Hierarchic-EEG2Text: Assessing EEG-To-Text Decoding across Hierarchical Abstraction Levels
An electroencephalogram (EEG) records the spatially averaged electrical activity of neurons in the brain, measured from the human scalp. Prior studies have explored EEG-based classification of objects or concepts, often for passive viewing of briefly…
Authors: Anupam Sharma, Harish Katti, Prajwal Singh
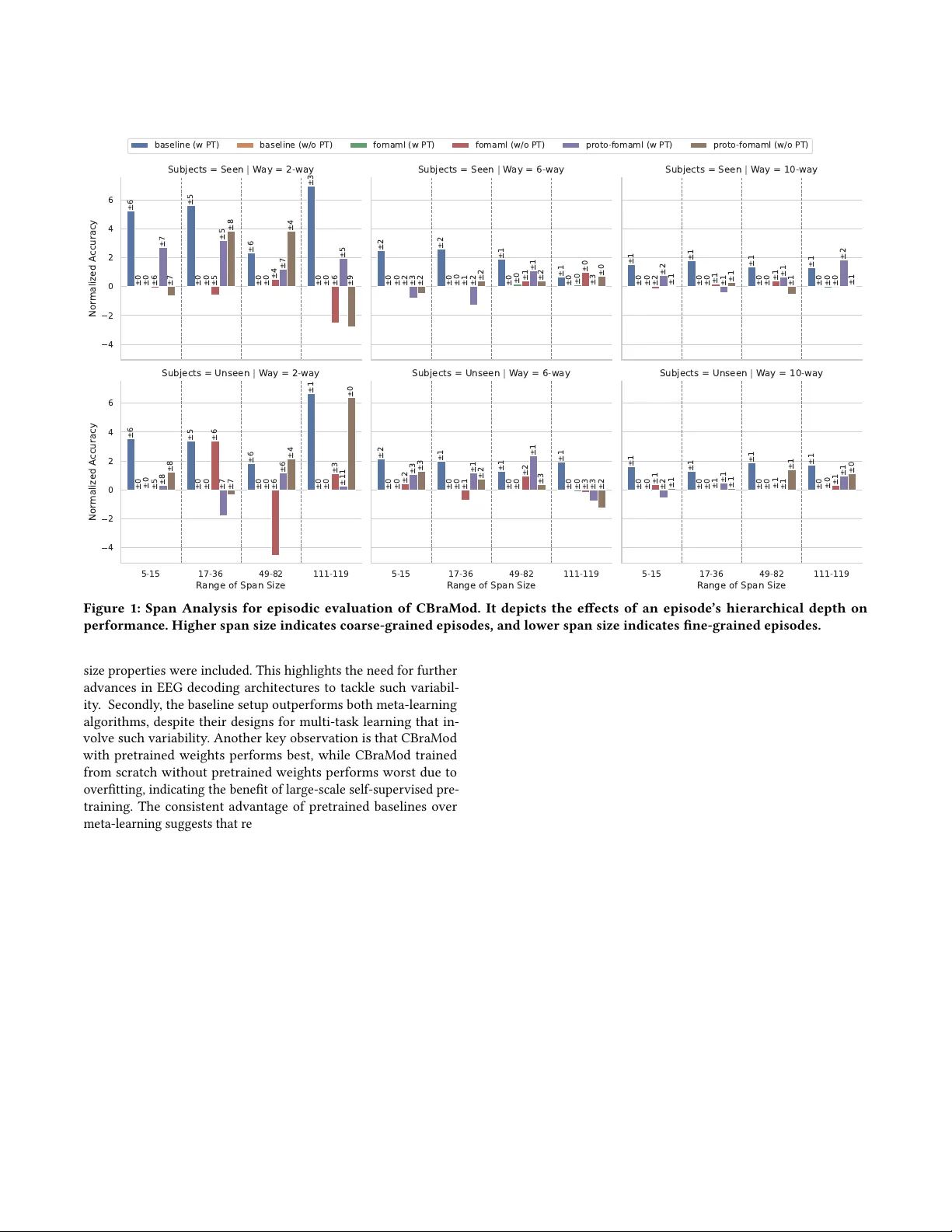
Hierarchic-EEG2T ext: Assessing EEG- T o- T ext Deco ding across Hierarchical Abstraction Levels Anupam Sharma sharmaanupam@iitgn.ac.in II T Gandhinagar Gandhinagar, Gujarat, India Harish Katti kattih2@nih.gov NIMH, NIH USA Prajwal Singh singh_prajwal@iitgn.ac.in II T Gandhinagar Gandhinagar, Gujarat, India Shanmuganathan Raman shanmuga@iitgn.ac.in II T Gandhinagar Gandhinagar, Gujarat, India Krishna Miyapuram kprasad@iitgn.ac.in II T Gandhinagar Gandhinagar, Gujarat, India Abstract An electroencephalogram (EEG) records the spatially averaged elec- trical activity of neurons in the brain, measured from the human scalp. Prior studies hav e explored EEG-based classication of ob- jects or concepts, often for passiv e viewing of briey presented image or video stimuli, with limited classes. Because EEG exhibits a low signal-to-noise ratio, recognizing ne-grained representations across a large number of classes remains challenging; howev er , abstract-level object representations may exist. In this work, we investigate whether EEG captures object representations across multiple hierarchical le vels, and pr op ose episodic analysis, in which a Machine Learning (ML) model is evaluated across various, yet related, classication tasks (episodes). Unlike prior episodic EEG studies that rely on xed or randomly sampled classes of equal cardi- nality , we adopt hierarchy-aware episode sampling using W ordNet to generate episodes with variable classes of diverse hierarchy . W e also present the largest episodic framework in the EEG domain for detecting obser ved text from EEG signals in the PEERS dataset, com- prising 931538 EEG samples under 1610 obje ct labels, acquired from 264 human participants (subjects) performing controlled cognitive tasks, enabling the study of neural dynamics underlying p erception, decision-making, and performance monitoring. W e examine how the semantic abstraction level aects classi- cation performance across multiple learning techniques and archi- tectures, providing a comprehensiv e analysis. The mo dels tend to improve performance when the classication categories are drawn from higher levels of the hierarchy , suggesting sensitivity to abstrac- tion. Our work highlights abstraction depth as an underexplor e d dimension of EEG decoding and motivates future research in this direction. CCS Concepts • Applied computing → Bioinformatics ; • Computing method- ologies → Multi-task learning . Ke y words EEG2T ext, BCI, Hierarchical Modeling, Meta-Learning 1 Introduction Electroencephalography (EEG) is a non-invasive and cost-eective technique for measuring electrical activity in the human brain. EEG records spatially averaged electrical activity across the dendrites of neurons in the underlying brain tissue, measured from the human scalp via electrodes [ 6 ]. Due to spatial averaging, EEG do es not capture all underlying neural activity , limiting the amount of ne- grained information that can be recovered from the signal [6]. Despite these limitations, several studies hav e attempte d to de- velop machine learning (ML) models that map EEG signals to the corresponding stimuli. Often, the stimuli are visual, and EEG is recorded while humans passively view images from a xed set of categories. In these settings, ML models are trained to classify EEG signals into the corresponding category [ 15 , 23 , 24 , 27 , 30 , 38 ], where the number of categories typically ranges from 10 to 80 . In other studies, EEG signals are mapped to visually presented words or text [ 12 , 13 , 18 , 28 ], where the number of categories equals the vocabulary size, which can be in the thousands. For example , the Zuco dataset [12] contains approximately 21 K wor ds. While these studies demonstrate that EEG contains information related to the presented stimulus, our ndings show that decoding performance degrades as the number of categories increases. This raises a fundamental question: rather than asking if EEG can sup- port ne-grained classication o ver a large label space, we ask ho w much information it captures at varying levels of abstraction. Prior work in cognitive neuroscience has shown that neural r epresenta- tions of objects during visual processing evolve hierarchically ov er time [ 3 , 5 ]. Howev er , most EEG deco ding studies evaluate perfor- mance using a at label space, without e xplicitly considering the semantic hierarchy among categories. W e further note that many existing datasets rely on abrupt pr esentation of visual stimuli, such as images or videos, during passive viewing tasks. Such stimuli are likely to elicit stereotyped brain responses across large regions [ 35 ], which may benet classication models but may not reect real- world perception, decision-making, or performance monitoring. In contrast, tasks involving real-world object concepts are likely to introduce greater subjectivity across participants. In this work, we investigate whether EEG captures abstract, hierarchical r epresenta- tions of objects during such challenging real-world tasks. Instead of evaluating models jointly across all categories, we propose an episodic evaluation framework in which each episode consists of a smaller classication task. Unlike most episodic learning studies in the EEG domain, which construct episodes from random samples, we design episodes that follow a semantic hierarchy . This allows us to probe EEG representations at multiple lev els of abstraction. 1 Anupam Sharma, Harish Kai, Prajwal Singh, Shanmuganathan Raman, and Krishna Miyapuram T o this end, we leverage the Penn Electrophysiology of Encoding and Retrieval Study (PEERS) dataset [ 14 ], which consists of EEG sig- nals recorded while participants viewed approximately 1 . 6 K words representing real-world objects. The large vocabulary and num- ber of samples make this dataset suitable for episodic analysis. T o construct the semantic hierarchy , we use NLTK’s W ordNet [ 2 , 32 ], which links words and concepts via the IS- A relationship. W ordNet groups synonyms into synsets, and synsets are connected via IS- A relations, which we use to build a Directed Acyclic Graph (D AG). The leaf nodes correspond to words in the PEERS dataset, while internal nodes represent synsets. Each internal node denes a clas- sication task over its descendant leaf nodes, and sampling nodes at dierent depths of the D AG yields episodes at varying levels. By using this strategy , we construct the largest episodic EEG-to- text decoding framework, comprising 931538 EEG samples under 1610 labels from 264 subje cts. W e evaluate both non-episodic and episodic approaches, including meta-learning algorithms, across multiple modern architectures. Our results sho w that while mod- ern architectures (e ven with self-supervised pretraining) fail under non-episodic evaluation, they perform comparatively better , though near chance, under hierarchical episodic evaluation. Moreover , per- formance improves as ne-grained classes are r eplace d with more abstract classes. These ndings suggest that while EEG may not capture ne-grained representations, it does encode information at higher levels of semantic abstraction. Our contribution is a con- trolled evaluation framework that systematically e xamines which levels of semantic abstraction are accessible from the EEG during realistic cognitive tasks. 2 Background This se ction briey introduces the evaluation and learning ap- proaches used in our work. 2.1 Episodic V s Non-Episodic Evaluation 2.1.1 Non-Episodic Evaluation. In this work, we refer to the evalu- ation of an ML model in a typical classication task as non-episodic evaluation. Assume a Deep Neural Network (DNN) model trained for classifying samples into a set of classes 𝐶 𝑡 𝑟 𝑎𝑖𝑛 . When the model is evaluated on the task, the set of classes in the test set 𝐶 𝑒 𝑣 𝑎𝑙 typ- ically remains the same as 𝐶 𝑡 𝑟 𝑎𝑖𝑛 , and the numb er of units in the network’s last layer doesn’t change during testing. 2.1.2 Episodic Evaluation. Assume a DNN model trained for classi- fying samples into a set of classes 𝐶 𝑡 𝑟 𝑎𝑖𝑛 is tested on a new classi- cation task with a set of classes 𝐶 𝑒 𝑣 𝑎𝑙 where | 𝐶 𝑒 𝑣 𝑎𝑙 − 𝐶 𝑡 𝑟 𝑎𝑖𝑛 | ≥ 1 . In such cases, the last layer needs to be replaced with number of units equal to 𝐶 𝑒 𝑣 𝑎𝑙 and the model parameters needs to be update d using set of some samples S = { ( x 1 , 𝑦 1 ) , ( x 2 , 𝑦 2 ) , . . . ( x 𝐾 , 𝑦 𝐾 ) } from the new task and then the performance is e valuate d on the set of un- seen samples of that task Q = { ( x ∗ 1 , 𝑦 ∗ 1 ) , ( x ∗ 2 , 𝑦 ∗ 2 ) , . . . ( x ∗ 𝑇 , 𝑦 ∗ 𝑇 ) } . Here S and Q are known as the Support Set and Query Set respectively . When, | 𝐶 𝑒 𝑣 𝑎𝑙 | = 𝑁 and the numb er of samples p er class, 𝑘 𝑐 = 𝑘 , we refer the task as " 𝑁 -way , 𝑘 -shot" classication task. When a model is evaluated on numerous such tasks independently , we call it episodic evaluation, where each task is referred to as an episode. 2.2 Episodic Learning Approaches There exist many episodic learning approaches, out of which w e focus mainly on meta-learning algorithms. Meta-learning is the ability of a model (or learner) to gain experience across multiple tasks (or episodes), such that, given a new episode with a very few samples, it quickly adapts. Here, we select episodic gradient- based meta-learning appr oaches, specically Model-A gnostic Meta- Learning (MAML) [ 10 ] and its variants. In the context of gradient- based methods, the term adapting quickly refers to a few parameter updates. Here, we briey describ e the meta-learning approaches used in this work: MAML [ 10 ] : Given an episode with 𝐾 classes and an emb ed- ding function 𝑓 ( ., 𝜃 ) , a learnable linear layer clf ( ., 𝜙 ) is added on it and trained on the support set of the episode via gradient descent iterations, and evaluated on the query set. This step is performed independently for each episode, and the loss on the query set across all training episodes is aggregated. Which is then backpropagated through within-episo de iterations to compute gradients of the quer y loss with respect to 𝜃 and 𝜙 . These gradient is then used to up date the parameters, and this is referred to as the meta-update. However , this involves computing second-order derivatives, which can b e computationally expensive. Hence , we use its rst-order approxi- mation, also known as fo-MAML [ 10 ], where the within-episode gradients are ignored during the meta-update. Proto-MAML [ 31 ] : Proto-MAML is inspired by Prototypical networks [ 25 ], where a prototype p i for class 𝑐 𝑖 is the average of the embeddings of the samples of the class 𝑐 𝑖 in the support set. A query sample is classied as class 𝑐 𝑖 if the embedding of the sample is nearest to its prototype p i in the Euclidean space. Snell et al . [25] explains that prototypical networks can be re-interpreted as a linear layer applied on the embe ddings from 𝑓 ( ., 𝜃 ) where the weights for the unit repr esenting the class 𝑐 𝑖 is w i = 2 p i and bias is 𝑏 𝑖 = − | | p i | | 2 . Proto-MAML uses this assignment of w i and 𝑏 𝑖 to initialize the parameters of clf ( ., 𝜙 ) . Here, we use the fo-MAML with the prototypical assignment of parameters of clf ( ., 𝜙 ) and refer to this version as proto-fo-MAML. 3 Related W ork Detecting observed or imagined text from EEG has been actively studied in the literature. Some earlier works have achieved go od per- formance in EEG-to- T ext decoding with closed-vocabular y datasets containing very few classes [ 20 , 22 ]. Recent works focus on open vocabulary EEG-to- T ext decoding with thousands of classes, wher e they either attempt to reconstruct [ 18 , 28 , 34 ] or semantically sum- marize [ 19 ] the text a p erson views on a screen from the EEG signals. Howev er , an EEG might not capture representations of each word, including all parts of speech, but it might capture representations of nouns corresponding to real objects. It is known that the human brain processes visual objects hierar chically [ 3 , 5 ]. Here, we explore whether representations of objects in the brain induce d via textual stimuli of the object follow a similar hierarchy . As far as hierarchical modelling is concerned, the works of Zhu et al . [38] and Triantallou et al . [31] are closely related to our work. Zhu et al . [38] created EEG-ImageNet, which is a dataset of EEG and image pairs across 80 classes, where 40 classes are coarse-grained, distinct classes from ImageNet [ 7 ], whereas the other 40 classes 2 Hierarchic-EEG2T ext: Assessing EEG- To- T ext Decoding across Hierarchical Abstraction Levels come from 5 groups corresponding to concepts in W ordNet with 8 categories each. How ever , EEG-ImageNet e xhibits a very limited hierarchy comprising only 5 concepts from W ordNet. In contrast, our test split contains 75 concepts, enabling a rigorous hierarchical study . Triantallou et al . [31] performs a similar strategy as ours to build a hierarchy . However , our goal diers fundamentally in terms of using hierarchy-aware episodes as a probing tool to analyze neural representations under var ying ontological abstraction, rather than training general-purpose few-shot learners. W e also perform rigorous hierarchical studies given a rich hierarchy in the test split, unlike [31]. Regarding episodic Learning in the EEG deco ding literature, most studies focus on cross-subject fe w-shot learning. As the EEG signal across subjects varies widely , they address this issue by treating each subject as an episo de and applying episodic meta-learning, enabling the models to adapt quickly to novel subjects [ 1 , 4 , 9 , 11 ]. In most cases, episodes have a limited lab els that remain xed across episodes. In a realistic scenario, this might not be the case; hence, we ne ed a more realistic organization of episo des, for which we adopt a hierarchical structure. 4 Hierarchic-EEG2T ext In this section, we elaborate on how we build the framework for assessing EEG-to- T ext deco ding across hierarchical abstraction levels. W e rst briey describe the dataset and the prepr o cessing pipeline, then describe building the concept hierarchy , and nally describe the episode sampling strategy . 4.1 Dataset W e used the PEERS dataset [ 14 ] for our experiments. The PEERS dataset consists of EEG signals r e corded while subjects observed English words displayed on the screen (and later recalled them) under varying conditions in which they performed de cision-making and arithmetic tasks, thereby inducing signal variability . The dataset consists of ve major experiments grouped into 3 sections: ltpFR , ltpFR2 , and VFFR , in which 300 + subjects contributed 7000 + sessions of 90 minutes each, observing words from a pool of 1638 English words. In this work, w e have used ltpFR and ltpFR2 groups, whose descriptions are provided in appendix Section A. 4.1.1 Alignment of Multiple Montage. EEG signals in the PEERS dataset were recorded using 3 dierent electrode layouts: (i) 129- channel GSN 200, (ii) 129-channel HydroCel GSN, and (iii) 128- channel BioSemi headcap. In this work, our main objective is to perform a hierarchical study of EEG-to- T ext, rather than montage- agnostic EEG processing. Although we use a recent montage ag- nostic architecture, for a fair comparison with traditional EEG architectures, we sele ct 96 channels so that all EEG data can be used in the study . For channel selection, we use one of the layouts as the reference layout and apply 𝑘 -nearest neighbor to nd the corresponding channel in the other layout. W e do so because not all subjects have EEG electrode placement in exactly the same way . There will always b e some variability in electrode placement across subjects and sessions due to dierences in head shape and manual headset use. An electrode 𝑥 may sometimes be placed closer to its neighbor 𝑦 and sometimes farther apart. The detailed steps involved in the selection of the channels are outlined as follows: Step 1: W e consider the BioSemi ABC layout (used by the 128- channel BioSemi headcap) as the reference layout. For each elec- trode in the reference , we nd 8 -near est neighbors in the other tw o (target) layouts using the known 𝑥 𝑦𝑧 -location of electrodes. This way we get a tuples in the form of ( 𝑒 𝑟 𝑖 , e t i ) where 𝑒 𝑟 𝑖 is an electrode in the reference layout and e t i is a list of neighbors in the target layout such that e t i 𝑗 is the 𝑗 𝑡 ℎ nearest neighbor of 𝑒 𝑟 𝑖 . Step 2: There might be a case where two electrodes in the r ef- erence layout have the same nearest neighbor . In other words, for 𝑖 ≠ 𝑗 , there may exist two tuples ( 𝑒 𝑟 𝑖 , e t i ) and ( 𝑒 𝑟 𝑗 , e t j ) such that e t i 1 = e t j 1 . W e use the Euclidean distance 𝑑 ( ., . ) to resolve such con- icts, and repeat this step 8 times. If the nearest-neighbor list is exhausted to only 1 electrode, we skip that tuple during conict resolution. If there are still duplicates, only one is r etaine d. Step 3: After de-duplication at step 2 , we select all tuples such that there exists a nearest neighbor for a reference ele ctrode in both the layouts. 4.1.2 Pre-processing. As we also study ar chite ctures pre-trained on the T UEG corpus [ 21 , 33 ], we follow pre-processing steps similar to those use d in [ 33 ], i.e. , (i) re-reference the data to the average, (ii) extract electrodes as per selection in Se ction 4.1.1 based on the layout, (iii) downsample to 200 Hz, (iv ) apply a band-pass lter from 0 . 3 − 75 Hz, (v) set the unit to 100 𝜇𝑉 . W e use d 1 -sec EEG signal window for each word in the dataset. 4.2 Hierarchy of Concepts In order to create a hierar chy of concepts, we used NLTK’s W ord- Net [ 2 , 32 ] interface to build a Directed Acyclic Graph (DA G) using the IS-A relationship. Key steps involved in the creation of DA G are as follows: Intializing the D AG. W e consider all the words in the PEERS Dataset [ 14 ] as the leaves of the D A G. For each leaf node, we use the closest synonym from the synset r eturned by W ordNet as the parent of the leaf node. Then, we use the hypernym-path from the root in W ordNet to the given synonym to create the path from the root to the leaf. W e discard all words whose synsets are not available in W ordNet, resulting in a DA G with a single root, where each leaf node corresponds to a word in the dataset and each internal node represents a W ordNet concept. Removal of Broad W ords. The set of wor ds in the PEERS dataset contains several words that ar e too broad ( e . g . animal, mam- mal, creature, and so on ) and are placed close to the root. In our experiments, we considered words with narrower meanings and discarded broader ones similar to W ordNet concepts. T o identify such words, w e compute the total number of siblings of each leaf node and subtract this numb er from the total number of leaf nodes reachable by the parent of the corresponding leaf node. If the r esult is too high ( ≥ 45 ), the word is possibly too broad. W e remov e such words from the D AG ( che ck appendix Section B for related details). D A Gs for Train- V al- T est Split. For meta-train we use data from “ltp_FR” and for meta-validation and meta-test , we use the 576 words from the “ltp_FR2” group of the PEERS dataset. This choice ensures that each task has sucient samples in b oth the support and query sets during episodic evaluation, as words in the “ltp_FR2” group are shown to each subje ct more times than those in the “ltp_FR” 3 Anupam Sharma, Harish Kai, Prajwal Singh, Shanmuganathan Raman, and Krishna Miyapuram group. W e retain all ( word, subje ct) pairs with ≥ 23 o ccurrences and remove these pairs from the meta-train split. The selected words and subjects are then randomly divided between the meta-validation and meta-test splits. Although initializing the DA G with all words helped lter out overly broad concepts, we reconstruct the DA G separately for each of the meta-train , meta-validation , and meta- test based only on the words assigne d to that split. This results in a meta-train split with 1126 words, 204 subjects, and 484832 samples; a meta-validation split with 92 words, 15 subjects, and 32393 samples; and a meta-test split with 392 words, 45 subjects, and 414313 samples. 4.3 Episode Sampling W e use the episode sampling method similar to that in [ 31 ]. W e present the key steps as follows: Sampling Classes. For each DA G, we rst identify the set of eligible internal nodes. W e discard nodes that are too close to the root (see appendix Section B) and retain internal nodes having at least 5 reachable leaf nodes. W e then uniformly sample one internal node from this eligible set and treat the leaf nodes reachable from it as the candidate classes. If the number of reachable leaf no des is ≥ 10 , we randomly select 10 words as the classes; otherwise, we use the entire set of reachable leaves. W e refer to the set of reachable leaves from an internal node as the "span" of the node, and to the span’s size as the "span length" . Shots for Quer y Set. Number of samples per class for the query set is kept constant across all episodes and is determined by Equa- tion (1). 𝑘 𝑞 = min n 10 , min 𝑐 ∈ C ⌊ 0 . 5 ∗ | S ( 𝑐 ) | ⌋ o (1) where S ( 𝑐 ) is the set of samples available for class 𝑐 and C is set of classes sampled for the episo de. Equation (1) ensures that at least half the samples for all classes considered in the episode are available for the support set. T otal Support Size. T o avoid a too large support set, the numb er of samples for each class is limited to at most 100. Sp ecically , the total support size is determined by Equation (2). | D 𝑠𝑢 𝑝 | = min n 100 , 𝑐 ∈ C ⌈ 𝛽 ∗ min { 100 , | S ( 𝑐 ) | − 𝑘 𝑞 }⌉ o (2) where 𝛽 is uniformly sampled from ( 0 , 1 ] , which ensures episodes of both large and small support sets. Shots for Support Set. First, the proportion of available samples per class that would contribute to the supp ort set is determined by the following normalized exponential function: 𝑅 𝑐 = exp ( 𝛼 𝑐 + log ( |S ( 𝑐 ) | ) ) Í 𝑐 ′ ∈ C exp ( 𝛼 𝑐 ′ + log ( |S ( 𝑐 ′ ) | ) ) (3) where 𝛼 𝑐 is uniformly sampled from [ log ( 0 . 5 ) , log ( 0 . 2 ) ) which brings in some noise in the distribution. Finally , the shots per class are determined as: 𝑘 𝑠𝑢 𝑝 𝑐 = min { ⌊ 𝑅 𝑐 ∗ ( | D 𝑠𝑢 𝑝 | − | C | ) ⌋ + 1 , | S ( 𝑐 ) | − 𝑘 𝑞 } (4) While sampling episodes for episodic training, we ensur e that the supp ort and query sets are disjoint not only within each episode but also across all episodes. During episodic evaluation, we iterated through all the eligible internal nodes, and for each such no de, we sampled I instances of episodes to ensure most leaves fr om the span are considered, wher e I 𝑚𝑒 𝑡 𝑎 − 𝑣𝑎𝑙 𝑖𝑑 𝑎𝑡 𝑖𝑜 𝑛 = 5 and I 𝑚𝑒 𝑡 𝑎 − 𝑡 𝑒 𝑠 𝑡 = 10 . W e report the mean and standard deviation of performances across all internal nodes. 4.4 Metrics For all experiments, we have r ep orted the "chance-adjusted accu- racy" or the "normalized accuracy" for classication tasks, so that the evaluation scale remains the same across 𝑁 -way classication tasks with varying 𝑁 . The normalized accuracy for an 𝑁 − 𝑤 𝑎 𝑦 classication task is dened as: Normalized Accuracy = 𝐴 − 1 𝑁 1 − 1 𝑁 ∗ 100 Where 𝐴 is either accuracy or balanced accuracy . A normalized accuracy of 0 is as poor as a random guess, while a negative value indicates performance poorer than a random guess. The closer the value is to 100 , the better . 5 Experiments and Results Our primary obje ctive is to study EEG-to- T ext decoding at various hierarchical levels. Through our experiments, we show that per- forming non-episodic e valuation with a large numb er of classes can be dicult for DNN models and that hierarchical episodic evalua- tion yields insights into various levels of abstraction. W e perform our experiments on three architectures: (i) EEGNet [ 17 ] is a tra- ditional EEG de coding architecture mainly built of convolution layers, (ii) NICE-EEG [ 26 ] is a modern EEG decoding architecture built with a spatial transformer followed by convolution layers, and (iii) CBraMod [ 33 ] is a foundational model pretrained on a large EEG corpus. W e used CBraMod, b oth with pre-trained (w PT) and without pre-trained (w/o PT) weights, to study the eect of self-supervise d pretraining. 5.1 Episodic Evaluation For episo dic evaluation, we trained the architectures in two dierent setups covering three algorithms: (i) Baseline , where we train the architectures with all the classes of meta-train together as a typical classication task in a non-episo dic manner , but perform validation and evaluation in an episo dic manner as described in Section 4.3, (ii) Episodic learning, wher e we train the architectures using fo-MAML and proto-fo-MAML. T able 1 sp ecies overall episodic performance for 2 − 𝑤 𝑎𝑦 , 6 − 𝑤 𝑎𝑦 , and 10 − 𝑤 𝑎𝑦 episodes. This also reects the episo dic performance on unseen classes and subjects, as the sets of classes and subjects for meta-train , meta-val , and meta-test are disjoint. The key obser- vations are that object categorization fr om brain-wide EEG activity during real-world tasks is very challenging, and that there is modest improvement in performance compared to non-episodic evalua- tion, as shown in T able 3, suggesting better performance in some episodes. The near-chance p erformance, specically on 6 − 𝑤 𝑎𝑦 and 10 − 𝑤 𝑎𝑦 classication tasks, could be due to the greater comple xity and variability of EEG signals when subjects engage in real-world reasoning. In some trials, the w ords were displayed without addi- tional tasks, while in others, decision tasks involving animacy and 4 Hierarchic-EEG2T ext: Assessing EEG- To- T ext Decoding across Hierarchical Abstraction Levels 4 2 0 2 4 6 Nor malized A ccuracy ±6 ±5 ±6 ±3 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±6 ±5 ±4 ±6 ±7 ±5 ±7 ±5 ±7 ±8 ±4 ±9 Subjects = Seen | W ay = 2-way ±2 ±2 ±1 ±1 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±2 ±1 ±1 ±0 ±3 ±2 ±1 ±3 ±2 ±2 ±2 ±0 Subjects = Seen | W ay = 6-way ±1 ±1 ±1 ±1 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±2 ±1 ±1 ±0 ±2 ±1 ±1 ±2 ±1 ±1 ±1 ±1 Subjects = Seen | W ay = 10-way 5-15 17-36 49-82 111-119 R ange of Span Size 4 2 0 2 4 6 Nor malized A ccuracy ±6 ±5 ±6 ±1 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±5 ±6 ±6 ±3 ±8 ±7 ±6 ±11 ±8 ±7 ±4 ±0 Subjects = Unseen | W ay = 2-way 5-15 17-36 49-82 111-119 R ange of Span Size ±2 ±1 ±1 ±1 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±2 ±1 ±2 ±3 ±3 ±1 ±1 ±3 ±3 ±2 ±3 ±2 Subjects = Unseen | W ay = 6-way 5-15 17-36 49-82 111-119 R ange of Span Size ±1 ±1 ±1 ±1 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±0 ±1 ±1 ±1 ±1 ±2 ±1 ±1 ±1 ±1 ±1 ±1 ±0 Subjects = Unseen | W ay = 10-way baseline (w PT) baseline (w/o PT) fomaml (w PT) fomaml (w/o PT) pr oto -fomaml (w PT) pr oto -fomaml (w/o PT) Figure 1: Span Analysis for episodic evaluation of CBraMod. It depicts the ee cts of an episode’s hierarchical depth on performance. Higher span size indicates coarse-graine d episodes, and lower span size indicates ne-grained episodes. size properties were included. This highlights the need for further advances in EEG decoding architectures to tackle such variabil- ity . Se condly , the baseline setup outperforms both meta-learning algorithms, despite their designs for multi-task learning that in- volve such variability . Another key observation is that CBraMod with pretrained weights performs best, while CBraMod traine d from scratch without pretrained weights p erforms worst due to overtting, indicating the benet of large-scale self-super vised pre- training. The consistent advantage of pretrained baselines over meta-learning suggests that repr esentation quality dominates adap- tation in high-noise EEG settings. Meta-learning may amplify noise when task boundaries are weakly dened. Similar results have be en found for episodic learning for images, where a self-super vised pretrained model performs better than sophisticate d meta-learning algorithms [29]. Beyond these reasons, we want to emphasize again that the stimuli and tasks in the PEERS dataset reect real-world reasoning and are also closer to clinical applications. Brain activity in PEERS is likely to be more abstract and complex than that of image/video EEG datasets ( e . g . SEED [ 8 , 37 ], SEED-I V [ 36 ], EEGCVPR40 [ 27 ], ThoughtViz [ 15 , 16 ]), etc, where visual stimuli evoke wider and more stereotype d brain activity [ 35 ] and b enet ML models for categorization. W e b elieve that our evaluation brings forth the challenges of meta-learning on EEG datasets with mor e complex tasks. W e also evaluated performance on 9 seen subjects from the ltpFR group of the PEERS dataset, which had classes included in the meta-test . Although these subje cts were observed by the mo del during training, the set of classes still remained disjoint. T able 2 species the episodic performance for the se en subjects. While most observations remain the same as for unseen subjects, overall performance increased specically for CBraMod with pretrained weights. Another key observation here is that the standard deviation is quite high in the p erformance aggregated across all the internal nodes, which indicates that the model may have performed b etter for some episodes/concepts, while for some, it performed poorer , which highlights the need for more ne-grained analysis, which we discuss in the next section. 5.2 Hierarchical Analysis The results in the pre vious se ction provide a coarse-grained view of the EEG-to- T ext decoding across episodes. Here, w e attempt to provide a ne-grained view via: (i) Span Analysis, where we study performance at dierent depths of concepts, and (ii) Abstraction Analysis, where we pick classes from dierent lev els of the hierar- chy D AG. For the upcoming sections, we use CBraMod due to its superior performance. 5.2.1 Span A nalysis. As dened earlier , w e refer to the set of reach- able leaves from an internal node as the "span" of that node in the 5 Anupam Sharma, Harish Kai, Prajwal Singh, Shanmuganathan Raman, and Krishna Miyapuram T able 1: Normalized Accuracy for episodic evaluation on unseen subje cts Embedder Baseline fo-MAML [10] prot o -fo-MAML [31] 2-w ay 6-w ay 10-w ay 2-w ay 6-w ay 10-w ay 2-w ay 6-w ay 10-w ay EEGNet [17] 0.91 ± 2.6 0.40 ± 1.1 0.57 ± 0.8 0.02 ± 0.2 -0.02 ± 0.1 0.00 ± 0.1 0.14 ± 0.5 0.04 ± 0.4 0.00 ± 0.3 NICE EEG [26] 2.08 ± 4.0 1.18 ± 1.1 0.88 ± 1.1 0.02 ± 0.7 0.10 ± 0.4 0.00 ± 0.4 0.12 ± 0.8 0.03 ± 0.4 -0.06 ± 0.5 CBraMod [33] (w/o pt) 0.00 ± 0.0 0.00 ± 0.0 0.00 ± 0.0 0.28 ± 5.3 0.22 ± 2.1 0.22 ± 1.1 1.22 ± 7.1 0.99 ± 2.8 0.36 ± 1.30 CBraMod [33] (w pt) 3.53 ± 6.0 2.04 ± 1.4 1.54 ± 1.0 0.04 ± 0.4 -0.04 ± 0.2 -0.03 ± 0.1 -0.01 ± 7.6 1.09 ± 2.3 -0.02 ± 1.4 T able 2: Normalized Accuracy for episodic evaluation on seen subje cts Embedder Baseline fo-MAML [10] prot o -fo-MAML [31] 2-w ay 6-w ay 10-w ay 2-w ay 6-w ay 10-w ay 2-w ay 6-w ay 10-w ay EEGNet [17] 1.27 ± 2.3 0.5 ± 0.9 0.49 ± 0.6 -0.03 ± 0.3 -0.02 ± 0.1 -0.01 ± 0.1 0.09 ± 0.7 0.01 ± 0.4 0.06 ± 0.3 NICE EEG [26] 2.36 ± 3.0 1.02 ± 1.4 0.84 ± 0.9 -0.11 ± 0.7 0.01 ± 0.4 -0.06 ± 0.2 -0.34 ± 1.1 -0.11 ± 0.6 0.09 ± 0.5 CBraMod [33] (w/o pt) 0.00 ± 0.0 0.00 ± 0.0 0.00 ± 0.0 -0.22 ± 5.8 0.03 ± 1.6 0.04 ± 1.3 0.37 ± 6.9 -0.18 ± 2.4 0.08 ± 1.2 CBraMod [33] (w pt) 5.17 ± 5.5 2.38 ± 1.9 1.57 ± 0.9 0.01 ± 0.1 0.00 ± 0.2 -0.02 ± 0.2 2.66 ± 6.6 -0.70 ± 2.5 0.44 ± 1.6 2 W ay 6 W ay 10 W ay 10 5 0 5 10 15 20 Nor malized A ccuracy Figure 2: Fine-grained Span Analysis for episo dic evaluation of CBraMod on unse en subje cts (w PT) trained via baseline learning algorithm. The word cloud represents the concepts represented by the internal nodes in the DA G of the meta-test split. W ord size and numeric sux repr esent the span size of the no de, and brightness represents the normalized classication accuracy . hierarchy D AG, and to the span’s car dinality as the "span length" . The span of an internal node also species how close the node is to the root (how broad is the meaning of the concept) and how far the node is from the root (how narrow is the meaning of the concept). The broader the span size, the broader the concept is. W e use span instead of the number of hops, as the DA G might not be balanced. Figure 1 visualizes the performance as we vary the span size of an internal node in the DA G of meta-test for unse en and seen subjects. As the span size ranges from 5 to 119 across the DA G, we divide them into four divisions: (i) Group of very narrow nodes having span size from 5 to 15 , (ii) Group of mod- erately narrow no des having span size from 17 to 36 , (iii) Group of moderately broad nodes having span size from 49 to 82 , and (iv) Group of broad no des having span size from 111 to 119 . W e can observe from Figure 1 that baseline learning shows consistent behavior when pretrained weights are used, whereas other learning methods remain unstable , often performing below chance . One key observation from the consistent behavior of the baseline learning is that the performance for the broader concepts ( having span size ranging from 111 to 119 ) remains the highest for 2 − 𝑤 𝑎𝑦 classica- tion. This could be because sampling tw o classes from a broad span set could return very distinct classes. Coarse-grained classication seems easier than ne-grained classication. But this might be true only for 2 − 𝑤 𝑎𝑦 classication and not in general, as observed by the dip in p erformance for 6 − 𝑤 𝑎 𝑦 and 10 − 𝑤 𝑎 𝑦 , which may b e because of the presence of more classes of very similar meaning, making classication dicult ( check Figure 4 in the appendix for an example). Similar behavior can be obser ved for the narrower (having span size from 5 to 15 ) and moderately narrower no des (having span size from 17 to 36 ), where the performance remains better for 2 − 𝑤 𝑎𝑦 classication, but when we put more classes as in 6 − 𝑤 𝑎𝑦 and 10 − 𝑤 𝑎𝑦 classication tasks, the performance dips. Figure 2 provides a more ne-grained analysis of the variation of accuracy vs the span size via word clouds. The numeric sux and size of words (W ordNet concepts) in the word cloud repre- sent the span size i . e ., the larger the word, the broader the node or concept. The brightness of the words r epresents the performance. The brighter the words, the higher the performance. The word 6 Hierarchic-EEG2T ext: Assessing EEG- To- T ext Decoding across Hierarchical Abstraction Levels T able 3: Normalized (balance d) accuracy on joint evaluation with 1126 classes, together with a stratied train-val-test split. Embedder Train Test EEGNet [17] 0.03 0.00 NICE EEG [26] 53.24 0.01 CBraMod [33] (w/o pt) 0.00 0.00 CBraMod [33] (w pt) 1.55 0.02 cloud visualization gives a clear view of the observation in Fig- ure 1 for the unse en subjects. Broader concepts ( like artifact.119 , organism.111 , living_thing.111 ) perform well in 2 − 𝑤 𝑎𝑦 clas- sication, but their performance dips for 6 − 𝑤 𝑎𝑦 and 10 − 𝑤 𝑎𝑦 as the brightness of the concepts in the word cloud dips. Another key observation from Figure 1 is that the p erformance for CBraMod (w PT) for baseline learning is the lowest for the moderately broader concepts in 2 − 𝑤 𝑎𝑦 task, suggesting the presence of ver y simi- lar classes in the span set. As per Figure 2, this group includes concepts like causal_agent.72 , person.62 , matter.49 that have very similar classes. For example , the intersection of the span set of causal_agent.72 and person.62 contains classes like ACT OR, A CTRESS, HOSTESS, GIRL, DAUGH TER, D ANCER, etc, which just depict an image of a person. Similarly , most words in the span set of matter.49 represents some kind of food items (check ap- pendix Section D for full list), and dierentiating such items via EEG representations can be a dicult task, which explains the low performance. 5.2.2 Abstraction A nalysis. In this section, we study how classes at dierent levels of the hierarchy contribute to EEG-to-T ext de- coding. In all the previous sections, we use d the leaf node of the D A G as the classes in the classication task. Here, we select the concepts represented by internal nodes that are ancestors of the leaf nodes with ℎ hops in between them. If ℎ = 1 , then we prune all the leaf nodes and consider the new leaves as the classes, and we refer to the new set of classes as 𝐿 − 1 . If ℎ = 2 , we prune twice and refer to the resulting set of classes as 𝐿 − 2 . After pruning, we assign samples to the new classes using the ancestor-descendant mapping b etween the old and new leaves. T owards this end, we considered three sets of classes: 𝐿 − 2 , 𝐿 − 3 , and 𝐿 − 4 . For each set, w e trained the model independently using all learning methods and evaluated performance episo dically . An important point to note is that when classes are selected from the leaves without any pruning, the classes are disjoint across meta-train , meta-validation , and meta-test . Ho wever , when we prune the D AG, the set of classes begins to overlap across the splits. Specically , ∼ 25% of test classes overlapped with that of the train classes for all three sets 𝐿 − 2 , 𝐿 − 3 , and 𝐿 − 4 . Figur e 3 visualizes the episodic performance of CBraMod on the three sets trained with various learning approaches. As in earlier results, the baseline learning method performs consistently , while meta-learning remains unstable and shows no trend. How- ever , for the baseline method, overall performance incr eases in most cases. Specically , when CBraMod is trained without pretraining, its performance improves at 𝐿 − 4 . Mor eover , it beats the case when CBraMod is initialized with pretrained weights. This observation yields two insights: (i) the possibility of more distinct classes as we move a few hops above the last level of the hierarchy , and (ii) im- provement in the results at 𝐿 − 4 indicates that EEG representations are sensitive to lev els of abstraction in the ontological hierarchy . W e emphasize that absolute performance remains near chance, and variance is high across episodes. Our goal is not to demonstrate strong decoding accuracy , but to analyze relative trends across con- trolled hierarchical conditions under identical evaluation protocols. 5.3 Non-Episodic Evaluation In this experiment, we train and evaluate the architectures in a non- episodic manner , where we use the data under meta-train and divide them into stratied train-validation-test splits (note that meta-train , meta-val , and meta-test splits are meant for episodic learning only). W e train the architectures to map EEG samples to 1126 classes, and the set of classes remains the same for both training and evaluation, as described in Se ction 2.1.1. The T able 3 sp ecies the performance of the architectures in the train and test sets in terms of normalized balanced accuracy (mean of recall for all classes). W e obser ve that all architectures fail to generalize to the test set. This highlights the diculty of classifying signals into a large set of classes. One possible reason is that certain words (or leaf nodes) under the same internal node in the DA G may share high semantic similarity (see Figure 4 in the appendix for an example). EEG might not capture representations for each of them, and multiple such instances make the classication task dicult when all classes are considered together . On the other hand, as we show in Section 5.1, performing an independent classication task for such nodes by treating their span sets as classes may yield dierent results, as the span sets of some nodes may contain more distinct objects compared to others. 6 Limitations and Ethical Considerations In this work, we fo cus on hierarchical analysis of EEG-to-T ext decoding to understand how EEG captures object representations in the brain that correspond to textual stimuli. W e used the PEERS [ 14 ] dataset, which contains large classes of real objects. Howe ver , even the most modern architecture, such as CBraMod, performed close to chance level, according to our ndings. This may have o ccurred because of high variability in the dataset, as the subjects also p erformed additional tasks while viewing words corresponding to obje cts. This implies that the current methods fail to capture representations from EEG alone and may require support from other modalities. In this direction, it would be interesting to study how aligning EEG representations with other modalities, such as textual representations, would help. As a part of future work, we plan to explor e this direction to provide more r obust insights. Additionally , we will explore other vision-based datasets on which ML models have achieved higher accuracy , to evaluate the b enets of meta-learning and ontological priors. Regarding ethical considerations, we haven’t recorded physi- ological signals; instead, we use d a publicly available dataset. In- formation about subje cts is already anonymized by the dataset authors, and we ensure that our methodology doesn’t extract any information that can be used to identify subjects. 7 Anupam Sharma, Harish Kai, Prajwal Singh, Shanmuganathan Raman, and Krishna Miyapuram 2 0 2 4 6 Nor malized A ccuracy ±3 ±3 ±6 ±0 ±2 ±4 ±0 ±0 ±4 ±7 ±6 ±8 ±7 ±6 ±6 ±7 ±5 ±6 Subjects = Seen | W ay = 2 ±1 ±1 ±1 ±0 ±2 ±1 ±0 ±0 ±2 ±2 ±2 ±3 ±2 ±3 ±2 ±2 ±2 ±2 Subjects = Seen | W ay = 6 ±1 ±1 ±0 ±0 ±1 ±1 ±0 ±0 ±1 ±1 ±1 ±2 ±1 ±2 ±1 ±1 ±1 ±2 Subjects = Seen | W ay = 10 L -2 L -3 L -4 P runing 2 0 2 4 6 Nor malized A ccuracy ±4 ±2 ±7 ±0 ±1 ±7 ±0 ±0 ±4 ±8 ±7 ±10 ±7 ±6 ±8 ±6 ±5 ±8 Subjects = Unseen | W ay = 2 L -2 L -3 L -4 P runing ±1 ±1 ±1 ±0 ±1 ±2 ±0 ±0 ±1 ±2 ±2 ±3 ±2 ±2 ±3 ±3 ±2 ±2 Subjects = Unseen | W ay = 6 L -2 L -3 L -4 P runing ±1 ±1 ±1 ±0 ±1 ±1 ±0 ±0 ±1 ±2 ±1 ±1 ±2 ±1 ±1 ±1 ±1 ±1 Subjects = Unseen | W ay = 10 baseline (w PT) baseline (w/o PT) fomaml (w PT) fomaml (w/o PT) pr oto -fomaml (w PT) pr oto -fomaml (w/o PT) Figure 3: Abstraction Analysis for episodic evaluation of CBraMod. V alue of ℎ in 𝐿 − ℎ species the number of pruning steps performed on the DA G. As the value of ℎ increases, more abstract classes are considered. 7 Conclusion In this work, we study EEG-to- T ext decoding across hierarchical abstraction levels. W e show that classifying EEG signals into a large set of classes corresponding to their respective textual stimuli can be dicult, as some objects may share very similar meanings. EEG, as a standalone signal, might not capture subtle details across similar objects, but it may have a more abstract representation of them. Hence, we pr op ose to study EEG-to- T ext decoding in an episodic manner , with episodes sampled hierarchically . Firstly , we found that while non-episodic evaluation fails, the model performs b etter when evaluated episodically , indicating the pr esence of hierarchical representations in EEG. Secondly , we observed that coarse-grained tasks were easier than ne-grained tasks, but this was true only for binary classication. As we bring more classes to the task, both ne- grained and coarse-grained tasks b ecome equally dicult. Another key nding is that models perform b etter when we attempt mapping signals to abstract classes ( e . g ., instead of considering BO Y , GIRL, MAN, WOMAN as dierent classes, consider them as one class - PERSON). This suggests that EEG representations are sensitiv e to abstraction. Additionally , by adopting an episodic approach, we created the largest episodic evaluation framework in the EEG domain, facili- tating the ML community in developing ecient episodic learning algorithms for EEG decoding tasks. In this regar d, we found that self-supervise d pretrained models can outperform complex meta- learning techniques in EEG-to- T ext decoding. Our research highlights the importance of abstraction depth in the context of EEG-to- T ext decoding. W e hope this work will inspire further studies to enhance the ecacy of EEG-based applications across various elds. Acknowledgments W e would like to thank Atharv Nangare from II T Gandhinagar for introducing us to the PEERS dataset and for the time he spent discussing its applications. References [1] Swapnil Bhosale, Rupayan Chakraborty, and Sunil Kumar Kopparapu. 2022. Calibration free meta learning based approach for subje ct independent EEG emotion recognition. Biomedical Signal Processing and Control 72 (2022), 103289. [2] Steven Bird. 2006. NLTK: the natural language toolkit. In Proce edings of the COLING/ACL 2006 interactive presentation sessions . 69–72. [3] Thomas Carlson, David A T ovar , Arjen Alink, and Nikolaus Kriegeskorte. 2013. Representational dynamics of object vision: the rst 1000 ms. Journal of vision 13, 10 (2013), 1–1. [4] Cheng Chen, Hao Fang, Y uxiao Yang, and Yi Zhou. 2025. Model-agnostic meta- learning for EEG-based inter-subject emotion recognition. Journal of Neural Engineering 22, 1 (2025), 016008. [5] Radoslaw Martin Cichy, Dimitrios Pantazis, and Aude Oliva. 2014. Resolving human object recognition in space and time. Nature neuroscience 17, 3 (2014), 455–462. [6] Mike X Cohen. 2014. A nalyzing neural time series data: theory and practice . MI T press. [7] Jia Deng, W ei Dong, Richard Socher , Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Im- agenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition . Ieee, 248–255. 8 Hierarchic-EEG2T ext: Assessing EEG- To- T ext Decoding across Hierarchical Abstraction Levels [8] Ruo-Nan Duan, Jia- Yi Zhu, and Bao-Liang Lu. 2013. Dierential entropy feature for EEG-based emotion classication. In 6th International IEEE/EMBS Conference on Neural Engineering (NER) . IEEE, 81–84. [9] Tiehang Duan, Mohammad Abuzar Shaikh, Mihir Chauhan, Jun Chu, Rohini K Srihari, Archita Pathak, and Sargur N Srihari. 2020. Meta learn on constrained transfer learning for low resource cr oss subje ct EEG classication. IEEE Access 8 (2020), 224791–224802. [10] Chelsea Finn, Pieter Abb eel, and Sergey Levine. 2017. Model-agnostic meta- learning for fast adaptation of deep networks. In International conference on machine learning . PMLR, 1126–1135. [11] Ji- Wung Han, So yeon Bak, Jun-Mo Kim, W o ohyeok Choi, Dong-Hee Shin, Y oung- Han Son, and T ae-Eui Kam. 2024. Meta-eeg: Meta-learning-based class-relevant eeg representation learning for zero-calibration brain–computer interfaces. Ex- pert Systems with A pplications 238 (2024), 121986. [12] Nora Hollenstein, Jonathan Rotsztejn, Marius Troendle, Andreas Pedroni, Ce Zhang, and Nicolas Langer . 2018. ZuCo, a simultaneous EEG and eye-tracking resource for natural sentence reading. Scientic data 5, 1 (2018), 1–13. [13] Nora Hollenstein, Marius Troendle, Ce Zhang, and Nicolas Langer . 2020. ZuCo 2.0: A dataset of physiological recordings during natural reading and annotation. In Procee dings of the Twelfth Language Resources and Evaluation Conference . 138–146. [14] Michael J. Kahana, Joseph H. Rudoler, Lynn J. Lohnas, Karl Healey , Ada Aka, Adam Broitman, Elizabeth Crutchley , Patrick Crutchley , K ylie H. Alm, Brandon S. Katerman, Nicole E. Miller , Joel R. Kuhn, Y uxuan Li, Nicole M. Long, Jonathan Miller , Madison D. Paron, Jesse K. Pazdera, Isaac Pedisich, and Christoph T . W eidemann. 2023. "Penn Electrophysiology of Enco ding and Retrieval Study (PEERS)" . doi:doi:10.18112/openneuro.ds004395.v2.0.0 [15] Blair Kaneshiro, Marcos Perreau Guimaraes, Hyung-Suk Kim, Anthony M Norcia, and Patrick Suppes. 2015. A representational similarity analysis of the dynamics of object processing using single-trial EEG classication. Plos one 10, 8 (2015), e0135697. [16] Pradeep Kumar , Rajkumar Saini, Partha Pratim Roy , Pawan Kumar Sahu, and Debi Prosad Dogra. 2018. Envisione d sp eech recognition using EEG sensors. Personal and Ubiquitous Computing 22, 1 (2018), 185–199. [17] V ernon J Lawhern, Amelia J Solon, Nicholas R W aytowich, Stephen M Gordon, Chou P Hung, and Brent J Lance . 2018. EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces. Journal of neural engineering 15, 5 (2018), 056013. [18] Hanwen Liu, Daniel Hajialigol, Benny Antony , Aiguo Han, and Xuan W ang. 2024. Eeg2text: Open vocabulary eeg-to-text decoding with eeg pre-training and multi-view transformer . arXiv preprint arXiv:2405.02165 (2024). [19] Xiaozhao Liu, Dinggang Shen, and Xihui Liu. 2025. Learning Interpretable Representations Leads to Semantically Faithful EEG-to- T ext Generation. arXiv preprint arXiv:2505.17099 (2025). [20] Nicolás Nieto, Victoria Peterson, Hugo Leonardo Runer , Juan Esteban Kamienkowski, and Ruben Spies. 2022. Thinking out loud, an open-access EEG-based BCI dataset for inner speech recognition. Scientic data 9, 1 (2022), 52. [21] Iyad Obeid and Joseph Picone. 2016. The temple university hospital EEG data corpus. Frontiers in neuroscience 10 (2016), 196. [22] Pramit Saha, Muhammad Abdul-Magee d, and Sidney Fels. 2019. Speak Y our Mind. T owards Imagined Speech Recognition With Hierarchical Deep Learning (2019). [23] Prajwal Singh, Dwip Dalal, Gautam V ashishtha, Krishna Miyapuram, and Shan- muganathan Raman. 2024. Learning robust deep visual representations from eeg brain recordings. In Proceedings of the IEEE/CVF Winter Conference on A pplications of Computer Vision . 7553–7562. [24] Prajwal Singh, Pankaj Pandey , Krishna Miyapuram, and Shanmuganathan Raman. 2023. EEG2IMAGE: image reconstruction from EEG brain signals. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 1–5. [25] Jake Snell, Kevin Swersky , and Richard Zemel. 2017. Prototypical networks for few-shot learning. Advances in neural information processing systems 30 (2017). [26] Y onghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun W ang, and Xiaorong Gao. 2023. Decoding natural images from eeg for object recognition. arXiv preprint arXiv:2308.13234 (2023). [27] Concetto Spampinato, Simone Palazzo, Isaak Kavasidis, Daniela Giordano, Nasim Souly , and Mubarak Shah. 2017. Deep learning human mind for automated visual classication. In Proceedings of the IEEE conference on computer vision and pattern recognition . 6809–6817. [28] Yitian T ao, Y an Liang, Luoyu W ang, Y ongqing Li, Qing Y ang, and Han Zhang. 2025. See: Semantically aligned eeg-to-text translation. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Spee ch and Signal Processing (ICASSP) . IEEE, 1–5. [29] Y onglong Tian, Yue Wang, Dilip Krishnan, Joshua B T enenbaum, and P hillip Isola. 2020. Rethinking few-shot image classication: a good embedding is all you need? . In European conference on computer vision . Springer , 266–282. [30] Praveen Tirupattur , Y ogesh Singh Rawat, Concetto Spampinato, and Mubarak Shah. 2018. Thoughtviz: Visualizing human thoughts using generative adversarial network. In Proceedings of the 26th ACM international conference on Multimedia . 950–958. [31] Eleni Triantallou, Tyler Zhu, Vincent Dumoulin, Pascal Lamblin, Utku Evci, Kelvin Xu, Ross Goroshin, Carles Gelada, Kevin Swersky , Pierre- Antoine Man- zagol, et al . 2019. Meta-dataset: A dataset of datasets for learning to learn from few examples. arXiv preprint arXiv:1903.03096 (2019). [32] Princeton University . 2019. W ordNet | A Lexical Database for English. https: //wordnet.princeton.edu/ [33] Jiquan W ang, Sha Zhao, Zhiling Luo, Y angxuan Zhou, Haiteng Jiang, Shijian Li, T ao Li, and Gang Pan. 2024. Cbramod: A criss-cross brain foundation model for eeg decoding. arXiv preprint arXiv:2412.07236 (2024). [34] Zhenhailong W ang and Heng Ji. 2022. Open vocabulary electroencephalography- to-text decoding and zero-shot sentiment classication. In Proceedings of the AAAI Conference on Articial Intelligence , V ol. 36. 5350–5358. [35] Daniel LK Yamins, Ha Hong, Charles F Cadieu, Ethan A Solomon, Darren Seibert, and James J DiCarlo. 2014. Performance-optimize d hierarchical models predict neural responses in higher visual cortex. Proce edings of the national academy of sciences 111, 23 (2014), 8619–8624. [36] W . Zheng, W . Liu, Y. Lu, B. Lu, and A. Cichocki. 2018. EmotionMeter: A Mul- timodal Framework for Recognizing Human Emotions. IEEE Transactions on Cybernetics (2018), 1–13. doi:10.1109/TCYB.2018.2797176 [37] W ei-Long Zheng and Bao-Liang Lu. 2015. Investigating Critical Frequency Bands and Channels for EEG-based Emotion Recognition with Deep Neural Networks. IEEE Transactions on Autonomous Mental Development 7, 3 (2015), 162–175. doi:10.1109/TAMD .2015.2431497 [38] Shuqi Zhu, Ziyi Y e, Qingyao Ai, and Yiqun Liu. 2024. Eeg-imagenet: An elec- troencephalogram dataset and benchmarks with image visual stimuli of multi- granularity labels. arXiv preprint arXiv:2406.07151 (2024). A Dataset The PEERS dataset was recorded via 5 major r e cording experiments out of which we used the data of 4 experiments whose description is provided below: Experiment 1 and 3 : Each session in the experiment consists of a series of 16 trials, each involving 16 visually presented words, followed by a recall task in which subjects recall as many words as they can. Each word is pr esente d for 3 s, with an inter-stimulus interval (ISI) ranging from 0 . 8 s to 1 . 2 s. Each session consists of three kinds of trials - (i) 4 No Task Trials , where subject observes the presented words, (ii) 8 T ask Trials , where in 4 of the trials a subject decide if the object represented by the presented wor d t in a shoebox (also known as size task) and in the remaining 4 trials a subject decide if the object is living being (also known as animacy task), and (iii) 4 T ask-Shift Trials , where both the size and animacy task e xists within the same trial. Experiment 3 diers fr om experiment 1 in the recall task, where in experiment 3 , a subject also verbalizes the words the y recall. Experiment 2 : This experiment introduces distractor intervals in addition to the word-based intervals in a trial. In the distractor interval, a math problem app eared on the screen in the form of 𝐴 + 𝐵 + 𝐶 = ? where 𝐴 , 𝐵 , and 𝐶 are positive single-digit numbers. Experiment 4 : Experiment 4 used a p ool of 576 words selected from the original pool. Each word is displayed to all 98 subjects involved in this experiment. Each session had 24 trials, with each trial presenting 24 words individually for 1 . 6 s, with ISI ranging from 0 . 8 s to 1 . 2 s, followed by a distractor inter val. Experiments 1 , 2 , and 3 of the PEERS dataset is also referred as ( ltpFR ) and experiment 4 as ( ltpFR2 ). B Discarded Lab els and Nodes in D AG The word “BLUEJA Y" had no synonym in W ordNet. Discarded words having too broad meaning ar e liste d below , where the rst 9 Anupam Sharma, Harish Kai, Prajwal Singh, Shanmuganathan Raman, and Krishna Miyapuram location.n.01 point.n.02 region.n.03 geographical _point.n.01 geographical _area.n.01 address.n.02 port.n.01 workplace.n.01 residence.n.01 home.n.01 HOME PORT F ARM farm.n.01 ranch.n.01 RANCH tract.n.01 grassland.n.01 praire.n.01 PRAIRE hayfield.n.01 MEADOW field.n.01 FIELD As we move lower in the DAG, the concepts become fine-grained As we move higher in the DAG, the concepts become coarser Fine-grained classes Coarser classes with more distinct items Node closer to root will have mix of distinct and fine-grained classes Figure 4: Subgraph of the D AG for meta-train split showing leaf nodes sharing the same internal node having high similarity in meaning ( e . g ., F ARM, RANCH). In the presence of multiple such instances, EEG might not capture representations for each of them, making non-episodic EEG-to- T ext classication with all lab els together a dicult task. value in the braces species the number of leaf nodes spanned by its parent, and the second value species the number of siblings: • CREA T URE (121, 9) • ANIMAL (121, 9) • PERSON (278, 58) • BEAST (121, 9) • MAMMAL (56, 2) The discarded internal nodes correspond to the following syn- onyms/concepts: ‘whole.n.02’ , ‘object.n.01’ , ‘physical_entity .n.01’ . The removal of these nodes also leads to the removal of 22 more words ( still retaining ∼ 98% of total words in the PEERS Dataset). C Hyperparameter Settings In this section, we provide details related to the e xperiment setup. T able 4 and table 5 provide the hyper-parameter settings use d for training the models via non-episodic and episodic learning, respectively . D W ords Under Moderately Broad Concepts This section lists the words under the span set of moderately broad concepts. matter .49: SALAD , MAPLE, P UDDING, COFFEE, ORANGE, P AST A, BRANDY , GRAPE, PORK, PLASTER, P APER, KLEENEX, T able 4: Hyperparameter settings for experiments with non- episodic evaluation Hyperparamters Settings Embedding dim 1024 Dropout 0.05 Learning rate 0.0003 Epoch 50 W eight De cay 0.001 Optimizer AdamW BEA VER, BARLEY , LA V A, TREA T , GARBA GE, PIZZA, SUPPER, CAND Y, OZONE, JELLO, HONEY , MEA T , DRUG, LUNCH, POISON, P ASTRY , SODA, TROU T , QU AIL, SNACK, OIN TMEN T , SLIME, CUST ARD, CIGAR, JELL Y , PO WDER, SPONGE, SALT , A TOM, GLASS, CHAMP A GNE, COCKTAIL, KET CHUP, APPLE, BA CON, RADISH, GREASE causal_agent.72: VIKING, REBEL, SPHINX, VIRUS, CONVICT , FRIEND , MUMMY, PRINCESS, DI VER, P A TIENT , LODGE, BRANDY , INF AN T , BABY , WIFE, W ASHER, PISTON, HIKER, SERVER, DEN- TIST , H USBAND, HOSTESS, CAPTI VE, SISTER, DANCER, W OMAN, JUGGLER, LO VER, DRIVER, DRUG, ACTOR, A GEN T , SIBLING, 10 Hierarchic-EEG2T ext: Assessing EEG- To- T ext Decoding across Hierarchical Abstraction Levels T able 5: Hyperparameter settings for experiments with episodic evaluation Learning Method Hyperparameters Settings Common to both Embedding Dim 512 Dropout 0.05 Baseline Learning Rate 0.0003 Epochs 50 Batch Size 128 Optimizer AdamW Meta-Learning Outer Learning Rate 0.0003 Inner Learning Rate 0.01 No. of inner updates 5 Inner Optimizer Gradient Descent Outer Optimizer Adam T otal Meta Steps 5351 Number of episodes in a Batch 4 CA TCHER, DINER, GIRL, P UPIL, LADY , INMA TE, SPOUSE, W AI T - RESS, DAUGHTER, GANGSTER, ACTRESS, MARINE, TEA CHER, OIN TMEN T , SERV AN T , EXPERT , CASHIER, CIGAR, KEEPER, HOOD , CHEMIST , CHAUFFEUR, V AGRAN T , POET , NOMAD , COCKTAIL, CHAMP A GNE, MAILMAN, PILOT , PRINCE, WORKER, P ARTNER, WI TNESS, BANKER, PREA CHER, T YPIST , DONOR, OU TLA W , TO ASTER person.62: VIKING, REBEL, SPHINX, CON VICT , FRIEND, MUMMY , PRINCESS, DI VER, P A TIENT , LODGE, INF AN T , BABY , WIFE, W ASHER, PISTON, HIKER, SERVER, DEN TIST , HUSBAND, HOSTESS, CAP- TIVE, SISTER, DANCER, WOMAN, JUGGLER, LO VER, ACTOR, SIBLING, CA TCHER, DINER, GIRL, P UPIL, LAD Y, INMA TE, SPOUSE, W AI TRESS, DAUGHTER, GANGSTER, ACTRESS, MARINE, TEA CHER, SERV AN T , EXPERT , CASHIER, KEEPER, HOOD, CHEMIST , V A - GRAN T , POET , NOMAD , MAILMAN, PILOT , PRINCE, WORKER, P ARTNER, WI TNESS, BANKER, PREACHER, T YPIST , DONOR, OU TLA W , TO ASTER 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment