CTC-TTS: LLM-based dual-streaming text-to-speech with CTC alignment
Large-language-model (LLM)-based text-to-speech (TTS) systems can generate natural speech, but most are not designed for low-latency dual-streaming synthesis. High-quality dual-streaming TTS depends on accurate text--speech alignment and well-designe…
Authors: Hanwen Liu, Saierdaer Yusuyin, Hao Huang
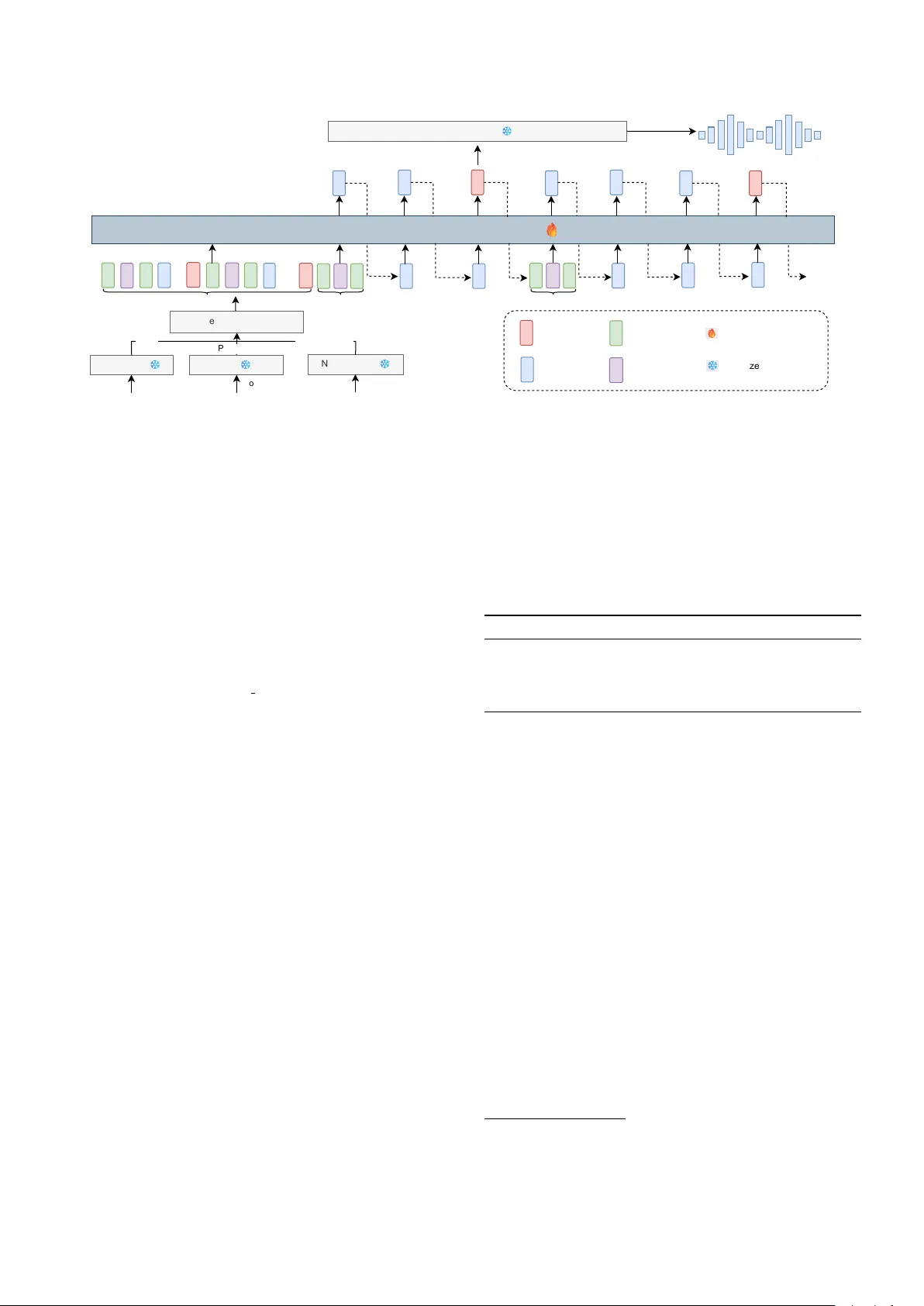
CTC-TTS: LLM-based dual-str eaming text-to-speech with CTC alignment Hanwen Liu ID 1 , Saier daer Y usuyin ID 1 , Hao Huang ID 1 , Zhijian Ou ID 2 , ∗∗ 1 School of Computer Science and T echnology , Xinjiang Univ ersity , China 2 Speech Processing and Machine Intelligence (SPMI) Lab, Tsinghua Uni versity , China huanghao@xju.edu.cn, ozj@tsinghua.edu.cn Abstract Large-language-model (LLM)-based text-to-speech (TTS) sys- tems can generate natural speech, but most are not designed for low-latenc y dual-streaming synthesis. High-quality dual- streaming TTS depends on accurate text–speech alignment and well-designed training sequences that balance synthesis qual- ity and latency . Prior work often relies on GMM-HMM based forced-alignment toolkits (e.g., MF A), which are pipeline- heavy and less flexible than neural aligners; fixed-ratio inter- leaving of text and speech tokens struggles to capture text– speech alignment regularities. W e propose CTC-TTS, which replaces MF A with a CTC based aligner and introduces a bi- word based interleaving strategy . T wo variants are designed: CTC-TTS-L (token concatenation along the sequence length) for higher quality and CTC-TTS-F (embedding stacking along the feature dimension) for lower latenc y . Experiments show that CTC-TTS outperforms fixed-ratio interleaving and MF A-based baselines on streaming synthesis and zero-shot tasks. Speech samples are av ailable at https://ctctts.github.io/ . Index T erms : dual-streaming TTS, CTC alignment 1. Introduction In recent years, large language model (LLM)-based methods [1, 2, 3, 4] that treat text-to-speech (TTS) as a language modeling task have gained widespread attention. These methods typically con vert continuous speech signals into discrete token sequences with a neural audio codec (N A C) [5, 6, 7], predict the sequence using an LLM, and finally reconstruct the speech wav eform via the N A C decoder . Howe v er , most LLM-based TTS systems are not designed for lo w-latency dual-streaming synthesis [1, 2, 3]. High-quality dual-streaming TTS requires accurate text–speech alignment and well-designed training sequences that balance synthesis quality and latency . Prior work often relies on GMM-HMM based forced-alignment toolkits (e.g., Montreal F orced Aligner , MF A) [8], which are pipeline-heavy and less flexible than neu- ral aligners. Meanwhile, fixed-ratio interleaving of text and speech tokens struggles to capture alignment regularities be- tween text and speech, making it more difficult for the model to learn reliable temporal dependencies. Alignment-aware in- terleaving can alleviate this issue b ut still typically depends on MF A; existing methods adopt dif ferent alignment units (e.g., words, BPEs, or phonemes) and div erse sequence organiza- tions, as revie wed in Section 2. T o address these limitations, we propose CTC-TTS , a Connectionist T emporal Classification (CTC)-based [9] dual- streaming TTS method that improv es both alignment and se- quence organization. CTC alignment introduces a blank symbol ** indicates the corresponding author . 0 This paper has been submitted to INTERSPEECH 2026. and yields a robust structural correspondence without requir- ing frame-accurate phoneme boundaries. This le vel of align- ment is sufficient for an autoregressiv e model to learn to map local phoneme groups to speech tokens, reducing learning com- plexity compared with fixed-ratio interlea ving and avoiding the heavy pipeline of MF A. Based on word-le vel phoneme–speech alignment, we construct bi-wor d blocks: phonemes of the cur- rent word plus the separator and phonemes of the next word, followed by the speech tok ens aligned to the current word. T o balance synthesis quality and latency , we design two variants based on different interleaving implementations of phonemes and speech tokens for bi-words. CTC-TTS-L con- catenates text and speech tokens along the sequence length di- mension to enhance generation quality . CTC-TTS-F stacks text and speech embeddings along the feature dimension, enabling synthesis to start from the first phoneme and thus reducing first- packet latency . Experiments show that CTC-TTS outperforms strong baselines on streaming synthesis and zero-shot tasks. Our main contributions are: (1) a lightweight CTC-based phoneme-speech alignment procedure for LLM-based TTS; (2) a bi-word interleaving strate gy with compact look-ahead; (3) two variants (CTC-TTS-L/F) that realize different quality- latency trade-of fs and improve streaming and zero-shot results. 2. Related W ork Early LLM-based TTS methods concatenate full speech tokens after the complete text input, leading to large first-packet la- tency (FPL) [1, 3]. Dual-streaming methods therefore construct interleav ed text–speech sequences so that an autoregressi ve de- coder can generate speech tokens while text tok ens arrives. Non-aligned interleaving. IST -LM [10], CosyV oice2 [4], and StreamMel [11] use fixed-ratio interleaving of text and speech. LLMV ox [12] stacks phoneme and speech embeddings in the feature dimension to reduce FPL. Aligned interleaving . SpeakStream [13] uses word-lev el forced alignment to pair chunked speech with a window of text words. SyncSpeech [14] applies MF A for speech–BPE (Byte Pair Encoding) [15] alignment and generates speech tokens per BPE token. ELLA-V [16] employs MF A for phoneme– speech alignment and aligned interleaving, outperforming the non-aligned V ALL-E [1]. Interleaving design. Interleaving schemes reflect quality- latency trade-offs in streaming speech synthesis, by using dif- ferent amounts of look-ahead. SpeakStream trades latency for quality via the text-window size and speech hop. SyncSpeech introduces duration modeling, increasing model complexity . ELLA-V adopts global advance (prepending all phonemes for global context) and local advance (shifting phonemes forward for local context). In this paper, we adopt a bi-word interleav- ing unit to balance synthesis quality and latency . 3. CTC-TTS 3.1. Speech–phoneme alignment Giv en input speech features, a CTC-based automatic speech recognition (ASR) model outputs a posterior distribution over text labels 1 at each frame. From this distribution, we obtain the maximum-probability alignment path π ∗ via the V iterbi algo- rithm [9]: π ∗ = argmax π T Y t =1 P ( π t | x t ) (1) where x t denotes the acoustic feature at frame t , π = ( π 1 , . . . , π T ) is a frame-lev el alignment path over an extended alphabet (phonemes plus the blank symbol), and P ( π t | x t ) is the posterior probability at frame t computed from the logits produced by the neural-network based acoustic model. In CTC, multiple consecutiv e frames may share the same label and blank labels may appear between phoneme labels; the standard col- lapse operation (mer ge repeats and remov e blanks) maps a path to the corresponding phoneme sequence [9]. In the path π ∗ , phoneme labels usually lag their actual speech onset, and blank labels may correspond to silence or ad- jacent phoneme regions [17]. W e therefore assign each blank label to its first subsequent phoneme. If π ∗ ends with blank labels, these trailing blanks are assigned to the final phoneme label, yielding the refined path ˆ π . In our experiments, the CTC model conv erts speech into acoustic features at 25 frames per second, while the NA C conv erts speech into a discrete token sequence s at 75 frames per second, the length ratio between ˆ π and s = ( s 1 , . . . , s 3 T ) is 1:3. W e thus map each phoneme label in ˆ π to three corresponding speech tokens in s , such that the i -th phoneme ˆ π i is aligned to the discrete speech tokens [ s 3 i − 2 , s 3 i − 1 , s 3 i ] . Unlike GMM-HMM forced alignment, the CTC alignment used here is not intended to provide frame-accurate phoneme boundaries. Instead, it provides a stable structural alignment that is sufficient for constructing word-lev el phoneme–speech blocks and for learning the mapping from local phoneme groups to speech tokens. 3.2. Interleaving schemes After aligning phonemes and speech, we derive the speech se- quence corresponding to the phonemes of each word. Since a word’ s pronunciation depends on its context, we construct the sequence illustrated in Figure 1(a): after the phonemes of the current word, we append the w ord separator between the current and ne xt word (space, comma, period, question mark and exclamation mark), together with the phonemes of the ne xt word, followed by the speech tokens corresponding to the cur- rent word, and end with a block terminator ⟨ eob ⟩ . For the k -th word, we refer to this as a (bi-word) phoneme–speech block b k . For the last word, which has no subsequent word, we insert an ⟨ eos ⟩ as a placeholder for the future word. Concatenating all phoneme–speech blocks yields the complete training sequence for an utterance: Y = b 1 ⊕ b 2 ⊕ · · · . The model trained on such text–speech sequences constructed by length-wise con- catenation is denoted as CTC-TTS-L (Figure 1a). CTC-TTS-L only starts generating speech tokens after re- ceiving phonemes for the first two words, which increases first- packet latency . T o mitigate this issue, we follow LLMV ox [12] 1 In this work, we use phonemes as te xt labels; exploring graphemes or subwords as alignment units is left for future work. p p sep ... ...... eob p p ... token embedding s s s s s ... ... ... ... ... ... word separator speech s sep zero tensor 0 eob pad phoneme p Interleaving Schemes phonemes of current word phonemes of next word speech of current word (a) Splicing in length (b) Feature stacking 0 p p s sep s p s p s pad s pad 0 eob Figure 1: One bi-word block in the two text–speech interleaving schemes: (a) CTC-TTS-L and (b) CTC-TTS-F . and instead stack phoneme and speech embeddings along the feature dimension (Figure 1b). For each block, we append ⟨ pad ⟩ tokens to the phoneme sequence so that its length matches the speech-token sequence length, then stack them along the fea- ture dimension. For initialization, the first phoneme of the ini- tial block and the ⟨ eob ⟩ token are both stacked with an all-zero tensor . During inference, the model can generate speech to- kens immediately after reading the first phoneme (stacked with zeros), which reduces first-packet latency . The model trained with feature-lev el stacking is denoted as CTC-TTS-F . 3.3. Model architectur e Figure 2 illustrates the CTC-TTS framew ork (shown for CTC- TTS-L); CTC-TTS-F is analogous and omitted for brevity . Since this paper adopts a single-codebook NA C, only one au- toregressi ve T ransformer is used to predict speech tokens and the ⟨ eob ⟩ symbol. Let the training sequence be rewritten as Y = y 1 , · · · , y | Y | , where | Y | denotes the sequence length. The training objectiv e is to minimize the cross-entropy loss ov er speech tokens and ⟨ eob ⟩ : L = − X t =1 , ··· , | Y | ; t / ∈T log P ( y t | y T oken p p eob s s sep ... p p ... sep sep sep p p p sep Word Separator CTC-TTS Prompt T okens T arget T okens T arget T okens Chunk-aware Streaming Output Personalized Speech Prompt Speech Prompt Speech Logits Speech T okens Figure 2: Overview of CTC-TTS-L. Components include: (1) a G2P model that converts text to phonemes; (2) a CTC-based ASR model for speech–phoneme alignment; (3) a decoder-only LM that models interleaved text and speech tokens; (4) a neural audio codec; and (5) an alignment-and-interleaving module implementing Sections 3.1–3.2. CTC-TTS-F shares the same components but uses feature- level stac king (Fig . 1b) and is omitted for bre vity . No prompts ar e r equired in single-speak er settings. 4. Experimental setup 4.1. Pre-trained models and dataset selection W e use a LibriSpeech-trained monolingual Whistle [18, 19] as the CTC model (115M parameters), which is a Conformer- based [20] ASR model with weak phonetic supervision. Phonetisaurus [21], a WFST -based [22] G2P toolkit, con verts English text to IP A phonemes. W avT okenizer [5], a single- codebook NA C, enables a single autoregressi ve model to pre- dict all speech tokens. T o obtain the speech–phoneme align- ment, we use the forced align function in T orchaudio, which takes CTC posteriors as input and implements Eq. (1) via the V iterbi algorithm. Single-speaker streaming experiments . W e evaluate dual-streaming generation with the two CTC-TTS variants against LLMV ox [12]. Following LLMV ox, we use the V oice- Assistant400K [23] single-speaker dataset (1750 h training, 50 h validation, 5 h test) after filtering untranscribable utterances via Phonetisaurus. W e reproduce LLMV ox on this dataset for com- parison and adopt the same chunk-aw are streaming speech out- put paradigm as LLMV ox. Multi-speaker zero-shot experiments . W e compare our alignment and interleaving schemes with baselines on two tasks (continuation and cross-speaker). Different model are trained on the 960-hour LibriSpeech dataset. For ev aluation, the con- tinuation task uses 4–10 s utterances from test-clean , while the cross-speak er task uses Seed-TTS [2] test-en . W e repro- duce ELLA-V’ s local-advance setting with the same backbone, N AC, and data splits for f air comparison. 4.2. T raining configuration W e use 12 T ransformer decoder layers with 16 attention heads, 1024 embedding dimension, 4096 feed-forward dimension, and 0.3 dropout. For CTC-TTS-F , text and speech embedding di- mensions are 256 and 768. For single-speaker experiments, the parameters are adjusted to 4 decoder layers, 12 attention heads, 768 embedding dimension, 3072 feed-forward dimen- sion, 0 dropout, 256 text embedding dimension, and 512 speech T able 1: Comparison between CTC-TTS and LLMV ox. LLMV ox interleaves text and speech at a fixed ratio and stacks embed- dings in the feature dimension. CTC-TTS-F stacks embeddings in the feature dimension, while CTC-TTS-L concatenates tokens along the length dimension. #P arams refers to model parame- ters, and N A indicates not applied. Method #Params WER% ↓ CER% ↓ FPL-A ↓ UTMOS ↑ Ground T ruth N A N A N A N A 4.27 LLMV ox 31.5M 2.40 1.36 167 4.15 CTC-TTS-F 33.6M 1.80 1.04 159 4.15 CTC-TTS-L 34.7M 1.50 0.79 210 4.15 embedding dimension. All models are trained on 4 R TX 3090 GPUs with a total batch size of 32. W e use the AdamW [24] op- timizer ( β 1 = 0 . 9 , β 2 = 0 . 95 , ϵ = 10 − 6 ) and a cosine learning rate scheduler with warm-up to 3 × 10 − 4 in 25k steps. Train- ing steps are 320k for multi-speaker and 1M for single-speaker . The weight decay is set to 0.1. W e use flash-attention [25] for fast training and KV -Cache for inference. 4.3. Evaluation metrics Objective metrics . W e use W ord Error Rate (WER) and Character Error Rate (CER) to ev aluate intelligibility . whisper-large-v3 [26] and Conformer-T ransducer 2 are used as ASR models for single- and multi-speaker experiments, respectiv ely . Speech naturalness is measured by UTMOS [27]. First-packet latency (FPL-A, assuming the full text is av ailable for TTS) is reported for single-speaker experiments. Speaker similarity (SPK) is computed using WavLM-Base-Plus-SV [28] embeddings. Subjective metrics . W e conduct Mean Opinion Score (MOS) for naturalness and Similarity MOS (SMOS) for speaker simi- larity . 30 samples are randomly selected per system and eval- uated by 20 listeners on a 1–5 scale, with results reported as mean scores with 95% confidence intervals. 2 https://huggingface.co/nvidia/stt_en_ conformer_transducer_xlarge T able 2: Experimental r esults of differ ent methods on the continuation task ( bold : best, underline: second best). Group Method Paras WER% ↓ CER% ↓ SPK ↑ UTMOS ↑ MOS ↑ SMOS ↑ Ground T ruth N A N A 1.92 0.69 N A 4.086 4 . 28 ± 0 . 060 4 . 60 ± 0 . 048 Our Method CTC-TTS-F 158.47M 5.20 2.68 0.930 4.013 4 . 31 ± 0 . 057 4 . 58 ± 0 . 050 CTC-TTS-L 159.58M 4.82 2.47 0.929 4.050 4 . 33 ± 0 . 061 4 . 60 ± 0 . 049 Ablation CTC+ELLA-V 159.58M 12.01 7.37 0.928 4.021 4 . 00 ± 0 . 062 4 . 39 ± 0 . 058 MF A+ELLA-V 159.58M 10.98 6.99 0.928 4.021 3 . 94 ± 0 . 066 4 . 44 ± 0 . 056 MF A+bi-word 159.58M 5.14 2.63 0.930 4.010 4 . 25 ± 0 . 061 4 . 50 ± 0 . 051 T able 3: Experimental r esults of differ ent methods on the cr oss-speaker task. Group Method Paras WER% ↓ CER% ↓ SPK ↑ UTMOS ↑ MOS ↑ SMOS ↑ Ground T ruth N A N A N A N A N A 3.527 4 . 18 ± 0 . 068 4 . 14 ± 0 . 072 Our Method CTC-TTS-F 158.47M 8.02 4.20 0.880 3.903 4 . 16 ± 0 . 064 3 . 85 ± 0 . 071 CTC-TTS-L 159.58M 6.33 3.21 0.878 3.971 4 . 23 ± 0 . 060 3 . 98 ± 0 . 073 Ablation CTC+ELLA-V 159.58M 20.86 11.73 0.869 3.848 3 . 88 ± 0 . 073 3 . 94 ± 0 . 073 MF A+ELLA-V 159.58M 34.89 19.58 0.872 3.873 3 . 75 ± 0 . 071 3 . 88 ± 0 . 074 MF A+bi-word 159.58M 7.53 3.99 0.874 3.840 4 . 14 ± 0 . 068 3 . 83 ± 0 . 076 5. Experimental results 5.1. Single-speaker str eaming experiments T able 1 shows the results of LLMV ox and the tw o CTC-TTS variants using greedy search. Compared to LLMV ox, CTC- TTS-F achieves lower WER and CER while maintaining a shorter FPL-A (ms). The key dif ference lies in its adoption of CTC alignment and bi-word based sequences, demonstrat- ing the advantages of these two designs. Compared to CTC- TTS-F , CTC-TTS-L deliv ers ev en lower WER and CER with a slightly higher FPL-A. The two variants can be selected based on latency and quality requirements. All three methods hav e identical UTMOS scores (reflecting comparable naturalness), as UTMOS prioritizes speech naturalness ov er content. 5.2. Multi-speaker zer o-shot experiments For the multi-speaker experiments, we reproduce the ELLA-V setup on the zero-shot task using MF A alignment and ELLA- V’ s training sequence, which we refer to as MF A+ELLA-V . W e further conduct ablation studies with dif ferent alignment and training sequences: CTC alignment with ELLA-V’ s sequence (CTC+ELLA-V), and MF A alignment with CTC-TTS-L ’ s se- quence (MF A+bi-word). Following ELLA-V , we use nucleus sampling in multi-speaker generation for more stable results. Continuation . Giv en a text segment and its corresponding 3-second prefix ed speech, the task aims to synthesize speech for the remaining text. Results are shown in T able 2. For meth- ods using bi-word sequences, CTC-TTS-F achie ves competi- tiv e performance compared with MF A+bi-word, while CTC- TTS-L outperforms MF A+bi-word in all metrics e xcept SPK— demonstrating the superiority of CTC alignment. For methods using CTC alignment, our methods outperform CTC+ELLA-V across the board, which may stem from the limited context pro- vided by ELLA-V’ s local advance mechanism and further val- idates the advantage of the bi-word interleaving scheme. No- tably , CTC-TTS-L deli vers near-optimal performance on the entire continuation task, highlighting the merits of combining CTC alignment, bi-word training sequences, and length-wise token concatenation. Cross-speak er . Gi ven about 3 seconds of speech and its transcribed te xt as a prompt, this task synthesizes speech for another utterance. Results are sho wn in T able 3. Due to the out- of-domain testing, all results are slightly worse than in the con- tinuation task, but the overall trends are similar . As in the con- tinuation task, CTC-TTS-L achiev es near-optimal performance on the cross-speaker task. CTC-TTS-F is slightly worse than MF A+bi-word; howe ver , CTC-TTS-F uses feature-lev el stack- ing, whereas MF A+bi-word uses length-wise concatenation, so they are not directly comparable. Overall, combining CTC alignment with bi-word sequences achie ves strong performance in this out-of-domain setting. When using ELLA-V’ s train- ing sequence, both CTC+ELLA-V and MF A+ELLA-V yield poor performance, highlighting the limitations of ELLA-V’ s sequence organization. Notably , CTC+ELLA-V outperforms MF A+ELLA-V in WER and CER, whereas MF A+ELLA-V is better on the in-domain continuation task. This indicates that MF A alignment performs well for in-domain continuation, while CTC alignment generalizes better to out-of-domain cross- speaker scenarios. 6. Conclusion This paper presents CTC-TTS, which uses CTC alignment to deri ve phoneme–speech correspondence for an LLM-based dual-streaming TTS model and trains on bi-word interlea ved sequences. W e introduce two variants, CTC-TTS-L and CTC- TTS-F , which implement bi-word interleaving along the length and feature dimensions, respecti vely , pro viding a practical quality–latency trade-off. Experiments show that CTC-TTS outperforms fixed-ratio interleaving and MF A-based baselines on streaming synthesis and zero-shot tasks. Potentially inter- esting future work includes replacing the current WFST -based Phonetisaurus with neural G2P models such as the CTC-based one in JSA-SPG [29], and lev eraging recent progress in neu- ral forced alignment and speech–text alignment models to ob- tain more precise boundaries and further improve sequence con- struction and streaming controllability . The code will be re- leased upon paper acceptance. 7. Generative AI Use Disclosur e Generativ e AI tools are used in this work only for language edit- ing, polishing, and formatting of the manuscript. They are not used to generate any core content, research ideas, experimental designs, results, or major textual parts of the paper . All scien- tific contributions, including model design, experiments, analy- sis, and conclusions, are completed by the authors. 8. References [1] S. Chen, C. W ang, Y . W u, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. W ang, J. Li, L. He, S. Zhao, and F . W ei, “Neural codec language models are zero-shot te xt-to-speech synthesizers, ” IEEE/ACM T rans. A udio, Speech, Langua ge Pr ocess. , vol. 33, pp. 705–718, 2025. [2] P . Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gao, M. Gong, P . Huang, Q. Huang, Z. Huang, Y . Huo, D. Jia, C. Li, F . Li, H. Li, J. Li, X. Li, X. Li, L. Liu, S. Liu, S. Liu, X. Liu, Y . Liu, Z. Liu, L. Lu, J. Pan, X. W ang, Y . W ang, Y . W ang, Z. W ei, J. Wu, C. Y ao, Y . Y ang, Y . Y i, J. Zhang, Q. Zhang, S. Zhang, W . Zhang, Y . Zhang, Z. Zhao, D. Zhong, and X. Zhuang, “Seed-TTS: A family of high-quality versatile speech generation models, ” , 2024. [3] Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Y ang, H. Hu, S. Zheng, Y . Gu, Z. Ma, Z. Gao, and Z. Y an, “CosyV oice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens, ” , 2024. [4] Z. Du, Y . W ang, Q. Chen, X. Shi, X. Lv , T . Zhao, Z. Gao, Y . Y ang, C. Gao, H. W ang, F . Y u, H. Liu, Z. Sheng, Y . Gu, C. Deng, W . W ang, S. Zhang, Z. Y an, and J. Zhou, “CosyV oice 2: Scal- able streaming speech synthesis with large language models, ” arXiv:2412.10117 , 2024. [5] S. Ji, Z. Jiang, W . W ang, Y . Chen, M. Fang, J. Zuo, Q. Y ang, X. Cheng, Z. W ang, R. Li, Z. Zhang, X. Y ang, R. Huang, Y . Jiang, Q. Chen, S. Zheng, and Z. Zhao, “W avT okenizer: An efficient acoustic discrete codec tokenizer for audio language modeling, ” in Proc. International Conference on Learning Representations (ICLR) , 2025. [6] N. Zeghidour , A. Luebs, A. Omran, J. Skoglund, and M. T agliasacchi, “SoundStream: An end-to-end neural audio codec, ” IEEE/ACM T rans. A udio, Speech, Language Pr ocess. , vol. 30, pp. 495–507, 2022. [7] A. D ´ efossez, N. Zeghidour , N. Usunier , L. Bottou, and F . Bach, “High fidelity neural audio compression, ” T rans. Mach. Learn. Res. , 2023. [8] M. McAuliffe, M. Socolof, S. Mihuc, M. W agner, and M. Son- deregger , “Montreal Forced Aligner: Trainable te xt-speech align- ment using Kaldi, ” in Pr oc. Interspeech , 2017. [9] A. Graves, S. Fern ´ andez, F . Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks, ” in Pr oc. Interna- tional Confer ence on Machine Learning (ICML) , 2006. [10] Y . Y ang, S. Liu, J. Li, H. W ang, L. Meng, H. Sun, Y . Liang, Z. Ma, Y . Hu, R. Zhao, Y . Lu, and X. Chen, “Interleaved speech-text language models for simple streaming text-to-speech synthesis, ” arXiv:2412.16102 , 2024. [11] Y . Gong, X. Feng, S. Liu, Z. Xu, C. Zhang, Y . W u, J. Li, H. Peng, and F . W ei, “StreamMel: Real-time zero-shot text-to-speech via interleav ed continuous autoregressive modeling, ” IEEE Signal Pr ocess. Lett. , vol. 31, pp. 3530–3534, 2024. [12] S. Shikhar, M. I. Kurpath, S. S. Mullappilly , J. Lahoud, F . S. Khan, R. M. Anwer , S. Khan, and H. Cholakkal, “LLMVoX: Autore- gressiv e streaming text-to-speech model for any LLM, ” in Proc. F indings of the Association for Computational Linguistics (A CL) , 2025. [13] R. H. Bai, Z. Gu, T . Likhomanenko, and N. Jaitly , “Speak- Stream: Streaming text-to-speech with interleaved data, ” arXiv:2505.19206 , 2025. [14] Z. Sheng, Z. Du, S. Zhang, Z. Y an, Y . Y ang, and Z. Ling, “Sync- Speech: Lo w-latency and efficient dual-stream text-to-speech based on temporal mask ed transformer , ” , 2025. [15] R. Sennrich, B. Haddow , and A. Birch, “Neural machine transla- tion of rare words with subword units, ” in Pr oc. Annual Meeting of the Association for Computational Linguistics (ACL) , 2016. [16] Y . Song, Z. Chen, X. W ang, Z. Ma, and X. Chen, “ELLA-V: Sta- ble neural codec language modeling with alignment-guided se- quence reordering, ” in Proc. AAAI Conference on Artificial Intel- ligence (AAAI) , 2025. [17] R. Huang, X. Zhang, Z. Ni, L. Sun, M. Hira, J. Hwang, V . Manohar , V . Pratap, M. W iesner, S. W atanabe, D. Povey , and S. Khudanpur, “Less peaky and more accurate CTC forced align- ment by label priors, ” in Pr oc. IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2024. [18] V . Panayotov , G. Chen, D. Pove y , and S. Khudanpur, “Lib- riSpeech: An ASR corpus based on public domain audio books, ” in Pr oc. IEEE International Confer ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 2015. [19] S. Y usuyin, T . Ma, H. Huang, W . Zhao, and Z. Ou, “Whis- tle: Data-efficient multilingual and crosslingual speech recogni- tion via weakly phonetic supervision, ” IEEE/ACM T rans. Audio, Speech, Languag e Process. , v ol. 33, pp. 1440–1453, 2025. [20] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar , Y . Zhang, J. Y u, W . Han, S. W ang, Z. Zhang, Y . W u, and R. Pang, “Conformer: Con volution-augmented transformer for speech recognition, ” in Pr oc. Interspeech , 2020. [21] J. R. Nov ak, N. Minematsu, and K. Hirose, “Phonetisaurus: Ex- ploring grapheme-to-phoneme con version with joint n-gram mod- els in the WFST framework, ” Nat. Lang. Eng. , vol. 22, no. 6, pp. 907–938, 2016. [22] M. Mohri, F . Pereira, and M. Riley , Speech r ecognition with weighted finite-state transducers . Springer, 2008, pp. 559–584. [23] Z. Xie and C. Wu, “Mini-Omni: Language models can hear, talk while thinking in streaming, ” , 2024. [24] I. Loshchilov and F . Hutter , “Decoupled weight decay regulariza- tion, ” in Pr oc. International Conference on Learning Repr esenta- tions (ICLR) , 2019. [25] T . Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´ e, “FlashAttention: Fast and memory-ef ficient exact attention with I/O-a wareness, ” in Pr oc. Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2022. [26] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeav ey , and I. Sutskev er, “Robust speech recognition via large-scale weak su- pervision, ” in Proc. International Confer ence on Machine Learn- ing (ICML) , 2023. [27] T . Saeki, D. Xin, W . Nakata, T . Koriyama, S. T akamichi, and H. Saruwatari, “UTMOS: UT okyo-SaruLab system for V oice- MOS challenge 2022, ” in Pr oc. Interspeech , 2022. [28] S. Chen, C. W ang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T . Y oshioka, X. Xiao, J. W u, L. Zhou, S. Ren, Y . Qian, Y . Qian, M. Zeng, X. Y u, and F . W ei, “W avLM: Lar ge-scale self- supervised pre-training for full stack speech processing, ” IEEE J. Sel. T op. Signal Pr ocess. , vol. 16, no. 6, pp. 1505–1518, 2022. [29] S. Y usuyin, T . Ma, H. Huang, and Z. Ou, “Pronunciation- lexicon free training for phoneme-based crosslingual ASR via joint stochastic approximation, ” IEEE/A CM T rans. A udio, Speec h, Language Pr ocess. , vol. 34, pp. 272–284, 2026.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment