MDM-ASR: Bridging Accuracy and Efficiency in ASR with Diffusion-Based Non-Autoregressive Decoding
In sequence-to-sequence Transformer ASR, autoregressive (AR) models achieve strong accuracy but suffer from slow decoding, while non-autoregressive (NAR) models enable parallel decoding at the cost of degraded performance. We propose a principled NAR…
Authors: Hao Yen, Pin-Jui Ku, Ante Jukić
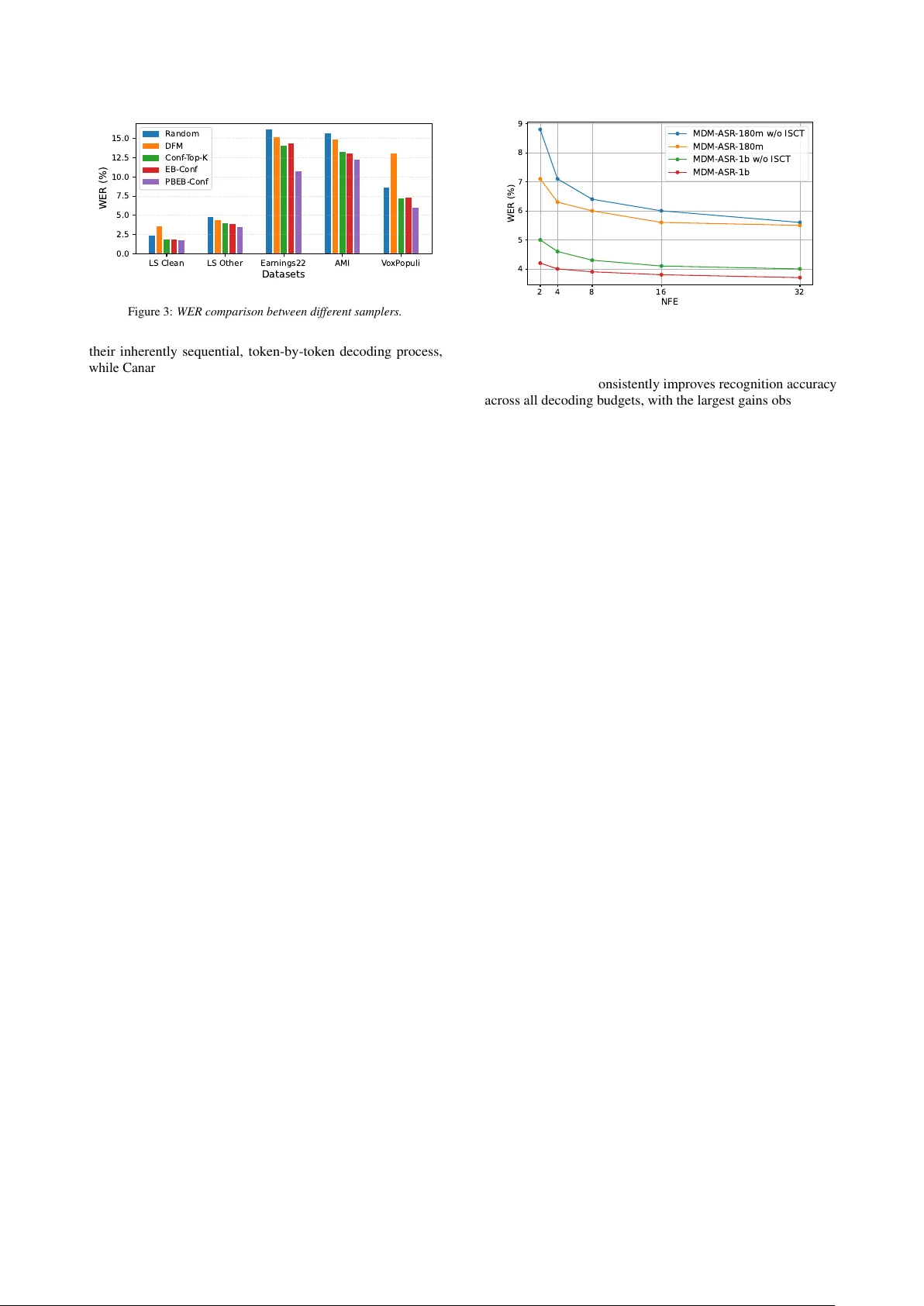
MDM-ASR: Bridging Accuracy and Efficiency in ASR with Diffusion-Based Non-A utor egr essiv e Decoding Hao Y en 1 , ∗ , Pin-J ui K u 1 , ∗ , Ante J uki ´ c 3 , Sabato Mar co Siniscalc hi 1 , 2 1 Georgia Institute of T echnology , USA 2 Uni versit ` a degli Studi di P alermo, Italy 3 NVIDIA, USA rick.yen@gatech.edu, pku9@gatech.edu, ajukic@nvidia.com Abstract In sequence-to-sequence Transformer ASR, autoregressi v e (AR) models achiev e strong accurac y but suf fer from slo w decoding, while non-autoregressi v e (N AR) models enable parallel decod- ing at the cost of degraded performance. W e propose a principled N AR ASR framework based on Masked Diffusion Models to significantly reduce this gap. A pre-trained speech encoder is coupled with a Transformer diffusion decoder conditioned on acoustic features and partially masked transcripts for parallel token prediction. T o mitigate the training–inference mismatch, we introduce Iterative Self-Corr ection T raining that exposes the model to its own intermediate predictions. W e also design an P osition-Biased Entr opy-Bounded Confidence-based sampler with positional bias to further boost results. Experiments across multiple benchmarks demonstrate consistent gains over prior N AR models and competitiv e performance with strong AR base- lines, while retaining parallel decoding efficienc y . Index T erms : automatic speech recognition, discrete diffusion, masked dif fusion model, non-autoregressi v e 1. Introduction Automatic Speech Recognition (ASR) [ 1 ] has become a cor - nerstone technology , powering applications from smart home devices and virtual assistants to real-time transcription. Over the past decade, deep learning adv ances hav e greatly impro ved ASR accuracy and rob ustness. Connectionist T emporal Classification (CTC) [ 2 , 3 ], which enables alignment-free training by mapping input frames directly to output sequences, initially rev olution- ized ASR. CTC-based models are non-autoregressiv e (NAR), allowing parallel tok en decoding, and typically combine strong encoders, such as W av2V ec2.0 [ 4 ], HuBER T [ 5 ], or MMS [ 6 ], with a CTC prediction head and loss. This design enables very fast decoding [ 7 , 8 ] across benchmarks [ 9 ]. Ho wev er , the strong conditional independence assumption between output tokens limits the modeling of rich linguistic dependencies, often result- ing in performance degradation [ 10 ] and pre venting CTC from dominating state-of-the-art ASR. T o address CTC’ s limitations, Conformer-based transduc- ers [ 11 , 12 , 13 , 14 ] combine a Conformer [ 15 ] encoder with an autore gressiv e (AR) token predictor via a joint network, making them well suited for streaming ASR. Another class of AR models are sequence-to-sequence (seq2seq) Transformer ASR systems [ 16 , 17 ], which le verage an encoder -decoder archi- tecture [ 18 , 19 ] with cross-attention to implicitly align speech frames and output tokens. This approach has produced highly competitiv e fully T ransformer-based systems, including Whis- per [ 20 ] and Canary [ 21 ], achieving strong accurac y across mul- * These authors contributed equally . tiple languages and domains. Despite their effecti veness, AR models generate tokens sequentially , so inference time grows linearly with output length. Maintaining long-range context dur- ing decoding further increases computational cost, limiting their suitability for real-time or large-scale applications [1, 10]. In text generation, NAR models ha ve recently gained con- siderable attention, demonstrating their potential to be a valid alternativ e to AR solutions. In particular , models based on diffu- sion [ 22 , 23 ] and flo w-matching [ 24 , 25 ] frame works enable par - allel sequence generation and allow a fle xible trade-off between accuracy and efficienc y through iterativ e refinement. Among them, masked diffusion models (MDMs) [ 26 , 27 , 28 , 29 ] hav e emerged as a promising solution for sequence modeling. In- stead of generating tokens one by one, MDMs start from a masked sequence and iterati v ely predict multiple tokens in par - allel. This bidirectional refinement process allows the model to use both past and future contexts at e very step, leading to improv ed modeling capacity while significantly reducing infer- ence latency . MDMs have sho wn promise in unconditional text generation [ 30 , 31 , 32 ] and zero-shot ev aluation [ 33 , 34 ] for lan- guage modeling tasks. Gi ven that ASR fundamentally performs text generation conditioned on speech, these advances suggest that diffusion-based N AR generation may also be beneficial for speech recognition. Howe v er , the scalability of MDMs and their effecti v eness for ASR ha ve not been fully explored. Moreover , very recent studies on diffusion-based ASR [ 35 , 36 , 37 ] and flow-matching ASR [ 38 ] report a substantial performance gap compared with strong AR ASR models. In this work, we study N AR modeling within the standard seq2seq T ransformer ASR framew ork and seek to close the per- formance gap between AR and N AR approaches. T o this end, we introduce an audio-conditioned masked dif fusion decoder that replaces con v entional left-to-right AR decoding while preserving the encoder–decoder architecture. Our model consists of a s trong pre-trained speech encoder to e xtract high-le vel acoustic repre- sentations, which are then consumed by a Transformer -based discrete diffusion decoder that iterativ ely refines masked token sequences. At each diffusion decoding step, the decoder jointly conditions on the complete acoustic embedding and the partially masked text sequence, enabling par allel token updates and bidi- rectional context modeling across the entire output. Unlike prior diffusion ASR attempts that couple separately trained speech and text components via an additional fusion module [ 37 , 36 ], or recent flo w-matching ASR ef forts that introduce an additional auxiliary modeling [ 38 ], our model builds directly on a stan- dard encoder–decoder ASR architecture and replaces sequential decoding with a masked diffusion generation process. More- ov er , unlike earlier BER T -style masked refinement ASR [ 39 ], which relies on ad-hoc objectiv es without an explicit generati ve interpretation, we employ a discrete dif fusion formulation with a training objecti v e deriv ed from the forward corruption pro- cess. The resulting diffusion loss, including the noise-dependent reweighting term, provides each refinement step with a clear probabilistic interpretation. In addition, it defines a theoreti- cally grounded multi-step generativ e model, whose inference procedure is fully consistent with the training process. Building on this framework, we propose sev eral practical techniques to further improv e performance. First, Iterative Self- Corr ection T raining (ISCT) reduces the mismatch between train- ing and inference by exposing the model to intermediate de- coding states. Second, we explore multiple inference strategies, including the Entr opy-Bounded Confidence (EB-Conf) sampler for stable and efficient decoding, and the P osition-Biased EB- Conf (PBEB-Conf) sampler to incorporate positional bias. Ex- periments on four benchmark English datasets sho w that our model achieves competiti ve accuracy with strong AR systems while delivering significantly faster decoding and consistently outperforming existing generati v e N AR ASR models. On mul- tilingual tasks, it demonstrates robust performance across lan- guages. Comprehensive ablation studies further e xamine model scaling, ISCT , and inference strategies, providing clear insights into system design and empirical behavior . 2. Related W ork 2.1. Masked Diffusion Model Discrete diffusion models [ 26 , 27 , 40 , 41 , 42 ] extend dif fusion- based generati ve modeling to categorical variables, enabling diffusion-style learning in discrete tok en spaces such as text. In contrast to continuous dif fusion models that progressi vely inject Gaussian noise into signals, discrete diffusion defines a stochastic corruption process over a finite vocab ulary and learns a corresponding rev erse-time denoising process. Let x be a one-hot v ector in { 0 , 1 } |V | representing a clean token from the vocab ulary V with size |V | . A forward noising process constructs a sequence of latent v ariables z t , inde xed by a continuous diffusion time t ∈ [0 , 1] . A commonly used formulation is the masked diffusion pr ocess , in which tokens are progressiv ely replaced by an absorbing mask state, denoted with a special [MASK] token in V . The marginal forward distrib ution at time t is defined as q ( z t | x ) = Cat ( z t ; α t x + (1 − α t ) m ) , (1) where Cat( · ; p ) denotes a categorical distribution over |V | classes with probabilities p ∈ ∆ |V | , where ∆ |V | denotes the |V | - dimensional probability simplex that sums to 1, m is the one-hot vector corresponding to the mask token, and α t : [0 , 1] → [0 , 1] is a monotonically decreasing noise schedule satisfying α 0 ≈ 1 and α 1 ≈ 0 . As t increases, probability mass gradually shifts from the original token to the absorbing mask state. Under this absorbing-state construction, the conditional distribution of an intermediate latent v ariable z s giv en a later v ariable z t and the clean token x , for 0 < s < t < 1 , admits a closed-form expression q ( z s | z t , x ) = Cat z s ; α s − α t 1 − α t x + 1 − α s 1 − α t z t . (2) This posterior provides a con v enient parameterization for defin- ing the rev erse-time denoising process. The generativ e model learns a parameterized rev erse transi- tion p θ ( z s | z t ) by replacing the unkno wn clean token x in (2) with a neural network prediction x θ ( z t , t ) , which outputs a cat- egorical distrib ution ov er the v ocabulary V conditioned on the noisy input z t and diffusion time t . In the masked dif fusion set- ting, the rev erse transition simplifies to the follo wing piece wise form p θ ( z s | z t ) = q ( z s | z t , x θ ( z t , t )) = ( Cat( z s ; z t ) , z t = m Cat z s ; (1 − α s ) m +( α s − α t ) x θ ( z t ,t ) 1 − α t , z t = m That is, positions that are already unmasked remain unchanged, while masked positions are progressi vely unmasked using the model’ s predictions. For a sequence of length L , the clean sequence can be written as x (1: L ) = { x (1) , . . . , x ( L ) } , and the corresponding masked sequence at time t is denoted z (1: L ) t . The corruption process is applied independently across token positions. T raining is performed by randomly sampling dif fusion time t , generating corrupted sequences z (1: L ) t using the forward process, and max- imizing the likelihood of the original clean tokens under the model’ s rev erse predictions. The training objecti ve for the whole sequence can be written as L = E q Z 1 0 α ′ t 1 − α t L X ℓ =1 log D x ( ℓ ) θ ( z (1: L ) t , t ) , x ( ℓ ) E d t. (3) where α ′ t = d α t d t and x ( ℓ ) θ ( · ) denotes the predicted probability for token at position ℓ . This objectiv e encourages accurate recon- struction of masked tokens across all noise le vels, yielding a fully non-autoregressi ve generati v e model ov er discrete sequences. 2.2. Diffusion-/Flow-matching based N AR ASR Research on generative NAR models for ASR remains rela- tiv ely limited. T o the best of our knowledge, only a fe w studies hav e in v estigated this direction, most notably T ransfusion [ 35 ], FFDM [ 36 ] and Whisfusion [ 37 ]. On the one hand, Transfusion and FFDM formulate ASR using a multinomial dif fusion process ov er discrete output tokens, enabling parallel decoding across time steps. On the other hand, Whisfusion combines a pretrained Whisper encoder with a pretrained text dif fusion decoder , con- nected through a lightweight cross-attention module, with the goal of reducing the inference latency typically associated with autoregressi ve generation. The model is trained in a two-stage manner , where the speech encoder and text diffusion decoder are pretrained independently , followed by a separate training stage to learn their acoustic–text fusion, making the ov erall training pipeline more complex and less end-to-end compared to a unified ASR frame work. Despite these initial eff orts, diffusion-based generativ e N AR ASR models ha ve been e v aluated primarily on a single English-only dataset and lack comprehensi v e experiments on more benchmark datasets or additional ablation studies. More- ov er , their recognition accurac y remains notably below that of current state-of-the-art AR ASR models, lea ving their scalability and generalization capabilities insufficiently e xplored. More recently , Drax [ 38 ] introduces a N AR ASR framew ork based on discrete flow matching (DFM) [ 24 ], providing an al- ternativ e to diffusion-based generativ e modeling. In addition, Drax formulates ASR as a transport process from a uniform text distrib ution to the target transcript, and introduces an audio- conditioned intermediate distribution along this probability path to better align training with inference. During inference, decod- ing follows the learned flo w trajectory through this predefined intermediate state rather than directly denoising from the source distribution. Despite the relatively competiti v e recognition accu- racy and improv ed accuracy-ef ficienc y trade-of fs, its probability path design introduces additional components and hyperparame- ters that require careful tuning, and the intermediate distribution may still fail to capture the full v ariability of inference dynamics across div erse acoustic contexts. 2.3. Iterative Mask ed Refinement NAR ASR It is worth pointing out that a few prior works have explored N AR ASR through iterati ve refinement of tok en-lev el transcrip- tion hypotheses, where partially observed output sequences are progressiv ely completed and corrected across multiple decoding steps. At a high level, these models share the idea of predicting missing tokens in parallel and progressi vely refining the output ov er multiple iterations. Representativ e examples include Mask- CTC [ 43 , 44 ], Imputer [ 45 ], and Align-Refine [ 46 ]. Howe ver , these methods differ from dif fusion-based model in both training and inference procedures. In particular , these models typically rely on either CTC-style alignments or dynamic programming to handle variable-length outputs. Moreov er , the refinement steps usually require repeated re-alignment between acoustic frames and text tok ens. This reliance on explicit alignment introduces additional algorithmic complexity and constrains model design, leading to more complex training and inference process. The most similar work to ours is [ 39 ], which formulates ASR as an audio-conditioned masked language model trained with a BER T -style objectiv e [ 47 ]. A key distinction from our model lies in the underlying generativ e formulation. As pointed out in [ 26 , 48 ], BER T -style masked reconstruction objectiv es, which apply a uniform loss over ev ery noise-le vel without noise- dependent reweighting are not equi valent to discrete diffusion objectiv es and do not faithfully optimize the model likelihood. In contrast, discrete diffusion training introduces e xplicit re weight- ing α ′ t 1 − α t in (3) to compensate for the varying e xpected number of masked positions across noise lev els, which is deri v ed from the forward corruption process, yielding a principled multi-step rev erse-time generativ e model. This distinction is particularly concerning for [ 39 ], where training follows a BER T -style objec- tiv e while inference attempts to perform a multi-step iterativ e refinement resembling discrete diffusion. W e argue that the mis- match between training and inference behaviors may lead to suboptimal solutions. In addition, their ev aluation is limited to a small number of refinement steps and is conducted mainly on Japanese and Chinese datasets. As noted in [ 39 ], performance on English and Latin alphabet based task are more challenging to their model, making it difficult to assess its robustness and general applicability across languages and decoding settings. 3. Masked Diffusion Based ASR 3.1. A udio-conditioned Mask ed Diffusion Model Masked dif fusion models can be naturally extended to ASR by conditioning the discrete denoising process on an acoustic input. In this setting, the goal is to generate a sequence of linguistic tokens that correspond to a given speech signal, while retain- ing the N AR advantages of discrete diffusion modeling. Let a ∈ R T × D denote an input acoustic representation extracted by a pretrained speech encoder , where T is the number of time frames and D is the feature dimension. Let x (1: L ) denote the corresponding target token sequence. As in Section 2.1, a for- ward diffusion process corrupts the clean token sequence into [mask] [mask] [mask] [mask] [mask] Masked Dif fusion Model for ASR Masked Dif fusion Model great ASR Model Masked Dif fusion [mask] ASR Model [mask] [mask] ASR Model [mask] [mask] [mask] ASR Non-causal T ransformer Decoder Pretrained Encoder Speech Dif fusion Acoustic Feature Figure 1: Overview of our MDM-ASR framework. a noisy sequence z (1: L ) t at diffusion time t . Importantly , the forward noising process remains unchanged and is independent of the audio signal. The distinction from con ventional MDMs arises in the re- verse denoising/unmasking process, which is no w conditioned on the acoustic input feature a . Therefore, the rev erse transition is parameterized as p θ ( z (1: L ) s | z (1: L ) t , a ) = L Y ℓ =1 p θ ( z ( ℓ ) s | z (1: L ) t , a ) , (4) where θ denotes model parameters. As before, the reverse tran- sition is constructed by replacing the unknown clean tokens with a neural network prediction, now conditioned on both the masked-corrupted sequences and the audio signal. Specifically , let x ( ℓ ) θ ( z (1: L ) t , a ) ∈ ∆ |V | denote the model-predicted categori- cal distribution over the vocab ulary at position ℓ , produced by an MDM decoder that attends to the acoustic representation a and the masked token sequence z (1: L ) t . Plugging this prediction into the posterior in (2) yields the audio-conditioned reverse transition p θ ( z ( ℓ ) s | z (1: L ) t , a ) = Cat( z ( ℓ ) s ; z ( ℓ ) t ) , z ( ℓ ) t = m Cat z ( ℓ ) s ; (1 − α s ) m +( α s − α t ) x ( ℓ ) θ ( z (1: L ) t , a ) 1 − α t , z ( ℓ ) t = m Follo wing [ 31 , 49 ], we introduce zero masking probabilities and carry-over properties for unmasked tokens to simplify the training objective in (3) by excluding the timestep t from the input in x θ ( · ) . In addition, we set the noise schedule α t = 1 − t as suggested in previous work [ 31 , 41 , 48 ]. Therefore, we arriv e at a modified training objectiv e L = E q Z 1 0 − 1 t X ℓ | z ℓ t = m log D x ( ℓ ) θ ( z (1: L ) t , a ) , x ( ℓ ) E d t. (5) This objectiv e can be interpreted as an audio-conditioned MDM language modeling loss where tokens that remain unmasked incur no loss, while masked positions are trained to directly reconstruct the original clean token sequence. 3.2. Model Architectur e Figure 1 illustrates the proposed MDM-based ASR model, referred to as MDM-ASR, which adopts a standard en- coder–decoder architecture augmented with a diffusion-based decoder . The speech input is first processed by a pre-trained speech encoder to produce high-le v el acoustic representations, which serve as conditioning information for a T ransformer -based text decoder via cross-attention. Apart from the decoding strat- egy , the overall architecture remains identical to con v entional encoder–decoder ASR models. The ke y distinction lies in the de- coder design. Instead of employing a causal self-attention mask as in AR decoding, the proposed decoder uses a non-causal self-attention mask, enabling each token position to attend to the entire output sequence. This bidirectional context allows the model to predict all tokens in parallel at each diffusion step, rather than generating them sequentially from left to right. As a result, the decoder can iterati vely refine the full transcript at ev ery inference step, ef fecti vely remo ving the sequential decod- ing bottleneck while preserving the representational strengths of encoder–decoder ASR models. 3.3. Iterative Self-Corr ection T raining A common challenge for MDMs is the mismatch between train- ing and inference. During standard training, the model only observes oracle corrupted sequences obtained by masking the ground-truth sequence. During inference, the model instead denoises sequences that are partly self-generated. Therefore, these sequences contain plausible decoding errors from pre vious iterations. The discrepancy between training and inference re- sembles the sampling mismatch introduced by teacher forcing in AR model training [ 50 , 51 ], which can lead to error propagation and degraded performance. T o mitigate the mismatch between training and multi-step inference, we adopt an iterative self-corr ection training (ISCT) approach inspired by [ 52 ]. ISCT explicitly simulates multiple masking/unmasking steps during training, allowing the model to learn to correct its own errors. Using two steps in the following as a proof of concept, we first sample an initial timestep t 1 and generate a masked sequence z t 1 from the ground-truth transcript x . The MDM decoder produces a preliminary reconstruction ˆ x = x θ ( z t 1 , a ) , which is an estimated clean token sequence for the gi ven speech. W e then sample another timestep t 2 and corrupt the model’ s o wn output by applying the forw ard masking process to ˆ x , yielding a partially masked sequence ˆ z t 2 = q ( ˆ z t 2 | ˆ x ) analogous to (1) . Feeding ˆ z t 2 into the decoder produces a refined prediction x θ ( ˆ z t 2 , a ) . W e can then extend the original training loss in (5) by adding a second term for this refinement step, essentially summing the cross-entropy objectiv es over both the first and second unmasking stages. Formally , the ISCT objectiv e L ISCT can be expressed as L ISCT = E q Z 1 0 − 1 t 1 X ℓ | z ℓ t 1 = m log D x ( ℓ ) θ ( z (1: L ) t 1 , a ) , x ( ℓ ) E d t 1 + E q Z 1 0 − 1 t 2 X ℓ | ˆ z ℓ t 2 = m log D x ( ℓ ) θ ( ˆ z (1: L ) t 2 , a ) , x ( ℓ ) E d t 2 (6) It is important to note that prior flo w-matching models [ 25 , 53 , 54 ], including Drax [ 38 ], addresses the training–inference mismatch by introducing a fixed audio-conditioned intermediate distribution along a predefined probability path. Howe ver , this method tightly couples the training dynamics with the chosen inference path, making design choices dif ficult and non-tri vial. In contrast, ISCT directly exposes the model to its o wn interme- diate decoding states. By corrupting and refining the model’s self-generated predictions during training, the MDM decoder learns to correct realistic errors that arise during iterati v e infer- ence, rather than relying on a handcrafted or static intermediate representation. This data-driven process allows the model to capture a broader range of inference dynamics induced by acous- tic v ariability , early mispredictions, and domain mismatch. As a result, ISCT provides a closer alignment between training and inference in the proposed MDM-ASR, leading to improved robustness and generalization across di v erse speech conditions. 3.4. Inference Samplers As discussed in Section 1, a k ey adv antage of MDMs over AR models lies in their fle xibility during inference. Unlike AR de- coding, which follo ws a fix ed left-to-right order , MDMs allow tokens to be decoded in arbitrary orders. Moreover , multiple tokens can be decoded in parallel to trade of f accuracy for effi- ciency . This flexibility enables a v ariety of decoding strate gies beyond the v anilla random-unmasking sampler [ 31 ], motiv ating a series of works that dev elop more advanced sampling meth- ods [ 55 , 56 , 57 , 58 ]. In this section, we describe the inference samplers ev aluated in our e xperiments, including our proposed combination of entropy-bounded decoding and positional bias. 3.4.1. Discr ete Flow-Matching Sampler Although our ASR system is based on MDMs, we can still apply the Discrete Flow-Matching (DFM) sampler at inference time by interpreting the model’ s categorical predictions as a probability flow in the discrete token space. Although applying DFM in this setting is not entirely straightforward, for completeness and to ensure a f air comparison with flo w-matching based baselines, we also ev aluate this sampler in our experiments. At each decoding step, the predicted distrib ution x (1: L ) θ ( z t , a ) ov er clean tokens is used to construct a discrete flo w field that guides the ev olution of tokens to ward the predicted clean state. Let z ( ℓ ) t ∈ { 0 , 1 } |V | denote as a one-hot vector representing the current token at time t at position ℓ . The flow direction is defined as v ( ℓ ) = x ( ℓ ) θ ( z t , a ) − z ( ℓ ) t 1 − α t which represents a normalized drift from the current discrete state tow ard the predicted clean-token distrib ution at position ℓ . For a tar get time s with 0 < s < t , the categorical distrib ution at time s is obtained via a linear update p θ ( z ( ℓ ) s | z (1: L ) t , a ) = z ( ℓ ) t + ( α s − α t ) v ( ℓ ) from which z ( ℓ ) s are sampled to form the next decoding state. 3.4.2. Confidence-based Samplers While random unmasking mirrors the training-time masking procedure, prior studies hav e sho wn that the inference-time un- masking order can hav e a substantial impact on sampling quality , especially when prediction errors are present [ 55 ]. In such cases, selecting positions to unmask based on model-derived crite- ria, such as confidence, entropy , or margin computed from the predicted token distributions, consistently outperforms v anilla random unmasking [55, 57, 59]. One common class of confidence-based samplers is the Con- fidence T op- K (Conf-T op- K ) sampler [ 55 ]. At each decoding iteration, the model first computes token distributions for all currently masked positions and ranks them according to a con- fidence criterion. T oken positions are then ranked by the maxi- mum predicted probability , and the top K position are selected for unmasking. The parameter K controls an efficienc y-accuracy tradeoff: larger v alues of K reduce the number of function ev al- uations (NFEs) but may de grade decoding quality . T o improve ef ficiency without sacrificing quality , the Entropy-Bounded Confidence sampler (EB-Conf) [ 57 ] replaces the fixed K with an adapti v e selection rule. After sorting masked positions by confidence, EB-Conf selects the largest prefix set U whose predicted entropies satisfy an entropy-b udget constraint, X l ∈ U H x ( ℓ ) θ ( z (1: L ) t , a ) − max l ∈ U H x ( ℓ ) θ ( z (1: L ) t , a ) ≤ γ (7) and then unmasks all positions in U in the current decoding step. Intuitiv ely , when the model is simultaneously confident about many positions (lo w entropy), EB-Conf unmasks more tokens per iteration to reduce NFEs. Howe ver , when there is higher uncertainty , it automatically unmasks fewer tokens, mitigating the quality degradation observed with large fixed- K parallel unmasking. The threshold γ directly controls this behavior , with γ = 0 reducing to single-token unmasking and γ → ∞ allowing the unmasking of all remaining tokens in one decoding step. 3.4.3. P osition-Biased EB-Conf Sampler In addition to entropy-bounded selection, we propose to incor - porate the positional trajectory prior proposed in [58] to further improv e decoding performance. Specifically , we introduce a positional bias term P i = e − λi , where i denotes the token index and λ controls the strength of positional regularization. After computing the confidence scores c i for each mask ed position, we reweight them using the positional bias, yielding adjusted scores ˆ c i = P i · c i . This mechanism encourages earlier positions to be decoded first. The entropy-bounded criterion is then applied to the re-ranked positions to determine the adaptiv e unmasking set. W e refer to this combined strategy as the PBEB-Conf sampler . While EB-Conf [ 57 ] and the positional trajectory prior [ 58 ] were originally proposed as separate techniques, to the best of our knowledge, this is the first work to integrate entropy- bounded adaptive decoding with positional bias. Empirically , this combination consistently improv es decoding performance, as demonstrated in Section 5.4.1. 4. Experimental Setup 4.1. Datasets & Evaluation Metrics 4.1.1. Datasets For English-only e xperiments, we e v aluate our models on four datasets from the Hugging Face Open ASR benchmark: Lib- riSpeech [ 60 ], Earnings22 [ 61 ], AMI [ 62 , 63 ], and V oxPop- uli [ 64 ]. LibriSpeech is a widely used large-scale benchmark comprising approximately 1,000 hours of read English speech deriv ed from audiobooks, with standard ev aluation splits includ- ing test-clean and test-other . Earnings22 consists of 119 hours of earnings call recordings featuring speakers from a diverse set of global companies. The dataset is designed to capture substantial variability in speakers, accents, and finan- cial discourse, thereby reflecting realistic domain conditions. The AMI Meeting Corpus contains approximately 100 hours of multi-party meeting recordings collected across multiple record- ing channels. It provides manually produced orthographic tran- scriptions aligned at the word level, making it well suited for detailed ASR ev aluation in con versational settings. The V oxPop- uli dataset is a large-scale multilingual speech corpus deriv ed from European Parliament recordings, providing audio in o ver 20 languages. Following [ 65 ], we filter and partition each dataset into training, validation, and test sets, as summarized in T able 1. T able 1: English datasets description and statistics, including train, validation, and test splits in hours of audio data. Dataset Domain T rain (h) V al (h) T est (h) LibriSpeech Audiobook 960 11 10.74 Earnings22 Financial meetings 105 5 5.43 AMI Meetings 78 5 8.54 V oxPopuli European parliament 523 5 4.93 T able 2: MLS dataset description and statistics, including the 3 consid- er ed languages: German, Spanish, and F r enc h. Language T rain (h) V al (h) T est (h) German 1966.51 14.28 14.29 Spanish 917.68 9.99 10 French 1076.58 10.07 10.07 For multilingual studies, we use the commonly adopted Mul- tilingual LibriSpeech (MLS) [ 66 ] dataset. W e consider three non-English languages that are covered by the pretrained model, namely German (DE), Spanish (ES), and French (FR). The total amount of training data is approximately 4,000 hours. Detailed dataset statistics are summarized in T able 2. 4.1.2. Evaluation Metrics W e ev aluate our models in terms of both recognition accuracy and decoding efficiency . Recognition accuracy is measured using word error rate (WER). Prior to WER computation, both ground- truth transcripts and model predictions are normalized using the Whisper Normalizer [ 20 ]. Decoding efficiency is quantified by the in verse real-time factor (R TFx), defined as the ratio between the total duration of the audio and the total decoding time R TFx = T otal audio duration (s) Decoding time (s) . (8) An R TFx value greater than 1 indicates faster-than-real-time de- coding, with lar ger values corresponding to higher ef ficiency . For a fair comparison, all models are ev aluated on a single NVIDIA A100 GPU with a batch size of 1, using full-precision infer- ence and without any model compilation or runtime optimiza- tion. Runtime results on the LibriSpeech test-clean and test-other sets are av eraged ov er all utterances. 4.2. T raining & Inference Setup All experiments are conducted using Canary encoder-decoder ASR models implemented in NVIDIA NeMo [ 21 , 67 , 68 ]. Our MDM-based ASR system is initialized from the of- ficial pretrained canary-1b-flash checkpoint, which contains approximately 1B trainable parameters. Since canary-1b-flash is originally trained as an AR model, we modify the decoder self-attention mechanism by replacing causal attention with non-causal attention to support masked dif fusion decoding. Detailed information about Canary architecture can be found in [21, 69]. T raining is performed using the Adam optimizer [ 70 ] with a learning rate of 5 × 10 − 4 and a batch size of 8. All experiments adopt a two-step ISCT schedule, although the proposed approach naturally extends to a larger number of steps. During training, shorter sequences are padded with end-of-sentence ( EOS ) tok ens to achiev e uniform sequence lengths, treating EOS as a standard token. During inference, the model may generate multiple EOS tokens near the end of the sequence. Therefore, we truncate the T able 3: Evaluation results on four English benchmark test sets: LibriSpeech test-clean (LS Clean), LibriSpeech test-other (LS Other), Earnings22, AMI, and V oxP opuli. W e report wor d error r ate (WER), and decoding efficiency measur ed by RTFx. WERs for most baseline models are r eproduced fr om the HF leaderboar d, while models marked with † ar e obtained dir ectly fr om of ficial r eports or peer -r evie wed literatur e. RTFx for all models ar e computed using the corr esponding public-r eleased chec kpoints. A vg. refer s to the avera ge WER of the five test sets. Model WER (%) ↓ Params (B) RTFx ↑ LS Clean LS Other Earnings22 AMI V oxPopuli A vg. AR Whisper-lar ge-v3 2.0 3.9 11.3 16.0 9.5 8.5 1.5 12.83 O WSM-v3.1 † 2.4 5.0 15.4 20.4 8.4 10.3 1.0 15.52 Canary-1b-flash 1.5 2.9 12.8 13.1 5.6 7.2 1.0 29.25 Phi-4-multimodal 1.7 3.8 10.2 11.7 6.0 6.7 5.6 4.85 Qwen2-Audio † 1.6 3.6 14.1 15.2 7.1 8.3 8.4 4.18 V oxtral-Mini 1.9 4.1 10.7 16.3 7.1 8.0 3.0 12.19 NAR O WSM-CTC † 2.4 5.2 17.2 23.8 8.6 11.4 1.0 132.54 Parakeet-CTC 1.8 3.5 13.8 15.7 6.6 8.3 1.1 120.20 T ransFusion † 6.7 8.8 - - - - 0.2 0.57 Whisfusion † 8.3 17.0 - - - - 0.3 84.86 FDDM † 4.0 7.2 - - - - 0.6 - Drax † 2.6 5.7 15.2 13.9 8.6 9.2 1.2 11.32 MDM-ASR (ours) 1.8 3.6 10.7 12.2 6.0 6.9 1.0 46.81 output at the first EOS token and discard all subsequent positions. This strategy pre vents redundant refinement of positions beyond the underlying audio content and improves decoding stability and efficienc y without requiring explicit length prediction or ad- ditional heuristics [ 71 ]. Decoding is initialized with a maximum sequence length of 256 tok ens, which is suf ficient for standard ASR benchmarks. 4.3. Baselines W e compare our model against a diverse set of top-tier ASR models from the HuggingFace (HF) Open ASR Leaderboard [ 9 ], spanning large-scale AR, NAR, and diffusion-based models. Whisper [ 20 ] is a multilingual encoder–decoder model trained on approximately 5 million hours of weakly supervised speech–text data. Canary-1b-flash [ 21 ] is a family of multi-tasking mod- els based on Canary architecture [ 72 ] that supports four lan- guages (English, German, French, Spanish). SeamlessM4T - large-v2 [ 73 ] is a large-scale multilingual and multimodal sequence-to-sequence model that supports speech recognition across many languages, trained end-to-end on massi ve multilin- gual speech and text data. Phi-4-multimodal [ 74 ] is a lightweight open multimodal foundation model that lev erages the language, vision, and speech research and datasets used for Phi-3.5 and 4.0 models. Qwen2-Audio [ 75 ] extends the Qwen large language model [ 76 ] with an audio encoder to enable speech understand- ing and recognition. V oxtral [ 77 ] is b uilt on the Mistral LLM [ 78 ] backbone and integrates a dedicated speech encoder for ASR. For N AR models, we include strong CTC-based baselines. O WSM-CTC [ 7 ] is a fully open speech model trained on up to three million hours of curated English speech. Parakeet-CTC uses an XXL version of FastConformer [ 69 ], and is currently the best CTC-based model on the HF leaderboard. XLSR- 53 [ 79 , 80 ] is a multilingual speech representation model based on W av2V ec2.0, pretrained in a self-supervised manner on raw audio from 53 languages and commonly fine-tuned with a CTC objectiv e for multilingual ASR. W e also include the diffusion- and flow-matching based baselines as mentioned in Section 2.2, namely , T ransfusion [ 35 ], Whisfusion [ 37 ], FFDM [ 36 ], and Drax [ 38 ]. T ogether, these baselines span a broad spectrum of modern ASR models, including large encoder–decoder models, LLM-augmented models, as well as CTC- and dif fusion-based N AR methods. W e note that direct comparisons under identi- cal training conditions are often infeasible due to the nature of large-scale foundation models. For instance, Whisper-lar ge-v3 is trained on millions of hours of audio using proprietary data, undisclosed training pipelines, and substantial computational re- sources, making it impractical for us to reproduce or retrain under controlled and comparable settings. Therefore, following [ 38 ] and prior literature, we e v aluate our model against representati ve state-of-the-art ASR models to the best of our kno wledge, which are also among the top-ranked models on the HF leaderboard. W e also observe discrepancies among the results reported across prior literature. T o address this issue and ensure a consistent and reproducible ev aluation results, we adopt the of ficial scripts from [ 9 ] to reproduce the baseline results, thereby aligning the ev aluation setup for a f air comparison. 5. Results 5.1. English Benchmark Results T able 3 reports the results on the English-only benchmarks. Unless otherwise specified, MDM-ASR results are reported for our best-performing 1B model configuration, trained with ISCT , and decoded using the proposed PBEB-Conf sampler with λ = 0 . 2 , γ = 0 . 05 and a maximum NFE of 32. Among genera- tiv e N AR models, the proposed MDM-ASR establishes a new state-of-the-art to the best of our knowledge. Earlier dif fusion- based ASR models, including TransFusion, Whisfusion, and FFDM, either lack decoding efficienc y , e.g., R TFx of 0.57 for T ransfusion, or exhibit limited recognition accurac y , e.g., WER of 8.3% on LS Clean and 17% on LS Other for Whisfusion. Even compared with Drax, the strongest prior generati v e N AR base- line, MDM-ASR still achiev es consistently superior performance across all benchmarks with faster decoding speech, around 4.1x speedup in R TFx at a similar model size. On LibriSpeech, our model achiev es 1.8% WER on LS Clean and 3.6% on LS Other, improving upon Drax which reports 2.6% and 5.7% WER re- spectiv ely , corresponding to a relative WER improvement of T able 4: Multilingual evaluation r esults on the MLS dataset, including German (DE), Spanish (ES), and F renc h (FR). Results ar e r eproduced fr om the HF leaderboard, while models marked with † ar e obtained dir ectly fr om of ficial r eports or peer-r eviewed literatur e . Method WER (%) ↓ DE ES FR AR Whisper-larv e-v3 3.1 3.0 4.8 O WSM-v3.1 † 10.8 9.0 12.1 SeamlessM4T -lar ge-v2 † 6.1 4.1 5.4 Canary-1b-flash 4.4 2.7 4.5 Phi-4-multimodal 4.8 3.6 4.9 V oxtral-Mini 7.1 5.1 5.3 NAR O WSM-CTC † 11.9 10.3 12.9 XLSR-53 † 6.5 6.1 5.6 Drax † 7.7 5.4 7.1 MDM-ASR (ours) 3.6 2.9 3.8 approximately 31% on LS Clean and 37% on LS Other . Similar trends are observ ed on Earnings22, AMI, and V oxPopuli. MDM- ASR reduces WER from 15.2% to 10.7% for Earnings22, from 13.9% to 12.2% for AMI, and on V oxPopuli, from 8.6% to 6.0%, further indicating improved generalization to con versational and real-world speech. These results demonstrate that the proposed model yields a more effecti v e and ef ficient alternati v e to e xisting generativ e N AR ASR frame works. When compared with AR methods, we observe that although strong AR models remain competitiv e in absolute recognition ac- curacy , the gap between AR and NAR ASR is markedly reduced relativ e to prior N AR models. In particular , MDM-ASR achiev es comparable or e ven better performance on se veral challenging benchmarks, surpassing Whisper-lar ge-v3 on LS Other (3.6% to 3.9%), Earnings22 (10.7% to 11.3%), and AMI (12.2% to 16.0%), and outperforming O WSM-v3.1 on all fiv e English test sets. Even compared with the strongest AR model Canary-1b- flash, MDM-ASR achiev es better average WER of 6.9% ov er 7.2%. In addition, MDM-ASR achieves substantially higher decoding ef ficiency than all AR baselines, delivering approxi- mately 3.6x speedup ov er Whisper and 3.0x ov er O WSM. Even when compared with the fastest AR model, Canary-1b-flash, MDM-ASR still provides an efficienc y gain of about 1.6x . No- tably , Whisper and OWSM are trained on se v eral million hours of weakly supervised speech–text data, whereas MDM-ASR is trained on substantially less curated speech data, making these results particularly promising. A similar trend is observed when comparing against recent LLM-augmented ASR models, includ- ing Phi-4-multimodal, Qwen2-Audio, and V oxtral-Mini. These models benefit from strong pretrained large language model pri- ors and extensiv e textual kno wledge, which naturally enhance recognition performance. Despite this, MDM-ASR demonstrates competitiv e accuracy across di verse English benchmarks, further underscoring its effectiv eness in closing the performance gap between N AR and AR ASR models. For completeness, we also compare MDM-ASR with strong CTC-based ASR models, which represent the most widely adopted NAR paradigm in practice. CTC-based models such as O WSM-CTC and P arakeet-CTC of fer e xtremely fast decod- ing (R TFx > 100 ) due to their single-pass inference. Among them, Parakeet-CTC achie v es competiti ve performance on Lib- riSpeech, reflecting the strength of large-scale CTC models on clean read speech. Howe v er , on benchmarks such as Earn- 20 40 60 80 100 120 Sequence length 1 0 1 1 0 2 R TFx (log scale) Canary -1b-flash Whisper -lar ge- v3 MDM- ASR (Conf - T op-K) MDM- ASR (PBEB-Conf) Figure 2: The RTFx as a function of sequence length. Shaded r e gions indicate a ± 10% variability band around the fitted curve to illustrate the uncertainty of the estimated tr end. ings22, AMI, and V oxPopuli, MDM-ASR consistently outper- forms Parakeet-CTC. In general, MDM-ASR provides a more balanced accuracy profile across di verse benchmarks, achie ving lower WER while retaining the parallel decoding adv antages of N AR inference. 5.2. Multilingual Results T able 4 reports multilingual recognition results on MLS for German, Spanish, and French. Overall, MDM-ASR works ef fec- tiv ely with multilingual scenario and achie ves competiti v e accu- racy against strong AR and N AR baselines. In particular , MDM- ASR attains 3.6%/2.9%/3.8% WER on German/Spanish/French, substantially improving over the strongest prior generative N AR baseline Drax (7.7%/5.4%/7.1%), the CTC-based mod- els, such as O WSM-CTC (11.9%/10.3%/12.9%), and XLSR-53 (6.5%/6.1%/5.3%). When compared with AR models, MDM- ASR is on-par or exceeds sev eral widely used lar ge-scale models. For instance, it outperforms Whisper-lar ge-v3 on Spanish (2.9% vs. 3.0%) and French (3.8% vs.4.8%), and significantly surpasses SeamlessM4T -lar ge-v2 and OWSM-v3.1 across all three lan- guages. Notably , MDM-ASR also achieves lo wer WER than re- cent LLM-augmented ASR models, including Phi-4-multimodal (4.8%/3.6%/4.9%) and V oxtral-Mini (7.1%/5.1%/5.3%), across all three languages. W e note that these large-scale multilingual models, such as Whisper , OWSM, Phi-4-multimodal, and V ox- tral, are trained to support a much broader set of languages, resulting in substantially larger vocab ularies and more div erse modeling objectiv es, which may partially affect performance when ev aluated on a small subset of languages. Nevertheless, when compared under a more closely matched setup, namely Canary-1b-flash, which shares an identical encoder architecture and training paradigm, we still observe meaningful empirical gains on German (3.6% vs. 4.4%) and French (3.8% vs. 4.5%). These results suggest that the improvements achie v ed by MDM- ASR are not solely attributable to differences in language co v- erage, but rather reflect the effectiv eness of masked diffusion decoding for multilingual ASR within a N AR frame work. 5.3. Decoding Efficiency The ke y adv antage of our proposed MDM-ASR over AR mod- els lies in its decoding efficiency . Figure 2 shows how decod- ing speed, measured by R TFx, scales with output sequence length. As sequence length increases, AR models such as Whisper-lar ge-v3 exhibit steadily declining efficiency due to LS Clean LS Other Ear nings22 AMI V o xP opuli Datasets 0.0 2.5 5.0 7.5 10.0 12.5 15.0 WER (%) R andom DFM Conf - T op-K EB-Conf PBEB-Conf Figure 3: WER comparison between different sampler s. their inherently sequential, token-by-token decoding process, while Canary-1b-flash provides only limited scaling benefits but remains largely constant. In contrast, MDM-ASR maintains sub- stantially higher R TFx across all sequence lengths, with the per- formance gap widening for longer outputs. All confidence-based decoding variants further improve efficienc y , and the entropy- bounded strategies, including EB-Conf and PBEB-Conf, consis- tently achie ves the highest R TFx, outperforming AR baselines by a large margin throughout the entire range. For simplicity we present results on PBEB-Conf, while noting both methods demonstrate comparable speed. The slight decline in PBEB- Conf at longer sequence lengths stems from its adaptiv e update strategy , causing it to con ver ge toward Conf-T op- K performance, which is still faster than AR decoding. Ov erall, these results demonstrate the f av orable scaling properties of mask ed dif fusion decoding, which av oids the linear latency growth inherent to AR models and enables consistently faster -than-real-time per- formance, especially for long-form utterances where decoding efficienc y is most critical. 5.4. Ablation Studies 5.4.1. Effect of Sampler Choice In Section 3.4, we introduced fiv e inference samplers: Random- Unmasking, DFM, Conf-T op- K , EB-Conf, and PBEB-Conf. W e compare their decoding performance on five English test sets, as summarized in Figure 3. Overall, the Random-Unmasking and the DFM sampler yields clearly suboptimal performance across all test sets compared to the other three methods, espe- cially on the more challenging Earnings22 and AMI datasets. This behavior may partially explain the superior performance of our model compared to Drax, since the DFM sampler also selects unmasking positions in a largely random manner . In contrast, the confidence-based samplers achieve similar and con- sistently strong performance. This observation aligns with prior work [ 55 , 57 , 56 , 59 ] and indicates that the model’ s confidence estimates serve as a reliable proxy for decoding accuracy . Fur- thermore, adopting the EB-Conf sampler maintains decoding accuracy while impro ving inference speed, as discussed in Sec- tion 5.3. Finally , incorporating the positional bias term yields additional performance gains: the PBEB-Conf sampler consis- tently improv es results. 5.4.2. Effect of Iter ative Self-Corr ection T raining Figure 4 shows the ef fect of ISCT on WER across dif ferent NFEs for the MDM-ASR model with two different model sizes: MDM- ASR-180m with 180M parameters and MDM-ASR-1b with 1B parameters. For simplicity , we present results on LS Other , while noting that a similar trend is observed on LS Clean. For both 2 4 8 16 32 NFE 4 5 6 7 8 9 WER (%) MDM- ASR -180m w/o ISCT MDM- ASR -180m MDM- ASR -1b w/o ISCT MDM- ASR -1b Figure 4: Effect of the pr oposed ISCT . WER comparison on LS Other for 180M and 1B models under varying maximum NFEs. model sizes, ISCT consistently impro ves recognition accurac y across all decoding b udgets, with the lar gest gains observ ed at smaller numbers of decoding steps (2, 4, and 8), where early prediction errors are more difficult to correct through iterative refinement alone. This indicates that exposing the model to its own intermediate predictions during training ef fecti vely alle vi- ates the mismatch between training and inference in masked diffusion decoding. While the relative impro vements are smaller for the 1B model, they remain consistent across decoding steps and are particularly e vident on the more challenging LS Other set. Notably , these gains are achiev ed without additional infer - ence cost, highlighting ISCT as a practical and effecti v e strategy for improving both robustness and generalization in masked diffusion–based ASR. 6. Discussions and Conclusion Limitations: While the proposed MDM-ASR framew ork demonstrates competitiv e accuracy and f av orable decoding ef fi- ciency , sev eral limitations remain. Our ev aluation is limited to a subset of publicly av ailable datasets, and extending e xperiments to more div erse languages, domains, and real-world conditions, remains an important direction for future work. In addition, our results are based on only a specific subset of possible design choices. Inv estigating alternativ e encoders, adaptiv e masking schedules, advanced training techniques, and multiple steps of ISCT configurations may further impro ve performance and ro- bustness but is left for future exploration. Finally , while our work focuses on establishing the general performance of MDM-ASR on standard ASR benchmarks, we note that this framew ork can be extended to other ASR applications, including streaming ASR and domain adaptation, which we consider promising directions for future work. Conclusion: W e hav e presented MDM-ASR, a simple audio- conditioned masked diffusion frame work for non-autore gressiv e ASR that preserves the standard encoder-decoder architecture while replacing sequential left-to-right decoding with iterati ve parallel unmasking. T o better align training and inference, we proposed ISCT and in vestigated practical inference samplers that improv e stability and efficiency . Experiments on English and multilingual benchmarks show that MDM-ASR consistently outperforms prior generativ e N AR models and substantially nar- rows the gap to strong autoregressi v e models, while providing fa vorable ef ficienc y in decoding speed. W e further conduct com- prehensiv e ablation studies. T ogether, these results establish masked diffusion as a competitiv e and practical direction for effecti v e and efficient N AR ASR. W e will open our source code and all hyperparameters with pre-trained models in the future. 7. References [1] J. Li, “Recent advances in end-to-end automatic speech recogni- tion, ” in Proc. APSIP A , 2022. [2] A. Graves, S. Fern ´ andez, F . Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks, ” in Pr oc. ICML , 2006. [3] A. Grav es and N. Jaitly , “T owards end-to-end speech recognition with recurrent neural networks, ” in Pr oc. ICML , 2014. [4] A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framew ork for self-supervised learning of speech representations, ” in Pr oc. NeurIPS , 2020. [5] W .-N. Hsu, Y .-H. H. Tsai, B. Bolte, R. Salakhutdinov , and A. rah- man Mohamed, “Hubert: How much can a bad teacher benefit asr pre-training?” in Proc. ICASSP , 2021. [6] V . Pratap, A. Tjandra, B. Shi, P . T omasello, A. Babu, S. Kundu, A. Elkahky , Z. Ni, A. Vyas, M. Fazel-Zarandi, A. Bae vski, Y . Adi, X. Zhang, W .-N. Hsu, A. Conneau, and M. Auli, “Scaling speech technology to 1,000+ languages, ” arXiv , 2023. [7] Y . Peng, Y . Sudo, M. Shak eel, and S. W atanabe, “OWSM-CTC: An open encoder-only speech foundation model for speech recognition, translation, and language identification, ” in Proc. A CL , 2024. [8] Y . Peng, M. Shakeel, Y . Sudo, W . Chen, J. Tian, C.-J. Lin, and S. W atanabe, “Owsm v4: Improving open whisper-style speech models via data scaling and cleaning, ” in Proc. Interspeec h , 2025. [9] V . Sriv astav , S. Zheng, E. Bezzam, E. L. Bihan, N. Koluguri, P . ˙ Zelasko, S. Majumdar , A. Moumen, and S. Gandhi, “Open asr leaderboard: T owards reproducible and transparent multilingual and long-form speech recognition e valuation, ” arXiv preprint arXiv:2510.06961 , 2025. [Online]. A v ailable: https://huggingface.co/spaces/hf- audio/open asr leaderboard [10] S. W atanabe, T . Hori, S. Kim, J. R. Hershey , and T . Hayashi, “Hy- brid ctc/attention architecture for end-to-end speech recognition, ” IEEE Journal of Selected T opics in Signal Processing , 2017. [11] W . Huang, W . Hu, Y . T . Y eung, and X. Chen, “Con v-transformer transducer: Low latency , lo w frame rate, streamable end-to-end speech recognition, ” in Proc. Inter speech , 2020. [12] A. Tripathi, J. Kim, Q. Zhang, H. Lu, and H. Sak, “Transformer transducer: One model unifying streaming and non-streaming speech recognition, ” in Proc. ICASSP , 2020. [13] X. Chen, Y . W u, Z. W ang, S. Liu, and J. Li, “Developing real- time streaming transformer transducer for speech recognition on large-scale dataset, ” in Pr oc. ICASSP , 2020. [14] Q. Zhang, H. Lu, H. Sak, A. Tripathi, E. McDermott, S. Koo, and S. Kumar, “Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss, ” in Pr oc. ICASSP , 2020. [15] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar , Y . Zhang, J. Y u, W . Han, S. W ang, Z. Zhang, Y . W u, and R. Pang, “Conformer: Con v olution- augmented transformer for speech recognition, ” in Pr oc. Inter- speech , 2020. [16] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser , and I. Polosukhin, “ Attention is all you need, ” in Pr oc. NeurIPS , 2017. [17] L. Dong, S. Xu, and B. Xu, “Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition, ” in Proc. ICASSP , 2018. [18] J. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Bengio, “ Attention-based models for speech recognition, ” in Pr oc. NeurIPS , 2015. [19] W . Chan, N. Jaitly , Q. Le, and O. V inyals, “Listen, attend and spell: A neural network for lar ge v ocabulary conversational speech recognition, ” in Proc. ICASSP , 2016. [20] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeavey , and I. Sutske ver , “Robust speech recognition via large-scale weak su- pervision, ” in Proc. ICML , 2023. [21] P . Zelasko, K. Dhawan, D. Galvez, K. C. Puvvada, A. Pasad, N. R. K oluguri, K. Hu, V . Lavrukhin, J. Balam, and B. Ginsb urg, “T raining and inference efficiency of encoder-decoder speech models, ” arXiv pr eprint arXiv:2503.05931 , 2025. [Online]. A vailable: https://huggingface.co/nvidia/canary- 180m- flash [22] J. Sohl-Dickstein, E. W eiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynam- ics, ” in Proc. ICML , 2015. [23] J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models, ” in Proc. NeurIPS . Curran Associates, Inc., 2020. [24] I. Gat, T . Remez, N. Shaul, F . Kreuk, R. T . Q. Chen, G. Synnaev e, Y . Adi, and Y . Lipman, “Discrete flow matching, ” in Proc. NeurIPS , 2024. [25] N. Shaul, I. Gat, M. Ha vasi, D. Se v ero, A. Sriram, P . Holderrieth, B. Karrer, Y . Lipman, and R. T . Q. Chen, “Flow matching with general discrete paths: A kinetic-optimal perspective, ” in Pr oc. ICLR , 2025. [26] J. Austin, D. D. Johnson, J. Ho, D. T arlo w , and R. van den Berg, “Structured denoising diffusion models in discrete state-spaces, ” in Pr oc. NeurIPS , 2021. [27] E. Hoogeboom, D. Nielsen, P . Jaini, P . Forr ´ e, and M. W elling, “ Argmax flows and multinomial diffusion: Learning categorical distributions, ” in Pr oc. NeurIPS , 2021. [28] A. Campbell, J. Benton, V . D. Bortoli, T . Rainforth, G. Deligian- nidis, and A. Doucet, “ A continuous time frame work for discrete denoising models, ” in Proc. NeurIPS , 2022. [29] Z. He, T . Sun, Q. T ang, K. W ang, X. Huang, and X. Qiu, “Dif fu- sionBER T: Improving generativ e masked language models with diffusion models, ” in Pr oc. A CL , 2023. [30] L. Zheng, J. Y uan, L. Y u, and L. K ong, “ A reparameterized discrete diffusion model for te xt generation, ” in Pr oc. COLM , 2024. [31] S. S. Sahoo, M. Arriola, Y . Schiff, A. Gokaslan, E. Marroquin, J. T . Chiu, A. Rush, and V . Kuleshov , “Simple and effecti v e masked diffusion language models, ” in Pr oc. NeurIPS , 2024. [32] J. Y e, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, and L. K ong, “Dream 7b: Diffusion large language models, ” arXiv pr eprint arXiv:2508.15487 , 2025. [33] S. Nie, F . Zhu, C. Du, T . Pang, Q. Liu, G. Zeng, M. Lin, and C. Li, “Scaling up masked diffusion models on text, ” in Proc. ICLR , 2025. [34] S. S. Sahoo, J. Deschenaux, A. Gokaslan, G. W ang, J. T . Chiu, and V . Kuleshov , “The diffusion duality , ” in Proc. ICLR , 2025. [35] M. Baas, K. Elof f, and H. Kamper, “T ransfusion: Transcribing speech with multinomial diffusion, ” in Pr oc. SA CAIR , 2022. [36] C.-K. Y eh, C.-C. Chen, C.-H. Hsu, and J.-T . Chien, “Cross- Modality Diffusion Modeling and Sampling for Speech Recogni- tion, ” in Proc. Inter speech , 2024. [37] T . Kwon, J. Ahn, T . Y un, H. Jwa, Y . Choi, S. Park, N.-J. Kim, J. Kim, H. G. Ryu, and H.-J. Lee, “Whisfusion: Parallel asr decod- ing via a diffusion transformer , ” arXiv pr eprint arXiv:2508.07048 , 2025. [38] A. Navon, A. Shamsian, N. Glazer, Y . Segal-Feldman, G. Hetz, J. Keshet, and E. Fetaya, “Drax: Speech recognition with discrete flow matching, ” arXiv pr eprint arXiv:2510.04162 , 2025. [39] N. Chen, S. W atanabe, J. V illalba, P . ˙ Zelasko, and N. Dehak, “Non- autoregressi ve transformer for speech recognition, ” IEEE Signal Pr ocessing Letters , 2021. [40] A. Q. Nichol and P . Dhariwal, “Improved denoising diffusion probabilistic models, ” in Proc. ICML , 2021. [41] A. Lou, C. Meng, and S. Ermon, “Discrete diffusion modeling by estimating the ratios of the data distribution, ” in Pr oc. ICML , 2024. [42] S. Liu, J. Nam, A. Campbell, H. St ¨ ark, Y . Xu, T . Jaakkola, and R. G ´ omez-Bombarelli, “Think while you generate: Discrete diffu- sion with planned denoising, ” in 2025 , 2025. [43] Y . Higuchi, S. W atanabe, N. Chen, T . Ogawa, and T . Kobayashi, “Mask ctc: Non-autoregressiv e end-to-end asr with ctc and mask predict, ” in Proc. Inter speech , 2020. [44] Y . Higuchi, H. Inaguma, S. W atanabe, T . Oga wa, and T . K obayashi, “Improved mask-ctc for non-autoregressi ve end-to-end asr, ” in Proc. ICASSP , 2021. [45] C. Saharia, G. E. Hinton, M. Norouzi, N. Jaitly , and W . Chan, “Imputer: Sequence modelling via imputation and dynamic pro- gramming, ” in Proc. ICML , 2020. [46] E. A. Chi, J. Salazar , and K. Kirchhoff, “ Align-refine: Non- autoregressi ve speech recognition via iterative realignment, ” in Pr oc. N AA CL , 2021. [47] J. Devlin, M.-W . Chang, K. Lee, and K. T outanova, “BER T: Pre- training of deep bidirectional transformers for language under- standing, ” in Proc. N AA CL , 2019. [48] J. Shi, K. Han, Z. W ang, A. Doucet, and M. T itsias, “Simplified and generalized masked diffusion for discrete data, ” in Pr oc. NeurIPS , 2024. [49] J. Ou, S. Nie, K. Xue, F . Zhu, J. Sun, Z. Li, and C. Li, “Y our absorb- ing discrete diffusion secretly models the conditional distributions of clean data, ” in Proc. ICLR , 2025. [50] S. Bengio, O. V in yals, N. Jaitly , and N. Shazeer, “Scheduled sam- pling for sequence prediction with recurrent neural netw orks, ” in Pr oc. NeurIPS , 2015. [51] M. Ranzato, S. Chopra, M. Auli, and W . Zaremba, “Sequence lev el training with recurrent neural networks, ” in Pr oc. ICLR , 2016. [52] H. Y en, F . G. Germain, G. W ichern, and J. L. Roux, “Cold diffusion for speech enhancement, ” in Proc. ICASSP , 2023. [53] S. H. Lim, Y . W ang, A. Y u, E. Hart, M. W . Mahoney , X. S. Li, and N. B. Erichson, “Elucidating the design choice of probability paths in flow matching for forecasting, ” T ransaction on Machine Learning Resear ch , 2025. [54] M. Cross and A. Ragni, “Flowing straighter with conditional flow matching for accurate speech enhancement, ” arXiv preprint arXiv:2508.20584 , 2025. [55] J. Kim, K. Shah, V . K ontonis, S. M. Kakade, and S. Chen, “T rain for the worst, plan for the best: Understanding token ordering in masked dif fusions, ” in Proc. ICML , 2025. [56] R. Y u, X. Ma, and X. W ang, “Dimple: Discrete diffusion multi- modal large language model with parallel decoding, ” arXiv preprint arXiv:2505.16990 , 2025. [57] H. Ben-Hamu, I. Gat, D. Se vero, N. Nolte, and B. Karrer , “ Acceler- ated sampling from masked diffusion models via entropy bounded unmasking, ” in Proc. NeurIPS , 2025. [58] P . Huang, S. Liu, Z. Liu, Y . Y an, S. W ang, Z. Chen, and T . Xiao, “Pc-sampler: Position-aware calibration of decoding bias in masked diffusion models, ” arXiv pr eprint arXiv:2508.13021 , 2025. [59] P .-J. Ku, H. Huang, J.-M. Lemercier, S. S. Sahoo, Z. Chen, and A. Juki ´ c, “Discrete diffusion for generative modeling of text- aligned speech tokens, ” in Pr oc. ICASSP , 2026. [60] V . Panayotov , G. Chen, D. Povey , and S. Khudanpur , “Librispeech: an asr corpus based on public domain audio books, ” in Proc. ICASSP , 2015. [61] M. D. Rio, P . Ha, Q. McNamara, C. Miller, and S. Chandra, “Earnings-22: A practical benchmark for accents in the wild, ” in Pr oc. Interspeec h , 2022. [62] J. Carletta, “Unleashing the killer corpus: experiences in creating the multi-ev erything AMI meeting corpus, ” in Pr oc. LREC , 2007. [63] S. Renals, T . Hain, and H. Bourlard, “Recognition and interpreta- tion of meetings: The AMI and AMID A projects, ” in Proc. ASR U , 2007. [64] C. W ang, M. Riviere, A. Lee, A. W u, C. T alnikar, D. Haziza, M. Williamson, J. Pino, and E. Dupoux, “VoxPopuli: A large- scale multilingual speech corpus for representation learning, semi- supervised learning and interpretation, ” in Proc. A CL , 2021. [65] S. Gandhi, P . von Platen, and A. M. Rush, “Esb: A benchmark for multi-domain end-to-end speech recognition, ” in Pr oc. ICLR , 2022. [66] V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “Mls: A large-scale multilingual dataset for speech research, ” arXiv pr eprint arXiv:2012.03411 , 2020. [67] O. Kuchaiev , J. Li, H. Nguyen, O. Hrinchuk, R. Leary , B. Gins- bur g, S. Kriman, S. Beliaev , V . Lavrukhin, J. Cook, P . Castonguay , M. Popov a, J. Huang, and J. M. Cohen, “Nemo: a toolkit for building ai applications using neural modules, ” arXiv preprint arXiv:1909.09577 , 2019. [68] E. Harper et al. , “Nemo: a toolkit for con v ersational ai and lar ge language models, ” https://github.com/NVIDIA/NeMo, 2023. [69] D. Rekesh, N. R. K oluguri, S. Kriman, S. Majumdar, V . Noroozi, H. Huang, O. Hrinchuk, K. Puvvada, A. Kumar , J. Balam, and B. Ginsbur g, “Fast conformer with linearly scalable attention for efficient speech recognition, ” in Pr oc. ASR U , 2023. [70] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimiza- tion. ” in Proc. ICLR , 2015. [71] M. Ghazvininejad, O. Levy , Y . Liu, and L. Zettlemoyer , “Mask- predict: Parallel decoding of conditional masked language models, ” in Pr oc. EMNLP , 2019. [72] K. C. Puvvada, P . ˙ Zelasko, H. Huang, O. Hrinchuk, N. R. K oluguri, K. Dhawan, S. Majumdar , E. Rastorguev a, Z. Chen, V . Lavrukhin, J. Balam, and B. Ginsbur g, “Less is more: Accurate speech recog- nition & translation without web-scale data, ” in Pr oc. Interspeec h , 2024. [73] S. Communication et al. , “Seamlessm4t: Massively multi- lingual & multimodal machine translation, ” arXiv pr eprint arXiv:2308.11596 , 2023. [74] Microsoft et al. , “Phi-4-mini technical report: Compact yet pow- erful multimodal language models via mixture-of-loras, ” arXiv pr eprint arXiv:2503.01743 , 2025. [75] Y . Chu, J. Xu, Q. Y ang, H. W ei, X. W ei, Z. Guo, Y . Leng, Y . Lv , J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-audio technical report, ” arXiv pr eprint arXiv:2407.10759 , 2024. [76] Y . Chu, J. Xu, X. Zhou, Q. Y ang, S. Zhang, Z. Y an, C. Zhou, and J. Zhou, “Qwen-audio: Advancing univ ersal audio understanding via unified large-scale audio-language models, ” arXiv preprint arXiv:2311.07919 , 2023. [77] A. H. Liu et al. , “V oxtral, ” arXiv pr eprint arXiv:2507.13264 , 2025. [78] A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F . Bressand, G. Lengyel, G. Lample, L. Saulnier , L. R. Lavaud, M.-A. Lachaux, P . Stock, T . L. Scao, T . Lavril, T . W ang, T . Lacroix, and W . E. Sayed, “Mistral 7b, ” arXiv pr eprint arXiv:2310.06825 , 2023. [79] A. Conneau, A. Baevski, R. Collobert, A. rahman Mohamed, and M. Auli, “Unsupervised cross-lingual representation learning for speech recognition, ” arXiv preprint , 2020. [80] A. Babu, C. W ang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P . von Platen, Y . Saraf, J. Pino, A. Baevski, A. Con- neau, and M. Auli, “Xls-r: Self-supervised cross-lingual speech representation learning at scale, ” in Proc. Inter speech , 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment