Quantifying Dimensional Independence in Speech: An Information-Theoretic Framework for Disentangled Representation Learning
Speech signals encode emotional, linguistic, and pathological information within a shared acoustic channel; however, disentanglement is typically assessed indirectly through downstream task performance. We introduce an information-theoretic framework…
Authors: Bipasha Kashyap, Björn W. Schuller, Pubudu N. Pathirana
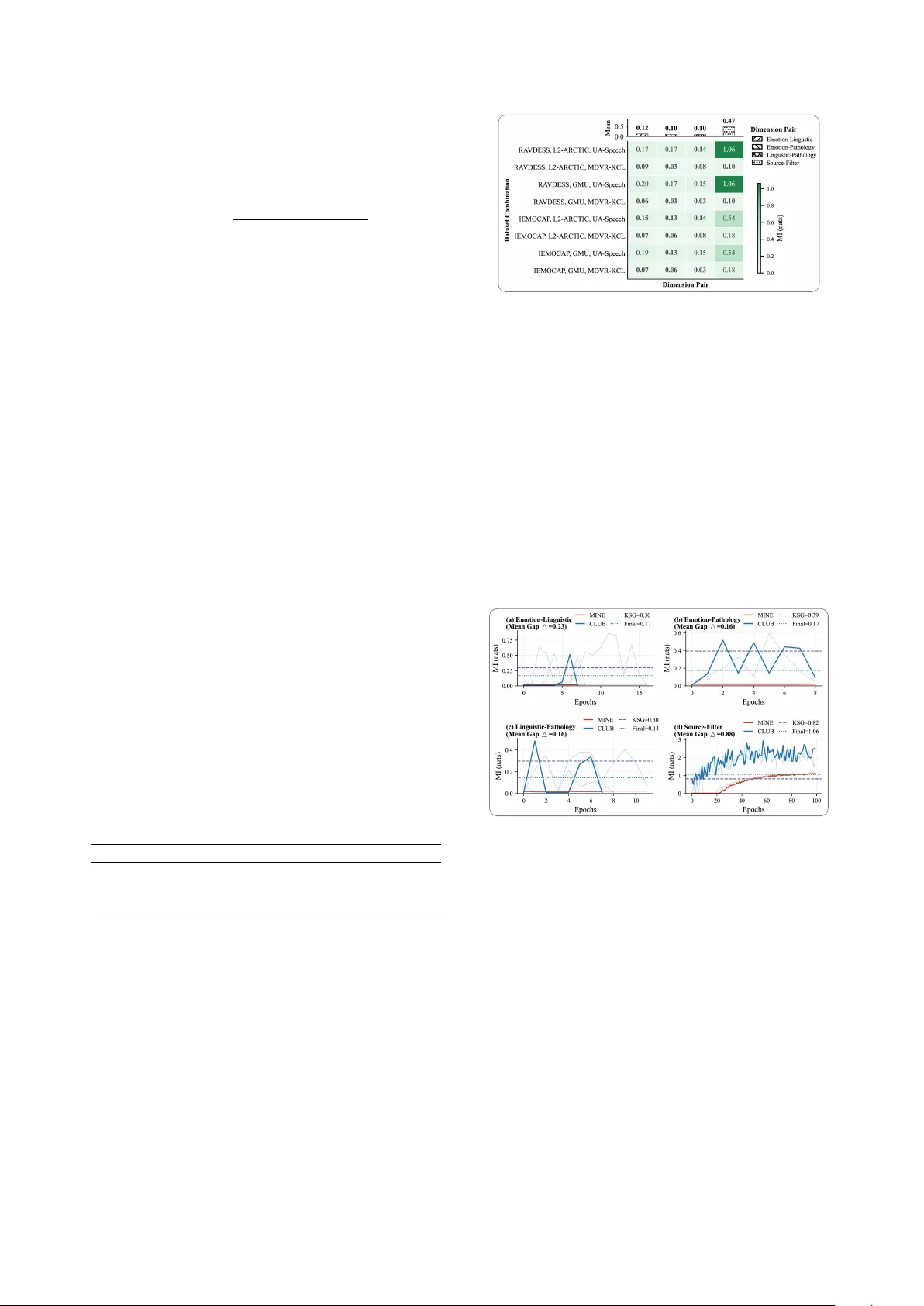
Quantifying Dimensional Independence in Speech: An Inf ormation-Theor etic Framework f or Disentangled Repr esentation Lear ning Bipasha Kashyap 1 , Bj ¨ orn W . Schuller 2 , 3 , Pubudu N. P athir ana 1 1 NSBE Research Lab, School of Engineering, Deakin Uni versity , Australia 2 Chair of Health Informatics (CHI), TUM Uni versity Hospital, German y 3 Group on Language, Audio & Music (GLAM), Imperial College London, UK b.kashyap@deakin.edu.au, schuller@tum.de, pubudu@deakin.edu.au Abstract Speech signals encode emotional, linguistic, and patholog- ical information within a shared acoustic channel; ho wev er , disentanglement is typically assessed indirectly through down- stream task performance. W e introduce an information-theoretic framew ork to quantify cross-dimension statistical dependence in handcrafted acoustic features by inte grating bounded neural mutual information (MI) estimation with non-parametric valida- tion. Across six corpora, cross-dimension MI remains low , with tight estimation bounds ( < 0 . 15 nats), indicating weak statistical coupling in the data considered, whereas Source–Filter MI is substantially higher (0.47 nats). Attrib ution analysis, defined as the proportion of total MI attributable to source v ersus filter com- ponents, rev eals source dominance for emotional dimensions (80%) and filter dominance for linguistic and pathological di- mensions (60% and 58%, respectiv ely). These findings pro vide a principled frame work for quantifying dimensional independence in speech. Index T erms : disentangled representations, mutual information estimation, speech dimensions, Source–Filter model, MINE, CLUB 1. Introduction Human speech signals simultaneously con vey emotional state, linguistic content, and potential pathological markers through a shared acoustic channel. Disentangling these dimensions is essential for downstream applications such as emotion recogni- tion [ 1 ], speaker verification [ 2 ], and clinical speech assessment [ 3 ]. Howev er , existing approaches lack principled measures of disentanglement quality and instead rely on downstream task performance as a proxy indicator of separation. The fundamental question remains: to what de gr ee ar e emo- tional, linguistic, and pathological speech dimensions statis- tically independent? If these dimensions exhibit high mutual information, complete disentanglement may be theoretically infeasible. Conv ersely , low mutual information suggests that appropriate inducti ve biases and representation constraints could enable effecti ve separation. Importantly , such independence properties must hold across linguistic and cultural variation if disentangled representations are to generalise across diverse speaker populations, including nati ve and non-nati ve speak ers, multilingual communities, and individuals with speech disorders. W e address this question using an information-theoretic framew ork integrating neural mutual information (MI) esti- mation with classical source–filter decomposition. Unlike correlation-based metrics, mutual information captures non- Submitted to INTERSPEECH 2026. linear dependencies, providing a principled basis for disentan- glement ev aluation [4]. Prior work in speech disentanglement has focused primar- ily on pairwise separation problems, most commonly speaker and emotion. Cho et al. [ 1 ] proposed a self-supervised distil- lation framework for cross-speaker emotion transfer , while Li et al. [ 2 ] emplo yed mutual information minimisation to learn domain-in variant speaker embeddings. Chang et al. [ 3 ] intro- duced speaker -in variant clustering for content representation learning. While these studies demonstrate progress in isolating specific factors, the y do not address the full three-dimensional structure formed by emotional, linguistic, and pathological infor- mation streams. Neural mutual information estimation has advanced sub- stantially in recent years. Mutual Information Neural Estima- tion (MINE) [ 4 ] provides a v ariational lower bound, while Con- trastiv e Log-ratio Upper Bound (CLUB) [ 5 ] offers a contrasti ve upper bound. Jointly applying these estimators enables tighter bracketing of true mutual information than either method alone. In this work, we extend bounded MI estimation with a non- parametric validation estimator , Kraskov-St ¨ ogbauer-Grassber ger (KSG) [ 6 ], to the analysis of multidimensional speech structure, enabling principled quantification of independence across speech information domains. Our contributions are summarised as follo ws: 1. A bounded mutual information estimation framework that combines neural estimators, MINE and CLUB, with non- parametric v alidation, KSG, incorporating exponential mo v- ing av erage (EMA) stabilised training and adapti ve uncertainty weighting; 2. Empirical analysis showing lo w cross-dimension mutual in- formation ( < 0 . 15 nats) in the considered datasets, consistent with weak statistical dependence between feature sets. 3. A source and filter attribution analysis revealing dimension- specific acoustic substrates. 4. Cross-corpus v alidation with estimation uncertainty < 0.35 nats. 2. Methodology 2.1. Problem Formulation Let the speech signal x be characterised by semantic dimensions: emotional e ∈ R 28 , linguistic l ∈ R 33 , and pathological p ∈ R 16 . The dimension numbers reflect the number of handcrafted acoustic descriptors assigned to each group (see Section 3.2 for the complete feature breakdo wn). Follo wing the source-filter model [ 7 ], we extract source s ∈ R 9 (glottal) and filter f ∈ R 32 (vocal tract) features. W e aim to quantify pairwise MI: I ( e ; l ) , I ( e ; p ) , I ( l ; p ) , and I ( s ; f ) . The proposed framew ork is shown in Figure 1. 2.2. Featur e Extraction For e very audio file, we e xtract fiv e feature sets using Praat [ 8 ], librosa [ 9 ], and openSMILE [ 10 ] for robust acoustic descriptor computation. Acoustic features are inherently multi-functional, such as jitter and shimmer serving as affecti ve and clinical markers, and formants encoding both phonetic identity and articulatory health [ 11 , 12 ]. Therefore, the semantic groupings belo w represent operationally defined featur e sets rather than strictly separable acoustic domains. The MI analysis quantifies the dependency between these defined feature sets. Source features set s ∈ R 9 capture glottal characteristics: F0 statistics (mean, std, range, median, Q1, Q3) and voice qual- ity measures (jitter, shimmer, HNR) reflecting laryngeal function [ 13 ]. Filter features set f ∈ R 32 capture vocal tract resonances: formant frequencies (F1, F2, F3) and bandwidths (B1, B2, B3), via Burg LPC analysis, and 13 MFCCs with delta coefficients [ 14 ]. Emotional features e ∈ R 28 combine source features with energy contours (RMS mean, std, max) and spectral descriptors (centroid, flux, rollof f). Linguistic features set l ∈ R 33 combine filter features with delta-delta MFCCs and temporal parameters (speaking rate, duration), capturing primarily phonetic content [ 15 ]. Pathological featur es set p ∈ R 16 target mostly clinical markers: voice quality measures, formant stability , and F2 tran- sition velocity , a key indicator of articulatory precision in motor speech disorders [ 16 ]. The partial feature overlap with source and filter sets (e.g., shared formant and v oice quality descriptors) is by design, as it enables the MI frame work to quantify pre- cisely how much shared information these operationally distinct groupings carry . 2.3. Bounded Neural MI Estimation Direct MI computation is intractable for high-dimensional contin- uous distributions. W e employ three complementary estimators providing bounds from multiple directions. 2.3.1. MINE with EMA Stabilisation The Mutual Information Neural Estimator (MINE) [ 4 ] provides a lo wer bound via the Donsker -V aradhan representation. F or any pair of feature vectors X ∈ R d x and Y ∈ R d y : I ( X ; Y ) ≥ E p ( x , y ) [ T θ ( x , y )] − log E p ( x ) p ( y ) [ e T θ ( x , y ) ] , (1) where T θ : R d x × R d y → R is a critic network. W e parameterise T θ as a 2-layer MLP with LayerNorm and LeakyReLU: T θ ( x , y ) = W 2 · LN ( LReLU ( W 1 [ x ; y ] + b 1 )) + b 2 , (2) with hidden dimension h = 256 and LeakyReLU slope 0.2. T o address high-variance gradients in the partition function estimate, we employ EMA stabilisation ov er training epochs t : ¯ Z t = (1 − α ) ¯ Z t − 1 + α · E batch [ e T θ ] , (3) with α = 0 . 01 and bias correction ˆ Z t = ¯ Z t / (1 − (1 − α ) t ) . The stabilised MINE objectiv e becomes: ˆ I MINE = E p ( x , y ) [ T θ ] − log( ˆ Z t + ϵ ) , (4) where ϵ = 10 − 8 prev ents numerical underflow . 2.3.2. CLUB with V ariance Clamping The Contrastiv e Log-ratio Upper Bound (CLUB)[5] provides: I ( X ; Y ) ≤ E p ( x , y ) [log q ϕ ( y | x )] − E p ( x ) p ( y ) [log q ϕ ( y | x )] , (5) with equality when q ϕ ( y | x ) = p ( y | x ) . W e model q ϕ as a diagonal Gaussian: q ϕ ( y | x ) = N ( y ; µ ϕ ( x ) , diag ( σ 2 ϕ ( x ))) , (6) Figure 1: Pr oposed frame work for quantifying dimensional inde- pendence. where µ ϕ and log σ 2 ϕ are MLP outputs. The log-likelihood decomposes as: log q ϕ ( y | x ) = − 1 2 d y X j =1 " log σ 2 ϕ,j + ( y j − µ ϕ,j ) 2 σ 2 ϕ,j # . (7) T o prev ent variance collapse or explosion, we clamp log- variance: log ˆ σ 2 ϕ = clamp (log σ 2 ϕ , − 6 , 2) , (8) constraining variance to [ e − 6 , e 2 ] ≈ [0 . 002 , 7 . 4] . 2.3.3. KSG Non-P arametric V alidation The Kraskov-St ¨ ogbauer-Grassber ger (KSG) estimator [ 6 ] pro- vides training-free validation using k -nearest neighbour statistics: ˆ I KSG = ψ ( k ) + ψ ( N ) − ⟨ ψ ( n x ( i ) + 1) + ψ ( n y ( i ) + 1) ⟩ i , (9) where ψ ( · ) is the digamma function, k = 5 is the neigh- bour count, N is the number of samples, and n x ( i ) , n y ( i ) are marginal neighbour counts within the k -th neighbour distance ϵ i computed using the Chebyshev ( L ∞ ) norm. W e use kd-trees for efficient nearest-neighbour search with O ( N log N ) tree con- struction. 2.3.4. Combined Estimation with Adaptive W eighting W e enforce theoretical bounds ˆ I MINE ≤ ˆ I CLUB and compute uncertainty: ∆ = ˆ I CLUB − ˆ I MINE . (10) The final MI estimate uses adaptiv e KSG-anchored weight- ing: ˆ I final = (1 − w ) · ˆ I MINE + ˆ I CLUB 2 + w · ˆ I KSG , (11) where the weight w increases with uncertainty: w = ( 0 . 3 if ∆ ≤ 1 . 0 min(0 . 6 , 0 . 3 + 0 . 1∆) if ∆ > 1 . 0 . (12) This fa vours neural estimates when bounds are tight, but anchors to KSG when uncertainty is high. 2.4. T raining Protocol W e employ ensemble training with M = 3 independent estima- tor pairs per configuration. Each estimator uses Adam optimi- sation ( η = 10 − 4 , weight decay 10 − 5 ) with gradient clipping (max norm 1.0) and ReduceLROnPlateau scheduling (factor 0.5, patience 10). Early stopping triggers when ∆ < 0 . 1 for 7+ con- secutiv e epochs. Final estimates average the last 10 of T training epochs ( T ≤ 100 ) across ensemble members, where ˆ I ( m ) t de- notes the MI estimate from ensemble member m at epoch t : ˆ I = 1 M M X m =1 1 10 T X t = T − 9 ˆ I ( m ) t . (13) 2.5. Source-Filter Attribution For each semantic dimension d ∈ { e , l , p } , we decompose MI into source and filter contributions using KSG estimates. The attribution ratio quantifies the proportion of total MI (source + filter) carried by each production component: A source ( d ) = ˆ I KSG ( s ; d ) ˆ I KSG ( s ; d ) + ˆ I KSG ( f ; d ) , (14) with A filter ( d ) = 1 − A source ( d ) . Unlike variance decomposition or Shapley attrib ution, this ratio reflects the relative information shared between each production subsystem and a gi ven semantic dimension. Bootstrap resampling ( B = 10 ) provides confidence intervals. 3. Experimental Setup 3.1. Datasets W e ev aluate the proposed frame work across six English speech corpora spanning three dimensions. Emotional : RA VDESS [ 17 ] (1,440 utterances, 24 actors, eight emotions) and IEMO- CAP [ 18 ] (10,039 utterances, scripted and improvised interac- tions). Linguistic : L2-ARCTIC [ 19 ] (26,867 utterances, 24 non-nativ e speakers, six nati ve language backgrounds) and the GMU Speech Accent Archiv e (2,140 speakers representing 177 nativ e languages, all producing a standard English paragraph). P athological : UA-Speech [ 20 ] (dysarthric English speech, 15 speakers) and MD VR-KCL (Parkinson’ s disease English speech via mobile recordings). T o ensure robustness and generalisability within the av ailable data, we generate all eight dataset combi- nations (2 × 2 × 2), validating consistenc y across corpus pairings beyond an y single accent, affecti ve, or clinical cohort. 3.2. Implementation Details Both the MINE and CLUB netw orks use 2-layer MLPs with 256 hidden units and ReLU activ ations. T raining uses the Adam optimiser with learning rate 10 − 4 for 100 epochs. Features are z-score normalised. W e use 500 samples per dataset, stratified to ensure balanced representation across speak ers and conditions within each corpus, prev enting degenerate sampling from single speakers or language backgrounds. T able 1: Cr oss-dimension mean MI analysis. MINE = lower bound, CLUB = upper bound, KSG = non-parametric k -NN estimator , F inal = KSG-anchor ed weighted estimate (Eq. 11). All values in nats. ∆ = CLUB − MINE measures estimation uncertainty . MI < 0.15 nats indicates near-independence. Pair MINE CLUB ∆ KSG Final (Mean ± Std) Emotion–Linguistic 0.00 0.14 0.14 0.25 0.12 ± 0.05 Emotion–Pathology 0.00 0.07 0.07 0.26 0.10 ± 0.06 Linguistic–Pathology 0.00 0.10 0.10 0.21 0.10 ± 0.05 Source–Filter 0.24 0.59 0.35 0.60 0.47 ± 0.38 4. Results 4.1. Cross-Dimension Mutual Information T able 1 aggregates across all dataset combinations: it reports mean MI for each pair across all estimators (MINE, CLUB, KSG, Final), plus mean uncertainty . All cross-dimension pairs exhibit mean MI (Final) belo w 0.15 nats with tight uncertainty bounds ( ∆ < 0 . 15 nats), indicating near-independence in the examined feature space. Key observations: (i) Near-Zer o Cr oss-Dimension MI. The Emotion–Pathology and Linguistic–P athology pairs exhibit the lowest MI (0.10 nats), suggesting these dimensions occupy nearly independent subspaces in acoustic feature space. Emotion– Linguistic shows slightly higher coupling (0.12 nats), likely Figure 2: Cr oss-dimension MI (Final) heatmap acr oss dataset combinations. Lower values (lighter) indicate gr eater indepen- dence between feature sets. T op marginal bars show per-pair means averag ed acr oss all combinations. reflecting shared prosodic components (e.g., F0 contours influ- encing both emotional expression and linguistic stress patterns [ 11 ]). Howev er , this coupling remains negligible. (ii) Bounded Estimation V alidity . All estimates satisfy MINE ≤ CLUB, con- firming theoretical validity . The tight bounds ( ∆ < 0 . 15 for cross-dimension pairs) indicate that both estimators conv erged to similar values, pro viding high confidence in the estimates. KSG values closely match the neural combined estimates, pro viding independent v alidation. (iii) Sour ce-F ilter Coupling. Source- Filter MI (Final, 0.47 nats) is substantially higher than cross- dimension pairs but lower than classical acoustic theory might predict. This suggests that e ven production-le vel features main- tain quasi-independence when properly extracted, supporting the source-filter decomposition assumption. Figure 3: MI estimation con ver gence acr oss dimensions: (a) Emotion–Linguistic, (b) Emotion–P athology , (c) Linguis- tic–P athology , and (d) Sour ce–F ilter . P er-ensemble MINE and CLUB trajectories are shown (offset for visual clarity), alongside the KSG baseline (dashed) and the final consensus estimate for a r epr esentative dataset combination (RA VDESS, L2-ARCTIC, U A-Speech). The mean estimator gap ( ∆ ) over the final 10 train- ing epochs is r eported, demonstrating pr ogr essive r eduction and con ver gence over tr aining. 4.2. Cross-Cor pus Consistency Figure 2 shows MI (Final) across all 8 dataset combinations. Cross-dimension pairs consistently sho w very low MI (0.03–0.20 nats) while Source-Filter shows higher b ut stable coupling (0.1– 1.06 nats). The consistency across combinations suggests that the observed independence patterns are not artef acts of specific corpus pairings. Standard deviations remain belo w 0.1 nats for cross-dimension estimates, whereas Source-Filter shows a higher value (0.38) (T able 1) reflecting dataset-dependent coupling dif- ferences, likely driv en by recording conditions and speaker pop- ulations. 4.3. Con vergence Analysis Figure 3 re veals distinct con ver gence patterns for one dataset combination (RA VDESS, L2- ARCTIC, U A-Speech). Cross- dimension pairs con verge rapidly (8–16 epochs) with early stop- ping triggered by ∆ < 0 . 1 , consistent with low true MI making the estimation problem easier . Source-Filter requires full train- ing (100 epochs) with continued refinement, reflecting higher underlying dependence. 4.4. Source-Filter Attribution Figure 4 rev eals dimension-specific acoustic substrates. V al- ues denote the proportion of mutual information attributed to source versus filter components. Emotional features are consis- tently source-dominated across all eight dataset combinations (80%, 95% CI [0.76, 0.85]), consistent with the role of F0, jitter, shimmer , and voice quality in af fect encoding [ 21 ]. In contrast, linguistic featur es show filter dominance (60%), reflecting the articulatory basis of phonetic contrasts via formant structure and spectral shaping. P athological features similarly exhibit filter dominance (58%), suggesting articulatory impairment con- tributes slightly more than laryngeal dysfunction, consistent with clinical observ ations of dysarthria [ 12 , 22 , 23 , 24 ]. While emotional dimensions remain stably source-dri ven, linguistic and pathological dimensions display greater inter -combination variability . Figure 4: Sour ce–F ilter attrib ution acr oss semantic dimensions. Stack ed bars show the mean proportion of MI carried by Sour ce vs. F ilter components (Eq. 3); individual dataset combinations ar e overlaid as jitter points. Error bar s indicate 95% CI. 5. Discussion 5.1. Theoretical Implications Our bounded mutual information estimation framew ork rev eals consistently low cross-dimension MI (belo w 0.15 nats) in hand- crafted acoustic feature space, substantially lower than the 0.69– 1.96 nats reported in prior w ork using con ventional or single- estimator approaches that can be biased or v ariance-unstable in high-dimensional settings [ 4 , 5 ]. These near-zero residual dependencies carry important implications. Disentanglement Feasibility . Low MI upper bounds (CLUB < 0.15 nats) indicate that near-perfect dimensional disentanglement is theoretically achiev able for these feature sets, with negligible irreducible shared information ev en under a worst-case interpre- tation. Information-Theoretic Interpretation. An MI of ∼ 0.10 nats implies that kno wledge of one dimension (e.g., pathology) provides ne gligible predictive information about another dimen- sion (e.g., linguistic or emotion), supporting assumptions of near-independent modelling in practical speech systems. 5.2. Methodological Contributions The proposed framew ork addresses known limitations of neural MI estimators. EMA Stabilisation. Bias-corrected exponential moving av er- ages stabilise the MINE partition function, reducing gradient variance while preserving asymptotic unbiasedness. V ariance Clamping. Constraining CLUB log-v ariance to [ − 6 , 2] prev ents div ergence in lo w-MI regimes where conditional and mar ginal distributions con ver ge. Adaptive Anchoring. KSG-anchored weighting improves robustness when neural bounds di verge, prioritising non-parametric estimates under high estimator dis- agreement. 5.3. Implications for Encoder Design The low cross-dimension MI observ ed in handcrafted features motiv ates se veral design principles for speech encoders, pending validation on learned representations. Separate Pathways. Near -zero cross-dimension MI ( < 0.1 nats) supports dimension-specific encoder branches with minimal in- formation sharing. Featur e Alignment. Attribution analysis suggests linguistic encoders should prioritise filter features (for- mants, spectral structure), while emotional encoders benefit from source-dominated cues (F0, voice quality). Regularisation T ar - gets. Empirical MI baselines ( ∼ 0.10 nats) provide realistic disentanglement regularisation objectives. Cross-Lingual Ro- bustness. Consistency across accent-div ersity corpora cov er- ing ov er 177 language backgrounds pro vides initial e vidence for language-robust separability , though typologically diverse speech production systems [25] remain to be tested. 5.4. Limitations Sev eral limitations bound the scope of our conclusions. First, the analysis operates on handcrafted acoustic features; whether learned representations from self-supervised models such as wa v2vec 2.0 [ 26 ] or HuBER T [ 27 ] preserve the observed dimen- sional independence remains an open question. Second, the MI estimates characterise static feature distributions, and temporal dynamics (e.g., prosodic contours over utterances) may rev eal additional cross-dimension dependencies. Third, the feature groupings are one of se veral plausible partitions, and partial ov erlap between groups (e.g., shared formant and voice quality descriptors) means that the measured MI reflects properties of the chosen operationalisation rather than of abstract speech di- mensions per se. Fourth, the corpora are not representativ e across pathologies or emotional speech paradigms, and confounding factors, recording conditions, nati ve vs. non-nati ve speaker sta- tus, and corpus-specific mixed ef fects exert additional influence on the extracted features. T aken together , these considerations position the present work as demonstrating a methodological framew ork and providing initial empirical findings that open a new perspectiv e on mutual dependency analysis in speech; individual numerical results should be interpreted accordingly . Future work will extend this frame work to learned neural repre- sentations [26, 27] and broader clinical populations [28]. 6. Conclusion W e presented a bounded information-theoretic framew ork for quantifying dimensional independence in speech. Across six corpora, emotional, linguistic, and pathological feature sets e x- hibited, in the considered data, near -zero mutual information (0.10–0.12 nats) with tight estimation bounds ( ∆ < 0 . 15 nats), while Source–Filter coupling w as substantially higher (0.47 nats). Source–Filter attribution re vealed dimension-specific acoustic substrates: emotional features were source-dominated (80%), whereas linguistic and pathological features sho wed predomi- nantly filter-based encoding. V alidated across six corpora, these findings provide initial empirical support and a principled frame- work for measuring cross-dimension statistical dependence in speech representations. 7. References [1] D. H. Cho, H. S. Oh, S. B. Kim, and S. W . Lee, “Diemo-tts: Disen- tangled emotion representations via self-supervised distillation for cross-speaker emotion transfer in text-to-speech, ” in Proc. Inter - speech , 2025, pp. 4373–4377. [2] J. Li, T . Jiang, L. Li, Q. Hong, and B. Xia, “Mutual information- based embedding decoupling for domain generalization in speaker verification, ” in Pr oc. Interspeech , 2023, pp. 3147–3151. [3] H. J. Chang, A. H. Liu, and J. Glass, “Self-supervised fine-tuning for improved content representations by speak er-in variant cluster - ing, ” in Proc. Inter speech , 2023, pp. 3989–3993. [4] M. I. Belghazi, A. Baratin, S. Rajeswar , S. Ozair , Y . Bengio, A. Courville, and R. D. Hjelm, “Mutual information neural es- timation, ” in Proceedings of the 35th International Confer ence on Machine Learning (ICML) , ser . Proceedings of Machine Learning Research, vol. 80, 2018, pp. 531–540. [5] P . Cheng, W . Hao, S. Dai, J. Liu, Z. Gan, and L. Carin, “Club: A contrastive log-ratio upper bound of mutual information, ” in Pr oceedings of the 37th International Conference on Machine Learning (ICML) , ser . Proceedings of Machine Learning Research, vol. 119, 2020, pp. 1779–1788. [6] A. Kraskov , H. St ¨ ogbauer , and P . Grassberger , “Estimating mutual information, ” Physical Review E , vol. 69, p. 066138, 2004. [7] G. F ant, Acoustic Theory of Speech Production . The Hague: Mouton, 1970. [8] P . Boersma and D. W eenink, “Praat: Doing phonetics by computer, ” http://www .praat.org, 2001. [9] B. McFee, C. Raffel, D. Liang, D. P . W . Ellis, M. McV icar , E. Bat- tenberg, and O. Nieto, “librosa: Audio and music signal analysis in python, ” in Pr oceedings of the 14th Python in Science Conference (SciPy) , 2015, pp. 18–24. [10] F . Eyben, M. W ¨ ollmer , and B. Schuller , “opensmile – the munich versatile and fast open-source audio feature extractor , ” in Pr oceed- ings of the 18th ACM International Conference on Multimedia , 2010, pp. 1459–1462. [11] B. W . Schuller, “Speech emotion recognition: T wo decades in a nutshell, benchmarks, and ongoing trends, ” IEEE T ransactions on Affective Computing , v ol. 9, no. 1, pp. 1–20, 2018. [12] R. D. Kent, “Research on speech motor control and its disorders: A revie w and prospecti ve, ” Journal of Communication Disor ders , vol. 33, no. 5, pp. 391–428, 2000. [13] J. P . T eixeira, C. Oli veira, and C. Lopes, “V ocal acoustic analysis: Jitter , shimmer and hnr parameters, ” Procedia T echnology , vol. 9, pp. 1112–1122, 2013. [14] S. Davis and P . Mermelstein, “Comparison of parametric represen- tations for monosyllabic word recognition in continuously spoken sentences, ” IEEE T ransactions on Acoustics, Speec h, and Signal Pr ocessing , vol. 28, no. 4, pp. 357–366, 1980. [15] X. Huang, A. Acero, and H.-W . Hon, Spoken Language Pr ocessing: A Guide to Theory , Algorithm, and System Development . Prentice Hall, 2001. [16] S. Skodda, W . V isser , and U. Schlegel, “V owel articulation in parkinson’ s disease, ” Journal of V oice , vol. 25, no. 4, pp. 467–472, 2011. [17] S. R. Livingstone and F . A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess), ” PLOS ONE , vol. 13, no. 5, p. e0196391, 2018. [18] C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower , S. Kim, J. Chang, S. Lee, and S. Narayanan, “Iemocap: Interacti ve emo- tional dyadic motion capture database, ” Language Resour ces and Evaluation , vol. 42, no. 4, pp. 335–359, 2008. [19] G. Zhao, S. Sonsaat, J. Levis, E. Chukharev-Hudilainen, and R. Gutierrez-Osuna, “L2-arctic: A non-native english speech cor - pus, ” in Proc. Inter speech , 2018, pp. 2783–2787. [20] H. Kim, M. Hasegawa-Johnson, A. Perlman, J. Gunderson, T . Huang, K. W atkin, and S. Frame, “Dysarthric speech database for universal access research, ” in Proc. Interspeec h , 2008, pp. 1741–1744. [21] K. R. Scherer, “V ocal communication of emotion: A review of research paradigms, ” Speech Communication , vol. 40, pp. 99–120, 2003. [22] J. Rusz, R. Cmejla, H. Ruzickov a, and E. Ruzicka, “ Acoustic mark- ers of speech motor disorders in parkinson’ s disease, ” Movement Disor ders , vol. 26, no. 4, pp. 721–728, 2011. [23] B. Kashyap, M. Horne, P . N. Pathirana, L. Power , and D. Sz- mulewicz, “ Automated topographic prominence based quantitativ e assessment of speech timing in cerebellar ataxia, ” Biomedical Sig- nal Pr ocessing and Contr ol , vol. 57, p. 101758, 2020. [24] B. Kashyap, P . N. Pathirana, M. Horne, L. Power , and D. Sz- mulewicz, “Quantitati ve assessment of speech in cerebellar ataxia using magnitude and phase based cepstrum, ” Annals of Biomedical Engineering , vol. 48, no. 4, pp. 1322–1336, 2020. [25] P . Ladefoged and S. F . Disner, V owels and consonants . John W iley & Sons, 2012. [26] A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framew ork for self-supervised learning of speech representations, ” Advances in neural information processing systems , vol. 33, pp. 12 449–12 460, 2020. [27] W .-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov , and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units, ” IEEE/ACM trans- actions on audio, speech, and language pr ocessing , vol. 29, pp. 3451–3460, 2021. [28] J. R. Duffy et al. , Motor speec h disorder s: Substrates, dif ferential diagnosis, and management . Else vier Health Sciences, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment