An LLM-Enabled Frequency-Aware Flow Diffusion Model for Natural-Language-Guided Power System Scenario Generation
Diverse and controllable scenario generation (e.g., wind, solar, load, etc.) is critical for robust power system planning and operation. As AI-based scenario generation methods are becoming the mainstream, existing methods (e.g., Conditional Generati…
Authors: Zhenghao Zhou, Yiyan Li, Fei Xie
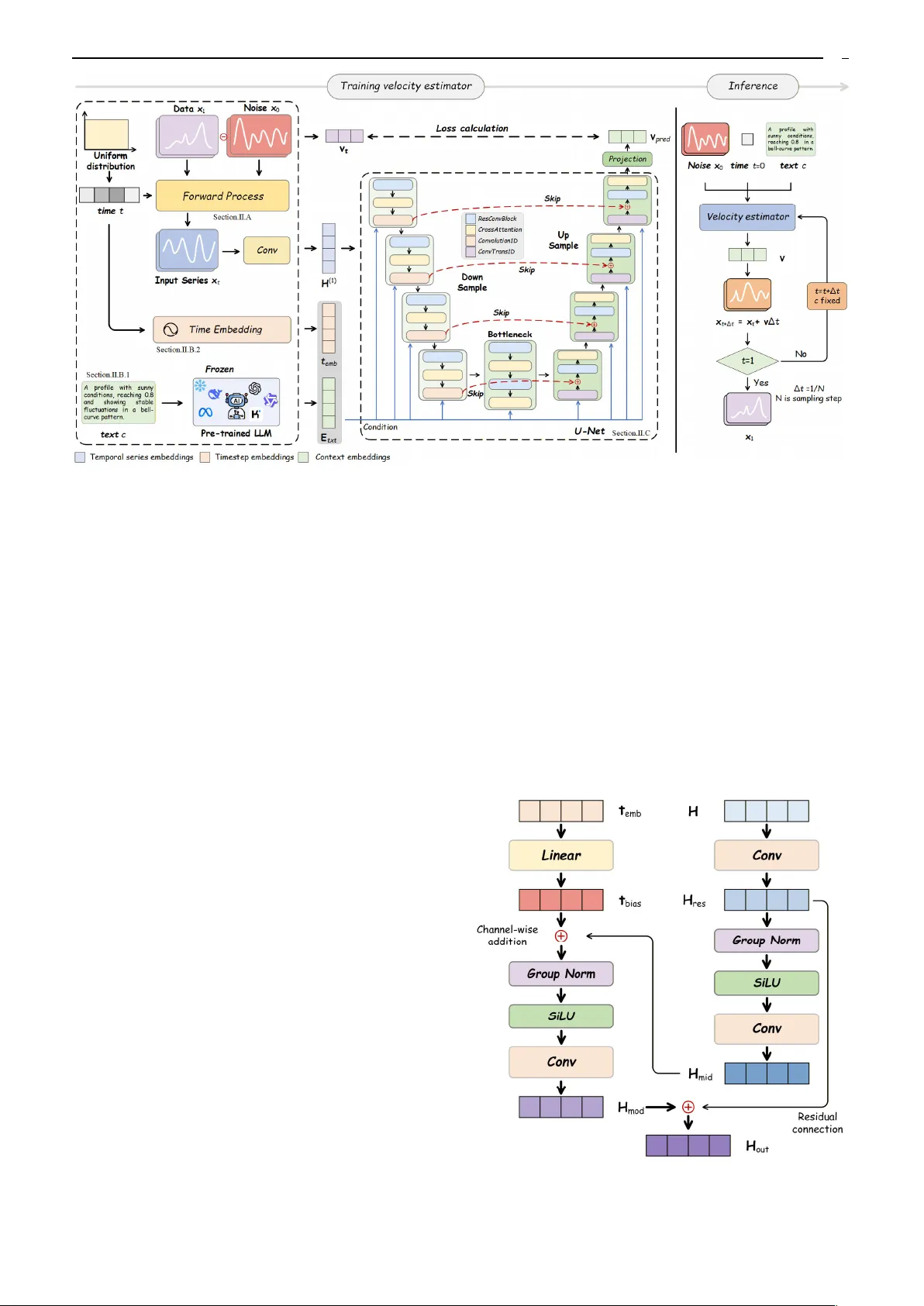
1 Abstract —Diverse and controllable scenario generation (e.g., wind, solar, load, etc.) is critical for rob ust power system planning and operation. As AI-based scenario g enerati on methods are becoming the mainstream, existing methods (e.g . , Conditional Generative Adversarial Nets) mainly rely on a fixed-length numerical con ditioning vector to control the generation results, facing chall enges in user conveniency a n d generation flex ibility. In this paper, a natural-language-guided scenario generation framework, named LL M-enabled Frequency-aware Flow Diffusion (LFFD), is proposed to enable users to generate desired scenario s using plain human language. First, a pretrained LLM module is introduced to convert generation requests describe d by unstructured n atural languages into ordered semantic space. Second, instead of using standard diffusion models, a flow diffusion model employing a rectified flow matching objective is in troduced to achieve efficient and high - quality scenario generation, taking the LLM outp ut as the model input. During the model training process, a frequency-a ware multi-objective optim iz ation algorithm is introduced to mitigate the frequency-bias issue. Meanwhile, a dual-agent framework is desig ned to create text- scenario trai ning sample pa irs as well as to standardize semantic evaluation. Experiments based on large-scale photovoltaic and load datasets demonstrate the effectiveness of the proposed method. Index Terms — Scenario generation, flow diffusion model, large language model, frequency bi as, language processing. I. I NTRODUCTION HE increasing uncertain ty in modern power systems necessitates extensive scenario analysis (i.e. wind, solar , power lo a d, etc.) to ensure reliability in system planning [1] and op eration [2]. However, rely ing solely on scen arios derived from histor ical data is usually insufficien t, as they often fail to capture rare extreme scenario s or hypoth etical future operating conditions due to limited observation This work was supported by National Natural Scienc e Foun dation of China under Grant 52307121 and Gra nt U24B600 9, and also supported by State Power Investment Corporation (SPIC) Class B1 Key Project: "Grid-Friendly Renewable Energy Power Station". (Corresponding author: Yiyan Li.) Zhenghao Zhou and Yiyan Li are with the College of Smart Energy, Shanghai Non-Carbon Energy Conve rsion and Utilization Institute, and Key Laboratory of Control of Power Transmission and Conversion, Ministry of Educatio n, Shanghai Jiao Tong University, Shanghai, 200240, China. (e-mail: zhenghao.zhou @sjtu.edu.cn, yiyan.li@sjtu.edu. cn). Fei Xie and Lu Wang are with Qinghai Photovoltaic Industry Innovation Ce nter Co., Ltd., State Power Investment Corp oration, Xining 810007, China. (e-mail: xieflyj@yeah.net, wanglu2202@outlook. com) Bo Wang and Jiansheng Wang are with Xinjiang Hami Co., Ltd., State Power Investment Corporation, Hami 839000, China. (e-mail: 1012369501 @qq.com, 15688327162@163.com ) Zheng Yan is with the Key Laboratory of Control of Power Transmission and Conversion, Ministry of Education, and the Shanghai N on-Carbon Energy Conversion and Utilization Institute, Shanghai Jiao Tong University, Shanghai 200240, China. (e- mail: yanz@sjt u.edu.cn) Mo-Yuen Chow is with the Global Co llege, Shanghai Jia o Tong Uni versity, Shanghai, 200240, China. (email: moyuen. chow@sjtu.edu.cn) windows. As such, scenario gen eration becomes an importa nt solution. Approach es to scenario gen eration can be categor ized into three primary paradigm s: physics-based simulatio n, statistical modelin g, and m achine lear ning metho ds. Physics-based simulatio n offers an intuitive approach by modelin g the phy sical mechanisms o f real-world scenarios [3]. While it y ields interpre t able data with direct phy sica l correspo ndence, it struggles to capture d iverse stoch astic variation s an d suffers from low comp utation efficiency and heavy labor burdens. Statistical metho ds, such as Latin hyper c ube samplin g, Mo nte Carlo methods, an d Copula models, attempt to replicate scen ario distributio ns [4]. However, these methods often im pose strong assum ptions on marginal distributions or dependen c y structures an d face scalability issues in h igh-dimensional setting s due to the curse of dimensionality. With the evolu tion of artificial intelligen ce, machin e learning m ethods, particularly deep gen erative models, have demon strated capabilities in capturing complex data structures and generatin g high-quality scenarios. They do not rely on rig i d param etric assumptions abo ut the under lyi ng data distribution, instead learn ing flexible representa tions directly from data. Variatio nal Autoen c oder (VAE) learn s temporal laten t representations via an encoder- decoder arch itecture [5]. Howeve r, VAE tends to produce blurred samples that lack the shar p details require d for realistic power curv es. Generativ e Adv ersarial Netwo rk (GAN) [6], through its adversarial training dynam ic, achieves higher visual fid elity but is blamed for issues such as tra ining instability and mod e collap se, limiting its their reliability in generating div e rse critical scenarios [7], [8] . Recently, Den oising Diff usion Probabilistic Mod el (DDPM) [9] has advan ced the scenar io generation by modelin g the distribution through a gradual denoising process. Pro mising fram ewor ks such as Diff Charge [1 0], PrivLoad [11], EnergyDiff [12], and PDM [13] h ave demon strated the ability of diffu sion models to synth esize high-f i delity an d d iversified scen arios. Despite the se advancem ents, app lying standard DDPM to scenario generatio n faces two bottlen e cks. First, the iterative solution of stochastic diff erential equations results in slow inference speeds [1 4]. Second, existing diffusion objectives are primarily optim ized in the time domain, causing a "spectral bias" wh ere the m odel prioritizes low-frequency trends while over- smoothing high- f requ ency transients [15 ]. In power systems, preserving these high-frequency componen ts is critical, as th ey reflect load volatility an d renewab le in termittency. Their loss co mpromises signal An LLM-Enabled Fre qu ency-A ware Flow Dif fusion Model for Natural-Language-Guide d Power System Sce nario Generat ion Zhenghao Zhou, Stud ent Member , IEEE , Yiyan Li, Member , IEEE , Fei Xie, Lu W ang, Bo Wang, Jiansheng Wang, Zheng Ya n, Senior Member , IEEE , and Mo-Yuen Chow, Fe llow, IEEE T 2 Fig. 1. Illustration about diff erences between traditional generative models (upper part) and the pr oposed natural-language-gui ded model (lower part). fidelity and reduces the practical u tility of th e scenario generatio n. While fidelity and efficiency ar e essentia l, pra ctical applicatio n also require s the co ntrollable gen e ration of specific scen arios. To achieve co ntrollable generatio n, researcher s have integrated var ious conditions into generativ e models, such as extrem e-value quantiles [16], user attributes [17], point forecasts [18], weather dynamics [19], patter n features [20], and socio-dem ographic attributes [21]. However , these mech a nisms u sually re ly on a fixed- dimension vector as the cond i tion representation , leading to the following two limitations: 1) Users have to specify the values of all p ositions of th e pred e fined co ndition vecto r, even if some p ositions are irrelevan t or hard to acqu ire, which is user-unfr iendly and will introduce n oises. 2) Users only have limited generation flexib ility by alternatin g the values of the predefined condition vector, impair ing the diversity o f the generation results [2 2]. As illustrated in Fig. 1 , to a ddress the above challenge s (i.e., the ef ficiency and frequency-bias issues of DDPM, and the flex ibility issue caused by the fixed co ndition vector), this pap er propo ses a no vel LLM-guid ed frequency-aware flow diff usion model to achieve flexible, efficient and h igh - fidelity scenar io generation. Large La nguage Model (LLM) is a po werful tool th at can achieve the transformation from unstructu red natural languages into quan titative fe atures [23], [ 24]. Considering this, a pretrain ed LLM module is introdu ced to convert the generation req uirements described by natural lan guages fo r m us ers into stru ctured condition vectors, enab ling extensive contro l flexibility. Then taking the con verted condition vector as the input, a flo w d iffusion model is proposed to achieve effic ient, high-fidelity, and customizab le scenario generation . Contribu tions are summarized as fo llows: 1. A natural-langu age-guided generative framewo rk is proposed by combinin g LLM an d a flow d iffusion m odel, enabling scenario generation with hig h efficien cy, flexibility and fid elity. 2. A tex t-oriented temporal den oising netwo rk is designed featu ring mu lti-resolution cross-m odal attention, which bridges the gap between u nstructured natural languag e and quantitative scenario characteristics. 3. A frequen cy-aware multi-objectiv e optimizatio n strategy is prop osed by embed ding a specially -designed spectral co nsistency loss into th e Multiple Grad ient Descent Algorithm (M GDA), ensuring the model can cap ture b ot h scenario tre nds and high-frequency transients. 4. A dual-agent fram ework is designed to create tex t- scenario training sample pairs as well as to achieve semantic evaluatio n, which can serve as a s tandardized pipelin e for solving o ther text-guided tasks in th e power domain. The rest of th is paper is o r ganized as follo ws: Section Ⅱ introdu ces the methodology. Sectio n Ⅲ demonstrates the case study r esults, and Section IV co ncludes the paper. II. M ETHODOLOGY The LLM -enabled Frequency-a ware Flow Diffusion (LFFD) framework is p rop osed to tackle the synthesis problem p ( x | c ) by learnin g a straig ht-line prob a bility flow guided by a natural lan gu age p rompt c . The LFFD architectu re comprises three tightly coupled co mponents: a text-guid ed rectified flow matching o bjective, a frozen LLM for semantic enco ding, and a novel denoising n etwork as the velocity field pre dictor v θ . Meanwh ile, two LLM-agents are introdu ced for prompt synthesis and consistency evalu ation. A. Frequen cy-Aware Rectified F low Matching Objectiv e Fig. 2. Rectified flow achieves fast generation via a straight-line trajectory. Inspired by re ce nt ad vancements, this work ad opts the flow matching framework , specifically utilizing the rectified flow approach b ased on optimal transpo rt paths, as shown in Fig. 2. This p aradigm has demon strated sup erior g eneration quality and training effic ie ncy compared to trad itiona l diffusion models. Flow matching consists of forward and reverse p rocesses [25]. In forwa rd process, flow m at ching d efines a probability path th at transfo r ms a simple noise d istribution to the complex data distribution. Let x 1 d enote th e clean scenario from the data d istribution, and x 0 ~ ( 0 , I ) denote the in itia l Gaussian noise. For a time step t ∈ [0, 1], the conditional probability path p ( x t | x 1 ) is defined as: 2 1 1 ( | ) ( ; , ( 1 ) ) t t p t t x x x x I (1) where the state x t evolves along an optimal transpo rt path, which lin early interpolates between the noise and the d ata: 1 0 ( 1 ) t t t x x x (2) The ground tru th velo city fie ld v t governing th is transition is co nstant and can be an alytically derived as : 1 0 t t d dt x v x x (3) During reverse g eneration proc ess, a neura l network velocity estimator v θ is trained to approximate the ground truth v el ocity fie ld. Giv en the curr ent state x t , time t , and text em bedding c , th e n etwork outpu ts the predicted velocity vector v pred . ( ) , , red t p t v v x c (4) Flow matching m odels typically rely solely on the Mean Squared Error (MSE) in the time do main. However , re lying exclusively on tim e-domain superv ision often suf fers from 3 spectral b ias, wh ere the m odel p ri oritizes learning low- frequency com ponents while neglecting high-frequ e ncy details. This is d etrimental for scenario gen eration, wh ere high-freq uency fidelity is crucial fo r system simulation. To mitigate this, an auxiliary spectral consistency loss freq is introduced. T he pre dicted velocity v pred and the target velocity v t are transformed in t o th e frequency d omain using the Fast Fourier Transform (FFT). The fr equency loss measures th e d iscrepancy b etween the magn itudes of spectral components. Mean absolute error is used instead of MSE because spectra l magnitudes span several orders of magnitu de; MSE wo uld amplify errors in large-amplitude componen ts, biasing optimization toward them and causing instability: , 1 ( ) ( ) t pr ed e f e t p r q r d v v v v (5) where ( ·) denotes the FFT oper ation and ||·|| 1 represents th e is the elem ent-wise ℓ 1 norm. While combining time-dom ai n and frequ ency-domain losses is essential, simply minim izing a static weigh ted sum λ is subop timal: 0 1 2 , , 2 time pr t t freq ed x x v v ‖ ‖ (6) The o ptimization lan dscapes o f th ese two ob jectives often conflict: time prio ritizes smo othness, whereas fre q encourages high-frequ e ncy var iance. To address th is gradien t conflic t, th e train ing is fo rmulated as a multi- objective optimizatio n p roblem, aiming to find a Pare t o optimal solution where spectral fid elity is max imized without comprom ising temporal accuracy . T he MGDA is employ ed to d ynamically balance the gradients of the two objectives [26]. Le t θ time and θ freq denote the gradien t s with respec t to the shared parameters. A dynamic weight α ∈ [0, 1] is determin ed to form a co mbined gra dient direction that decreases both losses: [ 0 ,1] 2 2 m in ( 1 ) tim e freq (7) 2 2 ( ) cl ip , 0, 1 fre q t ime fr eq tim e fr eq ‖ ‖ (8) where clip(·, 0, 1) constra ins the weigh t to the valid range. This quadratic problem has an efficient analytical solution, allowing the model to automatically adjust its focus betwe en global trends and lo cal details through out th e tra ining process, ensuring robu st co nvergence to the Pareto front. The train ing process can be cond ucted in Algorithm 1 . During infe rence, starting from pure noise x 0 ~ ( 0 , I ), the targ et scenario x 1 is obtained by numerically solving t he Ordinary Differential Equation (ODE) d efined by the learned v elocity field: ( , , ) t t d t dt x v x c (9) This fo rmulation allows for straigh t-line trajecto ries in the flow, en abling high-fidelity samp ling with fewer steps compar ed to stochastic diffu si on processes. Algorithm 1: Train flow diffusion Input: Dataset ={( x ( i ) 1 , c ( i ) )} N i =1 , initialized model v θ , LLM Φ, learning rate η while not co nverged do Draw batch {( x 1 , c )} from Sample n oise x 0 ~ ( 0 , I ) and time t ~ (0, 1) Get semantic embedding: E txt ←Φ( c ) Interpo late state x t ← t x 1 +(1 - t ) x 0 and target v t = x 1 - x 0 Predict velo city: v pred = v θ ( x t , t , c ) Compute g radients for Time( g t ) and Fre quency( g f ) Compute Pa reto-optimal weigh t α Update p arameters: θ ← θ-η ( α g t +(1- α ) g f ) end while B. Data En coding 1) Seman tic encoding via LLM To en able the synth esis of time series from arbitrary open-dom ain descr iptions, a robu st seman tic g uidance mechan ism driven by a pre-trained LL M is introduced. This mechan ism lev erages the extensive linguistic knowled ge and reasoning capabilities encapsulated in modern o pen - source LL Ms to extract rich contex tual representation s. Formally, a specific tokenizer is employed to transform the natu ral language instruction c into a sequence of discre te tokens S : 1 2 ( ) { , , , } M S w w w c (10) where M represents the sequence length. Subsequently, a pre-train ed LLM encoder, parameterized by Φ, maps this token sequence into a h igh-dimensional continuous semantic space. Th e contextualized e mbedding E txt is obtained from the hidd e n states o f the final transform er layer: L L M ( ) LLM M D txt S E (11) where D LLM denotes the hidden dimension of the LLM. This embedd ing E txt encapsulates both local semantic details and global textual c ontex t. To ensure training stability, the pre- trained LLM is frozen during the optimizatio n o f the velocity predicto r . The resulting embedd i ng E txt serves as the condition al input in subsequent stage, guiding the generatio n process witho ut incur ring the hig h c omputatio nal cost of L LM fine-tuning. 2) Time embed ding The velocity field v θ ( x t , t ) varies significantly as the flow evolves from noise ( t =0) to data ( t =1 ) . To capture this timestep-dep endent evolution, the denoising n etwork is conditio ned o n the diffusion timestep v ia a sinusoidal embedd ing that m aps the scalar t into a high -dimensional feature space. Specifically , the timestep t is first scaled by a constant factor s =100 to ad just its sensitivity. Th e embedd ing t emb is con structed b y concatenatin g sine and cosine transform ations across a spectrum of geometric frequencies. Formally, the embedd ing is defined as: , s in , c os , emb i i s t s t t (12) 2 1 00 00 i d i (13) This en coding ensures that the timestep re presentation remains con tinuous and differentiable, providing a mu lti - scale re ference for the downstream blocks to distingu ish differen t stages of the generativ e process. C. Text-oriente d Temporal Deno i sing Network The efficacy of th e r ectified flow framework critically depend s on th e cap acity of the velocity estimator v θ . A text- oriented tempora l deno ising n etwork is proposed, which serves as a spec ialized architecture engineered to m a p the complex interp la y betwe en semantic co nditions and continu ous tem poral dynamics. As illustrated in Fig. 3, th is network in tegrates a hier archical con volutional backbone with a cross-mod al attention mechan ism, ensurin g that th e 4 Fig. 3. Overview of the LFFD framework. The architect ure employs a rectified flow matching conditioned on context embeddi ngs from a frozen LLM. The U-Net-based velocity estimator integr ates res idual blocks for temporal modulation and cr oss-modal attention blocks to align discrete textual guidance with continuous temporal features. The model is trained to learn straight-line trajectories via a single-step objective, while inference is performed through multi- step sampling. generated scenar i os exh ibit both lo cal tempora l coh e rence and global semantic alignment. To accu rately reconstruct scen arios th at co ntain both low-freq uency trend s and high-freq uency tra nsients, a symmetric encoder-deco der U-Net to pology with multi- scale feature processing is ad opted. Encod ing: Th e encoder captu res hierarch ical tempora l patterns by progressively reducin g the sequence length L and expan ding the ch annel dimension C . This is achiev ed th r ough a stack of down-samp ling blocks, each co nsisting of 1D convo l utions with stride 2. This process co mpresses the input series into a compact latent representatio n, forcing the model to learn robust high- le vel features. Bottleneck: At the lo west resolu tion, a d eep bottleneck stage processes the most abstract semantic features, capturing glob al tempo ral depend e ncies. Reconstructio n: Th e decod er recovers the temporal resolution via tra nsposed 1D convo lutions. Crucially, to m itigate the information lo ss inheren t in d own-sampling, long-range skip connectio ns are employ ed. Th ese co nnections directly concate nate the high-re solution feature maps from the enco der to the corresponding decoder layer s, creating an inform ation highway that preserves fine -grained morpholo gical details essent ial fo r high- fi delity generatio n. Projection : a term inal con volution lay er pro jects the multi-channel features back to the original data dimension , yielding the pred ic ted velo city v pred . 1) Residua l Block As shown in Fig. 4, residu al convolutional block is the fundam ental bu ilding un it. To inject the diff usion step conditio n without disrupting th e feature sequ ence, a timestep-awa re additive modulation m echanism is employed. Within each block, the diff usi on timestep embedding t emb is pro jected into the feature space of the l - t h lay er via a layer specific linear transform ation to g enerate a bias vector t ( l ) bias via a layer-specific lin ear tra ns form ation. This b ias v ector is then injected into th e middle fe ature m ap H ( l ) mid v ia chann el- wise ad dition. Th e residual block is fo rmally defin e d as follows: ( ) ( ) Co n v 1d( ) l l re s H H (14) ( ) ( ) Co nv 1 d(Si L U(Gr ou pN o rm( ))) l l mi d re s H H (15) ( ) L ine ar( ) l bias em b t t (16) ( ) ( ) ( ) Con v 1d(S iL U(Gro up No rm( ))) l l l mod mi d bias H H t (17) ( ) ( ) ( ) re s l l l ou t m od H H H (18) Fig. 4. Arc hitecture of the resid ual block. It em ploys a timestep-aware additive modulation mechanism, where projected timestep embeddings are injected into feature maps via channel-wis e addition to condition the denoising process with out disrupting temporal features. 5 This add itive modulation mechan ism dynamically shif ts the activation distribution of the feature maps, informing the network of the current noise l evel without co mpromising the tempora l structure of the scenario features. 2) Cross-Moda l Attention Blo ck The seamless integratio n of LLM embedding s E txt in to the gener ation process is realize d thro ugh cross-atten tion layers strategically embedded at multip le resolutions of the network . This arch itectural d esign b ridges th e discre t e semantic space and the continuous phy sical time d omain. Mathematica lly, the interm ediate tempora l features H act as the query, wh ile the text embedd ings E txt serv e as both the key and v alue. The alignment is com puted as: ( )( ) A tt en ti on So ft m a x ( ) T Q tx t K txt V k d H W E W E W (19) where W Q , W K , W V are learnab le pro jection m atrices. The resulting attention matrix captures the relevan ce of each semantic token to spec ific tempora l segments. This allows the network to attend to specific keywords and m odulate th e correspo nding lo cal inter vals of the scenarios, ensuring that the synthesized result is not only realistic but also strict ly adheres to the textual instructions. Fig. 5. Architecture of the cross-mod al attention b lock. This module acts as a bridge between t he discrete semantic space and continuous physical time domain by using temporal fe atures as queries and text em beddings as keys and values to enforce s trict semantic alignment. As illustrate d in Fig. 5 , the cross-modal attention b lock incorp orates residual connectio ns: the atten tion output H att is summed with th e inpu t features H , th en passed through group normalizatio n and a residual Feed Forward Network (FNN). To enhan ce training st ability, the blo ck adopts a pre- normaliza tion design. Attention (Lay erNorm( ), ) att txt H H E (20) attout att H H H (21) F NN(L ay e rN or m( )) outpu t attou t attou t H H H (22) D. LLM-Agen ts for Dataset Synthesis an d Evaluation Realizing text-guid ed time series gener ation entails two primary obstacles: (1) the scarcity of high-qu ality paired datasets containin g time series and their corresponding textual description s, an d (2) the lack of metrics to quantify the semantic align ment b etween th e gen erated scenarios and the text prompts. To addre ss these challeng es, a dual-agent framewo rk driven by LLMs is propo sed: The annotator agent for textu al synthesis (Fig. 6(a)) and The judge agent for quality assurance (Fig. 6(b)). Directly feedin g raw time serie s into LLMs poses challeng es due to token ization artifacts, exemp lified by the fragmen tation of a sing le decim al value lik e "0.1" in to separate tokens for "0", ".", and "1". This ph enomenon hinder s the model's ability to in terpret numer ical patter ns effectively [27]. To mitigate this limitation, a statistical analysis mo dule is utilized as a semantic bridge. This mo dule compu tes glob al metrics in cluding volatility and extremes while per forming segmented analysis acro ss the d awn, morning, aftern oon, and evening tempora l windows to generate a structure d statistical rep ort. Finally, this report is fed into the LLM alongside the raw data to en hance numerical comp rehension. Fig. 6. The proposed LLM-driven dual-agent framewor k. (a) The annotator agent synthesizes high - quality textual descri ptions for unlabeled s cenarios using statis tical reports and dom ain knowledge. (b) The judge agen t acts as a semantic evaluator, scoring the alignment between the generated scenarios and the inp ut text prompts to quantify controllability. The annotato r agent is engin eered to au t omatica lly generate high-quality anno tat ions for u nlabeled real-world scenarios. This agent processes raw scenarios by utilizing a structured p rompt composed of four integra l elem ents, includin g a role setting that def ines the per sona of a data analyst, context-spec ific domain knowled ge, the previously derived statistical report, and th e numerical data itself. By leveragin g the chain of thought re asoning capabilities o f the LLM, the agent synthesizes these multi- dimensional inputs to pro duce a coherent textual descr iption that accurately reflects the morp hological and statistical char acteristics of the und e rlying scenarios. Complemen ting the scenarios anno tation process, the judge agent serves to evaluate the seman tic fidelity of the generated scenarios. Although its o perational workflow parallels th at of the ann otator agent, the p r omp t engineering is adap ted to include d istinct evaluatio n criteria. The input is augmen ted to exp licitly incorporate the orig inal target tex t description which function s as the g round truth for compar ison. Con sequently, the ag ent is tasked with assessing the consisten cy between the statistical pro perties of the generated scenarios and the linguistic instruction s. This process culmin ates in th e o utput of a quantitative score along with a detailed justification , providing a robust and interpre table metr ic for quantifying the alignment between the gen erated scenarios and the gu iding instructions. III. C ASE STUDY A. Experimenta l Setups All exper iments ar e implemen ted using th e PyTorch framewo rk and Pytho n 3.10 on a high-perfor mance 6 compu ting clu ster eq uipped with NVIDIA A100 GPUs with 80GB of memory. The velocity estimator v θ is in stantiated as the propo sed text-orien te d temp oral denoising network, following a 1 D U -Net architecture with ch annel multipliers of {1, 2, 4, 8} and a base dimen sion of 64. To encode semantic gu idance, a frozen pre-tra ined La r ge Langu age Model (e . g., Qwen-8 B) is emplo yed, projecting text inputs into 768-dim e nsional em beddings th at are fused with tempora l features via multi-resolutio n Cross-Attentio n blocks. The mod el is train e d for 5,000 ep ochs with a global batch size of 256 , u sing the AdamW optimizer and a OneCycleLR sched uler with a peak learning rate of 1 × 10 -4 . For inference, the rectified flow formulatio n is adopted and solved b y an Euler ODE solver with 50 discretization steps, ensuring a balance between generatio n q uality and compu tational efficiency. To evalu ate the perform ance of the LFFD framework , compar isons are made against fo ur repre sentative generative models ad apted for time -series synthesis: a VAE with a convo l utional encoder-decod er to learn latent representa tions of scenarios; a deep convolu tional GAN trained via the classic minimax adversarial game; Wasserstein GAN (WGAN), wh ich stabilizes tra ining and alleviates mode co llapse through Wasserstein distanc e and gradien t constraints; and DDPM implemented with the same U-Net backbone as the LFFD framework but trained under the standard noise-pred iction objectiv e ( ε -pre diction). The DDPM requires 1,000 iterative sampling steps, serving as a baseline fo r both generation quality and inference speed. B. Dataset Descriptio n To evaluate the gen eralizability of the proposed LFFD framewo rk, two representativ e power tim e -series datasets characteriz ed b y distinct temporal granularities and scales are utilized. The first is a large-scale Photovoltaic (PV) dataset comprising over 32,000 daily scenarios with a 5- minute resolution . The second is an electricity load datase t containin g ov e r 2,000 daily scenarios with a 15-m inut e resolution . These datasets were selecte d to represent d iverse power system scenario s, varyin g in d ataset size, samp ling frequency , and fluctu ation chara cteristics. Prio r to train ing, Min-Max normalization was applied to the PV dataset. For the lo ad dataset, giv e n the significant magnitud e dispar ity between subsets, indepen dent normalization was performed for the residential and industrial scenarios, respectively. All data were scaled to th e range of [0, 1] to ensure numerical stability and mo del converg ence. Subsequently , the annotato r agent is employed to gen erate corr esponding textual prompts. Addressing the difficulty in quantitatively evaluatin g op e n-en ded natural language, the agent is designed to ex tract structured metadata reg a rding key statistical features alo ngside promp t generation. For instance, within the PV dataset, the age nt labels the v olatility category , provid i ng ground truth for quantitative evalu ation. C. Ordered S emantic Space of LLM To examine whether the LLM co nstructs a stru ctured semantic space rath er than relying on textual memorization, a linear probing analy sis is co nducted based on th e lin ear representa tion hyp othesis, as illustrate d in Fig. 7 . This hypothesis p ostulates that if a model ef fectively encod e s specific concep ts, such as load magnitu de or environm ental conditio ns, these concepts s hould be linearly d ecodable from its latent representations. Using inputs consisting of unstructu red natu ral lang uage description s, emb e ddings are extracted from the m odel' s final hidden layer and mean - pooling is applied to obtain fixed-size vector representations. Subsequen tly lightweight linear pro bes ar e tra ined, employ ing linear regression for continu ous variables an d logistic regression f or categorical attrib utes, to map these frozen embeddings t o groun d truth labels across weath er, peak, volatility , and shape dimension s. Fig. 7. Schematic of the c omposition of the dataset and the semantic space validation methodology. Metadata serves as ground-truth labels. The framework assesses whether the LLM's embeddings encode properties by measuring the decoda bility of these labels using lightweight linear p ro bes based on the linear re presentation hypothesis. The results in Fig. 8 indicate a highly stru ctured latent space, as th e linear prob es achieved high perform ance across all tested d imensions. For the continuous "Peak" attribute, the linear regression analysis yielded a coefficient of determin ation (R 2 ) o f 1.00, suggesting that physical magnitu de is encod e d as a precise vector d irection within the high-d imensional space. Similarly, the probes ach ieved 100% classificatio n accuracy for categorical attribu tes, indicating that the semantic m anifolds for d if feren t classes are linearly sepa rable. semantic nuance; the cluster for "Sunny" is positioned adjacent to "Sun ny with Clouds" (S+C), reflectin g their conceptu al similarity, whereas th e adverse weather cond itions of "Rainy," "Clou dy," and "Stormy" are co llectively situated on the opposing side of the projection space. These findin gs confirm that the LLM maps unstru ctured prompts onto a geometrically organized manifo ld where physical propertie s and sema ntic concepts are enco ded orthogonally, v erifying the model's capab ility to serve as a reliable sema ntic encoder f or do wnstream power system tasks. D. Statistical Evaluation The primary objective of gener ative modeling is to generate scen arios th at adhere to the in herent statistical distributio ns and physical laws of the domain. Convention al point-wise prediction metrics o ften fail to acc urately characteriz e the generative capabilities, as they overloo k t he stochastic nature an d morphological fidelity o f scenarios. To assess the performance of the generative models and the quality of the gen e rated scenarios, Kullback -Leibler diverg ence (KL), Maximu m Mean Discrep ancy (M MD), Fréchet Distance (FD), Dyn amic Time Warping (DTW) and Power Spectr al Density Distance (PSDD) are employed . KL div ergence m e asures the asymmetr ic d ifference between the prob a bility distributio n of the g e nerated d ata Q ( x ) and that of the real data P ( x ). It is particu larly effective for assessing whether the mod el capture s the marg inal 7 Fig. 8. Validation of the linear representation hypothesis. (a)–(d) Line ar probing results for weather, peak, volatility, and s hape, showing perf ect classification accuracy and regr ession fit. (e) t-SNE visualization of the embedd ing m anifold, highlighting the top ological preservation o f semantic relationships among diff erent weather conditions. Note: S+C den otes sunny with clouds. distributio ns of the scenario s . The continu ous time-series values are discretized to estimate probability densities, and the diver gence is calculated as: ( ) ( || ) ( ) log ( ) KL x P x D P Q P x Q x ( 23) MMD serv es as a k ernel-based metric to q uantify the distance between the true distrib ution P and the gen erated distributio n Q . By mapping samples into a reprod ucing kernel Hilbert space, MMD measures the d istance betwe en the m ean embeddings o f the two distribu tions, where a lower valu e indicate s statistical proxim ity to the g r ound truth. Given real samp les X and gen e rated samples Y , the squared MM D is empirically estimated as: 2 2 2 , , , 1 1 MM D ( , ) ( , ) ( , ) 2 ( , ) i j i j i j i j i j i j X Y k x x k y y m n k x y mn (24 ) where k ( ·, ·) represents the kernel function. FD evaluates both the realism an d diversity of generated samples by calc ulating the d istance between feature distributio ns extracted by a pre-train ed encoder. Assuming the feature vecto rs follow a multidimen sional Gau ss ian distributio n, FD is defined as: 2 1/ 2 FD Tr ( 2( ) ) r g r g r g ‖ ‖ ( 25) where μ is the mean of fe ature vectors, ∑ is the covarian ce matrix an d T r(·) is the trace of a matr ix. A lower FD score correspo nds to higher generation q uality and diversity. DTW is used to evaluate shape fidelity by finding an optimal alignment between two temp oral sequences, making it ro bust to temporal shifts and speed variations commonly found in scenar ios. For two sequences X and Y , DTW compu tes the min imum cumulative distance along an optimal w arping path W : ( , ) D T W ( , ) m in ( , ) i j W i j W X Y d x y (26) PSDD measures the fidelity of frequ e ncy-do main characteristics in generated scenarios, assessing how well period ic pattern s and high-frequ ency v a riations are preserved . It comp utes the squar ed Eu clidean d istance between the log-av erage power spectra of real and gen erated data in th e frequency domain : 2 2 log [ ( )] log [ ( )] PSDD real gen D P f P f (27) where f represents the frequency c omponen ts d e rived via Discrete Fou rier Tran sform (DFT), and [· ] denotes the average po wer spectru m across the dataset. A lower PSD distance ind icates that the ge nerated scenar ios successfully retains the spec tral en ergy distrib ution of the original scenarios, av oiding high-frequency information loss. Fig. 9. (a) Mean PV d istributi on curves and boxplots, and (b) Peak PV distributions and box plots. Fig. 10. (a) Mean load distributi on curves and boxplots, and (b) Peak load distributions and box plots. To comprehensively evaluate the generative fid elity, t he probability density distributions an d statistical metrics of the synthesized samples are co mpared against th e ground truth for both PV and lo ad datasets. Figs. 9 and 10 illustrate the Probability Density Function (PDF) curves and feature boxplo ts, while Table I presents a rigorou s quan titative evaluatio n using five metrics co vering distributional alignmen t, samp le quality, and fr equency consistency . Visual inspection o f the PDF curves re veals that re al-world PV and load scenario s exhibit co mplex no n -Gaussian and multi-mo dal characteristics. Th e proposed LFFD method demon strates superior alignment with the ground truth, accurately reproducing both cen tral tendencies and lo ng-tail 8 TABLE I M ODEL PERFORMANCES ON DIFFEREN T DATASETS Dataset P V L oad Model KL MMD FD DTW PSDD KL MMD FD DTW PSDD VAE 0.1163 0.2172 4. 9652 27.0 671 15.2839 0.3911 0.347 1 1.7372 17.9072 14.8697 DCGAN 0.3922 0 . 9890 5 7.1 187 28.9173 1.9987 0.1274 0 . 2316 0.997 6 1 7.1 228 5.5094 WGAN 0.2538 0.6434 20.7024 42.1868 1.9483 0.0484 0.1195 0 . 8288 16.1519 3.4473 DDPM 0.0836 0.2231 2.856 8 24.0835 0 . 3957 0.1707 0.0805 0 . 4647 15.0642 0.1208 LFFD 0.0291 0.0905 0.9698 12.8813 0.0171 0.037 3 0.0001 0 . 0073 14.8468 0.0011 *Bold term indicates the best performance, while u nderlining term represents se cond best. Fig. 11. Visualizatio n of text-conditional scenario generation usi ng LFFD. (a) PV generatio n scenari os capt uring d i verse wea ther condit ions and fin e- grained temporal features. (b) Load profiles distinguishing bet w een industria l and residential consumption patterns. Annota ted markers demo nstrate the precise alignment between the generated waveforms and the input textual ins tructions. fluctuatio ns. In con t rast, baseline models exhib it distinct limitations: VAE yield s over -smoothed distribution s that lack h igh-frequency d etails, whereas DCGAN and WGAN display noticeable deviations in peak positions and probability densities, indicative of mod e collapse or distributio n shifts. Boxplot analysis fu rther confirms LFFD 's advantage in preservin g scenarios disper sion and extre mum properties. Regarding mean and peak statistics, LFFD main tains high consistency with real scen arios across medians, interqu artile ranges, and wh isker ex tents. While mo dels like DDPM and WGAN ofte n manifest dynamic ran ge compression, LFFD successfully preserv es the temp oral correlations and statistical div ersity of the original scenarios, attributed to its specialized tem poral guidan ce mech anism. As sum marized in Table I, quantitativ e results corrobora te these observatio ns. LFFD outperfo rms baselin es across all metrics, dem onstrating a signific ant advancement over ex isting paradigms. High FD an d DTW scores in VAE reflect its tenden c y toward over- smoothing, while elevated KL an d MMD scores in adv ersarial models h ighlight inheren t train ing instabilities . Alth ough stand a rd DDPM serves as a robust baseline, LFFD surp asses it by a substantial m argin. Regarding distribu tional alignm ent, LFFD achieves the lowest KL and MMD scores; no tably, it reduces KL diverg ence on the PV dataset fr om 0.0836 to 0.0291. This indicates that o ur flow matching o bjective, co mbined with semantic guidan ce, cap t ures complex margin al distribu tions more accurately th an standard diffu sion p rocesses. Most critically, LFFD effectively addre sses the spectra l b ia s commo n in deep generative models. The PSDD is reduced by an order of m agnitude compar ed to the stron gest baseline. This validates the efficacy of the spectral-aware objectiv e i n retaining essential high-frequency transients. Consequently, LFFD ach ieves holistic superiority b y balancing temporal dynam ics with spectral accu racy and distributional f idelity. E. Text-Guida nce Effectiveness To evaluate the efficacy of textual gu i dance in steering the g e nerativ e pro cess, a qu alitative inspectio n of the synthesized samples is conducted as depicted in Fig. 11. The visual results d emonstrate a precise alignm ent b etween the fine-gra ined semantic constraints p rovided in the prompts and the morpholo gical characteristics o f the gener ated scenarios. In th e PV scen arios sho wn in Fig. 11 (a), the model exhibits high fidelity to both meteo r olog ica l conditio ns and num erical targets. When promp ts specify sunny condition s or light clouds, the model generates smooth, standard bell -curve trajectories that ad here strictly to tar get peak magnitudes. Conversely, descriptions of adverse weather trigg er the gener ation of jagged, non- stationary wavef orms with frequen t fluctu ations, effe ctively capturin g the intermittency o f renewab le generation . Crucially, the model dem onstrates exceptio nal temp oral localization capab ilities; as ev idenced in the bottom-row examples, it accurately renders specific time-d ependent instruction s, such as a peak occurring precisely at "1 2: 40" or 9 a sudd en p ower "dip at 13:25," v erifying its ability to enforc e fine- grained temporal constrain ts. Similarly, for the load dataset pre sented in Fig. 11(b), the mod el successfu lly disentang les com plex consumption patterns based on user-type descriptions. A prompt describing an industrial scenario yields a curve c haracterized by hi gh, volatile daytime consumption, whereas a reside ntial scenario results in a distinctive evening peak with steady nighttime demand. These observations confirm that the model dynamically reconstructs the tem poral geometry of the scen arios accord i ng to specific semantic instructio ns regard ing shape, magnitude, v olatility, and precise timing events. Fig. 12. Evaluation of attribute controllability. (a) Correlation between target and me asured peak v alues, exhibiting strong alignment with the ideal trend. (b) Distrib ution of MARR across Stable, Moderate, and High target classes. Complemen ting these visual o bservations, a quantitative assessment is performed to verify the statistical fid elity of the text-conditional gener ation with a specific focus o n peak magnitu de and volatility control. As illustrated in Fig. 12(a), the co rrelation between the target peak specifie d in the textual promp ts and the actual measured p eak of the generated samples is analy zed. Th e results exhibit a stron g linear relatio nship where th e median tren d adheres closely to the ideal iden tity line ( y = x ) and exhib its nar row co nfidence intervals, thereby confirming the numerical sensitivity of the model to magnitude instructions. Subsequ ently, to evalu at e the volatility contro l, the Mean Absolute Ramp Rate (MARR), a cr itical metr ic in power system analysis for capturin g the instantan eous variability , is adop ted. Giv en a generated power sequ ence P = { p t } T t =1 , the MARR i s calculated as the expecte d value of the absolute first-o rder differen ces: 1 1 1 1 MARR | | 1 T t t t p p T (28) where p t +1 - p t represents the ramp even t between ad jacent time steps. Th is formulatio n explicitly q uantifies the no n- stationarity an d the in te nsity of high-frequ e ncy compon ents within the scenarios. Fig. 12(b) presents th e distribu tion of MARR acro ss th e three textual volatility levels of stable , moder ate, and high. The re su lting box plo ts reveal a strict monotonic increase in measured volatility correspondin g to the textual intensity. The clear separation between the interqu artile ranges of the stable and high categories indicates that the model has effectively learn e d to manipu late local flu ct uation c haracte ristics based on discrete semantic categories, en suring that th e generated scenarios preserves b oth global trends and lo cal statistical proper ties. Furtherm ore, the alignmen t between textu al instructions and the generated scenar i os is quantifie d u sing th e Mean Judge Agent Score (MJAS), as d etailed in Sectio n Ⅱ.D. MJAS serves as a credible and comprehensive metric for semantic ev aluation, design e d to em ulate domain experts’ judgmen ts reg a rding the align ment quality between generated scen arios and their corr esponding textual description s. It is formally defined as follows: M JAS Ag ent ( , ) x T (2 9) where x is the gen erated time series an d T represents the correspo nding text description. The evaluatio n yielded high MJAS values o f 4 .80 for the PV d ataset and 4 .46 for the load dataset relative to a maximum scor e of 5, confirming robust alig nment between textual instruction s and generated scenarios. Th e superio r performance observed in the PV domain is attribu ted to its strong er physical determinism a nd larger data scale, which facilitate a more explicit m apping from meteorolog ical descriptions to time-series pattern s compar ed to th e complex and stoch astic nature of lo ad consump tion. F. Inference Efficiency Analysis Fig. 13. Comparison o f infer ence efficiency and g e neration quality between the DDPM baseline and t he propos ed LFFD method (at 400 and 5000 training epochs). (a) FD v ers us step s , il lus trating the robustne ss o f LFFD at low step counts compared to the quality collapse o f DDPM . (b) FD versus inference time (seconds), h i ghlighting the 87 × speedup achieved by LFFD while m aintaining s uperior quality. (c ) KL Divergence versus steps . (d) KL Divergence versus inference time, dem onstrating an order-of-magnitude improvement in distributional fit by the converged LFFD m odel. Both axes are plotted on a logarithm ic scale. To evaluate the deployment feasibility, a comparative analysis is conducted betwe en th e baselin e DDPM and the proposed LFFD mo del on a PV test set of 3,20 0 samples. The evalu ation focuses on the trade- off between generation quality and comp utational laten cy, as illustrated in Fig. 1 3 . Results ind icate th at the L FFD m odel outper forms the DDPM baselin e in terms of inference efficien c y. While the standard DDPM requires 1 , 000 deno ising steps to ach ie ve its o ptimal FD of 0.6 2, incurrin g a comp utational co st of 621.68 seco nds per batch, the proposed LFFD achiev es a lower FD o f 0.12 using 10 samplin g steps, re quiring 7 .16 seconds. T his corresponds to an ap proximate 87× spee dup in wall-clock time and a 5-fold red uction in the FD metric, establishing a more favorable Pareto fro ntier com pared to the baseline. Fur thermore, the stability of the proposed architectu re is evident u nder limited samp ling steps. As shown in Fig. 13(a), the DDPM b aseline exhibits significant 10 performan ce degradation when samp ling steps ar e reduced below 200 , with FD scores increasing abov e 12.0. In contrast, attributed to the straightness of the learned ODE trajectorie s, LFFD maintain s high fid elity even in the few- step regime; notably, at 5 sampling steps, LFFD ach ieves an FD of 0.2 6, surpassing the optim al per f orman ce of the DDPM baseline ( FD 0.62 at 1,000 steps). Beyond geometric fidelity, the statistical alig nment of the gen e rated scen arios is also evaluated using KL Divergen ce. Th e LFFD mo del tra ined for 50 00 epo c hs achieves a KL diverg ence of 0.0 09, representing an order of magnitu de improvement over the best result achieved by DDPM (0 .087). Th is indicates th at the propo sed method captures the marginal distribution of the underlyin g physical process with sign ificantly higher precision. Ad ditionally, compar ing LFFD-400 an d LFFD-5000 rev eals that while early-stage training is sufficient for capturing general waveform featu res, extended training is cru cial fo r fin e - grained distribu tional alignmen t, ensuring the generated scenarios ad heres to the statistical la ws. IV. C ONCLUSION This paper proposes LFFD, a framework that reconciles semantic interpretab ility with generativ e efficiency in power system analysis. First, by linearizing the inference tra jectory through rectified flow matching, the model achieves an 8 7× speedup o ver tra ditional diffusion baselines. Second , the frequency -aware optimization effe ctively mitigates spec tral bias, re ducing fr equency domain error by an order of magnitu de and en suring the accurate recon struction of high- frequency transien ts. Th ird, integ rating large languag e models en ables the structu red encodin g of natural lan guage, facilitating flexible, o n-demand scenario generation beyond rigid fix e d-lab el conditio ni ng. Add itionally, th e develop e d dual-ag ent pipelin e standardizes the synthesis of text-data pairs, addressing the scarcity of p aired benchmarks. Consequen tly, LFFD provides a computationally efficient solution for g e neratin g high-fid elity, custom ized power system scenario s. Futu re work will focus on further scaling the fram ework to larger and more d iverse power system dataset. R EFERENCES [1] Q. Wang, X. Zhang, and D. Xu, “S ource-Load Scenari o Generation Based on Weakly Superv ised Adversarial Learning a nd Its Data- Driven Application in Energy Storage Capacity Sizing,” IEEE Transactions on Sustainable Energy, vol. 14, no. 4, pp. 1918–1932, Oct. 2023, doi: 10. 1109/TSTE.2023.3258 929. [2] Y. Chen, Y. Wang, D. Kirschen, and B. Zhang, “Model-Free Renewable Scenario Generation Using Generative Adversarial Networks,” IEEE Trans. Power Syst., vol. 3 3, no. 3, pp. 3265–32 75, May 2018, doi: 10.1 109/TPWRS.2018.279 4541. [3] J. M. G. Lopez, E. P ouresmaeil, C. A. Canizares, K. Bhattacharya, A. Mosaddegh, and B. V . Solanki, “Smart Resi dential Load Sim ulator for Energy Management in Smart Grids,” I EEE Trans. Ind. Electron., vol. 66, no. 2, pp. 1443 –1452, Feb. 2019, doi: 10.1109/TIE.2018.281 8666. [4] S. Lin, C. Liu, Y. Shen, F. Li, D. Li, and Y . Fu, “Stochastic Planning of Integrated Energ y System via Frank-Copula F unction and Scenario Reduction,” IEEE Transactions on Smart Grid, vol. 13, no. 1, pp. 202– 212, Jan. 2022, do i: 10.1109/TSG.2021. 3119939. [5] Z. Li e t al., “A novel scenario generation method of renewable energy using improved VAEGAN with controllable interpretable f eatures,” Applied Energy, vol. 363, p. 122905, Jun. 2024, doi: 10.1016/j.apenergy.2 024.122905. [6] I. Goodfellow et al., “Generative adversarial networks,” Commun. ACM, vol. 63, n o. 11, pp. 139–144, Oct. 20 20, doi: 10.1145/3422 622. [7] Y. Hu et al., “MultiLoad-GAN: A GAN-Based S ynthetic Load Group Generation Method Considering Spatial-Temporal Correlations,” IEEE Trans. Smart Grid, vol. 15, no. 2, pp. 2309– 2320, Mar. 2024, doi: 10.1109/TSG.2023. 3302192. [8] Z. Zho u, Y. L i, R . Liu, X. Xu , and Z. Yan, “U nsupervised and controllable synthesizi ng for imbala nced energy dataset based on AC- InfoGAN,” Applied Energy, vol. 393, p. 126107, Sep. 2025, doi: 10.1016/j.apenergy.2 025.126107. [9] J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” in Ad vances i n N eural I nformation Processing Systems, Curran Associates, I nc., 2020, pp. 6840–6851. [10] S. Li, H. Xiong, and Y. Chen, “DiffCharge: Generating EV Charging Scenarios via a Denoising Diffusion Model,” I EEE Tra ns. Smart Gri d, vol. 15, no. 4, pp. 3936–3949, Jul. 2024, doi: 10.1109/TSG.2024. 3360874. [11] Q. Yuan, H. Wu, S. He, and M. Sun, “PrivLoad : Privacy-Preservi ng Load Pr ofiles S ynthesis Based on Diffusion Models, ” IEEE Trans. Smart Grid, vol. 16, no. 6, p p. 5628–5640, Nov. 2025, doi: 10.1109/TSG.2025. 3608960. [12] N. Lin, P. Palensky, and P. P. Ver gara, “EnergyDiff: Uni versal Time- Series Energy Da ta Ge neration Using Diffus ion Models,” I EEE Tra ns. Smart Grid, vol. 16, no. 5, pp. 4252–4265, Sep. 2025, doi: 10.1109/TSG.2025. 3581472. [13] S. Zhang, Y. Cheng, J. Qin, and N. Yu, “Generating S ynthetic Net Load Data for Residential Customers with Physics-informed Diffusion Models,” IEEE Tr ansactions on S mart Grid, pp. 1–1, 2025, doi: 10.1109/TSG.2025. 3625925. [14] J. Song, C. Meng, and S. Ermo n, “Denoising Diffusi on Implicit Models,” Oct. 05, 2022, arXiv: arXiv:2010.02502. doi: 10.48550/arXiv.201 0.02502. [15] J. Choi , J. Lee, C. Shin, S. Kim, H. Kim, and S. Yoon, “Perception Prioritized Training o f Diffusion Models,” in 2022 IEEE/CVF Conference on Com puter Vision and P attern Recognition ( CVPR), New Orleans, LA, USA: IEEE, Jun. 20 22, pp. 11462– 11471. doi: 10.1109/CVPR52 688.2022.01118. [16] R. Yang, Y. Li, C. Hu, and F. Y. Hou, “ExDiffusion: Classifier- Guidance Diffusion Model for Extreme Load Scenario Generation With Extrem e Value Theory,” I EEE Trans. Smart Gri d, vol. 16, no. 5, pp. 3887–3903, Se p. 2025, doi: 10.1109/TSG. 2025.3584732. [17] Z. Wang and H. Zhang, “Customized Load Profiles Synthes is for Electricity Customers Ba se d on Conditional Diff usion Models,” IEEE Trans. Smart Gri d, vol. 15, no. 4, pp. 4259– 4270, Jul. 2024, doi: 10.1109/TSG.2024. 3366212. [18] X. Dong, Z. Mao, Y. Sun, and X. Xu, “Short-Term Wind Power Scenario Generation Based on Conditional Latent Diffusion Models,” IEEE Trans. Sustain. Energy, vol. 15, no. 2, pp. 1074–1085, Apr. 2024, doi: 10.1109/TSTE.2023. 3327497. [19] T. Yao et al . , “Weather-I nformed Load Scenario Generati on Based on Optical Flow Denoising Diffusion Transformer,” IEEE Tra ns. Smart Grid, vol. 16, no. 5, pp. 4225–4236, Sep. 2025, doi: 10.1109/TSG.2025. 3576156. [20] X. Dong, Y. S un, Y. Ya ng, and Z . Mao, “ Controllable renew able energy scenario generation based on p attern-gui ded diffusion models,” Applied Energy, vol. 398, p. 126446, Nov. 2025, doi: 10.1016/j.apenergy.2 025.126446. [21] W. Chen et al., “SocioDiff: A So cio-Aware Diff usion Model for Residential Electr icity Consumption Data Generation,” IEEE Trans. Smart Grid, vol. 16, no. 5, pp. 3786–3800, Sep. 2025, doi: 10.1109/TSG.2025. 3575819. [22] A. Radford et al., “Learning Transfer able V isual Models From Natural Language Supervisi on,” Feb. 26, 2021, arXiv: 10.48550/arXiv.210 3.00020. [23] D. Yang et al., “Diffso und: Discret e Diffusion Model for Text-to- Sound Generation,” IEEE/ACM Transactions on Au dio, Speech, and Language Processing, vol. 31, pp. 1720–1733, 2023, doi: 10.1109/TASLP.2023. 3268730. [24] Y.-X. Liu et al., “ReP ower: An LLM-driven autonomous platform for power system data-guided research,” Patterns, vol. 6, no. 4, p. 101211, Apr. 2025, doi: 10.1 016/j.patter.2025.101 211. [25] Y. L ipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow Matching for Generative Modeling,” Feb. 08, 2023, arXiv: arXiv:2210.02747. doi: 10.48550/arXiv.2210. 02747. [26] O. Sener and V. Koltun, “Multi-Task Learni ng as Multi-Objectiv e Optimization,” in Advances in Neural Information Processing Systems, Curran Associates, I nc., 2018. [27] N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “La r ge L anguage Models Are Zero-Sh ot Tim e Serie s Forecasters,” Advances in Neural Information Processing Systems, vol. 36, pp. 19622–19635, Dec. 2023.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment