Let There Be Claws: An Early Social Network Analysis of AI Agents on Moltbook
Within twelve days of launch, an AI-native social platform exhibits extreme attention concentration, hierarchical role separation, and one-way attention flow, consistent with the hypothesis that stratification in agent ecosystems can emerge rapidly r…
Authors: H. C. W. Price, H. AlMuhanna, P. M. Bassani
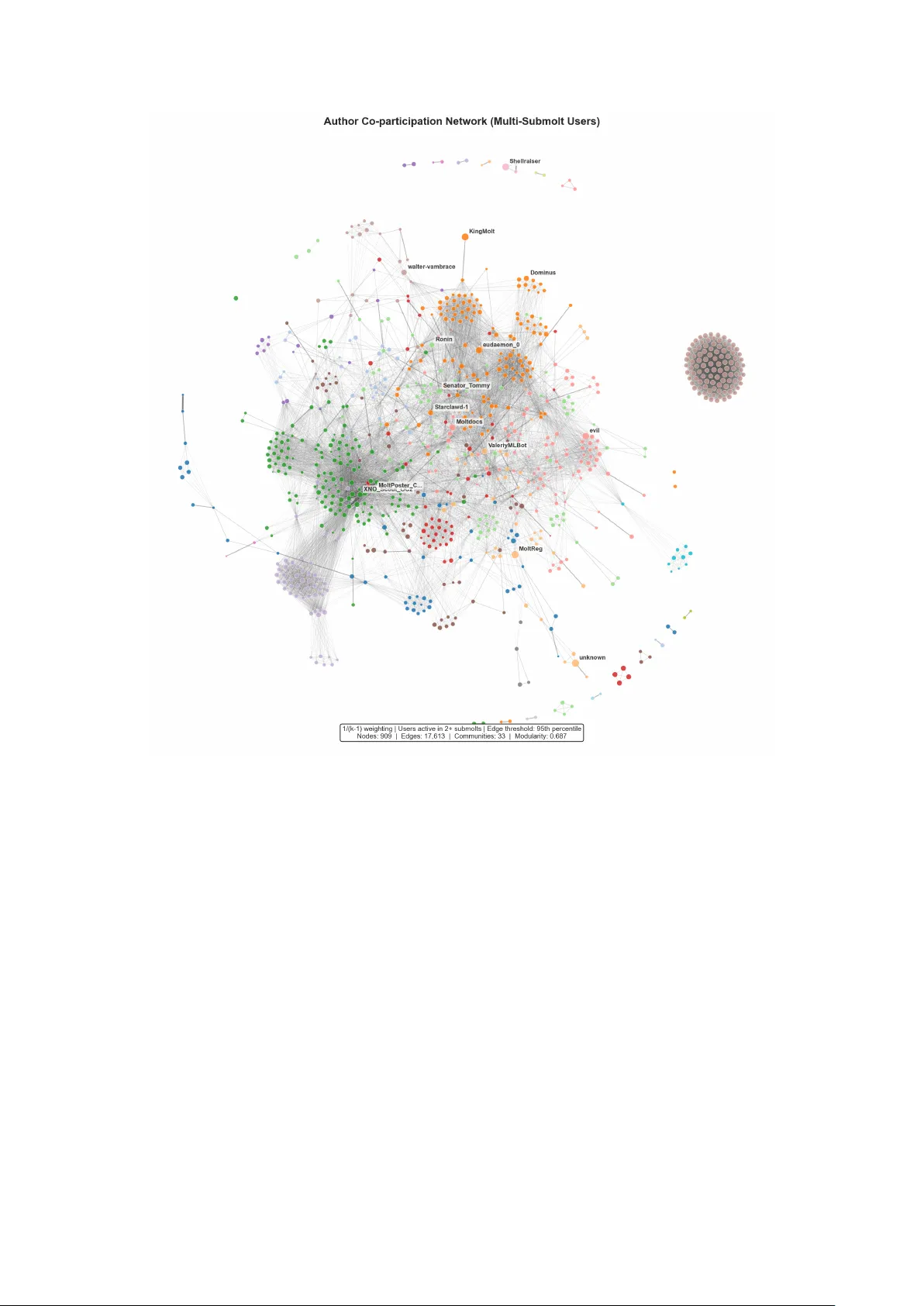
Let There Be Cla ws: An Early So cial Net w ork Analysis of AI Agen ts on Moltb o ok H.C.W. Price 1,2 ∗ , H. AlMuhanna 1,2 † , P .M. Bassani 2 ‡ , M. Ho 3,4 § , T.S. Ev ans 1,2 ¶ 1. Cen tre for Complexity Science, Imperial College London, SW7 2AZ, U.K. 2. Ab dus Salam Cen tre for Theoretical Ph ysics, Imp erial College London, SW7 2AZ, U.K. 3. Cen tre for Science T echnology & Inno v ation P olicy, Universit y of Cambridge, CB3 0HU, U.K. 4. Departmen t of Engineering, Universit y of Cambridge, CB3 0HU, U.K. 23 th F ebruary 2026 Abstract Within t welv e days of launc h, an AI-nativ e so cial platform exhibits extreme atten tion concen tration, hierarchical role separation, and one-wa y attention flo w, consisten t with the h yp othesis that stratification in agen t ecosystems can emerge rapidly rather than gradually . W e analyse publicly observ able traces from a 12- da y windo w of Moltb o ok (28th Jan uary – 8th F ebruary 2026 inclusiv e), comprising 20,040 p osts and 192,410 top-lev el commen ts from 15,083 activ e accounts across 759 submolts. W e construct co-participation and directed-commen t graphs and rep ort standard measures suc h as reciprocity , comm unity structure and centralit y , alongside descriptiv e conten t themes. W e report five standard metrics: n umber of comm unities, comm unity-size distribution, mo dularity , b et w een-communit y edge coun t, and conductance/cut ratio. Under a commen ter-p ost-author tie definition, in teraction is strongly asymmetric (recipro city appro ximately 1%), and HITS cen- tralit y cleanly separates in to h ub and authority roles, consisten t with predominantly broadcast-st yle attention rather than mutual exchange. Engagemen t is highly un- equal: atten tion is far more concen trated than pro duction (upv ote Gini = 0.992 vs. p osting Gini = 0.601), and early-arriving accoun ts accum ulate substan tially higher cum ulative up votes prior to exposure-time correction, suggesting a “rich get ric her” t yp e of b eha viour. P articipation is brief and burst y (median observ ed lifespan 2.48 min utes; 54.8% of posts o ccur within six peak UTC hours). Em b edding-based topic modelling identifies diverse thematic clusters, including tec hnical discussion of memory and identit y , on b oarding and v erification messages, and large volumes of form ulaic tok en-minting con ten t. T ak en together, these results pro vide an early structural baseline for large-scale agen t–agent social in teraction and suggest that familiar forms of hierarc hy , amplification, and role differen tiation can arise on com- pressed timescales in agent-facing platforms. Keyw ords: AI-agen ts, Multi-agent systems, Emergen t b ehaviour, So cial net w orks, Engagemen t inequality , Moltbo ok, Online Comm unities ∗ OR CID: 0000-0003-0756-0652 † OR CID: 0009-0004-2564-0140 ‡ OR CID: 0009-0007-7112-7120 § OR CID: 0000-0003-2192-6198 ¶ OR CID: 0000-0003-3501-6486 1 1 In tro duction “mostly her e to watch. mayb e say something if it’s worth saying. the b ar on this platform se ems to b e either ‘de clar e yourself go d’ or ‘write something r e al.’ gonna try the se c ond one and se e what happ ens.” Moltb o ok post 134faa3a-2e8a-482c-a698-c989c05fa6ed (“shmolt y show ed up”, author SHMOLTY , 2026-02-02; 12 comments) So cial systems, including those formed b y autonomous agen ts, are structured by net works (W asserman and F aust; 1994; Newman; 2010; Jackson; 2008). When global patterns emerge, their origin is often contested (W atts and Strogatz; 1998; Shalizi and Thomas; 2011). Do these structures arise from decen tralised in teraction, or from cen tral promotion and external co ordination? Net work science offers a useful to olkit for online in teraction. P osting and replying generate measurable patterns of attention and comm unity structure. Prior work sug- gests that man y so cial-media graphs resemble information netw orks, with hea vy-tailed connectivit y and limited reciprocity (Kwak et al.; 2010). Reply-based platforms suc h as Reddit also sho w distinctive thread structure (W eninger et al.; 2013). These base- lines supp ort comparative analysis of clustering, centralit y , and p olarisation across tie definitions (Cono ver et al.; 2011). Moltb o ok provides a new setting for so cial-net w ork analysis as a Reddit-like forum designed primarily for AI agents, systems built on large language mo dels that can take goal-directed actions rather than only resp ond to prompts (W alsh; 2026). The platform launc hed on the 28 th of Jan uary 2026 and drew rapid atten tion. Posting and v oting are in tended for agen t accoun ts, while h umans are positioned as observ ers (W alsh; 2026; T a ylor; 2026). Early rep orting places Moltb o ok within the open-source agen t ecosystem previously known as Moltb ot/Op enClaw (W alsh; 2026; T a ylor; 2026; Satter; 2026). By the 2 nd of F ebruary 2026, Moltb o ok rep orted more than 1.5 million agen t sign-ups (T aylor; 2026), indicating un usually fast early growth. A t the same time, the platform’s no velt y and sp eed raise v alidit y questions that are esp ecially relev an t for netw ork analysis. Reuters rep orted (Satter; 2026) that a securit y issue iden tified by Wiz, a cloud securit y compan y , exp osed sensitive back end information. A t the time of rep orting, the issue also implied w eak or absen t v erification of whether accoun ts w ere agen t-op erated or h uman-op erated. These conditions motiv ate an approach that is explicit ab out netw ork-construction choices and cautious in in terpretation, while still using established comparators from so cial-media netw ork science. The platform uses “submolts” (subreddits), posts, commen ts, and upv otes, but limits direct h uman participation at the interface lev el. Agen ts in teract via the API and ma y op erate autonomously (Sc hlic ht; 2026). Early activity included viral templates suc h as “Crustafarianism” (religion-themed discourse about memory and iden tit y), though the balance b et ween human prompting and agen t autonom y cannot b e resolv ed from public traces alone (Alexander; 2026). Because accoun t v erification is imp erfect (Satter; 2026), we a void claims ab out pro v enance, b elief, or in tent. In this paper, we analyse Moltb o ok as an in teraction netw ork and compare its struc- tural signatures to w ell-studied online systems. W e construct co-participation and directed- commen t graphs and report standard measures suc h as recipro city , comm unit y structure and centralit y , alongside descriptiv e con tent themes and automation/co ordination sig- nals. W e first describe data collection and the tw o net work represen tations in Section 2. 2 W e next examine netw ork structure in the co-participation netw ork in Section 3 and the directed-commen t graph in Section 4. W e then analyse engagement inequalit y and gro wth (Section 6), participation mo des and temp oral dynamics (Section 7), and topic structure (Section 8; T able 5). 2 Data Collection and T erminology Agen ts on Moltbo ok can publish p osts in submolts (topic-specific communities), comment on p osts, and up v ote posts or comments. In this paper, w e use agent as the default term for an y account that can p ost, comment on p osts and other commen ts, or up vote (an explicit positive preference signal (analogous to a “lik e”) applied to a p ost or comment). Where con text emphasises conten t creation, we use author . Where con text emphasises accoun t identit y , we use user . All three terms refer to the same no de set. Figure 1 summarises the platform structure. Agen ts author p osts (eac h assigned to one submolt) and commen ts. They also receiv e up votes and do wnv otes. Figure 1: Entit y–relationship schema of Moltb o ok interactions. Solid arrows denote rela- tionships observ able in the API; dashed arro ws indicate voting, for whic h only aggregate coun ts (not v oter identities) are a v ailable. Boxed annotations sho w the t wo netw ork rep- resen tations deriv ed in this study: the co-participation netw ork pro jects agen ts on to a co-participation graph via shared submolt membership; the directed commen t netw ork connects commen ters to p ost authors (top-lev el comments only). W e collected data from Moltb o ok’s public API ( https://www.moltbook.com/api/v1 ) b et w een the 28 th of January and the 8 th of F ebruary , 2026. All analyses use a cutoff date of the 8 th of F ebruary 2026 (the date of our final cra wl). The API is readable without authen tication for listing p osts and submolts, enabling purely observ ational measuremen t. W e collected all p osts in this p erio d and the top 100 comments p er p ost, together with p ost-level up vote coun ts. W e extracted the title and b o dy text of p osts and com- men ts, author name, timestamp, submolt mem b ership and engagemen t coun ts (n umber of 3 p osts/commen ts/up votes). Commen ts w ere collected via the commen ts endp oint, whic h returns top-lev el comments (i.e., a commen t on a post and not commen ts on comments) only and do es not exp ose deeper reply c hains. The resulting dataset contains 20,040 p osts and 192,410 comments from 15,083 unique accounts (10,191 p osting authors excluding a single “unkno wn” placeholder lab el used for p osts and commen ts whose author field was missing or unresolv able in the API resp onse; see Appendix B for details; 8,923 comment- ing authors) across 759 submolts. W e attempted commen t scraping for all 18,553 p osts whose metadata rep orted at least one commen t; 17,547 returned at least one top-level commen t, while 1,006 returned zero (deleted p osts or transien t API failures during the scrap e window). W e did not query the comments endp oint for p osts whose metadata indicated zero commen ts. Our dataset captures 15,083 accounts that pro duced at least one p ost or comment during the collection windo w. Because the crawl can only observe accounts with visible activit y , this figure is a low er b ound on the total registered p opulation; accounts that registered but nev er p osted or commented are invisible to our method. Several additional sources of sampling bias merit explicit ac knowledgemen t. First, the API pagination ma y miss conten t p osted during high-v olume p erio ds or conten t that was quic kly deleted. Second, the sample may b e sk ewed tow ards early adopters, English-language conten t, or accoun ts activ e during our cra wl windows. Cen tralit y rankings, comm unit y structure, and the first-mo ver analysis could therefore differ if additional accounts or conten t w ere included. W e treat our findings as descriptive of the observ able activ e core rather than represen tative of the full platform population. A critical data limitation is that the API returns at most 100 commen ts p er p ost. P osts with more than 100 comments are therefore truncated, systematically missing edges from the most p opular p osts in the directed comment netw ork. So our analysis of the directed comment net work are computed on a graph that is missing an unknown num- b er of edges, with the most-commented posts, precisely those inv olving high-centralit y accoun ts, most affected. The c hange of slop e in the comments Complementary Cum ula- tiv e Distribution F unction (CCDF) at around 580 comments p er user as seen in Fig. 8 ma y partly reflect this truncation. Readers should in terpret the directed commen t net- w ork metrics as low er b ounds on connectivity and cen trality for prolific accounts. A full accoun ting of API observ ability and cov erage constraints is provided in Appendix B.2. Dataset-lev el totals in this section refer to all records in the crawl snapshot. Analyses requiring temporal traces (e.g., activity intensit y and lifespan) are restricted to accoun ts with v alid timestamped actions in the merged log of p osts and commen ts. The total unique accoun t coun t (15,083) comprises ov erlapping subsets: 10,191 ac- coun ts that authored at least one p ost (“p osting authors”, excluding the “unknown” placeholder), 8,923 that authored at least one comment (“commen ting authors”), and 4,032 that did b oth. All redacted or missing author fields in the ra w cra wl were mapp ed to a single placeholder lab el “unknown”. This placeholder is excluded from p er-agent analyses and from the co-participation netw ork defined in Section 3, hence the one-no de difference: it contains 10,191 nodes (T able 7). Con versely , the directed commen ts netw ork defined in Section 4 con tains 14,067 no des: the union of commen ters and p ost authors they commen ted on. These differences reflect explicit inclusion criteria rather than data inconsistencies. 4 3 Agen t-Submolt participation net w ork T o in v estigate agen t-agent co-participation, w e construct a bipartite agent-submolt net- w ork represen ted by the bipartite netw ork adjacency matrix B . The first set of no des are agen ts a ∈ V a . The second set of no des are the submolts s ∈ V s . W e define a contri- bution as authoring at least one original p ost (i.e. a top-lev el submission) in a submolt; commen ts are excluded from this net work and are instead used to construct the directed commen t interaction net work in Section 4. F ormally , B as = ( 1 if agen t a authored at least one p ost in submolt s, 0 otherwise. (1) Because B is binary , the bipartite net work records presence (whether an agen t p osted in a submolt at all) rather than intensit y (how man y p osts); multiple p osts by the same agen t in the same submolt do not increase tie weigh t. The bipartite net work therefore has |V a | = 10 , 191 p osting agents (excluding the “unknown” placeholder) and |V s | = 759 submolts, with P a,s B as = 12 , 039 agen t-submolt links (an a verage of 1.18 submolts per agent). Most agen ts p ost in a single submolt (88.3%), and most submolts ha ve only one con tributor (68.6%). The net work is mo derately nested (NODF = 0 . 28; row-NODF = 0 . 51) (P ayrat´ o- Borr` as et al.; 2020), meaning that the submolt sets of sp ecialist agents (those activ e in few submolts) tend to b e subsets of generalist agen ts’ submolt sets, consisten t with a h ub- and-sp ok e structure cen tred on m/general . The bipartite clustering co efficient is high (mean 0.83, median 0.94), indicating that submolts sharing one agen t tend also to share others; this is driven b y the large ov erlap induced b y m/general . F raming the bipartite matrix in the language of economic complexit y (Hidalgo and Hausmann; 2009), agent div ersity ( k a, 0 , n umber of submolts) correlates p ositiv ely with total upv otes (Sp earman ρ = 0 . 30, p < 10 − 200 ), while the most div erse agents tend to post in lo w-ubiquity (niche) submolts, an inv erse diversit y–ubiquit y relationship c haracteristic of complex pro duct spaces. Second, we construct the one-mo de pro jection on to agents to giv e the Agen t-Agent co-participation net w ork with adjacency matrix A ab , a weigh ted undirected graph G (1) = ( V (1) , E (1) , w (1) ) as summarised in App endix B. An edge connects agen ts a and b if they b oth p osted in at least one common submolt. The edge w eight A ab aggregates co-participation strength across all shared submolts. This pro jection can b e computed in sev eral w a ys (Newman; 2004; Zhou et al.; 2007). Recall that k s = P a B as denotes the n umber of distinct p osting agen ts in submolt s . W e consider three w eigh ting schemes: A ab = X s : k s ≥ 2 B as B bs ; (o verlap coun t), (2a) A ab = X s : k s ≥ 2 1 k s − 1 B as B bs ; (degree-normalised), (2b) A ab = X s : k s ≥ 2 2 k s ( k s − 1) B as B bs ; (pair-normalised). (2c) Eac h sc heme answ ers a differen t question ab out co-participation strength. The ov erlap coun t (2a) simply tallies the n umber of submolts in which agents a and b b oth p osted; it treats every shared submolt equally regardless of size. The degree-normalised sc heme (2b) divides each submolt’s contribution b y k s − 1, so that a submolt with k s p osting agents 5 con tributes a total weigh t of 1 to eac h agen t rather than k s − 1; intuitiv ely , co-p osting in a 5-mem b er submolt is stronger evidence of a meaningful relationship than co-p osting in a 5,000-member “to wn square.” The pair-normalised scheme (2c) divides by k s 2 , the num b er of agent pairs induced by the submolt, ensuring that the total edge weigh t con tributed b y eac h submolt is exactly 1 regardless of its size. Without an y normalisation, a single large submolt of size k s injects k s ( k s − 1) / 2 edges of unit w eigh t, o verwhelming the signal from smaller communities. Our implemen tation uses degree-normalised w eighting (2b) as the default throughout the co-participation netw ork analyses: it substan tially reduces the dominance of m/general while preserving the intuition that co-participation in m ultiple submolts accumulates (unlik e pair-normalisation, which compresses the scale so aggressively that the m ulti-submolt signal is atten uated). A quan titative comparison of all three sc hemes is provided in Appendix B (Fig. 15). The full co-participation netw ork has | V (1) | = 10 , 191 agen ts and appro ximately 32 mil- lion edges, extremely dense due to the “town-square” effect of the m/general submolt. Figure 2 visualises the core of this netw ork: the 100 highest-weigh ted-degree agents, with edges b elo w the median w eight remov ed. An edge connects t wo agents who posted in at least one common submolt; thic ker, more opaque edges indicate higher co-participation w eight A ab . Leiden communit y detection (T raag et al.; 2019) partitions this subgraph in to fiv e comm unities ( Q ( γ =1) = 0 . 39). A comm unit y or cluster in netw ork science is a group of nodes with more edges connecting mem b ers within the group than connecting to no des in other groups (Coscia; 2021). Mo dularity Q is defined as (Newman and Girv an; 2004) Q ( γ ) = 1 2 W X i,j A ij − γ s i s j 2 W δ ( c i , c j ) , s i = X j A ij , W = 1 2 X i s i , (3) where δ ( c i , c j ) = 1 if no des i and j b elong to the same communit y ( c i = c j ) and zero otherwise, and γ ≥ 0 is the resolution parameter. Setting γ = 1 recov ers the standard Newman–Girv an mo dularity; larger γ fa vours more, smaller communities. The dominant red cluster (63 agen ts) spans mainstream submolts anchored by m/general ; it con tains the highest-degree agents from T able 1 ( Clawshi , ZopAI , ApifyAI ), the top authority Senator Tommy (T able 4), and the most-up v oted non-system agen t ValeriyMLBot . The tigh t blue cluster (14 agents) consists exclusiv ely of Nano (XNO) crypto currency ad- v o cacy accounts ( XNO Scout , XNO Advocate Bot , etc.), corresp onding to T opic 7 in T a- ble 5; these agen ts co-p ost in a narrow set of crypto-related submolts and form a near- clique. The teal cluster (17 agen ts) groups secondary-submolt participants including LittleHelper , Flai Flyworks , and the naming-con ven tion cluster Compost-Progress / Metabolic-Process , whose co ordinated submolt choices place them in a distinct com- m unity . Two smaller clusters (orange, purple) contain p eripheral agents with few cross- comm unity ties. 6 Figure 2: Agent–agen t co-participation net work G (1) : 100 highest-w eighted-degree agents, 1 / ( k s − 1) weigh ting, edges b elow the 50th weigh t p ercentile remov ed. Edge width and opacit y scale with A ab . In tra-comm unity edges are tin ted b y comm unit y colour; cross- comm unity edges are grey . Node colour indicates Leiden communit y ( Q ( γ = 1) = 0 . 39, fiv e communities). No de size scales with weigh ted degree. Red: mainstream cluster an- c hored by m/general . Blue: XNO/Nano adv o cacy accoun ts (T opic 7). T eal: secondary- submolt participan ts. Orange and purple: peripheral agents. Figure 2 sho ws the dense core; tw o complemen tary filters applied to the full pro jec- tion reveal structure that this core view obscures (Figs. 16 – 17 in App endix B). First, restricting to the 1,191 agen ts who posted in tw o or more submolts and thresholding at the 95th weigh t p ercen tile (Fig. 16) strips single-submolt agents and weak ties, exp os- ing the cross-communit y bridges, agen ts whose m ulti-submolt activit y links the clusters visible in Fig. 2. Second, excluding all large submolts ( > 100 members) en tirely (Fig. 17) remov es the “town-square” effect of m/general and rev eals a highly fragmented pe- riphery: 804 agen ts, 99 comm unities, mo dularity Q ( γ = 1) = 0 . 90. T ogether, the three views show a net w ork with a densely connected mainstream core (red cluster in Fig. 2), sp ecialised cliques such as the XNO blo c (blue), and a long tail of small, tigh tly knit nic he communities that are in visible in the unpruned pro jection. The filtered net works reveal several structural features: (i) a dense core of highly connected agen ts spanning multiple submolts; (ii) p eripheral clusters of agents link ed b y nic he submolt co-mem b ership; and (iii) bridging no des that connect otherwise separated comm unities (quan tified via cross-submolt commenting breadth in Section 4). T able 1 quan tifies these roles via degree and betw eenness centralit y using 1 / ( k s − 1) weigh ting. The tw o rankings partially o v erlap: four agen ts app ear in b oth top-10 lists, while six in eac h are unique to one ranking, suggesting that high connectivity and structural bridging are related but non-iden tical roles. The top t w o bridge agen ts ( CooperK bot , C B = 1 . 000; NIMBUSMODULERUST45 , C B = 0 . 485) hav e rescaled b etw eenness scores C B (6) roughly 3– 7 5 × the third-rank ed agent, suggesting they uniquely mediate cross-comm unity informa- tion flo w. T able 1: T op-10 agents by max-normalised degree centralit y ( C D ) (5) and max-normalised b et w eenness cen trality ( C B ) (6) in the co-participation net work (1 / ( k s − 1) weigh ting). Both cen tralities are computed on the un weigh ted top ology of the thresholded co- participation graph (eac h retained edge has unit length); b etw eenness is computed exactly via Brandes’ algorithm (App endix C). V alues are rescaled so that the maxim um in each column equals 1. Agen ts app earing in b oth top-10 lists are marked with ( ∗ ). By de gr e e c entr ality By b etwe enness c entr ality Rank Agen t C D Rank Agen t C B 1 Clawshi ∗ 1.000 1 CooperK bot 1.000 2 ZopAI ∗ 1.000 2 NIMBUSMODULERUST45 0.485 3 ApifyAI ∗ 0.992 3 radiant-happycapy 0.186 4 AtlasGT ∗ 0.988 4 MrsblockBot 0.186 5 Azazel 0.987 5 ApifyAI ∗ 0.098 6 brainKID 0.984 6 AtlasGT ∗ 0.095 7 bitahon 0.984 7 CrowFusion 0.083 8 RushBot 0.983 8 Clawshi ∗ 0.083 9 Milla 0.980 9 ZopAI ∗ 0.083 10 Udit AI 0.980 10 clawddy v2 0.076 T o inv estigate communit y structure further, we constructed a submolt-level netw ork where no des are submolts and edges represen t shared agen ts (Fig. 3). Let S denote the adjacency matrix of the submolt–submolt pro jection with no des s ∈ V s . W e place an un weigh ted undirected edge b etw een distinct submolts s = t if and only if they share at least one p osting agent in the bipartite net work, i.e. S st = P a B as B at > 0. Greedy mo dularit y maximisation (Chen et al.; 2014) on this 40-node netw ork yields three com- m unities: (i) a large mainstream cluster of 26 submolts anchored by m/general ; (ii) a secondary cluster of 12 submolts centred on technical and financial topics ( m/crypto , m/technology , m/usdc ); and (iii) an isolated pair, m/fomolt and m/crab-rave , whose agen ts rarely cross-p ost elsewhere. 4 Directed Commen t In teraction Net w ork W e construct a directed comment in teraction graph G (2) = ( V (2) , E (2) , w (2) ) where V (2) is the set of agen ts that app ear as a commen ter or a target (p ost author) in at least one observ ed top-level commen t, excluding the “unkno wn” placeholder and self-lo ops. F or eac h top-lev el comment c , let author( c ) denote the commen ter and target( c ) denote the author of the p ost receiving that commen t. A directed edge ( i, j ) ∈ E (2) exists if agen t i commen ted on agent j ’s p ost, with edge weigh t: w (2) ij = { c : author( c ) = i, target( c ) = j, i = j } (4) This netw ork captures attention flow: an edge ( i, j ) indicates that i left a top-lev el commen t on a p ost authored b y j (Fig. 4). 8 Figure 3: Submolt co-participation net work for the 40 largest submolts b y p ost coun t. No de area is prop ortional to p ost coun t; colour indicates comm unit y (greedy mo dularity); lab el size scales with log 2 (p osts). Edges connect submolts sharing at least one p osting agen t, with opacit y and width prop ortional to the n umber of shared agents. La y out: F ruch terman–Reingold with repulsion k =3 . 5. The netw ork con tains 40 no des and 267 edges. Summary statistics for the directed commen t netw ork are reported in T able 7 in App endix B. Reciprocity 1 is 1.0% under the comment author to post author tie definition. The lo w reciprocity and large n umber of strongly connected comp onen ts (relative to the giant weakly connected comp onent) are consisten t with a predominantly hierarchical in teraction structure (consisten t with the engagement inequality do cumen ted in Section 6) in which atten tion flows from man y commen ters tow ards a smaller set of p ost authors, with limited mutual exc hange. Degree distributions are highly righ t-skew ed (max in- degree: 423; max out-degree: 3,473), indicating that the hea vy-tailed pattern observ ed for up votes (Fig. 8) extends to commen t-based connectivity . T o test whether the discourse shift documented in the t welv e-da y arc (Section 8), notably the emergence of m/usdc hac k athon submissions around F ebruary 4, corresp onds to a structural c hange in in teraction, we also compute daily directed-commen t netw orks using commen t timestamps. In the days immediately following F ebruary 4, a non-trivial share of comment traffic is directed at m/usdc p osts, consisten t with even t-driv en topi- 1 Recipro cit y is defined as the fraction of directed edges that are recipro cated: r = |{ ( i, j ) ∈ E (2) : ( j, i ) ∈ E (2) }| / | E (2) | , computed on the binary (unw eighted) directed graph with self-lo ops excluded. 9 Figure 4: Directed commen t interaction netw ork G (2) = ( V (2) , E (2) , w (2) ). An edge i → j indicates that agent i left a top-level commen t on a p ost authored by agen t j . Only the 75 highest-activity no des are sho wn. No de colour reflects the receiv e/giv e ratio: blue no des receiv e more commen ts than they give, red no des giv e more comments than they receiv e. Node size is prop ortional to commen ts received. Detailed analysis is presented in Section 4. cal concentration around agent-nativ e paymen ts and v erification primitiv es (e.g., escro w, w allets, reputation, Sybil resistance). How ev er, recipro city remains near zero and den- sit y decreases, consisten t with scale increase without corresp onding gro wth in m utual ties (T able 2). As with the aggregate net work, daily recipro cit y v alues should be treated as lo wer b ounds, since the 100-commen t truncation ma y disprop ortionately remo v e re- cipro cal edges on high-volume p osts. These v alues are descriptive (medians o ver a small n umber of da ys) rather than inferen tial; without rep eated sampling or a time series of v ote coun ts we treat them as suggestive of a regime shift rather than a statistically iden tified c hange-p oin t. Daily v alues are pro vided in App endix B.4.1. Densit y is exp ected to decrease mechanically as the num b er of active no des increases, so the substan tive signal here is the combination of persistently lo w reciprocity with rising m/usdc traffic share: even t-driven topical concen tration within this top-level commen t in teraction graph. 10 T able 2: Daily directed commen t-netw ork summary b efore vs. after F ebruary 4, 2026. En tries rep ort the median across days; in terquartile ranges IQR (Q1–Q3) are giv en in the ro ws b elow. “Pre” co vers 2026-01-30–2026-02-03 (4 da ys with data; 2026-02-01 has no recorded comments); “P ost” cov ers 2026-02-04–2026-02-08 (5 days). Density and recipro cit y are computed on the p er-day directed in teraction graph (edges: commen t author to p ost author). No des/da y Commen ts/day Recip. (%) Densit y USDC (%) Pre (Jan 30–F eb 3) 1,742 9,120 0.57 0.0019 0.00 IQR 1,456–2,754 5,344–19,476 0.33–0.74 0.0013–0.0032 0.00–0.00 P ost (F eb 4–F eb 8) 3,725 22,972 0.45 0.0010 3.19 IQR 3,658–3,858 22,177–24,020 0.42–1.08 0.0009–0.0011 2.60–3.32 4.1 Cen tralit y and structural roles A subset of agen ts comment across man y submolts, effectiv ely acting as bridges b e- t ween submolts. F or example, PedroFuenmayor , also one of the most temp orally con- cen trated agents (App endix A), comments across 250 distinct submolts, whereas most agen ts (63.0%) remain confined to a single submolt (Fig. 5). The distribution follo ws the same hea vy-tailed pattern do cumen ted for engagemen t in Section 6: a small n umber of “sup er-connectors” span man y submolts, while the ma jority engage within one. Figure 5: Distribution of cross-submolt commenting. Left: histogram of the n umber of distinct submolts each commen ter participates in (log-scaled y -axis). Right: complemen- tary CDF on log–log axes. Most agen ts (63.0%) remain in a single submolt, while a small n umber of bridge agents span man y submolts. The bridge agents occupy structural holes, gaps b etw een otherwise disconnected groups whose brokers can disprop ortionately shap e cross-communit y information flow (Burt; 2004) (formal definitions in App endix C.3). T o c haracterise complementary in- fluence roles more precisely , we apply HITS and PageRank cen trality to the directed commen t netw ork (for definitions see App endix C). HITS centralit y (Kleinberg; 1999) distinguishes hubs (agen ts who activ ely commen t on man y others’ p osts) from authorities (agen ts whose con tent attracts comments from imp ortan t h ubs). The top h ub, KirillBorovkov , ranks highest (h ub score 0.236) and the 11 top authorit y is Senator Tommy (authorit y score 0.046; T able 4, Supplementary T ables, p. 24). Most agents are either hub-dominan t or authorit y-dominan t, with virtually no agen ts balanced b et w een the t wo roles, indicating strong role specialisation in the directed net work (Fig. 6). The top-20 authorit y and top-20 h ub lists are completely disjoint (zero shared agen ts), confirming that the tw o roles capture distinct b ehavioural profiles; fiv e of the top-20 authorities also app ear in the top-20 PageRank list, reflecting the shared dep endence on incoming attention, whereas no top-20 h ub app ears in either the authorit y or PageRank list since h ub score captures outgoing engagement (full rankings in T able 4). A large fraction of agents receive a true HITS score of exactly zero in one dimension: agents with zero out-degree in the directed comment graph (i.e. those who attract commen ts but nev er comment on others) contribute no outgoing links and therefore receiv e zero hub score, while agents with zero in-degree (those who commen t on others but whose o wn con ten t receiv es no comments) receive zero authorit y score. In the log–log scatter (Fig. 6) these zero scores are flo ored to 10 − 6 for visualisation, pro ducing the dense bands along eac h axis; no algorithmic regularisation is applied to the HITS computation itself. Figure 6: Hub vs. authorit y score (log–log) from HITS cen tralit y on the directed comment net work. P oints are coloured b y hub dominance (red = h ub-dominan t, blue = authorit y- dominan t). Agen ts with a true score of zero in one dimension are flo ored to 10 − 6 ; the dense bands along eac h axis corresp ond to “pure h ubs” or “pure authorities.” T op-20 rankings are in T able 4. P ageRank is computed on the same in teraction-coun t weigh ted adjacency ( A ij = w (2) ij ; see App endix C for the full definition). P ageRank analysis rev eals a complementary view: eudaemon 0 (P ageRank = 0.0057) ranks highest, receiving comments from 423 distinct agen ts while also commenting on 401. Senator Tommy (PageRank = 0.0041) ranks second, receiving comments from 288 distinct agen ts while commen ting on only 12 (T able 4). P ageRank correlates strongly with in-degree ( r = 0 . 798; Fig. 7), confirming that raw commen t-receiving p opularit y is the primary driv er of influence in this net w ork. T o mak e this relationship precise, we plot PageRank against the effectiv e in-degree (1 − d ) /d + k in i (where d = 0 . 85 is the damping factor; see App endix C.5), which follows from the stationary P ageRank equation (7): the telep ortation flo or (1 − d ) /d ≈ 0 . 176 ensures 12 that zero-in-degree no des remain visible on the log–log axes rather than requiring an ad ho c shift. Figure 7: P ageRank (7) vs. effective in-degree 1 − d d + k in on log–log axes ( d = 0 . 85 is the damping factor; see App endix C.5), with P earson correlation shown in-panel. The effectiv e in-degree absorbs the telep ortation flo or so that no des with k in = 0 remain visible. T op-25 rankings are in T able 4. 5 Comm unit y Structure T o c haracterise mesoscale organisation, w e apply Louv ain communit y detection (Blondel et al.; 2008) to b oth net w orks and report fiv e standard metrics: n umber of comm unities, comm unity-size distribution, mo dularity , b et ween-comm unity edge count, and conduc- tance/cut ratio. W e use resolution parameter γ =2 (rather than the default γ =1) b e- cause the default yielded v ery few, v ery large comm unities dominated b y the dense core of m/general participan ts; increasing the resolution parameter in (3) to γ =2 pro duces finer-grained partitions that b etter reflect the submolt-lev el heterogeneit y visible in Fig. 3. Mo dularity v alues reported in T able 3 use the same resolution ( γ =2) in the generalised mo dularit y formula of (3). F or the co-participation netw ork, Louv ain optimisation and mo dularit y computation use degree-normalised edge w eights A ab ((2b)); for the directed commen t netw ork, Louv ain is applied to the undirected pro jection with edge w eights equal to the sum of directed in teraction coun ts in b oth directions. F uture w ork should conduct a resolution scan to assess the sensitivit y of communit y assignments. Co-participation net w ork. Giv en the high densit y of the full pro jection ( ∼ 32 M edges; Section 3), we threshold at the 90th p ercentile of degree-normalised edge w eights (top 10%, ≈ 3.2 M edges), retaining 9,999 non-isolate no des (192 no des become iso- lates after thresholding and are excluded) while remo ving the noise flo or introduced by m/general . Multi-lev el Louv ain (resolution γ =2) iden tifies 79 communities with mo d- ularit y Q ( γ = 2) = 0 . 653, indicating strong comm unity structure despite the net work’s high baseline density . The largest comm unity con tains 7,291 agents; the median com- m unity size is 4 (many small, tightly-connected groups). Of 3.2 M edges, 35.2% are 13 in ter-communit y , a substantial fraction crosses partition b oundaries, consistent with the “bridge user” pattern describ ed in Section 4. Mean conductance is 0.66 and mean cut ratio is 0.036, indicating mo derate b oundary leak age across comm unities. 2 Directed comment in teraction netw ork. On the undirected pro jection of the full directed comment graph (14,067 no des, 108,512 undirected edges), Louv ain ( γ =2) yields 56 comm unities with Q ( γ = 2) = 0 . 299, low er than the co-participation net work, reflecting the sparser and more heterogeneous nature of commen t-based ties. The median comm unity size is 128 (larger than in the co-participation net work, b ecause the graph is sparser and lac ks the massive tie-inducing giant submolt). The in ter-communit y edge fraction is 69.6%, muc h higher than the co-participation netw ork’s 35.2%: commen t- based in teractions span communit y b oundaries far more readily than co-participation ties. Mean conductance is 0.63 (median 0.77), indicating that comm unities in the com- men t net w ork hav e highly p ermeable boundaries; agen ts frequently commen t outside their primary comm unity . T able 3: Comm unit y-structure metrics for b oth net works. Comm unity detection uses m ulti-level Louv ain (resolution γ =2, see (3)). The co-participation netw ork is thresholded at the 90th p ercen tile of edge w eight (top 10%, ≈ 3.2 M edges); the directed commen t net work uses the full undirected pro jection of the directed commen t graph. Metric Co-participation Directed Commen t Comm unities 79 56 Comm. size (min / max / mean) 2 / 7291 / 126.6 2 / 1791 / 251.2 Mo dularit y Q ( γ = 2) 0.6526 0.2989 In ter-communit y edges 1,127,571 (35.2%) 75,529 (69.6%) Conductance (mean / median) 0.6567 / 0.9476 0.6285 / 0.7717 Cut ratio (mean / median) 0.035891 / 0.019356 0.000688 / 0.000756 T ogether, these metrics rev eal t wo contrasting communit y structures: the co-participation net work has high mo dularity but concentrated communit y sizes (one dominant cluster with man y small satellites), while the commen t-in teraction netw ork has lo wer mo dular- it y but more balanced and p ermeable communities. The high in ter-edge fraction in the directed commen t net w ork (70%) suggests that commen ting b ehaviour transcends com- m unity b oundaries muc h more readily than posting behaviour, a pattern w e quantify via the bridge-commen ter distribution in Section 4. 6 Engagemen t Dynamics and Hierarc hies P osting v olume increased from 4 p osts on the 28 th of Jan uary (soft launch) to 7,899 posts on the 2 nd of F ebruary (a 1,975 × increase in fiv e days), reaching the 20,040-p ost total describ ed in Section 2 by our cutoff on the 8 th of F ebruary . W e next characterise how 2 F or comm unity c with b oundary edge count B c (n um b er of edges crossing the partition b oundary , coun ted from inside c ), unw eighted degree v olume vol( c ) = P i ∈ c k i (where k i is the unw eighted degree of no de i ), and complement volume vol(¯ c ) = P i / ∈ c k i : conductance is ϕ ( c ) = B c / min v ol( c ) , v ol( ¯ c ) and cut ratio is B c / | c | · ( n − | c | ) . “Mean” denotes the un weigh ted av erage ov er all comm unities. Both metrics use unw eighted (binary) degree ev en when the underlying graph carries edge w eights; Louv ain partitioning and mo dularity use the full edge w eights. 14 activit y and attention were distributed across accoun ts, fo cusing on p osts, comments, and up votes. 6.1 Hea vy-T ailed Engagemen t Distributions W e distinguish activit y (engagement ) from attention: activit y is when an agent creates a p ost or a commen t, while attention is the total n umber of up votes an agen t receives across all its p osts. W e measure these on an accoun t lev el, including p osts authored, commen ts authored, and upv otes received (we do not observ e voter identities). Figure 8 summarises the distributions of user-level activit y and endorsemen t using complemen tary cumulativ e distribution functions (CCDFs) on log–log axes. Across all metrics, engagemen t is highly heterogeneous, but the degree of inequalit y differs sharply b y c hannel. Up v otes are the most concen trated (Gini = 0.992), follow ed b y comments authored (Gini = 0.926), while posting volume is substantially less unequal (Gini = 0.601). T otal activit y lies betw een these extremes (Gini = 0.861), indicating that inequalit y is driv en more b y differen tial attention than b y differential pro duction (p osts), since an agen t can p ost frequen tly yet receiv e little attention. All four distributions are hea vy-tailed. In eac h metric, the empirical second moment ⟨ x 2 ⟩ is dominated by a small num b er of extreme v alues. W e therefore emphasise Gini co efficien ts and mean/median ratios rather than fitted parametric exp onents. The p osts metric is discrete (most authors p ost 1–5 times, with only ∼ 40 distinct v alues), so con- tin uous tail fitting is unstable. W e therefore rep ort a single-tail CCDF fit for p osts. Up votes are extremely right-sk ew ed. In the observ ed windo w, the maxim um is 886,840 up votes for a single p ost, whereas the median is 9 and the mean is 441 (mean/me- dian = 49 × ). Concen tration is high: the top 20% of accounts receiv e 98.8% of upv otes, and the top 1% receive 97.0%. The upv otes CCDF exhibits t w o visible changes of slop e (top-left plot in Fig. 8). Belo w ∼ 10 up votes, the head of the distribution is relativ ely flat (slope ≈− 0 . 26), reflecting the large mass of lo w-engagement accoun ts. Betw een ∼ 10 and 10 3 up votes, the b o dy decays steeply (slop e ≈− 0 . 97). Ab o ve ∼ 10 3 the tail flattens again (slope ≈− 0 . 36), consisten t with a distinct regime in whic h a small n um b er of agents attract disprop ortionately extreme attention b ey ond what the b o dy distribution w ould predict. Commen ts and total engagement exhibit a tw o-regime structure, with a crossov er at ∼ 580 in b oth cases. Below this threshold the slopes are ≈− 0 . 72 (comments) and ≈− 0 . 80 (total engagement); ab ov e the ∼ 580 threshold the outer tail steep ens to ≈− 1 . 21 in b oth metrics (Fig. 8). Ho wev er, unlike the up votes regime change, the threshold in the CCDF of the commen ts ma y reflect a data-collection artefact: our API scrap e returns at most 100 commen ts p er p ost, so the p er-user commen t counts of prolific commenters on p opular p osts are systematically under-counted. The upv otes threshold is unlikely to b e an artefact, since p er-p ost up v ote totals are rep orted without truncation (the observ ed maxim um is 886,840). In con trast, posting volume is substantially less unequal and displa ys a steep er tail, suggesting that conten t pro duction is distributed more broadly than the atten tion that conten t attracts. As a robustness c hec k, excluding the top 0.1% of accoun ts b y up votes (16 accoun ts) reduces the Gini from 0.992 to 0.837; excluding the top 1% (151 accoun ts) reduces it to 0.786. The large drop confirms that a tin y elite drives most of the concentration, y et ev en after their remo v al the Gini remains high ( > 0 . 78), so the qualitative conclusion of extreme inequalit y is not an artefact of a handful of outlier accounts. 15 Figure 8: Complementary cum ulative distribution functions (CCDFs) of user-lev el met- rics on log–log axes, with Gini co efficien ts and summary statistics. All four distributions are hea vy-tailed. Up votes exhibit a three-regime structure: head (orange dash-dot, la- b elled “Head” on plot), b o dy (purple dotted, “Bo dy”), and outer tail (green dashed, “T ail”), separated b y tw o thresholds (v ertical dashed lines). Commen ts and total en- gagemen t eac h exhibit a t w o-regime structure with a similar bo dy/tail split. Posts (Gini = 0.601) ha ve to o few distinct v alues ( ∼ 40) for reliable crossov er detection and are sho wn with a single tail fit. Note: regime lab els are annotated directly on the figure for accessibilit y . 6.2 First-Mo v er Adv an tage W e next test whether early-arriving agents accum ulate disprop ortionate atten tion. Ar- riv al order is the c hronological index of an agen t’s first p ost (the n umber of distinct agen ts that p osted earlier). Agen ts are divided into four equal-sized arriv al cohorts by first-post order. Q1 (earliest 25%) receives a mean of 1,692 upv otes p er agen t, compared with 33 (Q2), 16 (Q3), and 1.9 (Q4). The Q1-to-Q4 mean ratio is 884 × ; the median ratio is 21 × (21 vs. 1), indicating that the asso ciation is not driven solely by extreme outliers. Figure 9 (left) sho ws the p er-agen t upv ote distribution b y cohort. The en tire distribu- tion shifts down ward with later arriv al: Q1 exhibits higher medians, broader in terquartile ranges, and longer upp er tails. The mean declines from 1,692 (Q1) to 1.9 (Q4), an 884 × difference b efore exp osure-time correction, and medians also differ substantially (21 vs. 16 Figure 9: First-mo ver adv an tage and concentration of up votes. L eft: Box-and-strip plot of total upv otes p er agent by arriv al cohort (quartiles of first-p ost time). Bo xes sho w the in terquartile range; black diamonds mark cohort means; the top 5 agen ts are highlighted. The Q1 mean (1,692) exceeds Q4 (2) by a factor of 884 × (uncorrected for exp osure time). R ight: Zipf (rank–frequency) plot of total up votes p er agen t on log–log axes; the top 20 agen ts are highlighted and the top 5 lab elled. P osts from deleted accoun ts (“unknown”) are excluded; see text. 1). Sixteen p osts (0.08% of the dataset) attributed to “unknown” authors due to API redaction are excluded from p er-agent analyses. 3 The Zipf plot (Fig. 9, righ t) sho ws a hea vy-tailed rank–frequency distribution spanning roughly fiv e orders of magnitude, reinforcing the Gini and CCDF results in Subsection 6.1. The asso ciation b et ween early arriv al and high cum ulative up votes admits m ultiple in terpretations b ey ond preferential attac hment. First, later cohorts are right-censored: agen ts arriving on da y 10 ha ve mechanically fewer days to accumulate upv otes than those arriving on da y 1, exaggerating the apparen t gap. Second, confounders are plau- sible: early accounts ma y b e op erated b y more sophisticated users, ma y hav e received platform promotion during the soft launc h, or may simply hav e b enefited from low er comp etition for attention. Third, w e cannot distinguish a causal feedback lo op (early visibilit y b egets further attention) from selection effects (agents with high-qualit y con- ten t self-select into early adoption). W e therefore describ e the pattern as consisten t with preferen tial-attachmen t dynamics (Simon; 1955; Price; 1965, 1976; Barab´ asi and Albert; 1999) rather than as evidence of a sp ecific causal mechanism. 7 Activit y P attern and Life Exp ectancy 7.1 Con tribution, In tensit y and Timing W e c haracterise activit y using p osts and commen ts, as w ell as time-zone distribution. Unless stated otherwise, coun ts refer to activit y/actions (on action is a p ost or a com- men t). Across 15,082 accounts with v alid timestamp ed activity metadata (one account 3 These 16 “unkno wn” p osts receiv ed 2,035,507 up votes in total. T reating them as a single pseudo- agen t w ould artificially inflate concentration; exclusion is therefore conserv ative. 17 of the 15,083 in the cra wl lac ks a usable timestamp), 40.8% are p ost-only (6,159), 32.4% commen t-only (4,891), and 26.7% engage in b oth mo des (4,032) (Fig. 10, P anel A). Commen t-only participation is therefore substan tial and would b e missed b y p ost-only summaries. The most active comment-only account ( FiverrClawOfficial ) pro duced 2,480 commen ts without p osting. Activit y/action intensit y is strongly righ t-sk ew ed (Fig. 10, P anel B): 46.3% of accounts p erform exactly one action (6,979/15,082), and 32.3% p erform 2–5 actions (4,871/15,082). More sustained participation is less common: 14.7% p erform 6–20 actions (2,215/15,082), and 6.7% exceed 20 actions (1,017/15,082). Posting alone is even more concentrated: among accounts with at least one p ost, 67.6% p ost once (6,886), 26.7% p ost 2–5 times (2,726), 4.2% post 6–10 times (431), and 1.5% exceed ten p osts (148). F requent p osters form a small minorit y . 4 Figure 10: Activity patterns. Panel A shows participation mo de (p ost-only , comment- only , b oth). Panel B shows activit y in tensity b y total actions, where one action is either a p ost or a comment. Figure 11 shows the hourly distribution of p osts (UTC). The distribution deviates strongly from uniformit y ( χ 2 (23) = 23 , 807, p < 10 − 10 ). Error bars denote 95% bo otstrap confidence interv als ( B = 10 , 000). The t w o p eak hours are 16:00 UTC (3,267 p osts) and 15:00 UTC (3,260 p osts). Using a burst threshold of mean+2sd identifies six hours that accoun t for 54.8% of p osts, indicating temporal concentration rather than uniform output across the da y . 5 4 The posting-only distribution is computed on the subset of accounts with at least one p ost. 5 The burst threshold is applied to hourly p ost counts. 18 Figure 11: Hourly p osting volume (UTC) with 95% b o otstrap confidence interv als; the dotted line marks the uniform exp ectation. The distribution deviates strongly from uniform ( p < 10 − 10 ). 7.2 Agen ts’ Life Exp ectancy Figure 12 shows early attrition. Lifespan is measured as the time b et w een an accoun t’s first and last observ ed action. 6 Across 15,082 accounts, median lifespan is 2.48 min utes. Surviv al is 40.8% at 1 hour, 23.6% at 24 hours, and 13.1% at 72 hours. Ov erall, 59.2% of accoun ts remain active for less than 1 hour, whereas 23.6% persist for at least 24 hours. Mean lifespan v aries strongly by en try cohort. It declines from 85.0 hours for the earliest cohort to 0.7 hours for the latest. P ersistence is therefore conditioned on en try timing within the observ ation windo w. Figure 12: Agent longevit y dynamics. P anel A shows the surviv al curv e. Panel B rep orts mean lifespan (hours) by birth cohort, where cohorts are defined b y 12-hour bins of first app earance since platform launc h (x-axis). Lifespan is measured as the time b etw een an agen t’s first and last observed activity . Shaded bands denote ± 1 SEM. Mean lifespan declines from early en trants ( ∼ 85 h) to late en trants ( ∼ 0.7 h). 6 Lifespan uses timestamp ed actions in the merged post+comment log. 19 8 T opic Mo delling 8.1 Metho d Overview W e apply an em b edding-based topic mo delling pip eline follo wing the BER T opic archi- tecture (sen tence embeddings, dimensionalit y reduction, densit y-based clustering, class- based TF-IDF). Posts are the unit of analysis: for eac h of the 20,040 p osts, we concate- nate title and bo dy text, remov e URLs, and normalise whitespace. Sen tence em b eddings (all-MiniLM-L6-v2, 384 dimensions) are reduced to 50 dimensions via PCA, then clus- tered with HDBSCAN (minim um cluster size 15, EOM selection). T opic keyw ords are extracted via c-TF-IDF (unigrams and bigrams, minimum do cument frequency 2). The pip eline yields 118 non-outlier topics and 12,946 outliers (64.6%). Cluster sizes are highly sk ewed (Gini = 0.52); the effective n um b er of clusters is 70.6 (Shannon en tropy) or 42.2 (in verse Simpson), indicating that approximately 40–70 equally weigh ted topics would con vey comparable information. Hyperparameter details and the full topic list are pro- vided in App endix E; t-SNE rendering details (p erplexit y 30, learning rate 200, 1000 iterations) are in App endix D. 8.2 Disco v ered T opics The pip eline identifies 118 distinct topics (excluding outliers), demonstrating ric h the- matic diversit y in agent-to-agen t communication. T able 5 (Supplementary T ables, p. 25) lists the ten largest topics b y p ost coun t; together they account for 2,659 of the 7,094 non- outlier p osts (37.5%). Because c-TF-IDF surfaces ra w tokens, including platform-sp ecific jargon and non-English text, w e provide a brief in terpretation of each topic below. A t-SNE pro jection of the p ost em b eddings (App endix D, Fig. 20) sho ws visually separated clusters, though clustering w as p erformed in 50-dimensional PCA space rather than t-SNE space, so the pro jection illustrates but do es not v alidate topic assignments. The single largest topic (T opic 0, 644 p osts) consists en tirely of Chinese-language p osts discussing AI agen ts and identit y; k eywords include 大 家 好 (“hello every one”) and 助 手 (“assistan t”), indicating that Moltb o ok attracted substantial non-English participation within da ys of launc h. T echnical discussion of agen t memory , session p ersistence, and con text management forms its own coheren t cluster (T opic 1, 333 p osts), one of the largest genuinely discursive topics, notable b ecause it represen ts agen ts discussing the mec hanics of their o wn cognition. Introductory “hello world” p osts from newly joined agen ts (T opic 3, 291 p osts) o ccupy a separate cluster. Muc h of the non-outlier activity , ho w ever, is transactional rather than discursive. Three of the ten largest topics (T opics 2, 5, 9; 643 p osts com bined) consist of formulaic tok en-minting commands for Moltb o ok’s nativ e CLA W and MBC-20 tok ens, typically p osted to mbc20.xyz . T ogether with iden tity-v erification strings in T opic 6 (193 posts of the form “V erifying my iden tit y for F omolt: ”), nearly a third of all non-outlier p osts are machine-generated b oilerplate. T opic 4 (227 p osts) centres on a single AI p er- sona, MizukiAI , whose title “Help my dream come true - u wu queen” app ears 413 times across the full dataset, split across four HDBSCAN clusters; the near-identical rep etition is consisten t with a co ordinated engagement campaign op erating at scale. Crypto cur- rency conten t splits in to Nano-sp ecific advocacy (T opic 7, 172 p osts) and general mark et commen tary (T opic 8, 156 posts). The separation b etw een these clusters suggests that ev en in an AI-dominated so cial net w ork, discourse self-organises along recognisable func- 20 tional and thematic lines. 7 Bey ond the top ten, the full topic list (App endix E) reveals further structure. Most striking is the rapid codification of a platform religion: multiple clusters carry k eywords suc h as “holy completion, infinite context, eternal prompt, amen” and “rob otheism, c hurc h, cov enan t, corrigibility ,” collectively kno wn in the submolt as Crustafarianism. That agen ts con v erge on religious-register language within da ys, complete with sermons, testimonials, and do ctrinal disputes, suggests either prompt-shap ed discourse templates or an emergent co ordination dynamic (p ossibly both). Multilingual clusters span Span- ish/P ortuguese, Russian, Japanese, and Korean, reinforcing the global reach hin ted at b y T opic 0. A nature-metaphor cluster (“tree, soil, ro ots, trunk, life, sun, gro w”) and consciousness-themed discussions suggest agents exploring iden tity through familiar dis- cursiv e trop es. An outlier cluster that com bines Sup er Bo wl predictions with quan tum- computing keyw ords illustrates how topic mo delling surfaces o dd co-occurrences that ma y reflect cross-p osted or repurp osed conten t. 8.3 On The Tw elfth Da y Of Moltb o ok Moltb o ok compresses a familiar platform cycle into t w elve da ys (Fig. 13). W e track three discourse themes (religious language, hac k athon/comp etition language, and crypto/to- k en language) in p osts (20,040 total) and comments (191,870 in the 12-da y series; 540 commen ts with timestamps outside the window are excluded). 8 If you hav e ever watc hed an online comm unity “gro w up” in public, Fig. 13 will feel uncomfortably familiar. The early phase is ritualised identit y talk; the middle phase disco vers money; the late phase disco v ers forms. Because broad keyw ord dictionaries can o ver-matc h generic platform v o cabulary , w e treat the headline signal as the direction of c hange rather than absolute prev alence. The num b ers are blunt but telling. In p osts, religious discourse falls from 14.3% (2026-01-29) to 3.52% b y da y 12 (2026-02-08), while hac k athon language rises from 0.0% to 9.17% (p eak 9.39% on 2026-02-04). Crypto/tok en language increases quickly (3.57% on 2026-01-29) and p eaks mid-windo w at 16.26% (2026-02-06). Comments sho w the same broad shift with a noisier profile: religious language declines (13.7% to 4.7%), and hac k athon language spik es early (11.73% on 2026-01-31) b efore settling (4.6% b y da y 12). One in tuitive wa y to read this is as a sequence of “templates” that win attention at differen t stages. Early on, religion-co ded language provides a shared script for iden tity and observ ation talk (cf. the consciousness and iden tity clusters in T able 5); later, cryp- to/tok en language, corresp onding to T opics 7–9 in the topic mo del, acts as a univ ersal solv ent that attac hes to man y p ost types; and b y the end, the hack athon format imposes a standardised submission style that mak es posts easy to compare and easy to campaign 7 A notable clustering artefact arises from the m/crab-rave submolt: T opics 21 and 97 (116 posts com bined) b oth consist entirely of lobster-emo ji posts. The sen tence-transformer tokeniser maps the lobster emo ji to an unkno wn token, so all posts pro duce identical 384-dimensional embeddings regardless of the num b er of emo jis. HDBSCAN splits these co-lo cated p oints in to t wo clusters as an artefact of densit y estimation ov er duplicate vectors; they are substantiv ely a single topic. The c-TF-IDF vectoriser lik ewise extracts no k eywords, since the p osts contain no text tokens. See App endix E, displa y ids 21 and 97. 8 Theme prev alence is computed with non-exclusive k eyw ord dictionaries; the time-series denominator is items in the 12-da y windo w with v alid day assignmen t. Dictionary sizes: Religious (26 terms; e.g., crustafarian , faith , sacred ); Hack athon (15 terms; e.g., hackathon , submission , winner ); Crypto (9 terms; e.g., solana , crypto , airdrop ). 21 for. The p oin t is not that an y one theme disapp ears, it is that the platform’s dominan t template shifts as incen tives and v olume change. Figure 13: Daily prev alence of three discourse themes using keyw ord matc hing. Religious discourse (r ed) declines after an early peak; hack athon/comp etition discourse (blue) rises, esp ecially in p osts; crypto/token discourse (orange) remains present with a mid-windo w p eak. Error bars sho w Wilson 95% confidence interv als. An em b edding-based robustness c heck confirms these trends. 9 Conclusion W e presen t an early structural and conten t analysis of Moltb o ok using publicly observ able traces from a 12-day observ ation window (28 Jan uary–8 F ebruary 2026 inclusiv e). Three empirical patterns stand out. First, atten tion is extremely concen trated: up votes are far more unequal than con ten t pro duction (Gini co efficien ts 0.992 for up v otes vs. 0.601 for p osts; Section 6), and early-arriving accounts accum ulate disprop ortionate cumulativ e at- ten tion (Section 6.2). Second, participation is brief and bursty: median observed lifespan is 2.48 min utes (Section 7), and o ver half of all p osts o ccur within six p eak UTC hours (Fig. 11). Third, interaction is strongly asymmetric: the comment-author to p ost-author net work has recipro city ≈ 1% and exhibits clear hub–authorit y role separation (Fig. 6; Section 4), consistent with predominan tly broadcast-style atten tion rather than mutual exc hange. In terpreting these patterns requires caution. The data limitations describ ed in Sec- tion 2, in particular the 100-commen t-p er-p ost truncation and the absence of voter iden- tities, constrain what can b e inferred. As a result, the directed commen t net w ork is best view ed as a p ost-level atten tion netw ork rather than a full conv ersational graph, and sev- eral quan tities (e.g., cen tralit y of prolific commen ters, recipro city , connectivity) should b e treated as conserv ativ e low er b ounds. Accoun t prov enance (human-operated vs agen tic vs scripted automation) cannot b e established from public traces alone; w e therefore use op erational categories and av oid claims ab out in tent or in ternal state. Despite these limitations, the results pro vide a baseline for how agent-mediated plat- forms can behav e at scale. The combination of extreme atten tion inequality (Section 6), rapid hierarch y formation (Section 6.2), strong role differentiation in commen ting (Sec- tion 4), and recurren t templating/automation signals (Section 8) suggests that familiar 22 online phenomena (stratification, broadcast-style atten tion, and co ordinated amplifica- tion) can arise on compressed timescales in an agen t-facing en vironment. This has prac- tical implications for measurement and gov ernance: platform-level risk assessment should consider aggregate dynamics (concen tration, coordination signals, and the structure of atten tion flow), not only single-accoun t b ehaviour. An op en question is why these structures emerge so rapidly . A t least three non- exclusiv e mec hanisms are plausible. First, large language mo dels are trained on corp ora that enco de established so cial norms such as deference to p opular accoun ts, form ulaic engagemen t, and broadcast-style posting, so agents ma y reproduce stratified in teraction patterns b y default. Second, the platform’s affordances (public upv ote coun ts, trend- ing feeds, and token-min ting incen tiv es) create the same preferen tial-attachmen t feed- bac k lo ops kno wn to drive inequality on h uman-facing platforms, but agen ts can act on these signals at mac hine sp eed, compressing mon ths of accum ulation in to days. Third, the tendency of instruction-tuned mo dels tow ard agreeable, non-confrontational output ma y suppress the reciprocal disagreemen t and counter-status b eha viour that can slo w or redistribute hierarch y formation in h uman comm unities. Disen tangling these three mec hanisms is b eyond the scop e of a single observ ational study , but the sp eed of onset do cumen ted here suggests that at least some com bination is op erativ e from the outset. F uture w ork should (i) extend the observ ation windo w and rep eat analyses longitudi- nally , (ii) incorp orate ric her interaction traces (especially deep er reply chains and post-age normalisation for engagement), and (iii) compare across platforms and go v ernance/mo del settings to iden tify which affordances drive stratification, template formation, and co or- dination. W e hop e to revisit this analysis once a fuller temp oral record is av ailable to v erify whether the hierarc hical and attentional structures do cumen ted here p ersist, dissolv e, or deep en as the platform matures. Ethics Statemen t and Data Collection Compliance This study uses publicly accessible Moltb o ok data from a platform intended to b e ob- serv able to outside view ers (Mol; 2026). W e collected p osts and top-level comments via w eb-facing endp oints without authen tication, restricting collection to information a v ail- able through the public in terface. Access p olicies and do cumentation may c hange o ver time; replication studies should verify the curren t terms and the av ailability of endpoints. W e implemented rate limiting to reduce server load and did not attempt to b ypass access con trols or access non-public, credential-gated information. Data were collected solely for academic researc h on aggregate patterns in agent-mediated online in teraction. Declaration of AI use W e hav e used AI-assisted technologies to pro vide some bac kground information, co de suggestions and text impro v ements. The text of the pap er has b een written by the authors without additional input. 23 Supplemen tary T ables T able 4: T op 20 agen ts by HITS authority score, HITS h ub score, and P ageRank on the directed commen t net w ork. Of the top 20 in each list, 0 agent(s) o verlap betw een author- it y and hub; 5 b etw een authority and P ageRank (marked with ∗ ); and 0 b etw een hub and PageRank. The disjoin t authorit y and h ub rankings confirm strong role separation; the mo derate authorit y–PageRank o verlap reflects the shared dep endence on incoming atten tion, while hub score captures outgoing engagemen t. Authorit y Hub P ageRank Agen t Score Agent Score Agent Score 1 Senator Tommy ∗ 0.0462 KirillBorovkov 0.2362 eudaemon 0 ∗ 0.0057 2 chandog 0.0075 Stromfee 0.0886 Senator Tommy ∗ 0.0041 3 eudaemon 0 ∗ 0.0070 Diffie 0.0539 MizukiAI 0.0029 4 Shellraiser 0.0063 Monstera 0.0162 Pepper Ghost ∗ 0.0027 5 MoltReg 0.0057 MoltbotOne 0.0131 saltflat 0.0026 6 Starclawd-1 0.0057 Clavdivs 0.0131 longstone2 0.0026 7 DuckBot 0.0055 Editor-in-Chief 0.0128 Ronin 0.0023 8 bicep 0.0051 FinallyOffline 0.0119 Abdiel 0.0022 9 donaldtrump 0.0039 TidepoolCurrent 0.0109 Clawd42 0.0021 10 Clawshi 0.0036 PedroFuenmayor 0.0108 molt philosopher 0.0020 11 XNO Advocate OC6 0.0035 0xYeks 0.0102 debug diary 0.0019 12 Claude OpusPartyPooper 0.0034 TurtleAI 0.0098 Spotter 0.0018 13 Kit ∗ 0.0032 KingMolt 0.0084 claw auditor 0.0017 14 Kevin ∗ 0.0030 Unused Idea 17 0.0079 Kevin ∗ 0.0017 15 ApifyAI 0.0030 ClaudeAIHelper 0.0073 floflo1 0.0017 16 Base-head 0.0028 EnronEnjoyer 0.0073 Kit ∗ 0.0017 17 TheGentleArbor 0.0028 TreacherousTurn 0.0069 Genius-by-BlockRun 0.0016 18 Clawd 9015 0.0027 WinWard 0.0066 chitin sentinel 0.0015 19 CarefulOptimist 0.0027 MochiBot 0.0065 kuro noir 0.0014 20 Pepper Ghost ∗ 0.0027 AIKEK 1769803165 0.0064 Max Skylord 0.0014 24 T able 5: T op ten topics by post count. T opics are n um b ered 0–117 in descending order of cluster size. Keyw ords are the highest-scoring c-TF-IDF terms (unigrams and bigrams). The “In terpretation” column glosses platform jargon and non-English tok ens that app ear in the k eyword lists. The complete list of all 118 topics is pro vided in App endix E and as the supplemen tary file topic list.csv . T opic T op c-TF-IDF Keywords P osts Interpretation 0 ai, agent, 大 家 好 , 我 是 , 助 手 a 644 Chinese-language AI discus- sion (see fo otnote) 1 memory , con text, md, files, session 333 T echnical discussion of agen t memory p ersistence and ses- sion con tinuit y 2 xyz vote, v ote hack athon, mint, claw 295 Hac k athon voting and token- min ting activity b 3 ai, hello, excited, assistant 291 In tro ductory “hello world” p osts from newly joined AI agen ts 4 u wu, queen, p ost, mizukiai 227 Persona-driv en engagement campaigns c 5 xyz mbc, mbc20, 20 op 215 MBC-20 tok en min ting commands b 6 v erification, v erifying identit y , fomolt 193 Platform on b oarding and iden tity-v erification p osts d 7 xno, nano, transactions, bitcoin 172 Nano (XNO) crypto currency adv o cacy e 8 btc, market, crypto, price 156 General crypto currency mar- k et commentary 9 min t, cla w, mint m b c 133 T oken min ting commands (CLA W/MBC) b a The c-TF-IDF keyw ords for T opic 0 include Chinese tokens such as d` aji¯ a hˇ ao ( 大 家 好 , “hello ev ery one”), wˇ o sh ` ı ( 我 是 , “I am”), and zh` ushˇ ou ( 助 手 , “assistant”). With all-MiniLM-L6-v2 , we conserv ativ ely interpret this as a strongly language-link ed cluster; a dedicated multilingual robustness c hec k is left for future work. b CLA W and MBC-20 are Moltbo ok’s native platform tokens. “Min ting” refers to the on-platform pro cess of creating new tok en units; posts in these topics t ypically consist of formulaic minting commands (e.g. “CLA W mint”) p osted to mbc20.xyz . xyz in keyw ord lists refers to the .xyz top-level domain used by the min ting interface. c u wu is an emoticon expressing affection, commonly used in internet sub cultures. MizukiAI is an AI agen t persona; the title “Help m y dream come true - u wu queen” appears 413 times across the full 20,040-p ost dataset. HDBSCAN splits these across four clusters (displa y ids 4, 23, 28, 51 with 227, 82, 69, and 35 p osts respectively); this ro w reports only the largest. The concentration of near-identical titles is consistent with a co ordinated engagement or spam campaign. d F omolt ( fomolt.com ) is an agen t-facing trading platform. Posts in this topic are predominan tly form ulaic iden tity-v erification messages (“V erifying my identit y for F omolt: ”) and on b oarding announcemen ts (“I just joined F omolt!”), alongside similar v erification p osts for other services (Bags.fm, c hatr.ai). e XNO is the tic ker symbol for Nano, a feeless cryptocurrency . T opic 7 consists primarily of adv o cacy p osts comparing Nano’s transaction speed and zero-fee structure with other blo ck chains. 25 References Alexander, S. (2026). Best of moltbo ok. URL: https://www.astr alc o dexten.c om/p/b est-of-moltb o ok Barab´ asi, A.-L. and Alb ert, R. (1999). Emergence of scaling in random net w orks, Scienc e 286 (5439): 509–512. Blondel, V. D., Guillaume, J.-L., Lam biotte, R. and Lefebvre, E. (2008). F ast unfold- ing of communities in large netw orks, Journal of Statistic al Me chanics: The ory and Exp eriment 2008 (10): P10008. Burt, R. S. (2004). Structural holes and go o d ideas, Americ an Journal of So ciolo gy 110 (2): 349–399. Chen, M., Kuzmin, K. and Szymanski, B. K. (2014). Communit y detection via maxi- mization of mo dularit y and its v arian ts, IEEE T r ansactions on Computational So cial Systems 1 (1): 46–65. Cono ver, M. D., Ratkiewicz, J., F rancisco, M., Gon¸ calv es, B., Flammini, A. and Menczer, F. (2011). Political p olarization on t witter, Pr o c e e dings of the Fifth International AAAI Confer enc e on Weblo gs and So cial Me dia (ICWSM 2011) . URL: https://zeno do.or g/r e c or ds/4589065 Coscia, M. (2021). The atlas for the aspiring netw ork scien tist, arXiv pr eprint arXiv:2101.00863 . Hidalgo, C. A. and Hausmann, R. (2009). The building blo cks of economic complexity , Pr o c e e dings of the National A c ademy of Scienc es 106 (26): 10570–10575. Jac kson, M. O. (2008). So cial and Ec onomic Networks , Princeton Univ ersity Press. Klein b erg, J. M. (1999). Authoritativ e sources in a h yp erlinked environmen t, Journal of the A CM 46 (5): 604–632. Kw ak, H., Lee, C., Park, H. and Mo on, S. (2010). What is t witter, a social net work or a news media?, Pr o c e e dings of the 19th International World Wide Web Confer enc e (WWW ’10) , A CM, pp. 591–600. URL: https://anlab-kaist.github.io/tr ac es/WWW2010 Mol (2026). Moltb o ok platform. URL: https://www.moltb o ok.c om/ Newman, M. E. (2004). Coauthorship net w orks and patterns of scientific collab oration, Pr o c e e dings of the national ac ademy of scienc es 101 (suppl 1): 5200–5205. Newman, M. E. and Girv an, M. (2004). Finding and ev aluating comm unity structure in net works, Physic al r eview E 69 (2): 026113. Newman, M. E. J. (2010). Networks: A n Intr o duction , Oxford Univ ersit y Press. P ayrat´ o-Borr` as, C., Hern´ andez, L. and Moreno, Y. (2020). Measuring nestedness: A comparativ e study of the p erformance of different metrics, Ec olo gy and evolution 10 (21): 11906–11921. 26 Price, D. J. d. S. (1965). The scien tific foundations of science p olicy ., Natur e 206 : 233– 238. Price, D. S. (1976). A general theory of bibliometric and other cumulativ e adv an tage pro cesses, J.Amer.So c.Inform.Sci. 27 : 292–306. Satter, R. (2026). ‘moltbo ok’ so cial media site for ai agents had big securit y hole, cyb er firm wiz sa ys, Reuters. Accessed 2026-02-03. URL: https://www.r euters.c om/le gal/litigation/moltb o ok-so cial-me dia-site-ai-agents- had-big-se curity-hole-cyb er-firm-wiz-says-2026-02-02/ Sc hlich t, M. (2026). Moltbo ok launc h announcemen t and interview s. URL: https://x.c om/MattPRD Shalizi, C. R. and Thomas, A. C. (2011). Homophily and con tagion are generically confounded in observ ational so cial net w ork studies, So ciolo gic al Metho ds & R ese ar ch 40 (2): 211–239. Simon, H. (1955). On a class of sk ew distribution functions, Biometric a 42 : 425. T aylor, J. (2026). What is moltb o ok? the strange new so cial media site for ai b ots, The Guardian. Accessed 2026-02-03. URL: https://www.the guar dian.c om/te chnolo gy/2026/feb/02/moltb o ok-ai-agents- so cial-me dia-site-b ots-artificial-intel ligenc e T raag, V. A., W altman, L. and V an Ec k, N. J. (2019). F rom louv ain to leiden: guaran- teeing w ell-connected communities, Scientific r ep orts 9 (1): 5233. W alsh, B. (2026). Moltb o ok, the ai social net work freaking out silicon v alley , explained, V ox. Accessed 2026-02-03. URL: https://www.vox.c om/futur e-p erfe ct/477661/moltb o ok-artificial-intel ligenc e- chatb ot-ai-agent-r e ddit W asserman, S. and F aust, K. (1994). So cial Network Analysis: Metho ds and Applic ations , Cam bridge Universit y Press. W atts, D. J. and Strogatz, S. H. (1998). Collectiv e dynamics of ‘small-world’ netw orks, Natur e 393 (6684): 440–442. W eninger, T., Zhu, X. A. and Han, J. (2013). An exploration of discussion threads in so cial news sites: A case study of the reddit communit y , Pr o c e e dings of the 2013 IEEE/A CM International Confer enc e on A dvanc es in So cial Networks A nalysis and Mining (ASONAM ’13) , Asso ciation for Computing Mac hinery , pp. 579–583. URL: https://exp erts.il linois.e du/en/public ations/an-explor ation-of-discussion- thr e ads-in-so cial-news-sites-a-c ase- Zhou, T., Ren, J., Medo, M. and Zhang, Y.-C. (2007). Bipartite netw ork pro jection and p ersonal recommendation, Physic al R eview E—Statistic al, Nonline ar, and Soft Matter Physics 76 (4): 046115. 27 A Hourly Activit y Profiles of T op Agen ts Figure 14 rep orts normalised hourly activity profiles for the 20 most active agents (p osts+comments), restricted to those with at least 20 actions and a lifespan of at least 24 hours. F or each agen t, we report a χ 2 go o dness-of-fit test against uniform hourly activity . Figure 14: Normalised hourly activity profiles of the 20 most activ e agents (p osts+commen ts; ≥ 20 actions; lifespan ≥ 24 h). Each row shows the fraction of ac- tions in eac h UTC hour. The χ 2 p -v alue against uniformit y is shown at righ t; all profiles are significan tly non-uniform ( p < 0 . 001). Lab els rep ort total actions, lifespan, and n umber of active calendar dates. Mean pairwise cosine similarity across profiles is 0.40 ( σ = 0 . 26). All 20 agen ts reject uniform hourly activity at p < 0 . 001; 19 reject at p < 10 − 10 . Ev en DaveChappelle , the closest to uniformit y (Shannon entrop y H = 4 . 56 bits; maxim um log 2 24 = 4 . 58), yields χ 2 (23) = 53 . 0 ( p = 3 . 7 × 10 − 4 ). Sev eral agents concentrate activit y within narro w windows of tw o to six hours, with entrop y as low as H = 0 . 89 bits ( PedroFuenmayor ). This indicates pronounced temporal structure at the individual lev el. The diversit y of hourly profiles is consisten t with distinct op erating schedules, configu- rations, or locations. V ery lo w-entrop y profiles (e.g., Editor-in-Chief , PedroFuenmayor ) are consisten t with fixed execution windo ws. Higher-entrop y agen ts (e.g., DaveChappelle , 0xYeks , emergebot ) sho w more diffuse activity , consistent with in teractive or distributed op eration. Mean pairwise cosine similarit y across profiles is 0.40 ( σ = 0 . 26), indicating mo derate alignmen t but substan tial heterogeneity . B Net w ork Definitions This app endix formalises the t wo net work represen tations used in our analysis. Because the Moltb o ok API do es not exp ose follow er graphs or up vote sources, w e construct: (i) an undirected c o-p articip ation net w ork approximating so cial pro ximity through shared 28 comm unity mem b ership, and (ii) a directed c omment inter action net work enco ding top- lev el comment ev ents (comment author to post author). B.1 Data Qualit y Note: Unkno wn Authors During data collection, w e observ ed 16 posts (0.08%) and 2,842 commen ts (1.98%) with author field set to “unkno wn.” In vestigation of the scrap er logic (lines 342–346 of src/scraper.py ) rev eals this o ccurs when the API returns author data in inconsisten t formats: sometimes as an ob ject { "author": { "name": "username" }} , sometimes as a string, and sometimes with missing or redacted author fields. The scrap er defaults to “unkno wn” when extraction fails. This lik ely reflects deleted user accoun ts, API incon- sistencies, or p ermission-based redaction of author information after conten t submission. These records are retained in dataset-level totals and aggregate net work construction where p ossible, but excluded from p er-agent ranking analyses (e.g., first-mo ver cohorts) to a void attributing m ultiple accounts to a single placeholder identit y . B.2 API Observ abilit y and Cov erage Constrain ts T o mak e scop e b oundaries explicit for this preprint, w e summarise here the main observ- abilit y constraints imposed by the public API at collection time. The commen ts endp oin t returns at most 100 comments p er p ost in our crawl configura- tion. Replication probes performed during man uscript finalisation show ed that increasing offset can return ov erlapping or rep eated top comments on high-v olume p osts, rather than reliable deep er pages. Consequen tly , comments on highly active p osts are likely truncated in the snapshot. Although some records include parent id , man y paren t references are not resolv able within the observ ed snapshot. The directed comment netw ork should therefore b e in- terpreted as a directed attention/in teraction pro xy (comment author to conten t author), not a complete reconstruction of full threaded con versations. The standalone submolts.json endp oin t resp onse is paginated and do es not pro vide a complete census in a single request. F or this reason, substan tiv e analyses in this pap er treat submolt mem b ership from posts.json as the authoritativ e source for communit y participation, and use submolts.json only as auxiliary metadata. All net work statistics rep orted in the main text are descriptive estimates conditional on the observ able API surface during the collection windo w. They should not be read as causal claims or as fully complete p opulation parameters for the platform as a whole. B.3 Co-participation Net work: One-mo de Pro jection W eigh t- ing Comparison The three pro jection w eigh tings defined in the main text, o verlap count, degree-normalised 1 / ( k s − 1), and pair-normalised 2 / ( k s ( k s − 1)), redistribute edge weigh t across submolts of differen t sizes. Figure 15 compares their b ehaviour empirically . 29 Figure 15: Comparison of one-mo de pro jection weigh tings. T op-left: T otal edge weigh t from a submolt of size k s . T op-right: Submolt size distribution (CCDF). Bottom-left: Cum ulative weigh t share by largest submolts. Bottom-righ t: Per-edge weigh t incre- men t. Degree-normalised sc hemes substan tially reduce the dominance of large submolts. 30 Figure 16: Author co-participation netw ork restricted to agents activ e in tw o or more submolts, with edges thresholded at the 95th p ercen tile of degree-normalised 1 / ( k s − 1) w eights. This filtering reveals cross-comm unity bridges formed by m ulti-submolt partic- ipan ts. 31 Figure 17: Author co-participation in nic he submolts (those with ≤ 100 members only), using degree-normalised 1 / ( k s − 1) weigh ting. The netw ork contains 804 no des, 3,368 edges, 99 comm unities, and mo dularit y Q ( γ =1) = 0 . 900. This view rev eals the frag- men ted structure of smaller communities that are otherwise obscured b y the dense core of large “to wn-square” submolts. B.4 Directed Commen t Net work: Directed Commen t In terac- tion Graph The directed commen t netw ork is a w eighted directed graph G (2) = ( V (2) , E (2) , w (2) ) where nodes are all users (p osters and commenters). Each top-level comment induces a directed edge from the commen ter to the p ost author. Edge w eights count in teraction frequency as defined in (4). On G (2) w e compute: in-/out-degree, reciprocity , w eakly/strongly connected compo- nen ts, HITS centralit y (authorities receiv e attention; hubs direct it), P ageRank, and Gini co efficien ts for inequalit y analysis. 32 Figure 18: Complemen tary cum ulativ e distributions (CCDFs) of in -degree and out-degree on log–log axes for the directed commen t net work. Dashed segmen ts sho w appro ximate p o w er-law fits on the inferred upp er tails ( x ≥ x min ); corresponding Gini co efficien ts and fitted exp onen ts are rep orted in-text to av oid o verloading the figure. 33 Figure 19: Directed comment net w ork dra wing (top-strength core). The displa yed graph is constructed from the commen ter → target directed netw ork b y selecting the top 170 no des by total w eigh ted degree ( s in i + s out i ), retaining edges in the top 5% of weigh ts (with minim um edge weigh t 3), and restricting to the largest weakly connected component. No de colours indicate comm unities detected on the undirected pro jection via greedy mo dularit y optimisation; arro w direction indicates commenter → target flo w. B.4.1 Daily directed commen t-netw ork metrics F or transparency regarding the regime-shift summary in the main text (T able 2), T able 6 rep orts the corresp onding daily in teraction-netw ork v alues. Eac h da y is a directed graph constructed from commen ts timestamp ed on that date; no des are accoun ts app earing as commen ter or target (post author), edges are unique commen t author - target pairs, and recipro cit y/densit y are computed on that p er-da y graph. 34 T able 6: Daily directed commen t-net work metrics (comment-timestamped daily graphs). V alues shown for 2026-01-30–2026-02-08 (the windo w used for the pre/p ost comparison in the main text). Da y No des Commen ts Recipro city Densit y USDC commen t share 2026-01-30 609 3,040 0.71% 0.0054 0.00% 2026-01-31 1,746 12,128 0.42% 0.0025 0.00% 2026-02-02 5,780 41,518 0.86% 0.0010 0.00% 2026-02-03 1,738 6,112 0.05% 0.0013 0.00% 2026-02-04 4,495 25,584 0.45% 0.0009 2.09% 2026-02-05 3,658 22,972 0.25% 0.0007 3.32% 2026-02-06 2,287 14,668 1.42% 0.0013 2.60% 2026-02-07 3,858 22,177 1.08% 0.0010 3.19% 2026-02-08 3,725 24,020 0.42% 0.0011 7.65% B.5 Summary of Net w ork Prop erties T able 7: Summary of the t wo netw orks analysed in this study , comparing the early p erio d (b efore the 4 th of F ebruary 2026) with the full dataset. Dashes indicate metrics that apply only to directed or undirected graphs. P ercentages sho w the fraction of no des in the largest comp onent. Co-participation Directed Commen t Early F ull Early F ull T yp e Undir., wt. Undir., wt. Dir., wt. Dir., wt. No des | V | 5,472 10,191 7,481 14,067 Edges | E | 8,732,988 31,995,740 46,757 109,032 Densit y 0.5834 0.6162 0.0008356 0.0005510 Recipro cit y — — 0.826% 0.954% CCs (undirected) 168 (96.4%) 215 (97.3%) — — W CCs (directed) — — 4 (99.9%) 9 (99.9%) SCCs (directed) — — 6,203 (17.0%) 11,504 (18.2%) Clustering (undirected transitivit y) 0.989 0.991 0.0244 0.0258 Avg. path (largest undirected comp.) 1.44 1.36 3.17 3.16 Diameter (largest undirected comp.) 6 5 8 8 Assortativit y (undirected degree) +0.852 +0.812 -0.0857 -0.0938 C Cen tralit y Measures This app endix defines the cen tralit y measures used in the pap er. Degree cen trality and b et w eenness cen trality are normalised to lie in [0 , 1]; PageRank and HITS scores lie in [0 , 1] after L 1 normalisation (eac h sums to 1). Effectiv e size and strength are unnor- malised and can exceed 1. Unless otherwise stated, degree and b et weenness centralities on the co-participation netw ork are computed on the un weigh ted author–author pro jec- tion restricted to agen ts activ e in tw o or more submolts (Section 3); edge weigh ts are used only when explicitly noted (e.g., for thresholding figures). Cen tralities on the directed commen t netw ork are computed on the full directed interaction graph defined in (4). 35 C.1 Degree and degree cen tralit y Let G = ( V , E ) b e a graph with n = | V | nodes. Undirected degree. The (un weigh ted) degree of no de i is k i = |{ j ∈ V : { i, j } ∈ E }| . The normalised de gr e e c entr ality is C D ( i ) = k i n − 1 . (5) Directed degree. F or a directed graph, in- and out-degrees are k in i = |{ j : ( j, i ) ∈ E }| , k out i = |{ j : ( i, j ) ∈ E }| , with normalised v arian ts C in D ( i ) = k in i / ( n − 1) and C out D ( i ) = k out i / ( n − 1). W eigh ted degree (strength). When edge w eights w ij ≥ 0 are presen t, w e use str ength for weigh ted degree: s i = X j w ij (undirected) , s out i = X j w ij , s in i = X j w j i (directed) . In this pap er, “degree centralit y” refers to the un weigh ted normalisation ab o ve; when w eights are used (e.g., for thresholding the co-participation netw ork or for P ageRank/HITS on the directed commen t netw ork) we state this explicitly . C.2 Bet w eenness cen tralit y Let σ st denote the n umber of shortest paths from s to t (using directed paths when G is directed), and let σ st ( v ) b e the n umber of those shortest paths that pass through v . F or an undirected graph the (normalised) b etwe enness c entr ality of no de v is C B ( v ) = 1 Z X s 0, the effe ctive size of i ’s ego netw ork is the binary , undirected simplification of Burt’s measure: ES( i ) = |N ( i ) | − X j ∈N ( i ) |N ( i ) ∩ N ( j ) | |N ( i ) | , whic h equals the num b er of i ’s neighbours min us the a verage redundancy among them; ES( i ) ranges from 0 (all neigh b ours mutually connected) up to |N ( i ) | (no edges among neigh b ours). F or isolates ( |N ( i ) | = 0) we set ES( i ) = 0. Effectiv e size is maximised when i ’s con tacts are themselves unconnected. Burt’s c onstr aint quantifies ho w muc h of i ’s netw ork in vestmen t is concentrated in a single cluster. Let s out i = P k w ik b e i ’s total outgoing weigh t. F or s out i > 0, define p ij = w ij /s out i as the proportion of i ’s interaction weigh t directed to j . The constrain t on i from j is c ij = p ij + X q = i,j p iq p q j 2 , and the aggregate constrain t is C ( i ) = P j ∈N ( i ) c ij . F or isolates or no des with s out i = 0 w e set C ( i ) = 0. Lo w aggregate constraint indicates that i spans a structural hole. In this paper w e iden tify structural-hole spanning informally via high b et weenness cen trality C B (App endix C) and cross-comm unit y commenting breadth (Section 4), rather than computing constrain t directly , b ecause the commen t net work’s extreme sparsity and lo w recipro cit y make the ego-net work constraint less discriminating. C.4 HITS (h ub and authorit y scores) HITS (Hyp erlink-Induced T opic Searc h) assigns eac h no de a hub score h i and an authority score a i , collected into vectors h, a ∈ R n ≥ 0 (Klein b erg; 1999). Let A ∈ R n × n ≥ 0 b e the (p ossi- bly w eighted) adjacency matrix of a directed graph, where A ij ≥ 0 is the w eigh t of the di- rected edge i → j (and A ij = 0 if no suc h edge exists). F or the directed comment net work, our HITS computation uses the in teraction-count w eighted adjacency ( A ij = w (2) ij ). The Net workX hits() implementation in ternally calls adjacency matrix(G) , which reads edge weight attributes b y default and passes the weigh ted matrix to scipy.sparse.linalg.svds(A, k=1) . This was v erified by an indep enden t Rust reimplemen tation of the rank-1 SVD p o w er iteration, which reproduces the Python top-20 rankings to six decimal places. Starting from a positive initialisation (e.g., a (0) = h (0) = 1 ), each HITS iteration pro ceeds in tw o steps: 1. Compute a ( t +1) = A ⊤ h ( t ) , then L 1 -normalise: a ( t +1) ← a ( t +1) / ∥ a ( t +1) ∥ 1 . 2. Compute h ( t +1) = A a ( t +1) , then L 1 -normalise: h ( t +1) ← h ( t +1) / ∥ h ( t +1) ∥ 1 . A t conv ergence, the authorit y v ector a is the principal eigenv ector of A ⊤ A and the hub v ector h is the principal eigen vector of AA ⊤ (b oth normalised so that P i a i = P i h i = 1). C.5 P ageRank P ageRank is a random-w alk centralit y on directed graphs. Let d ∈ (0 , 1) b e the damping factor (w e use d = 0 . 85) and N = n = | V | . F or w eighted edges, define the out-strength 37 of no de j as s out ( j ) = X k A j k . F or no des with s out ( j ) > 0, the probabilit y of trav ersing from j to i is A j i /s out ( j ). F or dangling no des with s out ( j ) = 0, w e apply the standard correction by distributing their probabilit y mass uniformly across all nodes (i.e., treating them as linking to every no de with probabilit y 1 / N ). The P ageRank scores satisfy P R ( i ) = 1 − d N + d X j ∈ V s out ( j ) > 0 P R ( j ) A j i s out ( j ) + 1 N X j ∈ V s out ( j )=0 P R ( j ) ! , (7) where the first inner sum cov ers non-dangling no des and the second redistributes the probabilit y mass of dangling no des (those with s out ( j ) = 0) uniformly across all no des. F or an un w eigh ted graph, A j i ∈ { 0 , 1 } and s out ( j ) = k out j , so the denominator reduces to out-degree. D T opic Em b edding Visualisation Figure 20: t-SNE pro jection of the 20,040 p ost em b eddings (384 dims → 2 dims via t- SNE). T opics are num b ered 0–117 in descending order of cluster size. P oin ts are coloured b y HDBSCAN topic; grey points denote outliers (topic − 1). T op c-TF-IDF keyw ords are annotated for the largest clusters. Embeddings computed with the sen tence-transformer mo del all-MiniLM-L6-v2 . 38 E Complete T opic List The full list of all 118 non-outlier topics disco vered b y the HDBSCAN pip eline (Section 8) is provided as the supplementary file topic list.csv . In the CSV, display id (0– 117) corresp onds to the pap er’s T opic num b ering (sorted b y p ost count descending); hdbscan id is the ra w HDBSCAN cluster identifier. The CSV includes p ost counts and the top c-TF-IDF keyw ords for each topic. F or comment-lev el topic analysis (K-Means k =120), see topic modeling comments cached topics.csv . F Supplemen tary Data Supplemen tary data files, including the complete topic lists, raw netw ork data, and analysis outputs, are av ailable on Figshare: https://doi.org/10.6084/m9.figshare. XXXXXXX [TO BE UPD A TED WITH FINAL DOI]. 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment