HONEST-CAV: Hierarchical Optimization of Network Signals and Trajectories for Connected and Automated Vehicles with Multi-Agent Reinforcement Learning
This study presents a hierarchical, network-level traffic flow control framework for mixed traffic consisting of Human-driven Vehicles (HVs), Connected and Automated Vehicles (CAVs). The framework jointly optimizes vehicle-level eco-driving behaviors…
Authors: Ziyan Zhang, Changxin Wan, Peng Hao
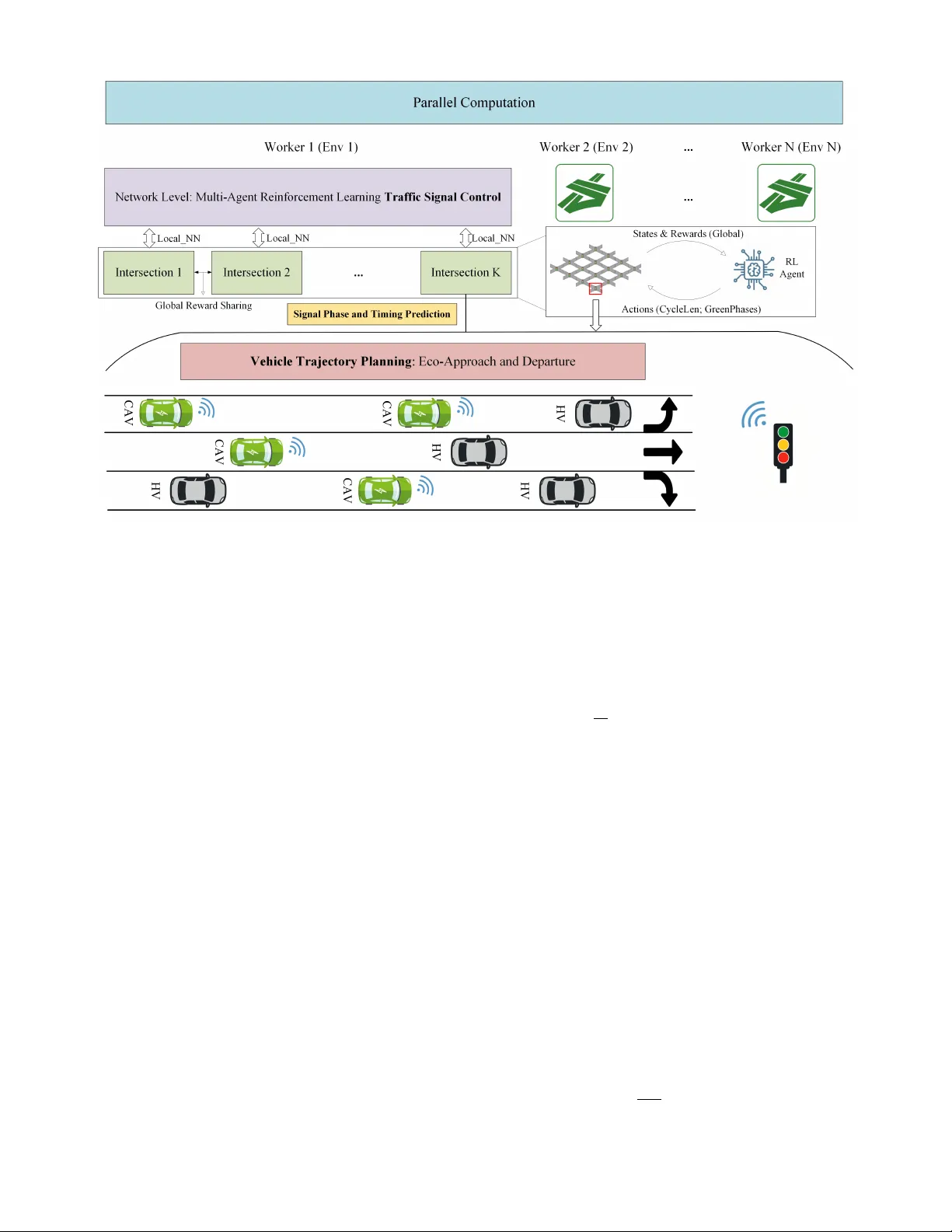
HONEST -CA V : Hierarchical Optimization of Network Signals and T rajectories for Connected and Automated V ehicles with Multi-Agent Reinforcement Learning Ziyan Zhang ∗ , † , Changxin W an † , Peng Hao, Member , IEEE , Kanok Boriboonsomsin, Member , IEEE , Matthe w J. Barth, F ellow , IEEE , Y ongkang Liu, Seyhan Ucar , Guoyuan W u, Senior Member , IEEE Abstract —This study presents a hierar chical, network-level traffic flow contr ol framework f or mixed traffic consisting of Human-driven V ehicles (HVs), Connected and A utomated V ehi- cles (CA Vs). The framework jointly optimizes vehicle-lev el eco- driving behaviors and intersection-level traffic signal control to enhance o verall network efficiency and decrease energy con- sumption. A decentralized Multi-Agent Reinf orcement Lear ning (MARL) approach by V alue Decomposition Network (VDN) manages cycle-based traffic signal control (TSC) at intersections, while an innovative Signal Phase and Timing (SPaT) predic- tion method integrates a Machine Learning-based T rajectory Planning Algorithm (ML TP A) to guide CA Vs in executing Eco- Appr oach and Departure (EAD) maneuvers. The framework is evaluated across varying CA V proportions and powertrain types to assess its effects on mobility and energy performance. Experimental results conducted in a 4×4 real-world network demonstrate that the MARL-based TSC method outperforms the baseline model (i.e., W ebster method) in speed, fuel con- sumption, and idling time. In addition, with ML TP A, HONEST - CA V benefits the traffic system further in energy consumption and idling time. With a 60% CA V proportion, vehicle average speed, fuel consumption, and idling time can be impro ved/sa ved by 7.67%, 10.23%, and 45.83% compared with the baseline. Furthermore, discussions on CA V proportions and powertrain types ar e conducted to quantify the performance of the proposed method with the impact of automation and electrification. Index T erms —Eco-driving, Adaptive signal control, Multi- agent reinf orcement learning, Mixed traffic flow I . I N T R O D U C T I O N Due to the rapid growth of traf fic demand and fuel usage in urban cities, traffic operation and management methods, such as vehicle trajectory planning and intersection adaptiv e signal control, have become increasingly critical for traf fic efficienc y improv ement and ener gy savings [ 1 ]–[ 3 ]. Howe ver , con ven- tional methods still treat trajectory planning and traffic signal The work is funded by T oyota InfoT ech Labs. Ziyan Zhang, Changxin W an, Peng Hao, Guoyuan W u, Kanok Boriboon- somsin, and Matthew J. Barth are with the College of Engineering, Center for Environmental Research and T echnology , University of California at Riv erside, Riv erside, CA, 92507. Y ongkang Liu and Seyhan Ucar are with the InfoT ech Labs, T oyota Motor North America, Mountain V iew , CA, 94043. ∗ Corresponding author . e-mail: ziyan.zhang@email.ucr.edu † Ziyan Zhang and Changxin W an contributed equally to this work. Accepted at IV 2026. Final version to appear in IEEE Xplore. control as separate problems, limiting the potential benefits of connected mobility , especially under mixed traffic conditions [ 4 ]–[ 6 ]. Connected and Automated V ehicles (CA Vs), enabled by V ehicle-to-Infrastructure (V2I) communication technology , offer new opportunities for the collaboration of vehicle trajec- tory planning and traffic signal control. The vehicle-signal cooperati ve control has drawn sus- tained attention since 2010 [ 7 ]. Early works demonstrated the promise of cooperati ve signal–vehicle control but were mainly limited to isolated intersections by rule-based methods [ 7 ], [ 8 ]. Later formulations extended to mixed-inte ger programming [ 9 ], [ 10 ] to achiev e global optima, while it is difficult to scale up due to the highly computational burden. The learning-based method, such as imitation learning (IL) for vehicles [ 6 ] and multi-agent reinforcement learning (MARL) for intersections [ 11 ], has been integrated by a hierarchical framework to achiev e vehicle-signal cooperati ve control while considering computational efficiency . Overall, existing co-optimization approaches remain con- strained by computational burden and limited scalability . Re- cent research trends emphasize learning-based methods with a hierarchical framework capable of handling mixed traffic and broader network structures with computational ef ficiency . Moreov er , an Internal Comb ustion Engine V ehicle (ICEV) powertrain type is basically assumed in existing methods, while the performance with different po wertrain types (i.e., electric vehicle) is rarely considered. In this study , we propose a hierarchical framew ork based on MARL and IL to address the co-optimization of traffic control in large-scale networks with CA Vs. At the intersection lev el, the MARL with the value decomposition network (VDN) is applied for traffic signal control. At the vehicle control layer , we incorporate an IL-based Eco-Approach and Departure (EAD) strategy [ 6 ]. Moreo ver , a nov el green phase prediction algorithm is proposed to facilitate coordination between the two layers. The proposed framework is modular and scalable, allowing for the replacement or integration of different traffic signal control and EAD methods. With trained MARL-based signal control and the vehicle-le vel EAD strategy , the frame- work demonstrates strong potential for real-time, scalable deployment in larger urban networks. The main contributions of this paper are as follows: (1) Proposing a hierarchical co-optimization framework with high scalability and real-time efficienc y for signal and vehicle control at the network level, enabling coordinated decision-making across multiple intersections and vehicles. (2) Introducing a MARL-based traffic signal control ap- proach enhanced with multi-processing, which significantly accelerates the training process by simulating multiple traffic scenarios in parallel, improving scalability and robustness. (3) De veloping a Signal Phase and T iming (SPaT) prediction method based on historical data and current traffic conditions to improv e the reliability of EAD strategies, thereby enhancing fuel efficiency and reducing emissions. (4) Analyzing the performance of the proposed framework under varying CA V/CAEV proportions in dif ferent po wertrain types, demonstrating its effecti veness, adaptability , and gener - alization capability across div erse traffic environments. I I . P RO B L E M D E S C R I P T I O N This study focuses on an urban network consisting of multiple signalized intersections, and two types of vehicles, i.e., HVs and CA Vs are considered. The goal of this study is to achie ve a global minimum of both the ov erall network’ s efficienc y and energy consumption by dynamically adjusting the SP aT settings of the intersections and regulating the dri ving behaviors of CA Vs. Howe ver , it is challenging to obtain such a global optimum due to the complicated interactions between the signal control and vehicle trajectory planning. Instead, a hierarchical mixed traf fic flow control framew ork that decouples this interaction is applied to achie ve the global optimal approximately , as illustrated in Fig. 1 . The goal is no w divided into two parts: (i) intersection-lev el signal control for network efficiency improvement, and (ii) v ehicle-le vel EAD strategy for energy savings. The detailed modules for this framew ork are as follows: For intersections, it is assumed that they have uniform channelization and exhibit the capacity to collect real-time traffic flow information (e.g., density , av erage speed) by road- side units (RSUs), and then dynamically optimize their SPaT actions (i.e., cycle length and green phase durations) to reduce the overall network delay and queue length. The key challenge lies in coordinating the actions of individual intersections to improv e ov erall network efficiency . T o address this, we adopt a MARL-based traffic signal control (TSC) framework that incorporates global reward estimation, enabling agents to account for network-lev el performance with local decisions. For each CA V , its longitudinal trajectory can be optimized by regulating its speed profile that allows crossing during the green light window [ T start , T end ] with minimal energy usage, while such a time windo w is not static under RL-based signal control. Therefore, a prediction mechanism is proposed to estimate the next-c ycle passing interv al [ T pred start , T pred end ] for real-time vehicle-lev el trajectory planning. I I I . M E T H O D O L O G Y A. MARL-based T raffic Signal Contr ol MARL-based control methods can be generally cate go- rized into (1) centralized training and centralized execution (CTCE) and (2) centralized training and decentralized ex e- cution (CTDE) approaches [ 12 ]. CTCE can achieve globally optimal signal plans but suf fers from high computational cost and latency , making it unsuitable for lar ge-scale real-time deployment. In contrast, CTDE treats each intersection as an autonomous agent, enabling scalable and efficient network- lev el coordination. Therefore, we adopt a CTDE framework for intersection-level MARL-based TSC. As illustrated in Fig. 1 , each intersection collects local tran- sitions (state–action–re ward), while a global rew ard is formed by aggregating cycle-based performance across the network. These experiences are jointly used to train a shared policy , which benefits from di verse traffic dynamics and improves con vergence and generalization. T o further accelerate training, we employ an asynchronous multi-processing scheme, where multiple simulation processes run in parallel, update the shared global policy together [ 13 ], and periodically update the local policy . Additionally , we adopt a cycle-based control strategy , where signal timing (c ycle length and green splits) is updated once per cycle. This provides more stable signal patterns and is particularly compatible with EAD-based vehicle trajectory planning, which relies on predictable green intervals. The objectiv e of the MARL-based algorithm is to learn a policy π that maximizes the expected cumulativ e global rew ard R global with entropy regularization: J ( π ) = X t E s t , a t [ r global ( s t , a t ) + α H ( π ( ·| s t ))] (1) where s t = ∪ i s i t and a t = ∪ i a i t denote the global state, action at t -th cycle. α is the temperature coefficient, and H ( π ( ·| s t )) denotes the entropy of the policy for better exploration. 1) Definition of States: The state space is constructed to capture the spatio-temporal traf fic information at a four-legged intersection over a full signal cycle. W e first divide the entire intersection state into 12 lane-based states (i.e., 4 directions multiple 3 lanes), respectiv ely . For each lane-based state, a weighted temporal aggre gation method is introduced to capture second traf fic states o ver a full signal cycle while considering three time-weighted av erage cases. The formulas of the state space s i t for each intersection are as follows: s i t = {∪ 4 d =1 ∪ 3 l =1 ∪ 3 p =1 ˆ s i t ( d, l, p ) } s t ( d, l, p ) = X τ w p τ · o τ ( d, p ) / X τ w p τ w p τ = λ p · w p τ +1 , p = 0 , 1 , 2 λ 0 = 1 . 05 , λ 1 = 1 . 0 , λ 2 = 0 . 95 (2) where ˆ s t ( d, l, p ) denotes the l -th lane-based state with p -th time-weighted average cases at d -th direction. τ means the τ -th time-step at the current phase of each intersection. w p τ represents the importance of τ -th step-lev el traffic state with Fig. 1: The Schematic Diagram of HONEST -CA V p -th time-weighted av erage cases, w p τ =0 = 1 , p = 1 , 2 , 3 . λ p determines the p -th temporal weighting pattern, respectiv ely . o τ ( d, p ) represents the observation collected by RSUs equipped in each lane at time step τ . In this study , four types of information are considered to be collected, defined by: o τ ( d, p ) = { Occ , A vgSpd , QLen , CA VPR } (3) where Occ, A vgSpd, QLen, and CA VPR present the traffic flow density , average speed, queue length, and CA V penetra- tion rate within the detection range. Giv en 4 directions, 3 lanes per direction and 3 aggregated time states per lane, and 4 traffic features per state, the state input of each intersection agent is a 144-dimensional vector , which provides a comprehensive representation of intersection-lev el traffic dynamics for downstream RL tasks. 2) Definition of Actions: The SPaT setting consists of left and straight phases for west-east and north-south direction pairs. The intersection agent aims to optimize the cycle length and green duration of the 4 phases, so the action space for each agent can be determined as a 5-dimensional vector a i t = { u i t , v i t,j } , where j = 1 , . . . , 4 , defined as follows: • Cycle Length Change Ratio u i t ∈ [ − 0 . 7 , 0 . 7] : a scalar states the relative change ratio to the base cycle length. • Green-to-Cycle Ratio of Each Phase v i t,j ∈ [0 , 1] : the green-to-cycle ratio of the i -th phase. T o achie ve cooperative signal control, all the signal agents are assumed to take action synchronically , so a common cycle length is required for the intersection agents. Moreover , the action for green duration needs to rescale with a summation of 1, and a minimum green time is needed for the intersection to cov er the start-up lost time and ensure driving safety . Based on the abo ve rules, the SP aT setting for the next c ycle for gi ven an action a i t are computed by: t cyc = 1 N N X i =1 clip t cyc ,b (1 + u i t ) , 30 , 150 t i gre = t min + t adj · Softmax v i t,j t adj = t cyc − 4 · t switch − 4 · t min (4) where t cyc denotes the duration of next common c ycle length. t adj is the adjustable duration for green phases. t i gre is the j -th green duration, including W -E left, W -E straight, N-S left, and N-S straight. A switch phase is between two consecutiv e green phases. t cy c,b , t switch , and t min represent the basic c ycle length, switch phase, and the minimum green time duration. clip ( · , min , max) limits a value to within a specified range. Softmax( · ) represents the softmax operator . 3) Definition of Rewar d: Specifically , the global reward is defined as the summation of local agents’ rew ard. The local rew ard at each decision step (i.e., each c ycle) is defined as the accumulated c ycle-average passed vehicle numbers and queue length across all directions; the global reward is defined as the av erage value of local re wards of all agents: r global t = 1 t cy c N X i =1 t cyc X τ =1 ( p τ i − ω q τ i ) (5) where p τ i , q τ i denote the number of the passed v ehicles and queue length for the i -th intersection at the τ -th time step during the t -th signal cycle. ω is the weight penalty for queue length, ω = 12 . Such a reward encourages agent to pass more vehicles with less queue length. 4) Multi-Agent Soft Actor-Critic: A Multi-Agent Soft Actor-Critic (MASA C) algorithm is developed to enable co- ordinated signal control. Each intersection agent is equipped with a local policy network (actor) and a local value function (critic), while sharing a global rew ard to achieve cooperati ve optimization across the network. T o accurately estimate the global reward, the global Q-value function is approximated by the aggregation of distributed local Q-functions using a value decomposition network (VDN) [ 14 ]: Q ( s t , a t ) ≈ N X i =1 Q i ( s i t , a i t | θ i ) (6) where θ i is the critic network for i -th intersection. Follo wing the standard SA C principle [ 15 ], each local actor network π ϑ i generates an action based on its own local observation s i t , while the global critic aggregates the outputs from all local Q-functions to estimate the o verall v alue. Accordingly , the actor loss of agent i is optimized with respect to the global value: J π i ( ϑ i ) = E s i t ∼D , a i t ∼ π ϑ i h α log π ϑ i ( a i t | s i t ) − Q ( s t , s t ) i (7) where and D denotes the replay buf fer . The critic network minimizes the temporal-difference (TD) error of the global re ward using the L2 loss: J Q i ( θ i ) = E ( s t , a t ,r global t , s t +1 ) ∼D h y t − Q ( s t , a t ) i 2 y t = r global t + γ Q ( s t +1 , a t +1 ) (8) where γ is the discount factor and a t +1 ∼ π ( s t +1 ) . During training, a shared actor ( θ 1 = . . . θ N = θ ) and critic network ( ϑ 1 = . . . ϑ N = ϑ ) is implemented for each intersection for robust training, the critic parameters are softly updated with target networks to enhance stability . B. Signal Phase and T iming Prediction Algorithm Accurate generation of CA V speed profiles requires kno wl- edge of the corresponding green passing interval. Ho wever , under RL-based traf fic signal control, the SPaT of the next cycle is not determined until the current c ycle ends, thus neces- sitating prediction. Existing SP aT prediction methods in semi- actuated or adapti ve signal systems mainly rely on historical phase patterns and often assume relativ ely stable cycle lengths, limiting their effecti veness under dynamic conditions [ 16 ]. In this work, because the signal timing is determined by an adaptiv e RL policy , we first estimate the upcoming SPaT by executing the trained policy based on currently observ ed intersection states. Howev er, early-cycle observations may be insufficient for accurate inference. T o address this, we propose a hybrid prediction mechanism that blends the policy-driv en estimate with historical SPaT patterns using a time-dependent weighting factor , as sho wn in Fig. 2 . This approach improves robustness when real-time state information is limited. HPhase = ⌊ (1 − β ) · RPhase + β · PPhase ⌋ β = min τ t cyc , 1 . 0 (9) where HPhase, RPhase and PPhase represents hybrid phases, recorded phases and predicted phases, respectively . Fig. 2: The SPaT Prediction Algorithm C. Imitation Learning Based V ehicle T rajectory Planning Regarding v ehicle trajectory planning, Eco-Approach and Departure (EAD) strategies generally face a trade-off be- tween computational ef ficiency and trajectory optimality . Rule- based methods offer real-time execution but often lack preci- sion under dynamic traffic conditions [ 17 ], [ 18 ]. In contrast, optimization-based approaches, such as the Graph-Based Tra- jectory Planning Algorithm (GBTP A) [ 19 ], can produce near- optimal trajectories by minimizing objectiv es such as energy or acceleration, but their high computational cost limits real- time deployment, especially in large-scale networks [ 6 ]. T o address this issue, the Machine Learning Trajectory Planning Algorithm (ML TP A) [ 6 ] was dev eloped as a surro- gate model trained on GBTP A-generated optimal trajectories. ML TP A imitate the optimal trajectories from GBTP A accuracy while significantly reducing computation, enabling real-time EAD control. Therefore, ML TP A is used in this study to generate the initial speed profile for CA Vs. GBTP A, which forms the basis of ML TP A, constructs a state-space graph where nodes represent vehicle states and edges encode energy-related transition costs. The optimal trajectory is identified via Dijkstra’ s algorithm. Algorithm 1 summarizes the corresponding input and output settings. Algorithm 1 Algorithm for GBTP A Inputs: PassingIntervalStart #The earliest time the vehicle can cross the intersection. PassingInterv alEnd #The latest time the vehicle can cross the intersection. DistanceT oSignal #The distance between the vehicle and the intersection. InstantV elocity #The instantaneous velocity of the vehicle. Output: SpeedProfile I V . S I M U L AT I O N A N D E V A L U A T I O N In this section, we first utilized a simulated network to test the performance of our proposed HONEST -CA V , and discussed the impact of CA V proportions and po wertrain type to on the proposed hierarchical co-optimization framework. A. Simulation Settings The simulation experiments are conducted using the open- source traf fic simulator SUMO [ 20 ]. As sho wn in Fig. 3 , a real-world 4 × 4 urban network in Hangzhou with calibrated traffic demand from CityFlow [ 21 ] is adopted. The simulation starts with an empty netw ork and terminates after all vehicles hav e exited. The traffic stream consists of both HVs and CA Vs, modeled based on SUMO’ s default passenger ICEV configuration. Moreo ver , multiple random seeds are used to achiev e sampling diversity across training episodes, ensuring statistical robustness and generalization of the results. Regarding the training configuration of HONEST -CA V , the number of parallel worker processes for multi-processing is set to N = 8 , and the maximum number of training episodes/epochs K is 150. For the SA C-based traf fic signal control agent, the learning rate, discount factor , batch size, and replay buf fer capacity are set to 0.0003, 0.99, 32, and 100,000, respectively . Fig. 3: The En vironment of T raffic Network B. P erformance on Benchmark Scenario In this section, we compare the conv entional W ebster SPaT - based TSC method [ 22 ], which serves as the baseline, with the independent reinforcement learning (IRL) approach and the proposed MARL-based global-reward-sharing TSC method. First, the W ebster method is a signal control strategy that minimizes the total traf fic delay at each individual intersec- tion under static traffic demand. The traffic demand at each intersection is estimated by counting historically observed passing vehicles over a 400-second interv al, and the Krauss model is adopted as the car-follo wing model. Second, the IRL algorithm updates each intersection independently using its local re ward and a local Q-network. Finally , we integrate the ML TP A with the MARL-based TSC to further enhance overall system performance with the assistance of CA Vs, where the CA V penetration rate is set to 60%. Network-le vel performance is ev aluated using three metrics: av erage energy consumption (total ener gy usage divided by total vehicle trav el distance), average idling time (total idling time per vehicle), and average speed (total travel distance di- vided by total trav el time). Each RL-based method is ev aluated ov er 50 Monte Carlo simulations with different random seeds, and the averaged results are summarized in T able I . The reward training curves for IRL TSC + Krauss, MARL TSC + Krauss and MARL TSC + ML TP A (under a fixed CA V proportion) are presented in Fig. 4 . The reward values con verge as training progresses, demonstrating the stabil- ity and ef fecti veness of the proposed HONEST -CA V frame- work. Howe ver , the training reward becomes smaller when ML TP A is added, this is mainly because ML TP A makes traffic smoother but increases the measured queue occupancy and reduces per -cycle throughput, causing lo wer training reward ev en though the ov erall traffic efficiency becomes better . (a) IRL+Krauss (b) MARL+Krauss (c) MARL+ML TP A Fig. 4: The Rew ard Training Curves Overall, the results indicate that jointly optimizing TSC and vehicle trajectory planning leads to significant performance gains over the baseline, including reductions in energy con- sumption and idling time, as well as improvements in traffic flow ef ficiency . C. Discussion of CA V Pr oportions and P owertrain T ypes In this paper , the CA V/CAEV proportion is defined as the ratio of CA Vs/CAEVs among all vehicles generated within a fixed network area during the simulation period of each episode. T o comprehensiv ely ev aluate the performance of HONEST -CA V under varying proportions, we train the model with randomly generated proportion for each episode, and conduct 50 testing experiments using dif ferent random seeds, with proportions reasonably distributed across the range of [10%, 90%]. Specifically , for energy consumption ev aluation, EV energy consumption (kWh) is con verted to its gasoline- equiv alent (L) based on the lower heating value energy equiv alence, using 1 kWh ≈ 3.6 MJ ≈ 0.112 L of gasoline [ 23 ]. The MMPEVEM electricity consumption model [ 24 ], a SUMO-compatible EV powertrain model that computes energy consumption and regenerati ve braking by explicitly modeling powertrain components and operating states. The effecti ve reward training curve for HONEST -CA V and HONEST -CAEV are depicted in Fig. 5 . (a) ICEV En vironment (b) EV En vironment Fig. 5: The Re ward Training Curves with Random Proportions T ABLE I: Performance Comparison in the Benchmark Scenario Metric Baseline IRL TSC + Krauss MARL TSC + Krauss MARL TSC + ML TP A A vg. Energy (L/100 km) 11.71 11.32 (-3.33%) 10.99 (-6.13%) 10.51 (-10.23%) A vg. Idling Time (s/v eh) 49.79 47.05 (-5.51%) 36.32 (-27.05%) 26.97 (-45.83%) A vg. Speed (m/s) 8.21 8.51(+3.52%) 8.72 (+6.25%) 8.84 (+7.67%) Moreov er , to quantify HONEST -CA V’ s performance across different CA V proportions, we cluster the results from all random seeds into four proportion ranges—[10%, 30%), [30%, 50%), [50%, 70%), and [70%, 90%], and average the corre- sponding performance metrics, as sho wn in T able II and Fig. 6 . W e observed that performance metrics consistently improve with higher CA V proportions. Compared to the baseline model (Demand-based Fixed TSC + Krauss Model), HONEST -CA V achiev es improv ements of 9.15% in average speed, 12.62% in energy consumption, and 57.47% in idling time within the [70%, 90%] CA V proportion range. These results demonstrate the scalability and rob ustness of HONEST -CA V across v arying CA V proportions and highlight its ability to fully exploit the potential benefits of connected and automated vehicles. Fig. 6: The Savings under Different CA V/CAEV Proportions In T able III , the baseline results are obtained under a fully electrified environment. For HONEST -CAEV , similar performance trends are observed as the CA V/CAEV propor- tion increases; howe ver , the overall energy consumption is consistently lo wer across all proportion ranges, demonstrating the additional benefits brought by electrification. In particu- lar , compared with the ICEV environment, HONEST -CAEV achiev es up to a 90.13% reduction in energy consumption within the [70%, 90%] CA V proportion range. V . C O N C L U S I O N A N D F U T U R E W O R K This paper presents a hierarchical co-optimization frame- work for vehicle trajectory planning and traffic signal control in large-scale urban networks with CA Vs. By integrating a model-free MARL approach for traffic signal control with a learning-based EAD strategy at the v ehicle le vel, the proposed framew ork effecti vely bridges real-time signal control with individual vehicle trajectory optimization. A ke y component of the framew ork is a green phase prediction algorithm, which enables coordination between signal and v ehicle control layers, ensuring the timely generation of smooth and energy-ef ficient speed profiles for CA Vs. Through comprehensi ve experiments across v arious netw ork sizes and CA V proportions, the results demonstrate the ro- bustness, scalability , and effecti veness of the proposed method in improving traffic efficienc y and reducing energy consump- tion. In the benchmark scenario, the proposed HONEST -CA V significantly outperformed the baseline in terms of energy consumption, idling time, av erage speed and simulation time. Moreov er , HONEST -CA V continues to improve perfor- mance as the CA V proportion increases, demonstrating strong scalability and robustness across varying levels of CA V de- ployment, and effecti vely harnessing the potential benefits of CA V to enhance ov erall traf fic system efficiency . In addition, with the ICEV replaced to EV , the energy usage is further reduced, which reveals the potential of traffic electrification. In future work, a zone division approach would be con- sidered for city-lev el networks, applying the HONEST -CA V framew ork within each zone. This additional zone-lev el layer will enable the e xtension of our method to full-scale urban deployments. R E F E R E N C E S [1] N. Serok, S. Havlin, and E. Blumenfeld Lieberthal, “Identification, cost ev aluation, and prioritization of urban traffic congestions and their origin, ” Scientific reports , v ol. 12, no. 1, p. 13026, 2022. [2] S. C. Davis and R. G. Boundy , “T ransportation ener gy data book: Edition 39, ” Oak Ridge National Laboratory (ORNL), Oak Ridge, TN (United States), T ech. Rep., 2021. [3] Z. Hussain, M. Kaleem Khan, and Z. Xia, “In vestigating the role of green transport, en vironmental taxes and expenditures in mitigating the transport co2 emissions, ” T ransportation Letters , vol. 15, no. 5, pp. 439– 449, 2023. [4] B. Zhou, Q. Zhou, S. Hu, D. Ma, S. Jin, and D.-H. Lee, “Cooperati ve traffic signal control using a distrib uted agent-based deep reinforcement learning with incentiv e communication, ” IEEE Tr ansactions on Intelli- gent T ransportation Systems , vol. 25, no. 8, pp. 10 147–10 160, 2024. [5] M. H. Almannaa, H. Chen, H. A. Rakha, A. Loulizi, and I. El-Shawarby , “Field implementation and testing of an automated eco-cooperative adaptiv e cruise control system in the vicinity of signalized intersections, ” T ransportation resear ch part D: transport and en vir onment , vol. 67, pp. 244–262, 2019. [6] D. Esaid, P . Hao, G. W u, F . Y e, Z. W ei, K. Boriboonsomsin, and M. Barth, “Machine learning-based eco-approach and departure: Real- time trajectory optimization at connected signalized intersections, ” SAE International J ournal of Sustainable T ransportation, Energy , En viron- ment, & P olicy , no. 13-03-01-0004, pp. 41–53, 2021. [7] K. J. Malak orn and B. Park, “ Assessment of mobility , energy , and en vironment impacts of intellidrive-based cooperative adaptive cruise control and intelligent traffic signal control, ” in Proceedings of the 2010 IEEE International Symposium on Sustainable Systems and T echnology . IEEE, 2010, pp. 1–6. [8] Z. Li, L. Elefteriadou, and S. Ranka, “Signal control optimization for automated vehicles at isolated signalized intersections, ” T ransportation Resear ch P art C: Emerging T echnologies , v ol. 49, pp. 1–18, 2014. [9] C. Y u, Y . Feng, H. X. Liu, W . Ma, and X. Y ang, “Integrated optimization of traffic signals and vehicle trajectories at isolated urban intersections, ” T ransportation resear ch part B: methodological , vol. 112, pp. 89–112, 2018. [10] M. T ajalli and A. Hajbabaie, “Traf fic signal timing and trajectory optimization in a mixed autonomy traffic stream, ” IEEE T ransactions on Intelligent T ransportation Systems , vol. 23, no. 7, pp. 6525–6538, 2021. T ABLE II: Performance Comparison under Different CA V Proportions Metric 0.1-0.3 0.3-0.5 0.5-0.7 0.7-0.9 A vg. Energy (L/100 km) 10.79 (-7.88%) 10.59 (-9.57%) 10.41 (-11.11%) 10.23 (-12.62%) A vg. Idling Time (s/v eh) 32.06 (-35.60%) 28.17 (-43.42%) 24.61 (-50.56%) 21.18 (-57.47%) A vg. Speed (m/s) 8.80 (+7.16%) 8.86 (+7.93%) 8.92 (+8.62%) 8.96 (+9.15%) T ABLE III: Performance Comparison under Different CAEV Proportions Metric Baseline (EV -based) 0.1-0.3 0.3-0.5 0.5-0.7 0.7-0.9 A vg. Energy (L/100 km) 1.08 1.06 (-1.88%) 1.04 (-3.43%) 1.03 (-4.74%) 1.01 (-6.20%) A vg. Idling Time (s/v eh) 49.80 34.37 (-30.98%) 30.69 (-38.38%) 28.48 (-42.82%) 25.63 (-48.53%) A vg. Speed (m/s) 8.21 8.74 (+6.41%) 8.81 (+7.35%) 8.85 (+7.78%) 8.90 (+8.45%) [11] H. Mei, X. Lei, L. Da, B. Shi, and H. W ei, “Libsignal: an open library for traffic signal control, ” Machine Learning , pp. 1–37, 2023. [12] M. Hua, X. Qi, D. Chen, K. Jiang, Z. E. Liu, H. Sun, Q. Zhou, and H. Xu, “Multi-agent reinforcement learning for connected and automated vehicles control: Recent advancements and future prospects, ” IEEE T ransactions on Automation Science and Engineering , 2025. [13] V . Mnih, A. P . Badia, M. Mirza, A. Graves, T . Lillicrap, T . Harley , D. Silver , and K. Kavukcuoglu, “ Asynchronous methods for deep rein- forcement learning, ” in International confer ence on machine learning . PmLR, 2016, pp. 1928–1937. [14] P . Sunehag, G. Le ver, A. Gruslys, W . M. Czarnecki, V . Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. T uyls et al. , “V alue-decomposition networks for cooperative multi-agent learning, ” arXiv pr eprint arXiv:1706.05296 , 2017. [15] T . Haarnoja, A. Zhou, P . Abbeel, and S. Levine, “Soft actor-critic: Of f- policy maximum entropy deep reinforcement learning with a stochastic actor , ” in International confer ence on mac hine learning . Pmlr , 2018, pp. 1861–1870. [16] A. Genser, M. A. Makridis, K. Y ang, L. Amb ¨ uhl, M. Menendez, and A. K ouvelas, “Time-to-green predictions for fully-actuated signal control systems with supervised learning, ” IEEE T ransactions on Intelligent T ransportation Systems , vol. 25, no. 7, pp. 7417–7430, 2024. [17] B. Asadi and A. V ahidi, “Predictiv e use of traffic signal state for fuel saving, ” IF AC Proceedings V olumes , vol. 42, no. 15, pp. 484–489, 2009. [18] P . Hao, G. Wu, K. Boriboonsomsin, and M. J. Barth, “Developing a framew ork of eco-approach and departure application for actuated signal control, ” in 2015 IEEE Intelligent V ehicles Symposium (IV) . IEEE, 2015, pp. 796–801. [19] P . Hao, K. Boriboonsomsin, C. W ang, G. W u, and M. Barth, “Connected eco-approach and departure system for diesel trucks, ” SAE International Journal of Commer cial V ehicles , vol. 14, no. 02-14-02-0017, pp. 217– 227, 2021. [20] P . A. Lopez, M. Behrisch, L. Biek er-W alz, J. Erdmann, Y .-P . Fl ¨ otter ¨ od, R. Hilbrich, L. L ¨ ucken, J. Rummel, P . W agner , and E. Wießner , “Microscopic traf fic simulation using sumo, ” in 2018 21st international confer ence on intelligent transportation systems (ITSC) . Ieee, 2018, pp. 2575–2582. [21] H. W ei, G. Zheng, V . Gayah, and Z. Li, “ A survey on traffic signal control methods, ” arXiv preprint , 2019. [22] F . V . W ebster , “T raffic signal settings, ” T ech. Rep., 1958. [23] A. F . D. Center , “Fuel properties comparison, ” US Department of Ener gy , p. 4, 2014. [24] L. K och, D. S. Buse, M. W egener , S. Schoenberg, K. Badalian, J. Andert et al. , “ Accurate physics-based modeling of electric v ehicle energy consumption in the sumo traf fic microsimulator, ” in 2021 IEEE Inter- national Intelligent T ransportation Systems Confer ence (ITSC) . IEEE, 2021, pp. 1650–1657.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment