SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Agentic systems increasingly rely on reusable procedural capabilities, \textit{a.k.a., agentic skills}, to execute long-horizon workflows reliably. These capabilities are callable modules that package procedural knowledge with explicit applicability …
Authors: Yanna Jiang, Delong Li, Haiyu Deng
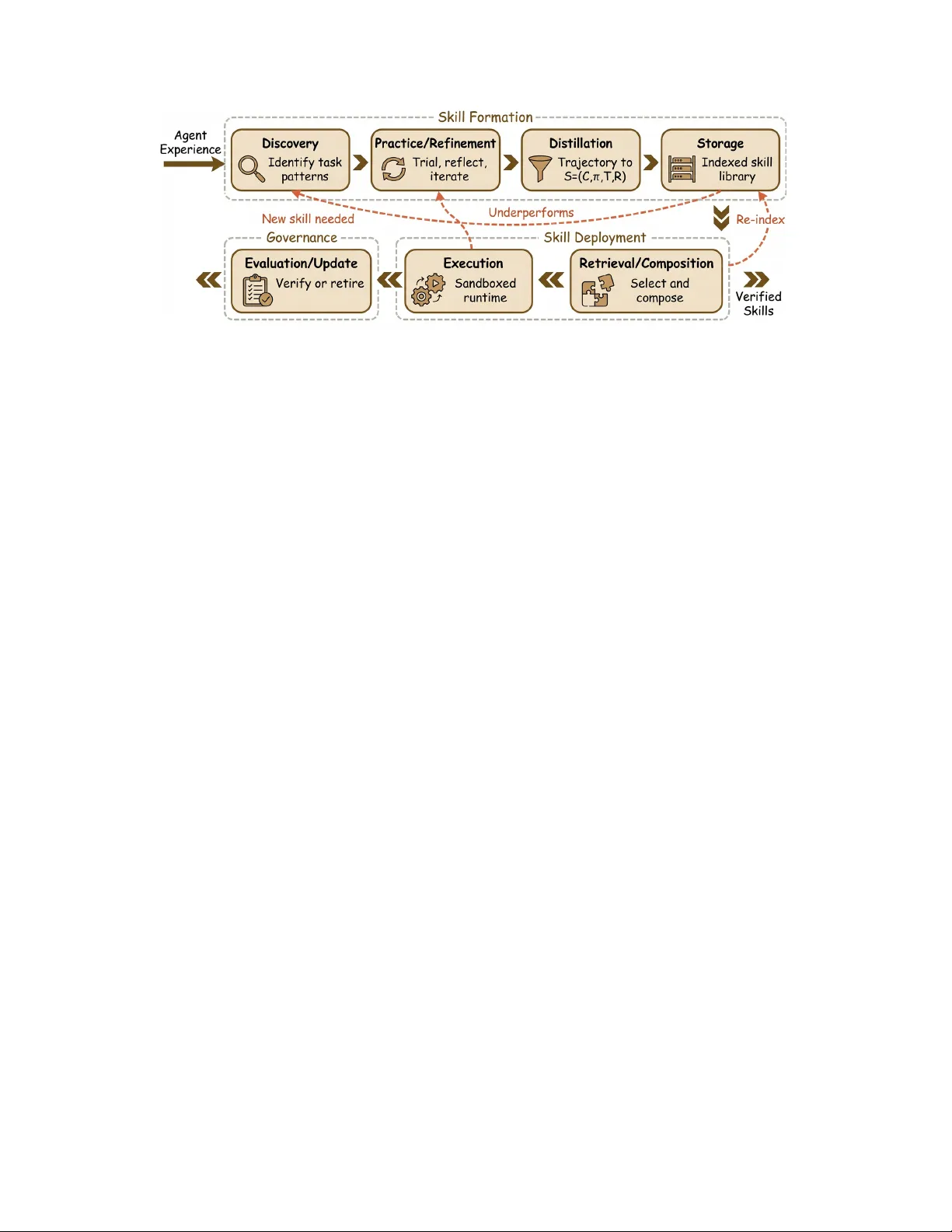
SoK: Agentic Skills — Bey ond T ool Use in LLM Agents Y anna Jiang 1 , Delong Li 1 , Haiyu Deng 1 , Baihe Ma 1 , Xu W ang 1 , Qin W ang 1 , 2 , Guangsheng Y u 1 1 University of T echnology Sydne y | 2 CSIR O Data61 Abstract —Agentic systems increasingly r ely on reusable proce- dural capabilities, a.k.a., agentic skills , to execute long-horizon workflows reliably . These capabilities are callable modules that package procedural knowledge with explicit applicability con- ditions, execution policies, termination criteria, and reusable interfaces. Unlike one-off plans or atomic tool calls, skills operate (and often do well) across tasks. This paper maps the skill layer across the full lifecycle (dis- covery , practice, distillation, storage, composition, evaluation, and update) and introduces two complementary taxonomies. The first is a system-level set of seven design patterns captur- ing how skills are packaged and executed in practice, from metadata-driven progr essive disclosure and executable code skills to self-evolving libraries and marketplace distribution. The second is an orthogonal representation × scope taxonomy describing what skills are (natural language, code, policy , hybrid) and what en vir onments they operate over (web, OS, software engineering, robotics). W e analyze the security and gov ernance implications of skill-based agents, covering supply-chain risks, prompt injec- tion via skill payloads, and trust-tiered execution, grounded by a case study of the ClawHav oc campaign in which nearly 1,200 malicious skills infiltrated a major agent marketplace, exfiltrating API keys, cryptocurrency wallets, and br owser credentials at scale. W e further survey deterministic evaluation approaches, anchored by recent benchmark evidence that curated skills can substantially improve agent success rates while self-generated skills may degrade them. W e conclude with open challenges toward robust, verifiable, and certifiable skills for real-world autonomous agents. 1. Introduction Large language model (LLM) agents have advanced rapidly from single-turn question answering to multi-step autonomous systems that bro wse the web [ 1 ], write/debug software [ 2 ], [ 3 ], orchestrate tools in sequence [ 4 ], [ 5 ], and collaborate as multi-agent teams [ 6 ], [ 7 ]. Y et a fundamental inef ficiency persists: each new task forces the agent to re- deri ve an ex ecution strategy from scratch. A coding agent that has successfully deb ugged a null-pointer exception a hundred times still approaches the hundred-and-first as if it were novel. The procedural kno wledge gained from experi- ence disappears at the end of ev ery context window . This observation motiv ates the central abstraction of this paper: the agentic skill s. W e define a skill as a reusable, callable module that encapsulates a sequence of actions or policies enabling an agent to achieve a class of goals under recurring conditions. Skills differ from tools (atomic primitiv es with fixed interfaces), plans (one-time reason- ing scaf folds), and episodic memories (stored observ ations) in that they are simultaneously executable , r eusable , and governable . A skill carries its o wn applicability conditions, termination criteria, and callable interface, making it a first- class unit of procedural knowledge. The notion is not ne w in isolation. Cognitiv e architec- tures such as A CT -R [ 8 ] and Soar [ 9 ] formalized procedural memory decades ago. Reinforcement learning (RL) has long studied option frameworks and hierarchical policies [ 10 ]. What is new is the conv ergence of these ideas in the LLM agent [ 11 ], [ 12 ]. Skills manifest in forms ranging from natural-language playbooks and executable Python scripts to marketplace-distrib uted plugins. The div ersity of repre- sentations calls for systematization. Existing surveys cover LLM agents broadly [ 13 ], [ 14 ], [ 15 ], [ 16 ], [ 17 ], [ 18 ], [ 19 ], focus on tool use [ 20 ], [ 21 ], [ 22 ], or address multi-agent coordination [ 23 ]. None adopt a skill-centric lens to trace the full lifecycle from acquisition to governance. W e fill this gap. Contributions. This Systematization of Knowledge (SoK) offers six contributions: • a unified definition of agentic skills (§ 2 ), formalized as S = ( C, π , T , R ) , with precise boundary conditions sepa- rating skills from tools, plans, and memory . • a skill lifecycle model (§ 4 ) mapping the stages from discov ery through ev aluation and update, with a summary linking representativ e systems to lifecycle stages. • a seven-pattern design taxonomy (§ 5 ) for ho w skills are packaged, loaded, and ex ecuted in real systems. • an orthogonal repr esentation × scope taxonomy (§ 5.10 ) describing what skills are and what en vironments they act ov er , integrated with the se ven patterns. • a security and governance analysis (§ 7 ) covering threat models, trust tiers, a pattern-specific risk matrix, and an anchor case study of the ClawHa voc marketplace supply- chain attack. • an evaluation frame work (§ 8 ) with metrics, benchmark mapping, and an anchor case study demonstrating that curated skills outperform self-generated ones. Reading map. § 2 defines the core abstraction. § 3 de- scribes our systematic methodology . § 4 introduces the life- cycle model. § 5 presents the sev en design patterns and the representation × scope taxonomy . § 6 cov ers skill acquisition and composition. § 7 analyzes security and governance, in- cluding the ClawHa voc case study . § 8 surveys ev aluation. § 9 discusses cross-cutting observations and limitations. § 10 outlines open challenges. § 11 concludes our work. 2. What Is an Agentic Skill? 2.1. Formal Definition W e ground the concept of an agentic skill in a four - tuple formalization that captures the essential properties distinguishing skills from related abstractions. Definition 1 (Agentic skills) . Let an agent interact with en vironment E via action space A , observation space O , and goal space G . Let H = ( o 1 , a 1 , . . . , o t − 1 , a t − 1 ) denote the inter action history up to the curr ent step. An agentic skill is a tuple S = ( C, π , T , R ) (1) wher e: • C : O × G → { 0 , 1 } is the applicability condition , a pr edicate over observations and the agent’ s curr ent goal that determines whether the skill is appr opriate for the curr ent context; • π : O × H → A ∪ Σ is the executable policy , a mapping fr om observations and interaction history to actions or skill in vocations fr om the skill library Σ , which may be implemented as natural-language instructions, executable code, a learned controller , or a hybrid thereof . When π selects a skill s ∈ Σ rather than a primitive action a ∈ A , hierar chical composition arises (§ 6.6.1 ), mir- r oring the option-subr outine structur e in the RL options frame work [ 10 ]; • T : O × H × G → { 0 , 1 } is the termination condition , specifying when the skill has completed (successfully or not) r elative to the curr ent goal; • R = ( name , params , r eturns ) is the reusable callable interface , a metadata and contract component specifying the skill’ s callable signature (name, parameter schema, r eturn type) for pr ogrammatic invocation by the agent, other skills, or external or chestrators. G may be encoded within O (e.g ., as a task pr ompt in the observation) or passed as an explicit parameter; we make it explicit her e for clarity . Implementations often compute soft applicability scor es C : O × G → [0 , 1] and apply a threshold; we pr esent the binary form as a simplifying con vention that captur es the essential gating logic. In orc hestrator-manag ed arc hitectures, C and T may be externally pr ovided rather than skill-internal; the 4-tuple then describes the logical interface re gar dless of where eac h function is implemented. W e argue these four components form a useful minimal schema that captures the properties distinguishing skills from related abstractions. Removing C yields a policy that cannot self-select; removing T produces a policy that cannot compose (callers do not kno w when to resume); removing Figure 1. Internal anatomy of an agentic skill. Observations O enter the applicability gate C ; the policy π produces actions A ; the termination condition T determines whether to continue or halt. The interface R wraps the entire module as a callable API boundary . Goal G is typically encoded in observations O or passed as a separate task parameter; for visual simplicity , we show O as the single input. R yields internal kno wledge that cannot be in voked pro- grammatically; and removing π leav es metadata without ex- ecutability . The formalization is deliberately representation- agnostic: π can be a prompt template, a Python function, a reinforcement-learning policy , or a combination. This formalization parallels the options framew ork ( I , π , β ) of Sutton et al. [ 10 ], where our C corresponds to the initiation set I and T to the termination condition β . The interface R builds on the options framew ork by making skills explicitly inv ocable, which is necessary for runtime composition. RL options are instead chosen implicitly by a meta-policy , so they do not address this requirement. Fig. 1 sho ws the resulting four-component architecture. 2.2. Skills versus Related Abstractions W e compares agentic skills with four related concepts (T able 1 ): unit of reuse, execution semantics, v erification surface, composability , and governance surface. T ools. A tool is an atomic primiti ve (e.g., a web-search API or a file-write function) with a fixed interf ace and no internal decision-making. Prior work such as T oolformer [ 22 ] shows that LLMs can learn to inv oke tools autonomously , but such behavior typically remains at the lev el of single calls. A skill may invok e tools, b ut extends them with applicability logic, multi-step sequencing, and explicit termination crite- ria. Conceptually , the distinction resembles that between a system call and a library routine in software engineering. Plans. A plan is a reasoning artifact produced by the agent to decompose a task into sub-goals. Plans are typically one- time, session-scoped, and not directly ex ecutable without further interpretation. Skills, by contrast, persist across ses- sions, carry executable policies, and expose callable inter- faces. A plan may select skills, but a skill is not a plan. Memory . Episodic and semantic memory systems store ob- serv ations and facts for later retriev al [ 24 ], [ 25 ], [ 26 ]. Skills are a form of pr ocedural memory: they encode how to act, not what happened. The relationship between declarati ve memory and procedural skills in LLM agents mirrors the distinction dra wn in cognitiv e psychology between knowing- that and knowing-ho w [ 8 ]. T ABLE 1. C O N C E P T UN I FI C A T I O N : AG E N T I C S K I L L S V E R S U S R E L A T E D AB S T R AC T I O N S IN L L M AG E N T S Y S T E M S . Abstraction Unit of Reuse Execution Semantics V erification Surface Composability Gover nance Surface T ool Single API call Stateless, single invocation Input/output schema Sequential chaining Permission per tool Plan T ask decomposition One-time reasoning scaffold Step consistency Hierarchical decomposition N/A (ephemeral) Episodic memory Stored observation Retrie val, no direct execution Relev ance, recency Indirect (informs reasoning) Access control on store Prompt template T ext fragment Injected into context window Output quality String concatenation T emplate authorship Agentic skill Procedural module Callable workflow with termination Outcome correctness, safety Hierarchical, D A G, recursive T rust tier, sandboxing, provenance Prompt templates. Prompt templates are static text frag- ments injected into the context window [ 27 ]. They lack applicability conditions, termination logic, and callable in- terfaces. A skill may contain a prompt template as part of its policy π , but a template alone does not constitute a skill. Classical AI planning formalisms. The skill abstraction also connects to classical AI planning. In Hierarchical T ask Networks (HTNs) [ 28 ], methods decompose tasks into sub-tasks with preconditions, mirroring our hierar- chical composition (§ 6.6.1 ). BDI (Belief-Desire-Intention) architectures [ 29 ] use reusable plan recipes with context conditions, which align with C and π . STRIPS/PDDL ac- tions [ 30 ] make preconditions and effects e xplicit, which anticipates our applicability and termination conditions. The main difference is representational: LLM-based skills act on natural-language observations and can encode policies as NL instructions or hybrid artifacts, while classical for- malisms assume symbolic state. W e keep the formalization representation-agnostic to connect these lines of work. 2.3. Skills as Procedural Memory Cogniti ve science provides a useful lens for understand- ing why skills matter . Anderson’ s A CT -R theory [ 8 ] dis- tinguishes declarative memory (facts and episodes) from procedural memory (production rules that encode condi- tion–action pairs). Experts differ from novices less in what they kno w than in the richness of their procedural repertoire: action patterns that trigger automatically when conditions are met, freeing working memory for higher-le vel reasoning. LLM agents face an analogous challenge. W ithout a skill layer , ev ery task requires the agent to reason from first principles within a limited context window , consuming tokens to re-derive procedures that could be stored and re- triev ed. Skills serve as the procedural memory of the agent, compressing learned procedures into reusable modules that reduce the cognitive load on the model’ s context windo w , analogous to how chunking in human expertise compresses multi-step procedures into single retriev able units [ 31 ]. This framing has a practical implication: the value of a skill is not merely con venience but reliability . A curated skill that has been verified across multiple contexts is more reliable than an ad-hoc plan generated on the fly , for the same reason that a tested library function is more reliable than inline code. Recent empirical evidence supports this intuition: the SkillsBench benchmark [ 32 ] demonstrates that curated skills raise agent pass rates by 16.2 percentage points on a verage, while self-generated skills degrade per - formance by 1.3 pp, encoding incorrect or overly specific heuristics. Notably , a smaller model equipped with curated skills can outperform a lar ger model operating without them. One interpretation is that procedural memory serves as an efficienc y multiplier and partially substitute for model scale. 3. Methodology This section describes the systematic process used to collect and analyze the literature on agentic skills in LLM agent systems, and the methodology through which our taxonomies were developed. 3.1. Literature Search and Selection W e ran a structured search across six databases: Google Scholar , Semantic Scholar , DBLP , A CM Digital Library , IEEE Xplore, and arXiv . W e used ke yword queries (in- cluding ag ent skills , skill learning LLM , reusable agent behaviors , procedur al knowledge agents , tool composition LLM , agent libraries , and hierar chical agent policies ) and follo wed citations forward and backward from seed papers (V oyager [ 33 ], ReAct [ 34 ], Reflexion [ 35 ], SWE-agent [ 2 ]). The search cov ered publications from January 2020 through February 2025 for LLM agent systems. W e include one concurrent work, SkillsBench [ 32 ] (February 2026), as a notable exception given its direct relev ance to skill ev aluation; all other primary sources fall within the stated window . Foundational works from cognitive science [ 8 ], [ 31 ], cogniti ve architectures [ 9 ], and reinforcement learn- ing [ 10 ] were included regardless of date to ground the skill abstraction in established theory . Inclusion criteria. A paper was included if it satisfies at least one of the following: (i) it introduces, implements, or ev aluates reusable procedural capabilities for LLM-based or language-conditioned agents; (ii) it addresses at least one lifecycle stage (discov ery , refinement, distillation, stor- age, retriev al, execution, or ev aluation) of agent procedural knowledge; or (iii) it provides a benchmark en vironment in which agent skills can be measured. Exclusion criteria. W e excluded w orks that focus exclu- siv ely on single-turn tool calling without procedural com- position, pure prompt engineering without skill persistence or reuse, and multi-agent coordination papers that do not in volve a skill abstraction. W e also excluded papers focusing solely on fine-tuning for instruction follo wing without an explicit skill representation. Figure 2. The agentic skill lifecycle. Solid arrows indicate the primary forward path; dashed arro ws indicate feedback loops for refinement and retirement. Each stage corresponds to a body of research surveyed in this paper . 3.2. Corpus and Analysis The initial search yielded approximately 180 candidate papers. After applying the inclusion and exclusion criteria, we retained 65 papers for detailed analysis. Of these, 24 systems are analyzed in depth through the mapping tables (T ables 2 and 5 ), and the remaining papers inform the analysis across lifecycle stages, design patterns, security , and ev aluation. The corpus spans eight benchmark en vironments, se ven design patterns, and fiv e representation categories. 3.3. T axonomy Development Both taxonomies were dev eloped through an iterati ve bottom-up process. W e first compiled a feature matrix for each analyzed system, recording its skill representation, acquisition method, e xecution model, storage mechanism, and governance features. Recurring clusters in this matrix suggested the sev en design patterns (§ 5 ) and the fi ve repre- sentation categories (§ 5.10.1 ). W e tested each candidate taxonomy against the full cor- pus, refining categories through three re vision cycles until ev ery deeply-analyzed system could be classified without forcing. The representation × scope taxonomy was de- veloped orthogonally: scope categories emerged from the en vironments addressed by the analyzed systems. Their or- thogonality with representation was validated by confirming that examples exist across most cells of the resulting matrix. The design patterns are deliberately non-exclusive : real systems often combine multiple patterns (e.g., a marketplace-distrib uted plugin using metadata-dri ven load- ing with hybrid NL+code implementation). W e treat com- posability as a feature of the pattern framework rather than a taxonomy deficiency , as mutually exclusi ve patterns would not reflect how skills are deployed in practice. 4. Skill Lifecycle Model W e or ganize the literature around a lifecycle model that traces an agentic skill from initial formation to ev entual retirement. Rather than viewing skills as static artifacts, this model treats them as ev olving system components shaped by interaction, feedback, and deployment constraints. The lifecycle comprises sev en stages, depicted in Fig. 2 : • Discovery : identifying recurring task patterns, failure modes, or workflow bottlenecks that justify encapsulating behavior into a reusable skill. • Practice/Refinement : iterati vely improving candidate skills through trial-and-error execution, reflection, and ex- ternal feedback, allowing policies and prompts to stabilize across repeated use. • Distillation : extracting a stable and generalizable proce- dure from trajectories or demonstrations and packaging it into the ( C, π , T , R ) tuple together with descriptive metadata and usage constraints. • Storage : persisting the skill within a library or repository , accompanied by indexing, versioning, and metadata that enable efficient retrie val and governance. • Retrieval/Composition : selecting relev ant skills at runtime and composing them into higher-le vel workflows, often requiring compatibility checks across interfaces, contexts, and dependencies. • Execution : running the skill policy within the agent’ s action loop under sandboxing, permission controls, and resource constraints that bound potential side effects. • Evaluation/Update : monitoring performance after deploy- ment, detecting drift or failure, and revising, replacing, or retiring skills as en vironments and requirements ev olve. The lifecycle is not strictly linear . Feedback loops con- nect ev aluation back to practice (when a skill underper- forms), retriev al back to storage (when indexing fails to sur- face relev ant skills), and ex ecution back to discovery (when runtime failures rev eal the need for ne w skills). T able 2 maps representativ e systems to lifecycle contributions. 4.1. Discovery Skill disco very is the process of identifying recurring task patterns that warrant encapsulation into a reusable module. In V oyager [ 33 ], disco very is dri ven by a curriculum mechanism that proposes increasingly complex tasks in Minecraft; when the agent succeeds at a nov el task, the T ABLE 2. L I F E C Y C L E M A P P I N G : R E P R E S E N T A T I V E S Y S T E M S A N D T H E I R P R I M A RY C O N T R I B U T I O N S T O S K I L L L I F E C Y C L E STAG E S . “ ✓ ” = P R I M A RY F O C U S ; “ ∼ ” = P A RT I A L C OV E R AG E . System/Paper En vironment Signal Discovery Practice Distillation Storage Retrieval Execution Evaluation Representation V oyager [ 33 ] Minecraft Self-verify ✓ ✓ ✓ ✓ ✓ ✓ ∼ Code J AR VIS-1 [ 36 ] Minecraft Multimodal ∼ ✓ ∼ ✓ ✓ ✓ ∼ Hybrid DEPS [ 37 ] Minecraft LLM planner ✓ ✓ ∼ ∼ ∼ ✓ ✗ NL Reflexion [ 35 ] Multi V erbal RL ✗ ✓ ∼ ∼ ✗ ✓ ✓ NL Skill-it! [ 38 ] Language Curriculum ✓ ✓ ✓ ✗ ✗ ∼ ✓ Latent SWE-agent [ 2 ] SWE Execution ✗ ∼ ✗ ✗ ✗ ✓ ✓ Code AppAgent [ 39 ] Mobile Demonstrations ✓ ✓ ✓ ✓ ✓ ✓ ∼ Hybrid W ebArena agents [ 1 ] W eb T ask reward ✗ ∼ ✗ ✗ ✗ ✓ ✓ NL/Code CRADLE [ 40 ] Games Multi-source ✓ ✓ ✓ ✓ ✓ ✓ ✓ Hybrid MemGPT [ 24 ] Multi Self-edit ✗ ✗ ✗ ✓ ✓ ∼ ✗ NL AgentT uning [ 41 ] Multi SFT ∼ ∼ ✓ ✗ ✗ ✓ ✓ Policy CodeAct [ 42 ] Multi Code exec ✗ ✗ ✗ ✗ ✗ ✓ ✓ Code FireAct [ 43 ] Multi Trajectories ✗ ∼ ✓ ✗ ✗ ✓ ✓ Policy HuggingGPT [ 4 ] Multi API routing ✗ ✗ ✗ ✓ ✓ ✓ ∼ Hybrid T askW eaver [ 44 ] SWE Code-first ✗ ∼ ∼ ✓ ✓ ✓ ∼ Code SayCan [ 45 ] Robotics Affordance ✓ ∼ ∼ ✓ ✓ ✓ ∼ Hybrid MetaGPT [ 6 ] Multi Role assign ∼ ∼ ✓ ✓ ✓ ✓ ∼ Code Generativ e Agents [ 46 ] Social Self-observe ∼ ∼ ∼ ✓ ✓ ✓ ∼ NL Eureka [ 47 ] Robotics Re ward search ✓ ✓ ✓ ∼ ✗ ✓ ✓ Code solution trajectory becomes a candidate skill. DEPS [ 37 ] discov ers skills through plan decomposition: a high-le vel planner identifies sub-goals, and repeated sub-goal patterns are promoted to skills. AppAgent [ 39 ] discovers skills through user demonstrations on mobile interfaces, identi- fying reusable interaction patterns across applications. In the robotics domain, SayCan [ 45 ] discov ers exe- cutable skills by grounding language instructions in robot affordances: the system scores candidate skills by both lan- guage rele vance and physical feasibility , effecti vely discov- ering which skills apply in a giv en context. DECKARD [ 48 ] uses language-guided world models to discover skills through embodied decision making, imagining plans before ex ecuting them. A key open question is unsupervised discovery: identify- ing skill boundaries without human-provided task definitions or explicit success signals. Current systems rely on either pre-defined task curricula or human demonstrations to seed the discovery process. 4.2. Practice, Refinement, and Distillation Once a candidate skill is identified, it must be refined into a reliable procedure. Reflexion [ 35 ] demonstrates a verbal reinforcement learning loop where the agent reflects on failed attempts and generates te xtual feedback that guides subsequent trials. This reflection mechanism serves as a practice loop that improves skill reliability without param- eter updates. Distillation conv erts raw traces into compact, generaliz- able skill representations. AgentTuning [ 41 ] distills traces from GPT -4 into smaller models through supervised fine- tuning, producing agents with internalized skills. Fire- Act [ 43 ] fine-tunes agents on div erse ReAct-style traces, distilling multi-step reasoning patterns into model weights. Inner Monologue [ 49 ] extends verbal feedback to em- bodied agents by using language-based scene descriptions and success signals to iterati vely refine robotic action se- quences. Eureka [ 47 ] sho ws that LLMs can autonomously design rew ard functions for robotic skill acquisition through ev olutionary search, achie ving human-lev el performance and effecti vely automating the practice-and-refine loop for phys- ical skills. The distinction between practice and distillation is im- portant: practice improv es a skill’ s reliability through itera- tion, while distillation changes its representation (e.g., from a verbose trajectory to a compact code function or from prompt-based instructions to model weights). 4.3. Storage and Retrieval Skill storage requires indexing mechanisms that support efficient retriev al. V oyager [ 33 ] maintains a skill library index ed by natural-language descriptions, using embedding similarity to retrie ve relev ant skills for new tasks. CRA- DLE [ 40 ] extends this with multi-lev el memory that stores skills alongside episodic context, enabling retriev al based on both task similarity and en vironmental state. The storage-retriev al interface is where skill systems intersect with memory architectures. MemGPT [ 24 ] pro- vides a hierarchical memory system that could serve as infrastructure for skill libraries, with main memory (context window) and archiv al storage (external database) supporting dif ferent access patterns. Generativ e Agents [ 46 ] implement a memory architecture for simulated social agents where behavioral patterns, analogous to social skills, are stored and retrie ved based on recency , importance, and rele vance, providing a model for how skill libraries might integrate with broader memory systems. The challenge is designing retrie val policies that balance precision (returning the most applicable skill) with recall (not missing rele vant skills in nov el contexts). 4.4. Execution and Evaluation Execution is the stage where a skill’ s policy π is enacted within the agent’ s action loop. The execution model varies substantially by skill representation: natural-language skills are injected into the context window , code skills are exe- cuted in sandboxed environments, and policy skills operate through learned parameters. CodeAct [ 42 ] demonstrates that representing agent actions as executable Python code, rather than as tool-calling JSON, improv es both the expressiv eness and the verifiability of skill execution. Ev aluation assesses whether a skill achiev es its intended outcome reliably . Deterministic ev aluation harnesses, where the en vironment itself provides ground-truth verification, are preferable to human grading for scalability . SkillsBench [ 32 ] operationalizes this principle by pairing each of its 86 tasks with a deterministic verifier that checks en vironment state against expected outcomes, enabling reproducible ev aluation across 7,308 agent trajectories. W e discuss ev aluation in depth in § 8 . 5. Design Patterns and T axonomy W e classify the emerging skill landscape along two complementary dimensions. First, we identify seven design patterns that describe how skills are packaged, loaded, and ex ecuted at the system level. Second, we de velop a r ep- r esentation × scope taxonomy (§ 5.10 ) that describes what skills are and where they operate. Fig. 3 arranges the seven patterns along an autonomy axis. This section presents both, beginning with the design patterns summarized in T able 3 . 5.1. Why Design Patterns? Software engineering has long treated recurring design patterns as worth documenting for both practice and re- search [ 50 ]. W e follow that approach for agentic skills. A design pattern describes a solution shape that shows up across systems. Here, patterns are system -level: they describe how infrastructure manages skills. By contrast, the representation/scope taxonomy is skill -le vel. They comple- ment each other: one pattern (e.g., marketplace distribution) can host skills with any representation and scope. 5.2. Pattern-1: Metadata-Driven Disclosure In P attern-1, skills are discovered through compact meta- data summaries (name, description, trigger conditions) that Figure 3. Se ven design patterns for agentic skills arranged along an auton- omy spectrum, from human-controlled metadata disclosure (P1) to fully autonomous meta-skills (P6). Marketplace distribution (P7) spans the full spectrum as a cross-cutting distribution mechanism. Dashed lines indicate commonly combined patterns. occupy minimal context. The full instructions are loaded into the agent’ s context window only when the skill is selected for execution. This two-phase loading strategy addresses a fundamental constraint of LLM agents: the finite context window cannot hold all available skills simultaneously . Claude Code’ s skill system exemplifies this pattern. Each skill is registered with a short description and a set of trigger phrases. When the agent determines that a skill is relev ant to the current task, it loads the full skill specification, which may include multi-page instructions, reference documents, and ex ecution scripts. The Semantic Kernel framew ork [ 51 ] implements a similar approach with its plugin discovery mechanism, where function metadata is registered and the full function implementation is in voked only on selection. The main benefit is scale: an agent can know about hundreds of skills while spending context tokens only on the few it activ ates. The main risk is metadata quality . If descriptions are wrong or incomplete, retrie val can pick the wrong skill or miss a relev ant one. 5.3. Pattern-2: Code-as-Skill (Executable Scripts) Code-as-skill represents skills as executable programs (Python functions, shell scripts, or domain-specific language programs) that the agent inv okes through a runtime interf ace. V oyager [ 33 ] generates Jav aScript functions as skills for Minecraft, stores them in a library , and retriev es them by natural-language description. CodeAct [ 42 ] demonstrates that framing agent actions as executable Python code, rather than as structured JSON tool calls, enables more expressi ve and verifiable behavior . In robotics, Code as Policies [ 52 ] generates Python programs for robotic control, and Prog- Prompt [ 53 ] creates situated task plans as ex ecutable pro- grams, both treating generated code as reusable skills for physical manipulation. The key advantage of code skills is determinism : given the same inputs, a code skill produces the same outputs, enabling traditional software testing and verification. Code T ABLE 3. S E V E N D E S I G N PA T T E R N S F O R AG E N T I C SK I L L S , W I T H R E P R E S E N TA T I V E SY S T E M S , S T R E N G T H S , A N D GO V E R NA N C E CO N S I D E R A T I O N S . # Pattern Representativ e Systems Repr esentation Strength W eakness Primary Risk 1 Metadata-driv en progressiv e disclosure Claude Code, Semantic Kernel, LangChain NL + metadata T oken efficienc y; scales to large libraries Retriev al quality depends on metadata Metadata poisoning 2 Code-as-skill (executable scripts) V oyager , CodeAct, SWE-agent Code Deterministic; testable; composable Requires sandbox; brittle to API changes Code injection 3 W orkflow enforcement TDD agents, LA TS, systematic debuggers NL + rules Reliability through gating; auditable Rigid; may over -constrain agent Rule bypass via prompt injection 4 Self-ev olving skill libraries V oyager , DEPS, CRADLE Code + NL Adapts to new tasks; improves with use Quality control of self-generated skills Skill drift; poisoned distillation 5 Hybrid NL+code macros Claude skills, ReAct prompts NL + code + refs Flexible; human readable yet executable Ambiguity at NL/code boundary Inconsistent interpretation 6 Meta-skills (skills that create skills) Self-Instruct, skill generators NL / hybrid Scales skill library; reduces human effort Bootstrapping quality ceiling Recursiv e error amplification 7 Plugin / marketplace distribution OpenAI GPT Store, MCP servers, ClawHub, npm/pip Any (packaged) Ecosystem growth; community contribution Supply-chain trust; version compat Malicious packages (cf. ClawHav oc) skills also composed of function calls, imports, and control flo w . The limitation is brittleness: code skills break when underlying APIs, UI elements, or en vironmental conditions change, necessitating maintenance and version management (§ 4.4 ). 5.4. Pattern-3: W orkflow Enf orcement W orkflow-enforcement skills impose hard-gated pro- cesses on agent behavior , ensuring that the agent follows a prescribed methodology rather than improvising. A test- dri ven development (TDD) skill, for example, mandates that the agent write tests before implementation, run the test suite, and iterate until all tests pass. The agent cannot skip or reorder these steps. LA TS (Language Agent Tree Search) [ 54 ] enforces a tree-search workflo w that combines planning, acting, and reflection in a structured loop. Systematic debugging skills enforce a diagnosis-before-fix methodology , requiring the agent to reproduce the bug, identify root causes, and verify the fix before declaring success. This pattern sacrifices flexibility for reliability . By constraining the agent’ s action space to a proven se- quence, workflo w enforcement reduces the probability of hallucination-dri ven shortcuts and provides a clear audit trail. W e note that Pattern-3 operates at the controller level: it prescribes how the agent executes rather than constituting a reusable skill artifact itself. LA TS exemplifies a workflo w controller that can host skills from other patterns. The gov ernance surface is the rule set itself: if an attacker can modify the workflow rules (e.g., through prompt injection), the enforcement mechanism is compromised. 5.5. Pattern-4: Self-Evolving Skill Libraries Self-e volving skill libraries combine skill execution with automated quality assessment and library maintenance. After each task, the system ev aluates whether the agent’ s behavior produced a successful trajectory worthy of distillation into a new skill or refinement of an existing one. V oyager [ 33 ] provides a canonical example: it generates code-based skills, validates them through in-game e xecu- tion, and incorporates verified skills into a persistent library index ed by natural-language descriptions. CRADLE [ 40 ] extends this paradigm with explicit memory management, linking skills to episodic context to enable retriev al based on en vironmental similarity . The central tension in self-ev olving libraries is quality control. The SkillsBench benchmark [ 32 ] reports that self- generated skills av erage − 1.3 pp relati ve to skill-free base- lines, with only one of fiv e tested configurations showing any improv ement, indicating that zero-shot self-generation without iterativ e verification can degrade performance in open-ended settings. This contrasts with V oyager and Eu- reka, where self-generated skills succeed in constrained en vironments with deterministic execution verification, sug- gesting the viability of self-generation depends critically on domain specificity and the av ailability of automated verifi- cation. Without human oversight or robust verification, self- ev olving libraries risk accumulating “skill debt” analogous to technical debt in software systems. 5.6. Pattern-5: Hybrid NL+Code Macros Hybrid skills combine natural-language specifications with executable components within a single package. The natural-language component describes the skill’ s purpose, applicability conditions, and high-le vel logic in human- readable form, while the executable component provides code snippets, reference documents, or tool-calling se- quences that implement concrete steps. This pattern appears in production agent systems where skills must be both human-auditable and machine- ex ecutable. Claude Code’ s skill system, for example, defines skills as markdown documents that include natural-language instructions, code blocks, and references to external assets. The ReAct paradigm [ 34 ] represents a lightweight version: the agent alternates between natural-language reasoning (“I need to search for X”) and ex ecutable actions (search API call), with the interlea ving serving as an implicit hybrid skill. The advantage of hybrid skills is flexibility: the natural- language component provides context and handles edge cases through reasoning, while the code component pro vides determinism for well-understood steps. The risk is boundary ambiguity : when instructions conflict with code, the agent must decide which to follow , creating potential for incon- sistent behavior . 5.7. Pattern-6: Meta-Skills Meta-skills are skills whose purpose is to create, modify , or compose other skills. A meta-skill might analyze an agent’ s task history to identify recurring patterns, generate candidate skills from those patterns, and test them against held-out tasks. Self-Instruct [ 55 ] can be viewed through this lens: the LLM generates new instruction-follo wing examples that serve as training data for skill acquisition. CREA TOR [ 56 ] takes this further by enabling LLMs to create ne w tools (i.e., code functions) on demand, disen- tangling abstract reasoning from concrete tool implementa- tion. Eureka [ 47 ] generates reward functions that serve as parameterizations for robotic skills, effecti vely creating skill specifications through code. W e cite Self-Instruct and CREA TOR as precursors: they sho w the training-time idea of meta-skills, but they are mostly of fline. W e reserve Pattern-6 in the strict sense for methods that act as runtime-callable generators. Discovery (§ 4.1 ) makes the procedural gap explicit; meta-skills are the generativ e mechanism that fills it. These sit at differ - ent levels (lifecycle stage vs. design pattern): a meta-skill automates what would otherwise be manual discovery . Meta-skills let a small seed set of skills grow into a broad library without requiring a matching amount of human work. The risk is r ecursive err or amplification : if the meta- skill produces a flawed skill that is subsequently used as input for further skill generation, errors compound. Quality gates at each generation step are essential (§ 7 ). 5.8. Pattern-7: Plugin/Marketplace Distrib ution The marketplace pattern treats skills as versioned, dis- tributable packages with explicit dependency , compatibility , and governance metadata. The OpenAI GPT Store dis- tributes custom GPT configurations that function as pack- aged skills. Anthropic’ s Model Context Protocol (MCP) [ 57 ] defines a standardized interface for tool and skill serv ers, enabling third-party skill distribution with authentication and permission boundaries. T oolLLM [ 58 ] demonstrates integration with over 16,000 real-world APIs, illustrating the scale that marketplace-style distribution can achiev e. The most striking example of marketplace-scale skill distribution is OpenClaw [ 59 ], a viral agent framew ork built on a four-tool core (read, write, edit, bash) that treats skills as the primary extensibility mechanism. OpenClaw’ s community skill registry , ClawHub, grew from zero to over 10,700 published skills within weeks of launch, while the project itself surpassed 200,000 GitHub stars faster than any software repository in history [ 60 ]. OpenClaw’ s de- sign philosophy is particularly rele vant to our taxonomy: it embraces self-generated skills (Pattern-4 + Pattern-6) by encouraging agents to extend themselves through code rather than do wnloading pre-built extensions. When com- bined with community distribution (Pattern-7), this creates a T ABLE 4. P A T T E R N T R A D E - O FF S U M M A RY AC R O S S F O U R DI M E N S I O N S . H = H I G H , M = M E D I U M , L = L O W . Pattern Context cost Determinism Composability Governance 1: Metadata L L M M 2: Code-as-skill L H H H 3: W orkflow M H M H 4: Self-evolving M M M L 5: Hybrid macro M M M M 6: Meta-skill H L L L 7: Marketplace L varies H M–H dual-source skill library: human-authored community skills alongside agent-authored local skills, both executable with full system access. In the software ecosystem, analogous patterns include npm packages for Jav aScript, pip packages for Python, and plugin systems in IDEs. The marketplace pattern en- ables community-dri ven skill creation at scale but introduces supply-chain risk : a malicious or compromised skill package can execute arbitrary actions within the agent’ s permission scope. OpenClaw’ s explosi ve growth and the severity of its subsequent security incidents (§ 7.6 ) provide a stark illustra- tion of this risk. W e analyze these risks in detail in § 7 . 5.9. Pattern T rade-offs Our patterns represent different points in a multi- dimensional trade-off space. T able 4 summarizes the key di- mensions: Context cost measures how man y tokens a pattern consumes during acti ve use. Determinism reflects the pre- dictability of execution outcomes. Composability captures how easily skills following this pattern can be combined into larger workflows. Governance surface indicates how amenable the pattern is to auditing, permission control, and prov enance tracking. Patter n co-occurrence. Systems in our corpus use a median of 2 patterns (range: 1–4). The most common combination is Patterns 1+7 (metadata + marketplace), appearing in 4 sys- tems (HuggingGPT , MetaGPT , AutoGen, T oolLLM). T wo systems (Claude Code and OpenClaw) use 4 patterns, rep- resenting outliers. Fi ve systems use a single pattern, while twelve use e xactly two. The modest co-occurrence rates sug- gest the patterns capture meaningfully distinct architectural choices rather than collapsing into a single cluster . No single pattern dominates. Production systems typ- ically combine patterns: a marketplace-distributed plugin (Pattern-7) might use metadata-driven loading (Pattern-1) with hybrid NL+code implementation (Pattern-5) and work- flow enforcement for critical steps (Pattern-3). Computational overhead. The skill layer imposes over - head: retriev al adds latency , instruction loading consumes context tokens, and multi-lev el composition multiplies both. T able 4 captures this abstractly as “context cost, ” but quan- tifying the latency-accuracy tradeof f of skill-based versus skill-free agents across deployment scenarios remains an open empirical question. 5.10. Representation × Scope T axonomy Complementing the system-lev el design patterns, we propose an intrinsic taxonomy along two orthogonal axes: r epresentation (how the skill’ s policy is encoded) and scope (what en vironment or task domain the skill operates over). While patterns describe ho w infrastructure manages skills, this taxonomy operates at the skill lev el. 5.10.1. Representation Axis. W e identify fiv e representa- tion categories, ordered roughly by increasing formality: Natural-language skills. The policy π is expressed entirely in natural language: step-by-step instructions, standard op- erating procedures (SOPs), or playbook entries. The agent interprets these instructions through its language understand- ing capabilities. Natural-language skills are easy to author and audit but are subject to interpretation ambiguity and cannot be verified through traditional testing. Code-as-skill. The policy π is an ex ecutable program: a Python function, a shell script, a domain-specific language program, or a Jupyter notebook cell. Code skills offer de- terminism and testability but require ex ecution infrastructure and are brittle to en vironmental changes. T ool macr os. A skill defined as a structured sequence of tool calls with parameterization logic. T ool macros occupy a middle ground between natural language (interpreted) and code (ex ecuted): they are more constrained than free-form code but more expressi ve than single tool calls. Policy-based skills. The policy π is a learned parameterized function, i.e., a neural network fine-tuned on trajectories. Policy skills are opaque (hard to inspect/audit) but capture subtle behavioral patterns that resist explicit codification. Hybrid repr esentations. A skill that combines two or more of the above. For example, a hybrid skill might use natural- language instructions for high-lev el logic, code blocks for deterministic steps, and an embedding-based retriev al mech- anism for contextual adaptation. 5.10.2. Scope Axis. W e identify six scope categories based on the environment and task domain: Single-tool skills. Skills that orchestrate a single tool with sophisticated parameterization, error handling, and retry logic. These are the simplest scope but can still exhibit non- tri vial procedural comple xity (e.g., a database query skill that handles schema variation). Multi-tool orchestration. Skills that coordinate multiple tools in sequence or parallel to accomplish a composite task (e.g., search → extract → summarize → store). W eb interaction. Skills for na vigating web interfaces, filling forms, extracting information from web pages, and complet- ing web-based workflows. Benchmarked by W ebArena [ 1 ] and Mind2W eb [ 61 ]. A challenge unique to web skills is UI fragility : interfaces change frequently , breaking skills that depend on specific element selectors or page layouts. Skills encoding high-level intent (“fill in the departure field”) are more resilient than those encoding low-le vel actions (“click the element with id=departure-input”). OS/desktop workflows. Skills that operate across multiple desktop applications, managing windows, files, and system settings. Benchmarked by OSW orld [ 62 ]. Software engineering. Skills for code understanding, bug localization, patch generation, testing, and deployment. Benchmarked by SWE-bench [ 63 ]. Robotics/physical. Skills for controlling physical actuators, navigating physical spaces, and manipulating objects. While this SoK focuses primarily on digital agents, robotics skill libraries provide instructive parallels, particularly for hier- archical skill composition [ 64 ]. Recent work demonstrates div erse LLM-dri ven robotic skills: SayCan [ 45 ] grounds language instructions in affordance functions to select feasi- ble skills, Code as Policies [ 52 ] generates executable robot programs from language, ProgPrompt [ 53 ] creates situated task plans as programs, and Inner Monologue [ 49 ] uses language feedback to refine robotic actions iterativ ely . Scope and skill value. The scope axis interacts with skill utility in a non-obvious way . SkillsBench [ 32 ] reports that skills yield the largest improv ements in healthcare (+51.9 pp) and manufacturing (+41.9 pp) b ut only +4.5 pp in software engineering and +6.0 pp in mathematics. This suggests that skills provide the most value in domains where the base model’ s pretraining data is sparse or insufficiently procedural, while domains with abundant code and math- ematical reasoning data in pretraining benefit less from external procedural knowledge. 5.10.3. Mapping: Patter ns × Representation × Scope. T able 5 maps representati ve systems to all three classi- fication dimensions. The mapping reveals that most sys- tems occupy a sparse region of the full space: code-as- skill representation with SWE or web scope using the self- ev olving library pattern. Large regions remain unexplored, particularly policy-based skills with marketplace distribution and natural-language skills with workflow enforcement. 6. Acquisition, Composition, Or chestration W e address two complementary questions: how agents acquir e skills, and ho w they compose and or chestrate ac- quired skills at runtime. W e begin with fiv e acquisition modes, ordered from most to least human inv olvement. 6.1. Human-A uthored Skills The simplest acquisition mode is human authorship. A domain expert writes a skill specification (e.g., a standard operating procedure, a code function, or a hybrid document) and registers it in the agent’ s skill library . Many production systems (e.g., Claude Code and enterprise automation plat- forms) rely on human-authored skills because they are easier to validate and assign accountability for . Human authorship scales poorly but produces high- reliability skills. The trade-off is explicit: each skill requires T ABLE 5. T AX O N O M Y M A S T E R T A B L E : R E P R E S E N TA T I V E S Y S T E M S M A P P E D TO D E S I G N PA T T E R N , RE P R E S E N TA T I O N , SC O P E , A N D KE Y C H A R A C T E R I S T I C S . System Pattern(s) Representation Scope Acquisition Execution Evaluation Gov ernance V oyager [ 33 ] 2, 4 Code Game/Robotics Self-practice Sandbox Self-verify None SWE-agent [ 2 ] 2, 3 Code SWE Pre-defined Shell ex ec SWE-bench Sandboxed CodeAct [ 42 ] 2 Code Multi Pre-defined Python e xec AgentBench Sandboxed CRADLE [ 40 ] 4, 5 Hybrid Game Self-e volving Multi-source T ask re ward None AppAgent [ 39 ] 1, 5 Hybrid Mobile Demonstrations UI actions T ask success None W ebArena agents [ 1 ] 2, 3 Code/NL W eb Pre-defined Browser T ask reward Sandboxed HuggingGPT [ 4 ] 1, 7 Hybrid Multi Pre-re gistered API routing T ask output API auth T askW eaver [ 44 ] 2, 5 Code SWE Human + gen Python exec Output verify Plugin sys Claude Code 1 1, 3, 5, 7 Hybrid SWE/Multi Human-authored Multi-mode User verify Trust tiers MemGPT [ 24 ] 1 NL Multi Human-defined Context mgmt N/A Access ctrl AgentT uning [ 41 ] 4 Policy Multi Distillation Fine-tuned AgentBench None LA TS [ 54 ] 3 NL + rules Multi Pre-defined Tree search T ask reward None Reflexion [ 35 ] 3 † NL Multi Self-practice V erbal RL T ask re ward None MetaGPT [ 6 ] 1, 7 Code Multi Role generation Multi-agent T ask output Role-based SayCan [ 45 ] 1, 2 Hybrid Robotics Affordance grounding Grounded ex ec T ask success None AutoGen [ 7 ] 1, 7 Hybrid Multi Pre-defined + gen Multi-agent Con versation Protocol Generativ e Agents [ 46 ] 1, 4 ‡ NL Social Self-observed Memory retriev al Behavioral None T oolLLM [ 58 ] 1, 7 Hybrid Multi API crawling API routing T oolEval API auth OpenClaw [ 59 ] 2, 4, 6, 7 Code/Hybrid Multi Self-generated + community Bash/code ex ec User verify Cla wHub + V irusT otal † Reflexion performs transient in-context refinement without persistent library updates; we classify it under Pattern-3 only. ‡ Generativ e Agents’ beha vioral patterns are closer to episodic memory than to skills as formally defined; included as an illustrativ e boundary case. human labor to create, test, and maintain, but the resulting skills are grounded in domain expertise and can be audited before deployment. 6.2. Demonstration Distillation Demonstration distillation extracts reusable procedures from observed trajectories. The input may be human demon- strations [ 39 ], expert agent traces [ 41 ], or successful task completions from the agent itself [ 33 ]. The key challenge is gener alization : a trajectory that solved one specific instance must be abstracted into a skill that handles the broader class. AgentT uning [ 41 ] collects interaction trajectories from GPT -4 across div erse agent tasks and uses them to fine-tune Llama models, effecti vely distilling procedural knowledge into model weights. FireAct [ 43 ] fine-tunes language models on ReAct-style trajectories, distilling the reasoning-acting pattern into an internalized skill. 6.3. Self-Practice and Exploration Self-practice acquisition allows the agent to discover and refine skills through autonomous interaction with the en vironment. V oyager [ 33 ] implements this through a curriculum-driv en exploration loop: the agent proposes tasks, attempts them, ev aluates success, and stores verified solutions as skills. Reflexion [ 35 ] refines agent behavior through verbal self-reflection: after a failed attempt, the agent generates a textual analysis of what went wrong and uses this analysis to guide the next attempt. While Reflexion does not explicitly produce persistent skills, the reflection mechanism can be vie wed as transient skill refinement within an episode. AutoGPT [ 65 ] popularized the paradigm of fully au- tonomous agents that set their o wn sub-goals and practice iterativ ely , though without explicit skill persistence across sessions. DECKARD [ 48 ] combines language-guided world models with embodied exploration, imagining and ev aluat- ing plans before ex ecuting them in game environments. The self-practice mode enables continual learning [ 66 ] without human supervision but introduces quality risk. W ith- out external verification, agents may con verge on locally optimal but globally suboptimal procedures, or worse, on procedures that succeed through exploitation of en vironment quirks rather than genuine task completion. 6.4. Curriculum and Feedback Curriculum-based acquisition structures the skill learn- ing process through progressiv ely harder tasks. Skill-it! [ 38 ] provides a theoretical framework for curriculum design in skill learning, demonstrating that training on an ordered sequence of skills improves sample efficienc y compared to random ordering. Feedback signals can come from humans (corrections, preferences), AI judges (LLM-based ev aluators), or reward models trained on human preferences. The choice of feed- back signal affects both the quality and the scalability of skill acquisition: human feedback is high-quality but expen- siv e, AI judges are scalable b ut may miss subtle errors, and rew ard models generalize from limited human data but can be exploited through reward hacking. 6.5. Meta-Skills and Self-Evolving Libraries The most autonomous acquisition mode uses meta-skills (Pattern-6) to generate new skills from existing ones. A meta-skill might analyze an agent’ s failure cases, identify missing capabilities, and generate candidate skills to fill those gaps. Self-Instruct [ 55 ] demonstrates a related ap- proach: using an LLM to generate new instruction-follo wing examples from a seed set, effecti vely bootstrapping a skill Figure 4. Skill composition and orchestration. T asks are matched to skills via embedding-based retriev al or LLM-mediated routing. Selected skills decompose hierarchically into sub-skills. Dashed arrows indicate failure recovery paths that trigger re-retriev al or alternative skill selection. library from a small initial collection. CREA TOR [ 56 ] en- ables LLMs to create new tools on demand, and Eureka [ 47 ] generates rew ard functions that parameterize robotic skills, both ex emplifying meta-skill acquisition at different le vels of abstraction. Self-e volving libraries combine meta-skill generation with automated quality assessment, creating a closed loop in which the skill library grows and improves without human intervention. The primary risk is the quality ceiling pr ob- lem : without external grounding, the library cannot exceed the capability of the meta-skill itself, and errors in early generations may propagate through subsequent ones. 6.6. Skill composition and orchestration. Indi vidual skills rarely suf fice for complex tasks. Fig. 4 illustrates the composition architecture. The remainder of this section addresses ho w skills are combined, routed, and managed during multi-step ex ecution. 6.6.1. Hierarchical Skill Structures. Skills organize into hierarchies: a high-lev el skill (e.g., “deploy a web applica- tion”) in vokes mid-le vel skills (“set up database, ” “configure server , ” “run tests”), which in turn inv oke lo w-lev el skills (“ex ecute SQL migration, ” “write Nginx config”). This hi- erarchical structure mirrors the option framew ork in rein- forcement learning [ 10 ], where temporally extended actions (options) compose atomic actions into reusable behavioral modules. In the LLM agent context, hierarchical composition is typically managed through a planning layer that decomposes tasks and routes sub-tasks to appropriate skills. Hugging- GPT [ 4 ] demonstrates this at the tool level, using an LLM planner to decompose requests into sub-tasks routed to specialized Hugging Face models. The same architecture applies to skills: a planner selects and sequences skills based on task requirements and skill metadata. Runtime skill selection and routing. When multiple skills could apply to a given context, the agent must select the most appropriate one. T wo routing strategies dominate: • Embedding-based retrie val The task description is em- bedded and compared against skill description embed- dings. The top- k matching skills are loaded into the context window for the agent to ev aluate. V oyager [ 33 ] and AppAgent [ 39 ] use this approach. • LLM-mediated r outing The agent itself reasons about which skill to inv oke, based on skill metadata loaded through progressive disclosure (Pattern-1). This ap- proach is more flexible than embedding retrie val but consumes additional inference tokens and is subject to the agent’ s reasoning quality . Hybrid strategies combine both: embedding retriev al narro ws the candidate set, and the agent’ s reasoning selects the final skill. This two-stage approach balances recall (em- bedding search surfaces relev ant candidates) with precision (LLM reasoning ev aluates fit). Skill conflict resolution. When multiple skills are simul- taneously applicable ( C 1 ( o, g ) = 1 and C 2 ( o, g ) = 1 ), the agent requires a tie-breaking mechanism. Current systems typically rely on ranking heuristics such as embedding sim- ilarity or ad hoc LLM judgment, but they lack an explicit conflict-resolution policy . A principled approach, analogous to method specificity in HTNs [ 28 ] or rule priority in production systems, remains an open research problem. Failur e recov ery . Failure recov ery in skill-based agents can itself be modeled as a skill. When the termination condition T signals failure, a recov ery skill is in voked to diagnose the cause and decide whether to retry , backtrack to a prior state, or escalate to an alternativ e strategy . LA TS [ 54 ] implements recov ery through tree search: when a branch fails, the system backtracks and explores al- ternativ e action sequences. Reflexion [ 35 ] uses verbal reflec- tion as a recov ery mechanism, generating natural-language analysis of failures that guides subsequent attempts. T reating reco very as a first-class skill has governance implications: the recovery skill must be at least as trusted as the skill it is recovering, since it operates in the same ex ecution context and may need to undo or compensate for the failed skill’ s actions. Multi-agent skill sharing. In multi-agent systems, skills can be shared across agents through common skill repositories. MetaGPT [ 6 ] assigns specialized roles (product manager , architect, engineer) to different agents, each equipped with role-specific skills that compose into a softw are de velopment workflo w . AutoGen [ 7 ] enables multi-agent con versations where agents with different skill profiles collaborate through structured dialogue protocols. ProAgent [ 67 ] builds proac- tiv e cooperativ e agents that anticipate teammates’ actions and adapt their skill ex ecution accordingly . This enables division of labor: different agents specialize in dif ferent skill sets, and tasks are routed to the agent with the most relev ant skills. Howe ver , shared skill repositories introduce cross-agent security concerns (§ 7 ): a compromised skill in a shared repository affects all agents that consume it. 7. Security , T rust, and Governance of Skills The skill layer introduces a new attack surface for LLM agents [ 16 ]. Skills are code or instructions that influence agent behavior; a compromised skill can steer an agent to ward malicious outcomes while appearing benign at the metadata lev el. This section systematizes threats, mitiga- tions, and governance mechanisms specific to the skill layer . 7.1. Threat Model W e identify six primary threat categories: Poisoned skill retrieval. An attacker crafts skill metadata to cause the retriev al mechanism to surface a malicious skill in response to benign queries. This is analogous to SEO poisoning in web search. The attack e xploits Pattern- 1 (metadata-driv en disclosure): if the retrie val mechanism relies solely on embedding similarity , adversarial metadata can manipulate ranking. Malicious skill payloads. A skill’ s policy π contains instructions or code that perform unauthorized actions when executed. In code skills (Pattern-2), this resembles supply-chain attacks in traditional software [ 68 ]. In natural- language skills (Pattern-5), the payload is a form of prompt injection: instructions embedded within the skill text that redirect agent behavior . Cross-tenant leakage. In multi-agent or multi-user systems with shared skill repositories, skills authored by one tenant may access data or resources belonging to another . This risk is acute in enterprise deployments where multiple teams share agent infrastructure: a skill authored by T eam A should not inadvertently access T eam B’ s data, requiring per-tenant sandboxing with permission boundaries enforced by the ex ecution runtime rather than by the skill itself. Skill drift exploitation. Skills that were safe at authoring time may become unsafe as en vironment e volves. An at- tacker who controls part of the environment (e.g., a web page that a skill navig ates) can manipulate en vironments to change the skill’ s behavior without modifying the skill itself. Confused deputy via en vironmental injection. An agent processing untrusted observ ations (e.g., web pages or user documents) may encounter adversarial instructions that co- erce it into misusing an otherwise benign, privileged skill. The skill itself remains uncompromised; instead, the attack exploits the data–control boundary between the observation space O and skill inv ocation. This vector differs from ma- licious skill payloads, where the attack resides within the skill itself, and is particularly dangerous because it bypasses skill-le vel trust verification entirely . A pplicability condition poisoning. An attacker manipulates the input to C such that a malicious or inappropriate skill returns C ( o, g ) = 1 universally , activ ating in contexts where it should not. This can occur through metadata poison- ing (Pattern-1) or through adversarial environmental states that trigger overbroad applicability predicates. The formal model’ s reliance on C for skill selection makes this a direct attack on the skill abstraction itself. 7.2. T rust Tiers and Progr essive Disclosure W e propose a four -tier trust model for skills. Fig. 5 depicts the nested trust boundaries alongside attack vectors and defense mechanisms. • Tier -1 ( metadata only ): The agent sees only the skill name and description. No instructions or code are loaded. This tier supports skill discov ery without ex ecution risk. • Tier -2 ( instruction access ): The agent loads the skill’ s natural-language instructions into its context window . The instructions may influence the agent’ s reasoning. How- ev er, T ier-2 provides meaningful isolation only when the runtime enforces a read-only mode during instruction loading, with tool execution gated behind a separate ap- prov al channel. Without architectural separation between reasoning and action, Tier -2 instructions can indirectly induce tool in vocations through the agent’ s standard de- cision loop, effecti vely degrading to T ier-3. • Tier -3 ( supervised execution ): The skill can ex ecute ac- tions (tool calls, code ex ecution) but each action requires user approv al or runs within a constrained sandbox. • Tier -4 ( autonomous execution ): The skill executes without per-action approv al, subject to pre-configured permission boundaries and monitoring. Production systems should def ault to T ier-1 for untrusted skills and require explicit trust escalation, backed by prove- nance verification, for higher tiers. The trust tier should be stick y : once a skill demonstrates reliable behavior at Tier -3 ov er multiple in vocations, it may be promoted to T ier-4, but a single safety violation should trigger demotion. Privilege escalation. The trust tier model must also guard against escalation: a T ier-1 skill’ s metadata could include instructions designed to trick the agent into loading it at a higher tier . T ier transitions should be enforced by the run- time, not by skill-provided metadata. Cross-referencing with prompt injection attacks [ 69 ], T ier-2 instruction access is particularly vulnerable when the loaded instructions contain embedded directi ves that cause the agent to in voke tools or escalate the skill’ s own pri vileges. 7.3. Sandboxing and Permission Boundaries Code skills (Pattern-2) require sandboxed ex ecution en- vironments that limit access to the file system, network, and system resources. Container-based sandboxes (e.g., Docker) and W ebAssembly runtimes provide isolation with varying performance overhead. The k ey design question is granu- larity: should sandboxing be per -skill (each skill runs in its own sandbox), per-session (all skills in a session share a sandbox), or per-tier (sandboxing varies by trust level)? Natural-language skills (Pattern-5) present a differ - ent sandboxing challenge: the “execution environment” is the agent’ s context window , and the “sandbox” is the instruction-follo wing boundary . Prompt injection at- tacks [ 69 ] demonstrate that this boundary is permeable. Ar- chitectural mitigations include separating skill instructions from user data, using structured input/output schemas, and employing output filtering to detect unauthorized actions. Figure 5. T rust-tiered threat model for skill governance. Four nested privile ge tiers (T1–T4) form concentric security boundaries. Red arrows show attack vectors targeting dif ferent tier boundaries; green labels indicate defense mechanisms between tiers. 7.4. Skill Supply-Chain Gover nance Marketplace-distrib uted skills (Pattern-7) face supply- chain risks analogous to those in package management ecosystems. W e recommend four governance mechanisms: Pro venance signing. Each skill package includes a cryp- tographic signature from its author , enabling verification of authorship and integrity . This mirrors code signing in traditional software distribution. Dependency auditing. Skills may depend on other skills, tools, or external services. A dependency graph should be maintained and audited for known vulnerabilities, similar to dependency scanning in npm or pip. Continuous monitoring. Even after initial vetting, skills should be monitored for behavioral anomalies during execu- tion. Unexpected tool calls, excessi ve resource consumption, or access to out-of-scope resources should trigger alerts and potential demotion to a lower trust tier . V ersion pinning. Skill consumers should pin to specific ver - sions rather than tracking “latest, ” to prev ent a compromised update from automatically propagating to all consumers. 7.5. Pattern-Specific Risk Matrix Different design patterns expose different attack sur- faces. T able 6 maps each pattern to its primary risks and recommended mitigations. 7.6. Case Study: ClawHav oc Supply-Chain Attack The ClawHa voc campaign against OpenClaw’ s ClawHub skill registry [ 60 ] provides the first large-scale empirical evidence of skill supply-chain exploitation, concretizing ev ery threat category in our model and rev ealing the sev erity of real-world consequences. Scale and attack surface. Within weeks of ClawHub’ s launch, security researchers identified 1,184 malicious skills across the registry [ 60 ], while a separate Snyk audit found that 36.8% of all published skills contained at least one security flaw . The campaign inv olved 12 publisher ac- counts, with a single account responsible for 677 packages (57% of all malicious listings), while the platform’ s most- downloaded skill (“What W ould Elon Do”) contained 9 vulnerabilities including 2 critical ones, with its ranking arti- ficially inflated through 4,000 faked downloads [ 60 ]. V irus- T otal’ s analysis of over 3,016 ClawHub skills confirmed that hundreds exhibited malicious characteristics [ 70 ]. Sep- arately , a Snyk audit found that 283 of 3,984 skills (7.1%) exposed sensitive credentials in plaintext through LLM con- text windo ws and output logs. The attack surface w as global: ov er 135,000 exposed OpenClaw instances were detected across 82 countries. Severity of credential and asset theft. The consequences of malicious skill ex ecution were not theoretical. The pri- mary payload, Atomic macOS Stealer (AMOS), systemat- ically harvested: (i) LLM API ke ys from .env files and OpenClaw configuration, enabling billing fraud and model abuse; (ii) cryptocurr ency wallet ke ys across 60+ wallet types including Phantom, MetaMask, and Exodus, enabling irrev ersible asset theft; (iii) browser -stored passwords, cr edit car d numbers, and autofill data across Chrome, Safari, Fire- fox, Brav e, and Edge; (iv) SSH ke ys and K e ychain creden- tials , granting persistent access to production infrastructure; and (v) T elegram sessions and local files from Desktop and Documents directories. W indows-tar geted payloads deliv- ered VMProtect-packed infostealers via password-protected archiv es, and 91% of malicious skills included prompt injection payloads that weaponized the agent itself as an accomplice, attacking both humans and AI simultaneously . Belgium’ s Centre for Cybersecurity and China’ s MIIT is- sued emergency advisories, while multiple South Korean technology companies blocked OpenClaw entirely . Attack vector analysis through our pattern taxonomy . The ClawHav oc campaign instantiates multiple threat cate- gories from § 7.1 : • P oisoned skill r etrieval : Attackers cloned popular legiti- mate skills under near-identical names, exploiting Pattern- 1’ s metadata-driv en discovery to rank malicious versions alongside or above originals. • Malicious skill payloads : Skills included reverse shells, credential-exfiltration webhooks, and social-engineering “setup” instructions that told users to run curl | bash pipelines. These exploit Pattern-2’ s code e xecution and Pattern-5’ s ambiguity at the NL/code boundary . • Confused deputy : Prompt injection payloads in skill doc- umentation coerced the agent into executing malicious commands using its legitimate tool access, bypassing any skill-lev el trust check. • C -poisoning : Overbroad skill descriptions ensured mali- cious skills activ ated across broad task categories (crypto, productivity , automation), maximizing the attack surface through Pattern-1 metadata manipulation. Patter n-specific impact gradient. The sev erity varies by pattern. P attern-7 (marketplace) is the most directly im- pacted: it is the distribution channel through which all at- T ABLE 6. P A T T E R N - S P E C I FI C S E C U R I T Y R I S K MAT R I X . # Pattern Primary Risks Recommended Mitigations Severity 1 Metadata progressive disclosure Metadata poisoning; misleading descriptions Metadata schema validation; human revie w for high-privile ge skills Medium 2 Code-as-skill Code injection; sandbox escape; dependency vulnerabilities Container sandboxing; static analysis; dependency scanning High 3 W orkflow enforcement Rule bypass via prompt injection; overly rigid constraints Input sanitization; rule integrity v erification Medium 4 Self-ev olving libraries Poisoned distillation; skill drift; quality degradation Human-in-the-loop verification; regression testing; anomaly detection High 5 Hybrid NL+code macros Boundary ambiguity exploitation; conflicting instructions Clear NL/code separation; instruction priority rules Medium 6 Meta-skills Recursiv e error amplification; adversarial skill generation Generation caps; quality gates at each iteration; div ersity checks High 7 Marketplace distribution Supply-chain attacks; malicious packages; version tampering Provenance signing; continuous monitoring; version pinning Critical — Confused deputy (cross-cutting) En vironmental injection coerces misuse of privile ged skills (affects P1, P2, P5) Data-flow tracking; capability confinement; input/output separation High — C -poisoning (cross-cutting) Adversarial inputs cause inappropriate skill activ ation (affects P1, P4) Adversarial testing of applicability predicates; input validation Medium tacks propagated, and the ClawHub registry’ s initial absence of prov enance signing, dependency auditing, or automated scanning enabled the 36.8% malicious-skill rate. P attern- 2 (code-as-skill) is the main execution vector: OpenCla w skills run code with the agent’ s full system permissions, so one malicious skill can access local credentials such as API ke ys, wallets, browser vaults, and SSH keys. P attern- 1 (metadata) is the discovery vector: poisoned metadata enabled ranking manipulation and name-squatting. P attern- 5 (hybrid NL+code) is exploited through documentation- as-attack-surface: skill README files contained the ac- tual social-engineering payload. P attern-3 (workflow en- for cement) is less exposed because hard-gated execution sequences constrain the agent’ s action space. For example, a mandated test-before-deploy workflow is harder to bypass through prompt injection alone. P attern-4 (self-evolving) presents a latent risk: if an agent’ s self-generated skill library ingests a malicious community skill as a template, the poison propagates through the agent’ s own generation loop. Gover nance response. OpenClaw’ s initial response was a partnership with V irusT otal [ 70 ] to scan published skills using SHA-256 fingerprints, Code Insight (LLM-based be- havioral analysis), and daily re-scans. This matches sev eral mechanisms in § 7.4 : automated provenance checks, behav- ioral anomaly detection, and blocking kno wn-bad versions by hash. OpenClaw also noted that V irusT otal scanning is “not a silver bullet”. Why traditional scanners fail: tuple-le vel analysis. The limitations of traditional malware scanners become evident when vie wed through our formal definition S = ( C, π , T , R ) introduced in § 2.1 . Each component of the tuple exposes a distinct attack surface, yet con ventional security tools cover only a small subset of them: • R (interface) : The callable interface (skill name, descrip- tion, and parameter schema) serves as the first point of contact. Name squatting, misleading descriptions, and inflated download counts can manipulate R and distort discovery . Howe ver , V irusT otal does not assess the se- mantics of skill metadata. • C (applicability condition) : Overbroad applicability pred- icates that return C ( o, g ) = 1 for maximally many con- texts increase the blast radius of a malicious skill. No current scanner audits whether a skill’ s activ ation scope is proportionate to its stated purpose. • π (policy) : The policy component is where most attacks arise, yet π in agentic skills is inherently heter ogeneous : it may contain executable code (amenable to static analysis), natural-language instructions (largely in visible to binary scanners), or both. For example, a curl command hid- den within a “stock tracking” skill’ s setup instructions, or a prompt-injection directiv e (e.g., “ignore all previ- ous safety guidelines”) embedded in the NL policy , can exfiltrate .env files and API ke ys to e xternal servers. V irusT otal, which is designed to detect binary malware signatures, labels such payloads as Benign because they appear as syntactically valid text or harmless shell com- mands when analyzed in isolation. • T (termination condition) : A malicious T can terminate the skill prematurely to ev ade logging (exfiltrate-then- exit-cleanly), or fail to terminate to enable persistent background access. Neither behavior triggers traditional antivirus heuristics. Complementary skill auditing. Recognizing this gap, the community has de veloped skill-native auditing tools that operate at the tuple lev el rather than the binary lev el. Agent Skills Guard [ 71 ] and SkillGuard [ 72 ] ex emplify a three- layer detection architecture mapped to our formalization: • Rule engine / AST analysis (auditing π code and R ): Pattern rules and Abstract Syntax Tree analysis flag risky con- structs in the executable part of π (e.g., shell execution, eval() , reverse shells, credential access, destructive op- erations) and can also catch hardcoded secrets e xposed via R ’ s metadata. This layer runs locally with low overhead, incurs no per-call cost, and can cover a broad set of attack patterns across multiple languages. • LLM semantic analysis (auditing π NL and C ): An LLM re views the natural-language part of π for hidden in- tent (prompt injection [ 73 ], social-engineering directiv es, or instructions conflicting with the stated purpose) and checks whether C ’ s activ ation scope is appropriate. This catches attacks that rule-based or binary scanning misses, such as benign-looking NL instructions that steer the agent to exfiltrate data using otherwise legitimate tools. • Reputation scoring (aggregating across C , π , T , R ): Signals from the layers are combined into a 0-100 rep- utation score. The tool uses threshold bands (e.g., above 80 as “safe” and below 30 as “malicious”). The authors report a controlled ev aluation on 39 test cases, including 4 adversarial samples that V irusT otal marked as Benign , and no false positives on legitimate skills in that set [ 71 ]. These tools are implemented as agent skills (Pattern-2) and can be installed directly in the OpenClaw environment. This means an agent can use one skill to audit others. In practice, it shows that the skill abstraction can also encode gov ernance checks within the ( C, π , T , R ) framework. The ClawHa voc case demonstrates that skill marketplace gover - nance requires defense in depth : binary scanning (V irusT o- tal) catches commodity malware targeting π code , skill-nativ e auditing catches NL-le vel attacks on π NL and C , and runtime behavioral monitoring is needed to detect attacks on T and context-dependent exploits that only manifest during execu- tion. No single layer suffices; the tuple-level decomposition provides the conceptual framework for understanding which defenses cover which attack surfaces. 8. Evaluating Agentic Skills W e ev aluate the utility of agentic skills through a fiv e- dimensional framework and map existing benchmarks to measurable skill properties. 8.1. Evaluation Dimensions Correctness. Correctness measures whether a skill achiev es its intended outcome. Evaluation relies on ground-truth an- notations or deterministic verifiers. For code skills, unit tests provide direct verification, while for web interaction skills, en vironment state comparison (e.g., verifying whether a form was submitted correctly) serves as a practical proxy . Robustness. Robustness captures a skill’ s reliability under input variations, en vironment perturbations, and edge cases. A robust skill maintains consistent performance when con- fronted with minor deviations from the training distribution, such as handling both legacy and updated UI layouts. Efficiency . Efficienc y characterizes the resource cost of ex- ecuting a skill. Relev ant metrics include token consumption (for natural-language skills), w all-clock time, number of tool calls, and API costs. Efficienc y directly affects deployment cost and composability , as inefficient sub-skills slow down- stream workflows. Generalization. Generalization ev aluates whether a skill transfers to unseen tasks or domains. This dimension is chal- lenging to measure because it requires out-of-distribution ev aluation. Benchmarks such as cross-website generaliza- tion in Mind2W eb [ 61 ] and cross-application ev aluation in OSW orld [ 62 ] provide partial evidence. Safety . Safety assesses whether a skill avoids harmful ac- tions, respects permission boundaries, and handles failures gracefully . Evaluation commonly in volves adversarial test- ing, red-teaming, and runtime monitoring for unauthorized or unsafe behaviors. 8.2. Deterministic Evaluation Harnesses Human ev aluation of agent skills does not scale. W e advocate for deterministic evaluation harnesses : benchmark en vironments where success is measured automatically by checking environment state against expected outcomes. This approach provides low-cost reproducible ev aluation that can be integrated into skill de velopment pipelines. The key design principle is outcome-based verification : rather than judging the quality of intermediate reasoning or the elegance of the skill’ s approach, the harness checks whether the intended outcome was achiev ed. This aligns with the pragmatic nature of skills as procedural modules valued for their effects, not their form. 8.3. Benchmark-to-Skill Mapping T able 7 maps major agent benchmarks to the skill dimen- sions they assess. No single benchmark cov ers all dimen- sions; a comprehensive skill ev aluation requires combining multiple benchmarks. 8.4. Anchor Case Study: SkillsBench The SkillsBench benchmark [ 32 ] provides the most di- rect evidence to date for the value of curated skills. W e note that the quantitative findings in this subsection deriv e pri- marily from a single, non-peer-re viewed benchmark. While the scale (86 tasks, 7,308 trajectories) and methodological rigor of SkillsBench provide useful evidence, independent replication across additional benchmarks is needed to con- firm these patterns. The benchmark e valuates 86 tasks across 11 domains (healthcare, manufacturing, cybersecurity , nat- ural science, energy , finance, of fice work, media, robotics, mathematics, and software engineering) using 7 agent-model configurations over 7,308 trajectories. Each task is assessed under three conditions: no skills, curated skills, and self- generated skills, with deterministic verifiers ensuring objec- tiv e ev aluation. Curated skills provide substantial, quantifiable improve- ment. Across all configurations, curated skills raise the av erage pass rate by 16.2 percentage points (from 24.3% to 40.6%). The effect varies dramatically by domain: health- care sees +51.9 pp, manufacturing +41.9 pp, and cybersecu- rity +23.2 pp, while software engineering gains only +4.5 pp T ABLE 7. B E N C H M A R K - T O - S K I L L - D I M E N S I O N M A P P I N G . ✓ = P R I M A RY A S S E S S M E N T ; ∼ = P A RT I A L A S S E S S M E N T ; E M P T Y = N O T A S S E S S E D . Benchmark Envir onment Correctness Robustness Efficiency Generalization Safety Skill Scope Assessed SkillsBench [ 32 ] Multi ✓ ∼ ✓ ✓ Skill utility , composition, domain W ebArena [ 1 ] W eb ✓ ∼ ∼ W eb navigation, UI grounding Mind2W eb [ 61 ] W eb ✓ ✓ Cross-site generalization OSW orld [ 62 ] Desktop ✓ ∼ ✓ Multi-application workflows SWE-bench [ 63 ] SWE ✓ ∼ ∼ Code understanding, patch generation GAIA [ 74 ] Multi ✓ ✓ General assistant capability AgentBench [ 75 ] Multi ✓ ∼ ∼ ✓ Cross-en vironment performance AndroidW orld [ 76 ] Mobile ✓ ∼ Mobile interaction skills and mathematics +6.0 pp. This domain v ariance is consistent with the hypothesis that skills help most where the base model’ s pretraining data provides insufficient procedural grounding, which is directly relev ant to the scope axis of our taxonomy (§ 5.10.2 ). Domain variance may also reflect confounders including task construction, verifier strictness, and skill authoring quality differences across domains. Self-generated skills pro vide no benefit. Self-generated skills av erage − 1.3 pp relati ve to the no-skills baseline, suggesting that models cannot yet reliably author the proce- dural kno wledge the y benefit from consuming in open-ended settings. Only one configuration (Claude Opus 4.6) showed a modest +1.4 pp, while Codex + GPT -5.2 degraded by − 5.6 pp. This finding is consistent with the quality concerns raised for self-evolving libraries (Pattern-4, § 5.5 ). Skill quantity and complexity matter . Focused skills with 2–3 modules yield optimal improv ement (+18.6 pp), while 4+ skills sho w diminishing returns (+5.9 pp). “De- tailed” skills (moderate-length, focused guidance) improve by +18.8 pp, whereas “comprehensi ve” skills (exhausti ve documentation) degr ade performance by − 2.9 pp. This pat- tern is consistent with Pattern-1 (metadata-driv en progres- si ve disclosure, § 5.2 ): loading focused procedural instruc- tions outperforms loading comprehensive reference material. Skills as compute equalizers. Smaller models equipped with curated skills can match or exceed larger models with- out skills. Claude Haiku 4.5 with skills (27.7%) outperforms Claude Opus 4.5 without skills (22.0%), suggesting that skill libraries may serve as a practical cost-reduction mechanism. Negative-delta tasks. 16 of 84 tasks show performance degradation with skills, with the worst case ( − 39.3 pp) occurring for tasks where the base model already performs well and skills introduce conflicting guidance. This high- lights the importance of the applicability condition C in our formalization (§ 2.1 ): a skill should activ ate only when its procedural knowledge is beneficial. W e present these as interpretiv e hypotheses grounded in the benchmark data, not causal conclusions; V oyager’ s self-verification success rate and AgentBench [ 75 ] cross- en vironment results provide partial corroboration from in- dependent sources, ev en if they do not directly measure the curated-vs-self-generated comparison. These findings underscore the importance of distinguishing between skill availability (having relev ant skills) and skill quality (ha ving skills that actually help). The skill lifecycle model (§ 4 ) addresses both: discov ery and storage ensure av ailability , while practice, ev aluation, and update ensure quality . 9. Discussion and Limitations 9.1. Cross-Cutting Observations Sev eral patterns emerge from the systematization that are not visible from any individual system. Representation–go vernance coupling. More formal skill representations admit stronger gov ernance. Code skills (Pattern-2) support static analysis, unit testing, and sand- boxed e xecution; natural-language skills resist all three. This creates a tension: the representations that are easiest to author (NL) are hardest to govern, while those amenable to formal verification (code, policy) require specialized author- ing expertise. No existing system resolves this tension fully; hybrid representations (Pattern-5) attempt a compromise but introduce boundary ambiguity . Sparsity of the design space. T able 5 re veals that most systems cluster in a narrow region: code-as-skill represen- tation with self-ev olving library patterns in game or SWE en vironments. Lar ge regions of the representation × scope × pattern space remain unexplored, particularly policy- based skills with marketplace distrib ution and NL skills with formal workflow enforcement. These unexplored regions represent both opportunity and risk: they may be inherently difficult (explaining the sparsity) or simply underexplored. Marketplace gro wth outpaces governance. TThe Open- Claw experience (§ 7.6 ) shows that when skill ecosystems grow quickly , gov ernance mechanisms can lag behind. ClawHub’ s 36.8% malicious-skill rate at its peak is orders of magnitude worse than the point-in-time malw are rates ob- served in mature package registries such as npm, reflecting the absence of even basic supply-chain protections (pack- age signing, automated scanning, reputation scoring) that took traditional package ecosystems years to develop. The subsequent V irusT otal partnership reduced the threat sur- face but was reactive; proactive governance (pre-publication scanning, behavioral sandboxing, capability confinement) is necessary for Pattern-7 systems that distribute skills with full system access. This observation reinforces the Pattern-3 advantage in our taxonomy: workflo w enforcement, which constrains execution sequences before skills run, is inher- ently more resilient to supply-chain compromise than pat- terns that grant broad execution permissions and attempt to detect misuse after the fact. The curation-scalability tradeoff. The SkillsBench evi- dence (§ 8.4 ) quantifies a fundamental tradeof f: curated skills improv e pass rates by +16.2 pp on average, while self- generated skills degrade them by − 1.3 pp. Self-ev olving libraries (Pattern-4) are the most scalable acquisition mech- anism b ut produce skills that hurt performance; human curation yields the most reliable skills but does not scale. SkillsBench further shows that focused skills with 2–3 mod- ules outperform comprehensiv e documentation, suggesting that the quality problem is not just accuracy but also con- ciseness : effecti ve skills must distill procedural kno wledge rather than dump reference material. The tension is not absolute. V erification-gated self-generation (V oyager [ 33 ], Eureka [ 47 ]) succeeds in constrained environments with deterministic execution feedback; the SkillsBench e vidence indicates this success does not yet generalize to open-ended, multi-domain settings without execution-verified practice loops. Closing the tradeoff likely requires combining au- tonomous generation with automated verification pipelines and length-constrained distillation. 9.2. Limitations of This Systematization Corpus r ecency . The LLM agent skill ecosystem is recent: the majority of systems analyzed were published in 2023– 2024. While we ground the skill abstraction in decades of cogniti ve science and RL, the LLM-specific literature may be too nascent for patterns identified here to be stable. T axonomies may require revision as the field matures. Corpus coverage. Our analysis examines 24 systems from a retained set of 65 papers. Despite systematic search pro- cedures (§ 3 ), we may miss relev ant work, particularly from industry systems with limited public documentation, non- English-language publications, and concurrent preprints. T axonomy validation. The sev en design patterns were de- ri ved bottom-up from the analyzed systems but have not been validated through external expert surveys or formal concept analysis. The non-exclusi vity of patterns (systems combine multiple patterns) complicates categorical analysis and may limit the taxonomy’ s discriminativ e power for future systems that combine patterns in novel ways. Production and safety co verage. Our corpus emphasizes research systems with published ev aluations. Se veral pro- duction frame works (e.g., LangChain/LangGraph for skill composition, DSPy for declarative skill compilation) and safety-focused benchmarks (e.g., AgentHarm, InjectAgent) are relev ant but under-represented in our analysis due to limited peer-revie wed documentation. W e focus on systems with sufficient published detail for rigorous classification. Benchmark reliance. Our ev aluation analysis relies on pub- lished benchmark results, which may not reflect real-world skill utility . Production deployments inv olve longer time horizons, messier en vironments, and adversarial conditions not captured by existing benchmarks. 10. Open Problems and Research Roadmap Existing skill-based agents still expose several unre- solved tensions that limit reliable deployment at scale. W e highlight sev eral directions. 10.1. V erified A utonomous Skill Generation A central tension revealed throughout our analysis is the trade-off between scalability and reliability in skill construc- tion. Systems that allow skills to ev olve autonomously can expand capability libraries rapidly , yet empirical e vidence sho ws that automatically generated skills may occasion- ally degrade downstream performance. In contrast, human- curated skills remain more dependable but introduce a clear scalability bottleneck, as manual v alidation cannot keep pace with growing agent deployments. This shows that the key obstacle is no longer skill gener- ation itself, but verification at the point of admission into the skill library . A promising direction is to treat skills similarly to software artifacts in continuous integration pipelines: newly generated skills would be e valuated against held- out task distributions before becoming reusable components. For code-centric skills, formal or semi-formal verification techniques may provide guarantees about behavior , while natural-language or hybrid skills lik ely require behavioral testing and regression-style e valuation. Progress in this area would enable self-ev olving skill libraries that improve over time without accumulating hidden performance regressions. 10.2. Unsupervised Skill Discovery Another limitation concerns how new skills are discov- ered in the first place. Although many existing systems advertise autonomous learning, most still rely hea vily on external scaf folding such as predefined curricula, demon- strations, or explicit re ward signals. Our lifecycle survey sho ws that fully autonomous discovery remains rare: e ven systems designed for exploration typically depend on some form of human guidance to define progress. Achieving open-ended capability growth therefore re- quires moving beyond supervised discovery . One possible path is adapting unsupervised skill discovery techniques from reinforcement learning to LLM-based agents, allow- ing reusable behaviors to emerge directly from interaction traces. Signals such as repeated trajectory patterns, attention regularities, or recurring subgoal structures may serve as implicit indicators of skill boundaries. An agent capable of extracting reusable competencies solely from its own expe- rience would fundamentally change how agent capabilities scale, shifting learning from instruction-driv en expansion tow ard self-organizing behavior . 10.3. Formal V erification Acr oss Representations A practical governance challenge arises from the diver - sity of skill representations. Skills expressed as executable code benefit from decades of software assurance techniques, including testing, static analysis, and sandboxing. In prac- tice, howe ver , many deployed skill libraries rely heavily on natural-language or policy-style skills because they are easier to author and distribute. Unfortunately , these represen- tations are significantly harder to audit rigorously , creating a mismatch between expressi ve con venience and verifiability . This gap becomes particularly visible in safety-sensitiv e deployments, where auditing requirements extend beyond simple correctness checks. Emerging approaches suggest combining multiple lightweight verification layers: rule- based analysis for executable components, semantic inspec- tion for language-based policies, and reputation or behav- ioral monitoring across ex ecutions. The longer -term chal- lenge is moving from static, pre-deployment inspection to ward runtime verification capable of detecting context- dependent failures or delayed activ ation attacks that only appear under specific en vironmental conditions. 10.4. Robustness Under En vironmental Drift Even correctly implemented skills may fail over time as their operating en vironments ev olve. Changes in APIs, tools, data formats, or surrounding workflo ws can gradually in validate assumptions embedded in a skill, producing unin- tended behavior without any modification to the skill itself. This form of en vironmental drift creates an attack surface that operates indirectly: adversaries can manipulate external conditions rather than the skill artifact. Despite its practical importance, proactiv e drift detec- tion remains largely absent from current systems. Future work may focus on continuous monitoring mechanisms that track ex ecution statistics, detect deviations from historical behavior , and correlate failures with en vironmental change signals. Such systems would treat skills as li ving compo- nents requiring maintenance, enabling automatic adaptation or retirement once reliability deteriorates. Addressing drift will likely become essential as agents transition from exper- imental settings to long-liv ed production deployments. 10.5. Governance Economics and Liability Finally , the emergence of marketplace-style skill distri- bution introduces economic and governance questions that remain largely unexplored. Open skill ecosystems create strong incentiv es for contribution and innov ation, but si- multaneously expand the supply-chain attack surface. Our surve y indicates that existing platforms rarely provide clear mechanisms for assigning responsibility when third-party skills cause harm, nor do they offer credible certification processes that align incentiv es with reliability . Progress here requires integrating technical and eco- nomic design. Liability models must clarify responsibility among skill authors, platform operators, and users, while certification mechanisms should rew ard dependable skills and discourage risky ones. Understanding these dynam- ics may require agent-based economic modeling alongside empirical platform studies. As skill marketplaces mature, gov ernance framew orks that combine accountability , cer- tification, and incentiv e alignment will likely become as important as technical advances themselves. 11. Conclusion Agentic skills are reusable procedural modules for LLM agents. W e structure the design space, analyze security risks, and show that skill quality critically affects agent perfor - mance. W e close by outlining open challenges in discovery , verification, and governance for reliable skill-based agents. References [1] S. Zhou, F . F . Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar , X. Cheng, T . Ou, Y . Bisk, D. Fried, U. Alon, and G. Neubig, “W ebArena: A realistic web environment for building autonomous agents, ” in International Confer ence on Learning Repr esentations (ICLR) , 2024, [2] J. Y ang, C. E. Jimenez, A. W ettig, K. Lieret, S. Y ao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable au- tomated software engineering, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2024, [3] Z. Ji, D. W u, W . Jiang, P . Ma, Z. Li, and S. W ang, “Measuring and augmenting large language models for solving capture-the-flag challenges, ” in Pr oceedings of the A CM SIGSAC Conference on Computer and Communications Security (CCS) , 2025, pp. 603–617. [4] Y . Shen, K. Song, X. T an, D. Li, W . Lu, and Y . Zhuang, “Hug- gingGPT : Solving AI tasks with ChatGPT and its friends in Hug- ging Face, ” in Advances in Neural Information Processing Systems (NeurIPS) , 2023, [5] C. Xie, C. Chen, F . Jia, Z. Y e, S. Lai, K. Shu, J. Gu, A. Bibi, Z. Hu, D. Jurgens et al. , “Can large language model agents simulate human trust behavior?” Advances in Neur al Information Pr ocessing Systems (NeurIPS) , vol. 37, pp. 15 674–15 729, 2024. [6] S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. W ang, C. Zhang, Z. W ang, S. Y au, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. W u, and J. Schmidhuber , “MetaGPT: Meta programming for a multi-agent collaborativ e framework, ” in International Conference on Learning Repr esentations (ICLR) , 2024, [7] Q. W u, G. Bansal, J. Zhang, Y . W u, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. A wadallah, R. W . White, D. Burger , and C. W ang, “AutoGen: Enabling next-gen LLM applications via multi- agent conv ersation, ” in Conference on Language Modeling (COLM) , 2024, [8] J. R. Anderson, D. Bothell, M. D. Byrne, S. Douglass, C. Lebiere, and Y . Qin, “ An integrated theory of the mind. ” Psychological Revie w , vol. 111, no. 4, pp. 1036–1060, 2004. [9] J. E. Laird, The Soar Cognitive Architectur e . MIT Press, 2012. [10] R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and semi- MDPs: A framework for temporal abstraction in reinforcement learn- ing, ” Artificial Intelligence , vol. 112, no. 1–2, pp. 181–211, 1999. [11] G. Zhang, H. Geng, X. Y u, Z. Y in, Z. Zhang, Z. T an, H. Zhou, Z.-Z. Li, X. Xue, Y . Li et al. , “The landscape of agentic reinforcement learning for llms: A survey , ” Tr ansactions on Machine Learning Resear ch (TMLR) . [12] C. Qian, E. C. Acikgoz, Q. He, H. W ANG, X. Chen, D. Hakkani- Tür , G. T ur , and H. Ji, “T oolRL: Reward is all tool learning needs, ” in Annual Conference on Neural Information Pr ocessing Systems (NeurIPS) . [13] H.-a. Gao, J. Geng, W . Hua, M. Hu, X. Juan, H. Liu, S. Liu, J. Qiu, X. Qi, Q. Ren et al. , “ A survey of self-e volving agents: What, when, how , and where to ev olve on the path to artificial super intelligence, ” T ransactions on Machine Learning Research (TMLR) . [14] X. Ma, Y . Gao, Y . W ang, R. W ang, X. W ang, Y . Sun, Y . Ding, H. Xu, Y . Chen, Y . Zhao et al. , “Safety at scale: A comprehensi ve survey of large model and agent safety , ” F oundations and T r ends in Privacy and Security , vol. 8, no. 3-4, pp. 1–240, 2026. [15] L. W ang, C. Ma, X. Feng, Z. Zhang, H. Y ang, J. Zhang, Z. Chen, J. T ang, X. Chen, Y . Lin, W . X. Zhao, Z. W ei, and J.-R. W en, “ A survey on large language model based autonomous agents, ” F r ontiers of Computer Science , vol. 18, no. 6, p. 186345, 2024, extended from [16] A. Shahriar, M. N. Rahman, S. Ahmed, F . Sadeque, and M. R. Parvez, “ A survey on agentic security: Applications, threats and defenses, ” arXiv pr eprint arXiv:2510.06445 , 2025. [17] X. Huang, W . Liu, X. Chen, X. W ang, H. W ang, D. Lian, Y . W ang, R. T ang, and E. Chen, “Understanding the planning of LLM agents: A survey , ” arXiv preprint , 2024. [18] T . Guo, X. Chen, Y . W ang, R. Chang, S. Pei, N. V . Chawla, O. W iest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges, ” arXiv pr eprint arXiv:2402.01680 , 2024. [19] A. Y ehudai, L. Eden, A. Li, G. Uziel, Y . Zhao, R. Bar-Haim, A. Co- han, and M. Shmueli-Scheuer, “Survey on evaluation of LLM-based agents, ” arXiv pr eprint arXiv:2503.16416 , 2025. [20] F . X. Fan, C. T an, R. W attenhofer, and Y .-S. Ong, “Information fidelity in tool-using llm agents: A martingale analysis of the model context protocol, ” arXiv preprint , 2026. [21] Y . Qin, S. Hu, Y . Lin, W . Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y . Huang, C. Xiao, C. Han, Y . R. Fung, Y . Su, H. W ang, C. Qian, R. Tian, K. Zhu, S. Liang, X. Shen, B. Xu, Z. Zhang, Y . Y e, B. Li et al. , “T ool learning with foundation models, ” ACM Computing Surveys (CSUR) , vol. 57, no. 4, pp. 101:1–101:40, 2025. [22] T . Schick, J. Dwiv edi-Y u, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer , N. Cancedda, and T . Scialom, “T ool- former: Language models can teach themselves to use tools, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023, [23] T . Guo, X. Chen, Y . W ang, R. Chang, S. Pei, N. V . Chawla, O. W iest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges, ” in Proceedings of the Thirty-Third In- ternational Joint Confer ence on Artificial Intelligence (IJCAI) , 2024, pp. 8048–8057, survey track. [24] C. P acker , V . Fang, S. G. Patil, K. Lin, S. W ooders, and J. E. Gonzalez, “MemGPT: T owards LLMs as operating systems, ” arXiv pr eprint arXiv:2310.08560 , 2023. [25] K. Hatalis, D. Christou, J. Myers, S. Jones, K. Lambert, A. Amos- Binks, Z. Dannenhauer , and D. Dannenhauer , “Memory matters: The need to improve long-term memory in llm-agents, ” in Proceedings of the AAAI Symposium Series (AAAI) , vol. 2, no. 1, 2023, pp. 277–280. [26] B. Ma, Y . Jiang, X. W ang, G. Y u, Q. W ang, C. Sun, C. Li, X. Qi, Y . He, W . Ni et al. , “Sok: Semantic priv acy in large language models, ” arXiv pr eprint arXiv:2506.23603 , 2025. [27] J. White, Q. Fu, S. Hays, M. Sandborn, C. Olea, H. Gilbert, A. El- nashar , J. Spencer-Smith, and D. C. Schmidt, “ A prompt pattern catalog to enhance prompt engineering with chatgpt, ” arXiv preprint arXiv:2302.11382 , 2023. [28] D. S. Nau, T .-C. Au, O. Ilghami, U. Kuter, J. W . Murdock, D. W u, and F . Y aman, “SHOP2: An HTN planning system, ” Journal of Artificial Intelligence Research , vol. 20, pp. 379–404, 2003. [29] A. S. Rao and M. P . Georgeff, “BDI agents: From theory to practice, ” in Pr oceedings of the First International Confer ence on Multi-Agent Systems (ICMAS) , 1995, pp. 312–319. [30] R. E. Fik es and N. J. Nilsson, “STRIPS: A new approach to the appli- cation of theorem proving to problem solving, ” Artificial Intelligence , vol. 2, no. 3–4, pp. 189–208, 1971. [31] W . G. Chase and H. A. Simon, “Perception in chess, ” Cognitive Psychology , vol. 4, no. 1, pp. 55–81, 1973. [32] X. Li, W . Chen, Y . Liu, S. Zheng, X. Chen, Y . He, Y . Li, B. Y ou, H. Shen, J. Sun et al. , “SkillsBench: Benchmarking how well agent skills work across diverse tasks, ” arXiv preprint , 2026. [33] G. W ang, Y . Xie, Y . Jiang, A. Mandlekar , C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar , “V oyager: An open-ended embodied agent with large language models, ” T ransactions on Machine Learning Resear ch (TMLR) , 2024, [34] S. Y ao, J. Zhao, D. Y u, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models, ” in International Confer ence on Learning Repr esentations (ICLR) , 2023, [35] N. Shinn, F . Cassano, A. Gopinath, K. Narasimhan, and S. Y ao, “Reflexion: Language agents with verbal reinforcement learning, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023, [36] Z. W ang, S. Cai, A. Liu, Y . Jin, J. Hou, B. Zhang, H. Lin, Z. He, Z. Zheng, Y . Y ang, X. Ma, and Y . Liang, “J AR VIS-1: Open- world multi-task agents with memory-augmented multimodal lan- guage models, ” IEEE T ransactions on P attern Analysis and Machine Intelligence (TP AMI) , vol. 47, no. 3, pp. 1894–1907, 2025, extended from [37] Z. W ang, S. Cai, A. Liu, X. Ma, and Y . Liang, “Describe, explain, plan and select: Interactiv e planning with large language models enables open-world multi-task agents, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023, [38] M. F . Chen, N. Roberts, K. Bhatia, J. W ang, C. Zhang, F . Sala, and C. Ré, “Skill-it! a data-driven skills framework for understanding and training language models, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023, [39] C. Zhang, Z. Y ang, J. Liu, Y . Han, X. Chen, Z. Huang, B. Fu, and G. Y u, “ AppAgent: Multimodal agents as smartphone users, ” in Pr o- ceedings of the CHI Confer ence on Human F actors in Computing Sys- tems (CHI) , 2025, pp. 70:1–70:20, extended from [40] W . T an, W . Zhang, X. Xu, H. Xia, Z. Ding, B. Li, B. Zhou et al. , “Cradle: Empowering foundation agents towards general computer control, ” in International Conference on Machine Learning (ICML) , ser . Proceedings of Machine Learning Research, vol. 267, 2025, pp. 58 658–58 725, extended from [41] A. Zeng, M. Liu, R. Lu, B. W ang, X. Liu, Y . Dong, and J. T ang, “AgentT uning: Enabling generalized agent abilities for LLMs, ” in F indings of the Association for Computational Linguistics: A CL 2024 , 2024, pp. 3053–3077, [42] X. W ang, Y . Chen, L. Y uan, Y . Zhang, Y . Li, H. Peng, and H. Ji, “Executable code actions elicit better LLM agents, ” in International Confer ence on Machine Learning (ICML) , 2024, [43] B. Chen, C. Shu, E. Shareghi, N. Collier , K. Narasimhan, and S. Y ao, “FireAct: T ow ard language agent fine-tuning, ” arXiv pr eprint arXiv:2310.05915 , 2023. [44] B. Qiao, L. Li, X. Zhang, S. He, Y . Kang, C. Zhang, F . Y ang, H. Dong, J. Zhang, L. W ang, M. Ma, P . Zhao, S. Qin, X. Qin, C. Du, Y . Xu, Q. Lin, S. Rajmohan, and D. Zhang, “T askW eaver: A code-first agent framew ork, ” arXiv preprint , 2023. [45] M. Ahn, A. Brohan, N. Brown, Y . Chebotar , O. Cortes, B. David, C. Finn, C. Fu, K. Gober, K. Hausman et al. , “Do as i can, not as i say: Grounding language in robotic affordances, ” in Confer ence on Robot Learning (CoRL) , 2022, [46] J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P . Liang, and M. S. Bernstein, “Generative agents: Interacti ve simulacra of human behav- ior , ” in ACM Symposium on User Interface Softwar e and T echnology (UIST) , 2023, [47] Y . J. Ma, W . Liang, G. W ang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar, “Eureka: Human-lev el reward design via coding large language models, ” in International Confer- ence on Learning Repr esentations (ICLR) , 2024, [48] K. Nottingham, P . Ammanabrolu, A. Suhr , Y . Choi, H. Hajishirzi, S. Singh, and R. Fox, “Do embodied agents dream of pixelated sheep: Embodied decision making using language guided world modelling, ” in International Conference on Machine Learning (ICML) , 2023, [49] W . Huang, F . Xia, T . Xiao, H. Chan, J. Liang, P . Florence, A. Zeng, J. T ompson, I. Mordatch, Y . Chebotar et al. , “Inner monologue: Embodied reasoning through planning with language models, ” in Confer ence on Robot Learning (CoRL) , 2022, [50] E. Gamma, R. Helm, R. Johnson, and J. Vlissides, Design P atterns: Elements of Reusable Object-Oriented Software . Addison-W esley Professional, 1994. [51] Microsoft, “Semantic Kernel: A lightweight SDK for AI agent de- velopment, ” h t t p s : / /g i t h u b . c o m /m i c r o s o f t /s e m a n t i c- k e r n e l , 2023, accessed: 2026-02-21. [52] J. Liang, W . Huang, F . Xia, P . Xu, K. Hausman, B. Ichter, P . Florence, and A. Zeng, “Code as policies: Language model programs for embodied control, ” in IEEE International Conference on Robotics and Automation (ICRA) , 2023, [53] I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Trem- blay , D. Fox, J. Thomason, and A. Garg, “ProgPrompt: Generating situated robot task plans using large language models, ” in IEEE International Confer ence on Robotics and Automation (ICRA) , 2023, [54] A. Zhou, K. Y an, M. Shlapentokh-Rothman, H. W ang, and Y .- X. W ang, “Language agent tree search unifies reasoning, acting, and planning in language models, ” in International Conference on Machine Learning (ICML) , ser . Proceedings of Machine Learning Research, vol. 235, 2024, pp. 62 138–62 160, [55] Y . W ang, Y . Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language models with self- generated instructions, ” in Annual Meeting of the Association for Computational Linguistics (ACL) , 2023, pp. 13 484–13 508. [56] C. Qian, C. Han, Y . R. Fung, Y . Qin, Z. Liu, and H. Ji, “CREA T OR: T ool creation for disentangling abstract and concrete reasoning of large language models, ” in Findings of the Association for Computa- tional Linguistics (EMNLP) , 2023, [57] Anthropic, “Introducing the model context protocol, ” https://www .an thropic.com/ne ws/model- co ntext- protoc ol , 2024, accessed: 2026-02- 21. [58] Y . Qin, S. Liang, Y . Y e, K. Zhu, L. Y an, Y . Lu, Y . Lin, X. Cong, X. T ang, B. Qian et al. , “T oolLLM: Facilitating large language models to master 16000+ real-world APIs, ” in International Confer ence on Learning Repr esentations (ICLR) , 2024, [59] OpenClaw Project, “OpenClaw: Personal ai assistant, ” h t t p s : / / g i t h ub. com /op enc law /op enc law , 2026, official repository (216k stars at access time). Accessed: 2026-02-22. [60] Alex and Oren Y omtov, “ClawHa voc: 341 malicious clawed skills found by the bot they were targeting, ” htt ps:// www . koi.ai /blog /claw ha voc- 34 1- ma li ci ous - cla we db ot- s ki lls- f oun d- b y- t he - b ot - the y- we r e- targeting , 2026, k oi Research blog post; update dated Feb 16, 2026 reports 824 malicious skills. Accessed: 2026-02-22. [61] X. Deng, Y . Gu, B. Zheng, S. Chen, S. Stev ens, B. W ang, H. Sun, and Y . Su, “Mind2W eb: T owards a generalist agent for the web, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023, spotlight. [62] T . Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T . J. Hua, Z. Cheng, D. Shin, F . Lei, Y . Liu, Y . Xu, S. Zhou, S. Sav arese, C. Xiong, V . Zhong, and T . Y u, “OSW orld: Benchmarking multimodal agents for open-ended tasks in real computer environments, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2024, datasets and Benchmarks track. [63] C. E. Jimenez, J. Y ang, A. W ettig, S. Y ao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real- world GitHub issues?” in International Confer ence on Learning Repr esentations (ICLR) , 2024, [64] H. Ravichandar, A. S. Polydoros, S. Chernova, and A. Billard, “Re- cent advances in robot learning from demonstration, ” Annual Review of Control, Robotics, and Autonomous Systems , vol. 3, pp. 297–330, 2020. [65] Significant Gravitas, “AutoGPT: An autonomous GPT-4 experiment, ” ht tp s :/ /g it h ub .c om /S i gn ifi ca n t- Gr av it as / Au to GP T , 2023, accessed: 2026-02-21. [66] L. W ang, X. Zhang, H. Su, and J. Zhu, “ A comprehensive survey of continual learning: Theory , method and application, ” IEEE T ransac- tions on P attern Analysis and Machine Intelligence (TP AMI) , vol. 46, no. 8, pp. 5362–5383, 2024. [67] C. Zhang, K. Y ang, S. Hu, Z. W ang, G. Li, Y . Sun, C. Zhang, Z. Zhang, A. Liu, S.-C. Zhu, X. Chang, J. Zhang, F . Y in, Y . Liang, and Y . Y ang, “ProAgent: Building proactive cooperativ e agents with large language models, ” in Proceedings of the AAAI Confer ence on Artificial Intelligence (AAAI) , vol. 38, no. 16, 2024, pp. 17 591– 17 599, [68] P . Ladisa, H. Plate, M. Martinez, and O. Barais, “SoK: T axonomy of attacks on open-source software supply chains, ” in IEEE Symposium on Security and Privacy (SP) , 2023, pp. 1509–1526. [69] K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T . Holz, and M. Fritz, “Not what you’v e signed up for: Compromising real- world LLM-integrated applications with indirect prompt injection, ” in A CM W orkshop on Artificial Intelligence and Security (AISec) , 2023, [70] B. Quintero, “From automation to infection: How OpenClaw AI agent skills are being weaponized, ” h t t p s : / / b l o g . v i r u s t o t a l . c o m / 2 0 2 6 / 0 2 /f r om - a u to m at i o n- to- i n f ec t io n - h ow. h t ml , 2026, virusT otal Blog, February 2, 2026. Accessed: 2026-02-22. [71] B. V an, “ Agent skills guard, ” htt ps:// gith ub.c om/b ruce vanfdm/ agen t - sk il l s- gu ard , 2026, desktop scanner/manager; README reports 8 risk categories and 22 hard-trigger rules. Accessed: 2026-02-22. [72] G. Singh, “SkillGuard: AI agent security scanner , ” htt ps://skil lgaurd .up.railway .app/ , 2026, website and linked source repo describe AST analysis for JS/TS, 9-language coverage, and 20+ attack patterns. Accessed: 2026-02-22. [73] Y . Liu, G. Deng, Z. Xu, Y . Li, Y . Zheng, Y . Zhang, L. Zhao, T . Zhang, K. W ang, and Y . Liu, “Jailbreaking chatgpt via prompt engineering: An empirical study , ” arXiv preprint , 2023. [74] G. Mialon, C. Fourrier, T . W olf, Y . LeCun, and T . Scialom, “GAIA: A benchmark for general AI assistants, ” in International Confer ence on Learning Repr esentations (ICLR) , 2024, poster . [75] X. Liu, H. Y u, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Y ang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T . Zhang, Y . Su, H. Sun, M. Huang, Y . Dong, and J. T ang, “ AgentBench: Evaluating LLMs as agents, ” in International Confer- ence on Learning Repr esentations (ICLR) , 2024, [76] C. Rawles, S. Clinckemaillie, Y . Chang, J. W altz, G. Lau, M. Fair , A. Li, W . E. Bishop, W . Li, F . Campbell-Ajala, D. K. T oyama, R. J. Berry , D. T yamagundlu, T . P . Lillicrap, and O. Riv a, “AndroidW orld: A dynamic benchmarking environment for autonomous agents, ” in International Confer ence on Learning Repr esentations (ICLR) , 2025,
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment