MeanVoiceFlow: One-step Nonparallel Voice Conversion with Mean Flows
In voice conversion (VC) applications, diffusion and flow-matching models have exhibited exceptional speech quality and speaker similarity performances. However, they are limited by slow conversion owing to their iterative inference. Consequently, we…
Authors: Takuhiro Kaneko, Hirokazu Kameoka, Kou Tanaka
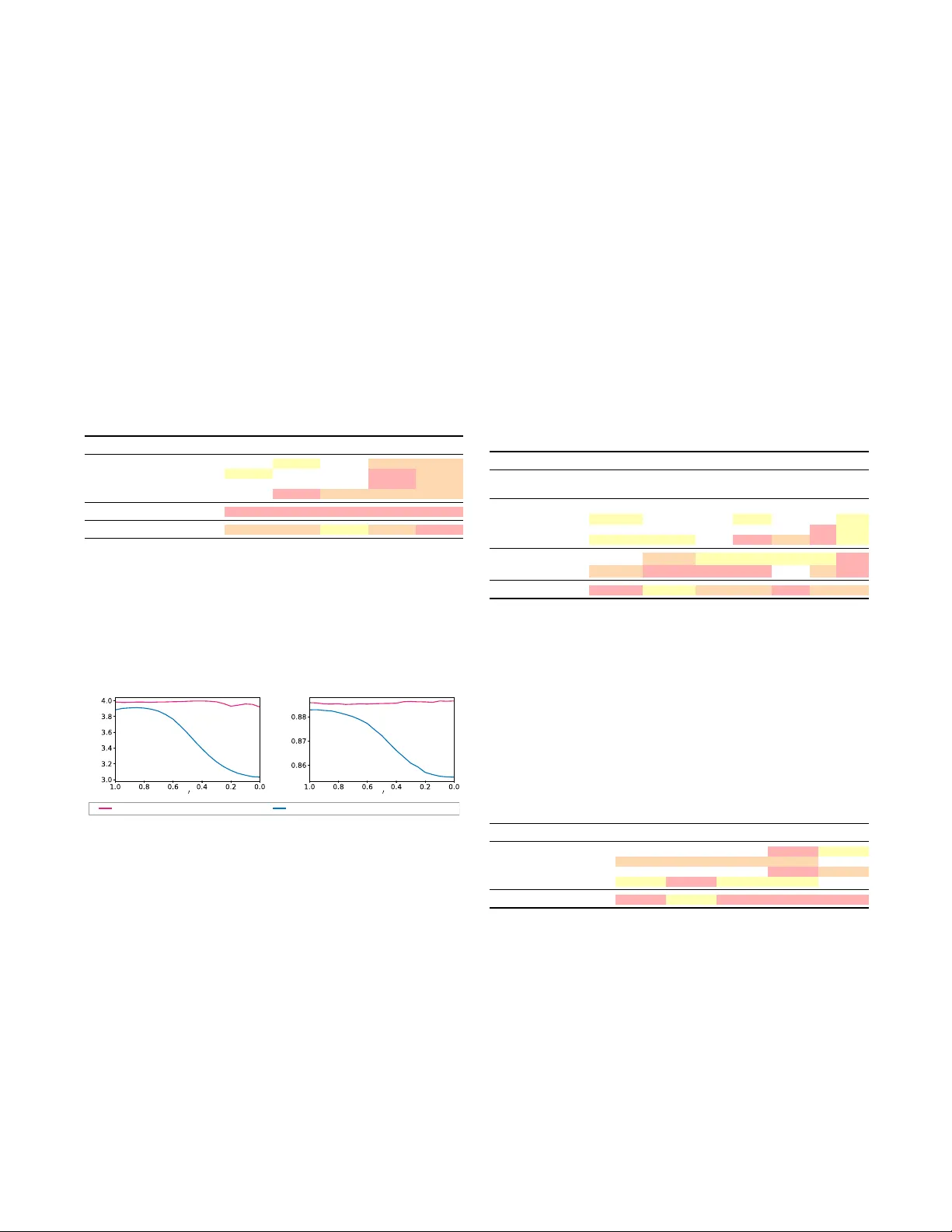
MEANV OICEFLO W : ONE-STEP NONP ARALLEL V OICE CONVERSION WITH MEAN FLO WS T akuhir o Kaneko, Hir okazu Kameoka, Kou T anaka, Y uto K ondo NTT , Inc., Japan ABSTRA CT In voice conv ersion (VC) applications, diffusion and flow-matching models hav e exhibited exceptional speech quality and speaker sim- ilarity performances. Howe ver , they are limited by slo w conv er- sion owing to their iterativ e inference. Consequently , we propose MeanV oiceFlow , a nov el one-step nonparallel VC model based on mean flows, which can be trained from scratch without requiring pretraining or distillation. Unlike conv entional flow matching that uses instantaneous velocity , mean flows employ a verage velocity to more accurately compute the time integral along the inference path in a single step. Howe ver , training the average velocity requires its deriv ativ e to compute the target velocity , which can cause instability . Therefore, we introduce a structur al mar gin r econstruction loss as a zer o-input constraint , which moderately regularizes the input–output behavior of the model without harmful statistical av eraging. Fur- thermore, we propose conditional diffused-input training in which a mixture of noise and source data is used as input to the model during both training and inference. This enables the model to ef- fectiv ely lev erage source information while maintaining consistenc y between training and inference. Experimental results validate the effecti veness of these techniques and demonstrate that MeanV oice- Flow achiev es performance comparable to that of previous multi- step and distillation-based models, e ven when trained fr om scratc h . 1 Index T erms — V oice conv ersion, flow matching, mean flows, nonparallel training, fast sampling 1. INTR ODUCTION V oice conv ersion (VC) con verts one v oice to another while preserv- ing the underlying linguistic information, and has been widely stud- ied to enrich speech communication. Existing studies have largely focused on parallel VC, as it is simple to train. Howe ver , recent research efforts hav e shifted toward nonparallel VC because of its greater practical applicability and the fewer constraints on its train- ing data. In addition, recent advances in deep generativ e models (e.g., [ 1 – 5 ]) ha ve led to significant breakthroughs (e.g., [ 6 – 12 ]) that address the challenges inherent to training nonparallel VC as a con- sequence of the absence of supervised paired data. In particular, diffusion models [ 13 – 15 ] hav e recently garnered attention across various research fields, and their applications to VC [ 16 – 20 ] hav e demonstrated strong speech quality and speaker similarity . Ho wev er , a notable limitation of diffusion-based VC is its slow con version speed, resulting from iterativ e denoising steps. Consequently , flow matching models [ 21 – 23 ] and their applications to VC [ 24 – 28 ] hav e been proposed. These models learn vector fields that define flow paths between two probabilistic distributions. This formulation yields straighter trajectories than those in dif fusion 1 Audio samples are available at https://www.kecl.ntt.co.jp/ people/kaneko.takuhiro/projects/meanvoiceflow/ . r t t x x (a) Instantaneous velocity (b) A verage velocity (conventional flow matching) (mean flows) v ( z t , t ) u ( z t , r , t ) ¯ = 0 u (¯ , 0 , 1) p prior p prior p data p data Fig. 1 . Comparison of (a) instantaneous velocity used in conv en- tional flow matching and (b) av erage velocity used in mean flows. (a) Instantaneous velocity v ( z t , t ) (blue arrow) represents the tan- gent direction of the path for a single time step t . (b) A vera ge veloc- ity u ( z t , r , t ) (orange arrow) aligns with the displacement between two time steps r and t . In MeanV oiceFlow , a zer o-input constraint is imposed on u (¯ ϵ, 0 , 1) (green arro w), the a verage velocity for a zero- input sample ¯ ϵ = 0 , using a structural margin reconstruction loss to moderately guide learning. models, thereby improving sampling efficiency . Howe ver , the per- formance still degrades significantly when the number of sampling steps is reduced, particularly in the one-step case. Knowledge distillation is a promising approach to this problem in which a multi-step teacher model (e.g., dif fusion or flo w matching model) is trained and subsequently distilled into a one-step student model (e.g., [ 29 – 31 ]). Some studies [ 32 , 33 ] combine knowledge distillation with adversarial training [ 3 ] to enhance performance. In VC, similar methods ha ve also been explored [ 34 – 36 ], and have demonstrated that the performance exhibited by this combination can match that of multi-step models. Howe ver , this approach has two drawbacks: (1) increased training cost , as it requires training both teacher and student models, and (2) training instability , as ad- versarial training is prone to div ergence and often requires a pre- trained feature extractor (e.g., a pretrained HiFi-GAN vocoder [ 37 ]) for stabilization. T o address these limitations, we propose MeanV oiceFlow , a nov el one-step nonparallel VC model based on mean flows [ 38 ], which can be trained from scratch without requiring pretraining or distillation. This is enabled by replacing instantaneous velocity , which is used in con ventional flow matching [ 21 – 23 ], with avera ge velocity . As illustrated in Fig. 1 , conv entional flow matching uses the instantaneous velocity v ( z t , t ) (Fig. 1 (a)), which represents the tangent direction of the path at t . The path integral is approximated by discretizing the path and integrating these velocities using an ordinary differential equation (ODE) solv er (e.g., Euler method). Howe ver , such discretization can introduce integration errors, par- ticularly when using coarse steps. In contrast, mean flows use the av erage velocity u ( z t , r , t ) (Fig. 1 (b)), which corresponds to the displacement between two time steps r and t . This allows the path 1 integral to be computed directly using this velocity , without nu- merical approximation, thereby enabling more accurate one-step inference. Howe ver , a key challenge in training the av erage velocity is that computing the target velocity requires its deriv ativ e, which can be inaccurate during training. A simple solution in volves regularizing the input–output behavior of the model using an element-wise re- construction loss (e.g., mean squared error loss). Howev er, overly strong constraints often cause statistical averaging, leading to per- ceptually buzzy outputs. Consequently , we introduce a structural mar gin r econstruction loss as a zer o-input constraint , which moder- ates the regularization by (1) using a structural similarity index mea- sure (SSIM) [ 39 ]-based loss instead of a direct element-wise loss, (2) applying a margin to ignore high-quality samples, and (3) restricting the constraint to zero-input samples (green arrow in Fig. 1 (b)). Furthermore, unlik e previous studies (e.g., [ 34 ]) that feed a mix- ture of noise and source data only during inference, we apply it dur- ing training as well. This strategy , termed conditional diffused-input training , enables effecti ve use of source information while maintain- ing consistency between training and inference. MeanV oiceFlow was experimentally ev aluated for nonparallel any-to-an y (i.e., zer o-shot ) VC tasks. The results verified the effi- cacy of the proposed techniques and demonstrated that MeanV oice- Flow can achie ve performance comparable to that of pre vious multi- step and distillation-based models, ev en when trained fr om scratch , without requiring pretraining or distillation. The remainder of this paper is organized as follows: Section 2 revie ws flow matching and mean flows, which forms the basis of MeanV oiceFlow . Section 3 introduces the proposed MeanV oice- Flow . Section 4 presents experimental results. Section 5 concludes the paper and discusses directions for future research. 2. PRELIMINARIES 2.1. Flow matching Flow matching [ 21 – 23 ] is a technique for learning to match the flows between two probabilistic distributions. Giv en data x ∼ p data ( x ) (specifically , a log-mel spectrogram in our task) and prior ϵ ∼ p prior ( ϵ ) (typically , p prior = N (0 , 1) ), a flow path is defined as follows: z t = (1 − t ) x + tϵ (1) for time step t ∈ [0 , 1] . The corresponding conditional velocity is defined as v t = v t ( z t | x ) = dz t dt = ϵ − x . T o ensure that z t does not correspond to multiple ( x, ϵ ) pairs, the marginal instantaneous velocity (Fig. 1 (a)) is introduced as v ( z t , t ) = E p t ( v t | z t ) [ v t ] . T raining. A neural network v θ ( z t , t ) , parameterized by θ , is trained to approximate v ( z t , t ) . Howe ver , a flow matching loss defined as L FM = E [ d ( v θ ( z t , t ) , v ( z t , t ))] , where d ( · , · ) denotes a distance metric, is intractable because computing v ( z t , t ) requires marginal- ization over ( x, ϵ ) . Alternativ ely , v t ( z t | x ) is used as the target, and a conditional flow matching loss is minimized: L CFM = E [ d ( v θ ( z t , t ) , v t ( z t | x ))] . (2) It has been shown in [ 21 ] that minimizing L CFM is theoretically equiv alent to minimizing the original flow matching loss L FM . Sampling. A sample is generated from z 1 = ϵ ∼ p prior ( ϵ ) by solving the ODE dz t dt = v θ ( z t , t ) . The solution can be expressed as: z r = z t − Z t r v θ ( z r , τ ) dτ (3) for another time step r < t . Howe ver , the exact computation of this integral is intractable in practice. Therefore, flow matching typically approximates it by discretizing time and solving the resulting ODE using numerical methods such as Euler integration. 2.2. Mean flows Discretization using the instantaneous velocity v ( z t , t ) (Fig. 1 (a)), as discussed in the pre vious section, can result in significant errors, particularly with few time steps. Consequently , mean flows [ 38 ] introduce the average velocity (Fig. 1 (b)), defined as u ( z t , r , t ) = 1 t − r R t r v ( z τ , τ ) dτ , which corresponds to the displacement between two times steps r and t , inherently incorporating integration over time. By multiplying both sides by t − r , dif ferentiating with respect to t , and rearranging terms, we obtain a mean flow identity: u ( z t , r , t ) = v ( z t , t ) − ( t − r ) d dt u ( z t , r , t ) . (4) The total deriv ativ e d dt u ( z t , r , t ) can be expanded in partial deriva- tiv es as d dt u ( z t , r , t ) = v ( z t , t ) ∂ z u + ∂ t u . This expansion can be further rewritten as the Jacobian-vector product (JVP) between the Jacobian matrix of u , that is, [ ∂ z u, ∂ r u, ∂ t u ] , and the tangent vec- tor [ v , 0 , 1] . This JVP can be efficiently computed using the jvp interface a vailable in modern deep learning libraries. T raining. A neural network u θ ( z t , r , t ) is optimized to satisfy the mean flow identity (Eq. 4 ) by minimizing a mean flo w loss: L MF = E [ d ( u θ ( z t , r , t ) , sg( u tgt ))] , (5) where the target v elocity u tgt is defined as: u tgt = v t − ( t − r )( v t ∂ z u θ + ∂ t u θ ) , (6) and sg denotes a stop-gradient operation. Follo wing the mean flow study [ 38 ], in the experiments, we adopt the adaptively weighted loss [ 40 ] as the distance metric d in Eq. 5 , defined as d ( a, b ) = ∥ a − b ∥ 2 2 sg( ∥ a − b ∥ 2 2 +10 − 3 ) . Additionally , we randomly set r = t with a prob- ability of 0 . 75 to stabilize training, thereby blending the training of the instantaneous and av erage velocity fields. Sampling. A sample is generated from z 1 = ϵ ∼ p prior using z r = z t − ( t − r ) u θ ( z t , r , t ) , (7) where the time integral, which is used in flow matching (Eq. 3 ), is replaced with the product of the time duration and av erage velocity , ( t − r ) u θ ( z t , r , t ) , which reduces discretization errors. In the one- step sampling case, Eq. 7 simplifies to z 0 = z 1 − u θ ( z 1 , 0 , 1) . (8) 3. MEANV OICEFLO W 3.1. Extension to conditional generation Thus far , we have described the formulation for unconditional gen- eration. Howe ver , VC aims to modify speaker identity while pre- serving linguistic content. Hence, we adopt conditional generation that incorporates speaker and linguistic information. Formally , we extend av erage velocity u ( z t , r , t ) introduced in Section 2.2 to its conditional form u ( z t , r , t, s, c ) , where s and c denote the speaker embedding (e.g., extracted via a speaker encoder [ 41 ]) and content embedding (e.g., extracted via a bottleneck feature extractor [ 42 ]), respectiv ely . This extension is fully compatible with the mean flow algorithm described above and only requires replacing the av erage velocity with its conditional form. For clarity , we omit s and c if this omission does not affect understanding. 2 3.2. Zero-input constraint As defined in Eq. 6 , the target velocity u tgt in mean flows depends on the deriv ative of u θ , which may be inaccurate when u θ is un- der training, leading to instability . A simple solution is to regularize the input–output behavior of the model using a direct element-wise reconstruction loss L rec = E ∥ ˆ x − x ∥ p p , where ˆ x denotes the out- put z 0 from Eq. 8 , x denotes the ground-truth data, and p typically takes a value of 1 or 2 . Howe ver , such a strong constraint can cause ov er-smoothing (i.e., statistical a veraging), as often observ ed in v ari- ational autoencoder-based models [ 1 ]. Consequently , we introduce a structural margin reconstruction loss as a zer o-input constraint : L zerorec = E [max(1 − SSIM( ¯ x, x ) , m )] , (9) where SSIM denotes the SSIM similarity [ 39 ], ¯ x denotes the output z 0 from Eq. 8 with zero input z 1 = ¯ ϵ = 0 , and m is a margin, em- pirically set to 0 . 3 . T o avoid over -regularization in L rec , we adopt the following three strategies for L zerorec : (1) Structural compar- ison: W e use an SSIM-based loss instead of a direct element-wise loss, focusing on structural rather than point-wise similarities. (2) Margin-based relaxation: A margin m is introduced to prev ent penalizing high-quality samples, which are trained only with L MF . (3) Selective application: The constraint is applied only to zero- input samples (i.e., the center of p prior , marked by the green arrow in Fig. 1 (b)). Accordingly , the final objective is defined as: L MVF = L MF + λ L zerorec , (10) where λ is a weighting hyperparameter empirically set to 1 . 3.3. Conditional diffused-input training As VC aims to con vert voice while preserving linguistic content, it is essential to utilize the source input effecti vely , without omis- sion or redundancy . Consequently , prior diffusion-based VC meth- ods (e.g., [ 34 ]) have proposed feeding diffused source data ϵ src t ′ = (1 − t ′ ) x src + t ′ ϵ 2 into the model during inference (Fig. 2 (b)), rather than using pure noise ϵ ∼ N (0 , 1) (Fig. 2 (a)), where x src denotes the source data and t ′ ∈ [0 , 1] is a mixing ratio, empirically set to 0 . 95 during inference. W e use superscripts src and tgt to denote data related to the source and target speakers, respecti vely . Howe ver , this method introduces a training–inference mismatch: the model is trained only on pure noise ϵ (Fig. 2 (c)), b ut receives the diffused source data ϵ src t ′ during inference (Fig. 2 (b)). This discrepancy can degrade performance, since the model is not exposed during training to the input distribution encountered at inference time. Consequently , we adopt conditional diffused-input training , feeding diffused source data ϵ src t ′ during training as well (Fig. 2 (d)). Specifically , ϵ src t ′ is constructed such that the speaker identity differs from the tar get, simulating the actual con version process. How- ev er, in nonparallel VC, paired source–target data are unav ailable, making it challenging to obtain such diffused source data directly . T o ov ercome this, we synthesize ϵ src t ′ using the model itself. For - mally , given x tgt , we approximately define the diffused source data based on Eq. 7 as ˆ ϵ src t ′ = sg( z 1 − (1 − t ′ ) u θ ( z 1 , t ′ , 1 , s src , c tgt )) , where z 1 = ϵ ∼ N (0 , 1) , s src is obtained by shuffling s tgt within the batch, and the stop-gradient operation sg is applied to simplify learning. W e then replace ϵ and x in Section 2 with ˆ ϵ src t ′ and x tgt , respectiv ely . In practice, we provide t ′ as an additional conditional 2 More specifically , in a diffusion-based VC model [ 34 ], the diffused source data is constructed as ϵ src S K = p ¯ α S K x src + p 1 − ¯ α S K ϵ to pre- serve v ariance (see Eq. 9 in [ 34 ] for details). In this study , we modify this formulation to match the linear mixture defined in Eq. 1 . (a) Pure noise input inference (b) Conditional diffused-input inference (c) Pure noise input training (d) Conditional diffused-input training ( , s tgt , c src ) x tgt ( , s tgt , c tgt ) x tgt ( src t , s tgt , c tgt ) x tgt ( src t , s tgt , c src ) x tgt Mismatch Match (proposed) (previous) Fig. 2 . Comparison of input types during inference and training. Previous studies (e.g., [ 34 ]) use input type (c) during training and (b) during inference, causing a training–inference mismatch. In con- trast, the proposed method uses (d) during training and (b) during inference, effecti vely eliminating this mismatch. input to help the model distinguish input types, with negligible com- putational overhead. Furthermore, to stabilize training, we use ˆ ϵ src t ′ for half of the batch and pure noise ϵ ∼ N (0 , 1) for the other half. 4. EXPERIMENTS 4.1. Experimental setup Data. W e conducted experiments on nonparallel any-to-any (i.e., zer o-shot ) VC tasks to ev aluate MeanV oiceFlow . The experimen- tal design followed that of a previous study on fast diffusion-based VC ( F astV oiceGrad [ 34 ]) which was used as the baseline model. The main ev aluations (Section 4.2 and 4.3 ) were performed on the VCTK dataset [ 43 ], which contains the speech recordings of 110 English speakers. T o examine dataset dependency (Section 4.4 ), we additionally used the train-clean subset of the LibriTTS dataset [ 44 ], which contains the speech recordings of 1,151 English speakers. W e excluded ten ev aluation speakers and ten evaluation sentences from the training set to simulate unseen-to-unseen VC scenarios. All au- dio clips were downsampled to 22.05 kHz, and 80-dimensional log- mel spectrograms were e xtracted using an FFT size of 1024, hop size of 256, and window size of 1024. These spectrograms were used as the con version targets, i.e., as x . Implementation. T o isolate the ef fect of training methods, we adopted the same network architectures as the baseline [ 34 ]. The av erage velocity u θ , corresponding to the noise predictor ϵ θ in [ 34 ], was implemented using a U-Net [ 45 ] with 12 conv olution layers, 512 hidden channels, two downsampling and upsampling stages, gated linear units [ 46 ], and weight normalization [ 47 ]. Speak er and content embeddings s and c were extracted using a speaker encoder [ 41 ] and a bottleneck feature extractor [ 17 ], respectiv ely . W aveforms were synthesized from log-mel spectrograms using HiFi-GAN V1 [ 37 ]. Models were trained using the Adam opti- mizer [ 48 ] with a batch size of 32 , learning rate of 0 . 0002 , β 1 of 0 . 5 , and β 2 of 0 . 9 . Training was performed for 500 epochs using a cosine learning rate schedule with a linear warm-up ov er the first 10k steps. During training, t , r , and t ′ were sampled from a logit-normal distribution [ 49 ] by applying the sigmoid function to samples from N (0 , 1) ; the lar ger of t and r was assigned to t , and the smaller to r . Evaluation metrics. For efficient model comparison, we primarily relied on objecti ve metrics and performed subjecti ve ev aluations for the critical comparisons (Section 4.3 ). The fiv e objective met- rics were as follows: (1) pMOS s ↑ : Predicted mean opinion score (MOS) for synthesized speech using UTMOS [ 50 ]. (2) pMOS n ↑ : Predicted MOS for noise-suppressed speech using DNSMOS [ 51 ]. (3) pMOS v ↑ : Predicted MOS for voice-con verted speech using DNSMOS Pro [ 52 ] on VCC2018 [ 53 ]. (4) CER ↓ : Character error rate using Whisper-lar ge-v3 [ 54 ], measuring speech intelligibility . (5) SECS ↑ : Speaker embedding cosine similarity using W avLM Base+ [ 55 ], measuring speaker similarity . W e computed these met- rics for 8,100 unique speaker –sentence pairs from the ev aluation set. Audio samples are av ailable online. 1 3 4.2. Component analysis Analysis of zero-input constraint (Section 3.2 ). W e e v aluated the effecti veness of three techniques for zero-input constraint: (1) struc- tural comparison , (2) mar gin-based r elaxation , and (3) selective application . T o isolate the effect of the loss function, conditional diffused-input training was not applied in this experiment. As sho wn in T able 1 , the baseline ( A ) used only L MF (Eq. 5 ). Configurations ( B )–( D ) added reconstruction losses to this baseline. Element-wise losses in ( B ) and ( C ) impro ved pMOS s but degraded pMOS n and pMOS v owing to over -smoothing. Using an SSIM loss in ( D ) mit- igated this issue, though pMOS s remained low . Introducing a mar- gin in ( E ) further improved all scores by softening the constraint. Howe ver , applying the constraint to all inputs in ( F ) caused over - smoothing again and reduced scores, particularly in pMOS v . These results highlight the importance of incorporating the reconstruction loss and validate the proposed configuration ( E ). T able 1 . Analysis of zero-input constraint. Performance changes were analyzed while varying metric , margin , and input type in the constraint. ( E ) denotes the proposed configuration. Metric Margin Input pMOS s ↑ pMOS n ↑ pMOS v ↑ CER ↓ SECS ↑ ( A ) – – – 3.72 3.73 4.00 1.3 0.882 ( B ) L1 – Zero 3.81 3.65 3.96 1.2 0.882 ( C ) L2 – Zero 3.80 3.66 3.98 1.2 0.882 ( D ) SSIM – Zero 3.79 3.77 4.05 1.3 0.882 ( E ) SSIM ✓ Zero 3.90 3.77 4.08 1.2 0.883 ( F ) SSIM ✓ All 3.89 3.76 4.03 1.3 0.883 Analysis of conditional diffused-input training (Section 3.3 ). W e ev aluated the effectiv eness of conditional diffused-input training by comparing models trained with and without it while varying the mix- ing ratio t ′ during inference. As shown in Fig. 3 , the proposed train- ing impro ved robustness to t ′ and peak performance for both pMOS s and SECS . Similar trends were observed for pMOS n and pMOS v while CER remained nearly constant. These results validate the util- ity of conditional diffused-input training. (a) Speech quality ( pMOS s ↑ ) (b) Speaker similarity ( SECS ↑ ) t t pMOS s SECS With conditional di ffused-input training Without conditional dif fused-input training Fig. 3 . Analysis of conditional diffused-input training. Conditional diffused-input training (pink line) enhances both robustness to the mixing ratio t ′ and peak performance. 4.3. Comparisons with prior models W e compared MeanV oiceFlow with previous models to assess its relativ e efficacy . W e maintained consistent network architectures and v aried only the training procedures to isolate the impact of training strate gies. W e ev aluated six baselines: V oiceGrad-DM- 1/30 [ 16 ]: Diffusion [ 15 ]-based V oiceGrad, e valuated with 1 and 30 NFEs (number of function e valuations, i.e., reverse diffusion steps). The smaller the NFE, the faster the inference. V oiceGrad- FM-1/30 [ 28 ]: Flow matching [ 22 ]-based V oiceGrad, ev aluated with 1 and 30 NFEs. F astV oiceGrad [ 34 ]: One-step diffusion-based VC model with distillation and adversarial training [ 32 ]. F astV oice- Grad+ [ 36 ]: FastV oiceGrad with an enhanced discriminator . W e also ev aluated DiffVC-30 [ 18 ], a commonly used baseline, and gr ound-truth speech as reference anchors. For comprehensi ve ev al- uation, we performed MOS tests on 90 speaker –sentence pairs per model. Naturalness was assessed using a five-point scale ( nMOS : 1 = bad, 2 = poor, 3 = fair , 4 = good, and 5 = excellent) and speaker similarity w as assessed using a four -point scale ( sMOS : 1 = dif ferent (sure), 2 = different (not sure), 3 = same (not sure), and 4 = same (sure)). The tests were performed online with ten participants, and ov er 200 responses were collected for each model. As summarized in T able 2 , MeanV oiceFlow outperforms one-step models trained from scratch ( V oiceGrad-DM-1 and V oiceGrad-FM-1 ), and achieves performance comparable to that of multi-step models ( V oiceGrad- DM-30 and V oiceGrad-FM-30 ) and one-step models enhanced by distillation and adversarial training ( F astV oiceGrad and F astV oice- Grad+ ). Notably , MeanV oiceFlow achieves this strong performance without r equiring pr etraining or distillation . T able 2 . Comparisons with prior models. † indicates models that re- quire additional modules (a pretrained teacher and a pretrained fea- ture extractor for the discriminator) and extra training procedures (distillation and adversarial training). For nMOS and sMOS , ∗ in- dicates a statistically significant dif ference from MeanV oiceFlow based on the Mann–Whitney U test ( p < 0 . 05 ). V alues following ± represent 95% confidence intervals. Model NFE ↓ nMOS ↑ sMOS ↑ pMOS s ↑ pMOS n ↑ pMOS v ↑ CER ↓ SECS ↑ Ground truth – 4.26 ± 0.10 ∗ 3.62 ± 0.08 ∗ 4.14 3.75 4.05 0.1 0.940 DiffVC 30 3.59 ± 0.11 ∗ 2.55 ± 0.13 ∗ 3.76 3.75 4.03 5.4 0.880 V oiceGrad-DM 1 2.77 ± 0.09 ∗ 2.48 ± 0.13 ∗ 3.72 3.68 3.99 1.4 0.884 V oiceGrad-DM 30 3.79 ± 0.11 2.70 ± 0.13 ∗ 3.88 3.77 4.02 1.4 0.885 V oiceGrad-FM 1 3.14 ± 0.11 ∗ 2.60 ± 0.13 ∗ 3.81 3.69 4.01 1.1 0.885 V oiceGrad-FM 30 3.79 ± 0.10 2.92 ± 0.12 3.88 3.79 4.05 1.1 0.885 FastV oiceGrad † 1 3.73 ± 0.09 ∗ 2.93 ± 0.11 3.96 3.77 4.04 1.3 0.888 FastV oiceGrad+ † 1 3.81 ± 0.10 2.99 ± 0.13 3.99 3.79 4.03 1.2 0.888 MeanV oiceFlow 1 3.87 ± 0.09 2.92 ± 0.13 3.98 3.78 4.10 1.2 0.886 4.4. V ersatility analysis T o examine dataset dependency , we ev aluated V oiceGrad-DM- 1/30 , V oiceGrad-FM-1/30 , and MeanV oiceFlow , which were trained under similar conditions (i.e., fr om scratc h ), on the LibriTTS dataset [ 44 ]. As summarized in T able 3 , a similar trend was ob- served: MeanV oiceFlow outperforms one-step models ( V oiceGrad- DM-1 and V oiceGrad-FM-1 ) and achie ves performance comparable to that of multi-step models ( V oiceGrad-DM-30 and V oiceGrad-FM- 30 ). Audio samples are available online. 1 T able 3 . V ersatility analysis on LibriTTS. Models trained under sim- ilar conditions (i.e., fr om scratch ) were compared. Model NFE ↓ pMOS s ↑ pMOS n ↑ pMOS v ↑ CER ↓ SECS ↑ V oiceGrad-DM 1 3.20 3.32 3.26 1.1 0.873 V oiceGrad-DM 30 3.81 3.75 3.58 1.2 0.865 V oiceGrad-FM 1 3.22 3.38 3.28 1.1 0.875 V oiceGrad-FM 30 3.77 3.77 3.38 1.3 0.866 MeanV oiceFlow 1 3.93 3.70 3.70 1.1 0.879 5. CONCLUSION W e proposed MeanV oiceFlow , a nov el one-step nonparallel VC model built upon mean flows, which can be trained from scratc h without requiring pretraining or distillation. T o enhance its per- formance, we introduced zer o-input constr aint and conditional diffused-input training . Experiments demonstrate the effecti veness of these techniques and sho w that the proposed method achie ves per- formance comparable to that of previous multi-step and distillation- based models. The application of mean flows in speech remains underexplored; thus, extending the proposed approach to other speech-related tasks is a promising direction for future work. 4 6. REFERENCES [1] Diederik P . Kingma and Max W elling, “ Auto-encoding v ariational Bayes, ” in ICLR , 2014. [2] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra, “Stochastic back- propagation and approximate inference in deep generativ e models, ” in ICML , 2014. [3] Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde- Farley , Sherjil Ozair , Aaron Courville, and Y oshua Bengio, “Generative adver- sarial nets, ” in NIPS , 2014. [4] A ¨ aron van den Oord, Oriol V inyals, and K oray Kavukcuoglu, “Neural discrete representation learning, ” in NIPS , 2017. [5] Laurent Dinh, David Krueger, and Y oshua Bengio, “NICE: Non-linear indepen- dent components estimation, ” in ICLR W orkshop , 2015. [6] Chin-Cheng Hsu, Hsin-T e Hwang, Yi-Chiao W u, Y u Tsao, and Hsin-Min W ang, “V oice conv ersion from unaligned corpora using variational autoencoding W asser- stein generativ e adversarial networks, ” in Interspeech , 2017. [7] Hirokazu Kameoka, T akuhiro Kaneko, K ou T anaka, and Nobukatsu Hojo, “A CV AE-VC: Non-parallel voice conv ersion with auxiliary classifier variational autoencoder , ” IEEE/ACM Tr ans. Audio Speech Lang. Process. , v ol. 27, no. 9, pp. 1432–1443, 2019. [8] T akuhiro Kaneko and Hirokazu Kameoka, “CycleGAN-VC: Non-parallel voice con version using cycle-consistent adv ersarial networks, ” in EUSIPCO , 2018. [9] Hirokazu Kameoka, T akuhiro Kaneko, K ou T anaka, and Nobukatsu Hojo, “StarGAN-VC: Non-parallel many-to-man y voice con version using star genera- tiv e adversarial networks, ” in SLT , 2018. [10] Kaizhi Qian, Y ang Zhang, Shiyu Chang, Xuesong Y ang, and Mark Hasegaw a- Johnson, “AutoVC: Zero-shot voice style transfer with only autoencoder loss, ” in ICML , 2019. [11] Y en-Hao Chen, Da-Y i Wu, Tsung-Han W u, and Hung-yi Lee, “A GAIN-VC: A one-shot voice conversion using activ ation guidance and adaptiv e instance nor - malization, ” in ICASSP , 2021. [12] Joan Serr ` a, Santiago Pascual, and Carlos Segura Perales, “Blow: A single-scale hyperconditioned flow for non-parallel raw-audio voice con version, ” in NeurIPS , 2019. [13] Jascha Sohl-Dickstein, Eric W eiss, Niru Maheswaranathan, and Surya Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics, ” in ICML , 2015. [14] Y ang Song and Stefano Ermon, “Generative modeling by estimating gradients of the data distribution, ” in NeurIPS , 2019. [15] Jonathan Ho, Ajay Jain, and Pieter Abbeel, “Denoising diffusion probabilistic models, ” in NeurIPS , 2020. [16] Hirokazu Kameoka, T akuhiro Kaneko, Kou T anaka, Nobukatsu Hojo, and Shogo Seki, “V oiceGrad: Non-parallel any-to-many voice conversion with annealed Langevin dynamics, ” IEEE/A CM Tr ans. Audio Speech Lang. Pr ocess. , vol. 32, pp. 2213–2226, 2024. [17] Songxiang Liu, Y uewen Cao, Dan Su, and Helen Meng, “Dif fSVC: A diffusion probabilistic model for singing voice con version, ” in ASR U , 2021. [18] V adim Popov , Ivan V ovk, Vladimir Gogoryan, T asnima Sadekova, Mikhail Kudi- nov , and Jiansheng W ei, “Dif fusion-based voice con version with fast maximum likelihood sampling scheme, ” in ICLR , 2022. [19] Ha-Y eong Choi, Sang-Hoon Lee, and Seong-Whan Lee, “Diff-HierVC: Diffusion-based hierarchical voice conversion with robust pitch generation and masked prior for zero-shot speaker adaptation, ” in Interspeech , 2023. [20] Ha-Y eong Choi, Sang-Hoon Lee, and Seong-Whan Lee, “DDDM-VC: Decoupled denoising diffusion models with disentangled representation and prior mixup for verified robust v oice conversion, ” in AAAI , 2024. [21] Y aron Lipman, Ricky T . Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le, “Flo w matching for generativ e modeling,” in ICLR , 2023. [22] Xingchao Liu, Chengyue Gong, and Qiang Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow , ” in ICLR , 2023. [23] Michael S. Albergo and Eric V anden-Eijnden, “Building normalizing flows with stochastic interpolants, ” in ICLR , 2023. [24] Jixun Y ao, Y ang Y uguang, Y u Pan, Ziqian Ning, Jianhao Y e, Hongbin Zhou, and Lei Xie, “StableVC: Style controllable zero-shot voice conv ersion with condi- tional flow matching, ” in AAAI , 2025. [25] Ha-Y eong Choi and Jaehan Park, “V oicePrompter: Robust zero-shot voice con- version with voice prompt and conditional flo w matching, ” in ICASSP , 2025. [26] Jialong Zuo, Shengpeng Ji, Minghui Fang, Ziyue Jiang, Xize Cheng, Qian Y ang, W enrui Liu, Guangyan Zhang, Zehai Tu, Yiwen Guo, and Zhou Zhao, “Enhanc- ing expressive voice conversion with discrete pitch-conditioned flow matching model, ” in ICASSP , 2025. [27] Pengyu Ren, W enhao Guan, Kaidi W ang, Peijie Chen, Qingyang Hong, and Lin Li, “ReFlow-VC: Zero-shot voice con version based on rectified flow and speaker feature optimization, ” in Interspeech , 2025. [28] Hirokazu Kameoka, T akuhiro Kaneko, Kou T anaka, and Y uto Kondo, “La- tentV oiceGrad: Nonparallel voice conv ersion with latent diffusion/flow-matching models, ” IEEE/ACM Tr ans. Audio Speech Lang. Pr ocess. , vol. 33, pp. 4071–4084, 2025. [29] Tim Salimans and Jonathan Ho, “Progressive distillation for fast sampling of diffusion models, ” in ICLR , 2022. [30] Y ang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever , “Consistenc y models, ” in ICML , 2023. [31] Y ang Song and Prafulla Dhariwal, “Improved techniques for training consistency models, ” in ICLR , 2024. [32] Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach, “ Adver- sarial diffusion distillation, ” in ECCV , 2024. [33] Axel Sauer , Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach, “Fast high-resolution image synthesis with latent adversarial diffusion distillation, ” in SIGGRAPH Asia , 2024. [34] T akuhiro Kanek o, Hirokazu Kameoka, K ou T anaka, and Y uto K ondo, “FastV oice- Grad: One-step diffusion-based voice con version with adv ersarial conditional dif- fusion distillation, ” in Interspeech , 2024. [35] T akuhiro Kaneko, Hirokazu Kameoka, Kou T anaka, and Y uto K ondo, “Faster- V oiceGrad: Faster one-step dif fusion-based v oice con version with adv ersarial dif- fusion con version distillation, ” in Interspeech , 2025. [36] T akuhiro Kaneko, Hirokazu Kameoka, Kou T anaka, and Y uto Kondo, “V ocoder- projected feature discriminator , ” in Interspeech , 2025. [37] Jungil K ong, Jaehyeon Kim, and Jaekyoung Bae, “HiFi-GAN: Generativ e ad- versarial networks for ef ficient and high fidelity speech synthesis, ” in NeurIPS , 2020. [38] Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico K olter, and Kaiming He, “Mean flows for one-step generati ve modeling, ” in NeurIPS , 2025. [39] Zhou W ang, Alan C. Bovik, Hamid R. Sheikh, and Eero P . Simoncelli, “Image quality assessment: from error visibility to structural similarity , ” IEEE T rans. Image Process. , v ol. 13, no. 4, pp. 600–612, 2004. [40] Zhengyang Geng, Ashwini Pokle, W illiam Luo, Justin Lin, and J. Zico Kolter , “Consistency models made easy , ” in ICLR , 2025. [41] Y e Jia, Y u Zhang, Ron J. W eiss, Quan W ang, Jonathan Shen, Fei Ren, Zhifeng Chen, Patrick Nguyen, Ruoming Pang, Ignacio Lopez Moreno, and Y onghui Wu, “Transfer learning from speaker verification to multispeaker text-to-speech syn- thesis, ” in NeurIPS , 2018. [42] Songxiang Liu, Y uewen Cao, Disong W ang, Xixin Wu, Xunying Liu, and He- len Meng, “ Any-to-many voice con version with location-relative sequence-to- sequence modeling, ” IEEE/ACM T rans. Audio Speech Lang. Process. , v ol. 29, pp. 1717–1728, 2021. [43] Junichi Y amagishi, Christophe V eaux, and Kirsten MacDonald, “CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92), ” 2019. [44] Heiga Zen, V iet Dang, Rob Clark, Y u Zhang, Ron J. W eiss, Y e Jia, Zhifeng Chen, and Y onghui W u, “LibriTTS: A corpus deriv ed from LibriSpeech for text-to- speech, ” in Interspeech , 2019. [45] Olaf Ronneberger , Philipp Fischer, and Thomas Brox, “U-net: Conv olutional networks for biomedical image segmentation, ” in MICCAI , 2015. [46] Y ann N. Dauphin, Angela Fan, Michael Auli, and David Grangier, “Language modeling with gated con volutional networks, ” in ICML , 2017. [47] Tim Salimans and Diederik P . Kingma, “W eight normalization: A simple repa- rameterization to accelerate training of deep neural networks, ” in NIPS , 2016. [48] Diederik P . Kingma and Jimmy Ba, “ Adam: A method for stochastic optimiza- tion, ” in ICLR , 2015. [49] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨ uller , Harry Saini, Y am Levi, Dominik Lorenz, Axel Sauer , Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lace y , Alex Goodwin, Y annik Marek, and Robin Rombach, “Scaling rectified flow transformers for high-resolution im- age synthesis, ” in ICML , 2024. [50] T akaaki Saeki, Detai Xin, W ataru Nakata, T omoki K oriyama, Shinnosuke T akamichi, and Hiroshi Saruwatari, “UTMOS: UT okyo-SaruLab system for V oiceMOS Challenge 2022, ” in Interspeech , 2022. [51] Chandan K. A. Reddy , Vishak Gopal, and Ross Cutler, “DNSMOS: A non- intrusiv e perceptual objecti ve speech quality metric to evaluate noise suppressors, ” in ICASSP , 2021. [52] Fredrik Cumlin, Xinyu Liang, V ictor Ungureanu, Chandan K. A. Reddy, Chris- tian Sch ¨ uldt, and Saikat Chatterjee, “DNSMOS Pro: A reduced-size DNN for probabilistic MOS of speech, ” in Interspeech , 2024. [53] Jaime Lorenzo-Trueba, Junichi Y amagishi, T omoki T oda, Daisuke Saito, Fer- nando Villa vicencio, T omi Kinnunen, and Zhenhua Ling, “The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods, ” in Odyssey , 2018. [54] Alec Radford, Jong W ook Kim, T ao Xu, Gre g Brockman, Christine McLeavey , and Ilya Sutskev er, “Robust speech recognition via large-scale weak supervision, ” in ICML , 2023. [55] Sanyuan Chen, Chengyi W ang, Zhengyang Chen, Y u W u, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, T akuya Y oshioka, Xiong Xiao, Jian W u, Long Zhou, Shuo Ren, Y anmin Qian, Y ao Qian, Jian Wu, Michael Zeng, Xiangzhan Y u, and Furu W ei, “W avLM: Large-scale self-supervised pre-training for full stack speech processing, ” IEEE J. Sel. T op. Signal Process. , v ol. 16, no. 6, pp. 1505–1518, 2022. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment