MD-AirComp+: Adaptive Quantization for Blind Massive Digital Over-the-Air Computation
Recent research has shown that unsourced massive access (UMA) is naturally well-suited for over-the-air computation (AirComp), as it does not require knowledge of each individual signal, as demonstrated by the massive digital AirComp (MD-AirComp) sch…
Authors: Li Qiao, Yueqing Wang, Hanjun Jiang
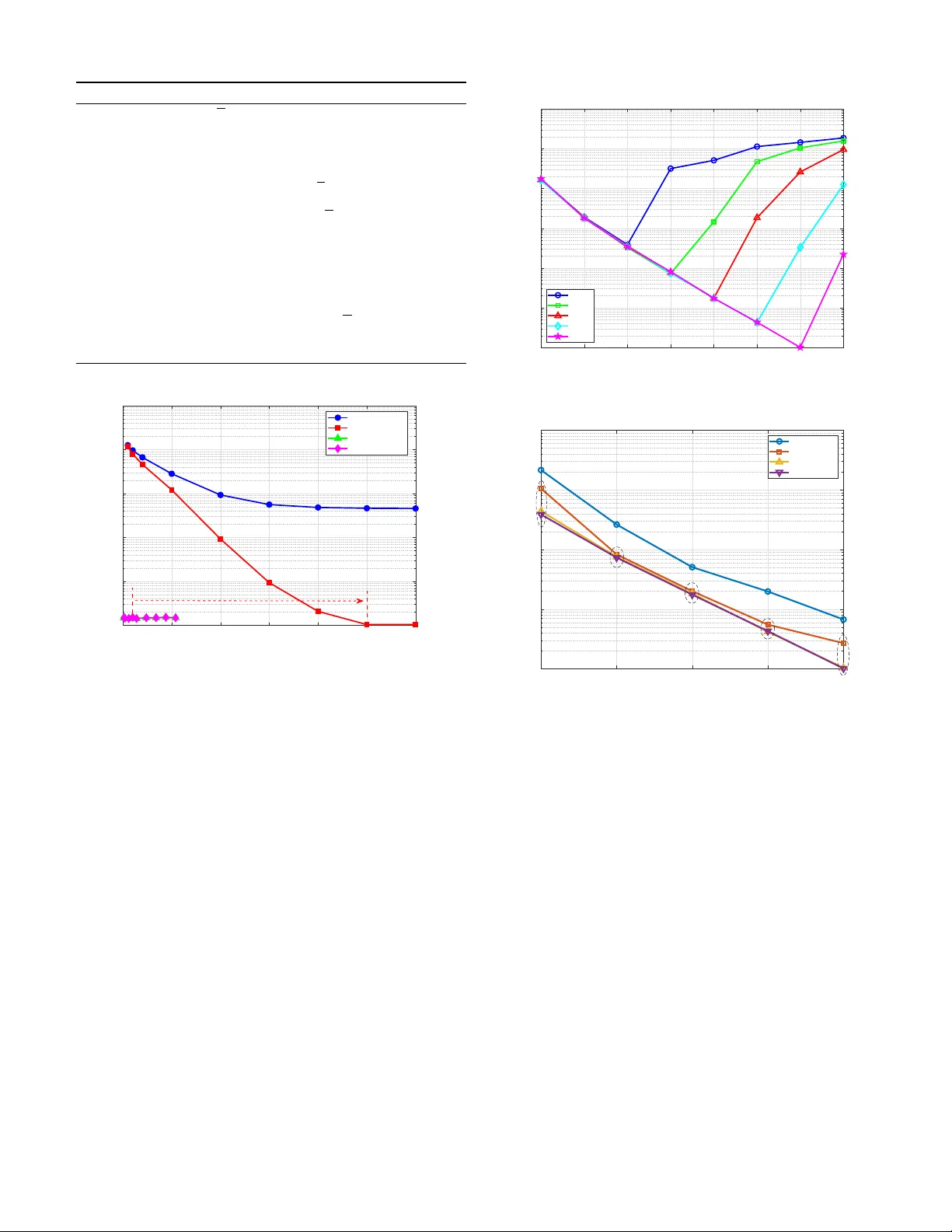
1 MD-AirComp+: Adapti v e Quantization for Blind Massi v e Digital Over -the-Air Computation Li Qiao, Member , IEEE , Y ueqing W ang, Hanjun Jiang, Xinhua Liu, Y ixuan Xing, Y ongpeng W u, Senior Member , IEEE , and Zhen Gao, Senior Member , IEEE Abstract —Recent resear ch has shown that unsour ced massive access (UMA) is naturally well-suited for o ver -the-air compu- tation (AirComp), as it does not requir e knowledge of each individual signal, as demonstrated by the massive digital Air- Comp (MD-AirComp) scheme proposed in [1], [2]. The MD- AirComp scheme has prov en effective in federated edge lear ning and is highly compatible with current digital wireless networks. Howev er , it depends on channel pre-equalization, which may amplify computation err ors in the presence of channel estimation inaccuracies, thus limiting its practical use. In this paper , we propose a blind MD-AirComp+ scheme, which takes advantage of the channel hardening effect in massive multiple-input multiple- output (MIMO) systems. W e provide an upper bound on the computation mean square error , analyze the trade-off between computation accuracy and communication overhead, and deter- mine the optimal quantization level. Additionally , we introduce a deep unfolding algorithm to reduce the computational complexity of solving the underdetermined detection problem formulated as a least absolute shrinkage and selection operator optimization problem. Simulation results confirm the effectiveness of the proposed MD-AirComp+ framework, the optimal quantization selection strategy , and the low-complexity detection algorithm. Index T erms —Internet of Things (IoT), digital over -the-air computation, unsourced massive access, adaptive quantization, compressed sensing. I . I N T R O D U C T I O N The integration of the Internet of Things (IoT) and Artifi- cial Intelligence (AI), known as the Artificial Intelligence of Things (AIoT), represents a piv otal paradigm shift for next- generation wireless networks [3]. T o realize ubiquitous intel- ligence, these networks are ev olving into multi-dimensional integrated architectures—encompassing space, air , ground, and sea—to ensure seamless connecti vity across di verse and complex environments [4], [5]. At its core, the efficacy of AI, particularly deep learning (DL), relies on three essential pillars: data, computational power , and algorithms [6]. AIoT ecosystems provide both abundant data from heterogeneous sensors and distributed computational resources, empowered by energy-ef ficient edge hardware that facilitates local pro- cessing [7]. Consequently , a multitude of AIoT devices can ex ecute distributed AI tasks, such as federated learning [8], [9], [10] and collaborativ e inference [11], [12]. In these distributed settings, the communication paradigm is shifting from traditional bit-lev el transmission toward task-oriented L. Qiao is with the Department of Electrical and Electronic Engineer- ing, The University of Hong Kong, Pokfulam Road, Hong Kong (e-mail: qiaoli@hku.hk). Y . W ang and X. Liu are with the School of Information and Electronics, Beijing Institute of T echnology , Beijing 100081, China. H. Jiang, Y . Xing, and Z. Gao are with the School of Interdisciplinary Science, Beijing Institute of T echnology , Beijing 100081, China (e-mail: gaozhen16@bit.edu.cn). Y . W u is with the Department of Electronic Engineering, Shanghai Jiao T ong University , Minhang, Shanghai 200240, China. and context-aware frame works, where information exchange is increasingly dictated by the specific requirements of the underlying AI applications [13]. A fundamental challenge in this context is the efficient fusion of information from geo- graphically dispersed processing units. This bottleneck lies at the intersection of massiv e-scale communication and computa- tion, necessitating a seamless integration of both domains. T o address this, over -the-air computation (AirComp) has emerged as a promising solution, consolidating communication and computation into a unified process to significantly enhance the overall performance of AIoT systems [14]. A. Literatur e Re view AirComp transforms the uplink multiple access channel into a sum computing mechanism. Depending on the coding and modulation techniques used, AirComp can be categorized into two main schemes: analog and digital. 1) Analog AirComp: In analog AirComp, each device’ s signal undergoes pre-equalization by applying the inv erse of the uplink (UL) channel gain from the de vice to the base station (BS), which acts as the parameter server . The pre- equalized signals are then modulated onto the amplitude of the transmit wa veform. Through simultaneous transmission from multiple devices, the receiv er can directly obtain the sum of the local signals by exploiting the superposed wav eform ov er the multiple access channel (MA C). These properties make AirComp well-suited for joint computation and communica- tion across a large number of devices. As a result, analog AirComp has been widely adopted in federated learning and inference. For instance, in federated edge learning (FEEL), the local model updates from various devices are compressed and transmitted via AirComp, after which the BS optimizes the receiv er by accounting for the computational results rather than the communication error rate [15], [16], [17]. The use of multi-input multi-output (MIMO) systems for AirComp is explored in [18]. The impact of imperfect de vice syn- chronization is in vestigated in [19]. The statistical properties of massiv e MIMO channels are leveraged to enable blind FEEL [20], [21]. A comprehensive overvie w of FEEL can be found in [22]. In addition to standard architectures, recent works hav e explored reconfigurable intelligent surf aces (RIS) to enhance AirComp in complex environments [23]. In the context of federated and collaborati ve inference tasks, local devices perform AI inference, and the inference results are aggregated over AirComp at the BS [24], [25]. Additionally , the authors of [26], [27] propose fusing intermediate feature elements via AirComp, which improv es inference accurac y with limited communication o verhead. 2 2) Digital AirComp: While analog AirComp shows sig- nificant potential, most current wireless networks, including those based on 3rd Generation Partnership Project (3GPP) standards, predominantly rely on digital communication proto- cols and hardware [28]. Consequently , both existing and future networks may not support the flexible modulation schemes required for analog AirComp. In digital communication sys- tems, quantization—the process of transforming continuous values into discrete sets—represents an initial step. One-bit quantization is particularly well-suited for aggregation over the MA C, serving as the foundation for works such as [29] and subsequent extensions to FEEL in [30], [31], [32]. These studies typically employ one-bit gradient quantization coupled with digital modulation—specifically BPSK or QPSK—at the edge de vices, while the central server performs gradient decoding via majority voting. Furthermore, the authors of [30] and [31] introduce non-coherent detection methods, enabling digital AirComp with multi-bit quantization without requiring channel state information (CSI). Beyond communication ef fi- ciency , this paradigm has been further adapted to enhance the resilience of federated learning against Byzantine attacks [32]. Despite its benefits, this approach necessitates multiple frequency allocations to represent different quantization le vels, raising concerns about spectral efficienc y . Moreover , although the con ver gence of FEEL with one-bit quantization is guar- anteed by the frame work of sign stochastic gradient descent (SignSGD), higher accuracy is essential for other tasks, such as federated inference [25], [26], multi-sensor localization [33], and federated conformal prediction [34]. Recent studies [35], [36], [21] hav e proposed coding schemes that facilitate func- tion computation using superimposed digital constellations. Furthermore, adaptiv e quantization plays a critical role in balancing the trade-of fs between communication and compu- tation [37], a concept also explored in various downstream tasks, such as federated learning [38], [39], [40]. Ho wev er, the design of adaptive quantization in digital AirComp remains underdev eloped. Specifically , most existing schemes [37], [38], [39], [40] rely on the idealized assumption of error-free channels, which limits their applicability in practical wireless en vironments. Moreov er , they are not designed to exploit the wa veform superposition property of the MA C, making their extension to digital AirComp a non-trivial challenge. 3) Random Access and AirComp: From a random access perspectiv e, AirComp can be viewed as an approach that tightly integrates random access with computation-aware data transmission [41], [42]. Such integration inherently relies on massiv e access technologies, which are designed to support massiv e connectivity under stringent latency and signaling constraints. In traditional sourced massive access, compressed sensing (CS)-based algorithms have been extensi vely de vel- oped for acti ve device detection, channel estimation, and data detection across various scenarios [43], [44]. Howe ver , when the receiver focuses on the collecti ve data rather than individual device identities, the paradigm shifts from sourced access to unsourced massi ve access (UMA) [45], [46], [47], [48]. Moreover , UMA enables all de vices to share a common random access codebook, offering both practicality and ease of implementation. A comprehensiv e introduction to UMA can be found in [49]. Since the receiv er in UMA is only concerned with the transmitted messages rather than device identities, it naturally aligns with the objecti ves of computing tasks. Building on this synergy , the authors of [1], [2] redesigned UMA for digital AirComp, resulting in the con- cept of massiv e digital AirComp (MD-AirComp), which was demonstrated to be effecti ve both theoretically and through simulations for FEEL tasks. Interestingly , the concept of MD-AirComp is similar to type-based multiple access (TBMA) schemes introduced in [50], although the random access codebook in [50] is orthog- onal, leading to significantly higher communication ov erhead. More recently , the theoretical analysis of MD-AirComp and TBMA at a massiv e scale has been conducted in [33]. More- ov er , the authors of [34] applied TBMA in federated conformal prediction. Similar to most existing digital AirComp schemes, MD-AirComp [1], [2] and the TBMA-based AirComp ap- proaches in [33], [34] employ channel pre-equalization and use fixed quantization lev els, without accounting for variations in bandwidth and channel conditions. Such a design reduces flexibility and leads to degraded computation accuracy under constrained communication resources and imperfect CSI. B. Contributions T o overcome the limitations of existing digital AirComp schemes, this work proposes the MD-AirComp+ framework, which offers the follo wing ke y contrib utions. • Communication-efficient blind MD-AirComp method: T o eliminate the overhead and potential errors associ- ated with channel pre-equalization, MD-AirComp+ ex- ploits the statistical properties of massiv e MIMO. In this way , the receiver can mitigate the impact of unknown channels without requiring indi vidual CSI from multiple devices. Moreover , the frame work adaptively determines the optimal quantization lev el according to bandwidth and channel conditions, thereby achieving a balance between computing accuracy and communication overhead. • MSE analysis and optimal quantization level selec- tion: W e analytically establish an upper bound on the computation mean squared error (MSE). Furthermore, we characterize the interplay among quantization lev el, bandwidth, and signal-to-noise ratio (SNR), and demon- strate the existence of an optimal quantization le vel that minimizes the computation MSE, thereby balancing computing precision with communication overhead. • Deep unf olding-aided low-complexity algorithm: T o address the high computational complexity of the receiv er-side detection algorithm, we introduce a deep unfolding method, where a neural network is used to model key iterativ e parameters. This results in a 25-fold reduction in the number of iterations required to achiev e con vergence. Notation : Boldface lower and upper -case symbols denote column vectors and matrices, respectiv ely . For a matrix A , A T , A ∗ , A H , and ∥ A ∥ F denote the transpose, complex conjugate, Hermitian transpose, and Frobenius norm of A , respectiv ely . For a vector x , ∥ x ∥ p denotes the ℓ p norm of 3 x . [ K ] denotes the set { 1 , 2 , ..., K } . I K denotes the identity matrix with dimension K × K . I I . S Y S T E M M O D E L As depicted in Figure 1, we consider a general digital AirComp framework in which K distributed de vices each hold local signals s k . These devices apply pre-processing opera- tions, such as quantization and modulation, before transmitting the processed signals to a common edge server . The serv er’ s objectiv e is to compute a desired function, f ( s 1 , . . . , s K ) , of all local observ ations—such as an average or weighted sum—by performing post-processing on the aggregated signals receiv ed over the multiple access channel. AirComp exploits the wav eform superposition property of wireless channels to enable low-latency , bandwidth-ef ficient data aggregation in large-scale networks. In addition to FEEL and federated inference, two other prominent application scenarios of digital AirComp are dis- cussed below . 1) Federated conformal prediction: In federated conformal prediction, each client computes a local predictive probability vector for a given input sample [51]. Rather than transmitting raw data or full model parameters, clients transmit only these local prediction vectors; as sho wn in [34], they can be aggregated via digital AirComp to form calibrated prediction sets with guaranteed coverage. This approach enables reliable uncertainty quantification while substantially reducing com- munication overhead. 2) Multi-sensor collaborativ e localization: In collabora- tiv e localization, multiple sensors (such as distributed access points, base stations, or vehicles) collect noisy measurements of a target’ s position [52]. Each sensor computes a local statistic (e.g., a likelihood score or coordinate estimate) and transmits it to the edge serv er for fusion [53]. By le veraging digital AirComp, the server can efficiently aggregate these statistics to deriv e an accurate global position estimate, as discussed in [33]. This approach enables scalable and timely localization in dense IoT networks. a) Remark 1.: While FEEL can tolerate some quanti- zation errors during training due to the iterative nature of model updates [16], [2], inference-driv en applications such as federated conformal prediction and multi-sensor localization demand higher reliability and accuracy , as highlighted in [34], [33], [24]. Consequently , minimizing computational errors is generally the main optimization goal in digital AirComp schemes. A. MD-AirComp Overview By integrating communication and computation, MD- AirComp, as proposed in [1], [2], achiev es low communication latency while remaining compatible with existing digital wire- less networks. In this section, we first present the frame work of MD-AirComp, and the enhanced MD-AirComp+ will be introduced in the subsequent section. W e consider a system with K devices, where the continuous source signal generated by the k -th device is denoted as s k = [ s 1 k , s 2 k , . . . , s W k ] T ∈ R W , ∀ k ∈ [ K ] , with W representing the .. . Device 1 Device 2 Device K Server Pre-Processing Pre-Processing Pre-Processing Post-Processing Noise Fig. 1. Illustration of a typical digital AirComp scenario. dimension of each source signal. Then, each source signal is stochastically quantized to x k = [ x 1 k , x 2 k , . . . , x W k ] T ∈ R W using a codebook u = [ u 1 , . . . , u Q ] T ∈ R Q , where Q = 2 J denotes the number of codewords. For each symbol i ∈ [ W ] , the quantized signal is expressed as x i k = u T z i k , (1) where z i k ∈ { 0 , 1 } Q is the one-hot index vector corresponding to the k -th source. Collecting all index vectors across W sym- bols yields Z k = [ z 1 k , . . . , z W k ] ∈ { 0 , 1 } Q × W . For notational simplicity , we focus on a single symbol in the subsequent analysis and omit the index i . During the uplink transmission, the recei ved signal at the server Y ∈ C L × M is giv en by Y = g P K X k =1 z k h T k + N , (2) where P ∈ C L × Q denotes the random access preambles (or sensing matrix), L is the preamble length (i.e., the number of measurements), and N is additi ve white Gaussian noise (A WGN) with variance σ 2 per entry . According to [2], the function g ( · ) implements pre-equalization at the transmitters to mitigate channel distortion h k ∈ C M , where M denotes the number of antennas at the receiver . Based on Y , an estimate b z of the summation P K k =1 z k is obtained, from which the estimated av erage signal is b x = 1 K u T b z . (3) The true average signal is defined as ¯ s ≜ 1 K P K k =1 s k . a) Stochastic Uniform Quantizer .: W e employ the widely adopted stochastic uniform quantizer Q u ( · ) based on the predefined codebook u = [ u 1 , . . . , u Q ] T with Q = 2 J quantization le vels. For each entry of a W -dimensional source vector s k = [ s 1 k , . . . , s W k ] T , the quantizer randomly assigns the value to one of two adjacent code words according to its relativ e position between them. Specifically , for the i -th entry s i k , i ∈ [ W ] , we first determine an index l ∈ { 1 , . . . , Q − 1 } such that u l ≤ s i k < u l +1 . 4 Codebook-Based Modulation Quantization Signal 2 . . Codebook-Based Modulation Quantization Signal 1 Server Received Signal Detection Digital Aggregation Modulation Codebook Codebook-Based Modulation Quantization Signal K Quantization Codebook Channel Hardening Summed CSI Shared Codebooks Bandwidth Budget Optimal quantization level . . . Comp. Results Device K Device 2 Device 1 Fig. 2. Illustration of the proposed MD-AirComp+ scheme. Then the stochastic quantization output x i k is giv en by x i k = u l +1 , with probability s i k − u l u l +1 − u l , u l , otherwise . (4) Equiv alently , the index vector z i k ∈ { 0 , 1 } Q is a one-hot vector with the position corresponding to the randomly chosen codew ord. For inputs that are outside the codebook range, we define Q u ( s i k ) as the nearest boundary codeword, i.e., the codew ord corresponding to the extreme values of the code- book. This stochastic quantization ensures that the expectation of the quantized value equals the original continuous value within each quantization interv al [54]. It is worth noting that MD-AirComp can also lev erage vector quantization (VQ) to further improve communication efficienc y , as discussed in [1], [2]. In this paper, howe ver , we mainly focus on scalar quantization, while the extension to VQ is demonstrated in the simulation part. I I I . P R O P O S E D M D - A I R C O M P + S C H E M E This subsection highlights two critical limitations of the original MD-AirComp scheme and motiv ates the enhanced MD-AirComp+ design. 1) Sensitivity to channel reciprocity and estimation er - rors. The original MD-AirComp assumes reciprocity between the uplink and do wnlink channels. Thus, the estimated down- link channel is used at the transmitter for pre-equalization. Howe ver , as the channel estimation error increases, i.e., the function g ( · ) in (2) cannot perfectly pre-equalize the channel, the accuracy of the aggregated summation inevitably degrades. As for inference tasks, e.g., [34], [33], [24], such estimation errors directly impair performance and become unacceptable. 2) T rade-off between quantization and computing ac- curacy . General downstream tasks such as inference typi- cally demand much higher quantization fidelity than FEEL: finer quantization improv es accuracy but also increases the dimensionality of the target signal z . When combined with limited system resources (e.g., the preamble length L ), this higher signal dimension leads to more detection errors, which in turn e xacerbate reconstruction errors. Therefore, the trade- off between quantization precision and computational accu- racy poses a critical challenge for the original MD-AirComp scheme when applied to general computing tasks. 2 6 2 9 2 10 2 11 2 12 2 13 Number of Antennas M 10 -4 10 -3 10 -2 MSE c Fig. 3. Illustration of the channel hardening effect in massiv e MIMO system. Motiv ated by these challenges, we propose the MD- AirComp+ scheme, which is specifically designed to tackle the lack of accurate individual CSI for different users, and meet the quantization fidelity requirements for general computing tasks, while mitigating the impact of higher signal dimensions. A. Blind Channel Mitigation In our system, we leverage the principle of channel harden- ing, similar to the approach used in [20], [21]. In a massiv e MIMO system, as the number of antennas at the BS increases, the channel fading becomes more predictable and stable, leading to channel hardening [55]. This phenomenon causes the inner products of the channel vectors for the same user to approach a large constant value (related to M ), while the inner products between different users’ channel vectors approach zero, implying orthogonality between them. In our approach, we assume that at the initial time slot, K devices transmit a common pilot signal. The server then estimates the summation of the K channel vectors, i.e., h = P K k =1 h k , where each h k follows a complex Gaussian distribution (Rayleigh channel assumption). Estimating ¯ h via a common pilot requires much lower ov erhead than individual CSI. W ithout loss of generality , we assume that h is perfectly estimated. By multiplying h ∗ to the system model in (2), we obtain Y h ∗ M = P K X k =1 z k h T k h ∗ M + Nh ∗ M (5) ( a ) ≈ P K X k =1 z k + Nh ∗ M , where ( a ) ≈ is valid when M is sufficiently large. As illustrated in Figure 3, the y-axis represents the channel hardening metric MSE c = 1 K 2 H H H M − I K 2 F , where K = 10 and H = [ h 1 , h 2 , . . . , h K ] ∈ C M × K . It is evident from Figure 3 that MSE c decreases monotonically as the number of antennas increases, thereby empirically validating the channel hardening effect. In practical deployments, such as 5G NR systems with 5 256 antennas, this effect is sufficiently pronounced to stabilize the composite channel gain. The impact of non-ideal channel hardening under finite antenna counts will be e valuated in detail in the simulation section. B. LASSO-Based Sparse Signal Detection For notational simplicity , we reformulate (5) as y = Pz + n , (6) where y = Yh ∗ M and n = Nh ∗ M . This equation represents a sparse signal detection problem, where y is the observed noisy measurement, Pz is the signal model, and n is the noise. T o solv e this problem, we employ the iterativ e shrinkage- thresholding algorithm (IST A), which is commonly used to solve the least absolute shrinkage and selection operator (LASSO) problem. The LASSO problem is formulated as: ˆ z = arg min z 1 2 ∥ y − Pz ∥ 2 + ρ ∥ z ∥ 1 , (7) where ρ is a regularization parameter and ∥ z ∥ 1 is the ℓ 1 -norm that enforces sparsity on the solution vector z . W e begin by recalling the formulation of IST A [56]. The original algorithm aims at solving the LASSO problem through the iterative update equations: z ( t +1) ← T β z ( t ) − µ P H ( Pz ( t ) − y ) , (8) where T β is the soft-thresholding operator defined as: T β ( x ) = sign ( x ) · max(0 , | x | − β ) . (9) The parameter µ represents the step size. The conv ergence of IST A can be analyzed when the step size µ satisfies the condition: µ ≤ 1 λ max ( P H P ) , (10) where λ max ( P H P ) is the largest eigenv alue of P H P . This condition ensures the stability and conv ergence of the algo- rithm. Thus, we set µ = 1 λ max ( P H P ) . The iterative process is repeated until con vergence, provid- ing an estimate for the sparse vector ˆ z , which corresponds to the sparse signal we are detecting. I V . C O M M U N I C A T I O N A N D A C C U R AC Y T R A D E - O FF A N A L Y S I S W e no w decompose the recov ery error between the original signal average ¯ s and the reconstructed av erage b x into two terms. First, insert and subtract the quantized average ¯ x ≜ 1 K P K k =1 x k = 1 K u T P K k =1 z k : ¯ s − b x = ( ¯ s − ¯ x ) + ( ¯ x − b x ) = 1 K K X k =1 ( s k − x k ) | {z } (I): quantization term + u T 1 K K X k =1 z k − 1 K b z ! | {z } (II): detection term . (11) Now , we can compute the total error by taking the squared norm and expectation MSE ≜ E ∥ ¯ s − b x ∥ 2 2 (12) = E 1 K K X k =1 ( s k − x k ) | {z } a + u T 1 K ( K X k =1 z k − b z ) | {z } b 2 2 . Expanding the squared norm, we get the following additive upper bound: MSE ≤ 2 E ∥ a ∥ 2 2 + 2 E ∥ b ∥ 2 2 . (13) In the following, we analyze the two error terms one-by-one. A. Step 1 — quantization err or The scalar quantization step size is ∆ = 2 R 2 J , if each scalar of s k lies in [ − R, R ] . The per-scalar mean squared quantization error of a uniform quantizer is E ∥ s k − x k ∥ 2 2 = ∆ 2 12 = (2 R ) 2 12 · 4 J = R 2 3 · 4 J ≜ Q ( J ) , (14) where we explicitly emphasize the dependence on J . Due to the linearity and identical distrib ution of quantization errors across sources, we can deri ve E ∥ a ∥ 2 2 = E 1 K K X k =1 ( s k − x k ) 2 2 (15) = 1 K 2 K X k =1 E ∥ s k − x k ∥ 2 2 = 1 K Q ( J ) . B. Step 2 — LASSO for r ecovering z and its err or bound Under the typical assumptions, e.g., P satisfies restricted isometry property (RIP) conditions and noise is Gaussian, we can in voke a standard LASSO-type error bound. In our model, each device maps its signal to a single codeword; thus, the number of non-zero elements in the frequency vector z is ∥ z ∥ 0 ≤ min( K, 2 J ) ≤ K . While the actual sparsity ∥ z ∥ 0 may be smaller than K due to “collisions” (multiple devices falling into the same quantization bin) at low resolutions, we use K as a distribution-agnostic upper bound to deri ve a rob ust performance guarantee. Hence, a representative bound E b z − z 2 2 ≤ C 0 K σ 2 2 J log 2 J L , (16) holds with high probability provided that L = Ω( K log (2 J /K )) , where C 0 is a constant depending on the estimator and sensing matrix properties [57]. Then, according to the Cauchy–Schwarz inequality , its expected squared norm can be bounded as E ∥ b ∥ 2 2 ≤ ∥ 1 K u T ∥ 2 2 E ∥ b z − z ∥ 2 2 . ≤ C 0 ∥ u ∥ 2 2 σ 2 2 J log 2 J K L . (17) 6 Algorithm 1 Proposed MD-AirComp+ Scheme Require: Preamble length L (determined by bandwidth/latency con- straints); Noise variance σ 2 ; Number of devices K . Ensure: Aggregated result at the server . 1: Initialization: The server initiates a network-wide beacon trans- mission for time and frequency synchronization. 2: Channel Estimation: All de vices transmit a common pilot signal during the initial slot. The server estimates the composite channel via least-squares (LS) or linear minimum mean square error (LMMSE) based on the receiv ed pilots. 3: Adaptive Quantization: Given L , K , σ 2 , and the detection algorithm, determine the optimal quantization level Q according to (19). 4: Codeword Selection: Each device selects modulation codew ords Pz k based on the quantization in Step 3. 5: Simultaneous T ransmission: All active devices transmit their data-embedded preambles simultaneously over the uplink; the server receives the superposed signals. 6: Post-processing: The server multiplies y with ¯ h H / M to exploit the channel hardening effect. 7: Aggregation: The server solves the sparse recov ery problem, e.g., via (7), to find ˆ z , then computes the final estimated av erage ˆ x = 1 K u T ˆ z . a) T otal bound.: By applying (15) and (17) into (13), we can obtain the total upper bound as MSE ≲ 2 K Q ( J ) | {z } quantization + C 0 ∥ u ∥ 2 2 2 σ 2 2 J log 2 J K L | {z } detection (18) = 2 R 2 3 K 4 J + C 0 ∥ u ∥ 2 2 2 σ 2 2 J log 2 J K L . C. Optimal Q Analysis under Pr eamble Length L and SNR Constraints Since the number of quantization lev els is Q = 2 J , the MSE upper bound can be approximated as MSE ≲ 2 R 2 3 K Q 2 + C 0 ∥ u ∥ 2 2 2 σ 2 Q log Q K L . (19) It is evident that the MSE diver ges as Q → 0 + or Q → + ∞ , implying the existence of an optimal quantization level Q ∗ that minimizes the total error . Since the second deriv ative of the MSE with respect to Q is positiv e for all Q > 0 , the objectiv e function is strictly con vex, ensuring that any critical point corresponds to a unique global minimum. The MSE performance is governed by a fundamental trade- off between quantization resolution and detection robustness under a fixed preamble length L . Specifically , as Q increases, the quantization distortion decreases due to the finer resolution fidelity . Ho wever , since L represents a finite bandwidth b udget, a lar ger Q renders the sparse recovery problem increasingly underdetermined as the sensing matrix P ∈ C L × Q becomes “fatter”. This expansion of the hypothesis space causes the detection error to gro w , ev entually outweighing the gains in quantization precision. Although our analytical bound (16) uses K as a conserv ative proxy for the sparsity ∥ z ∥ 0 ≤ K , it accurately captures the U-shaped scaling law and the existence of an optimal Q ∗ . The optimal lev el thus represents the equi- librium point where the marginal improvement in quantization accuracy is perfectly balanced against the escalating risk of detection failure under limited observ ation resources. Finally , the proposed MD-AirComp+ scheme is summarized in Algorithm 1. The ke y difference compared to MD-AirComp is the handling of CSI and the quantization parameter selection according to the gi ven bandwidth and the noise lev el. V . L O W - C O M P L E X I T Y D E T E C T I O N A L G O R I T H M D E S I G N While the IST A provides a principled approach to solving the LASSO problem, its conv ergence rate can be relativ ely slow because both the step size µ and the thresholding param- eter β are fixed during iterations. Inspired by the idea of algo- rithm unfolding, the learned IST A (LIST A) [56] accelerates the con vergence by treating the parameters and operators in volved in the IST A update as learnable. Specifically , LIST A learns the optimal step sizes and thresholding parameters at each iteration from data, and generalizes the fixed matrices in IST A into trainable linear transforms. This data-driv en adaptation allows LIST A to achieve faster con ver gence and improved recov ery accuracy compared to the traditional IST A [58]. W e adopt the unfolded form of IST A by parameterizing the iteration-dependent step sizes, thresholds, and linear operators. Giv en the IST A formulation (8), LIST A replaces the fixed parameters with learnable ones z ( t +1) ← T β ( t ) z ( t ) − µ ( t ) Bz ( t ) + Ay , (20) where A , B , { β ( t ) , µ ( t ) } are all trainable parameters learned from data. The soft-thresholding operator T β ( t ) ( · ) is applied element-wise at each iteration. The adopted IST A and LIST A algorithms are summarized in Algorithm 2. Unlike IST A which uses a conservati ve fixed step size to guarantee con- ver gence for any sparse signal, LIST A learns the underlying distribution of the sensing matrix P and the data. By em- ploying data-dri ven weights, it can effecti vely “na vigate” the optimization landscape more efficiently , resulting in the 25- fold complexity reduction observed in Figure 4. a) Remark 2.: While this work does not aim to optimize the detection module itself, it is worth noting that adv anced message-passing and Bayesian inference frame works exploit- ing prior statistical information, such as [59], are in principle capable of handling the detection challenges encountered in blind MD-AirComp systems. Integrating such approaches with the proposed quantization-adaptiv e framework is an interesting direction for future w ork. V I . S I M U L A T I O N R E S U LTS In the simulations, the number of active devices is set to K = 10 , where each device generates a random v alue drawn from a uniform distribution over the interv al [0 , 1] . The choice of [0 , 1] is general: it can represent probabilistic outcomes of inference tasks such as classification [34], or alternativ ely , coordination within a normalized square area [33]. The modulation codebook P 0 is a fix ed matrix, where each element is drawn from a complex Gaussian distribution, with dimensions 60 × 256 . This codebook is shared between the transmitter and the receiver . A subset of the codebook, denoted as P , is selected from P 0 , corresponding to a subarray 7 Algorithm 2 IST A and LIST A Update Rules Require: Measurement y , sensing matrix P , maximum iteration T and T ′ for IST A and LIST A. Ensure: Estimated sparse signal z ( T ) 1: IST A: 2: Initialize z (0) = 0 ; set step size µ = 1 L with L = λ max ( P H P ) ; 3: for t = 0 to T − 1 do 4: z ( t +1) ← T β z ( t ) − µ P H Pz ( t ) − y ; 5: end for 6: LIST A: 7: Initialize z (0) = 0 ; learnable { A , B , β ( t ) , µ ( t ) } from training data; 8: for t = 0 to T − 1 do 9: z ( t +1) ← T β ( t ) z ( t ) − µ ( t ) Bz ( t ) + A y ; 10: end for 11: return z ( T ) . 0 50 100 150 200 250 300 Number of Iterations 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 MSE ISTA Improved ISTA LISTA Improved LISTA x 25 Fig. 4. Conv ergence and MSE comparison: IST A versus LIST A and their improved variants of size L × Q , where the parameters L and Q are adjustable. The number of antennas is set to M = 1024 , unless otherwise specified. The noise is modeled as complex Gaussian noise, and the massive MIMO channel under goes Rayleigh fading. W e consider the MSE metric as defined in (12). A. Con ver gence of the LIST A Algorithm Figure 4 illustrates the con vergence beha vior and MSE performance of IST A, LIST A, and their improv ed variants, namely “Improved IST A ” and “Improved LIST A. ” In this case, we set L = 25 , Q = 32 , and SNR = 10 dB. The improv ed versions incorporate prior information to enhance performance further . Specifically , because the non-zero elements in z are integers, we apply rounding to the estimated v alues of b z after IST A/LIST A estimation. It is e vident from the results that LIST A con verges after just 10 iterations, whereas IST A re- quires 25 times more iterations. Furthermore, LIST A naturally incorporates the integer constraint through parameter training, while IST A fails to do so, leading to a higher MSE plateau. After applying the improv ed IST A, the final con ver gence plateau slightly exceeds that of LIST A, but at a significantly higher computational cost. Therefore, LIST A pro ves to be an effecti ve method in applications where lower computational 1 2 3 4 5 6 7 8 Quantization Bits J (Since Q = 2 J ) 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 MSE L = 10 L = 20 L = 30 L = 40 L = 50 (a) 10 20 30 40 50 Preamble Length L 10 -6 10 -5 10 -4 10 -3 10 -2 MSE Q=4 Q=16 Q=32 Q=32 Q=64 SNR = -5 dB SNR = 0 dB SNR = 10 dB SNR = 20 dB Q=8 Q=16 Q=32 Q=64 Q=128 (b) Fig. 5. (a) MSE versus the number of quantization levels Q , with fixed L and SNR = 20 dB. (b) Optimal number of quantization le vels Q ∗ versus preamble length L . ov erhead is desired, achieving ov er 25 times reduction in complexity with only a minor loss in detection accuracy . In the subsequent analysis, we use the “Improv ed IST A ” algorithm with 300 iterations, which ensures optimal performance. B. Optimal Q Selection Figure 5 illustrates the impact of quantization lev els Q ∈ { 2 1 , . . . , 2 8 } , preamble length L , and SNR on the MSE performance. As sho wn in Figure 5(a), with SNR set to 20 dB, the MSE exhibits a prominent U-shaped trend as Q increases. This reveals a fundamental design trade-of f: the total error is gov erned by a quantization-limited region on the left, where a coarse codebook causes high distortion, and a detection- limited region on the right, where a larger Q increases the dimensionality of the sparse vector z , thereby exacerbating recov ery errors under limited preamble resources. The optimal Q ∗ thus represents the equilibrium point that minimizes the total MSE for a gi ven L . Specifically , Figure 5(b) confirms that as the bandwidth (preamble length L ) increases, the optimal 8 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 2 10 Quantization Levels ( Q ) 0 10 20 30 40 50 60 70 80 90 100 110 K =10 (Uniform) K =10 (Gaussian =0.15) K =50 (Uniform) K =50 (Gaussian =0.15) K =100 (Uniform) K =100 (Gaussian =0.15) Fig. 6. Effectiv e sparsity ∥ z ∥ 0 versus quantization levels Q for different K and data distributions. MSE decreases significantly , highlighting the practical benefits of our adaptive quantization strategy . Notably , the preamble length L exerts a more dominant influence on Q ∗ selection than the SNR; while v ariations between 5 and 20 dB hav e minimal impact, detection performance only degrades sharply at very low SNR (e.g., 0 dB), leading to a shift toward smaller optimal Q . C. Insight on Sparsity Dynamics Figure 6 explores the dynamics of effecti ve sparsity ∥ z ∥ 0 across v arying Q and K . At low-to-medium resolutions, “collision-induced sparsification” limits ∥ z ∥ 0 significantly be- low K , acting as a self-regulating mechanism that pre vents detection complexity from scaling linearly with device density . This ensures system robustness in the quantization-limited region ev en as K increases. Furthermore, non-uniform data distributions (e.g., truncated Gaussian N (0 . 5 , 0 . 15 2 ) ) further intensify this effect compared to the uniform case. As Q grows, ∥ z ∥ 0 con verges to K , escalating detection challenges within the high-dimensional search space. This behavior con- firms that using K in the MSE bound (16) provides a robust, worst-case estimate and justifies the existence of an optimal Q ∗ that balances resolution fidelity against the challenges of sparse recovery across v arying AIoT network densities. D. Effect of Antenna Number M Figure 7 illustrates the MSE performance as a function of the number of receive antennas M at SNR = 20 dB. As M increases, the channel hardening ef fect becomes more pro- nounced, leading to a more stable composite channel gain and a corresponding reduction in MSE. Notably , the experimental results in Figure 7 are shown to asymptotically approach the “Ideal” baseline—which represents a pure A WGN scenario with constant SNR. This con ver gence proves that in practical massiv e MIMO scales, the proposed MD-AirComp+ frame- work ef fectiv ely mitigates channel fading and achiev es near- optimal computation accuracy . Most importantly , it demon- strates that such high performance can be maintained without 100 200 300 400 500 600 700 800 900 1000 Number of Antennas M 10 -5 10 -4 10 -3 10 -2 MSE L =20, Q =16 L =20, Q =16, Ideal L =30, Q =32 L =30, Q =32, Ideal Fig. 7. MSE versus the number of receive antennas M . 0 5 10 15 20 SNR (dB) 10 -4 10 -3 10 -2 10 -1 MSE Scalar 2-bit ( Q =4) Vector 2-bit ( Q =4) Vector 3-bit ( Q =8) Vector 4-bit ( Q =16) Vector 5-bit ( Q =32) Vector 6-bit ( Q =64) Fig. 8. Comparison of MSE vs. SNR for various quantization schemes with the same total channel uses. the overhead of acquiring precise individual CSI, validating the robustness of our blind mitigation strategy . E. V ector-Quantized MD-AirComp+ The extension of scalar quantization, as outlined in (1), to VQ is straightforward and does not change the system model (2) or the detection framew ork. Ho wev er , we hypothesize that VQ-based MD-AirComp+ of fers superior computational accuracy compared to the scalar quantization counterpart, particularly in bandwidth-constrained en vironments. T o substantiate this claim, we simulate a scenario inspired by federated conformal prediction [34]. Each de vice indepen- dently generates a 10 -dimensional probability vector , which corresponds to the softmax output in classification tasks. The simulation setup considers K = 10 devices and a fixed total of L = 40 channel uses. In the scalar quantization baseline, the vector is transmitted element-wise, using L 10 = 4 channel uses per element (thus, the scalar quantization le vel is limited to Q = 4 ). In contrast, for the VQ approach, a shared codebook of Q centroids { c 1 , . . . , c Q } is pre-constructed via K-means clustering on a representati ve probability simplex [2]. Each 9 device maps its 10-dimensional vector to the nearest centroid and transmits the index in one shot using the full L = 40 resources. Since the codebook is shared, the server’ s task remains the recovery of the frequency vector z (i.e., the count of de vices assigned to each centroid). This demonstrates that our detection framework is inherently agnostic to the dimen- sionality of the source, effecti vely le veraging the structured nature of VQ to reduce distortion within the same bandwidth constraint. W e ev aluate multiple VQ codebook sizes, Q ∈ { 4 , 8 , 16 , 32 , 64 } , to assess the impact on performance. De- pending on the relationship between L and Q , the modulation codebook and detection algorithm are chosen accordingly . Specifically , when L ≥ Q , the Q columns of the modulation codebook P are selected from an L × L normalized discrete Fourier transform matrix, and a matched-filter receiver is used. When L < Q , a submatrix from P 0 is used, and signal recov ery is carried out via Algorithm 2. The numerical results are presented in Figure 8. As illustrated in Figure 8, for a total channel uses of L = 40 , all VQ-based schemes outperform the scalar quantized ap- proach in terms of computing MSE. This performance en- hancement stems from the exploitation of the structured nature of the probability vectors in the VQ scheme, allo wing for lower distortion, especially at very lo w rates. Notably , when Q = 64 , the detection problem becomes underdetermined, leading to a degradation in MSE performance at lo w SNRs, specifically for SNR < 10 dB. This observation highlights the inherent trade-off between computational accuracy and com- munication o verhead in VQ-based setups, where excessi vely large codebook sizes may introduce additional detection errors, thus compromising overall performance. V I I . C O N C L U S I O N W e propose the MD-AirComp+ framework for ef ficient uplink computation in large-scale networks, le veraging mas- siv e MIMO properties to a void channel pre-equalization. The framew ork adaptiv ely selects the optimal quantization lev el, balancing accurac y and communication overhead. Through MSE analysis, we identify the optimal quantization level that minimizes computing error under limited resources. Addition- ally , a deep unfolding method is introduced to reduce receiver - side detection complexity , achieving 25x faster conv ergence with enhanced performance through prior information. Our approach of fers an ef ficient and scalable solution for appli- cations like collaborativ e inference and federated conformal predictions in wireless netw orks. R E F E R E N C E S [1] L. Qiao, Z. Gao, Z. Li, and D. G ¨ und ¨ uz, “Unsourced massiv e access- based digital ov er-the-air computation for efficient federated edge learn- ing, ” in Pr oc. IEEE Int. Symp. Inf. Theory (ISIT) , (T aipei, T aiwan), pp. 2003–2008, 2023. [2] L. Qiao, Z. Gao, M. B. Mashhadi, and D. G ¨ und ¨ uz, “Massive digital over -the-air computation for communication-efficient federated edge learning, ” IEEE J. Select. Areas Commun. , vol. 42, no. 11, pp. 3078– 3094, 2024. [3] J. Zhang and D. T ao, “Empowering things with intelligence: A survey of the progress, challenges, and opportunities in artificial intelligence of things, ” IEEE Internet Things J. , vol. 8, no. 10, pp. 7789–7817, 2020. [4] H. Liu et al. , “Near-space communications: The last piece of 6g space–air–ground–sea integrated network puzzle, ” Space: Science & T echnology , vol. 4, p. 0176, 2024. [5] X. Liu et al. , “T oward near-space communication network in the 6G and beyond era, ” Space: Science & T echnology , vol. 5, p. 0337, 2025. [6] Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning, ” natur e , vol. 521, no. 7553, pp. 436–444, 2015. [7] X. W ang, Z. T ang, J. Guo, T . Meng, C. W ang, T . W ang, and W . Jia, “Empowering edge intelligence: A comprehensive survey on on-device AI models, ” A CM Computing Surve ys , vol. 57, no. 9, pp. 1–39, 2025. [8] D. C. Nguyen, M. Ding, P . N. Pathirana, A. Seneviratne, J. Li, and H. V . Poor , “Federated learning for internet of things: A comprehensiv e sur- vey , ” IEEE Commun. Surv . T utor . , vol. 23, pp. 1622–1658, thirdquarter 2021. [9] M. B. Mashhadi, M. Mahdavimoghadam, R. T afazolli, and W . Saad, “Collaborativ e learning with a drone orchestrator , ” IEEE T rans. V eh. T echnol. , vol. 73, no. 1, pp. 637–650, 2023. [10] D. G ¨ und ¨ uz, D. B. Kurka, M. Jankowski, M. M. Amiri, E. Ozfatura, and S. Sreekumar, “Communicate to learn at the edge, ” IEEE Commun. Mag. , vol. 58, pp. 14–19, Dec. 2020. [11] N. Shlezinger and I. V . Baji ´ c, “Collaborative inference for AI- empowered IoT devices, ” IEEE Internet Things J. , vol. 5, no. 4, pp. 92– 98, 2023. [12] C. Zhang, X. Zheng, X. T ao, C. Hu, W . Zhang, and L. Zhu, “Distributed collaborativ e inference system in next-generation networks and commu- nication, ” IEEE T rans. Cogn. Commun. Netw . , 2025. [13] L. Qiao, M. B. Mashhadi, Z. Gao, R. T afazolli, M. Bennis, and D. Niyato, “T oken communications: A large model-dri ven framew ork for cross-modal context-a ware semantic communications, ” IEEE W ireless Commun. , vol. 32, no. 5, pp. 80–88, 2025. [14] A. S ¸ ahin and R. Y ang, “ A survey on over -the-air computation, ” IEEE Commun. Surv . T utor . , vol. 25, pp. 1877–1908, thirdquarter 2023. [15] M. M. Amiri and D. G ¨ und ¨ uz, “Federated learning over wireless fading channels, ” IEEE T rans. W ireless Commun. , vol. 19, pp. 3546–3557, May 2020. [16] G. Zhu, Y . W ang, and K. Huang, “Broadband analog aggregation for low-latenc y federated edge learning, ” IEEE T rans. Wir eless Commun. , vol. 19, pp. 491–506, Jan. 2020. [17] M. M. Amiri and D. G ¨ und ¨ uz, “Machine learning at the wireless edge: Distributed stochastic gradient descent over -the-air, ” IEEE T rans. Signal Pr ocessing , vol. 68, pp. 2155–2169, Mar. 2020. [18] K. Y ang, T . Jiang, Y . Shi, and Z. Ding, “Federated learning via over - the-air computation, ” IEEE T rans. W ireless Commun. , vol. 19, pp. 2022– 2035, Mar . 2020. [19] Y . Shao, D. G ¨ und ¨ uz, and S. C. Liew , “Federated edge learning with misaligned over -the-air computation, ” IEEE T rans. W ireless Commun. , vol. 21, pp. 3951–3964, Jun. 2022. [20] M. M. Amiri, T . M. Duman, D. G ¨ und ¨ uz, S. R. Kulkarni, and H. V . Poor , “Blind federated edge learning, ” IEEE T rans. W ir eless Commun. , vol. 20, no. 8, pp. 5129–5143, 2021. [21] S. Razavikia, J. M. B. D. S. J ´ unior , and C. Fischione, “Blind federated learning via over -the-air q-QAM, ” IEEE T rans. W ireless Commun. , 2024. [22] M. Chen, D. G ¨ und ¨ uz, K. Huang, W . Saad, M. Bennis, A. V . Feljan, and H. V . Poor, “Distrib uted learning in wireless networks: Recent progress and future challenges, ” IEEE J. Select. Areas Commun. , vol. 39, pp. 3579–3605, Dec. 2021. [23] A. Zheng, W . Ni, W . W ang, H. Tian, Y . C. Eldar, and C. Y uen, “Multi- functional RIS for distributed over-the-air computation in base station free environments, ” IEEE T rans. Commun. , vol. 73, no. 10, pp. 8840– 8855, 2025. [24] S. F . Y ilmaz, B. Hasırcıo, L. Qiao, D. G ¨ und ¨ uz, et al. , “Private collabo- rativ e edge inference via over-the-air computation, ” IEEE T rans. Mach. Learn. Commun. Netw . , 2025. [25] Z. Zhou, J. Xie, M. Huang, T . Ouyang, F . Liu, and X. Chen, “T owards federated inference: An online model ensemble framework for cooper- ativ e edge AI, ” in Pr oc. IEEE Int. Conf. on Computer Communications (INFOCOM) , pp. 1–10, IEEE, 2025. [26] W . F . Lo, N. Mital, H. Wu, and D. G ¨ und ¨ uz, “Collaborative semantic communication for edge inference, ” IEEE W ir eless Commun. Lett. , vol. 12, no. 7, pp. 1125–1129, 2023. [27] Z. Liu, Q. Lan, A. E. Kalør , P . Popovski, and K. Huang, “Over-the- air multi-vie w pooling for distributed sensing, ” IEEE Tr ans. W ir eless Commun. , vol. 23, no. 7, pp. 7652–7667, 2023. [28] 3GPP , “5G NR overall description stage-2, ” T ech. Rep. TS 38.300 V15.3.1, 3rd Generation Partnership Project (3GPP), Oct. 2018. 10 [29] G. Zhu, Y . Du, D. G ¨ und ¨ uz, and K. Huang, “One-bit over-the-air aggregation for communication-ef ficient federated edge learning: Design and conver gence analysis, ” IEEE T rans. Wir eless Commun. , vol. 20, pp. 2120–2135, Mar. 2021. [30] A. S ¸ ahin, “Distributed learning over a wireless network with non- coherent majority vote computation, ” IEEE T rans. W ireless Commun. , vol. 22, pp. 8020–8034, Nov . 2023. [31] A. S ¸ ahin, “Over-the-air computation based on balanced number systems for federated edge learning, ” IEEE T rans. W ir eless Commun. , vol. 23, no. 5, pp. 4564–4579, 2024. [32] Y . Miao, W . Ni, and H. T ian, “One-bit aggreg ation for over-the-air federated learning against Byzantine attacks, ” IEEE Signal Pr ocessing Lett. , vol. 31, pp. 1024–1028, 2024. [33] K.-H. Ngo, D. P . Krishnan, K. Okumus, G. Durisi, and E. G. Str ¨ om, “T ype-based unsourced multiple access, ” in Pr oc. IEEE Int. W orkshop Signal Process. Adv . W ireless Commun. (SP A WC) , pp. 911–915, IEEE, 2024. [34] M. Zhu, M. Zecchin, S. Park, C. Guo, C. Feng, and O. Simeone, “Fed- erated inference with reliable uncertainty quantification over wireless channels via conformal prediction, ” IEEE Tr ans. Signal Pr ocessing , vol. 72, pp. 1235–1250, 2024. [35] S. Razavikia, J. M. Barros da Silva, and C. Fischione, “ChannelComp: A general method for computation by communications, ” IEEE Tr ans. Commun. , vol. 72, no. 2, pp. 692–706, 2024. [36] S. Razavikia, J. M. B. da Silva, and C. Fischione, “SumComp: Coding for digital ov er-the-air computation via the ring of inte gers, ” IEEE T rans. Commun. , vol. 73, no. 2, pp. 752–767, 2024. [37] S. Li, M. A. Maddah-Ali, Q. Y u, and A. S. A vestimehr , “ A fundamental tradeoff between computation and communication in distributed com- puting, ” IEEE T rans. Inform. Theory , vol. 64, no. 1, pp. 109–128, 2017. [38] D. Jhunjhunwala, A. Gadhikar, G. Joshi, and Y . C. Eldar , “ Adaptiv e quantization of model updates for communication-ef ficient federated learning, ” in Pr oc. IEEE Int. Conf . Acoust. Speech Sig. Pr ocess. , (T oronto, ON, Canada), 2021. [39] A. R. et al., “FedP A Q: A communication-efficient federated learning method with periodic averaging and quantization, ” in Int. Conf. Artif. Intell. Stat. , pp. 2021–2031, 2020. [40] L. Qu, S. Song, and C.-Y . Tsui, “Feddq: Communication-ef ficient federated learning with descending quantization, ” in Pr oc. IEEE Global Commun. Conf. (GLOBECOM) , (Rio de Janeiro, Brazil), pp. 281–286, 2022. [41] X. Chen, D. W . K. Ng, W . Y u, E. G. Larsson, N. Al-Dhahir, and R. Schober , “Massive access for 5G and beyond, ” IEEE J. Select. Ar eas Commun. , vol. 39, pp. 615–637, Mar . 2021. [42] Z. Gao et al., “Compressiv e-sensing-based grant-free massi ve access for 6G massiv e communication, ” IEEE Internet Things J. , vol. 11, no. 5, pp. 7411–7435, 2023. [43] M. Ke et al., “Compressiv e sensing-based adaptive active user detection and channel estimation: Massiv e access meets massiv e MIMO, ” IEEE T rans. Signal Pr ocessing , vol. 68, pp. 764–779, 2020. [44] L. Qiao, J. Zhang, Z. Gao, D. W . K. Ng, M. Di Renzo, and M.-S. Alouini, “Massive access in media modulation based massiv e machine- type communications, ” IEEE T rans. W ireless Commun. , vol. 21, no. 1, pp. 339–356, 2021. [45] Y . Polyanskiy , “ A perspective on massive random-access, ” Pr oc. IEEE Int. Symp. Inform. Theory (ISIT) , pp. 1–5, Jun. 2017. [46] Y . W u, X. Gao, S. Zhou, W . Y ang, Y . Polyanskiy , and G. Caire, “Massiv e access for future wireless communication systems, ” IEEE W ireless Commun. , vol. 27, no. 4, pp. 148–156, 2020. [47] T . Li, Y . W u, M. Zheng, W . Zhang, C. Xing, J. An, X.-G. Xia, and C. Xiao, “Joint device detection, channel estimation, and data decoding with collision resolution for mimo massiv e unsourced random access, ” IEEE J. Select. Ar eas Commun. , vol. 40, no. 5, pp. 1535–1555, 2022. [48] M. Ke et al., “Next-generation URLLC with massiv e devices: A unified semi-blind detection framew ork for sourced and unsourced random access, ” IEEE J . Select. Ar eas Commun. , vol. 41, no. 7, pp. 2223–2244, 2023. [49] G. Liv a and Y . Polyanskiy , “Unsourced multiple access: A coding paradigm for massive random access, ” Proc. IEEE , 2024. [50] G. Mergen and L. T ong, “T ype based estimation over multiaccess channels, ” IEEE Tr ans. Signal Pr ocessing , vol. 54, no. 2, pp. 613–626, 2006. [51] P . Humbert, B. Le Bars, A. Bellet, and S. Arlot, “One-shot federated con- formal prediction, ” in Proc. Int. Conf. Mach. Learn. (ICML) , pp. 14153– 14177, PMLR, 2023. [52] M. Ke et al., “Massi ve access in cell-free massive MIMO-based Internet of Things: Cloud computing and edge computing paradigms, ” IEEE J. Select. Ar eas Commun. , vol. 39, no. 3, pp. 756–772, 2020. [53] L. Qiao et al., “Sensing user’ s activity , channel, and location with near- field extra-lar ge-scale MIMO, ” IEEE T rans. Commun. , vol. 72, no. 2, pp. 890–906, 2023. [54] A. T . Suresh, X. Y . Felix, S. Kumar, and H. B. McMahan, “Distributed mean estimation with limited communication, ” in Pr oc. Int. Conf. Mach. Learn. (ICML) , pp. 3329–3337, PMLR, 2017. [55] L. Lu, G. Y . Li, A. L. Swindlehurst, A. Ashikhmin, and R. Zhang, “ An overvie w of massiv e MIMO: Benefits and challenges, ” IEEE J. Sel. T opics Signal Pr ocess. , vol. 8, no. 5, pp. 742–758, 2014. [56] K. Gregor and Y . LeCun, “Learning fast approximations of sparse coding, ” in Pr oc. Int. Conf. Mach. Learn. (ICML) , pp. 399–406, 2010. [57] E. J. Candes and M. A. Davenport, “How well can we estimate a sparse vector?, ” Applied and Computational Harmonic Analysis , vol. 34, no. 2, pp. 317–323, 2013. [58] N. Shlezinger, J. Whang, Y . C. Eldar , and A. G. Dimakis, “Model-based deep learning, ” Pr oc. IEEE , vol. 111, no. 5, pp. 465–499, 2023. [59] L. Qiao et al., “Joint activity and blind information detection for U A V- assisted massive IoT access, ” IEEE J. Select. Areas Commun. , vol. 40, no. 5, pp. 1489–1508, 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment