A data-driven model-free physical-informed deep operator network for solving nonlinear dynamic system
The existing physical-informed Deep Operator Networks are mostly based on either the well-known mathematical formula of the system or huge amounts of data for different scenarios. However, in some cases, it is difficult to get the exact mathematical …
Authors: Jieming Sun, Lichun Li
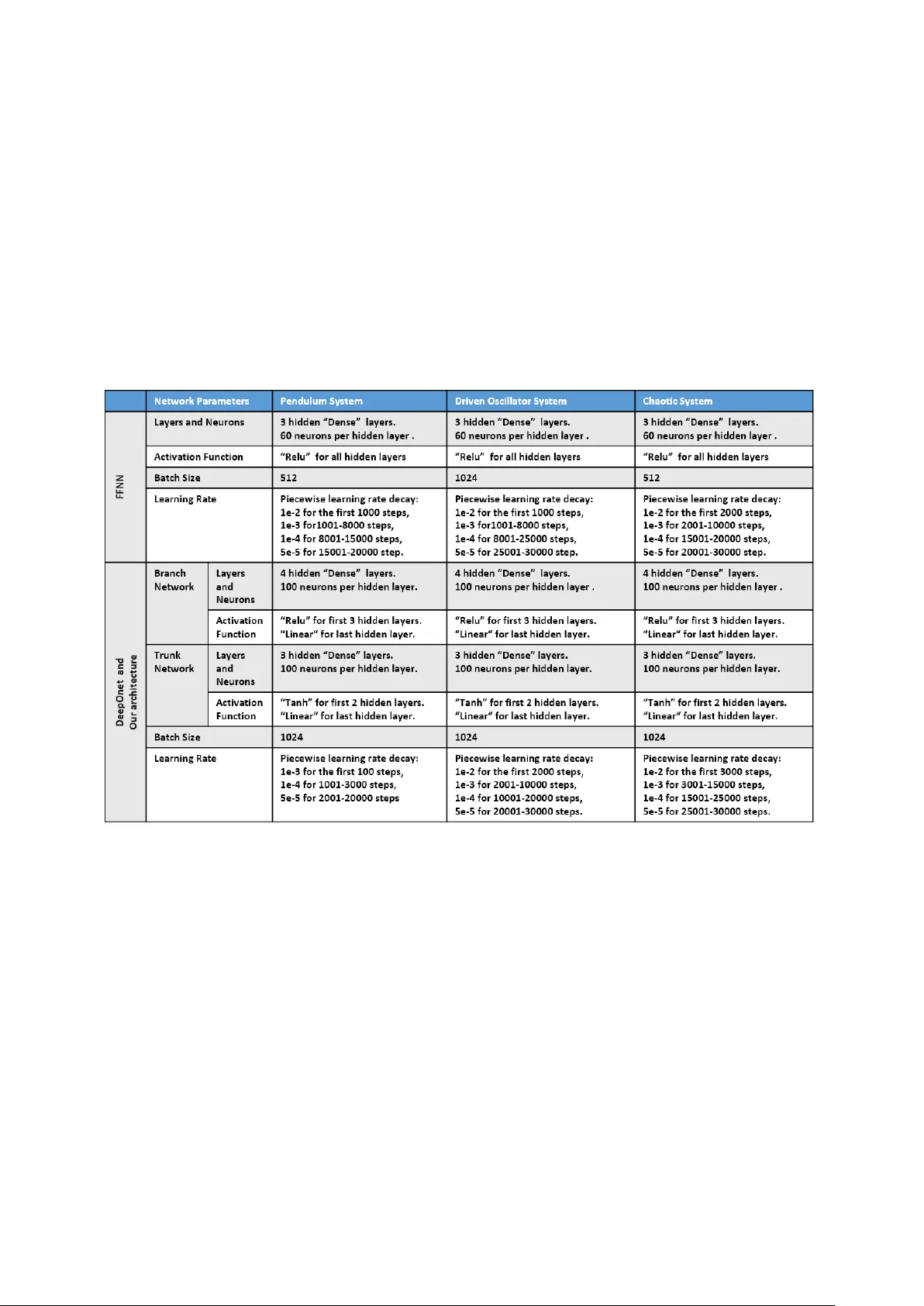
A Data-Driven Model-Fr ee Physics-Informed Deep Operator Network for Solving Nonlinear Dynamic Systems Jieming Sun a, ∗ , Lichun Li a a Department of Industrial and Manufacturing Engineering, F AMU-FSU College of Engineering, Florida State University , T allahassee, 32306, FL, USA Abstract The existing physical-informed Deep Operator Networks ar e mostly based on either the well-known math- ematical formula of the system or huge amounts of data for differ ent scenarios. However , in some cases, it is difficult to get the exact mathematical formula and vast amounts of data in some dynamic systems, we can only get a few experimental data or limited mathematical information. T o address the cases, we propose a data-driven model-free physical-informed Deep Operator Network (DeepOnet) framework to learn the nonlinear dynamic systems from few available data. W e first explore the short-term dependence of the available data and use a surrogate machine learning model to extract the short-term dependence. Then, the surrogate machine learning model is incorporated into the DeepOnet as the physical information part. Then, the constructed DeepOnet is trained to simulate the system’s dynamic response for given con- trol inputs and initial conditions. Numerical experiments on dif ferent systems confirm that our DeepOnet framework learns to approximate the dynamic r esponse of some nonlinear dynamic systems ef fectively . Keywords: DeepOnet, Short-term dependence, Physical-informed, Model-free, Data-driven. 1. Introduction In the vast realm of dynamic systems analysis, estimating and anticipating states in dynamic systems stands as a cornerstone in numerous scientific and engineering domains. This pivotal endeavor involves deducing an evolving signal based on its historical observations—even when these observations may devi- ate from the signal being estimated—alongside any understood physical principles governing its progres- sion [1]. The increasing complexity of these systems has ignited substantial interest in the scientific community to conceive tools that can expedite the numerical simulation of dynamic systems. In a groundbreaking development, the Deep Operator Network (DeepONet)[2] was proposed as a framework to learn nonlin- ear operators, essentially facilitating mappings from one functional space to another . The foundational principle behind DeepONet is based on the universal appr oximation theorem of operators, which postu- lates that nonlinear operators can be approximated with the assistance of scattered data streams. Deep- ONet has been tweaked to include a physics-based understanding by using a loss function inspired by the Physics-informed neural network [3]. This gave rise to the Physical-informed DeepOnet [4], expanding its usefulness in various applications. Furthermore, a myriad of resear chers have employed DeepONet for analyzing or learning dynamic systems, as demonstrated in works like [5], [6], and [7]. Y et, a common thread among these studies is the reliance on existing Deep Operator Networks or their derivatives, which predominantly lean on either ∗ Corresponding author Email addresses: js18hc@fsu.edu (Jieming Sun), lichunli@eng.famu.fsu.edu (Lichun Li) 1 Both authors contributed equally to this work. established mathematical formulas of the system or huge amounts of data. Regrettably , in certain instances, procuring a pr ecise mathematical formula or extensive datasets for dynamic systems becomes a daunting task. W e might find ourselves restricted to a handful of experimental data points or scant mathematical insights. In this paper , we address the challenge of of fline state estimation in dynamic systems operating under constraints of limited information. This constraint pertains both to the availability of data and the com- prehensive understanding of the system’s physical rules or equations. In certain scenarios, acquiring an exact mathematical representation or formula of the system’s dynamics proves to be a challenge [8][9]. Our grasp of the system model might be restricted, knowing, for instance, that the system can be defined by an Ordinary Differential Equation (ODE) of a particular order , but lacking specificity in the formula itself. Data constraints further compound this challenge. Experimental endeavors, vital for understanding and mapping these systems, often come with significant costs [10], thus limiting the number of feasible experiments. T o tackle the challenges presented, we intr oduce a data-driven, model-fr ee, physics-informed Deep Op- erator Network (DeepOnet) approach. This approach focuses on deciphering nonlinear dynamic systems even when only limited data and limited system information is accessible. Section 2 sheds light on the foundational concepts requir ed for our discussion, encapsulating introductions to PINN, DeepOnet, and the principle of short-term dependency . Our methodology takes center stage in section 3. Here, we first delve into the short-term dependence present in the available data. Subsequently , we employ a surro- gate machine learning model to capture this dependence. This model is then seamlessly integrated into DeepOnet, serving as its physics-informed component. Following this, we train the developed DeepOnet, directing it to emulate the system’s dynamic reactions based on specified control inputs and starting con- ditions. Our exploration culminates in section 4, where, through numerical tests on diverse systems, we demonstrate the pr oficiency of our DeepOnet model in closely approximating the dynamic responses of certain nonlinear dynamic systems. 2. Preliminary In this section, we provide an overview of Physics-informed Neural Networks (PINN), Deep Operator Neural Networks (DeepOnet), and short-term dependency , all of which are utilized in our study . 2.1. Physical-informed Neural Networks In r ecent times, Physics-informed Neural Networks (PINN) have emerged as a noteworthy advance- ment in numerical computing, captivating the interest of researchers across the domains of science and engineering [3]. This method, initially introduced by Karniadakis and his team [11, 12, 13], leverages ma- chine learning to train neural networks, aiming to approximate solutions to partial differ ential equations (PDEs) and similar physics-oriented challenges. What differentiates PINNs is their ability to integrate physical conservation principles and established physical knowledge into their architecture. This not only guarantees the pr ecise depiction of underlying physics but also lessens the reliance on traditional supervised learning. W ith PINNs, it becomes feasible to predict system state variables for any temporal instance. Mor eover , these networks exhibit resilience against data imperfections, like noise or omissions, and consistently produce predictions that resonate with established physical truths. This is attributed to their capability to pr ocess available data in harmony with any physical laws defined by nonlinear PDEs. A key feature of PINNs is their fusion of data fr om both measurements and PDEs, achieved by assimilating the PDEs into the loss function of the neural network through automatic dif ferentiation. Consider a neural network function ˆ y ( x i , t i , θ ) with specific activation functions and a weight matrix θ . This matrix θ r epresents the degrees of freedom determined by the network’s width and depth. The goal is to identify θ that minimizes the loss function. The total loss of the PINN combines the data loss L D and the physical loss L F , defined as: L = w D L D + w F L F (1) 2 Here, the data loss L D measures the discr epancy between the neural network’s predicted value y ( x i , t i , θ ) and the actual measurement ¯ y from the initial and boundary conditions. Using the mean squared error (MSE) loss, it is expressed as: L D = M S E D = 1 N D N D X i = 1 | ( x i , t i , θ ) − ¯ y i | 2 (2) The physical loss, denoted as L F , serves as an unsupervised metric, gr ounded in a distinct physical rule depicted by F () . It is quantified using the MSE, which we label as M S E F . The expression for L F is: L F = M S E F = 1 N F N F X j = 1 | F ( ˆ y ( x j , t j , θ )) | 2 ( x j , t j ) (3) Where ( x i , t i ) and ( x j , t j ) are points sampled from initial/boundary locations and across the entire do- main, r espectively . The weights w D and w F balance the data and physical losses. Their values can be preset or adjusted dynamically , playing a pivotal role in enhancing the effectiveness of PINNs. This loss-function modified minimization appr oach fits naturally into the traditional deep learning framework [14]. The network is trained by minimizing the loss function using various optimization al- gorithms such as Adam[15] or L-BFGS [16]. During training, the optimizer adjusts θ the set of weights and biases in the neural network to minimize the loss function. The training process continues until the loss function reaches a pre-defined threshold, indicating that the network has learned an accurate approxima- tion of the solution that satisfies the physical constraints. The strength of PINN lies in its ability to handle sparse data by integrating physical principles. As highlighted in section 1, our aim is to address challenges posed by limited data, and in this context, PINN proves instrumental. However , we encounter another hurdle: the restricted system model information prevents us from accessing the exact formulation of the physical rules. Consequently , the conventional PINN approach might not be fully applicable. In this study , we substitute the physical rule with the concept of short-term dependency , as elaborated in section 2.3. 2.2. Deep Operator Network DeepOnet is a type of neural network architecture proposed by Lulu and co-workers in the seminal paper [2] as a framework to learn nonlinear operators (i.e., mappings from a function space to another function space). They designed DeepOnet based on the universal approximation theorem of operators [17]. The Universal Approximation Theorem is a fundamental result in the field of neural networks and machine learning. It is widely known that neural networks are universal approximators of continuous functions. A less known and perhaps more powerful result is that a neural network with a single hidden layer containing a sufficient number of neurons can approximate any continuous function on a compact subset of Euclidean space. In other wor ds, given any function that maps inputs to outputs, a neural net- work architectur e exists with a single hidden layer that can approximate the function to any desired level of accuracy . DeepOnet extends the Universal Approximation Theor em to deep neural networks (DNNs) with small generalization errors. DeepOnet also defines a new and relatively under-explor ed realm for DNN- based approaches that map infinite-dimensional functional spaces rather than finite-dimensional vector spaces (functional regr ession). 3 Figure 1: The DeepOnet architectur e DeepOnet architecture consists of two neural networks: one encodes the input function at fixed sensor points (branch net), while another encodes the information related to the spatial-temporal coordinates of the output function (trunk net). In general, the input u to the branch net is flexible, i.e., it can take the shape of the physical domain, the initial or boundary conditions, constant or variable, source terms, etc. The trunk net takes the spatial and temporal coor dinates y as the input. The goal of the DeepOnet is to learn the solution operator G () that can be evaluated at spatial-temporal coordinates, I (input to the trunk net). The output G () of the DeepOnet for a specified input vector u 0 , is a scalar-valued function of I expressed as G ( u )( I ) as G ( u )( I ) = b ( u 0 ) | {z } branch · t k ( I ) | {z } tr unk (4) Similar to PINN, DeepOnet’s trainable parameters, denoted by θ , are derived by minimizing a loss function. DeepOnet primarily utilizes a data loss, which quantifies the discrepancy between the true value ¯ y and its prediction G ( u )( I ) for the given input ( u 0 , I ) . This loss, when calculated using the mean squared error (m.s.e.), can be r epresented as: L D = M S E D = 1 N D N D X i = 1 | G ( u )( I i ) − ¯ y i | 2 (5) . DeepOnet’s adaptability stems from its capability to utilize various branch and trunk networks like FNNs, CNNs, RNNs, and ResNets, allowing it to cater to diverse data types and challenges. It can discern both explicit operators, such as integrals, and implicit ones repr esenting deterministic and stochastic dif- ferential equations. DeepOnets excel in rapid predictions of intricate dynamics for novel parameters while preserving accuracy due to training on vast input-output pair datasets. While they may not surpass the accuracy of numerical solvers rooted in mathematical principles, DeepOnets offer superior computational efficiency , making them faster , especially for complex problems. Furthermor e, their data-driven learning enables them to discern and predict based on discerned data patterns. DeepOnet offers versatility over PINN by accommodating a broader spectrum of operators, such as those emerging in PDEs, integral equations, and varied computational procedures. Y et, one challenge with DeepOnet is its substantial reliance on experimental data to comprehend the system’s dynamics. In 4 situations where data is sparse, the principles of PINN can be beneficial. PINN integrates known physical laws, providing an enhancement to DeepOnet’s performance, especially when data is limited. However , in the context of our study , the physical laws governing the system are elusive. This paper delineates our methodology to enhance the efficacy of DeepOnet under the constraints of limited data and scarce system information. 2.3. Short-term Dependency Dynamic systems, often termed sequential models, exhibit pronounced long-term dependencies. This signifies that present outputs are influenced substantially by historical data. Recent findings demonstrate that both long-term memory models like r ecurrent neural networks (RNNs) and short-term memory mod- els such as feed-forward neural networks (FFNNs) have analogous efficacies when approximating the dy- namics of such systems. This similarity in performance propels many practitioners towards the more sim- plistic FFNNs, regardless of the vast memory benefits offer ed by RNNs. Both models maintain consistency in modeling sequential data [18, 19, 20, 21]. Our prior research [22] aimed to decipher short-term dependencies in discrete-time dynamic systems. W e meticulously examined systems defined by continuous timelines and values, trying to furnish analyti- cal perspectives on their short-term dependencies. Our primary focus was a particular subset of nonlinear dynamic systems guided by or dinary differential equations (ODE), wherein only system variables ar e per- ceptible. T o illustrate, consider the class of nonlinear dynamic systems delineated below: d n x dt n = F ( x , d x dt , d 2 x dt 2 , . . . , d n − 1 x dt n − 1 , u ) y = x (6) In this repr esentation, x denotes the system state, u indicates the system input, and y is the system output. The differ ential terms relate to the system state, while the function F () embodies the system’s governing principles. The system represented by equation (6) encapsulates or dinary differential equations, which are fundamental in numerous mathematical, social, and scientific realms. These applications span from geometry and analytical mechanics to astronomy , climate predictions, epidemiological models, stock trend analysis, and mor e [23] [24]. When employing the Euler method [25] to sample this continuous time system at intervals of δ seconds, the resulting discr ete-time system adheres to the subsequent differ ence equation: x ( t + 1) = x ( t ) + δ d x dt ( t ) d x dt ( t + 1) = d x dt ( t ) + δ d 2 x dt 2 ( t ) . . . d n − 1 x dt n − 1 ( t + 1) = d n − 1 x dt n − 1 ( t ) + δ d n x dt n ( t ) d n x dt n ( t + 1) = d n x dt n ( t ) + δ F ( ... ) y ( t ) = x ( t ) (7) where δ is the sampling period, we assume that δ is small enough such that the difference between the outputs of the approximated sampled system (7) and the tr ue sampled system is negligible. Theorem 2.1. The approximated sampled discrete time system (7) is n -step dependent, i.e. there exists a function γ mapping from x ( t − n ) , . . . , x ( t − 1) and u ( t − n ) , . . . , u ( t − 1) to x ( t ) . Theorem 2.1 posits that when the sampling period is adequately minute, ensuring the Euler method provides a close approximation, the contemporary output exclusively hinges on the preceding n -step in- puts and outputs, with n repr esenting the highest order of differential value. Remarkably , for the class of nonlinear dynamic systems defined in equation (6), even in the absence of explicit knowledge of the governing function F () , we can still elucidate its short-term dependencies. 5 3. Methodology As outlined in Section 1, this paper ’s primary objective is to estimate system states while grappling with limited system model details and sparse experimental data. T o be mor e pr ecise r egarding the system model information, the system’s dynamics can be repr esented by an Ordinary Differ ential Equation (ODE) of a known order . Leveraging this known ODE order , combined with the preliminary insights on short-term dependency discussed in Section 2.3, enables us to discern the system’s short-term dependencies. 3.1. Using Machine Learning Models to Learn Short-T erm Dependency In our proposed methodology , we integrate the system’s short-term dependency into DeepOnet. This short-term dependency , viewed as an intrinsic system rule, is then incorporated into the network’s loss function. W e first explore the historical data needed to anticipate the subsequent output. The purpose of this step is to build a mapping from history data (initial condition, history control inputs, and history states) to the current state. When the system meets the criteria of the class of nonlinear dynamic systems, as repr esented in equation 6, emphasizing its highest n th order differ ential, it is inferred fr om Theorem2.1 that the system has an n -step dependency . This implies that a function, termed as γ , exists that connects past system states x ( t − n ) , . . . , x ( t − 1) and preceding control actions u ( t − n ) , . . . , u ( t − 1) to the current state x ( t ) . T o capture this short-term dependency , represented by the γ function, within the dynamic system, we resort to a machine learning model, potentially a neural network. Specifically , its inputs comprise past system states spanning x ( t − n ) , . . . , x ( t − 1) and earlier control inputs u ( t − n ) , . . . , u ( t − 1) , while the output is predicting the current system state x ( t ) . The detailed design of this machine learning model can be observed in the subsequent Figure 2. Figure 2: Using machine learning model to learn the short-term dependency . If we employ previous states x ( t − n ) , . . . , x ( t − 1) to forecast the current state x ( t ) as the left part in above Figure 2, this is feasible given that the sampling period δ is sufficiently small. Due to the diminutive natur e of the sampling period, there’s a pronounced resemblance between the current and the preceding state, denoted as x ( t ) ≈ x ( t + 1) . In such circumstances, the model might bypass the dynamic behavior and merely approximate the current state to the preceding one. T o circumvent this state correlation, we opt to utilize the system state x ( t − n ) in conjunction with lower or der dif ferential values d x dt ( t − n ) , . . . , d n − 1 x dt n − 1 ( t − n ) as inputs, with the intent of predicting the highest or der differential value d n x dt n ( t ) . 3.2. Model-free physical-informed deep operator network Once the short-term dependence is captured through a machine learning model, we combine it with DeepOnet. The DeepOnet can directly formulate the mapping between the initial state, control inputs sequence, and the time steps to the current state. While DeepOnet typically requir es extensive data for training, we face a limitation of data in our situation. T o address this, we leverage the short-term depen- dence to enhance the performance of DeepOnet. 6 Our ar chitecture adopts the structur e of the DeepOnet framework, consisting of both a branch and a trunk network. The branch network processes the initial system state x (0) together with a sequence of control inputs, initiating fr om u (0) and extending as u (1) , u (2) , . . . , u ( t ) , . . . . Concurr ently , the trunk network receives the time step t as input. The ultimate output of DeepOnet is the anticipated system state ˆ x ( t ) . The combined loss L , used to train our architecture, is the sum of the conventional data loss L dat a and the physics-informed loss L P . The data loss L dat a arises from the dif ference between the actual system state x ( t ) and the DeepOnet’s estimated state ˆ x ( t ) . For the physics-informed loss, we employ Auto Differential [26] to compute differential values d ˆ x dt ( t ) , d 2 ˆ x dt 2 ( t ) , . . . , d n − 1 ˆ x dt n − 1 ( t ) , d n ˆ x dt n ( t ) of the projected system state ˆ x ( t ) . The model, which learns short-term dependence, takes in the predicted state ˆ x ( t ) , lower order differential values d ˆ x dt ( t ) , d 2 ˆ x dt 2 ( t ) , . . . , d n − 1 ˆ x dt n − 1 ( t ) , and control inputs u ( t + n − 1) , . . . , u ( t ) . Subsequently , it forecasts the highest differential value d n ¯ x dt n ( t ) . The physics-informed loss L P is derived from the discr epancy between d n ˆ x dt n ( t ) and d n ¯ x dt n ( t ) . Figure 3: The proposed model-fr ee physical-informed DeepOnet architectur e Our proposed method combines the advantages of both Physics Informed Neural Networks (PINN) and Deep Operator Networks (DeepOnet) to addr ess the limitations associated with limited system model information and a small amount of experimental data. PINN is known for its ability to work with limited data and uses a neural network to solve the differential equation-based model. However , it assumes a known model, which may not always be available in practical applications. On the other hand, DeepOnet is a model-free technique that does not r equire a known model, making it suitable for cases where system model information is limited. However , it typically r equires a large number of experiments to learn the system behavior accurately . By combining the strengths of both methods, our proposed technique aims to overcome the limitations of limited system model information and small amounts of experimental data, while still being able to accurately predict system behavior under different inputs or conditions. In addition, our proposed method also incorporates our previous research on short-term dependency , which considers the influence of past states or inputs on the system’s current state. This allows us to capture the memory and history of the system, further enhancing the accuracy and robustness of our appr oach. 7 4. Result In this section, we apply our method to three different systems based on ODEs to comprehensively evaluate its performance. The first, the well-known Pendulum system, is stabilized by setting the control input within a specific range. The second, the Driven Oscillator system, is made marginally unstable with a specific control input range. Both of these systems are modeled by 2nd-order ODEs. Additionally , we have tested our method on a more complex 3r d-order ODE system, the Chaotic Jerk system. 4.1. Pendulum System The pendulum system from [27] was previously discussed. It involves swinging a pendulum from a downward to an upright position. The system is defined by: ¨ x ( 1 4 ml 2 + I ) + 1 2 ml sin( x ) = u ( t ) − b ˙ x (8) Here, x represents the pendulum angle, ˙ x its angular velocity , and u ( t ) the control input. For this study , parameters are: m = 1 kg, l = 1 m, I = 1 12 ml 2 , and b = 0 . 01 sNm/rad. Below are detailed steps on how we implemented our method for the Pendulum system: 1. Data Generation Data are obtained fr om numerical simulations generated using the Euler method. Algorithm 1 Euler method numerical simulation 1: Define initial state x (0) , ˙ x (0) 2: Input control sequence u (0) , u (1) , u (2) , ..., u ( t ) ,... 3: Input system parameters: m , l , g , b 4: Set sampling period d t = 0 . 001 s 5: for t = 0 to T − 1 do 6: ˙ x ( t + 1) ← ˙ x ( t ) + d t · u ( t ) − b ˙ x ( t ) − 1 2 mgl sin( x ( t )) 1 4 ml 2 + l 7: x ( t + 1) ← x ( t + 1) + d t · ˙ x ( t ) 8: end for 9: End in T step T o ensure stable behavior in the pendulum system, the control input is defined as u ( t ) = − c · ˙ x ( t ) , where c is a constant parameter . This paper addresses challenges related to limited system data. As a result, only five sets of training datasets are produced, corresponding to c values from 0.35 to 0.75 with 0.1 intervals. Furthermore, ten test datasets have been created with c values ranging from 0.3 to 0.84 in increments of 0.06. 2. Using Machine Learning Models to Learn Short-T erm Dependency W e are investigating the short-term dependency in the pendulum system. Since we only know that the order of the partial differential equation (8) is 2 , based on Theorem 2.1, we can infer that the system state x t only depends on the most recent 2-step states and control inputs, namely x ( t − 1) , x ( t − 2) , u ( t − 1) , and u ( t − 2) . W e utilized a Feed-forward Neural Network (FFNN) to discern the short-term dependency , employ- ing five groups of data generated as outlined in section 3.1. The hyper-parameters of FFNN is shown in T able 1. Upon completing the training process, our FFNN model demonstrated stability and was adept at accurately predicting the second dif ferential value ¨ x ( t − 1) of the pendulum’s angle. 8 3. Combining the Machine Learning Model with DeepOnet After capturing the short-term dependence on the FFNN, we integrated the FFNN with DeepOnet to devise a Physical-informed DeepOnet structure. Our architectur e, tailored for the pendulum sys- tem, encompasses both a branch and a trunk network. As shown in Figure 3. The branch network processes the initial system state x (0) alongside the control input sequence u (0) , u (1) , u (2) , ..., u ( t ) , ... . Conversely , the trunk network is ftime instant: t . The culmination of the DeepOnet’s computations is the forecasted system state, specifically ˆ x ( t ) . The hyper-parameters of DeepOnet are shown in T able 1. T able 1: Networks Hyperparameters for Three Systems Once our approach’s network is trained, we employ 10 test datasets, generated as per Step 1, to assess its performance. It’s crucial to highlight that while these test datasets differ from the training data, their underlying control inputs are analogous to the training set. W e employ DeepOnet as a benchmark for gauging the efficacy of our method. Figure 4 and 5 provide a comparative study of the estimation results between our method and the benchmark, DeepOnet. 9 Figure 4: T est Results of DeepOnet on the Pendulum System without Noise Figure 5: T est Results of Our Approach on the Pendulum System without Noise By comparing Figure 4 and 5, our method showcases superior accuracy in its predictions, closely align- ing with the true values throughout the displayed scenarios. Conversely , although DeepOnet captures the general trends, it presents noticeable discrepancies in specific plots, notably the first 3 datasets. This con- trast highlights the refined reliability and precision of our technique when compared to the conventional DeepOnet. A mor e quantified differ entiation is observed when examining the average mean absolute err or (MAE). W ith an MAE of 17.98 for DeepOnet in contrast to a significantly lower 6.23 for our method, it’s evident that our approach of fers enhanced performance. Implementation with Noisy Data The results presented thus far pertain to noise-free data. For a more comprehensive evaluation, we tested our approach using data with measur ement noise, which is often pr esent in real-world systems. This noisy data is generated using the Euler method, as described in step 1, with the introduction of Gaussian noise to simulate measurement inaccuracies. The Gaussian noise is represented by the probability density function (PDF) of a Gaussian distribution: N ( x | µ, σ 2 ) = 1 √ 2 πσ 2 e − ( x − µ ) 2 2 σ 2 (9) where µ denotes the mean and σ 2 signifies the variance. T o simulate varying noise levels, we kept µ = 0 and adjusted the value of σ 2 . In this paper , we present the r esult of noise data when the variance σ = 0 . 002 . Figure 6 is the comparison between the noisy-fr ee data and noisy data. Figure 6: Comparison between noise-free data and measur ement-noise data ( µ = 0 . 002 ) in Pendulum system 10 For the noisy dataset, we first use the Savitzky-Golay filter [28] to smooth the noise data. This filter is renowned in signal processing for its robust noise elimination capabilities and for enhancing the signal’s smoothness. A notable merit of the Savitzky-Golay filter is its proficiency in calculating the smoothed derivatives of the data. Utilizing the procedur es detailed in steps 2 and 3, we trained the corresponding FFNN and integrated model, which has the same parameters as the noisy-free case. T o provide a tangible comparison of the efficacy of our approach against existing methods, we present Figures 7 and 8. These visuals distinctly showcase the contrast between the results yielded by our approach and those of DeepOnet. T o quantify this performance disparity further , we calculated the MAE. Our approach yielded an MAE of 7.57, whereas DeepOnet’s was 19.27. Figure 7: T est Results of DeepOnet on the Pendulum System with Measurement Noise Figure 8: T est Results of Our Approach on the Pendulum System with Measurement Noise 4.2. Driven Oscillator System As introduced by the work in [29], the Driven Oscillator System is a classic representation of an oscilla- tor subjected to an external force. It’s a foundational tool in the study of numerous physical pr ocesses, and its behavior intricately changes with variations in the driving force and inherent oscillator properties. The governing dynamics of this system can be expressed as: m ¨ x + c ˙ x + k x = F 0 u (10) Here, m characterizes the oscillator ’s mass, x its displacement, ˙ x its velocity , and ¨ x its acceleration. The parameters c and k are the damping and stiffness coefficients, respectively . The driving force’s amplitude and angular fr equency are repr esented by F 0 and w . In our specific system setup, we selected values of m = 0 . 5 , k = 50 , c = 1 , and F 0 = 4 . Regarding the data for this system, it’s derived using the Euler method, as referenced in Step 1. W e’ve generated 5 training datasets. T o instill a mar ginally unstable behavior in the oscillator , the angular fre- quency w was controlled between values 9 to 11 with a step of 0.5 for these datasets. Additionally , 10 test datasets were formulated with angular fr equencies w ranging from 8.5 to 11.2, incr emented by 0.3. Once the data was generated, both the FFNN and our proposed structure were trained. The hyperpa- rameters for both the FFNN and DeepOnet, as used in our approach, can be found in T able 1. W e evaluated the models using ten test datasets to gauge their performance. A comparative analysis of the estimation results between our method and the benchmark, DeepOnet, is presented in Figures 9 and 10. Notably , our method demonstrated superior performance, especially for Dataset 9. T o provide a numerical assessment of this performance differ ence, we computed the Mean Absolute Error (MAE). Our method achieved an MAE of 16.69, in contrast to DeepOnet’s MAE of 36.22. 11 Figure 9: T est Results of DeepOnet on the Oscillator System without Noise Figure 10: T est Results of Our Approach on the Oscillator Sys- tem without Noise Implementation with Noisy Data W e further evaluated our approach by introducing measurement noise to the data. Specifically , Gaus- sian noise, as defined in equation 9, was incorporated. The results with a noise variance, σ , of 0.01 are discussed below . A comparative visual repr esentation between the noise-free and noisy data is provided in Figure 11. Figure 11: Comparison between noise-free data and measur ement-noise data ( µ = 0 . 02 ) in Driven Oscillator system In the context of measurement noise, the performance results are depicted in Figures 12 and 13. While DeepOnet’s predictions sometimes diverge from the actual outcomes, notably in Datasets 2, 6, 7, and 9, Our Approach more consistently mirrors the true data across the majority of the datasets. From a quantitative perspective, we determined the MAE for both methods. DeepOnet register ed an MAE of 39.46, in contrast to the notably superior MAE of 19.10 achieved by our method. Even though both methods bring forth meaningful contributions, Our Approach evidently emerges as the more r eliable and precise alternative in these scenarios. 12 Figure 12: T est Results of DeepOnet on the Oscillator System with Measurement Noise Figure 13: T est Results of Our Approach on the Oscillator Sys- tem with Measurement Noise 4.3. Chaotic Jerk System T o validate the applicability of our method in handling high-order differential systems, we have chosen to implement it in a chaotic jerk system. A jerk is defined as the rate of change of acceleration, which corresponds to the third derivative of position with respect to time. In dynamical systems, a chaotic jerk system typically exhibits unpredictable and highly sensitive behavior to initial conditions. Chaotic systems, including chaotic jerk systems, ar e characterized by complex and non-repeating patterns of motion, known as chaotic attractors. For our analysis, we utilize a simple chaotic jerk function described by Sprott [30]. The formula for this function is presented below: ... x + A ¨ x − ˙ x 2 + x = u (11) In this equation, x repr esents the state variable, ˙ x repr esents its first derivative, ¨ x repr esents its second derivative, and ... x represents its thir d derivative. The parameter A determines the strength of the damping term, and u repr esents the control input. The u is further represented as u ( t ) = F ( t ) · sin ( wt ) , where F is the force, w is frequency . Regarding the data for this system, it’s derived using the Euler method, as referenced in Step 1. W e’ve generated 10 training datasets. In order to have some curve behavior in the Jerk system, the F is set from 1.09 to 1.9 with an interval of 0.09, and the fr equency w was controlled between values 2 to 2.81 with a step of 0.0.09 for these datasets. Additionally , 5 test datasets were formulated with force F ranging from 1.2 to 2, incremented by 0.2, and fr equencies w ranging from 2 to 2.5, incr emented by 0.1. Once the data was generated, both the FFNN and our proposed structure were trained. The hyperpa- rameters for both the FFNN and DeepOnet, as used in our approach, can be found in T able 1. W e evalu- ated the models using ten test datasets to gauge their performance. The estimative outcomes between our strategy and the benchmark, DeepOnet, are delineated in Figures 14 and 15. Remarkably , our technique showcased enhanced accuracy across all test datasets. The MAE was also calculated in a quantified perfor- mance comparison. While our method registered an MAE of 19.8, DeepOnet recorded an MAE of 10.5. In a direct juxtaposition of results for the Jerk System without noise, our method unambiguously manifests greater pr ecision and dependability . 13 Figure 14: T est Results of DeepOnet on the Jerk System without Noise Figure 15: T est Results of Our Approach on the Jerk System without Noise Implementation with Noisy Data W e further evaluated our approach by introducing measurement noise to the data. Specifically , Gaus- sian noise, as defined in equation 9, was incorporated. Results for the noisy data, with a variance, σ , set to 0.03, ar e detailed. Figure 16 pr ovides a comparative visual repr esentation between the noise-free and noisy data. Figure 16: Comparison between noise-free data and measur ement-noise data ( µ = 0 . 002 ) in Chaotic Jerk system Performance evaluations under the influence of measurement noise are showcased in Figures 17 and 18. Across all test datasets, our approach consistently outperforms DeepOnet. T o pr ovide a numerical per- spective on this performance differ ence, we calculated the Mean Absolute Error (MAE). While DeepOnet yielded an MAE of 22.2, our method achieved a lower value of 18.7. Figure 17: T est Results of DeepOnet on the Jerk System with Measurement Noise Figure 18: T est Results of Our Approach on the Jerk System with Measurement Noise 14 5. Conclusion In the rapidly evolving landscape of dynamic systems analysis, the challenges of sparse data and incom- plete system modeling continue to pose significant hurdles. In our investigation, we successfully tackled these challenges with a novel appr oach gr ounded in a data-driven model-fr ee physical-informed Deep Op- erator Network (DeepOnet) framework. This approach distinguished itself by tapping into the short-term dependencies inherent in the limited data, thereby harnessing the power of a surrogate machine-learning model. This surrogate model then seamlessly integrated with DeepOnet, infusing it with critical physical insights. Our evaluation was methodical, encompassing three unique dynamic systems, each characterized by its own set of complexities, behaviors, and underlying ODE foundations. Acr oss this spectrum of sys- tems, our method consistently demonstrated superiority over the original DeepOnet, not only for pristine, noise-free data but also when the data was tainted with measurement noise. This resilience in the face of noise underscores the robustness of our methodology , highlighting its potential applicability in real-world scenarios fraught with uncertainties. In conclusion, our endeavors in this study mark a significant stride in the realm of offline state es- timation for dynamic systems. By effectively navigating the twin challenges of limited data and model ambiguity , we’ve showcased the potential of our approach. As the quest for more efficient, accurate, and versatile state estimation techniques persists, our research stands as a beacon, illuminating the path for- ward and underscoring the pr omise that data-driven methodologies hold in bridging the knowledge gaps of today . References [1] C. M. Close, D. K. Frederick, J. C. Newell, Modeling and analysis of dynamic systems, John W iley & Sons, 2001. [2] L. Lu, P . Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via deeponet based on the universal approximation theor em of operators, Nature machine intelligence 3 (3) (2021) 218–229. [3] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P . Perdikaris, S. W ang, L. Y ang, Physics-informed machine learning, Nature Reviews Physics 3 (6) (2021) 422–440. [4] S. W ang, H. W ang, P . Perdikaris, Learning the solution operator of parametric partial dif ferential equa- tions with physics-informed deeponets, Science advances 7 (40) (2021) eabi8605. [5] G. Lin, C. Moya, Z. Zhang, Learning the dynamical r esponse of nonlinear non-autonomous dynamical systems with deep operator neural networks, Engineering Applications of Artificial Intelligence 125 (2023) 106689. [6] Y . W ang, L. Zhang, Z. Li, Modeling of nonlinear dynamic system based on deep operator network, in: 2021 China Automation Congress (CAC), IEEE, 2021, pp. 5914–5918. [7] S. Garg, H. Gupta, S. Chakraborty , Assessment of deeponet for reliability analysis of stochastic non- linear dynamical systems, arXiv preprint arXiv:2201.13145 (2022). [8] Y . Bar-Y am, General features of complex systems, Encyclopedia of Life Support Systems (EOLSS), UNESCO, EOLSS Publishers, Oxford, UK 1 (2002). [9] R. C. D. R. H. Bishop, Modern control systems, 2011. [10] J. THON, The financial cost of doing science (2023). [11] M. Raissi, P . Per dikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning frame- work for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational physics 378 (2019) 686–707. 15 [12] M. Raissi, P . Perdikaris, G. E. Karniadakis, Physics informed deep learning (part i): Data-driven solu- tions of nonlinear partial differ ential equations, arXiv preprint arXiv:1711.10561 (2017). [13] M. Raissi, Deep hidden physics models: Deep learning of nonlinear partial dif ferential equations, The Journal of Machine Learning Research 19 (1) (2018) 932–955. [14] J. D. Kelleher , Deep learning, MIT press, 2019. [15] D. P . Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint (2014). [16] R. H. Byrd, P . Lu, J. Nocedal, C. Zhu, A limited memory algorithm for bound constrained optimization, SIAM Journal on scientific computing 16 (5) (1995) 1190–1208. [17] T . Chen, H. Chen, Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems, IEEE T ransactions on Neural Networks 6 (4) (1995) 911–917. [18] K. Kelchtermans, T . T uytelaars, How hard is it to cross the room?–training (recurrent) neural networks to steer a uav , arXiv preprint arXiv:1702.07600 (2017). [19] Y . N. Dauphin, A. Fan, M. Auli, D. Grangier , Language modeling with gated convolutional networks, in: International conference on machine learning, PMLR, 2017, pp. 933–941. [20] S. Bai, J. Z. Kolter , V . Koltun, An empirical evaluation of generic convolutional and r ecurrent networks for sequence modeling, arXiv preprint arXiv:1803.01271 (2018). [21] A. Oord, Y . Li, I. Babuschkin, K. Simonyan, O. V inyals, K. Kavukcuoglu, G. Driessche, E. Lockhart, L. Cobo, F . Stimberg, et al., Parallel wavenet: Fast high-fidelity speech synthesis, in: International conference on machine learning, PMLR, 2018, pp. 3918–3926. [22] J. Sun, L. Li, Short-term dependency of a class of nonlinear continuous time dynamic systems, Engi- neering Applications of Artificial Intelligence 105 (2021) 104402. [23] C. Chicone, Ordinary differ ential equations with applications, V ol. 34, Springer Science & Business Media, 2006. [24] B. Denis, An overview of numerical and analytical methods for solving ordinary differ ential equa- tions, arXiv preprint arXiv:2012.07558 (2020). [25] R. L. Burden, Numerical analysis, Br ooks/Cole Cengage Learning, 2011. [26] R. D. Neidinger , Introduction to automatic differentiation and matlab object-oriented programming, SIAM review 52 (3) (2010) 545–563. [27] G. Li, C. Moya, Z. Zhang, On learning the dynamical response of nonlinear control systems with deep operator networks, arXiv preprint arXiv:2206.06536 (2022). [28] A. Savitzky , M. J. Golay , Smoothing and differ entiation of data by simplified least squares procedures., Analytical chemistry 36 (8) (1964) 1627–1639. [29] G. S. University , Driven oscillator , http://hyperphysics.phy- astr.gsu.edu/hbase/oscdr. html . [30] J. Sprott, Some simple chaotic jerk functions, American Journal of Physics 65 (6) (1997) 537–543. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment