Exploiting block triangular submatrices in KKT systems
We propose a method for solving Karush-Kuhn-Tucker (KKT) systems that exploits block triangular submatrices by first using a Schur complement decomposition to isolate the block triangular submatrices then performing a block backsolve where only diago…
Authors: Robert Parker, Manuel Garcia, Russell Bent
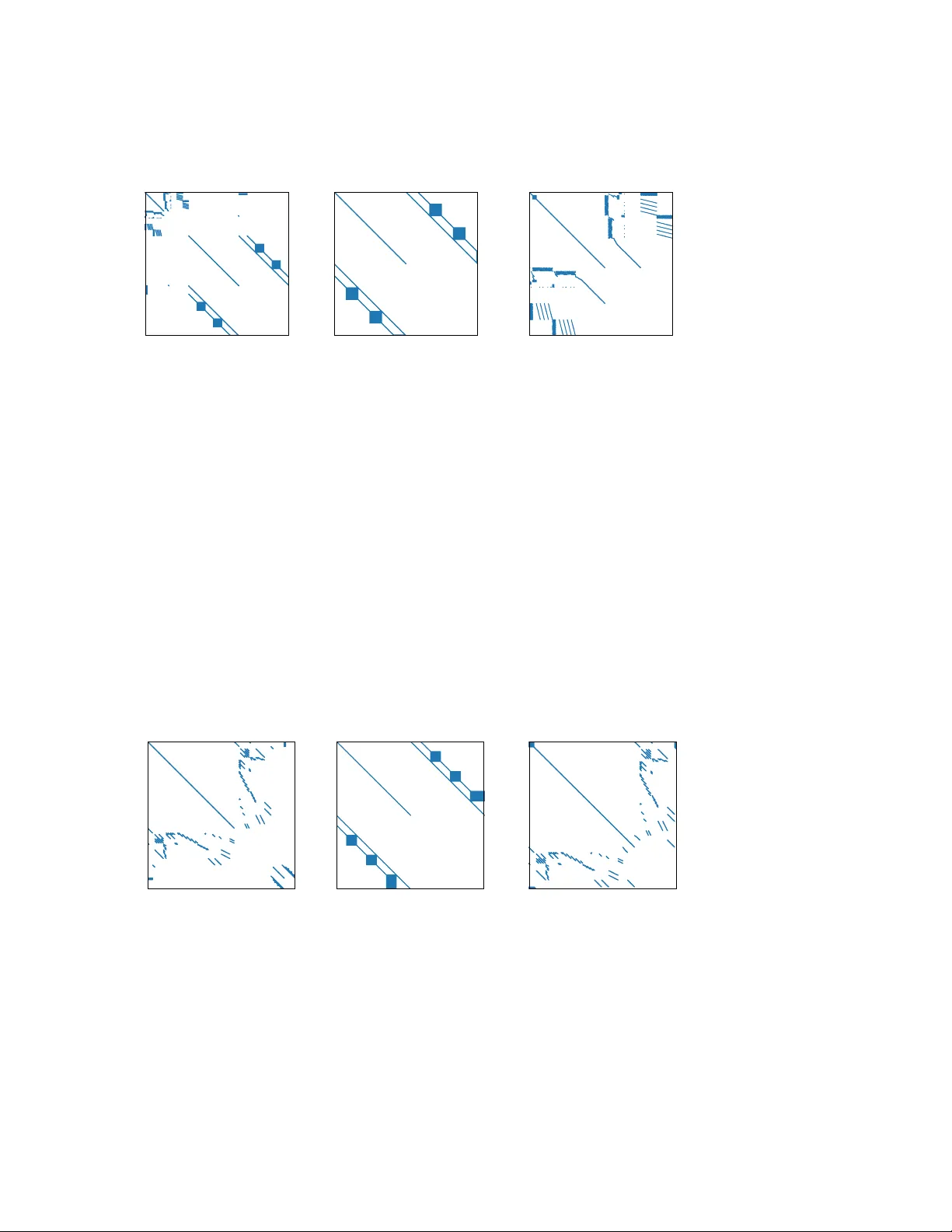
EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS ∗ ROBER T P ARKER † , MANUEL GARCIA † , AND RUSSELL BENT † Abstract. W e propose a metho d for solving Karush-Kuhn-T uck er (KKT) systems that exploits block triangular submatrices by first using a Sch ur complement decomp osition to isolate the block triangular submatrices then p erforming a block backsolv e where only diagonal blocks of the blo c k triangular form need to be factorized. W e show that factorizing reducible symmetric-indefinite matrices with standard 1 × 1 or 2 × 2 pivots yields fill-in outside the diagonal blo c ks of the blo c k triangular form, in contrast to our prop osed method. While exploiting a block triangular submatrix has limited fill-in, unsymmetric matrix factorization methods do not reveal inertia, whic h is required by interior p oin t metho ds for nonconv ex optimization. W e sho w that our target matrix has inertia that is kno wn a priori , letting us compute inertia of the KKT matrix by Sylv ester’s law. Finally , we demonstrate the computational advan tage of this metho d on KKT systems from optimization problems with neural netw ork surrogates in their constraints. Our method achiev es up to 15 × speedups ov er state-of-the-art symmetric indefinite matrix factorization metho ds MA57 and MA86 in a constant-hardw are comparison. Key w ords. Symmetric-indefinite matrices, in terior point metho ds, neural netw orks, blo ck triangular matrices, Sch ur complemen t MSC co des. 15B99, 65F05, 65F50 1. In tro duction. F actorizing symmetric, indefinite Karush-Kuhn-T uc k er (KKT) matrices is a computational b ottlenec k in in terior p oin t metho ds for noncon- v ex, lo cal optimization. Methods for solving the KKT linear system can b e grouped in to three broad categories: 1. Direct metho ds, 2. Iterativ e metho ds, and 3. Decomposition metho ds (including Sch ur complement and n ull space decom- p ositions). In terior p oin t metho ds for noncon vex optimization most commonly use direct methods for solving their KKT systems. These methods factorize the matrix in to the pro duct LB L T , where L is low er triangular and B is block-diagonal with a combination of 1 × 1 and 2 × 2 blo cks. These blocks correspond to 1 × 1 or 2 × 2 pivots selected b y the metho d of Bunc h and Kaufman [8]. The factors are typically computed b y m ultifron tal [24] or superno dal [45] methods, whic h ha ve b een implemen ted in several widely-used co des, e.g., MA57 [22], MA86 [36], MA97 [37], UMFP ACK [19], and others. Iterativ e methods (e.g., Krylov subspace metho ds) hav e also been used to solv e KKT systems [4, 17]. These metho ds do not require storing the matrix or its factors in memory simultaneously and their repeated matrix-v ector m ultiplications can be parallelized on GPUs. Ho w ever, the ill-conditioning encoun tered in in terior point metho ds leads to slo w conv ergence [67], making these methods less p opular in interior p oin t implementations, esp ecially for nonconv ex optimization. Nonetheless, iterative linear solvers for interior p oin t metho ds are an active area of research, with w ork fo cused on improving preconditioning [10, 57] and analyzing the impact of inexact linear algebra [66]. ∗ Submitted to the editors DA TE. F unding: F unded by the Los Alamos National Lab oratory LDRD program. LA-UR-26-20941. † Los Alamos National Lab oratory , Los Alamos, NM 1 2 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT Decomp osition metho ds exploit the block structure of the KKT matrix, KKT = A B T B , to decomp ose the linear system solve into solv es inv olving smaller systems. These smaller systems may then b e solved with either direct or iterative metho ds. Null space methods are d ecomp ositions that exploit a partition of v ariables into “dep enden t v ariables” and “degrees of freedom” in order to compute a basis for the null space of B [4, 15]. This basis is then used to reduce the KKT system to a smaller system in the dimension of the n umber of degrees of freedom (the num b er of v ariables min us the n um b er of equalit y constraints). These metho ds are typically effective if the num b er of degrees of freedom is small, although constructing the null space basis can also b e a bottleneck. T o ov ercome this b ottleneck in the context of transien t stability constrained optimal pow er flo w, Geng et al. [28, 29] ha ve exploited a blo c k triangular decomp osition for the unsymmetric solve required to construct the null space basis. Sc h ur complemen t metho ds exploit the nonsingularit y of one or more symmet- ric submatrices of the KKT matrix to decomp ose the linear system solve in to mul- tiple smaller solv es. Benzi et al. [4] describ e a basic Sch ur complemen t method exploiting the nonsingularit y of A . A similar metho d relying on regularization of A has b een described by Golub and Grief [30] and implemen ted in the HyKKT solv er [56] using a direct metho d to construct the Sc hur complement and an iter- ativ e metho d to solve the system inv olving the Sch ur complemen t matrix. In con trast to these general-purp ose Sch ur complemen t metho ds, man y suc h methods ha ve ex- ploited problem-sp ecific structures to factorize KKT matrices in parallel. F or linear programs, Gondzio and Sarkissian [31], Grigoriadis and Khachiy an [33], Lustig and Li [48], and others hav e exploited decomp osable blo ck structures in interior p oin t metho ds. In the con text of nonconv ex optimization, W righ t [65] and Jin et al. [40] ha v e exploited nonsingular diagonal blo cks in blo ck tridiagonal matrices, while Laird and Biegler [43] hav e exploited indep enden t submatrices due to distinct scenarios in sto c hastic optimization and Kang et al. [41] hav e exploited nonsingular submatrices at each time p oin t in dynamic optimization. Our contribution is a Sc hur complement metho d that, instead of exploiting man y indep enden t, nonsingular submatrices, exploits a single nonsingular submatrix that has a fav orable structure for factorization and backsolv es. The structure we exploit is a blo c k triangular structure (see Subsection 2.4) that allo ws us to limit fill-in to diagonal blo c ks of this block triangular form, which is not p ossible when factorizing these same systems with standard direct metho ds. Specifically , we: 1. Propose a nov el com bination of symmetric Sch ur complemen t and unsym- metric blo c k triangular decomp osition algorithms, 2. Demonstrate that standard 1 × 1 and 2 × 2 pivoting leads to fill-in outside the diagonal blocks of block triangular submatrices, 3. Pro ve that regularization on the relev ant blo c k in our KKT matrices is b oth undesirable and unnecessary , and 4. Demonstrate the computational adv an tage of our approach on KKT matrices deriv ed from optimization problems with neural net w ork constraints. (See [11, 58, 46] for bac kground and applications of these optimization problems.) Our results sho w that exploiting one large submatrix with a sp ecial structure can b e adv an tageous in Sch ur complement methods for symmetric, indefinite systems. While parallel computing is outside the scop e of this work, w e note that exploiting a single large, nonsingular submatrix has potential to exploit GPU acceleration as data EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 3 transfer o v erhead is lo w compared to the p oten tial sp eedup that can be gained by pro cessing this submatrix in parallel. 2. Bac kground. 2.1. In terior p oin t metho ds. W e consider symmetric indefinite linear systems from in terior point methods for solving nonlinear optimization problems in the form giv en by Equation (2.1): (2.1) min x φ ( x ) sub ject to f ( x ) = 0 x ≥ 0 Here, x is a v ector of decision v ariables and functions φ and f are t wice contin uously differen tiable. W e note that this formulation do es not preclude general inequalities; for our purp oses, w e assume they hav e already b een reform ulated with a slack v ariable. In terior p oint metho ds conv erge to lo cal solutions by up dating an initial guess x 0 using a search direction computed by solving the linear system in Equation (2.2), referred to as the KKT system. (2.2) ∇ 2 L + Σ ∇ f T ∇ f d x d λ = − ∇L f Here, L is the Lagrangian function, λ is the v ector of Lagrange m ultipliers of the equalit y constrain ts, and Σ is a diagonal matrix containing the ratio of bound mul- tipliers, ν , to v ariable v alues. The matrix in Equation (2.2), referred to as the KKT matrix, is symmetric and indefinite. 2.2. Inertia. Interior p oin t metho ds usually require linear algebra subroutines that can not only solve KKT systems but that can also compute the inertia of the KKT matrix. Inertia is defined as the n um b ers of p ositiv e, negative, and zero eigenv alues of a symmetric matrix. Inertia is often rev ealed by symmetric matrix factorization metho ds using Sylv ester’s La w of Inertia [62], which states that tw o congruent matri- ces hav e the same inertia. That is, if A and B are symmetric and R is nonsingular, then (2.3) A = R T B R ⇒ Inertia( A ) = Inertia( B ) 2.3. Sc hur complement. The Sch ur complement is the matrix obtained by piv oting on a nonsingular submatrix. F or a symmetric matrix M = A B T B C with C nonsingular, the Sch ur complement of M with resp ect to C is S = A − B T C − 1 B When solving the linear system M x = r , or A B T B C x A x C = r A r C , the Sch ur complemen t can b e used to decomp ose the factorization and bac ksolve phases into steps inv olving only S or C , as sho wn in Algorithms 2.1 and 2.2. 4 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT Algorithm 2.1 : Matrix factorization using the Sch ur complement 1: Inputs: Matrix M = A B T B C 2: factorize ( C ) 3: S ← A − B T C − 1 B 4: factorize ( S ) 5: Return: factors ( C ), factors ( S ) Algorithm 2.2 : Bac ksolv e using factors of the Sch ur complemen t 1: Inputs: factors ( C ), factors ( S ), right-hand side r = ( r A , r C ) 2: r S ← r A − B T C − 1 r C 3: x A ← S − 1 r S 4: r C ← r C − B r A 5: x C ← C − 1 r C 6: Return: x = ( x A , x C ) The adv antage of solving a system via this decomp osition is that only matrices C and S need to b e factorized, rather than the full ma trix M . This is b eneficial if the fill-in in A due to B T C − 1 B is relatively limited, that is, if a ma jority of B ’s columns are empty , or if C ’s structure can b e exploited b y a sp ecialized algorithm. When solving linear systems via a Sch ur complemen t, inertia is determined b y the Haynsw orth inertia additivity form ula [35]: (2.4) Inertia A B T B C = Inertia ( C ) + Inertia A − B T C − 1 B . 2.4. Blo c k triangular decomp osition. An n × n matrix M is r e ducible into blo c k triangular form if it may be permuted (by ro w and column p erm utations P and Q ) to ha v e the form (2.5) P M Q = M 11 0 M 12 M 22 , where M 11 is k × k and M 22 is ( n − k ) × ( n − k ) for some k b et ween one and n − 1. That is, M is reducible if there exists a p ermutation that rev eals a k × ( n − k ) zero submatrix. (This definition is due to F rob enius [25]. Some sources, e.g., [54, 18], use the equiv alent Str ong Hal l Pr op erty .) Here, the submatrices M 11 and M 22 ma y themselv es b e reducible. The problem of decomp osing a matrix into irreducible blo ck triangular form has b een studied by Duff and Reid [23, 21], Gusta vson [34], Ho well [38], and others. When solving a linear system of equations defined b y a reducible matrix, only the matrices on the diagonal need to b e factorized. F or example, when solving the system M X = B , where M decomp oses in to b blo c ks, i.e., M 11 . . . . . . M 1 b · · · M bb X 1 . . . X b = B 1 . . . B b , EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 5 the follo wing equation ma y b e used to sequen tially compute the blocks of the solution: (2.6) X i = M − 1 ii B i − i − 1 X j =1 M j i X j for i in { 1 , . . . , b } . The primary adv antage of this pro cedure is that fill-in (nonzero entries that are pres- en t in a matrix’s factors but not the matrix itself ) is limited to the submatrices along the diagonal, M ii , as these are the only matrices that are factorized. By contrast, a t ypical LU factorization of the matrix M abov e ma y ha ve fill-in anywhere in or under the diagonal blo c ks. Additionally , L2 (matrix-vector) and L3 (matrix-matrix) BLAS are used directly in the backsolv e pro cedure, Equation (2.6). In typical multif rontal and superno dal algorithms for symmetric-indefinite linear systems, p erformance b en- efits are obtained by aggregating rows and columns into dense submatrices on which L2 and L3 BLAS can efficien tly op erate. Exploiting a blo c k triangular form (irre- ducible or otherwise) gives us more control o v er the data structures used to handle the off-diagonal submatrices. That is, these data structures may be sparse, dense, or some com bination thereof and can be chosen to optimize the relativ ely simple matrix subtraction and multiplication op erations in Equation (2.6), rather than c hosen for p erformance in a more complicated factorization algorithm. 2.5. Graphs of sparse matrices. The sparsit y pattern of an m × n matrix ma y b e represen ted as an undirected bipartite graph. One set of nodes represen ts the ro ws and the other represents the columns. There exists an edge ( i, j ) if the matrix en try at ro w i and column j is structurally nonzero. F or a square, n × n , matrix, a directed graph on a single set of nodes { 1 , . . . , n } ma y b e defined. The graph has a directed edge ( i, j ) if a structurally nonzero matrix en try exists at row i and column j . These graphs are well-studied in the sparse matrix literature (see, e.g., [18]). In this work, they are necessary only for the statement and proof of Theorem 3.4. 2.6. Neural net works. The metho ds we use and develop in this w ork are ap- plicable to general blo c k triangular submatrices, including those found in m ultip eriod and discretized dynamic optimization problems. Here, w e demonstrate the benefits of our approach on block triangular submatrices that arise in neural netw ork-constrained optimization problems. These optimization problems arise in design and con trol with neural net w ork surrogates, neural netw ork verification, and adv ersarial example prob- lems [49]. W e address KKT matrices derived from nonlinear optimization problems with neural net work constraints. A neural net work, y = NN( x ), is a function de- fined by rep eated application of an affine transformation and a nonlinear activ ation function σ o ver L lay ers: (2.7) y l = σ l ( W l y l − 1 + b l ) l ∈ { 1 , . . . , L } , where y 0 = x and y = y L . In this context, training w eigh ts W l and b l are considered constan t. W e consider optimization problems with neural netw orks included in the constrain ts using a full-space form ulation [58, 11, 20] in which intermediate v ariables and constraints are introduced for ev ery lay er of the neural netw ork. The neural net w ork constraints in our optimization problem are: (2.8) y l = σ l ( z l ) z l = W l y l − 1 + b l for all l ∈ { 1 , · · · , L } 6 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT W e note that these neural net work equations ha ve a triangular incidence matrix. Ho w- ev er, it is con venien t to represent them in block triangular form, shown in Figure 1, where blo c ks corresp ond to la y ers of the neural net work. 0 20 40 60 80 100 0 20 40 60 80 100 Fig. 1 . Incidenc e matrix structur e of neur al network c onstr aints. R ows ar e e quations and c olumns ar e output or interme diate variables. Each b ox along the diagonal c ontains the variables (and c onstr aints) for a p articular layer of the network, i.e., y l , z l , and the asso ciate d c onstr aints fr om Equation (2.8) . The dashe d boxes under the diagonal c ontain the nonzer os corr esp onding to the links b etwe en these variables and the variables of the next layer. That, is they c ontain the W l matric es fr om Equation (2.8) . 3. Exploiting blo c k triangularity within the Shur complement. 3.1. Our approach. W e address KKT matrices deriv ed from the following sp e- cial case of Equation (2.1): (3.1) min x,y φ ( x, y ) sub ject to f ( x, y ) = 0 g ( x, y ) = 0 L ≤ ( x, y ) ≤ U Here, w e assume that ∇ y g is nonsingular and block-lo wer triangular (with square, nonsingular blo c ks along the diagonal). Let the row and column dimensions of ∇ y g b e n y . The KKT system of Equation (3.1) is: (3.2) W xx ∇ x f T W xy ∇ x g T ∇ x f ∇ y f W y x ∇ y f T W y y ∇ y g T ∇ x g ∇ y g d x d λ f d y d λ g = − ∇ x L f ∇ y L g P artitioning Equation (3.2) as shown abov e, we rewrite the system as Equation (3.3) for simplicity . (3.3) A B T B C d A d C = r A r C W e will solv e KKT systems of this form b y p erforming a Sch ur complement reduction with respect to submatrix C , whic h w e refer to as the pivot matrix . Because ∇ y g EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 7 is blo c k-lo wer triangular, C may b e p erm uted to hav e block-lo w er triangular form as w ell. Sp ecifically , the following p ermutation vectors p ermute C to blo c k lo w er triangular form: (3.4) Column p erm utation: { 1 , . . . , n y , 2 n y , . . . , n y + 1 } Ro w p erm utation: { n y + 1 , . . . , 2 n y , n y , . . . , 1 } . These p erm utation vectors are defined such that the row or column index at the i -th p osition of the p erm utation vector is the index of the row or column in the original matrix that is p erm uted to p osition i in the new matrix. This p erm utation is illustrated with p erm utation matrices P and Q in Figure 2. P C Q = = Fig. 2 . Permutation of C to blo ck triangular form W e solv e Equation (3.3) using a Sch ur complemen t with resp ect to C via Algo- rithms 2.1 and 2.2. The computational b ottlenecks of this pro cedure are factorizing the pivot matrix, C , performing many backsolv es with this matrix to construct the Sc h ur complement matrix, S , and factorizing this Sch ur complement matrix. W e p erform factorizations and backsolv es that exploit C ’s blo ck triangular structure as describ ed in Subsection 2.4. 3.2. Application to neural net work submatrices. The ab o ve metho ds ap- ply to general block triangular Jacobian submatrices ∇ y g . How ever, our motiv ation for dev eloping this metho d is to exploit the structure of a neural netw ork’s Jacobian. W e no w discuss the adv an tages that this particular structure gives us. T o exploit the structure of neural netw ork constrain ts, w e let constrain t function g (the function whose structure we exploit) be the functions in Equation (2.7). The v ariables w e exploit are the outputs of the neural net work and in termediate v ariables defined at eac h lay er: { z 1 , y 1 , . . . , z L , y L } . The Jacobian matrix has the follo wing structure: 1 (3.5) I Σ 1 I W 2 . . . . . . I W L I Σ L I . Here, Σ i is the diagonal matrix containing en tries σ ′ i ( z i ), where σ ′ i is the first deriv- ativ e of the activ ation function σ i , applied element wise. This Jacobian matrix (3.5) is lo w er triangular. How ever, when exploiting this structure, it is adv antageous to consider blo c ks each corresp onding to a lay er of the neural net work, as sho wn. In 1 The structures sho wn in Figure 1 and Equation (3.5) differ due to differen t orderings of v ariables and equations. 8 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT this aggregation, diagonal blo c ks are themselves diagonal and off-diagonal blocks are either diagonal matrices con taining deriv atives of activ ation functions or the dense w eigh t matrices that serve as in ter-lay er connections. Because the diagonal blocks are iden tit y matrices, they do not need to b e factorized and the blo ck triangular bac k- solv e procedure, Equation (2.6), will incur no fill-in. F urthermore, the off-diagonal matrices, M j i in Equation (2.6), are either diagonal or fully dense. W e store these dense matrices as contiguous arrays (rather than with a COO or CSC sparse matrix data structure) to take adv an tage of efficien t L3 BLAS op erations. Finally , w e observe that for the case of a neural netw ork’s Jacobian, Equation (2.6) is v ery similar to the forw ard pass through the netw ork: X j is the solution for a previous la y er’s in termediate v ariables, M j i is the in ter-lay er weigh t matrix, and the bac ksolv e with M ii tak es the place of an activ ation function. 3.3. Fill-in. The core b enefit of our prop osed algorithm is that we do not hav e to factorize the pivot matrix, C , directly . Instead, we factorize only the diagonal blocks of C ’s blo c k triangular form, C ii , and therefore only incur fill-in in these blo c ks. As w e will sho w, this pro cedure incurs significantly less fill-in than we exp ect when factorizing the symmetric matrix C directly . Constructing the Sc h ur complement matrix S , ho wev er, incurs fill-in in the columns of B that are nonzero. 2 Therefore, our metho d is particularly effective when the num b er of nonzero columns of B , i.e., the n umber of v ariables and constrain ts “linking” A and C , is small. W e will now sho w that 1 × 1 and 2 × 2 pivots used b y traditional symmetric indefinite linear solv ers do not capture the structure of C and lead to fill-in outside of its diagonal blo cks. F or simplicit y , we rewrite C in its symmetric form as C = D E T E , then partition D and E : D = d 11 D T 21 D T 31 D 21 D 22 D T 32 D 31 D 32 D 33 and E = e 11 E 12 E 13 E 21 E 22 E 23 E 33 . Here, d 11 and e 11 are scalars corresponding to a piv ot and e 11 E 12 E 21 E 22 and E 33 are tw o square diagonal blo c ks in a block triangular form of E . Submatrix E 22 has the ro ws and columns that are in the same diagonal block as our piv ot while E 33 has ro w and column indices that are in a differen t diagonal block. With our prop osed algorithm, fill-in is limited to these diagonal blocks. That is, our algorithm incurs no fill-in in E 13 , E 23 , their transp oses, or D . In the rest of this section, w e will show that 1 × 1 or 2 × 2 pivots lead to fill-in in D and in the E 23 and E T 23 blo c ks. Applying p erm utation matrix P to put a p oten tial 2 × 2 pivot inv olving e 11 in 2 See the dense blo c ks in the Sch ur complement matrices in Figures 3 to 5. In our neural net- work application, these dense blocks correspond to the neural net work’s inputs and the constraints containing any output of the network. EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 9 the upp er left of the matrix, (3.6) P C P T = d 11 e 11 D T 21 E T 21 D T 31 e 11 E 12 E 13 D 21 E T 12 D 22 E T 22 D T 32 E 21 E 22 E 23 D 31 E T 13 D 32 E T 23 D 33 E T 33 E 33 . W e will sho w that 1 × 1 and 2 × 2 pivots may cause fill-in in D and in off-diagonal blo c ks of E (i.e., in E 23 ), in con trast to our prop osed metho d. Theorem 3.1. L et C b e the matrix in the right-hand side of Equation (3.6) . A 1 × 1 pivot on d 11 may r esult in fil l-in everywher e exc ept the last blo ck r ow and c olumn. Pr o of of The or em 3.1 . After pivoting on d 11 , the remainder of the matrix is the Sc h ur complement: E 12 E 13 E T 12 D 22 E T 22 D T 32 E 22 E 23 E T 13 D 32 E T 23 D 33 E T 33 E 33 − e 11 D 21 E 21 D 31 0 1 d 11 e 11 D T 21 E T 21 D T 31 0 . Expanding the second term, this b ecomes: E 12 E 13 E T 12 D 22 E T 22 D T 32 E 22 E 23 E T 13 D 32 E T 23 D 33 E T 33 E 33 − e 2 11 e 11 D T 21 e 11 E T 21 e 11 D T 31 0 D 21 e 11 D 21 D T 21 D 21 E T 21 D 21 D T 31 0 E 21 e 11 E 21 D T 21 E 21 E T 21 E 21 D T 31 0 D 31 e 11 D 31 D T 21 D 31 E T 21 D 31 D T 31 0 0 0 0 0 0 An y nonzero entries in the second term that are not in the first term are fill-in. These en tries may exist in any of the nonzero blocks of the second term, which p opulate the en tire matrix other than the last blo ck ro w and column. Theorem 3.2. L et C b e the matrix in the right-hand side of Equation (3.6) . A 2 × 2 pivot on d 11 e 11 e 11 r esults in fil l-in in the D 22 , E 22 , D 32 , E 23 , and D 33 blo cks and their tr ansp oses, if applic able. Pr o of of The or em 3.2 . After piv oting on d 11 e 11 e 11 , the remainder of C is the Sc h ur complement: D 22 E T 22 D T 32 E 22 E 23 D 32 E T 23 D 33 E T 33 E 33 − D 21 E T 12 E 21 0 D 31 E T 13 0 0 " 1 e 11 1 e 11 − d 11 e 2 11 # D T 21 E T 21 D T 31 0 E 12 0 E 13 0 Expanding the second term, this b ecomes: 1 e 11 E T 12 D T 21 + D 21 E 12 − d 11 e 11 E T 12 E 12 E T 12 E T 21 E T 12 D T 31 + D 21 E 13 − d 11 e 11 E T 13 E 13 0 E 21 E 12 0 E 21 E 13 0 E T 13 D T 21 + D 31 E 12 − d 11 e 11 E T 13 E 12 E T 13 E T 21 E T 13 D T 31 + D 31 E 13 − d 11 e 11 E T 13 E 13 0 0 0 0 0 10 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT An y nonzero entries in the second term that are not in the first term are fill-in. These en tries ma y exist in an y of the nonzero blo c ks of the second term, which are limited to the D 22 , E 22 , D 23 , E 23 , and D 33 blo c ks of the original matrix (and their transposes). Theorems 3.1 and 3.2 apply to pivots induced by p erm uting E to blo c k upp er- triangular form. A similar result holds when E is initially in blo c k- lower triangular form. W e do not claim that either of these will result in a minimum-fill ordering or even that our results prov e that a 2 × 2 pivot is alwa ys strictly b etter than a 1 × 1 piv ot, as this will dep end on sparsity patterns of the submatrices. How ever, these block-fill-in analyses giv e us reason to prefer a 2 × 2 piv ot in v olving e 11 to a 1 × 1 piv ot. Our exp erience, which w e justify with results in Subsection 5.2, is that traditional symmetric indefinite linear solvers prioritize 1 × 1 piv ots. W e hypothesize that this is one reason for the large fill-in w e will observ e. W e again highlight that neither 1 × 1 nor 2 × 2 pivots obtain the fav orable result of our sp ecialized metho d that fill-in is limited to diagonal blo cks of E . 3.4. Inertia and regularization. Interior point metho ds require linear algebra subroutines that can not only solve KKT systems but that can also compute the inertia of the KKT matrix. As discussed in Subsection 2.3, Sch ur complement methods t ypically use the Haynsw orth formula to c heck inertia giv en the inertia of the factorized piv ot and Sch ur complement matrices. How ev er, our block triangular factorization of C do es not rev eal its inertia. F ortunately , our assumption that ∇ y g is nonsingular implies that the inertia of C is ( n y , n y , 0) via Theorem 3.3 (a sp ecial case of Lemma 3.2 in [32]). Theorem 3.3. L et C b e as define d in Equation (3.3) : C = W y y ∇ y g T ∇ y g , wher e ∇ y g is n y × n y and nonsingular. The inertia of C is ( n y , n y , 0) . Pr o of of The or em 3.3 . Let R = I − 1 2 W y y ∇ y g − 1 ∇ y g − 1 . Then RC R T = I I . The matrix I I , where I is n y × n y , has inertia ( n y , n y , 0). Then, because R is nonsingular, by Sylv ester’s Law of Inertia, C has inertia ( n y , n y , 0) as w ell. The inertia of C is therefore known a priori , so as long as an inertia-revealing metho d (i.e., an LB L T factorization) is used for the factorization of the Sc hur com- plemen t matrix, w e can reco v er the inertia of the original matrix as well. In terior p oin t metho ds use inertia to chec k conditions required for global con- v ergence. In particular, the search direction computed m ust b e a descen t direction for the barrier ob jectiv e function when pro jected in to the null space of the equalit y constrain t Jacobian [64]. This condition is met if the inertia of the KKT matrix is ( n, m, 0), where n is the num b er of v ariables and m is the num b er of equalit y con- strain ts. If the KKT matrix is factorized and the inertia is incorrect, a multiple of the EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 11 iden tit y matrix is added to the (1 , 1) or (2 , 2) blo c k of the KKT matrix, depending on whether more p ositiv e or negative eigenv alues are needed. While inertia correction is necessary for conv ergence of interior p oin t methods, adding multiples of the identit y matrix to C causes it to lose its property of reducibil- it y . This is formalized in Theorem 3.4. Theorem 3.4. L et S b e the fol lowing symmetric, blo ck- 2 × 2 matrix: S = I B T B I . L et G B b e the bip artite gr aph of B . If G B is c onne cte d, then S is irr e ducible. W e use the following theorem (V arga [63], Theorem 1.17): Theorem 3.5. L et M b e an n × n matrix and G its dir e cte d gr aph. M is irr e- ducible if and only if G is str ongly c onne cte d. Pr o of of The or em 3.4 . By Theorem 3.5, it is sufficient to show that the directed graph of S , G S , is strongly connected. Let n b e the ro w and column dimension of B . The low er-left blo ck, B , adds edges from { 1 , . . . , n } to { n + 1 , . . . , 2 n } (corresp onding to nonzero entries of B ) to G S while the upp er-righ t blo c k, B T , adds the rev erse edges. W e compress these pairs of edges to form an undirected graph, where connectivit y in the undirected graph is equiv alen t to strong connectivity in the directed graph. This undirected graph is iden tical to B ’s bipartite graph, G B , with the following node mapping: Nodes { 1 , . . . , n } in G S map to column no des in G B while { n + 1 , . . . , 2 n } in G S map to ro w no des in G B . Therefore connectivit y of G B implies strong connectivit y of G S , which (b y Theorem 3.5) is equiv alen t to irreducibilit y of S . The regularized form of our pivot matrix, denoted ˜ C , is: ˜ C = W y y + δ y I ∇ y g T ∇ y g δ g I . Submatrix ∇ y g is the Jacobian of neural netw ork constraints and has a connected bipartite graph. Then by Theorem 3.4, ˜ C do es not decomp ose via blo c k triangular- ization. Therefore, we do not add regularization terms in the pivot matrix. W e assume ∇ y g is nonsingular, so regularization is not necessary to correct zero eigen v alues. 4. T est problems. W e test our metho d on KKT matrices from three optimiza- tion problems in volving neural netw ork constraints: Adversarial generation for an MNIST image classifier (denoted “MNIST”), securit y-constrained optimal p o w er flow with transien t feasibility encoded by a neural net work surrogate (denoted “SCOPF”), and load shed verification of pow er line switc hing decisions made by a neural net- w ork (denoted “LSV”). Structural properties of the neural netw orks and resulting optimization problems are shown in T ables 1 and 2. 4.1. Adv ersarial image generation (MNIST). The MNIST set of hand- written digits [44] is a set of images of handwritten digits commonly used in machine learning b enc hmarks. W e hav e trained a set of neural netw orks to classify these im- ages using PyT orch [53] and the Adam optimizer [42]. The net works eac h accept a 28 × 28 gra yscale image and output scores for eac h digit, 0-9, that may be interpreted as a probability of the image b eing that digit. The total num b ers of neurons and trained parameters in the three netw orks we test for this problem are shown in T a- ble 1. After training these neural netw orks, our goals is to find a minimal perturbation 12 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT T a ble 1 Pr op erties of neur al network models use d in this work Model N. inputs N. outputs N. neurons N. layers N. param. Activ ation MNIST 784 10 3k 7 1M T anh+SoftMax 5k 7 5M T anh+SoftMax 11k 7 18M T anh+SoftMax SCOPF 117 37 1k 5 578k T anh 5k 7 4M T anh 12k 10 15M T anh LSV 423 186 993 5 111k Sigmoid 2k 5 837k Sigmoid 6k 5 9M Sigmoid T a ble 2 Structur e of optimization problems with differ ent neur al networks emb e dde d Mo del N. param. N. v ar. N. con. Jac. NNZ Hess. NNZ MNIST 1M 7k 5k 1M 2k 5M 12k 11k 5M 5k 18M 22k 21k 18M 10k SCOPF 578k 4k 4k 567k 9k 4M 11k 11k 4M 12k 15M 25k 25k 15M 19k LSV 111k 8k 4k 125k 4k 837k 10k 6k 854k 5k 9M 19k 15k 9M 10k to a reference image that results in a particular misclassification. This optimization problem is giv en b y Equation (4.1), whic h is inspired b y the minimal-adversarial-input form ulations of Mo das et al. [50] and Croce and Hein [16]. (4.1) min x ∥ x − x ref ∥ 1 sub ject to y = NN( x ) y t ≥ 0 . 6 Here, x ∈ R 784 con tains grayscale v alues of the generated image and x ref con tains those of the reference image. V ector y ∈ R 10 con tains the output score of each digit and t is the co ordinate corresp onding to the (misclassified) target lab el of the generated image. W e note that t is a constant parameter ch osen at the time we formulate the problem. W e enforce that the new image is classified as the target with a probabilit y of at least 60%. The sparsity structures of this problem’s KKT, piv ot, and Sch ur complemen t matrices are shown in Figure 3. 4.2. Securit y-constrained AC optimal p o w er flow (SCOPF). Security - constrained alternating current (A C) optimal p ow er flow (SCOPF) is an optimization problem for dispatching generators in an electric pow er grid in which feasibilit y of the grid (with respect to voltage, line flow, and load satisfaction constraints) is enforced for a set of c ontingencies k ∈ K [3]. Eac h contingency represen ts the loss of a set EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 13 0 4000 8000 12000 0 4000 8000 12000 KKT matrix 13429 × 13429, NNZ=1478637 0 2000 4000 6000 8000 10000 0 2000 4000 6000 8000 10000 Pivot matrix, C 10282 × 10282, NNZ=1066578 0 1000 2000 3000 0 1000 2000 3000 Sch ur complemen t, S 3158 × 3158, NNZ=321136 Fig. 3 . Structur e of KKT, pivot, and Schur c omplement matric es for the smal lest instance of the MNIST test pr oblem. The KKT matrix is in the or der shown in Equation (3.2) . of generators and/or pow er lines. Instead of enforcing feasibilit y at the grid’s new steady state, w e enforce feasibility of the first 30 seconds of the transien t resp onse. Sp ecifically , w e enforce that the frequency at each bus remains ab ov e η = 59 . 4 Hz. Instead of inserting differential equations describing transient grid b eha vior into the optimization problem (as done b y , e.g., Gan et al. [26]), w e use a neural netw ork that predicts the minim um frequency o v er this horizon. A simplified formulation is given in Equation (4.2): (4.2) min S g ,V c ( R ( S g )) sub ject to F k ( S g , V , S d ) ≤ 0 k ∈ { 0 , . . . , K } y k = NN k ( x ) y k ≥ η k ∈ { 1 , . . . , K } Here, S g is a vector of complex A C p o wer generations for each generator in the net w ork, V is a vector of complex bus voltages, c is a quadratic cost function, and S d is a constant vector of complex pow er demands. Constraint F k ≤ 0 represen ts the set of constraints enforcing feasibilit y of the p o w er netw ork for con tingency k (see [9]), where k = 0 refers to the base-case net work, and NN k is the neural netw ork function predicting minim um frequency follo w ing contingency k . This formulation is inspired b y that of Garcia et al. [27]. W e consider a simple instance of Equation (4.2) defined on a 37-bus syn thetic test grid [7, 6] with a single contingency outaging generator 5 on bus 23. Here, the neural net w ork has 117 inputs and 37 outputs. This surrogate is trained on data from 110 high-fidelity simulations using Po werW orld [55] with generations and loads uniformly sampled from within a ± 20% in terv al of eac h nominal v alue. These neural netw orks hav e b et ween five and ten la y ers and b etw een 500 and 1,500 neurons per la yer (see T able 1). The sparsity structures of this problem’s KKT, piv ot, and Sc h ur complement matrices are sho wn in Figure 4. 4.3. Line switching verification (LSV). Our final test problem maximizes load shed due to line switching decisions made by a neural netw ork that accepts loading conditions and wildfire risk (for ev ery bus in a p o wer netw ork) as inputs. This is Problem 3 presen ted by Chev alier et al. [12]. The goal of the problem in [12] is to maximize load shed due to neural netw ork switching decisions and an op erator that acts to minimize a combination of load shed and wildfire risk. This bilevel 14 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT 0 2000 4000 6000 8000 0 2000 4000 6000 8000 KKT matrix 8726 × 8726, NNZ=577160 0 2000 4000 6000 0 2000 4000 6000 Pivot matrix, C 6074 × 6074, NNZ=526074 0 1000 2000 3000 0 1000 2000 3000 Sch ur complemen t, S 3161 × 3161, NNZ=16585 Fig. 4 . Structur e of KKT, pivot, and Schur c omplement matric es for the smal lest instance of the SCOPF test pr oblem. problem is giv en by Equation (4.3). (4.3) max x,y ,p g C 1 ( x, y , p g ) sub ject to y = NN( x ) p g ∈ argmin p g ∈F ( x,y ) C 2 ( x, y , p g ) Here, b oth inner and outer problems are non-con v ex. The feasible set of the inner problem, F ( x, y ), is defined by the pow er flo w equations with fixed loading, x , and line switc hing decisions, y . T o approximate this problem with a single-level optimization problem, we follow [12] and relax the inner problem with a second-order cone relax- ation [39], dualize the (now conv ex) inner problem, and combine the tw o levels of the optimization to yield a single-lev el noncon v ex maximization problem. W e refer the reader to [12] for further details, including a description of ho w these neural net works are trained. 0 4000 8000 12000 0 4000 8000 12000 KKT matrix 12711 × 12711, NNZ=140924 0 500 1000 1500 0 500 1000 1500 Pivot matrix, C 1908 × 1908, NNZ=58868 0 2000 4000 6000 8000 10000 0 2000 4000 6000 8000 10000 Sch ur complemen t, S 11737 × 11737, NNZ=213776 Fig. 5 . Structur e of KKT, pivot, and Schur c omplement matric es for the smal lest instance of the LSV test pr oblem. 5. Results. 5.1. Computational setting. Our metho d is implemented in Julia 1.11 [5]. Optimization mo dels are implemented in JuMP [47], using Po werModels [14] and P o werModelsSecurityConstrained [13] for the SCOPF problem. Neural netw ork mo d- els are trained using PyT orch and embedded in to the JuMP mo dels using MathOptAI [20]. KKT matrices are extracted from eac h optimization problem using MadNLP EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 15 [60, 59, 61] and we use block triangular and blo c k-diagonal decomp ositions provided b y MathProgIncidence [52]. W e compare our metho d against the HSL MA57 [22] and MA86 [36] linear solvers. While MA86 can exploit parallel pro cessing of the assembly tree and our algorithm can exploit L3 BLAS (matrix-matrix op erations) parallelism, w e run all exp erimen ts with a single pro cessor in order to mak e a constant-hardw are comparison. This is done by setting the num b er of OMP threads (used b y MA86) to one and with the follo wing Julia options: LinearAlgebra.BLAS.set_num_threads(1) LinearAlgebra.BLAS.lbt_set_num_threads(1) These results w ere pro duced using the Selene sup ercomputer at Los Alamos Na- tional Lab oratory on a compute no de with tw o Intel 8468V 3.8 GHz pro cessors and 2TB of RAM. Co de and instructions to repro duce these results can b e found at h ttps://gith ub.com/Robbybp/moai- examples. 5.2. Numerical results. T o ev aluate our metho d for each combination of opti- mization problem and neural net work, we extract KKT matrices (and corresponding righ t-hand-sides) from the first ten iterations of the MadNLP interior point method 3 and compare the p erformance of our metho d with that of MA57 and MA86 on these linear systems. The KKT matrices at eac h iteration ha v e the same structure, so we only p erform a single symbolic factorization (referred to as “initialization”). Then w e factorize the KKT matrix and backsolv e with each of our ten KKT systems. Bac k- solv es are rep eated in iterativ e refinemen t un til the max-norm of the residual is b elo w 10 − 5 . T able 3 rep orts the total time required, broken down into initialization, factor- ization, and backsolv e steps for the ten linear systems as w ell as the av erage residual max-norm and a verage n um b er of refinement iterations required. These bac ksolve run- times include all refinement iterations. The sp eedup factor is a ratio of our solver’s run time in the factorization plus bac ksolve phases to that of MA57 or MA86. W e omit initialization time from this calculation as this step is amortized ov er many iterations of an interior point metho d. W e note that our metho d computes the same inertia as MA57 or MA86 in ev ery case. Our metho d achiev es low er factorization times at the cost of more exp ensiv e initializations and backsolv es. Our faster factorizations make up for slo w er backsolv es and achiev e ov erall speedups b et w een 2.9 × and 15 × for the largest neural net works considered even though more iterations of iterativ e refinement are sometimes required. W e hypothesize that our metho d outp erforms MA57 and MA86 due to its limited fill-in when factorizing the blo c k triangularizable pivot matrix. As discussed in Sub- section 3.3, w e exp ect MA57 and MA86 to incur significan t fill-in when factorizing the original KKT matrix or the pivot matrix. T able 4 shows that this is the case. This table sho ws the size of the matrix factors and n umber of floating p oin t op erations required by these solv ers on the original, piv ot, and Sch ur complemen t matrices. F or the original KKT and pivot matrices, MA57 and MA86 require factors 3-4 × larger than the original matrix. W e attribute this fill-in partially to the relatively small n um b er of 2 × 2 pivots selected b y these algorithms. The num b er of 2 × 2 piv ots is equal to ab out 25% of the matrix dimension, corresponding to ab out 50% of rows and columns in the factor matrices. Our analysis in Subsection 3.3 indicates that fill-in w ould b e reduced if all of the pivots (at least in the pivot matrix) were 2 × 2. While our metho d already outp erforms MA57 and MA86 running on identical 3 T o mak e sure we compare different linear solv ers on the same KKT systems, w e alwa ys compute MadNLP’s search direction with our linear solver. 16 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT T a ble 3 Runtime results for ten KKT matrix factorizations for e ach model-solver c ombination. F or e ach pr oblem, we c omp are our metho d to a state-of-the-art alternative. Model Solver NN param. T otal run time (s) Average Init. F act. Solve Resid. Refin. iter. Sp eedup ( × ) MNIST MA57 1M 0.04 2 0.1 2.7E-06 0 – 5M 0.1 22 0.5 3.3E-07 0 – 18M 1 125 2 1.3E-06 0 – MNIST Ours 1M 0.5 6 0.4 2.4E-08 1 0.25 5M 3 12 1 8.2E-07 2 1.7 18M 10 31 13 3.1E-06 7 2.9 SCOPF MA86 578k 0.03 3 0.1 7.3E-07 1 – 4M 0.2 32 1 2.9E-10 1 – 15M 0.8 171 4 3.5E-10 1 – SCOPF Ours 578k 0.2 1 0.1 1.9E-06 1 2.6 4M 2 3 0.7 1.4E-06 1 10 15M 7 9 3 2.5E-08 1 15 LSV MA86 111k 0.01 0.3 0.03 1.1E-08 0 – 837k 0.04 5 0.1 6.8E-07 0 – 9M 0.5 149 1 1.3E-06 0 – LSV Ours 111k 0.06 0.6 0.04 1.4E-06 0 0.51 837k 0.4 3 0.3 2.1E-06 2 1.6 9M 6 14 3 2.9E-06 3 8.8 T a ble 4 F actor sizes and flo ating p oint op er ations r e quire d to factorize KKT, pivot, and Schur c omple- ment matric es Model Solv er NN param. Matrix Matrix dim. NNZ F actor NNZ FLOPs N. 2 × 2 pivots MNIST MA57 18M KKT 44k 18M 65M 177B 10k Pivot 41k 16M 50M 138B 10k Sch ur 3k 321k 323k 168M 0 SCOPF MA86 15M KKT 51k 16M 72M 127B 17k Pivot 48k 15M 71M 124B 17k Sch ur 3k 16k 104k 5M 1k LSV MA86 9M KKT 36k 9M 44M 105B 13k Pivot 24k 8M 39M 84B 7k Sch ur 11k 213k 588k 136M 5k hardw are, there is significant opp ortunit y to further impro ve our implementation. T able 5 sho ws a breakdo wn of runtime of the factorization and backsolv e phases of our implementation. W e first note that our factorization phase is dominated either b y the cost to factorize the pivot matrix, C , or by the cost to build the Sc hur comple- men t, i.e., p erforming the matrix subtraction, bac ksolve, and m ultiplication necessary to compute S = A − B T C − 1 B . These are the steps in lines 2 and 3 of Algorithm 2.1. When building the Sch ur complemen t, backsolv es in volving C (as describ ed by Equa- tion (2.6)) are the dominant computation cost. While the blocks of the solution matrix (or v ector), X i , need to b e computed sequentially , the subtraction and multiplication op erations used to construct these blo cks (i.e., B i − P i − 1 j =1 C j i X j ) can exploit single instruction, multiple data (SIMD) parallelism on m ultiple CPU cores or a GPU. De- EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 17 T a ble 5 Br e akdown of solve times with our Schur c omplement solver Mo del NN param. F actorize (s) P ercent of factorize time (%) Bac ksolve (s) Build Sc hur Sch ur Piv ot MNIST 1M 6 88 1 6 0.4 5M 13 76 1 17 2 18M 32 70 0 26 13 SCOPF 578k 0.4 46 2 44 0.1 4M 3 26 0 67 0.8 15M 10 25 0 68 3 LSV 111k 0.6 72 14 3 0.05 837k 2 84 3 9 0.3 9M 15 65 0 29 3 p ending on the structure of C ii (i.e., if it is blo c k-diagonal), the bac ksolv e ma y b e parallelized as w ell. F actorizing the individual diagonal blo cks of the pivot matrix (i.e., C ii ) can also b e parallelized. 6. Conclusion. W e hav e sho wn that exploiting block triangular submatrices can yield up to 15 × p erformance improv ements when solving KKT systems compared to off-the-shelf m ultifron tal and superno dal metho ds. W e hav e provided a theoretical justification for this sp eed up based on limited fill-in achiev ed with our metho d and ha v e justified that the lack of inertia information from an unsymmetric blo c k triangu- lar solver is not prohibitive to using this metho d in nonlinear optimization methods. In fact, we hav e shown that our decomp osition method will fail if inertia correction is attempted in the block triangular matrix that we exploit. These results motiv ate several directions for future work. First, the metho ds w e hav e developed can be applied to man y other optimization problems with blo ck triangular structures. F or example, many sequen tial (dynamic or m ulti-p eriod) opti- mization problems hav e this blo ck triangular structure. Additionally , man y problems that are not explicitly sequential may hav e large block triangular submatrices that can be exploited by our metho ds. W e ha ve shown in previous work that large trian- gular submatrices can b e automatically iden tified [51]; future w ork should use Sch ur complemen t decompositions to exploit these submatrices in KKT systems. Addition- ally , the metho ds dev elop ed in [51] may be relaxed to automatically iden tify large blo ck -triangular submatrices. Finally , a key adv antage of our prop osed metho d is that sev eral of the computational b ottlenec ks (bac ksolving with the piv ot matrix and constructing the Sch ur complemen t) can be parallelized on SIMD hardware. This de- comp osition should b e implemented on GPUs with effort made to reduce CPU-GPU data transfer. This work demonstrates that structure-exploiting decomp osition algorithms can accelerate linear system solves even in the absence of adv anced hardw are. W e intend this work to motiv ate researc h in to additional structures that can b e exploited in KKT systems. W e b elieve that there is a significant opp ortunit y improv e performance of optimization algorithms through tighter integration b et ween optimization problems and linear solvers. Here, w e prop ose one metho d for improving p erformance in this w a y , although there is m uch that can be done to further dev elop this method and others. 18 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT Ac knowledgmen ts. This w ork was funded b y the Los Alamos National Lab o- ratory LDRD program under the Artimis pro ject, the Center for Nonlinear Studies, and an ISTI Rapid Response a ward. W e thank Alexis Montoison for helpful con versations ab out our metho d, the HSL libraries, and an earlier draft of this manuscript. App endix A. Size of submatrices. T able 6 con tains the dimensions and n um- b er of (structural) nonzero en tries for KKT matrices and each submatrix considered in Equation (3.3). App endix B. Comparison of linear solvers. T o justify our use of MA57 and MA86, w e ev aluate the time required to solve MadNLP’s KKT system at the initial guess with the solvers MA57 [22], MA86 [36], and MA97 [37] from the HSL library . The results are shown in T able 7. Each solv er uses default options other than the pivot order, which we set to an approximate minim um degree (AMD) [1] v ariant with efficient handling of dense ro ws [2]. The results indicate that MA57 is the most p erforman t solv er for the MNIST test problem, while MA86 is most p erforman t for the SCOPF and LSV problems. While MA86 and MA97 can exploit mu lticore parallelism, w e run all solvers (including ours) with a single thread to make a constan t-hardware comparison. REFERENCES [1] P. R. Amestoy, T. A. Da vis, and I. S. Duff , An approximate minimum de gre e or dering algorithm , SIAM Journal on Matrix Analysis and Applications, 17 (1996), pp. 886–905, https://doi.org/10.1137/S0895479894278952. [2] P. R. Amestoy, H. S. Dollar, J. K. Reid, and J. A. Scott , A n approximate minimum de- gr e e algorithm for matric es with dense r ows , T ech. Report RAL-TR-2004-015, Rutherford Appleton Lab oratory , 2004. [3] I. Ara vena, D. K. Molzahn, S. Zhang, C. G. Petra, F. E. Cur tis, S. Tu, A. W ¨ achter, E. Wei, E. W ong, A. Gholami, K. Sun, X. A. Sun, S. T. Elber t, J. T. Holzer, and A. Veeramany , R e cent developments in se curity-c onstr aine d AC optimal p ower flow: Overview of chal lenge 1 in the ARP A-E grid optimization comp etition , Op erations Re- search, 71 (2023), pp. 1997–2014, https://doi.org/10.1287/opre.2022.0315. [4] M. Benzi, G. H. Golub, and J. Liesen , Numeric al solution of sadd le p oint pr oblems , Acta Numerica, 14 (2005), p. 1–137, h ttps://doi.org/10.1017/S0962492904000212. [5] J. Bezanson, A. Edelman, S. Karpinski, and V. B. Shah , Julia: A fresh appr o ach to numer- ic al c omputing , SIAM Review, 59 (2017), pp. 65–98, https://doi.org/10.1137/141000671. [6] A. Birchfield , Hawaii synthetic grid – 37 buses , 2023, https://electricgrids.engr.tam u.edu/ haw aii40/. Accessed 2024-12-10. [7] A. B. Birchfield, T. Xu, K. M. Gegner, K. S. Shetye, and T. J. Overbye , Grid structur al char acteristics as validation criteria for synthetic networks , IEEE T ransactions on Po wer Systems, 32 (2017), pp. 3258–3265, h ttps://doi.org/10.1109/TPWRS.2016.2616385. [8] J. R. Bunch and L. Kaufman , Some stable metho ds for c alculating inertia and solving sym- metric line ar systems , Mathematics of Computation, (1977), pp. 163–179. [9] M. B. Cain, R. P. O’Neill, and A. Castillo , History of optimal p ower flow and formulations , tech. rep ort, F ederal Energy Regulatory Commission, 2012. [10] L. Casacio, C. L yra, A. R. L. Oliveira, and C. O. Castro , Impr oving the pr e condi- tioning of line ar systems from interior point metho ds , Computers & Op erations Re- search, 85 (2017), pp. 129–138, h ttps://doi.org/https://doi.org/10.1016/j.cor.2017.04.005, https://www.sciencedirect.com/science/article/pii/S0305054817300965. [11] F. Ceccon, J. Jal ving, J. Haddad, A. Thebel t, C. Tsa y, C. D. Laird, and R. Misener , OML T: Optimization & machine learning to olkit , Journal of Machine Learning Research, 23 (2022), pp. 1–8, http://jmlr.org/papers/v23/22- 0277.html. [12] S. Chev alier, D. St arkenburg, R. P arker, and N. Rhodes , Maximal lo ad she dding verifi- c ation for neur al network mo dels of AC line switching , 2025, h 23806, EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 19 T a ble 6 Size of submatric es for each mo del and neur al network Mo del NN param. Matrix N. ro w N. col NNZ MNIST 1M KKT 13k 13k 1M A 3k 3k 5k B 10k 3k 401k Piv ot matrix ( C ) 10k 10k 1M Sc hur complement ( S ) 3k 3k 321k MNIST 5M KKT 23k 23k 5M A 3k 3k 5k B 20k 3k 802k Piv ot matrix ( C ) 20k 20k 4M Sc hur complement ( S ) 3k 3k 321k MNIST 18M KKT 44k 44k 18M A 3k 3k 5k B 41k 3k 1M Piv ot matrix ( C ) 41k 41k 16M Sc hur complement ( S ) 3k 3k 321k SCOPF 578k KKT 9k 9k 578k A 3k 3k 10k B 6k 3k 39k Piv ot matrix ( C ) 6k 6k 526k Sc hur complement ( S ) 3k 3k 16k SCOPF 4M KKT 23k 23k 4M A 3k 3k 10k B 20k 3k 78k Piv ot matrix ( C ) 20k 20k 4M Sc hur complement ( S ) 3k 3k 16k SCOPF 15M KKT 51k 51k 16M A 3k 3k 10k B 48k 3k 117k Piv ot matrix ( C ) 48k 48k 15M Sc hur complement ( S ) 3k 3k 16k LSV 111k KKT 13k 13k 142k A 11k 11k 28k B 1k 11k 54k Piv ot matrix ( C ) 1k 1k 58k Sc hur complement ( S ) 11k 11k 213k LSV 837k KKT 18k 18k 876k A 11k 11k 28k B 6k 11k 216k Piv ot matrix ( C ) 6k 6k 627k Sc hur complement ( S ) 11k 11k 213k LSV 9M KKT 36k 36k 9M A 11k 11k 28k B 24k 11k 866k Piv ot matrix ( C ) 24k 24k 8M Sc hur complement ( S ) 11k 11k 213k 20 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT T a ble 7 Runtime of thr e e line ar solvers on the KKT matrix at the initial guess Mo del Solver NN param. Initialize F actorize Backsolv e Residual MNIST MA57 1M 0.04 0.2 0.01 5.6E-10 5M 0.2 2 0.05 9.5E-11 18M 0.5 13 0.2 1.8E-11 MA86 1M 0.06 0.7 0.02 6.7E-16 5M 0.2 5 0.09 1.1E-15 18M 1 30 0.3 6.1E-15 MA97 1M 0.08 2 0.02 1.8E-15 5M 0.4 15 0.08 9.1E-16 18M* – – – – SCOPF MA57 578k 0.02 0.3 < 0 . 01 7.7E-09 4M 0.1 5 0.05 5.9E-09 15M 0.5 28 0.2 5.0E-09 MA86 578k 0.02 0.3 0.01 5.3E-09 4M 0.2 3 0.06 2.1E-09 15M 0.8 17 0.3 1.8E-09 MA97 578k 0.03 1 0.01 7.4E-09 4M 0.3 11 0.06 2.9E-09 15M* – – – – LSV MA57 111k 0.01 0.03 < 0 . 01 8.7E-11 837k 0.2 0.7 0.01 2.8E-12 9M † – – – – MA86 111k 0.01 0.03 < 0 . 01 4.4E-09 837k 0.04 0.5 0.01 2.6E-12 9M 0.5 15 0.2 2.0E-12 MA97 111k 0.01 0.03 < 0 . 01 6.1E-11 837k 0.05 1 0.01 4.5E-12 18M* – – – – ∗ Segmentation fault † Int32 overflo w [13] C. Coffrin , PowerModelsSe curityConstr aine d.jl , 2022, h ttps://github.com/lanl- ansi/ Po werModelsSecurityConstrained.jl. Accessed 2024-12-10. [14] C. Coffrin, R. Bent, K. Sundar, Y. Ng, and M. Lubin , PowerMo dels.jl: An op en-sourc e fr amework for exploring power flow formulations , in 2018 Po wer Systems Computation Conference (PSCC), June 2018, pp. 1–8, h ttps://doi.org/10.23919/PSCC.2018.8442948. [15] T. F. Coleman , L arge Sp arse Numeric al Optimization , Lecture Notes in Computer Science, Springer, 1984. [16] F. Croce and M. Hein , Minimal ly distorte d adversarial examples with a fast adaptive b ound- ary attack , ICML’20, JMLR.org, 2020. [17] F. E. Cur tis, O. Schenk, and A. W ¨ achter , A n interior-p oint algorithm for lar ge-sc ale non- line ar optimization with inexact step computations , SIAM Journal on Scien tific Computing, 32 (2010), pp. 3447–3475, https://doi.org/10.1137/090747634. [18] T. A. D a vis , Dir ect Metho ds for Sp arse Line ar Systems , So ciet y of Industrial and Applied Mathematics, 2006. [19] T. A. Da vis and I. S. Duff , An unsymmetric-pattern multifrontal metho d for sp arse LU factorization , SIAM Journal on Matrix Analysis and Applications, 18 (1997), pp. 140–158, https://doi.org/10.1137/S0895479894246905. [20] O. Dowson, R. B. P arker, and R. Bent , MathOptAI.jl: Emb e d tr a ine d machine le arning EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 21 pr e dictors into JuMP models , 2025, https://arxiv.org/abs/2507.03159, abs/2507.03159. [21] I. S. DUFF , On permutations to blo ck triangular form , IMA Journal of Applied Mathematics, 19 (1977), pp. 339–342, https://doi.org/10.1093/imamat/19.3.339. [22] I. S. Duff , MA57—a co de for the solution of sp arse symmetric definite and indefinite systems , 30 (2004), https://doi.org/10.1145/992200.992202. [23] I. S. Duff and J. K. Reid , An implementation of T arjan ’s algorithm for the blo ck tri- angularization of a matrix , ACM T rans. Math. Softw., 4 (1978), p. 137–147, https: //doi.org/10.1145/355780.355785. [24] I. S. Duff and J. K. Reid , The multifr ontal solution of indefinite sp arse symmetric line ar , ACM T rans. Math. Softw., 9 (1983), p. 302–325, h ttps://doi.org/10.1145/356044.356047. [25] F. G. Frobenius , ¨ Ub er matrizen aus nicht ne gativen elementen , Sitzungsberich te der K¨ oniglich Preussischen Akademie der Wissensc haften zu Berlin, 26 (1912), pp. 456–477. [26] D. Gan, R. Thomas, and R. Zimmerman , Stability-c onstr aine d optimal power flow , IEEE T ransactions on Po wer Systems, 15 (2000), pp. 535–540, https://doi.org/10.1109/59. 867137. [27] M. Garcia, N. LoGiudice, R. P arker, and R. Bent , T r ansient stability-c onstr ained OPF: Neur al network surro gate mo dels and pricing stability , 2025, 01844, [28] G. Geng and Q. Jiang , A two-level p ar al lel de c omp osition appr o ach for tr ansient stability c onstr aine d optimal power flow , IEEE T ransactions on P ow er Systems, 27 (2012), pp. 2063– 2073, https://doi.org/10.1109/TPWRS.2012.2190111. [29] G. Geng, Q. Jiang, and Y. Sun , Par al lel tr ansient stability-c onstr aine d optimal p ower flow using gpu as c opr o cessor , IEEE T ransactions on Smart Grid, 8 (2017), pp. 1436–1445, https://doi.org/10.1109/TSG.2016.2639551. [30] G. H. Golub and C. Greif , On solving blo ck-structur e d indefinite linear systems , SIAM Journal on Scientific Computing, 24 (2003), pp. 2076–2092, https://doi.org/10.1137/ S1064827500375096. [31] J. Gondzio and R. Sarkissian , Par al lel interior-p oint solver for structure d line ar pr o- gr ams , Mathematical Programming, 96 (2003), pp. 561–584, https://doi.org/10.1007/ s10107- 003- 0379- 5, h ttps://doi.org/10.1007/s10107- 003- 0379- 5. [32] N. I. M. Gould , On pr actic al c onditions for the existenc e and uniqueness of solutions to the gener al e quality quadr atic pro gr amming problem , Mathematical Programming, 32 (1985), pp. 90–99, https://doi.org/10.1007/BF01585660, h ttps://doi.org/10.1007/BF01585660. [33] M. D. Grigoriadis and L. G. Khachiy an , An interior point metho d for bor der e d blo ck- diagonal line ar pro gr ams , SIAM Journal on Optimization, 6 (1996), pp. 913–932, https: //doi.org/10.1137/S1052623494263609. [34] F. Gust a vson , Finding the blo ck lower triangular form of a sp arse matrix , in Sparse Matrix Computations, J. R. Bunch and D. J. Rose, eds., Academic Press, 1976, pp. 275–289, https://doi.org/h ttps://doi.org/10.1016/B978- 0- 12- 141050- 6.50021- 0. [35] E. V. Ha ynswor th , Determination of the inertia of a p artitione d Hermitian matrix , Linear Algebra and its Applications, 1 (1968), pp. 73–81, https://doi.org/h ttps: //doi.org/10.1016/0024- 3795(68)90050- 5, https://www.sciencedirect.com/science/article/ pii/0024379568900505. [36] J. D. Hogg and J. A. Scott , A n indefinite sparse dir ect solver for large pr oblems on multic or e machines , T ec h. Rep ort RAL-TR-2010-011, Rutherford Appleton Lab oratory , 2010. [37] J. D. Hogg and J. A. Scott , HSL MA97: a bit-comp atible multifr ontal c o de for sp arse sym- metric systems , T ech. Report RAL-TR-2011-024, Rutherford Appleton Lab oratory , 2011. [38] T. D. Howell , Partitioning using P AQ++ , in Sparse Matrix Computations, J. R. Bunc h and D. J. Rose, eds., Academic Press, 1976, pp. 23–37, h ttps://doi.org/https://doi.org/10. 1016/B978- 0- 12- 141050- 6.50007- 6. [39] R. Jabr , Radial distribution lo ad flow using c onic pro gr amming , IEEE T ransactions on Po wer Systems, 21 (2006), pp. 1458–1459, h ttps://doi.org/10.1109/TPWRS.2006.879234. [40] D. Jin, A. Montoison, and S. Shin , Harnessing b atche d BLAS/LAP ACK kernels on GPUs for p ar al lel solutions of block tridiagonal systems , 2025, [41] J. Kang, Y. Cao, D. P. Word, and C. Laird , An interior-p oint metho d for efficient solu- tion of blo ck-structur e d NLP pr oblems using an implicit Schur-c omplement de c omp osition , Computers & Chemical Engineering, 71 (2014), pp. 563–573, h ttps://doi.org/https://doi. org/10.1016/j.compchemeng.2014.09.013, h ttps://www.sciencedirect.com/science/article/ pii/S0098135414002798. [42] D. P. Kingma and J. Ba , A dam: A metho d for sto chastic optimization , 2017, https://arxiv. 22 ROBER T P ARKER, MANUEL GARCIA, AND R USSELL BENT org/abs/1412.6980, [43] C. D. Laird and L. T. Biegler , L ar ge-sc ale nonline ar pr o gr amming for multi-sc enario opti- mization , in Mo deling, Simulation and Optimization of Complex Processes, H. G. Bo c k, E. Kostina, H. X. Phu, and R. Rannac her, eds., Berlin, Heidelberg, 2008, Springer Berlin Heidelberg, pp. 323–336. [44] Y. LeCun, C. Cor tes, and C. J. C. Burges , The MNIST datab ase of handwritten digits , (1998), http://y ann.lecun.com/exdb/mnist/. [45] J. W. H. Liu, E. G. Ng, a nd B. W. Peyton , On finding superno des for sp arse matrix com- putations , SIAM Journal on Matrix Analysis and Applications, 14 (1993), pp. 242–252, https://doi.org/10.1137/0614019. [46] F. J. L ´ opez-Flores, C. Ram ´ ırez-M ´ arquez, and J. Ponce-Or tega , Pr o c ess systems en- gine ering to ols for optimization of tr aine d machine le arning mo dels: Comp ar ative and p ersp e ctive , Industrial & Engineering Chemistry Research, 63 (2024), pp. 13966–13979, https://doi.org/10.1021/acs.iecr.4c00632, https://doi.org/10.1021/acs.iecr.4c00632. [47] M. Lubin, O. Dowson, J. D. Garcia, J. Huchette, B. Lega t, and J. P. Vielma , JuMP 1.0: R e cent impr ovements to a mo deling language for mathematic al optimization , Math- ematical Programming Computation, 15 (2023), pp. 581–589, https://doi.org/10.1007/ s12532- 023- 00239- 3, h ttps://doi.org/10.1007/s12532- 023- 00239- 3. [48] I. J. Lustig and G. Li , An implementation of a p ar al lel primal-dual interior p oint metho d for blo ck-structur e d line ar pr o gr ams , Computational Optimization and Applications, 1 (1992), pp. 141–161, https://doi.org/10.1007/BF00253804, h ttps://doi.org/10.1007/BF00253804. [49] F. J. L ´ opez-Flores, C. Ram ´ ırez-M ´ arquez, and J. M. Ponce-Or tega , Pr o c ess systems en- gine ering to ols for optimization of tr aine d machine le arning mo dels: Comp ar ative and p ersp e ctive , Industrial & Engineering Chemistry Research, 63 (2024), pp. 13966–13979, https://doi.org/10.1021/acs.iecr.4c00632. [50] A. Modas, S.-M. Moosa vi-Dezfooli, and P. Frossard , Sp arseF o ol: A few pixels make a big differ enc e , in 2019 IEEE/CVF Conference on Computer Vision and P attern Recognition (CVPR), 2019, pp. 9079–9088, https://doi.org/10.1109/CVPR.2019.00930. [51] S. Naik, L. Biegler, R. Bent, and R. P arker , V ariable aggr e gation for nonline ar optimiza- tion pr oblems , 2025, h ttps://arxiv.org/abs/2502.13869, [52] R. B. P arker, B. L. Nicholson, J. D. Siirola, and L. T. Biegler , Applications of the Dul- mage–Mendelsohn de c omp osition for debugging nonlinear optimization pr oblems , Com- puters & Chemical Engineering, 178 (2023), p. 108383, https://doi.org/h ttps://doi.org/ 10.1016/j.compchemeng.2023.108383, https://www.sciencedirect.com/science/article/pii/ S0098135423002533. [53] A. P aszke, S. Gross, F. Massa, A. Lerer, J. Bradbur y, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. , Pytor ch: An imp er ative style, high-p erformanc e de ep le arning libr ary , Adv ances in neural information processing systems, 32 (2019). [54] A. Pothen and C.-J. F an , Computing the blo ck triangular form of a sp arse matrix , ACM T rans. Math. Soft w., 16 (1990), p. 303–324, h ttps://doi.org/10.1145/98267.98287. [55] PowerW orld Corpora tion , PowerWorld Simulator Manual , Champaign, IL, USA. https://www.pow erworld.com/W ebHelp/ Accessed December 10, 2024. [56] S. Regev, N.-Y. Chiang, E. Dar ve, C. G. Petra, M. A. Saunders, K. ´ Swir ydowicz, and S. Pele ˇ s , HyKKT: a hybrid dir e ct-iter ative metho d for solving KKT linear systems , Optimization Methods and Soft ware, 38 (2023), pp. 332–355, https://doi.org/10.1080/ 10556788.2022.2124990. [57] L. Schork and J. Gondzio , Implementation of an interior p oint metho d with b asis pr e- c onditioning , Mathematical Programming Computation, 12 (2020), pp. 603–635, https: //doi.org/10.1007/s12532- 020- 00181- 8, h ttps://doi.org/10.1007/s12532- 020- 00181- 8. [58] A. M. Schweidtmann and A. Mitsos , Deterministic glob al optimization with artificial neur al networks emb e dde d , Journal of Optimization Theory and Applications, 180 (2019), pp. 925– 948. [59] S. Shin, M. Anitescu, and F. P aca ud , Ac c eler ating optimal p ower flow with GPUs: SIMD abstr action of nonline ar pr o gr ams and c ondense d-sp ac e interior-p oint methods , Electric Po wer Systems Research, 236 (2024), p. 110651, h ttps://doi.org/https://doi.org/10.1016/ j.epsr.2024.110651. [60] S. Shin, C. Coffrin, K. Sund ar, and V. M. Za v ala , Gr aph-b ase d mode ling and de c omp osition of ener gy infr astructur es , IF AC-PapersOnLine, 54 (2021), pp. 693–698. [61] S. Shin and contributors , MadNLP.jl , 2025, h ttps://github.com/MadNLP/MadNLP .jl. Ac- cessed 2025-09-04. [62] J. J. Syl vester , A demonstr ation of the theor em that every homo gene ous quadratic p olynomial is r e ducible by r eal ortho gonal substitutions to the form of a sum of p ositive and ne gative EXPLOITING BLOCK TRIANGULAR SUBMA TRICES IN KKT SYSTEMS 23 squar es , Philosophical Magazine, 4 (1852), pp. 138–142. [63] R. S. V arga , Matrix Iter ative Analysis , Springer, second ed., 2000. [64] A. W ¨ achter and L. T. Biegler , Line se ar ch filter metho ds for nonline ar pro gr amming: Motivation and global c onver genc e , SIAM Journal on Optimization, 16 (2005), pp. 1–31, https://doi.org/10.1137/S1052623403426556. [65] S. J. Wright , Partitioned dynamic pr o gramming for optimal c ontr ol , SIAM Journal on Opti- mization, 1 (1991), pp. 620–642, h ttps://doi.org/10.1137/0801037. [66] F. Zanetti and J. Gondzio , A new stopping criterion for Krylov solvers applie d in interior p oint methods , SIAM Journal on Scientific Computing, 45 (2023), pp. A703–A728, https: //doi.org/10.1137/22M1490041. [67] K. ´ Swir ydowicz, E. Dar ve, W. Jones, J. Maack, S. Regev, M. A. Saunders, S. J. Thomas, and S. Pele ˇ s , Line ar solvers for p ower grid optimization pr oblems: A r e- view of GPU-ac c eler ate d linear solvers , P arallel Computing, 111 (2022), p. 102870, https://doi.org/h ttps://doi.org/10.1016/j.parco.2021.102870, https://www.sciencedirect. com/science/article/pii/S0167819121001125.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment