FedPSA: Modeling Behavioral Staleness in Asynchronous Federated Learning
Asynchronous Federated Learning (AFL) has emerged as a significant research area in recent years. By not waiting for slower clients and executing the training process concurrently, it achieves faster training speed compared to traditional federated learning. However, due to the staleness introduced by the asynchronous process, its performance may degrade in some scenarios. Existing methods often use the round difference between the current model and the global model as the sole measure of staleness, which is coarse-grained and lacks observation of the model itself, thereby limiting the performance ceiling of asynchronous methods. In this paper, we propose FedPSA (Parameter Sensitivity-based Asynchronous Federated Learning), a more fine-grained AFL framework that leverages parameter sensitivity to measure model obsolescence and establishes a dynamic momentum queue to assess the current training phase in real time, thereby adjusting the tolerance for outdated information dynamically. Extensive experiments on multiple datasets and comparisons with various methods demonstrate the superior performance of FedPSA, achieving up to 6.37% improvement over baseline methods and 1.93% over the current state-of-the-art method.
💡 Research Summary
The paper introduces FedPSA, a novel asynchronous federated learning (AFL) framework that replaces the traditional round‑gap‑based staleness metric with a behavior‑aware measure derived from parameter sensitivity. In conventional AFL, the server assigns aggregation weights solely based on the version difference (i.e., how many communication rounds have elapsed) between a client’s local model and the current global model. This coarse‑grained approach ignores two crucial aspects: (1) the training stage of the global model, and (2) the heterogeneity of client data distributions. Consequently, updates that are equally “old” in terms of rounds may have vastly different relevance, especially early in training or under non‑IID data.
FedPSA addresses these issues through two complementary mechanisms. First, each client computes a sensitivity vector on a shared calibration batch, quantifying how each model parameter influences the loss. To keep communication overhead low, the high‑dimensional sensitivity vector is compressed using random projection sketching. The server receives these sketches and computes cosine similarity between the client’s sensitivity pattern and that of the current global model. This similarity serves as a behavioral staleness score: a high similarity indicates that the client’s update is still aligned with the global training dynamics, while a low similarity signals potential conflict.
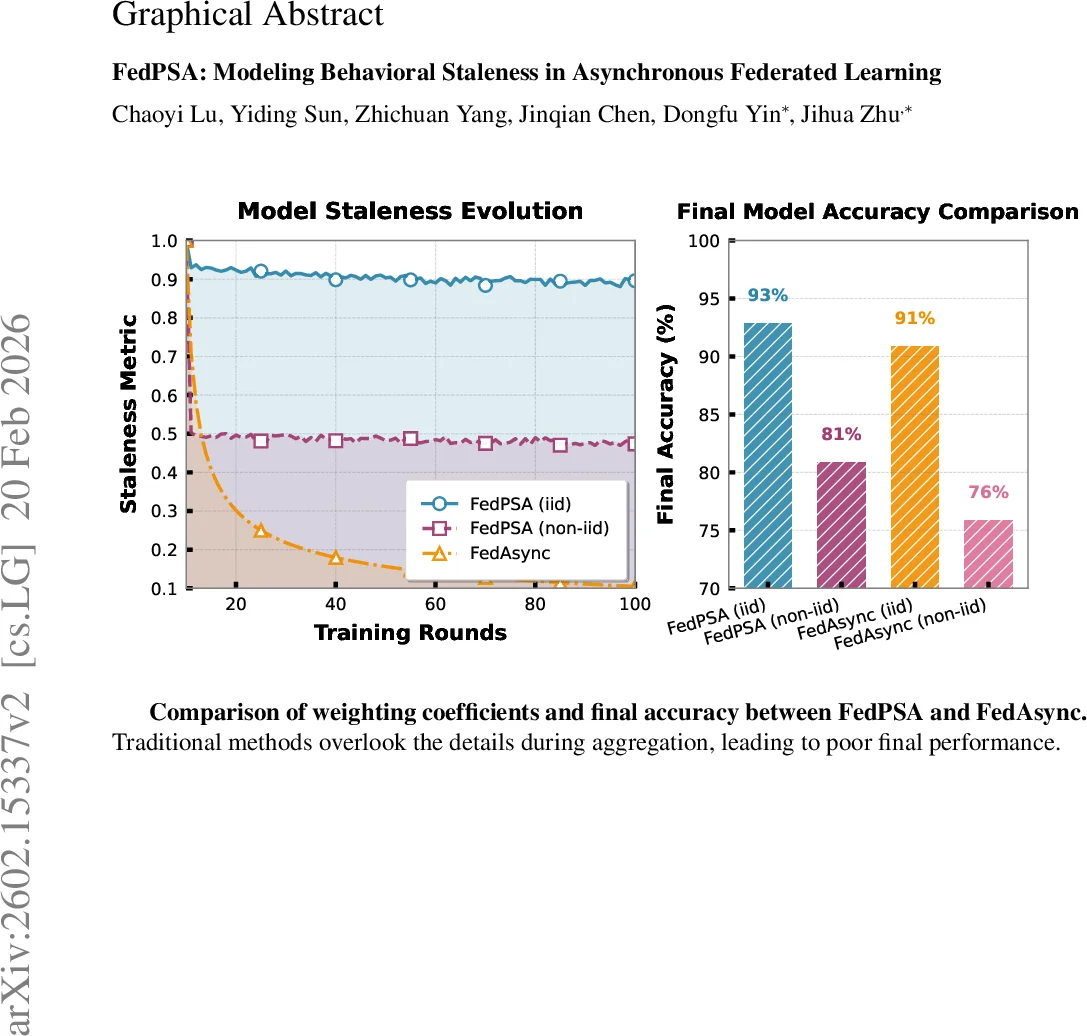
Second, FedPSA maintains a dynamic momentum queue on the server. The queue stores recent client momentum (gradient) information, and its average is interpreted as a “temperature” that reflects the current training phase. During early, exploratory stages the temperature is high, allowing larger tolerance for sensitivity discrepancies; as training converges, the temperature drops, tightening the tolerance and sharply reducing the weight of stale or divergent updates.
The final aggregation weight for a client i is computed by feeding both the behavioral similarity and the temperature into a softmax‑type function:
α_i = softmax( similarity_i / τ ), where τ is the temperature derived from the momentum queue. This formulation yields fine‑grained, stage‑adaptive weighting without requiring explicit waiting for all clients.
Methodologically, the approach is efficient: sensitivity calculation is limited to a small calibration batch, and random projection reduces the sketch size to O(log d) dimensions, where d is the model size. Server‑side operations consist of queue management and cosine similarity computation, both lightweight even with thousands of concurrent clients.
Extensive experiments were conducted on CIFAR‑10, FEMNIST, and Shakespeare datasets under both IID and non‑IID partitions. FedPSA was compared against FedAsync, FedASMU, FedF‑A, and recent buffer‑based AFL methods. Results show consistent improvements of 3.8 %–6.4 % in final test accuracy, with the largest gains observed in highly asynchronous and heterogeneous settings. Ablation studies confirm that neither the sensitivity‑based weighting nor the momentum‑queue alone can achieve the full benefit; their combination yields the reported 6.37 % improvement over baselines and 1.93 % over the prior state‑of‑the‑art.
The authors acknowledge limitations: the calibration batch must adequately represent the overall data distribution, and random projection may incur some information loss. Moreover, scalability to tens of thousands of clients may require further optimization of the queue and communication protocols.
In summary, FedPSA pioneers a shift from time‑based to behavior‑based staleness modeling in asynchronous federated learning. By integrating parameter sensitivity with a dynamic training‑phase estimator, it delivers both faster convergence and higher final accuracy, paving the way for more robust and efficient AFL deployments in real‑world, heterogeneous environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment