Multi-Modal Sensing Residual-Corrected GNN for mmWave Path Loss Prediction via Synesthesia of Machines
To support sixth-generation (6G)-enabled intelligent transportation systems (ITSs), a multi-modal sensing residual-corrected graph neural network (MM-ResGNN) framework is proposed for millimeter-wave (mmWave) path loss prediction in vehicular communi…
Authors: Mengyuan Lu, Lu Bai, Xiang Cheng
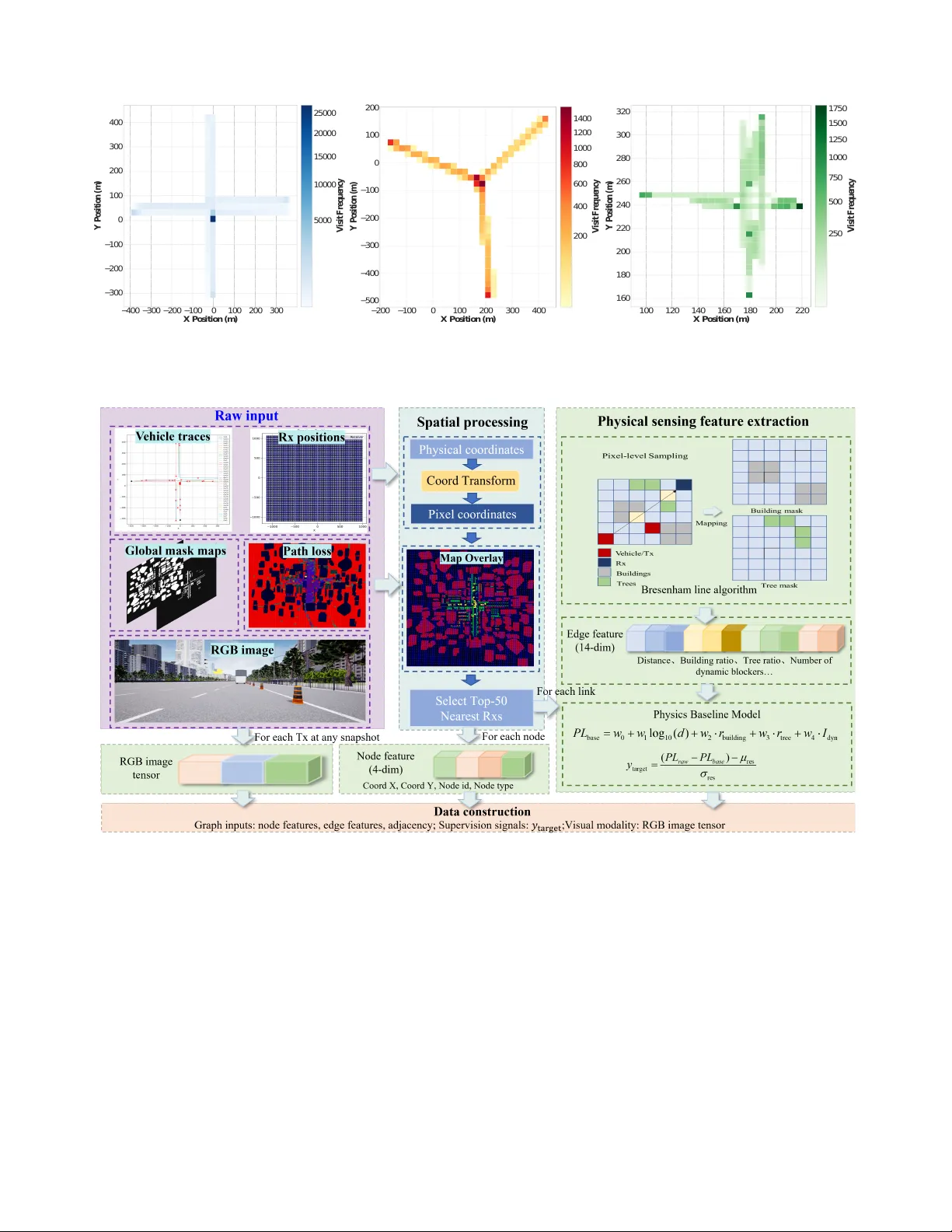
IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 1 Multi-Modal Sensing Residual-Corrected GNN for mmW a v e Path Loss Prediction via Synesthesia of Machines Mengyuan Lu, Member , IEEE , Lu Bai, Senior Member , IEEE , and Xiang Cheng, F ellow , IEEE Abstract —T o support sixth-generation (6G)-enabled intelligent transportation systems (ITSs), a multi-modal sensing residual- corrected graph neural network (MM-ResGNN) framework is proposed for millimeter -wa ve (mmW ave) path loss prediction in vehicular communications for the first time. The propagation en vironment is f ormulated as an en vir onment sensing path loss graph (ESPL-Graph), where nodes r epresent the transmitter (Tx) and recei ver (Rx) entities and edges jointly describe Tx– Rx transmission links and Rx–Rx spatial correlation links. Meanwhile, a geometry-driven physical baseline is introduced to decouple deterministic attenuation trends fr om stochastic residual variations. A vehicular multi-modal path loss dataset (VMMPL) is constructed, which covers three repr esentative scenarios, including the urban wide lane, urban crossr oad, and suburban f orking road en vir onments, and achiev es precise alignment between RGB images and global semantic information in the physical space, and link-level ray-tracing (R T)-based path loss data in the electromagnetic space. In MM-ResGNN, topology- aware graph representations and fine-grained visual semantics are synergistically integrated through a gated fusion mechanism to estimate the path loss residual relative to the physical baseline. Experimental results demonstrate that MM-ResGNN achieves significant improvements over empirical models and conventional data-driven baselines, with a normalized mean squared error (NMSE) of 0.0098, a mean absolute error (MAE) of 5.7991 dB, and a mean absolute per centage error (MAPE) of 5.0498%. Furthermore, MM-ResGNN exhibits rob ust cross-scenario gen- eralization through a few-shot fine-tuning strategy , enabling accurate path loss prediction in unseen vehicular en vir onments with limited labeled data. Index T erms —Sixth-generation (6G), intelligent transportation systems (ITSs), vehicular networks, path loss prediction, graph neural network (GNN). I . I N T R O D U C T I O N Intelligent transportation systems (ITSs) constitute a core component of modern smart cities and play a critical role in traffic safety enhancement, mobility impro vement, and sustain- able transportation development [1]–[3]. W ith the ev olution tow ard sixth-generation (6G)-enabled ITSs, reliable vehicu- lar connectivity requires accurate channel characterization to M. Lu is with the Joint SDU-NTU Centre for Artificial Intelligence Research (C-F AIR), Shandong Univ ersity , Jinan, 250101, P . R. China, and also with the School of Software, Shandong University , Jinan 250101, P . R. China (e-mail: mengyuanlu@mail.sdu.edu.cn). L. Bai is with the Joint SDU-NTU Centre for Artificial Intelligence Research (C-F AIR), Shandong University , Jinan, 250101, P . R. China (e-mail: lubai@sdu.edu.cn). X. Cheng are with the State Ke y Laboratory of Photonics and Communica- tions, School of Electronics, Peking University , Beijing, 100871, P . R. China (email: xiangcheng@pku.edu.cn). support high-mobility communications and stringent quality- of-service requirements [4], [5]. P ath loss plays a funda- mental role in quantifying signal attenuation and serves as a cornerstone for network coverage planning, power control, and interference management [6]–[8]. In realistic v ehicular en vironments, signal propagation is jointly affected by static elements, such as buildings and roadside infrastructure, and dynamic elements, such as vehicles, forming a heterogeneous propagation space with complex interactions. Consequently , path loss depends not only on individual transmitter (Tx) and recei ver (Rx) characteristics, but also exhibits pronounced spatial dependency and topological correlation among multiple communication links [9], which substantially increases the difficulty of accurate prediction. Path loss modeling has been extensi vely in vestigated from early-generation cellular systems to contemporary fifth- generation (5G) networks. Con ventional analytical and empir- ical path loss models, such as the free-space model and the close-in model, hav e been widely adopted owing to concise mathematical formulations and physical interpretability [10]. Empirical path loss models pro vide a fundamental charac- terization of large-scale signal attenuation under simplified propagation assumptions and are typically calibrated utiliz- ing empirically tuned parameters. Howe ver , the simplified propagation assumptions adopted in the empirical models are insufficient to characterize complex vehicular environments, in which signal propagation is jointly affected by buildings, vehicles, and surrounding infrastructure [11], [12]. As a result, limited prediction accuracy and generalization capability are observed when the empirical models are applied to realistic ITS scenarios. T o address these challenges, data-driv en approaches have been e xplored for path loss prediction. Machine learning (ML)-based methods were employed to model nonlinear rela- tionships between en vironmental features and path loss in ve- hicular scenarios [13]–[15]. Con ventional ML algorithms, in- cluding support vector machines (SVMs) and random forests, demonstrated impro ved prediction performance compared with empirical models [16], [17]. Howe ver , the con ventional ML algorithms typically treated each Tx–Rx link as an independent sample and relied heavily on handcrafted features, thereby neglecting spatial correlation and inter-link dependency in dense road networks. More recently , deep learning (DL)-based approaches lev eraged visual representations, such as satellite images and city maps, to infer path loss by extracting high- lev el semantic information related to b uilding density and IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 2 road layouts [18]–[20]. Despite improved generalization, the models based on visual images were generally b uilt on regular grid representations and lacked explicit mechanisms to capture network topology and link-lev el interactions. Graph neural networks (GNNs) have been recognized as an effecti ve tool for modeling structured wireless systems by explicitly representing network entities and their inter- actions. GNN-based approaches have demonstrated promis- ing performance in v arious wireless applications, including resource allocation, routing optimization, and distributed in- ference [21]–[24]. By aggregating information over network topology , GNNs are well suited to capture spatial dependency and inter-link correlation in wireless networks. Nevertheless, the application of GNNs to millimeter-wa ve (mmW ave) path loss prediction remains limited. In existing studies, graph constructions are often simplified and mainly based on ge- ographical proximity or basic link geometry [25], [26]. Such simplified graph constructions lead to low-dimensional rep- resentations, which are insufficient to characterize complex blockage patterns and link heterogeneity in realistic vehicular en vironments. In realistic mmW av e vehicular en vironments, signal propa- gation is highly sensitive to environmental characteristics, in- cluding obstacle types, local structural configurations, and the presence of dynamic objects. En vironmental sensing modal- ities, such as visual images, are of great importance for capturing fine-grained semantic information that is closely related to mmW av e propagation mechanisms. Howe ver , such en vironmental sensing information is rarely incorporated into existing graph-based path loss modeling framew orks. As a result, fine-grained semantic information related to obstacle types, local structural configurations, and dynamic objects is difficult to be adequately represented when path loss prediction relies solely on geometric features. Inspired by synesthesia of machines (SoM) [27] and multi- modal intelligent channel modeling (MMICM) [28], [29], en vironmental sensing can be jointly exploited with topology- aware representations to improve path loss prediction in com- plex vehicular en vironments. V isual information, such as RGB images, provides semantic cues about obstacles and local structures that are not captured by geometry-only features. Howe ver , existing graph-based path loss models rarely incor- porate aligned en vironmental sensing, and publicly available vehicular datasets with synchronized sensing data and link- lev el path loss labels remain limited. T o address these issues, a multi-modal sensing residual-corrected graph neural network (MM-ResGNN) is proposed for mmW ave path loss prediction for ITSs. The propagation en vironment is abstracted as an en vironment sensing path loss graph (ESPL-Graph), which enables explicit modeling of spatial dependenc y and inter - link correlation among multiple communication links in dense vehicular networks. A geometry-driven physical baseline is in- corporated to separate deterministic attenuation from residual variations induced by complex en vironments, while visual se- mantic information is jointly exploited to capture fine-grained en vironmental characteristics that are difficult to represent uti- lizing geometry-only features. In addition, a vehicular multi- modal path loss (VMMPL) dataset is constructed to support the e valuation of the proposed MM-ResGNN, which achiev es precise alignment between RGB images and global semantic information in the physical space, and link-level path loss data in the electromagnetic space across three representativ e vehicular scenarios. The main contributions are summarized as follows. 1) A novel MM-ResGNN framew ork is developed for vehicular mmW ave path loss prediction. The pro- posed residual-corrected modeling paradigm integrates a geometry-driv en physical baseline with multi-modal graph learning to characterize lar ge-scale signal attenua- tion. The decoupling of deterministic propagation trends and stochastic en vironmental v ariations enables accurate and robust path loss estimation in complex intelligent transportation scenarios. 2) T o support the ev aluation of the proposed MM-ResGNN, a ne w VMMPL dataset is constructed, which also facil- itates a broad range of future research on multi-modal data-driv en path loss modeling, topology-aware learning, and en vironment-aware mmW av e channel characteriza- tion for ITSs. The VMMPL dataset achiev es precise alignment between RGB images and global semantic information in the physical space, and link-lev el path loss data in the electromagnetic space and covers three representativ e vehicular scenarios. The VMMPL dataset operates at a carrier frequency of 28 GHz with a bandwidth of 2 GHz and contains 41.8k synchronized RGB images and corresponding path loss measurements. 3) T o explicitly model spatial dependency and inter-link correlation in vehicular communication en vironments for ITSs, a nov el ESPL-Graph is formulated, which provides a general and extensible graph-based abstraction for representing topology-aw are interactions among com- munication links and can be readily applied to graph learning–based wireless modeling and inference tasks. In the proposed ESPL-Graph formulation, nodes represent Tx and Rx entities, while edges jointly characterize Tx–Rx transmission links and spatial correlation rela- tionships among Rxs. Based on ESPL-Graph, a ded- icated MM-ResGNN architecture integrates topology- aware graph representations and fine-grained visual se- mantics through a gated fusion mechanism for residual path loss estimation. 4) Experimental results demonstrate that MM-ResGNN achiev es significant improvements over empirical mod- els and con ventional data-driven baselines, with a nor- malized mean squared error (NMSE) of 0.0098, a mean absolute error (MAE) of 5.7991 dB, and a mean absolute percentage error (MAPE) of 5.0498%. The proposed framew ork further exhibits strong generalization capa- bility across different vehicular scenarios under a few- shot fine-tuning setting, which validates its robustness and practical applicability . The remainder of this paper is organized as follows. Sec- tion II presents the construction of the VMMPL dataset for mmW av e path loss prediction. Section III describes the architecture and design of the proposed MM-ResGNN. In IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 3 Fig. 1. Illustration of the mmW ave path loss prediction task in the urban scenario. The Tx (red vehicle) communicates with a dense grid of ground Rxs (blue dots). The prediction targets are the links connected to the nearest 50 Rxs (highlighted in the green zone). Section IV , the simulation settings and a comprehensive performance ev aluation and analysis are introduced. Finally , conclusions are drawn in Section V . I I . V M M P L D AT A S E T C O N S T RU C T I O N T o support the development of MM-ResGNN, a vehicular multi-modal path loss dataset, referred to as the VMMPL dataset, is constructed. The VMMPL dataset features precise spatio-temporal alignment between RGB images and global semantic information in the physical space, and link-lev el path loss data in the electromagnetic space. Dataset construction is based on a heterogeneous co-simulation platform integrating AirSim [31] and W ireless InSite [32], where photorealistic physical en vironments and high-fidelity ray-tracing (R T)-based radio propagation are jointly captured. As illustrated in Fig. 1, the prediction task focuses on estimating the path loss for the K = 50 nearest Rxs associated with a dynamic v ehicular Tx, where dominant communication links in the local vicinity are captured. Although K = 50 is adopted for e valuation, the proposed framework can be readily extended to predict path loss for an arbitrary number of Rxs according to different network configurations and application requirements. In this work, K is fixed to ensure a fair and consistent comparison across scenarios and baselines, while controlling the graph size and computational cost. A. Scenario Configuration The VMMPL dataset comprises three representativ e road scenarios spanning dense urban to suburban vehicular en viron- ments, as illustrated in Fig. 2. T o ensure consistency between AirSim and Wireless InSite, a dual-space alignment mecha- nism is employed during dataset construction. In the geometric domain, three-dimensional models of buildings, roads, and vehicles are synchronized in scale and coordinate origin. In the temporal domain, the states of all dynamic elements are updated synchronously at each snapshot to maintain temporal alignment between the physical and electromagnetic spaces. Urban Wide Lane (Dense Urban Scenario) : The urban wide lane scenario is modeled after a major metropolitan Fig. 2. V isualization of the constructed VMMPL dataset across three scenarios. The VMMPL dataset includes global masks (building and tree), ego-centric RGB images captured by the vehicle, aligned 3D physical en vi- ronments in AirSim and Wireless InSite, and the corresponding ground-truth path loss heatmaps. arterial road with an ultra-wide roadway and dense high-rise buildings. 40 dynamic vehicles are deployed along parallel lanes, and the trajectory density is shown in Fig. 3(a). Owing to its large spatial coverage and div erse blockage conditions, the urban wide lane scenario is adopted as the primary training dataset. Suburban Forking Road (Suburban Scenario): The sub- urban forking road scenario represents a Y -shaped road bifur- cation located in a low-density en vironment with sparse low- rise buildings and ve getation coverage. 25 dynamic vehicles are deployed along the bifurcated road segments, and the trajectory density is shown in Fig. 3(b). The suburban forking road scenario is utilized to examine model adaptability in open suburban vehicular en vironments. Urban Crossr oad (Regular Urban Scenario): The urban crossroad scenario corresponds to a bidirectional intersection surrounded by medium-rise buildings arranged in a grid-based Manhattan layout. 20 dynamic vehicles are deployed within the intersection area, and the trajectory density is shown in Fig. 3(c). The urban crossroad scenario is employed to ev aluate cross-scenario generalization under regular urban topologies. B. Data Collection and Pr ocessing After scenario construction and platform synchronization, a data generation pipeline is established to deploy commu- nication transceiv ers, record synchronized multi-modal obser- vations, and conv ert simulation outputs into graph-structured samples. 1) T ransceiver Deployment and T rajectory Configuration: The communication system operates at a carrier frequency of 28 GHz with a bandwidth of 2 GHz. The Tx is mounted on dynamic vehicles at a height of 2.0 m, and vehicle trajectories are configured along the road network. A dense grid of Rxs is deployed on the ground plane at a height of 1.5 m, including 5,183 nodes in the urban wide lane scenario, 5,159 nodes in the urban crossroad scenario, and 4,964 nodes in the suburban forking road scenario. The resulting VMMPL dataset contains 32.3k snapshots × 5.18k links per snapshot for the wide lane IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 4 − 4 0 0 − 3 0 0 − 2 0 0 − 1 0 0 0 1 0 0 2 0 0 3 0 0 X P o s i t i o n ( m ) − 3 0 0 − 2 0 0 − 1 0 0 0 1 0 0 2 0 0 3 0 0 4 0 0 Y P o s i t i o n ( m ) 5 0 0 0 1 0 0 0 0 1 5 0 0 0 2 0 0 0 0 2 5 0 0 0 V i s i t F r e q u e n c y (a) Urban Wide Lane − 2 0 0 − 1 0 0 0 1 0 0 2 0 0 3 0 0 4 0 0 X P o s i t i o n ( m ) − 5 0 0 − 4 0 0 − 3 0 0 − 2 0 0 − 1 0 0 0 1 0 0 2 0 0 Y P o s i t i o n ( m ) 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 V i s i t F r e q u e n c y (b) Sub urban Forking Road 1 0 0 1 2 0 1 4 0 1 6 0 1 8 0 2 0 0 2 2 0 X P o s i t i o n ( m ) 1 6 0 1 8 0 2 0 0 2 2 0 2 4 0 2 6 0 2 8 0 3 0 0 3 2 0 Y P o s i t i o n ( m ) 2 5 0 5 0 0 7 5 0 1 0 0 0 1 2 5 0 1 5 0 0 1 7 5 0 V i s i t F r e q u e n c y (c) Urban Crossroad Fig. 3. V ehicle trajectory density heatmaps across the three representative scenarios. The heatmaps illustrate the spatial coverage and diverse mobility patterns, reflecting dif ferent traffic densities and roadway topologies. Fig. 4. W orkflow of the data processing and graph construction pipeline. The raw multi-modal data (left) are spatially aligned and transformed into pixel coordinates. A physics-aware feature extraction module (right) utilizes the Bresenham line algorithm to compute blockage features from semantic masks. Finally , a physical baseline model is applied to decouple the deterministic path loss component, generating the graph-structured inputs and residual targets for the neural network. scenario, 4.42k snapshots × 5.16k links per snapshot for the crossroad scenario, and 5.07k snapshots × 4.96k links per snapshot for the forking road scenario. 2) Multi-Modal Data Acquisition: For each snapshot, multi-modal data are recorded in a synchronized manner , as illustrated in Fig. 2. The visual modality includes ego-centric RGB images captured from the Tx perspective. In addition, global binary masks for buildings and trees are generated to support blockage-related analysis. The electromagnetic modal- ity consists of ground-truth path loss values for all Tx–Rx links computed utilizing R T in Wireless InSite. Physical state information is also logged, including the global 3D coordinates of transceiv ers and other dynamic vehicles, which supports geometry-related feature extraction. 3) ESPL-Graph F ormulation and Residual T ar get Construc- tion: T o transform the VMMPL dataset into graph-structured representations compatible with MM-ResGNN, an ESPL- Graph is formulated for each Tx, as illustrated in Fig. 4. For a giv en Tx, a local communication graph is defined as G = ( V , E ) , where the node set V consists of the Tx and its K = 50 nearest Rxs. The edge set E is composed of two types of edges. T ransmission edges connect the Tx to each associated Rx to represent Tx–Rx links. Correlation edges connect neighboring Rxs to model spatial correlation induced IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 5 by common blockage conditions and surrounding structures. The correlation edges are constructed based on a k -nearest neighbor (KNN) criterion in the spatial domain [33]. Each node in V is initialized with a feature vector compris- ing its spatial coordinates and transceiv er type, i.e., indicating whether the node is a Tx or an Rx. For each Tx–Rx transmis- sion edge, a 14-dimensional physics-aware feature vector is extracted to describe geometric and en vironmental attributes along the propagation path. Feature extraction is performed utilizing the Bresenham ray-casting algorithm, as shown in the right panel of Fig. 4. The extracted features include the logarithmic Tx–Rx distance, blockage ratios associated with buildings and trees, and normalized distances to dynamic blockers such as vehicles. The feature vector is assigned as the edge attribute of the corresponding transmission Tx–Rx edge. Correlation edges connect neighboring Rxs to facilitate the exchange of node information, modeling spatial correlation induced by common blockage conditions and surrounding structures. T o decouple large-scale deterministic attenuation trends from complex stochastic variations, a geometry-driv en physi- cal baseline model is adopted for Tx–Rx transmission edges as a fixed reference for residual learning. The physical baseline path loss is defined as P L base = w 0 + w 1 log 10 ( d ) + w 2 · r building + w 3 · r tree + w 4 · I dyn where d denotes the Tx–Rx distance, r building and r tree represent the blockage ratios of buildings and trees along the propagation path, respectiv ely , and I dyn indicates the presence of dynamic blockers. The coefficients { w i } are pre-estimated via least-squares fitting on the training subset of the VMMPL dataset and remain fixed during model training and inference. Based on the physical baseline, the raw path loss value associated with each Tx–Rx transmission edge is transformed into a normalized residual learning target giv en by y target = ( P L raw − P L base ) − µ res σ res where µ res and σ res denote the mean and standard deviation of the residuals computed on the training set. C. Statistical Analysis and Physical Insights T o e xamine the di versity of the constructed VMMPL dataset, path loss statistics are analyzed for the three scenarios. The analysis is conducted based on the Tx–Rx links formed between each Tx and its nearest 50 Rxs, and the histograms and empirical cumulative distribution functions (CDFs) are shown in Fig. 5. The urban wide lane scenario exhibits a wide path loss dynamic range with a mean value of 110.68 dB, as illustrated in Fig. 5(a). High-rise b uildings and large-scale blockages produce a tail in the high-loss region above 150 dB and reflect deep fading conditions in non-line-of-sight (NLoS) areas. The suburban forking road scenario presents a mean path loss of 107.13 dB, as depicted in Fig. 5(b). The urban crossroad scenario yields a lo wer mean path loss of 75.77 dB, as sho wn in Fig. 5(c). The separation among these statis- tical profiles confirms that the constructed VMMPL dataset captures distinct propagation characteristics across diverse intelligent transportation system environments, which provides a comprehensi ve benchmark for ev aluating prediction accuracy (a) W ide Lane scenario (b) F orking Road scenario (c) Crossroad scenario Fig. 5. Statistical distribution of the path loss across three scenarios. The left panels present the frequency histograms with mean and median markers, while the right panels depict the empirical CDFs, highlighting the distinct electromagnetic scales. and cross-scenario generalization capability of the proposed MM-ResGNN. I I I . F R A M E W O R K O F T H E P R O P O S E D M M - R E S G N N In this section, the overall frame work of the proposed MM- ResGNN is presented. As illustrated in Fig. 6, the proposed ar- chitecture follows a dual-branch residual correction paradigm for mmW ave path loss prediction in complex vehicular en vi- ronments. The upper left module in Fig. 6 corresponds to a physics-embedded graph learning module, which takes graph- structured inputs with physics-aware node and edge features and performs topology-aware message passing to model spatial dependency and inter-link correlation. In parallel, the bottom left module in Fig. 6 represents the visual semantic module, which extracts high-le vel en vironmental semantics from ego- centric RGB images and maps them to Tx–Rx links. The outputs of these two branches are fused through a gated cross- modal fusion and correction module, shown on the right side of Fig. 6, which adaptiv ely balances geometry-driven and visual features to predict a normalized residual. The predicted IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 6 Fig. 6. The overall architecture of MM-ResGNN. The framew ork comprises two parallel branches, i.e., a physics-embedded graph learning branch for topological reasoning and a visual semantic branch for environmental texture extraction. A gated fusion module dynamically integrates these multi-modal features to predict the normalized residual, which is added to the physical baseline to obtain the final path loss. residual is finally combined with a geometry-dri ven physical baseline to obtain the final path loss estimate. A. Physics-Embedded Graph Learning Branc h T o capture the structural dependency of wireless channels, a physics-embedded graph learning branch is designed, cor- responding to the upper left module in Fig. 6. This module operates on the ESPL-Graph and processes physics-aw are node and edge features derived from geometric and en viron- mental attrib utes. Unlike con ventional GNNs that treat features as abstract vectors, this module explicitly embeds domain knowledge into feature encoding and message passing. A physics-aw are grouped encoding strategy and an anisotropic aggregation mechanism are jointly employed to ensure that the learned representations are both physically meaningful and topologically consistent. 1) Physics-A war e Gr ouped Edge Encoding: As sho wn in the upper left module of Fig. 6, edge features with physics grouping are processed by a physics-aware grouped encoding module. Directly projecting heterogeneous edge features into a shared latent space may suppress contributions from smaller- scale physical factors, such as en vironmental blockages. T o mitigate this issue, the 14-dimensional edge feature vector is partitioned into six sub-groups according to their physi- cal meanings, including propagation distance, environmental blockage, link type, and relativ e position. Each sub-group is processed by an independent edge multilayer perceptron (MLP), and the resulting embeddings are concatenated and fused through a linear projection layer followed by layer normalization. 2) Anisotr opic T opological Aggr egation via Graph T rans- former: The encoded node and edge features are then fed into a stack of T ransformerCon v layers, as illustrated in the central part of Fig. 6. By leveraging multi-head attention, the graph transformer enables anisotropic message aggregation, which is essential for modeling directional signal propagation and blockage-sensitiv e mmW av e channels [34]. For a center node u and neighboring node v , the feature update at layer l is expressed as h ( l +1) u = W O · Concat H k =1 X v ∈N ( u ) α ( k ) uv W ( k ) V h ( l ) v (1) where N ( u ) denotes the neighborhood set of node u , and H is the number of attention heads. The attention coefficient α ( k ) uv measures the importance of neighboring node v to node u under the k -th attention head, computed as α ( k ) uv = Softmax v ( W ( k ) Q h ( l ) u ) T W ( k ) K h ( l ) v + W ( k ) E h ( l ) e uv √ d k ! (2) where W ( k ) Q , W ( k ) K , and W ( k ) E are the projection matrices for queries, keys, and edge attributes, respectiv ely . An adaptiv e edge–node fusion mechanism is utilized to refine the edge representation after message passing. For a directed edge e uv , the updated edge feature is computed as h ( l +1) e uv = α · h ( l ) e uv + β · h ( l ) u + γ · h ( l ) v (3) where α , β , and γ are learnable fusion coefficients, obtained via a softmax-based gating network. IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 7 B. V isual Semantic Branc h The visual semantic branch, shown in the bottom left module of Fig. 6, aims to incorporate fine-grained en viron- mental semantics from ego-centric RGB images into path loss prediction. This branch is composed of two closely related components. First, high-level semantic representations are ex- tracted from RGB images to characterize local en vironmental textures and structures. Then, the extracted visual features are mapped to graph-structured Tx–Rx links in a topology-aware manner , such that visual semantics are associated only with transmission links relev ant to path loss estimation. Based on this two-stage design, visual information is effecti vely aligned with the graph-based geometric representations. 1) Semantic F eatur e Extraction and T ransfer Learning: A pre-trained ResNet-18 [35] is utilized to extract high-lev el semantic representations. T ransfer learning is employed to fine-tune the network for path loss prediction. Shallow layers are frozen, preserving univ ersal spatial features, while high- lev el layers are fine-tuned to extract domain-specific features related to path loss in vehicular en vironments. 2) T opology-A war e F eature Mapping: As illustrated by the Tx–Rx link filter in Fig. 6, visual features are selec- tiv ely associated with Tx–Rx transmission edges, while Rx– Rx correlation edges are assigned zero-padding. This design ensures that visual semantics enhance path loss estimation only for transmission links without contaminating correlation modeling. C. Gated Cr oss-Modal Fusion and Residual Correction The gated cross-modal fusion and correction module, shown on the right side of Fig. 6, adaptiv ely integrates geometry- driv en graph features and visual semantic features. A gating coefficient is learned to balance the contributions of the two modalities under different propagation conditions. The fused representation is utilized to predict a normalized residual, which is added to the geometry-driv en physical baseline to obtain the final path loss estimate. The gating coefficient w ∈ [0 , 1] is computed as w = σ ( W g [ f g eo ∥ f v is ] + b g ) (4) where σ ( · ) is the sigmoid activ ation function. The final fused representation is f f inal = w · f g eo + (1 − w ) · f v is . (5) The fused representation is utilized to predict the normalized residual, which is added to the physical baseline to obtain the final path loss estimate: ˆ P L = P L base ( x phy ) + ∆ ˆ P L · σ res + µ res (6) This formulation encourages the network to focus on comple x propagation ef fects caused by local environmental structures and dynamic obstacles, improving prediction accuracy . I V . S I M U L A T I O N R E S U LT S A N D A NA LY S I S This section presents simulation results for mmW ave path loss prediction and provides a mechanism-oriented analysis of the proposed MM-ResGNN. The e valuation includes compar- isons with empirical and data-dri ven baselines, ablation studies on key architectural components, and cross-scenario transfer learning under limited target-domain supervision. A. Experimental Setup and Implementation Details 1) Experimental Setup: A vehicle-wise data splitting strat- egy is adopted to ev aluate generalization under unseen mo- bility patterns. Instead of randomly shuf fling snapshots, the dataset is partitioned according to unique vehicle IDs. Specif- ically , 70% of the vehicles and their complete trajectories are utilized for training, 15% for validation, and 15% for testing. This protocol prevents information leakage caused by temporally correlated snapshots and provides a rigorous assessment of generalization. The proposed model is implemented in PyT orch and op- timized utilizing AdamW with an initial learning rate of 5 × 10 − 4 and a weight decay of 5 × 10 − 5 . T raining is conducted for 200 epochs with a batch size of 32, and a plateau-based learning rate scheduler is applied. The GNN branch consists of three TransformerCon v layers with four attention heads and a hidden dimension of 128. The visual branch adopts an ImageNet-pretrained ResNet-18 backbone and is fine-tuned following the strategy described in Section III. 2) Evaluation Metrics: Three metrics are employed to quantify prediction accuracy from complementary perspec- tiv es. The mean absolute error (MAE) is adopted to measure the average absolute deviation in decibels and is defined as MAE = 1 N N X i =1 | y i − ˆ y i | (7) where y i and ˆ y i denote the ground-truth and predicted path loss of the i -th link, respectiv ely , and N is the number of ev aluated samples. MAE directly reflects the link-level prediction error on the dB scale and is therefore particularly suitable for assessing absolute path loss de viations in mmW a ve systems with large dynamic ranges. The normalized mean squared error (NMSE) is adopted to ev aluate the overall goodness of fit relati ve to the signal energy and is formulated as NMSE = P N i =1 ( y i − ˆ y i ) 2 P N i =1 y 2 i . (8) By normalizing the squared error by the energy of the path loss values, NMSE enables fair comparison across scenarios with different path loss dynamic ranges. The mean absolute percentage error (MAPE) is computed to assess relative prediction accuracy and is giv en by MAPE = 1 N N X i =1 y i − ˆ y i y i × 100% . (9) MAPE emphasizes relativ e deviations and complements MAE by normalizing errors with respect to the path loss magnitude. IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 8 Unless otherwise specified, all metrics are computed on the reconstructed path loss ˆ P L after adding the predicted residual to the physical baseline described in Section II. B. P erformance Evaluation in the Urban W ide Lane Scenario 1) Baselines: For quantitati ve comparison, the proposed MM-ResGNN is ev aluated against representativ e empirical path loss models and data-driv en baselines. The selected base- lines are designed to isolate the effects of physical modeling, geometric features, graph topology , and visual semantics. For clarity , the ev aluated baselines are grouped according to their modeling paradigms and denoted by category-lev el identifiers. Specifically , C0 denotes the geometry-driv en physical base- line, which is gi ven in Section II-B. C1 represents standardized and empirical path loss models, and C2–C4 correspond to representativ e data-driven baselines with increasing modeling complexity . a) Empirical Models (C1): T o benchmark the proposed MM-ResGNN against authoritative and widely adopted an- alytical baselines, sev eral representative empirical path loss models are considered. These models serve as fundamental ref- erences in mmW av e channel modeling and 5G standardization, and primarily characterize large-scale propagation behavior under simplified physical assumptions. Free-Space Path Loss (FSPL) [36]: FSPL represents the theoretical lower bound of path loss under ideal line-of-sight (LoS) conditions without any blockage or scattering and is widely adopted as a fundamental reference model in wireless communications. It is giv en by P L FSPL ( d ) = 32 . 4 + 20 log 10 ( d ) + 20 log 10 ( f c ) , (10) where d is the Tx–Rx distance in meters and f c is the carrier frequency in GHz. 3GPP TR 38.901 Urban Microcell (UMi) [37]: The UMi path loss model follows the standardized formulations speci- fied in 3GPP TR 38.901, which constitutes the authoritati ve channel modeling reference for 5G new radio (NR) systems. This model has been extensi vely utilized in both academic research and industrial ev aluation for UMi mmW av e deploy- ments. In this work, the corresponding 3GPP expressions and recommended parameter settings are adopted without site- specific calibration. Alpha-Beta-Gamma (ABG) [38]: The ABG model is a measurement-driv en empirical path loss model deriv ed from extensi ve multi-frequency propagation campaigns and has been widely recognized as a benchmark model for mmW ave channel characterization. It expresses path loss as a function of distance and frequency: P L ABG ( d ) = 10 α log 10 ( d ) + β + 10 γ log 10 ( f c ) , (11) where α controls distance dependence, β is an offset term, and γ captures frequency dependence. b) Data-Driven Baselines: T o systematically ev aluate the contribution of each module and the superiority of the proposed architecture, three categories of data-dri ven baselines are implemented. Geometry-driv en MLP (C2): A MLP is employed to regress the path loss residual directly from the 14-dimensional physics-aw are edge feature v ector . Each Tx–Rx link is treated as an independent sample, and neither graph topology nor visual en vironmental information is incorporated. This MLP baseline reflects the prediction accuracy achiev able utilizing localized geometric features only . V ision-based ResNet-18 (C3): A con volutional neural net- work (CNN) based on ResNet-18 is utilized to ev aluate the standalone contribution of visual information. Semantic features are extracted from ego-centric RGB images and mapped to path loss values through a regression head. Explicit geometric features, such as propagation distance and blockage ratios, are not included. Uni-modal geometric GNN (C4): A graph-based model is constructed utilizing the same heterogeneous graph topol- ogy and physics-aware edge features as the proposed MM- ResGNN, while excluding the visual semantic branch. This configuration isolates the contribution of graph topology and geometric reasoning without multi-modal fusion. 2) P erformance Analysis: Before presenting quantitativ e comparisons, Fig. 7 provides a representativ e snapshot-level visualization in the urban wide lane scenario, which qualita- tiv ely illustrates the spatial distribution of path loss and high- lights localized prediction errors caused by complex blockage and topology . Quantitativ e path loss prediction results in the urban wide lane scenario are summarized in T able I. The pro- posed MM-ResGNN is compared with the physical baseline, standardized empirical models, and representativ e uni-modal data-driv en baselines. MAE is primarily utilized to reflect absolute prediction deviations on the dB scale, while MAPE emphasizes relati ve errors and is more sensiti ve to inaccuracies in lo w path loss re gions. NMSE is further reported to assess the ov erall goodness of fit normalized by signal energy , providing a complementary global measure that enables fair comparison across scenarios with different path loss dynamic ranges. As reported in T able I, empirical models (C1) e xhibit limited accuracy in the urban wide lane scenario. The 3GPP UMi model, ABG model, and FSPL yield MAE v alues exceeding 11 dB. These results indicate that empirical formulations cal- ibrated on averaged propagation conditions are insufficient to capture site-specific blockage and multipath ef fects. Compared with standardized empirical models, the geometry-driven phys- ical baseline (C0) achieves a noticeable performance improv e- ment across all ev aluation metrics. By explicitly incorporating site-aware geometric information, such as propagation distance and blockage ratios, the physical baseline is able to partially capture en vironment-dependent attenuation ef fects that are not represented in av eraged empirical formulations. Howe ver , the performance gap between the physical baseline and data- driv en models indicates that the low-dimensional parametric formulation of C0 remains insufficient to model complex interactions induced by heterogeneous structures and dynamic obstacles in realistic vehicular environments. The uni-modal data-driven baselines highlight the limita- tions of relying on a single modality . The geometry-driv en MLP (C2) and the uni-modal geometric GNN (C4) achiev e lower prediction errors than empirical models (C1) and the IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 9 1 5 0 0 1 6 0 0 1 7 0 0 1 8 0 0 1 9 0 0 2 0 0 0 2 1 0 0 X P i x e l C o o r d i n a t e 2 1 0 0 2 2 0 0 2 3 0 0 2 4 0 0 2 5 0 0 2 6 0 0 Y P i x e l C o o r d i n a t e N e t w o r k T o p o l o g y & E r r o r D i s t r i b u t i o n R X T X 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 | E r r o r | ( d B ) 1 5 0 0 1 6 0 0 1 7 0 0 1 8 0 0 1 9 0 0 2 0 0 0 2 1 0 0 X P i x e l C o o r d i n a t e 2 1 0 0 2 2 0 0 2 3 0 0 2 4 0 0 2 5 0 0 2 6 0 0 Y P i x e l C o o r d i n a t e G r o u n d T r u t h H e a t m a p 1 0 0 1 1 5 1 3 0 1 4 5 1 6 0 1 7 5 1 9 0 2 0 5 P a t h L o s s ( d B ) 1 5 0 0 1 6 0 0 1 7 0 0 1 8 0 0 1 9 0 0 2 0 0 0 2 1 0 0 X P i x e l C o o r d i n a t e 2 1 0 0 2 2 0 0 2 3 0 0 2 4 0 0 2 5 0 0 2 6 0 0 Y P i x e l C o o r d i n a t e P r e d i c t i o n H e a t m a p 9 6 1 0 8 1 2 0 1 3 2 1 4 4 1 5 6 1 6 8 1 8 0 1 9 2 2 0 4 P a t h L o s s ( d B ) 1 5 0 0 1 6 0 0 1 7 0 0 1 8 0 0 1 9 0 0 2 0 0 0 2 1 0 0 X P i x e l C o o r d i n a t e 2 1 0 0 2 2 0 0 2 3 0 0 2 4 0 0 2 5 0 0 2 6 0 0 Y P i x e l C o o r d i n a t e E r r o r H e a t m a p ( M A E = 0 . 7 4 d B ) 0 . 0 0 . 4 0 . 8 1 . 2 1 . 6 2 . 0 2 . 4 2 . 8 3 . 2 | E r r o r | ( d B ) Fig. 7. V isualization of path loss prediction results for a representative snapshot in the urban wide lane scenario. The communication graph topology is illustrated with edge colors indicating the prediction error magnitude. The ground-truth and predicted path loss heatmaps are presented together with the spatial distribution of prediction errors. The MAE for the illustrated snapshot is 0.74 dB. geometry-driv en physical baseline (C0), indicating that geo- metric features and topological modeling provide an ef fectiv e inductiv e bias for capturing large-scale attenuation trends. Howe ver , their performance remains limited by the absence of fine-grained en vironmental semantics, which restricts their ability to correct absolute de viations caused by local blockage and heterogeneous structures. The vision-based ResNet-18 (C3) captures environmental context through visual semantics and achieves a comparable absolute error , but exhibits a higher relativ e error , implying that visual information alone lacks reliable geometric scaling in distance-sensiti ve mmW a ve propagation. By jointly exploiting topology-aware geometric reasoning and visual semantic information, the proposed MM- ResGNN consistently outperforms all uni-modal baselines across different error metrics, demonstrating its capability to accurately model both absolute attenuation lev els and relati ve variations under complex propagation conditions. T ABLE I P A T H L O S S P R E D I C T I O N P E R F O R M A N C E C O M PAR I S O N ID Model / Configuration MAE (dB) NMSE MAPE (%) C0 Physical Baseline 7.9543 0.0145 7.0264 C1 3GPP UMi (NLoS) 12.8960 0.0233 11.8740 ABG model 12.9244 0.0233 11.9014 FSPL model 11.5091 0.0238 9.7506 C2 Geometry-driv en MLP 6.8109 0.0124 5.8538 C3 V ision-based ResNet-18 7.0116 0.0130 6.0698 C4 Uni-modal Geometric GNN 6.5817 0.0116 5.6846 A0 MM-ResGNN 5.7991 0.0098 5.0498 C. Ablation Studies and Mechanism Analysis A systematic ablation study is conducted to quantify the contributions of dif ferent architectural components and feature design choices in the proposed MM-ResGNN. The e valuation focuses on three aspects, including the selection of GNN oper- ators, the role of residual learning and collaborati ve topology , P h y s i c a l B a s e l i n e U n i - m o d a l G e o m e t r i c G N N G e o m e t r y - d r i v e n M L P V i s i o n - b a s e d R e s N e t - 1 8 M M - R e s G N N 5 . 0 5 . 5 6 . 0 6 . 5 7 . 0 7 . 5 8 . 0 8 . 5 M A E M A E 4 . 5 5 . 0 5 . 5 6 . 0 6 . 5 7 . 0 7 . 5 M A P E M A P E (a) Comparison with baseline models F u l l M M - R e s G N N D i r e c t R e g r e s s i o n w / o R x → R x C o r r e l a t i o n E d g e s w / o D i r e c t i o n a l F e a t u r e s w / o T x S p e e d F e a t u r e s w / o D y n a m i c B l o c e r F e a t u r e s w / o S t a t i c O b s t a c l e F e a t u r e s 5 . 0 5 . 2 5 . 4 5 . 6 5 . 8 6 . 0 6 . 2 6 . 4 6 . 6 6 . 8 M A E M A E 4 . 6 4 . 8 5 . 0 5 . 2 5 . 4 5 . 6 5 . 8 M A P E M A P E (b) Ablation study of internal modules Fig. 8. Quantitati ve performance analysis in the Urban W ide Lane scenario. (a) Comparison between the physical baseline, single-modal variants, and the proposed MM-ResGNN. (b) Impact of individual components on prediction accuracy , highlighting the significance of residual learning and topological correlations. and the impact of physics-aw are feature engineering. Quanti- tativ e results are summarized in T able II. The corresponding ablation trends are also illustrated in Fig. 8(b). 1) Analysis of GNN Ar chitectur es: The impact of different GNN operators is e valuated by replacing the Transformer - based con volution with graph con volutional network (GCN) and graph attention network (GA T) variants, denoted as V1 and V2, respectiv ely . As reported in T able II, the GCN- based variant results in an MAE of 6.47 dB. The isotropic aggregation mechanism of GCN assigns equal importance to neighboring nodes and therefore does not explicitly account for directional propagation characteristics. The GA T -based variant reduces the MAE to 6.16 dB by introducing attention-based weighting among neighbors. Howe ver , edge attributes are not directly incorporated into the attention computation, which limits the ability to exploit physics-aw are channel features. In contrast, the Transformer - based operator achieves the lowest MAE by integrating high- dimensional edge features into the attention mechanism, en- abling anisotropic aggregation that is consistent with the direc- tional and blockage-sensiti ve nature of mmW a ve propagation. 2) Impact of Residual Learning and Collaborative T opol- ogy: The ef fect of residual learning is e valuated by comparing the proposed MM-ResGNN with a direct regression variant without baseline decoupling, denoted as A1. As shown in T able II, the removal of residual learning increases the MAE from 5.80 dB to 6.40 dB. This performance de gradation indicates that separating large-scale deterministic attenuation from stochastic residual components simplifies the learning objectiv e and improv es optimization stability . IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 10 The role of collaborative topology is examined by removing Rx–Rx correlation edges, resulting in variant A2. The MAE increases to 6.40 dB under this configuration. The observed degradation suggests that spatial correlations among neigh- boring Rxs pro vide complementary contextual information, which contributes to enforcing spatial consistency in path loss prediction across the local region. 3) Contribution of Physics-A war e F eatur e Engineering: The contribution of indi vidual feature groups is analyzed through variants A3 to A7. Among all feature categories, static obstacle features associated with b uildings and trees are observed to be the most influential. As reported in T able II, re- moving static obstacle features increases the MAE to 6.25 dB, indicating that large-scale blockage induced by permanent structures dominates mmW a ve path loss variation in dense urban en vironments. Directional features and dynamic block er features also contribute to prediction accuracy . Excluding directional features in A3 increases the MAE to 5.99 dB, while remo ving dynamic blocker features in A5 results in an MAE of 6.00 dB. These results suggest that angular alignment and transient occlusions play a non-negligible role in characterizing localized NLoS conditions. The Tx speed feature, ev aluated in A4, leads to a moderate performance degradation with an MAE of 5.94 dB. Although the impact is less pronounced than static blockage features, motion-related information provides complementary cues for modeling time- varying shado wing effects. The effecti veness of the proposed grouped edge encoder is validated by comparing A0 with the flat MLP-based encoder A7. The grouped encoding strategy achieves lo wer error by processing heterogeneous physical quantities in separate embedding subspaces, which mitigates the dominance of lar ge- scale features, such as distance and preserves the contribution of fine-grained propagation factors. Overall, the ablation re- sults demonstrate that accurate mmW av e path loss prediction benefits from the joint consideration of anisotropic topological aggregation, residual-based physical decoupling, and struc- tured encoding of heterogeneous propagation features. T ABLE II A B L ATI O N S T U DY A N D A R C H I T E C T U R A L A N A LY S I S R E S U LT S ID Ablation / Configuration MAE (dB) NMSE MAPE (%) A0 Full MM-ResGNN 5.7991 0.0098 5.0498 GNN Oper ator Analysis V1 GCN-based multi-modal variant 6.4657 0.0115 5.6132 V2 GA T -based multi-modal variant 6.1579 0.0104 5.3465 Mechanism & T opology Ablation A1 Direct Re gression 6.3980 0.0117 5.4831 A2 w/o Rx–Rx Correlation Edges 6.3981 0.0115 5.5778 F eature Engineering Ablation A3 w/o Directional features 5.9882 0.0101 5.2000 A4 w/o Tx speed feature 5.9437 0.0101 5.1489 A5 w/o Dynamic blocker fea- tures 5.9987 0.0103 5.2047 A6 w/o Static obstacle fea- tures 6.2503 0.0105 5.4404 A7 Flat Edge Encoder 5.9990 0.0102 5.2182 Overall, the ablation studies provide a comprehensive val- idation of the proposed MM-ResGNN design. The results consistently show that no single component alone is suf ficient to achieve accurate mmW av e path loss prediction in complex vehicular en vironments. Anisotropic graph aggregation is es- sential for modeling directional and blockage-sensitiv e prop- agation, residual learning effecti vely stabilizes optimization by decoupling deterministic attenuation from stochastic v aria- tions, and physics-aw are feature engineering enables the net- work to exploit heterogeneous propagation cues in a structured manner . The observed performance degradation in all ablated variants confirms that these components play complementary roles and must be jointly considered to accurately characterize large-scale path loss under realistic propagation conditions. D. Fusion Strate gy and Backbone Efficiency The strategic selection of cross-modal integration mecha- nisms and visual feature extractors is critical for optimizing the balance between prediction fidelity and inference efficienc y . T able III summarizes a series of comparativ e experiments designed to validate the efficac y of the proposed gated fusion strategy and the choice of the con volutional backbone. 1) Cr oss-Modal Fusion Mechanisms: The influence of dif- ferent cross-modal fusion strategies is e valuated by comparing gated fusion, feature concatenation, and cross-attention-based fusion. Quantitative results are summarized in T able III. Fea- ture concatenation results in an MAE of 6.04 dB, indicat- ing limited effecti veness in jointly modeling heterogeneous geometric and visual representations. Cross-attention-based fusion achiev es an MAE of 5.81 dB, which is comparable to the performance obtained with gated fusion. Ho wev er , cross- attention introduces additional computational overhead due to pairwise attention operations between modalities. In contrast, gated fusion achie ves an MAE of 5.80 dB while maintaining a lightweight structure and enabling adaptiv e regulation of geometric and visual contributions. The results indicate that explicitly modeling modality importance through a gating mechanism provides an effecti ve balance between prediction accuracy and computational efficiency . 2) V isual Backbone Selection: The effect of visual back- bone depth is examined by replacing the ResNet-18 backbone with a deeper ResNet-50 architecture. As reported in T a- ble III, the ResNet-18 backbone achie ves an MAE of 5.80 dB, whereas the ResNet-50 backbone yields a slightly higher MAE of 5.88 dB. The observ ed performance dif ference indicates that mmW av e path loss prediction primarily benefits from visual cues related to coarse structural layouts, blockage contours, and material boundaries. Such propagation-rele vant informa- tion is effecti vely captured by shallower con volutional layers, while deeper semantic abstractions do not provide additional discriminativ e gains for this task. These observations confirm that lightweight visual backbones are sufficient for extracting en vironmental semantics relev ant to mmW av e propagation, enabling efficient multi-modal learning without unnecessary model complexity . Overall, the results in T able III demonstrate that both the fusion strategy and the choice of visual backbone play a critical role in balancing prediction accuracy and compu- tational efficienc y . Explicitly modeling modality importance IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 11 T ABLE III I M PAC T O F F U S I O N S T R ATE G Y A N D V I S UA L B A C K B O N E S E L E C T I O N ID Configuration MAE (dB) NMSE MAPE (%) A0 Gated Fusion 5.7991 0.0098 5.0498 A8 Concatenation Fusion 6.0413 0.0103 5.2657 A9 Cross-Attention Fusion 5.8123 0.0099 5.0491 A10 ResNet-50 Backbone 5.8794 0.0101 5.1008 through gated fusion enables effecti ve integration of geo- metric and visual representations without introducing exces- siv e computational overhead. Meanwhile, the comparable or inferior performance of deeper visual backbones indicates that mmW av e path loss prediction primarily relies on coarse structural and blockage-related visual cues rather than high- lev el semantic abstractions. These observations confirm that a lightweight gated fusion mechanism combined with a shallow con volutional backbone provides an efficient and effecti ve design choice for multi-modal mmW av e path loss modeling. E. Cr oss-Scenario Generalization and F ew-Shot Adaptation Cross-scenario generalization capability is ev aluated to as- sess the robustness and practical applicability of the proposed MM-ResGNN under domain shifts. The model is pre-trained on the urban wide lane scenario and transferred to two target scenarios with distinct topological and en vironmental charac- teristics, i.e., the urban crossroad scenario and the suburban forking road scenario. The e valuation focuses on both full- data transfer performance and data-efficient adaptation under limited target-domain supervision. 1) Benchmark of Basic Generalization Capability: Gener- alization performance is first ev aluated utilizing the complete target-domain datasets. Three transfer strate gies are considered under full target-domain supervision to examine different aspects of model generalization and adaptation. T raining from scratch serv es as a reference to e valuate the intrinsic learnabil- ity of the target scenario without prior knowledge. Full fine- tuning of the pre-trained model utilizing all av ailable target- domain data assesses the transferability of learned represen- tations when suf ficient supervision is provided. Freezing the pre-trained backbone while retraining only the re gression head isolates the contribution of domain-in variant features learned during pre-training. The comparati ve results are illustrated in Fig. 9 and summarized in T able IV. As reported in T able IV, full fine-tuning achie ves compa- rable performance to training from scratch across both target scenarios, and yields a slight gain in the suburban forking road scenario, while being marginally worse in the urban crossroad scenario. In the suburban forking road scenario, the MAE reaches 5.88 dB under full fine-tuning, compared with 5.92 dB obtained by training from scratch. This observation indicates that the representations learned in the urban wide lane scenario retain transferability across different roadway geometries and en vironmental layouts. When the backbone is frozen, prediction accuracy decreases relative to full fine- tuning. This behavior suggests that a portion of the learned representations captures domain-inv ariant propagation charac- teristics, while scenario-specific adaptation primarily benefits from updating higher-le vel layers. F r o m S c r a t c h P r e t r a i n F r o z e n 3 . 0 3 . 5 4 . 0 4 . 5 5 . 0 5 . 5 6 . 0 6 . 5 7 . 0 M A E C r o s s r o a d F o r k i n g R o a d 3 . 8 4 . 0 4 . 2 4 . 4 4 . 6 4 . 8 5 . 0 5 . 2 5 . 4 M A P E Fig. 9. Benchmark of generalization performance across scenarios. The bar charts represent MAE, while the dashed lines with diamond markers indicate MAPE trends for different transfer strategies. 5 % 1 0 % 2 0 % 5 0 % 1 0 0 % D a t a P e r c e n t a g e ( % ) 3 . 0 3 . 2 3 . 4 3 . 6 3 . 8 4 . 0 4 . 2 4 . 4 M A E F r o m S c r a t c h F r o z e n F u l l T u n i n g (a) Urban crossroad scenario 5 % 1 0 % 2 0 % 5 0 % 1 0 0 % D a t a P e r c e n t a g e ( % ) 5 . 8 6 . 0 6 . 2 6 . 4 6 . 6 6 . 8 7 . 0 M A E F r o m S c r a t c h F r o z e n F u l l T u n i n g (b) Sub urban forking road scenario Fig. 10. Data efficiency analysis. The curves illustrate the MAE performance as a function of target data percentage for four training strategies. 2) Data Efficiency in F ew-Shot Adaptation: In contrast to the full-data setting above, few-shot adaptation is ev aluated by progressively reducing the proportion of labeled target- domain data from 5% to 100%. The MAE trends for the urban crossroad and suburban forking road scenarios are illustrated in Fig. 10, and detailed numerical results are reported in T able V. The performance comparison in T able V reveals distinct adaptation behaviors across the two target scenarios. In the IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 12 T ABLE IV B E N C H M A R K O F T R A N S F E R L E A R N I N G P E R F O R M A N C E O N T A R G E T S C E N A R I O S ( 1 0 0 % D AT A ) T arget Scenario Strategy MAE (dB) NMSE MAPE (%) Urban Crossroad Scratch 3.4920 0.0070 4.1606 Pretrain 3.5514 0.0071 4.2576 Frozen 4.0245 0.0071 4.9069 Suburban Forking Scratch 5.9226 0.0111 4.8787 Pretrain 5.8817 0.0110 4.8364 Frozen 6.1614 0.0114 5.1247 T ABLE V D AT A E FFI C I E N C Y A N D F E W - S H O T A DA P TA T I O N P E R F O R M A N C E T arget Scenario Ratio Scratch Fr ozen Full T un- ing Urban Crossroad 5% 3.4675 3.8868 3.5225 10% 3.5136 4.0294 3.3366 20% 3.8082 4.2135 3.5371 50% 3.3396 4.1967 3.4646 100% 3.4920 4.0245 3.5514 Suburban Forking 5% 6.6703 6.5289 6.4348 10% 6.6018 6.2170 6.1522 20% 6.3747 6.2525 6.0028 50% 6.5790 6.2434 5.9203 100% 5.9206 6.1614 5.8817 suburban forking road scenario, the full-tuning strategy consis- tently outperforms the scratch-based approach across all data ratios. Notably , at the 5% data threshold, full-tuning achiev es an MAE of 6.43 dB, while the scratch-based model yields a significantly higher error of 6.67 dB. Even the frozen backbone strategy provides a more accurate prediction, i.e., 6.53 dB, than training from scratch in this low-data regime. Such a trend indicates that the irre gular scattering and sparse vegetation characteristics of the suburban environment are inherently dif- ficult to characterize with limited samples. The representations learned from the propagation-rich wide lane scenario serve as a robust physical prior , effecti vely regularizing the model and prev enting over -fitting under sparse supervision. In the urban crossroad scenario, the scratch-based model exhibits surprisingly competiti ve performance, particularly at the 5% and 50% data ratios. This behavior suggests that the highly structured Manhattan-grid geometry and the resulting street-canyon effects are relativ ely easy for the GNN to inter- nalize ev en with a minimal number of samples. Howe ver , the full-tuning strategy still achieves the optimal MAE of 3.34 dB at the 10% ratio, surpassing the scratch-based model’ s 3.51 dB. The marginal performance gain in the crossroad scenario, compared to the suburban scenario, implies that the “corner effects” and intersection-specific shadowing patterns require highly localized optimization, reducing the relati ve importance of source-domain knowledge. T ABLE VI C R O S S - D O M A I N T R A N S F E R A B I L I T Y E VAL UATI O N ( 1 0 % D AT A , F R O Z E N S T R ATE G Y ) Source T arget MAE (dB) NMSE MAPE (%) W ide Lane Crossroad 3.9917 0.0072 4.8445 W ide Lane Forking 6.2187 0.0111 5.1973 Crossroad F orking 6.7614 0.0110 5.7830 Forking Crossroad 4.0344 0.0071 4.9048 Overall, the data efficienc y analysis confirms that pre- training provides a more stable and accurate initialization for optimization, especially in en vironments with high propagation complexity . While structured urban scenes allow for rapid learning from scratch, the transfer of MM-ResGNN is essential for maintaining high-fidelity path loss prediction in irregular and data-constrained scenarios. 3) Analysis of Cr oss-Domain T ransferability: Cross- domain transferability among dif ferent source–target pairs is quantified in T able VI. Transferring from the urban wide lane scenario to the urban crossroad scenario achieves an MAE of 3.99 dB, which is substantially lo wer than the MAE of 6.22 dB observed when transferring to the suburban forking road sce- nario. The observed performance difference is consistent with the underlying propagation en vironments. Urban scenarios share similar building materials, street-canyon structures, and multipath characteristics, which facilitates feature reuse across domains. In contrast, the suburban forking road scenario is dominated by vegetation scattering and ground reflections, resulting in a propagation en vironment that dif fers significantly from dense urban settings. These results indicate that source- domain selection plays a critical role in transfer learning for machine synesthesia-based channel modeling, and that pre-training on propagation-rich urban environments provides more transferable representations. Overall, the cross-scenario experiments demonstrate that the proposed MM-ResGNN learns transferable representations that generalize effecti vely across heterogeneous vehicular en- vironments. Under full target-domain supervision, pre-training provides performance comparable to or better than training from scratch, indicating that the learned representations cap- ture domain-in variant propagation characteristics. More im- portantly , under limited-data regimes, MM-ResGNN exhibits clear advantages in data efficiency , particularly in complex suburban en vironments where propagation mechanisms are difficult to learn from sparse samples. The cross-domain trans- fer results further suggest that pre-training on propagation- rich urban scenarios yields more reusable representations, highlighting the importance of source-domain selection for practical deployment. T ogether , these findings confirm that MM-ResGNN offers robust generalization and adaptation ca- pabilities for mmW ave path loss prediction under realistic domain shifts. V . C O N C L U S I O N S This paper studies mmW ave path loss prediction for vehic- ular scenarios utilizing the VMMPL dataset, which achieves precise alignment between RGB images and global semantic information in the physical space, and link-le vel R T -based path loss data in the electromagnetic space across three represen- tativ e vehicular scenarios. Based on an ESPL-Graph repre- sentation, MM-ResGNN combines a geometry-dri ven physi- cal baseline with residual learning, and integrates topology- aware graph features with visual semantics via gated fusion. Simulation results show that MM-ResGNN outperforms em- pirical models and uni-modal baselines. In the urban wide lane scenario, MM-ResGNN achiev es an MAE of 5.7991 dB IEEE TRANSA CTIONS ON INTELLIGENT TRANSPOR T A TION SYSTEMS, V OL. XX, NO. XX, XX 2026 13 and an NMSE of 0.0098. Cross-scenario experiments further indicate that the learned representations can be adapted to ne w en vironments utilizing fe w-shot fine-tuning, improving data efficienc y when target-domain labels are limited. Future work will in vestigate deployment-oriented e xtensions, such as beam management and en vironment-aware network optimization, as well as the impact of varying Rx density and graph size under practical sensing constraints. V I . S I M P L E R E F E R E N C E S Y ou can manually copy in the resultant .bbl file and set second ar gument of \ begin to the number of references (used to reserve space for the reference number labels box). R E F E R E N C E S [1] F . Zhu, Z. Li, S. Chen, and G. Xiong, “P arallel transportation management and control system and its applications in building smart cities, ” IEEE T rans. Intell. Tr ansp. Syst. , v ol. 17, no. 6, pp. 1576–1585, Jun. 2016. [2] M. Noor-A-Rahim et al. , “6G for vehicle-to-ev erything (V2X) commu- nications: Enabling technologies, challenges, and opportunities, ” Pr oc. IEEE , v ol. 110, no. 6, pp. 712–734, Jun. 2022. [3] A. Boualouache, A. A. Jolfaei, and T . Engel, “Multi-process federated learning with stacking for securing 6G-V2X network slicing at cross- borders, ” IEEE Tr ans. Intell. T ransp. Syst. , vol. 25, no. 9, pp. 10941– 10952, Sept. 2024. [4] R. Liu et al. , “6G enabled advanced transportation systems, ” IEEE T rans. Intell. T ransp. Syst. , v ol. 25, no. 9, pp. 10564–10580, Sep. 2024. [5] Y . Niu et al. , “Interference management for integrated sensing and communication systems: A survey , ” IEEE Internet Things J. , vol. 12, no. 7, pp. 8110–8134, Apr . 2025. [6] R. Borralho, A. Mohamed, A. U. Quddus, P . V ieira, and R. T afazolli, “ A survey on coverage enhancement in cellular networks: Challenges and solutions for future deployments, ” IEEE Commun. Surve ys T uts. , vol. 23, no. 2, pp. 1302–1341, secondquarter 2021. [7] R. A. Hussain and W . K. Saad, “ A comprehensiv e survey of path loss types in different wireless communication en vironments, ” in Pr oc. IEEE I2CACIS’24 , Shah Alam, Malaysia, Aug. 2024, pp. 249–255. [8] B. Zhu, E. Bedeer, H. H. Nguyen, R. Barton, and Z. Gao, “U A V trajectory planning for AoI-minimal data collection in U A V -aided IoT netw orks by T ransformer , ” IEEE T rans. W ireless Commun. , vol. 22, no. 2, pp. 1343– 1358, Feb . 2023. [9] C. Hazirbas, L. Ma, C. Domokos, and D. Cremers, “FuseNet: Incorporat- ing depth into semantic segmentation via fusion-based CNN architecture, ” in Pr oc. A CCV’16 , T aipei, T aiwan, Mar . 2016, pp. 213–228. [10] T . S. Rappaport et al. , “Overview of millimeter wave communications for fifth-generation (5G) wireless networks-with a focus on propagation models, ” IEEE Tr ans. Antennas Pr opag. , vol. 65, no. 12, pp. 6213-–6230, Dec. 2017. [11] X. Cai et al., “ An empirical air-to-ground channel model based on passiv e measurements in L TE, ” IEEE T rans. V eh. T echnol. , vol. 68, no. 2, pp. 1140–1154, Feb. 2019. [12] W . T ang et al., “Path loss modeling and measurements for reconfigurable intelligent surfaces in the millimeter-wa ve frequenc y band, ” IEEE Tr ans. Commun , v ol. 70, no. 9, pp. 6259–6276, Sept. 2022. [13] I. F . M. Rafie, S. Y . Lim, and M. J. H. Chung, “Path loss prediction in urban areas: A machine learning approach, ” IEEE Antennas W ireless Pr opag. Lett. , vol. 22, no. 4, pp. 809–813, Apr. 2023. [14] A. Gupta et al. , “Machine learning-based urban canyon path loss pre- diction using 28 GHz Manhattan measurements, ” IEEE T rans. Antennas Pr opag. , v ol. 70, no. 6, pp. 4096–4111, Jun. 2022. [15] G. Xia et al. , “P ath loss prediction in urban environments with Sionna- R T based on accurate propagation scene models at 2.8 GHz, ” IEEE T rans. Antennas Pr opag. , vol. 72, no. 10, pp. 7986–7997, Oct. 2024. [16] Y . Nu ˜ nez, L. Lovisolo, L. da Silva Mello, and C. Orihuela, “On the interpretability of machine learning regression for path-loss prediction of millimeter-wa ve links, ” Expert Syst. Appl. , vol. 215, no. 14, p. 119324, Nov . 2022. [17] Y . Nu ˜ nez et al. , “P ath loss prediction for v ehicular-to-infrastructure com- munication using machine learning techniques, ” in Pr oc. IEEE VCC’23 , New Y ork, America, No v . 2023, pp. 270–275. [18] O. Ahmadien, H. F . Ates, T . Baykas, and B. K. Gunturk, “Predicting path loss distribution of an area from satellite images using deep learning, ” IEEE Access , vol. 8, no. 1, pp. 64982–64991, Apr. 2020. [19] K. Inoue, K. Ichige, T . Nagao, and T . Hayashi, “Learning-based predic- tion method for radio wav e propagation using images of b uilding maps, ” IEEE Antennas W ireless Propag . Lett. , v ol. 21, no. 1, pp. 124–128, Oct. 2022. [20] C. W ang et al. , “Channel path loss prediction using satellite images: A deep learning approach, ” IEEE T rans. Mach. Learn. Commun. Netw . , vol. 2, no. 1, pp. 1357–1368, Dec. 2024. [21] T . Chen et al. , “ A GNN-based supervised learning framework for resource allocation in wireless IoT networks, ” IEEE Internet Things J . , vol. 9, no. 3, pp. 1712–1724, Jun. 2021. [22] Y . W ang, Y . Li, Q. Shi, et al. , “ENGNN: A general edge-update empowered GNN architecture for radio resource management in wireless networks, ” IEEE Tr ans. Wir eless Commun. , vol. 23, no. 6, pp. 5330–5344, Oct. 2023. [23] Y . Huang et al. , “ A GNN-enabled multipath routing algorithm for spatial-temporal varying LEO satellite networks, ” IEEE T rans. V eh. T echnol. , v ol. 73, no. 4, pp. 5454–5468, Apr . 2024. [24] Y . Y ang, Z. Zhang, Y . T ian, R. Jin, and C. Huang, “Implementing graph neural networks over wireless networks via over -the-air computing: A joint communication and computation framew ork, ” IEEE W ireless Commun. , v ol. 30, no. 3, pp. 62–69, Jun. 2023. [25] X. Liu, K. Guo, R. Sun, et al. , “ A path loss prediction scheme based on graph neural networks and geographical information, ” in Pr oc. ET AI’25 , Harbin, China, Jul. 2025, pp. 1–6. [26] X. W ang et al. , “Graph neural network enabled propagation graph method for channel modeling, ” IEEE T rans. V eh. T echnol. , vol. 73, no. 9, pp. 12280–12289, Sept. 2024. [27] X. Cheng et al. , “Intelligent multi-modal sensing-communication inte- gration: Synesthesia of Machines, ” IEEE Commun. Surveys Tuts. , vol. 26, no. 1, pp. 258–301, firstquarter 2024. [28] L. Bai, Z. Huang, M. Sun, X. Cheng, and L. Cui, “Multi-modal intelligent channel modeling: A new modeling paradigm via Synesthesia of Machines, ” IEEE Commun. Surveys T uts. , vol. 28, pp. 2612–2649, Apr . 2025. [29] L. Bai, Z. Han, X. Cai and X. Cheng, “Multi-modal intelli- gent channel modeling framework for 6G-enabled network ed intel- ligent systems, ” IEEE W ireless Commun. , early access, 2026, doi: 10.1109/MWC.2025.3624714. [30] X. Cheng et al., “SynthSoM: A synthetic intelligent multi-modal sensing-communication dataset for Synesthesia of Machines (SoM)”, Sci. Data , v ol. 12, pp. 819—833, May 2025. [31] S. Shah, D. Dey , C. Lovett, and A. Kapoor, “ AirSim: High-fidelity visual and physical simulation for autonomous vehicles, ” in Field and Service Robotics , M. Hutter and R. Siegwart, Eds. Cham, Switzerland: Springer , Nov . 2017, pp. 621–635. [32] Remcom. W ireless InSite. [Online]. A vailable: https://www .remcom.com/wireless-insite-em-propagation-software [Publication date: Jan. 2017, Accessed date: Mar . 2022]. [33] P . Cunningham and S. J. Delany , “k-cearest ceighbour classifiers: A tutorial, ” ACM Comput. Surv . , v ol. 54, no. 6, pp. 1–25, Jul. 2022. [34] S. Y un, M. Jeong, R. Kim, J. Kang, and H. J. Kim, “Graph transformer networks, ” in Proc. NeurIPS’19 , V ancouver , Canada, Dec. 2019, pp. 11983–11993. [35] W . Xu, Y .-L. Fu, and D. Zhu, “ResNet and its application to medical image processing: Research progress and challenges, ” Comput. Methods Pr ograms Biomed. , vol. 240, Art. no. 107660, Jun. 2022. [36] T . S. Rappaport et al. , “Overview of millimeter wave communications for fifth-generation (5G) wireless networks-with a focus on propagation models, ” IEEE T rans. Antennas Propa g. , vol. 65, no. 12, pp. 6213–6230, Dec. 2017. [37] T echnical Specification Group Radio Access Network; Study on Channel Model for F requencies F r om 0.5 to 100 GHz (Release 14) , docu- ment TR 38.901 V ersion 14.2.0, 3GPP , Sep. 2017. [Online]. A vailable: http://www .3gpp.org/DynaReport/38901.htm [38] T . S. Rappaport, G. R. MacCartney , M. K. Samimi, and S. Sun, “Wide- band millimeter-wav e propagation measurements and channel models for future wireless communication system design, ” IEEE T rans. Commun. , vol. 63, no. 9, pp. 3029–3056, Sept. 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment