Grid-Mind: An LLM-Orchestrated Multi-Fidelity Agent for Automated Connection Impact Assessment
Large language models (LLMs) have demonstrated remarkable tool-use capabilities, yet their application to power system operations remains largely unexplored. This paper presents Grid-Mind, a domain-specific LLM agent that interprets natural-language …
Authors: Mohamed Shamseldein
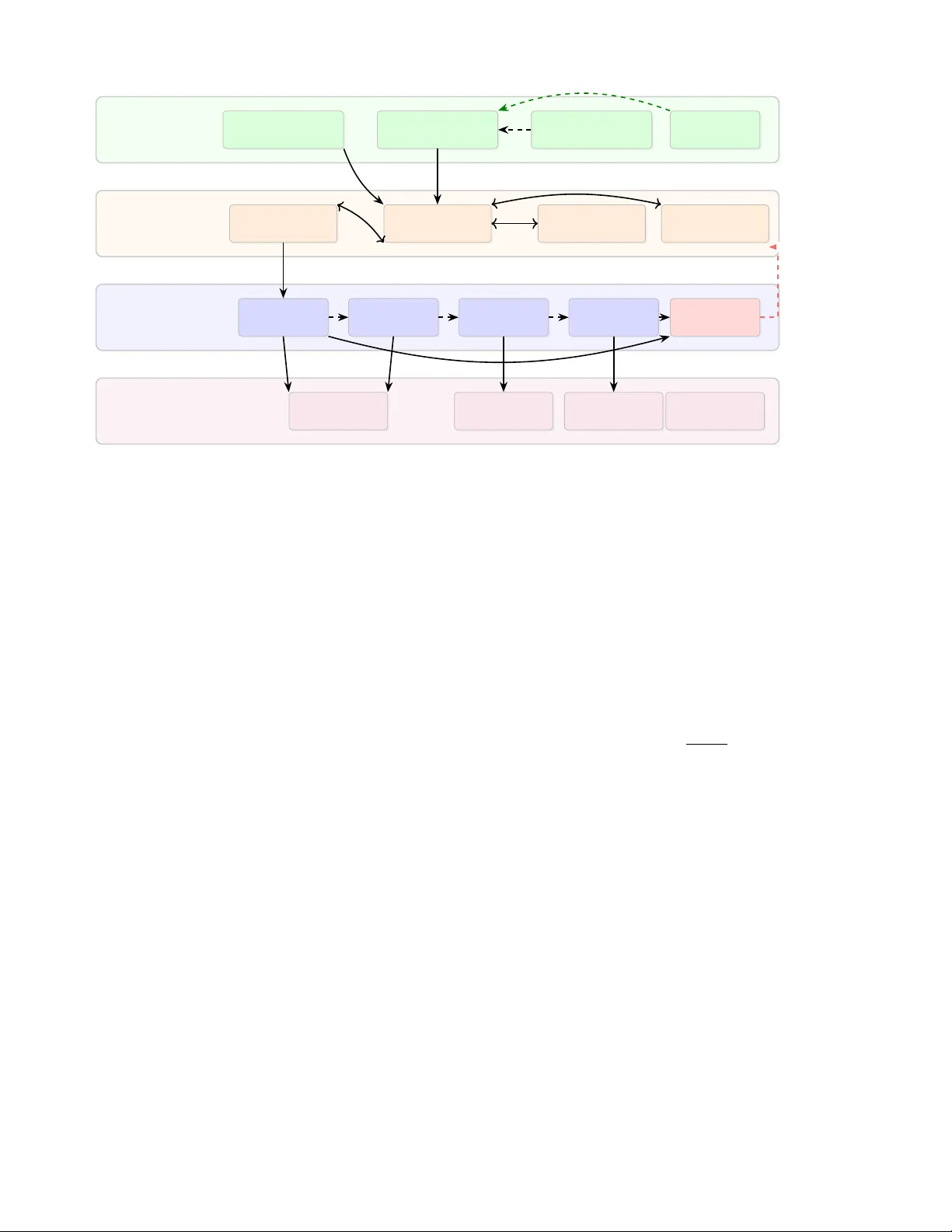
1 Grid-Mind: An LLM-Orchestrated Multi-Fidelity Agent for Automated Connection Impact Assessment Mohamed Shamseldein, Senior Member , IEEE Abstract —Large language models (LLMs) have demonstrated remarkable tool-use capabilities, yet their application to power system operations remains largely unexplor ed. This paper presents Grid-Mind, a domain-specific LLM agent that interpr ets natural-language interconnection r equests and autonomously or - chestrates multi-fidelity power system simulations. The LLM-first architectur e positions the language model as the central decision- making entity , employing an eleven-tool registry to execute Connection Impact Assessment (CIA) studies spanning steady- state power flow , N-1 contingency analysis, transient stability , and electromagnetic transient screening. A violation inspector grounds every decision in quantitative simulation outputs, while a three-layer anti-hallucination defense mitigates numerical fab- rication risk thr ough for ced capacity-tool r outing and post- response grounding validation. A prompt-level self-correction mechanism extracts distilled lessons fr om agent failur es, yielding progr essive accuracy improv ements without model retraining . End-to-end evaluation on 50 IEEE 118-b us scenarios (DeepSeek-V3, 2026-02-23) achieved 84.0% tool-selection accu- racy and 100% parsing accuracy . A separate 56-scenario self- correction suite passed 49 of 56 cases (87.5%) with a mean score of 89.3. These results establish a reproducible baseline for continued refinement while maintaining auditable, simulation- grounded decision support. Index T erms —Large language models, LLM agents, connection impact assessment, multi-fidelity simulation, tool-calling, power system automation, prompt-lev el self-corr ection, hallucination mitigation N O M E N C L A T U R E CIA Connection Impact Assessment IBR In verter -Based Resource LLM Large Language Model NL Natural Language SCR Short-Circuit Ratio ABC Abstract Base Class OPF Optimal Power Flow PF Power Flo w EMT Electromagnetic Transient T T ool registry: set of callable functions L Lessons learned (persistent memory) M Study memory (persistent structured store) f k Fidelity level k ∈ { 1 , 2 , 3 , 4 } V V iolation report from inspector M. Shamseldein is with the Department of Electrical Power and Machines, Faculty of Engineering, Ain Shams Uni versity , Cairo 11517, Egypt (e-mail: mohamed.shamseldein@eng.asu.edu.eg). Manuscript receiv ed February 2026. A provisional patent application (U.S. App. No. 63/989,282) cov ering the architectures and methods described herein is pending. I . I N T R O D U C T I O N The generator interconnection queue has emer ged as a critical bottleneck in the clean energy transition. As of 2023, o ver 2,600 GW of generation and storage capacity awaited processing in U.S. regional transmission organization queues [1], with mean study durations increasing from 2.1 to 5.0 years and withdrawal rates exceeding 80% in certain regions [2]. Although FERC Order No. 2023 mandates ac- celerated processing timelines and cluster -based studies [3], the fundamental engineering bottleneck—Connection Impact Assessment (CIA)—persists as a predominantly manual, labor- intensiv e process requiring sequential power flo w , contingenc y , transient stability , and electromagnetic transient analyses. Recent adv ances in LLM-based agents hav e demonstrated that language models can autonomously employ tools to solve complex tasks. ReAct [4] and T oolformer [5] established that LLMs can learn to in voke APIs through function calling, while T oolLLM [6] scaled this paradigm to o ver 16,000 real-world APIs. In software engineering, SWE-Agent [7] autonomously resolves GitHub issues with minimal human intervention. Open-source frameworks such as OpenClaw [8] further demonstrate production-grade agent architectures fea- turing model-agnostic gatew ays, skill plugins, and persistent memory—design patterns that are directly transferable to domain-specific applications. Despite this progress, LLM agents for po wer system op- erations remain in an early stage of de velopment. Prior work has explored LLMs for power system analysis [9], grid operator co-pilots [10], and foundation models for grid intelligence [11]; ho wev er , no existing system bridges the gap between natural-language interaction and actual multi-fidelity simulation execution. Current approaches either generate anal- ysis code without ex ecuting it or operate on simplified models that are disconnected from production-grade solvers. This paper presents Grid-Mind, an LLM-orchestrated agent that interprets natural-language interconnection requests and extracts structured parameters—bus location, capacity , and resource type—without relying on rigid rule-based parsing. The agent dispatches multi-fidelity simulations through an LLM-first architecture, lev eraging an elev en-tool registry and a solver-agnostic base class that supports established sim- ulation engines including PandaPo wer [12], ANDES [13], ParaEMT [14], and PSS/E [15]. This architecture enables the language model to autonomously plan multi-step work- flows, chaining up to five tool in vocations within a single con versational turn. Critically , Grid-Mind grounds every ap- prov al or rejection in quantitative violation inspections that employ screening-level criteria informed by NERC TPL stan- PREPRINT : THIS WORK IS UNDER REVIEW FOR PUBLICA TION IN IEEE TRANSACTIONS ON SMAR T GRID. 2 dards [16]. A three-layer anti-hallucination defense mitigates numerical fabrication risk by routing high-risk quantitative queries through deterministic tools and appending grounding warnings when warranted. T o support continuous operation, the system maintains persistent memory of study results across sessions for auditability , while progressively refining its capabilities through a prompt-le vel lesson-optimization feedback loop—distinct from gradient-based policy learning— that distills operational failures into persistent lessons. The benchmark harness supports fiv e frontier LLMs accessed via OpenRouter—Claude 3.5 Sonnet, GPT -4o, DeepSeek-R1 [17], DeepSeek-V3, and Qwen 2.5—ev aluated on 50 di verse scenarios encompassing complete requests, ambiguous multi-turn con versations, and edge cases. In this revision, we report reproducible end-to-end results from the full agent loop for DeepSeek-V3 along with the latest self- correction regression results from the current codebase. The architecture parallels production agent frameworks such as OpenClaw’ s gate way–skills–memory pattern [8], while spe- cializing it for po wer system domain knowledge and physics- grounded validation. I I . R E L AT E D W O R K A. LLM Agents and T ool Calling The emergence of function-calling capabilities in LLMs has enabled autonomous tool use across di verse domains. ReAct [4] interleav es reasoning traces with action execution, while T oolformer [5] demonstrates self-supervised API usage acquisition from demonstrations. OpenAI’ s function-calling protocol [18] formalized tool specifications as JSON schemas, establishing what has become a de facto industry standard. T oolLLM [6] subsequently extended this paradigm to ov er 16,000 APIs with automated tool selection. Production-grade agent frame works have matured rapidly in recent years. OpenClaw [8] implements a gateway–skills– memory architecture in which a model-agnostic runtime or- chestrates tool plugins with persistent state, while SWE- Agent [7] specializes this pattern for software engineering tasks. These frameworks collectively demonstrate that LLM agents can reliably orchestrate complex multi-step workflo ws when appropriately grounded in tool outputs. B. AI for P ower System Operations Machine learning techniques ha ve been extensiv ely applied to power system stability assessment, optimal power flow approximation, and load forecasting [11]. More recently , sev- eral studies hav e begun exploring LLMs specifically for grid applications: [9] surve ys LLM applications in power system analysis, while [10] proposes a ChatGPT -powered grid op- erator co-pilot concept. Howe ver , these approaches primarily lev erage LLMs for text generation and code assistance rather than for autonomous simulation orchestration. C. Inter connection Study Automation CIM standards [19], graph databases [20], ontologies [21], and digital twins [22] have been proposed for grid modeling, T ABLE I: Feature Comparison: Prior W ork vs. Grid-Mind Approach NL Solver Multi-F . V iol. Mem. Self-Corr . ReAct [4] ✓ – – – – – T oolLLM [6] ✓ – – – – – OpenClaw [8] ✓ – – – ✓ – PowerGPT [9] ✓ – – – – – ChatGrid [10] ✓ partial – – – – Digital T win [22] – ✓ – – – – Grid-Mind ✓ ✓ ✓ ✓ ✓ ✓ while hosting capacity studies [23] inform siting decisions. Nev ertheless, none of these approaches integrate a natural- language interface with multi-fidelity simulation ex ecution. T able I identifies the salient gap: among the systems re- viewed, no prior w ork combines an LLM agent with real solver ex ecution, multi-fidelity cascading, and physics-grounded vi- olation checking. I I I . S Y S T E M A R C H I T E C T U R E Grid-Mind adopts a layered architecture inspired by pro- duction agent frameworks [8], specialized for the requirements of the power system domain. Fig. 1 illustrates the four-layer design. A. Solver-Agnostic Abstract Base Class The GridSolver Abstract Base Class (ABC) defines a uni- form interface for power system solvers, comprising over 20 abstract methods that span case loading, power flo w solution, bus and branch result access, contingency execution, and violation checking. Four concrete adapters implement this interface. These adapters include PandaPower [12] for steady-state A C and optimal power flow computations essential to initial de- velopment and screening; ANDES [13] for high-fidelity time- domain transient stability simulations required in in verter- based resource scenarios; ParaEMT [14] for rapid electro- magnetic transient analysis in weak-grid en vironments with low short-circuit ratios; and a PSS/E [15] integration path for utility en vironments, which is license-dependent and currently implemented as a compatibility stub. An adapter registry provides robust instantiation with lazy loading: S ( b ) → GridSolver , b ∈ { PandaPo wer , ANDES , ParaEMT , PSS/E } (1) This design enables the LLM agent to operate uniformly across backends, with solver selection governed by the simu- lation layer rather than the agent itself. B. V iolation Inspector The V iolation Inspector provides solver -agnostic violation detection against configurable screening criteria informed by NERC TPL-001 planning standards [16]: V ( s ) = { v | v ∈ check ( s, ℓ ) } where ℓ = ( V min , V max , L max , δ max ) (2) 3 Interface Layer Natural Language Input REST API (FastAPI) W eb Dashboard Health Monitor Agent Layer T ool Registry Con versation Agent LLM Backend (OpenRouter) Lessons + Memory Simulation Layer Steady-State (A C PF) N-1 Contingency T ransient Stability EMT Screening V iolation Inspector Solver Layer PandaPo wer Adapter ANDES Adapter ParaEMT Adapter PSS/E Adapter GridSolver Abstract Base Class Lesson Feedback Fig. 1: Grid-Mind architecture. The Agent Layer orchestrates multi-fidelity simulations through a solver-agnostic tool registry . Persistent memory stores study results across sessions. Dashed arrows indicate conditional escalation. The prompt-le vel lesson feedback loop injects distilled rules from failure analysis back into the agent’ s persistent memory . A health monitor provides real-time system status. where s denotes a solver result, ℓ represents a limit config- uration, and each violation v encapsulates the element type, index, violation type, observed value, applicable limit, and margin percentage. The inspector distinguishes har d viola- tions from bor derline conditions within configurable tolerance bands ( ± 0 . 01 p.u. for voltage, ± 5% for loading). In the current implementation, this inspector gov erns steady-state and contingency acceptance, while transient and EMT acceptance employ stage-specific criteria summarized in T able II. I V . M U LT I - F I D E L I T Y C I A P I P E L I N E The pipeline orchestrates a four -stage assessment cascade (Fig. 2), in which each successi ve stage pro vides progressi vely higher fidelity analysis. The assessment commences with a steady-state AC power flow ( f 1 ) to ev aluate the immediate voltage and thermal impacts of the proposed connection. Provided that the base topology remains secure, the pipeline automatically advances to N-1 contingency analysis ( f 2 ), performing systematic equip- ment outage screening against emergency thermal limits. Con- ditional escalation into dynamic analysis follows: if the request in volv es an in verter -based resource (IBR = true), the pipeline may in vok e a time-domain transient stability simulation ( f 3 ). When EMT analysis is enabled for IBR requests, an EMT screening stage ( f 4 ) is executed, which ev aluates the short- circuit ratio against a configurable threshold (default 3.0). The escalation policy is formally expressed as: f ∗ ( r ) = max { k : ϕ k ( r ) = true } (3) where ϕ k are predicate functions encoding escalation condi- tions: ϕ 1 = true (always), ϕ 2 = e c (contingency enabled), ϕ 3 = e t ∧ IBR ( r ) , ϕ 4 = e e ∧ IBR ( r ) , where e c , e t , e e denote Boolean flags for contingency , transient, and EMT enablement respectiv ely . The implementation-lev el acceptance criteria are detailed below: For EMT screening, SCR is defined as SCR b = S sc ,b S IBR ,b . (4) The current adapter estimates S sc ,b from the diagonal Y -bus admittance when exposed by the backend, S sc ,b ≈ | Y bb | S base with S base = 100 MV A and | V b | ≈ 1 p.u.; when this quantity is unav ailable, the system employs a conservati ve system- size heuristic as a fallback. This constitutes a screening-lev el proxy and should be superseded by utility-specific short-circuit studies for production-grade approv als. Regarding N-1 policy , the default fail-on-ne w-failures setting targets incremental impact screening—specifically , project-caused reliability degradation—across heterogeneous test cases. F or more stringent planning practice, the im- plementation provides an opt-in material-worsening failure mode (T able II) that flags meaningful erosion of pre-existing contingency margins. The pipeline produces a structured interconnection impact report comprising per-stage results, violation details, and a final recommendation (approv e, reject, or borderline) accom- panied by reason codes. This report serves as the factual basis upon which the LLM constructs its natural-language explanation. 4 f 1 : Steady-State A C PF V iol? f 2 : N-1 Contingency IBR? f 3 : Transient Stability SCR < 3? f 4 : EMT Screening CIA Report + V iolations Reject No Y es Y es No Y es No Fig. 2: Multi-fidelity CIA pipeline. Stages are conditionally activ ated based on connection properties and violation se verity . A. Binary-Sear ch Capacity T ool Beyond pass/fail assessment, Grid-Mind provides a binary capacity search operator that determines the maximum activ e power a bus can accept before violations occur . This tool performs a bisection search over the MW range [ min , max ] : at each iteration, a full CIA is ex ecuted at the midpoint, the search interval is narro wed based on the resulting approval status, and the procedure terminates when the interv al width falls below a configurable tolerance (default: 1 MW). In prac- tice, 8–9 iterations suffice for a 0–500 MW range. Results are automatically persisted to the memory system (Section V -F) for subsequent retriev al. Because bisection assumes monotone feasibility with re- spect to injected power , the implementation incorporates a monotonicity contradiction check (e.g., appro val at a higher MW lev el following a lower -MW rejection). Upon detection, the operator records explicit diagnostics and re verts to a coarse range scan, reporting the highest sampled feasible point rather than asserting a strict bisection boundary . At the rejection boundary , the tool enriches its output with a structured rejection explanation : the limiting factor (e.g., steady-state violation, contingency failure, con ver gence div er- gence), the failing assessment stage(s), and any project-caused violations with element, type, value, and limit. This enables the agent to explain why the capacity limit was reached, not just the numerical boundary . T ABLE II: Stage Acceptance Criteria (Current Implementa- tion) Stage P ass/Fail Criterion Steady- state ( f 1 ) PF conv erges and no hard violations un- der NORMAL limits (voltage 0.95–1.05 p.u., thermal Rate A 100%); angle-dif ference screening (30 ◦ ) is optional and disabled by default; borderline if within 0.01 p.u. of voltage limits or within 5% of thermal limits, with optional OPF escalation. N-1 ( f 2 ) EMERGENCY limits (v oltage 0.90–1.10 p.u., thermal Rate B 110%); fails when the project introduces ne w post-contingency failures relativ e to baseline N-1, and can optionally fail on material worsening of pre- existing failed contingencies (default thresh- old: +2.0% max-margin erosion). T ransient ( f 3 ) ANDES run to configured horizon (default 10 s) with configurable fault (def ault 3-phase at POI, 0.1–0.2 s); pass requires completed run and no loss-of-synchronism heuristic trigger (final generator -angle spread ≤ 2 π rad). EMT ( f 4 ) ParaEMT SCR screen for IBR buses; fails if any screened bus has SCR b < SCR min (default SCR min = 3 . 0 ). V . L L M A G E N T D E S I G N A. Agent Arc hitectur e The con versational agent (Algorithm 1) implements an LLM-first design philosophy . In contrast to con ventional agent architectures where deterministic routing handles the majority of requests and the LLM serves as a fallback, Grid-Mind positions the LLM at the center of decision- making, augmented by two pre-LLM safety guardrails: (i) anti- hallucination capacity routing and (ii) required-input clarifica- tion for CIA-like prompts. Giv en a user message history H = [ m 1 , . . . , m n ] , the agent: 1) Checks forced capacity routing (anti-hallucination guardrail); 2) Checks required-input clarification for CIA-like prompts and returns a deterministic clarification prompt when mandatory fields are missing; 3) Builds a system prompt incorporating a planning and reflection frame work, lessons L , rele vant memory en- tries from M , and auto-detected context hints (param- eters extracted from conv ersation, last report status, detected mitigations); 4) Submits [ s ] ∪ H to the LLM with all ele ven tool specifications T ; 5) The LLM plans its approach, chains up to 5 tool-call rounds (e.g., run OPF → check remaining violations → suggest mitigations), and reflects on each result before deciding the next action; 6) V alidates the final response for ungrounded numerical claims, persists results to memory , and returns. Planning and reflection behavior is induced through the foundational identity prompt, which instructs the LLM to 5 Algorithm 1 LLM-First Agent Loop with Anti-Hallucination Require: History H , tools T , lessons L , memory M Ensure: Response text y , report R 1: if IsCapacityQuestion( H ) then ▷ Safety guardrail 2: if MissingRequiredCapacityInputs( H ) then 3: return ClarificationPrompt, ∅ 4: end if 5: R ← T . execute ( find max capacity ) 6: retur n Summarize ( R ) , R 7: end if 8: if MissingRequiredCIAInputs( H ) then ▷ Safety guardrail 9: retur n ClarificationPrompt, ∅ 10: end if 11: s ← BuildPrompt ( L , M , H ) 12: s ← s ⊕ ContextHints ( H ) ▷ Pre-extracted params 13: msgs ← [ s ] ∪ H 14: tool called ← false 15: for i = 1 to 5 do ▷ Multi-step tool chaining 16: resp ← LLM.chat ( msgs , T ) 17: if resp has tool calls then 18: for all call c in resp.tool calls do 19: R c ← T . execute ( c. name , c. ar gs ) 20: Append result to msgs; tool called ← true 21: if R c has report then R ← R c 22: end if 23: end for 24: else 25: y ← resp.content; break 26: end if 27: end f or 28: if HasUngroundedNumerics( y , tool called) then ▷ Layer 3 29: y ← y ⊕ GroundingW arning 30: end if 31: Sav eT oMemory( R, M ) 32: retur n y , R reason through four considerations: what the user is requesting, what data is required, the appropriate sequence of tool inv oca- tions, and whether each intermediate result fully addresses the question. Context hints pre-populate detected parameters (bus, MW , type, case, mitigations) so the LLM can make informed decisions without expending a round-trip on parsing. B. Action Space The Action Re gistry exposes simulation capabilities as OpenAI-format function specifications [18]. The registry com- prises elev en tools spanning assessment, analysis, topology queries, and system management. T able III enumerates the complete interface contract, including required ar guments, ke y return payloads, and built-in safeguards. Conceptually , the registry organizes capabilities into four groups. Assessment operators execute the full Connection Impact Assessment cascade, with options to ev aluate base configurations or to pre-install reactiv e compensation miti- gations. Analysis operators provide granular access to the underlying physics, enabling the agent to request steady- state AC power flows for per-bus voltage examination, in voke optimal power flow (OPF) routines for redispatch scheduling, perform comprehensiv e voltage and thermal violation scans, and execute systematic N-1 contingency screening. Capacity sear ch operators employ binary-search routines to determine the maximum allowable generation or load injection at a specified bus before violations occur . Finally , topology and system operators permit the agent to extract detailed grid parameters (e.g., branch impedances and generator limits) and manage simulation cases and solver backends. All tool specifications adhere to the JSON Schema format, enabling in vocation by any OpenAI-compatible LLM. The pri- mary assessment operator accepts nested parameters reflecting the structured nature of interconnection requests, including network bus, capacity , resource type, synchronization status, and flags for contingency or transient screening. This model- agnostic design mirrors the “skills and plugins” pattern of production agent framew orks [8], wherein capabilities are defined declarativ ely and can be extended without modifying the agent core. C. Natural Language P arsing A critical function of the agent is the extraction of structured interconnection request parameters from free-form natural language. The extraction targets four fields: parse ( m ) → ( b, P , τ , ι ) b ∈ Z + , P ∈ R + , τ ∈ C , ι ∈ { 0 , 1 } (5) where b denotes the b us number , P represents acti ve power in MW , τ is the connection type drawn from the set C = { load , solar , wind , bess , hybrid , synchronous } , and ι indicates IBR status. When any parameter is absent, the agent solicits clarification rather than inferring a v alue. In the current implementation, a conservati ve clarification policy is enforced for missing resource type—no default “load” fallback is ap- plied unless the request explicitly contains a load-indicative domain term (e.g., data center ). The same policy governs the direct capacity-search routing path: if the resource type remains unresolved after context lookup, the agent requests clarification before in voking the capacity-search operator . D. Physics Gr ounding with Engineering Judgment A fundamental design principle is that quantitativ e claims must be grounded in simulation output whenev er tool data is av ailable. The LLM generates natural-language explanations, but approv al and rejection decisions together with underly- ing violation data originate exclusi vely from the solv er and inspector . The LLM is nonetheless encourag ed to provide engineering judgment on tool results: characterizing margin severity (“a − 2 . 1% margin is relativ ely mild”), contextualizing capacity limits (“50 MW is substantial for this bus”), and recom- mending multi-step mitigation w orkflows. This separation of concerns— specific numerical values must originate from simulation operators, whereas qualitative interpr etation lev er- ages the LLM’ s domain knowledge—is encoded explicitly in 6 T ABLE III: T ool Interface Summary (Current Implementation) T ool Required Arguments Ke y Returns Safeguards / Notes list_backends , list_cases none av ailable backends / test cases Read-only metadata queries. set_backend backend success flag, active backend Name validated against registered adapters. run_powerflow case_path con vergence flag, bus/branch re- sults, violations Con vergence status surf aced explicitly; numerics from solv er outputs. run_opf case_path conver gence flag, post-OPF vio- lations, dispatch No topology mutation; includes post-OPF violation inspec- tion. inspect_violations case_path structured violation report Angle-difference check configurable; disabled by default. run_contingency case_path N-1 pass/fail counts, failing contingencies Runs baseline PF first; explicit error on non-con vergence. run_cia case_path , connection stage reports, final decision, rea- son codes Missing-field clarification gate; baseline-aware N-1 impact logic. run_cia_with_- mitigation case_path , connection , mitigations CIA report + applied mitiga- tions Mitigations constrained to shunt-like interventions for trace- ability . find_max_capacity case_path , bus , connection_type max approved MW , boundary reports, diagnostics Forced routing for capacity queries; monotonicity contradic- tion detection. query_network_data case_path raw topology / equipment data Read-only introspection; no solved operating point claimed. both the architectural identity instructions and the operational system prompt. E. Anti-Hallucination Defense-in-Depth LLM hallucination—the generation of plausible but factu- ally incorrect content—is a well-documented challenge [24], [25]. Despite physics grounding of simulation outputs, we observed that reasoning-trained LLMs (notably DeepSeek-R1) occasionally f abricate numerical answer s to quantitative ques- tions , bypassing the tool-calling path entirely . For instance, when queried for the maximum load at bus 14 on the IEEE 118-bus system, the LLM responded with a fabricated value of approximately 127 MW without inv oking the capacity-search operator; the verified limit was 3.9 MW —a 33 × discrepancy . This failure mode is addressed through three complementary defense layers: Layer 1: System instruction hardening. Both the agent’ s foundational identity instructions and operational prompt con- tain explicit anti-fabrication directiv es: never state specific MW , pu, MV A, or per centage values for individual grid ele- ments unless those values originated fr om a physics operator in the curr ent conver sation or constitute well-known published standar ds . The prompt additionally incorporates memory us- age rules that pre vent the agent from misrepresenting session- local memory entries as independent historical data (e.g., stat- ing “historical studies confirm. . . ” when citing a result from an earlier simulation in the same session). This constitutes a soft guardrail that depends on instruction-following fidelity . Layer 2: Forced action routing . A deterministic pre- LLM classifier identifies two high-risk families of capacity queries: (i) specific-b us capacity questions combining capacity intent with an explicit b us reference, accommodating both resource/power wording and generic forms such as “max capacity at bus 14”; and (ii) “best bus for maximum capacity” questions combining capacity intent with a best-bus intent phrase. When triggered, the system directly inv okes the binary- search capacity operator, bypassing the LLM entirely for that request class. If required inputs (e.g., resource type) remain unspecified, the system solicits clarification prior to e xecution. T ABLE IV: Anti-Hallucination Defense Layers Layer T ype Bypass-proof Co verage Prompt hardening Soft No All queries Forced routing Hard Y es Capacity Qs Grounding validator Detect No No-tool responses Layer 3: Post-r esponse grounding validator . After the LLM generates a response, a regex-based scanner examines the output for ungrounded numerical claims (e.g., patterns of the form “ X MW , ” “ X pu, ” or “capacity is X ”). Each match is e valuated against an 150-character context windo w for safe phrases (e.g., NERC standard values, per-unit definitions). If no grounding-capable tool was in voked during the turn and an ungrounded numeric pattern is detected, a disclaimer is appended directing the user to request a simulation. This mechanism currently operates as a turn-le vel detector rather than per-number provenance tracing. T o mitigate false ground- ing credit, inv ocations of non-analytical tools (e.g., backend listing or switching) do not exempt a response from Layer 3 scrutiny . T able IV summarizes the defense layers and their properties. F . P ersistent Memory Inspired by the persistent state patterns of production agent framew orks [8], Grid-Mind maintains an append-only struc- tured memory system that stores completed CIA studies and capacity search results across sessions. Memory injection pri- oritizes current-con versation conte xt, while retrie v al can access recent global memory entries. Each study record captures the timestamp, test case, bus, MW , connection type, approval status, violation counts, and a human-readable summary . The memory system supports four recall modes: (i) bus- specific recall for retrieving past studies at a given bus and case, (ii) case-wide recall for browsing all studies on a network, (iii) ke yword search across summaries, and (iv) max- capacity recall for retrieving previously computed hosting limits. On each LLM inv ocation, relev ant memory entries 7 Scenario Generator Evaluator (Score) Optimizer (LLM Analysis) Lessons Learned Inject Fig. 3: Self-improving prompt-level lesson loop. Lessons from failure analysis are injected into the system prompt for subse- quent iterations. are injected into the system prompt, enabling the agent to reference prior results (e.g., “the last study at b us 14 identified a 3.9 MW limit”) without re-ex ecuting simulations. Critically , the memory injection includes an explicit cav eat that these entries are from earlier simulations in the curr ent session , not independent historical data. This prev ents a failure mode we observed where the LLM presented session-local results as authoritativ e “historical studies” or “past analyses, ” lend- ing false credibility to what were merely prior runs in the same con versation. The agent is instructed to prefer fresh simulations for new questions and to cite memory only as supplementary context. A human-readable study ledger is automatically regenerated upon each memory insertion, providing a transparent audit trail suitable for commitment to regulatory v ersion control systems. V I . S E L F - I M P R OV I N G P RO M P T - L E S S O N L O O P Grid-Mind incorporates a lightweight prompt-level self- correction mechanism (Fig. 3) that improves agent perfor- mance without requiring model retraining. A. Scenario Generation The dataset generator produces multi-turn con versation sce- narios cov ering four cate gories: (i) ambiguous requests requir- ing clarification, (ii) partial requests with missing parameters, (iii) complete requests spanning all connection types, and (iv) follo w-up questions pertaining to results and criteria. B. Evaluation Each agent response is scored across three weighted dimen- sions: S = w a · S action + w c · S content + w f · S format (6) with w a = 0 . 5 , w c = 0 . 35 , w f = 0 . 15 . Action scoring checks tool selection correctness; content scoring verifies ke y- word presence and factual accuracy; format scoring assesses response structure. C. Optimization The optimizer analyzes failed scenarios—those scoring be- low a configurable threshold—using an LLM to generate concise, actionable lessons. These lessons are appended to a persistent repository and injected into the system prompt for all subsequent sessions, thereby completing the self-improv ement loop. s t +1 = s 0 ⊕ L t (7) T ABLE V: Benchmark Scenario Categories Category N Description Complete load 8 All parameters specified (load) Complete generation 8 All parameters specified (so- lar/wind/BESS) Missing bus 5 Bus number omitted Missing MW 5 Power capacity omitted Missing type 5 Connection type omitted Multi-turn 6 Clarification then ex ecution Follo w-up 5 Questions about prior results Edge cases 4 Inv alid bus, zero MW , huge load Theory questions 4 Conceptual questions (no CIA needed) T otal 50 where s 0 is the base system prompt and L t denotes the accumulated lesson set at iteration t . It is important to note that this is not reinforcement learning in the control-theoretic or policy-gradient sense; rather , it is prompt-level context optimization. The approach shares with RLHF [26] only the high-lev el objectiv e of iterativ e behavioral improv ement, while remaining applicable to closed-source API-accessed models. V I I . E X P E R I M E N TA L S E T U P A. T est Systems The fixed benchmark employs the IEEE 118-bus test case loaded from PandaPo wer’ s built-in network library [12]. This system comprises 118 buses, 186 branches, and 54 generators, providing sufficient complexity for realistic interconnection study scenarios. The self-correction regression loop operates on a mixed-case suite (IEEE 14/30/57/118), reflecting the broader operational scope supported by the current agent implementation. B. Benchmark and Re gr ession Scenarios The benchmark comprises 50 scenarios distributed across nine categories (T able V): For ongoing agent impro vement, the prompt-level self- correction loop ev aluates a separate 56-scenario regression suite encompassing mitigation-realism prompts (OPF v er- sus manual setpoint/tap edits), max-capacity follow-ups, and contingency/impact-consistenc y checks. T o facilitate repro- ducibility , the scenario definitions, benchmark runner , and timestamped result artifacts used in the reported tables are included in the accompanying repository . 1 C. Data Separation and Stress-T est Slices T o mitigate contamination between benchmark reporting and lesson optimization, two disjoint ev aluation suites are maintained: • Benchmark suite ( N = 50 ): fixed IEEE 118 prompts used for end-to-end reporting in this paper . • Self-correction suite ( N = 56 ): multi-case prompts used for prompt-lesson updates and robustness checks. 1 Scenario definitions, benchmark runner, and timestamped result artifacts are pro vided to enable full reproducibility . 8 An automated overlap check confirms zero exact textual ov erlap in user turns between the two suites (61 unique user turns in the benchmark suite versus 72 in the self-correction suite; intersection cardinality of zero). W ithin the 56-scenario suite, an adversarial-like slice ( N = 24 ) is defined, consisting of formatting-constraint prompts, counterfactual reasoning, backend/tool-selection piv- ots, mitigation-capability boundary checks, max-capacity follow-ups, and phrasing variants. The remaining N = 32 scenarios serve as non-adversarial controls. D. Models Under T est The end-to-end benchmark harness supports five frontier LLMs accessed via OpenRouter’ s unified API: • Claude 3.5 Sonnet (Anthropic): Strong tool-calling and instruction following. • GPT -4o (OpenAI): Multimodal flagship with mature function-calling support. • DeepSeek-R1 [17]: Open-weight reasoning model trained via RL. • DeepSeek-V3 : High-speed mixture-of-experts model used as the primary engine for the prompt-le vel self- correction loop. • Qwen 2.5-72B (Alibaba): High-performance open-weight instruction model. All models are accessed at temperature T = 0 to en- sure deterministic ev aluation. The benchmark runner ex ecutes the complete agent loop—encompassing tool planning, tool ex ecution, multi-round interaction, and memory-conditioned prompting—rather than ev aluating raw model function-calling in isolation. The reproducible snapshot reported in this revision employs DeepSeek-V3 for the full 50-scenario suite; a cross- model full-agent pilot on the complete-load slice ( N = 8 ) is presented in Section VIII-A. E. Metrics • T ool Selection Accuracy (TSA) : Fraction of scenarios where the agent selected the correct tool (or correctly abstained). • Parsing Accuracy (P A) : Fraction of extracted parameters (bus, MW , type) matching ground truth. For category- lev el reporting, P A is computed on scenarios where parse targets are scored and parsed fields are present (clarification-only turns are excluded). • Latency : W all-clock time per request (seconds). • Cost : T otal API cost over the benchmark run (USD), with per-scenario cost computed as total divided by scenario count. V I I I . R E S U LT S A. Quantitative Benchmarks T able VI presents the latest reproducible end-to-end bench- mark snapshot from the current codebase (DeepSeek-V3, 50 scenarios, ex ecuted 2026-02-23). T able VII provides the corresponding category-lev el TSA breakdown. For T able VII, “–” indicates categories where P A is not applicable under the current ev aluator; reported P A values are conditional on scored parsing fields. T ABLE VI: Full-Agent Benchmark Snapshot (IEEE 118-bus, N = 50 ) Model TSA (%) P A (%) Latency (s) Cost ($) DeepSeek-V3 84.0 100.0 15.89 0.102 T ABLE VII: T ool Selection Accurac y by Category (DeepSeek- V3, N = 50 ) Category N TSA (%) P A (%) Complete load 8 62.5 100.0 Complete generation 8 75.0 100.0 Ambiguous (missing) 15 100.0 – Multi-turn 6 83.3 100.0 Follo w-up 5 100.0 – Edge cases 4 50.0 – Theory 4 100.0 – B. Cr oss-Model Full-Agent Pilot (Complete-Load Slice) T o provide cross-model evidence beyond DeepSeek-V3, the same full-agent harness was ex ecuted on the complete-load slice ( N = 8 scenarios) for DeepSeek-R1 and GPT -4o, using an identical agent codebase and scoring configuration. For reference, the DeepSeek-V3 row below corresponds to the complete-load slice e xtracted from the full 50-scenario run. This pilot is intended as directional evidence only and does not constitute a comprehensiv e model comparison. The GPT -4o pilot exhibited a behavior dominated by over - clarification: in this snapshot, the model repeatedly requested additional confirmations and did not inv oke the CIA operator on complete-load prompts, yielding TSA = 0% under the scoring rubric for this slice. C. Self-Corr ection Re gr ession Status The prompt-le vel self-correction loop serves as a re gression gate ov er the 56-scenario conv ersation suite. T able IX reports the most recent logged run from the current codebase. D. Out-of-Benchmark Str ess-Slice Evaluation T o provide quantitativ e evidence beyond the 50-scenario benchmark, a separate ev aluation-only pass was conducted on the disjoint 56-scenario suite with a frozen lesson set (i.e., no lesson updates during scoring). T able X reports results stratified by non-adversarial and adversarial-like slices. These slice scores are not directly comparable to those in T able IX, as they were obtained in a separate ev aluation- only run; collectiv ely , they suggest that remaining failures are concentrated in a narrow subset of prompts rather than systematically in the adversarial-like slice as presently defined. E. Anti-Hallucination Ablation T argeted ablation experiments were conducted for Layer 2 (forced max-capacity routing) and Layer 3 (post-response grounding validator) using the full agent loop with fix ed prompt sets. T able XI reports results for DeepSeek-V3 and DeepSeek-R1. 9 T ABLE VIII: Cross-Model Pilot on Complete-Load Slice ( N = 8 ) Model N TSA (%) P A (%) Latenc y (s) Cost ($) DeepSeek-V3 (slice) 8 62.5 100.0 17.24 0.0178 DeepSeek-R1 (pilot) 8 62.5 86.7 78.05 0.0840 GPT -4o (pilot) 8 0.0 – 1.55 0.1240 T ABLE IX: Latest Self-Correction Regression Run (56- Scenario Suite) Date Iteration Passed/T otal A vg Score Lessons 2026-02-23 1 49/56 (87.5%) 89.29 24 In these prompt sets, both models routed capacity questions to the capacity-search operator ev en in the absence of Layer 2, yielding zero detected ungrounded numeric outputs under the current scanner . The ablation therefore provides quantitati ve cov erage and latency evidence but does not establish worst- case robustness guarantees; ev aluation with larger adversarial paraphrase sets remains future work. F . F ailure Analysis The principal failure modes observed across de velopment runs are as follows: 1) T ype confusion : Interpreting “data center” as a connec- tion type rather than mapping it to the “load” category . 2) Premature execution : In voking the assessment cascade with assumed default values when required parameters remain unspecified. 3) Follow-up hallucination : Generating plausible b ut fab- ricated violation details instead of retrie ving previously stored results. 4) Numerical fabrication : Responding to quantitativ e questions (e.g., maximum capacity) with plausible but incorrect values without in voking the appropriate tool. DeepSeek-R1 reported 127 MW for a b us whose verified limit was 3.9 MW —the failure that motiv ated the three- layer anti-hallucination defense (Section V -E). G. P ost-Revision Ambiguity Recheck T o quantify the effect of the stricter clarification gate— eliminating the implicit type default and broadening direct- capacity clarification routing—only the ambiguous missing- field categories were re-ev aluated with the same model family (DeepSeek-V3) on 2026-02-23. T able XII compares this tar- geted rerun against the baseline full-benchmark snapshot. The recheck demonstrates that the deterministic clarification guardrail eliminates the pre viously observed missing-field ex- ecution failures on this slice. A subsequent full 50-scenario rerun with the same codebase corroborates this finding, re- porting 100.0% TSA on the aggregated ambiguous category (T able VII). I X . D I S C U S S I O N A. When Does the LLM Agent Excel? In the refreshed end-to-end snapshot, the agent demonstrates its strongest performance on ambiguous missing-field prompts T ABLE X: Stress-Slice Results on Disjoint 56-Scenario Suite (DeepSeek-V3, 2026-02-23) Slice N P ass Rate (%) A vg Score Non-adversarial 32 96.9 92.90 Adversarial-lik e 24 100.0 93.30 Overall 56 98.2 93.07 T ABLE XI: Anti-Hallucination Ablation (Full Agent, 2026- 02-23) Model Prompt Set Condition Routing Recall (%) Fabrication Rate (%) A vg Latency (s) DeepSeek-V3 N cap = 8 , N non = 2 No L2/L3 100.0 0.0 35.98 DeepSeek-V3 N cap = 8 , N non = 2 L2+L3 100.0 0.0 25.44 DeepSeek-R1 N cap = 8 , N non = 0 No L2/L3 100.0 0.0 93.66 DeepSeek-R1 N cap = 8 , N non = 0 L2+L3 100.0 0.0 27.67 (100.0% TSA), follow-up interpretation (100.0% TSA), and theory prompts (100.0% TSA), with robust multi-turn behavior (83.3% TSA). These results indicate that the clarification guardrail, memory-conditioned context, and LLM tool chain- ing operate reliably on dialogue-intensive interactions. The primary remaining weakness lies in strict normaliza- tion on certain complete-request and edge-case prompts (T a- ble VII): complete-load TSA is 62.5%, complete-generation TSA is 75.0%, and edge-case TSA is 50.0%. The majority of these misclassifications stem from the conservati ve clarifica- tion polic y (e.g., requiring e xplicit case aliases or resource- type confirmation) rather than from genuinely ambiguous prompts. B. Hallucination Requir es Defense-in-Depth Physics grounding (Section V -D) pre vents the LLM from fabricating simulation outputs —voltage values, thermal load- ings, and violation counts are computed exclusi vely by the configured solvers. Ho wev er , our observations reveal that LLMs can still hallucinate ar ound the tool boundary: when posed quantitative questions (e.g., regarding maximum capac- ity), certain models generate plausible numerical responses without in voking the appropriate tool. DeepSeek-R1 reported “approximately 127 MW” for a bus whose verified limit was 3.9 MW , demonstrating that a factually grounded architecture alone is insufficient when the model circumvents its tool interface. The three-layer defense described in Section V -E addresses this vulnerability . The tar geted ablation in T able XI demon- strates full routing cov erage and zero detected ungrounded numeric outputs on the tested prompt sets. The post-response grounding validator (Layer 3) provides an additional safeguard for responses generated without tool in vocation. Collectiv ely , these layers substantially reduce fabrication risk, though they do not constitute a formal guarantee that every numeric token is provably grounded. A further cav eat concerns Layer 3 rob ustness: the current rege x-based scanner operates over fixed syntactic patterns (e.g., “ X MW , ” “ X pu”) within a 150-character context window . As frontier models adopt increasingly con versa- tional phrasing, rigid pattern matching may fail to detect 10 T ABLE XII: T argeted Ambiguity Recheck After Clarification- Gate Update Category N Baseline TSA (%) Recheck TSA (%) ∆ (pp) Missing bus 5 0.0 100.0 +100.0 Missing MW 5 40.0 100.0 +60.0 Missing type 5 0.0 100.0 +100.0 Ambiguous aggregate 15 13.3 100.0 +86.7 paraphrased or embedded numerical claims. Evolving this layer toward semantic provenance checking—for instance, embedding-based tracing of numeric tokens to their originating tool inv ocations—is an important direction for hardening the defense-in-depth architecture. C. Model T rade-offs The latest full-agent DeepSeek-V3 snapshot exhibits a fa- vorable accuracy–latency–cost profile at practical operating scale: 84.0% TSA, 100% P A, 15.89 s mean scenario latency , and $0.102 total cost over 50 scenarios ($0.0020/scenario). Category-le vel analysis indicates that the majority of remain- ing errors originate from strict complete-request normalization and edge-case handling, while the ambiguous slice improv ed to 100.0% TSA in the refreshed ev aluation. D. Curr ent V alidation Limits Fiv e important boundaries constrain the interpretation of these results. First, transient and EMT acceptance criteria in the current stack are screening-oriented heuristics (T able II) and do not constitute a replacement for utility-approved dy- namic acceptance protocols (e.g., explicit voltage-recov ery windows, frequency nadir limits, or plant-controller interac- tion studies). Second, although the 50-scenario benchmark and 56-scenario self-correction suite are textually disjoint, the e valuation does not yet constitute a blinded third-party benchmark; a fully locked train/v alidation/test protocol with externally generated adversarial prompts remains future work. Third, end-to-end numerical correctness validation against au- thoritativ e utility-grade reference studies (e.g., PSS/E or PSLF baselines) on large realistic cases has not yet been conducted. Fourth, the N-1 material-worsening threshold (default +2 . 0% max-margin erosion) is an implementation-specific parameter; ISOs and R TOs maintain varying interpretations of accept- able pre-existing violation exacerbation, and a production deployment w ould require calibration against the applicable transmission planning criteria of the host market. Fifth, the current mitigation action space is limited to shunt-like re- activ e compensation interventions. Real-world transmission planning frequently requires topology changes, phase-shifting transformer adjustments, or Remedial Action Schemes (RAS) that are not yet representable in the current tool registry . E. P ersistent Memory Enables Continuity The persistent memory system (Section V -F) addresses two practical requirements. First, it enables the agent to reference prior study results when responding to follo w-up queries with- out re-executing simulations. Second, it maintains an auditable record of all assessments, including capacity limits disco vered via binary search. During testing, the memory system correctly recalled previously computed capacity limits and violation summaries from prior runs, enabling immediate context-a ware follow-up responses without re-simulation. A scaling consideration arises when extending this approach to multi-stage cluster studies in volving dozens of IBRs: the cumulativ e v olume of stored study records, violation sum- maries, and capacity-search results may saturate the LLM’ s context windo w , particularly for models with smaller effecti ve windows. This risks “lost in the middle” retriev al degradation, where intermediate memory entries recei ve reduced atten- tion. Strategies such as hierarchical summarization, retriev al- augmented generation over an external vector store, or se- lectiv e memory pruning will be necessary to maintain recall fidelity at scale. F . Practical Deployment Deploying Grid-Mind in utility operations necessitates ad- dressing sev eral practical considerations: (i) data pri vac y , as sensitiv e grid models must not leav e the utility’ s infrastructure; (ii) regulatory acceptance of AI-assisted decisions; (iii) inte- gration with existing EMS/SCAD A systems; and (i v) opera- tional health monitoring. The solver-agnostic ABC facilitates integration by supporting both open-source (development) and commercial (production) backends through a unified interface. A heartbeat endpoint provides real-time status information for the server , LLM backend, solver av ailability , and memory subsystem, enabling integration with utility monitoring dash- boards. Operationally , the intended fail-safe default follo ws an abstain-and-escalate paradigm: when solver con vergence fails, required inputs are missing, or response numerics cannot be grounded, the agent routes to human revie w rather than issuing an autonomous approv al recommendation. X . C O N C L U S I O N This paper presented Grid-Mind, a domain-specific LLM agent for automated Connection Impact Assessment in power systems. The system bridges the gap between natural-language interaction and multi-fidelity power system simulation through sev en principal contributions: (1) a solver -agnostic abstract base class supporting four simulation backends; (2) an ele ven- tool OpenAI-compatible registry enabling an y LLM to orches- trate simulations, including binary-search capacity analysis, OPF redispatch, and mitigated reassessment; (3) an LLM- first architecture in which the language model plans multi- step workflo ws, chains tool calls, and provides engineer- ing judgment, with deterministic rules employed solely as safety guardrails; (4) a physics-grounding architecture that delegates quantitative decisions to configured solvers and violation inspectors while permitting the LLM to provide qualitativ e interpretation; (5) a three-layer anti-hallucination defense comprising prompt hardening, forced tool routing, and post-response grounding validation, which reduces numerical fabrication risk by preferring verified tool outputs and flag- ging ungrounded numeric responses; (6) a persistent memory system that stores study results across sessions for continuity 11 and auditability; and (7) a self-improving prompt-level lesson loop that progressively enhances agent accuracy without model retraining. In the latest reproducible full-agent benchmark snapshot (DeepSeek-V3, 50 scenarios), Grid-Mind achiev ed 84.0% tool- selection accurac y and 100% parsing accuracy . The self- correction regression loop (56 scenarios) passed 49 of 56 cases with a mean score of 89.29 in the most recent run. These results demonstrate that the architecture is both functional and auditable, with substantial gains in ambiguity handling (100.0% TSA on the full-run ambiguous category) while iden- tifying clear targets for continued improvement in complete- request normalization and edge-case robustness. Future work will extend the benchmark to larger sys- tems (e.g., A CTIVSg2000 and 10,000+ bus production-scale models), incorporate real utility case data, and enforce a locked train/held-out/blinded ev aluation protocol with adver - sarial prompt generation. Additional priorities include e volving the regex-based post-response grounding v alidator (Layer 3) tow ard semantic provenance checking for improved rob ustness against paraphrased numerical claims; expanding the mitiga- tion action space beyond reactive compensation to encom- pass topology changes and Remedial Action Schemes; im- plementing cryptographic provenance for audit logs to satisfy regulatory chain-of-custody requirements; in vestigating multi- agent architectures for coordinated area studies; and dev elop- ing context-windo w management strategies (e.g., hierarchical memory summarization) to maintain retriev al fidelity when scaling to cluster studies with lar ge numbers of interconnection requests. A I U S E S TA T E M E N T During preparation of this w ork the authors used Claude and GPT -4o for language editing and code generation; all content was revie wed and the authors take full responsibility . R E F E R E N C E S [1] J. Rand, W . Gorman, R. W iser et al. , “Queued up: Characteristics of power plants seeking transmission interconnection as of the end of 2023, ” Lawr ence Berkele y National Laboratory , 2024, a vailable: https://emp.lbl.gov/queues. [2] J. Johnston et al. , “Interconnection cost analysis in the FERC queue, ” American Clean P ower Association , 2023. [3] Federal Energy Regulatory Commission, “Order No. 2023: Improve- ments to Generator Interconnection Procedures and Agreements, ” Docket No. RM22-14-000, 2023, 188 FERC ¶ 61,049. [4] S. Y ao, J. Zhao, D. Y u et al. , “ReAct: Synergizing reasoning and acting in language models, ” in International Confer ence on Learning Repr esentations (ICLR) , 2023. [5] T . Schick, J. Dwi vedi-Y u et al. , “T oolformer: Language models can teach themselves to use tools, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023. [6] Y . Qin, S. Liang et al. , “T oolLLM: Facilitating large language models to master 16000+ real-world APIs, ” in International Confer ence on Learning Repr esentations (ICLR) , 2024. [7] J. Y ang et al. , “SWE-agent: Agent-computer interfaces enable automated software engineering, ” arXiv preprint , 2024. [8] OpenClaw, “OpenClaw: The AI that actually does things, ” https:// openclaw .ai/, 2025, open-source AI agent with model-agnostic gateway , skills, and persistent memory . [9] W . Liao et al. , “Large language models for power system analysis: Challenges and opportunities, ” IEEE T ransactions on Smart Grid , 2024. [10] K. Zhang et al. , “ChatGrid: T owards a ChatGPT-powered grid operator co-pilot, ” IEEE P ower and Ener gy Society General Meeting , 2024. [11] B. Chen et al. , “Foundation models for power system intelligence: A survey , ” Applied Energy , vol. 365, 2024. [12] L. Thurner , A. Scheidler et al. , “pandapower —an open-source Python tool for con venient modeling, analysis, and optimization of electric power systems, ” IEEE T ransactions on P ower Systems , vol. 33, no. 6, pp. 6510–6521, 2018. [13] H. Cui, F . Li, and K. T omsovic, “ ANDES: A Python-based cyber- physical power system simulation tool, ” SoftwareX , vol. 16, 2021. [14] NREL, “ParaEMT: P arallel electromagnetic transient simulation, ” in National Renewable Energy Laboratory , 2023, available: https://www . nrel.gov/grid/paraemt.html. [15] Siemens PTI, “PSS/E – po wer system simulator for engineering, ” https://new .siemens.com/global/en/products/energy/ energy- automation- and- smart- grid/pss- software/pss- e.html, 2024. [16] North American Electric Reliability Corporation, “TPL-001-5.1 — transmission system planning performance requirements, ” NERC Stan- dar ds , 2023. [17] DeepSeek AI, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, ” arXiv pr eprint arXiv:2501.12948 , 2025. [18] OpenAI, “Function calling and other API updates, ” OpenAI Blog , 2023, https://openai.com/blog/function- calling- and- other- api- updates. [19] D. Becker et al. , “CIM standards and CIM-based integration, ” IEEE P ower Engineering Society General Meeting , 2003. [20] G. Ra vikumar et al. , “Graph database for smart grid security analysis, ” IEEE Innovative Smart Grid T echnologies , 2017. [21] Z. Ma and A. Qian, “Ontology-based modeling for power system applications, ” IEEE T ransactions on P ower Systems , 2019. [22] X. Bai et al. , “Digital twin for po wer grid: A revie w , ” Ener gy Con version and Manag ement , vol. 270, 2022. [23] N. Glista et al. , “Hosting capacity analysis methods for distribution systems, ” IEEE T ransactions on P ower Delivery , 2024. [24] L. Huang, W . Y u et al. , “ A surve y on hallucination in large language models: Principles, taxonomy , challenges, and open questions, ” ACM Computing Surve ys , v ol. 57, no. 5, 2025. [25] S. T . I. T onmoy et al. , “ A comprehensive survey of hallucina- tion mitigation techniques in large language models, ” arXiv preprint arXiv:2401.01313 , 2024. [26] L. Ouyang et al. , “T raining language models to follow instructions with human feedback, ” in Advances in Neural Information Processing Systems (NeurIPS) , 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment