Interactive Learning of Single-Index Models via Stochastic Gradient Descent
Stochastic gradient descent (SGD) is a cornerstone algorithm for high-dimensional optimization, renowned for its empirical successes. Recent theoretical advances have provided a deep understanding of how SGD enables feature learning in high-dimension…
Authors: Nived Rajaraman, Yanjun Han
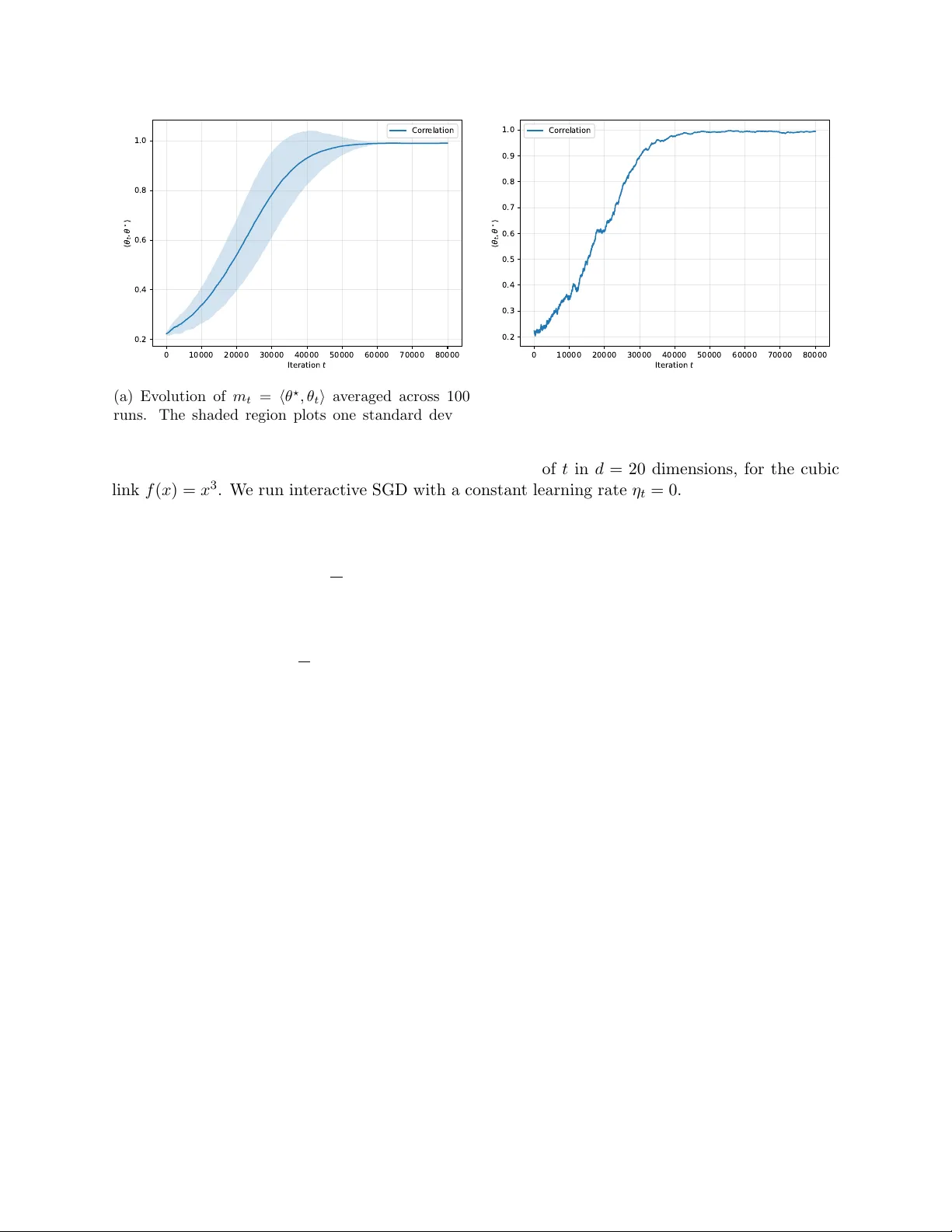
In teractiv e Learning of Single-Index Mo dels via Sto c hastic Gradien t Descen t Niv ed Ra jaraman, Y anjun Han ∗ F ebruary 23, 2026 Abstract Sto c hastic gradien t descent (SGD) is a cornerstone algorithm for high-dimensional optimiza- tion, renowned for its empirical successes. Recen t theoretical adv ances ha ve provided a deep understanding of how SGD enables feature learning in high-dimensional nonlinear mo dels, most notably the single-index mo del with i.i.d. data. In this work, w e study the sequen tial learn- ing problem for single-index mo dels, also kno wn as generalized linear bandits or ridge bandits, where SGD is a simple and natural solution, y et its learning dynamics remain largely unexplored. W e show that, similar to the optimal interactiv e learner, SGD undergo es a distinct “burn-in” phase b efore en tering the “learning” phase in this setting. Moreo ver, with an appropriately c hosen learning rate schedule, a single SGD pro cedure simultaneously achiev es near-optimal (or b est-known) sample complexit y and regret guaran tees across both phases, for a broad class of link functions. Our results demonstrate that SGD remains highly competitive for learning single-index models under adaptiv e data. 1 In tro duction Sto c hastic gradient descen t (SGD) and its man y v ariants ha v e achiev ed remark able empirical success in solving high-dimensional optimization problems in mac hine learning. Recent theoretical adv ances ha ve provided rigorous analyses of SGD in high-dimensional, non-con vex settings for a range of statistical and machine learning tasks, suc h as te nsor decomp osition [GHJY15], PCA [WML17], phase retriev al [CCFM19, TV23], to name a few. A particularly intriguing setting is that of single- index mo dels [DH18, BA GJ21] (and generalizations to multi-index mo dels [AAM22, AAM23, DLS22, ASKL23, BBPV25]) with Gaussian data. In this framework, eac h observ ation ( x t , y t ) consists of a Gaussian feature x t ∼ N (0 , I d ) and a noisy outcome y t = f ( ⟨ θ ⋆ , x t ⟩ ) + ε t , where f : R → R is a known link function, θ ⋆ ∈ S d − 1 is an unknown parameter vector on the unit sphere in R d , and ε t denotes the unobserv ed noise. With a learning rate η t > 0 and a random initialization θ 1 ∼ Unif ( S d − 1 ), the SGD up date for learning single-index mo dels is given b y θ t +1 / 2 = θ t − η t ( f ( ⟨ θ t , x t ⟩ ) − y t ) f ′ ( ⟨ θ t , x t ⟩ ) · ( I − θ t θ ⊤ t ) x t , θ t +1 = θ t +1 / 2 ∥ θ t +1 / 2 ∥ . (1) ∗ Niv ed Ra jaraman is with Microsoft Researc h NYC, email: nrajaraman@microsoft.com . Y anjun Han is with the Couran t Institute of Mathematical Sciences and Center for Data Science, New Y ork Universit y , email: yanjunhan@ nyu.edu . 1 Here, the first up date is a descen t step of the p opulation loss θ 7→ 1 2 E ( f ( ⟨ θ , x ⟩ ) − y ) 2 at θ = θ t , whose spherical gradient 1 is estimated based on the curren t sample ( x t , y t ). It is w ell kno wn (cf. e.g. [BAGJ21]) that the evolution of SGD in this context exhibits tw o distinct phases: an initial “searc h” phase, during which the c orr elation ⟨ θ t , θ ⋆ ⟩ gradually improv es from O ( d − 1 / 2 ) to Ω(1), follo wed by a “descen t” phase in which the iterates θ t con verge rapidly to the global optimum θ ⋆ , driving ⟨ θ t , θ ⋆ ⟩ arbitrarily close to 1. Bey ond statistical learning, single-index mo dels hav e found applications in interactiv e decision- making problems, including bandits and reinforcement learning, where the rew ard is a nonlinear function of the action. An example is manipulation with ob ject in teraction, which represen ts one of the largest op en problems in rob otics [BK19] and requires designing go o d sequen tial decision rules that can deal with sparse and non-linear reward functions and contin uous action spaces [ZGR + 19]. This setting is kno wn as the gener alize d line ar b andit or ridge b andit in the bandit literature, where the mean reward satisfies E [ r t | a t ] = f ( ⟨ θ ⋆ , a t ⟩ ) with a known link function f . Classical results [F CGS10, R VR14] sho w that when 0 < c 1 ≤ f ′ ( x ) ≤ c 2 ev erywhere, b oth the optimal regret and the optimal learner are essen tially the same as in the linear bandit case (where f ( x ) = x ). Recen t studies [LH21, HHK + 21, RHJR24] hav e considered c hallenging settings where f ′ ( x ) could b e small around x = 0. This line of work yields tw o main insights: 1. While the final “learning” phase has the same regret as linear bandits, there could b e a long “burn-in” p erio d until the learner can identify some action a t with ⟨ θ ⋆ , a t ⟩ = Ω(1); 2. New exploration algorithms are necessary during this burn-in p erio d, as classical metho ds suc h as UCB are prov ably sub optimal for minimizing the initial exploration cost. In resp onse to the second p oin t, this line of research has prop osed v arious exploration strategies for the burn-in phase that are often tailored to the sp ecific link function f and rely on noisy gradient estimates via zeroth-order optimization. In contrast, SGD offers a natural and straightforw ard al- ternativ e, as its in trinsic “search” and “descent” phases align w ell with the “burn-in” and “learning” phases encountered in interactiv e decision-making. This pap er is devoted to a systematic study of SGD for learning single-index mo dels, including the aforementioned c hallenging setting where f ′ ( x ) could be small around x ≈ 0, within interactiv e decision-making settings. In these scenarios, the actions a t are no longer Gaussian, prompting us to adopt the following exploration strategy: a t = q 1 − σ 2 t θ t + σ t Z t , Z t ∼ Unif n a ∈ S d − 1 : ⟨ a, θ t ⟩ = 0 o , (2) where an additional h yp erparameter σ t ∈ [0 , 1] gov erns the exploration-exploitation tradeoff. After pla ying the action a t and observing the reward r t , we up date the parameter θ t via the same SGD as (1): θ t +1 / 2 = θ t − η t ( f ( ⟨ θ t , a t ⟩ ) − r t ) f ′ ( ⟨ θ t , a t ⟩ ) · ( I − θ t θ ⊤ t ) a t , θ t +1 = θ t +1 / 2 ∥ θ t +1 / 2 ∥ . (3) By simple algebra, the sto chastic gradien t in (3) is also an un biased estimator of the p opulation (spherical) gradient of θ 7→ 1 2 E ( f ( ⟨ θ , a ⟩ ) − r ) 2 at θ = θ t , with the distribution of a giv en by (2) and the reward r = f ( ⟨ θ ⋆ , a ⟩ ) + ε . Our main result will establish that, for a broad class of link functions, this SGD pro cedure, with appropriately c hosen hyperparameters ( η t , σ t ), achiev es near- optimal p erformance in b oth the burn-in and learning phases. 1 Recall that the spherical gradient of a function f : S d − 1 → R is defined as ∇ f = Df − ∂ f ∂ r ∂ ∂ r , where D f is the Euclidean gradient, and ∂ ∂ r is the deriv ativ e in the radial direction. 2 Notation. F or x ∈ R d , let ∥ x ∥ b e its ℓ 2 norm. F or x, y ∈ R d , let ⟨ x, y ⟩ b e their inner pro duct. Let S d − 1 b e the unit sphere in R d . Throughout this pap er w e will use θ ⋆ ∈ S d − 1 to denote the true parameter, θ t to denote the current estimate, and m t = ⟨ θ ⋆ , θ t ⟩ ∈ [ − 1 , 1] to denote the c orr elation . The standard asymptotic notations o, O , Ω, etc. are used throughout the pap er, and we also use e O , e Ω, etc. to denote the resp ectiv e meanings with hidden p oly-logarithmic factors. 1.1 Main results First w e giv e a formal form ulation of the single-index model in the in teractive setting. Let θ ⋆ ∈ S d − 1 b e an unknown parameter vector, and A = S d − 1 b e the action space. Up on c ho osing an action a t ∈ A , the learner receives a rew ard r t = f ( ⟨ θ ⋆ , a t ⟩ ) + ε t for a known link function f : [ − 1 , 1] → R and an unobserved noise ε t whic h is assumed to b e zero-mean and 1-subGaussian. Remark 1.1. The sc aling c onsider e d her e differs crucial ly fr om the prior study on le arning single- index mo dels under non-inter active envir onments (such as [DH18, BA GJ21] with Gaussian or i.i.d. fe atur es). In the non-inter active setting, it is usual ly assume d that x t ∼ N (0 , I d ) , so that ∥ x t ∥ ≍ √ d . In the inter active setting, we stick to the c onvention that actions b elong to the unit ℓ 2 b al l, in line with settings c onsider e d in the b andit liter atur e [F CGS10, R VR14, RHJR24]. As a c onse quenc e, sample c omplexity c omp arisons b etwe en the inter active and non-inter active settings must b e made with c ar e. We discuss this in mor e detail in Se ction 5 and c omp ar e with r esults establishe d for online SGD with Gaussian fe atur es [BAGJ21] after normalizing for the differ enc e in sc aling. Throughout the pap er we make the follo wing mild assumptions on the link function f . Assumption 1.2. The fol lowing c onditions hold for the link function f : 1. (monotonicit y) f : [ − 1 , 1] → [ − 1 , 1] is non-de cr e asing, with ∥ f ∥ ∞ ≤ 1 ; 2. (lo cally linear near x = 1) 0 < γ 1 ≤ f ′ ( x ) ≤ γ 2 for al l x ∈ [1 − γ 0 , 1] , with absolute c onstants γ 0 , γ 1 , γ 2 > 0 . Without loss of gener ality we assume that γ 0 ≤ 0 . 1 . In Assumption 1.2, the monotonicity condition is taken from [RHJR24] to ensure that rew ard maximization is aligned with p arameter estimation, where improving the alignmen t ⟨ θ ⋆ , a t ⟩ directly increases the learner’s reward. In addition, when it comes to SGD, w e will sho w in Section 5 that the p opulation loss asso ciated with the SGD dynamics in (3) is decreasing in the correlation m t = ⟨ θ ⋆ , θ t ⟩ only if f is increasing. Without monotonicity , there also exists a counterexample where the SGD can nev er mak e meaningful progress (cf. Prop osition 5.1). Similar to [RHJR24], this condition can b e generalized to f being even and non-decreasing on [0 , 1], whic h cov ers, for example, f ( x ) = | x | p for all p > 0. The second condition in Assumption 1.2 is v ery mild, satisfied b y many natural functions, and ensures that the problem lo cally resembles a linear bandit near the global optimum a t ≈ θ ⋆ . Finally , we emphasize that this lo cal linearit y do es not exclude the non trivial scenario where f ′ ( x ) is very small when x ≈ 0. Our first result is the SGD dynamics in the learning phase, under Assumption 1.2. Theorem 1.3 (Learning Phase) . L et ε, δ > 0 . Under Assumption 1.2, let ( a t , θ t ) t ≥ 1 b e given by the SGD evolution in (2) and (3) , with an initialization θ 1 such that ⟨ θ 1 , θ ⋆ ⟩ ≥ 1 − γ 0 / 4 . 1. (Pur e explor ation) By cho osing η t = e Θ( d t ∧ 1 d ) and σ 2 t = Θ(1) , it holds that m T ≥ 1 − ε with pr ob ability at le ast 1 − δ T , with T = e O ( d 2 ε ) . 2. (R e gr et minimization) By cho osing η t = e Θ( 1 √ t ∧ 1 d ) and σ 2 t = e Θ( d √ t ∧ 1) , with pr ob ability at le ast 1 − δ T it holds that P T t =1 ( f (1) − f ( m t )) = e O ( d √ T ) . 3 Both upp er b ounds in Theorem 1.3 are near-optimal and matc h the low er b ounds Ω( d 2 ε ) and Ω( d √ T ) for the resp ectiv e tasks, shown in Theorem 1.7 of [RHJR24]. In other w ords, SGD with prop er learing rate and exploration sc hedules achiev es an optimal learning p erformance in the learning phase, giv en a “w arm start” θ 1 with ⟨ θ 1 , θ ⋆ ⟩ ≥ 1 − γ 0 / 2. T o search for this “warm start” through the burn-in phase, we additionally make one of the following assumptions. Assumption 1.4. Ther e is an absolute c onstant c 0 > 0 such that f ′ ( x ) ≥ c 0 for al l x ∈ [0 , 1] . Assumption 1.5. The link function f is c onvex on [0 , 1] . Sp ecifically , Assumption 1.4 and 1.5 cov er tw o different regimes of generalized linear bandits: Assumption 1.4 corresp onds to the classical “linear bandit” regime studied in [FCGS10, R VR14], and Assumption 1.5 cov ers the case with a long burn-in p erio d where f ′ ( x ) is small at the b eginning, e.g. in [LH21, HHK + 21]. W e will discuss the challenges in dropping the conv exity assumption for the SGD analysis in Section 5. Under Assumption 1.4 or 1.5, our next result characterizes the SGD dynamics in the burn-in phase. Theorem 1.6 (Burn-in Phase) . L et δ > 0 , and Assumption 1.2 hold. L et ( a t , θ t ) t ≥ 1 b e given by the SGD evolution in (2) and (3) , with an initialization θ 1 such that ⟨ θ 1 , θ ⋆ ⟩ ≥ 1 √ d . 1. Under Assumption 1.4, by cho osing η t = e Θ( 1 d 2 ) and σ 2 t = Θ(1) , it holds that m T ≥ 1 − γ 0 / 4 with pr ob ability at le ast 1 − δ T , wher e T = e O ( d 2 ) . 2. Under Assumption 1.5, by cho osing an appr opriate le arning r ate sche dule (cf. L emma 4.2) and σ 2 t = Θ(1) , it holds that m T ≥ 1 − γ 0 / 4 with pr ob ability at le ast 1 − δ T , wher e T = e O d 2 Z 1 − γ 0 / 4 1 / (2 √ d ) m f ′ ( m ) 2 d m . Note that for θ 1 ∼ Unif ( S d − 1 ), the condition ⟨ θ ⋆ , θ 1 ⟩ ≥ 1 / √ d is fulfilled with a constant prob- abilit y . A simple h yp othesis testing subroutine in [RHJR24, Lemma 3.1] could further certify it using e O (( f (1 / √ d ) − f (0)) − 2 ) samples. Therefore, com bining Theorem 1.3 and 1.6, w e hav e the follo wing corollary on the ov erall complexit y of SGD. Corollary 1.7 (Overall sample complexit y and regret) . Under Assumption 1.2 and Assumption 1.4 or 1.5, the SGD evolution in (2) and (3) with pr op er ( η t , σ t ) t ≥ 1 and a hyp othesis testing subr outine for initialization satisfies the fol lowing: 1. (Pur e explor ation) F or ε, δ > 0 , m T ≥ 1 − ε with pr ob ability at le ast 1 − δ T , wher e T = e O d 2 Z 1 − γ 0 / 4 1 / (2 √ d ) m f ′ ( m ) 2 d m + d 2 ε . 2. (R e gr et minimization) F or δ > 0 , with pr ob ability at le ast 1 − δ T , the r e gr et satisfies T X t =1 ( f (1) − f ( m t )) = e O min n T , d 2 Z 1 − γ 0 / 2 1 / (2 √ d ) m f ′ ( m ) 2 d m + d √ T o . 4 0 10000 20000 30000 40000 50000 60000 70000 80000 I t e r a t i o n t 0.2 0.4 0.6 0.8 1.0 t , Cor r elation (a) Evolution of m t = ⟨ θ ⋆ , θ t ⟩ av eraged across 100 runs. The shaded region plots one standard devia- tion. 0 10000 20000 30000 40000 50000 60000 70000 80000 I t e r a t i o n t 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 t , Cor r elation (b) A single tra jectory of m t = ⟨ θ ⋆ , θ t ⟩ . Figure 1: Correlation m t = ⟨ θ t , θ ⋆ ⟩ plotted as a function of t in d = 20 dimensions, for the cubic link f ( x ) = x 3 . W e run interactiv e SGD with a constant learning rate η t = 0 . 002 for all t , using an exploration schedule with σ t = 0 . 5 until m t reac hes 0 . 7 and σ t = 0 . 2 thereafter. Under Assumption 1.4, Corollary 1.7 yields an ov erall sample complexity b ound e O ( d 2 /ε ) and a regret b ound e O (min { T , d √ T } ), b oth of which are kno wn to b e near-optimal, e.g., in the case of linear bandits [LS20, W CS + 22]. Under Assumption 1.5, the upp er b ounds in Corollary 1.7 also match the b est known guarantees in [RHJR24], using a differen t algorithm based on succes- siv e hypothesis testing. In the sp ecial case f ( x ) = x p with o dd p ≥ 3, SGD ac hieves a regret b ound e O (min { T , d p + d √ T } ), which is near-optimal [HHK + 21, RHJR24]. By contrast, many other approac hes, including all non-in teractiv e algorithms (in particular, non-in teractive SGD) and UCB- based metho ds, pro v ably incur a larger burn-in cost of e Ω( d p +1 ) [RHJR24]. Therefore, it is striking that SGD attains optimal p erformance even in the burn-in phase, while simultaneously staying optimal in the learning phase. T aken together, these results highlight SGD as a natural, efficient, and highly comp etitive algorithm with near-optimal statistical guarantees for learning single-index mo dels in the interactiv e setting. As a numerical example, Figure 1 illustrates the evolution of m t obtained by SGD with a constant learning rate for the cubic link f ( x ) = x 3 , shown either as an a verage ov er 100 runs (left panel) or as a single tra jectory (righ t panel). W e observe that, despite the non-con vex loss landscap e and p oten tially non-monotonic progress, SGD consistently delivers strong p erformance during b oth the burn-in and learning phases. 1.2 Related work Single-index models. Analyzing feature learning in non-linear functions of lo w-dimensional fea- tures has a long history . The approximation and statistical asp ects are well understo od in [Bar02, Bac17]; by contrast, the computational asp ects remain more c hallenging, and p ositive results t ypi- cally require additional assumptions on the link function and/or the data distribution. F o cusing on the link function f , a rich line of w ork [KS09, SSSS10, KKSK11, Sol17, F CG20, YO20, W u22] has ex- ploited its monotonicit y or inv ertibilit y to obtain efficien t learning guaran tees under broad distribu- tional assumptions. At the other end of the sp ectrum, the seminal works [DH18, BAGJ21] dev elop ed a harmonic-analysis framew ork for studying SGD under Gaussian data, sparking extensive follow-up 5 researc h [AAM22, BBSS22, DLS22, BAGJ22, AAM23, ZPVB23, DPVLB24, BA GP24, BBPV25]. A represen tative finding for the single-index mo del is that the sample complexity of SGD is go verned by the information exp onent of the link function, i.e., the index of its first non-zero Hermite co efficien t. In the in teractive setting, how ev er, where the data distribution is no longer i.i.d., the information exp onen t ceases to b e an informativ e measure of SGD’s p erformance. W e defer more discussions to Section 5. Generalized linear bandits. The most canonical examples of generalized linear bandits are linear bandits [DHK08, R T10, CLRS11] and ridge bandits with 0 < c 1 ≤ | f ′ ( · ) | ≤ c 2 ev erywhere. In both cases, the minimax regret is e Θ( d √ T ) [F CGS10, A YPS11, R VR14], attained b y algorithms suc h as LinUCB and information-directed sampling. F or more challenging con vex link functions, the sp ecial cases f ( x ) = x 2 and f ( x ) = x p with p ≥ 2 w ere analyzed in [LH21, HHK + 21], using either successive searching algorithms or noisy p ow er metho ds. These results w ere substantially generalized by [RHJR24], which iden tified the existence of a general burn-in p eriod and established tigh t upp er and low er b ounds on the optimal burn-in cost via differential equations. In particular, their upp er b ound strengthens Corollary 1.7 in the absence of conv exit y , using an refined algorithm of [LH21] during the burn-in phase and an ETC (explore-then-commit) algorithm in the learning phase. By contrast, we show that a single, muc h simpler SGD algorithm ac hieves the same upp er b ound for con vex f . A related line of work [FYY23, KL Y + 25] studied the single-index mo del with an unknown link function, where the central idea is to estimate the score function. Their resulting algorithms are of the ETC type, and the regret guarantees rely on a p ositiv e low er b ound for f ′ . Gradien t descent in online learning and bandits. Gradient and mirror descen t are classical algorithms in online settings (including online learning and online conv ex optimization [CBL06, H + 16, Ora19]), as w ell as in bandit problems with gradien t estimation, suc h as EXP3 for adv ersarial m ulti-armed bandits and FTRL for adv ersarial linear bandits [LS20]. A distinct feature of our w ork is that our SGD remains a first-order metho d ev en in this bandit problem, in con trast to the zeroth- order sto chastic optimization usually used for single-index mo dels such as [HHK + 21]. Moreov er, the SGD dynamics for single-index mo dels demand a more fine-grained analysis than that required b y standard online learning guarantees. F urther details are pro vided in Section 5. 1.3 Organization The rest of this pap er is organized as follows. In Section 2 we presen t a general analysis of the SGD up date, including b ounds on the mean drift, sto chastic term, and normalization error. In Section 3 and 4, w e analyze the learning and burn-in phases, resp ectively . Additional discussion is provided in Section 5, and detailed pro ofs are deferred to the app endix. 2 Analysis of the SGD up date T o establish our main results Theorem 1.3 and 1.6, w e first understand the properties of eac h SGD up date in (2) and (3). At each time step t , the improv ement on the correlation from m t := ⟨ θ ⋆ , θ t ⟩ to m t +1 := ⟨ θ ⋆ , θ t +1 ⟩ consists of three parts: 1. Drift : the mean improv emen t E [ m t +1 / 2 |F t ] − m t of the descent step in (3), where m t +1 / 2 := ⟨ θ ⋆ , θ t +1 / 2 ⟩ , and F t denotes all historic observ ations up to the end of time t . 6 2. Martingale differ enc e : the sto chastic term m t +1 / 2 − E [ m t +1 / 2 |F t ] with zero mean. 3. Normalization err or : the difference m t +1 − m t +1 / 2 due to the normalization step in (3). W e will present generic lemmas to b ound eac h of the ab ov e terms in this section, and use them to analyze the learning and burn-in phases in the next t wo sections. W e start from the drift. Lemma 2.1 (Drift) . L et d ≥ 3 . The fol lowing identity holds for the drift: E [ m t +1 / 2 |F t ] − m t = η t σ 2 t d − 2 f ′ p 1 − σ 2 t (1 − m 2 t ) · E f ′ p 1 − σ 2 t m t + σ t q 1 − m 2 t X (1 − X 2 ) F t . wher e X fol lows the one-dimensional mar ginal of the uniform distribution over S d − 2 . In p articular, if m t > 0 , E [ m t +1 / 2 |F t ] − m t ≥ c dr ( η t σ 2 t d f ′ p 1 − σ 2 t (1 − m 2 t ) under Assumption 1.4 η t σ 2 t d f ′ p 1 − σ 2 t (1 − m 2 t ) f ′ ( p 1 − σ 2 t m t ) under Assumption 1.5 , for a universal c onstant c dr > 0 . The next result concerns the sub exponential concentration prop erty of the martingale difference. Lemma 2.2 (Martingale difference) . The Ψ 1 -Orlicz norm (i.e., the sub exp onential norm) of the martingale differ enc e has the fol lowing upp er b ound, c onditione d on F t : ∥ m t +1 / 2 − E [ m t +1 / 2 |F t ] ∥ Ψ 1 ≤ K t ≜ C se r 1 − m 2 t d η t σ t f ′ p 1 − σ 2 t , wher e C se > 0 is a universal c onstant. Based on Lemma 2.2, we pro ceed to consider the (disc oun ted) sum of martingale differences. F or t 0 ≥ 0 and β > 0, let S t 0 ,β t := t − 1 X s = t 0 β s − t 0 m s +1 / 2 − E [ m s +1 / 2 |F s ] b e a martingale adapted to {F t } t ≥ t 0 , and V t 0 ,β t := P t − 1 s = t 0 β 2( s − t 0 ) K 2 s b e a proxy for its predictable quadratic v ariation. The follo wing result is a self-normalized concentration inequality for suc h pro cesses established in [WWR23, Theorem 3.1]: Lemma 2.3 (Sum of martingale differences) . L et η t ≤ ( C se γ 2 ) − 1 and σ 2 t ≤ γ 0 for al l t ≥ 1 , and β ≥ 0 . F or δ > 0 , it holds that P ∃ t ≥ t 0 : | S t 0 ,β t | ≥ C mt q V t 0 ,β t ∨ 1 log 1 + log( V t 0 ,β t ∨ 1) δ ! and β t − t 0 ≤ 2 F t 0 ! ≤ δ, for some universal c onstant C mt > 0 . Note that when β ∈ [0 , 1], the condition β t − t 0 ≤ 2 is v acuous. F or β > 1, this condition results in a smaller range of t ∈ [ t 0 , t 0 + log β 2]. Finally , we bound the normalization error m t +1 − m t +1 / 2 . Lemma 2.4 (Normalization error) . With pr ob ability at le ast 1 − δ , it holds that m t +1 ≥ m t +1 / 2 − C nm · η 2 t σ 2 t f ′ p 1 − σ 2 t 2 log(1 /δ ) , for some universal c onstant C nm > 0 . In addition, if m t +1 / 2 ≥ 0 , then with pr ob ability 1 − δ , m t +1 / 2 ≥ m t +1 ≥ m t +1 / 2 1 − C nm · η 2 t σ 2 t f ′ p 1 − σ 2 t 2 log(1 /δ ) . 7 3 Analysis of the learning phase In this section we analyze the SGD dynamics in the learning phase, giv en a “warm start” θ 1 with m 1 = ⟨ θ ⋆ , θ 1 ⟩ ≥ 1 − γ 0 / 4. 3.1 Pure exploration The crux of the pro of of Theorem 1.3 lies in the follo wing lemma, which shows that starting from a correlation m t ≥ 1 − ε , SGD will improv e it to 1 − ε/ 2 after e O ( d 2 /ε ) steps. Lemma 3.1 (Lo cal improv emen t for pure exploration) . Supp ose m t ≥ 1 − ε for some ε ≤ γ 0 / 4 . L et ι := log 2 ( d/εδ ) , and for s ≥ t , set η s ≡ η := cε dι , σ 2 s ≡ σ 2 := γ 0 , wher e c > 0 is a smal l absolute c onstant. Then for ∆ := C d/η and a lar ge absolute c onstant C > 0 indep endent of c , we have m t +∆ ≥ 1 − ε/ 2 with pr ob ability at le ast 1 − ∆ δ . W e call the time in terv al [ t, t + ∆] an “ep o c h”, and c ho ose the learning rate based on the ep och. Lemma 3.1 shows that, as long as the correlation is large at the b eginning of an ep och, then it m ust be impro ved in a linear rate at the end of the ep och. Therefore, by induction and a geometric series calculation, it is clear that the learning rate schedule given by Lemma 3.1 corresp onds to η t = e Θ( d t ∧ 1 d ), and Lemma 3.1 gives an ov erall sample complexity e O ( d 2 ε ) for pure exploration. In the sequel we pro ve Lemma 3.1. W e first show that by induction on s that with probabilit y at least 1 − ∆ δ / 3, m s ≥ 1 − 2 ε for all s ∈ [ t, t + ∆]. The base case s = t is ensured b y the assumption m t ≥ 1 − ε . F or the inductive step, supp ose m t , . . . , m s − 1 ≥ 1 − 2 ε . Then m s − m t = s − 1 X r = t h E [ m r +1 / 2 |F r ] − m r | {z } ≥ 0 by Lemma 2.1 + m r +1 / 2 − E [ m r +1 / 2 |F r ] | {z } =: A r + m r +1 − m r +1 / 2 | {z } =: B r i . Thanks to the inductiv e h yp othesis, K r = O ( η p ε d ) for all r ∈ [ t, s − 1] in Lemma 2.2, so Lemma 2.3 (with t 0 = t, β = 1) gives, s − 1 X r = t A r = O η r ∆ ε d log ∆ δ ! = O √ η ε log ∆ δ < ε 8 with probability 1 − δ 6 , by choosing c > 0 small enough. Similarly , s − 1 X r = t | B r | = O ∆ η 2 log ∆ δ = O dη log ∆ δ < ε 8 with probabilit y 1 − δ 6 , by Lemma 2.4 and c ho osing c > 0 small enough. This implies that m s ≥ m t − ε 4 > 1 − 2 ε with probability 1 − δ 3 , completing the induction. Conditioned on the even t m s ≥ 1 − 2 ε for all s ∈ [ t, t + ∆], w e distinguish into tw o regimes in this ep o c h. Let T 0 ≥ t b e the stopping time when m s > 1 − ε/ 4 for the first time. 8 Regime I: t ≤ s < T 0 . In this regime m s ∈ [1 − 2 ε, 1 − ε/ 4]. W e show that T 0 ≤ t + ∆ with probabilit y 1 − ∆ δ / 3. If T 0 > t + ∆, using the same high-probability b ounds, we ha ve m t +∆ − m t ≥ t +∆ − 1 X s = t E [ m s +1 / 2 |F s ] − m s − ε 4 with probability 1 − ∆ δ / 3. By Lemma 2.1 with 1 − m 2 s = Ω( ε ) and p 1 − σ 2 s m s ≥ 1 − γ 0 for s < T 0 , the total drift is Ω( ∆ η ε d ) = Ω( C ε ). Therefore, for a large absolute constant C > 0, we would ha ve m t +∆ ≥ 1 − ε/ 4, a contradiction to the assumption T 0 > t + ∆. Regime I I: s ≥ T 0 . As shown ab o ve, this regime is non-empty with high probability . The same induction starting from s = T 0 sho ws that, with probability 1 − ∆ δ / 3, m s ≥ m T 0 − ε/ 4 holds for all s ∈ [ T 0 , t + ∆]. In particular, c ho osing s = t + ∆ gives the desired result m t +∆ ≥ 1 − ε/ 2. 1 − ε 1 − ε 2 1 − ε 4 1 − 2 ε t T 0 t + ∆ Figure 2: A n example b ehavior of SGD for pur e explor ation in the le arning phase (cf. L emma 3.1). F or appropriately chosen learning rates, if the correlation hits m t ≥ 1 − ε at time t , the SGD dynamics will enjoy the following b eha viors with high probability: ( i ) the tra jectory will never degrade to o significantly , satisfying m s ≥ 1 − 2 ε for all t ≤ s ≤ t + ∆; ( ii ) at some time s = T 0 ∈ [ t, t + ∆], m s impro ves to at least 1 − ε 4 ; and ( iii ) thereafter, m s ma y decrease, but will never fall b elo w 1 − ε 2 for all T 0 ≤ s ≤ t + ∆. An illustration of our pro of technique is displa yed in Figure 2. 3.2 Regret minimization The pro of of Theorem 1.3 for regret minimization follo ws similarly from the following lemma. Lemma 3.2 (Local impro vemen t for regret minimization) . Supp ose m t ≥ 1 − ε for some ε ≤ γ 0 / 4 . L et ι := log 2 ( d/εδ ) , and for s ≥ t , set η s ≡ η := cε dι , σ 2 s ≡ σ 2 := ε, wher e c > 0 is a smal l absolute c onstant. Then for ∆ := C d/ ( η ε ) and a lar ge absolute c onstant C > 0 indep endent of c , with pr ob ability at le ast 1 − ∆ δ , we have ⟨ θ ⋆ , a s ⟩ ≥ 1 − 4 ε for al l s ∈ [ t, t + ∆] , and m t +∆ ≥ 1 − ε/ 2 . 9 The main distinction in Lemma 3.2 is the choice of a smaller σ 2 s to encourage exploitation for a small regret: using the lo cal linearit y assumption in Assumption 1.2, the total regret in the ep och is t +∆ X s = t ( f (1) − f ( ⟨ θ ⋆ , a s ⟩ )) ≤ (∆ + 1) · 4 γ 2 ε = e O d 2 ε with probability 1 − ∆ δ. In addition, the duration of each ep och b ecomes longer, with a corresp ondence ε = e Θ( d √ t ∧ 1). This corresp ondence giv es the learning rate and exploration schedule in Theorem 1.3, as well as the e O ( d √ T ) regret b ound. The pro of of Lemma 3.2 is deferred to the app endix. 4 Analysis of the burn-in phase The analysis of the SGD dynamics in the burn-in phase relies on similar induction ideas, with a more complicated tradeoff among the three components in the correlation impro vemen t m t +1 − m t . 4.1 Link function with deriv ative low er b ound W e first inv estigate the simpler scenario in Assumption 1.4, i.e., f ′ ( x ) ≥ c 0 for all x ∈ [0 , 1]. In this case, Theorem 1.6 is a direct consequence of the following lemma: Lemma 4.1 (Burn-in phase under Assumption 1.4) . Supp ose m 1 ≥ 1 √ d . L et ι := log 2 ( d/δ ) , and set η t ≡ η := c dι , σ 2 t ≡ σ 2 := γ 0 , wher e c > 0 is a universal c onstant. Then for T := C d/η and a lar ge absolute c onstant C > 0 indep endent of c , we have m T ≥ 1 − γ 0 / 4 with pr ob ability at le ast 1 − T δ . In the sequel we present the pro of of Lemma 4.1. Again we consider the stopping time T 0 = min { t ≥ 1 : m t ≥ 1 − γ 0 / 8 } and splits into t wo regimes. Regime I: t ≤ T 0 . If T 0 > T , w e prov e b y induction that m t ≥ 1 2 √ d + c 1 η ( t − 1) d for all t ∈ [1 , T ] with probabilit y at least 1 − T δ , for some absolute constan t c ′ > 0 independent of c . The base case t = 1 is our assumption. Now suppose this low er bound holds for m 1 , . . . , m t − 1 , then by Lemma 2.1 and 2.4, with probability at least 1 − δ 4 , for each s = 1 , . . . , t − 1, E [ m s +1 / 2 |F s ] − m s + m s +1 − m s +1 / 2 = Ω η d − O η 2 log( 2 δ ) = Ω η d b y our choice of η . Here we hav e critically used the condition m s = 1 − Ω(1) for s < T 0 when applying Lemma 2.1, and the inductiv e hypothesis to ensure m s > 0. By Lemma 2.2 and 2.3, with probabilit y 1 − δ 4 , the sum of martingale difference is at most O ( η q T d log( T δ )) = O ( √ η log( T δ )) ≤ 1 2 √ d for c > 0 small enough. Therefore, m t ≥ m 1 − 1 2 √ d + t − 1 X s =1 Ω η d ≥ 1 2 √ d + Ω η ( t − 1) d , completing the induction step. No w choosing t = T with C > 0 large enough sho ws the opp osite result m T ≥ 1 − γ 0 / 8, implying that the even t T 0 > T only o ccurs with probability at most T δ / 2. 10 Regime I I: T 0 ≤ t ≤ T . Under the high-probability ev ent T 0 ≤ T and starting from t = T 0 , m T − m T 0 = T − 1 X t = T 0 h E [ m t +1 / 2 |F t ] − m t | {z } ≥ 0 by Lemma 2.1 + m t +1 / 2 − E [ m t +1 / 2 |F t ] | {z } =: A t + m t +1 − m t +1 / 2 | {z } =: B t i . By Lemma 2.2 and 2.3, | T − 1 X t = T 0 A t | = O ( η r T d log( T δ )) = O ( √ η log( T δ )) < γ 0 16 with probability 1 − T δ / 2, for c > 0 small enough. In addition, Lemma 2.4 gives T − 1 X t = T 0 | B t | = O ( T η 2 log( T δ )) = O ( dη log( T δ )) < γ 0 16 with probabilit y 1 − T δ / 2, again for c > 0 small enough. Therefore, at the end of this regime, m T ≥ m T 0 − γ 0 / 8 ≥ 1 − γ 0 / 4 with probability 1 − T δ , as desired. 4.2 Con v ex link function When f is conv ex in Assumption 1.5, we establish the following lemma. Lemma 4.2 (Lo cal improv emen t for con vex link function) . F or 1 ≤ k ≤ d − 1 , let m k := (1 − γ 0 ) 2 p k /d , and m k := (1 − γ 0 / 4) p k /d . Supp ose that m t ≥ m k at the b e ginning of the k -th ep o ch. L et ι := log 2 ( d/δ ) , and for s ≥ t , set η s ≡ η := cf ′ ( m k ) ιdm k , σ 2 s ≡ σ 2 := γ 0 , wher e c > 0 is a smal l absolute c onstant. Then for ∆ := C d ( m k +1 − m k ) / ( η f ′ ( m k )) and a lar ge absolute c onstant C > 0 indep endent of c , we have m t +∆ ≥ m k +1 with pr ob ability at le ast 1 − ∆ δ . Since m 1 ≥ p 1 /d ≥ m 1 , a recursiv e application of Lemma 4.2 for k = 1 , . . . , d − 1 leads to m T ≥ 1 − γ 0 / 4 with probability at least 1 − T δ , with (recall that γ 0 ≤ 0 . 1) T = O log 2 d δ · d 2 d − 1 X k =1 m k ( m k +1 − m k ) f ′ ( m k ) 2 ! = e O d 2 Z 1 − γ 0 / 4 1 2 √ d x d x f ′ ( x ) 2 ! . This completes the pro of of Theorem 1.6. The pro of of Lemma 4.2 is more inv olv ed, and we defer the details to the app endix. 5 Discussion Comparison with other descen t algorithms. Our SGD up date in (3) is an online gradi- en t descent applied to the loss ℓ t ( θ ) := 1 2 ( r t − f ( ⟨ θ , a t ⟩ )) 2 , with a t c hosen according to (2). A t ypical guaran tee in online learning takes the form (e.g., via the sequen tial Rademac her complex- it y [RST15]) T X t =1 ( f ( ⟨ θ t , a t ⟩ ) − f ( ⟨ θ ⋆ , a t ⟩ )) 2 = e O ( d ) . 11 whic h is known as an online regression oracle [FR20, FK QR21]. Ho wev er, this oracle guarantee alone do es not yield the optimal regret of θ t in single-index mo dels; see Theorem 1.5 of [RHJR24] for a general negativ e result. This motiv ates us to mov e beyond standard online learning guarantees and directly analyze the SGD dynamics. A different descen t algorithm for single-index mo dels is also in [HHK + 21], using zeroth-order sto c hastic optimization to appro ximate the gradien t and implemen t a noisy p ow er metho d. In con trast, our SGD is not a zeroth-order metho d: rather than p erforming gradient descent on the link function θ 7→ f ( ⟨ θ ⋆ , θ ⟩ ) where only a zeroth-order oracle is a v ailable, we apply gradien t descent to the p opulation loss θ 7→ 1 2 E ( r − f ( ⟨ θ , a ⟩ )) 2 for whic h an un biased gradient estimator exists for ev ery θ . This c hange of ob jective makes SGD a natural y et nov el solution to nonlinear ridge bandits. Necessit y of monotonicit y . Throughout this pap er w e assume that the link function f is mono- tone, an assumption that is not needed in the non-in teractive setting (see, e.g., [BAGJ21]). This condition, ho wev er, turns out to b e essen tially necessary for SGD to succeed under our exploration strategy (2). Indeed, when σ t ≡ σ , SGD is p erformed on the p opulation loss E h ( r t − f ( ⟨ θ t , a t ⟩ )) 2 i = E h ( f ( ⟨ θ ⋆ , a t ⟩ ) − f ( ⟨ θ t , a t ⟩ )) 2 i + V ar( r t ) = E f p 1 − σ 2 − f p 1 − σ 2 ⟨ θ ⋆ , θ t ⟩ + σ ⟨ θ ⋆ , Z t ⟩ 2 + V ar( r t ) ≈ f p 1 − σ 2 − f p 1 − σ 2 ⟨ θ ⋆ , θ t ⟩ 2 + V ar( r t ) , where the last appro ximation uses that ⟨ θ ⋆ , Z t ⟩ is t ypically of order e O (1 / √ d ) and th us often neg- ligible. Recall that for SGD to succeed at the p opulation level, the p opulation loss must decrease with the alignment ⟨ θ ⋆ , θ t ⟩ (stated as Assumption A in [BA GJ21]). T reating V ar( r t ) as a constant, this requires f to b e increasing on [0 , √ 1 − σ 2 ] in the interactiv e setting (assuming f ′ (0) > 0). Hence, whenev er σ is b ounded aw ay from 1, a monotonicity assumption on f is indisp ensable in the interactiv e setting. By con trast, when σ = 1 the monotonicity condition is unnecessary: in this case (2) reduces to pure exploration, and the problem essentially collapses to the non-interactiv e setting. Ho wev er, this would eliminate the statistical b enefits of interaction. W e also provide an explicit counterexample to formally supp ort the ab o ve in tuition. Prop osition 5.1. Consider the SGD dynamics in (3) applie d to the link function f ( m ) = 0 if m ≤ 0 − m if 0 < m ≤ 1 3 m − 2 3 if 1 3 < m ≤ 1 , with any initialization m 1 = ⟨ θ ⋆ , θ 1 ⟩ ≤ 0 . 1 , any explor ation sche dule σ t ≤ 0 . 1 , and any le arning r ate η t ≤ c log( T /δ ) for some smal l absolute c onstant c > 0 . Then P (max t ∈ [ T ] m t ≤ 0 . 2) ≥ 1 − δ . Note that the ab ov e link function f violates the monotonicit y condition: it first decreases and then increases on [0 , 1]. By c ho osing δ = T − 2 , Prop osition 5.1 shows that with an y practical initialization, an y exploration sc hedule that do es not essentially corresp ond to a non-interactiv e exploration, and an y learning rate that is not to o large to escap e the lo cal optima, with high probabilit y the resulting SGD cannot achiev e an alignmen t b etter than a small constant (sa y 0 . 2). 12 Comparison with information exp onen t. In the non-interactiv e case with a t ∼ N (0 , I d ), it is kno wn that the information exp onent of f determines the sample complexit y of SGD. In the in teractive case, how ev er, the monotonicit y of f ensures that the information exp onen t is alwa ys 1. Indeed, for the first Hermite p olynomial H 1 ( x ) = x , Chebyshev’s sum inequality yields E Z ∼N (0 , 1) [ f ( Z ) H 1 ( Z )] ≥ E Z ∼N (0 , 1) [ f ( Z )] · E Z ∼N (0 , 1) [ H 1 ( Z )] = 0 , with equalit y iff f ≡ c is a constan t. Moreov er, the sample complexity predicted b y the information exp onen t is no longer tigh t. F or instance, when f ( x ) = x p with an o dd p ≥ 3, the sample complexit y of SGD with a t ∼ N (0 , I d /d ) is e O ( d p +1 ) (see remark below), which is strictly w orse than the e O ( d p ) guaran tee obtained by our in teractive SGD. These observ ations show that the information exp onen t ceases to b e an informativ e measure for SGD in the interactiv e case, for the actions a t are no longer Gaussian. Remark 5.2. F or f ( x ) = x p with o dd p ≥ 3 , the p opulation squar e loss has information exp onent e qual to 1 . L et c 1 b e the c o efficient of the line ar term ⟨ θ ⋆ , θ t ⟩ in E X ∼N (0 ,I d ) h ( f ( ⟨ θ ⋆ , X ⟩ ) − f ( ⟨ θ t , X ⟩ )) 2 i , then c 1 = − 2 u 1 ( f ) 2 with u 1 ( f ) b eing the first Hermite c o efficient of f . When we sc ale down the input fe atur es into X ∼ N (0 , I d /d ) , we effe ctively change f to e f ( x ) = ( x/ √ d ) p , so c 1 b e c omes d − p c 1 . Ther efor e, the SNR effe ctively worsens by a factor of d p . Dropping the con vexit y assumption. The conv exit y assumption in Assumption 1.5 is not required in the statistical complexit y framework developed for ridge bandits in [RHJR24]. Relying only on the monotonicity of f , they establish the upp er b ound e O d 2 Z 1 / 2 1 / √ d d[ x 2 ] max 1 √ d ≤ y ≤ x f ′ ( y ) 2 on the sample complexity of finding an action a t with ⟨ θ ⋆ , a t ⟩ ≥ 1 / 2. In comparison, under our con vexit y assumption the denominator simplifies to f ′ ( x ) 2 . There are tw o main obstacles to re- co vering this sharp er b ound. First, our analysis in Lemma 2.4 requires a conserv ativ e c hoice of the learning rate η t , which in turn dep ends on having a low er b ound for f ′ ( m t ) at the current correlation m t . Obtaining such a b ound is c hallenging without further conditions on f . In this pap er we handle this b y using f ′ ( m t ) ≥ c in the generalized linear case, and f ′ ( m t ) ≥ f ′ ( m t ) in the con vex case, where m t ≤ m t is known. Second, achieving the factor max 1 / √ d ≤ y ≤ x f ′ ( y ) 2 requires a careful tuning of σ t to target the maximizer of f ′ , which in turn relies on kno wledge of the curren t correlation m t . In [RHJR24], this is accomplished by running a separate h yp othesis test. How ev er, suc h an additional testing step is not compatible with the dynamics of SGD. A Pro ofs of main lemmas A.1 Pro of of Corollary 1.7 By Theorem 1.3 and 1.6, it remains to sho w that both the initialization cost e O (( f (1 / √ d ) − f (0)) − 2 ) and the burn-in cost e O ( d 2 ) under Assumption 1.4 are dominated by the integral. 13 F or the initialization cost, w e hav e 1 ( f ( 1 √ d ) − f (0)) 2 (a) ≤ 1 ( f ( 1 √ d ) − f ( 1 2 √ d )) 2 = 4 d 2 √ d R 1 / √ d 1 / (2 √ d ) f ′ ( m )d m 2 (b) ≤ 4 d · 2 √ d Z 1 / √ d 1 / (2 √ d ) 1 f ′ ( m ) 2 d m ≤ 16 d 2 Z 1 / √ d 1 / (2 √ d ) m f ′ ( m ) 2 d m, where (a) follows from the monotonicity of f , and (b) applies Jensen’s inequality . F or the burn-in cost e O ( d 2 ) under Assumption 1.4, we simply note that f ′ ( x ) ≤ γ 2 when x ∈ [1 − γ 0 , 1] by Assumption 1.2, so that d 2 Z 1 − γ 0 / 4 1 − γ 0 m f ′ ( m ) 2 d m ≥ d 2 · 3 γ 0 4 1 − γ 0 γ 2 2 = Ω( d 2 ) . These complete the pro of. A.2 Pro of of Lemma 2.1 Observ e that E [ θ t +1 / 2 |F t ] = E θ t − η t σ t ( f ( ⟨ a t , θ t ⟩ ) − f ( ⟨ a t , θ ⋆ ⟩ ) − N t ) f ′ ( ⟨ a t , θ t ⟩ ) · Z t F t = θ t − η t σ t E ( f ( ⟨ a t , θ t ⟩ ) − f ( ⟨ a t , θ ⋆ ⟩ )) f ′ ( ⟨ a t , θ t ⟩ ) · Z t F t . Recall that a t = p 1 − σ 2 t θ t + σ t Z t in (2). Since Z t ⊥ θ t almost surely , ⟨ a t , θ t ⟩ = p 1 − σ 2 t . T aking an inner pro duct with θ ⋆ on b oth sides, E [ m t +1 / 2 |F t ] − m t = η t σ t f ′ p 1 − σ 2 t · E h f p 1 − σ 2 t ⟨ θ t , θ ⋆ ⟩ + σ t ⟨ Z t , θ ⋆ ⟩ ⟨ Z t , θ ⋆ ⟩ F t i . Since Z t ∼ Unif ( { x ∈ S d − 1 : x ⊥ θ t } ), the random v ariable (1 − m 2 t ) − 1 / 2 ⟨ Z t , θ ⋆ ⟩ is distributed as the one-dimensional marginal of a uniform random vector on S d − 2 ; denote by X a random v ariable follo wing this distribution. Consequently , for g ( x ) = f p 1 − σ 2 t ⟨ θ t , θ ⋆ ⟩ + σ t q 1 − m 2 t x , an application of the spherical Stein’s lemma (cf. Lemma B.4) gives E [ m t +1 / 2 |F t ] − m t = η t σ t f ′ p 1 − σ 2 t q 1 − m 2 t · E [ g ( X ) X |F t ] = η t σ t d − 2 f ′ p 1 − σ 2 t q 1 − m 2 t · E g ′ ( X ) (1 − X 2 ) F t = η t σ 2 t d − 2 f ′ p 1 − σ 2 t (1 − m 2 t ) · E f ′ p 1 − σ 2 t m t + σ t q 1 − m 2 t X (1 − X 2 ) F t . This is the desired identit y . F or the other inequalities, under Assumption 1.4 and m t ≥ 0, for h ( x ) = f ′ p 1 − σ 2 t ⟨ θ t , θ ⋆ ⟩ + σ t q 1 − m 2 t x ≥ 0 , 14 w e hav e E [ h ( X )(1 − X 2 )] ≥ E [ h ( X )(1 − X 2 ) 1 ( X ≥ 0)] ≥ c 0 E [(1 − X 2 ) 1 ( X ≥ 0)] = c 0 · d − 2 2( d − 1) = Ω(1) for d ≥ 3. Under Assumption 1.5 and m t ≥ 0, we then write E [ h ( X )(1 − X 2 )] ≥ E [ h ( X )(1 − X 2 ) 1 ( X ≥ 0)] ≥ f ′ ( p 1 − σ 2 t m t ) · E [(1 − X 2 ) 1 ( X ≥ 0)] = Ω( f ′ ( p 1 − σ 2 t m t )) . A.3 Pro of of Lemma 2.2 By definition, m t +1 / 2 − m t = η t σ t ( f ( ⟨ a t , θ ⋆ ⟩ ) + N t − f ( ⟨ a t , θ t ⟩ )) f ′ ( ⟨ a t , θ t ⟩ ) · ⟨ Z t , θ ⋆ ⟩ Define tw o new random v ariables: ξ (1) = η t σ t ( f ( ⟨ a t , θ ⋆ ⟩ ) − f ( ⟨ a t , θ t ⟩ )) f ′ ( ⟨ a t , θ t ⟩ ) · ⟨ Z t , θ ⋆ ⟩ , ξ (2) = η t σ t N t f ′ ( ⟨ a t , θ t ⟩ ) · ⟨ Z t , θ ⋆ ⟩ , suc h that m t +1 / 2 − m t = ξ (1) + ξ (2) . W e will show that each of these random v ariables is sub expo- nen tial with a b ounded Ψ 1 -Orlicz norm. F or ξ (1) , note that | f ( ⟨ a t , θ ⋆ ⟩ ) − f ( ⟨ a t , θ t ⟩ ) | ≤ 2 ∥ f ∥ ∞ and ⟨ a t , θ t ⟩ = p 1 − σ 2 t . In addition, ⟨ Z t , θ ⋆ ⟩ d = q 1 − m 2 t X , where X follows the one-dimensional marginal of a uniform random v ector on S d − 2 . By Lemma B.5, it holds that ∥ X ∥ Ψ 2 ≤ ∥N (0 , d − 1 ) ∥ Ψ 2 = O ( d − 1 / 2 ). Therefore, ∥ ξ (1) ∥ Ψ 1 (a) = O ( ∥ ξ (1) ∥ Ψ 2 ) = O η t σ t f ′ ( p 1 − σ 2 t ) p 1 − m 2 t √ d ! , where (a) follows from [V er18, Remark 2.8.8]. F or ξ (2) , note that ∥ N t ∥ Ψ 2 ≤ 1 by the 1-subGaussian assumption on the noise. Therefore, by indep endence of Z t and N t , [V er18, Lemma 2.8.6] giv es ∥ ξ (2) ∥ Ψ 1 ≤ η t σ t f ′ ( p 1 − σ 2 t ) ∥ N t ∥ Ψ 2 ∥⟨ Z t , θ ⋆ ⟩∥ Ψ 2 = O η t σ t f ′ ( p 1 − σ 2 t ) p 1 − m 2 t √ d ! . Finally , the triangle inequality of the Ψ 1 norm gives ∥ m t +1 / 2 − E [ m t +1 / 2 |F t ] ∥ Ψ 1 ≤ ∥ ξ (1) ∥ Ψ 1 + ∥ ξ (2) ∥ Ψ 1 = O η t σ t f ′ ( p 1 − σ 2 t ) p 1 − m 2 t √ d ! . 15 A.4 Pro of of Lemma 2.3 F or notational simplicity w e write S t := S t 0 ,β t . By Lemma 2.2, log E [exp( λ ( S t +1 − S t )) |F t ] ≤ C β 2( t − t 0 ) K 2 t λ 2 , for all | λ | ≤ 1 C β t − t 0 K t . Here C > 0 is a univ ersal constan t. W e sho w that K t ≤ 1 almost surely . In fact, f ′ ( p 1 − σ 2 t ) ≤ γ 2 b y Assumption 1.2 when σ 2 t ≤ γ 0 , and K t ≤ C se η t γ 2 ≤ 1 b y the c hoice of η t . Consequen tly , for V t = C P t − 1 s = t 0 β 2( s − t 0 ) K 2 s , λ max := 1 2 C , and ψ ( λ ) = λ 2 1 − λ/λ max , λ ∈ [0 , λ max ) , it holds that E [exp( λS t +1 − ψ ( λ ) V t +1 ) |F t ] ≤ exp( λS t − ψ ( λ ) V t ) , λ ∈ [0 , λ max ) , β t − t 0 ≤ 2 . Therefore, the conditions of Lemma B.3 are fulfilled, and the claimed upp er tail of S t follo ws from c ho osing ω = 1. Replacing S t b y − S t in the ab o ve analysis giv es the low er tail of S t . A.5 Pro of of Lemma 2.4 Since θ t ⊥ Z t , the iterate θ t +1 / 2 in (3) satisfies ∥ θ t +1 / 2 ∥ 2 = 1 + η 2 t σ 2 t f ′ ( p 1 − σ 2 t ) 2 ( f ( ⟨ θ t , a t ⟩ ) − r t ) 2 . Therefore, ∥ θ t +1 / 2 ∥ ≥ 1, it is clear that m t +1 = m t +1 / 2 ∥ θ t +1 / 2 ∥ = m t +1 / 2 − m t +1 / 2 ∥ θ t +1 / 2 ∥ ∥ θ t +1 / 2 ∥ − 1 ≥ m t +1 / 2 − 1 2 η 2 t σ 2 t f ′ ( p 1 − σ 2 t ) 2 ( f ( ⟨ θ t , a t ⟩ ) − r t ) 2 , using √ 1 + x − 1 ≤ x 2 for x ≥ 0, and | m t +1 / 2 | / ∥ θ t +1 / 2 ∥ ≤ 1. The first statement now follows from the sub-Gaussian concentration of r t , which implies ( f ( ⟨ θ t , a t ⟩ ) − r t ) 2 = O (log(1 /δ )) with probabilit y at least 1 − δ . F or the second statemen t, m t +1 ≤ m t +1 / 2 follo ws from ∥ θ t +1 / 2 ∥ ≥ 1. The other direction follo ws from the same high-probability upp er b ound of ∥ θ t +1 / 2 ∥ − 1, and the simple inequality 1 1+ x ≥ 1 − x for x ≥ 0. A.6 Pro of of Lemma 3.2 As w e show ed in the pro of of Lemma 3.1, we will show by induction on s that with probability at least 1 − ∆ δ / 3, m s ≥ m t − ε 4 for all s ∈ [ t, t + ∆]. The base case s = t is ensured b y the assumption m t ≥ 1 − ε . F or the inductive step, the induction h yp othesis implies that m t , . . . , m s − 1 ≥ 1 − 2 ε . Then m s − m t = s − 1 X r = t h E [ m r +1 / 2 |F r ] − m r | {z } ≥ 0 by Lemma 2.1 + m r +1 / 2 − E [ m r +1 / 2 |F r ] | {z } =: A r + m r +1 − m r +1 / 2 | {z } =: B r i . 16 Thanks to the inductive h yp othesis, K r = O ( η ε √ d ) for all r ∈ [ t, s − 1] in Lemma 2.2, s o Lemma 2.3 (with t 0 = t, β = 1) gives | s − 1 X r = t A r | = O ( η r ∆ ε 2 d log( ∆ δ )) = O ( √ η ε log( ∆ δ )) < ε 8 with probability 1 − δ 6 , by choosing c > 0 small enough. Similarly , s − 1 X r = t | B r | = O (∆ η 2 ε log( ∆ δ )) = O ( dη log( ∆ δ )) < ε 8 with probabilit y 1 − δ 6 , by Lemma 2.4 and c ho osing c > 0 small enough. This implies that m s ≥ m t − ε 4 with probability 1 − δ 3 , completing the induction. Conditioned on the even t m s ≥ 1 − 2 ε for all s ∈ [ t, t + ∆], w e distinguish into tw o regimes in this ep o c h. Let T 0 ≥ t b e the stopping time where m s > 1 − ε/ 4 for the first time. Regime I: t ≤ s < T 0 . In this regime m s ∈ [1 − 2 ε, 1 − ε/ 4]. W e show that T 0 ≤ t + ∆ with probabilit y 1 − ∆ δ / 3. If T 0 > t + ∆, using the same high-probability b ounds, we ha ve m t +∆ − m t ≥ t +∆ − 1 X s = t E [ m s +1 / 2 |F s ] − m s − ε 4 with probability 1 − ∆ δ / 3. By Lemma 2.1 with 1 − m 2 s = Ω( ε ) and p 1 − σ 2 s m s ≥ 1 − γ 0 for s < T 0 , the total drift is Ω( ∆ η ε 2 d ) = Ω( C ε ). Therefore, for a large absolute constan t C > 0, we would ha ve m t +∆ ≥ 1 − ε/ 2, a contradiction to the assumption T 0 > t + ∆. Regime I I: s ≥ T 0 . As shown ab o ve, this regime is non-empty with high probability . The same induction starting from s = T 0 sho ws that, with probability 1 − ∆ δ / 3, m s ≥ m T 0 − ε/ 4 holds for all s ∈ [ T 0 , t + ∆]. In particular, c ho osing s = t + ∆ gives the desired result m t +∆ ≥ 1 − ε/ 2. Finally , to low er b ound ⟨ θ ⋆ , a s ⟩ during this ep o c h, we simply note that ⟨ θ ⋆ , a s ⟩ = p 1 − σ 2 s m s + σ s ⟨ θ ⋆ , Z s ⟩ = p 1 − σ 2 s m s + σ s ⟨ θ ⋆ − m s θ s , Z s ⟩ ≥ p 1 − σ 2 s m s − σ s ∥ θ ⋆ − m s θ s ∥ = p 1 − σ 2 s m s − σ s p 1 − m 2 s . Under the go o d even t m s ≥ m t − ε 4 ≥ 1 − 3 ε 2 , by σ s ≡ √ ε we hav e ⟨ θ ⋆ , a s ⟩ ≥ 1 − 4 ε , as desired. A.7 Pro of of Lemma 4.2 Let β := 1 − C nm γ 2 2 η 2 σ 2 log 4∆ δ , (4) with C nm giv en in Lemma 2.4. By the choice of η , when the constant c > 0 is small enough, we ha ve β ∈ (1 / 2 , 1). In addition, let T 0 = min n s ≥ t : m s ≥ 1 − γ 0 8 r k + 1 d o (5) b e the stopping time when the correlation m s first hits a given threshold. Unlike the other pro ofs, the even t T 0 ≤ t + ∆ no longer o ccurs with high probability , and our pro of will discuss b oth cases. 17 Case I: T 0 > t + ∆ . Define the following even t: E s := m s ≥ m k − γ 0 d + c ′ η f ′ ( m k ) d ( s − t ) , (6) where c ′ > 0 is a small absolute constan t (to b e chosen later) indep enden t of c . W e will prov e by induction that P (( ∪ s r = t E c r ) ∩ { T 0 > t + ∆ } ) ≤ ( s − t ) δ 2 , for all s = t, t + 1 , . . . , t + ∆ . (7) The base case follows from the assumption m t ≥ m k , so that P ( E c t ) = 0. F or the inductive step, supp ose that (7) holds for s − 1. Since P ( A ∪ B ) = P ( A ) + P ( A c ∩ B ), it suffices to prov e that P E c s ∩ ∩ s − 1 r = t E r ∩ { T 0 > t + ∆ } ≤ δ 2 . (8) T o this end, w e in tro duce some additional even ts. First, applying Lemma 2.3 with t 0 = t and β − 1 ≤ 2 in (4) gives P ( E s, 1 ) := P s X r = t m r +1 / 2 − E [ m r +1 / 2 |F r ] β r − t ≤ C η r ∆ d log d δ ! ≥ 1 − δ 4∆ , (9) for some absolute constant C > 0. T o see (9), note that β − ∆ = exp ( O ((1 − β )∆)) = exp O η 2 ∆ log d δ = exp O cC ιd = 1 + o c (1) d , (10) so that the condition β − ∆ ≤ 2 holds for small c > 0, and P s r = t β − 2( r − t ) = O ( s − t + 1) = O (∆). In addition, let E s, 2 b e the go od even t that the low er b ound in Lemma 2.4 holds for m s +1 , with δ / (4∆) in place of δ . Note that E r ∩ E r, 2 ∩ { T 0 > t + ∆ } implies that m r +1 ≥ β m r +1 / 2 = β m r +1 / 2 − E [ m r +1 / 2 |F t ] + E [ m r +1 / 2 |F t ] − m r + m r ≥ β m r +1 / 2 − E [ m r +1 / 2 |F t ] + c 1 η f ′ ( m k ) d + m r , where c 1 > 0 is an absolute constan t, and the last step in vok es Lemma 2.1, uses m r ≤ 1 − Ω(1) since r ≤ t + ∆ < T 0 , and p 1 − σ 2 m r ≥ p 1 − γ 0 m k − γ 0 d ≥ (1 − γ 0 ) 2 r k d = m k b y (6) and the definitions of m k , m k . Summing ov er r = t, . . . , s − 1, the even t ∩ s − 1 r = t ( E r ∩ E r, 2 ) ∩ { T 0 > t + ∆ } implies that m s ≥ β s − t m t + s − 1 X r = t m r +1 / 2 − E [ m r +1 / 2 |F t ] β r − t ! + c 1 η f ′ ( m k ) d s − 1 X r = t β r +1 − t . 18 In view of (9) and (10), a further intersection with E s − 1 implies that m s ≥ 1 − o c (1) d m k − C η r ∆ d log d δ + c ′ η f ′ ( m k ) d ( s − t ) = 1 − o c (1) d m k − O cC d + c ′ η f ′ ( m k ) d ( s − t ) ≥ m k − γ 0 d + c ′ η f ′ ( m k ) d ( s − t ) for c > 0 small enough; this is precisely the even t E s . In other words, we ha ve shown that E c s ∩ ∩ s − 1 r = t ( E r ∩ E r, 1 ∩ E r, 2 ) ∩ { T 0 > t + ∆ } = ∅ . (11) By (11), we ha ve P E c s ∩ ∩ s − 1 r = t E r ∩ { T 0 > t + ∆ } ≤ P ( ∪ s − 1 r = t E c r, 1 ) + P ∪ s − 1 r = t E c r, 2 ∩ ∩ s − 1 r = t ( E r ∩ E r, 1 ) ∩ { T 0 > t + ∆ } . By (9) and the union b ound, the first probabilit y is at most δ 4 . F or the second probabilit y , the same program ab o ve shows that ( ∩ r − 1 i = t E i, 2 ) ∩ ( ∩ r i = t ( E r ∩ E r, 1 )) ∩ { T 0 > t + ∆ } implies m r +1 / 2 ≥ 0, whic h is the prerequisite of Lemma 2.4. Therefore, the conditional probabilit y of E r, 2 is at least 1 − δ 4∆ , and by a union b ound the second probability is at most δ 4 . This prov es (8) and completes the induction. Finally , note that E t +∆ implies that m t +∆ ≥ m k − γ 0 d + c ′ η f ′ ( m k ) d ∆ = m k − γ 0 d + c ′ C ( m k +1 − m k ) ≥ m k +1 , b y choosing C > 0 large enough. Therefore, (7) w ith s = t + ∆ implies that P ( { m t +∆ < m k +1 } ∩ { T 0 > t + ∆ } ) ≤ ∆ δ 2 . (12) Case I I: T 0 ≤ t + ∆ . W e apply our usual program to this case: if T 0 ≤ t + ∆, then m t +∆ − m T 0 = t +∆ − 1 X s = T 0 h E [ m s +1 / 2 |F s ] − m t | {z } ≥ 0 by Lemma 2.1 + m s +1 / 2 − E [ m s +1 / 2 |F s ] | {z } =: A s + m s +1 − m s +1 / 2 | {z } =: B s i . By Lemma 2.3, with probability at least 1 − ∆ δ 4 , t +∆ − 1 X s = T 0 A s = O η r ∆ d log d δ = O cC d . By Lemma 2.4, with probability at least 1 − ∆ δ 4 , t +∆ − 1 X s = T 0 | B s | = O ∆ · η 2 log d δ = O cC d . 19 Therefore, conditioned on T 0 ≤ t + ∆, with probability at least 1 − ∆ δ 2 , m t +∆ ≥ 1 − γ 0 8 r k d − O cC d ≥ 1 − γ 0 4 r k d = m k for a small enough constant c > 0. In other words, P ( { m t +∆ < m k +1 } ∩ { T 0 ≤ t + ∆ } ) ≤ ∆ δ 2 . (13) Finally , a combination of (12) and (13) gives P ( m t +∆ < m k +1 ) ≤ ∆ δ , whic h is the desired result. A.8 Pro of of Prop osition 5.1 Let T 0 b e the first time t ≥ 1 such that m t ≥ 0 . 1. If T 0 > T , the target claim max t ∈ [ T ] m t ≤ 0 . 2 is clearly true. Hence in the sequel w e condition on the ev ent T 0 ≤ T . In addition, b y Gaussian tail b ounds, we ha ve max t ∈ [ T ] | r t | = O ( p log( T /δ )) with probability at least 1 − δ / 4. By (3), w e then ha ve a deterministic inequality m T 0 − 1 / 2 ≤ m T 0 − 1 + C η T 0 − 1 p log( T /δ ) ≤ m T 0 − 1 + 0 . 05 ≤ 0 . 15 , b y assumption of η t ≤ c log( T /δ ) for a sufficien tly small constant c > 0, and the definition of T 0 that m T 0 − 1 ≤ 0 . 1. By Lemma 2.4, this implies that m T 0 ≤ 0 . 15. In the sequel, w e start from m T 0 ∈ [0 . 1 , 0 . 15], and for notational simplicit y w e redefine m T 0 to b e our starting p oint, i.e. T 0 = 1. Next we consider the time in terv al [1 , T 1 ] with T 1 = min n t ≥ 1 : X s ≤ t η 2 s σ 2 s d ≥ c 1 log 2 ( T /δ ) o , for some absolute constant c 1 > 0 to b e chosen later. W e prov e the following claims. Claim I: max t ∈ [ T 1 ] m t ≤ 0 . 2 with probabilit y at least 1 − δ T 1 / (4 T ) . T o prov e this claim, w e first show that when m t ≤ 0 . 2, then E [ m t +1 / 2 |F t ] ≤ m t . (14) Indeed, by Lemma 2.1, E [ m t +1 / 2 |F t ] − m t = η t σ 2 t d − 2 f ′ p 1 − σ 2 t (1 − m 2 t ) · E f ′ p 1 − σ 2 t m t + σ t q 1 − m 2 t X (1 − X 2 ) F t . Since σ t ≤ 0 . 1 , m t ≤ 0 . 2, and | X | ≤ 1 almost surely , we hav e p 1 − σ 2 t m t + σ t q 1 − m 2 t X ≤ m t + σ t ≤ 0 . 3 < 1 3 . Since f ′ ( m ) ≤ 0 for all m ≤ 1 / 3 in our construction, and f ′ ( p 1 − σ 2 t ) > 0, we obtain (14). 20 Next, without loss of generality we assume that m t ≥ 0 for all t ∈ [ T 1 ], since a negativ e m t only mak es the target claim simpler. F or every t ∈ [ T 1 ], m t − m 1 = t − 1 X r =1 h E [ m r +1 / 2 |F r ] − m r | {z } ≤ 0 by (14) + m r +1 / 2 − E [ m r +1 / 2 |F r ] | {z } =: A r + m r +1 − m r +1 / 2 | {z } ≤ 0 by Lemma 2.4 i . By Lemma 2.3 with β = 1, we get t − 1 X r =1 A r ≤ C log T δ v u u t t − 1 X r =1 σ 2 r η 2 r d with probability at leas t 1 − δ / (4 T ), for some absolute constan t C > 0. By the definition of T 1 , w e obtain | P t − 1 r =1 A r | ≤ 0 . 05 for a sufficiently small c 1 > 0. Therefore, m t ≤ m 1 + 0 . 05 ≤ 0 . 2 with probabilit y at least 1 − δ / (4 T ), and an induction on t with a union b ound giv es the target claim. Claim I I: min t ∈ [ T 1 ] m t ≤ 0 . 1 with probabilit y at least 1 − δ T 1 / (4 T ) . In the sequel, w e condition on the go od even t in Claim I. Let T 2 b e the first time t ≥ 1 suc h that m t ≤ 0 . 1; note that it is p ossible to ha ve T 2 > T 1 or even T 2 = ∞ . W e first show that if m t ≥ 0 . 1, then E [ m t +1 / 2 |F t ] − m t ≤ − c 2 η t σ 2 t d (15) for some absolute constant c 2 > 0. Indeed, for σ t ≤ 0 . 1 , m t ∈ [0 . 1 , 0 . 2], and | X | ≤ 1, we ha ve 0 ≤ √ 0 . 99 m t − √ 0 . 99 σ t ≤ p 1 − σ 2 t m t + σ t q 1 − m 2 t X ≤ m t + σ t < 1 3 . Since f ′ ( m ) = − 1 for all m ∈ [0 , 1 / 3] in our construction, (15) follows from Lemma 2.1. Next, for every t ≤ min { T 2 , T 1 } , we write m t − m 1 = t − 1 X r =1 h E [ m r +1 / 2 |F r ] − m r | {z } ≤− c 2 η t σ 2 t d by (15) + m r +1 / 2 − E [ m r +1 / 2 |F r ] | {z } =: A r + m r +1 − m r +1 / 2 | {z } ≤ 0 by Lemma 2.4 i . Similar to Claim I, we hav e | P t − 1 r =1 A r | ≤ 0 . 05 with probability at least 1 − δ / (4 T ). On the other hand, the total drift is T 1 − 1 X r =1 E [ m r +1 / 2 |F r ] − m r ≤ − c 2 d T 1 − 1 X r =1 η t σ 2 t (a) ≤ − c 2 log 2 ( T /δ ) cd T 1 − 1 X r =1 η 2 t σ 2 t (b) ≤ − c 1 c 2 2 c , where (a) uses the upp er b ound of η t , and (b) uses the definition of T 1 . By c ho osing c > 0 small enough, the total drift can b e made smaller than − 0 . 1, so that if T 2 > T 1 , then m T 1 ≤ m 1 − 0 . 1 + 0 . 05 ≤ 0 . 1, which in turn means that T 2 ≤ T 1 , a contradiction. Therefore, with probabilit y at least 1 − δ T 1 / (4 T ), we hav e T 2 ≤ T 1 , or equiv alen tly min t ∈ [ T 1 ] m t ≤ 0 . 1. Finally , it is clear that a rep eated application of Claim I and I I implies Proposition 5.1: starting from the first time T 0 with m T 0 ≥ 0 . 1, the ab o v e claims show that with high probability , future alignmen t m t will fall b elo w 0 . 1 b efore it rises ab o ve 0 . 2. Once m t falls b elo w 0 . 1, we repeat the en tire pro cess again and w ait for the next time it falls b elo w 0 . 1. Since the failure probability at eac h step of the analysis is at most δ /T , a union b ound giv es the total failure probability of δ . 21 B Auxiliary results Belo w we state a self-normalized concen tration inequality for martingales [WWR23, Theorem 3.1] adapted to our setting. Definition B.1 (CGF-like function) . A function ψ : [0 , λ max ) → R ≥ 0 is said to b e CGF-like if it is ( a ) twic e c ontinuously-differ entiable on its domain, ( b ) strictly c onvex, ( c ) satisfies ψ (0) = ψ ′ (0) = 0 , and ( d ) ψ ′′ (0) > 0 . Definition B.2 (Sub- ψ ) . L et ψ : [0 , λ max ) → R ≥ 0 b e a CGF-like function. L et { S t } t ≥ 0 and { V t } t ≥ 0 b e r esp e ctively R -value d and R ≥ 0 -value d pr o c esses adapte d to some filtr ation {F t } t ≥ 0 . We say that { S t , V t } t ≥ 0 is sub- ψ if for every λ ∈ [0 , λ max ) , M λ t := exp ( λS t − ψ ( λ ) V t ) ≤ L λ t , wher e { L λ t } t ≥ 0 is a non-ne gative sup ermartingale adapte d to {F t } t ≥ 0 . The follo wing result is a corollary of [WWR23, Theorem 3.1] with the choice h ( k ) = (1 + k ) 2 for k ≥ 1. Lemma B.3 (Self-normalized concen tration inequality) . Supp ose { S t , V t } t ≥ 0 is a r e al-value d sub- ψ pr o c ess for ψ : [0 , λ max ) → R ≥ 0 satisfying ψ ( λ ) = λ 2 1 − λ/λ max on its domain. L et δ ∈ (0 , 1) denote the err or pr ob ability. Define the function ℓ : R ≥ 0 → R ≥ 0 by ℓ ω ( v ) = 2 log (1 + log ( v ω ∨ 1)) + log 1 δ , then ther e exists a universal c onstant C > 0 such that, Pr ∃ t ≥ 1 : S t ≥ C p ( V t ∨ ω − 1 ) ℓ ω ( V t ) + λ − 1 max ℓ ω ( V t ) ≤ δ. Pr o of. By simple algebra, the con vex conjugate ψ ⋆ of ψ satisfies ( ψ ⋆ ) − 1 ( u ) = 2 √ u + λ − 1 max u . The rest follows from [WWR23, Theorem 3.1]. Lemma B.4 (Spherical Stein’s Lemma) . Supp ose Z ∼ Unif ( S d − 1 ) and c onsider a fixe d α ∈ R d and let X = ⟨ α, Z ⟩ . F or any b ounde d function f , E [ X f ( X )] = 1 d − 1 E f ′ ( X )(1 − X 2 ) . Pr o of. The density of X is given by P d ( x ) ≜ 2 1 − x 2 d − 1 2 − 1 Beta 1 2 , d − 1 2 I ( | x | ≤ 1) . 22 Consequen tly , E [ X f ( X )] = Z 1 − 1 xf ( x ) · 2 1 − x 2 d − 1 2 − 1 Beta 1 2 , k − 1 2 d x ( a ) = 2 d − 1 Z 1 − 1 f ′ ( x ) · 1 − x 2 d − 1 2 Beta 1 2 , k − 1 2 d x = 1 d − 1 Z 1 − 1 f ′ ( x )(1 − x 2 ) · 2 1 − x 2 d − 1 2 − 1 Beta 1 2 , k − 1 2 d x = 1 d − 1 E f ′ ( X )(1 − X 2 ) , where ( a ) follows from in tegration by parts. Lemma B.5. Supp ose X ∼ N (0 , I /d ) and X ′ ∼ Unif ( S d − 1 ) . F or any fixe d α ∈ R d , ⟨ α, X ⟩ 2 dominates ⟨ α , X ′ ⟩ 2 in the c onvex or der. Namely, for every c onvex function g : R → R , E [ g ( ⟨ α, X ′ ⟩ 2 )] ≤ E [ g ( ⟨ α, X ⟩ 2 )] . Pr o of. Observe that X follo ws the same distribution as N X ′ , where N and X ′ are indep endent, and N is a scaled chi-squared random v ariable such that E [ N 2 ] = 1. Therefore, E [ g ( ⟨ α, X ⟩ 2 )] = E [ g ( N 2 ⟨ α, X ′ ⟩ 2 )] = E [ E [ g ( N 2 ⟨ α, X ′ ⟩ 2 ) | X ′ ]] ≥ E [ g ( E [ N 2 ] ⟨ α, X ′ ⟩ 2 )] = E g ⟨ α, X ′ ⟩ 2 . References [AAM22] Emman uel Abbe, Enric Boix Adsera, and Theo dor Misiakiewicz. The merged-staircase prop ert y: a necessary and nearly sufficient condition for sgd learning of sparse functions on t wo-la y er neural net works. In Confer enc e on L e arning The ory , pages 4782–4887. PMLR, 2022. [AAM23] Emman uel Abb e, Enric Boix Adsera, and Theo dor Misiakiewicz. Sgd learning on neural net works: leap complexity and saddle-to-saddle dynamics. In The Thirty Sixth A nnual Confer enc e on L e arning The ory , pages 2552–2623. PMLR, 2023. [ASKL23] Luca Arnab oldi, Ludo vic Stephan, Floren t Krzak ala, and Bruno Loureiro. F rom high- dimensional & mean-field dynamics to dimensionless odes: A unifying approac h to sgd in tw o-la yers netw orks. In The Thirty Sixth A nnual Confer enc e on L e arning The ory , pages 1199–1227. PMLR, 2023. [A YPS11] Y asin Abbasi-Y adk ori, D´ avid P´ al, and Csaba Szep esv´ ari. Impro ved algorithms for linear stochastic bandits. A dvanc es in neur al information pr o c essing systems , 24, 2011. 23 [Bac17] F rancis Bach. Breaking the curse of dimensionalit y with conv ex neural netw orks. Journal of Machine L e arning R ese ar ch , 18(19):1–53, 2017. [BA GJ21] Gerard Ben Arous, Reza Gheissari, and Auk osh Jagannath. Online sto c hastic gradien t descen t on non-conv ex losses from high-dimensional inference. Journal of Machine L e arning R ese ar ch , 22(106):1–51, 2021. [BA GJ22] Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. High-dimensional limit theorems for sgd: Effective dynamics and critical scaling. A dvanc es in neur al infor- mation pr o c essing systems , 35:25349–25362, 2022. [BA GP24] G ´ erard Ben Arous, C ´ edric Gerb elot, and V anessa Piccolo. High-dimensional optimiza- tion for multi-spik ed tensor p ca. arXiv pr eprint arXiv:2408.06401 , 2024. [Bar02] Andrew R Barron. Univ ersal approximation bounds for sup erpositions of a sigmoidal function. IEEE T r ansactions on Information the ory , 39(3):930–945, 2002. [BBPV25] Alb erto Bietti, Joan Bruna, and Loucas Pillaud-Vivien. On learning gaussian m ulti- index mo dels with gradien t flo w part i: General prop erties and t wo-timescale learning. Communic ations on Pur e and Applie d Mathematics , 2025. [BBSS22] Alb erto Bietti, Joan Bruna, Clayton Sanford, and Min Jae Song. Learning single- index models with shallo w neural net works. A dvanc es in neur al information pr o c essing systems , 35:9768–9783, 2022. [BK19] Aude Billard and Danica Kragic. T rends and challenges in rob ot manipulation. Sci- enc e , 364(6446):eaat8414, 2019. [CBL06] Nicolo Cesa-Bianchi and G´ ab or Lugosi. Pr e diction, le arning, and games . Cambridge univ ersity press, 2006. [CCFM19] Y uxin Chen, Y uejie Chi, Jianqing F an, and Cong Ma. Gradient descent with random initialization: F ast global conv ergence for nonconv ex phase retriev al. Mathematic al Pr o gr amming , 176:5–37, 2019. [CLRS11] W ei Ch u, Lihong Li, Lev Reyzin, and Rob ert Schapire. Con textual bandits with linear pay off functions. In Pr o c e e dings of the F ourte enth International Confer enc e on A rtificial Intel ligenc e and Statistics , pages 208–214. JMLR W orkshop and Conference Pro ceedings, 2011. [DH18] Rishabh Dudeja and Daniel Hsu. Learning single-index mo dels in gaussian space. In Confer enc e On L e arning The ory , pages 1887–1930. PMLR, 2018. [DHK08] V arsha Dani, Thomas P Ha y es, and Sham M Kak ade. Sto chastic linear optimization under bandit feedback. Confer enc e on L e arning The ory , pages 355–366, 2008. [DLS22] Alexandru Damian, Jason Lee, and Mahdi Soltanolkotabi. Neural netw orks can learn represen tations with gradien t descen t. In Confer enc e on L e arning The ory , pages 5413– 5452. PMLR, 2022. [DPVLB24] Alex Damian, Loucas Pillaud-Vivien, Jason Lee, and Joan Bruna. Computational- statistical gaps in gaussian single-index models. In The Thirty Seventh Annual Con- fer enc e on L e arning The ory , pages 1262–1262. PMLR, 2024. 24 [F CG20] Sp encer F rei, Y uan Cao, and Quanquan Gu. Agnostic learning of a single neuron with gradien t descent. A dvanc es in Neur al Information Pr o c essing Systems , 33:5417–5428, 2020. [F CGS10] Sarah Filippi, Olivier Capp e, Aur ´ elien Garivier, and Csaba Szep esv´ ari. P arametric bandits: The generalized linear case. A dvanc es in neur al information pr o c essing sys- tems , 23, 2010. [FK QR21] Dylan J F oster, Sham M Kak ade, Jian Qian, and Alexander Rakhlin. The statistical complexit y of in teractive decision making. arXiv pr eprint arXiv:2112.13487 , 2021. [FR20] Dylan F oster and Alexander Rakhlin. Beyond ucb: Optimal and efficien t contextual bandits with regression oracles. In International c onfer enc e on machine le arning , pages 3199–3210. PMLR, 2020. [FYY23] Jianqing F an, Zh uoran Y ang, and Mengxin Y u. Understanding implicit regulariza- tion in ov er-parameterized single index mo del. Journal of the A meric an Statistic al Asso ciation , 118(544):2315–2328, 2023. [GHJY15] Rong Ge, F urong Huang, Chi Jin, and Y ang Y uan. Escaping from saddle p oints—online sto c hastic gradient for tensor decomp osition. In Confer enc e on le arning the ory , pages 797–842. PMLR, 2015. [H + 16] Elad Hazan et al. In tro duction to online conv ex optimization. F oundations and T r ends ® in Optimization , 2(3-4):157–325, 2016. [HHK + 21] Baihe Huang, Kaixuan Huang, Sham Kak ade, Jason D Lee, Qi Lei, Runzhe W ang, and Jiaqi Y ang. Optimal gradient-based algorithms for non-concav e bandit optimization. A dvanc es in Neur al Information Pr o c essing Systems , 34:29101–29115, 2021. [KKSK11] Sham M Kak ade, V arun Kanade, Ohad Shamir, and Adam Kalai. Efficien t learning of generalized linear and single index mo dels with isotonic regression. A dvanc es in Neur al Information Pr o c essing Systems , 24, 2011. [KL Y + 25] Y ue Kang, Mingshuo Liu, Bongso o Yi, Jing Lyu, Zhi Zhang, Doudou Zhou, and Y ao Li. Single index bandits: Generalized linear contextual bandits with unknown reward functions. arXiv pr eprint arXiv:2506.12751 , 2025. [KS09] Adam T auman Kalai and Ravi Sastry . The isotron algorithm: High-dimensional iso- tonic regression. In COL T , volume 1, page 9, 2009. [LH21] T or Lattimore and Botao Hao. Bandit phase retriev al. A dvanc es in Neur al Information Pr o c essing Systems , 34:18801–18811, 2021. [LS20] T or Lattimore and Csaba Szepesv´ ari. Bandit algorithms . Cambridge Univ ersity Press, 2020. [Ora19] F rancesco Orab ona. A mo dern introduction to online learning. arXiv pr eprint arXiv:1912.13213 , 2019. [RHJR24] Niv ed Ra jaraman, Y anjun Han, Jiantao Jiao, and Kannan Ramchandran. Statisti- cal complexity and optimal algorithms for nonlinear ridge bandits. The A nnals of Statistics , 52(6):2557–2582, 2024. 25 [RST15] Alexander Rakhlin, Karthik Sridharan, and Ambuj T ewari. Online learning via se- quen tial complexities. J. Mach. L e arn. R es. , 16(1):155–186, 2015. [R T10] Paat Rusmevic hientong and John N Tsitsiklis. Linearly parameterized bandits. Math- ematics of Op er ations R ese ar ch , 35(2):395–411, 2010. [R VR14] Daniel Russo and Benjamin V an Ro y . Learning to optimize via information-directed sampling. A dvanc es in neur al information pr o c essing systems , 27, 2014. [Sol17] Mahdi Soltanolkotabi. Learning relus via gradien t descent. A dvanc es in neur al infor- mation pr o c essing systems , 30, 2017. [SSSS10] Shai Shalev-Shw artz, Ohad Shamir, and Karthik Sridharan. Learning kernel-based halfspaces with the zero-one loss. arXiv pr eprint arXiv:1005.3681 , 2010. [TV23] Y an Sh uo T an and Roman V ersh ynin. Online sto c hastic gradient descen t w ith arbi- trary initialization solv es non-smo oth, non-conv ex phase retriev al. Journal of Machine L e arning R ese ar ch , 24(58):1–47, 2023. [V er18] Roman V ersh ynin. High-dimensional pr ob ability: An intr o duction with applic ations in data scienc e , volume 47. Cambridge universit y press, 2018. [W CS + 22] Andrew J W agenmak er, Yifang Chen, Max Simcho witz, Simon Du, and Kevin Jamieson. Reward-free RL is no harder than reward-a w are RL in linear Marko v deci- sion pro cesses. In International Confer enc e on Machine L e arning , pages 22430–22456. PMLR, 2022. [WML17] Ch uang W ang, Jonathan Mattingly , and Y ue M Lu. Scaling limit: Exact and tractable analysis of online learning algorithms with applications to regularized regression and p ca. arXiv pr eprint arXiv:1712.04332 , 2017. [W u22] Lei W u. Learning a single neuron for non-monotonic activ ation functions. In Inter- national c onfer enc e on artificial intel ligenc e and statistics , pages 4178–4197. PMLR, 2022. [WWR23] Justin Whitehouse, Zhiw ei Steven W u, and Aadit ya Ramdas. Time-uniform self-normalized concen tration for vector-v alued pro cesses. arXiv pr eprint arXiv:2310.09100 , 2023. [YO20] Gilad Y eh udai and Shamir Ohad. Learning a single neuron with gradient metho ds. In Confer enc e on L e arning The ory , pages 3756–3786. PMLR, 2020. [ZGR + 19] Henry Zhu, Abhishek Gupta, Aravind Ra jeswaran, Sergey Levine, and Vik ash Kumar. Dexterous manipulation with deep reinforcement learning: Efficient, general, and lo w- cost. In 2019 International Confer enc e on R ob otics and Automation (ICRA) , pages 3651–3657. IEEE, 2019. [ZPVB23] Aaron Zw eig, Loucas Pillaud-Vivien, and Joan Bruna. On single-index mo dels b ey ond gaussian data. A dvanc es in Neur al Information Pr o c essing Systems , 36:10210–10222, 2023. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment