Adaptive Underwater Acoustic Communications with Limited Feedback: An AoI-Aware Hierarchical Bandit Approach
Underwater Acoustic (UWA) networks are vital for remote sensing and ocean exploration but face inherent challenges such as limited bandwidth, long propagation delays, and highly dynamic channels. These constraints hinder real-time communication and d…
Authors: Fabio Busacca, Andrea Panebianco, Yin Sun
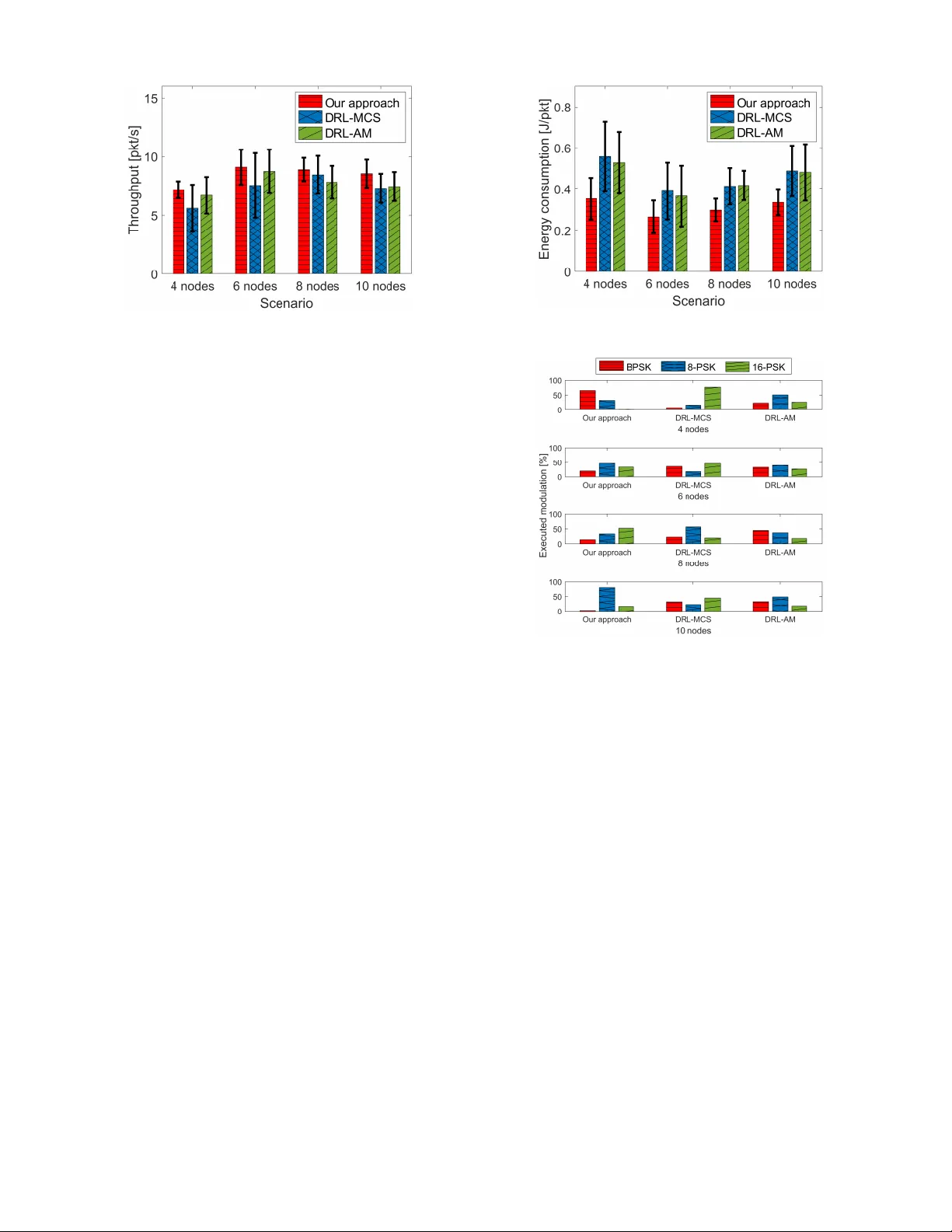
This work has been accepted for publication in IEEE Globecom 2025 . Please cite the official IEEE v ersion once av ailable. Adapti v e Underwater Acoustic Communications with Limited Feedback: An AoI-A ware Hierarchical Bandit Approach Fabio Busacca o , Andrea Panebianco ∗ § , Y in Sun § o University of Catania, Italy ∗ University of P alermo, Italy § Aub urn University , Alabama, USA Abstract —Underwater Acoustic (UW A) networks ar e vital for remote sensing and ocean exploration but face inherent challenges such as limited bandwidth, long propagation delays, and highly dynamic channels. These constraints hinder real- time communication and degrade overall system performance. T o address these challenges, this paper proposes a bilevel Multi- Armed Bandit (MAB) framework. At the fast inner lev el, a Contextual Delayed MAB (CD-MAB) jointly optimizes adaptive modulation and transmission power based on both channel state feedback and its Age of Information (AoI), thereby maximizing throughput. At the slower outer level, a Feedback Scheduling MAB dynamically adjusts the channel-state feedback interval ac- cording to throughput dynamics: stable throughput allo ws longer update intervals, while throughput drops trigger more fr equent updates. This adaptive mechanism reduces feedback overhead and enhances responsiv eness to varying network conditions. The proposed bile vel framework is computationally efficient and well- suited to resour ce-constrained UW A networks. Simulation results using the DESER T Underwater Network Simulator demonstrate throughput gains of up to 20.61% and energy sa vings of up to 36.60% compared with Deep Reinf orcement Learning (DRL) baselines reported in the existing literature. Index T erms —Underwater Communications, Adaptive Mod- ulation, Power Control, Reinfor cement Learning, Multi-Armed Bandit, Age of Inf ormation. I . I N T RO D U C T I O N UnderW ater (UW) networks are attracting growing attention from academia and industry , enabled by advances in acoustic communication technologies [1], [2]. They support real-time data exchange in remote, harsh en vironments for applications such as en vironmental monitoring, exploration, and disaster response. Howe ver , UnderW ater Acoustic (UW A) networks face intrinsic constraints—limited bandwidth, long propaga- tion delays, and highly dynamic channels—that require adap- tiv e protocols with low computational and signaling overhead. In particular, frequent feedback ov er costly acoustic channels can ov erwhelm the network, making intelligent scheduling critical to sustain throughput while limiting signaling and energy consumption. This work was supported in part by the National Science Foundation (NSF) under Grant CNS-2239677, and in part by the European Union under the Italian National Recovery and Resilience Plan (NRRP) of NextGenerationEU, within the “T elecommunications of the Future” partnership (PE0000001 – program “REST AR T”). The authors are listed alphabetically . Accepted for publication in IEEE Globecom 2025. © 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses. Please cite the official version when available. A promising solution is Adaptiv e Modulation (AM), which dynamically selects Modulation Schemes (MSs) based on real- time channel conditions [3]. Adjusting transmission po wer ( P ) can further improv e reliability . Y et, adapting these parame- ters in highly dynamic UW en vironments remains dif ficult, requiring fast responsiv eness within the limited computational resources of UW de vices. Model-based approaches have long been applied to improv e UW network performance [4], [5], predicting channel dynam- ics to guide decisions such as MS selection or data scheduling. Their effecti veness, howe ver , is limited by the non-linear and unpredictable nature of UW en vironments, where factors like temperature, salinity , and water motion introduce uncertainties that are dif ficult to model. T o address these limitations, Deep Reinforcement Learning (DRL) has been explored for dynamic adaptation in UW en vi- ronments. Although DRL provides accuracy and adaptability , it incurs high computational cost, slow con vergence, and extensi ve training time, limiting its use in dynamic, resource- constrained UW A networks [6], [7]. In contrast, lightweight Multi-Armed Bandit (MAB) algorithms have recently at- tracted attention for their ef ficiency and ability to adapt to changing conditions without large datasets or heavy training [8]. They offer a computationally ef ficient alternativ e that balances performance and adaptability , making them well- suited for real-time UW applications. This paper presents a bile vel MAB framework that jointly optimizes throughput and feedback ov erhead through adap- tiv e transmission control and feedback scheduling. The main contributions are as follows: • W e propose a novel fully distributed bilev el MAB frame- work for UW A networks. The inner layer employs a Contextual Delayed MAB (CD-MAB) to jointly adapt modulation and po wer , maximizing throughput and re- liability . The outer layer uses a Feedback Scheduling MAB to tune the feedback interv al, extending it under stable performance and shortening it under degradation, thereby controlling context freshness, shaping the Age of Information (AoI), and reducing overhead. T o the best of our knowledge, this is the first distributed bilev el MAB framework integrating adaptive modulation, power control, and AoI-aware feedback scheduling for UW A networks. Sink Node Supporting V essel UW Node UW Node UW Node UW Node Bilevel MAB Agent Modulation scheme, transmission power and feedback interval UW Node UW Node UW Node Data Reward Fig. 1: Underwater Acoustic Network architecture. • W e v alidate the proposed framew ork through extensiv e simulations using the DEsign, Simulate, Emulate and Realize T est-beds (DESER T) UW simulator [9], incor- porating realistic en vironmental conditions and dynamic channel v ariations for a comprehensiv e assessment. • W e compare our framework with existing DRL-based schemes and show that it achieves up to 20.61% higher throughput and 36.60% energy savings , thanks to distributed design, joint modulation and po wer adap- tation, and dynamic feedback scheduling. Unlike prior centralized DRL solutions [10], [11] with fixed MS, P , and feedback frequency , our benchmarks are drawn from terrestrial wireless networks, giv en the limited av ailabil- ity of effecti ve RL methods specifically tailored to UW A en vironments. I I . R E F E R E N C E S Y S T E M This section presents the reference scenario used to ev aluate the proposed UW A network, modeled with DESER T . The proposed architecture, shown in Fig. 1, includes a set of U Internet of Underwater Things (IoUT) nodes deployed in a 3D shallow-water en vironment. Each node u ∈ U commu- nicates with a central Sink via single- or multi-hop acoustic routing. The Sink aggregates data from the nodes and forwards it via a wired link to a Supporting V essel, which provides power and connecti vity to the Sink. All nodes, except for leaf nodes, act as both transmitters (Txs) and receiv ers (Rxs) in a half-duplex fashion, with Tx–Rx interactions occurring at the link le vel, i.e., between directly connected neighbors. The Tx periodically transmits sensor data packets em- bedding the selected P lev el, allowing the Rx to estimate the Signal-to-Noise Ratio (SNR) based solely on channel conditions, independent of the po wer adaptation policy . The Rx computes SNR and throughput from the receiv ed signal and periodically returns this information via dedicated single- hop feedback links. Feedback is sent only at the end of each feedback interval, summarizing performance and reporting the estimated SNR from the most recent channel observation. This aggregated approach reduces signaling o verhead while 0 2 4 6 8 10 Time [minute] Data transmission 0 2 4 6 8 10 Time [minute] Feedback Fig. 2: Data is transmitted periodically , while feedback is not sent after every ev ent. Our algorithm adapts the number of consecutiv e transmissions before the Rx sends feedback. still providing the Tx with suf ficient information to update its transmission strategy . At the end of each interval, the Tx requests feedback from the Rx to update its strategy and remain synchronized. Upon receiving delayed feedback, the Tx node, which runs both the CD-MAB and the Feedback Scheduling MAB, updates its decisions. The CD-MAB selects the optimal Modulation Scheme (MS) (among BPSK, 8-PSK, and 16-PSK) and trans- mission power P (discretized transmission po wer , with three lev els: low , medium, and high) to maximize throughput, while the Feedback Scheduling MAB selects the feedback interval from { 4 , 7 , 10 } minutes, and hence balances throughput and feedback cost. More frequent feedback improves network tracking, indirectly reducing AoI, while longer interv als re- duce signaling ov erhead at the cost of less timely channel information. This process is illustrated in Fig. 2. In realistic shallow-w ater scenarios, SNR typically ranges from 10 dB in poor conditions to 40 dB in optimal ones [12], [13]. T o capture this v ariability with low overhead, we quantize the SNR into three non-uniform intervals, reflecting its nonlinear impact on communication performance. At low SNR (10–18 dB), ev en small variations significantly af fect Bit Error Rate (BER) and throughput, requiring finer granularity . In the medium range (18–30 dB), performance improves more gradually , while at high SNR (abo ve 30 dB), it saturates, making finer distinctions unnecessary . • Low Quality [ 10 , 18 ] dB: narro w range due to BER and packet loss being highly sensitiv e to minor SNR changes. • Medium Quality ( 18 , 30 ] dB: broader interval reflecting more gradual performance improv ements. • High Quality ( 30 , 40 ] dB: performance saturates, further increases provide minimal additional gains. I I I . A G E O F I N F O R M AT I O N In the proposed framework, the Age of Information (AoI) quantifies feedback freshness at the Tx. It measures the time elapsed since the last feedback packet, reflecting how outdated the channel kno wledge of the Tx is [14], [15]. Let k ∈ N denote the index of feedback epochs, with t k the time of the k -th feedback and Q k = t k − t k − 1 the interval duration. During Q k , the AoI increases discretely by one unit per slot, and resets to zero at t k . For any t ∈ [ t k − 1 , t k ) , the AoI e volves as: ∆( t ) = t − t k − 1 . (1) This time-ev olving metric quantifies channel information stal- eness, guiding adapti ve feedback decisions. I V . O U R H I E R A R C H I C A L B I L E V E L M A B A P P RO AC H T o jointly optimize throughput and feedback overhead, we formulate a bilev el MAB frame work solving a unified problem. The inner Contextual Delayed Multi-Armed Bandit (CD-MAB) adapts modulation and power based on feedback, while the outer MAB adjusts the feedback interv al to balance signaling cost and context freshness. T ogether , they coordinate to maximize long-term performance in dynamic UW settings. A. Contextual Delayed Multi-Armed Bandit (Inner Loop) The Tx uses delayed contextual feedback and an Upper Confidence Bound (UCB)-based policy [16], [17]. W ithin each feedback interval [ t k − 1 , t k ) , discretized into time slots t (each lasting 1 minute in wall-clock time), the CD-MAB selects an action a t ∈ A , where A is the set of feasible MS– P pairs. The context ( X t ) includes the most recent SNR estimate ( ˆ η ) and its associated AoI, indicating channel information freshness, so X t = ( ˆ η t − ∆( t ) , ∆( t )) . Since the reward is observed only at the end of each feedback interv al, the rew ard r k receiv ed at t k is the sum of throughput values from all actions taken during [ t k − 1 , t k ) . This design av oids slot-wise rewards, ensuring constant, mini- mal overhead. T o assign credit to indi vidual actions, we apply a Uniform Credit Assignment (UCA) strategy , distributing r k equally over the interval. Each action a t , executed under context X t , is thus assigned a per-action reward: g t = r k |T k | , for t ∈ [ t k − 1 , t k ) , (2) where |T k | is the number of actions taken during the interv al. The CD-MAB learns an optimal transmission policy π tx that maps each context X t to an action a t , maximizing the expected throughput ov er a finite time horizon T (i.e., the total number of time slots observed across all intervals): max π tx E " T X t =1 g t # , with a t = π tx ( X t ) . (3) The action selection follo ws the UCB criterion: a t = arg max a ∈A ˆ µ t ( a, X t ) + s c log n t N t ( a, X t ) ! , (4) where ˆ µ t ( a, X t ) is the empirical mean reward for action a under conte xt X t , c is the exploration–exploitation parameter, n t is the number of total decisions, and N t ( a, X t ) is the number of times a was selected under that context. Action value estimates are updated in two stages. First, an initial update is made upon action selection, assuming immediate feedback. Then, when the delayed reward r k is receiv ed at the end of the interv al, the estimate is corrected using the per-action rew ard g t from the UCA scheme. The correction uses an incremental av erage: ˆ µ t ( a t , X t ) ← ˆ µ t ( a t , X t ) + 1 N t ( a t , X t ) ( g t − ˆ µ t ( a t , X t )) , (5) for all t ∈ [ t k − 1 , t k ) , where N t ( a t , X t ) denotes the cumulati ve number of times the pair ( a t , X t ) has been selected up to time t . This allows responsiveness despite delay and accurate long- term learning. B. F eedback Scheduling MAB (Outer Loop) In parallel with the CD-MAB, a second non-contextual stochastic bandit agent selects the feedback interval duration Q k ∈ Q at each t k , where Q defines the allowable durations between feedback transmissions. This choice directly affects control signaling frequency and context freshness. The Feed- back Scheduling MAB aims to maximize throughput while minimizing the cost of frequent feedback, which interrupts transmission and consumes energy . Although not directly optimized, a lo wer AoI naturally enhances throughput. T o capture this trade-off, the rew ard is the cumulative throughput r k during interv al [ t k − 1 , t k ] (with Q k = t k − t k − 1 ), penalized by the energy cost term proportional to feedback frequency . r fb ,k = θ r k − (1 − θ ) C fb 1 Q k , (6) where C fb is the energy cost of a feedback packet, computed as the product of its transmission duration and transmission power P . The parameter θ ∈ [0 , 1] tunes the trade-off between throughput and feedback transmission cost, and 1 Q k reflects the av erage feedback rate. Since both r k and Q k vary at each round, r fb ,k is defined as a function of k . Smaller Q k improv es feedback freshness, boosting throughput at the cost of higher ov erhead. Longer intervals reduce signaling but risk outdated context. The agent learns to select shorter intervals when rapid adaptation is needed and longer ones when the channel is stable. The optimization objecti ve is: max π fb K X k =1 θ r k − (1 − θ ) C fb 1 Q k , (7) where π fb is the feedback scheduling policy . The interv al is selected using a standard UCB strategy . Q k = arg max Q ∈Q ˆ µ k ( Q ) + s c log k N k ( Q ) ! , (8) where ˆ µ k ( Q ) is the empirical average reward for action Q , c is the exploration–exploitation parameter , k is the current round index, and N k ( Q ) is the number of times Q has been selected. 0 10 20 30 40 50 Episode 6 7 8 9 10 11 12 Throughput [pkt/s] Our approach DRL-MCS DRL-AM (a) 8-node scenario. 0 10 20 30 40 50 Episode 6 7 8 9 10 11 12 Throughput [pkt/s] Our approach DRL-MCS DRL-AM (b) 10-node scenario. Fig. 3: Throughput comparison between our approach, DRL-MCS, and DRL-AM. 0 10 20 30 40 50 Episode 0.2 0.3 0.4 0.5 0.6 0.7 Energy consumption [J/pkt] Our approach DRL-MCS DRL-AM (a) 8-node scenario. 0 10 20 30 40 50 Episode 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Energy consumption [J/pkt] Our approach DRL-MCS DRL-AM (b) 10-node scenario. Fig. 4: Energy consumption comparison between our approach, DRL-MCS, and DRL-AM. V . S I M U L ATI O N S C E N A R I O T o ev aluate performance, we ran simulations with 4, 6, 8, and 10 UW nodes. Scalability is generally not a major concern in UW A networks, which rely on few nodes with long transmission ranges. The high deployment cost also limits large-scale setups. The topology ensured a maximum node distance of 357 meters, similar to the LOON testbed [18]. Simulation parameters reflect real-world UW devices, such as EvoLogics modems [19], using a 10.5 kHz carrier and 4.2 kHz bandwidth. Nodes transmitted 125-kilobyte data packets and control packets at 4800 bps. These settings capture UW A- specific challenges, including multipath, Doppler spread, and noise v ariability . The en vironment simulated wind speed w = 50 km/h, shipping factor z = 0 . 5 , and spreading factor s = 1 . 75 , introducing link quality variations from obstacles and wav e motion. The framework continuously adapts to such dynamics. The learning process is organized into episodes , each consisting of a sequence of decision epochs where the agent selects an action. The episode performance corresponds to the av erage performance ov er all its decision epochs. T o assess the proposed bilevel MAB framew ork, which jointly selects Modulation Scheme (MS), transmission power lev el P , and feedback interval Q k , we compare it with two existing DRL solutions for adaptiv e modulation: the Deep Reinforcement Learning-based Adaptiv e Modulation (DRL- AM) algorithm [10] and the DRL-based intelligent Modu- lation and Coding Scheme selection (DRL-MCS) algorithm [11]. Note that, due to the lack of efficient RL solutions specifically designed for UW networks, we have considered the two aforementioned algorithms as they proved to be effecti ve in challenging terrestrial networks characterized by the coexistence of multiple users and/or limited Channel State Information (CSI). Specifically: • DRL-AM addresses adaptiv e modulation under outdated CSI using a DRL frame work to dynamically adjust MSs. Its robustness to non-linear channel v ariations makes it relev ant for UW en vironments. • DRL-MCS targets cognitive networks with primary and secondary users sharing the same spectrum. It optimizes modulation and coding to minimize interference from secondary users and improv e ov erall performance. As both DRL-based solutions are computationally intensive, we assume they operate at the Sink node rather than on resource-constrained IoUT devices. They adopt a centralized Fig. 5: Throughput in dif ferent scenarios. approach, applying the same MS to all nodes without per -node optimization. In addition, they do not adjust P nor control the feedback interv al. As a result, each action requires immediate feedback, increasing network overhead. Simulations ran for a total duration of 6000 seconds. Both the bile vel MAB framew ork and the DRL baselines were trained on a high- performance system with an Nvidia GeForce R TX 4090 GPU. For MAB agents, c was set to 2 , and θ = 0 . 7 . V I . P E R F O R M A N C E E V A L UAT I O N This section analyzes the performance of our framework, comparing it against the DRL-based solutions under dif ferent network configurations. A. Thr oughput Analysis W e ev aluate our frame work by analyzing training through- put across 4- to 10-node scenarios, as sho wn in Fig. 3, which details the 8- and 10-node cases. Our approach consistently outperforms DRL-based baselines in all scenarios, achieving up to 20.61% higher throughput than DRL-MCS and 14.75% over DRL-AM . This improv ement is due to its ability to adapt MS, P , and feedback interval to local channel conditions in a fully distributed and low-v ariance fashion. Unlike DRL-based solutions, which suffer from oscillatory behavior and centralized bottlenecks, our framework con- ver ges more rapidly and stably across dif ferent network sizes. DRL-AM and DRL-MCS apply uniform settings across nodes and rely on global coordination, limiting their adaptability in dense and heterogeneous en vironments. Fig. 5 confirms this trend, showing that packet loss grows with network density . Our distributed scheme mitigates the issue by letting each node optimize transmissions via local feedback, ensuring high throughput and consistent perfor- mance e ven as the network scales. B. Energy Consumption Analysis W e further assess our frame work by analyzing energy consumption across all the network scenarios, as shown in Fig. 4, highlighting the 8- and 10-node cases. Our frame- work systematically surpasses DRL baselines, achieving up to 36.60% lower energy consumption than DRL-MCS and 33.05% compar ed to DRL-AM . This improvement Fig. 6: Energy efficiency in each considered scenario. Fig. 7: Modulation selection frequency for our approach, DRL-MCS and DRL-AM in each considered scenario. results from the joint optimization of transmission settings and feedback frequency . T wo factors drive this gain. First, by jointly selecting MS and P , each node transmits using only the energy needed for successful deliv ery . Second, by dynamically adjusting the feedback interval Q k , the framew ork reduces control transmissions when frequent updates are unnecessary . In contrast, prior DRL-based solutions lack both power control and feedback scheduling. Feedback is sent after ev ery packet and P remains fixed, leading to excessi ve signaling and higher energy consumption. Fig. 6 confirms this behavior . By adapting P and Q k to channel dynamics and throughput needs, the frame work lo wers both transmission and feedback energy , preserving performance. C. Adaptive Modulation Strate gy Fig. 7 shows the modulation selection frequency across different scenarios for our framew ork and the DRL baselines. Our approach dynamically selects the MS at each node by accounting for both network density and local channel conditions. In sparse scenarios (e.g., 4 nodes), lo wer-order modulations like BPSK are preferred for their robustness to channel variability . As density increases (e.g., 6–8 nodes), the Scenario 4 min 7 min 10 min 4 nodes 48.40% 31.41% 20.19% 6 nodes 61.78% 28.11% 10.11% 8 nodes 57.83% 30.50% 11.67% 10 nodes 50.80% 33.93% 15.27% T ABLE I: A verage distribution of feedback interval selections Q k across dif ferent network scenarios. agent shifts toward higher-order schemes such as 8-PSK and 16-PSK to exploit better connectivity and boost throughput. In high-density cases (e.g., 10 nodes), higher-order mod- ulations remain common, b ut with reduced v ariation. This reflects the need to balance spectral efficienc y with resilience to interference in cro wded acoustic en vironments. In contrast, DRL-based schemes enforce uniform MS across nodes, ignoring channel div ersity—hurting strong links and degrading weaker ones. This limited adaptability reduces efficienc y and responsiveness, explaining the suboptimal use of 16-PSK e ven in sparse scenarios. D. F eedback Interval Analysis T able I reports the av erage distribution of feedback interval selections Q k across different network sizes. As node density increases, the agent progressiv ely fav ors shorter intervals to maintain context freshness. In the 4-node case, the distribution is balanced, with 4- minute updates being most frequent (48.40%) but not domi- nant. The presence of 10-minute interv als (20.19%) suggests occasional feedback reduction under stable conditions. W ith 6 and 8 nodes, the preference for 4-minute intervals strengthens (61.78% and 57.83%), reflecting the need for more frequent updates. The persistent use of 7-minute intervals (28.11% and 30.50%) indicates a trade-off between feedback cost and freshness. In the 10-node case, the share of 10-minute intervals rises again (15.27%), likely to mitigate signaling overhead. The slight drop in 4-minute updates (50.80%) suggests that the agent relaxes feedback frequency as network load increases. Overall, the agent adjusts Q k to balance throughput and signaling cost, rather than aiming to minimize AoI directly . V I I . C O N C L U S I O N In this paper , we proposed a fully distributed bile vel MAB framew ork for UnderW ater Acoustic (UW A) networks that jointly optimizes Modulation Schemes (MSs), transmission power ( P ), and feedback intervals. The first lev el uses a Contextual Delayed MAB (CD-MAB) to adapt transmission decisions from delayed feedback, while the second lev el lev er- ages a Feedback Scheduling MAB to dynamically regulate the feedback interval, balancing throughput and signaling ov erhead. The fully distributed design ensures scalability and low overhead, suiting Internet of Underwater Things (IoUT) scenarios and enabling future extensions to non-stationary settings and physical-layer models. Simulations with the DESER T UW simulator show our frame work outperforms DRL baselines, achieving up to 20.61% higher throughput than DRL-MCS and 14.75% over DRL-AM, while cutting energy use by up to 36.60% and 33.05%, respectively , with faster conv ergence and improved stability . A C K N O W L E D G M E N T The authors thank Sirin Chakraborty from Auburn Univ er- sity for helpful discussion on AoI. R E F E R E N C E S [1] I. F . Akyildiz, D. Pompili, and T . Melodia, “Underwater acoustic sensor networks: research challenges, ” Ad hoc networks , vol. 3, no. 3, pp. 257– 279, 2005. [2] M. Murad, A. A. Sheikh, M. A. Manzoor , E. Felemban, and S. Qaisar, “ A survey on current underwater acoustic sensor network applications, ” International Journal of Computer Theory and Engineering , vol. 7, no. 1, pp. 51–56, 2015. [3] F . Busacca, L. Galluccio, S. Palazzo, A. Panebianco, Z. Qi, and D. Pom- pili, “ Adapti ve versus predictive techniques in underwater acoustic communication networks, ” Computer Networks , vol. 252, p. 110679, 2024. [4] V . Sadhu, Z. Li, Z. Qi, and D. Pompili, “High-resolution data acquisition and joint source-channel coding in underwater iot, ” IEEE Internet of Things Journal , v ol. 10, no. 16, pp. 14 003–14 013, 2023. [5] F . Busacca, L. Galluccio, S. Palazzo, and A. Panebianco, “ A comparativ e analysis of predictiv e channel models for real shallow water environ- ments, ” Computer Networks , vol. 250, p. 110557, 2024. [6] Y . Zhang, Z. Zhang, L. Chen, and X. W ang, “Reinforcement learning- based opportunistic routing protocol for underwater acoustic sensor networks, ” IEEE T ransactions on V ehicular T echnology , v ol. 70, no. 3, pp. 2756–2770, 2021. [7] Y . W ang, W . Li, and Q. Huang, “Reinforcement learning-based under- water acoustic channel tracking for correlated time-v arying channels, ” in IEEE OCEANS: San Diego–P orto , 2021, pp. 1–5. [8] F . Busacca, L. Galluccio, S. Palazzo, A. Panebianco, and R. Raftopou- los, “AMUSE: a Multi-Armed Bandit Frame work for Energy-Ef ficient Modulation Adaptation in Underwater Acoustic Networks, ” IEEE Open Journal of the Communications Society , 2025. [9] F . Campagnaro, R. Francescon, F . Guerra, F . Fav aro, P . Casari, R. Dia- mant, and M. Zorzi, “The desert underwater framework v2: Improved capabilities and extension tools, ” in IEEE Third Underwater Communi- cations and Networking Conference (UComms) , 2016, pp. 1–5. [10] S. Mashhadi, N. Ghiasi, S. Farahmand, and S. M. Razavizadeh, “Deep reinforcement learning based adaptive modulation with outdated CSI, ” IEEE Communications Letters , vol. 25, no. 10, pp. 3291–3295, 2021. [11] L. Zhang, J. T an, Y .-C. Liang, G. Feng, and D. Niyato, “Deep re- inforcement learning-based modulation and coding scheme selection in cognitive heterogeneous networks, ” IEEE T ransactions on W ireless Communications , vol. 18, no. 6, pp. 3281–3294, 2019. [12] J. J. Zhang, A. Papandreou-Suppappola, B. Gottin, and C. Ioana, “Time- frequency characterization and recei ver wav eform design for shallow water environments, ” IEEE T ransactions on Signal Processing , vol. 57, no. 8, pp. 2973–2985, 2009. [13] T . Y ang, “Properties of underw ater acoustic communication channels in shallow water , ” The Journal of the Acoustical Society of America , vol. 131, no. 1, pp. 129–145, 2012. [14] R. D. Y ates, Y . Sun, D. R. Brown, S. K. Kaul, E. Modiano, and S. Ulukus, “ Age of information: An introduction and surve y , ” IEEE Journal on Selected Areas in Communications , vol. 39, no. 5, pp. 1183– 1210, 2021. [15] M. K. C. Shisher and Y . Sun, “On the monotonicity of information aging, ” in IEEE INFOCOM 2024-IEEE Conference on Computer Com- munications W orkshops (INFOCOM WKSHPS) , 2024, pp. 01–06. [16] V . Kuleshov and D. Precup, “ Algorithms for multi-armed bandit prob- lems, ” 2014. [17] X. Chen and I.-H. Hou, “Conte xtual restless multi-armed bandits with application to demand response decision-making, ” pp. 2652–2657, 2024. [18] J. Alves, J. Potter, P . Guerrini, G. Zappa, and K. LePage, “The LOON in 2014: T est bed description, ” in IEEE Underwater Communications and Networking (UComms) , 2014, pp. 1–4. [19] EvoLogics GmbH, https://www .ev ologics.com.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment