SeedFlood: A Step Toward Scalable Decentralized Training of LLMs
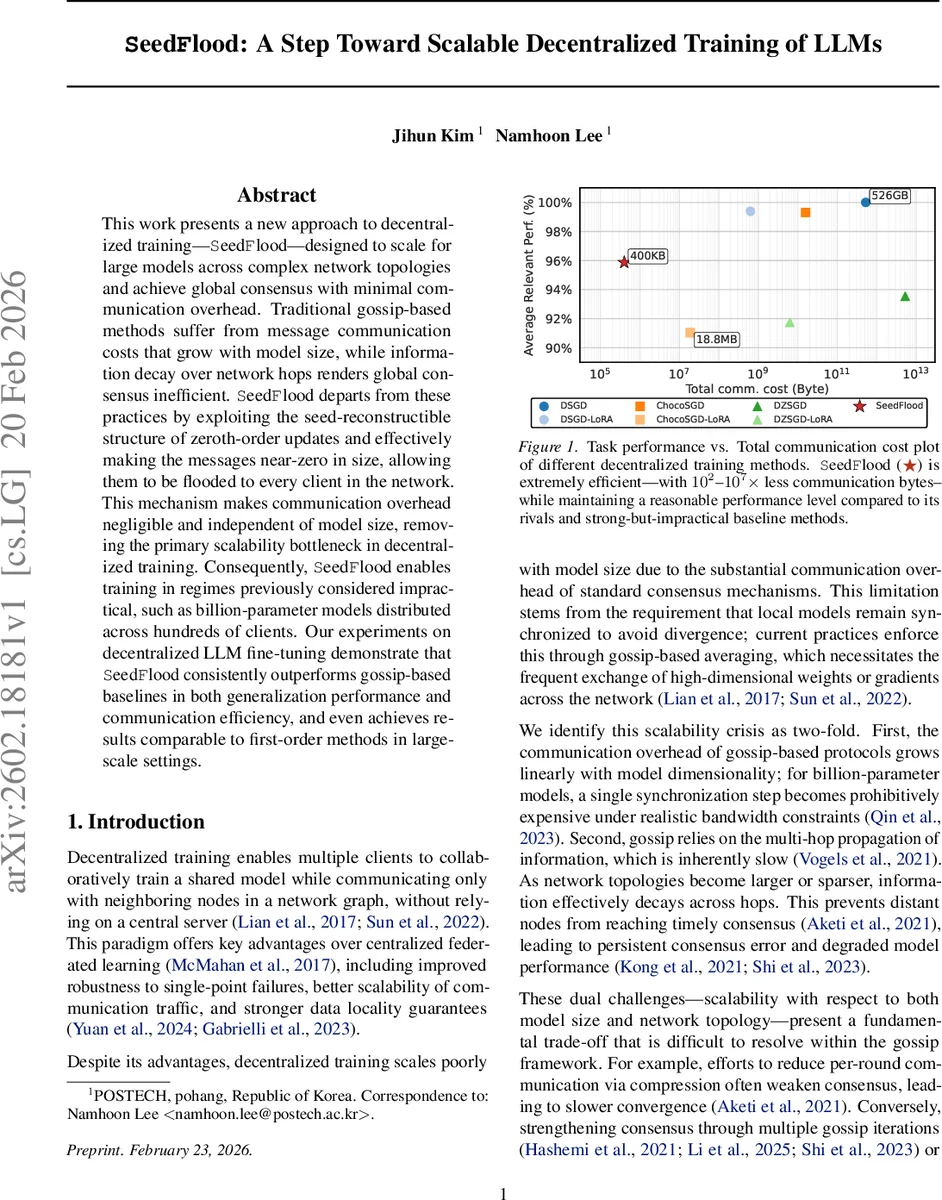
This work presents a new approach to decentralized training-SeedFlood-designed to scale for large models across complex network topologies and achieve global consensus with minimal communication overhead. Traditional gossip-based methods suffer from message communication costs that grow with model size, while information decay over network hops renders global consensus inefficient. SeedFlood departs from these practices by exploiting the seed-reconstructible structure of zeroth-order updates and effectively making the messages near-zero in size, allowing them to be flooded to every client in the network. This mechanism makes communication overhead negligible and independent of model size, removing the primary scalability bottleneck in decentralized training. Consequently, SeedFlood enables training in regimes previously considered impractical, such as billion-parameter models distributed across hundreds of clients. Our experiments on decentralized LLM fine-tuning demonstrate thatSeedFlood consistently outperforms gossip-based baselines in both generalization performance and communication efficiency, and even achieves results comparable to first-order methods in large scale settings.
💡 Research Summary
SeedFlood introduces a fundamentally new paradigm for decentralized training of large language models (LLMs) by exploiting the seed‑reconstructible nature of zeroth‑order (ZO) updates and replacing gossip‑based averaging with a flooding‑based dissemination primitive. Traditional decentralized methods rely on gossip to exchange high‑dimensional model parameters or gradients among neighboring nodes, causing communication costs that scale linearly with the model size. This makes training billion‑parameter models across realistic networks impractical.
The key insight of SeedFlood is that a ZO update can be expressed as a pair (seed, scalar) because the perturbation vector used for gradient estimation can be deterministically regenerated from a shared random number generator (RNG) given the seed. Consequently, each update can be transmitted using a constant‑size payload independent of the model dimension d. However, simply plugging this representation into gossip leads to a new bottleneck: gossip repeatedly re‑weights and re‑applies past updates, requiring O(d) work per update and O(t·n·d) total computation after t rounds with n clients.
To avoid this, SeedFlood adopts a flooding protocol: when a client generates a ZO update, it broadcasts the seed‑scalar pair to all its neighbors; each neighbor forwards the message exactly once upon first receipt, and the process repeats until the update has traversed the network diameter. This all‑gather‑like dissemination guarantees that every client receives every update exactly once, eliminating the repeated reconstruction overhead inherent in gossip. The communication cost therefore becomes O(n) per round (one seed‑scalar per client) and is completely decoupled from the model size.
A remaining challenge is the computational load of applying O(n) updates per iteration, each requiring regeneration of a d‑dimensional perturbation. SeedFlood addresses this by restricting perturbations to a globally synchronized low‑rank subspace (dimension k ≪ d). All clients share the same orthonormal basis; each update is mapped to a canonical coordinate within this subspace. This design enables batch processing of all received updates via matrix multiplications (Subspace Canonical‑basis Gradient Estimation, SubCGE), reducing per‑iteration work to O(n·k + d·k) instead of O(n·d).
Empirical evaluation focuses on fine‑tuning a 1‑billion‑parameter transformer across 128, 256, and 512 clients under various graph topologies (complete, random geometric, ring). SeedFlood consistently achieves dramatically lower total communication—between 10² and 10⁷ times less than gossip‑based baselines such as DSGD, ChocoSGD, and DZSGD—while matching or surpassing their generalization performance. In sparse or high‑diameter networks, where gossip suffers from consensus decay, SeedFlood maintains stable convergence and often yields 1–2 % higher final perplexity scores. Moreover, in the largest setting (1 B parameters, 128 clients) SeedFlood’s final accuracy is within 0.1 % of first‑order decentralized SGD, yet its communication footprint is orders of magnitude smaller.
The paper also discusses limitations: flooding incurs a latency proportional to the network diameter, which can be mitigated by asynchronous pipelining or multi‑step flooding. Zeroth‑order estimation still requires two function evaluations per update, so computational cost remains higher than pure first‑order methods, though SubCGE alleviates this. Security considerations arise because seeds encode update directions; future work should explore privacy‑preserving seed handling.
In summary, SeedFlood demonstrates that when updates are seed‑reconstructible, the dominant scalability barrier in decentralized LLM training shifts from communication to computation, and that this shift can be efficiently managed through low‑rank subspace constraints and flooding. The approach opens a practical path for training massive models across edge devices, data‑center clusters, or hybrid environments where bandwidth is limited, and sets the stage for further research on asynchronous flooding, hybrid first‑order/zeroth‑order schemes, and secure seed dissemination.
Comments & Academic Discussion
Loading comments...
Leave a Comment