Memory-guided Prototypical Co-occurrence Learning for Mixed Emotion Recognition
Emotion recognition from multi-modal physiological and behavioral signals plays a pivotal role in affective computing, yet most existing models remain constrained to the prediction of singular emotions in controlled laboratory settings. Real-world hu…
Authors: Ming Li, Yong-Jin Liu, Fang Liu
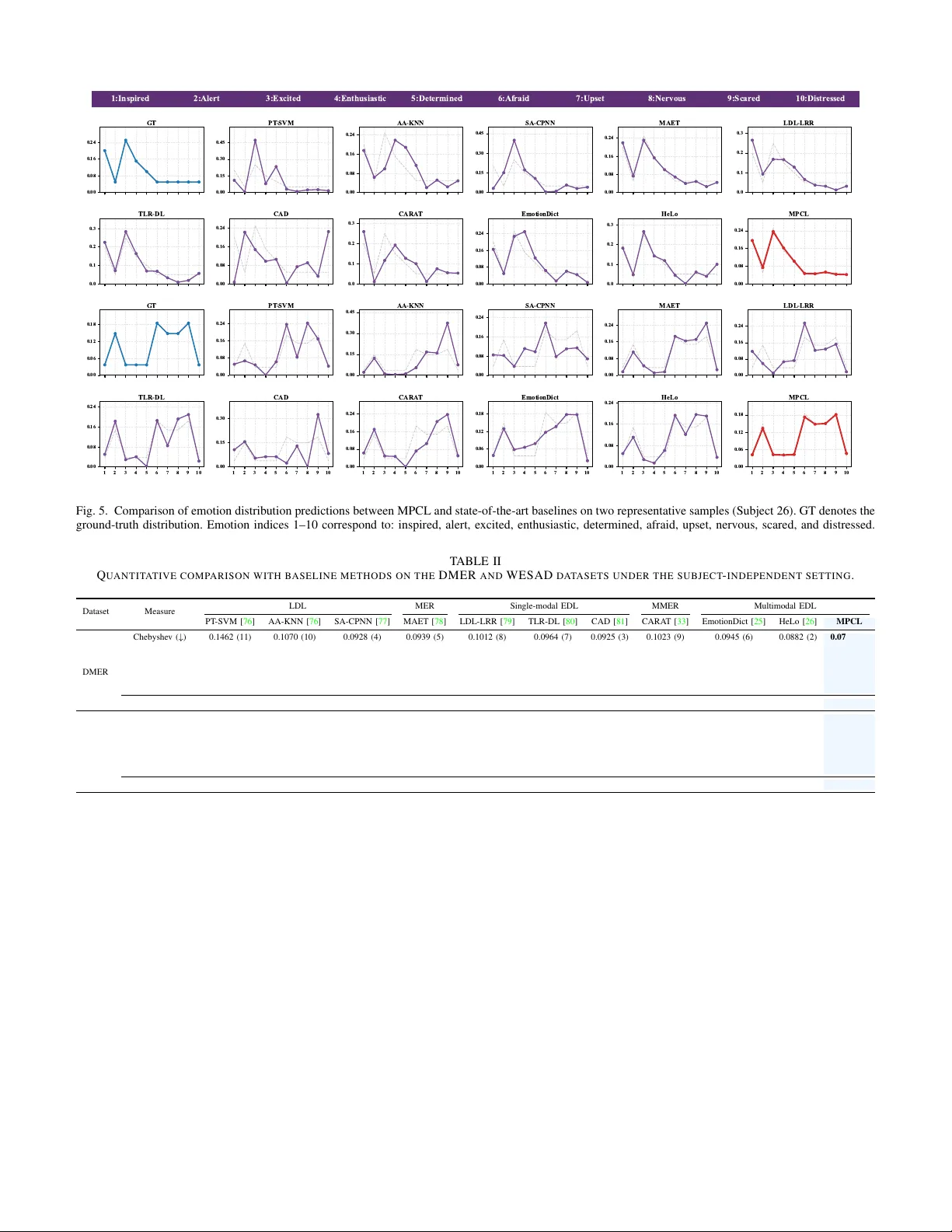
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 1 Memory-guided Prototypical Co-occurrence Learning for Mix ed Emotion Recognition Ming Li, Y ong-Jin Liu, Senior Member , IEEE , Fang Liu, Huankun Sheng, Y eying Fan, Y ixiang W ei, Minnan Luo, W eizhan Zhang, W enping W ang, F ellow , IEEE Abstract —Emotion recognition from multi-modal physiological and behavioral signals plays a piv otal r ole in affective computing, yet most existing models remain constrained to the prediction of singular emotions in controlled laboratory settings. Real- world human emotional experiences, by contrast, are often characterized by the simultaneous presence of multiple affectiv e states, spurring recent interest in mixed emotion recognition as an emotion distribution learning problem. Curr ent approaches, howev er , often neglect the valence consistency and structured correlations inher ent among coexisting emotions. T o addr ess this limitation, we propose a Memory-guided Prototypical Co- occurrence Learning (MPCL) framework that explicitly models emotion co-occurrence patterns. Specifically , we first fuse multi- modal signals via a multi-scale associative memory mechanism. T o capture cross-modal semantic relationships, we construct emotion-specific prototype memory banks, yielding rich physi- ological and behavioral representations, and employ prototype relation distillation to ensure cr oss-modal alignment in the latent prototype space. Furthermore, inspired by human cognitive memory systems, we introduce a memory retrie val strategy to extract semantic-level co-occurrence associations across emotion categories. Through this bottom-up hierarchical abstraction pr o- cess, our model learns affectiv ely informativ e representations for accurate emotion distribution prediction. Compr ehensive experiments on two public datasets demonstrate that MPCL con- sistently outperforms state-of-the-art methods in mixed emotion recognition, both quantitatively and qualitatively . Index T erms —Mixed-emotion recognition, associative memory , prototypical co-occurrence, multi-modal physiological signals. I . I N T RO D U C T I O N A FFECTIVE Intelligence seeks to equip machines with the ability to perceiv e and understand human emotions, a crucial step tow ard enabling natural and empathetic human- computer interaction. Achieving this goal requires both precise emotion recognition and a deeper comprehension of affecti ve states. Emotions are psychophysiological responses to external Ming Li, Y ong-Jin Liu, Huankun Sheng, Y eying Fan, and Y ixiang W ei are with MOE-K ey Laboratory of Perv asive Computing, Department of Computer Science and T echnology , Tsinghua University , Beijing, China. Y ong-Jin Liu is the corresponding author (e-mail: mingli thu, liuyongjin, shenghk, fanyeying@tsinghua.edu.cn, yx-wei22@mails.tsinghua.edu.cn). Fang Liu is with the K ey State Laboratory of Media Conver gence and Communication, Communication Uni versity of China, Beijing 100024, China (e-mail: fangliu@cuc.edu.cn). Minnan Luo and W eizhan Zhang are with the School of Computer Science and T echnology , and Shaanxi Province Key Laboratory of Big Data Knowl- edge Engineering, Xi’an Jiaotong Uni versity , Xi’an, Shaanxi 710049, China (e-mail: minnluo, zhangwzh@xjtu.edu.cn). W enping W ang is with the Department of Computer Science and Computer Engineering, T exas A&M Univ ersity , College Station, TX 77840 USA (e-mail: wenping@tamu.edu). This work was supported by the Natural Science Foundation of China (U2336214). stimuli, and their accurate decoding has significant impli- cations for fields such as healthcare and education [ 1 ]–[ 3 ]. Current research in emotion modeling primarily follows two theoretical frame works: (1) discrete models, which classify emotions into a set of basic categories [ 4 ]; and (2) dimen- sional models, which represent emotions as points within a continuous affecti ve space, such as the V alence-Arousal (V A) model [ 5 ] and the V alence-Arousal-Dominance (V AD) model [ 6 ]. Due to the inherent complexity and nuanced mechanisms underlying emotions, most studies have been conducted in controlled laboratory settings [ 7 ], [ 8 ]. While these efforts have generated high-quality datasets (e.g., [ 9 ]–[ 11 ]) and effecti ve recognition models (e.g., [ 12 ]–[ 14 ]), they typically simplify emotions into mutually exclusiv e, singular states. In real- world scenarios—such as ambiguous situations, social interac- tions, or conflicting ev ents—humans often experience multiple emotions simultaneously , a phenomenon referred to as mixed emotions . Mixed emotions are defined as the co-activ ation of two or more emotional states [ 15 ]. Gro wing psychological and neuroscientific e vidence indicates that human affecti ve ex- perience is rarely singular; rather, it in volves the interplay of multiple emotions, leading to richer and more complex psychological profiles [ 16 ], [ 17 ]. This poses a significant challenge for computational methods, as it requires not only identifying which emotions are present, but also quantifying their respecti ve intensities. Physiologically , mix ed emotions in- volv e coordinated activ ations across distrib uted brain regions, exhibiting intricate spatiotemporal dynamics [ 18 ], [ 19 ]. As a result, mixed emotion recognition has emerged as a growing research focus [ 20 ], representing a shift from basic emotion classification to ward more realistic and nuanced models of human af fect. This advancement is essential for unco vering the neural underpinnings and computational principles of complex emotional experiences. Mixed emotion recognition can be approached through multi-label classification [ 21 ], which identifies the presence of emotions, or through emotion distrib ution learning (EDL), which estimates the intensity of each emotion. EDL has been used to model emotional di versity in images [ 22 ] and to capture subtle emotional semantics in text [ 23 ]. Howe ver , single-modal data often fail to fully capture the complexity of mixed emotions. Recent studies hav e therefore turned to multimodal approaches that combine physiological and behavioral signals, supported by publicly av ailable datasets. For example, EDLConV Network [ 24 ] uses peripheral phys- iological signals—including electrocardiogram (ECG), heart JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 2 rate (HR), galvanic skin response (GSR), and skin temperature (SKT)—to decode the distribution of basic emotions. Emo- tionDict [ 25 ] further integrates electroencephalogram (EEG), peripheral signals, and facial videos to decompose mixed emotions into basic emotional components in a latent space. While these methods capture the presence and intensity of individual emotions, they largely treat emotion categories as independent, overlooking the intrinsic relationships among them. Helo [ 26 ] addresses this issue by modeling label cor- relations and exploiting cross-modal heterogeneity . Howe ver , it still relies on statistical dependencies derived from label distributions, without incorporating valence consistency and mutual exclusi vity priors inherent in the af fectiv e space. Psychological studies [ 27 ] indicate that emotions exhibit structured relationships based on valence. Emotions sharing the same v alence (e.g., both positiv e or both ne gativ e) are often positiv ely correlated and tend to manifest simultaneously , a phenomenon known as co-occurr ence [ 28 ]. In contrast, emo- tions with opposite valences typically engage in competitiv e or inhibitory interactions, making their simultaneous activ ation less likely [ 29 ]. This reflects the fact that same-valence emo- tions are proximal in af fecti ve space, whereas opposite-v alence emotions are more mutually exclusiv e [ 30 ]. Mixed emotions thus arise from combinations of basic emotions governed by these co-occurrence patterns. Nevertheless, most existing computational approaches ov erlook this intrinsic structure [ 31 ], [ 32 ] and instead focus on holistic and salient feature representations for distribution prediction. As a result, they fail to capture the internal co-occurrence relationships present in raw multimodal data, hindering the modeling of emotion interaction relationships and latent compositional structures. Moreov er , each basic emotion within a mixed state is associ- ated with specific feature activ ations [ 33 ], yet raw data often consist of low-le vel statistical features entangled with noise, rather than semantically disentangled representations. In such a feature-entangled space, directly modeling co-occurrence patterns may capture superficial data correlations rather than psychologically meaningful affecti ve structures. Inspired by the psychological principle of emotion co- occurrence, we propose a novel Memory-guided Pr ototypi- cal Co-occurr ence Learning (MPCL) framework to model the semantic structural associations among emotions. Our framew ork is organized into three interconnected stages. (1) Multimodal F eatur e Extraction and Fusion : this stage employs a multi-scale associativ e memory strategy to fuse multimodal physiological and behavioral signals, capturing intrinsic cor- relations and complementary information. (2) Pr ototypical Alignment and Co-occurr ence Learning : we extract fine- grained emotion prototypes to construct an emotion memory bank, yielding semantically rich embeddings by reconstructing physiological and behavioral features as weighted combi- nations of these prototypes. Prototype Relation Distillation (PRD) is employed to enforce structural alignment within the prototype-relational space, thereby ensuring semantic consis- tency across heterogeneous modalities. In this stage, drawing on human association memory mechanisms [ 34 ], [ 35 ], we further present Prototypical Co-occurrence Learning (PCL). PCL employs a memory retrie val strategy to aggregate similar samples within semantic neighborhoods, realizing semantic- lev el prototype co-occurrence, complemented by a contrastiv e learning objective to ensure cross-modal consistency . (3) Hi- erar chical Semantic Compression and Distribution Prediction : we derive highly condensed emotion representations via a bottom-up hierarchical abstraction strategy , enabling precise mixed emotion distribution prediction. The main contributions of this paper include: • W e propose a multi-scale associative memory fusion strategy to capture intrinsic emotion correlations in mul- timodal physiological data, and introduce a content- addressable memory mechanism to construct fine-grained prototype memory banks, generating semantically rich and structurally consistent representations. • Inspired by human cognitiv e memory mechanisms, we design a memory retriev al strategy to extract prototype- lev el semantic co-occurrences, effecti vely uncovering la- tent structural associations among distinct emotions. • W e dev elop a hierarchical semantic compression method that progressi vely abstracts af fective representations through bottom-up processing, enabling accurate emotion distribution learning. Extensi ve experiments on two pub- lic benchmarks demonstrate that our approach achiev es state-of-the-art performance in mixed emotion recogni- tion, both quantitatively and qualitativ ely . I I . R E L A T E D W O R K A. Multimodal Emotion Distribution Learning Emotion recognition plays a central role in affecti ve intel- ligence and commonly processes inputs from multiple modal- ities, including visual, auditory , textual, and physiological signals [ 36 ]. Among these, physiological signals are less susceptible to intentional control or masking, of fering a more direct reflection of genuine emotional states. In particular, electroencephalogram (EEG) has been widely adopted in af- fectiv e computing due to its millisecond temporal resolution in capturing cortical dynamics [ 37 ]. Compared to unimodal methods, multimodal emotion recognition (MER) achiev es su- perior performance by integrating complementary information across modalities, leading to the development of di verse fusion strategies [ 38 ], [ 39 ]. MER can be broadly categorized into single-label and multi-label recognition. While the majority of existing studies focus on single-label recognition—assuming each data sample is associated with one dominant emotion [ 40 ]—multi-label recognition aims to detect multiple coexisting emotions. The latter aligns more closely with psychological reality , where emotional experiences are often ambiguous and complex; individuals in real-world situations frequently undergo mixed emotions, characterized by the simultaneous presence of mul- tiple af fective states [ 41 ]. For instance, MA GDRA [ 42 ] models cross-modal interactions among visual, audio, and textual data, and incorporates a reinforced multi-label detection module to learn label correlations. Similarly , SeMuLPCD [ 43 ] employs a multimodal peer collaborativ e distillation mechanism to transfer complementary knowledge from unimodal networks to a fusion network for multi-label emotion prediction. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 3 T raditional multi-label emotion recognition typically for - mulates the task as multiple independent binary classification problems, thereby only identifying the presence or absence of each emotion. In contrast, multimodal emotion distribution learning (EDL) extends this by further quantifying the inten- sity of each emotional state. This perspecti ve resonates with the General Psycho-ev olutionary Theory [ 44 ], which posits that a set of basic emotion prototypes exists with varying intensities, and that comple x emotions arise from mixtures of these prototypes. Follo wing this notion, Shu et al. [ 24 ] designed the EDLConV model, which leverages feature corre- lations and temporal dynamics from peripheral physiological signals to decode mixed emotion distributions. EmotionDict [ 25 ] integrates peripheral physiology , EEG, and facial video features, using a dictionary learning module to decompose them into weighted combinations of basic emotional com- ponents. MEDL [ 45 ] learns emotion distributions and label correlations separately for video and audio modalities, and enforces consistency between cross-modal correlation matri- ces to predict the final emotion distribution. More recently , HeLo [ 26 ] incorporates Optimal T ransport theory to facilitate heterogeneous interactions between physiological and behav- ioral signals, and adopts a label correlation-driv en attention mechanism for distribution prediction. Although these methods effecti vely exploit cross-modal complementarity and label correlations, they primarily rely on data-driven statistical associations to model inter-label dependencies. Howe ver , psychological studies [ 46 ] confirm that emotions sharing the same valence are more likely to co-activ ate than those with opposite valences—a phenomenon known as emotion co-occurrence. Therefore, in this paper , we aim to incorporate this psychological prior to guide the learning of structured correlations among different emotional states. B. Prototype-based Repr esentation Learning Prototype learning aims to identify a representative center for each class, referred to as a prototype or centroid, and has been widely studied in pattern recognition and machine learning [ 47 ]. Early prototype-based methods predominantly relied on geometric distance metrics. For example, k-nearest neighbors (KNN) [ 48 ] determines the class of a query sample by its distance to training instances, while k-means clustering [ 49 ] and learning vector quantization (L VQ) [ 50 ] assign sam- ples to the nearest cluster centroids. Although such approaches reduce dependency on the full training set during inference, distance-based measures in high-dimensional feature spaces are often vulnerable to the curse of dimensionality and may fail to capture semantically meaningful relations. W ith the advancement of deep learning, prototype learn- ing has emer ged as a powerful framework for automatically learning discriminativ e representations. Initially proposed for few-shot image classification, Snell et al. [ 51 ] introduced pro- totypes as class-wise representativ es in a learned embedding space, where classification is performed by measuring the distance between a query sample and each prototype. This idea was later extended to fe w-shot semantic segmentation [ 52 ]. Inspired by these visual applications, prototype learning has been successfully adapted to emotion recognition. For instance, MapleNet [ 53 ] employs a shared encoder to align textual and visual features with emotion-specific prototypes, achieving cross-modal semantic alignment. PR-PL [ 54 ] uses prototype representations to model the latent semantic struc- ture of emotion categories in EEG signals, obtaining subject- in variant and generalizable af fectiv e representations. Another important line of research inte grates prototypes into contrastiv e learning frame works. While con ventional instance- wise contrasti ve methods focus on discriminating between augmented vie ws of the same sample, they often o verlook higher-le vel semantic structures. T o address this, prototypi- cal contrastiv e learning [ 55 ] introduces cluster centroids as prototypes and encourages samples to align with their cor- responding prototypes, thereby injecting semantic structures into the learned representation space. Like wise, ProtoCLIP [ 56 ] uses prototypes as stable anchors to cluster semanti- cally similar instances, improving grouping performance in vision–language contrastiv e learning. In the emotion recog- nition domain, SRMCL [ 57 ] proposes supervised prototype memory contrasti ve learning (PMCL) to enhance intra-class compactness for micro-expression recognition by contrasting current and historical prototypes. SCCL [ 58 ] lev erages sen- timent lexicon–deriv ed coordinates as predefined prototypes to perform cluster-le vel contrastive learning, capturing fine- grained emotional semantics. EmotionDict [ 25 ] incorporates a dictionary learning module that decomposes mixed emotions into linear combinations of basic emotion elements, strength- ening the expressiv eness of multimodal features. Despite their effecti veness, existing prototype-based meth- ods in emotion recognition suf fer from se veral limitations. Many rely on predefined prototypes, simple averaging over samples, or implicit basis representations, which are sensi- tiv e to noise and prone to prototype drift. This often leads to semantically blurred representations that fail to capture fine-grained affecti ve nuances and intra-class diversity . Fur- thermore, current cross-modal prototype alignment strategies typically neglect the global relational structure among proto- types, resulting in poor geometric consistency across modal- ities in the shared semantic space. In contrast, our approach presented in this paper reconstructs multimodal features as weighted combinations of fine-grained emotion prototypes to obtain semantically rich embeddings, and enforces cross- modal structural consistency through prototype relation dis- tillation, thereby preserving both local discriminability and global relational semantics. C. Associative Memory and Modern Hopfield Networks Associativ e memory networks are computational models that emulate the human brain’ s ability to store and retrieve patterns, allowing for the recovery of complete memories from partial or noisy inputs [ 59 ]. The classic Hopfield network, introduced in the 1980s, is an energy-based fully connected neural network that stores and retrie ves information through a symmetric weight matrix [ 60 ]. Recognized for its stability and associativ e recall properties, it has found broad application in JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 4 pattern recognition tasks [ 61 ]. Howe ver , the storage capacity of traditional binary Hopfield networks is notably limited. T o address this, researchers hav e proposed modern Hopfield networks (MHNs), also referred to as dense associati ve mem- ories (D AMs), primarily by redesigning the energy function. Krotov and Hopfield [ 62 ] generalized the neuron interaction from F ( x ) = x 2 to F ( x ) = x n , achieving a storage capacity that scales polynomially with dimension as d n − 1 . Demircigil et al. [ 63 ] further improv ed capacity to an exponential scale using F ( x ) = exp( x ) . More recently , Ramsauer et al. [ 64 ] extended the e xponential energy formulation to continuous states, introducing the continuous modern Hopfield network. Its retrie v al update rule permits single-step memory recall and is mathematically equiv alent to the attention mechanism in T ransformers, enabling seamless integration into deep learning framew orks for tasks such as feature aggregation, memory- augmented learning, prototype representation, and structured attention. Continuous MHNs have demonstrated strong performance across div erse applications, including immune repertoire clas- sification [ 65 ], chemical reaction prediction [ 66 ], and rein- forcement learning [ 67 ], owing to sev eral key properties. First, their associati ve memory mechanism supports effecti ve multi- modal fusion by modeling interactions between query patterns (states) and stored memory patterns (keys), thereby capturing intrinsic cross-modal correlations and complementary infor- mation. Second, MHNs possess notable feature aggregation capabilities, summarizing input representations within a mem- ory space via static, learnable state patterns. Moreover , MHNs facilitate memory representation learning by parameterizing the memory space as a trainable matrix — often constructed from training samples, reference sets, or prototypes — that can be optimized to encode the underlying structure of the data. Recently , MHNs ha ve also been incorporated into con- trastiv e learning frameworks to address the explaining-aw ay problem. Methods such as CLOOB [ 68 ] and CLOOME [ 69 ] employ MHNs to enrich the covariance structure of the original embeddings. By substituting original features with their retrie ved counterparts from the memory , these approaches reinforce frequently co-occurring feature patterns. Howe ver , existing retrie val strate gies are largely confined to feature-lev el similarity aggregation, often ov erlooking deeper, semantically structured relationships. In contrast, our work lev erages the memory retriev al mechanism of MHNs to model cross-modal co-occurrence consistency within a memory-augmented se- mantic space, thereby capturing richer and more structured affecti ve associations. I I I . M E T H O D S A. Preliminaries: Energy-Based Hopfield Networks 1) Energy Function: The ener gy-based continuous mod- ern Hopfield network [ 64 ] serves as the unified theoretical foundation for our proposed MPCL frame work. Unlike the traditional attention mechanism in Transformers, MHNs al- low the iterativ e optimization process to be interpreted as energy minimization. Formally , consider a state pattern (query) ξ ∈ R d and a set of M stored patterns (memory) X = ( x 1 , . . . , x M ) ∈ R d × M . The network dynamics are governed by an energy function E , defined via the Log-Sum-Exp (lse) function as: E ( ξ ) = − lse ( β , X T ξ ) + 1 2 ξ T ξ + C 0 = − 1 β log M X j =1 exp( β x T j ξ ) + 1 2 ξ T ξ + C 0 , (1) where β > 0 is the inv erse temperature parameter that controls the sharpness of the energy landscape, and C 0 is a normalization constant. The first term promotes alignment of the state vector ξ with the stored patterns (associati ve recall), while the quadratic term acts as a regularizer that constrains the norm of the state vector . 2) Update Rule and Unified Hopfield Operator: The update rule that minimizes the ener gy function in Eq. ( 1 ) in a single step is mathematically equiv alent to the well-known attention mechanism in Transformers [ 64 ], [ 70 ]: ξ new = X softmax ( β X T ξ ) . (2) T o provide a modular and concise description of our MPCL framew ork, we generalize this update rule into a matrix formulation and abstract it into a unified Hopfield operator . Giv en state patterns R ∈ R S × d k as queries, stored patterns Y ∈ R N × d k as keys, and pattern projections V ∈ R N × d v as values, the operator is defined as: Hopfield ( R , Y , V , β ) := softmax β R Y T V . (3) 3) Physical Interpretation: From a dynamical systems viewpoint, this operator implements content-addressable mem- ory retrie val, in which patterns stored in Y act as attractors (or metastable states) within the energy landscape. Although mathematically equiv alent to T ransformer attention, this up- date rule is rigorously proven to con ver ge to stationary points of the energy function, i.e., local minima or saddle points [ 64 ]. W ithin our framework, by configuring R , Y , V and β , we lev erage this operator to realize four key functional modules: cross-modal association (Section III-C ), prototype memory bank construction (Section III-D1 ), prototype co-occurrence (Section III-D3 ), and semantic compression (Section III-E ). B. T ask F ormulation and F ramework Overview 1) T ask F ormulation: W e formulate multimodal mixed emotion recognition as an emotion distrib ution learning prob- lem. Let D = { ( x i , y i ) } T i =1 denote a dataset containing T samples, where each sample x i = { x phy i , x beha i } consists of physiological signals and behavioral observations. Specif- ically , x phy i ∈ R C phy × d phy represents the set of physiological signals (e.g., EEG, GSR, or ECG), and x beha i ∈ R C beha × d beha corresponds to behavioral data such as facial videos. Here, C ( · ) and d ( · ) denote the number of channels and feature dimension per modality , respectiv ely . The label y i ∈ R E is a probability distribution ov er E emotion categories, satisfying the normalization constraint P E j =1 y i,j = 1 . Our objective is to learn a mapping function F ( x ; θ ) parameterized by θ that minimizes the div ergence between the predicted distribution ˆ y i and the ground truth y i . JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 5 Pr ot ot ypi c al C o - o c c u r r e n c e L e a r n i n g (P C L ) EEG GS R M u lti - m od al P h ys i ol ogi c al S i gn al s B e h avi or al S i gn al s P P G Lo w S c a l e M e di um S c a l e M u lti - sca l e A sso ci a t i v e F u si o n ( MS A F ) B e h avi or al E nc o de r P r ot ot yp e E xt r ac t i on P r ot ot yp e E xt r ac t i on M e m or y B an k M e m or y B an k R eco n st ru ct i o n R eco n st ru ct i o n Pr o t o t y pe R e la t io n D is t illa t i o n ( PR D ) H o p f i e l d La y e r 1 S e l f - A tte n ti o n L a y e r 1 … H o p f i e l d La y e r 2 S e l f - A tte n ti o n L a y e r 2 H o p f i e l d La y e r n S e l f - A tte n ti o n L a y e r n C l a s s i f i e r M emo ry R et ri ev a l w i t h V M emo ry R et ri ev a l w i t h U P r e d ic te d E mo tio n D is tr ib u tio n P r ot ot yp e - en h a n ced rep res en t a t i o n P r ot ot yp e - en h a n ced rep res en t a t i o n H i g h s ca l e ( a) M ul t i m odal Fe at ur e E xt r ac t i on and Fus i on ( b) Pr ot ot ypi c al A l i gnm e nt and C o - o c c u r r e n c e L e a r n i n g (c ) Hie r a r c h ic a l S e ma n tic C o mp r e s s io n a nd D i s t r i but i o n P r e d i c ti o n M emo ry R et ri ev a l w i t h U M emo ry R et ri ev a l w i t h V Fig. 1. Overvie w of the MPCL Framework, which consists of three stages. (a) Multimodal Feature Extraction and Fusion: the Multi-Scale Associative Fusion (MSAF) module fuses multi-modal physiological signals, while a separate behavioral encoder extracts structured beha vioral feature. (b) Prototypical Alignment and Co-occurrence Learning: emotion prototype memory banks are constructed from both modalities. The Prototype Relation Distillation (PRD) module enforces cross-modal structural alignment, and the Prototypical Co-occurrence Learning (PCL) module captures semantic-lev el co-occurrence patterns through memory retriev al. (c) Hierarchical Semantic Compression and Distrib ution Prediction: the Hierarchical Semantic Compression (HSC) module abstracts affecti ve representations via a bottom-up strategy , followed by a classifier that outputs the final emotion distrib ution. 2) F ramework Overview: As illustrated in Fig. 1 , our proposed MPCL frame work consists of three core stages: 1) Multimodal F eature Extraction and Fusion : The Multi- Scale Associative Fusion (MSAF) module encodes and in- tegrates multimodal physiological signals into a unified em- bedding through an associati ve memory mechanism. Con- currently , a behavior encoder maps input raw signals into structured behavioral embeddings. 2) Prototypical Alignment and Co-occurrence Learning : Emotion prototype memory banks are constructed from both physiological and behavioral embeddings. Pr ototype Relation Distillation (PRD) is utilized to perform prototype-based denoising and to enforce cross- modal structural alignment between the two modalities. Subse- quently , the Prototypical Co-occurr ence Learning (PCL) mod- ule reinforces cross-modal semantic co-occurrence consistency via memory retriev al and contrastive learning. 3) Hierarchical semantic compression and distribution prediction : The Hierar chical Semantic Compr ession (HSC) module abstracts high-lev el affecti ve concepts from the co-occurrence-enhanced representations. Finally , a classifier predicts the emotion dis- tribution for each sample. C. Multimodal F eature Extraction and Fusion Our framew ork processes both physiological and beha vioral signals. Distinct from e xternally observ able beha vioral signals (such as facial videos or accelerometer data), physiological signals capture a broad range of internal biological acti vi- ties—from central nervous activity (e.g., EEG) to cardiov as- cular (e.g., ECG or photoplethysmogram, PPG), electrodermal (e.g., GSR or electrodermal activity , ED A) and muscular (e.g., electromyography , EMG) dynamics. These continuous time series signals collectiv ely reflect the subject’ s intrinsic physi- ological state. T o exploit their inherent synergy , we prioritize the fusion of these modalities, as illustrated in Fig. 2 . After standard pre-processing (Section IV -B ), we denote the physiological signals as x phy ∈ R C phy × d phy and the behav- ioral signal as x beha ∈ R C beha × d beha . Based on the acquisition characteristics and typical precision of the recording devices, we further partition the physiological set x phy into a primary modality x pri ∈ R C pri × d pri (e.g., EEG) and a set of auxiliary modalities { x m } m ∈M aux , where M aux index es the auxiliary signals (e.g., M aux = { GSR , PPG } ). T o mitigate feature discrepancies across heterogeneous modalities, we employ modality-specific encoders f ( · ) to project all raw inputs into a unified latent space with feature dimension D and a standardized sequence length C . The projection process is formulated as: h pri = f pri ( x pri ) , h m = f m ( x m ) , h beha = f beha ( x beha ) (4) where h pri , h m ∈ R C × D are the projected physiological embeddings. For structural symmetry in later cross-modal interaction, the behavioral input is encoded and projected into h beha ∈ R K × D , where K = |M aux | · C , matching the aggregated sequence length of the physiological modality . T o fully exploit the complementary information across modalities, we propose a multi-scale fusion strategy gov- erned by a set of scaling parameters B = { β low , β mid , β high } (Fig. 2 ). Unlike standard attention that uses a fixed scaling JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 6 EEG GS R P P G L o w sca l e Med i u m sca l e H i g h sca l e C on c at P r o je c tio n Med i u m sca l e H i g h sca l e C on c at P r o je c tio n F F C on c at L aye r n or m L aye r n or m L o w sca l e M ul ti - m od al P h ysi ol o gi c al Si gnal s F us i on Fu si o n F p r ima r y mo d a lity Fig. 2. Fusion of multimodal physiological signals. EEG serves as the primary modality to integrate complementary information from auxiliary modalities (PPG and GSR) via a multi-scale associativ e memory mechanism. Three distinct scaling factors B = { β low , β mid , β high } are employed to modulate the granularity of information aggregation. factor mainly for gradient stability , our strategy le verages β to modulate the granularity of information aggregation, framing multimodal fusion as an energy minimization process. A smaller β promotes global context aggregation while sup- pressing modality-specific noise, whereas a larger β enforces precise local-feature alignment. For each scale β ∈ B , the Hopfield operator is applied as: h m β = Hopfield ( h pri , h m , h m , β ) (5) Granularity-specific representations are then concatenated along the feature dimension and projected back to the la- tent space D . Defining the concatenated feature as h m cat ∈ R C × ( |B|· D ) , the final fused representation z m phy ∈ R C × D is obtained via a learnable projection W proj ∈ R ( |B|· D ) × D and a residual connection: h m cat = Concat { h m β | β ∈ B} (6) z phy ,m = h pri + h m cat W proj (7) Finally , we aggregate the fused physiological representations from all auxiliary modalities. The resulting physiological and behavioral representations are: z phy = Concat { z phy ,m | m ∈ M aux } , z beha = h beha (8) D. Prototypical Alignment and Co-occurr ence Learning While we have obtained fused physiological and beha vioral embeddings, these representations essentially remain in a lo w- lev el feature space that lacks explicit semantic disentangle- ment. Directly modeling co-occurrence in such a space risks capturing spurious, data-lev el correlations rather than psycho- logically grounded emotional structures. T o address this, we introduce a prototypical modern Hopfield network that learns a set of fine-grained emotion prototypes and constructs a global emotion memory bank. As shown in Fig. 3 , our goal is to map heterogeneous multimodal signals into a unified, semantics- enhanced prototype space. P r o to ty p e E xt ract i on P r o to ty p e E xt ract i on ∈ × So f t ma x ∈ K × M ∈ × M em ory B an k ∈ M × D So f t ma x ∈ K × M ∈ M × M ∈ M × M : P r ototype R e la t io n D ist illa t io n ∈ K × D ∈ K × D P r ototyp i c al A l i gn me n t M em ory B an k ∈ M × D Fig. 3. Prototype alignment process. Prototype memory banks are first constructed separately for the physiological and behavioral modalities, re- spectiv ely . A semantics-enriched representation is then obtained as a weighted combination of prototypes from each bank. Meanwhile, the Prototype Relation Distillation (PRD) strategy enforces semantic structural consistency across the two modalities. 1) Prototype Memory Bank: Let z ∈ R K × D denote a generic input embedding (either z phy or z beha ). T o learn and extract prototypes, we employ two trainable parameter matri- ces: one for prototype addressing and the other for prototype storage. • Prototype Address Matrix W address ∈ R M × D stores representativ e signatures used for associati ve addressing. It defines the latent addressing space of the memory bank, where each row act as a reference pattern that interacts with the input query z to compute the prototype assignment weights. • Prototype Memory Matrix W memory ∈ R M × D stores the semantic content of each prototype. It provides the semantic basis for feature reconstruction, with each row corresponding to a learned prototype. The input embed- ding z is represented as a weighted aggregation of these prototype contents. Here, M denotes the memory capacity (i.e., the number of prototypes). First, we compute the addressing distribution A ∈ R K × M as: A = softmax ( β z W T address ) (9) where β = 1 / √ D is a scaling factor . This distribution repre- sents the weight (or probability) of each prototype, quantifying its contribution to the input sample. Next, we reconstruct the input z as a weighted combination of the prototype memories stored in W memory , yielding the semantics-enriched embedding z proto ∈ R K × D : z proto = A W memory = Hopfield ( z , W address , W memory , β ) (10) Notably , this learned prototype bank is subsequently used to initialize the hierarchical semantic compression module. 2) Prototype Relation Distillation (PRD): T o mitigate cross-modal heterogeneity and enforce semantic structural consistency , we propose a PRD strategy that le verages the extracted prototypes for cross-modal supervision. First, the JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 7 addressing weight matrix A from Eq. ( 9 ) serves as the student distribution, representing the instance-wise assignment probabilities ov er all prototypes. Concurrently , we construct a ”ground truth” relational structure among the learned proto- types to provide a teacher distrib ution. The semantic correla- tion matrix S ∈ R M × M is defined as: S = softmax W memory W T address τ dist (11) where τ dist is a temperature parameter . Each row S i captures the semantic distribution of the i -th prototype relati ve to the entire memory bank, of fering structure-aware soft labels for cross-modal distillation. W e then use the topological structure of the dominant proto- type from one modality to supervise the addressing distrib ution of the other modality . F or each sample in a mini-batch of size N , we first identify the pseudo-label prototype indices based on the maximum activ ation of the respectiv e teacher modalities: p ∗ i = arg max j ( A beha i,j ) , q ∗ i = arg max j ( A phy i,j ) (12) Subsequently , Kullback-Leibler (KL) div ergence [ 71 ] is em- ployed to enforce cross-modal semantic consistency . By min- imizing the div ergence between the student’ s addressing dis- tribution and the retriev ed teacher topology , the PRD loss is formulated as: L PRD = 1 2 N X i =1 D KL S beha p ∗ i ∥ A phy i + D KL S phy q ∗ i ∥ A beha i (13) 3) Prototypical Co-occurr ence Learning (PCL): T o un- cov er the relational structure of basic emotions within mixed emotional states, we leverage the memory retrie v al mecha- nism of Hopfield networks to amplify semantic co-occurrence patterns. As shown in Fig. 4 , this design is inspired by the brain’ s ability to extract co-occurrence regularities through visual perception and memory . Specifically , we first augment the raw input features z with the learned prototype features z proto , yielding prototype-enhanced representations: ˜ z phy = z phy + z phy proto , ˜ z beha = z beha + z beha proto (14) where ˜ z ( · ) ∈ R K × D denotes the prototype-enhanced represen- tation that preserv es both instance-specific details from the ra w input and the rich semantic context captured by the prototypes. Consider a mini-batch of N pairs of enhanced embed- dings { ( ˜ z phy i , ˜ z beha i ) } N i =1 . W e organize them into batch ma- trices ˜ Z phy = [ ˜ z phy 1 , . . . , ˜ z phy N ] and ˜ Z beha = [ ˜ z beha 1 , . . . , ˜ z beha N ] . These matrices simultaneously serve as stored embeddings: U = ˜ Z phy = [ u 1 , . . . , u N ] and V = ˜ Z beha = [ v 1 , . . . , v N ] . Before retriev al, all embeddings are normalized to unit length: ∥ ˜ z phy i ∥ = ∥ ˜ z beha i ∥ = ∥ u i ∥ = ∥ v i ∥ = 1 . Each indi vidual embedding ˜ z phy i and ˜ z beha i acts as state patterns (queries) to … y 1 y 2 y N … y 1 y 2 y N x 1 x 2 x N x 1 x 2 x N Ho p fie ld R e tr ie v a l w ith V Ho p fie ld R e tr ie v a l w ith U Ho p fie ld R e tr ie v a l w ith U … U yN … V y1 V y2 V yN … U x2 U xN V x1 V x2 V xN … … … U x1 U y1 U y2 S i m i l ar i t y t o an c h or P o s i t i v e s a m p l e N e gat i ve s am p l e P r ot ot yp i cal C o - occu rr en ce L earn i n g ( P C L ) Ho p fie ld R e tr ie v a l w ith V Fig. 4. Architecture of Prototypical Co-occurrence Learning (PCL). The phys- iological embedding x i and the beha vioral embedding y i retriev e associated representations U x i and U y i , respectively , via the Hopfield netw ork. W ithin the physiological embedding space, U x i (retriev ed via the physiological query) serves as an anchor that is contrasted with the positive sample U y i (retriev ed from the corresponding beha vioral query) and with neg ative samples U y j (retriev ed from mismatched beha vioral queries, where j = i ). The same procedure is applied symmetrically in the behavioral embedding space V . retriev e associated features from the stored patterns in U and V , respectiv ely: U ˜ z phy i = Hopfield ( ˜ z phy i , U , U , β ) (15) U ˜ z beha i = Hopfield ( ˜ z beha i , U , U , β ) (16) V ˜ z phy i = Hopfield ( ˜ z phy i , V , V , β ) (17) V ˜ z beha i = Hopfield ( ˜ z beha i , V , V , β ) (18) where β is the scaling parameter of the Hopfield net- work. Here, U ˜ z phy i denotes a physiological-retriev ed physi- ological embedding, while U ˜ z beha i is a behavioral-retrie ved physiological embedding. Similarly , V ˜ z phy i corresponds to a physiological-retrie ved beha vioral embedding, and V ˜ z beha i is a behavioral-retrie ved behavioral embedding. Guided by this memory retriev al mechanism, features that exhibit semantic consistenc y between the query and stored samples are reinforced, while spurious correlations are sup- pressed. After retrie val, all retrieved embeddings are re- normalized: ∥ U ˜ z phy i ∥ = ∥ U ˜ z beha i ∥ = ∥ V ˜ z phy i ∥ = ∥ V ˜ z beha i ∥ = 1 . Drawing inspiration from the CLOOB objecti ve [ 68 ], we define the Semantic-Le vel Leave One Out Boost (SemLOOB) loss as: L SemLOOB = − 1 N N X i =1 ln exp( τ − 1 pcl U T ˜ z phy i U ˜ z beha i ) P N j = i exp( τ − 1 pcl U T ˜ z phy i U ˜ z beha j ) − 1 N N X i =1 ln exp( τ − 1 pcl V T ˜ z phy i V ˜ z beha i ) P N j = i exp( τ − 1 pcl V T ˜ z phy j V ˜ z beha i ) (19) where τ pcl is a temperature parameter that scales the logits. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 8 E. Hierar chical Semantic Compr ession and Distribution Pr e- diction After amplifying semantic-level co-occurrences, we con- catenate the prototype-enhanced physiological and behavioral features to obtain the fused representation ˜ z fuse ∈ R 2 K × D : ˜ z fuse = Concat ([ ˜ z phy , ˜ z beha ]) (20) W e then introduce a Hierarchical Semantic Compression (HSC) strategy that iterati vely abstracts high-le vel affecti ve concepts from the fine-grained prototype space. Specifically , we stack L compression blocks, each containing a prototype abstraction layer follo wed by a multi-head self-attention layer (MHSA). Let H (0) = z fuse ∈ R 2 K × D denote the initial state. The update for the l -th layer ( 1 ≤ l ≤ L ) is: ˜ H ( l ) = Hopfield ( H ( l − 1) , W ( l ) lookup , W ( l ) content , β ) + H ( l − 1) (21) H ( l ) = MHSA ( ˜ H ( l ) ) + ˜ H ( l ) (22) where ˜ H ( l ) is the hidden state of the l -th layer . At each layer , the learnable content matrix W ( l ) content ∈ R M l × D serves as a set of semantic slots with v ariable capacity M l . Specifically , the slots of the first layer W (1) content are initialized from the prototype memory bank ( W memory ∈ R M × D ) (Section III-D1 ), and the slot capacity M l is progressi vely reduced across layers. This design gradually compresses fine-grained prototypes into highly abstract semantic representations whose structure aligns with the target emotion categories. The output of the final block is mapped into the emotion probability space to obtain the predicted distribution ˆ y i ∈ R E , where E is the number of emotion classes. W e use KL div ergence as the task loss to measure the discrepancy between the prediction ˆ y i and the ground truth distribution y i : L task = 1 N N X i =1 D KL ( y i ∥ ˆ y i ) (23) The ov erall training objective combines the three loss terms: L total = L task + L PRD + L SemLOOB (24) where L task aligns predictions with ground truth emotion distribution, L PRD enforces cross-modal semantic structural consistency , and L SemLOOB promotes cross-modal semantic co-occurrence consistency . I V . E X P E R I M E N T S A. Datasets T o the best of our knowledge, only two public multimodal datasets contain both physiological and behavioral signals av ailable for emotion distribution learning: DMER [ 72 ] and WESAD [ 73 ]. W e ev aluate our MPCL framework on both. 1) DMER: This dataset contains multimodal recording from 80 participants across four modalities: EEG, GSR, PPG, and frontal facial videos. Each participant watched 32 video clips and subsequently rated their emotional states using the 10-item short form of the Positive and Neg ativ e Af fect Sched- ule (P AN AS) [ 74 ]. The P AN AS scale includes fiv e positiv e emotions (inspired, alert, excited, enthusiastic, determined) and five negati ve emotions (afraid, upset, nervous, scared, distressed), each rated on a 5-point Likert scale from 1 (very slightly or not at all) to 5 (extremely). The raw scores are normalized to form emotion distributions, which serve as the ground-truth emotion labels. Due to incomplete physiological recordings for 7 participants, our experiments are conducted on the remaining 73 subjects. 2) WESAD: This dataset includes multimodal signals col- lected from 17 participants using wrist- and chest-worn sen- sors. The recorded modalities include ECG, EMG, ED A, and 3-axis accelerometer (A CC). Participants underwent stimulus-based inductions designed to elicit four emotional states: neutral, stress, amusement, and meditation. After each induction, the P AN AS scale was used to obtain ground-truth emotion labels. Data from two subjects were excluded because of sensor failures, lea ving 15 participants for our e xperiments. B. Data Pr ocessing and F eatur e Extr action T o ensure a fair comparison, we follow the preprocessing and feature extraction protocols described in the original dataset publications. 1) DMER: EEG signals were filtered using a 1–50Hz band- pass filter and a 50Hz notch filter to remov e noise. Artifact components were subsequently eliminated using independent component analysis (ICA) [ 75 ]. Dif ferential entropy (DE) fea- tures were extracted via Short-T ime Fourier T ransform (STFT) ov er five frequency bands: δ (1–3Hz), θ (4–7Hz), α (8–13Hz), β (14–30Hz), and γ (31–50Hz). GSR signals were band-pass filtered with a lower cutoff of 0.01Hz and an upper cutoff of 49Hz, while PPG signals were filtered in the 0.01–1.9Hz range. For facial video recordings, Local Binary Patterns on Three-Orthogonal Planes (LBP-TOP) features were computed on each 1-second video segment. In total, we obtained 90 EEG features, 28 GSR features, 27 PPG features, and 768 video features per sample. 2) WESAD: ECG signals were processed with a peak- detection algorithm to identify heartbeats, from which heart rate (HR) and heart rate variability (HR V) features were de- riv ed. For ED A, we computed the mean and standard deviation of the signal, then decomposed it into skin conductance le vel (SCL) and skin conductance response (SCR) components; the number of SCR peaks and their mean amplitude were recorded. For EMG, the mean, standard de viation, range, inte- gral, median, peak frequency and po wer spectral density (PSD) of the signal were computed. Additionally , the number of peaks and the mean, standard deviation, sum, and normalized sum of peak amplitudes were extracted. For A CC data, the mean, standard deviation, and absolute integral per axis were computed, as well as the magnitude (and sum) across all ax es, together with the peak frequency for each axis. Overall, each sample yields 73 ECG features, 4 EDA features, 14 EMG features, and 12 A CC features. C. Evaluation Metrics and Pr otocols T o ensure comparability with previous emotion distribu- tion learning research [ 25 ], [ 26 ], we ev aluate MPCL using six standard metrics. These include four distance measures: JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 9 T ABLE I Q UA N TI TA T IV E CO M PAR I S O N W I TH BA S EL I N E M E T HO D S O N TH E DM E R A N D W E S AD DAT A S ET S UN D E R T H E S U BJ E C T - D EP E N D EN T SE T T I NG . Dataset Mesure LDL MER Single-modal EDL MMER Multimodal EDL PT -SVM [ 76 ] AA-KNN [ 76 ] SA-CPNN [ 77 ] MAET [ 78 ] LDL-LRR [ 79 ] TLR-DL [ 80 ] CAD [ 81 ] CARA T [ 33 ] EmotionDict [ 25 ] HeLo [ 26 ] MPCL DMER Chebyshev ( ↓ ) 0.0851 (7) 0.0949 (10) 0.0917 (8) 0.0522 (3) 0.0936 (9) 0.0847 (6) 0.1017 (11) 0.0752 (4) 0.0753 (5) 0.0446 (2) 0.0346 (1) Clark ( ↓ ) 0.5787 (6) 0.6649 (10) 0.6333 (8) 0.3762 (3) 0.6529 (9) 0.5380 (4) 0.7517 (11) 0.5951 (7) 0.5463 (5) 0.3256 (2) 0.2369 (1) Canberra ( ↓ ) 1.5294 (7) 1.2357 (3) 1.8092 (9) 0.9875 (3) 1.8224 (10) 1.3271 (5) 1.9415 (11) 1.5965 (8) 1.4771 (6) 0.8664 (2) 0.6068 (1) KL ( ↓ ) 0.0837 (6) 0.1409 (10) 0.1048 (8) 0.0288 (2) 0.0644 (4) 0.0925 (7) 0.1460 (11) 0.1137 (9) 0.0766 (5) 0.0323 (3) 0.0177 (1) Cosine ( ↑ ) 0.9237 (8) 0.9315 (6) 0.9058 (9) 0.9688 (3) 0.9016 (10) 0.9339 (4) 0.8923 (11) 0.9332 (5) 0.9313 (7) 0.9714 (2) 0.9874 (1) Intersection ( ↑ ) 0.8417 (8) 0.8425 (7) 0.8150 (9) 0.9113 (3) 0.8136 (10) 0.8537 (5) 0.8077 (11) 0.8474 (6) 0.8492 (5) 0.9128 (2) 0.9427 (1) A verage Rank ( ↓ ) 7.00 (7) 7.67 (8) 8.50 (9) 2.83 (3) 8.67 (10) 5.17 (4) 11.00 (11) 6.50 (6) 5.50 (5) 2.17 (2) 1.00 (1) WESAD Chebyshev ( ↓ ) 0.0515 (8) 0.0346 (4) 0.0998 (11) 0.0347 (5) 0.0357 (7) 0.0622 (10) 0.0569 (9) 0.0354 (6) 0.0090 (3) 0.0073 (2) 0.0046 (1) Clark ( ↓ ) 0.3940 (8) 0.2779 (4) 0.7285 (11) 0.3503 (7) 0.2822 (6) 0.5381 (10) 0.4618 (9) 0.2812 (5) 0.0733 (3) 0.0653 (2) 0.0417 (1) Canberra ( ↓ ) 1.0249 (8) 0.7381 (4) 2.0746 (11) 0.9100 (7) 0.7466 (6) 1.3586 (10) 1.2199 (9) 0.7430 (5) 0.1876 (3) 0.1614 (2) 0.1026 (1) KL ( ↓ ) 0.0320 (8) 0.0243 (5) 0.1226 (10) 0.0251 (6) 0.0273 (7) 0.2051 (11) 0.0440 (9) 0.0210 (4) 0.0017 (3) 0.0010 (2) 0.0003 (1) Cosine ( ↑ ) 0.9728 (8) 0.9793 (7) 0.8918 (11) 0.9867 (4) 0.9821 (6) 0.9541 (10) 0.9624 (9) 0.9824 (5) 0.9985 (3) 0.9992 (2) 0.9998 (1) Intersection ( ↑ ) 0.9024 (8) 0.9297 (4) 0.7896 (11) 0.9213 (7) 0.9292 (6) 0.8746 (10) 0.8812 (9) 0.9296 (5) 0.9820 (3) 0.9905 (2) 0.9974 (1) A verage Rank ( ↓ ) 8.00 (8) 4.67 (4) 10.83 (11) 6.00 (6) 6.33 (7) 10.17 (10) 9.00 (9) 5.00 (5) 3.00 (3) 2.00 (2) 1.00 (1) Arrows ↓ and ↑ indicate “lower is better” and “higher is better”, respecti vely . Parenthesized values denote per-metric rankings and the a verage rank. The best result is highlighted in bold. Chebyshev ( ↓ ), Clark ( ↓ ), Canberra ( ↓ ), and K ullback-Leibler (KL) div ergence ( ↓ ), and two similarity coefficients: Cosine ( ↑ ) and Intersection ( ↑ ). An A verage Rank is also reported to summarize ov erall performance across all six metrics. T o comprehensively ev aluate our model on the DMER and WESAD datasets, we adopt both subject-dependent and subject-independent settings. In the subject-dependent setting, each subject’ s data are randomly split into 80% for training and 20% for testing, and the final performance is averaged over all subjects. F or the subject-independent ev aluation, we employ a Leav e-One-Subject-Out (LOSO) scheme, where one subject is held out for testing in each fold while the remaining subjects form the training set. The reported results are averaged over all folds. D. Implementation Details Our method is implemented in PyT orch and trained on an NVIDIA GeForce R TX 4090 GPU. W e use the Adam optimizer with a learning rate of 0.001, a batch size of 128, and train for 400 epochs. For the DMER dataset, EEG is treated as the primary modality , with GSR and PPG as auxiliary physiological modalities; f acial videos constitute the behavioral signal. For the WESAD dataset, ECG serves as the primary modality , while ED A and EMG are auxiliary modalities; ACC data is used as the beha vioral signal. In the MSAF module, embedding dimension D = 128 , and the scaling set B = { β low , β mid , β high } is { 8 , 14 . 3 , 22 } . For the prototype memory bank, the number of prototypes M = 100 , and the temperature parameter τ dist = 0 . 07 . For the PCL module, the scaling β = 14 . 3 , and the inv erse temperature parameter τ − 1 pcl = 50 . In the HSC module, the number of compression blocks L = 10 , and the capacity M l of the content matrix is progressiv ely reduced from 100 in the first layer to the number of emotion classes in the last layer . E. Experimental Results 1) Baselines: T o ev aluate the effecti veness of MPCL, we compare it against a comprehensive set of representativ e baselines on both the DMER and WESAD datasets. These baselines span five categories: • Classical label distrib ution learning (LDL): PT -SVM [ 76 ], AA-KNN [ 76 ], SA-CPNN [ 77 ]. • Multimodal emotion recognition (MER): MAET [ 78 ]. • Single-modal emotion distrib ution learning (single-modal EDL): LDL-LRR [ 79 ], TLRLDL [ 80 ], CAD [ 81 ]. • Multimodal multi-label emotion recognition (MMER): CARA T [ 33 ]. • Recent multimodal EDL (Multimodal EDL): Emotion- Dict [ 25 ], Helo [ 26 ]). As MER and MMER methods are originally designed for categorical classification, we apply a softmax function to their output layer to generate probability distrib utions. 2) Subject-dependent Experiments: T able I reports the quantitativ e results under the subject-dependent setting. MPCL consistently outperforms the all baselines across all six ev al- uation metrics on both datasets. In general, deep-learning- based approaches (MER, single-modal LDL, MMLER, and multimodal EDL) surpass classical LDL methods. W e further visualize the ground-truth and predicted emotion distributions for selected samples from the DMER dataset (Fig. 5 ). The emotion distrib utions exhibit clear semantic de- pendencies, reflected in the co-occurrence of emotions sharing the same valence. For instance, the first row shows simulta- neous acti vation of positi ve emotions (including inspired, ex- cited, enthusiastic, determined), while the second row presents a cluster of negati ve emotions (afraid, upset, nerv ous, scared). Most baselines fail to capture these intrinsic correlations and produce predictions with noticeable fluctuations. In contrast, MPCL effecti vely models the distribution patterns of co- occurring emotions, yielding predictions that align closely with the ground truth. 3) Subject-independent Experiments: T able II presents the results under the more challenging subject-independent set- ting, where inter-subject variability—especially in EEG sig- nals—poses significant difficulties. MPCL again achie ves the best performance on both datasets, demonstrating its ability to extract stable emotion-related features across different in- dividuals. Overall, by enhancing semantic-le vel co-occurrence among emotion prototypes, MPCL effecti vely captures the global topological structure of emotions. Both quantitative and qual- JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 10 Fig. 5. Comparison of emotion distribution predictions between MPCL and state-of-the-art baselines on tw o representative samples (Subject 26). GT denotes the ground-truth distribution. Emotion indices 1–10 correspond to: inspired, alert, excited, enthusiastic, determined, afraid, upset, nervous, scared, and distressed. T ABLE II Q UA N TI TA T IV E CO M PAR I S O N W I TH BA S EL I N E M E T HO D S O N TH E DM E R A N D W E S AD DAT A S ET S U N D E R T H E S U BJ E C T - I ND E P E ND E N T S E TT I N G . Dataset Measure LDL MER Single-modal EDL MMER Multimodal EDL PT -SVM [ 76 ] AA-KNN [ 76 ] SA-CPNN [ 77 ] MAET [ 78 ] LDL-LRR [ 79 ] TLR-DL [ 80 ] CAD [ 81 ] CARA T [ 33 ] EmotionDict [ 25 ] HeLo [ 26 ] MPCL DMER Chebyshev ( ↓ ) 0.1462 (11) 0.1070 (10) 0.0928 (4) 0.0939 (5) 0.1012 (8) 0.0964 (7) 0.0925 (3) 0.1023 (9) 0.0945 (6) 0.0882 (2) 0.0763 (1) Clark ( ↓ ) 1.2877 (11) 0.6860 (9) 0.6440 (4) 0.6605 (5) 0.6856 (8) 0.6702 (7) 0.6379 (3) 0.6909 (10) 0.6676 (6) 0.6289 (2) 0.5932 (1) Canberra ( ↓ ) 2.0459 (11) 1.8308 (7) 1.8542 (8) 1.7863 (3) 1.9071 (9) 1.8244 (6) 1.8104 (5) 1.9161 (10) 1.8092 (4) 1.7603 (2) 1.5843 (1) KL ( ↓ ) 0.5528 (11) 0.1227 (9) 0.1089 (5) 0.1088 (4) 0.1222 (8) 0.1142 (7) 0.1076 (3) 0.1245 (10) 0.1104 (6) 0.1027 (2) 0.1009 (1) Cosine ( ↑ ) 0.8295 (11) 0.8843 (10) 0.9022 (4) 0.9016 (5) 0.8917 (8) 0.8964 (7) 0.9036 (3) 0.8899 (9) 0.9001 (6) 0.9148 (2) 0.9273 (1) Intersection ( ↑ ) 0.7762 (11) 0.8050 (8) 0.8102 (6) 0.8147 (3) 0.8037 (9) 0.8087 (7) 0.8122 (4) 0.8026 (10) 0.8119 (5) 0.8194 (2) 0.8496 (1) A verage Rank ( ↓ ) 11.00 (11) 8.83 (9) 5.17 (5) 4.17 (4) 8.33 (8) 6.83 (7) 3.50 (3) 9.67 (10) 5.50 (6) 2.00 (2) 1.00 (1) WESAD Chebyshev ( ↓ ) 0.0471 (7) 0.0500 (9) 0.0894 (11) 0.0516 (10) 0.0466 (6) 0.0441 (4) 0.0481 (8) 0.0454 (5) 0.0421 (3) 0.0403 (2) 0.0314 (1) Clark ( ↓ ) 0.4506 (8) 0.4516 (10) 0.6394 (11) 0.4514 (9) 0.4471 (6) 0.4145 (4) 0.4488 (7) 0.4270 (5) 0.3631 (3) 0.3455 (2) 0.2973 (1) Canberra ( ↓ ) 1.1928 (10) 1.1762 (7) 1.7384 (11) 1.1666 (6) 1.1817 (8) 1.0746 (4) 1.1647 (5) 1.1874 (9) 0.9530 (3) 0.9329 (2) 0.8685 (1) KL ( ↓ ) 0.0347 (6) 0.0423 (9) 0.0944 (11) 0.0445 (10) 0.0343 (4) 0.0372 (8) 0.0366 (7) 0.0345 (5) 0.0282 (2) 0.0283 (3) 0.0228 (1) Cosine ( ↑ ) 0.9727 (6) 0.9663 (10) 0.9154 (11) 0.9678 (9) 0.9731 (4) 0.9695 (8) 0.9711 (7) 0.9731 (4) 0.9773 (3) 0.9790 (2) 0.9857 (1) Intersection ( ↑ ) 0.8935 (7) 0.8933 (9) 0.8254 (11) 0.8967 (4) 0.8945 (5) 0.8917 (10) 0.8935 (8) 0.8944 (6) 0.9126 (3) 0.9154 (2) 0.9371 (1) A verage Rank ( ↓ ) 7.33 (8) 9.00 (10) 11.00 (11) 8.00 (9) 5.50 (4) 6.33 (6) 7.00 (7) 5.67 (5) 2.83 (3) 2.17 (2) 1.00 (1) Arrows ↓ and ↑ indicate “lower is better” and “higher is better”, respecti vely . Parenthesized values denote per-metric rankings and the a verage rank. The best result is highlighted in bold. itativ e experiments confirm the superior predictive capability of our method. F . Ablation Study 1) Ablation on Main Components: T o validate the effec- tiv eness of each core component in the MPCL framework, we conducted ablation studies on four key modules: multi- scale associativ e fusion (MSAF), prototype relation distillation (PRD), prototypical co-occurrence learning (PCL), and hierar - chical semantic compression (HSC). T ables III and IV summa- rize the results (without each component) on DMER and WE- SAD under both subject-dependent and subject-independent settings. The results indicate that each component con- tributes significantly to overall performance. Specifically , PRD and PCL are the most influential modules—PRD enforces cross-modal prototype-topology alignment, while PCL am- plifies semantic-lev el co-occurrence among prototypes. HSC follows as a strong secondary contributor , progressiv ely ab- stracting fine-grained prototypes into compact emotion rep- resentations. Although MSAF exhibits a relativ ely moderate impact, it remains essential for effecti vely fusing multimodal physiological data. 2) Ablation on Modalities: W e further ev aluate the con- tribution of each individual modality through ablation studies (T ables V and VI ). All modalities consistently improve perfor- mance under both subject-dependent and subject-independent settings. For physiological signals, the primary modality (EEG on DMER, ECG on WESAD) contributes more substantially than the auxiliary ones (PPG/GSR on DMER, EMG/ED A on WESAD). The behavioral modality also yields significant gains, confirming that the integration of multimodal data is JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 11 T ABLE III A B LAT IO N S T U DY O F D I FF E RE N T C O M P ON E N TS O N T H E D M ER DA TA SE T . “ w/o ” I N D IC ATE S T H E R E M OV A L O F T H E C O R RE S P ON D I N G M O DU L E . Settings Measure w/o w/o w/o w/o MSAF PRD PCL HSC MPCL Subject- Dependent Chebyshev ( ↓ ) 0.0385 0.0425 0.0396 0.0388 0.0346 Clark ( ↓ ) 0.2643 0.2952 0.2914 0.2704 0.2369 Canberra ( ↓ ) 0.6652 0.7759 0.7466 0.6861 0.6068 KL ( ↓ ) 0.0258 0.0332 0.0317 0.0284 0.0177 Cosine ( ↑ ) 0.9766 0.9714 0.9702 0.9743 0.9874 Intersection ( ↑ ) 0.9326 0.9186 0.9221 0.9297 0.9427 Subject- Independent Chebyshev ( ↓ ) 0.0804 0.0885 0.0871 0.0824 0.0763 Clark ( ↓ ) 0.6253 0.6843 0.6759 0.6381 0.5932 Canberra ( ↓ ) 1.6681 1.7925 1.7638 1.6952 1.5843 KL ( ↓ ) 0.1138 0.1342 0.1296 0.1173 0.1009 Cosine ( ↑ ) 0.9145 0.8924 0.8967 0.9085 0.9273 Intersection ( ↑ ) 0.8362 0.8125 0.8168 0.8294 0.8496 T ABLE IV A B LAT IO N S T U DY O F D I FF E RE N T C O M P ON E N TS O N W E SA D DA TA SE T . “ w/o ” I N D IC ATE S T H E R E M OV A L O F T H E C O R RE S P ON D I N G M O DU L E . Settings Measure w/o w/o w/o w/o MSAF PRD PCL HSC MPCL Subject- Dependent Chebyshev ( ↓ ) 0.0062 0.0081 0.0083 0.0068 0.0046 Clark ( ↓ ) 0.0525 0.0692 0.0674 0.0563 0.0417 Canberra ( ↓ ) 0.1263 0.1682 0.1625 0.1342 0.1026 KL ( ↓ ) 0.0007 0.0015 0.0014 0.0009 0.0003 Cosine ( ↑ ) 0.9984 0.9961 0.9954 0.9980 0.9998 Intersection ( ↑ ) 0.9937 0.9842 0.9865 0.9912 0.9974 Subject- Independent Chebyshev ( ↓ ) 0.0382 0.0486 0.0475 0.0412 0.0314 Clark ( ↓ ) 0.3247 0.3642 0.3598 0.3325 0.2973 Canberra ( ↓ ) 0.9356 1.0542 1.0268 0.9584 0.8685 KL ( ↓ ) 0.0292 0.0385 0.0372 0.0315 0.0228 Cosine ( ↑ ) 0.9783 0.9654 0.9682 0.9745 0.9857 Intersection ( ↑ ) 0.9211 0.8954 0.9012 0.9156 0.9371 crucial for robust emotion distribution learning. 3) Comparison with Alternative Designs: T o demonstrate the advantages of the Hopfield-based modules in MPCL, we compare them against standard alternati ve designs. The following configurations are e valuated: • MSAF vs. T ransformer cr oss-attention Fusion: MSAF is replaced with standard T ransformer cross-attention (EEG/ECG as Query , auxiliary physiological signals as Ke y/V alue). • Prototype-le vel vs. Feature-le vel Co-occurrence: The prototype-enhanced representations ˜ z phy and ˜ z beha in PCL are replaced with raw features z phy and z beha . This modification degrades prototype-le vel co-occurrence to feature-lev el co-occurrence. • Memory-guided Retrieval vs. InfoNCE Alignment: The memory-retrie val mechanism is remov ed and the SemLOOB loss is replaced by InfoNCE loss (adapted from CLIP), i.e., directly performing cross-modal align- ment on the prototype-enhanced representations ˜ z phy and ˜ z beha . • HSC vs. T ransf ormer Encoder: HSC is replaced with standard T ransformer encoder layers while keeping the same number of layers L . Quantitativ e results (T able VII ) show the follo wing: • MSAF outperforms T ransformer cross-attention fusion, benefiting from its energy-minimization formulation and multi-scale associative memory retrie v al. Unlik e standard T ABLE V A B LAT IO N S T U DY O F D I FF E RE N T M O DA L I TI E S O N DM E R . “ w/o ” M E A NS T H E R E MOVAL O F T HE C OR R E S PO N D I NG M OD AL I T Y F RO M T H E I N P U T . Settings Measure w/o w/o w/o w/o PPG GSR EEG Video MPCL Subject- Dependent Chebyshev ( ↓ ) 0.0362 0.0371 0.0412 0.0465 0.0346 Clark ( ↓ ) 0.2485 0.2533 0.2847 0.3105 0.2369 Canberra ( ↓ ) 0.6250 0.6384 0.7259 0.8214 0.6068 KL ( ↓ ) 0.0198 0.0215 0.0296 0.0368 0.0177 Cosine ( ↑ ) 0.9825 0.9804 0.9735 0.9668 0.9874 Intersection ( ↑ ) 0.9385 0.9356 0.9242 0.9135 0.9427 Subject- Independent Chebyshev ( ↓ ) 0.0782 0.0805 0.0894 0.0965 0.0763 Clark ( ↓ ) 0.6085 0.6174 0.6628 0.7012 0.5932 Canberra ( ↓ ) 1.6150 1.6423 1.7456 1.8845 1.5843 KL ( ↓ ) 0.1065 0.1102 0.1287 0.1453 0.1009 Cosine ( ↑ ) 0.9215 0.9184 0.9015 0.8842 0.9273 Intersection ( ↑ ) 0.8425 0.8386 0.8205 0.8043 0.8496 T ABLE VI A B LAT IO N S T U DY O F D I FF E RE N T M O DA L I TI E S O N WE S A D . “ w/o ” ME A N S T H E R E MOVAL O F T HE C OR R E S PO N D I NG M OD AL I T Y F RO M T H E I N P U T . Settings Measure w/o w/o w/o w/o EMG ED A ECG ACC MPCL Subject- Dependent Chebyshev ( ↓ ) 0.0052 0.0055 0.0075 0.0092 0.0046 Clark ( ↓ ) 0.0458 0.0472 0.0585 0.0734 0.0417 Canberra ( ↓ ) 0.1105 0.1142 0.1428 0.1856 0.1026 KL ( ↓ ) 0.0004 0.0005 0.0011 0.0019 0.0003 Cosine ( ↑ ) 0.9992 0.9990 0.9972 0.9954 0.9998 Intersection ( ↑ ) 0.9962 0.9958 0.9885 0.9812 0.9974 Subject- Independent Chebyshev ( ↓ ) 0.0352 0.0361 0.0425 0.0515 0.0314 Clark ( ↓ ) 0.3105 0.3142 0.3426 0.3758 0.2973 Canberra ( ↓ ) 0.8950 0.9025 0.9854 1.0865 0.8685 KL ( ↓ ) 0.0256 0.0268 0.0345 0.0415 0.0228 Cosine ( ↑ ) 0.9815 0.9802 0.9715 0.9604 0.9857 Intersection ( ↑ ) 0.9285 0.9264 0.9085 0.8872 0.9371 attention mechanisms, Hopfield networks allow fle xible tuning of the in verse temperature β , since the fix ed- point dynamics is not strictly coupled to the dimension of the associative space d k . Consequently , this flexibil- ity enables MSAF to effecti vely capture complementary information across heterogeneous signals at varying gran- ularities. • Prototype-le vel co-occurrence surpasses feature-lev el co- occurrence, confirming that prototypes ef fectiv ely disen- tangle semantics and suppress noise, and amplifying co- occurrence within this space ef fectiv ely captures more meaningful emotion representations. • Memory-guided retrie val yields better results than global contrastiv e alignment, indicating that the Hopfield re- triev al process effecti vely amplifies features exhibiting semantic consistency between input and stored patterns while suppressing spurious correlations, thereby re vealing latent structural associations among emotions at a seman- tic le vel. • HSC is more effecti ve than a plain T ransformer encoder in simulating the cogniti ve progression from concrete signals to abstract affecti ve concepts. Its bottom-up com- pression strate gy—progressiv ely reducing semantic-slot capacity ( M l ) across layers—forces the model to con- dense fine-grained prototypes into highly abstract repre- sentations, thereby enabling accurate emotion distribution prediction. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 12 T ABLE VII C O MPA R IS O N W I T H A LTE R NATI V E D E S I GN S O N DM E R A N D W E S A D. “ w/ ” IN D I C A T ES T HAT T H E C O RR E S P ON D I N G M P CL M OD U L E I S R E P LA CE D BY T H E S P EC I FI ED A L T E RN A T I VE : C R OS S A T T N ( R EP L AC I N G M S AF ) , F E A T - C O ( RE P L AC I NG PR OT OT YP E - L EV E L C O - O CC U R R EN C E ), I NF O N C E ( R E P LA CI N G M E MO RY - G U ID E D R E T RI E V A L ), A ND T RA N S E N C ( R E P L AC IN G HS C ) . Protocol Measure DMER Dataset WESAD Dataset w/ CrossAttn w/ Feat-Co w/ InfoNCE w/ T ransEnc MPCL w/ CrossAttn w/ Feat-Co w/ InfoNCE w/ TransEnc MPCL Subject- Dependent Chebyshev ( ↓ ) 0.0363 0.0382 0.0374 0.0368 0.0346 0.0054 0.0067 0.0064 0.0059 0.0046 Clark ( ↓ ) 0.2497 0.2743 0.2648 0.2541 0.2369 0.0483 0.0556 0.0537 0.0498 0.0417 Canberra ( ↓ ) 0.6358 0.7012 0.6784 0.6486 0.6068 0.1147 0.1384 0.1319 0.1217 0.1026 KL ( ↓ ) 0.0213 0.0287 0.0246 0.0238 0.0177 0.0006 0.0011 0.0009 0.0007 0.0003 Cosine ( ↑ ) 0.9823 0.9748 0.9782 0.9791 0.9874 0.9989 0.9972 0.9976 0.9984 0.9998 Intersection ( ↑ ) 0.9367 0.9284 0.9316 0.9352 0.9427 0.9961 0.9918 0.9924 0.9953 0.9974 Subject- Independent Chebyshev ( ↓ ) 0.0794 0.0846 0.0817 0.0803 0.0763 0.0346 0.0414 0.0378 0.0367 0.0314 Clark ( ↓ ) 0.6124 0.6542 0.6389 0.6217 0.5932 0.3118 0.3456 0.3294 0.3207 0.2973 Canberra ( ↓ ) 1.6356 1.7248 1.6892 1.6583 1.5843 0.8943 0.9654 0.9287 0.9248 0.8685 KL ( ↓ ) 0.1087 0.1243 0.1164 0.1126 0.1009 0.0264 0.0326 0.0298 0.0282 0.0228 Cosine ( ↑ ) 0.9214 0.9056 0.9123 0.9158 0.9273 0.9813 0.9718 0.9746 0.9782 0.9857 Intersection ( ↑ ) 0.8423 0.8264 0.8327 0.8356 0.8496 0.9294 0.9153 0.9196 0.9224 0.9371 T ABLE VIII A B LAT IO N S T U DY O F D I FF E RE N T S C A L IN G S T R A T E GI E S ( β ) I N TH E MS A F M O D U LE O N T HE D ME R DA TA SE T U N D E R B OT H S U B JE C T -D E P EN D E N T A N D S U BJ E C T - I ND E P E ND E N T P ROT O C OL S . Configuration Subject-Dependent Subject-Independent Chebyshev ( ↓ ) Clark ( ↓ ) Canberra ( ↓ ) KL ( ↓ ) Cosine ( ↑ ) Intersection ( ↑ ) Chebyshev ( ↓ ) Clark ( ↓ ) Canberra ( ↓ ) KL ( ↓ ) Cosine ( ↑ ) Intersection ( ↑ ) β low 0.0368 0.2548 0.6477 0.0234 0.9782 0.9362 0.0794 0.6153 1.6458 0.1106 0.9167 0.8384 β mid 0.0364 0.2519 0.6423 0.0227 0.9793 0.9374 0.0787 0.6121 1.6376 0.1092 0.9182 0.8403 β high 0.0369 0.2576 0.6546 0.0243 0.9776 0.9358 0.0799 0.6184 1.6521 0.1114 0.9156 0.8372 { β low , β mid } 0.0353 0.2447 0.6245 0.0204 0.9824 0.9403 0.0774 0.6023 1.6102 0.1051 0.9221 0.8453 { β mid , β high } 0.0357 0.2468 0.6281 0.0209 0.9817 0.9392 0.0779 0.6051 1.6149 0.1062 0.9213 0.8441 { β low , β high } 0.0359 0.2492 0.6318 0.0216 0.9804 0.9383 0.0783 0.6082 1.6197 0.1073 0.9201 0.8426 B = { β low , β mid , β high } 0.0346 0.2369 0.6068 0.0177 0.9874 0.9427 0.0763 0.5932 1.5843 0.1009 0.9273 0.8496 Canberra ( ↓ ) K L ( ↓ ) Cosine ( ↑ ) Intersection ( ↑ ) Chebyshev ( ↓ ) Clark ( ↓ ) 10 50 100 500 1000 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 10 50 100 500 1000 0.2 0.3 0.4 0.5 0.6 0.7 10 50 100 500 1000 0.5 0.7 0.9 1.1 1.3 1.5 1.7 1.9 Subject - Dependent Subject - Independent 10 50 100 500 1000 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 10 50 100 500 1000 0.88 0.9 0.92 0.94 0.96 0.98 1 10 50 100 500 1000 0.8 0.82 0.84 0.86 0.88 0.9 0.92 0.94 Fig. 6. Ablation study of the number of prototypes M on the DMER dataset under subject-dependent and subject-independent settings. 4) Hyperparameter Analysis: W e ablate key hyperparame- ters of MPCL on the DMER dataset. • Scales in MSAF: T able VIII shows that the three-scale setting B = { β low , β mid , β high } performs best. Smaller β values promote global commonality aggregation, while larger ones emphasize local similarity . • Number of prototypes M : Fig. 6 indicates optimal perfor- mance at M = 100 . T oo few prototypes cannot capture rich semantics, whereas too many lead to redundancy and sparsity . • Parameters in PCL: Fig. 7 sho ws the optimal combi- nation β = 14 . 3 1 and τ − 1 pcl = 50 , among vary values 1 The v alue 14.3 is the reciprocal of τ = 0 . 07 , which is the commonly used parameter value in contrastive learning [ 82 ]. Canberra ( ↓ ) K L ( ↓ ) Cosine ( ↑ ) Intersection ( ↑ ) Chebyshev ( ↓ ) Clark ( ↓ ) 14.3 30 50 70 0.034 0.0345 0.035 0.0355 0.036 0.0365 0.037 0.0375 0.038 0.0385 β = 22 β = 8 β = 14.3 14.3 30 50 70 0.235 0.24 0.245 0.25 0.255 0.26 14.3 30 50 70 0.605 0.615 0.625 0.635 0.645 0.655 0.665 14.3 30 50 70 0.017 0.018 0.019 0.02 0.021 0.022 0.023 0.024 14.3 30 50 70 0.98 0.982 0.984 0.986 0.988 0.99 14.3 30 50 70 0.93 0.932 0.934 0.936 0.938 0.94 0.942 0.944 β = 22 β = 8 β = 14.3 β = 22 β = 8 β = 14.3 β = 22 β = 8 β = 14.3 β = 22 β = 8 β = 14.3 β = 22 β = 8 β = 14.3 Fig. 7. Ablation study of the PCL module on the DMER dataset over different v alues of β and τ − 1 pcl . The horizontal axis shows τ − 1 pcl ; distinct curves correspond to different β values. β ∈ (8 , 14 . 3 , 22) and τ − 1 pcl ∈ (14 . 3 , 30 , 50 , 70) . • Number of compression blocks L : Fig. 8 demonstrates that L = 10 yields the best trade-off between ab- straction capacity and computational cost. Fe wer layers under-abstract features, while more layers of fer diminish- ing returns. G. V isualization Analysis T o examine the ability of MPCL in capturing complex co- occurrence relationships among emotions, we compute the Pearson correlation coef ficients between predicted emotion distributions across all test samples and visualize the resulting JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 13 Canberra ( ↓ ) K L ( ↓ ) Cosine ( ↑ ) Intersection ( ↑ ) Chebyshev ( ↓ ) Clark ( ↓ ) 1 5 10 15 20 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 1 5 10 15 20 0.02 0.12 0.22 0.32 0.42 0.52 0.62 0.72 1 5 10 15 20 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 1 5 10 15 20 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 1 5 10 15 20 0.9 0.92 0.94 0.96 0.98 1 1 5 10 15 20 0.8 0.82 0.84 0.86 0.88 0.9 0.92 0.94 0.96 Subject - Dependent Subject - Independent Fig. 8. Ablation study of the number of compression blocks L in the HSC module on DMER under subject-dependent and subject-independent setting. Ground T ruth Helo MPCL Subject 2 Subject 14 Fig. 9. V isualization of emotion-label correlation matrices. Red intensity indicates the strength of correlation. label-correlation matrix. Fig. 9 presents a comparison for two subjects. Compared to the HeLo method [ 26 ], the correlation matrix produced by MPCL aligns more closely with the ground truth (GT) in both pattern structure and intensity distribu- tion. HeLo primarily models label dependencies by intro- ducing learnable label embeddings and utilizing true label correlations as supervision signals. In contrast, MPCL le ver- ages a Hopfield memory retriev al mechanism to amplify co-occurrence patterns among emotion prototypes, thereby learning semantic structural relations among emotions without explicit label-correlation supervision. The results show that MPCL effecti vely recovers the intrinsic af fectiv e structure, highlighting its advantage in emotion distribution learning. V . C O N C L U S I O N In this paper , we introduced the memory-guided proto- typical co-occurrence learning (MPCL) framework, a no vel approach that lev erages associative memory mechanisms to mine prototype co-occurrence patterns and semantic structural relationships in mixed-emotion recognition. By employing associativ e memory networks, MPCL achieves multi-scale fusion of multimodal physiological data. T o capture cross- modal semantic associations, we construct emotion prototype memory banks from both physiological and behavioral sig- nals, producing semantically enriched representations through prototype-weighted reconstruction. Inspired by the interplay between human perception and memory retriev al, we de- sign a memory retrie val mechanism that reinforces frequently co-occurring emotion prototypes, thereby modeling prototype co-occurrence at a semantic lev el. Finally , a hierarchical se- mantic compression module further refines the af fecti ve repre- sentations, enabling accurate emotion-distribution prediction. Extensiv e subject-dependent and subject-independent experi- ments on two public datasets (DMER and WESAD) demon- strate that MPCL consistently outperforms state-of-the-art baselines in mixed-emotion distribution learning. R E F E R E N C E S [1] W . W ang, F . Qi, D. P . Wipf, C. Cai, T . Y u, Y . Li, Y . Zhang, Z. Y u, and W . Wu, “Sparse bayesian learning for end-to-end eeg decoding, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 45, no. 12, pp. 15 632–15 649, 2023. [2] W . W u, Y . Zhang, J. Jiang, M. V . Lucas, G. A. Fonzo, C. E. Rolle, C. Cooper, C. Chin-Fatt, N. Krepel, C. A. Cornelssen et al. , “ An electroencephalographic signature predicts antidepressant response in major depression, ” Nature biotec hnology , vol. 38, no. 4, pp. 439–447, 2020. [3] D. Liu, W . Dai, H. Zhang, X. Jin, J. Cao, and W . Kong, “Brain- machine coupled learning method for facial emotion recognition, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 45, no. 9, pp. 10 703–10 717, 2023. [4] R. Plutchik, Emotions and life: P erspectives fr om psychology , biology , and evolution. American Psychological Association, 2003. [5] J. A. Russell, “ A circumplex model of affect. ” Journal of personality and social psychology , vol. 39, no. 6, p. 1161, 1980. [6] A. Mehrabian, “Pleasure-arousal-dominance: A general framew ork for describing and measuring individual dif ferences in temperament, ” Cur - r ent psychology , vol. 14, no. 4, pp. 261–292, 1996. [7] K. Fu, C. Du, S. W ang, and H. He, “Multi-vie w multi-label fine-grained emotion decoding from human brain activity , ” IEEE T ransactions on Neural Networks and Learning Systems , vol. 35, no. 7, pp. 9026–9040, 2022. [8] M. Li, J. Pan, Y . Gao, Y . Shen, F . Luo, J. Dai, A. Hao, and H. Qin, “Neurophysiological and subjective analysis of vr emotion induction paradigm, ” IEEE T ransactions on V isualization and Computer Graphics , vol. 28, no. 11, pp. 3832–3842, 2022. [9] Y .-J. Liu, M. Y u, G. Zhao, J. Song, Y . Ge, and Y . Shi, “Real-time movie-induced discrete emotion recognition from eeg signals, ” IEEE T ransactions on Af fective Computing , vol. 9, no. 4, pp. 550–562, 2017. [10] R. K osti, J. M. Alvarez, A. Recasens, and A. Lapedriza, “Context based emotion recognition using emotic dataset, ” IEEE T ransactions on P attern Analysis and Mac hine Intelligence , v ol. 42, no. 11, pp. 2755–2766, 2019. [11] S. Zhao, X. Y ao, J. Y ang, G. Jia, G. Ding, T .-S. Chua, B. W . Schuller , and K. K eutzer, “ Af fective image content analysis: T wo decades review and new perspectives, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 44, no. 10, pp. 6729–6751, 2021. [12] X. W ang and C. Zong, “Learning emotion category representation to detect emotion relations across languages, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , 2025. [13] Y . Y ang, Z. W ang, Y . Song, Z. Jia, B. W ang, T .-P . Jung, and F . W an, “Exploiting the intrinsic neighborhood semantic structure for domain adaptation in eeg-based emotion recognition, ” IEEE T ransactions on Affective Computing , vol. 16, no. 3, pp. 2466–2478, 2025. [14] Z. Cheng, Z.-Q. Cheng, J.-Y . He, K. W ang, Y . Lin, Z. Lian, X. Peng, and A. Hauptmann, “Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning, ” Advances in Neural Information Pr ocessing Systems , v ol. 37, pp. 110 805–110 853, 2024. [15] P . W illiams and J. L. Aaker , “Can mixed emotions peacefully coexist?” Journal of consumer resear ch , vol. 28, no. 4, pp. 636–649, 2002. [16] V . Y . Oh and E. M. T ong, “Specificity in the study of mixed emotions: A theoretical framework, ” P ersonality and Social Psycholo gy Review , vol. 26, no. 4, pp. 283–314, 2022. [17] G. Zhao, Y . Zhang, G. Zhang, D. Zhang, and Y .-J. Liu, “Multi-target positiv e emotion recognition from eeg signals, ” IEEE T ransactions on Affective Computing , vol. 14, no. 1, pp. 370–381, 2020. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 14 [18] V . Man, H. U. Nohlen, H. Melo, and W . A. Cunningham, “Hierarchical brain systems support multiple representations of valence and mixed affect, ” Emotion Review , vol. 9, no. 2, pp. 124–132, 2017. [19] K. C. Berridge, “ Affectiv e valence in the brain: modules or modes?” Natur e Reviews Neur oscience , v ol. 20, no. 4, pp. 225–234, 2019. [20] S. D. Kreibig and J. J. Gross, “Understanding mixed emotions: paradigms and measures, ” Curr ent opinion in behavioral sciences , vol. 15, pp. 62–71, 2017. [21] Y . Kang and Y .-S. Cho, “Beyond single emotion: Multi-label approach to conv ersational emotion recognition, ” in Pr oceedings of the AAAI Confer ence on Artificial Intelligence , vol. 39, no. 23, 2025, pp. 24 321– 24 329. [22] Q. Xu, S. Y uan, Y . W ei, J. W u, L. W ang, and C. Wu, “Multiple feature refining network for visual emotion distribution learning, ” in Pr oceedings of the AAAI Confer ence on Artificial Intelligence , vol. 39, no. 9, 2025, pp. 8924–8932. [23] Y . Zhang, J. Fu, D. She, Y . Zhang, S. W ang, and J. Y ang, “T ext emotion distribution learning via multi-task conv olutional neural network. ” in IJCAI , 2018, pp. 4595–4601. [24] Y . Shu, P . Y ang, N. Liu, S. Zhang, G. Zhao, and Y .-J. Liu, “Emotion distribution learning based on peripheral physiological signals, ” IEEE T ransactions on Affective Computing , vol. 14, no. 3, pp. 2470–2483, 2023. [25] F . Liu, P . Y ang, Y . Shu, F . Y an, G. Zhang, and Y .-J. Liu, “Emotion dictionary learning with modality attentions for mixed emotion e xplo- ration, ” IEEE T ransactions on Affective C omputing , vol. 15, no. 3, pp. 1289–1302, 2024. [26] C. Zheng, C. Tian, J. W en, D. Zhang, and Q. Zhu, “Helo: Heteroge- neous multi-modal fusion with label correlation for emotion distribution learning, ” in Pr oceedings of the 33r d A CM International Conference on Multimedia , 2025, pp. 5519–5527. [27] M. M. Moore and E. A. Martin, “T aking stock and moving forward: A personalized perspecti ve on mix ed emotions, ” P erspectives on Psyc ho- logical Science , vol. 17, no. 5, pp. 1258–1275, 2022. [28] “The co-occurrence of emotions in daily life: A multilevel approach, ” Journal of Resear ch in P ersonality , vol. 39, no. 3, pp. 325–335, 2005. [29] P . Primoceri and J. Ullrich, “Cross-valence inhibition in forming and retrieving ambiv alent attitudes, ” British Journal of Social Psychology , vol. 62, no. 1, pp. 540–560, 2023. [30] M. Malezieux, A. S. Klein, and N. Gogolla, “Neural circuits for emotion, ” Annual r eview of neur oscience , v ol. 46, no. 1, pp. 211–231, 2023. [31] J. Y ang, J. Li, L. Li, X. W ang, and X. Gao, “ A circular-structured rep- resentation for visual emotion distribution learning, ” in Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , 2021, pp. 4237–4246. [32] Z. Zhao and X. Ma, “T ext emotion distribution learning from small sample: A meta-learning approach, ” in Pr oceedings of the 2019 Confer - ence on Empirical Methods in Natural Language Pr ocessing and the 9th International Joint Confer ence on Natural Language Pr ocessing (EMNLP-IJCNLP) , 2019, pp. 3957–3967. [33] C. Peng, K. Chen, L. Shou, and G. Chen, “Carat: contrastive feature reconstruction and aggregation for multi-modal multi-label emotion recognition, ” in Proceedings of the AAAI Confer ence on Artificial Intelligence , vol. 38, no. 13, 2024, pp. 14 581–14 589. [34] M. F . Bonner and R. A. Epstein, “Object representations in the human brain reflect the co-occurrence statistics of vision and language, ” Nature communications , vol. 12, no. 1, p. 4081, 2021. [35] M. C. Potter , “Conceptual short term memory in perception and thought, ” F r ontiers in Psyc hology , vol. 3, p. 113, 2012. [36] H. Liu, S. Y ang, Y . Zhang, M. W ang, F . Gong, C. Xie, G. Liu, Z. Liu, Y .-J. Liu, B.-L. Lu, and D. Zhang, “Libeer: A comprehensive benchmark and algorithm library for eeg-based emotion recognition, ” IEEE T ransactions on Affective Computing , vol. 16, no. 4, pp. 3596– 3613, 2025. [37] M. Y e, C. L. P . Chen, and T . Zhang, “Hierarchical dynamic graph con volutional network with interpretability for eeg-based emotion recog- nition, ” IEEE T ransactions on Neur al Networks and Learning Systems , vol. 36, no. 11, pp. 19 489–19 500, 2025. [38] J. Li, X. W ang, and Z. Zeng, “Tracing intricate cues in dialogue: Joint graph structure and sentiment dynamics for multimodal emotion recogni- tion, ” IEEE Tr ansactions on P attern Analysis and Machine Intelligence , 2025. [39] Y . Li, Y . W ang, and Z. Cui, “Decoupled multimodal distilling for emotion recognition, ” in Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , 2023, pp. 6631–6640. [40] W .-B. Jiang, X.-H. Liu, W .-L. Zheng, and B.-L. Lu, “Seed-vii: A multi- modal dataset of six basic emotions with continuous labels for emotion recognition, ” IEEE Tr ansactions on Affective Computing , vol. 16, no. 2, pp. 969–985, 2025. [41] I. Grossmann and P . C. Ellsworth, “What are mixed emotions and what conditions foster them? life-span experiences, culture and social awareness, ” Curr ent Opinion in Behavioral Sciences , vol. 15, pp. 1–5, 2017. [42] X. Li, J. Liu, Y . Xie, P . Gong, X. Zhang, and H. He, “Magdra: a multi- modal attention graph network with dynamic routing-by-agreement for multi-label emotion recognition, ” Knowledge-Based Systems , vol. 283, p. 111126, 2024. [43] S. Anand, N. K. De vulapally , S. D. Bhattacharjee, and J. Y uan, “Multi- label emotion analysis in conv ersation via multimodal kno wledge dis- tillation, ” in Pr oceedings of the 31st A CM international conference on multimedia , 2023, pp. 6090–6100. [44] R. Plutchik, “ A general psychoev olutionary theory of emotion, ” in Theories of emotion . Elsevier , 1980, pp. 3–33. [45] X. Jia and X. Shen, “Multimodal emotion distrib ution learning, ” Cog- nitive Computation , vol. 14, no. 6, pp. 2141–2152, 2022. [46] H.-C. Chou, C.-C. Lee, and C. Busso, “Exploiting co-occurrence fre- quency of emotions in perceptual evaluations to train a speech emotion classifier , ” Interspeech 2022 , 2022. [47] C.-L. Liu and M. Nakagawa, “Evaluation of prototype learning al- gorithms for nearest-neighbor classifier in application to handwritten character recognition, ” P attern Recognition , vol. 34, no. 3, pp. 601–615, 2001. [48] S. A. Dudani, “The distance-weighted k-nearest-neighbor rule, ” IEEE T ransactions on Systems, Man, and Cybernetics , no. 4, pp. 325–327, 1976. [49] M. Caron, P . Bojano wski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features, ” in Proceedings of the Eur opean conference on computer vision (ECCV) , 2018, pp. 132–149. [50] T . Kohonen, “The self-organizing map, ” Proceedings of the IEEE , vol. 78, no. 9, pp. 1464–1480, 2002. [51] J. Snell, K. Swersk y , and R. Zemel, “Prototypical networks for fe w-shot learning, ” Advances in neural information processing systems , vol. 30, 2017. [52] N. Dong and E. P . Xing, “Fe w-shot semantic se gmentation with proto- type learning. ” in BMVC , v ol. 3, no. 4, 2018, p. 4. [53] K. Y ang, Y . Luo, Z. Zhang, C. L. P . Chen, and T . Zhang, “Multimodal affect perception with large language model enhancement network, ” IEEE T ransactions on Affective Computing , pp. 1–17, 2025. [54] R. Zhou, Z. Zhang, H. Fu, L. Zhang, L. Li, G. Huang, F . Li, X. Y ang, Y . Dong, Y .-T . Zhang et al. , “Pr-pl: A no vel prototypical representation based pairwise learning framework for emotion recognition using eeg signals, ” IEEE T ransactions on Af fective Computing , vol. 15, no. 2, pp. 657–670, 2023. [55] J. Li, P . Zhou, C. Xiong, and S. C. Hoi, “Prototypical contrastive learn- ing of unsupervised representations, ” arXiv pr eprint arXiv:2005.04966 , 2020. [56] D. Chen, Z. W u, F . Liu, Z. Y ang, S. Zheng, Y . T an, and E. Zhou, “Protoclip: Prototypical contrasti ve language image pretraining, ” IEEE T ransactions on Neural Networks and Learning Systems , vol. 36, no. 1, pp. 610–624, 2025. [57] Y . Bao, C. Wu, P . Zhang, C. Shan, Y . Qi, and X. Ben, “Boosting micro- expression recognition via self-expression reconstruction and mem- ory contrastiv e learning, ” IEEE T ransactions on Affective Computing , vol. 15, no. 4, pp. 2083–2096, 2024. [58] K. Y ang, T . Zhang, H. Alhuzali, and S. Ananiadou, “Cluster-le vel contrastiv e learning for emotion recognition in con versations, ” IEEE T ransactions on Affective Computing , vol. 14, no. 4, pp. 3269–3280, 2023. [59] R. McEliece, E. Posner , E. Rodemich, and S. V enkatesh, “The capacity of the hopfield associative memory , ” IEEE transactions on Information Theory , vol. 33, no. 4, pp. 461–482, 2003. [60] J. J. Hopfield, “Neurons with graded response have collectiv e compu- tational properties like those of two-state neurons. ” Pr oceedings of the national academy of sciences , vol. 81, no. 10, pp. 3088–3092, 1984. [61] J. Zhang, Q. Fu, X. Chen, L. Du, Z. Li, G. W ang, S. Han, D. Zhang et al. , “Out-of-distribution detection based on in-distribution data pat- terns memorization with modern hopfield energy , ” in The Eleventh International Conference on Learning Representations , 2022. [62] D. Krotov and J. J. Hopfield, “Dense associativ e memory for pat- tern recognition, ” Advances in neural information pr ocessing systems , vol. 29, 2016. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 15 [63] M. Demircigil, J. Heusel, M. L ¨ owe, S. Upgang, and F . V ermet, “On a model of associativ e memory with huge storage capacity , ” J ournal of Statistical Physics , vol. 168, no. 2, pp. 288–299, 2017. [64] H. Ramsauer, B. Sch ¨ afl, J. Lehner , P . Seidl, M. Widrich, L. Gruber, M. Holzleitner , T . Adler, D. Kreil, M. K. Kopp et al. , “Hopfield networks is all you need, ” in International Conference on Learning Repr esentations , 2021. [65] M. W idrich, B. Sch ¨ afl, M. Pa vlovi ´ c, H. Ramsauer , L. Gruber , M. Hol- zleitner , J. Brandstetter , G. K. Sandve, V . Greif f, S. Hochreiter et al. , “Modern hopfield netw orks and attention for immune repertoire classi- fication, ” Advances in neural information processing systems , vol. 33, pp. 18 832–18 845, 2020. [66] P . Seidl, P . Renz, N. Dyubank ova, P . Neves, J. V erhoeven, J. K. W egner, M. Segler , S. Hochreiter , and G. Klambauer , “Improving fe w-and zero- shot reaction template prediction using modern hopfield networks, ” Journal of chemical information and modeling , vol. 62, no. 9, pp. 2111– 2120, 2022. [67] M. Widrich, M. Hofmarcher, V . P . Patil, A. Bitto-Nemling, and S. Hochreiter, “Modern hopfield networks for return decomposition for delayed rewards, ” in Deep RL W orkshop NeurIPS 2021 , 2021. [68] A. F ¨ urst, E. Rumetshofer, J. Lehner , V . T . Tran, F . T ang, H. Ramsauer , D. Kreil, M. K opp, G. Klambauer , A. Bitto et al. , “Cloob: Modern hopfield networks with infoloob outperform clip, ” Advances in neural information pr ocessing systems , v ol. 35, pp. 20 450–20 468, 2022. [69] A. Sanchez-Fernandez, E. Rumetshofer, S. Hochreiter , and G. Klam- bauer , “Cloome: contrastive learning unlocks bioimaging databases for queries with chemical structures, ” Natur e Communications , vol. 14, no. 1, p. 7339, 2023. [70] A. V aswani, N. Shazeer , N. Parmar, J. Uszk oreit, L. Jones, A. N. Gomez, Ł. Kaiser , and I. Polosukhin, “ Attention is all you need, ” Advances in neural information pr ocessing systems , v ol. 30, 2017. [71] S. Kullback and R. A. Leibler , “On information and sufficienc y , ” The annals of mathematical statistics , vol. 22, no. 1, pp. 79–86, 1951. [72] P . Y ang, N. Liu, X. Liu, Y . Shu, W . Ji, Z. Ren, J. Sheng, M. Y u, R. Y i, D. Zhang et al. , “ A multimodal dataset for mix ed emotion recognition, ” Scientific Data , vol. 11, no. 1, p. 847, 2024. [73] P . Schmidt, A. Reiss, R. Duerichen, C. Marberger , and K. V an Laer- hoven, “Introducing wesad, a multimodal dataset for wearable stress and affect detection, ” in Proceedings of the 20th ACM international confer ence on multimodal interaction , 2018, pp. 400–408. [74] A. Mackinnon, A. F . Jorm, H. Christensen, A. E. K orten, P . A. Jacomb, and B. Rodgers, “ A short form of the positiv e and negativ e affect schedule: Evaluation of factorial v alidity and in variance across demo- graphic variables in a community sample, ” P ersonality and Individual differ ences , vol. 27, no. 3, pp. 405–416, 1999. [75] T .-W . Lee, “Independent component analysis, ” in Independent compo- nent analysis: Theory and applications . Springer, 1998, pp. 27–66. [76] X. Geng, “Label distrib ution learning, ” IEEE T ransactions on Knowl- edge and Data Engineering , v ol. 28, no. 7, pp. 1734–1748, 2016. [77] X. Geng, C. Y in, and Z.-H. Zhou, “Facial age estimation by learning from label distributions, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 35, no. 10, pp. 2401–2412, 2013. [78] W .-B. Jiang, X.-H. Liu, W .-L. Zheng, and B.-L. Lu, “Multimodal adap- tiv e emotion transformer with flexible modality inputs on a novel dataset with continuous labels, ” in pr oceedings of the 31st A CM international confer ence on multimedia , 2023, pp. 5975–5984. [79] X. Jia, X. Shen, W . Li, Y . Lu, and J. Zhu, “Label distribution learning by maintaining label ranking relation, ” IEEE T ransactions on Knowledge and Data Engineering , v ol. 35, no. 2, pp. 1695–1707, 2021. [80] Z. Kou, J. W ang, J. T ang, Y . Jia, B. Shi, and X. Geng, “Exploiting multi-label correlation in label distrib ution learning, ” in Pr oceedings of the Thirty-Thir d International J oint Confer ence on Artificial Intelligence , 2024, pp. 4326–4334. [81] C. W en, X. Zhang, X. Y ao, and J. Y ang, “Ordinal label distribution learning, ” in Proceedings of the IEEE/CVF international conference on computer vision , 2023, pp. 23 481–23 491. [82] A. Radford, J. W . Kim, C. Hallacy , A. Ramesh, G. Goh, S. Agarw al, G. Sastry , A. Askell, P . Mishkin, J. Clark et al. , “Learning transferable visual models from natural language supervision, ” in International confer ence on mac hine learning . PmLR, 2021, pp. 8748–8763.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment