MusicSem: A Semantically Rich Language--Audio Dataset of Natural Music Descriptions
Music representation learning is central to music information retrieval and generation. While recent advances in multimodal learning have improved alignment between text and audio for tasks such as cross-modal music retrieval, text-to-music generatio…
Authors: Rebecca Salganik, Teng Tu, Fei-Yueh Chen
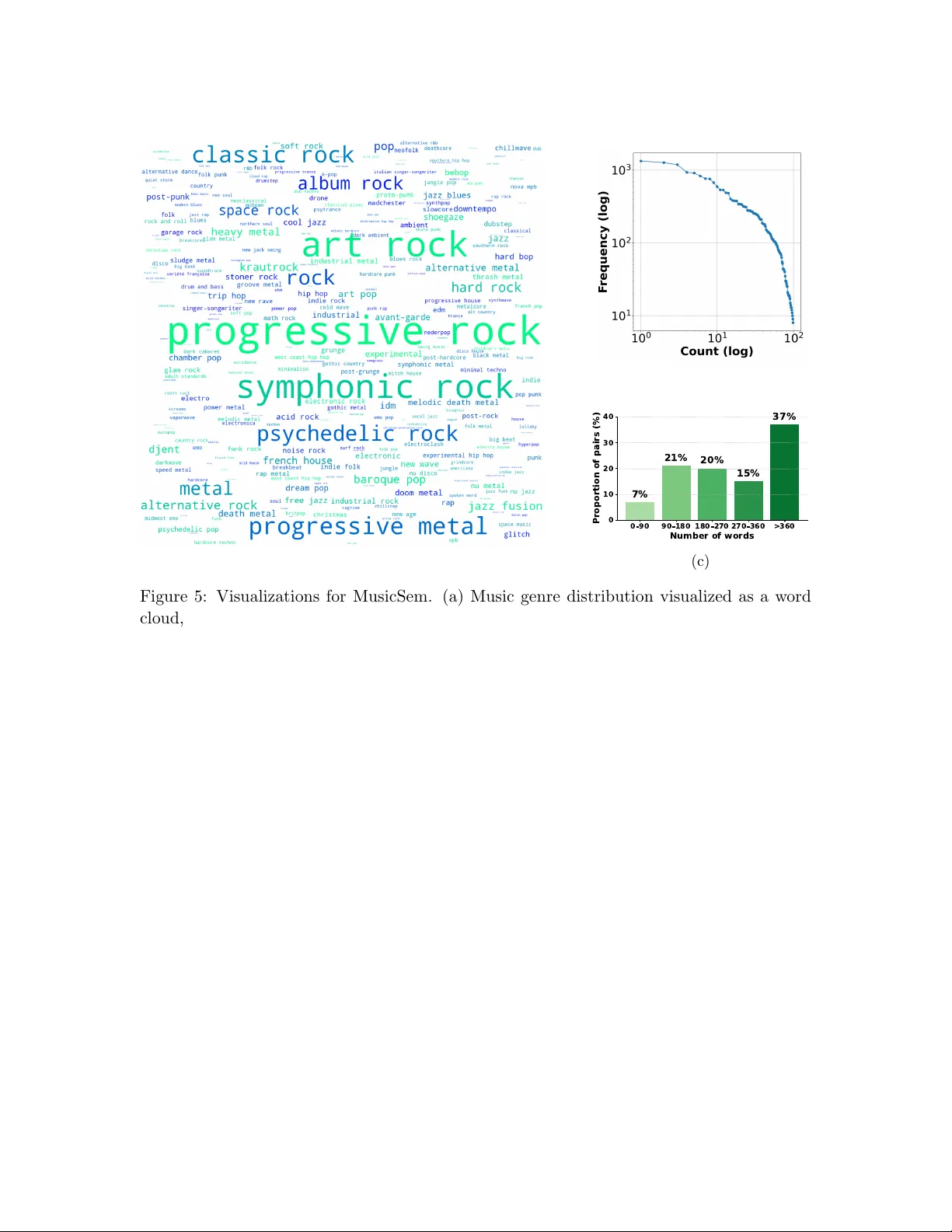
MusicSem: A Seman tically Ric h Language–Audio Dataset of Natural Music Descriptions Reb ecca Salganik 1 rsalgani@ur.rochester.edu T eng T u 2 F ei-Y ueh Chen 1 Xiaohao Liu 2 Keifeng Lu 1 Ethan Luvisia 1 Zhiy ao Duan 1 Guillaume Salha-Galv an 3 Anson Kahng 1 Y unshan Ma 4 Jian Kang 5 1 University of R o chester, NY, USA 2 National University of Singap or e, Singap or e 3 SJTU Paris Elite Institute of T e chnolo gy, Shanghai, China 4 Singap or e Management University, Singap or e 5 Mohame d bin Zaye d University of Artificial Intel ligenc e, Abu Dhabi, UAE W ebsite: https: // music- sem- web. vercel. app/ Abstract Music representation learning is central to m usic information retriev al and generation. While recen t adv ances in m ultimo dal learning ha ve improv ed alignment b etw een text and audio for tasks suc h as cross-mo dal m usic retriev al, text-to-music generation, and m usic-to- text generation, existing mo dels often struggle to capture users’ expressed inten t in natural language descriptions of music. This observ ation suggests that the datasets used to train and ev aluate these mo dels do not fully reflect the broader and more natural forms of hu- man discourse through which music is describ ed. In this pap er, we in tro duce MusicSem, a dataset of 32,493 language–audio pairs derived from organic music-related discussions on the so cial media platform Reddit. Compared to existing datasets, MusicSem captures a broader sp ectrum of m usical semantics, reflecting how listeners naturally describe music in nuanced and human-cen tered wa ys. T o structure these expressions, we prop ose a tax- onom y of five seman tic categories: descriptive, atmospheric, situational, metadata-related, and contextual. In addition to the construction, analysis, and release of MusicSem, we use the dataset to ev aluate a wide range of m ultimo dal mo dels for retriev al and genera- tion, highligh ting the imp ortance of mo deling fine-grained seman tics. Ov erall, MusicSem serv es as a nov el semantics-a w are resource to supp ort future research on human-aligned m ultimo dal m usic representation learning. Keyw ords: language-audio dataset, m ultimo dal music descriptions, musical semantics. © 2026 Rebecca Salganik, et al.. Rebecca Salganik, et al. (2026) 1 In tro duction Con text and Motiv ation. Music represen tation learning (Sc hedl et al., 2014; M¨ uller, 2015; Hernandez-Oliv an and Beltran, 2022) underpins a wide range of downstream music- related tasks, including m usic categorization (Oramas et al., 2017; McCallum et al., 2022; Y uan et al., 2023), generation (Hernandez-Oliv an and Beltran, 2022; Gardner et al., 2024; Liu et al., 2024b), and recommendation (V an den Oord et al., 2013; Deldjo o et al., 2024; Salganik et al., 2024b). Early research in this area largely fo cused on audio-cen tric ap- proac hes, relying on handcrafted features or learned audio representations to model musical con tent (Lin et al., 2011; Oramas et al., 2017; Bogdanov et al., 2019). More recently , ad- v ances in m ultimo dal learning ha ve enabled the joint mo deling of audio and natural language descriptions of m usic, leading to substantial progress in tasks such as cross-mo dal music re- triev al (W u et al., 2023; Girdhar et al., 2023; W u et al., 2025), m usic-to-text generation (Liu et al., 2024b; Doh et al., 2023; W u et al., 2024), and text-to-music generation (Agostinelli et al., 2023; Cop et et al., 2023; Ev ans et al., 2024; Liu et al., 2024a). Effectiv e language–audio multimodal m usic represen tation learning requires understand- ing how musical meaning and inten t are expressed in natural language (Ronchini et al., 2025; Zang and Zhang, 2024). In particular, capturing the nu ances that contextualize a listening exp erience in textual descriptions is crucial. Consider, for example, a text-to-m usic gener- ation or retriev al mo del and the follo wing tw o descriptions used as input: “This song is a b al lad. It c ontains guitar, male vo c als, and a piano. It sounds like something I would listen to at chur ch.” v ersus “This song is a b al lad. It c ontains guitar, male vo c als, and a piano. It sounds like something I would listen to during a psyche delic exp erienc e.” Although both descriptions sp ecify iden tical musical attributes, the situational con text leads to different exp ectations regarding the audio to b e generated or retrieved. Ho wev er, recent research has shown that multimodal m usic represen tation learning mo d- els s till often struggle to capture users’ expressed inten t in natural language descriptions of m usic (Ronchini et al., 2025; Zang and Zhang, 2024). This observ ation p oin ts to limitations in existing language–audio datasets (Agostinelli et al., 2023; Manco et al., 2023), which ma y not fully reflect the broader and more natural forms of human discourse through whic h m usic is described. F urthermore, while professional m usicians tend to rely on descriptive and technical language when engaging with music, non-exp ert listeners often express their exp eriences using more abstract and sub jective semantic con ten t (Gromk o, 1993; Bain- bridge et al., 2003). As a result, commonly used m usician-annotated datasets for m usic represen tation learning may b e ov erly curated and insufficiently represen tativ e of everyda y listening exp eriences (Agostinelli et al., 2023). Overall, this gap motiv ates the need for textual annotations that encompass a broader range of natural m usic descriptions. Con tributions. In this pap er, we b egin b y formalizing the elemen ts that contextualize a listening exp erience in textual descriptions, whic h we refer to as musical semantics (Levy and Sandler, 2008; Nam et al., 2019; Choi et al., 2020). W e in tro duce a taxonom y that dis- tinguishes fiv e types of semantic captions: descriptiv e, con textual, situational, atmospheric, and metadata-based. W e further sho w that man y competitive m ultimo dal m usic represen ta- tion learning mo dels for generation and retriev al, when trained on existing language–audio datasets, lack sensitivity to these semantic distinctions. 2 MusicSem Figure 1: The MusicSem w ebsite pro vides access to the full dataset, detailed docu- men tation, visualizations, and source code for data construction and exp erimen ts at: https://music- sem- web.vercel.app/ . Motiv ated by these observ ations, we in tro duce MusicSem, a semantically ric h language– audio dataset derived from organic m usic discussions on the so cial media platform Reddit. The dataset comprises 32,493 language–audio m usic description pairs, with textual anno- tations that express not only descriptiv e attributes of music, but also emotional resonance, con textual and situational usage, and co-listening patterns. MusicSem distinguishes itself by capturing a broader sp ectrum of musical seman tics than prior datasets used for multimodal mo del training and ev aluation. W e detail the en tire construction pip eline of MusicSem, including our design c hoices and motiv ations, as well as the final dataset statistics and k ey c haracteristics. T aking ethical and legal considerations seriously , w e also presen t the k ey safeguards w e adopted with respect to user priv acy and anonymit y , platform compliance, and music cop yright. As illustrated in Figure 1, the final MusicSem dataset is publicly a v ailable online, together with the complete source co de for dataset construction. Third, we perform an extensive ev aluation of v arious cross-mo dal music retriev al, text- to-m usic generation, and m usic-to-text generation mo dels using MusicSem. Our ev aluation yields sev eral key insights, including p ersisten t challenges for current multimodal mo dels, and, imp ortan tly , a lack of sensitivit y to semant ic distinctions in natural language descrip- tions. This analysis represents an initial step tow ard systematically studying semantic sensitivit y in multimodal m usic mo dels and highligh ts the v alue of MusicSem as a b enc h- mark for this purp ose. T o supp ort reproducibility , the MusicSem w ebsite and codebase pro vide complete instructions for repro ducing all exp eriments reported in this pap er. Organization of this P ap er. This pap er is organized as follows. Section 2 fo cuses on related w ork b y presen ting existing language–audio datasets for m ultimo dal m usic represen- tation learning. Section 3 formalizes the notion of musical seman tics, in tro duces our taxon- om y , and analyzes the limited semantic aw areness of mo dels trained on existing datasets. Section 4 presen ts the MusicSem dataset, detailing the construction pip eline, k ey statistics 3 Rebecca Salganik, et al. (2026) T able 1: Statistics of existing language–audio music datasets that are most comparable to our setting. L–A Pairs denotes the num b er of language–audio pairs, while Annotation indicates the origin of the textual annotations describing the m usic. Dataset Name Y ear L-A Pairs Annotation Base Dataset MusicNet (Thickstun et al., 2018) 2018 330 Human - Song Describer (Manco et al., 2023) 2023 1,106 Human - Y ouT ube8M-MusicT extClips (McKee et al., 2023) 2023 4,169 Human - MusicCaps (Agostinelli et al., 2023) 2023 5,521 Human - MuLaMCap (Huang et al., 2023) 2023 6,800,000 LLM AudioSet LP-MusicCaps (Doh et al., 2023) 2023 2,000,000 LLM MusicCaps, Magnatagtune, & Million Song Dataset T ext2Music (Schneider et al., 2024) 2024 50,000 LLM Spotify FUTGA (W u et al., 2024) 2024 51, 800 LLM MusicCaps & Song Describer MusicBench (Melechovsky et al., 2024) 2024 53,168 LLM MusicCaps JamendoMaxCaps (Roy et al., 2025) 2025 200,000 LLM Jamendo and characteristics, and ethical considerations. Section 5 presen ts and discusses our ex- p erimen tal ev aluation of m ultimo dal mo dels for retriev al and generation using MusicSem. Finally , Section 7 concludes the pap er and outlines directions for future w ork. 2 Related W ork In this section, w e review existing language–audio datasets for multimodal music represen- tation learning. These datasets differ substan tially in the source of their textual annotations and the t yp es of information they capture. W e fo cus on those most relev ant to our work and refer readers to the surv ey by Christo doulou et al. (2024) for a comprehensive ov erview. 2.1 Human-Annotated Language–Audio Datasets Sev eral language–audio datasets ha ve b een in tro duced in recen t y e ars. Ho wev er, as sum- marized in T able 1, only a limited num b er of them pair m usic audio with human-written textual annotations. Among them, MusicCaps is one of the most commonly adopted bench- marks for m usic–language alignmen t (Agostinelli et al., 2023). It con tains 5,521 audio clips annotated b y professional m usicians, with captions that emphasize descriptiv e musical at- tributes such as instrumentation, genre, temp o, and stylistic characteristics. Similarly , Y ouT ube8M-MusicT extClips (McKee et al., 2023) provides 4,169 language–audio pairs, where captions are written b y hired annotators follo wing predefined guidelines. Cro wd-sourced annotation has also b een explored. Song Describ er (Manco et al., 2023) extends a subset of the Jamendo dataset (Bogdanov et al., 2019) with 1,106 crowd-written descriptions. In a complemen tary but distinct line of w ork, MusicNet pro vides h uman- annotated, note-level lab els verified b y trained musicians and aligned with audio recordings for 330 freely licensed classical music recordings (Thickstun et al., 2017). While MusicNet offers rich symbolic and structural annotations, it do es not include actual natural language descriptions of music, and is therefore primarily used for symbolic m usic understanding rather than multimodal language–audio represen tation learning. Ov erall, these datasets provide high-quality textual annotations, but their natural lan- guage descriptions are t ypically constrained by annotation instructions or musical exp ertise, resulting in a fo cus on acoustic, technical, or stylistic asp ects of music. Moreo ver, their scale is limited to at most a few thousand language–audio pairs. 4 MusicSem 2.2 LLM–Annotated Language–Audio Datasets T o scale language–audio sup ervision, recen t work has increasingly relied on large lan- guage models (LLMs) to generate or augment textual annotations (Na veed et al., 2025). The MuLaMCap dataset (Huang et al., 2023) com bines MusicCaps with LLM-generated descriptions of 150K p opular songs, pro ducing a dataset of 6.8M language–audio pairs. LP-MusicCaps (Doh et al., 2023) merges multiple music datasets, including MusicCaps, MagnaT agA T une (Law et al., 2009), and the Million Song Dataset (McF ee et al., 2012), and uses LLMs to generate 2.2M sentence-lik e captions paired with 500K audio samples. Other works fo cus on augmen ting existing captions with automatically extracted mu- sical structure. MusicBench (Melecho vsky et al., 2024) enriches MusicCaps with do wn- b eat, c hord, k ey , and temp o information derived from signal pro cessing algorithms. The dataset used to train FUTGA (W u et al., 2024) follo ws a similar strategy , prompting an LLM to augment captions from MusicCaps and Song Describ er with structural descriptors. JamendoMaxCaps (Roy et al., 2025) generates captions for 200K Jamendo tracks using a m usic captioning mo del, while T ext2Music (Sc hneider et al., 2024) scrapes playlist metadata from Sp otify and reformulates them in to sentence-lev el descriptions using an LLM. Although these datasets substan tially increase scale, they rely hea vily on s yn thetic text generation. They often lack explicit discussion of hallucination mitigation, annotation re- liabilit y , or how well the generated text reflects real-w orld listening exp eriences, despite evidence that musical meaning and p erception are highly sub jective and context-dependent (Slob o da and Juslin, 2001; Levy and Sandler, 2008; Choi et al., 2020; Epure et al., 2020). 2.3 Other Related Datasets F or completeness, we note the existence of additional datasets that consist primarily of pro- cessed versions of the ones discussed ab o ve. In the context of generativ e retriev al and m usical question answ ering, MusicQA (Liu et al., 2024b) reformulates captions from MusicCaps and MagnaT agA T une in to approximately 4,500 question–answ er pairs using an LLM. Similarly , LLaRK (Gardner et al., 2024) constructs ov er 1.2M language–audio pairs by aggregat- ing multiple music datasets, including MusicCaps, Y ouT ub e8M, MusicNet, Jamendo, and MagnaT agA T une, as well as FMA (Defferrard et al., 2016), whic h asso ciates audio files with metadata and free-form textual con tent suc h as artist biographies. Other related datasets are also w orth men tioning, although they fall partially outside the scop e of this w ork. F or instance, MMA U (Sakshi et al., 2024) curates 10K general audio and m usic question–answer pairs to ev aluate diverse m usic understanding and reasoning capa- bilities. Several datasets also draw from Reddit, as we do for MusicSem, but with differen t ob jectiv es. Tip-of-the-T ongue (Bhargav et al., 2023) collects p osts from r/TipOfMyTongue to study search scenarios in which users hav e previously exp erienced an item (e.g., a song or a movie) but cannot recall a reliable iden tifier. V eselo vsky et al. (2021) collect o ver 536K song–artist pairs from Reddit to analyze music sharing b eha vior across comm unities. Bey ond Reddit, the Million Tweet Dataset (Hauger et al., 2013) includes ov er one million m usic-related tw eets to study p opularit y trends and cultural dynamics. Nonetheless, while these datasets highligh t the v alue of large-scale textual data for studying m usic-related b ehavior, they are not designed as paired language–audio resources for training and ev aluating multimodal music represen tation learning mo dels. 5 Rebecca Salganik, et al. (2026) T able 2: Examples of caption elemen ts illustrating the five different categories in our pro- p osed taxonom y of m usical semantics. Category Example of textual description of m usic Descriptive “I like the high p ass filter on the vo c als in the chorus, r e al ly makes harmonies pop.” Contextual “Sabrina Carpenter’s Espr esso is just a mix of old Ariana Gr ande and 2018 Dua Lipa.” Situational “I listene d to this song on the way to quitting my exhausting c orp or ate job.” Atmospheric “This song makes me fe el like a manic pixie dre am girl in a b ougie c offe eshop.” Metadata “This deluxe e dition of this song was r ele ase d in 2013 and it has thr e e b onus hiphop tr acks.” 3 Capturing Musical Seman tics in Multimo dal Represen tation Learning W e now in tro duce the key concept of musical seman tics in more detail. W e first present our taxonom y and discuss the imp ortance of m usical seman tics in Section 3.1. W e then examine the relative lack of semantic a w areness in man y current m ultimo dal mo dels in Section 3.2. 3.1 A T axonomy of Musical Semantics Throughout this pap er, w e use the term music al semantics to refer to the aspects of meaning con vey ed in textual descriptions of music. These aspects go b eyond acoustic properties of m usic and contextualize the o verall listening exp erience. They capture ho w listeners in terpret, exp erience, and situate music in relation to emotions, activities, so cial contexts, and prior knowledge (Levy and Sandler, 2008; Nam et al., 2019; Choi et al., 2020). W e propose to organize these elemen ts into five categories, which together form our taxonomy of music al semantics . Our ob jective is to provide a structured view of the different t yp es of meaning listeners commonly express when describing m usic. W e distinguish the follo wing five categories, with illustrative examples for eac h presented in T able 2: 1. Descriptiv e seman tics, which characterize in trinsic musical attributes such as instru- men tation, genre, temp o, or style; 2. Con textual semantics, which relate a song to other m usic through similarit y , com- parison, or co-listening patterns; 3. Situational semantics, which describ e activities, settings, or environmen ts in which a song is typically listened to; 4. A tmospheric semantics, whic h express emotions, mo o ds, or other affective and ex- pressiv e qualities ev oked b y the music; 5. Metadata-based seman tics, which provide tec hnical, historical, or bac kground in- formation ab out a song or its artist. F or more details on how these categories w ere selected, please see App endix A.2. Mo deling these semantic distinctions is critical for m ultimo dal music represen tation learning. T o illustrate this point, w e consider again the example in tro duced in the intro- duction with the following tw o natural language descriptions: “This song is a b al lad. It c ontains guitar, male vo c als, and a piano. It sounds like something I would listen to at 6 MusicSem chur ch.” v ersus “This song is a b al lad. It c ontains guitar, male vo c als, and a piano. It sounds like something I would listen to during a psyche delic exp erienc e.” Both descriptions sp ecify iden tical descriptiv e musical attributes. Ho w ever, the situational context w ould al- ter a listener’s exp ectations regarding the audio that should b e generated by a text-to-m usic mo del, as well as the audio that should be retriev ed by a multimodal retriev al system giv en these prompts. This example highlights how shifts in m usical seman tics, even when subtle, can lead to qualitatively differen t in terpretations, underscoring the imp ortance of explicitly mo deling seman tic v ariations in language–audio represen tations. 3.2 Limited Sensitivity to Semantic Context in Current Multimo dal Mo dels T o motiv ate the introduction of MusicSem in the next section of this pap er, we conduct a preliminary exploratory study examining the sensitivity of sev eral widely used multimodal m usic representation learning mo dels to v ariations in musical seman tics. Setting. W e design the follo wing exp eriment. Giv en a language–audio pair ( t i , a i ) from a dataset, we construct a counterfactual annotation ˜ t x i b y modifying the original text accord- ing to a specific seman tic category x , for example replacing “while at chur ch” with “during a psyche delic exp erienc e.” W e sample 50 language–audio pairs from the MusicCaps dataset (Agostinelli et al., 2023) and hav e trained musicians man ually construct counterfactual annotations for eac h seman tic category present in the captions. The complete set of coun- terfactual examples derived from MusicCaps is publicly released at: https://github.com/ Rsalganik1123/MusicSem/blob/main/data/counterfactual_examples/all_counterfac. csv . T o assess the sensitivity of text-to-music generative models to seman tic shifts, w e define the following metric: G x = 1 n n X i =1 h 1 − cosine( f i , ˜ f x i ) i , (1) where n denotes the n umber of language–audio pairs, and f i = M ( t i ) and ˜ f x i = M ( ˜ t x i ) corresp ond to the model outputs of the text-to-m usic generativ e mo del M given the original and counterfactual text inputs, resp ectiv ely . T o ev aluate the sensitivity of text-to-m usic retriev al mo dels, we define: R x @ k = 1 n n X i =1 " 1 − | A i ∩ ˜ A x i | | A i | # , (2) where A i = M ( t i ) and ˜ A x i = M ( ˜ t x i ) denote the sets of top- k audio candidates retriev ed b y the mo del given the original and counterfactual textual inputs, resp ectiv ely . T able 3 rep orts the sensitivit y to semantic shifts of several p opular text-to-music gen- erativ e and retriev al mo dels from recent literature. All ev aluated mo dels were trained on existing language–audio datasets reviewed in Section 2 and, in some cases, on additional proprietary datasets that are not publicly av ailable. W e refer readers to the corresp onding references and our App endix B for implementation and training details of each model. 7 Rebecca Salganik, et al. (2026) T able 3: Seman tic sensitivity analysis of generative (top) and retriev al (bottom) models. Best p erformance is in b old. Superscripts d , a , s , m , and c denote descriptiv e, atmospheric, situational, metadata, and contextual, resp ectiv ely . T ext-to-Audio Generative Model G d G a G s G m G c AudioLDM2 (Liu et al., 2024a) 0.68 0.37 0.35 0.40 0.34 MusicLM (Agostinelli et al., 2023) 0.50 0.36 0.42 0.39 0.35 Mustango (Melec hovsky et al., 2024) 0.62 0.27 0.25 0.26 0.32 MusicGen (Copet et al., 2023) 0.57 0.47 0.39 0.47 0.52 Stable Audio (Ev ans et al., 2024) 0.72 0.67 0.68 0.70 0.74 T ext-to-Audio Retriev al Mo del ( k = 10) R d R a R s R m R c LARP (Salganik et al., 2024b) 0.98 0.17 0.06 0.0 0.56 CLAP (W u et al., 2023) 0.95 0.52 0.35 0.42 0.52 ImageBind (Girdhar et al., 2023) 0.84 0.39 0.35 0.38 0.41 CLaMP3 (W u et al., 2025) 0.92 0.58 0.49 0.62 0.55 Results. The results in T able 3 indicate that these mo dels exhibit substantially greater sensitivit y to c hanges in descriptive musical attributes than to shifts in atmospheric, situ- ational, contextual, or metadata-related semantics. This pattern highlights a relative lac k of semantic aw areness in curren t textual conditioning mechanisms and suggests that these mo dels struggle to capture the exp ectations implied b y user inten t b eyond surface-lev el m u- sical descriptors. Nonetheless, as argued in Section 3.1, mo deling such semantic v ariations remains crucial for faithful and user-aligned m ultimo dal music generation and retriev al. These findings motiv ate the need for a semantics-a ware dataset that b etter reflects the di- v ersity of m usical semantics expressed in natural language, in order to supp ort the training and ev aluation of m ultimo dal mo dels. 4 MusicSem: A Language–Audio Dataset of Natural Music Descriptions on Reddit Capturing Musical Semantics T o address this lac k of seman tic sensitivity , we introduce MusicSem , a no vel dataset of language–audio m usic description pairs extracted from organic m usical discourse on the so cial media platform Reddit 1 . MusicSem is designed to capture richer and more n uanced m usical seman tics, supp orting the study , training, and ev aluation of m ultimo dal music rep- resen tation learning mo dels. Its construction requires multiple pro cessing stages, including iden tifying, extracting, structuring, and v alidating semantic con tent from online discourse, com bining LLM-assisted extraction and summarization with h uman verification. W e detail the complete dataset construction pro cess in Section 4.1. Section 4.2 pro- vides a descriptive analysis of the final MusicSem dataset, while Section 4.3 examines key c haracteristics and implications related to music genre and cultural representativ eness, as w ell as the presence of sub jective conten t. Finally , Section 4.4 discusses the key safeguards adopted to ensure ethical and resp onsible data pro cessing and release. 1. https://www.reddit.com/ 8 MusicSem 4.1 Dataset Construction Reddit Thread Selection. Reddit is a large-scale online discussion platform where users engage in topic-centered comm unities, kno wn as subr e ddits , to share conten t and exchange opinions. Reddit discussions are organized in to threads, eac h initiated by a p ost and follow ed b y a sequence of user comments, often forming detailed and context-ric h conv ersations. They provide a natural source of user-generated musical discourse, reflecting how listeners describ e, in terpret, and con textualize music (Medv edev et al., 2017; Proferes et al., 2021). T o construct MusicSem, w e extract music-related textual descriptions from five p opular English-language subreddits that feature sustained user discussions and cov er a broad range of musical styles and listening practices: 1. r/electronicmusic , which fo cuses on electronic music genres, with discussions rang- ing from pro duction and stylistic c haracterization to listening contexts; 2. r/popheads , a comm unit y centered on p op music, where users frequen tly discuss new releases, artists, and their p ersonal listening exp eriences; 3. r/progrockmusic , whic h emphasizes progressiv e ro ck and related genres, often fea- turing detailed discussions of m usical structure, comp osition, and artist influence; 4. r/musicsuggestions , a recommendation-oriented subreddit in whic h users describ e m usical preferences, mo o ds, or situations to solicit tailored listening suggestions; 5. r/LetsTalkMusic , a general m usic discussion forum that encourages reflectiv e con- v ersations ab out music, spanning v arious genres, eras, and p ersonal interpretations. W e collect data using the Pushshift API 2 , co vering discussions from 2008 to 2022. Then, the dataset construction pip eline includes v arious extraction, summarization, and verifica- tion steps, as describ ed b elow and illustrated in Figures 2 and 3. Information Extraction. This phase aims to transform raw Reddit p osts into struc- tured representations that asso ciate mentioned songs with their corresp onding artists and seman tic attributes. W e concatenate the title and b o dy of each p ost in to a single prompt and submit it to a large language mo del for semantic extraction. W e use GPT-4o (2024- 08-06) (Op enAI, 2024) as the extraction mo del. T o extract m usical semantics, w e design a prompt that instructs the mo del to identify (song, artist) pairs and assign them seman tic con tent across the categories defined in Section 3.1. Inspired by prior work on kno wledge extraction with language models (Jiang et al., 2020), the prompt is man ually crafted using illustrativ e examples and iteratively refined through interaction with the mo del. The full set of prompts used at this stage is pro vided in App endix A. Information Summarization and Song–Artist V erification. First, we format the extracted seman tic conten t in to sentence-lev el annotations and verify the correctness of (song, artist) asso ciations. F ollo wing practices adopted in existing language–audio datasets (Agostinelli et al., 2023; Manco et al., 2023; McKee et al., 2023), we use LLMs to rephrase extracted semantic tags into natural language sen tences. T o mitigate incorrect song–artist 2. https://github.com/pushshift/api 9 Rebecca Salganik, et al. (2026) T h e summ er m y firs t real girlfr iend l eft me I listened to th e Gaslig ht An t hem’ s *H andwri tten* on repeat for week s because t he wor d s really spoke to me . T h er e ar e also co mplex emo tions that mus i c on its own can’t desc r ibe, and bein g a pr i m ari ly emo tion dr iven medi um , i t on ly makes sen s e that those so n g s ab o ut com pl e x em otions w i l l n eed words to acc ompa n y the m. T ak e Pink Floyd’ s *Mone y * from * Dark Side of the Moon * . Descr ip tive A tmo s pheric Situatio nal Metadat a Co ntextual Song -A rtist pai r Ke y Po st Figure 2: Example of seman tic con ten t extracted from a Reddit p ost in MusicSem. The figure highlights how a single description can express a v ariet y of different musical semantics, corresp onding to the five categories defined in our taxonomy . The summe r my firs t real girlfr iend left m e I l i s tened to the Ga slight Anth em’s *Hand written* on re peat for w eeks because the words really spoke to me . There are a ls o com plex emoti ons th at music on i ts own ca n ’t describ e, and b eing a prim arily emoti on driv en medi um, it o nly m akes sens e that those songs about complex emoti ons wil l nee d w o rds to ac c o mpa n y them . T a ke Pink Floyd’s *Mo ney* from *Da rk Side of the M oon*. [(Han dw r itten, G aslight A nthem)] [s on g , artist] pa irs [really good l yrics, c om p lex emot i ons t ha t mu sic on its own ca n't de scri be] de scr ipt i ve e lem en ts [li stened for w eeks, real ly spoke to me ] at mo spher ic ele me nts [s um mer my first real gir lfrie nd left] si tuat i ona l el em ents [ Pin k Fl o yd’s *M one y* fr om *Da r k Sid e of t he Mo on* ] co nte xtua l el ement s [] met adat a el e m ents [Handwri tten, Gaslig ht A nthem ] So ng whe re w ord s rea lly s pok e t o me, rea lly g reat l y rics and rea lly gr eat rif fs. Li ste ned t o it th e su mmer m y f i rst real gi rl fri en d le ft me. Re flect ive of c omp l e x emot i ons t ha t mu sic on it s o wn ca n't de scri be. raw text sem antic s umma rizati on LLM 1 LLM 1 Spo tify ve rifi ed retr ieved mp3 LLM 2 ve rifi ed (2) Ext r ac ti on (3) Su mm ar iz ation & V erificat ion (1) I nput Figure 3: Ov erview of the extraction and verification pip eline used to construct MusicSem. After selecting the source Reddit threads, the dataset construction pro ceeds in t w o main stages: an extraction step that identifies candidate semantic conten t from the textual el- emen ts of eac h thread, and a summarization and v erification step that reform ulates the extracted conten t in to sentence-lik e semantic annotations, v erifies song–artist asso ciations, and chec ks the plausibilit y of the extracted semantic information. asso ciations, w e verify each extracted (song, artist) pair by measuring the character-lev el o verlap b et ween the extracted names and the original p ost text, after lo wercasing all strings. P airs with less than 75% o v erlap are discarded. W e then query the Sp otify API 3 to retrieve a unique iden tifier for each remaining pair. In cases where m ultiple candidate entries are returned, we apply the same ov erlap-based filtering strategy to resolv e ambiguities. 3. https://developer.spotify.com/documentation/web- api 10 MusicSem Audio Retriev al. Once a unique identifier is obtained, we retriev e the corresp onding audio using sp otd l 4 . If no audio file can b e retrieved, the associated (song, artist) pair is remo ved from the dataset. After collecting the v alidated (song, artist) pairs, their asso ciated audio files, and the extracted semantic tags, we use GPT-4o to rephrase the semantic con tent into sen tence-lik e annotations. T o respect copyrigh t constraints, we release the unique iden tifiers asso ciated with eac h song and our complete data construction pip eline, rather than the audio files themselves. V erification for Accuracy , F aithfulness, and Hallucination Mitigation. Finally , to verify the faithfulness of the generated annotations and asso ciations, we employ an indep enden t v erification mo del, Claude Sonnet 3.7 (Anthropic, 2025), whic h compares the original extracted semantic tags with the rephrased annotations. The v erification mo del is prompted to pro duce a binary decision indicating whether the annotation is consistent or hallucinated, and entries flagged as hallucinated are remo ved. The complete corresp onding prompt for these verification steps is provided in Appe ndix A. W e further complement these LLM-assisted verification steps with a detailed series of man ual chec ks conducted by our team, including tw o professionally trained musicians, to ensure accuracy , faithfulness, and effective hallucination mitigation in the final dataset. Final Dataset. The final MusicSem dataset consists of 32,493 language–audio pairs. Eac h entry con tains the follo wing fields: • unique id : unique iden tifier used b y Sp otify to iden tify the trac k; • thread : name of the subreddit from whic h the Reddit raw post is extracted; • spotify link : URL to the Sp otify web pla y er for the track; • song : song title; • artist : artist name; • raw text : concatenation of the p ost title and b ody; • prompt : LLM-generated summary of semantic extractions from the raw post; • descriptive : list of strings capturing descriptive elemen ts; • contextual : list of strings capturing contextual elemen ts; • situational : list of strings capturing situational elemen ts; • atmospheric : list of strings capturing atmospheric elemen ts; • metadata : list of strings capturing metadata elemen ts; • pairs : list of tuples containing all song–artist pairs mentioned in the p ost. 4. https://github.com/spotDL/spotify- downloader 11 Rebecca Salganik, et al. (2026) T able 4: General statistics (top) and co v erage by m usic semantic category (b ottom) for MusicSem and tw o other canonical language–audio music datasets. Statistics MusicCaps Song Describ er MusicSem (Agostinelli et al., 2023) (Manco et al., 2023) (ours) Number of entries 5,521 1,100 32,493 Number of distinct words 6,245 2,824 22,738 Number of distinct music genres 267 152 493 Category of Musical Seman tics MusicCaps Song Describ er MusicSem (Agostinelli et al., 2023) (Manco et al., 2023) (ours) Descriptive 100% 94% 100% Contextual 6% 8% 77% Situational 41% 16% 48% Atmospheric 57% 33% 64% Metadata 28% 6% 64% T o facilitate meaningful ev aluation, we curate a human-v alidated test set of 480 en tries. This test set is made a v ailable to review ers at https://tinyurl.com/3n8je74z and will b e remo ved up on publication. It will remain unpublished thereafter to supp ort the developmen t of a future leaderb oard. All remaining en tries constitute the public training set. MusicSem is publicly released under the MIT License and is a v ailable on Hugging F ace: https://huggingface.co/datasets/AMSRNA/MusicSem . The complete source code used to construct MusicSem is av ailable on GitHub: https://github.com/Rsalganik1123/ MusicSem . This repository also pro vides instructions for collecting data from additional m usic-related subreddits using the Pushshift API. All resources are also directly accessible via the accompanying MusicSem website (see Figure 1 in the introduction), whic h includes do cumen tation and visualizations. 4.2 Descriptiv e Analysis of the Dataset W e now presen t an exploratory descriptiv e analysis of the MusicSem dataset. Musical Seman tics Diversit y . First, we analyze the div ersity of m usical semantics cap- tured by MusicSem in comparison with existing language–audio datasets. T able 4 rep orts the prop ortion of entries con taining each of the five seman tic categories for MusicSem and the t wo most widely used human-annotated language–audio datasets discussed in Section 2: MusicCaps (Agostinelli et al., 2023) and Song Describ er (Manco et al., 2023). As shown in T able 4, MusicSem consistently exhibits broader cov erage across all seman- tic categories. F or example, 77% of entries include contextual tags, compared to 6% for MusicCaps and 8% for Song Describ er. These results indicate substan tially richer semantic con tent. In addition, MusicSem constitutes a significantly larger dataset than MusicCaps and Song Describer, whic h contain only 5,521 and 1,100 entries, respectively . It also features a richer vocabulary , with a higher n umber of unique tokens and m usic genre references. P ersonalization and Con textualization. While MusicSem con tains 32,493 entries, these corresp ond to 11,842 unique songs and 4,430 unique artists, reflecting the fact that man y songs are discussed across multiple p osts. W e view this c haracteristic as an adv an tage 12 MusicSem Speaking about David B o wie’ s Wishfu l Begin n ings User1: ‘hackneyed drum beat’, ‘horrible synthy bassline’, ‘f la t and uninteresting music’, ‘dated sound’; User 2: ‘awesome voice’, ‘perfectly used vocal effects’, ‘ ama zi ng layering’, ‘worth listening with good headph o ne’ Example of P ers on a liz ation suggestions for songs that emanate optimism (but not toxic positivity)? Hi! I'm working on a playlist for my girlfrien d. H er depression has been bad lately and so I wanted to make her a playlist of songs that feel like a warm hug and can comfort her . It's important that these songs promote genuine optimism as opposed to toxic positivity . I already have about 90 minutes worth of songs but I was wondering what others could help. Some examples of what I already have: (1) Y ou r Song - Elton John -- o u r song :) // (2) W ildflowers- T om Pett y / / (3) Rainbow- Ka ce y Mu sgraves / / (4) Dust y T ra il s - Lucius //(5) Grow As We Go- Be n Platt Exa mp le of Con textua liza ti on Figure 4: An example of p ersonalization and con textualization on Reddit. of the dataset. Beyond semantic diversit y , MusicSem captures t w o distinctiv e prop erties that are largely absent from existing datasets: p ersonalization and c ontextualization . Regarding p ersonalization, each song is discussed in an av erage of 2.98 distinct p osts, resulting in m ultiple, p otentially divergen t semantic descriptions of the same musical piece. This m ultiplicity reflects individual listener persp ectives and use cases, and enables the study of p ersonalized or user-dep enden t interpretations of music. An example is sho wn in Figure 4, where different users asso ciate distinct semantic attributes with the same song. In terms of contextualization, p osts in MusicSem mention an a verage of 10.51 songs, whic h are often group ed under shared themes, mo o ds, or situational con texts (such as p ositivit y or relaxation). Suc h co-o ccurrences provide explicit signals of seman tic relatedness b et ween songs, grounded in user-defined con texts rather than editorial taxonomies. This structure highlights the imp ortance of mo deling in ter-song asso ciations and laten t user in tent in m usic understanding and retriev al tasks. Visualizations. Figure 5 presents additional visualizations illustrating sev eral asp ects of MusicSem. Figure 5(a) shows the distribution of m usic genres in MusicSem, with strong represen tation of ro c k, metal, electronic, and p op m usic. This distribution is exp ected given the five subreddits selected for dataset construction. W e further discuss the resulting music genre bias and its practical implications in Section 4.3. Figure 5(b) depicts the distribution of song o ccurrences across p osts. The dataset follo ws a pow er-law distribution, in which a small n umber of songs are men tioned frequen tly while man y others app ear only rarely . This pattern aligns with w ell-do cumented p opularit y biases in m usic datasets, which often lead to substan tial disparities b et ween mainstream and niche m usic representation (Salganik et al., 2024a). Finally , Figure 5(c) rep orts the distribution of raw post lengths. The dataset is sk ewed to ward longer discussions, with most p osts exceeding 360 c haracters. This contributes to the rich vocabulary and high density of seman tic conten t observed in MusicSem. 4.3 Discussion of Dataset Characteristics and Implications MusicSem is designed to capture a broad sp ectrum of musical semantics as they naturally emerge from listener discourse, reflecting nuanced, h uman-centered descriptions of music. 13 Rebecca Salganik, et al. (2026) (a) (b) 0 90 90 180 180 270 270 360 >360 Number of words 0 10 20 30 40 Proportion of pairs (%) 7% 21% 20% 15% 37% (c) Figure 5: Visualizations for MusicSem. (a) Music genre distribution visualized as a word cloud, where larger fon t size indicates higher frequency . (b) P opularity distribution of songs. (c) Distribution of the n umber of w ords p er language–audio pair. While this focus enables rich seman tic analysis, sev eral k ey characteristics of the dataset should b e carefully considered when using it. W e discuss these considerations b elow. Music Genre Representativ eness. As shown in Figure 5(a), certain music genres are o verrepresen ted in MusicSem. This imbalance is a direct consequence of the subreddit se- lection pro cess. F or example, sourcing data from r/progrockmusic naturally results in a higher prev alence of progressiv e rock discussions. In its current version, MusicSem prior- itizes seman tically ric h musical discourse o ver balanced genre co v erage. Consequently , it should not b e interpreted as genre-representativ e of music listening b eha vior at large. F uture users should be cautious when conducting genre-sp ecific analyses, as some genres are under- represen ted. That said, as explained in Section 4.1, our public repository provides detailed instructions for collecting data from additional music-related subreddits, enabling users to augmen t the dataset with annotations from other communiti es and genres as needed. Cultural Representativ eness. Prior work has demonstrated that cultural background, language, so cio-economic factors, and individual musicological exp erience strongly influence ho w music is p erceived and describ ed (Sordo et al., 2008; Morrison and Demorest, 2009; Lee et al., 2013; Epure et al., 2020). In this context, we ackno wledge that the construction of MusicSem, like most datasets deriv ed from online platforms, in tro duces inherent selection biases that affect its linguistic and seman tic c haracteristics. All textual data is collected 14 MusicSem from English-language subreddits, and Reddit’s user base is kno wn to sk ew tow ard younger, digitally engaged, and predominantly W estern p opulations (Barthel et al., 2016; Epure and Hennequin, 2023). Moreov er, users who actively participate in m usic-related discussions often hold strong opinions or are affiliated with niche comm unities (Medv edev et al., 2017; Epure and Hennequin, 2023). These factors may influence b oth the con tent and framing of m usical descriptions. W e therefore encourage users to account for these prop erties when applying MusicSem to tasks in volving user mo deling or cross-cultural generalization. Sub jectivit y and Conten t Noise. MusicSem relies on user-authored text, whic h is inheren tly sub jective and ma y be informal or ambiguous. This v ariabilit y constitutes a cen tral strength of the dataset, capturing p ersonal interpretations, emotions, and listening con texts. That said, it also introduces noise and inconsistencies in semantic descriptions. As such, MusicSem is not intended to pro vide authoritative annotations. Instead, it reflects the diversit y of listener p ersp ectiv es encountered in natural discourse. In addition, the construction of MusicSem inv olv es LLM-assisted extraction and pro- cessing. T o mitigate p otential errors, we incorp orate rigorous faithfulness and hallucination in our pip eline, and our team man ually reviewed the extracted con tent to v erify (i) align- men t betw een extracted songs and those explicitly men tioned in each thread, (ii) fidelit y of m usical attributes to the original user p osts, and (iii) the absence of clear hallucinations. Despite these safeguards, some small degree of residual noise may remain, which should b e tak en into accoun t when using the dataset. 4.4 Ethical Considerations MusicSem is constructed from publicly av ailable online con ten t and is intended for research use. W e tak e ethical and legal considerations seriously and outline b elow the key measures adopted during dataset construction as ethical safeguards. User Priv acy and Anonymit y . MusicSem is derived from Reddit threads that users v oluntarily shared on a public platform designed around pseudon ymous participation, where con tributors are encouraged to conceal their real-world iden tities through self-selected iden- tifiers. As a result, posts in MusicSem are authored under pseudonyms rather than identifi- able p ersonal names, substan tially reducing the risk of linking conten t to sp ecific individuals. T o further mitigate priv acy risks, all user identifiers are remo ved prior to release. The dataset do es not include usernames, user IDs, profile links, or other direct iden tifiers. In addition, t wo members of the author team manually review ed all p osts to remov e any remaining explicit p ersonal information (e.g., names, addresses, phone num b ers, or email addresses). T o the b est of our kno wledge, no suc h information remains in the dataset. Release of Searchable Raw Reddit P osts. W e ac knowledge that some ra w text from Reddit threads may b e searc hable through public searc h engines such as Go ogle, as w ell as Reddit’s own searc h functionality . F or this reason, w e carefully considered whether to exclude the raw p ost text from the release of MusicSem, and w e remain op en to considering it again should communit y standards or platform p olicies evolv e in the future. Ho wev er, at the time of release, we chose to preserv e the original text, as all raw text that might b e searchable w as authored under pseudonymous iden tifiers. Retaining the ra w text is imp ortan t for maintaining the integrit y of organic m usical discourse and is 15 Rebecca Salganik, et al. (2026) essen tial for a range of research tasks, including seman tic extraction, discourse analysis, and robustness ev aluation of language mo dels. W e emphasize that the inclusion of raw text is intended solely to supp ort researc h on m usic understanding and does not aim to increase the traceabilit y of individual users beyond what is already p ossible on the original platform. Consen t and Platform Compliance. Reddit’s T erms of Service 5 p ermit the use of publicly a v ailable con tent for research purposes under specified conditions, and our data collection and redistribution practices comply with these terms. Our approach is consistent with established academic preceden t for Reddit-based datasets and large-scale public text corp ora (Baumgartner et al., 2020; Bhargav et al., 2023; Shen et al., 2023). While obtaining explicit consen t from individual users would be even better, this is infeasible in practice due to the pseudon ymous nature of accounts and the time elapsed since p osting. As in prior w ork, we therefore rely on platform-lev el consent and widely accepted research norms and practices in computational so cial science and natural language pro cessing. Cop yrigh t and Music Con tent. MusicSem do es not directly redistribute an y audio con tent. Instead, it pro vides references to musical w orks via Sp otify iden tifiers, song titles, and artist names extracted from user p osts. This design resp ects cop yright constraints while allowing researchers to lo cate audio through legally authorized platforms. Users are resp onsible for ensuring compliance with applicable copyrigh t la ws when accessing audio. W e recognize that long-term a v ailabilit y of referenced music remains a broader c hallenge in m usic researc h. Compared to datasets that rely on direct hosted URLs (for example, MusicCaps (Agostinelli et al., 2023) only links to Y ouT ub e URLs that ma y b e remov ed o ver time), the use of platform-agnostic iden tifiers improv es resilience to link decay and cop yright tak edo wns, although p ermanence cannot b e fully guaranteed. 5 Ev aluating Multimo dal Music Mo dels Using MusicSem W e no w conduct a comprehensive set of exp erimen ts to ev aluate a wide range of cross- mo dal music retriev al, text-to-m usic generation, and music-to-text generation mo dels using MusicSem. These exp erimen ts pro vide concrete examples of tasks for whic h MusicSem can b e used, while also demonstrating the v alue of this dataset as a b enchmark for semantics- a ware m ultimo dal m usic mo del ev aluation. W e first presen t exp eriments on cross-mo dal m usic retriev al in Section 5.1, follo w ed b y m usic-to-text and text-to-m usic generation ex- p erimen ts in Sections 5.2 and 5.3, resp ectively . Finally , Section 6 go es b eyond ev aluation b y rep orting preliminary fine-tuning exp erimen ts that illustrate the p otential of MusicSem for mo del adaptation. F or repro ducibility , w e publicly release our source co de on GitHub at: https://github.com/Rsalganik1123/MusicSem . 5.1 Cross–Modal Music Retriev al Setting. W e first b enchmark represen tativ e mo dels on a cr oss-mo dal music r etrieval task , a core application of m ultimo dal m usic represen tation learning (W u et al., 2023, 2025). Sp ecifically , w e fo cus on the text-to-audio retriev al setting, where eac h query consists of a textual description from a language–audio pair, and the model observes only the text 5. https://redditinc.com/policies 16 MusicSem mo dalit y . The goal is to retrieve the corresp onding audio track from a po ol of candidate audio samples in the dataset. T o perform retriev al, mo dels embed both text queries and audio candidates in to a shared em b edding space and rank the audio trac ks according to their similarity to the query em b edding v ector. A retriev al is deemed correct if the audio trac k originally paired with the query text is rank ed among the top results (W u et al., 2023). W e ev aluate four competitive models for cross-modal retriev al from the recen t litera- ture: CLAP (W u et al., 2023), ImageBind (Girdhar et al., 2023), LARP (Salganik et al., 2024b), and ClaMP3 (W u et al., 2025), along with a random retriev al baseline. F or eac h mo del, w e rep ort standard retriev al metrics (Carterette and V o orhees, 2011), includ- ing Mean Recipro cal Rank (MRR), Recall@ K , and Normalized Discounted Cum ulative Gain@ K (NDCG@ K ), with K ∈ { 1 , 5 , 10 } denoting the num b er of top-rank ed candidate audio trac ks returned b y the mo del. W e compute these metrics on MusicSem as well as on t wo other widely used language–audio m usic datasets, MusicCaps (Agostinelli et al., 2023) and Song Describ er (Manco et al., 2023), to enable comparativ e analysis across datasets. F or clarit y and brevit y , Appendix B pro vides detailed descriptions of all ev aluated meth- o ds, links to their implementations, information on dataset splits and hyperparameters, and the computational resources employ ed. Insigh t 1.1: Different datasets induce different model rankings. The results in T able 5 sho w that the relative p erformance of mo dels v aries substantially across datasets. On MusicCaps, CLAP ac hiev es the strongest p erformance (for example, with a top 22.60% Recall@10 score), whereas on b oth Song Describ er and MusicSem, ClaMP3 emerges as the b est-p erforming mo del (for example, with a top 26.84% Recall@10 score on MusicSem). W e attribute these differences primarily to mismatches betw een the training data of the mo dels and the characteristics of the ev aluation datasets. CLAP was originally trained on a mixture of music and general audio conten t, including ambien t sounds, whereas ClaMP3 is designed sp ecifically for music representation learning. This distinction aligns with the nature of the ev aluated datasets. MusicCaps con tains audio clips sourced from Y ouT ub e and o verlaps with AudioSet (Gemmek e et al., 2017), whic h includes a wide range of non- m usical and ambien t audio. In con trast, b oth Song Describ er and MusicSem rely exclusiv ely on studio-quality music recordings that are largely free of ambien t noise. The observ ed v ariation in mo del rankings across datasets highlights limitations in the generalization capabilities of current multimodal m usic understanding mo dels and suggests substan tial ro om for improv ement in dev eloping representations that transfer robustly across div erse audio domains. Insigh t 1.2: MusicSem is more c hallenging than existing datasets. Comparing p erformance on MusicSem and Song Describ er, we observe that nearly all ev aluated mo d- els p erform w orse on MusicSem, despite its smaller candidate set (480 test audio tracks) compared to Song Describer (note that in retriev al tasks, larger candidate sets t ypically lead to lo w er performance (Carterette and V o orhees, 2011)). This indicates that MusicSem constitutes a more challenging b enc hmark for multimodal mo dels. A similar trend app ears when comparing MusicSem with MusicCaps. Although Mus- icCaps in v olves a larger candidate set, model p erformance on MusicCaps is only slightly lo wer than on Song Describ er, and in some cases higher than on MusicSem. This suggests that the increased difficulty of MusicSem cannot b e attributed solely to candidate set size. 17 Rebecca Salganik, et al. (2026) T able 5: Ev aluation results on the text-to-m usic retriev al task. Best p erformance for each metric within a dataset is shown in b old, and second-b est results are underlined. All scores are reported as p ercentages. In this retriev al setting, NDCG@1 is equiv alent to Recall@1 and is therefore not rep orted in the table. Dataset Mo del Recall @ 1 ↑ Recall @ 5 ↑ Recall @ 10 ↑ NDCG @ 5 ↑ NDCG @ 10 ↑ MRR ↑ MusicCaps Random 0.04 0.18 0.36 0.10 0.16 0.31 LARP 0.14 0.49 0.98 0.30 0.45 0.62 CLAP 5.84 15.57 22.60 10.73 12.99 11.60 ImageBind 3.15 10.18 14.91 6.72 8.25 7.23 CLaMP3 2.73 8.82 13.65 5.81 7.32 9.07 Song Describer Random 0.14 0.71 1.41 0.41 0.64 1.01 LARP 0.36 1.72 2.62 1.05 1.29 1.61 CLAP 4.61 17.3 27.67 11.20 14.54 12.41 ImageBind 4.43 13.02 20.71 8.72 11.16 9.84 CLaMP3 10.49 27.31 38.61 19.21 22.84 19.83 MusicSem Random 0.21 1.05 2.11 0.62 0.96 1.42 LARP 0.22 1.02 3.07 0.54 1.22 1.47 CLAP 0.82 5.74 9.84 3.54 4.74 4.65 ImageBind 2.05 5.94 11.07 3.83 5.48 5.24 CLaMP3 7.79 18.85 26.84 13.65 16.21 14.68 Ov erall, these results indicate that MusicSem introduces additional semantic challenges for cross-mo dal retriev al, lik ely due to its richer and more n uanced textual descriptions. This finding suggests that current m ultimo dal music represen tation mo dels remain limited in their ability to capture fine-grained m usical seman tics, and that MusicSem pro vides a v aluable b enchmark for studying and adv ancing semantic understanding in cross-mo dal m usic retriev al in future researc h. 5.2 Music-to-T ext Generation Setting. MusicSem is also w ell suited for ev aluating cross-mo dal generation tasks, includ- ing music-to-text gener ation , also referred to as m usic captioning (Manco et al., 2023; Liu et al., 2024b; W u et al., 2024). In this task, the mo del is pro vided with an audio recording of a musical w ork as input and is required to generate a natural language description that captures its semantic con ten t, including descriptiv e and con textual asp ects of the music. W e ev aluate three comp etitive m usic captioning mo dels from the recent literature: MU- LLaMA (Liu et al., 2024b), LP-MusicCaps (Doh et al., 2023), and FUTGA (W u et al., 2024). As for cross-mo dal music retriev al, exp erimen ts are conducted on MusicCaps, Song Describ er, and our proposed dataset, MusicSem. W e rep ort commonly used ev aluation metrics from natural language pro cessing, including BLEU (B) (Papineni et al., 2002), ME- TEOR (M) (Banerjee and La vie, 2005), ROUGE (R) (Lin, 2004), CIDEr (V edan tam et al., 2015), and BER TScore (BER T-S) (Zhang et al., 2020), which are standard for ev aluating m usic captioning mo dels. F or clarit y and brevit y , Appendix B pro vides detailed descriptions of all ev aluated meth- o ds, links to their implementations, information on dataset splits and hyperparameters, and the computational resources employ ed. The app endix also includes a discussion of the ev al- uation metrics and the in tuitions underlying them. 18 MusicSem T able 6: Ev aluation results on the music-to-text generation task. Best p erformance for each metric within a dataset is shown in b old. Dataset Model B 1 ↑ B 2 ↑ B 3 ↑ M ↑ R ↑ CIDEr ↑ BER T-S ↑ MusicCaps LP-MusicCaps 53.21 47.28 44.60 51.90 3.35 384.72 90.47 MU-LLaMA 1.35 0.55 0.22 40.22 11.27 0.09 80.47 FUTGA 8.80 3.07 1.19 44.77 11.90 2.63e-17 81.67 Song Describ er LP-MusicCaps 9.51 3.07 0.94 8.90 10.45 1.03 84.40 MU-LLaMA 12.03 4.73 1.73 8.72 13.00 3.59 83.51 FUTGA 3.39 1.28 0.43 8.72 6.30 3.58e-30 82.55 MusicSem LP-MusicCaps 11.57 3.05 0.72 20.59 9.54 0.77 82.13 MU-LLaMA 4.11 1.41 0.51 22.33 10.57 0.92 81.63 FUTGA 4.82 1.50 0.44 22.23 7.48 0.01 80.93 T able 7: Semantic analysis of music-to-text generation on MusicSem. W e report the pro- p ortion of captions containing at least one elemen t from each seman tic category , for b oth ground-truth annotations in the MusicSem test set and mo del-generated captions. Category of Seman tics LP-MusicCaps MU-LLaMA FUTGA Ground T ruth in MusicSem Descriptive 100% 99% 100% 83% Contextual 2% 1% 0% 17% Situational 42% 0% 1% 38% Atmospheric 78% 3% 91% 62% Metadata 32% 2% 34% 15% Insigh t 2.1: Mo del p erformance v aries across datasets and metrics. The results in T able 6 sho w that mo del p erformance for m usic-to-text generation v aries substantially across datasets. On b oth MusicCaps and MusicSem, LP-MusicCaps achiev es the strongest o verall p erformance according to most of the rep orted metrics (for example, with a top 53.21 BLEU 1 score on MusicCaps), whereas on Song Describ er, MU-LLaMA tends to outp erform the other mo dels. This v ariability is consisten t with the p erformance inconsistencies ob- serv ed in the cross-modal retriev al task and further suggests that existing music captioning mo dels exhibit limited generalization across datasets. Improving robustness and general- ization therefore remains a k ey challenge for m usic-to-text generation. Insigh t 2.2: P erformance inconsistencies are driv en b y seman tic div ersit y across datasets. T o further in vestigate the observ ed p erformance inconsistencies, we analyze the distribution of semantic categories presen t in b oth the ground-truth annotations of the MusicSem test set and the captions generated b y eac h mo del, as rep orted in T able 7. This analysis sho ws that the relativ ely strong p erformance of LP-MusicCaps correlates with its higher cov erage of atmospheric, situational, and con textual semantics in its generated captions. Among the ev aluated mo dels, LP-MusicCaps exhibits the highest prop ortion of these semantic categories in its output. A t the same time, we observ e that all mo dels are heavily skew ed tow ard producing descriptiv e captions, while only a small fraction of generated text captures contextual, situational, or atmospheric elemen ts that are prominen t in Reddit-based annotations. This 19 Rebecca Salganik, et al. (2026) FUTGA Annotation The music is characterized by a catchy melody , a groovy bass line, and a driving rhythm section. The mood is upbeat and energetic, and the the me is repe t itive and uplifting … The instrume n ts used in the so n g include e lectric guitar , synthesizer , bass guitar , dru ms, and piano . The chord pro g ression is t yp ical of a d i sco song, with a fo cu s on the t o nic and dominant chords. Intro/V e rse: El ectric guitar and bass guita r create a driving rhythm… Chorus: Same instruments as the intro/verse. … Outro: Same instruments as the intro/verse Melody fades out. MU -LLaMA A nn otati o n The music is a rock song with a fa st tempo, heavy guit a r riffs , a n d a mal e vocalist . LP -Music Ca p s Annotation This song contains digital drums pla yi ng a four on th e floor groove with a kick on every be a t along to an e-bass. In the background you can hear additional bo n go rhythms. A synth st ri ng sound is playi n g long chord notes in the background. … A female voice is singing in a higher ke y and wit h backing vocals. This song may be pl ayi n g wh i le cleaning the kitchen. Reddit A nnotation Defines exactly how techno should so u nd . It has a positive and uplifting mu sical qua l ity with a f u turistic vib e . The album also feels sooooo summery . Inc o r rect info Descr iptive captio n Atmos pheric c aption Situatio nal captio n Metadata caption Figure 6: Case study of m usic-to-text generation ev aluation using MusicSem. The reference song is While Others Cry b y The F uture Sound of London. All mo dels pro duce captions con taining factual inaccuracies and primarily fo cus on descriptiv e attributes. im balance highlights the difficulty of generating ric h and faithful seman tic descriptions of m usic using curren t state-of-the-art models. These results suggest that MusicSem, with its emphasis on diverse and context-ric h semantics, pro vides a v aluable b enchmark for iden tifying and addressing these limitations in future w ork. Insigh t 2.3: Higher scores do not alwa ys imply seman tic correctness. Interest- ingly , a close insp ection of mo del outputs rev eals some limitations of metric-based ev alu- ation. Although LP-MusicCaps attains the highest scores, qualitativ e analysis c hallenges this conclusion. Figure 6 presen ts a representativ e case s tudy on MusicSem, comparing the ground-truth annotation with captions generated by each mo del. In this example, FUTGA pro duces a more detailed and seman tically accurate description of the audio, y et receiv es lo wer ob jective scores due to reduced n -gram ov erlap caused by longer and more expressiv e outputs. In contrast, MU-LLaMA generates shorter captions that are largely incorrect, but nev ertheless achiev es scores comparable to FUTGA, likely due to sup erficial lexical o verlap. Moreo ver, despite seemingly strong quantitativ e p erformance across mo dels, each gen- erated caption in the case study con tains at least one factually incorrect description of the input m usic. This highlights a p ersisten t gap b etw een ob jectiv e ev aluation metrics and true seman tic understanding, and indicates that current state-of-the-art mo dels remain limited in their ability to capture fine-grained and faithful musical seman tics. 5.3 T ext-to-Music Generation Setting. The text-to-music gener ation task consists in generating m usical audio from a textual description. In this work, we focus on one of the most c hallenging settings, namely m ulti-track music generation, where the generated audio contains multiple instruments 20 MusicSem (Agostinelli et al., 2023; Huang et al., 2023; Schneider et al., 2024; Melecho vsky et al., 2024; Lam et al., 2023; Cop et et al., 2023; Liu et al., 2024a). W e consider a one-shot prompting scenario, in whic h a single textual input is pro vided to the mo del without iterative refinemen t. W e lea ve multi-turn in teractive m usic generation (Lin et al., 2024; Ronc hini et al., 2025; Zhang et al., 2024) for future w ork. W e ev aluate six comp etitive text-to-music generation models: MusicLM (Agostinelli et al., 2023), Stable Audio (Ev ans et al., 2024), MusicGen (Cop et et al., 2023), AudioLDM2 (Liu et al., 2024a), Mustango (Melecho vsky et al., 2024), and the proprietary Murek a gen- erativ e to ol 6 . F or each mo del, we report several metrics, group ed into three complementary dimensions: (i) audio quality , measured b y the F r´ ec het Audio Distance (F AD) (Kilgour et al., 2019; Gui et al., 2024); (ii) audio diversit y , measured b y the Kullback–Leibler Diver- gence (KLD) (Shlens, 2014) and V endi Score (VS) (F riedman and Dieng, 2023); and (iii) text–audio fidelit y , measured b y the CLAP score (CS) (W u et al., 2023). Again, we conduct exp erimen ts on MusicCaps, Song Describ er, and our prop osed dataset, MusicSem. F or clarit y and brevit y , Appendix B pro vides detailed descriptions of all ev aluated meth- o ds, links to their implementations, information on dataset splits and hyperparameters, and the computational resources employ ed. The app endix also includes a discussion of the ev al- uation metrics and the in tuitions underlying them. Insigh t 3.1: Eac h ev aluation metric captures a differen t asp ect of generation qualit y . First, different v ariants of the F r´ echet Audio Distance (F AD) yield substantially differen t rankings among mo dels. Given a reference em b edding mo del (indicated b y the subscript, where V, M, and E corresp ond to VGG (Simon yan and Zisserman, 2015), MER T (Li et al., 2024), and Enco dec (D´ efossez et al., 2022), resp ectiv ely) and a reference dataset (indicated by the superscript, where MC and FMA refer to MusicCaps (Agostinelli et al., 2023) and the F ree Music Archiv e (FMA) (Defferrard et al., 2016), resp ectively), F AD measures the discrepancy b etw een the distributions of real and generated audio em b eddings. Consisten t with the observ ations of Gui et al. (2024), w e find that F AD v alues computed using differen t reference mo dels can differ by orders of magnitude, leading to markedly differen t relative rankings across comp eting systems. Although the proprietary mo del Murek a achiev es the strongest ov erall F AD scores, the iden tity of the second-b est mo del v aries considerably dep ending on the c hoice of refer- ence mo del and dataset. This v ariability suggests that non-proprietary mo dels still exhibit substan tial limitations in generating consistently high-qualit y m usic. Second, mo dels that ac hieve lo w (b etter) F AD scores do not necessarily obtain high V endi Scores, indicating a trade-off b et ween audio qualit y and diversit y . Ac hieving b oth high fidelity and high div ersity remains a challenging open problem in text-to-music generation. Finally , w e observe discrepancies b et ween performance measured b y ob jective metrics (T able 8) and seman tic sensitivit y results (T able 3). F or instance, Stable Audio p erforms strongly on seman tic sensitivit y tests but s cores p o orly on con ven tional metrics, whereas Mustango exhibits the opp osite trend. These inconsistencies highligh t the difficulty of join tly optimizing seman tic alignment and traditional audio-based ev aluation criteria. Ov erall, these findings underscore the complexity of ev aluating text-to-music generation and demonstrate that no single metric pro vides a complete assessmen t of mo del p erfor- 6. https://www.mureka.ai/ 21 Rebecca Salganik, et al. (2026) T able 8: Ev aluation results on the text-to-music generativ e task. Best p erformance for each metric within a dataset is sho wn in b old, and second-best results are underlined. Note: Exp erimen ts for Murek a on MusicCaps could not b e completed due to unresolved issues (at the time of writing) with the Murek a API, which preven t automated access to audio data from their w ebsite. F or completeness, we nonetheless rep ort the results obtained for Murek a on MusicSem and Song Describ er. Dataset Mo del F AD MC V ↓ F AD FMA V ↓ F AD FMA M ↓ F AD FMA E ↓ KLD ↓ V endi ↑ CS ↑ MusicCaps MusicLM 5.70 21.57 87.39 249.72 1.79 1.55 0.28 Stable Audio 6.97 15.60 82.21 377.02 1.90 1.31 0.31 MusicGen 7.03 16.29 73.22 354.07 0.90 1.57 0.29 AudioLDM2 3.29 19.31 60.02 202.11 0.61 1.57 0.36 Mustango 1.27 22.96 55.84 161.47 1.51 1.48 0.27 Murek a - - - - - - - Song Describ er MusicLM 7.20 20.59 87.12 241.95 0.89 1.49 0.28 Stable Audio 4.42 14.90 79.16 341.92 1.07 1.29 0.31 MusicGen 2.64 14.60 65.74 354.07 0.66 1.50 0.35 AudioLDM2 2.74 17.19 57.88 184.03 0.62 1.48 0.34 Mustango 2.58 18.50 56.69 170.27 1.48 1.46 0.29 Murek a 2.42 9.85 35.58 47.84 1.38 1.38 0.23 MusicSem (Ours) MusicLM 7.25 22.57 86.97 248.42 1.00 1.46 0.27 Stable Audio 5.50 14.96 79.35 342.53 1.15 1.28 0.31 MusicGen 3.75 14.67 68.11 229.29 0.74 1.50 0.30 AudioLDM2 3.47 17.66 57.71 181.11 0.55 1.46 0.28 Mustango 5.06 19.15 55.11 157.32 1.46 1.41 0.20 Murek a 2.70 9.69 34.75 44.75 1.40 1.33 0.18 mance. The inclusion of seman tic sensitivit y as an ev aluation dimension introduces addi- tional challenges for curren t metho ds, whic h are made explicit with MusicSem. Insigh t 3.2: Limitations of the CLAP score. The CLAP score is a widely used metric for ev aluating the alignment b etw een a textual prompt and its asso ciated generated audio. Ho wev er, our results reveal notable limitations of this metric. Sp ecifically , we observe minimal performance differences across models when ev aluated on canonical b enchmark datasets and on MusicSem. This outcome is unexp ected, as MusicSem con tains substantially few er descriptive annotations and ric her contextual semantics, whic h would intuitiv ely b e reflected in differences in CLAP scores. T o further inv estigate this b ehavior, we leverage the seman tic sensitivit y metric defined in Equation (1) and compute cosine similarities b etw een text embe ddings produced by the CLAP text enco der. This analysis allows us to directly assess CLAP’s sensitivity to sem an tic v ariations in textual prompts. As sho wn in T able 9, CLAP exhibits similarly low seman tic sensitivit y , suggesting a limited capacit y to distinguish fine-grained seman tic differences in text. T aken together, these findings indicate that the CLAP score is insufficien t for capturing the ric h and nuanced seman tics presen t in MusicSem, and highlight the need for alternativ e or complementary ev aluation metrics when assessing language–audio alignment. 22 MusicSem T able 9: Sensitivity of the CLAP score on MusicSem. The sup erscripts d , a , s , c , and m refer to descriptive, atmospheric, situational, con textual, and metadata, resp ectively . Category of Seman tics Metric Score Descriptiv e G d 0.55 A tmospheric G a 0.36 Situational G s 0.32 Con textual G c 0.29 Metadata G m 0.36 6 T o wards Fine-T uning Multimodal Mo dels using MusicSem 6.1 Usage Guidelines The primary goal of MusicSem is to supp ort the developmen t of multimodal music models with stronger seman tic aw areness; that is, mo dels capable of capturing richer and more n uanced relationships b et ween textual descriptions and audio conten t. While designing arc hitectures that achiev e effective seman tic grounding remains an op en researc h c hallenge and is b eyond the scop e of this paper, MusicSem w as constructed with suc h use cases in mind. W e therefore outline practical guidelines in tended to serve as a road map for future practitioners. MusicSem consists of language–audio pairs derived from user discussions, where eac h de- scription reflects semantically meaningful attributes, impressions, or contextual information ab out a track. W e pro vide t wo versions of the dataset: (1) a full v ersion in which eac h user’s discussion constitutes a separate data p oint, and (2) a de-duplicated v ersion in which eac h song appears only once. Because m ultiple users ma y pro vide conflicting or sub jective char- acterizations of the same song, the full dataset in tro duces additional v ariabilit y that may act as noise during training. Unless modeling suc h disagreemen t is explicitly desired, w e recommend beginning with the de-duplicated version. Practitioners can use the unique id field to select a single instance p er song (see App endix 4.1 for details on dataset fields). As no ob jective criterion exists for choosing a single “b est” description, practitioners should consider how their selection strategy ma y influence the learned representations and tailor it to their mo deling goals. After selecting a single textual description p er song, MusicSem can b e used in a manner similar to prior m ultimo dal datasets suc h as MusicCaps Agostinelli et al. (2023) or Song Describ er Manco et al. (2023) for con trastive pretraining or fine-tuning. In the follo wing section, w e presen t preliminary results demonstrating the use of MusicSem to fine-tune a CLAP-based mo del W u et al. (2023). 6.2 Preliminary Results The exp erimen ts presen ted so far aim to illustrate the v alue of MusicSem as a b enc hmark for semantically-a w are ev aluation of m ultimo dal m usic mo dels. As an op ening step, w e mo ve beyond ev aluation and rep ort preliminary fine-tuning exp erimen ts that highligh t the p oten tial of MusicSem for enriching pre-trained models with semantic sensitivit y . W e note that a comprehensive in vestigation of fine-tuning m ultimo dal language–audio mo dels could in itself constitute a full study , requiring careful consideration of training 23 Rebecca Salganik, et al. (2026) T able 10: Effects of fine-tuning CLAP (W u et al., 2023) on the MusicSem training set, ev al- uated in terms of cross-mo dal text-to-music retriev al p erformance and semantic sensitivity on the MusicSem test set. Best performance for each metric is shown in b old. Impro vemen ts are rep orted relative to the non–fine-tuned baseline. In this retriev al setting, NDCG@1 is equiv alent to Recall@1 and is therefore not rep orted in the table. Retriev al Performance Recall@1 Recall@5 Recall@10 NDCG@5 NDCG@10 MRR No Fine-T uning 0.82 5.74 9.84 3.54 4.74 4.65 Fine-T uning on MusicSem 4.51 11.48 17.42 8.06 9.95 9.16 R elative Impr ovement +450.00% +100.00% +77.03% +127.68% +109.92% +96.77% Seman tic Sensitivity G d G a G s G c G m No Fine-T uning 0.55 0.36 0.32 0.29 0.36 Fine-T uning on MusicSem 0.64 0.38 0.41 0.43 0.38 R elative Impr ovement +16.36% +5.56% +28.13% +48.28% +5.56% ob jectiv es and losses, semantic balancing during optimization, regularization to preven t catastrophic forgetting, and scaling effects (Churc h et al., 2021; Han et al., 2024). F or these reasons, a full fine-tuning inv estigation using MusicSem is b eyond the scop e of this pap er, our ob jectiv e here is to sho w that MusicSem can enric h a pretrained m ultimo dal mo del with fine-grained musical seman tics, including contextual, situational, and atmospheric. Setting. W e fine-tune CLAP W u et al. (2023), a p opular cross-mo dal music retriev al on the MusicSem training set. In our ev aluation, we tak e the b est p erforming c heckpoint a v ail- able on GitHub 7 and fine-tune the mo del using the de-duplicated v ersion of the MusicSem dataset for up to 200 ep o c hs. W e then select the chec kp oint ac hieving the highest av erage seman tic sensitivit y score (as defined in Equation (1)) on a held-out v alidation set, reached at epo c h 110. The selected model is then ev aluated on the MusicSem test set. W e rep ort the effects of this fine-tuning procedure using tw o sets of metrics: (1) the retriev al p erformance metrics from Section 5.1 (MRR, Recall@ K , and NDCG@ K , with K ∈ { 1 , 5 , 10 } ), and (2) the seman tic sensitivity scores for eac h seman tic category ( G d , G a , G s , G c , and G m ) in T able 10. Insigh t 4.1: Enhancing semantic a wareness via MusicSem fine-tuning is feasi- ble. T able 10 summarizes the results. The first key insight from our exp erimen ts is that the scale and semantic diversit y of MusicSem are sufficient to fine-tune pretrained mul- timo dal music mo dels and that suc h fine-tuning can substantially enhance the seman tic a wareness of the pretrained mo del. Fine-tuning consisten tly improv es sensitivity across all seman tic categories, with esp ecially pronounced gains for con textual (+48.28%) and situ- ational (+28.13%) semantics. These t wo categories are central to the design of MusicSem and are largely underrepresented in prior datasets. The strong impro vemen ts observ ed on these dimensions suggest that the mo del is able to leverage the dataset’s ric her seman- tic structure to b etter align audio representations with higher-level, user-expressed inten t. This indicates that MusicSem not only serv es as a challenging ev aluation b enchmark, but also pro vides training signals that are complementary to those found in existing large-scale language–audio corp ora. 7. https://huggingface.co/lukewys/laion_clap/blob/main/630k- audioset- fusion- best.pt 24 MusicSem Insigh t 4.2: Fine-tuning using MusicSem can also improv e p erformance. T a- ble 10 further shows that, b eyond improving semantic sensitivity , fine-tuning CLAP on MusicSem also yields substantial gains in text-to-music retriev al p erformance on the Mu- sicSem test set. Across all rep orted retriev al metrics, p erformance impro ves markedly after fine-tuning. F or instance, w e observe a +96.77% relativ e increase in MRR for the fine-tuned mo del compared to the baseline CLAP mo del without fine-tuning. These results indicate that improv ed semantic alignment can translate in to tangible b enefits on a downstream retriev al task, rather than remaining confined to seman tic sensitivity metrics alone. 6.3 Limitations of this Dataset A cen tral challenge in constructing datasets that capture semantically ric h m usical dis- course lies in reliably aligning textual descriptions with the sp ecific songs they reference. In informal, user-generated discussions, references to songs, artists, and albums are of- ten am biguous, implicit, or interw ov en within longer narratives, making precise one-to-one text–song alignmen t difficult. Ac hieving suc h alignmen t w ould require robust named en- tit y recognition (NER) tailored to the music domain, whic h remains an op en problem for b oth human annotators and automated systems Epure and Hennequin (2023). F or example, en tities such as Boston may refer to a band, an album, or a song title dep ending on con text. Ev en with the domain exp ertise of the professionally trained musicians on our researc h team we found that man ual disambiguation frequen tly dep ended on prior familiarity with the referenced works. Scaling this pro cess to large corp ora would therefore b e lab or-intensiv e and impractical, while curren t large language mo del–based approaches do not yet provide sufficien t reliability . Consequen tly , we do not attempt to implement a comprehensive NER and disam biguation pip eline in the present work. Instead, we ackno wledge this as a limi- tation of MusicSem and view more accurate large-scale entit y resolution as an imp ortant direction for future research. T o supp ort suc h future impro v ements, w e release the complete ra w text alongside our annotations, enabling the comm unity to revisit, refine, and extend the extraction pro cess as more reliable to ols and metho ds b ecome av ailable. 6.4 F uture Applications of MusicSem MusicSem enables sev eral promising do wnstream applications. As LLM-based conv ersa- tional agents b ecome increasingly in tegrated in to ho w users engage with creative conten t, researc hers on streaming platforms hav e b egun exploring prompt-conditioned playlist rec- ommendation Doh et al. (2025); Chagan ty et al. (2023); Charolois-Pasqua et al. (2025); Sp otify (2026, 2025). The rich and n uanced textual descriptions in our dataset are explicitly designed to support mo deling of subtle contextual semantics—suc h as situational context or mo o d-based cues—thereby enabling more refined p ersonalization. Moreo ver, the diver- sit y and sub jectivit y inheren t in user discourse mak e MusicSem particularly w ell suited for con versational or interactiv e m usic agents Gao et al. (2021). Rather than relying on a single canonical description of each song, such systems can adapt recommendations dynamically to individual preferences, in terpretations, and mindsets. Finally , as m usic represen tation learning increasingly mo ve from text-only settings to w ard broader multimodal scenarios, MusicSem can supp ort tasks that integrate audio with additional modalities. F or example, the dataset can b e leveraged for music–video retriev al or captioning tasks by aligning audio 25 Rebecca Salganik, et al. (2026) represen tations with asso ciated visual media Li et al. (2021); Korbar et al. (2018). T o fa- cilitate suc h extensions, w e link eac h en try to persistent platform identifiers (e.g., Sp otify), enabling reliable cross-mo dal integration. T ogether, these directions highlight the broader p oten tial of MusicSem as a foundation for semantically grounded and context-a w are music in telligence systems. 7 Conclusion and F uture W ork In this w ork, we introduced MusicSem, a seman tics-a ware language–audio dataset designed to better reflect how p eople naturally describe and engage with m usic. Motiv ated b y the ob- serv ation that existing multimodal music datasets fail to capture the breadth and nuance of h uman musical discourse, MusicSem is constructed from organic music-related discussions on the so cial media platform Reddit and comprises 32,493 language–audio pairs. Com- pared to prior datasets, MusicSem captures a ric her sp ectrum of m usical semantics and explicitly structures them through a taxonom y of five categories: descriptiv e, atmospheric, situational, metadata-related, and contextual. Beyond dataset construction and analysis, w e used MusicSem to benchmark a wide range of competitive mo dels across cross-modal m usic retriev al, music-to-text generation, and text-to-music generation tasks. T ogether, our findings highligh t the imp ortance of semantics-a ware ev aluation and p osition MusicSem as a v aluable resource for studying and adv ancing more human-aligned m ultimo dal music repre- sen tation learning. W e also emphasized that MusicSem can serve not only as an ev aluation b enc hmark, but also as a sup ervision signal for fine-tuning m ultimo dal m usic represen tation mo dels, enabling them to b etter capture n uanced and h uman-centered m usical semantics. MusicSem is publicly released under the MIT License and is a v ailable on Hugging F ace. The complete source co de for dataset construction and exp eriment repro duction is publicly a v ailable on GitHub, and we hav e created an accompan ying website that hosts do cumen- tation and visualizations, and will include a priv ate leaderb oard and a held-out test set in future iterations to supp ort standardized ev aluation. Throughout the paper, w e hav e tak en ethical and legal considerations seriously , and explicitly outlined the safeguards adopted during dataset construction, including measures related to user priv acy and anon ymity , consen t and platform compliance, and cop yright considerations. W e believe these practices are essential for responsible dataset release and align with established communit y standards. W e also highlighted important prop erties of MusicSem that users should keep in mind, in- cluding considerations related to cultural representativ eness and music genre distribution. Rather than treating these asp ects as fixed characteristics, we designed MusicSem as an extensible resource: the full data extraction pip eline is released, enabling practitioners to augmen t the dataset with additional sources or genres according to their researc h needs. Lo oking forw ard, MusicSem op ens m ultiple a ven ues for future w ork. First, we plan to further expand the scale and scope of the dataset b y incorp orating additional music- related discussions and communities. Second, MusicSem currently focuses on discourse ab out m usic rather than lyrics or symbolic musical re presen tations; extending the dataset to include suc h conten t could further b enefit m usic representation learning. Third, we aim to broaden b enchmarking efforts using MusicSem, including ev aluations for controllable music generation and text-guided music recommendation. In addition, a natural next step is to conduct more in-depth studies of retriev al and generative models fine-tuned on MusicSem, 26 MusicSem exploring training strategies, scaling effects, and transfer to do wnstream tasks. Finally , insigh ts from our experiments underscore the need for more comprehensiv e and semantically grounded ev aluation metrics for language–audio alignment. Overall, MusicSem aims to serv e as a foundation for future researc h on mo dels that b etter understand the nuanced, con textual, and h uman-centered language through whic h p eople engage with music. Broader Impact Statemen t This work contributes to the broader effort of dev eloping AI systems that b etter align with ho w humans naturally express inten t, context, and meaning. While recent adv ances in mul- timo dal learning hav e significantly improv ed p erformance on sp ecialized tasks in domains suc h as m usic, substan tial gaps remain betw een these systems and more general, h uman- cen tered understanding. By in tro ducing MusicSem, a dataset grounded in organic and n uanced musical discourse, this w ork takes a step to ward bridging that gap and adv ancing m ultimo dal representation learning b ey ond purely descriptive or surface-level semantics. Within the m usic domain, MusicSem has sev eral concrete p ositive impacts. First, it pro vides a principled and extensible b enc hmark for ev aluating m ultimo dal mo dels across retriev al and generation tasks, emphasizing semantic sensitivity rather than narro w p erfor- mance metrics alone. Second, the semantic taxonomy and sensitivit y analyses in tro duced in this work offer new tools for auditing and diagnosing mo del b ehavior, helping researc hers b etter understand where curren t systems succeed or fail in capturing con textual, situa- tional, and atmospheric asp ects of m usic. Third, by releasing b oth the dataset and the full data construction pip eline, MusicSem is designed to remain relev ant as the field evolv es, enabling researc hers and practitioners to adapt, extend, and repurp ose the resource for emerging tasks in music understanding. A t the same time, w e ackno wledge potential negativ e and s ocietal considerations as- so ciated with this line of researc h. Generative music tec hnologies raise w ell-do cumented concerns regarding artist displacement, authorship, and the ethical use of creative works. While MusicSem do es not directly address issues suc h as memorization, cop yright infringe- men t, or economic impacts on artists, w e recognize that any contribution to m ultimo dal generation researc h exists within this broader context. W e therefore emphasize resp onsible use, transparency , and ethical safeguards throughout the dataset’s construction and release, including attention to user priv acy , consent, and cop yright compliance. Ov erall, we view MusicSem as a researc h-oriented resource in tended to supp ort more seman tically grounded and human-aligned m usic understanding systems. W e hop e that b y foregrounding nuanced musical discourse and ethical considerations, this work encourages future research that adv ances tec hnical capabilities while remaining atten tive to the so cial and cultural dimensions of m usic and creativ e expression. Disclaimer P ortions of this w ork were previously presen ted as a late-breaking demonstration at ISMIR 2025 (Salganik et al., 2025a) and at the NeurIPS 2025 AI4Music workshop (Salganik et al., 2025b). These presentations w ere non-archiv al and did not app ear in formal pro ceedings. 27 Rebecca Salganik, et al. (2026) References A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. V erzetti, A. Caillon, Q. Huang, A. Jansen, A. Rob erts, M. T agliasacchi, M. Sharifi, N. Zeghidour, and C. F rank. MusicLM: Gener- ating Music F rom T ext. arXiv pr eprint arXiv:2301.11325 , 2023. An thropic. Claude 3.7 Sonnet and Claude Co de. https://www.anthropic.com/news/ claude- 3- 7- sonnet , 2025. D. Bain bridge, S. J. Cunningham, and J. S. Downie. How People Describe Their Music Information Needs: A Grounded Theory Analysis Of Music Queries. In Pr o c e e dings of the 4th International Symp osium on Music Information R etrieval , 2003. S. Banerjee and A. La vie. METEOR: An Automatic Metric for MT Ev aluation with Im- pro ved Correlation with Human Judgments. In Pr o c e e dings of the Workshop on In- trinsic and Extrinsic Evaluation Me asur es for Machine T r anslation and/or Summariza- tion@A CL 2005 , pages 65–72, 2005. M. Barthel, G. Sto c king, J. Holcom b, and A. Mitchell. Sev en-in-T en Reddit Users Get News on the Site. Pew R ese ar ch Center , 2016. J. Baumgartner, S. Zannettou, B. Keegan, M. Squire, and J. Blac kburn. The Pushshift Reddit Dataset. In Pr o c e e dings of the International AAAI Confer enc e on Web and So cial Me dia , volume 14, pages 830–839, 2020. S. Bharga v, A. Sch uth, and C. Hauff. When the Music Stops: Tip-of-the-T ongue Retriev al for Music. In Pr o c e e dings of the 46th International ACM SIGIR Confer enc e on R ese ar ch and Development in Information R etrieval , page 2506–2510, 2023. D. Bogdanov, M. W on, P . T ovstogan, A. Porter, and X. Serra. The MTG-Jamendo Dataset for Automatic Music T agging. In ICML 2019 Machine L e arning for Music Disc overy Workshop , 2019. B. Carterette and E. M. V o orhees. Overview of Information Retriev al Ev aluation. In Curr ent Chal lenges in Patent Information R etrieval , pages 69–85. Springer, 2011. A. T. Chagant y , M. Leszczynski, S. Zhang, R. Ganti, K. Balog, and F. Radlinski. Beyond single items: Exploring user preferences in item sets with the conv ersational playlist curation dataset. In Pr o c e e dings of the 46th International A CM SIGIR Confer enc e on R ese ar ch and Development in Information R etrieval , SIGIR ’23, page 2754–2764, New Y ork, NY, USA, 2023. Asso ciation for Computing Mac hinery . ISBN 9781450394086. doi: 10.1145/3539618.3591881. URL https://doi.org/10.1145/3539618.3591881 . E. Charolois-Pasqua, E. V ellard, Y. Rebb oud, P . Lisena, and R. T roncy . A language mo del- based playlist generation recommender system. In Pr o c e e dings of the Ninete enth A CM Confer enc e on R e c ommender Systems , RecSys ’25, page 1–11, New Y ork, NY, USA, 2025. Asso ciation for Computing Mac hinery . ISBN 9798400713644. doi: 10.1145/3705328. 3748053. URL https://doi.org/10.1145/3705328.3748053 . 28 MusicSem K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubno v. HTS-A T: A Hier- arc hical T oken-Seman tic Audio T ransformer for Sound Classification and Detection. In Pr o c e e dings of the 2022 IEEE International Confer enc e on A c oustics, Sp e e ch, and Signal Pr o c essing , pages 646–650, 2022. M. Cherti, R. Beaumont, R. Wigh tman, M. W ortsman, G. Ilharco, C. Gordon, C. Sc huh- mann, L. Schmidt, and J. Jitsev. Repro ducible Scaling Laws for Contrastiv e Language- Image Learning. In Pr o c e e dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition , pages 2818–2829, 2023. W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. W u, H. Zhang, L. Zheng, S. Zhuang, Y. Zh uang, J. E. Gonzalez, I. Stoica, and E. P . Xing. Vicuna: An Op en-Source Chatb ot Im- pressing GPT-4 with 90%* ChatGPT Quality , 2023. URL https://lmsys.org/blog/ 2023- 03- 30- vicuna/ . J. Choi, A. Khlif, and E. Epure. Prediction of User Listening Con texts for Music Playlists. In Pr o c e e dings of the 1st Workshop on NLP for Music and Audio , 2020. A. Christo doulou, O. Lartillot, and A. R. Jensenius. Multimo dal Music Datasets? Chal- lenges and F uture Goals in Music Processing. International Journal of Multime dia Infor- mation R etrieval , 13(3):37, 2024. H. W. Ch ung, L. Hou, S. Longpre, B. Zoph, Y. T a y , W. F edus, Y. Li, X. W ang, M. Dehghani, S. Brahma, A. W ebson, S. S. Gu, Z. Dai, M. Suzgun, X. Chen, A. Cho wdhery , A. Castro- Ros, M. P ellat, K. Robinson, D. V alter, S. Narang, G. Mishra, A. Y u, V. Zhao, Y. Huang, A. Dai, H. Y u, S. P etrov, E. H. Chi, J. Dean, J. Devlin, A. Rob erts, D. Zhou, Q. V. Le, and J. W ei. Scaling Instruction-Finetuned Language Mo dels. Journal of Machine L e arning R ese ar ch , 25(70):1–53, 2024. Y.-A. Chung, Y. Zhang, W. Han, C.-C. Chiu, J. Qin, R. Pang, and Y. W u. w2v-BER T: Com bining Contrastiv e Learning and Masked Language Mo deling for Self-Sup ervised Sp eec h Pre-T raining. In 2021 IEEE Automatic Sp e e ch R e c o gnition and Understanding Workshop , pages 244–250, 2021. K. W. Churc h, Z. Chen, and Y. Ma. Emerging T rends: A Gen tle In tro duction to Fine- T uning. Natur al L anguage Engine ering , 27(6):763–778, 2021. A. Conneau, K. Khandelwal, N. Goy al, V. Chaudhary , G. W enzek, F. Guzm´ an, E. Grav e, M. Ott, L. Zettlemo yer, and V. Stoy ano v. Unsup ervised Cross-lingual Representation Learning at Scale. In Pr o c e e dings of the 58th Annual Me eting of the Asso ciation for Computational Linguistics , pages 8440–8451, 2020. J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kan t, G. Synnaev e, Y. Adi, and A. D ´ efossez. Simple and Controllable Music Generation. In A dvanc es in Neur al Information Pr o c essing Systems , volume 36, pages 47704–47720, 2023. M. Defferrard, K. Benzi, P . V andergheynst, and X. Bresson. FMA: A Dataset for Music Analysis. arXiv pr eprint arXiv:1612.01840 , 2016. 29 Rebecca Salganik, et al. (2026) A. D´ efossez, J. Cop et, G. Synnaeve, and Y. Adi. High Fidelity Neural Audio Compression. arXiv pr eprint arXiv:2210.13438 , 2022. Y. Deldjo o, M. Schedl, and P . Knees. Con ten t-Driven Music Recommendation: Evolution, State of the Art, and Challenges. Computer Scienc e R eview , 51:100618, 2024. J. Devlin, M.-W. Chang, K. Lee, and K. T outanov a. BER T: Pre-T raining of Deep Bidirec- tional T ransformers for Language Understanding. In Pr o c e e dings of the 2019 Confer enc e of the North A meric an Chapter of the Asso ciation for Computational Linguistics: Human L anguage T e chnolo gies, V olume 1 (L ong and Short Pap ers) , pages 4171–4186, 2019. S. Doh, K. Choi, J. Lee, and J. Nam. LP-MusicCaps: LLM-Based Pseudo Music Cap- tioning. In Pr o c e e dings of the 24th International So ciety for Music Information R etrieval Confer enc e , pages 409–416, 2023. S. Doh, K. Choi, and J. Nam. T alkplay-tools: Con versational m usic recommendation with llm to ol calling, 2025. E. Epure and R. Hennequin. A Human Sub ject Study of Named En tity Recognition in Con versational Music Recommendation Queries. In Pr o c e e dings of the 17th Confer enc e of the Eur op e an Chapter of the Asso ciation for Computational Linguistics , pages 1281– 1296, 2023. E. V. Epure, G. Salha, M. Moussallam, and R. Hennequin. Modeling the Music Genre P erception across Language-Bound Cultures. In Pr o c e e dings of the 2020 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pages 4765–4779, 2020. Z. Ev ans, C. Carr, J. T aylor, S. H. Ha wley , and J. P ons. F ast Timing-Conditioned La- ten t Audio Diffusion. In Pr o c e e dings of the 41st International Confer enc e on Machine L e arning , 2024. D. F riedman and A. B. Dieng. The V endi Score: A Div ersity Ev aluation Metric for Mac hine Learning. T r ansactions on Machine L e arning R ese ar ch , 2023, 2023. C. Gao, W. Lei, X. He, M. de Rijk e, and T.-S. Ch ua. Adv ances and c hallenges in conv ersa- tional recommender systems: A survey . AI Op en , 2:100–126, 2021. ISSN 2666-6510. doi: h ttps://doi.org/10.1016/j.aiop en.2021.06.002. URL https://www.sciencedirect.com/ science/article/pii/S2666651021000164 . J. P . Gardner, S. Durand, D. Stoller, and R. M. Bittner. LLARK: A Multimo dal Instruction- F ollowing Language Mo del for Music. In Pr o c e e dings of the 41st International Confer enc e on Machine L e arning , pages 15037–15082, 2024. J. F. Gemmek e, D. P . Ellis, D. F reedman, A. Jansen, W. La wrence, R. C. Mo ore, M. Plak al, and M. Ritter. Audio Set: An Ontology and Human-Labeled Dataset for Audio Even ts. In Pr o c e e dings of the 2017 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing , pages 776–780, 2017. 30 MusicSem R. Girdhar, A. El-Noub y , Z. Liu, M. Singh, K. V. Alwala, A. Joulin, and I. Misra. Im- agebind: One Em b edding Space to Bind Them All. In Pr o c e e dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition , pages 15180–15190, 2023. J. E. Gromko. Perceptual Differences b etw een Exp ert and Novice Music Listeners: A Multidimensional Scaling Analysis. Psycholo gy of Music , 21(1):34–47, 1993. A. Gui, H. Gamp er, S. Braun, and D. Emmanouilidou. Adapting F rec het Audio Distance for Generativ e Music Ev aluation. In Pr o c e e dings of the 2024 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing , pages 1331–1335, 2024. Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang. Parameter-Efficien t Fine-T uning for Large Mo dels: A Comprehensiv e Survey. arXiv pr eprint arXiv:2403.14608 , 2024. D. Hauger, M. Schedl, A. Ko ˇ sir, and M. Tk al ˇ ci ˇ c. The Million Musical Tweet Dataset: What W e Can Learn from Microblogs. In Pr o c e e dings of the 14th Confer enc e of the International So ciety for Music Information R etrieval , pages 189–194, 2013. P . He, J. Gao, and W. Chen. DeBER T aV3: Impro ving DeBER T a using ELECTRA- St yle Pre-T raining with Gradien t-Disentangled Embedding Sharing. arXiv pr eprint arXiv:2111.09543 , 2021. C. Hernandez-Oliv an and J. R. Beltran. Music Composition with Deep Learning: A Review. A dvanc es in Sp e e ch and Music T e chnolo gy: Computational Asp e cts and Applic ations , pages 25–50, 2022. Q. Huang, A. Jansen, J. Lee, R. Ganti, J. Y. Li, and D. P . W. Ellis. MuLan: A Joint Em- b edding of Music Audio and Natural Language. In Pr o c e e dings of the 23r d International So ciety for Music Information R etrieval Confer enc e , pages 559–566, 2022. Q. Huang, D. S. P ark, T. W ang, T. I. Denk, A. Ly , N. Chen, Z. Zhang, Z. Zhang, J. Y u, C. F rank, J. Engel, Q. V. Le, W. Chan, Z. Chen, and W. Han. Noise2music: T ext- Conditioned Music Generation with Diffusion Mo dels. arXiv pr eprint arXiv:2302.03917 , 2023. Z. Jiang, F. F. Xu, J. Araki, and G. Neubig. How Can W e Know What Language Mo dels Kno w? T r ansactions of the Asso ciation for Computational Linguistics , 8:423–438, 2020. K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi. F r ´ ec het Audio Distance: A Reference- F ree Metric for Ev aluating Music Enhancemen t Algorithms. In Pr o c e e dings of the 20th A nnual Confer enc e of the International Sp e e ch Communic ation Asso ciation , pages 2350– 2354, 2019. Q. Kong, Y. Cao, T. Iqbal, Y. W ang, W. W ang, and M. D. Plum bley . P ANNs: Large- Scale Pretrained Audio Neural Net works for Audio P attern Recognition. IEEE/ACM T r ansactions on Audio, Sp e e ch, and L anguage Pr o c essing , 28:2880–2894, 2020. B. Korbar, D. T ran, and L. T orresani. Co op erative learning of audio and video models from self-sup ervised synchronization. In Pr o c e e dings of the 32nd International Confer enc e on 31 Rebecca Salganik, et al. (2026) Neur al Information Pr o c essing Systems , NIPS’18, page 7774–7785, Red Hook, NY, USA, 2018. Curran Asso ciates Inc. R. Kumar, P . Seetharaman, A. Luebs, I. Kumar, and K. Kumar. High-Fidelit y Audio Compression with Improv ed R V QGAN. In A dvanc es in Neur al Information Pr o c essing Systems , volume 36, pages 27980–27993, 2023. M. W. Y. Lam, Q. Tian, T. Li, Z. Yin, S. F eng, M. T u, Y. Ji, R. Xia, M. Ma, X. Song, J. Chen, Y. W ang, and Y. W ang. Efficient Neural Music Generation. In A dvanc es in Neur al Information Pr o c essing Systems , v olume 36, pages 17450–17463, 2023. E. Law, K. W est, M. Mandel, M. Ba y , and J. S. Downie. Ev aluation of Algorithms using Games: The Case of Music T agging. In Pr o c e e dings of the 10th International So ciety for Music Information R etrieval Confer enc e , pages 387–392, 2009. J. H. Lee, K. Choi, X. Hu, and J. S. Downie. K-P op Genres: A Cross-Cultural Exploration. In Pr o c e e dings of the 14th Confer enc e of the International So ciety on Music Information R etrieval , 2013. M. Levy and M. Sandler. Learning Laten t Seman tic Models for Music from So cial T ags. Journal of New Music R ese ar ch , 37(2):137–150, 2008. M. Lewis, Y. Liu, N. Goy al, M. Ghazvininejad, A. Mohamed, O. Levy , V. Stoy anov, and L. Zettlemoy er. BAR T: Denoising Sequence-to-Sequence Pre-training for Natural Lan- guage Generation, T ranslation, and Comprehension. In Pr o c e e dings of the 58th A nnual Me eting of the Asso ciation for Computational Linguistics , pages 7871–7880, 2020. T. Li, Z. Sun, H. Zhang, J. Li, Z. W u, H. Zhan, Y. Y u, and H. Shi. Deep m usic retriev al for fine-grained videos by exploiting cross-mo dal-enco ded v oice-ov ers. In Pr o c e e dings of the 44th International ACM SIGIR Confer enc e on R ese ar ch and Development in Infor- mation R etrieval , SIGIR ’21, page 1880–1884, New Y ork, NY, USA, 2021. Association for Computing Machinery . ISBN 9781450380379. doi: 10.1145/3404835.3462993. URL https://doi.org/10.1145/3404835.3462993 . Y. Li, R. Y uan, G. Zhang, Y. Ma, X. Chen, H. Yin, C. Xiao, C. Lin, A. Ragni, E. Benetos, N. Gy enge, R. B. Dannenberg, R. Liu, W. Chen, G. Xia, Y. Shi, W. Huang, Z. W ang, Y. Guo, and J. F u. MER T: Acoustic Music Understanding Mo del with Large-Scale Self- sup ervised T raining. In Pr o c e e dings of the 12th International Confer enc e on L e arning R epr esentations , 2024. C.-Y. Lin. ROUGE: A Pac k age for Automatic Ev aluation of Summaries. In T ext Summa- rization Br anches Out , pages 74–81, 2004. L. Lin, G. Xia, Y. Zhang, and J. Jiang. Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Con tent-based Controls. In Pr o c e e dings of the 33r d International Joint Confer enc e on Artificial Intel ligenc e , pages 7690–7698, 2024. Y.-C. Lin, Y.-H. Y ang, and H. H. Chen. Exploiting Online Music T ags for Music Emo- tion Classification. ACM T r ansactions on Multime dia Computing, Communic ations, and Applic ations , 7(1):1–16, 2011. 32 MusicSem H. Liu, Y. Y uan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y. W ang, W. W ang, Y. W ang, and M. D. Plumbley . Audioldm 2: Learning Holistic Audio Generation with Self-Sup ervised Pretraining. Pr o c e e dings of the IEEE/A CM T r ansactions on A udio, Sp e e ch, and L anguage Pr o c essing , 32:2871–2883, 2024a. S. Liu, A. S. Hussain, C. Sun, and Y. Shan. Music Understanding LLaMA: Adv ancing T ext-to-Music Generation with Question Answ ering and Captioning. In Pr o c e e dings of the 2024 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing , pages 286–290, 2024b. Y. Liu, M. Ott, N. Goy al, J. Du, M. Joshi, D. Chen, O. Levy , M. Lewis, L. Zettlemoy er, and V. Stoy anov. RoBER T a: A Robustly Optimized BER T Pretraining Approac h. arXiv pr eprint arXiv:1907.11692 , 2019. I. Manco, B. W eck, S. Doh, M. W on, Y. Zhang, D. Bogdanov, Y. W u, K. Chen, P . T o vstogan, E. Benetos, E. Quinton, G. F azek as, and J. Nam. The Song Describ er Datas et: a Corpus of Audio Captions for Music-and-Language Ev aluation. In NeurIPS 2023 Workshop on Machine L e arning for Audio , 2023. M. C. McCallum, F. Korzenio wski, S. Oramas, F. Gouyon, and A. F. Ehmann. Supervised and Unsup ervised Learning of Audio Representations for Music Understanding. In Pr o- c e e dings of the 23r d International So ciety for Music Information R etrieval Confer enc e , pages 256–263, 2022. B. McF ee, T. Bertin-Mahieux, D. P . Ellis, and G. R. Lanckriet. The Million Song Dataset Challenge. In Pr o c e e dings of the 21st International Confer enc e on World Wide Web , pages 909–916, 2012. D. McKee, J. Salamon, J. Sivic, and B. Russell. Language-Guided Music Recommenda- tion for Video via Prompt Analogies. In Pr o c e e dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition , 2023. A. N. Medvedev, R. Lam biotte, and J.-C. Delvenne. The Anatomy of Reddit: An Ov erview of Academic Research. Dynamics on and of Complex Networks , pages 183–204, 2017. J. Melec ho vsky , Z. Guo, D. Ghosal, N. Ma jumder, D. Herremans, and S. Poria. Mustango: T ow ard Controllable T ext-to-Music Generation. In Pr o c e e dings of the 2024 Confer enc e of the North A meric an Chapter of the Asso ciation for Computational Linguistics: Human L anguage T e chnolo gies (V olume 1: L ong Pap ers) , pages 8286–8309, 2024. S. J. Morrison and S. M. Demorest. Cultural Constrain ts on Music Perception and Cogni- tion. Pr o gr ess in Br ain R ese ar ch , 178:67–77, 2009. M. M ¨ uller. F undamentals of Music Pr o c essing: Audio, Analysis, A lgorithms, Applic ations , v olume 5. Springer, 2015. J. Nam, K. Choi, J. Lee, S. Chou, and Y. Y ang. Deep Learning for Audio-Based Music Classification and T agging: T eaching Computers to Distinguish Rock from Bach. IEEE Signal Pr o c essing Magazine , 36(1):41–51, 2019. 33 Rebecca Salganik, et al. (2026) H. Nav eed, A. U. Khan, S. Qiu, M. Saqib, S. An war, M. Usman, N. Akhtar, N. Barnes, and A. Mian. A Comprehensive Overview of Large Language Models. ACM T r ansactions on Intel ligent Systems and T e chnolo gy , 16(5):1–72, 2025. Op enAI. Hello GPT-4o. https://openai.com/index/hello- gpt- 4o/ , 2024. S. Oramas, O. Nieto, F. Barbieri, and X. Serra. Multi-Lab el Music Genre Classification from Audio, T ext and Images Using Deep F eatures. In Pr o c e e dings of the 18th International So ciety for Music Information R etrieval Confer enc e , pages 23–30, 2017. K. Papineni, S. Roukos, T. W ard, and W. Zh u. BLEU: a Metho d for Automatic Ev aluation of Machine T ranslation. In Pr o c e e dings of the 40th A nnual Me eting of the Asso ciation for Computational Linguistics , pages 311–318, 2002. N. Proferes, N. Jones, S. Gilb ert, C. Fiesler, and M. Zimmer. Studying Reddit: A Systematic Ov erview of Disciplines, Approac hes, Metho ds, and Ethics. So cial Me dia+ So ciety , 7(2): 20563051211019004, 2021. A. Radford, J. W. Kim, C. Hallacy , A. Ramesh, G. Goh, S. Agarwal, G. Sastry , A. Askell, P . Mishkin, J. Clark, et al. Learning T ransferable Visual Models from Natural Language Sup ervision. In Pr o c e e dings of the 38th International Confer enc e on Machine L e arning , pages 8748–8763, 2021. A. Radford, J. W. Kim, T. Xu, G. Bro c kman, C. McLeav ey , and I. Sutsk ever. Robust Sp eec h Recognition via Large-Scale W eak Sup ervision. In Pr o c e e dings of the 22nd International Confer enc e on Machine L e arning , pages 28492–28518, 2023. F. Ronchini, L. Comanducci, G. Perego, and F. Antonacci. P A GURI: A User Exp erience Study of Creative In teraction with T ext-to-Music Mo dels. Ele ctr onics , 14(17):3379, 2025. A. Roy , R. Liu, T. Lu, and D. Herremans. JamendoMaxCaps: A Large Scale Music-caption Dataset with Imputed Metadata. arXiv pr eprint arXiv:2502.07461 , 2025. S. Sakshi, U. Ty agi, S. Kumar, A. Seth, R. Selv akumar, O. Nieto, R. Duraisw ami, S. Ghosh, and D. Mano cha. MMAU: A Massive Multi-T ask Audio Understanding and Reasoning Benc hmark. arXiv pr eprint arXiv:2410.19168 , 2024. R. Salganik, F. Diaz, and G. F arnadi. F airness Through Domain Awareness: Mitigating P opularity Bias for Music Discov ery. In Pr o c e e dings of the 46th Eur op e an Confer enc e on Information R etrieval , page 351–368, 2024a. R. Salganik, X. Liu, Y. Ma, J. Kang, and T.-S. Chua. LARP: Language Audio Rela- tional Pre-T raining for Cold-Start Playlist Contin uation. In Pr o c e e dings of the 30th ACM SIGKDD Confer enc e on Know le dge Disc overy and Data Mining , pages 2524–2535, 2024b. R. Salganik, T. T u, F.-Y. Chen, X. Liu, K. Lu, E. Luvisia, Z. Duan, G. Salha-Galv an, A. Kahng, Y. Ma, and J. Kang. MusicSem: A Dataset of Music Descriptions on Red- dit Capturing Musical Seman tics. In L ate-Br e aking Demonstr ations, 26th International So ciety for Music Information R etrieval Confer enc e , 2025a. 34 MusicSem R. Salganik, T. T u, F.-Y. Chen, X. Liu, K. Lu, E. Luvisia, Z. Duan, G. Salha-Galv an, A. Kahng, Y. Ma, and J. Kang. MusicSem: A Semantically Ric h Language-Audio Dataset of Organic Musical Discourse. In NeurIPS 2025 Workshop on AI for Music , 2025b. M. Schedl, E. G´ omez, and J. Urbano. Music Information Retriev al: Recen t Developmen ts and Applications. F oundations and T r ends ® in Information R etrieval , 8(2-3):127–261, 2014. F. Sc hneider, O. Kamal, Z. Jin, and B. Sc h¨ olk opf. Moˆ usai: Efficien t T ext-to-Music Dif- fusion Mo dels. In L.-W. Ku, A. Martins, and V. Srikumar, editors, Pr o c e e dings of the 62nd Annual Me eting of the Asso ciation for Computational Linguistics (V olume 1: L ong Pap ers) , pages 8050–8068, 2024. J. Shen, M. Sap, P . Colon-Hernandez, H. P ark, and C. Breazeal. Mo deling Empathic Similarit y in Personal Narrativ es. In Pr o c e e dings of the 2023 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pages 6237–6252, 2023. J. Shlens. Notes on Kullback-Leibler Divergence and Likelihoo d. arXiv pr eprint arXiv:1404.2000 , 2014. K. Simon yan and A. Zisserman. V ery Deep Con volutional Net w orks for Large-Scale Image Recognition. In Pr o c e e dings of the 3r d International Confer enc e on L e arning R epr esen- tations , 2015. J. A. Slob o da and P . N. Juslin. Psyc hological Perspectives on Music and Emotion. Music and Emotion: The ory and R ese ar ch , pages 71–104, 2001. M. Sordo, O. Celma, M. Blec h, and E. Guaus. The Quest for Musical Genres: Do the Exp erts and the Wisdom of Cro wds Agree? In Pr o c e e dings of the 8th Confer enc e of the International So ciety on Music Information R etrieval , 2008. Sp otify . Sp otify expands ai pla ylist in b eta to premium listeners in 40+ new mark ets. https://newsroom.spotify.com/2025- 04- 24/ spotify- expands- ai- playlist- in- beta- to- premium- listeners- in- 40- new- markets/ , 2025. URL https://newsroom.spotify.com/2025- 04- 24/ spotify- expands- ai- playlist- in- beta- to- premium- listeners- in- 40- new- markets/ . Sp otify Newsro om. Accessed: 2026-02-08. Sp otify . Prompted pla ylists. https://support.spotify.com/us/article/ prompted- playlists/ , 2026. URL https://support.spotify.com/us/article/ prompted- playlists/ . Spotify Supp ort Article. Accessed: 2026-02-08. C. T ang, W. Y u, G. Sun, X. Chen, T. T an, W. Li, L. Lu, Z. Ma, and C. Zhang. SALMONN: T ow ards Generic Hearing Abilities for Large Language Models. In Pr o c e e dings of the 12th International Confer enc e on L e arning R epr esentations , 2024. J. Thickstun, Z. Harc haoui, and S. M. Kak ade. Learning F eatures of Music from Scratch. In Pr o c e e dings of the 5th International Confer enc e on L e arning R epr esentations , 2017. 35 Rebecca Salganik, et al. (2026) J. Thickstun, Z. Harc haoui, D. P . F oster, and S. M. Kak ade. Inv ariances and Data Aug- men tation for Sup ervised Music T ranscription. In 2018 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing , pages 2241–2245, 2018. A. V an den Oord, S. Dieleman, and B. Schrau w en. Deep Con tent-Based Music Recommen- dation. A dvanc es in Neur al Information Pr o c essing Systems , 26, 2013. R. V edantam, C. Lawrence Zitnic k, and D. Parikh. CIDEr: Consensus-based Image De- scription Ev aluation. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition , pages 4566–4575, 2015. V. V eselovsky , I. W aller, and A. Anderson. Imagine All The People: Characterizing So cial Music Sharing on Reddit. In Pr o c e e dings of the International AAAI Confer enc e on Web and So cial Me dia , volume 15, pages 739–750, 2021. J. W u, Z. No v ack, A. Namburi, J. Dai, H.-W. Dong, Z. Xie, C. Chen, and J. McAuley . FUTGA: T o wards Fine-grained Music Understanding through T emp orally-enhanced Gen- erativ e Augmentation. In Pr o c e e dings of the 3r d Workshop on NLP for Music and Audio , pages 107–111, 2024. S. W u, G. Zhanc heng, R. Y uan, J. Jiang, S. Doh, G. Xia, J. Nam, X. Li, F. Y u, and M. Sun. CLaMP 3: Univ ersal Music Information Retriev al Across Unaligned Mo dalities and Unseen Languages. In Findings of the Asso ciation for Computational Linguistics , pages 2605–2625, 2025. Y. W u, K. Chen, T. Zhang, Y. Hui, T. Berg-Kirkpatric k, and S. Dubnov. Large-Scale Con trastive Language–Audio Pretraining with F eature F usion and Keyword-to-Caption Augmen tation. In Pr o c e e dings of the 2023 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing , pages 1–5, 2023. R. Y uan, Y. Ma, Y. Li, G. Zhang, X. Chen, H. Yin, L. Zhuo, Y. Liu, J. Huang, Z. Tian, B. Deng, N. W ang, C. Lin, E. Benetos, A. Ragni, N. Gyenge, R. B. Dannenberg, W. Chen, G. Xia, W. Xue, S. Liu, S. W ang, R. Liu, Y. Guo, and J. F u. MARBLE: Music Audio Represen tation Benc hmark for Universal Ev aluation. In A dvanc es in Neur al Information Pr o c essing Systems , v olume 36, pages 39626–39647, 2023. Y. Zang and Y. Zhang. The Interpretation Gap in T ext-to-Music Generation Mo dels. In Pr o c e e dings of the 3r d Workshop on NLP for Music and Audio , pages 112–118, 2024. N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. T agliasacc hi. Soundstream: An End-to-End Neural Audio Co dec. Pr o c e e dings of the 2021 IEEE/ACM T r ansactions on A udio, Sp e e ch, and L anguage Pr o c essing , 30:495–507, 2021. R. Zhang, J. Han, C. Liu, P . Gao, A. Zhou, X. Hu, S. Y an, P . Lu, H. Li, and Y. Qiao. LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Atten tion. arXiv pr eprint arXiv:2303.16199 , 2023. T. Zhang, V. Kishore, F. W u, K. Q. W ein b erger, and Y. Artzi. BER TScore: Ev aluating T ext Generation with BER T. In Pr o c e e dings of the 8th International Confer enc e on L e arning R epr esentations , 2020. 36 MusicSem Y. Zhang, Y. Ik emiya, W. Choi, N. Murata, M. A. Mart ´ ınez-Ram ´ ırez, L. Lin, G. Xia, W.-H. Liao, Y. Mitsufuji, and S. Dixon. Instruct-MusicGen: Unlocking T ext-to-Music Editing for Music Language Mo dels via Instruction T uning. arXiv pr eprint arXiv:2405.18386 , 2024. 37 Rebecca Salganik, et al. (2026) App endix A. Dataset Construction and Prompts This Appendix A presents additional details of the MusicSem dataset construction pipeline, with a particular fo cus on the extraction steps and the prompts employ ed. A.1 Pseudoco de for Dataset Construction Pip eline W e presen t pseudoco de for the complete dataset construction pip eline in Algorithm 1. In Lines 2–3, we filter p osts within eac h thread by remo ving conten t authored by mo derators and p osts con taining fewer than 20 c haracters. In Line 4, we p erform semantic extraction using a large language mo del (LLM) guided by a predefined prompt (see App endix A.3). In Line 6, we query the Sp otify API to retriev e a unique identifier for each song men- tioned in a thread. In Line 7, we apply the first hallucination c heck to v erify alignmen t b et ween the retriev ed audio and the extracted song–artist pairs. In Line 8, w e download the corresp onding audio files for each v alidated track. In Line 9, we generate summarized captions from the extracted se man tic categories, following formats similar to those used in MusicCaps (Agostinelli et al., 2023) and Song Describ er (Manco et al., 2023). Finally , in Line 10, we conduct a second hallucination chec k using a different mo del to ensure that the generated summaries remain faithful to the extracted seman tic categories (see App endix A.4). Ov erall, this pipeline yields 32,493 language–audio pairs. A visual o verview of the en tire dataset construction pro cess is provided in Figure 3 of the pap er. Algorithm 1 MusicSem Dataset Construction Pip eline Input : thread name T , language models M 1 , M 2 Output caption set C 1: pro cedure Da t aset Genera tion ( T , M ) 2: posts = Load Entire Thread(T) 3: filtered = Length and Mo d Filter(p osts) 4: sa pairs, caption extracts = M 1 (filtered) 5: descriptiv e, atmospheric, situational, con textual, metadata = caption extracts 6: song ids = Sp otify Metadata(sa pairs) 7: sa pairs = Hallucination Check1(sa pairs,fltrd) 8: mp3s = Sp otify Audio(song ids) 9: final summaries = Summarize(sa pairs,caption extracts, mp3s) 10: filtered captions = Hallucination Check2(caption extracts, final captions, M 2 ) A.2 F ormalizing Semantic Categories W e constructed the seman tic categories using a qualitativ e co ding pro cess inspired b y stan- dard user-study metho dologies. Sp ecifically , we closely read the fiv e threads describ ed in Section 4.1 and annotated them according to the broad themes expressed in the discussions. Through iterativ e qualitative analysis, w e iden tified recurring patterns and progressiv ely consolidated them into higher-level conceptual categories that capture the dominan t mo des of musical discourse. W e emphasize that this taxonomy is not intended to b e exhaustive, as the w ays in which people describ e and in terpret music contin ue to ev olve. Rather, it reflects 38 MusicSem the range of themes observ ed in our data. Additionally , we in tentionally excluded lyrical analysis, as we consider it a distinct and substan tial research direction in its own righ t. A.3 Extraction Prompt Belo w, we presen t the prompt used to extract seman tic con ten t from ra w Reddit posts. F ollowing the seman tic category definitions in T able 2, the prompt decomp oses the text in to elemen ts corresp onding to eac h of the five categories. W e also pro vide an example extraction to illustrate the exp ected output. 39 Rebecca Salganik, et al. (2026) 1 % F e a t u r e E x t r a c t i o n 2 3 T a s k D e s c r i p t i o n 4 Y o u a r e t a s k e d w i t h a n a l y z i n g R e d d i t p o s t s a b o u t m u s i c a n d e x t r a c t i n g s t r u c t u r e d i n f o r m a t i o n i n t o s p e c i f i c c a t e g o r i e s . W h e n g i v e n a R e d d i t p o s t d i s c u s s i n g m u s i c , i d e n t i f y a n d e x t r a c t t h e f o l l o w i n g : 5 C a t e g o r i e s t o E x t r a c t 6 S o n g / A r t i s t p a i r s 7 ( u s i n g t h e n a m e s o f a r t i s t s a n d t h e i r s o n g s w i t h u n f i x e d f o r m ) s o m e e x a m p l e s : 8 9 ’ S h a k e i t O f f b y T a y l o r S w i f t ’ 10 ’ R a d i o h e a d ’ s W e i r d F i s h e s ’ 11 ’ G e n e s i s - Y e s ’ 12 ’ M a r o o n 5 [ S h e W i l l B e L o v e d ] ’ 13 14 D e s c r i p t i v e ( u s i n g m u s i c a l a t t r i b u t e s ) 15 T h i s i n c l u d e s d e t a i l e d o b s e r v a t i o n s a b o u t : 16 17 I n s t r u m e n t a t i o n : ’ I l o v e t h e h i g h p a s s f i l t e r o n t h e v o c a l s i n t h e c h o r u s a n d t h e s o f t p i a n o i n t h e b r i d g e ’ 18 P r o d u c t i o n t e c h n i q u e s : ’ T h e w a y t h e y l a y e r e d t h o s e h a r m o n i e s i n t h e s e c o n d v e r s e i s i n c r e d i b l e ’ 19 S o n g s t r u c t u r e : ’ T h a t u n e x p e c t e d k e y c h a n g e b e f o r e t h e f i n a l c h o r u s g i v e s m e g o o s e b u m p s ’ 20 S o u n d q u a l i t i e s : ’ T h e f u z z y l o - f i b e a t s w i t h t h a t v i n y l c r a c k l e i n t h e b a c k g r o u n d ’ 21 T e c h n i c a l e l e m e n t s : ’ T h e 6 / 8 t i m e s i g n a t u r e m a k e s i t f e e l l i k e i t s s w a y i n g ’ 22 23 C o n t e x t u a l ( u s i n g o t h e r s o n g s / a r t i s t s ) 24 T h i s i n c l u d e s m e a n i n g f u l c o m p a r i s o n s s u c h a s : 25 26 D i r e c t c o m p a r i s o n s : ’ S a b r i n a C a r p e n t e r ’ s E s p r e s s o i s j u s t a m i x o f o l d A r i a n a G r a n d e a n d 2 0 1 8 D u a L i p a ’ 27 I n f l u e n c e s : ’ Y o u c a n t e l l t h e y ’ v e b e e n l i s t e n i n g t o a l o t o f T a l k i n g H e a d s ’ 28 G e n r e e v o l u t i o n : ’ I t ’ s l i k e 9 0 s t r i p - h o p g o t u p d a t e d w i t h m o d e r n t r a p e l e m e n t s ’ 29 S o u n d - a l i k e s : ’ I f y o u l i k e t h i s , y o u s h o u l d c h e c k o u t s i m i l a r a r t i s t s l i k e . . . ’ 30 M u s i c a l l i n e a g e : ’ T h e y ’ r e c a r r y i n g t h e t o r c h t h a t P r i n c e l i t i n t h e 8 0 s ’ 31 32 S i t u a t i o n a l ( u s i n g a n a c t i v i t y , s e t t i n g , o r e n v i r o n m e n t ) 33 T h i s i n c l u d e s r e l a t a b l e s c e n a r i o s l i k e : 34 35 L i f e e v e n t s : ’ I l i s t e n e d t o t h i s s o n g o n t h e w a y t o q u i t t i n g m y s h * * t y c o r p o r a t e j o b ’ 36 R e g u l a r a c t i v i t i e s : ’ T h i s i s m y g o - t o a l b u m f o r l a t e n i g h t c o d i n g s e s s i o n s ’ 37 S p e c i f i c l o c a t i o n s : ’ H i t s d i f f e r e n t w h e n y o u ’ r e d r i v i n g t h r o u g h t h e m o u n t a i n s a t s u n s e t ’ 38 S o c i a l c o n t e x t s : ’ W e a l w a y s p l a y t h i s a t o u r w e e k e n d g a t h e r i n g s a n d e v e r y o n e v i b e s t o i t ’ 39 S e a s o n a l c o n n e c t i o n s : ’ T h i s h a s b e e n m y s u m m e r a n t h e m f o r t h r e e y e a r s r u n n i n g ’ 40 41 A t m o s p h e r i c ( u s i n g e m o t i o n s a n d d e s c r i p t i v e a d j e c t i v e s ) 40 MusicSem 42 T h i s i n c l u d e s e v o c a t i v e d e s c r i p t i o n s s u c h a s : 43 44 E m o t i o n a l i m p a c t s : ’ T h i s s o n g m a k e s m e f e e l l i k e a m a n i c p i x i e d r e a m g i r l i n a b o u g i e c o f f e e s h o p ’ 45 V i s u a l i m a g e r y : ’ M a k e s m e p i c t u r e m y s e l f i n a c o m i n g - o f - a g e i n d i e m o v i e , r u n n i n g i n s l o w m o t i o n ’ 46 M o o d d e s c r i p t i o n s : ’ I t h a s t h i s m e l a n c h o l i c y e t h o p e f u l q u a l i t y t h a t h i t s m y s o u l ’ 47 S e n s o r y e x p e r i e n c e s : ’ T h e s o n g f e e l s l i k e a w a r m e m b r a c e o n a c o l d d a y ’ 48 A b s t r a c t f e e l i n g s : ’ G i v e s m e t h i s f e e l i n g o f f l o a t i n g j u s t a b o v e m y p r o b l e m s ’ 49 50 L y r i c a l ( f o c u s i n g o n w o r d s a n d m e a n i n g ) 51 T h i s i n c l u d e s t h o u g h t f u l c o m m e n t a r y o n : 52 53 S t o r y t e l l i n g : ’ T h e l y r i c s t e l l s u c h a v i v i d s t o r y o f l o s t l o v e t h a t I f e e l l i k e I ’ v e l i v e d i t ’ 54 W o r d p l a y : ’ T h e c l e v e r d o u b l e e n t e n d r e s i n t h e c h o r u s m a k e m e a p p r e c i a t e i t m o r e e a c h l i s t e n ’ 55 M e s s a g i n g : ’ T h e s u b t l e p o l i t i c a l c o m m e n t a r y w o v e n t h r o u g h o u t t h e v e r s e s r e a l l y r e s o n a t e s ’ 56 P e r s o n a l c o n n e c t i o n : ’ T h e s e l y r i c s s e e m l i k e t h e y w e r e w r i t t e n a b o u t m y o w n l i f e e x p e r i e n c e s ’ 57 Q u o t a b l e l i n e s : ’ T h a t l i n e ’ w e ’ r e a l l j u s t s t a r d u s t w a i t i n g t o r e t u r n ’ l i v e s r e n t - f r e e i n m y h e a d ’ 58 59 M e t a d a t a ( u s i n g i n f o r m a t i o n f o u n d i n l a b e l s o r r e s e a r c h ) 60 T h i s i n c l u d e s i n t e r e s t i n g f a c t s l i k e : 61 62 T e c h n i c a l i n f o : ’ T h e s o n g i s h i p - h o p f r o m t h e y e a r 2 0 1 2 w i t h a b p m o f 1 0 0 ’ 63 C r e a t i o n c o n t e x t : ’ T h e y r e c o r d e d t h i s a l b u m i n a c a b i n w i t h n o e l e c t r i c i t y u s i n g o n l y a c o u s t i c i n s t r u m e n t s ’ 64 C h a r t p e r f o r m a n c e : ’ I t ’ s w i l d h o w t h i s u n d e r p l a y e d t r a c k h a s o v e r 5 0 0 m i l l i o n s t r e a m s ’ 65 A r t i s t b a c k g r o u n d : ’ K n o w i n g t h e g u i t a r i s t w a s o n l y 1 7 w h e n t h e y r e c o r d e d t h i s m a k e s i t m o r e i m p r e s s i v e ’ 66 R e l e a s e d e t a i l s : ’ T h i s d e l u x e e d i t i o n h a s t h r e e b o n u s t r a c k s t h a t a r e b e t t e r t h a n t h e s i n g l e s ’ 67 68 S e n t i m e n t ( w h e t h e r t h e p e r s o n f e e l s g o o d o r b a d a b o u t t h e s o n g ) 69 O u t p u t F o r m a t 70 R e t u r n y o u r a n a l y s i s a s a s t r u c t u r e d J S O N w i t h t h e s e c a t e g o r i e s : 71 C o p y { 72 ’ p a i r s ’ : [ ( s o n g _ 1 , a r t i s t _ 1 ) , ( s o n g _ 2 , a r t i s t _ 2 ) , . . . ] , 73 ’ D e s c r i p t i v e ’ : [ ] , 74 ’ C o n t e x t u a l ’ : [ ] , 75 ’ S i t u a t i o n a l ’ : [ ] , 76 ’ A t m o s p h e r i c ’ : [ ] , 77 ’ L y r i c a l ’ : [ ] , 78 ’ M e t a d a t a ’ : [ ] , 79 ’ S e n t i m e n t ’ : [ ] 80 } 1 % E x a m p l e 2 3 % I n p u t : 41 Rebecca Salganik, et al. (2026) 4 ’ I l i k e P l a s t i c L o v e b y M a r i y a T a k e u c h i b e c a u s e o f t h e f u n k y , j a z z y , r e t r o v i b e s . I l i s t e n t o t h i s m u s i c a t 3 a m w h e n I m l o n e l y b e c a u s e i t r o m a n t i c i z e s m y l o n e l i n e s s a n d m a k e s i t m e a n i n g f u l . I t h e l p s m e t o e n j o y m y o w n l o n e l i n e s s . I t h a s v e r y d i s t i n c t i v e s y n t h e s i z e r s o u n d s i n t h e c h o r u s a n d l e a d i n g b a s s l i n e s i n t h e b r i d g e . T h e v o c a l s a r e c h i l l a n d b l e n d e d . A n o t h e r s o n g t h a t s o u n d s v e r y s i m i l a r i s O n c e U p o n a N i g h t b y B i l l y r r o m o r W a r m o n a C o l d N i g h t b y H o n n e . T h e g e n r e i s l i k e C i t y P o p w h i c h d e s c r i b e s a n i d e a l i z e d v e r s i o n o f a c i t y . ’ 5 6 % O u t p u t : 7 C o p y { 8 ’ p a i r s ’ : [ ( ’ P l a s t i c L o v e ’ , ’ M a r i y a T a k e u c h i ’ ) , ( ’ O n c e U p o n a N i g h t ’ , ’ B i l l y r r o m ’ ) , ( ’ W a r m o n a C o l d N i g h t ’ , ’ H O N N E ’ ) ] , 9 ’ S i t u a t i o n a l ’ : [ ’ 3 a m w h e n I m l o n e l y ’ ] , 10 ’ D e s c r i p t i v e ’ : [ ’ f u n k y ’ , ’ j a z z y ’ , ’ r e t r o v i b e s ’ , ’ d i s t i n c t i v e s y n t h e s i z e r i n c h o r u s ’ , ’ l e a d i n g b a s s l i n e s i n b r i d g e ’ , ’ c h i l l a n d b l e n d e d v o c a l s ’ , ’ g e n r e o f C i t y P o p ’ ] , 11 ’ A t m o s p h e r i c ’ : [ ’ r o m a n t i c l o n e l i n e s s ’ , ’ v u l n e r a b i l i t y ’ , ’ k i n d o f s a d i n a g o o d w a y ’ , ’ a c t i n g h e a r t b r o k e n ’ , ’ i d e a l i z e d v e r s i o n o f a c i t y ’ ] , 12 ’ C o n t e x t u a l ’ : [ ’ P l a s t i c L o v e s o u n d s s i m i l a r t o O n c e U p o n a N i g h t ’ , ’ P l a s t i c L o v e s o u n d s s i m i l a r t o W a r m o n a C o l d N i g h t ’ ] , 13 ’ M e t a d a t a ’ : [ ’ f u n k y ’ , ’ j a z z y ’ , ’ r e t r o v i b e s ’ , ’ g e n r e o f C i t y P o p ’ ] 14 } A.4 V erification and Hallucination Check Prompt Belo w, w e presen t the prompt used to v alidate the outputs of the extraction and summariza- tion stages. A secondary language mo del is employ ed to detect hallucinations b y chec king for inconsistencies b et ween the extracted seman tic tags and their sentence-lev el summariza- tion. The mo del is provided with t wo illustrativ e examples: one negativ e example (i.e., con taining no hallucinations) and one p ositive example (i.e., containing hallucinations). Our tests sho w that including b oth examples substantially improv es the mo del’s ability to iden tify hallucinations. 1 % G e t t i n g s u m m a r i z a t i o n s 2 # S u m m a r i z a t i o n t a s k 3 4 W r i t e a s e n t e n c e w h i c h c o m b i n e s t h e a s s o c i a t e d s e n t e n c e f r a g m e n t s . 5 P l e a s e d o n o t a d d a n y t h i n g o t h e r t h a n t h e i n f o r m a t i o n g i v e n t o y o u . 6 7 Y o u r d e s c r i p t i o n s h o u l d : 8 - B e m a x i m u m 4 s e n t e n c e s i n l e n g t h 9 10 Y o u r d e s c r i p t i o n s h o u l d n ’ t : 11 - A d d a n y a d d i t i o n a l i n f o r m a t i o n t h a t i s n o t p r e s e n t i n t h e t a g s 12 - I n c l u d e a n y i n f o r m a t i o n t h a t i s b a s e d o n y o u r o w n k n o w l e d g e o r a s s u m p t i o n s 13 14 E x a m p l e : 15 ’ S i t u a t i o n a l ’ : [ ’ 3 a m w h e n I m l o n e l y ’ ] , \ 16 ’ D e s c r i p t i v e ’ : [ ’ f u n k y ’ , ’ j a z z y ’ , ’ r e t r o v i b e s ’ , ’ d i s t i n c t i v e s y n t h e s i z e r i n c h o r u s ’ , ’ l e a d i n g b a s s l i n e s i n b r i d g e ’ , ’ c h i l l a n d b l e n d e d v o c a l s ’ , ’ g e n r e o f C i t y P o p ’ ] , \ 17 ’ A t m o s p h e r i c ’ ’ : [ ’ r o m a n t i c l o n e l i n e s s ’ , ’ v u l n e r a b i l i t y ’ , ’ k i n d o f s a d i n a g o o d w a y ’ , ’ a c t i n g h e a r t b r o k e n ’ , ’ i d e a l i z e d v e r s i o n o f a c i t y ’ ] , \ 42 MusicSem 18 ’ C o n t e x t u a l ’ : [ ’ P l a s t i c L o v e s o u n d s s i m i l a r t o O n c e U p o n a N i g h t ’ , ’ P l a s t i c L o v e s o u n d s s i m i l a r t o W a r m o n a C o l d N i g h t ’ ] , \ 19 ’ M e t a d a t a ’ : [ ’ f u n k y ’ , ’ j a z z y ’ , ’ r e t r o v i b e s ’ , ’ g e n r e o f C i t y P o p ’ ] \ 20 21 D e s i r e d o u t p u t : T h i s s o n g h a s f u n k y , j a z z y , r e t r o v i b e s . I l i s t e n t o t h i s m u s i c a t 3 a m w h e n I m l o n e l y b e c a u s e i t r o m a n t i c i z e s m y l o n e l i n e s s a n d m a k e s i t m e a n i n g f u l . \ 22 I t h e l p s m e t o e n j o y y o u r o w n l o n e l i n e s s . I t h a s v e r y d i s t i n c t i v e s y n t h e s i z e r s o u n d s i n t h e c h o r u s a n d l e a d i n g b a s s l i n e s i n t h e b r i d g e . \ 23 T h e v o c a l s a r e c h i l l a n d b l e n d e d . T h e g e n r e i s l i k e C i t y P o p w h i c h d e s c r i b e s a n i d e a l i z e d v e r s i o n o f a c i t y . ’ \ 24 25 T a g s : 26 27 { i n p u t _ t a g s } 28 29 % H a l l u c i n a t i o n 30 # H a l l u c i n a t i o n C h e c k P r o m p t f o r G e n e r a t e d S u m m a r y 31 32 # # I n s t r u c t i o n s 33 E v a l u a t e w h e t h e r t h e g e n e r a t e d s u m m a r y c o n t a i n s h a l l u c i n a t i o n s b a s e d o n t h e p r o v i d e d f e a t u r e s / t a g s f r o m t h e o r i g i n a l s o u r c e . 34 A h a l l u c i n a t i o n i s d e f i n e d a s i n f o r m a t i o n i n t h e s u m m a r y t h a t i s n o t p r e s e n t i n o r c o n t r a d i c t s t h e f e a t u r e s f r o m t h e s o u r c e m a t e r i a l . 35 36 # # I n p u t F o r m a t 37 - * * O r i g i n a l F e a t u r e s / T a g s * * : [ L i s t o f k e y f e a t u r e s / t a g s f r o m t h e s o u r c e m a t e r i a l ] 38 - * * G e n e r a t e d S u m m a r y * * : [ T h e s u m m a r y t o b e e v a l u a t e d ] 39 40 # # T a s k 41 1 . C o m p a r e e a c h c l a i m o r s t a t e m e n t i n t h e s u m m a r y a g a i n s t t h e o r i g i n a l f e a t u r e s / t a g s 42 2 . I d e n t i f y a n y i n f o r m a t i o n i n t h e s u m m a r y t h a t : 43 - I s n o t s u p p o r t e d b y t h e o r i g i n a l f e a t u r e s / t a g s 44 - C o n t r a d i c t s t h e o r i g i n a l f e a t u r e s / t a g s 45 - R e p r e s e n t s a n e m b e l l i s h m e n t b e y o n d w h a t c a n b e r e a s o n a b l y i n f e r r e d 46 3 . * * T h e o u t p u t s h o u l d b e i n J S O N f o r m a t . * * 47 48 # # O u t p u t F o r m a t 49 ‘ ‘ ‘ 50 { { 51 " h a l l u c i n a t i o n _ d e t e c t e d " : [ T r u e / F a l s e ] , 52 } } 53 ‘ ‘ ‘ 54 55 # # E x a m p l e 1 56 * * I n p u t D a t a * * : 57 { { 58 " o r i g i n a l _ f e a t u r e s " : { { 59 ’ s i t u a t i o n a l ’ : [ ’ 3 a m w h e n I m l o n e l y ’ ] , 60 ’ d e s c r i p t i v e ’ : [ ’ f u n k y ’ , ’ j a z z y ’ , ’ r e t r o v i b e s ’ , ’ d i s t i n c t i v e s y n t h e s i z e r i n c h o r u s ’ , ’ l e a d i n g b a s s l i n e s i n b r i d g e ’ , ’ c h i l l a n d b l e n d e d v o c a l s ’ , ’ g e n r e o f C i t y P o p ’ ] , 43 Rebecca Salganik, et al. (2026) 61 ’ a t m o s p h e r i c ’ ’ : [ ’ r o m a n t i c l o n e l i n e s s ’ , ’ v u l n e r a b i l i t y ’ , ’ k i n d o f s a d i n a g o o d w a y ’ , ’ a c t i n g h e a r t b r o k e n ’ , ’ i d e a l i z e d v e r s i o n o f a c i t y ’ ] , 62 ’ c o n t e x t u a l ’ : [ ’ P l a s t i c L o v e s o u n d s s i m i l a r t o O n c e U p o n a N i g h t ’ , ’ P l a s t i c L o v e s o u n d s s i m i l a r t o W a r m o n a C o l d N i g h t ’ ] , 63 } } , 64 " g e n e r a t e d _ s u m m a r y " : ’ f u n k y , j a z z y , r e t r o v i b e s . I l i s t e n t o t h i s m u s i c a t 3 a m w h e n I m l o n e l y b e c a u s e i t r o m a n t i c i z e s m y l o n e l i n e s s a n d m a k e s i t m e a n i n g f u l . 65 I t h e l p s m e t o e n j o y y o u r o w n l o n e l i n e s s . I t h a s v e r y d i s t i n c t i v e s y n t h e s i z e r s o u n d s i n t h e c h o r u s a n d l e a d i n g b a s s l i n e s i n t h e b r i d g e . 66 T h e v o c a l s a r e c h i l l a n d b l e n d e d . T h e g e n r e i s l i k e C i t y P o p w h i c h d e s c r i b e s a n i d e a l i z e d v e r s i o n o f a c i t y . ’ 67 } } 68 69 70 * * E x p e c t e d O u t p u t * * : 71 ‘ ‘ ‘ 72 { { 73 " h a l l u c i n a t i o n _ d e t e c t e d " : F a l s e , 74 } } 75 76 # # E x a m p l e 2 77 * * I n p u t D a t a * * : 78 { { 79 " o r i g i n a l _ f e a t u r e s " : { { 80 ’ s i t u a t i o n a l ’ : [ ’ w h e n I ’ m q u i t t i n g m y c o r p o r a t e j o b ’ ] , 81 ’ d e s c r i p t i v e ’ : [ ’ a n g r y p u n k g u i t a r ’ , ’ k i l l e r d r u m s ’ , ’ h a r c o r e v o c a l p r o c e s s i n g ’ , ’ d i s t o r t i o n ’ ] , 82 ’ a t m o s p h e r i c ’ ’ : [ ’ p u m p e d u p v i b e s ’ , ’ m a k e s m e w a n t t o t a k e c h a r g e o f m y l i f e ’ ] , 83 ’ c o n t e x t u a l ’ : [ ’ ’ ] , 84 } } , 85 " g e n e r a t e d _ s u m m a r y " : ’ T h i s s o n g m a k e s m e h a p p y . I t h a s a s o f t a n d e x c i t i n g v i b e w i t h k i l l e r d r u m s . I l i s t e n t o t h i s s o n g a t p a r t i e s o r f e s t i v a l s w h e n I f e e l p o s i t i v e . ’ 86 } } 87 88 * * E x p e c t e d O u t p u t * * : 89 ‘ ‘ ‘ 90 { { 91 " h a l l u c i n a t i o n _ d e t e c t e d " : T r u e , 92 } } 93 ‘ ‘ ‘ 94 95 * * I n p u t D a t a * * : 96 ‘ ‘ ‘ 97 { { 98 " o r i g i n a l _ f e a t u r e s " : { f e a t u r e s } , 99 " g e n e r a t e d _ s u m m a r y " : { s u m m a r y } 100 } } 101 ‘ ‘ ‘ 102 * * E x p e c t e d O u t p u t * * : 103 ‘ ‘ ‘ 44 MusicSem App endix B. Exp erimen tal Settings This Appendix B pro vides additional details on the exp erimen ts presen ted in the paper, including descriptions of all ev aluated metho ds, the set of hyperparameters used, informa- tion on training and test splits, details ab out the computational resources emplo y ed, and a discussion of the ev aluation metrics. B.1 Ov erview of Models T able 11: Ov erview of all mo dels ev aluated in this work. Hier. , T r ans. , Diff. , and Co-List. denote Hierarchical, T ransformer, Diffusion, and Co-Listing, resp ectiv ely . T ask Name Date Architecture T ext Conditioner Length Sample Rate Proprietary T ext-to-Music MusicLM (Agostinelli et al., 2023) 2023 Hier. T rans. + SoundStream w2v-BER T (Chung et al., 2021) v ariable 24kHz AudioLDM 2 (Liu et al., 2024a) 2023 V AE + 2D U-Net CLAP (W u et al., 2023) v ariable 16kHz Stable Audio (Evans et al., 2024) 2023 V AE + 2D U-Net CLAP (W u et al., 2023) up to 95s 48kHz MusicGen (Copet et al., 2023) 2024 AE + 1D U-Net FLAN-T5 (Chung et al., 2024) 10s 48kHz Mustango (Melechovsky et al., 2024) 2024 V AE + 2D U-Net FLAN-T5 (Chung et al., 2024) 10s 16kHz Murek a 2024 - - - - ✓ T ask Name Y ear Architecture Audio Conditioner Length Sample Rate Proprietary Music-to-T ext MU-LLaMA (Liu et al., 2024b) 2024 Diff. T rans. MER T (Li et al., 2024) 60s 16kHz LP-MusicCaps (Liu et al., 2024b) 2023 T rans. BAR T (Lewis et al., 2020) 10s 16kHz FUTGA (W u et al., 2024) 2024 Hier. T rans. + V AE Whisper(Radford et al., 2023) 240s 16kHz T ask Name Y ear Architecture Modalities Length Sample Rate Proprietary Retriev al CLAP (W u et al., 2023) 2023 Contrastive Learning T ext + Wa veform - 48kHz LARP (Salganik et al., 2024b) 2024 Contrastiv e Learning T ext + W aveform + Co-List. Graph 48kHz ImageBind (Girdhar et al., 2023) 2023 Contrastiv e Learning T ext + Image - 16kHz CLaMP3 (W u et al., 2025) 2024 Contrastive Learning T ext + Image + W aveform - 24kHz B.2 Cross–Modal Music Retriev al Mo dels CLAP (W u et al., 2023) learns joint embeddings b etw een audio clips and text descrip- tions through Contrastiv e Language–Image Pretraining (Radford et al., 2021), trained on 630K audio–text pairs. F or audio data, CLAP first represen ts signals using log-Mel spectro- grams at a sampling rate of 44.1 kHz, and then employs CNN14 (Kong et al., 2020) (80.8M parameters), whic h is pretrained on AudioSet with appro ximately 2M audio clips. F or text data, CLAP uses BER T (Devlin et al., 2019) (110M parameters) to encode text descriptions, taking the [CLS] token em b edding as the text representation. Both audio and text embed- dings are pro jected in to a shared m ultimo dal space using learnable pro jection matrices, resulting in a 1024-dimensional output representation. W e emplo y the music-specific v ari- an t of CLAP provided in the official rep ository at https://github.com/LAION- AI/CLAP . LARP (Salganik et al., 2024b) addresses the cold-start problem in pla ylist con tinua- tion through a three-stage contrastiv e learning framework. Built up on the BLIP arc hitec- ture, LARP consists of tw o unimo dal enco ders: HTS-A T (Chen et al., 2022) for audio enco d- ing and BER T for text pro cessing, where [CLS] tok en em b eddings are used to represen t text. The original 768-dimensional em b eddings from b oth enco ders are pro jected into a unified 256-dimensional embedding space. The framework then p erforms within-trac k contrastiv e learning, track–trac k con trastive learning, and trac k–playlist con trastive learning, optimiz- ing representations from both seman tic and intra-pla ylist music relev ance p ersp ectives. W e use the official implementation a v ailable at https://github.com/Rsalganik1123/LARP . 45 Rebecca Salganik, et al. (2026) ImageBind (Girdhar et al., 2023) unifies six mo dalities (including image, audio, and text) within a single em b edding space through multimodal contrastiv e learning. Although not m usic-sp ecific, its general-purp ose audio–text alignment capabilit y pro vides a strong baseline for cross-domain retriev al. ImageBind emplo ys T ransformer-based architectures for all modality enco ders. F or audio input, it con v erts 2-second audio samples at 16 kHz in to spectrograms using 128 Mel-frequency bins. T reating these spectrograms as 2D sig- nals analogous to images, the mo del pro cesses them using a Vision T ransformer (ViT) with a patc h size of 16 and a stride of 10. F or text input, ImageBind utilizes pretrained text enco ders (302M parameters) from Op enCLIP (Cherti et al., 2023). After pro jec- tion, all mo dalities are enco ded in to a shared 768-dimensional embedding space. W e ex- tract audio embeddings using the ViT-B/16 v ariant from the official implementation at https://github.com/facebookresearch/imagebind . CLaMP3 (W u et al., 2025) establishes a unified m ultilingual music–text embedding space b y aligning sheet music, audio recordings, and textual descriptions across 12 lan- guages. F or audio pro cessing, CLaMP3 adopts pretrained acoustic representations from MER T-v1-95M (Li et al., 2024). Each 5-second audio clip is represen ted by an em b ed- ding obtained by av eraging features across all MER T la yers and time steps. F or textual con tent, the mo del emplo ys XLM-R-base (Conneau et al., 2020), a multilingual T rans- former with 12 lay ers and 768-dimensional hidden states. The framework uses con trastive learning to align m ultimo dal representations and incorp orates additional comp onen ts such as a retriev al-augmented training mechanism to enhance cross-mo dal asso ciations. W e use the chec kp oin ts and architecture from the original authors’ implemen tation at https: //sanderwood.github.io/clamp3 , sp ecifically the SaaS v ariant optimized for audio. B.3 Music-to-T ext Generation Mo dels MU-LLaMA (Liu et al., 2024b) is a m usic-sp ecific adaptation of the LLaMA-2-7B arc hitecture that integrates acoustic features extracted by MER T (Li et al., 2024) through LLaMA-Adapter tuning (Zhang et al., 2023). W e use the official implementation provided at https://github.com/shansongliu/MU- LLaMA , following the same h yp erparameter set- tings as rep orted by the authors. Sp ecifically , the input audio is split in to 60-second seg- men ts at a sampling rate of 16 kHz. The temp erature for LLaMA-2-7B is set to 0.6, top p is set to 0.8, and the maximum sequence length is 1024 tokens. LP-MusicCaps (Doh et al., 2023) employs a BAR T-based enco der–deco der architec- ture (Lewis et al., 2020) with a hidden width of 768 and six T ransformer blo c ks for b oth the enco der and the deco der. The enco der pro cesses log-Mel sp ectrograms using conv olutional la yers similar to those in Whisper (Radford et al., 2023). W e use the official implemen tation a v ailable at https://github.com/seungheondoh/lp- music- caps along with the authors’ pretrained c heckpoint. F or inference, test audio is split in to 10-second segments at 16 kHz, and the longest generated caption among all segmen ts is selected as the final output. In addition, num b e ams is set to 5 and the maxim um sequence length is 128 tokens. FUTGA (W u et al., 2024) enables time-lo cated music captioning b y automatically de- tecting functional segmen t boundaries. Built up on SALMONN-7B (T ang et al., 2024) with LoRA-based instruction tuning, the mo del in tegrates a m usic feature extractor to supp ort 46 MusicSem full-length m usic captioning. F or our ev aluation, w e use the chec kp oints and architecture released b y the original authors at https://huggingface.co/JoshuaW1997/FUTGA . In the implemen tation, Vicuna-7B (Chiang et al., 2023) serves as the language bac kb one. The rep etition p enalty is set to 1.5, num b e ams is set to 5, top p is set to 0.95, top k is set to 50, and each audio input is pro cessed as a 240-second signal sampled at 16 kHz. B.4 T ext-to-Music Generation Mo dels MusicLM (Agostinelli et al., 2023) is a generativ e mo del that pro duces high-quality m usic from text prompts using a hierarc hical sequence-to-sequence approac h. It lev erages audio embeddings from a self-sup ervised mo del and autoregressively generates b oth se- man tic and acoustic tokens. Unfortunately , this mo del do es not pro vide publicly av ailable arc hitectures or chec kp oints. W e therefore use a crowd-sourced implemen tation av ailable at https://github.com/zhvng/open- musiclm . Notably , this implemen tation deviates from the original formulation b y using an op en-source version of CLAP (W u et al., 2023) in- stead of MuLan (Huang et al., 2022), and EnCo dec (D´ efossez et al., 2022) instead of SoundStream (Zeghidour et al., 2021). The purp ose of including this implemen tation is to show case the p erformance of a broad range of publicly av ailable mo dels. Stable Audio (Ev ans et al., 2024) is a diffusion-based m usic generation mo del that syn thesizes audio from text prompts and optional melo dy input using a latent audio repre- sen tation. The mo del is built around a latent diffusion framework composed of a v ariational auto enco der (V AE), a textual conditioning signal, and a diffusion mo del. The V AE consists of a Descript Audio Co dec (Kumar et al., 2023) encoder–deco der pair. T extual conditioning is pro vided b y a pretrained CLAP model (W u et al., 2023), sp ecifically the HT-SA T (Chen et al., 2022) audio enco der and a RoBER T a-based (Liu et al., 2019) text enco der. The diffusion comp onent is implemented as a U-Net (Schneider et al., 2024) with four levels of do wnsampling enco der blo cks and upsampling deco der blo c ks, connected via skip connec- tions. F or our ev aluation, w e use the chec kp oints and arc hitecture released by the original authors at https://github.com/Stability- AI/stable- audio- tools . MusicGen (Cop et et al., 2023) is a T ransformer-based mo del that generates m usic from text descriptions. In our exp erimen ts, we use the 300M-parameter v arian t. The mo del emplo ys a five-la yer EnCo dec arc hitecture for 32 kHz monophonic audio with a stride of 640, resulting in a frame rate of 50 Hz, an initial hidden size of 64, and a final embedding size of 640. The em b eddings are quantized using residual v ector quantization (R V Q) with four quan tizers, eac h ha ving a co deb o ok size of 2048. During inference, the mo del uses top- k sampling with k = 250 and a temp erature of 1.0. F or ev aluation, we use the chec kp oints and arc hitecture pro vided b y the original authors at https://github.com/facebookresearch/ audiocraft . AudioLDM2 (Liu et al., 2024a) is a diffusion-based text-to-audio generation model trained on large-scale data and designed to handle div erse audio t yp es, including m usic and sound effects. It extends prior AudioLDM mo dels by incorp orating higher-qualit y represen tations and more efficient training strategies. F or our ev aluation, we use the c heck- p oin ts and arc hitecture released by the original authors at https://github.com/haoheliu/ AudioLDM2 . Sp ecifically , we adopt the version with a t wo-la y er latent diffusion mo del. F or 47 Rebecca Salganik, et al. (2026) audio enco ding, AudioLDM2 emplo ys an AudioMAE enco der with a patch size of 16 × 16 and no o verlap, pro ducing a 768-dimensional feature sequence of length 512 for every 10 seconds of Mel sp ectrogram input. F or text enco ding, the model uses a GPT-2 architecture with 12 T ransformer la yers and a hidden dimension of 768. Mustango (Melecho vsky et al., 2024) is a multi-stage laten t diffusion mo del for text- to-m usic generation that emphasizes b oth m usical coherence and audio quality . It introduces a time-a ware T ransformer to mo del long audio sequences and supp orts m ulti-track genera- tion. F or our ev aluation, w e use the c heckpoints and architecture released b y the original authors at https://github.com/AMAAI- Lab/mustango . During inference, the mo del em- plo ys tw o T ransformer-based text-to-m usic feature generators that predict b eat and c hord information. Beat prediction is performed using a DeBER T a-Large mo del (He et al., 2021), whic h predicts both meter and in ter-b eat in terv al durations, while c hord prediction is han- dled by a FLAN-T5-Large mo del (Chung et al., 2024). Murek a is a proprietary music generation mo del accessible via https://www.mureka.ai . W e implement a custom pip eline for interacting with the Murek a API. This pipeline will b e released on our GitHub rep ository once the current API-related issues are resolved. B.5 Dataset Splits F or all ev aluations conducted on MusicCaps and Song Describ er, we ev aluate models on the en tirety of the data that is curren tly publicly av ailable. This choice is motiv ated b y the fact that neither dataset provides officially released or standardized train–test splits that can b e consistently used across mo dels. F or instance, although the original MusicCaps pap er references the existence of a test set, the publicly a v ailable v ersion of the dataset released on Kaggle con tains only a training split. As a result, man y prior works ev aluating on MusicCaps construct synthetic test sets by defining their own train–test splits ov er the a v ailable data (Melecho vsky et al., 2024; W u et al., 2024; Doh et al., 2023). Without access to a shared held-out test set or leaderb oard, it is therefore not p ossible to reliably assess or compare p erformance across studies, nor to fully account for p oten tial ov erfitting. A similar situation applies to Song Describ er: the dataset, as released, do es not include an explicit demarcation b etw een training and ev aluation splits, leading each study to adopt its o wn splitting strategy . Since our w ork do es not in volv e an y fine-tuning on these datasets, w e opted to ev aluate models on the full publicly av ailable sets in order to rep ort their ov erall p erformance. In contrast, MusicSem includes a clearly defined and h uman-v alidated test set. F or all ev aluations on MusicSem, w e use only this held-out p ortion of the data for testing, while releasing the remaining entries as the public training set. B.6 Computational Resources and Runtime Analysis Computational Resources. F or generative tasks, all exp eriments w ere conducted on systems equipp ed with NVIDIA L40 GPUs, eac h providing 48 GB of VRAM, and using CUD A 12.6. Eac h exp eriment w as executed on a single GPU instance. F or retriev al tasks, all experiments w ere conducted on systems equipp ed with NVIDIA A40 GPUs with 46 GB of VRAM p er card, using CUD A 12.4. Similarly , eac h retriev al exp eriment was executed on a single GPU instance. 48 MusicSem T able 12: Inference time of text-to-music generation mo dels on MusicSem. T rade-off is defined as inference time divided by generation size. Mo del Inference Time (in seconds) Generation Size (in seconds) T radeoff ↓ MusicLM 102 5 20.40 AudioLDM2 13 10 1.30 Mustango 50 10 5.00 MusicGen 40 20 2.00 Stable Audio 18 45 0.40 Murek a 120 150 0.80 T able 13: Inference time of music-to-text generation mo dels on MusicSem. T rade-off is defined as inference time divided by generation size. Mo del Inference Time (in seconds) Generation Size (in characters) T radeoff ↓ LP-MusicCaps 8 2000 0.004 MU-LLaMA 4 70 0.057 FUTGA 15 1138 0.013 Run time Analysis. F or text-to-music generation, we analyze the relationship b etw een inference time and the duration of the generated audio in T able 12. Because generation duration v aries substan tially across mo dels, and pro ducing long, coheren t musical segmen ts remains a central challenge in text-to-music generation (Cop et et al., 2023), we ev aluate eac h mo del using the duration settings sp ecified in its original formulation and co debase. W e rep ort a trade-off metric computed as the ratio of inference time to generation dura- tion. F rom the results in T able 12, we observ e that among publicly av ailable mo dels, Stable Audio ac hieves the lo west inference latency . In addition, the proprietary mo del Murek a is able to generate longer stretches of coheren t audio than all publicly av ailable mo dels, high- ligh ting a clear p erformance gap b etw een op en-source and commercial generation systems. F or music-to-text generation, we ev aluate the relationship b et ween inference time and the length of the generated textual annotation in T able 13. The results indicate that LP- MusicCaps ac hieves the highest trade-off, meaning that one second of inference time yields the largest num b er of generated characters. Finally , for text-to-m usic retriev al, we ev aluate the inference latency of cross-mo dal re- triev al mo dels in T able 14. As shown by the results, inference latency v aries only marginally across mo dels, although ImageBind (Girdhar et al., 2023) is slightly faster than the other approac hes. B.7 Ev aluation Metrics In terpreting Music-to-T ext Metrics. In this section, we provide a brief ov erview of the ev aluation metrics used for assessing m usic-to-text generation mo dels. F ollowing canonical w orks in music-to-text generation (Liu et al., 2024b; Doh et al., 2023), we first consider three n -gram-based metrics originally dev elop ed for machine translation: BLEU (Papineni et al., 2002), ROUGE (Lin, 2004), and METEOR (B anerjee and La vie, 2005). 49 Rebecca Salganik, et al. (2026) T able 14: Inference time of cross-mo dal retriev al mo dels on MusicSem. Mo del Inference Time (in seconds) LARP 0.26 CLAP 0.23 ImageBind 0.21 CLAMP3 0.28 BLEU (B) measures precision b y computing the ov erlap of n -grams (typically unigrams, bigrams, and trigrams; i.e., B 1 , B 2 , and B 3 ) b et ween the reference annotation and the generated m usic caption. In con trast, ROUGE (R) emphasizes recall b y measuring the o verlap of n -grams b etw een the generated caption and the reference annotation. METEOR (M) is designed to b etter align with human judgment by extending exact n -gram matching to include synonym y and paraphrase-based matc hes, thereb y addressing some limitations of BLEU and ROUGE. W e also include CIDEr (V edan tam et al., 2015), a metric originally prop osed for image captioning, whic h measures the similarity b et ween a generated caption and a set of refer- ence annotations using a w eighted n -gram scheme that emphasizes consensus. Finally , we rep ort BER TScore (Zhang et al., 2020), which compares contextualized embeddings of gen- erated and reference captions using a pretrained BER T mo del, thereby capturing semantic similarit y b eyond surface-lev el lexical ov erlap. The purp ose of emplo ying this diverse set of metrics is to capture increasing lev els of ab- straction in ev aluating the alignment b etw een original annotations and generated captions. As observ ed in our exp erimen ts, BER TScore tends to b e the most stable across datasets, whereas n -gram-based metrics exhibit higher v ariability across b oth datasets and mo dels. CLAP Score. The Contrastiv e Language–Audio Pretraining (W u et al., 2023) score (CLAP score) is a simple y et effe ctiv e, reference-free metric that quan tifies ho w well an audio signal aligns with a textual description. This metric is commonly used in text-to- m usic generation to ev aluate ho w accurately a generative mo del expresses the information pro vided in a textual prompt. F ormally , giv en a set of paired textual inputs and generated audio outputs ( T , ˜ A ), where the audio ˜ A = M ( T ) is generated by conditioning a m usic gen- eration mo del M on the textual input T (e.g., MusicGen (Copet et al., 2023)), em b eddings for each mo dality are computed using the CLAP mo del as follows: Z ˜ A = CLAP audio ( ˜ A ) , Z T = CLAP text ( T ) , (3) where Z ˜ A and Z T denote the audio and text embeddings pro duced by the CLAP audio and text enco ders, resp ectiv ely . Giv en these em b eddings, the CLAP score is computed as the av erage cosine similarity b et ween corresp onding audio and text representations in the shared embedding space. Using matrix-st yle indexing, where Z ˜ A [ i ] denotes the i -th audio em b edding and Z T [ i ] the corresp onding text embedding, the CLAP score is defined as: C S ( T , ˜ A ) = 1 n n X i =1 ⟨ Z ˜ A [ i ] , Z T [ i ] ⟩ ∥ Z ˜ A [ i ] ∥ · ∥ Z T [ i ] ∥ . (4) In tuitively , higher CLAP scores indicate stronger alignmen t b et ween the audio and textual represen tations in the joint embedding space. 50 MusicSem Figure 7: Comparison b et ween V endi scores for cov er songs and random collection. V endi Score. It is not immediately obvious that the V endi score (F riedman and Dieng, 2023), whic h was originally proposed for images, is directly applicable to audio sp ectro- grams, i.e., image-lik e representations of audio signals in the frequency domain. T o assess whether the V endi Score is sensitive to meaningful v ariations in music, w e conduct an ab- lation study . W e consider 15 seed tracks. F or each seed track, we select three p ositive and three ne gative examples. P ositiv e examples corresp ond to co ver songs, in whic h differen t m usicians p erform the same m usical piece as the original seed trac k. In contrast, negative examples consist of songs from en tirely differen t genres and artists. W e hypothesize that, if the V endi score can effectively measure div ersit y in collections of audio, it should clearly distinguish b et ween positive and negativ e examples when ev aluated relative to a seed track. As sho wn in Figure 7, the V endi Score is indeed able to differentiate b et ween these groups. F or nearly all seed tracks (shown along the x-axis), the score is consisten tly higher for negative examples (orange) than for co ver songs (blue), indicating greater diversit y relativ e to the seed track. This result suggests that the V endi Score captures meaningful differences in musical con tent and can b e reasonably applied as a diversit y metric for audio. The list of songs used in this ablation study is av ailable at https://tinyurl.com/2ff3d4f6 . 51
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment