Accurate Data-Based State Estimation from Power Loads Inference in Electric Power Grids
Accurate state estimation is a crucial requirement for the reliable operation and control of electric power systems. Here, we construct a data-driven, numerical method to infer missing power load values in large-scale power grids. Given partial obser…
Authors: Philippe Jacquod, Laurent Pagnier, Daniel J. Gauthier
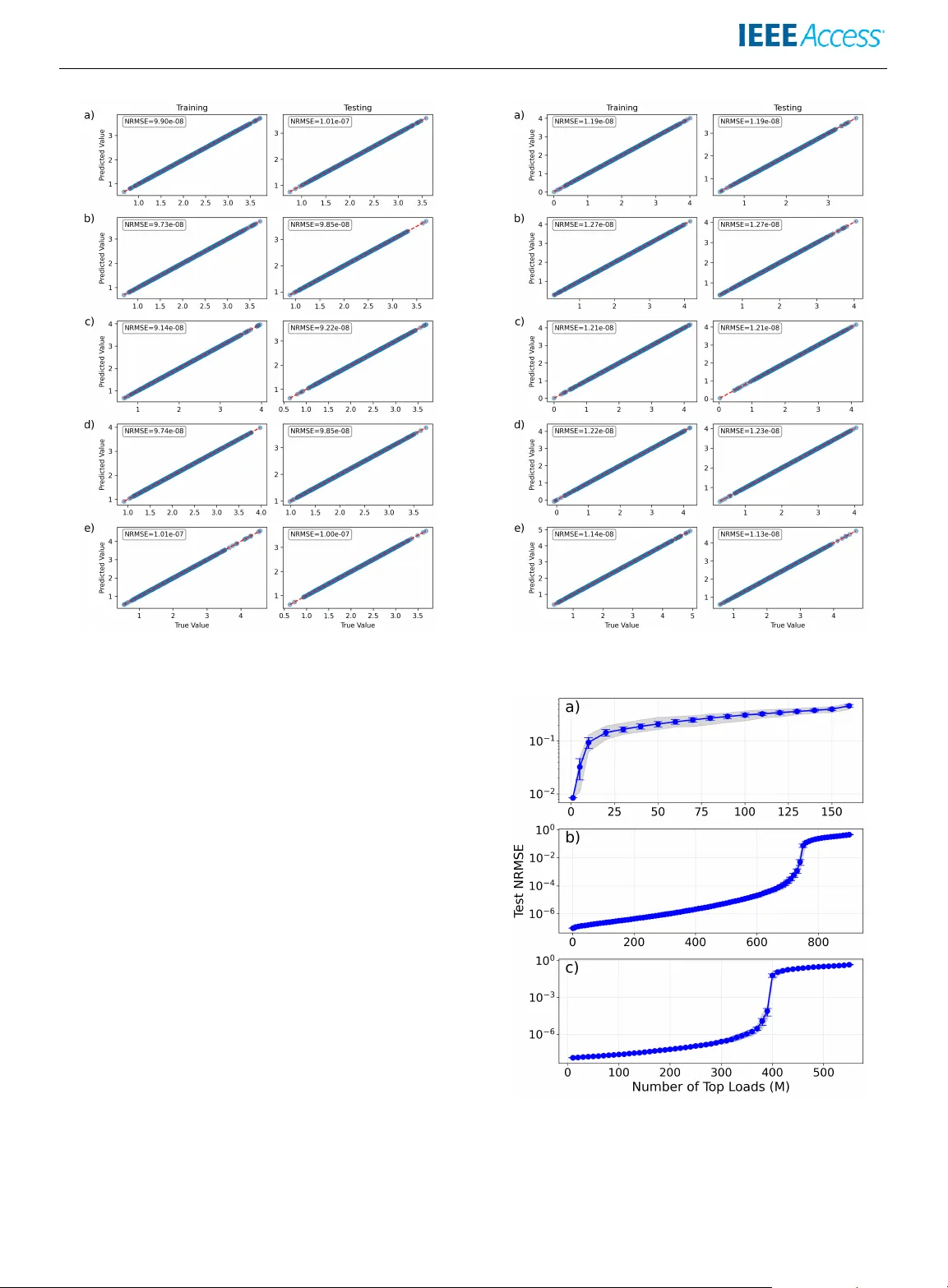
Digital Object Identifier 10.1109/ACCESS.2026.DOI Accurate Data-Based State Estimation fr om P o wer Loads Inference in Electric P o wer Grids PHILIPPE JA CQ UOD 1,2 , (Member , IEEE), LA URENT P A GNIER 3 , (MEMBER, IEEE) AND D ANIEL J. GA UTHIER 4 , 1 Department of Quantum Matter Physics, Univ ersity of Geneva, Gene va, Switzerland 2 School of Engineering, Univ ersity of Applied Sciences of W estern Switzerland HES-SO, Sion, Switzerland 3 Department of Mathematics, The Univ ersity of Arizona, Tucson, AZ 85721, USA 4 ResCon T echnologies, 1275 Kinnear Rd., Columbus, OH 43212, USA Corresponding author: Philippe Jacquod (e-mail: philippe.jacquod@unige.ch). PJ is grateful to the Andlinger Center for Energy and En vironment, Princeton Univ ersity , for its hospitality during the early stages of this project. ABSTRA CT Accurate state estimation is a crucial requirement for the reliable operation and control of electric power systems. Here, we construct a data-driv en, numerical method to infer missing po wer load values in large-scale power grids. Gi ven partial observ ations of power demands, the method estimates the operational state using a linear regression algorithm, e xploiting statistical correlations within synthetic training datasets. W e ev aluate the performance of the method on three synthetic transmission grid test systems. Numerical experiments demonstrate the high accuracy achie ved by the method in reconstructing missing demand values under various operating conditions. W e further apply the method to real data for the transmission po wer grid of Switzerland. Despite the restricted number of observations in this dataset, the method infers missing po wer loads rather accurately . Furthermore, Ne wton-Raphson po wer flo w solutions sho w that deviations between true and inferred v alues for po wer loads result in smaller de viations between true and inferred values for flows on power lines. This ensures that the estimated operational state correctly captures potential line contingencies. Overall, our results indicate that simple data-based regression techniques can provide an ef ficient and reliable alternativ e for state estimation in modern power grids. INDEX TERMS Electric Power System, Machine Learning, State Estimation. I. INTR ODUCTION Electric power systems are undergoing fundamental changes in their mode of operation. The decarbonization of the energy system requires a transition to ward renew able electricity gen- eration, replacing centralized, dispatchable generators based on grid-stabilizing rotating machines, with intermittent, ge- ographically distributed, and inertialess generators [1], [2]. Ensuring a safe supply of electricity as well as the stability of present and future po wer grids with large penetrations of rene wable energy poses significant challenges [3]–[7]. In particular , po wer grids increasingly operate closer to their operational limits [8], requiring fast and appropriate remedial actions by system operators. T o enable rapid response and effecti ve correctiv e measures, grid operators need to kno w the state of the system with maximum accuracy . T o this end, power grids are being further modernized through smart grid technologies, including advanced sensing and enhanced com- munication systems for real-time monitoring and control [9]. A precise representation of the operating state is the basis on which grid operators analyze the system, e valuate its security and stability , and decide on correctiv e measures and remedial actions. This typically relies on lar ge, multiv ariate sets of data, e.g. , on power injection, voltage amplitude, phase, and frequency at each substation, on the power flow on each line and so forth, acquired and transmitted via the Supervisory Control and Data Acquisition (SCAD A) system. These datasets are, ho wev er , often marred with errors, where data are missing or wrong due to faulty acquisition, erroneous transmission, or following a deception cyber-attack with false data injection [10]. Such occurrences will most certainly multiply in the future because the massiv e deployment of smart grid technologies increases the number of entrance doors to the communication system and the probability that one or a few electronic components malfunction [11]. It is imperativ e to de velop algorithmic solutions that detect such VOLUME 4, 2016 1 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids data anomalies and estimate the operating state of the system without the knowledge of missing or f aulty data. Data-based algorithms are natural candidates for anomaly detection and state estimation in the presence of missing or faulty data, regardless of the origin of the anomaly [12], [13]. Owing to their computational simplicity , the industry standard for state estimation is weighted least-square meth- ods, where the operating state is guessed as a minimum of a parabolic (conv ex) cost function [14]–[17]. They effecti vely find a local minimum to what is, in principle, a highly nonlinear problem. Not une xpectedly , Artificial Intelligence (AI) algorithms, such as genetic algorithms, particle swarm optimization algorithms, and neural networks, have been proposed to solve such nonlinear problems [18]–[23]. T o the best of our kno wledge, earlier works achie ve best estimates for state v ariables, which are v oltage magnitude and phases on all buses, i.e. the nodes on the network representing the power grid. Once these variables are known, the state of the system is unambiguously determined. The flows on each power line is easily computed from the power flow equations, provided the grid topology is kno wn [24]. In this work, we take a complementary approach by in- ferring not state variables, but instead acti ve and reactive power demands at load buses, i.e. , control v ariables. Our in vestigations are based on earlier works, where we con- structed a model for the synchronous transmission power grid of continental Europe [25]–[27], and generated large sets of statistically realistic data for such power grids, intended to be used for training and testing of machine learning (ML) algorithms [28], [29]. Using these two sets of tools, we train a simple linear regression algorithm, which deliv ers accu- rate estimates for po wer injections at each of the network’ s thousands of load nodes, e ven with rather large fractions of missing data. W e further apply our algorithm to a size- limited dataset of real historical data for the high v oltage transmission grid of Switzerland, where we show that not only the estimation of po wer injections is accurate, b ut that, once incorporated into a Newton-Raphson po wer flow solver , electric po wer flows on all lines are also estimated accurately . Our nov el contributions are demonstrating that: • state estimation in large electric power grids is success- ful using a simple, linear regression algorithm; • the model infers activ e po wer demands at load buses, i.e. , control v ariables, using only av ailable data; • the model works for synthetic data representing po wer grids of different sizes and po wer generation mixes; • the model works for a real power grid with historical data for activ e power generation. II. NO T A TION AND DEFINITIONS The stationary , operational state of a power grid is described by the solution to the power flo w equations, p i = X j v i v j [ G ij cos( θ i − θ j ) + B ij sin( θ i − θ j )] , (1a) q i = X j v i v j [ G ij sin( θ i − θ j ) − B ij cos( θ i − θ j )] . (1b) They connect activ e and reactive po wers p i and q i to voltage amplitudes and phases v i and θ i at the i = 1 , . . . M nodes of a network defined by the conductance ( G ij ) and susceptance ( B ij ) matrices modeling the power lines. Activ e and reactiv e powers are control v ariables, while v oltage amplitudes and phases are state v ariables, from which the operational state of the system can be computed. In particular , each term in the summation on the right-hand side of Eqs. (1) gi ves the acti ve [Eq. (1a)] or reactiv e [Eq. (1b)] po wer flow on the power line connecting nodes i and j , and whose conductance and susceptance are − G ij and − B ij . Nodes correspond either to generators or loads, depending on the sign of the activ e power . T o differentiate these two types of nodes, we introduce the notation g i = p i > 0 for generators and l i = p i < 0 for loads. Both types of nodes can inject ( q i > 0 ) or consume ( q i < 0 ) reactiv e po wer . There are M load loads and M gen generators, with M = M load + M gen . In real life, power grids are never exactly stationary , but ev olve slowly as generations are cranked up or down, fol- lowing increasing or decreasing loads. When considering the operational state at different times, a timestamp needs to be introduced, and below we will consider sequences of activ e power loads, l i,τ , and generations, g i,τ , at discrete time intervals labeled by τ = 1 , . . . N , where N giv es the number of observation times. Earlier methods focusing on the state variables { v i , θ i } directly give informations on line currents, power flows and possible line contingencies, v oltage drops and so forth, which are of central importance for grid operators. The state e val- uation to be presented belo w is based instead on the control variables { p i , q i } . It is therefore important to translate devia- tions of predicted vs. true power variables into deviations of predicted vs. true state variables. Here we do this under the standard assumption that susceptance terms dominate over conductance terms at high voltage le vels, | B ij | ≫ | G ij | . Linearizing the right-hand side of Eq. (1a) in voltage angle deviations θ i − θ (0) i = ∆ θ i between true θ (0) i and inferred θ i voltage angles, we obtain ∆ p i = X j ∆ p ij , (2a) ∆ p ij = B ij v i v j cos( θ (0) i − θ (0) j )(∆ θ i − ∆ θ j ) , (2b) which giv es a linear relation between power and voltage angle deviations. Note that similar linear relations between { p i , q i } and { v i , θ i } can be obtained by linearizing Eqs.(1a) and (1b) in both ∆ θ i and ∆ v i , even relaxing the simplifying assumption | B ij | ≫ | G ij | . 2 VOLUME 4, 2016 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids It is obvious from Eq. (2b) that power flow deviations ∆ p ij can be positive or negativ e, depending on the sign of ∆ θ i − ∆ θ j . W e therefore write ∆ p ij = ∆ p i + δ p ij as the sum of a finite (positi ve or ne gativ e) av erage, ∆ p i = c − 1 i P j ∆ p ij and a fluctuating term with zero av erage, P j δ p ij = 0 , with the connectivity c i giving the number of power lines connected to the i t h node. Using the linearized model, we find ∆ p 2 i = c 2 i ∆ p i 2 + c i V ar( δ p ij ) . If po wer flo w de viations are dominated by their av erage, then they are smaller than po wer injection deviations by a factor proportional to the node connectivity c i so that ∆ p ij ≃ ∆ p i /c i , whereas the reduction factor is proportional to the square root of the connecti vity | ∆ p ij | ≃ | ∆ p i | / √ c i if their fluctuations dominate. Either way , we conclude that small errors in inferring power injections should result in smaller errors in power flo ws. Furthermore, the error ∆ p ij may a priori go either way , increasing or decreasing the power flow , i.e . , | p ij + ∆ p ij | = | p ij | ± | ∆ p ij | , so that deviations may predict either more or less loaded power lines. III. INFERENCE MODEL In this section, we briefly outline the model for inferring power grid loads and methods for finding the model parame- ters. For each power grid observation τ = 1 , . . . N , we have a set of loads and generator values ℓ i,τ i = 1 , . . . , M load , g i,τ i = 1 , . . . , M gen . (3) In some studies, we remove the M ℓ top top loads – those corresponding to the largest acti ve power drawn from the grid – from the dataset and use the remaining M ℓ = M load − M ℓ top loads to infer the loads left out. The removed load data is gathered in a ro w vector y ℓ τ = [ ℓ M ℓ +1 ,τ , ℓ M ℓ +2 ,τ , . . . , ℓ M loads ,τ ] (4) of dimension (1 × M ℓ top ) . The remaining load data is gathered in a row v ector x ℓ τ = [ ℓ 1 ,τ , ℓ 2 ,τ , . . . , ℓ M ℓ ,τ , 1] , (5) of dimension (1 × ( M ℓ + 1)) . The row vector is augmented by a component equal to 1 at the end, which will be discussed below . In the machine learning community , x ℓ τ is called the ‘feature vector . ’ The observ ations are vertically concatenated to form ob- servation matrices X ℓ (dimension [ N × ( M ℓ +1)]) and Y ℓ (dimension ( N × M ℓ top ) ), where bold indicates a matrix. Our goal is to infer the left-out loads at each observ ation using the remaining load data. W e adopt a linear model giv en by Y ℓ = X ℓ W ℓ . (6) where the weight matrix W has dimension (( M ℓ + 1) × M ℓ top ) . The bias (or offset) of the linear model is taken into account by the 1 appearing in the last element of the row vector in Eq. (5) and the bottom row of W ℓ . While it is possible to use more complex models, our philosophy is to start with the simplest model and only increase its complexity as needed. Our task is to identify a single matrix W ℓ that works all observ ations. W e use a data-driv en approach for model identification known as supervised learning. Here, we use a subset of the observations to ‘train’ the model and then use the remaining observations to ‘test’ the model, where we use the machine learning community nomenclature. The test samples ha ve nev er been ‘seen’ by the model during training, and the iden- tified model is used to predict loads of future observations, also nev er seen by the model. This approach assumes that the training dataset is representati ve of the underlying probability distribution of the data. Equation (6) can be solved using re gularized least-squares regression, often referred to as ridge regression or Tikhono v regularization. This method obtains the weights through the relation W ℓ = [( X ℓ ) T X ℓ + α I ] − 1 ( X ℓ ) T Y ℓ , (7) where α is the ridge regression parameter , T is the matrix transpose, and I is the (( M ℓ + 1) × ( M ℓ + 1)) identity matrix. Regularization achiev es se veral equiv alent operations. It puts a floor α on the singular v alues of the data cov ari- ance matrix ( X ℓ ) T X ℓ to improve the numerical stability of the algorithm used to find the matrix in verse in Eq. (7). Equiv alently , it penalizes the L 2 norm of W ℓ , ensuring that the indi vidual matrix elements do not take on large values. Equiv alently , it prevents the model from over -fitting to the training data and thus improves its generalization to data it has not seen. In our studies, we find the regularized solution to Eq. (6) using the Python machine learning routine Ridge that is part of the sci-kit learn package [30], version 1.7.2. This routine uses singular-v alue decomposition for the matrix in verse, which is known to giv e accurate results for similar tasks [31]. W e also consider predicting the generator v alues. Here, we remov e the M g top top generators. The j th observations of all the loads and the remaining M g = M gen − M g top generators are gathered in a row vector x g j (dimension (1 × ( M g + M load + 1)) ) analogous to Eq. (5). The remov ed top gener - ators are gathered in a row v ector y g j . The observ ations and remov ed loads are v ertically stacked in matrices X g and Y g , respectiv ely , and the linear model is gi ven by Y g = X g W g . IV . D A T ASETS The synthetic datasets are obtained using the method de- scribed in Refs. [28], [29]. The y correspond to three dif ferent transmission grids coupling the 220 and 380 kV le vels. They giv e activ e power for • 163 loads and 36 generators for the Swiss power grid, • 908 loads and 61 generators for the Spanish power grid, • 560 loads and 101 generators for the German power grid. For each grid, these synthetic datasets correspond to 20 years with hourly resolution, for a total of 174,720 samples (each synthetic year corresponding to exactly 52 weeks, i.e. VOLUME 4, 2016 3 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids 364 days). V alues for each generator or load at each time step correspond to activ e power in per unit, corresponding to a base unit of 100 MW . Belo w , we use 80% of those datasets as training sets and the remaining 20% for testing the learned model. The experimental data were provided by the Swiss trans- mission system operator , Swissgrid, and consist of readings from every Swiss substation for the months of January and July 2015, with a 15-minute time resolution. Substations equipped with transformers usually ha ve two readings, one at each voltage le vel; additionally , measurements may be split across different busbars. This splitting is exogenous, as it depends on the operator’ s actions, and is therefore highly predictable by the operator . W e consequently consolidate busbar -lev el quantities into voltage-le vel quantities. W e also remov e trivial recordings, as they provide no useful infor- mation and would otherwise hinder the analysis. The system consists of 161 buses, 31 international and 244 national lines. V . RESUL TS A. INFERRING THE LARGEST FIVE LO ADS In this section, we study the prediction accuracy when ei- ther of the fiv e loads with largest active power demand are remov ed from the training dataset, and the remaining loads are used to predict them during model testing. W e focus on these fiv e largest loads, because failure to ev aluate them accurately would in general generate the largest errors in state estimation. For each dataset, we randomly select 80% of the data for training the model using Eq. (7), and use the trained model to predict the remaining data during the testing phase. Figures 1, 2, and 3 show the training and testing predicted loads as a function of the true values for the synthetic Swiss, Spanish, and Germany grids, respectiv ely , for α = 1 × 10 − 5 . The normalized root mean square error (NRMSE) is giv en in each panel. Here, the NRMSE is the root-mean-square error normalized by the standard de viation of each load distribution tak en from the training dataset. For all cases, the true and predicted results are highly correlated for the training and testing data, with the points clustering along the unit-slope line. The NRMSE is below ∼ 5 × 10 − 2 for the Swiss grid, and below ∼ 1 × 10 − 7 for the Spanish and German grids. Importantly , the NRMSE for the test samples is similar to that for the training samples, indicating good model generalization to data not seen during training. For the discussion in Sec. VII, we giv e the model training time for the task described in this section using an Intel 11 th Gen Core i7-1165G7 central processor unit with 16 GB random access memory . For the largest dataset (Spanish grid), there are 908 loads, and we remove the top 5 loads, resulting in 903 features and 139,776 observ ations (80% of the total dataset). The regularized regression takes 8.26 s. Applying the trained model to predict the training dataset, used to find the training error , tak es 364 ms, or 2.08 µ s per prediction (inference). FIGURE 1. Model performance for the synthetic Swiss power g r id. P anels a)-e) are predictions for the largest fiv e loads in descending order . B. MODEL PERFORMANCE FOR DIFFERENT M T o push the model, we in vestigate the model performance, quantified by the test NRMSE as a function of the number of left-out loads M . As seen in Fig. 4a), the Swiss grid performance degrades rapidly with increasing M , where the performance rolls ov er at M ∼ 12 . On the other hand, the Spanish (Fig. 4b)) and German (Fig. 4c)) grids have very good performance, but degrades approximately exponentially with M for M < 700 ( M < 400 ) for the Spanish (German) grids. Beyond this v alue, there is a rapid transition to high error for larger M . C. MODEL PERFORMANCE FOR DIFFERENT TRAINING SET SIZES An important practical question is the amount of training data required to obtain a given model error . Figure 5 shows the NRMSE as a function of the training set size for the three synthetic grids. Here, we first perform the random selection of the training and testing data points, and then we use a fraction of the training data for model determination. Specifically , the same testing data is used in all cases. The smallest training dataset size considered is 1,398 samples (1% of the training set size). For M = 1 (red lines) and all country grids, the error 4 VOLUME 4, 2016 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids FIGURE 2. Model performance for the synthetic Spanish power g r id. P anels a)-e) are predictions for the largest fiv e loads in descending order . decreases continuously as the model is provided with more data. A prediction error of 1% can be obtained for the Swiss grid for ∼ 1 . 1 × 10 5 training data points, whereas the minimum set size considered here (1,389) is enough for the Spanish and German grids. For M = 5 or 10, the performance for the Swiss grid is poor and does not improve with greater training data. On the other hand, the error is nearly identical for M = 1 and 5 for the Spanish and German grids, and is some what higher for M = 100 . In all cases, the curves follo w a similar pattern. D . MODEL WEIGHTS One important advantage of our linear model is that the model weights are proportional to the importance of a load in predicting the left-out loads. Figure 6 shows the weights for the case when the top 5 loads are left out. It is seen that the Swiss grid has a small number of important nodes (large weight magnitude), whereas the weights are all important for the Spanish and German grids. This may explain the relativ ely poor performance of the Swiss grid for more than a few left-out nodes as seen in Fig. 4. The 3d plots indicate that there are man y small weights for the synthetic Swiss grid compared to the other two. T o help make a quantitative statement about the weights, we plot the weight histogram sho wn in Fig. 7. W e fit the distrib ution to FIGURE 3. Model performance for the synthetic German power grid. P anels a)-e) are predictions for the largest fiv e loads in descending order . FIGURE 4. Model performance for inferring the loads with largest activ e power demand f or the synthetic a) Swiss, b) Spanish, and c) German grids, as a function of the number M of left-out loads. VOLUME 4, 2016 5 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids FIGURE 5. Model performance for different tr aining dataset sizes for the synthetic a) Swiss, b) Spanish, and c) German grids for diff erent values of M . The gra y band for M = 10 corresponds to the minimum and maximum prediction accuracy . Gaussian and Lorentzian functions and k eep the distrib ution with a reduced chi-square function ( χ 2 r ) closest to one. Here, the variance is taken as the square root of the number of observations. W e find that the model weight distributions for the Swiss and Spanish grids are best fit by the Lorentzian, whereas the German grid is best fit by a Gaussian. Notably , the Swiss grid has sev eral small weights that extend beyond the plot boundary , supporting our pre vious conclusion that there are a few large weights that dominate the model for the Swiss grid in comparison to the other two. E. PREDICTING REAL LO ADS AND INFERRING POWER FLO WS The above results hav e been obtained using synthetic datasets [28], [29] generated by an algorithm that preserves the degree of correlation observed in real, but size-limited historical datasets for the swiss high v oltage power grid. The latter provide po wer injections and loads for the months of January and July 2015, with an hourly resolution. Although likely too small for training our algorithms, we nev erthe- less apply our method to these size-limited but real-world datasets. The result is shown in Fig. 8. W e observe a high correlation between true and predicted loads, for the fi ve largest loads in the po wer system, despite the smallness of the training dataset. The NRMSE is ∼ 0 . 25 for all loads, which is signif- icantly higher than the above performances for the synthetic data. This is expected because we have 10 × fewer training samples compared to the synthetic datasets, and there is noise FIGURE 6. Model inter pretation. Model weights for the synthetic a) Swiss, b) Spanish, and c) German grid. Positiv e (negative) weights are shown as red (blue), and weights < 0.1 are not sho wn for clarity . in any real dataset. T o improve the prediction performance for this model, we set α = 10 4 found using a grid search. So far , we focused on inferring power loads. From the point of vie w of a grid operator , howe ver , other quantities such as voltage drops, current flo ws and power flows on lines are of higher importance, as they determine the presence or absence of contingencies that may jeopardize grid stabil- ity and the safety of power supply . W e want to determine whether the inaccuracies inherent to our method can be tolerated in the sense that: (i) the predicted flows are not too 6 VOLUME 4, 2016 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids FIGURE 7. Quantitative model interpretation. Histogram of the model weights for the synthetic a) Swiss , b) Spanish, and c) Ger man grid. The data is fit to either a Gaussian function a exp( − ( x − x 0 ) 2 /σ 2 ) or a Lorentzian function aγ 2 / ( γ 2 + ( x − x 0 ) 2 ) . The best-fit functions are: a) Lorentzian with a = 91.1, x 0 = − 0 . 042 , γ = 1 . 03 , and a reduced χ 2 r = 0.77; b) Lorentzian with a = 296., x 0 = 0.0087, γ = 3.55, and χ 2 r = 3.5; and c) Gaussian with a = 177., x 0 = 0.00237, σ = 0.0961, and χ 2 r = 2.52. FIGURE 8. Model performance on real data for the swiss high v oltage power grid. Panels a)-e) are compare predicted with true loads, f or the five largest loads in descending order . different from the real ones; and (ii) significant deviations between predicted and real flo ws do not systematically af fect already strongly loaded lines. T o that end, we numerically infer flows on power lines from power injections by solving Eq. (1) using a Newton-Raphson solver for both predicted and true po wer injection data for the Swiss transmission power grid. The result is shown in Fig. 9. It is seen that de via- tions rarely exceed 10 %, and that this does not systematically affect more hea vily loaded lines. FIGURE 9. Model performance on real data for the Swiss high voltage po wer grid: comparison of true and reconstr ucted flows obtained by Ne wton- Raphson solutions of the power flo w Eqs. (1) with data from Fig. 8. Blue (red) dots correspond to power flo ws below (above) 95 % of the thermal power . dashed lines indicate deviations of ± 10 %. T o quantify the accurac y of power flow reconstruction, we introduce three dif ferent metrics, which we briefly describe. From Eq. (1a), the real acti ve power flo w on the power line connecting buses i and j is p ij = v i v j G ij cos( θ i − θ j ) + B ij sin( θ i − θ j ) . (8) The statistical error in our estimation of the flow on that line can be quantified by the variance v ar[ p ij ] = N − 1 N X τ =1 [ p ij ( τ ) − ˆ p ij ( τ )] 2 , (9) ov er the testing set with N observation times, and ˆ p ij giv es the active power flows obtained from Eq. (1a) with the predicted values of p i from our ev aluation algorithm. The accuracy of the predicted power flo w solution can then be measured by av eraging o ver all po wer lines. This can be done in two ways, either by extending Eq. (9) to a global variance calculated over all po wer lines and taking the square root of the result, or by first taking the square root of Eq. (9) and av eraging over all power lines. In both instances, one normal- izes the result with the v ariance σ ij ≡ N − 1 P N τ =1 p ij ( τ ) − ⟨ p ij ( τ ) ⟩ 2 of the true power flo ws, calculated over all obser- VOLUME 4, 2016 7 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids vation times. One obtains the follo wing two metrics, M 1 = |E | − 1 X ij ∈E h N − 1 P N τ =1 [ p ij ( τ ) − ˆ p ij ( τ )] 2 σ 2 ij i 1 / 2 , (10) M 2 = |E | − 1 X ij ∈E N − 1 P N τ =1 [ p ij ( τ ) − ˆ p ij ( τ )] 2 σ 2 ij 1 / 2 . (11) For the data sho wn in Fig. 9, we obtain M 1 = 0 . 06862 and M 2 = 0 . 01515 . Despite the rather small number of observ ations in the training datasets, we see that the method accurately estimate the state of the system for this real-world test case. W e expect that our results would be of e ven better quality , if we had access to datasets with observation size comparable to the synthetic data treated in Sec. V -A. VI. PREDICTING GENERA T ORS W e finally turn to predicting the generators. Figure 10 sho ws the model performance when only a single generator is left out of the synthetic data set for the German grid. The model performance is poor , only slightly better than random guessing of the generator value. FIGURE 10. Predicting generators. Model performance for the a) tr aining and b) testing data sets for the German grid, where the single largest generator is left out of the model. W e attribute this behavior to the fact that, unlike loads, generators are not necessarily correlated for at least four reasons. First, they come in different types, ranging from very flexible (such as dam hydroelectric plants), to dispatchable with ramp-up and -down times (from less to more con- strained: gas, coal and nuclear power plants), to undispatch- able (run-of-riv er hydroelectric plants, solar photov oltaic plants and wind turbines). These varying degrees of flexi- bility explain why generators sometimes do not produce in situations where they did produce earlier . Second, generation is directly subjected to market rules and generators produce according to a mixture of short-, medium- and long-term contracts. Different operators hav e dif ferent business plans, which directly translate into dif ferent production profiles. Third, grid operators have a direct impact on generation to prev ent potential congestion. Fourth, many generators are optimized to produce close to their rated power . Therefore, their production profiles are not smooth, continuous curves, but look more lik e step functions. These four aspects reduce correlations between the gen- eration profiles of different plants, which explains why our relativ ely simple linear regression method performs poorly for generators. Ho wev er, one should keep in mind that al- most all generators connected to high- and extra-high-voltage transmission grids have large rated capacities typically ex- ceeding 100 MW . Moreover , there are typically ten times fewer generator than load nodes in a transmission grid. For these reasons, there are often redundant and more secure communication lines between generators and grid operators, reducing the frequency of e vents with corrupted generation data. VII. DISCUSSION W e construct a nov el, data-based method for state-estimation in high voltage transmission grids. The method is based on a simple linear regression algorithm, which infers control variables instead of state v ariables. Essentially all earlier state estimation methods rely on the state v ariables. Numerical results on realistic synthetic data [28], [29] for three different high voltage transmission grids demonstrated the accuracy of the method. Moreover , for large enough training datasets, we are able to reconstruct close to half the total number of loads with only a small, tolerable decrease in accuracy [see Fig. 4] for the larger Spanish and German grids. The ratio of inferrable loads is ho wev er significantly smaller for the smaller grid of Switzerland, where only few simultaneously missing loads can be accurately predicted. This is likely so for statistical reasons. Howe ver , specific details of the Swiss power grid, such as larger inhomogeneities in load distributions at dif ferent nodes, may also play a role. The method is further validated on real-life historical datasets for the Swiss power grid. Despite the small volume of data, state estimation works rather well there, with devi- ations between real and predicted v alues that are larger by one order of magnitude at most, but still with NRMSE on the order of 10 − 1 . It is very likely that a lar ger training dataset will bring this v alue down to the le vel of those obtained with the synthetic dataset. All other quantities of interest for system operators, such as voltage amplitudes and phases, or current and po wer flows on lines can be numerically inferred from the in- ferred power , i.e. , control v ariables, using standard Newton- Raphson solvers. W e show that the method reconstructs power flows quite accurately for the real Swiss power grid dataset. There are two aspects that deserve further in vestigation. First, we numerically determined which loads are more im- portant in predicting the left-out loads. This information is directly encoded in the elements of the weight matrix W ℓ defined in Eq. (6). W e find very different weight distribu- tions [see Fig. 7] for the dif ferent grids we considered. In particular , the distribution is Lorentzian for the Swiss and Spanish grids, while it is Gaussian for the German grid, with additionally very dif ferent distribution widths. W e deter- mined that this discrepancy is real, i.e. , not due to the fitting 8 VOLUME 4, 2016 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids procedure described in Section III, nor to the precise choice of the ridge regression parameter α . Beyond that, we cannot explain this observ ation. Second, it is unclear to us why the method performs so well for loads, b ut fails so dramatically for generators. W e should ho wev er keep in mind that all state estimation approaches suffer from some shortcomings. W e think that, despite these two points, our state estimation method seems promising for deployment working in parallel with other power grid prediction and modeling approaches. Our method adds one new complementary method to the suite of simulation tools. W e finally mention how our model can be used in practice. In one scenario, a grid operator loses communication with one or more node measurement system(s). Using the database of historical data, a model is trained to infer the missing data. T raining the model takes a few seconds of computer time as discussed in Sec. V -A. F or security applications, one model for each load can be trained and used to predict its behavior . Deviation from the expected behavior can indicate a node failure, or a hacking or spoofing attack on the grid. REFERENCES [1] O. Smith, O. Cattell, E. F arcot, R. D. O’Dea, and K. I. Hopcraft, “The effect of renewable energy incorporation on power grid stability and resilience, ” Science Advances , vol. 8, p. eabj6734, 2022. [2] European Commission and Joint Research Centre, “Co2 emissions of all world countries – jrc/iea/pbl 2022 report, ” 2022. [3] F . Milano, F . Dörfler , G. Hug, D. J. Hill, and G. V erbi ˇ c, “Foundations and challenges of low-inertia systems, ” in 2018 P ower Systems Computation Confer ence (PSCC) , 2018, p. 1. [4] M. A. Basit, S. Dilshad, R. Badar, and S. M. S. ur Rehman, “Limitations, challenges, and solution approaches in grid-connected renewable energy systems, ” International Journal of Energy Resear ch , vol. 44, pp. 4132– 4162, 2020. [5] P . Denholm, T . Mai, R. W . Kenyon, B. Kroposki, and M. O’Malley , “Inertia and the power grid: A guide without the spin, ” National Renewable Energy Laboratory (NREL), Golden, CO, T ech. Rep., 2020. [6] P . Mak olo, R. Zamora, and T . T . Lie, “The role of inertia for grid flexibility under high penetration of v ariable renewables – a revie w of challenges and solutions, ” Rene wable and Sustainable Ener gy Reviews , vol. 147, p. 111223, 2021. [7] T . Kërçi, M. Hurtado, M. Gjer gji, S. T weed, E. K ennedy , and F . Milano, “Frequency quality in lo w-inertia power systems, ” in 2023 IEEE P ower & Ener gy Society General Meeting (PESGM) , 2023, p. 1. [8] M. Martínez-Barbeito, D. Gomila, P . Colet, J. Fritzsch, and P . Jacquod, “T ransmission grid stability with large interregional power flows, ” Physi- cal Review Resear ch , v ol. 7, p. 013137, 2025. [9] C. P . Ohanu, S. A. Rufai, and U. C. Oluchi, “ A comprehensive revie w of recent developments in smart grid through renewable energy resources integration, ” Heliyon , vol. 10, p. e25705, 2024. [10] F . Pasqualetti, F . Dörfler , and F . Bullo, “ Attack detection and identification in cyber-physical systems, ” IEEE Tr ansactions on Automatic Control , vol. 58, p. 2715, 2013. [11] R. I. Ogie, “Cyber security incidents on critical infrastructure and indus- trial networks, ” in Pr oceedings of the 9th International Conference on Computer and Automation Engineering . Association for Computing Machinery , 2017, p. 254. [12] M. A. Pimentel, D. A. Clifton, L. Clifton, and L. T arassenko, “ A revie w of novelty detection, ” Signal Processing , v ol. 99, p. 215, 2014. [13] S. Thudumu, P . Branch, J. Jin, and J. Singh, “ A comprehensive survey of anomaly detection techniques for high dimensional big data, ” J ournal of Big Data , vol. 7, p. 42, 2020. [14] H. Dag and F . L. Alvarado, “T oward improved uses of the conjugate gradient method for power system applications, ” IEEE T ransactions on P ower Systems , v ol. 12, p. 1306, 1997. [15] A. Monticelli, “Electric power system state estimation, ” Pr oceedings of the IEEE , vol. 88, p. 262, 2002. [16] S. Kamireddy , N. S. Noel, and K. S. Anurag, “Comparison of state estimation algorithms for extreme contingencies, ” in Proceedings of the North American P ower Symposium , Calgary , Canada, 2008, p. 1. [17] D. Thukaram and S. K. V . Seshadri, “Linear programming approach for power system state estimation using upper bound optimisation tech- niques, ” International Journal of Emerging Electric P ower Systems , vol. 11, 2010. [18] B. Y ang, Y . Chen, and Z. Zhao, “Surv ey on applications of particle swarm optimisation in electric po wer systems, ” in 2007 International Confer ence on Contr ol and Automation , Guangzhou, China, 2007, p. 418. [19] P . W . Tsai, J. S. Pan, B. Y . Liao, and S. C. Chu, “Enhanced artificial bee colony optimisation, ” International Journal of Innovative Computing, Information and Contr ol , vol. 5, p. 1, 2009. [20] A. A. Hossam-Eldin, E. N. Abdallah, and M. S. El-Nozahy , “ A modified genetic algorithm based technique for solving the po wer system state esti- mation problem, ” in International Confer ence on Electrical and Computer Engineering , Oslo, Norway , 2009, p. 307. [21] J. P . Pandey and D. Singh, “ Application of radial basis neural netw ork for state estimation of power system networks, ” International J ournal of Engineering, Science and T echnology , vol. 2, p. 19, 2010. [22] S. Sundeep and G. Madhusudhanarao, “ A modified hopfield neural net- work method for equality constrained state estimation, ” International Journal of Advanced Engineering T echnology , v ol. 1, p. 224, 2011. [23] D. H. T ungadio, J. A. Jordaan, and M. W . Siti, “Power system state estimation solution using modified models of pso algorithm: Comparative study , ” Measur ement , vol. 92, p. 508, 2016. [24] J. Machowski, Z. Lubosny , J. W . Bialek, and J. R. Bumby , P ower System Dynamics: Stability and Control , 3rd ed. Hoboken, NJ, USA: John Wiley , 2020. [25] L. Pagnier and P . Jacquod, “Inertia location and slow network modes determine disturbance propagation in large-scale power grids, ” PLOS ONE , vol. 14, p. 1, 2019. [26] ——, “Pantagruel – a pan-european transmission grid and electricity generation model, ” 2019. [27] M. T yloo, L. Pagnier , and P . Jacquod, “The key player problem in complex oscillator networks and electric power grids: Resistance centralities iden- tify local vulnerabilities, ” Science Advances , vol. 5, p. eaa w8359, 2019. [28] M. Gillioz, G. Dubuis, and P . Jacquod, “ A large synthetic dataset for machine learning applications in power transmission grids, ” 2024. [29] ——, “ A large synthetic dataset for machine learning applications in power transmission grids, ” Scientific Data , vol. 12, p. 168, 2025. [30] scikit learn dev elopers. Ridge – scikit- learn 1.7.2 documentation. https://scikit- learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html. [31] E. Roque dos Santos and E. Bollt, “On the emergence of numerical instabilities in next generation reserv oir computing, ” Chaos , vol. 35, p. 123102, 2025. PHILIPPE JACQUOD (Member, IEEE) receiv ed the Diplom degree in theoretical physics from the ETHZ, Zürich, Switzerland, in 1992, and the PhD degree in natural sciences from the Univer - sity of Neuchâtel, Switzerland, in 1997. He is a professor with the Department of Quantum Matter Physics, Univ ersity of Genev a, Switzerland, and with the engineering department, Univ ersity of Applied Sciences of W estern Switzerland. From 2003 to 2005, he was an assistant professor with the theoretical physics department, University of Geneva, and from 2005 to 2013, he was a professor with the physics department, Uni versity of Arizona, T ucson, USA. His main current research interests are in dynamical aspects of power systems and in population dynamics in theoretical ecology . He has published more than 100 papers in international journals, books and conference proceedings. VOLUME 4, 2016 9 P . Jacquod, L. P agnier , D . Gauthier : Accurate Data-Based State Estimation from P ower Loads Inf erence in Electric Po wer Grids LA URENT P A GNIER (Member, IEEE) recei ved the M.S. and Ph.D. de grees in theoretical physics from EPFL, Lausanne, Switzerland, in 2014 and 2019, respectively . He is currently a Research Assistant Professor at the University of Arizona. His research interests include the development of novel modeling and monitoring methods for power systems. He is particularly interested in applying machine learning techniques to power systems, with an emphasis on impro ving the interpretability and trustworthiness of data-driv en methods to f acilitate their adoption within the power systems community . D ANIEL J . GA UTHIER is co-founder and chief technology officer of ResCon T echnologies. He re- ceiv ed the B.S., M.S., and Ph.D. degrees in optics from the Uni versity of Rochester , Rochester, NY , USA in 1982, 1983, and 1989, respectively . He was a post-doctoral researcher at the University of Oregon, OR, USA, from 1989-1991, a professor of ph ysics at Duke Uni versity , Durham, NC, USA, from 1992-2015, and a professor of physics at The Ohio State University , Columbus, OH, USA from 2016-2024. He is commercializing machine learning algorithms to solve industry-relev ant problems. He is a Fellow of Optica and the American Physical Society . 10 VOLUME 4, 2016
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment