093787 3.097018 2 × 10 − 2 2.50858307 2.51164389 2.55355501 2.33967662 2.48308444 2.11406271 7 × 10 − 3 2.45117172 2.46691815 2.50231234 2.45691435 2.48629936 2.45780365 2 × 10 − 3 2.50483624 2.54284684 2.42723123 2.43291903 2.43262172 2.42000318 2 × 10 − 4 3.6441706 3.79367606 3.70963343 3.57373738 3.61402575 3.42223287 2 × 10 − 5 4.16981506 4.1691486 4.1694754 4.16932933 4.16817395 4.16773876 B . 2 . 5 S H A M P O O O P T I M I Z E R Figure 10: Coordinate check plots for Shampoo optimizer under SP (top row); µ P (middle ro w); depth scaling (bottom row) for NanoGPT model. 21 Preprint T able 13: Mean validation loss for increasing model width and dif ferent learning rates for Shampoo on NanoGPT model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 1 × 10 − 2 2.64432065 3.00841006 3.26729711 3.39512682 4.17380921 9 × 10 − 3 2.6650331 2.89549454 3.20741065 3.45321918 3.41602135 5 × 10 − 3 2.63122805 2.67693043 3.30215279 3.32265353 3.36052688 3 × 10 − 3 2.67303157 2.85103401 3.37194387 3.46975843 3.49201838 1 × 10 − 3 2.90583165 2.97975628 3.61035117 3.57224735 3.72281067 T able 14: Mean validation loss for increasing model depth and dif ferent learning rates for Shampoo on NanoGPT model. The minimum loss for each depth is highlighted in green. LR / Depth 2 4 8 16 32 64 3 × 10 − 2 2.83468819 2.94637481 3.3811605 3.27378623 3.32534583 3.31375853 1 × 10 − 2 2.63917089 2.6383814 2.66823014 3.2278808 3.24864435 3.20088768 7 × 10 − 3 2.64190022 2.61007253 2.73991227 3.12863938 3.20985778 3.37485345 5 × 10 − 3 2.77703945 2.72295157 2.72794461 2.93629122 3.25431808 3.37258538 3 × 10 − 3 2.7143542 2.97368789 2.85365486 3.32030662 3.27988537 3.40830247 Figure 11: Mean v alidation loss for increasing model depth and dif ferent learning rates for AdamW (left) and ADOPT (right) on NanoGPT model. Figure 12: Mean validation loss for increasing model depth and dif ferent learning rates for LAMB (left) and Sophia (right) on NanoGPT model. 22 Preprint Figure 13: Mean validation loss for increasing model depth and dif ferent learning rates for Shampoo on NanoGPT model. B . 3 µ P O N L L A M A 2 T able 15: Hyperparameter v alues and training settings to test µ P on Llama2 model. Architecture Llama 2 W idth 256 (scaled to 2048) Depth 16 Number of attention heads 32 T otal parameters 154M (scaled to 1.38 B) Dataset W ikitext-103 Sequence length 4096 V ocab size 32000 T raining set tokens 100M Batch size 192 T raining steps 1026 LR decay style cosine rule, 51 steps warm-up Optimizer AdamW / ADOPT / LAMB / Sophia W eight decay 0.1 Dropout 0.0 µ P HP search range η ∈ [5 × 10 − 1 , 5 × 10 − 4 ] B . 3 . 1 A DA M W 23 Preprint Figure 14: Coordinate check plots for AdamW optimizer under SP (top row); µ P (middle row); depth scaling (bottom row) for Llama2 model. T able 16: V alidation loss for increasing model width and different learning rates for AdamW on Llama2 model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 5 × 10 − 1 4.55491 4.02676 3.81251 3.73573 3.79477 3 × 10 − 1 4.24978 3.90242 3.83252 3.89484 3.75046 1 × 10 − 1 4.48696 4.21314 4.05265 4.02101 3.95419 5 × 10 − 2 4.70421 4.4353 4.39753 4.34169 4.31635 1 × 10 − 1 5.57795 5.56284 5.56173 5.55771 5.55774 B . 3 . 2 A D O P T T able 17: V alidation loss for increasing model width and different learning rates for ADOPT on Llama2 model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 5 × 10 − 1 4.39033 4.02007 3.83932 3.77732 3.76814 3 × 10 − 1 4.11789 3.85536 3.72552 3.67802 3.66973 2 × 10 − 1 4.23765 3.87949 3.78242 3.80016 3.78846 1 × 10 − 1 4.32335 4.07597 3.9912 3.91654 3.95519 7 × 10 − 2 4.43819 4.22574 4.13565 4.06852 4.0683 5 × 10 − 2 4.64121 4.38096 4.31582 4.22186 4.21248 24 Preprint Figure 15: Coordinate check plots for ADOPT optimizer under SP (top row); µ P (middle row); depth scaling (bottom row) for Llama2 model. B . 3 . 3 L A M B Figure 16: Coordinate check plots for LAMB optimizer under SP (top row); µ P (middle ro w); depth scaling (bottom row) for Llama2 model. 25 Preprint T able 18: V alidation loss for increasing model width and different learning rates for LAMB on Llama2 model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 3 × 10 − 2 7.18452 6.35059 6.0384 6.52966 6.13429 1 × 10 − 2 5.58878 5.5638 5.56049 5.79174 6.01439 5 × 10 − 3 6.57476 6.60454 6.66398 6.98093 7.0471 1 × 10 − 3 10.25112 10.23998 10.22575 10.21199 10.19599 5 × 10 − 4 10.32997 10.32776 10.32398 10.32062 10.31677 B . 3 . 4 S O P H I A Figure 17: Coordinate check plots for Sophia optimizer under SP (top ro w); µ P (middle ro w); depth scaling (bottom row) for Llama2 model. T able 19: V alidation loss for increasing model width and different learning rates for Sophia on Llama2 model. The minimum loss for each width is highlighted in green. LR / W idth 128 256 512 1024 2048 5 × 10 − 1 7.19403 6.99576 6.68992 6.60376 6.31375 3 × 10 − 1 6.17604 5.90826 5.80694 5.6738 5.71962 1 × 10 − 1 4.14122 3.83654 3.75926 3.67419 3.62891 7 × 10 − 2 4.42758 4.31702 4.05756 3.93561 3.94189 5 × 10 − 2 4.76632 4.51022 4.41358 4.34452 4.30914 3 × 10 − 2 4.82305 4.79592 4.73067 4.67473 4.74689 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment