ReHear: Iterative Pseudo-Label Refinement for Semi-Supervised Speech Recognition via Audio Large Language Models
Semi-supervised learning in automatic speech recognition (ASR) typically relies on pseudo-labeling, which often suffers from confirmation bias and error accumulation due to noisy supervision. To address this limitation, we propose ReHear, a framework…
Authors: Zefang Liu, Chenyang Zhu, Sangwoo Cho
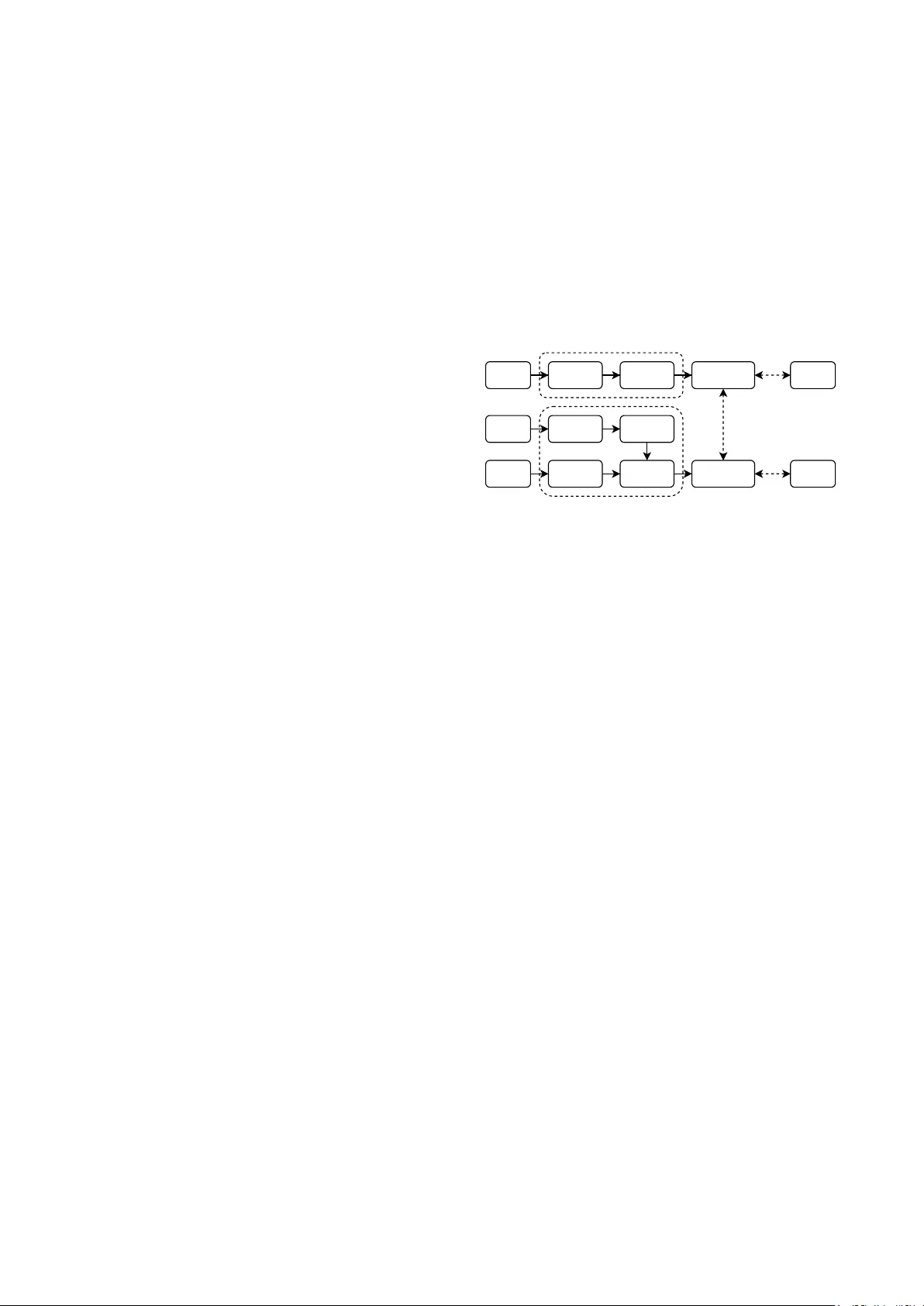
ReHear: Iterativ e Pseudo-Label Refinement f or Semi-Supervised Speech Recognition via A udio Large Language Models Zefang Liu 1 , Chenyang Zhu 1 , Sangwoo Cho 1 , Shi-Xiong Zhang 1 1 Capital One, USA zefang.liu@capitalone.com Abstract Semi-supervised learning in automatic speech recognition (ASR) typically relies on pseudo-labeling, which often suffers from confirmation bias and error accumulation due to noisy su- pervision. T o address this limitation, we propose ReHear , a framew ork for iterativ e pseudo-label refinement that integrates an instruction-tuned, audio-aw are large language model (LLM) into the self-training loop. Unlike conv entional text-based cor- rectors, our approach conditions the LLM on both the ASR hy- pothesis and the source audio, allowing it to recov er phoneti- cally accurate transcripts even from severe recognition errors. These refined pseudo-labels serve as high-fidelity targets for fine-tuning the ASR model in an iterative cycle. Experimental results across diverse benchmarks demonstrate that ReHear ef- fectiv ely mitigates error propagation, consistently outperform- ing both supervised and pseudo-labeling baselines. Index T erms : automatic speech recognition, lar ge language models, semi-supervised learning, pseudo-labeling 1. Introduction End-to-end (E2E) automatic speech recognition (ASR) sys- tems [1], exemplified by models lik e Conformer [2], Whis- per [3], and OLMoASR [4], have achiev ed state-of-the-art per- formance across a wide range of benchmarks. Although the uti- lization of massi ve, often weakly supervised web-scale datasets has endowed these models with impressiv e general capabili- ties, adapting them to the distinct acoustic and linguistic nu- ances of specific downstream tasks remains a significant chal- lenge. Achieving high precision in specialized domains, distinct accents, or lo w-resource languages typically demands high- quality , human-annotated data. Consequently , the prohibitive cost and scarcity of such ground-truth labels create a significant bottleneck, sev erely limiting the effectiv e deployment of these powerful models in scenarios where labeled data is sparse but unlabeled audio is abundant. T o mitigate the reliance on labeled data, semi-supervised learning (SSL), particularly through pseudo-labeling (PL), has emerged as a prev alent strategy . In this framew ork, a “teacher” ASR model generates transcriptions for a large corpus of unla- beled audio, which subsequently serve as targets to fine-tune a “student” model. Howe ver , the efficacy of this approach is fun- damentally limited by error propagation. As the teacher model is prone to misrecognitions, training the student on these noisy pseudo-labels can reinforce errors and destabilize the optimiza- tion process. Although v arious filtering strate gies based on con- fidence scores or uncertainty estimation have been proposed to curate the training data, they are often suboptimal; by discard- ing samples with lo w-confidence labels, these methods forfeit potentially valuable acoustic information contained in the dis- Audio Audio Encoder Audio Decoder Audio Encoder Audio Adapter T ext Embedding Language Decoder Pseudo Label Real Label Corrected Pseudo-Label Real Label Audio Pseudo Label ASR Model Audio LLM ASR Loss ASR Loss LM Loss Figure 1: Overview of the proposed ReHear framework. The pipeline employs an audio-aware LLM to refine hypotheses via multimodal conte xt, subsequently using these r efined pseudo- labels to iteratively fine-tune the ASR model on data. carded audio. In this work, we di ver ge from the traditional filtering paradigm and instead propose to actively refine noisy pseudo- labels. W e introduce ReHear , a no vel semi-supervised ASR framew ork that le verages the emergent capabilities of multi- modal audio large language models (Audio LLMs) [5, 6]. As illustrated in Figure 1, our approach employs a multimodal cor - rector that conditions on both the initial ASR hypothesis and the raw source audio. By grounding corrections directly in the acoustic signal, the model can disambiguate phonetic uncertain- ties and rectify errors that are intractable for text-only correc- tors. Specifically , we establish a collaborati ve loop between a base ASR model and an Audio LLM, where the latter refines the ASR’ s initial predictions to generate high-fidelity targets for subsequent fine-tuning. This cycle fosters a self-improving dy- namic, enabling the ASR system to effecti v ely e xploit lar ge- scale unlabeled data while progressively mitigating error prop- agation. Ultimately , ReHear offers a robust and data-efficient pathway to adapt ASR systems to new domains without the need for extensi ve human annotation. 2. Related W ork Pseudo-labeling (PL) has become a dominant paradigm for semi-supervised ASR [7, 8], significantly advanced by itera- tiv e pseudo-labeling (IPL) strategies where targets are contin- uously re-generated during training [9]. This process has been further refined through teacher-student frameworks utilizing ex- ponential mo ving av erage (EMA) [10] or momentum-based up- dates [11], alongside techniques for improved stability such as dynamic caching [12] and conv ergent teacher initialization [13]. T o mitigate error propagation from noisy labels, standard ap- proaches typically filter unlabeled data based on uncertainty metrics [14, 15], confidence scores [16], or multi-model con- sensus [17]. Div erging from sim ple filtering, recent research attempts to acti v ely correct noisy labels, utilizing methods rang- ing from modified CTC objectives [18], hybrid decoding strate- gies [19], and parameter-space bias correction [20] to LLMs serving as post-processors [21]. These include text-only de- noising LMs [22] and multimodal speech LLMs that lev erage source audio for correction [23]. Building on this, we propose an alternating iterativ e loop where an audio-aw are LLM acts as a corrector to refine pseudo-labels for ASR fine-tuning. Unlik e prior works that rely on complex ensembles or require computa- tionally expensi ve Audio LLMs for run-time inference, our ap- proach distills the corrector’ s knowledge directly into the ASR model, ensuring the final deployed system remains lightweight and efficient. 3. Methodology Our proposed ReHear framew ork orchestrates a self-improving training loop between a primary ASR model, denoted as M A , and an audio-a ware LLM functioning as a corrector , denoted as M L . As outlined in Algorithm 1, the protocol iterates through four sequential stages: ASR inference, LLM training, LLM in- ference, and ASR training. This cyclic design fosters a symbi- otic relationship where the two models mutually reinforce one another: an improved ASR model supplies more accurate ini- tial hypotheses, which enables the corrector to generate higher- fidelity pseudo-labels for subsequent ASR optimization. Algorithm 1 ReHear: Iterativ e Pseudo-Label Refinement Models: ASR model M A , Audio LLM M L Data: Labeled D L = { ( x l , y l ) } , Unlabeled D U = { x u } 1: for iteration t = 1 , . . . , T do 2: // ASR infer ence 3: D ′ L ← { ( x l , y l , M A ( x l )) | ( x l , y l ) ∈ D L } 4: D ′ U ← { ( x u , M A ( x u )) | x u ∈ D U } 5: // LLM training 6: T rain M L on D ′ L 7: // LLM infer ence 8: D ′′ U ← { ( x u , y ′ u , M L ( x u , T ( y ′ u ))) | ( x u , y ′ u ) ∈ D ′ U } 9: // Corr ection filtering (optional) 10: D f U ← { ( x u , y ′′ u ) | ( x u , y ′ u , y ′′ u ) ∈ D ′′ U , filter ( y ′ u , y ′′ u ) } 11: // ASR training 12: T rain M A on D L ∪ D f U 13: end for 14: retur n M A and M L In the initial ASR inference stage, the current ASR model M A generates hypotheses for both the labeled dataset D L = { ( x l , y l ) } and the unlabeled dataset D U = { x u } . For the la- beled data, this yields triplets ( x l , y l , y ′ l ) , where y ′ l = M A ( x l ) , which serv e as training examples for the corrector . Simulta- neously , initial noisy pseudo-labels y ′ u = M A ( x u ) are gener- ated for the unlabeled data to act as input for correction. Sub- sequently , in the LLM training stage, the Audio LLM M L is fine-tuned to perform ASR error correction. Specifically , it learns to map the multimodal inputs, comprising the audio x l and the hypothesis y ′ l , to the ground truth y l by minimizing the causal language modeling loss L LLM = − P log P ( y l | x l , T ( y ′ l ); θ L ) , where T ( · ) represents a prompt template wrap- ping the hypothesis. This step ef fecti vely conditions the LLM to identify and repair specific error patterns produced by the ASR model, le v eraging both acoustic e vidence and linguistic priors. The process then adv ances to the LLM infer ence stage, where the fine-tuned M L rectifies the noisy pseudo-labels y ′ u from the unlabeled set, producing refined transcriptions y ′′ u = M L ( x u , T ( y ′ u )) . T o safeguard quality , an optional filtering mechanism removes corrections exhibiting signs of hallucina- tion or excessi v e de viation, resulting in a high-fidelity subset D f U . Finally , in the ASR training stage, M A is fine-tuned on a combined corpus of the original labeled data and the fil- tered, corrected pseudo-labels. The objecti ve minimizes L AS R , defined as a sum of the supervised loss on D L and the semi- supervised loss on D f U . This updated M A is then carried ov er to the next cycle, closing the loop. The iterative process termi- nates when a predefined maximum iteration count is reached or when validation performance saturates. T o further safeguard the training process against occasional hallucinations generated by the LLM, we explore two filtering strategies. The first is a heuristic rule-based mechanism that im- poses constraints on character deviation and length consistency relativ e to the original ASR hypothesis, rejecting samples that exhibit significant div ergence or repetition loops. The second is a model-based approach where a pre-trained text encoder is fine-tuned as a binary classifier to predict whether a given cor- rection yields a lo wer word error rate (WER) than the initial hypothesis. In summary , by integrating this audio-aw are cor- rection, which can be optionally augmented by robust filtering, ReHear mitigates the noise accumulation typical of standard pseudo-labeling. This enables the ASR model to progressiv ely lev erage unlabeled data for sustained performance gains. 4. Experiments In this section, we outline the experimental setup, including dataset and implementation specifics, followed by a compre- hensiv e analysis of the main results and ablation studies. 4.1. Datasets T o ev aluate the ef ficacy of our proposed method in challeng- ing real-world contexts, we utilize four specialized corpora: Earnings-21 [24], Earnings-22 [25], SPGISpeech [26], and the AMI Meeting Corpus [27, 28]. Earnings-21 provides approxi- mately 39 hours of earnings calls across nine financial sectors, serving as a benchmark for entity-dense speech and named en- tity recognition. Building on this, Earnings-22 introduces 119 hours of recordings from global companies, specifically de- signed to test system rob ustness against di verse international accents. W e also incorporate SPGISpeech, a large-scale corpus originally containing 5 , 000 hours of formatted earnings calls; to facilitate efficient experimental iteration, we employ a rep- resentativ e sampled subset. Finally , to assess generalization to spontaneous conv ersational speech, we include the AMI corpus, which comprises 100 hours of multi-party meeting recordings characterized by unscripted dynamics and frequent disfluencies. All corpora consist of English speech, encompassing div erse domains and accents. T able 1 summarizes the detailed statistics and partition splits for the datasets used in our experiments. 4.2. Data Preparation W e tailor our preprocessing pipeline to handle the distinct formats of the corpora. For the long-form Earnings-21 and Earnings-22 datasets, we standardize raw recordings to 16 kHz and normalize transcripts by mapping non-speech annotations (e.g., laughter) to unified special tags. T o generate training- T able 1: Detailed statistics of the datasets utilized in e xperi- ments, r eporting the total duration for each partition split along with the averag e se gment duration. Split Earnings-21 Earnings-22 SPGISpeech AMI Labeled T rain 10.76h 21.81h 19.46h 16.37h Labeled V al 3.07h 9.87h 9.24h 8.94h Labeled T est 4.93h 12.41h 11.43h 8.68h Unlabeled 18.86h 63.67h 58.43h 61.49h T otal 37.63h 107.75h 98.55h 95.48h A vg. Duration 24.76s 24.13s 9.16s 2.56s ready samples, we employ a se gmentation pipeline using a pre- trained W av2V ec 2.0 model [29] coupled with CTC segmenta- tion [30, 31]. W e utilize sliding window inference for acoustic probabilities and align them with text using a backtracking win- dow of 8 , 000 to 100 , 000 frames. Adjacent segments with si- lence gaps under 2 s are merged, tar geting a maximum chunk duration of 30 s after adding 0 . 1 s boundary padding. Con- versely , for the pre-segmented SPGISpeech and AMI corpora, we bypass alignment and focus on consistency . The SPGIS- peech dataset (small version) is downsampled to create a repre- sentativ e subset: we sample 10% of the training set for labeled data and 30% for unlabeled, while retaining 10% of both valida- tion and test splits. For AMI independent headset microphones (IHM), we perform session-level partitioning by selecting 20% of the original training sessions as the labeled set and assign- ing the remainder to the unlabeled set. T o maintain data qual- ity , we apply rigorous filtering to discard segments shorter than 0 . 05 s, longer than 30 s, or containing empty transcripts. Across all datasets, partitioning is strictly managed at the source file or meeting le vel to ensure no speak er or context leakage occurs between splits. 4.3. Prompt T emplates T o adapt the LLM for the ASR correction task and ensure the output meets pseudo-labeling requirements (i.e., transcription only), we design specific instruction templates. For the primary audio-aware correction, we instruct the model to ground its out- put in acoustic features using the following template: “Corr ect the ASR hypothesis based on the pr ovided audio. T ranscribe the speech e xactly as spoken. Output strictly the corr ected text with- out any e xplanations or filler s. Hypothesis: < hypothesis > ” , where < hypothesis > is a placeholder for the ASR hypothesis. For the text-only variant where audio is unav ailable, we mod- ify this template by replacing the first two sentences with lin- guistic constraints: “Corr ect the ASR hypothesis by fixing typos and misspellings. Preserve the original style and do not para- phrase” . The remaining instructions are kept identical to ensure the model strictly avoids generating extraneous conv ersational content. 4.4. Experimental Setup W e utilize Whisper-Lar ge-v3 [3] as the base ASR model, V oxtral-Mini-3B-2507 [32] as the Audio LLM corrector , and DeBER T a-v3-Base [33] for model-based filtering. T o en- sure parameter efficienc y , we employ Low-Rank Adaptation (LoRA) [34] with rank 16 , scaling 32 , and dropout 0 . 05 . Both ASR and LLM backbones utilize 4-bit quantization (QLoRA) [35] with adapters applied to the ASR decoder and LLM language model, while the filter uses standard LoRA on its encoder . Training runs for 5 epochs with a global batch size of 128 and a cosine scheduler ( 10% warmup), using peak learn- ing rates of 5 × 10 − 4 for ASR, 10 − 4 for the LLM, and 10 − 3 for the model filter . During inference, we employ greedy decoding for ASR and beam search (width 5 ) for the LLM. For rule-based filtering, we discard corrections if the character error rate (CER) exceeds 0 . 15 , the length ratio falls outside [0 . 95 , 1 . 15] , the unique token ratio is below 0 . 40 , or if digit mismatches exceed 2 . W e ev aluate ReHear against iterativ e supervised learning (ISL) and two variants of iterativ e pseudo-labeling (IPL) [9, 12]: a standard nai ve IPL utilizing raw ASR hypotheses, and a robust rule-filtered IPL. For the latter , we apply strict criteria to re- tain only high-quality pseudo-labels: confidence at least 0 . 95 , speaking rate within [2 . 0 , 5 . 0] words/sec, and compression ratio at least 0 . 5 . For each configuration, we conduct 5 independent runs with 3 iterations, selecting the checkpoint with the lo w- est validation WER. All reported WER metrics are computed after standard text normalization, which includes lowercasing, removing punctuation, and stripping common filler words. W e implement our frame work using PyT orch [36, 37] and the Hug- ging Face ecosystem [38, 39, 40, 41, 42, 43], alongside tools for audio processing [31, 44, 45] and e valuation [46, 47]. All experiments were conducted on 8 NVIDIA A100 GPUs. 4.5. Experimental Results As presented in T able 2, traditional iterative pseudo-labeling (IPL) often struggles to improve upon the supervised baseline (ISL), particularly on challenging datasets like Earnings and AMI where confirmation bias leads to performance degrada- tion. Even when incorporating strict rule-based filtering (IPL + Rule) to reject confident errors, the method fails to consistently outperform the supervised baseline. In contrast, ReHear suc- cessfully mitigates this issue, consistently outperforming both ISL and IPL baselines across all benchmarks by le v eraging audio-aware LLM corrections to generate high-fidelity targets. This capability effectiv ely unlocks the potential of abundant unlabeled data, providing a cost-efficient solution for domains where manual annotation is expensiv e. Detailed analysis re- veals that the proposed frame work is particularly effectiv e in complex acoustic en vironments, such as the spontaneous finan- cial narratives in Earnings-21/22 and the multi-speaker meet- ing scenarios in AMI, achie ving substantial WER reductions on both labeled and unlabeled sets. Even on SPGISpeech, where the baseline is already accurate, our method yields further g ains. Regarding filtering strategies, rule-based constraints (ReHear + Rule) yield the highest stability , while the learned model filter (ReHear + Model) also deliv ers competiti ve results, al- beit slightly constrained by overfitting on limited labeled data. Notably , standard ReHear without additional filtering remains highly rob ust and frequently surpasses filtered IPL, demonstrat- ing that the audio-aware corrector significantly reduces the de- pendency on comple x post-hoc filtering mechanisms. 4.6. Ablation Studies T o inv estigate the contrib ution of specific design choices, we conduct ablation studies on the Earnings-21 dataset, reporting all results using the standard ReHear framework without addi- tional filtering mechanisms. 4.6.1. Modality and P osition W e analyze the contribution of acoustic features and their po- sitional encoding within the input sequence. As presented in T able 3, relying solely on the textual hypothesis (text-only) re- T able 2: W or d Error Rate (WER, %) comparison acr oss all datasets. W e report the mean and standar d deviation (subscript) on the labeled test and unlabeled sets. Bold indicates the best r esult, and underline indicates the second best. Method Earnings-21 Earnings-22 SPGISpeech AMI (IHM) T est Unlabeled T est Unlabeled T est Unlabeled T est Unlabeled ISL 6.76 ± 0 . 17 8.57 ± 0 . 19 12.54 ± 0 . 11 11.43 ± 0 . 09 2.41 ± 0 . 01 2.42 ± 0 . 02 9.66 ± 0 . 24 10.26 ± 0 . 29 IPL 8.02 ± 0 . 18 10.69 ± 0 . 10 14.02 ± 0 . 17 13.30 ± 0 . 08 2.83 ± 0 . 05 2.98 ± 0 . 08 16.52 ± 0 . 26 19.31 ± 0 . 13 IPL + Rule 7.59 ± 0 . 25 10.30 ± 0 . 17 13.64 ± 0 . 12 13.10 ± 0 . 08 2.57 ± 0 . 03 2.59 ± 0 . 04 11.00 ± 2 . 05 12.35 ± 1 . 86 ReHear 6.34 ± 0 . 26 7.87 ± 0 . 18 12.01 ± 0 . 08 10.63 ± 0 . 11 2.36 ± 0 . 01 2.23 ± 0 . 03 9.45 ± 0 . 23 10.30 ± 0 . 15 ReHear + Rule 6.35 ± 0 . 13 7.79 ± 0 . 08 11.82 ± 0 . 16 10.63 ± 0 . 16 2.37 ± 0 . 04 2.28 ± 0 . 04 9.35 ± 0 . 24 10.09 ± 0 . 22 ReHear + Model 6.55 ± 0 . 19 7.94 ± 0 . 15 12.05 ± 0 . 09 10.78 ± 0 . 09 2.39 ± 0 . 04 2.31 ± 0 . 04 9.74 ± 0 . 20 10.13 ± 0 . 29 sults in substantially higher error rates, indicating that without acoustic grounding, the LLM acts merely as a grammatical ed- itor unable to rectify phonetic errors. In contrast, incorporating audio leads to substantial gains across both settings. Notably , prefixing the hypothesis with audio embeddings (audio + text) achiev es the best performance on both sets. This suggests that conditioning the model on the source speech before presenting the potentially erroneous te xt facilitates more ef fecti ve error de- tection and correction. T able 3: Ablation study on input modality and positioning us- ing Earnings-21. W e compar e WER (%) on the labeled test and unlabeled sets for text-only inputs versus differ ent audio inte- gration str ate gies. Configuration T est Unlabeled T ext Only 7.74 ± 0 . 11 10.46 ± 0 . 12 T ext + Audio 6.34 ± 0 . 24 8.02 ± 0 . 24 Audio + T ext 6.34 ± 0 . 26 7.87 ± 0 . 18 4.6.2. Decoding Strate gies W e ev aluate the impact of different decoding strategies on the quality of Audio LLM-generated corrections. As shown in T able 4, deterministic beam search consistently yields signif- icantly lo wer error rates compared to greedy decoding and stochastic temperature sampling ( T = 0 . 7 ). The inferior per- formance of sampling suggests that introducing randomness is detrimental to the error correction task, where fidelity to the source audio is paramount ov er generation di versity . In con- trast, beam search f acilitates a more ef fecti ve e xploration of the hypothesis space. While a beam width of N = 3 achiev es the lo west WER on the labeled test set, increasing the width to N = 5 results in the best performance on the unlabeled set. Consequently , we employ beam search to ensure the generation of robust and acoustically grounded pseudo-labels. T able 4: Ablation study on LLM decoding str ate gies using Earnings-21. W e compare WER (%) on the labeled test and unlabeled sets for deterministic methods (greedy , beam searc h with varying widths) versus stochastic sampling . Strategy Configuration T est Unlabeled Greedy N = 1 6.59 ± 0 . 36 8.67 ± 0 . 34 Beam N = 3 6.21 ± 0 . 14 7.89 ± 0 . 19 Beam N = 5 6.34 ± 0 . 26 7.87 ± 0 . 18 Sampling T = 0 . 7 6.54 ± 0 . 22 8.72 ± 0 . 23 4.6.3. Iterative Dynamics W e in vestigate the impact of the self-training loop depth on per- formance using the Earnings-21 dataset. T o mitigate potential ov erfitting and noise accumulation during iterativ e updates, we introduce a decay strategy where the learning rate is halved and the number of training epochs is decremented by one at each subsequent iteration. As shown in T able 5, pseudo-labeling gains are realized rapidly . While the standard ReHear approach begins to degrade after the second iteration, the decay mecha- nism effectiv ely stabilizes training, maintaining robust perfor- mance over prolonged iterations. Notably , the WER reduction saturates around the second iteration. Consequently , extending the loop beyond this point yields diminishing returns, justifying our choice of setting the limit to 3 iterations for the main ex- periments to balance computational efficiency and performance stability . T able 5: Ablation study on iterative dynamics using Earnings- 21. W e compare WER (%) on the labeled test and unlabeled sets acr oss iter ations, with and without the training decay strate gy . Iteration Without Decay With Decay T est Unlabeled T est Unlabeled 0 8.98 ± 0 . 00 10.99 ± 0 . 00 8.98 ± 0 . 00 10.99 ± 0 . 00 1 6.48 ± 0 . 20 8.06 ± 0 . 12 6.30 ± 0 . 18 8.06 ± 0 . 29 2 6.35 ± 0 . 10 7.92 ± 0 . 15 6.43 ± 0 . 22 7.94 ± 0 . 13 3 6.51 ± 0 . 21 8.07 ± 0 . 17 6.42 ± 0 . 16 7.99 ± 0 . 12 4 6.75 ± 0 . 26 8.26 ± 0 . 29 6.48 ± 0 . 16 8.05 ± 0 . 19 5 6.77 ± 0 . 08 8.34 ± 0 . 28 6.53 ± 0 . 14 8.06 ± 0 . 19 5. Conclusion In this paper, we introduced a semi-supervised framework that employs instruction-tuned audio-aware large language models for speech recognition correction and iterati v e pseudo-labeling. By grounding the correction process directly in acoustic fea- tures, our method generates high-quality supervision signals that surpass those deriv ed from filtered pseudo-labels and text- only correction. Empirical ev aluations across multiple datasets confirm that this frame work consistently outperforms both supervised benchmarks and traditional pseudo-labeling tech- niques. Our analysis further demonstrates that incorporating au- dio context is the decisi v e factor in reducing recognition errors, offering a data-efficient pathway for enhancing system perfor- mance using unlabeled speech. 6. References [1] R. Prabha valkar , T . Hori, T . N. Sainath, R. Schl ¨ uter , and S. W atan- abe, “End-to-end speech recognition: A survey , ” IEEE/ACM T r ansactions on Audio, Speech, and Language Pr ocessing , vol. 32, pp. 325–351, 2023. [2] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar , Y . Zhang, J. Y u, W . Han, S. W ang, Z. Zhang, Y . W u et al. , “Conformer: Con volution- augmented Transformer for speech recognition, ” in Pr oc. Inter- speech 2020 , 2020, pp. 5036–5040. [3] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeavey , and I. Sutskev er , “Robust speech recognition via large-scale weak su- pervision, ” in Pr oceedings of the International Conference on Ma- chine Learning (ICML) . PMLR, 2023, pp. 28 492–28 518. [4] H. Ngo, M. Deitke, M. Bartelds, S. Pratt, J. Gardner , M. Jor - dan, and L. Schmidt, “OLMoASR: Open models and data for training rob ust speech recognition models, ” arXiv pr eprint arXiv:2508.20869 , 2025. [5] W . Cui, D. Y u, X. Jiao, Z. Meng, G. Zhang, Q. W ang, S. Y . Guo, and I. King, “Recent advances in speech language models: A survey , ” in Proceedings of the 63r d Annual Meeting of the As- sociation for Computational Linguistics (ACL) , 2025, pp. 13 943– 13 970. [6] Y . Xu, S.-X. Zhang, J. Y u, Z. Wu, and D. Y u, “Comparing discrete and continuous space LLMs for speech recognition, ” in Pr oc. In- terspeech 2024 , 2024, pp. 2509–2513. [7] J. Kahn, A. Lee, and A. Hannun, “Self-training for end-to- end speech recognition, ” in ICASSP 2020 - 2020 IEEE Interna- tional Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2020, pp. 7084–7088. [8] Y . Chen, W . W ang, and C. W ang, “Semi-supervised ASR by end- to-end self-training, ” in Proc. Interspeech 2020 , 2020, pp. 2787– 2791. [9] Q. Xu, T . Likhomanenko, J. Kahn, A. Hannun, G. Synnaeve, and R. Collobert, “Iterative pseudo-labeling for speech recognition, ” in Pr oc. Interspeec h 2020 , 2020, pp. 1006–1010. [10] V . Manohar , T . Likhomanenko, Q. Xu, W .-N. Hsu, R. Collobert, Y . Saraf, G. Zweig, and A. Mohamed, “Kaizen: Continuously improving teacher using exponential moving av erage for semi- supervised speech recognition, ” in 2021 IEEE Automatic Speech Recognition and Under standing W orkshop (ASR U) . IEEE, 2021, pp. 518–525. [11] Y . Higuchi, N. Moritz, J. Le Roux, and T . Hori, “Momentum pseudo-labeling for semi-supervised speech recognition, ” in Pr oc. Interspeech 2021 , 2021, pp. 726–730. [12] T . Likhomanenko, Q. Xu, J. Kahn, G. Synnaeve, and R. Collobert, “slimIPL: Language-model-free iterative pseudo-labeling, ” in Pr oc. Interspeec h 2021 , 2021, pp. 741–745. [13] N. T ade vosyan, N. Karpov , A. Andrusenko, V . Lavrukhin, and A. Jukic, “Unified semi-supervised pipeline for automatic speech recognition, ” in Proc. Inter speech 2025 , 2025, pp. 3184–3188. [14] S. Khurana, N. Moritz, T . Hori, and J. Le Roux, “Unsupervised domain adaptation for speech recognition via uncertainty driven self-training, ” in ICASSP 2021 - 2021 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2021, pp. 6553–6557. [15] E. Kim and K. Lee, “Uncertainty-aware self-training for CTC- based automatic speech recognition, ” in Proceedings of the AAAI Confer ence on Artificial Intelligence (AAAI) , vol. 39, no. 23, 2025, pp. 24 330–24 338. [16] Z. Jin, D. Zhong, X. Song, Z. Liu, N. Y e, and Q. Zeng, “Filter and e v olve: Progressiv e pseudo label refining for semi-supervised automatic speech recognition, ” arXiv preprint , 2022. [17] A. Carofilis, P . Rangappa, S. Madikeri, S. Kumar , S. Burdisso, J. Prakash, E. V illatoro-T ello, P . Motlicek, B. Sharma, K. Ha- cioglu et al. , “Better semi-supervised learning for multi-domain ASR through incremental retraining and data filtering, ” in Proc. Interspeech 2025 , 2025, pp. 3618–3622. [18] H. Zhu, D. Gao, G. Cheng, D. Pove y , P . Zhang, and Y . Y an, “ Al- ternativ e pseudo-labeling for semi-supervised automatic speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 31, pp. 3320–3330, 2023. [19] L. Zheng, H. Zhu, C. Y ang, X. W ang, G. Cheng, and T . Li, “Hy- brid pseudo-labeling for semi-supervised automatic speech recog- nition, ” in ICASSP 2025 - 2025 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2025, pp. 1–5. [20] Y .-C. Lin, Y .-H. Liang, H. Su, T .-Q. Lin, S.-T . Chen, Y .-N. Chen, and H.-y . Lee, “Pseudo2Real: T ask arithmetic for pseudo- label correction in automatic speech recognition, ” arXiv preprint arXiv:2510.08047 , 2025. [21] M. Shi, Z. Jin, Y . Xu, Y . Xu, S.-X. Zhang, K. W ei, Y . Shao, C. Zhang, and D. Y u, “ Adv ancing multi-talker ASR performance with lar ge language models, ” in 2024 IEEE Spoken Language T echnology W orkshop (SLT) . IEEE, 2024, pp. 14–21. [22] Z. Gu, T . Likhomanenko, H. Bai, E. McDermott, R. Collobert, and N. Jaitly , “Denoising LM: Pushing the limits of error correction models for speech recognition, ” arXiv preprint , 2024. [23] J. Prakash, B. Kumar , K. Hacioglu, B. Sharma, S. Gopalan, M. Chetlur , S. V enkatesan, and A. Stolcke, “Better pseudo- labeling with multi-ASR fusion and error correction by Speech- LLM, ” in Proc. Inter speech 2025 , 2025, pp. 579–583. [24] M. Del Rio, N. Delworth, R. W esterman, M. Huang, N. Bhandari, J. Palakapilly , Q. McNamara, J. Dong, P . ˙ Zelasko, and M. Jett ´ e, “Earnings-21: A practical benchmark for ASR in the wild, ” in Pr oc. Interspeec h 2021 , 2021, pp. 3465–3469. [25] M. Del Rio, P . Ha, Q. McNamara, C. Miller, and S. Chandra, “Earnings-22: A practical benchmark for accents in the wild, ” arXiv pr eprint arXiv:2203.15591 , 2022. [26] P . K. O’Neill, V . Lavrukhin, S. Majumdar, V . Noroozi, Y . Zhang, O. Kuchaiev , J. Balam, Y . Dovzhenko, K. Freyberg, M. D. Shul- man et al. , “SPGISpeech: 5,000 hours of transcribed financial au- dio for fully formatted end-to-end speech recognition, ” in Pr oc. Interspeech 2021 , 2021, pp. 1434–1438. [27] J. Carletta, “Unleashing the killer corpus: Experiences in creating the multi-ev erything AMI meeting corpus, ” Language Resources and Evaluation , vol. 41, no. 2, pp. 181–190, 2007. [28] S. Renals, T . Hain, and H. Bourlard, “Recognition and under- standing of meetings: The AMI and AMIDA projects, ” in 2007 IEEE W orkshop on Automatic Speech Recognition & Understand- ing (ASR U) . IEEE, 2007, pp. 238–247. [29] A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wa v2vec 2.0: A framework for self-supervised learning of speech repre- sentations, ” Advances in Neural Information Processing Systems (NeurIPS) , vol. 33, pp. 12 449–12 460, 2020. [30] A. Graves, S. Fern ´ andez, F . Gomez, and J. Schmidhuber , “Con- nectionist temporal classification: Labelling unsegmented se- quence data with recurrent neural networks, ” in Pr oceedings of the 23r d International Conference on Machine Learning (ICML) , 2006, pp. 369–376. [31] L. K ¨ urzinger , D. Winkelbauer , L. Li, T . W atzel, and G. Rigoll, “CTC-segmentation of large corpora for German end-to-end speech recognition, ” in International Confer ence on Speech and Computer (SPECOM) . Springer, 2020, pp. 267–278. [32] A. H. Liu, A. Ehrenberg, A. Lo, C. Denoix, C. Barreau, G. Lam- ple, J.-M. Delignon, K. R. Chandu, P . v on Platen, P . R. Mud- direddy et al. , “V oxtral: V oxel-based multimodal transformer for speech processing, ” arXiv preprint , 2025. [33] P . He, X. Liu, J. Gao, and W . Chen, “DeBER T a: Decoding- enhanced BER T with disentangled attention, ” in International Confer ence on Learning Repr esentations (ICLR) , 2021. [34] E. J. Hu, Y . Shen, P . W allis, Z. Allen-Zhu, Y . Li, S. W ang, L. W ang, W . Chen et al. , “LoRA: Low-rank adaptation of large language models, ” in International Conference on Learning Rep- r esentations (ICLR) , 2022. [35] T . Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer , “QLoRA: Efficient finetuning of quantized LLMs, ” Advances in Neural Information Pr ocessing Systems (NeurIPS) , vol. 36, pp. 10 088–10 115, 2023. [36] A. Paszke, S. Gross, F . Massa, A. Lerer, J. Bradbury , G. Chanan, T . Killeen, Z. Lin, N. Gimelshein, L. Antiga et al. , “PyT orch: An imperativ e style, high-performance deep learning library , ” Advances in Neural Information Processing Systems (NeurIPS) , vol. 32, 2019. [37] Y .-Y . Y ang, M. Hira, Z. Ni, A. Astafurov , C. Chen, C. Puhrsch, D. Pollack, D. Genzel, D. Greenberg, E. Z. Y ang et al. , “T orchAu- dio: Building blocks for audio and speech processing, ” in ICASSP 2022 - 2022 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2022, pp. 6982–6986. [38] T . W olf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P . Cistac, T . Rault, R. Louf, M. Funtowicz et al. , “Transformers: State-of-the-art natural language processing, ” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Pr ocessing: System Demonstrations (EMNLP) , 2020, pp. 38–45. [39] S. Gugger, L. Debut, T . W olf, P . Schmid, Z. Mueller, S. Man- grulkar , M. Sun, and B. Bossan, “ Accelerate: T raining and in- ference at scale made simple, efficient and adaptable, ” https: //github .com/huggingface/accelerate, 2022. [40] S. Mangrulkar, S. Gugger, L. Debut, Y . Belkada, S. Paul, B. Bossan, and M. T ietz, “PEFT: State-of-the-art parameter- efficient fine-tuning methods, ” https://github .com/huggingface/ peft, 2022. [41] T . Dettmers and L. Zettlemoyer, “The case for 4-bit precision: k- bit inference scaling laws, ” in Proceedings of the International Confer ence on Machine Learning (ICML) . PMLR, 2023, pp. 7750–7774. [42] L. V on W erra, L. T unstall, A. Thakur , S. Luccioni, T . Thrush, A. Piktus, F . Marty , N. Rajani, V . Mustar, and H. Ngo, “Evaluate & ev aluation on the hub: Better best practices for data and model measurements, ” in Pr oceedings of the 2022 Confer ence on Empir- ical Methods in Natural Language Processing: System Demon- strations (EMNLP) , 2022, pp. 128–136. [43] Q. Lhoest, A. V . Del Moral, Y . Jernite, A. Thakur, P . V on Platen, S. Patil, J. Chaumond, M. Drame, J. Plu, L. Tunstall et al. , “Datasets: A community library for natural language process- ing, ” in Pr oceedings of the 2021 Conference on Empirical Meth- ods in Natural Language Pr ocessing: System Demonstrations (EMNLP) , 2021, pp. 175–184. [44] B. McFee, C. Raffel, D. Liang, D. P . W . Ellis, M. McV icar , E. Bat- tenberg, and O. Nieto, “librosa: Audio and music signal analysis in Python, ” in Proceedings of the 14th Python in Science Confer- ence (SciPy) , 2015, pp. 18–24. [45] Y . Zhang, E. Bakhturina, and B. Ginsburg, “NeMo (inv erse) text normalization: From development to production, ” in Pr oc. Inter- speech 2021 , 2021, pp. 4857–4859. [46] A. C. Morris, V . Maier, and P . D. Green, “From WER and RIL to MER and WIL: Improved ev aluation measures for connected speech recognition, ” in Proc. Inter speech , 2004, pp. 2765–2768. [47] F . Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V . Dubourg et al. , “Scikit-learn: Machine learning in Python, ” Journal of Machine Learning Resear ch (JMLR) , v ol. 12, pp. 2825–2830, 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment