Semiparametric Uncertainty Quantification via Isotonized Posterior for Deconvolutions
We address the problem of uncertainty quantification for the deconvolution model \(Z = X + Y\), where \(X\) and \(Y\) are nonnegative random variables and the goal is to estimate the signal's distribution of \(X \sim F_0\) supported on~\([0,\infty)\)…
Authors: Francesco Gili, Geurt Jongbloed
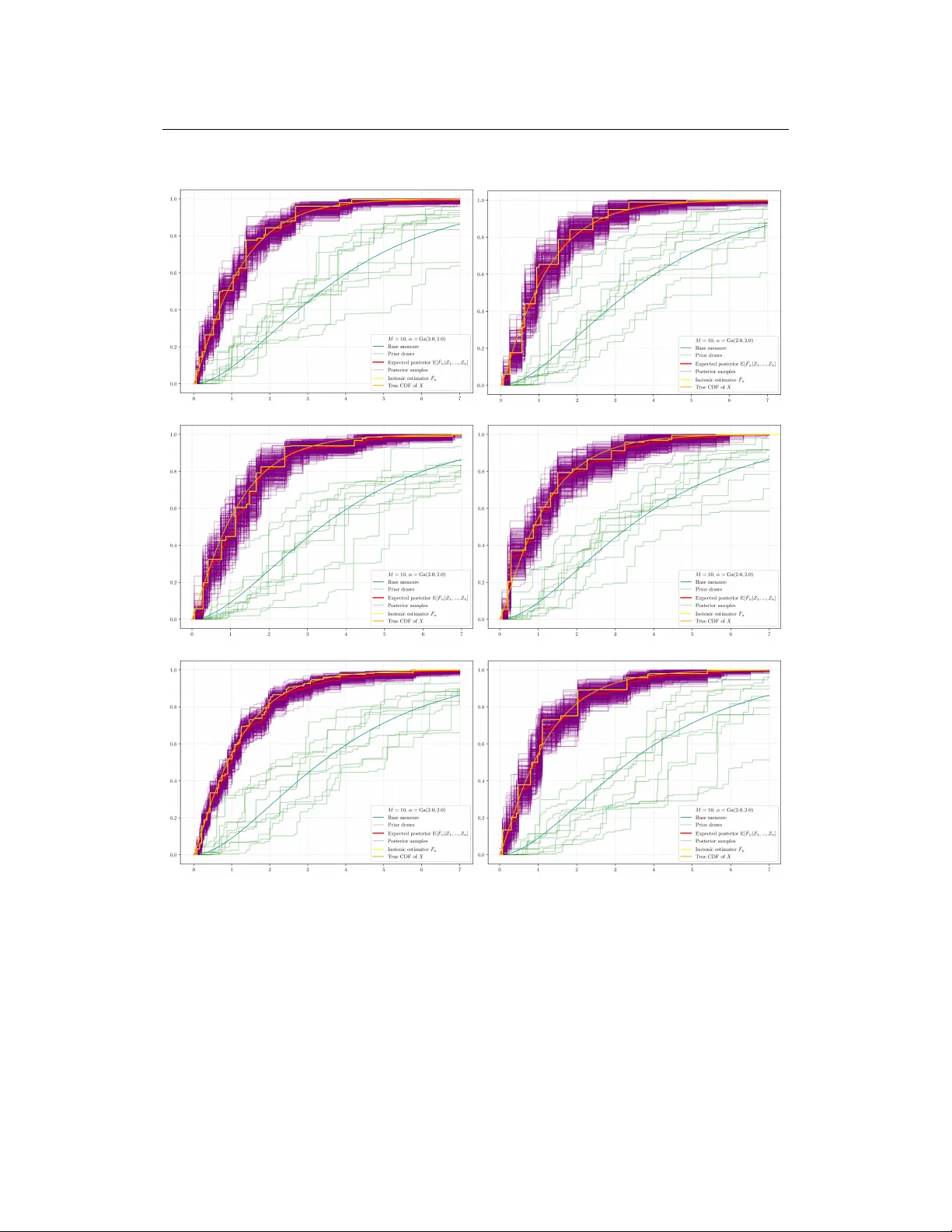
S E M I P A R A M E T R I C U N C E RT A I N T Y Q UA N T I FI C A T I O N V I A I S O T O N I Z E D P O S T E R I O R F O R D E C O N V O L U T I O N S Francesco Gili ∗ Geurt Jongbloed † Delft University of T echnology , Mekelwe g 4, Delft 2628CD, The Netherlands. February 23, 2026 A B S T R AC T W e address the problem of uncertainty quantification for the decon volution model Z = X + Y , where X and Y are nonnegati ve random variables and the goal is to estimate the signal’ s distrib ution of X ∼ F 0 supported on [0 , ∞ ) , from obser- vations where the noise distrib ution is kno wn. Existing frequentist methods often produce confidence intervals for F 0 ( x ) that depend on unknown nuisance parame- ters, such as the density of X and its deri vati ve, which are dif ficult to estimate in practice. This paper introduces a novel and computationally efficient nonparametric Bayesian approach, based on projecting the posterior , to overcome this limitation. Our method le verages the solution p to a specific V olterra integral equation as in [47], which relates the cumulative distribution function (CDF) of the signal, F 0 , to the distrib ution of the observ ables. W e place a Dirichlet Process prior directly on the distribution of the observ ed data Z , yielding a simple, conjugate posterior . T o ensure the resulting estimates for F 0 are valid CDFs, we isotonize posterior draws taking the Greatest Con vex Majorant of the primitive of the posterior draws and defining what we term the Isotonic In verse Posterior . W e show that this framework yields posterior credible sets for F 0 that are not only computationally fast to generate but also possess asymptotically correct frequentist coverage after a straightforward recalibration technique for the so-called Bayes Chernoff distribution introduced in [9]. Our approach thus does not require the estimation of nuisance parameters to deliv er uncertainty quantification for the parameter of interest F 0 ( x ) . The practical effecti veness and robustness of the method are demonstrated through a simulation study with various noise distrib utions for Y . Keyw ords Decon volution · Isotonic estimation · Efficienc y theory · Uncertainty Quantification ∗ F.Gili@tudelft.nl † G.Jongbloed@tudelft.nl Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions 1 Introduction In many statistical applications, one encounters situations where the observed data Z i arises from the sum of two independent components: a variable of interest X i , which is usually the quantity we are interested in, and another variable Y i whose distribution is assumed to be kno wn or to be inferred using expert kno wledge. This setup applies to many different areas of research. For example, X i might represent the true un- derlying quantity we aim to measure in an e xperiment or measurement, while Y i captures the random measurement error introduced during the process — and which is assumed to be additi ve in nature. In epidemiology , X i could correspond to the actual time of infection, and Y i to the incubation pe- riod. This framew ork plays a key role in approaches like back-calculation, which has been used in HIV/AIDS research to estimate historical infection rates based on observed diagnoses [1]. The sta- tistical properties of Y i vary significantly depending on the context: measurement errors are often modeled with symmetric distributions over the entire real line, such as the normal distribution, while durations — like incubation periods or the time until a component fails — are typically modeled with ske wed, non-negati ve distrib utions, such as the Gamma or W eibull distrib utions. This method of separating the distribution of X i from the one of Y i , which is called decon volution, is also key in other fields. For example, in image processing, a blurry image Z can be thought of as the true, sharp image X distorted by a blur effect Y caused by the camera or optics. Methods like the Richardson-Lucy algorithm are used to try and recover the original sharp image X [32, 36]. Similarly , in astronomical spectroscopy , the spectrum of light observed from a star or galaxy Z is the object’ s actual spectrum X that has been spread out or blurred by the telescope’ s instruments represented by additiv e noise Y . Decon volution helps scientists recov er the true details about the celestial object [4]. Another application is in seismology , where the seismic w aves recorded from under ground Z are a combination of the Earth’ s rock layer structure X and the seismic signal Y that was sent out or generated. Decon volution is thus a fundamental step to get clearer images of the Earth’ s subsurface [37]. More formally , throughout this paper we confine attention to the case where both X and Y are nonneg- ativ e random variables, i.e. we work on the half-line [0 , ∞ ) . Let X 1 , X 2 , . . . , X n denote a sample from an unknown distribution with distribution function F 0 supported on [0 , ∞ ) and, independent of that sample, Y 1 , Y 2 , . . . , Y n a sample from a kno wn distrib ution with density k on [0 , ∞ ) . Consider the problem of estimating F 0 based on the sample Z 1 , Z 2 , . . . , Z n , where Z i = X i + Y i . The density g 0 of Z i is the con volution of k and F 0 in the following sense: g 0 ( z ) = Z ∞ 0 k ( z − x ) dF 0 ( x ) =: k ∗ dF 0 ( z ) . For this reason, this estimation problem is kno wn as a decon volution problem. Suppose that, gi ven a kernel k , we hav e a function p li ving on [0 , ∞ ) , solving the integral equa- tion ( p ∗ k )( x ) := Z x 0 p ( x − y ) k ( y ) dy = ( 1 ∗ 1 )( x ) = x 1 ( x ) , (1.1) where the function 1 is defined by 1 ( x ) = 1 [0 , ∞ ) ( x ) . 2 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Then we can write, for each x > 0 and a Z having density function g 0 = k ∗ dF 0 , E[ p ( x − Z )] = ( p ∗ g 0 )( x ) = ( p ∗ k ∗ dF 0 )( x ) = ( 1 ∗ 1 ∗ dF 0 )( x ) = Z x 0 F 0 ( s ) ds =: H 0 ( x ) . (1.2) A crucial question concerning integral equation (1.1) is whether a function p exists that satisfies it. In Appendix B, we giv e a revie w of the literature on this topic. W e start by placing a Dirichlet Process prior directly on the distrib ution function of the observables: G ∼ DP( α ) . Giv en an observed sample Z 1 , . . . , Z n from cdf G 0 (associated with density g 0 ), the posterior distribution is (c.f. [19], Theorem 4.6 in [20]): G | Z 1 , . . . , Z n ∼ DP ( α + n G n ) , G n := 1 n n X i =1 δ Z i . (1.3) This choice of fers computational simplicity due to the conjugac y of the posterior . Lev eraging the in verse relations inherent to the problem, we define, by analogy with (1.2), the functional H G (with G in place of G 0 ) as H G ( x ) = Z [0 ,x ) p ( x − z ) dG ( z ) . (1.4) Similarly , the empirical counterpart of the left-hand side of (1.2) is giv en by a sample mean: H n ( x ) = Z [0 ,x ) p ( x − z ) d G n ( z ) = 1 n n X i =1 p ( x − Z i ) This function H n is an estimator for H 0 . T aking the deriv ativ e of some smoothed version of H n or H G ( H n and H G will in general not be differ- entiable) would therefore yield methodologies for the estimation of F 0 . W e call such a methodology an in verse methodology , since it is based on the inv erse relation F 0 ( x ) = d dx p ∗ g 0 ( x ) a.e. which follows from (1.2). Ho we ver , by using general smoothing techniques, for e xample kernel es- timation, we would not use the information that H 0 is con vex (which follows from (1.2) and the monotonicity of F 0 ). Consequently , inv erse estimators based on standard smoothing techniques will in general yield non-monotone estimators. T o remedy this, we isotonize the posterior draws using the following procedure. For T ∈ (0 , ∞ ] and a continuous function h : [0 , ∞ ) → [0 , ∞ ) , the Greatest Conv ex Minorant (GCM) of h on [0 , T ] and its right-hand side deriv ative, are gi ven for x ∈ [0 , T ] by: h ⋆ ( x ) := sup { f ( x ) : f ≤ h on [0 , T ] , f con ve x on [0 , T ] } , ( h ⋆ ) ′ + ( x ) := lim t → 0 + h ⋆ ( x + t ) − h ⋆ ( x ) t . 3 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions For an y x ∈ [0 , T ] , we define the isotonizations of the draws of the posterior as the right deri vati ve of H ⋆ G ev aluated at x , ˆ F G ( x ) = ( H ⋆ G ) ′ + ( x ) . (1.5) The posterior draws ˆ F G are now by construction monotone (isotonic with respect to natural ordering on R ), and therefore we call the posterior Isotonic In verse P osterior . Using the same procedure we define the Isotonic In verse Estimator of [47], for any x ∈ [0 , T ] , as: ˆ F n ( x ) = ( H ⋆ n ) ′ + ( x ) . (1.6) One possible choice for T in the definition of ˆ F G or ˆ F n is T = ∞ . As we will see in Section 2, we need finiteness of T in order to prove our asymptotic distribution result for a large class of densities k . If k is assumed monotone on [0 , ∞ ) , our result does allow the choice T = ∞ . For practical purposes, there is no difference between finite (b ut large) and infinite T . In the domain of nonparametric inference, frequentist methods often yield estimators with well- characterized asymptotic distributions (e.g., the Chernof f distribution for isotonic regression, c.f. [25]). These distrib utions are crucial for constructing asymptotic confidence interv als and understand- ing the estimator’ s behavior . Ho wev er , a significant practical limitation arises because these limiting distributions generally depend on unknown nuisance parameters. F or instance, in our decon volution problem of estimating F 0 ( x ) from samples Z 1 , . . . , Z n ∼ g 0 = k ∗ dF 0 , the limiting distribution depends on quantities such as g 0 ( x ) and, more critically , f 0 ( x ) (in a similar way as in the isotonic regression setting where the limit distribution often in volv es the deriv ativ e of the true underlying function). The necessity of estimating these nuisance parameters complicates the direct application of these asymptotic results for uncertainty quantification. This practical difficulty highlights the de- sirability of methods that can provide uncertainty quantification without relying on the estimation of such nuisance parameters. Bayesian nonparametric procedures of fer a promising alternative in this regard. As explored in approaches in the “projection-posterior” literature (c.f. [9, 48, 49]), a key advantage is that the resulting credible intervals can achiev e asymptotic frequentist co verage that is free of these nuisance parameters. The limiting co verage in such Bayesian framew orks can depend only on the chosen credibility lev el, not on characteristics of the true unknown function like its deriv a- tiv e f 0 ( x ) . This circumvents the harder problem of nuisance parameter estimation, leading to more direct and more robust inferential procedures for quantifying uncertainty in nonparametric models. Furthermore, another possible Bayesian approach would consist in placing a DP process prior directly on F . Ho we ver this procedure has some clear computational disadv antages due to the needed Gibbs sampling procedures to sample from the posterior . Thus the approach in this paper has two adv antages: (i) Computational speed : The Dirichlet posterior (1.3) is explicit and its projection can be effecti vely computed by the Pool-Adjacent-V iolators Algorithm (P A V A, c.f. [1]). (ii) Uncertainty quantification : The Bayesian framew ork inherently provides uncertainty quan- tification without the need to estimate nuisance parameters. W e sho w belo w that this is asymptotically correct in the frequentist sense, after an appropriate calibration. Advantage (ii) is the core contrib ution of this paper, as currently there are no nuisance-free methods in the literature for semiparametric uncertainty quantification of F 0 ( x ) for deconv olution problems 4 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions as treated in this paper . Projecting the unconstrained posterior distribution departs from a classical Bayesian framew ork which might assign a Dirichlet Process (DP) prior to F and employ a hierarchical model to sample from the density of the observations. Uncertainty quantification results for this approach are currently una vailable and, at the same time, this approach is not advantageous from a computational prespectiv e, being slower as described abo ve. Motivation and connections with the literatur e There is a v ast literature on decon volution problems, especially in the frequentist nonparametric lit- erature, where the nonparametric maximum likelihood estimator (NPMLE) is a central focus. For the special case where the kernel k is a decreasing density on [0 , ∞ ) and F 0 (0) = 0 , [26] study the NPMLE for F 0 , demonstrating its consistenc y and conjecturing its asymptotic distrib ution. They also introduce the broader problem of one-sided errors in con volution models, deriving NPMLEs for the c.d.f. in this context. While these NPMLEs often lack explicit expressions and require iterativ e com- putation, some particular cases yield more direct solutions. F or instance, uniform decon volution is addressed by [42, 44], and more recently by [45] who propose kernel-based estimators and inv ersion formulas. Exponential decon volution is tackled by [29, 30]. For situations lacking such e xplicit forms, [47] circumvent this by proposing an isotonic inv erse estimator . Man y of these maximum likelihood estimators, and the works surrounding them, share cube root asymptotics similar to the Grenander estimator for decreasing densities and NPMLEs in current status censoring problems (c.f. [25]), with a general focus on deri ving the asymptotic distributions of these monotonic estimators. An alterna- tiv e approach to decon volution utilizes the conv olution structure for in version via Fourier transform techniques. K ernel estimators based on this methodology are introduced by several authors (c.f. [18] and [16]), using direct in version formulas for gamma and Laplace decon volution are found in [43]. While these kernel-based methods can achie ve faster con vergence rates if the unkno wn F 0 is smooth, a notable disadvantage is that their resulting estimators for F 0 are not inherently monotone, unlik e the NPMLE and isotonic in verse estimators. W ithin the broader field of deconv olution, a lot of work is done to address the estimation of a signal distribution f observed with additi ve, kno wn-distribution noise. This noise generally is conceptual- ized as centered, differentiating it from one-sided error scenarios. Foundational studies on conv er- gence rates and optimality for kernel-based estimators include those by [8], [39], [40], [18], and [17]. Establishing sharp asymptotic optimality further is done by [5] and [6, 7]. Adaptiv e methodologies, particularly for bandwidth selection in models with known error distrib utions, also are extensi vely de- veloped. Some examples include wa velet-based methods [34], direct bandwidth selection techniques [15], and penalized projection strategies [11], with comprehensi ve treatments available in works like [33]. The estimation of the cumulative distrib ution function (c.d.f.) in conv olution models also re- ceiv es attention. Contributions from [50], [18], [27], [12], [13], and [14] primarily focus on pointwise estimation procedures, a consequence of the c.d.f. not being square-inte grable on R . The latter two studies address c.d.f. estimation with unkno wn error distributions, contingent on specific tail decay properties of the error’ s characteristic function, and achie ve optimal rates for Sobolev-class target functions. It is worth noting that the decon volution of non-negati ve variables also emerges in applied contexts such as actuarial and insurance modeling. Finally , some financial applications see contri- butions from [28] and [35] addressing one-sided errors, focusing on optimal adapti ve estimation in non-parametric regression where errors (often e xponential) are not assumed to be centered. A similar methodology to the one proposed in this paper — using an unconstrained conjugate prior for the distribution function of the observables and projecting the posterior samples into the space of 5 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions monotone functions — very recently is adopted in isotonic regression settings (c.f. [9, 48, 49]), iso- tonic density estimation (c.f. [10]), ODEs settings (c.f. [2, 3]) and for W icksell’ s problem ([21],[22]). [2, 3] dev elop Bayesian two-step methods for parameter inference in ODE models by embedding them in a nonparametric re gression frame work with B-spline priors. The parameter posterior is obtained by minimizing a discrepanc y between the estimated re gression function and the ODE solution, either via deriv ative matching or Runge–Kutta approximations. [3] further establishes a Bernstein–von Mises theorem for the Runge–Kutta-based method, showing that the resulting Bayes estimator is asymptot- ically efficient. Howe ver , their frame work relies on a very different type of prior modelling and the projection method does not entail isotonization. In [9], the authors study a nonparametric Bayesian regression model for a response variable Y with respect to a predictor variable X ∈ [0 , 1] , gi ven by Y = f ( X ) + ε , where f is a monotone increasing function and ε is a mean-zero random error . They propose a ”projection-posterior” estimator f ∗ , constructed using a finite random series of step func- tions with normal basis coefficients as a prior for f . Their main finding is that when f ∗ is centered at the maximum likelihood estimator (MLE) and rescaled appropriately , the Bernstein-von Mises (BvM) theorem does not hold. Howe ver , when f ∗ is instead centered at the true function f 0 , a BvM re- sult is obtained. This phenomenon resonates with the kno wn inconsistency of the bootstrap for the Grenander estimator in isotonic regression (c.f. [38]) and represents a key similarity with the present work. One of the ke y advantages our approach shares with the works in [2, 3, 9, 48, 49] is the computa- tional efficienc y , driv en by posterior conjugac y , as well as the relativ e simplicity of the asymptotic analysis. 2 Main results In this section, we present the main result of this paper, which establishes the asymptotic distribution of the isotonized posterior of ˆ F G , and we compare it with the asymptotic distribution attained by the isotonized in verse estimator (IIE) ˆ F n (c.f. [47]) for a fixed x ∈ [0 , T ) , where T is a positi ve constant. W e show in particular an interesting analogy . The results of [47] show that the IIE ˆ F n attains at cube n root rate an asymptotic distribution, which, up to constants, is the Chernof f distribution. Symmetri- cally , we show that under the same conditions, the isotonized posterior of ˆ F G attains at cube root rate an asymptotic distribution which, up to constants, is the Bayesian Chernoff distribution (2.17), as in- troduced in [9]. This curious phenomenon both confirms and extends the vision of [9], who introduced the Bayesian Chernof f distribution (2.17), pro ved its k ey properties (symmetry , monotone CDF , and the resulting recalibration procedure), and predicted that this distribution would play a central role in uncertainty quantification in nonparametric Bayesian inference far beyond the regression setting they originally considered. Indeed, also in the current setting, with a very different in verse problem and different prior , the Bayesian Chernoff distribution arises as the limiting distribution of the isotonized posterior of ˆ F G , confirming that the concept and the framew ork of [9] hav e a broad reach. Integral equation (1.1) is a V olterra equation of the first kind, of con volution type. The function p is sometimes called the resolvent of the first kind of k (see [24], page 158). In all what follo ws, we restrict our attention to the case where F 0 has support contained in [0 , ∞ ) . Furthermore, to prove consistency of the posterior ˆ F G , we hav e to impose a condition on p . The asymptotic distribution is deri ved under more stringent conditions (the same as in [47]) that the kernel k satisfies certain re gularity conditions, which we will specify below . 6 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Condition 1 . On bounded intervals, the function p has only finitely many discontinuities. All these discontinuities are finite in size. For the cube root asymptotics of ˆ F G ( x ) for x < T , we need a slightly stronger condition on p Condition 2 . The function p is H ¨ older continuous of order γ > 1 / 2 on (0 , ∞ ) and 0 < p (0) < ∞ and right continuous at zero. A crucial question concerning integral equation (1.1) is whether a function p exists that satisfies it. In Appendix B, we give a re view of the literature on this topic, showing that such a function p exists for many k ernels k of interest. W e also report a lemma, Lemma 9, that provides a sufficient condition for the existence of such a function p that satisfies the main condition required by the results in [47] and thus by our results, Condition 2. For conv enience of the reader , we report here without proof the main result of [47] for the IIE ˆ F n (c.f. Theorem 2 in [47]). Theorem 1 (Theorem 2 in [47]) . Let p satisfy Condition 2, 0 < T < ∞ and let x ∈ [0 , T ) be fixed and F 0 be such that F 0 has a continuous strictly positive derivative f 0 in a neighborhood of x . Then n 1 / 3 ( ˆ F n ( x ) − F 0 ( x )) con verg es in distribution as n → ∞ ; specifically , ∀ z ∈ R : P n 1 / 3 ( ˆ F n ( x ) − F 0 ( x )) ≤ z d − → P 2 2 / 3 f 0 ( x ) 1 / 3 g 0 ( x ) 1 / 3 k (0) 2 / 3 arg min t ∈ R { W 1 ( t ) + t 2 } ≤ z (2.1) wher e W 1 is two-sided Br ownian motion originating fr om 0 . Finally , we proceed to the main result of this paper , which establishes the asymptotic distribution of the isotonized posterior of ˆ F G . By stating it ne xt to Theorem 1, we highlight the analogy between the asymptotic distribution of the IIP and that of the IIE. Theorem 2. Suppose G ∼ DP( α ) , where the base measur e α has bounded density , and ˆ F G as in (1.5) . Let p satisfy Condition 2, 0 < T < ∞ and let x ∈ [0 , T ) be fixed and F 0 be such that F 0 has a continuous strictly positive derivative f 0 in a neighborhood of x . Then n 1 / 3 ( ˆ F G ( x ) − F 0 ( x )) con ver ges in distribution conditionally on Z 1 , . . . , Z n as n → ∞ ; specifically , ∀ z ∈ R : Π n 1 / 3 ( ˆ F G ( x ) − F 0 ( x )) ≤ z | Z 1 , . . . , Z n (2.2) d − − − − → n →∞ P 2 2 / 3 f 0 ( x ) 1 / 3 g 0 ( x ) 1 / 3 k (0) 2 / 3 arg min t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } ≤ z | W 1 , (2.3) wher e W 1 and W 2 ar e two independent Br ownian motions on R originating at 0 . Pr oof. Consider for a ∈ (0 , 1) and τ ∈ [0 , T ) the ev ent T G ( a ) > τ where: T G ( a ) := inf { t ∈ [0 , T ] : H G ( t ) − at is minimal } . (2.4) This ev ent tak es place if and only if the maximal affine function with slope a that is bounded abov e by H G coincides with H G at a point t 0 > τ , while for all t ≤ τ , it stays strictly beneath H G . This is equiv alent to the inequality ˆ F G ( τ ) < a . So ∀ τ ∈ [0 , T ) and a ∈ (0 , 1) : T G ( a ) ≤ τ ⇐ ⇒ ˆ F G ( τ ) ≥ a. 7 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Fix x ∈ (0 , T ) . Then, by Lemma 2, for a ∈ R and n sufficiently lar ge n 1 / 3 ( ˆ F G ( x ) − F 0 ( x )) < a ⇐ ⇒ inf { t ∈ [ − xn 1 / 3 , ( T − x ) n 1 / 3 ] : Z G ( t ) − at is minimal } > 0 , where Z G ( t ) := n 2 / 3 H G ( x + tn − 1 / 3 ) − H G ( x ) − F 0 ( x ) tn − 1 / 3 . (2.5) This process can be decomposed as Z G ( t ) = W G ( t ) + W n ( t ) + n 2 / 3 ( H 0 ( x + tn − 1 / 3 ) − H 0 ( x ) − F 0 ( x ) tn − 1 / 3 ) where: W G ( t ) := n 2 / 3 ( H G ( x + n − 1 / 3 t ) − H G ( x ) − H n ( x + n − 1 / 3 t ) + H n ( x )) , W n ( t ) := n 2 / 3 ( H n ( x + n − 1 / 3 t ) − H n ( x ) − H 0 ( x + n − 1 / 3 t ) + H 0 ( x )) . W e can rewrite W n ( t ) by identifying two processes: one of them con verging weakly and a remainder term that con ver ges to zero in probability . By defining the γ -H ¨ older continuous, γ > 1 / 2 , function ˜ p := p − p (0) 1 [0 , ∞ ) , and W n ( t ) := n 2 / 3 p (0) Z ∞ 0 ( 1 [0 ,x + n − 1 / 3 t ) ( z ) − 1 [0 ,x ) ( z )) d ( G n − G 0 )( z ) , R n ( t ) := n 2 / 3 Z ∞ 0 ( ˜ p ( x + n − 1 / 3 t − z ) − ˜ p ( x − z )) d ( G n − G 0 )( z ) , we can write: W n ( t ) = W n ( t ) + R n ( t ) . (2.6) Using the fact ˜ p = p − p (0) 1 [0 , ∞ ) is H ¨ older continuous of degree γ > 1 / 2 we hav e that as n → ∞ : sup | t |∈ K | R n ( t ) | G 0 − − → 0 (2.7) for all compact sets K ⊂ R (see appendix in [47] for a proof). By example 3.2.14. in [41], for ev ery compact K ⊂ R : W n ⇝ p g 0 ( x ) k (0) W 1 in ℓ ∞ ( K ) (2.8) where W 1 is a two sided standard Brownian Motion originating at 0 . No w , using T aylor’ s theorem, for n → ∞ n 2 / 3 ( H 0 ( x + n − 1 / 3 t ) − H 0 ( x ) − F 0 ( x ) n − 1 / 3 t ) = 1 2 f 0 ( x ) t 2 + o (1) , (2.9) uniformly for t in compacta. W e no w turn to studying W G . Define f n t ( z ) = n 1 / 3 ( p ( x + n − 1 / 3 t − z ) 1 [0 ,x + n − 1 / 3 t ) ( z ) − p ( x − z ) 1 [0 ,x ) ( z )) then, for independent Q ∼ DP ( α ) , B n ∼ DP ( n G n ) and V n ∼ Be ( | α | , n ) : Gf n t = V n Qf n t + (1 − V n ) B n f n t 8 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions and thus we study the process: W G ( t ) = n 1 / 3 ( G − G n ) f n t = n 1 / 3 V n ( Q − G n ) f n t + n 1 / 3 (1 − V n )( B n − G n ) f n t . By Lemma 3 (eq. (A.3)-(A.4)), the terms premultiplied by V n con ver ge to zero in probability under G 0 , so we can focus on the study of: W ∗ n ( t ) := n 1 / 3 ( B n − G n ) f n t . By Proposition G.2 in [20] for ε i i.i.d. ∼ Exp (1) and W ni := ε i / ¯ ε n , we ha ve ( W n 1 , . . . , W nn ) ∼ Dir ( n ; 1 /n, . . . , 1 /n ) . Since B n ∼ DP ( n G n ) , denoting by δ Z i Dirac measure at Z i , we hav e the following representation in distrib ution of B n (c.f. Example 3.7.9 in [41]): B n = 1 n n X i =1 W ni δ Z i . Because of this representation (c.f. section 3.7.2. in [41]), B n is also known as Bayesian bootstrap . Conclude, by Lemma 4, that uniformly for t in compacta: W ∗ n ( t ) = n 1 / 3 ( B n − G n ) f n t = 1 n 2 / 3 n X i =1 ( W ni − 1) f n t ( Z i ) = W ∗ n ( t ) + o p (1) . (2.10) where for ε i i.i.d. ∼ Exp (1) , the process W ∗ n , for ˜ f n t ( z ) := n 1 / 3 p (0) 1 [ x,x + n − 1 / 3 t ) ( z ) , is defined as: W ∗ n ( t ) = 1 √ n n X i =1 ( ε i − 1) 6 √ n ˜ f n t ( Z i ) . (2.11) Using the results in Appendix A, Lemma 5, which shows that W ∗ n con ver ges conditionally in ℓ ∞ ( K ) to √ g 0 ( x ) k (0) W 2 , together with Lemma 3 and (2.10), we hav e in probability under G 0 , as n → ∞ , W G | Z 1 , . . . , Z n ⇝ p g 0 ( x ) k (0) W 2 in ℓ ∞ ( K ) , (2.12) for ev ery compact K ⊂ R . Hence, by (2.6), (2.7), (2.8), (2.12) and Slutsk y’ s lemma, for e very compact K ⊂ R : ( W G ( t ) + W n ( t ) + n 2 / 3 ( H 0 ( x + tn − 1 / 3 ) − H 0 ( x ) − F 0 ( x ) tn − 1 / 3 ) : t ∈ K ) | Z 1 , . . . , Z n ⇝ p g 0 ( x ) k (0) W 1 ( t ) + p g 0 ( x ) k (0) W 2 ( t ) + 1 2 f 0 ( x ) t 2 : t ∈ K ! | W 1 . (2.13) Let us elaborate on why the unconditional con vergence W n ⇝ √ g 0 ( x ) k (0) W 1 in ℓ ∞ ( K ) (equation (2.8)) giv es rise to a conditional limit in volving W 1 in (2.13). The key observation is that W G is driven ex- clusiv ely by the Bayesian bootstrap weights ( ε i ) n i =1 , which are independent of the data ( Z 1 , . . . , Z n ) . Hence W G and W n are conditionally independent given the data. As n → ∞ : the orbit of W n (a 9 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions measurable function of the data alone) conv erges to √ g 0 ( x ) k (0) W 1 , and W G | Z 1 , . . . , Z n con ver ges inde- pendently to √ g 0 ( x ) k (0) W 2 . In the joint limit, the realization of W 1 (coming from W n ) plays the role of a fixed, conditioning object, while W 2 remains a fresh independent Brownian motion. Conditional on the data, an application of Slutsky’ s lemma in the conditional setting then yields (2.13) with the right-hand side conditioned on W 1 . Now , in order to apply Lemma A.3 in [22], we need to pro ve that there exists a stochastically bounded sequence ˜ M n such that: Π n inf { t ∈ [ − xn 1 / 3 , ( T − x ) n 1 / 3 ] : Z G ( t ) − at is minimal } ≤ ˜ M n | Z 1 , . . . , Z n G 0 − − → 1 (2.14) The proof of (2.14) is gi ven in Appendix A, Lemma 7. An application of Lemma A.3 in [22], together with (2.13) and (2.14) giv es: inf { t ∈ R : Z G ( t ) − at is minimal } | Z 1 , . . . , Z n ⇝ arg min t ∈ R p g 0 ( x ) k (0) W 1 ( t ) + p g 0 ( x ) k (0) W 2 ( t ) + 1 2 f 0 ( x ) t 2 − at ! | W 1 . Using that ∀ c > 0 , b ∈ R that as process the standard Brownian Motion satisfies W ( · /a 2 ) d = W ( · ) /a : argmin t ∈ R { c ( W 1 ( t ) + W 2 ( t )) + ( t − b ) 2 } d = c 2 / 3 argmin t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } + b. Note that this distributional equality holds jointly in the pair (argmin , W 1 ) : the time-rescaling t 7→ c 1 / 3 t is applied simultaneously to both W 1 and W 2 , so the rescaled W 1 ( c 1 / 3 · ) /c 1 / 6 has the same law as W 1 , and a joint rescaling ar gument shows that the equality in distribution is in the space of ( argmin , W 1 ) . Thus conditioning on W 1 on the right-hand side corresponds to conditioning on the same Bro wnian trajectory (up to the distributional scaling identity), and the conditional distribution of the argmin giv en W 1 is the same on both sides of the d = . Using the change of variable t → q 2 f 0 ( x ) t we get arg min t ∈ R p g 0 ( x ) k (0) W 1 ( t ) + p g 0 ( x ) k (0) W 2 ( t ) + 1 2 f 0 ( x ) t 2 − at ! d = g 0 ( x ) 1 / 3 k (0) 2 / 3 2 f 0 ( x ) 1 / 6+1 / 2 arg min t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } + a f 0 ( x ) , which prov es the claim, since: P arg min t ∈ R p g 0 ( x ) k (0) W 1 ( t ) + p g 0 ( x ) k (0) W 2 ( t ) + 1 2 f 0 ( x ) t 2 − at ! > 0 | W 1 ! = P g 0 ( x ) 1 / 3 k (0) 2 / 3 2 f 0 ( x ) 1 / 6+1 / 2 arg min t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } > − a f 0 ( x ) | W 1 ! = P 2 2 / 3 f 0 ( x ) 1 / 3 g 0 ( x ) 1 / 3 k (0) 2 / 3 arg min t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } ≤ a | W 1 . 10 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions The limiting distribution established in Theorem 2 is fundamental for establishing the asymptotic cov erage of credible intervals. For any gi ven n ≥ 1 and τ ∈ [0 , 1] , the credible interval is represented by I n,τ := [ Q n, 1 − τ / 2 , Q n,τ / 2 ] . Here, Q n,τ signifies the (1 − τ ) -quantile of the projection-posterior distribution associated with ˆ F G ( x ) : Q n,τ := inf { z ∈ R : Π( ˆ F G ( x ) ≤ z | Z 1 , . . . , Z n ) ≥ 1 − τ } . Consequently , F 0 ( x ) ≤ Q n,τ is true if and only if Π( ˆ F G ( x ) ≤ F 0 ( x ) | Z 1 , . . . , Z n ) ≤ 1 − τ . The limiting cov erage of the interval I n,τ as n → ∞ can be determined. T o begin, observe that P( F 0 ( x ) ≤ Q n,τ ) = P(Π( n 1 / 3 ( ˆ F G ( x ) − F 0 ( x )) ≤ 0 | Z 1 , . . . , Z n ) ≤ 1 − τ ) (2.15) → P P(argmin t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } ≤ 0 | W 1 ) ≤ 1 − τ . (2.16) This can be written as P( Z B ≤ 1 − τ ) , where Z B is specified as Z B := P(argmin t ∈ R { W 1 ( t ) + W 2 ( t ) + t 2 } ≤ 0 | W 1 ) . (2.17) The random variable Z B , having distribution known as the Bayes–Chernoff distribution, plays a piv- otal role in understanding the limiting co verage. While the distribution of Z B is analogous to the Chernoff distribution for the MLE, Z B takes values on the unit interv al and exhibits symmetry around 1 / 2 ( Z B = 1 − Z B in distribution). Employing (2.15), we arriv e at the primary conclusion regarding the limiting cov erage of I n,τ as n → ∞ : P( F 0 ( x ) ∈ I n,τ ) → P( τ / 2 ≤ Z B ≤ 1 − τ / 2) . Therefore, the limiting coverage of a (1 − τ ) -credible interv al does not necessarily equal (1 − τ ) . It can, howe ver , be computed using the distrib ution of Z B . Let us define A ( u ) = P( Z B ≤ u ) for u ∈ [0 , 1] . The function A is continuous, strictly increasing, and maps the interval [0 , 1] onto itself. Consequently , the in verse function A − 1 is well-defined and also strictly increasing. Additionally , the function A features a symmetry property , which is formalized in Lemma 3.5 in [9] and reported here for completeness. Lemma 1 (Lemma 3.5 in [9]) . The random variable Z B ∈ [0 , 1] is symmetrically distrib uted about 1 / 2 , and hence A (1 − u ) = 1 − A ( u ) , for all u ∈ [0 , 1] , A − 1 (1 − v ) = 1 − A − 1 ( v ) for all v ∈ [0 , 1] , and A (1 / 2) = 1 / 2 = A − 1 (1 / 2) . Using these properties, the limiting coverage P( τ / 2 ≤ Z B ≤ 1 − τ / 2) can be rewritten as A (1 − τ / 2) − A ( τ / 2) = A (1 − τ / 2) − (1 − A (1 − τ / 2)) = 2 A (1 − τ / 2) − 1 . A recalibration technique allows us to achie ve an y desired asymptotic cov erage, say 1 − β . For a two-sided credible interv al I n,τ , Theorem 2 and Lemma 1 imply that its asymptotic coverage is 2 A (1 − τ / 2) − 1 . T o obtain a desired cov erage of 1 − β , we set 2 A (1 − τ / 2) − 1 = 1 − β . This implies 1 − τ / 2 = A − 1 (1 − β / 2) , or τ / 2 = 1 − A − 1 (1 − β / 2) = A − 1 ( β / 2) . Thus, we choose τ = 2 A − 1 ( β / 2) (c.f. Corollary 3.6 in [9]). Corollary 1. F or any 0 < β < 1 , P( F 0 ( x ) ∈ I n, 2 A − 1 ( β / 2) ) → 1 − β . 11 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Value of u 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Probability A ( u ) Empirical CDF: A ( u ) = P ( Z B ≤ u ) Empirical CDF y = x (Uniform CDF) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Probability u 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Quantile A − 1 ( u ) Inverse CDF (Quantile Function): A − 1 ( u ) Empirical Quantile y = x (Uniform Quantile) Empirical CDF and Quantile Function of Z B Figure 1: The Bayes–Chernoff distribution Z B and its in verse function A − 1 , with the identity line for reference (the computations are based on 20000 gathered samples of Z B ). The back-calculation of the required credibility lev el 1 − τ = 1 − 2 A − 1 ( β / 2) to achie ve a cov erage lev el 1 − β can be obtained from a T able 2 in [9], which presents v alues of the function A − 1 . For con venience of the reader and for completeness, we report T able 2 from [9] here below , in T able 1 (we v erified via our simulations its correctness). Numerical calculations suggest that A ( u ) ≥ u for all v alues of u ≥ 1 / 2 where the computation has been numerically performed and the results are shown in Fig. 1. This implies that a credible interval typically has asymptotic coverage greater than its nominal cov erage, which may be called a rev erse Cox phenomenon. T able 1: T able of the v alues of the function A − 1 v 0.700 0.750 0.800 0.850 0.900 0.910 0.920 0.930 0.940 0.950 0.960 A − 1 ( v ) 0.677 0.723 0.771 0.820 0.874 0.885 0.897 0.909 0.922 0.934 0.946 v 0.965 0.970 0.975 0.980 0.985 0.990 0.995 0.996 0.997 0.998 0.999 A − 1 ( v ) 0.952 0.960 0.966 0.973 0.980 0.986 0.993 0.995 0.996 0.997 0.999 3 Simulation study In this section, we present simulations to illustrate the practical beha vior of the IIP in compar- ison to the IIE studied in [47]. In this simulation study , we analyze the setting where the un- derlying cdf F 0 is exponential with rate 1.2. Samples Z 1 , . . . , Z n used to compute the projec- tion posterior of the IIP are generated hierarchically: X 1 , . . . , X n ∼ F 0 , Y 1 , . . . , Y n ∼ k , with Z i = X i + Y i for all i . The noise density k which crucially determines the solvability of the V olterra integral equation in (1.1), is chosen from the following set: { Exp(1) , Mix : 1 4 Erlang(2) − 3 4 Exp(2) , HalfNorm(0 , 1) , HalfCauch y(0 , 2) , Lomax(10 , 1) , HalfLogistic } . W e recall the associ- ated kernels k in Fig. 2 and we plot the numerical solutions p (and the analytical solutions when av ailable) of the V olterra integral equation in (1.1) for each of these noise distrib utions. 12 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions 1 2 3 4 5 Exponential Kernel Numerical Solution Analytical: p ( x ) = 1 . 0 + x k ( y ) = e − y , for y ≥ 0 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 4 . 5 5 . 0 Mixed Erlang-Exp onential Kernel Numerical Solution Analytical: p ( x ) = 0 . 75 + x + 0 . 25 e − 4 x k ( y ) = (1 + 2 y ) e − 2 y (Mixture PDF) 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 4 . 5 5 . 0 Half-Normal Kernel Numerical Solution k ( y ) = p 2 /πe − y 2 / 2 , for y ≥ 0 1 2 3 4 5 Half-Cauch y Kernel Numerical Solution k ( y ) ∝ (1 + 4 y 2 ) − 1 , for y ≥ 0 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 0 1 2 3 4 Lomax Kernel Numerical Solution k ( y ) ∝ (1 + y ) − c − 1 , c = 10, for y ≥ 0 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 4 . 5 5 . 0 5 . 5 Half-Logistic Kernel Numerical Solution k ( y ) = 2 e − y (1+ e − y ) 2 , for y ≥ 0 x p ( x ) Figure 2: Resolv ent of proposed kernels. 13 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Exponential Noise Mixed Erlang Exp onential Noise Half-Normal Noise Half-Cauch y Noise Lomax Noise Half-Logistic Noise Figure 3: Combined deconv olution plots for n = 200 . In green, we plot draws of ˆ F G based on prior draws from G ∼ DP( M α ) with α ∼ Ga(2 , 2) and prior precision M = 10 ; in purple, draws from the isotonized posterior; in red, the a verage of these dra ws (approximating the posterior mean); in yellow , the (IIE); and in orange F 0 . 14 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Exponential Noise Mixed Erlang Exp onential Noise Half-Normal Noise Half-Cauch y Noise Lomax Noise Half-Logistic Noise Figure 4: Combined deconv olution plots with calibrated uncertainty quantification for n = 200 . In green, we plot dra ws of ˆ F G based on prior draws from G ∼ DP( M α ) with α ∼ Ga(2 , 2) and prior precision M = 10 ; in pink, the calibrated credible bands from the isotonized posterior; in red, the av erage of these draws (approximating the posterior mean); in yello w , the (IIE); and in orange F 0 . 15 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions The reasons why we chose this set of distrib utions are two: on the one hand, for our methodology to work we need k (0) = 0 , with k living on the positiv e real line. On the other hand, we want to illustrate the performance of the IIP in a variety of settings, including both light-tailed and heavy-tailed noise distrib utions. Thus we included a good variety of distributions, that go from light-tailed (e.g. exponential and half-normal) to heavy-tailed (e.g. Lomax with c = 10 , with tails proportional to y − 11 and which is a special case of Pareto) to very hea vy-tailed (e.g. half-Cauchy with tails proportional to y − 2 ). Because the underlying cdf F 0 is always the same, our simulations show that the IIP is able to recover the underlying cdf F 0 in all these settings, even when the noise distribution is very heavy- tailed. In particular , in Figure 3 we show the results of the IIP decon volution methodology compared to the IIE, visualizing the isonotized posterior draws, for the same kernels of Figure 2. W e observe that the Bayesian methodology agrees with the frequentist one. In Figure 4, we provide in the same simulation setting the recalibrated credible sets according to the recalibration 2 A − 1 (0 . 975) − 1 = 0 . 932 . The numerical solutions of the V olterra integral equation are computed using the trapezoidal rule, as described in detail here below . The plots use the following color scheme: green for draws of ˆ F G based on prior draws from G ∼ DP( M α ) (parameters M and α a pdf specified in the plots not necessarily in the abo ve mentioned set); purple for draws from the isotonized posterior; red for the av erage of these draws (approximating the posterior mean); yellow for the Isotonic In verse Estimator (IIE); and orange for F 0 . Overall, these simulations demonstrate that the IIP reliably reco vers the underlying distrib ution F 0 across a wide spectrum of noise distributions, ranging from light-tailed to extremely heavy-tailed. Despite substantial variation in the shape and tail beha vior of the k ernels k , the numerical solutions of the associated V olterra equations remain stable, and the resulting posterior draws closely track the frequentist IIE benchmark. The agreement between methods, together with the well-calibrated credible sets, highlights the robustness of the IIP and its practical ef fecti veness for decon volution in div erse settings. Numerical Solver of the V olterra Equation In order to compute the estimators in case p is not explicitly known, we use a numerical approxima- tion. The presented simulations need the unkno wn function p ( x ) solving the specific V olterra integral equation of the first kind: x 1 ( x ) = Z x 0 k ( x − t ) p ( t ) dt, x ≥ 0 . (3.1) The kernel k is a known function. The solver uses a numerical method based on the trapezoidal rule. A key requirement for this method is k (0) = 0 . W e be gin by discretizing the domain [0 , T ] into N equally spaced points, x n = nh , p n := p ( x n ) and k n := k ( x n ) , for n = 0 , 1 , . . . , N − 1 , with step size h := T / ( N − 1) . At each grid point x n , Equation (3.1) becomes: x n = nh = Z x n 0 k ( x n − t ) p ( t ) dt. (3.2) W e approximate the integral using the composite trapezoidal rule ov er the points t j = j h for j = 0 , . . . , n : nh ≈ h 1 2 k ( x n − t 0 ) p ( t 0 ) + n − 1 X j =1 k ( x n − t j ) p ( t j ) + 1 2 k ( x n − t n ) p ( t n ) . (3.3) 16 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Let k ( x n − t j ) := k (( n − j ) h ) = k n − j and k ( x n − t n ) := k (0) = k 0 , then dividing both sides by the step size h : n = 1 2 k n p 0 + n − 1 X j =1 p j k n − j + 1 2 k 0 p n . (3.4) W e can now rearrange this equation to solv e for the unkno wn term p n , assuming all pre vious values ( p 0 , . . . , p n − 1 ) are known. This giv es the recurrence relation for p n : p n = 2 k 0 n − 1 2 k n p 0 − n − 1 X j =1 p j k n − j . (3.5) T o start the recurrence, we need the value of p 0 = p (0) . This can be found by dif ferentiating the orig- inal integral equation using the Leibniz inte gral rule, which yields the relation 1 = k (0) p (0) . The algorithm implemented in the simulation proceeds as follows: 1. Discretize the domain [0 , T ] into N points with step size h . Pre-compute the kernel v alues k n for n = 0 , . . . , N − 1 . 2. Calculate the e xact initial value p 0 : p 0 = 1 /k 0 . 3. F or each step n = 1 , 2 , . . . , N − 1 , sequentially compute p n using the recurrence relation from Equation (3.5). This procedure yields a stable solution for all examples in Figure 2. 4 Conclusion This work introduces and e v aluates a nonparametric Bayesian method for uncertainty quantification in a specific class of statistical decon volution problems. T o address the challenge of nuisance-parameter- dependent confidence intervals in frequentist methods, we propose the ”Isotonic Inv erse Posterior . ” This approach combines a Dirichlet Process prior on the distribution of the observ ed data with an in verse operator and an isotonic re gression step to produce valid estimates for the signal’ s cumulativ e distribution function, F 0 . The procedure is computationally fast and, following a straightforward recalibration, its credible sets achiev e asymptotically correct frequentist cov erage without relying on nuisance parameter estimation. As demonstrated through simulations, the method performs ef fectiv ely across a variety of noise distrib utions. Acknowledgments The first author gratefully acknowledges the financial support of Aad van der V aart through his NWO Spinoza Prize. W e also thank Aad van der V aart for v aluable feedback on an earlier version of this manuscript. 17 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions A Complementary results Measur e-theor etical framework : in this paper , the sample space is ( R + , B ( R + )) , and M (with Borel σ -field M for the weak topology) is the collection of all Borel probability measures on ( R + , B ( R + )) . The Dirichlet process prior is a probability measure on M . A prior on the set of probability measures M is a probability measure on a sigma-field M of subsets of M . Alternativ ely , it can be vie wed as map from some probability space (Ω , U , Pr) into ( M , M ) . W e can think of the hierarchy of the spaces as follows: (Ω , U , Pr) → ( M , M ) → ( R + , B ( R + )) . W e put a Dirichlet process prior ov er G and write G ∼ Π = DP( α ) for some base measure α and prior precision | α | . This means that for any measurable set B ∈ M we have Π( B ) = Pr( G ∈ B ) . Throughout the paper , we use the notations P and E , which should be understood as the outer probability measure and outer expectation, respectively , whenev er issues of measurability in the considered processes arise (see [41] for a rigorous treatment of these topics). Furthermore, we use the notion of conditional con vergence in distribution. This happens if the bounded Lipschitz distance between the conditional law of Borel measurable X n giv en B n and a Borel probability measure L tends to zero, where the con vergence can be in outer probability . The sequence X n tends to L conditionally giv en B n in outer probability if d BL ( L ( X n | B n ) , L ) := sup f ∈ B L 1 E ( f ( X n ) | B n ) − Z f dL P − → 0 , (A.1) where B L 1 is the space of bounded Lipschitz functions with Lipschitz constant 1. In particular if Z 1 , . . . , Z n i.i.d. ∼ P Z , then X n | Z 1 , . . . , Z n ⇝ N (0 , σ 2 ) means: d BL P( X n ∈ · | Z 1 , . . . , Z n ) , N (0 , σ 2 ) P Z − − → 0 . (A.2) Lemma 2. Let x ∈ (0 , T ) , ˆ F G as in (1.5) and F 0 true underlying cdf . Then for a ∈ R and n sufficiently lar ge n 1 / 3 ( ˆ F G ( x ) − F 0 ( x )) < a ⇐ ⇒ inf { t ∈ [ − xn 1 / 3 , ( T − x ) n 1 / 3 ] : Z G ( t ) − at is minimal } > 0 , wher e, for H G as in (1.4) , Z G ( t ) := n 2 / 3 H G ( x + tn − 1 / 3 ) − H G ( x ) − F 0 ( x ) tn − 1 / 3 . Pr oof. Fix x ∈ (0 , T ) . Then for a ∈ R and n sufficiently lar ge n 1 / 3 ( ˆ F G ( x ) − F 0 ( x )) < a ⇐ ⇒ ˆ F G ( x ) < F 0 ( x ) + an − 1 / 3 (2.4) ⇐ ⇒ T G ( F 0 ( x ) + an − 1 / 3 ) > x ⇐ ⇒ inf { x + tn − 1 / 3 ∈ [0 , T ] : H G ( x + tn − 1 / 3 ) − H G ( x ) − F 0 ( x ) tn − 1 / 3 − atn − 2 / 3 is minimal } > x ⇐ ⇒ inf { t ∈ [ − xn 1 / 3 , ( T − x ) n 1 / 3 ] : n 2 / 3 ( H G ( x + tn − 1 / 3 ) − H G ( x ) − F 0 ( x ) tn − 1 / 3 ) − at is minimal } > 0 . 18 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Lemma 3. Let f n t ( z ) := n 1 / 3 ( p ( x + n − 1 / 3 t − z ) 1 [0 ,x + n − 1 / 3 t ) ( z ) − p ( x − z ) 1 [0 ,x ) ( z )) then, for in- dependent Q ∼ DP( α ) , B n ∼ DP( n G n ) and V n ∼ Be( | α | , n ) . As n → ∞ , under G 0 in pr obability: P( n 1 / 3 | V n ( Q − G n ) f n t | > ε | Z 1 , . . . , Z n ) G 0 − − → 0 . (A.3) and P( n 1 / 3 | V n ( B n − G n ) f n t | > ε | Z 1 , . . . , Z n ) G 0 − − → 0 . (A.4) Pr oof. Using the fact that p is H ¨ older continuous on (0 , ∞ ) of degree γ > 1 / 2 : | f n t ( z ) | = n 1 / 3 | p ( x + n − 1 / 3 t − z ) 1 [0 ,x ) ( z ) − ( x − z ) 1 [0 ,x ) ( z ) | + | p ( x + n − 1 / 3 t − z ) 1 [ x,x + n − 1 / 3 t ) ( z ) | ≲ n 1 / 3 | ( x + n − 1 / 3 t − z ) − ( x − z ) | γ 1 [0 ,x ) ( z ) + n 1 / 3 sup z ∈ [ x,x + n − 1 / 3 t ] | p ( x + n − 1 / 3 t − z ) | ≲ n 1 / 3 | n − 1 / 3 t 1 [0 ,x ) ( z ) | γ + n 1 / 3 sup z ∈ [ x,x + n − 1 / 3 t ] | x + n − 1 / 3 t − z | γ ≲ n 1 / 3 p (0) + n (1 − γ ) / 3 | t | γ . Note that E V n = | α | / ( | α | + n ) , thus ∀ ε > 0 by independence, γ > 1 / 2 as n → ∞ P( n 1 / 3 | V n ( Q − G n ) f n t | > ε | Z 1 , . . . , Z n ) ≲ n 1 / 3 ε − 1 E V n E[( Q + G n ) | f n t | | Z 1 , . . . , Z n ] ≲ n (2 − γ ) / 3 ε − 1 | α | | α | + n | t | γ → 0 . Similarly P( n 1 / 3 | V n ( B n − G n ) f n t | > ε | Z 1 , . . . , Z n ) G 0 − − → 0 . Lemma 4. F or W ∗ n as in (2.10) , in pr obability under G 0 , as n → ∞ : W ∗ n ( t ) = W ∗ n ( t ) + o p (1) . (A.5) wher e for ε i i.i.d. ∼ Exp(1) , the pr ocess W ∗ n is defined as: W ∗ n ( t ) = 1 √ n n X i =1 ( ε i − 1) 6 √ n ˜ f n t ( Z i ) . (A.6) and ˜ f n t ( z ) := n 1 / 3 p (0) 1 [ x,x + n − 1 / 3 t ) ( z ) . Pr oof. First recall the decomposition: W ∗ n ( t ) = n 1 / 3 ( B n − G n ) f n t = 1 n 2 / 3 n X i =1 ( W ni − 1) f n t ( Z i ) , 19 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions where W ni = ε i ¯ ε n . Because | ¯ ε n − 1 | = O p (1 / √ n ) , for almost e very sequence Z 1 , . . . , Z n conclude that uniformly in t in compacta: 1 n 2 / 3 n X i =1 ( W ni − 1) f n t ( Z i ) = 1 √ n n X i =1 ( ε i − 1) 6 √ n f n t ( Z i ) + o p (1) . Now consider the decomposition: f n t ( z ) = ˜ f n t ( z ) + r n t ( z ) where for ˜ p = p − p (0) 1 [0 , ∞ ) : r n t ( z ) := n 1 / 3 ( ˜ p ( x + n − 1 / 3 t − z ) − ˜ p ( x − z )) , ˜ f n t ( z ) := n 1 / 3 p (0) 1 [ x,x + n − 1 / 3 t ) ( z ) . W e obtain the claim that uniformly in t ov er compacta: W ∗ n ( t ) = W ∗ n ( t ) + o p (1) , (A.7) as soon as we show that for all compact K ⊂ R and ∀ ε > 0 : P sup t ∈ K 1 √ n n X i =1 ( ε i − 1) 6 √ n r n t ( Z i ) > ε | Z 1 , . . . , Z n ! G 0 − − → 0 . (A.8) For ˜ p = p − p (0) 1 [0 , ∞ ) , ˜ p is γ -H ¨ older continuous of degree γ > 1 / 2 . Define: R ∗ n ( t ) := 1 n 1 / 3 n X i =1 ( ε i − 1) ˜ p ( x + n − 1 / 3 t − Z i ) − ˜ p ( x − Z i ) . The claim is obtained if we show for an y K ∈ (0 , ∞ ) , sup | t |≤ K | R ∗ n ( t ) | G 0 − − → 0 . Let 0 = t 0 < t 1 < · · · < t K n = K and t − i = − t i , i = 1 , . . . , K n . No w note: sup | t |≤ K | R ∗ n ( t ) | = max − K n +1 ≤ i ≤ K n sup t ∈ [ t i − 1 ,t i ] | R ∗ n ( t ) | ≤ max − K n +1 ≤ i ≤ K n | R ∗ n ( t i ) | + sup t ∈ [ t i − 1 ,t i ] | R ∗ n ( t ) − R ∗ n ( t i ) | ! . Using Markov’ s inequality , we hav e: ε P sup | t |≤ K | R ∗ n ( t ) | > ε ! ≤ E sup | t |≤ K | R ∗ n ( t ) | ! ≤ E max − K n +1 ≤ i ≤ K n | R ∗ n ( t i ) | + E max − K n +1 ≤ i ≤ K n sup t ∈ [ t i − 1 ,t i ] | R ∗ n ( t ) − R ∗ n ( t i ) | ! . 20 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions For each t ∈ [ t i − 1 , t i ] and P n = 1 n P n i =1 δ ε i | R ∗ n ( t ) − R ∗ n ( t i ) | = n 2 / 3 Z ∞ 0 Z ∞ 0 ˜ p ( x + n − 1 / 3 t − z ) − ˜ p ( x + n − 1 / 3 t i − z ) ( ε − 1) d ( G n , P n )( z , ε ) ≤ 2 n 2 / 3 Ln − γ / 3 | t − t i | γ 1 + 1 n n X j =1 ε j = 2 n (2 − γ ) / 3 L | t − t i | γ 1 + 1 n n X j =1 ε j . T ake a grid of t i ’ s such that | t i − t i − 1 | γ = δ n − (2 − γ ) / 3 then E sup − K n +1 ≤ i ≤ K n sup t ∈ [ t i − 1 ,t i ] | R ∗ n ( t ) − R ∗ n ( t i ) | ! ≤ 4 Lδ, (which we can make small by taking δ small enough; note also that K n = O ( n (2 − γ ) / 3 γ ) ). W e can rewrite R ∗ n ( t ) = P n i =1 Y i where: Y i := n − 1 / 3 ( ε i − 1) ˜ p ( x + n − 1 / 3 t − Z i ) − ˜ p ( x − Z i ) . Note that Y i has expectation 0 and: | Y i | ≤ n − 1 / 3 ( Ln − γ / 3 | t | γ + C n − 1 / 3 | t | ) | ε i − 1 | ≤ ( C ′ n − (1+ γ ) / 3 + C K n − 2 / 3 ) | ε i − 1 | and because the exponential random v ariables ha ve finite Orlicz norm ∥ ε i ∥ ψ 1 < T , 0 < T < ∞ (where the Orlicz norm is defined as: ∥ X ∥ ψ 1 := inf { c > 0 : E[exp( | X | /c )] ≤ 2 } ), then for some finite constant K ′ : ∥ Y i ∥ ψ 1 ≤ K ′ ( C ′ n − (1+ γ ) / 3 + C K n − 2 / 3 ) . Therefore, ∥ Y i ∥ 2 ψ 1 ≤ 2( K ′ C ′ ) 2 n − (2+2 γ ) / 3 + 2( K C K ′ C ′ ) 2 n − 4 / 3 ≤ 2( K ′ C ′ ) 2 (1 + ( K C ) 2 ) n − (2+2 γ ) / 3 . By Example 2.2.12 and Lemma 2.2.10 in [41], for some constants C 1 , 2 , 3 : P( | R ∗ n ( t ) | > x ) = P n X i =1 Y i > x ! ≤ 2 exp − 1 2 x 2 C 1 n (1 − 2 γ ) / 3 + ( C 2 n − (1+ γ ) / 3 + C 3 n − 2 / 3 ) x . By applying Lemma 2.2.13 in [41] to R ∗ n ( t − K n +1 ) , . . . , R ∗ n ( t K n ) and ∥ · ∥ 1 ≲ ∥ · ∥ ψ 1 : E max − K n +1 ≤ i ≤ K n | R ∗ n ( t i ) | ≲ C ( C 2 n − (1+ γ ) / 3 + C 3 n − 2 / 3 ) log(1 + 2 K n ) (A.9) + C 1 / 2 1 n (1 − 2 γ ) / 6 p log(1 + 2 K n ) . (A.10) Because K n = O ( n (2 − γ ) / 3 γ ) , the result follows. 21 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Lemma 5. F or every compact K ⊂ R as n → ∞ : W ∗ n | Z 1 , . . . , Z n ⇝ s g 0 ( x ) k (0) W 2 in ℓ ∞ ( K ) . (A.11) wher e W ∗ n is as in (A.6) and W 2 is a two sided Br ownian Motion originating in 0 . Pr oof. First, for t ∈ R , we giv e the proof of the marginal con ver gence W ∗ n ( t ) | Z 1 , . . . , Z n ⇝ W 2 ( t ) (A.12) where W 2 is a two sided Brownian Motion originating in 0 . After that, we will show conditional asymptotic equicontinuity of the process W ∗ n , proving the claim (A.11). W ithout loss of generality , let t = 0 in R . W e apply Theorem 6.16 in [31] with ξ ni equal to: ξ ni := ( ε i − 1) ˜ f n t ( Z i ) n 2 / 3 = ( ε i − 1) n 1 / 3 p (0) 1 [ x,x + n − 1 / 3 t ] ( Z i ) . Therefore we need to show ∀ δ > 0 : n X i =1 P( | ε i − 1 || ˜ f n t ( Z i ) | > δ n 2 / 3 | Z 1 , . . . , Z n ) G 0 − − → 0 , (A.13) 1 n 4 / 3 n X i =1 E ( ε i − 1) ˜ f n t ( Z i ) 1 {| ε i − 1 || ˜ f n t ( Z i ) |≥ δ n 2 / 3 } | Z 1 , . . . , Z n G 0 − − → 0 , and (A.14) 1 n 4 / 3 n X i =1 V ar ( ε i − 1) ˜ f n t ( Z i ) 1 {| ε i − 1 || ˜ f n t ( Z i ) | <δ n 2 / 3 } | Z 1 , . . . , Z n G 0 − − → g 0 ( x ) k (0) 2 t. (A.15) For (A.13), use that | ˜ f n t ( Z i ) | ≤ p (0) n 1 / 3 , for all n big enough, unconditionally: n X i =1 P( | ε i − 1 || ˜ f n t ( Z i ) | > δ n 2 / 3 ) ≤ n P( | ε i − 1 | > δ n 1 / 3 /p (0)) = n Z λ> 1+ | t | − 1 δ n 1 / 3 e − λ dλ = ne − 1 −| t | − 1 δ n 1 / 3 → 0 . Now consider (A.14) and recall Z ∼ g 0 and ε ∼ Exp(1) in what follows. Because E ˜ f n t ( Z ) = O (1) since, as n → ∞ : E ˜ f n t ( Z ) = n 1 / 3 Z p (0) 1 [ x,x + n − 1 / 3 t ] ( z ) g 0 ( z ) dz = p (0) n 1 / 3 P( Z ∈ [ x, x + n − 1 / 3 t ]) → tp (0) g 0 ( x ) , and ε ⊥ ⊥ Z , we conclude that: E 1 n 2 / 3 n X i =1 E ( ε i − 1) ˜ f n t ( Z i ) 1 {| ε i − 1 || ˜ f n t ( Z i ) |≥ δ n 2 / 3 } | Z 1 , . . . , Z n 22 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions ≲ n 1 / 3 E( | ε − 1 | 1 {| ε − 1 |≥ δ n 1 / 3 /p (0) } )E ˜ f n t ( Z ) ≤ n 1 / 3 (1 + δ n 1 / 3 ) e − 1 − δ n 1 / 3 → 0 . For (A.15), some more work is needed. Note that: (A.15) = 1 n 4 / 3 n X i =1 E ( ˜ f n t ( Z i )) 2 ( ε i − 1) 2 1 {| ε i − 1 | ˜ f n t ( Z i ) <δ n 2 / 3 } | Z 1 , . . . , Z n − E ˜ f n t ( Z i )( ε i − 1) 1 {| ε i − 1 | ˜ f n t ( Z i ) <δ n 2 / 3 } | Z 1 , . . . , Z n 2 . First notice, because E( ε − 1) = 0 and ε ⊥ ⊥ Z : E 1 n 4 / 3 n X i =1 E ˜ f n t ( Z i )( ε i − 1) 1 {| ε i − 1 | ˜ f n t ( Z i ) >δ n 2 / 3 } | Z 1 , . . . , Z n 2 ! ≤ 1 n 1 / 3 E ( ˜ f n t ( Z )) 2 ( ε − 1) 2 1 {| ε − 1 | ˜ f n t ( Z ) >δ n 2 / 3 } ≤ 1 n 1 / 3 E ( ˜ f n t ( Z )) 2 ( ε − 1) 2 1 {| ε − 1 | >δ n 1 / 3 /p (0) } → 0 , because as n → ∞ 1 n 1 / 3 E ( ˜ f n t ( Z )) 2 = n 1 / 3 Z p 2 (0) 1 [ x,x + n − 1 / 3 t ] ( z ) g 0 ( z ) dz → p 2 (0) g 0 ( x ) t, and for all n big enough: E ( ε − 1) 2 1 {| ε − 1 | >δ n 1 / 3 } ≲ Z ∞ 1+ δ n 1 / 3 ( λ − 1) 2 e − λ dλ = ( δ n 1 / 3 ( δ n 1 / 3 + 2) + 2) e − 1 − δ n 1 / 3 → 0 . (A.16) Now using that E( ε − 1) 2 = 1 and that ε ⊥ ⊥ Z , we get for the domination term of (A.15): 1 n 4 / 3 n X i =1 E ( ˜ f n t ( Z i )) 2 ( ε i − 1) 2 1 {| ε i − 1 | ˜ f n t ( Z i ) <δ n 2 / 3 } | Z 1 , . . . , Z n = 1 n 4 / 3 n X i =1 E ( ˜ f n t ( Z i )) 2 ( ε i − 1) 2 (1 − 1 {| ε i − 1 | ˜ f n t ( Z i ) ≥ δ n 2 / 3 } ) | Z 1 , . . . , Z n = 1 n 4 / 3 n X i =1 ( ˜ f n t ( Z i )) 2 − 1 n 4 / 3 n X i =1 E ( ˜ f n t ( Z i )) 2 ( ε i − 1) 2 1 {| ε i − 1 | ˜ f n t ( Z i ) ≥ δ n 2 / 3 } | Z 1 , . . . , Z n . Now we show 1 n 4 / 3 P n i =1 ( ˜ f n t ( Z i )) 2 G 0 − − → t g 0 ( x ) k 2 (0) . W e apply Lemma 2.3 from the supplement of [22] with ξ ni := ( ˜ f n t ( Z i )) 2 /n 4 / 3 . F or all ε > 0 and all n big enough: n X i =1 E | ξ ni | 1 {| ξ ni | >ε } = 1 n 4 / 3 n X i =1 E ( ˜ f n t ( Z i )) 2 1 { ( ˜ f n t ( Z i )) 2 >εn 4 / 3 } 23 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions ≤ 1 n 4 / 3 n X i =1 E ( ˜ f n t ( Z i )) 2 1 { p 2 (0) >εn 2 / 3 } = 0 . Finally note, because p 2 (0) = 1 k 2 (0) : n X i =1 E ξ ni = n 1 / 3 p 2 (0) Z 1 [ x,x + n − 1 / 3 t ] ( z ) g 0 ( z ) dz → t g 0 ( x ) k 2 (0) . The f act that the ξ ni are nonne gativ e and P n i =1 E ξ ni → t g 0 ( x ) k 2 (0) imply P n i =1 E | ξ ni | = O (1) . Using (A.16) we conclude: 1 n 4 / 3 n X i =1 E ( ε i − 1) 2 ( ˜ f n t ( Z i )) 2 1 {| ε i − 1 | ˜ f n t ( Z i ) >δ n 2 / 3 } ≤ 1 n 4 / 3 n X i =1 ( ˜ f n t ( Z i )) 2 E ( ε − 1) 2 1 {| ε − 1 | >δ n 1 / 3 } → 0 . because 1 n 4 / 3 P n i =1 ( ˜ f n t ( Z i )) 2 = O G 0 (1) . Now we v erify the behavior of the cov ariance structure. Note that ∀ s, t ≥ 0 we ha ve the following con ver gence in probability as n → ∞ : Co v ( W ∗ n ( t ) , W ∗ n ( s ) | Z 1 , . . . , Z n ) con verges in probability under G 0 as n → ∞ to: Co v ( W ∗ n ( t ) , W ∗ n ( s )) = n 1 / 3 p 2 (0) Z ( 1 [ x,x + n − 1 / 3 t ] − 1 [0 ,x ] )( z )( 1 [ x,x + n − 1 / 3 s ] − 1 [0 ,x ] )( z ) dG 0 ( z ) = n 1 / 3 p 2 (0) P( Z ∈ [ x, x + n − 1 / 3 min( s, t )]) → g 0 ( x ) k 2 (0) min( s, t ) , conclude the con ver gence marginal con vergence in (A.12). Now to pro ve W ∗ n | Z 1 , . . . , Z n ⇝ s g 0 ( x ) k (0) W 2 in ℓ ∞ ( K ) (A.17) take the random class of functions (for ε ∼ Exp(1) ), for T > 0 ˜ F T ,δ n = { z 7→ n − 1 / 6 ( ε − 1)( ˜ f n t − ˜ f n s )( z ) : s, t ∈ R , | s − t | < δ, max {| s | , | t |} < T } , and the class of functions H T ,δ n, 3 whose functions for f ∈ ˜ F T ,δ n are gi ven by f / ( ε − 1) thus without the ε − 1 . These classes have square integrable en velopes ˜ F n,δ , H n,δ that satisfy for all δ > 0 small and all n big enough: ∥ ˜ F n,δ ∥ 2 2 = E( ε − 1) 2 ∥ H n,δ ∥ 2 2 ,G 0 = 1 n 1 / 3 Z ( ˜ f n t − ˜ f n s ) 2 ( z ) g 0 ( z ) dz = n 1 / 3 p 2 (0) Z 1 [ x + n − 1 / 3 s ∧ t,x + n − 1 / 3 s ∨ t ] ( z ) g 0 ( z ) dz ≲ p 2 (0) g 0 ( x ) δ. 24 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions For fixed s, t ∈ R , in view of (2.10), we prove conditional asymptotic equicontinuity of W ∗ n , i.e. ∀ η > 0 as n → ∞ , followed by δ > 0 the right hand side of the expression belo w con verges to 0 under G 0 : P sup | s − t | <δ | W ∗ n ( t ) − W ∗ n ( s ) | > η | Z 1 , . . . , Z n ! ≤ 1 η E " sup | s − t | <δ | W ∗ n ( t ) − W ∗ n ( s ) | | Z 1 , . . . , Z n # . By the maximal inequality in Theorem 2.14.1 in [41], as δ → 0 E " sup | s − t | <δ | W ∗ n ( t ) − W ∗ n ( s ) | # ≲ J (1 , ˜ F T ,δ n , L 2 ) ∥ ˜ F n,δ ∥ 2 ≲ √ δ → 0 . In the last con ver gence we use that: J (1 , ˜ F T ,δ n , L 2 ) := sup R Z 1 0 q log N ( η ∥ ˜ F n,δ ∥ 2 , ˜ F T ,δ n , L 2 ( R )) dη , where the L 2 ( R ) - square distance is gi ven for s, t and s ′ , t ′ ∈ R by: 1 n 1 / 3 Z ( ˜ f n s − ˜ f n t )( z ) − ( ˜ f n s ′ − ˜ f n t ′ )( z ) 2 dR ( z ) , (note that we did not take ε − 1 into account as E( ε − 1) 2 = 1 ). Furthermore we use J (1 , ˜ F T ,δ n , L 2 ) < ∞ as a consequence of Exercise 20 in [41] (p. 221), which implies that the function classes under consideration are VC of uniform bounded index. All together this prov es (A.11). Lemma 6. Assume Condition 1 holds and that F 0 is continuous at x . F or any T > 0 and x ∈ [0 , T ) , as n → ∞ , ∀ ε > 0 : Π n ( | ˆ F G ( x ) − F 0 ( x ) | > ε | Z 1 , . . . , Z n ) G 0 − − → 0 . Pr oof. Using Proposition 4.3 in [20], we obtain: E( H G ( x ) | Z 1 , . . . , Z n ) = 1 | α | + n Z x 0 p ( x − z ) d α + n X i =1 δ Z i ! ( z ) V ar( H G ( x ) | Z 1 , . . . , Z n ) = 1 1 + | α | + n 1 | α | + n Z x 0 p 2 ( x − z ) d α + n X i =1 δ Z i ! ( z ) Thus, using the conditional Chebyshev inequality , ∀ ε > 0 : Π n ( | H G ( x ) − H 0 ( x ) | > ε | Z 1 , . . . , Z n ) G 0 → 0 a.s. Because of the continuity of H 0 , the monotonicity of H G and H 0 and that H G (0) = H 0 (0) = 0 , ∀ T > 0 , ε > 0 : Π n sup 0 ≤ x ≤ T | H G ( x ) − H 0 ( x ) | > ε | Z 1 , . . . , Z n → 0 a.s. 25 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Now , since x ∈ [0 , T ) and F 0 is continuous at x , fix ε > 0 and h > 0 such that: H 0 ( x ) − H 0 ( x − h ) h − F 0 ( x ) < ε By the con ve xity of H ⋆ G (recall that it is the GCM of H G ) we hav e: H ⋆ G ( x ) − H ⋆ G ( x − h ) h ≤ ˆ F G ( x ) ≤ H ⋆ G ( x + h ) − H ⋆ G ( x ) h Thus: Π n ( ˆ F G ( x ) − F 0 ( x ) > 2 ε | Z 1 , . . . , Z n ) ≤ Π n H ⋆ G ( x ) − H ⋆ G ( x − h ) h ≥ H 0 ( x ) − H 0 ( x − h ) h + ε | Z 1 , . . . , Z n G 0 − − → 0 . Similarly: Π n ( ˆ F G ( x ) − F 0 ( x ) < − 2 ε | Z 1 , . . . , Z n ) G 0 − − → 0 . Lemma 7. F or Z G as in (2.5) , ther e exists a stoc hastically bounded sequence ˆ M n such that: Π n inf { t ∈ [ − xn 1 / 3 , ( T − x ) n 1 / 3 ] : Z G ( t ) − at is minimal } ≤ ˜ M n | Z 1 , . . . , Z n G 0 − − → 1 (A.18) Pr oof. First, for T G as in (2.4), we need to show consistency of T G at x . By the switch relation ∀ ε > 0 , Π n ( | T G ( F 0 ( x )) − x | > ε | Z 1 , . . . , Z n ) = Π n ( T G ( F 0 ( x )) > x + ε | Z 1 , . . . , Z n ) + Π n ( T G ( F 0 ( x )) < x − ε | Z 1 , . . . , Z n ) ≤ Π n ( ˆ F G ( x + ε ) < F 0 ( x ) | Z 1 , . . . , Z n ) + Π n ( ˆ F G ( x − ε ) > F 0 ( x ) | Z 1 , . . . , Z n ) G 0 − − → 0 (A.19) where in (A.19) we use that F 0 is strictly increasing at x by assumption and Lemma 6 in the above which giv es for ev ery η > 0 : Π n ( | ˆ F G ( x ± ε ) − F 0 ( x ± ε ) | > η | Z 1 , . . . , Z n ) → 0 under G 0 . The claim (A.18) is implied by the unconditional version of this con vergence and this entails proving that the rate for | T G ( F 0 ( x )) − x | is n 1 / 3 . Because of Lemma 6, we can proceed by verifying the rest of the conditions of Theorem 3.2.5 in [41] (or see Theorem 3.4.1 for a more general version). The argmin process we are interested in is: ˜ t n := argmin t { Z G ( t ) − at } . Thus note that we can write it as: ˜ t n = n 1 / 3 argmax t {− M n ( t ) } where M n ( t ) := Z ( p ( x + t − z ) − p ( x − z ) − F 0 ( x ) t ) d ( G − G n + G 0 )( z ) + Z ( p ( x + t − z ) − p ( x − z )) d ( G n − G 0 )( z ) − atn − 1 / 3 . 26 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions Moreov er define the deterministic function; M ( t ) := Z ( p ( x + t − z ) − p ( x − z ) − F 0 ( x ) t ) dG 0 ( z ) Note M n (0) = M (0) = 0 . Moreo ver note that as a consequence of T aylor’ s theorem ∃ δ 0 > 0 : ∀ t : | t | < δ 0 : − M ( t ) + M (0) ≲ −| t | 2 Follo wing Theorem 3.2.5. in [41], define d ( s, t ) := | s − t | . Consider the class of functions m t : R → R , for η > 0 : M η = { m t : m t ( z ) = p ( x + t − z ) − p ( x − z ) − F 0 ( x ) t, 0 < t < η } W e show that the en velope M η = sup 0 0 : ˜ M η = { ˜ m t : ˜ m t ( z ) = p ( x + t − z ) − p ( x − z ) : 0 < t < η } as aconsequence of the abov e, for the en velope ˜ M η := sup 0 0 , p ∗ k ( x ) = 1 k (0) ( 1 + m ) ∗ k ( x ) = ( 1 + m ) ∗ ( 1 − J )( x ) = 1 ∗ 1 ( x ) by the definition of J and (B.1). Lemma 8 (Lemma 1 in [46]) . Let the density k on [0 , ∞ ) satisfy Condition 3. Then a) ther e is a uniquely determined solution p to (1) which is bounded on bounded intervals and vanishes on ( −∞ , 0) b) writing J ∗ 1 = J and J ∗ n = J ∗ ( n − 1) ∗ J for n = 2 , 3 , . . . , this uniquely determined p on [0 , ∞ ) is given by p ( x ) = 1 k (0) 1 + ∞ X n =1 J ∗ n ( x ) ! = 1 k (0) 1 + ∞ X n =1 P n X j =1 T j ≤ x , (B.3) 28 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions wher e T 1 , T 2 , . . . is an iid sequence of random variables such that T 1 has distribution func- tion J . c) the function p is nonne gative and nondecr easing on [0 , ∞ ) . d) lim x →∞ p ( x ) x = 1 . Pr oof fr om [46]. All statements follo w from relation (5) together with known results from renewal theory . See, for example, [23] Theorem 10.1.11 for a), Lemma 10.1.7 for b) and Theorem 10.2.3 for d). P art c) is obvious from the definition of a rene wal function. Because of Condition 2, which we use to deriv e our main result Theorem 2, one interesting question is to kno w conditions on k under which p is Lipschitz continuous on interv als [0 , T ] for an y bounded T . Functions p associated with kernels satisfying Condition 3 do not hav e this property without further assumptions. It follows from (B.3) that a jump of k at a point x > 0 causes infinitely many jumps in the function p . The condition on k gi ven below in Lemma 9 is sufficient for k to guarantee that p is Lipschitz continuous on bounded intervals in [0 , ∞ ) . It gi ves thus a suf ficient condition for Condition 2 and thus also for Condition 1 to hold. Lemma 9 (Lemma 1 in [47]) . Let 0 < T < ∞ . Suppose the density k can be written as k ( x ) = k (0) 1 + Z x 0 l ( u ) du , x ∈ [0 , T ] for some bounded Bor el measurable function l : [0 , T ] → R . Then the unique continuous (on (0 , T ) ) solution p of (1.1) allows the r epresentation p ( x ) = 1 k (0) 1 + Z x 0 q ( u ) du , x ∈ [0 , T ] , wher e q is a bounded Bor el measurable function on [0 , T ] . Pr oof fr om [47]. Consider the type-II V olterra conv olution equation q ( x ) + Z x 0 l ( x − u ) q ( u ) du = − l ( x ) , or , equiv alently q + l ∗ q = − l. By Theorem 3.5 in Gripenberg, Londen and Staff ans (1990), it follo ws that the solution q of this equation uniquely exists. It is bounded and Borel measurable on [0 , T ] whene ver l is. Now define p = k (0) − 1 ( 1 + 1 ∗ q ) and observ e k ∗ p = k (0)( 1 + 1 ∗ l ) ∗ 1 + 1 ∗ q k (0) = 1 ∗ 1 + 1 ∗ 1 ∗ ( q + l + q ∗ l ) = 1 ∗ 1 . 29 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions References [1] A Y E R , M . , B R U N K , H . D . , E W I N G , G . M . , R E I D , W . T., and S I L V E R M A N , E . (1955). An Empirical Distrib ution Function for Sampling with Incomplete Information. The Annals of Mathe- matical Statistics , 26(4):641–647. http://www.jstor.org/stable/2236377 . [2] B H AU M I K , P . and G H O S A L , S . (2015a). Bayesian Two-Step Estimation in Dif ferential Equa- tion Models. Electr onic Journal of Statistics , 9(2):3124–3154. https://doi.org/10.1214/ 15- EJS1099 . [3] B H AU M I K , P . and G H O S A L , S . (2015b). Ef ficient Bayesian estimation and uncertainty quantifi- cation in ordinary differential equation models. Bernoulli , 23:3537–3570. https://doi.org/ 10.3150/16- BEJ856 . [4] B R A C E W E L L , R . N . and R O B E R T S , J . A . (1954). Aerial Smoothing in Radio Astronomy . A us- tralian J ournal of Physics , 7(4):615–640. https://doi.org/10.1071/PH540615 . [5] B U T U C E A , C . (2004). Decon volution of supersmooth densities with smooth noise. Can. J. Stat. , 32:181–192. https://doi.org/10.2307/3315941 . [6] B U T U C E A , C . and T S Y B A K OV , A . B . (2008a). Sharp optimality in density decon volution with dominating bias I. Theory Pr obab . Appl. , 52:24–39. https://doi.org/10.1137/ S0040585X97982840 . [7] B U T U C E A , C . and T S Y B A KO V , A . B . (2008b). Sharp optimality in density decon volution with dominating bias II. Theory Pr obab . Appl. , 52:237–249. https://doi.org/10.1137/ S0040585X97982992 . [8] C A R R O L L , R . J . and H A L L , P . (1988). Optimal rates of con vergence for deconv olving a density. J. Am. Stat. Assoc. , 83:1184–1186. https://doi.org/10.2307/2290153 . [9] C H A K R A B O RT Y , M . and G H O S A L , S . (2021). Coverage of Credible Intervals in Nonparametric Monotone Re gression. Annals of Statistics , 49(2):1011–1028. https://doi.org/10.1214/ 20- AOS1989 . [10] C H A K R A B O RT Y , M . and G H O S A L , S . (2022). Rates and cov erage for monotone densities using projection-posterior. Bernoulli , 28(2):1093 – 1119. https://doi.org/10.3150/21- BEJ1379 . [11] C O M T E , F . , R O Z E N H O L C , Y . , and T AU P I N , M . - L . (2006). Penalized contrast estimator for adaptiv e density deconv olution. Can. J. Stat. , 34:431–452. https://www.jstor.org/stable/ 20445213 . [12] D AT T N E R , I . , G O L D E N S H L U G E R , A ., and J U D I T S K Y , A . (2011). On decon volution of distri- bution functions. Ann. Statist. , 39:2477–2501. https://doi.org/10.1214/11- AOS907 . [13] D AT T N E R , I . and R E I S E R , B . (2013). Estimation of distribution functions in measurement error models. J. Stat. Plann. Inference , 143:479–493. https://doi.org/10.1016/j.jspi.2012. 09.004 . [14] D AT T N E R , I . , R E I SS , M . , and T R A B S , M . (2016). Adaptiv e quantile estimation in decon vo- lution with unkno wn error distribution. Bernoulli , 22:143–192. https://doi.org/10.3150/ 14- BEJ626 . [15] D E L A I G L E , A . and G I J B E L S , I . (2004). Bootstrap bandwidth selection in k ernel density esti- mation from a contaminated sample. Ann. Inst. Statist. Math. , 56:19–47. https://doi.org/10. 1007/BF02530523 . [16] D I G G L E , P . J . and H A L L , P . (1993). A F ourier Approach to Nonparametric Decon volution of a Density Estimate. Journal of the Royal Statistical Society . Series B (Methodological) , 55(2):523– 531. http://www.jstor.org/stable/2346211 . 30 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions [17] E F R O M OV I C H , S . (1997). Density estimation for the case of supersmooth measurement errors. J. Am. Stat. Assoc. , 92:526–535. https://doi.org/10.1080/01621459.1997.10474005 . [18] F A N , J . (1991). On the optimal rates of conv ergence for nonparametric decon volution problems. The Annals of Statistics , 19:1257–1272. https://doi.org/10.1214/aos/1176348248 . [19] F E R G U S O N , T . S . (1974). Prior Distributions on Spaces of Probability Measures. The Annals of Statistics , 2(4):615 – 629. https://doi.org/10.1214/aos/1176342752 . [20] G H O S A L , S . and V A N D E R V A A RT , A . (2017). Fundamentals of Nonparametric Bayesian In- fer ence . Cambridge Uni versity Press. [21] G I L I , F . , J O N G B L O E D , G . , and V A N D E R V A A RT , A . (2025a). Asymptotically Ef ficient Estima- tion under Local Constraint in W icksell’ s Problem. [22] G I L I , F . , J O N G B L O E D , G . , and V A N D E R V A A RT , A . (2025b). Semiparametric Bernstein-von Mises phenomenon via Isotonized Posterior in Wicksell’ s problem. T o appear in the Annals of Statistics . [23] G R I M M E T T , G . and S T I R Z A K E R , D . (1987). Pr obability and Random Pr ocesses . Oxford Uni- versity Press. [24] G R I P E N B E R G , G ., t. and S TA FF A N S , O . (1990). V olterra Inte gral and Functional Equations . Cambridge Univ ersity Press. [25] G RO E N E B O O M , P . and J O N G B L O E D , G . (2014). Nonpar ametric Estimation Under Shape Con- straints . Cambridge University Press. [26] G RO E N E B O O M , P . and W E L L N E R , J . A . (1992). Information bounds and nonparametric maxi- mum likelihood estimation. DMV Seminar , Birkh ¨ auser V erlag, Basel . Book. [27] H A L L , P . and L A H I R I , S . N . (2008). Estimation of distrib utions, moments and quantiles in deconv olution problems. Ann. Statist. , 36:2110–2134. https://www.jstor.org/stable/ 25464705 . [28] J I R A K , M . , M E I S T E R , A . , and R E I SS , M . (2014). Adaptiv e function estimation in nonparamet- ric regression with one-sided errors. Ann. Statist. , 42:1970–2002. https://doi.org/10.1214/ 14- AOS1248 . [29] J O N G B L O E D , G . (1995). Thr ee Statistical In verse Pr oblems, Estimators-algorithms- asymptotics . PhD Thesis, TU Delft. [30] J O N G B L O E D , G . (1998). Exponential decon volution: T wo asymptotically equi v alent estimators. Stat. Neerl. , 52:6–17. https://doi.org/10.1111/1467- 9574.00065 . [31] K A L L E N B E R G , O . (2021). F oundations of Modern Pr obability . Probability Theory and Stochastic Modelling. Springer , third edition. https://link.springer.com/book/10.1007/ 978- 3- 030- 61871- 1 . [32] L U C Y , L . B . (1974). An iterative technique for the rectification of observed distributions. The Astr onomical J ournal , 79:745–754. https://doi.org/10.1086/111605 . [33] M E I S T E R , A . (2009). Deconv olution problems in nonparametric statistics. Lecture Notes in Statistics, Springer -V erlag, Berlin . Book, DOI: 10.1007/978-3-540-87557-4. [34] P E N S K Y , M . and V I D A K OV I C , B . (1999). Adaptiv e wavelet estimator for nonparametric density decon volution. Ann. Statist. , 27:2033–2053. https://doi.org/10.1214/aos/1017939249 . [35] R E I SS , M . and S E L K , L . (2017). Estimating nonparametric functionals efficiently under one- sided errors. Bernoulli , 23:1022–1055. https://doi.org/10.48550/arXiv.1407.4229 . [36] R I C H A R D S O N , W . H . (1972). Bayesian-Based Iterati ve Method of Image Restoration. J ournal of the Optical Society of America , 62(1):55–59. https://doi.org/10.1364/JOSA.62.000055 . [37] R O B I N S O N , E . A . (1957). Predicti ve Decomposition of Seismic Traces. Geophysics , 22(4):767– 778. https://doi.org/10.1190/1.1438419 . 31 Semiparametric Uncertainty Quantification via Isotonized Posterior for Decon volutions [38] S E N , B . , B A N E R J E E , M ., and W O O D R O O F E , M . (2010). Inconsistency of Bootstrap: The Grenander Estimator . The Annals of Statistics , 38(4):1953–1977. https://doi.org/10.1214/ 09- AOS777 . [39] S T E FA N S K I , L . A . (1990). Rates of con vergence of some estimators in a class of decon volu- tion problems. Statist. Pr obab . Lett. , 9:229–235. https://doi.org/10.1016/0167- 7152(90) 90061- B . [40] S T E FA N S K I , L . A . and C A R R O L L , R . J . (1990). Deconv oluting kernel density estimators. Statis- tics , 21:169–184. https://doi.org/10.1080/02331889008802238 . [41] V A N D E R V A A RT , A . and W E L L N E R , J . (2023). Weak Con ver gence and Empirical Pr ocesses . Springer , New Y ork. [42] V A N E S , A . J . (1991). Uniform Deconv olution: Nonparametric Maximum Likelihood and In- verse Estimation. 335. https://doi.org/10.1007/978- 94- 011- 3222- 0_14 . [43] V A N E S , A . J . and K O K , A . R . (1998). Simple kernel estimators for certain nonparametric decon volution problems. Statistics and Pr obability Letters , 39(2):151–160. https://doi.org/ 10.1016/S0167- 7152(98)00054- 6 . [44] V A N E S , A . J . and V A N Z U I J L E N , M . C . A . (1996). Con vex Minorant Estimators of Distribu- tions in Non-Parametric Deconv olution Problems. Scandinavian J ournal of Statistics , 23(1):85– 104. http://www.jstor.org/stable/4616388 . [45] V A N E S , B . (2011). Combining kernel estimators in the uniform deconv olution problem. Stat. Neerl. , 65:275–296. https://doi.org/10.1111/j.1467- 9574.2011.00485.x . [46] V A N E S , B . , J O N G B L O E D , G . , and V A N Z U I J L E N , M . (1995). Nonparametric decon volution for decreasing kernels. Delft University of T echnology , F aculty of T echnical Mathematics and Informatics . [47] V A N E S , B . , J O N G B L O E D , G ., and V A N Z U I J L E N , M . (1998). Isotonic in verse estimators for nonparametric decon volution. The Annals of Statistics , 26:2395–2406. https://doi.org/10. 1214/aos/1024691476 . [48] W A N G , K . and G H O S A L , S . (2023a). Coverage of Credible Intervals in Bayesian Multi vari- ate Isotonic Re gression. Annals of Statistics , 51(3):1376–1400. https://doi.org/10.1214/ 23- AOS2298 . [49] W A N G , K . and G H O S A L , S . (2023b). Posterior Contraction and T esting for Multi variate Iso- tonic Regression. Electr onic Journal of Statistics , 17(1):798–822. https://doi.org/10.1214/ 23- EJS2115 . [50] Z H A N G , C . - H . (1990). Fourier methods for estimating mixing densities and distrib utions. Ann. Statist. , 18:806–831. https://doi.org/10.1214/aos/1176347627 . 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment