Drift Localization using Conformal Predictions
Concept drift -- the change of the distribution over time -- poses significant challenges for learning systems and is of central interest for monitoring. Understanding drift is thus paramount, and drift localization -- determining which samples are a…
Authors: Fabian Hinder, Valerie Vaquet, Johannes Brinkrolf
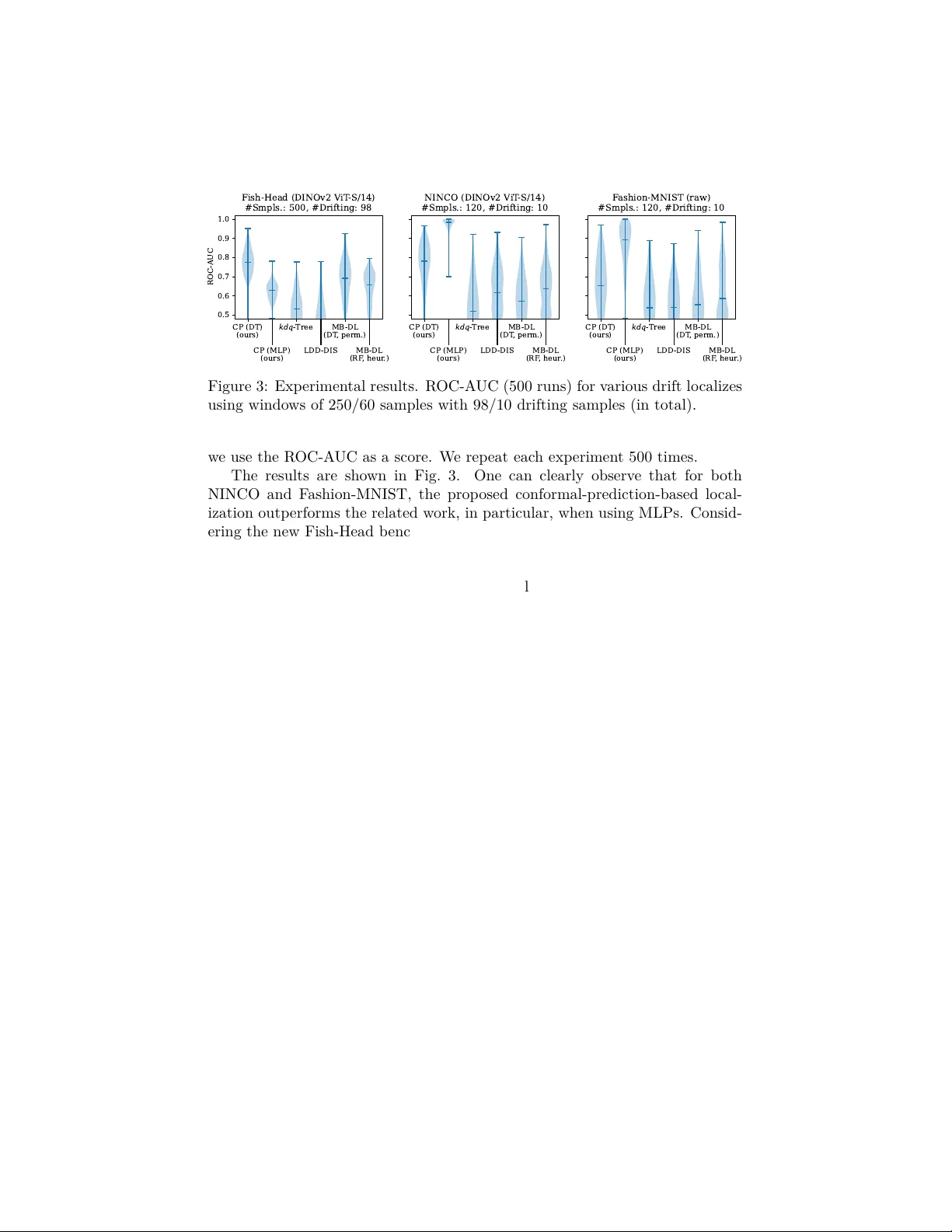
Drift Lo calization using Conformal Predictions ∗ F abian Hinder, V alerie V aquet, Johannes Brinkrolf, and Barbara Hammer † Bielefeld Universit y—F acult y of T ec hnology Inspiration 1, 33619 Bielefeld—Germany {fhinder,vvaquet,jbrinkro,bhammer}@techfak.uni-bielefeld.de F ebruary 24, 2026 Abstract Concept drift—the change of the distribution o ver time—p oses signif- ican t c hallenges for learning systems and is of cen tral in terest for mon- itoring. Understanding drift is th us paramount, and drift lo calization— determining which samples are aected by the drift—is essential. While sev eral approaches exist, most rely on lo cal testing sc hemes, which tend to fail in high-dimensional, low-signal settings. In this w ork, w e consider a fundamen tally dieren t approac h based on conformal predictions. W e dis- cuss and show the shortcomings of common approaches and demonstrate the p erformance of our approach on state-of-the-art image datasets. 1 In tro duction In the classical batch setting of machine learning, data are assumed to originate from a single source and to b e indep enden tly and identically distributed (i.i.d.). A relev ant extension is to allo w several dieren t data distributions. Examples include transfer learning, where source and target domains dier; federated learning, where mo dels are trained on data collected across distributed lo cations; and stream learning, where eac h time step ma y follo w a dieren t distribution [ 1 , 2 ]. In all these settings, the fact that the distributions may dier, a phenomenon referred to as c onc ept drift [ 1 ] or drift for short, pla ys a central role. In stream learning and system monitoring, this relates to changes o ver time; in transfer learning, to the dierences b et ween source and target distributions, etc. ∗ Paper was accepted at the 34th European Symp osium on Articial Neural Netw orks, Computational Intelligence and Machine Learning — ESANN 2026. † F unding in the scop e of the BMFTR project KI Akademie OWL under gran t agreement No. 16IS24057A and the ERC Synergy Grant “W ater-F utures” No. 951424 is gratefully ackno wledged. 0 0 F abian Hinder: https://orcid.org/0000- 0002- 1199- 4085 , V alerie V aquet: https://orcid.org/0000- 0001- 7659- 857X , Johannes Brinkrolf: https://orcid.org/ 0000- 0002- 0032- 7623 , and Barbara Hammer: https://orcid.org/0000- 0002- 0935- 5591 1 Gaining understanding of the drift is imperative [ 2 , 3 ]. Recent work on mo del-b ase d drift explanations [ 3 ] has enabled the usage of generic explainable AI (XAI) tec hniques to obtain such insigh ts. A k ey step of the approach is the iden tication of the aected samples, a task referred to as drift lo c aliza- tion [ 2 , 4 ]. While there are some metho ds addressing drift localization [ 2 , 1, 5 , 6 , 4 , 7 , 8 ], they mainly rely on lo cal statistical testing, whic h tends to fail on high-dimensional data, such as streams of images. In this work, we prop ose an alternativ e lo calization sc heme by applying conformal prediction to the under- lying idea of mo del-based drift lo calization [ 4 ]. W e rst summarize the setup, discuss the shortcomings of the related work, and recap conformal prediction (Section 2 ). W e then presen t our no vel metho dology in Section 3 and ev aluate it on tw o established and one nov el image stream in Section 4, b efore we conclude this w ork in Section 5 . 2 Related W ork 2.1 Concept Drift and Drift Lo calization In this work, we mainly consider concept drift in the context of stream learning and system monitoring; how ever, the denitions presented b elo w also extend to the other drifting scenarios discussed in the introduction. In stream learning, w e mo del an innite sequence of indep enden t observ ations X 1 , X 2 , . . . , each drawn from a p oten tially dieren t distribution X i ∼ D i [1]. Drift o ccurs when D i = D j for some i, j . A fully probabilistic framew ork was prop osed in [ 9 ], augmenting eac h sample X i with an observ ation timestamp T i . In this formulation, concept drift is equiv alent to statistical dep endence b et ween data X and time T . Based on this idea, drift localization—the task of nding all samples aected b y the drift—can be formalized as the lo cal and global temp oral distribution diering [4], i.e., L = { x : P T | X = x = P T } . It w as shown in [4, Thm. 1 and 2] that for nite time p oin ts, e.g., “b efore drift” and “after drift”, this set exists as the unique solution with certain prop erties and can b e approximated using estimators. Since most algorithms detect drift b et ween time windows [ 2 , 1 ], this justies man y approac hes and reduces drift localization to a probabilistic binary classication problem and a statistical test to assess the sev erity of the mismatch b et ween ˆ P T | X = x and ˆ P T relating to the data-p oint-wise H 0 -h yp othesis “ x is not drifting” [ 4 ]. 2.2 Lo calization Metho ds and Their Shortcomings There are a few approac hes for drift localization. Nearly all of them are based on comparing the time distribution of lo cal groups of p oints with the global reference, thus aligning with the considerations of [ 4 ]. Those groups are most commonly formed unsupervised, i.e., without taking the time point into accoun t. Classical kdq -trees [ 5 ] and quad-trees [ 8 ] recursively partition the data space along co ordinate axes; other approaches use k -means v ariants [ 7 ]. Besides those 2 partition-based, there exist k -neighborho o d-based approac hes lik e LDD-DIS [ 6 ]. The model-based approach, in tro duced in [ 4 ], diers from those in so far as they use the time information to choose a b etter-suited grouping, i.e., b y training a decision tree predicting T based on X , yet, due to ov ertting, data points used to construct the grouping cannot be used for analysis. F urthermore, they suggest a purely heuristic approach based on random forests. While those approaches dier in what statistic and normalization technique they use, all explore the idea of lo cal and global temp oral dierences. This induces a triad-o problem: using no ( kdq -tree, LDD-DIS, etc.) or only a few temp oral information, the obtained grouping is sub-optimal, leading to inaccurate estimates ˆ P T | x ∈ G ; employing muc h to impro ve grouping, w e are left with little data for the testing, resulting in low p er-group test p o wer—as the tests are p erformed separately on each group, even mo derate test-set sizes and group num b ers lead to comparably small per-group sample sizes. Both eects lead to an ov erall low testing pow er. W e thus aim for a technique that allo ws for a global v ariance analysis. 2.3 Conformal Prediction When training a classier, the target is usually to minimize the o verall expected error. Ho wev er, such a scheme do es not give any guarantees ab out the correct- ness of a single prediction. While probabilistic classication improv es on this situation in theory by providing class probabilities and thus a measure of un- certain ty , mo dels usually ov er- or undert, leading to sub-optimal assessments. Conformal prediction constitutes an alternative scheme returning a set of p oten tial classes F ( x ) ⊂ C . This allows one to ensure that the correct class is in the set with arbitrary high certaint y , i.e., P [ Y ∈ F ( X )] ≥ α for a conformal mo del F . Commonly , one minimizes the exp ected num b er of predicted classes. The most common wa y to create a conformal mo del is to wrap a class- wise scoring function, for instance, a probabilistic classier, in to a calibrated mo del. This calibrated mo del must b e trained on data that has not b een used b efore, yet, since it only pro cesses simple one-dimensional scores, the necessary calibration set can be comparably small. The usage of conformal p -v alues allo ws c ho osing α after training calibration, i.e., construct p y ( x ) so that P [ Y ∈ { y : p y ( X ) > α } ] > 1 − α holds for all α . 3 Conformal prediction for drift lo calization Curren t state-of-the-art drift lo calization tec hniques rely on lo cal statistical test- ing and either employ unsupervised grouping metho ds—whic h are not perfor- man t when considering high-dimensional data –, or face a trade-o problem b et ween optimizing grouping qualit y and test stabilit y . In this work, we pro- p ose to leverage conformal prediction to obtain a global testing scheme. In the follo wing, we rst describ e the general idea and then the algorithmic details. 3 As discussed before, [ 4 ] show ed that a p oin t x is non-drifting if and only if the conditional entrop y H ( T | X = x ) is maximal, assuming a nite time domain and uniform temp oral distribution, i.e., if w e are maximally uncertain ab out the observ ation time p oin t. Specically , in [ 4 ], this is used as a test statistic and then normalized using a p erm utation scheme. 0 100 200 300 400 500 Calibration Set Size 0.48 0.50 0.52 0.54 0.56 0.58 0.60 ROC-AUC MB -DL (DT) CP (DT) Figure 1: Eect of grouping- test/calibration-set sizes. (De- cision tree, Fish-head dataset, 500 samples, 98 drifting) T o approac h this using conformal predic- tions, recall that if c ∈ F ( x ) then w e can be v ery certain that the correct class is not c . Th us, following the ideas of [ 4 ], w e can re- ject the h yp othesis that x is non-drifting if w e can exclude one time p oint with certaint y , i.e., F ( x ) = T . By expressing F α using conformal p -v alues, i.e., F α ( x ) = { y ∈ C : p y ( x ) ≥ α } , w e can reject H 0 if the minimal conformal score is smaller α , i.e., w e obtain the p -v alue p drifting ( X ) = min y p y ( X ) . Using a proba- bilistic classier as a class-wise scoring func- tion, this relates to the probability of a large deviation of the class-probability from the global probability despite the sample b eing non-drifting, whic h is again in line with the considerations of [ 4 ]. Using conformal prediction has v arious adv antages compared to the local testing scheme. While conformal prediction still requires a calibration set, since this is only needed to calibrate a one-dimensional signal, it can b e chosen muc h smaller while still oering go od p erformance, allo wing us to use more samples for model training. W e displa y this eect in Fig. 1 . Here, a main dierence, also from an eciency p ersp ectiv e, is that for conformal prediction, w e can ev aluate whether a sample is drifting on the set used to train the model, not on the calibration set. Another adv antage is that w e are no longer limited to sp ecic models. Com- monly used lo cal tests require the mo dels to induce some kind of grouping. This is not the case for conformal prediction, thus making it compatible with an y scoring function. This not only mak es the metho d more compatible with the usage of sup ervised trained mo dels but also allo ws a muc h larger p o ol of p oten tial mo dels to choose from. The main hurdle for translating our considerations into an algorithm is the need for a calibration set to perform conformal predictions. W e prop ose using b ootstrapping as the out-of-bag samples constitute a natural calibration set of decen t size, even when o versampling. The mo del is thus trained on the in-bag samples and then calibrated using the out-of-bag samples. Using the calibrated mo dels, we assign p -v alues to the in-bag samples using the minimal conformal p -v alue. T o com bine the resulting p -v alues across several bo otstraps, we suggest using a median, whic h is equiv alent to an ensem ble of tests: we reject H 0 at lev el α if the ma jorit y of bo otstraps lead to a rejection. The ov erall sc heme is presen ted in Algorithm 1 . 4 Algorithm 1 Conformal Prediction for Drift Lo calization 1: Input: ( x i , y i ) n i =1 , y i ∈ C ; n bo ot ∈ N 2: Output: ( p i ) n i =1 3: P i ← [ ] for all i 4: for t = 1 , . . . , n bo ot do 5: ( I in , I oob ) ← SampleBootstrap ( { 1 , . . . , n } ) 6: θ ← TrainModel ( X I in , y I in ) 7: for i ∈ I in do 8: P i ← P i + min c ∈C 1 + ∑ k ∈ I oob : y k = c 1 [ f ( c | x k , θ ) ≤ f ( c | x i , θ )] 1 + |{ k ∈ I oob : y k = c }| 9: end for 10: end for 11: p i ← median( P i ) for all i 12: Return ( p i ) n i =1 4 Exp erimen ts W e are ev aluating the prop osed conformal-prediction-based approach on streams of images. More precisely , w e rely on the F ashion-MNIST [10] dataset and the No ImageNet Class Objects (NINCO) [11]. W e follo w the exp erimen tal setup by [ 4 ], randomly selecting one class for non-drifting, drifting b efore, and drifting after. While we use the F ashion-MNIST without further prepro cessing, for NINCO, w e use deep embeddings (DINOv2 ViT-S/14 [12]). 1 Fish-Head Dataset While this is a simple wa y to obtain drifting image data streams, w e prop ose to also consider a more subtle drifting scenario where we do not model drift b y switching up classes, but induce a more nuanced and realistic t yp e of drift. F or our no v el b enc hmark Fish-He ad data str e am , we rely on the ImageNet [13] subset “ImageNette” consisting of the classes “tenc h,” “English springer,” “cassette pla yer,” “chain sa w,” “c hurc h,” “F renc h horn,” “garbage truc k,” “gas pump,” “golf ball,” and “parach ute. ” W e manually split the class “tenc h” into the tw o sub-classes where the sh head is turned tow ards the left or right side, respectively; these are the drifting samples, all other samples are non-drifting. F or our analysis, w e again use a DINOv2 ViT-S/14 [12] mo del to em b ed the images. A simple analysis sho ws that non-drifting, drifting b efore, and drifting after are lineally separable in the em b edding. Eect of Bo otstraps If ev aluating via ROC-A UC scores, our metho d has tw o remaining “parameters”: the inner model used to perform the prediction and the num b er of b o otstraps. Here, our fo cus will b e on the num b er of b ootstraps. The results are presen ted in Fig. 2. 1 DINOv2 (released April 2023) w as trained on large-scale image data, whereas NINCO (released June 2023) is a curated out-of-distribution b enchmark. Given NINCO’s later release and evaluation-focused design, its inclusion in DINOv2’s training data is unlikely , though this cannot b e conrmed denitively . 5 0 50 100 150 200 250 300 #Bootstraps 0.5 0.6 0.7 0.8 ROC-AUC Fish-Head (DINOv2 V iT -S/14) #Smpls.: 500, #Drifting: 98 DT MLP Mean Median 25%-75% quantile Figure 2: Eect of num b er of b o otstraps on ROC-A UC. Figure shows aggrega- tion of 500 runs on FishHead dataset. F or our ev aluation, w e only take those data p oin ts into accoun t that are assigned a v alue, i.e., those that are at least once not contained in the hold-out set and hence assigned a v alue via CP . The remaining p oin ts are not tak en in to accoun t when forming the mean/median/quan tile. This pro cedure is v alid, as for more than 10 b o otstraps (nearly) all p oin ts are assigned a v alue. In fact, a closer insp ection sho ws that the num b er of times a data p oin ts assigned a v alue shows very little v ariance and grows approximately linearly with a rate of ≈ 0 . 64 . Notice that here we used “plain” b o otstraps, while for the actual implemen tation, we select a subset that maximizes the smallest n umber of times a sample is assigned a v alue relative to the num b er of b o otstraps. Considering the actual results (Fig. 2 ), we observe that for a small n umber of bo otstraps the increase is signican t, while for larger n umbers it tends to plateau out. This eect is more visible for the MLP , whic h seems to reac h its asymptotic state at ab out 75 samples. F or DT, the num b er larger than 300—a smaller analysis consideration 3 , 000 b o otstraps sho ws the v alue stabilizes at a R OC-AUC of ≈ 0 . 83 at ab out 1 , 500 b o otstraps. How ever, using an even larger n umber of b ootstraps further increases the computation time to o signicantly compared to that of other metho ds. This is mitigated by the aforemen tioned b ootstrapping scheme, as can b e seen in the ev aluation b elo w (Fig. 3 ), where we only use 100 b ootstraps, obtaining comparably or even slightly better results. Ov erall, we observe that the n umber of bo otstraps increases the p erformance, whic h stabilizes at a sucient size. Ev aluation of Method T o ev aluate our method, w e follo w the same pro ce- dure as [2] 2 . F or the simpler NINCO and F ashion-MNIST datasets, we use 2 × 60 samples with 10 drifting, for the Fish-Head dataset, we used 2 × 250 samples with 98 drifting; here, the increase w as necessary as otherwise no metho d yielded results ab ov e random chance. Besides the nov el conformal-prediction-based ap- proac h (CP) using decision trees (DT) and MLPs as mo dels, we ev aluate the mo del-based approac h (MB-DL; [ 4 ]) using p erm utations and decision trees on b ootstraps (DT, perm.) similar to Algorithm 1 and heuristic approach based on random forests (RF, heur.), LDD-DIS [ 6 ], and k dq -trees [ 5 ]. F ollowing [ 2 ], 2 See https://github.com/FabianHinder/Advanced- Drift- Localization for the code 6 CP (DT) (ours) CP (MLP) (ours) k d q - T r e e LDD -DIS MB -DL (DT , perm.) MB -DL (RF , heur .) 0.5 0.6 0.7 0.8 0.9 1.0 ROC-AUC Fish-Head (DINOv2 V iT -S/14) #Smpls.: 500, #Drifting: 98 CP (DT) (ours) CP (MLP) (ours) k d q - T r e e LDD -DIS MB -DL (DT , perm.) MB -DL (RF , heur .) NINCO (DINOv2 V iT -S/14) #Smpls.: 120, #Drifting: 10 CP (DT) (ours) CP (MLP) (ours) k d q - T r e e LDD -DIS MB -DL (DT , perm.) MB -DL (RF , heur .) F ashion-MNIST (raw) #Smpls.: 120, #Drifting: 10 Figure 3: Experimental results. ROC-A UC (500 runs) for v arious drift lo calizes using windo ws of 250/60 samples with 98/10 drifting samples (in total). w e use the ROC-A UC as a score. W e rep eat each exp erimen t 500 times. The results are shown in Fig. 3 . One can clearly observe that for both NINCO and F ashion-MNIST, the prop osed conformal-prediction-based lo cal- ization outp erforms the related work, in particular, when using MLPs. Consid- ering the new Fish-Head b enc hmark, we obtain that our metho d, realized with decision trees, outp erforms the other metho ds. In this setting, the mo del-based approac hes perform at a similar lev el to our MLP-based v ersion. Ov erall, the new data b enc hmark seems to b e a more challenging task, making it suitable for further ev aluation. 5 Conclusion and F uture W ork In this work, w e proposed a no vel strategy for drift lo calization, replacing the state-of-the-art lo cal testing in data segments with a conformal-prediction-based global strategy allowing for a larger mo del p ool while providing formal guar- an tees. W e exp erimen tally show ed the adv antage of the prop osed metho dology on established image data streams, showing that those can essen tially b e solved b y the presen ted metho d. Besides, we prop osed a nov el image stream b enc h- mark containing more subtle drift. As our exp erimen ts sho w, this b enc hmark is far more c hallenging, requiring a signicantly larger n umber of samples to ensure results b etter than random chance. F urther inv estigation and dev elop- men t that is b etter suited for small-sample size setups, and in particular, w ork in the case of only few drifting samples, is sub ject to future work. F urthermore, in vestigating the relev ance of the used deep embedding seems to b e a relev ant consideration. References [1] J. Lu, A. Liu, F. Dong, F. Gu, J. Gama, and G. Zhang. Learning under concept drift: A review. IEEE tr ansactions on know le dge and data engine ering , 2018. 7 [2] F. Hinder, V. V aquet, and B. Hammer. One or tw o things we kno w about concept drift— a surv ey on monitoring in evolving en vironments. part b: lo cating and explaining concept drift. F r ontiers in Articial Intel ligence , 2024. [3] F. Hinder, V. V aquet, J. Brinkrolf, and B. Hammer. Mo del-based explanations of concept drift. Neur o c omputing , 2023. [4] F. Hinder, V. V aquet, J. Brinkrolf, A. Artelt, and B. Hammer. Lo calization of concept drift: Identifying the drifting datap oints. In IJCNN , 2022. [5] T. Dasu, S. Krishnan, S. V enkatasubramanian, and K. Yi. An information-theoretic approach to detecting changes in multi-dimensional data streams. 2006. [6] A. Liu, Y. Song, G. Zhang, and J. Lu. Regional concept drift detection and density synchronized drift adaptation. In IJCAI , 2017. [7] A. Liu, J. Lu, and G. Zhang. Concept drift detection via equal intensit y k-means space partitioning. IEEE tr ansactions on cyb ernetics , 2020. [8] B. A. Ramos, C. L. Castro, T. A. Co elho, and P . P . Angelo v. Unsup ervised drift detection using quadtree spatial mapping. 2024. [9] F. Hinder, A. Artelt, and B. Hammer. T ow ards non-parametric drift detection via dy- namic adapting window indep endence drift detection (dawidd). In ICML , 2020. [10] H. Xiao, K. Rasul, and R. V ollgraf. F ashion-mnist: a nov el image dataset for b enc hmark- ing machine learning algorithms. arXiv pr eprint arXiv:1708.07747 , 2017. [11] J. Bitterwolf, M. Müller, and M. Hein. In or out? xing imagenet out-of-distribution detection ev aluation. In ICML , 2023. [12] M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V. Khalidov, P . F ernandez, D. Haziza, F. Massa, A. El-Nouby , et al. Dinov2: Learning robust visual features without supervision. arXiv pr eprint arXiv:2304.07193 , 2023. [13] J. Deng, W. Dong, R. So c her, L. Li, K. Li, and L. F ei-F ei. Imagenet: A large-scale hierarchical image database. In CVPR , 2009. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment