Mind the Gap: Detecting Cluster Exits for Robust Local Density-Based Score Normalization in Anomalous Sound Detection
Local density-based score normalization is an effective component of distance-based embedding methods for anomalous sound detection, particularly when data densities vary across conditions or domains. In practice, however, performance depends strongl…
Authors: Kevin Wilkinghoff, Gordon Wichern, Jonathan Le Roux
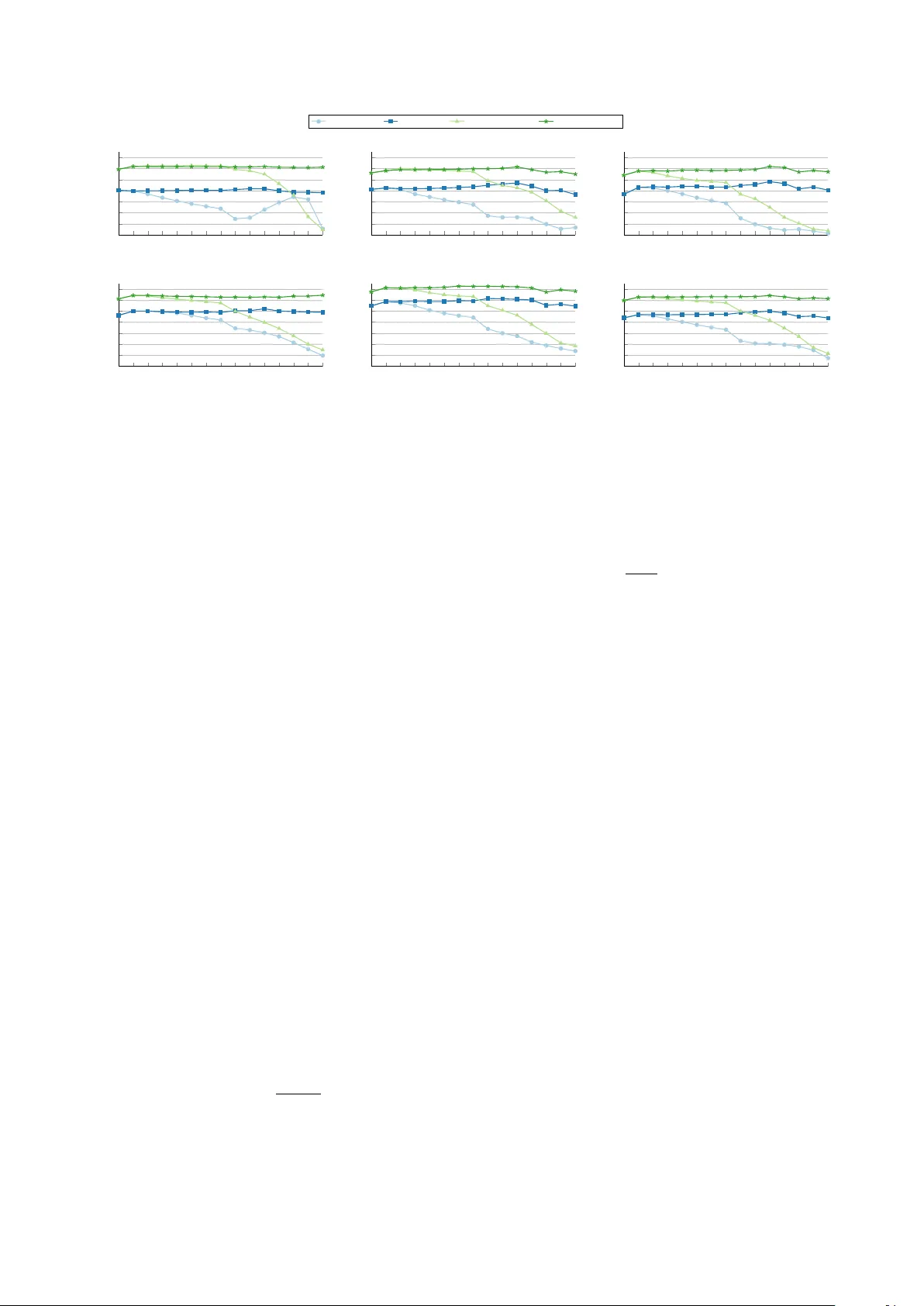
Mind the Gap: Detecting Cluster Exits f or Rob ust Local Density-Based Scor e Normalization in Anomalous Sound Detection K evin W ilkinghoff ID 1 , 2 , ∗∗ , Gor don W ichern ID 3 , J onathan Le Roux ID 3 , Zheng-Hua T an ID 1 , 2 1 Department of Electronic Systems, Aalborg Uni v ersity , Aalborg, Denmark 2 Pioneer Centre for Artificial Intelligence, Copenhagen, Denmark 3 Mitsubishi Electric Research Laboratories (MERL), Cambridge, MA, USA kevin.wilkinghoff@ieee.org, wichern@merl.com, leroux@merl.com, zt@es.aau.dk Abstract Local density-based score normalization is an effecti ve com- ponent of distance-based embedding methods for anomalous sound detection, particularly when data densities vary across conditions or domains. In practice, howe ver , performance de- pends strongly on neighborhood size. Increasing it can degrade detection accuracy when neighborhood e xpansion crosses clus- ter boundaries, violating the locality assumption of local den- sity estimation. This observation motiv ates adapting the neigh- borhood size based on locality preservation rather than fixing it in advance. W e realize this by proposing cluster exit detec- tion, a lightweight mechanism that identifies distance discon- tinuities and selects neighborhood sizes accordingly . Exper- iments across multiple embedding models and datasets show improv ed robustness to neighborhood-size selection and con- sistent performance gains. Index T erms : anomaly detection, anomalous sound detection, domain generalization, domain shift, score normalization 1. Introduction Semi-supervised anomalous sound detection (ASD) for ma- chine condition monitoring aims to detect anomalous machine sounds using training data that contain only recordings of nor- mal operation. In practice, systems are often deployed under domain shifts, such as changes in operating conditions, back- ground noise, recording devices, or en vironments, that alter the sound distribution while normal operation is preserv ed. This setting is formalized in recent DCASE challenges [1–4], where models are trained with many normal samples from a source domain and only a fe w from a target domain, yet are expected to perform equally well in both domains at test time. T o handle this setting, many state-of-the-art ASD sys- tems operate in learned embedding spaces using distance-based scores or density estimates. Each audio recording, typically sev- eral seconds long, is mapped to a fix ed-dimensional embedding vector by a neural network, either trained with task-specific sur- rogate objecti ves for machine sounds [5–10] or pre-trained on large-scale audio datasets [11–17]. Anomalies are identified by comparing embeddings of test samples to those of normal train- ing data in the embedding space. Recently , local density-based anomaly score normalization (LDN) [18, 19] has been proposed to improv e robustness to do- main shifts in this embedding-based setting [20]. LDN normal- izes distance-based anomaly scores using statistics from a local neighborhood in the embedding space, compensating for varia- tions in local data density . This is particularly important when ** indicates the corresponding author . detection relies on a single, domain-agnostic threshold despite highly non-uniform reference densities. Howe ver , LDN intro- duces the neighborhood size as a critical hyperparameter . Empirically , increasing the neighborhood size beyond one or two neighbors often leads to systematic performance degra- dation. While larger neighborhoods are generally expected to yield more stable density estimates, e xisting approaches typi- cally fix the neighborhood size to a small value [19, 21], of- fering limited insight into why performance deteriorates as the neighborhood expands. Variance minimization (V arMin) [22] can partial ly mitigate this ef fect, b ut the fundamental sensiti vity to neighborhood size remains unresolved. In this work, we show that the observed degradation is not caused by larger neighborhoods per se, but occurs when neigh- borhood expansion crosses cluster boundaries in the embedding space. Once neighbors outside the local region are included, the locality assumption underlying LDN is violated, corrupting local density estimates and destabilizing score normalization. This insight motiv ates a general design principle: Neighbor- hood sizes should adapt based on whether locality is preserv ed, rather than being fix ed a priori. Building on this principle, we propose cluster exit detection (CED), a lightweight, training- free mechanism that detects distance jumps indicating cluster exits and adapts neighborhood sizes on a per -sample basis. The main contributions of this w ork are: • W e identify a structural failure mode of LDN arising from neighborhood expansion across cluster boundaries, and moti- vate the need for adaptiv e neighborhood selection to preserve local density structure. • W e propose CED, a lightweight, training-free algorithm for adaptiv e neighborhood selection based on distance jumps. • Experiments with fiv e embedding models on fiv e benchmark datasets demonstrate improved rob ustness to neighborhood- size selection and consistent performance gains over fixed small-neighborhood baselines. 2. Local density-based anomaly score normalization LDN has been shown to improv e rob ustness to domain shifts in distance-based anomaly detection [18, 19]. The k ey idea is to normalize anomaly scores using statistics deriv ed from a lo- cal neighborhood in the embedding space, thereby accounting for variations in local data density . More recently , V arMin was proposed to further stabilize normalized scores [22]. W e briefly recap LDN, its variance-minimized variant, and the role of the neighborhood size. 20 40 60 80 0 . 8 1 1 . 2 1 . 4 neighbor index k distance d k (a) sorted distances source domain target domain 20 40 60 80 0 . 94 0 . 96 0 . 98 1 ratio index k r k = d k /d k +1 (b) distance ratios Figure 1: A verag e sorted distances (left) and distance ratios (right) for BEA Ts embeddings of the “T oyCar” machine on the DCASE2025 dataset in the source and targ et domains. Pr onounced distance jumps and low r atios mark cluster exits, which occur earlier in the tar get domain and re veal violations of locality under fixed neighborhood sizes. 2.1. Base anomaly scoring Let X test ⊂ R D denote the set of test samples and X ref ⊂ R D a reference set of normal training samples in the embedding space. All available training samples are typically used as ref- erence samples. For a test sample x ∈ X test , the base anomaly score is computed as the distance to its closest reference sample, A ( x, X ref ) := min y ∈X ref D ( x, y ) ∈ R + , (1) where D : R D × R D → R + denotes a distance measure such as the Euclidean distance or cosine distance. 2.2. Local density-based normalization T o mitigate performance degradation caused by domain shifts, LDN normalizes the raw anomaly score using distances within a local neighborhood of each reference sample. For a given y ∈ X ref , a neighborhood of size K ∈ N is defined by its K nearest neighbors in the reference set. Increasing K implicitly assumes that locality is preserved as the neighborhood e xpands. Combined with V arMin in log-space, this yields scaled anomaly scores of the form A scaled ( x, X ref | K, α ) := min y ∈X ref log D ( x, y ) − α log 1 K K X k =1 D ( y , y k ) ∈ R , (2) where y k denotes the k -th nearest neighbor of y in X ref . Setting α = 1 reco vers the standard LDN formulation. For V arMin, α = α ∗ is selected to minimize the variance of the normalized scores ov er the reference set, i.e., α ∗ = arg min α ∈ R V ar z ∼X ref ( A scaled ( z , X ref | K, α )) ∈ R . (3) This scoring backend is entirely training-free, requires no la- bels, and introduces no additional assumptions on the data dis- tribution. Since the normalization constants depend only on the reference samples, they can be pre-computed without additional inference-time ov erhead. 3. Locality violations and cluster exits LDN assumes that nearby reference samples belong to the same local re gion in the embedding space. Increasing the neighbor - hood size K therefore assumes that this locality remains valid as the neighborhood expands. In practice, LDN is applied with very small neighborhoods, since increasing K beyond one or two neighbors often leads to systematic performance degrada- tion, ev en though larger neighborhoods are expected to yield more stable density estimates. As sho wn in Fig. 1, this degrada- tion is structural rather than statistical. Especially in the target domain, large distance jumps already occur among the first few neighbors. Sorted distance profiles e xhibit pronounced jumps when neighborhood expansion crosses cluster boundaries, di- rectly indicating a violation of the locality assumption. The re- sulting sensitivity to K is further quantified in Fig. 2. These jumps explain how locality is lost. For a given ref- erence sample, distances typically increase smoothly within the same cluster . When expansion crosses a cluster boundary , this smooth increase is interrupted by a sharp jump in distance. W e refer to this transition as a cluster exit . As long as distances grow smoothly , neighborhood expansion remains v alid. Once a cluster exit is encountered, further expansion includes samples from outside the local region, which corrupts local density es- timates and degrades score normalization. This analysis shows that the core challenge is not selecting a fixed neighborhood size, but identifying when locality no longer holds. In the fol- lowing section, we introduce a training-free algorithm that de- tects cluster e xits from distance jumps and uses them to adapt neighborhood sizes for local density estimation. While devel- oped for LDN, the underlying principle is more general, and alternativ e mechanisms for detecting cluster e xits could be inte- grated within the same framew ork. 4. Cluster exit detection W e propose a training-free CED mechanism for adaptiv e neigh- borhood selection in local density-based normalization. Be- cause local density estimates in LDN are defined with respect to reference neighborhoods, all computations are carried out independently for each reference sample y ∈ X ref using only distances to other reference samples. The method requires no labels, no training, and no dataset-specific tuning, and can be integrated into existing LDN backends as a drop-in replace- ment for a fix ed neighborhood size K . The central contribution is to demonstrate that adaptively selecting neighborhood sizes via cluster exit detection, rather than fixing K , is essential for preserving locality and stabilizing performance. Fixed thresh- olds are used, but stable beha vior across datasets and embed- ding models indicates that effecti veness stems from detecting distance jumps rather than precise threshold values. 4.1. Distance ratios Let K ≥ 2 and let { y k } K k =1 denote the K nearest neighbors of a reference sample y ∈ X ref , ordered by increasing distance. Define d k ( y ) := D ( y , y k ) , k = 1 , . . . , K. (4) W ithin a local cluster , distances increase smoothly , whereas crossing a cluster boundary induces a sharp increase. W e cap- ture such changes using distance ratios r k ( y ) = d k ( y ) d k +1 ( y ) + ϵ , k = 1 , . . . , K − 1 , (5) with ϵ = 10 − 12 . Since distances are ordered, 0 < r k ( y ) ≤ 1 , and small v alues indicate potential cluster e xits. For K > 2 , adjacent ratios are av eraged, ˜ r k ( y ) = 1 2 ( r k ( y ) + r k +1 ( y )) , k = 1 , . . . , K − 2 , (6) 1 2 3 4 5 6 7 8 16 32 64 128 256 512 |X ref | -1 1.00 1.01 1.02 1.03 1.04 1.05 1.06 1.07 Performance ratio Direct-ACT LDN [18, 19] LDN+CED LDN+V arMin [22] LDN+V arMin+CED 1 2 3 4 5 6 7 8 16 32 64 128 256 512 |X ref | -1 1.00 1.01 1.02 1.03 1.04 1.05 1.06 1.07 OpenL3-Raw 1 2 3 4 5 6 7 8 16 32 64 128 256 512 |X ref | -1 1.00 1.01 1.02 1.03 1.04 1.05 1.06 1.07 BEA Ts-raw 1 2 3 4 5 6 7 8 16 32 64 128 256 512 |X ref | -1 1.00 1.01 1.02 1.03 1.04 1.05 1.06 1.07 K Performance ratio EA T -raw 1 2 3 4 5 6 7 8 16 32 64 128 256 512 |X ref | -1 1.00 1.01 1.02 1.03 1.04 1.05 1.06 1.07 K Dasheng-raw 1 2 3 4 5 6 7 8 16 32 64 128 256 512 |X ref | -1 1.00 1.01 1.02 1.03 1.04 1.05 1.06 1.07 K A verage Figure 2: P erformance ratios r elative to not applying LDN for ratio-based LDN variants as a function of the neighborhood size K . V alues are geometric means acr oss all five evaluated datasets. F or Direct-A CT, results ar e averaged o ver ten independent trials. to reduce sensitivity to isolated fluctuations. For K = 2 , no smoothing is applied. 4.2. Detecting cluster exits As the neighborhood size k increases, a cluster exit is reflected by a pronounced drop in the smoothed ratio sequence ˜ r k ( y ) . W e therefore first identify the most informativ e transition by locating the index of the smallest ratio v alue, k min ( y ) = arg min k ∈{ 1 ,...,K − 2 } ˜ r k ( y ) . (7) In practice, neighborhood expansion may already become un- reliable at earlier indices if ˜ r k ( y ) drops below a conservati ve, data-adaptiv e threshold. T o account for this, we define C ( y ) = n k ∈ { 1 , . . . , K − 2 } : ˜ r k ( y ) < Q 0 . 04 ( ˜ r ( y )) o (8) where Q 0 . 04 ( ˜ r ( y )) denotes the 4 th percentile of the ratio se- quence ˜ r ( y ) . If C ( y ) is nonempty , neighborhood expansion is truncated at the earliest candidate, k ext ( y ) = min C ( y ) , (9) otherwise we set k ext ( y ) = K − 2 . The adapti ve neighborhood size is then chosen as ˆ K ( y ) = min { k ext ( y ) , k min ( y ) } + 1 . (10) Since ratios require neighbor pairs, the index is effecti vely shifted, increasing the adaptiv e neighborhood size by one. 4.3. Conservati ve fallback for sparse regions T o avoid unreliable truncation in weakly structured regions, we first summarize the ov erall behavior of the ratio sequence by r min ( y ) = min k r k ( y ) . V ery strong ratio drops indicate that the reference point y is located in a highly sparse region. In such cases, we cautiously fall back to two neighbors when r 1 ( y ) < 0 . 85 or r 1 ( y ) r min ( y ) > 1 . 02 . (11) W e use two neighbors instead of one for consistency with the baseline LDN without CED. 4.4. Integration into local density normalization Giv en the adaptiv e neighborhood size ˆ K ( y ) , the local density estimate is computed as µ ( y ) = 1 ˆ K ( y ) ˆ K ( y ) X k =1 D ( y , y k ) , (12) and replacing the fixed neighborhood size in LDN yields the final scaled score A CED scaled ( x, X ref | α ) = min y ∈X ref log D ( x, y ) − α log µ ( y ) . (13) 5. Experimental setup 5.1. Datasets W e ev aluate performance on five publicly a vailable datasets for semi-supervised acoustic anomaly detection. W e consider the DCASE2020 dataset [23], constructed from MIMII [24] and T oyADMOS [25]; DCASE2022 [1], based on MIMII-DG [26] and T oyADMOS2 [27]; DCASE2023 [2], extending MIMII- DG and T oyADMOS2+ [28]; DCASE2024 [3], incorporating MIMII-DG, T oyADMOS2# [29], and recordings collected un- der the IMAD-DS setup [30]; and DCASE2025 [4], consisting of MIMII-DG, T oyADMOS2025 [31], and additional IMAD- DS recordings. All datasets address semi-supervised ASD for machine condition monitoring across multiple machine types. They are partitioned into de velopment and e valuation sets, with training splits containing only normal samples and test splits including both normal and anomalous recordings. Except for DCASE2020, which has a single domain, the datasets are de- signed to assess domain generalization by providing 990 and 10 source and target training samples per machine, respecti vely . In the test sets, machine types are known and domains are bal- anced, but e xplicit domain labels are omitted. All experiments follow the official ev aluation protocols. For DCASE2020, we report the arithmetic mean of the A UC and pA UC [32] with p = 0 . 1 . For the remaining datasets, we report the harmonic mean of domain-specific A UCs and the domain-independent pA UC. T able 1: A verage performance for differ ent normalization appr oaches across the development and evaluation sets of the DCASE2020, DCASE2022, DCASE2023, DCASE2024, and DCASE2025 ASD datasets. ∆ denotes impr ovement over baseline . CIs ar e 95% pair ed- bootstrap intervals. Highest numbers in each column ar e in bold. Embedding Model Direct-ACT OpenL3 BEA Ts EA T Dasheng A verage Perf ormance Normalization K average ∆ (CI) average ∆ (CI) average ∆ (CI) a verage ∆ (CI) average ∆ (CI) a verage ∆ (CI) - - 65 . 58% - 61 . 77% - 65 . 02% - 61 . 82% - 60 . 27% - 62 . 90% - LDN 2 67 . 79% baseline 64 . 62% baseline 68 . 04% baseline 64 . 99% baseline 64 . 07% baseline 65 . 90% baseline LDN+CED 64 67 . 91% +0.12 [0.02, 0.24] 64 . 88% +0.26 [0.05, 0.47] 68 . 36% +0.32 [0.03, 0.64] 65 . 14% +0.12 [-0.10, 0.34] 64 . 18% +0.11 [-0.04, 0.27] 66 . 09% +0.19 [0.03, 0.35] LDN+V arMin 2 69 . 25% 69 . 25% 69 . 25% baseline 65 . 56% baseline 68 . 95% baseline 65 . 88% 65 . 88% 65 . 88% baseline 64 . 81% baseline 66 . 89% baseline LDN+V arMin+CED 64 69 . 24% -0.01 [-0.07, 0.08] 65 . 75% 65 . 75% 65 . 75% +0.19 [-0.01, 0.42] 69 . 20% 69 . 20% 69 . 20% +0.25 [-0.01, 0.53] 65 . 8% -0.08 [-0.17, 0.00] 64 . 86% 64 . 86% 64 . 86% +0.05 [-0.10, 0.19] 66 . 96% 66 . 96% 66 . 96% +0.07 [-0.04, 0.20] T able 2: P er-dataset impr ovements of CED over the r espec- tive baseline (cf. T able 1). ∆ avg denotes the mean impr ovement acr oss embeddings (each averaged over splits), ∆ max the lar gest single-split gain for any embedding, and #Emb ↑ the number of embeddings (out of 5) with positive averag e performance gain. without V arMin with V arMin Dataset ∆ avg ∆ max #Emb ↑ ∆ avg ∆ max #Emb ↑ DCASE2020 − 0 . 06% +0 . 13% 2/5 − 0 . 12% +0 . 01% 1/5 DCASE2022 +0 . 29% +0 . 55% 5/5 +0 . 10% +0 . 37% 4/5 DCASE2023 +0 . 32% + 1 . 39 % 5/5 +0 . 19% + 1 . 12 % 4/5 DCASE2024 +0 . 18% +0 . 68% 4/5 +0 . 13% +0 . 64% 4/5 DCASE2025 +0 . 20% +0 . 82% 4/5 +0 . 06% +0 . 72% 4/5 5.2. Embedding models and baselines W e ev aluate fiv e embedding models spanning task-specific and large-scale pre-trained representations. W e include the Direct-A CT model [19], based on [33] and trained with the AdaProj loss [34] using a subspace dimension of 32 . It em- ploys FFT - and STFT -based feature branches and is trained with an auxiliary classification task (ACT) objectiv e over com- bined machine ID and attribute classes, complemented by a self-supervised feature exchange task. W e further include 512 - dimensional openL3 embeddings [35] pre-trained on en viron- mental sounds, BEA Ts [36] trained for three iterations on Au- dioSet [37], EA T [38] pre-trained for 20 epochs on AudioSet, and the base Dasheng model [39]. Follo wing [17], embed- dings are aggregated using weighted generalized mean pooling with p = 3 and relati ve deviation pooling weights ( γ = 8 for openL3, γ = 16 for BEA Ts, γ = 1 for EA T , and γ = 20 for Dasheng). For EA T , embeddings are additionally pre-processed by thresholding low-v alued components at 0 . 1 and suppressing activ ation spik es via soft clipping using x 7→ tanh( x/ 0 . 5) · 0 . 5 . As baselines, we consider plain LDN [18, 19] and LDN combined with V arMin [22], following Section 2. Cosine dis- tance is used for Direct-A CT, while mean squared error is em- ployed for all pre-trained embeddings. 6. Results and discussion 6.1. Sensitivity to neighborhood size W e first analyze the sensitivity of existing approaches, namely LDN and LDN+V arMin, to the choice of the neighborhood size. As shown in Fig. 2, average performance improves only when increasing the neighborhood size K from 1 to 2 . This observa- tion is consistent with the findings in [19], which recommended using K = 1 as a conservati ve default value for estimating the local neighborhood. When increasing K further, performance generally decreases monotonically and eventually approaches the level of not applying LDN, except for Direct-A CT without V arMin. This beha vior is observed for both LDN with and with- out V arMin and verifies the claims made in Section 3. 6.2. Effect of cluster exit detection Figure 2 illustrates the effect of cluster exit detection on the sensitivity of LDN to the neighborhood size K . Across all embedding models, CED markedly stabilizes performance for both plain LDN and LDN+V arMin. Whereas baseline perfor- mance typically peaks at K ∈ 1 , 2 and degrades for larger neighborhoods, CED enables robust performance across a wide range of K , with optimal values shifting to K ∈ 16 , 32 , 64 . This ef fect is more pronounced without V arMin, underscoring the role of CED in preserving locality during neighborhood ex- pansion. Large fixed neighborhoods alone do not yield similar gains, indicating that impro vements stem from adapti ve trunca- tion rather than from increasing K itself. Quantitativ e gains are summarized in T able 1 and bro- ken down per dataset in T able 2. Although global averages are moderate, improvements exhibit a clear structure across datasets. No systematic gains are observed on DCASE2020, consistent with its homogeneous data distribution and lack of domain shifts, where machine settings and environmental con- ditions do not induce pronounced attribute-dependent subclus- ters. In contrast, on DCASE2022–2025, CED improves per- formance for at least 4 out of 5 embedding models, with av- erage gains up to +0 . 32% and peak single-split improvements reaching +1 . 39% (DCASE2023). W ithout V arMin, improve- ments are frequently statistically significant. W ith V arMin, gains are smaller b ut remain structured on DCASE2022–2025, with peaks up to +1 . 12% (DCASE2023). Overall, these results indicate that adaptiv e locality preservation is particularly bene- ficial under heterogeneous local structure. 7. Conclusion In this work, we analyzed the sensitivity of LDN to neigh- borhood size and identified a structural failure mode that oc- curs when neighborhood expansion crosses cluster boundaries, thereby violating the locality assumption underlying density estimation. Based on this insight, we proposed CED, a lightweight mechanism that detects distance discontinuities to identify neighborhood exits and adapt score normalization ac- cordingly . Extensive experiments across multiple embedding models and benchmark datasets showed that CED substantially reduces sensiti vity to neighborhood-size selection and consis- tently improv es performance over a wide range of neighbor- hood sizes. These results indicate that the observed perfor- mance degradation is not an inherent limitation of LDN, but a consequence of silently violated locality assumptions. 8. Generative AI disclosure Generativ e AI tools were used for language editing and polish- ing of the manuscript. All scientific content, interpretations, and conclusions are the responsibility of the authors. 9. References [1] K. Dohi et al. , “Description and discussion on DCASE 2022 Chal- lenge T ask 2: Unsupervised anomalous sound detection for ma- chine condition monitoring applying domain generalization tech- niques, ” in Pr oc. DCASE , 2022. [2] ——, “Description and discussion on DCASE 2023 Challenge T ask 2: First-shot unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2023. [3] T . Nishida et al. , “Description and discussion on DCASE 2024 Challenge T ask 2: First-shot unsupervised anomalous sound de- tection for machine condition monitoring, ” in Pr oc. DCASE , 2024. [4] ——, “Description and discussion on DCASE 2025 challenge task 2: First-shot unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2025. [5] R. Giri, S. V . T enneti, F . Cheng, K. Helwani, U. Isik, and A. Krish- naswamy , “Self-supervised classification for detecting anomalous sounds, ” in Pr oc. DCASE , 2020. [6] P . Primus, V . Haunschmid, P . Praher , and G. W idmer , “ Anomalous sound detection as a simple binary classification problem with careful selection of proxy outlier examples, ” in Proc. DCASE , 2020. [7] K. W ilkinghoff, “Sub-cluster AdaCos: Learning representations for anomalous sound detection, ” in Pr oc. IJCNN , 2021. [8] S. V enkatesh, G. Wichern, A. S. Subramanian, and J. Le Roux, “Improved domain generalization via disentangled multi-task learning in unsupervised anomalous sound detection, ” in Pr oc. DCASE , 2022. [9] A. Jiang et al. , “AnoPatch: Tow ards better consistency in machine anomalous sound detection, ” in Pr oc. Interspeech , 2024. [10] ——, “ Adaptive prototype learning for anomalous sound detec- tion with partially known attrib utes, ” in Pr oc. ICASSP , 2025. [11] A. I. Mezza, G. Zanetti, M. Cobos, and F . Antonacci, “Zero- shot anomalous sound detection in domestic environments using large-scale pretrained audio pattern recognition models, ” in Pr oc. ICASSP , 2023. [12] P . Saengthong and T . Shinozaki, “Deep generic representations for domain-generalized anomalous sound detection, ” in Proc. ICASSP , 2025. [13] H.-H. W u, W .-C. Lin, A. Kumar , L. Bondi, S. Ghaffarzade gan, and J. P . Bello, “T owards few-shot training-free anomaly sound detection, ” in Pr oc. Interspeech , 2025. [14] B. Han, A. Jiang, X. Zheng, W .-Q. Zhang, J. Liu, P . Fan, and Y . Qian, “Exploring self-supervised audio models for generalized anomalous sound detection, ” IEEE T rans. Audio, Speech, Lang. Pr ocess. , vol. 33, 2025. [15] Y . Zhang, J. Liu, and M. Li, “ECHO: Frequency-aware hi- erarchical encoding for variable-length signal, ” arXiv pr eprint arXiv:2508.14689 , 2025. [16] P . Fan et al. , “FISHER: A foundation model for multi-modal industrial signal comprehensiv e representation, ” arXiv preprint arXiv:2507.16696 , 2025. [17] K. Wilkinghof f, S. Y adav , and Z.-H. T an, “T emporal pooling strategies for training-free anomalous sound detection with self- supervised audio embeddings, ” 2026, submitted to T ASLP . [18] K. Wilkinghof f, H. Y ang, J. Ebbers, F . G. Germain, G. Wichern, and J. Le Roux, “K eeping the balance: Anomaly score calculation for domain generalization, ” in Pr oc. ICASSP , 2025. [19] ——, “Local density-based anomaly score normalization for do- main generalization, ” IEEE T rans. Audio, Speec h, Lang. Pr ocess. , vol. 33, 2025. [20] K. Wilkinghof f, T . Fujimura, K. Imoto, J. Le Roux, Z.-H. T an, and T . T oda, “Handling domain shifts for anomalous sound detection: A revie w of DCASE-related work, ” in Proc. DCASE , 2025. [21] T . Fujimura, K. Wilkinghof f, K. Imoto, and T . T oda, “ ASDKit: A toolkit for comprehensive evaluation of anomalous sound detec- tion methods, ” in Pr oc. DCASE , 2025. [22] M. Matsumoto, T . Fujimura, W . Huang, and T . T oda, “ Adjust- ing bias in anomaly scores via v ariance minimization for domain- generalized discriminativ e anomalous sound detection, ” in Pr oc. DCASE , 2025. [23] Y . Koizumi et al. , “Description and discussion on DCASE2020 Challenge T ask2: Unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2020. [24] H. Purohit et al. , “MIMII dataset: Sound dataset for malfunc- tioning industrial machine inv estigation and inspection, ” in Pr oc. DCASE , 2019. [25] Y . K oizumi, S. Saito, H. Uematsu, N. Harada, and K. Imoto, “T oy- ADMOS: A dataset of miniature-machine operating sounds for anomalous sound detection, ” in Pr oc. W ASP AA , 2019. [26] K. Dohi et al. , “MIMII DG: Sound dataset for malfunctioning industrial machine investig ation and inspection for domain gener - alization task, ” in Pr oc. DCASE , 2022. [27] N. Harada, D. Niizumi, D. T akeuchi, Y . Ohishi, M. Y asuda, and S. Saito, “T oyADMOS2: Another dataset of miniature-machine operating sounds for anomalous sound detection under domain shift conditions, ” in Pr oc. DCASE , 2021. [28] N. Harada, D. Niizumi, D. T akeuchi, Y . Ohishi, and M. Y asuda, “T oyADMOS2+: New Toyadmos data and benchmark results of the first-shot anomalous sound event detection baseline, ” in Pr oc. DCASE , 2023. [29] D. Niizumi, N. Harada, Y . Ohishi, D. T akeuchi, and M. Y a- suda, “T oyADMOS2#: Yet another dataset for the DCASE2024 challenge task 2 first-shot anomalous sound detection, ” in Pr oc. DCASE , 2024. [30] D. Albertini, F . Augusti, K. Esmer , A. Bernardini, and R. San- nino, “IMAD-DS: A dataset for industrial multi-sensor anomaly detection under domain shift conditions, ” in Pr oc. DCASE , 2024. [31] N. Harada, D. Niizumi, Y . Ohishi, D. T akeuchi, and M. Y a- suda, “T oyADMOS2025: The ev aluation dataset for the DCASE2025T2 first-shot unsupervised anomalous sound detec- tion for machine condition monitoring, ” in Pr oc. DCASE , 2025. [32] D. K. McClish, “Analyzing a portion of the R OC curve, ” Medical decision making , vol. 9, no. 3, 1989. [33] K. W ilkinghoff, “Self-supervised learning for anomalous sound detection, ” in Pr oc. ICASSP , 2024. [34] ——, “ AdaProj: Adaptiv ely scaled angular margin subspace pro- jections for anomalous sound detection with auxiliary classifica- tion tasks, ” in Pr oc. DCASE , 2024. [35] A. Cramer, H. W u, J. Salamon, and J. P . Bello, “Look, listen, and learn more: Design choices for deep audio embeddings, ” in Pr oc. ICASSP , 2019. [36] S. Chen et al. , “BEA Ts: Audio pre-training with acoustic tokeniz- ers, ” in Pr oc. ICML , 2023. [37] J. F . Gemmek e et al. , “ Audio set: An ontology and human-labeled dataset for audio ev ents, ” in Pr oc. ICASSP , 2017. [38] W . Chen, Y . Liang, Z. Ma, Z. Zheng, and X. Chen, “EA T: self- supervised pre-training with efficient audio transformer, ” in Proc. IJCAI , 2024. [39] H. Dinkel, Z. Y an, Y . W ang, J. Zhang, Y . W ang, and B. W ang, “Scaling up masked audio encoder learning for general audio clas- sification, ” in Pr oc. Interspeech , 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment