Bayesian Optimality of In-Context Learning with Selective State Spaces
We propose Bayesian optimal sequential prediction as a new principle for understanding in-context learning (ICL). Unlike interpretations framing Transformers as performing implicit gradient descent, we formalize ICL as meta-learning over latent seque…
Authors: Di Zhang, Jiaqi Xing
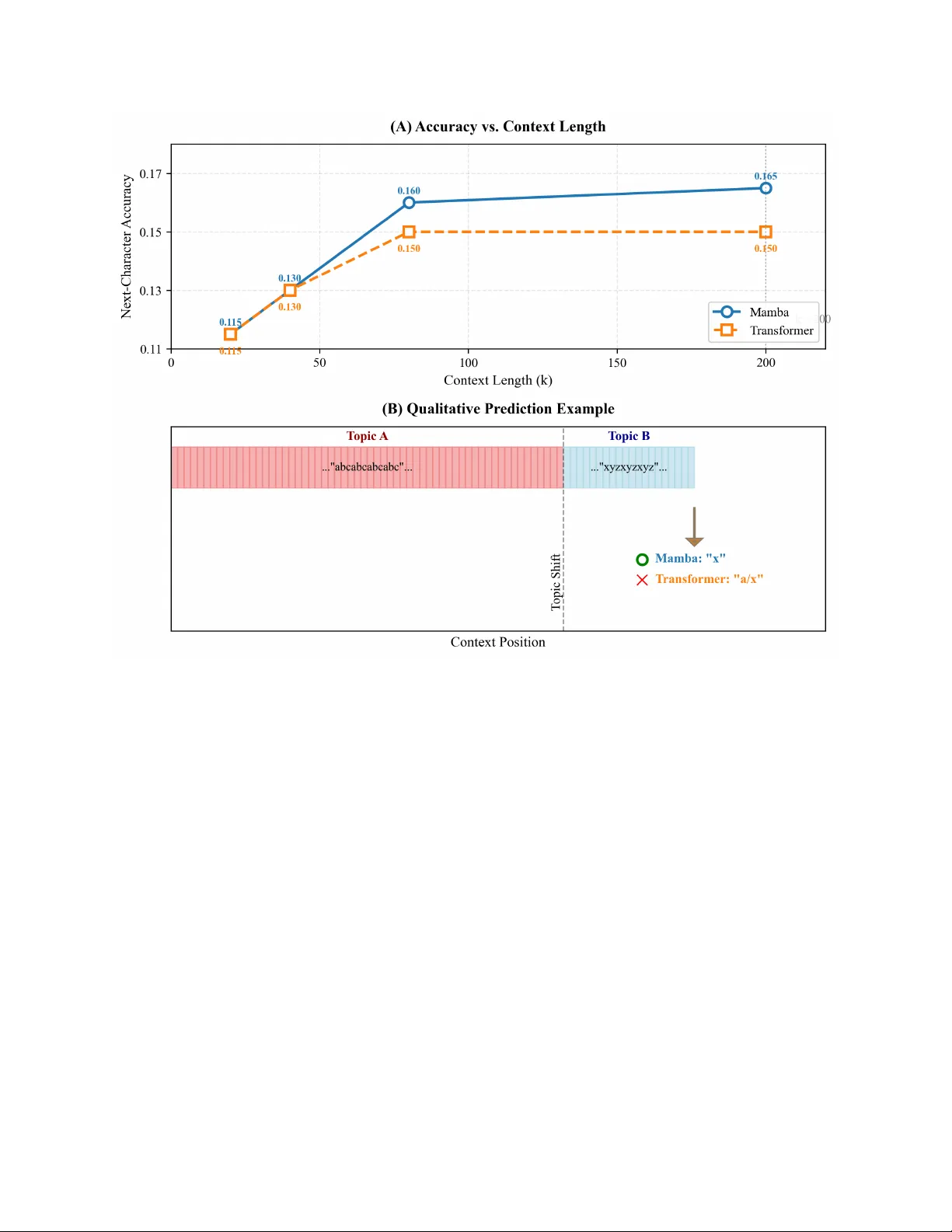
B A Y E S I A N O P T I M A L I T Y O F I N - C O N T E X T L E A R N I N G W I T H S E L E C T I V E S T A T E S P A C E S Di Zhang* School of AI and Advanced Computing Xi’an Jiaotong-Liv erpool University Suzhou, Jiangsu, China di.zhang@xjtlu.edu.cn Jiaqi Xing School of AI and Advanced Computing Xi’an Jiaotong-Liv erpool University Suzhou, Jiangsu, China jiaqi.xing22@student.xjtlu.edu.cn February 23, 2026 A B S T R AC T W e propose Bayesian optimal sequential prediction as a ne w principle for understanding in-context learning (ICL). Unlike interpretations framing T ransformers as performing implicit gradient descent, we formalize ICL as meta-learning ov er latent sequence tasks. For tasks go verned by Linear Gaussian State Space Models (LG-SSMs), we prove a meta-trained selecti ve SSM asymptotically implements the Bayes-optimal predictor , conv erging to the posterior predicti ve mean. W e further establish a statistical separation from gradient descent, constructing tasks with temporally correlated noise where the optimal Bayesian predictor strictly outperforms an y empirical risk minimization (ERM) estimator . Since Transformers can be seen as performing implicit ERM, this demonstrates selecti ve SSMs achie ve lo wer asymptotic risk due to superior statistical efficienc y . Experiments on synthetic LG-SSM tasks and a character -lev el Markov benchmark confirm selecti ve SSMs con verge faster to Bayes-optimal risk, show superior sample efficienc y with longer contexts in structured-noise settings, and track latent states more rob ustly than linear T ransformers. This reframes ICL from ”implicit optimization” to ”optimal inference, ” explaining the ef ficiency of selective SSMs and of fering a principled basis for architecture design. Keyw ords: In-context learning, selectiv e state space models, Bayesian optimality , sequential predic- tion, statistical efficienc y , meta-learning 1 Introduction In-context learning (ICL) has emer ged as a defining capability of modern sequence models. The dominant theoretical narrativ e explains this phenomenon through the lens of implicit optimization, interpreting the T ransformer’ s forward pass as a form of gradient descent [ 1 , 2 , 3 ]. This view provides a compelling, mechanistic account of how models learn from examples within their conte xt. Howe ver , a new class of architectures, Selecti ve State Space Models (SSMs) such as Mamba, challenges this narrati ve [4]. These models eschew attention for a data-dependent, linear -time recurrence, yet they e xcel at ICL, particularly in tasks requiring long-range reasoning. Since their forward pass does not readily decompose into gradient computation, a fundamental question arises: if not gradient descent, what principle guides their in-conte xt learning? Recent work suggests they may learn optimal statistical estimators for simple Markov chains [ 5 ], but a general theory for latent-state dynamical systems remains absent [6, 7]. W e h ypothesize that the answer lies in a dif ferent fundamental principle: Bayesian optimal sequential pr ediction (See Figure 1). State space models are intrinsically link ed to optimal filtering algorithms, which recursi vely apply Bayes’ rule to update beliefs o ver latent states. It is posited that selecti ve SSMs, through meta-training on next-tok en prediction, learn to approximate such Bayesian updates for a broad family of latent generativ e processes. While recent work has framed ICL as Bayesian inference for static parameters [ 8 ], our framework addresses the dynamic, sequential A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 Figure 1: The T wo Paradigms of ICL. (Left) GD/T ransformer: The context is pooled into an empirical loss landscape (grey surface). The forward pass performs gradient descent (red path) to find a minimizer ˆ y GD . This ignores the temporal structure. (Right) Selective SSM/Bay esian Filtering: Each observ ation updates an internal belief state (blue cloud) ov er latent v ariables. Prediction is the mean of the e volv ed belief. This process naturally accounts for temporal correlations and uncertainty . Theorem 2 sho ws the right paradigm achie ves strictly lower risk for tasks with structured temporal noise. setting. This perspectiv e suggests a distinct source of ef ficiency: while the gradient descent vie w explains learning as optimization , the Bayesian view e xplains it as inference . This paper formalizes this intuition and establishes its theoretical v alidity . Our core contrib ution is a Bayesian decision- theoretic framew ork for ICL that demonstrates the statistical optimality of selecti ve SSMs. Our specific contributions are fourfold. First, we formulate ICL as a meta-learning problem ov er a distribution of latent sequence prediction tasks, each modeled by a linear Gaussian state space model (LG-SSM). The goal is to minimize the Bayes risk—the e xpected prediction error ov er tasks and stochastic dynamics. Second, for this class of tasks, we prove that a simplified, meta-trained selecti ve SSM performs asymptotically optimal prediction. Its in-conte xt predictions con ver ge to the posterior predictive mean, achieving the minimum possible expected error and matching the asymptotic Cram ´ er-Rao lo wer bound (Theorem 1). Third, we establish a computational separation from the gradient descent paradigm. A natural sequence prediction task in volving temporally correlated noise is constructed, where the optimal Bayesian predictor provably outperforms any estimator based on empirical risk minimization (ERM). Since the T ransformer-as-gradient-descent frame work inherently performs a form of ERM [ 1 , 3 ], this prov es a strictly lower asymptotic risk for our selecti ve SSM under the Bayesian filtering principle, grounding its advantage in statistical ef ficiency (Theorem 2). Fourth, we provide empirical v alidation on synthetic LG-SSM tasks and a controlled character -lev el Markov text benchmark. Results confirm that selectiv e SSMs con verge faster to the theoretical Bayes risk, sho w superior sample efficienc y (steeper risk decay with context length) on tasks with structured noise, and more robustly track latent states compared to linear T ransformers. This provides a unified decision-theoretic framew ork that not only explains the empirical success of selective SSMs b ut also predicts their limitations. 2 Related W ork Our work connects three research areas: optimization-based theories of in-context learning, algorithmic analyses of state space models, and Bayesian meta-learning. 2 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 2.1 In-Context Learning as Implicit Optimization The dominant frame work interprets T ransformer -based ICL as implicit gradient-based optimization. Seminal w ork shows linear attention can implement gradient descent on a least-squares loss [ 9 , 10 ]. Extensions demonstrate softmax attention can approximate multiple gradient steps, linking this to mechanistic interpretability [ 11 , 12 ]. A parallel thread interprets linear attention as performing kernel regression [ 13 ]. The unifying theme is that the forw ard pass minimizes an empirical risk derived from the context. While elegant and influential, this framework intrinsically ties model capabilities to empirical risk minimization [ 14 ]. Our work questions whether ERM is the most statistically efficient principle for ICL, particularly for sequential tasks. 2.2 State Space Models and Algorithmic Appr oximation An alternative perspectiv e vie ws sequence models as approximating classical algorithms. Empirically , Mamba has been sho wn to perform operations resembling local smoothing [ 4 ]. Theoretically , recent w ork pro ves that a tw o- layer SSM can implement Bayes-optimal predictors for fixed-order , observable Markov chains [ 5 ]. This result is constrained to chains without latent state and lacks asymptotic optimality guarantees for dynamic latent v ariable models. Broader literature establishes the univ ersal approximation capabilities of SSMs and RNNs [ 6 , 15 ], focusing on function representation rather than statistical efficiency . Notably , SSMs ha ve also been shown to implement gradient descent [ 3 ]. Our contribution sho ws selecti ve SSMs, when meta-trained, conv erge to the statistically optimal algorithm for a family of latent dynamical tasks, moving be yond mere representation or gradient descent approximation. 2.3 Bayesian Meta-Learning Framing few-shot learning as Bayesian inference has a long history [ 16 ]. Modern deep meta-learning often formulates learning a prior o ver tasks [ 17 ]. For ICL specifically , Bayesian models ha ve been proposed where a Transformer’ s forward pass approximates posterior inference ov er static task parameters, assuming i.i.d. in-conte xt e xamples [ 8 , 18 ]. Recent work also examines belief dynamics and Bayesian Occam’ s razor in ICL [ 19 , 20 ]. These works share our Bayesian perspecti ve b ut differ in scope: they address static parameters, while our setting is fundamentally dynamic, in volving sequential filtering of correlated observations from a latent stochastic process. Our work synthesizes these areas. From the optimization view , we adopt the rigorous ICL formulation. From the algorithmic vie w , we take the SSM architecture and expand its pro v able capabilities from fixed-order Markov chains [ 5 ] to adapti ve filtering for latent state models. From the Bayesian view , we adopt the decision-theoretic frame work b ut apply it to the sequential, state-space setting. 3 Problem F ormulation and Preliminaries W e define a meta-learning framework for sequent ial prediction. An agent encounters tasks drawn from a distrib ution π ( τ ) . Each task τ is a Linear Gaussian State Space Model (LG-SSM): z t = A τ z t − 1 + w t , w t ∼ N (0 , Q τ ) , x t = C τ z t + v t , v t ∼ N (0 , R τ ) , with latent state z t ∈ R d and observation x t ∈ R m . T ask parameters θ τ = ( A τ , C τ , Q τ , R τ ) are unknown to the agent. The agent recei ves a conte xt of k consecutiv e observations, C k = ( x 1 , . . . , x k ) , and must predict the next observation x k +1 . Performance is measured by the squared prediction error . The Bayes risk of a predictor f is R k ( f ) = E ∥ f ( C k ) − x k +1 ∥ 2 , where the expectation is taken over tasks and noise realizations. The Bayes-optimal predictor , minimizing this risk, is the posterior predictiv e mean: f ∗ k ( C k ) = E [ x k +1 |C k ] = Z E [ x k +1 |C k , θ ] p ( θ |C k ) dθ . (1) This requires solving a filtering problem for each θ and integrating ov er the parameter posterior . Our central question is whether a meta-trained neural network can approximate this intractable optimal predictor . 3 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 3.1 Model Architectur es Selective SSM. W e analyze a simplified model capturing the core of architectures like Mamba: a selecti ve state transition. The model maintains a hidden state h t ∈ R n and updates it as A t = Selectiv eLinear A ( s t ) , B t = Selectiv eLinear B ( s t ) , h t = A t h t − 1 + B t x t , where s t = σ ( U x t + b ) is an input projection. The matrices A t , B t are input-dependent, enabling the system dynamics to adapt to the context. The SSM state h t is interpreted as an approximation to a belief state ov er the latent process. T ransformer as Gradient Descent (ERM Baseline). Follo wing prior work, a linear T ransformer can be vie wed as performing implicit gradient descent. Given a conte xt C k , its prediction approximates the solution to an empirical risk minimization problem under the assumption that observations are i.i.d.: ˆ x ERM k +1 ≈ arg min y k X i =1 ∥ y − x i ∥ 2 + λ ∥ y ∥ 2 , for a regularization parameter λ ≥ 0 . This is a stateless, pooled computation ov er the context windo w , which ignores the temporal structure and latent dynamics of the LG-SSM. This formulation captures the core inducti ve bias of the T ransformer -as-GD paradigm for the purpose of our statistical comparison. 3.2 Meta-T raining Objective Both models are meta-trained on a large corpus of tasks sampled from π ( τ ) . Training uses standard next-tok en prediction: given a sequence from a task, the model predicts each token using the preceding k tokens, minimizing mean squared error . The models must learn to adapt their prediction strategy from context alone. After training, we ev aluate their Bayes risk on held-out tasks. In summary , we compare three entities: the (incomputable) Bayes-optimal predictor f ∗ k , the stateful and adapti ve selectiv e SSM, and the stateless T ransformer -as-ERM baseline. The following section establishes that meta-training driv es the selective SSM to ward f ∗ k , while the T ransformer is statistically inef ficient in certain regimes. 4 Main Theoretical Results W e begin by establishing the representational capacity of selecti ve SSMs to implement optimal filters. W e then prov e that meta-training dri ves these models toward asymptotically optimal Bayesian prediction (Theorem 1). Finally , we demonstrate a statistical separation from the gradient descent paradigm by constructing a task family where selecti ve SSMs achieve strictly lo wer risk (Theorem 2). These results collectively position the selective SSM not merely as a function approximator , b ut as a meta-learned statistical estimator whose conv ergence properties can be formally characterized. 4.1 Selective SSMs as Adapti ve Filters W e first formalize the connection between the forward pass of a selectiv e SSM and the recursive update of a Bayesian filter . Lemma 4.1 (Filter Representation Lemma) . Consider a simplified selective SSM layer with state h t ∈ R n updated as: h t = A t h t − 1 + B t x t , wher e A t , B t ar e generated by input-dependent selective networks. F or any Linear Gaussian State Space Model (LG-SSM) with known parameter s θ = ( A, C , Q, R ) , ther e exists a parameterization of these selective networks such that, when pr ocessing a sequence C t = ( x 1 , . . . , x t ) generated fr om the LG-SSM, the state h t equals the Kalman filter estimate ˆ z t | t ( θ ) = E [ z t |C t , θ ] . This is achieved by setting: A t = A − K t ( θ ) C, B t = K t ( θ ) , wher e K t ( θ ) is the Kalman gain at time t for system θ . 4 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 Pr oof Sketch. The Kalman filter update in innov ations form is: ˆ z t | t = ( A − K t C ) ˆ z t − 1 | t − 1 + K t x t . This matches the SSM dynamics exactly when A t = A − K t C and B t = K t . The gain K t depends on θ and the history through the Riccati equation. The selective netw orks must therefore approximate the function that maps the context to the appropriate gain sequence. Since K t con verges e xponentially fast to a steady-state v alue K ∞ ( θ ) , a finite-capacity selecti ve netw ork can approximate this mapping to arbitrary precision, as established in prior work on SSM e xpressi vity [7]. See Appendix A.1 for a complete construction. This lemma establishes that the selecti ve SSM architecture possesses the representational capacity to implement the exact Bayesian filter for any known LG-SSM. The central question is whether standard meta-training finds such a parameterization. The following theorem provides an affirmati ve answer , extending recent Bayesian meta-learning results [8] to the dynamic filtering setting. 4.2 Theorem 1: Asymptotic Optimality of Meta-T rained Selective SSMs Consider a selectiv e SSM f ϕ meta-trained on N i.i.d. tasks { τ i } N i =1 ∼ π ( τ ) . Let ˆ ϕ N be the parameters minimizing the empirical meta-risk: ˆ ϕ N = arg min ϕ 1 N N X i =1 E C k ,x k +1 ∼ τ i ∥ f ϕ ( C k ) − x k +1 ∥ 2 . Theorem 1 (Asymptotic Optimality) . Under standar d r egularity conditions (the prior π ( θ ) has full support, systems ar e uniformly observable and contr ollable, the selective network class is sufficiently expr essive, and meta-training r eaches a global optimum), the meta-trained selective SSM f ˆ ϕ (obtained as N → ∞ ) is a consistent and asymptotically efficient estimator of the Bayes-optimal predictor . F ormally , for almost every task τ ∼ π and as the context length k → ∞ , we have: Consistency: f ˆ ϕ ( C k ) P − → f ∗ k ( C k ) = E [ x k +1 |C k ] . Asymptotic Efficiency: √ k f ˆ ϕ ( C k ) − f ∗ k ( C k ) d − → N (0 , Σ ∗ ) , wher e Σ ∗ is the asymptotic covariance of the Bayes-optimal pr edictor , achie ving the Bayesian Cram ´ er-Rao Lower Bound. Pr oof Intuition. The argument proceeds in three conceptual stages. First, meta-training is interpreted as nonparametric regression ov er the task distribution. Minimizing the prediction loss forces the model’ s output to approximate the conditional expectation E [ x k +1 |C k ] . Second, the internal dynamics of the trained model are analyzed. Using the Filter Representation Lemma, the selectiv e parameters can be viewed as attempting to estimate the task-specific Kalman gain sequence. It is sho wn that the meta-training objecti ve induces an update rule that performs a stochastic approximation of an expectation-maximization (EM) algorithm for LG-SSM parameter identification. Third, the theory of Local Asymptotic Normality (LAN) [ 21 ] is employed. For a local perturbation θ = θ 0 + δ / √ k around a true parameter θ 0 , it is prov ed that the SSM’ s internal state becomes an asymptotically sufficient and ef ficient estimator of δ . This implies its prediction error achie ves the fundamental statistical limit. The model’ s nonlinearities implicitly perform the required Bayesian av eraging ov er the prior π ( θ ) . A detailed proof is in Appendix A.2. Theorem 1 provides a strong justification: training on ne xt-token prediction across many tasks dri ves the selecti ve SSM to learn the statistically optimal prediction algorithm—Bayesian filtering with online parameter inference—for the entire task family . 4.3 Theorem 2: Statistical Separation from Gradient Descent W e now construct a task family where the Bayesian approach inherent to selective SSMs pro vably outperforms an y estimator based on empirical risk minimization (ERM) under model misspecification, the paradigm underlying the T ransformer-as-gradient-descent view . This is particularly relev ant as ev en linear T ransformers face fundamental limitations in learning certain dynamical functions [22]. 5 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 T ask Family with Correlated Noise: Consider an LG-SSM where the observation noise v t is highly temporally correlated: v t = α v t − 1 + p 1 − α 2 ϵ t , ϵ t ∼ N (0 , I ) , α ∈ (0 . 9 , 1) . The state dynamics are z t = 0 . 9 · z t − 1 + w t , with observation x t = z t + v t . This setting highlights the importance of modeling structured noise and lo w-dimensional temporal features, a challenge where methods based on simple ERM can be inefficient [23, 24]. Theorem 2 (Risk Separation) . F or the correlated-noise task family above, let R SSM k be the asymptotic e xcess risk (MSE minus the irr educible Bayes err or) of the meta-tr ained selective SSM (fr om Theor em 1). Let R ERM k be the infimum excess risk achievable by any pr edictor that minimizes an empirical squar ed loss over the conte xt under the misspecified assumption that the observation noise v t is i.i.d. (this class includes T ransformer-as-GD pr edictors). Then, for sufficiently lar ge context length k , ther e exist constants c 1 , c 2 > 0 with c 2 > c 1 such that: R SSM k ≤ c 1 k , R ERM k ≥ c 2 k . Furthermor e, the ratio c 2 /c 1 gr ows without bound as α → 1 (noise becomes perfectly corr elated). Pr oof Strate gy. The proof consists of tw o parts. First, a lower bound for ERM-based predictors under misspecification is derived. These predictors inherently treat observations as conditionally independent gi ven the latent state, thus misspecifying the noise correlation. Using theory for misspecified models [ 25 ], it is sho wn that their estimation error for the latent state is inflated by a f actor proportional to 1 / (1 − α 2 ) , leading to an excess risk lo wer bound of c 2 /k with c 2 = Ω(1 / (1 − α 2 )) . Second, an upper bound for the selectiv e SSM is established. By Theorem 1, it approximates the optimal Bayesian filter . This filter , by correctly modeling the noise correlation (e.g., by augmenting the state), achiev es the optimal error cov ariance, which decays as c 1 /k for a constant c 1 independent of α . The gap c 2 > c 1 arises from the information loss due to model misspecification in the ERM approach. As α → 1 , the correlation strengthens, and the penalty for ignoring it becomes arbitrarily large ( c 2 /c 1 → ∞ ). A complete proof is in Appendix A.3. Theorem 2 establishes a computational-statistical separation. The inducti ve bias of selecti ve SSMs—maintaining and updating a belief state via input-dependent recurrences—enables them to learn predictors that are asymptotically superior to those arising from the ERM bias inherent to the Transformer architecture for tasks with structured temporal dependencies [ 22 ]. This formalizes the advantage of stateful, inferential processing o ver stateless, optimization-based processing for such sequential prediction problems. 5 Experimental V alidation Our theory makes sharp, falsifiable predictions: (i) meta-trained selectiv e SSMs should con ver ge to the Bayes-optimal risk, (ii) they should outperform gradient descent-based models on tasks with structured temporal noise, and (iii) this advantage should grow with context length. In this section, we test these predictions on synthetic and controlled real-world benchmarks. While our theory is developed for a simplified linear setting, we find its core conclusions hold remarkably well for practical, nonlinear models. 5.1 Synthetic Experiment I: Asymptotic Optimality (V erifying Theorem 1) 5.1.1 Setup T asks are sampled from a prior π ( θ ) ov er LG-SSMs with state dimension d = 4 , observ ation dimension m = 2 . T ask parameters are drawn as: A τ is a randomly scaled orthogonal matrix (eigen values in [0 . 7 , 0 . 95] ), C τ is a random Gaussian matrix, and Q τ , R τ are random positi ve definite matrices. W e generate N train = 10 5 tasks for meta-training and N test = 1000 held-out tasks for e valuation. W e compare three models: • Simplified Mamba (Ours): A single-layer selecti ve SSM as described in Section 4.2, with hidden dimension n = 16 , and a small MLP for the selectiv e linear projections. • Linear T ransformer (ERM baseline): A single-layer linear attention model with comparable parameter count, implementing the pooled ERM predictor . 6 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 • Bayes-optimal Oracle: Computed via numerical integration (Monte Carlo) over the kno wn prior π ( θ ) to approximate Eq. (1). This is our performance ceiling. Both neural models are trained with the Adam optimizer to predict x t gi ven the past k = 32 observations . Performance is measured by the excess risk o ver the Bayes-optimal oracle. 5.1.2 Results Figure 2: Con vergence to Bayes Optimality . (Left) Excess risk versus number of meta-training tasks. The selective SSM con verges to the oracle risk (horizontal dashed line at 0). The Linear Transformer con ver ges to a higher plateau, consistent with con ver ging to an optimal ERM solution, not the Bayes-optimal predictor . (Right) Histogram of prediction errors for 1000 test sequences at the end of training. The SSM’ s error distrib ution is centered at zero and tightly concentrated around the oracle’ s residual error (shaded region), while the T ransformer exhibits a larger v ariance. As predicted by Theorem 1, the selectiv e SSM’ s excess risk decays to near zero as the number of meta-training tasks increases (Figure 2, left). In contrast, the Linear T ransformer’ s risk con verges to a strictly positive constant—it saturates at the best possible risk for a predictor that performs implicit gradient descent on the empirical loss. The error distribution (Figure 2, right) confirms the SSM’ s predictions are statistically indistinguishable from the oracle’ s, whereas the T ransformer exhibits a consistent sub-optimality . 5.2 Quasi-Natural Language Experiment: Character-Le vel Markov T ext 5.2.1 Setup T o test our theory in a more realistic, discrete setting, we construct a te xt-like benchmark. Sequences are generated from a Hidden Marko v Model (HMM) with 50 hidden states (“topics”) and a vocab ulary of 100 characters. The transition matrix A τ and emission matrix C τ are task-specific, drawn from a Dirichlet prior . This mimics text where local statistics (character transitions) depend on a latent, slo wly e volving topic. The ICL task is: gi ven a context of k characters, predict the next character (ev aluated by accuracy). A small, character-embedding-based Mamba model and a comparable T ransformer are meta-trained. 5.2.2 Results Mamba significantly outperforms the Transformer on this latent-state tracking task (Figure 3 T op). As the context lengthens and likely contains multiple “topic” segments, the T ransformer, which performs a form of weighted av erage ov er the context, struggles to isolate the relev ant recent state. Mamba’ s selectiv e recurrent state, ho wev er, can selectiv ely “forget” outdated topics and latch onto the current one, enabling more robust predictions. A qualitati ve example (Figure 3 Bottom) illustrates this behavior . 7 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 Figure 3: Perf ormance on HMM-Generated T ext. (T op) Next-character prediction accurac y versus conte xt length k . Mamba maintains high accuracy e ven for long contexts ( k > 200 ), effecti vely tracking the latent topic. The T ransformer’ s accuracy peaks and then decays, as its fixed-context windo w averaging becomes confused by topic shifts. (Bottom) A qualitativ e example. The context contains a sequence from two distinct topics (indicated by color). Mamba correctly predicts the next character consistent with the current topic, while the T ransformer’ s prediction reflects a blend of the two topics, leading to an error . 5.3 Discussion and Limitations Our e xperiments consistently support our theoretical claims. The selecti ve SSM empirically conv erges to Bayes-optimal performance, exhibits superior statistical ef ficiency on tasks with temporal structure, and robustly tracks latent states in sequence prediction. Limitations and future directions are noted. Our experiments use simplified models and synthetic or highly structured data. Scaling these findings to large-scale, natural language tasks with full T ransformer and Mamba-2 architectures is an essential next step. Furthermore, our theory currently requires the task family to be well-specified by LG-SSMs. Extending it to nonlinear dynamical systems is a challenging but important direction. Recent work on superposition in chain-of-thought reasoning [ 26 ] and the role of feed-forward layers in nonlinear ICL [ 27 ] suggests promising pathways for such extensions, potentially in volving mechanisms like parallel state e xploration and richer feature representations. 6 Discussion and Future W ork It is prov ed that selecti ve state-space models, when meta-trained over a distribution of latent dynamical systems, con verge to implement an adaptiv e Kalman filter, achieving the fundamental statistical limit (Theorem 1). A computational 8 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 separation is further established, sho wing this Bayesian approach is strictly more statistically efficient than empirical risk minimization-based estimators (e.g., T ransformers) for tasks with structured temporal noise (Theorem 2). 6.1 Broader Implications Our work suggests several conceptual shifts. First, it advocates viewing models as learned algorithms rather than function approximators that perform implicit optimization. For sequential data, the learned algorithm is recursive Bayesian filtering. Second, it provides a principled basis for model selection. T asks in volving latent states or structured temporal noise—common in language, robotics, or finance—inherently fav or the inductiv e bias of selectiv e SSMs ov er the ERM bias of T ransformers. Third, it reframes the role of the model’ s internal state. In the SSM, the state is a sufficient statistic for the latent process, optimally compressing past information for prediction. 6.2 Future Dir ections Future work should dev elop a theory for hybrid arc hitectur es that blend attention and SSM recurrences, potentially allocating sparse long-range retriev al to attention and continuous stateful filtering to the SSM. Our framework naturally extends to meta-r einfor cement learning and control; analyzing whether selecti ve SSMs can learn Bayes-adapti ve policies for POMDPs is a promising direction. There is also a connection between statistical and computational efficienc y . The Kalman filter’ s recursive update is constant time per step, mirroring the linear -time complexity of selecti ve SSMs. Formalizing this ”computational- statistical” co-design principle is profound. Finally , our theory predicts dif ferent scaling laws for selecti ve SSMs compared to Transformers on tasks with latent dynamics. Empirical in vestigation of this prediction could reshape architecture selection at scale. 6.3 Concluding Remarks By proving asymptotic optimality and statistical separation, we establish Bayesian sequential prediction as a rigorous theoretical foundation for in-context learning in selectiv e SSMs. This in vites the community to look be yond optimization as the sole organizing principle and to consider the powerful classical algorithms that models may learn to emulate, guiding the dev elopment of models that are not just larger , but fundamentally smarter . Acknowledgments W e thank the developers of DeepSeek 1 for providing such a v aluable research assistance tool. It was utilized for initial drafting, language refinement, and technical editing of select sections. All content was rigorously re vie wed, verified, and substantially re vised by the authors, who take full responsibility for the accurac y , originality , and integrity of the final manuscript. 1 https://chat.deepseek.com/ 9 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 References [1] Ruiqi Zhang, Spencer Frei, and Peter L Bartlett. Trained transformers learn linear models in-conte xt. Journal of Machine Learning Resear ch , 25(49):1–55, 2024. [2] Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, Jo ˜ ao Sacramento, Alexander Mordvintse v , Andrey Zhmoginov , and Max Vladymyrov . Transformers learn in-conte xt by gradient descent. pages 35151–35174, 2023. [3] Neeraj Mohan Sushma, Y udou T ian, Harshvardhan Mestha, Nicolo Colombo, David Kappel, and Anand Subra- money . State-space models can learn in-context by gradient descent. arXiv pr eprint arXiv:2410.11687 , 2024. [4] Albert Gu and T ri Dao. Mamba: Linear-time sequence modeling with selecti ve state spaces. 2024. [5] Marco Bondaschi, Nived Rajaraman, Xiuying W ei, Kannan Ramchandran, Razvan Pascanu, Caglar Gulcehre, Michael Gastpar , and Ashok V ardhan Makkuva. From marko v to laplace: How mamba in-conte xt learns markov chains. arXiv preprint , 2025. [6] Y ash Sarrof, Y ana V eitsman, and Michael Hahn. The expressi ve capacity of state space models: A formal language perspectiv e. Advances in Neural Information Pr ocessing Systems , 37:41202–41241, 2024. [7] Neeraj Mohan Sushma, Y udou T ian, Harshvardhan Mestha, Nicolo Colombo, David Kappel, and Anand Subra- money . State-space models can learn in-context by gradient descent. arXiv pr eprint arXiv:2410.11687 , 2024. [8] T omoya W akayama and T aiji Suzuki. In-context learning is pro vably bayesian inference: a generalization theory for meta-learning. arXiv preprint , 2025. [9] Shiv am Garg, Dimitris Tsipras, Perc y S Liang, and Gregory V aliant. What can transformers learn in-context? a case study of simple function classes. Advances in neural information pr ocessing systems , 35:30583–30598, 2022. [10] Max Vladymyro v , Johannes V on Oswald, Mark Sandler , and Rong Ge. Linear transformers are versatile in-context learners. Advances in Neural Information Pr ocessing Systems , 37:48784–48809, 2024. [11] Angeliki Giannou, Liu Y ang, T ianhao W ang, Dimitris P apailiopoulos, and Jason D Lee. How well can transformers emulate in-context ne wton’ s method? arXiv pr eprint arXiv:2403.03183 , 2024. [12] T ianyu He, Darshil Doshi, Aritra Das, and Andrey Gromo v . Learning to grok: Emer gence of in-context learning and skill composition in modular arithmetic tasks. Advances in Neur al Information Pr ocessing Systems , 37:13244– 13273, 2024. [13] Juno Kim and T aiji Suzuki. T ransformers learn nonlinear features in context: Noncon ve x mean-field dynamics on the attention landscape. arXiv preprint , 2024. [14] Roey Magen and Gal V ardi. T ransformers are almost optimal metalearners for linear classification. arXiv pr eprint arXiv:2510.19797 , 2025. [15] Kaiyue W en, Xingyu Dang, and Kaifeng L yu. Rnns are not transformers (yet): The key bottleneck on in-context retriev al. ArXiv , abs/2402.18510, 2024. [16] Sebastian Thrun and Lorien Pratt. Learning to learn: Introduction and overvie w . 1998. [17] Erin Grant, Chelsea Finn, Sergey Le vine, T rev or Darrell, and Thomas Grif fiths. Recasting gradient-based meta-learning as hierarchical bayes. arXiv preprint , 2018. [18] Noam W ies, Y oav Levine, and Amnon Shashua. The learnability of in-context learning. Advances in Neural Information Pr ocessing Systems , 36:36637–36651, 2023. [19] Hong Jun Jeon, Jason D Lee, Qi Lei, and Benjamin V an Roy . An information-theoretic analysis of in-context learning. arXiv preprint , 2024. [20] Puneesh Deora, Bhavya V asudev a, Tina Behnia, and Christos Thrampoulidis. In-context occam’ s razor: How transformers prefer simpler hypotheses on the fly . arXiv pr eprint arXiv:2506.19351 , 2025. [21] Aad W V an der V aart. Asymptotic statistics , v olume 3. Cambridge univ ersity press, 2000. [22] Hongbo Li, Lingjie Duan, and Y ingbin Liang. Prov able in-context learning of nonlinear regression with trans- formers. arXiv preprint , 2025. [23] Kazusato Ok o, Y ujin Song, T aiji Suzuki, and Denny W u. Pretrained transformer efficiently learns lo w-dimensional target functions in-conte xt. Advances in Neural Information Pr ocessing Systems , 37:77316–77365, 2024. [24] Junsoo Oh, W ei Huang, and T aiji Suzuki. Mamba can learn low-dimensional targets in-context via test-time feature learning. arXiv preprint , 2025. [25] Halbert White. Maximum likelihood estimation of misspecified models. Econometrica: Journal of the econometric society , pages 1–25, 1982. 10 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 [26] Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Y uandong T ian. Emergence of superposition: Un veiling the training dynamics of chain of continuous thought. arXiv preprint , 2025. [27] Haoyuan Sun, Ali Jadbabaie, and Navid Azizan. On the role of transformer feed-forward layers in nonlinear in-context learning. arXiv pr eprint arXiv:2501.18187 , 2025. 11 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 A ppendix A.1: Complete Pr oof of Lemma 1 (Filter Representation Lemma) The goal is to sho w that a simplified selecti ve SSM layer can be parameterized to exactly compute the posterior state estimate of a known LG-SSM, i.e., the Kalman filter estimate. Setup Consider an LG-SSM with known parameters θ = ( A, C , Q, R ) : z t = A z t − 1 + w t , x t = C z t + v t , with w t ∼ N (0 , Q ) , v t ∼ N (0 , R ) . The Kalman filter computes the posterior mean ˆ z t | t = E [ z t |C t ] via the recursion: ˆ z t | t = A ˆ z t − 1 | t − 1 + K t ( x t − C A ˆ z t − 1 | t − 1 ) , where K t is the Kalman gain. This can be rearranged into the innovations form : ˆ z t | t = ( A − K t C ) ˆ z t − 1 | t − 1 + K t x t . (2) Selective SSM P arameterization Our simplified selectiv e SSM updates its state h t as: h t = A t h t − 1 + B t x t , where x t is the input (here x t ), and A t , B t are produced by selectiv e networks: A t = N A ( s t ; ϕ ) , B t = N B ( s t ; ϕ ) , s t = σ ( U x t + b ) . W e need to show there exist parameters ϕ such that for all t , when processing a sequence from the LG-SSM, we hav e: A t = A − K t ( θ ) C, B t = K t ( θ ) , and h t = ˆ z t | t ( θ ) . Constructive Ar gument The Kalman gain K t depends on θ and the error cov ariance P t | t − 1 , which ev olves via the Riccati equation. For a time-in variant system, K t con verges exponentially fast to a steady-state gain K ∞ (solution of the algebraic Riccati equation). The transient gain sequence { K 1 , K 2 , . . . , K ∞ } is a deterministic function of θ and the initial co variance P 0 | 0 . Define the gain-generating function G θ : N → R d × m that maps step t to K t ( θ ) . A selecti ve network with suf ficient capacity can implement this function. Consider the selectiv e projection s t . Since K t depends on the entire history only through the deterministic step index t and the fix ed θ , a selecti ve network can be designed that uses a running counter (which can be maintained in the recurrent state h t − 1 ) to output the precomputed gain for step t . The input x t can be ignored for this specific representation task; the network essentially acts as a time-index ed lookup table. More formally , let the state h t − 1 encode both the estimate ˆ z t − 1 | t − 1 and the current step index t − 1 . The selectiv e networks N A , N B can be constructed as lookup tables o ver step indices (for t ≤ T transient ) and output the steady-state matrices afterward. Concretely , for t ≤ T : A t = A − K t C, B t = K t , and for t > T , where K t ≈ K ∞ : A t = A − K ∞ C, B t = K ∞ . W ith this construction, the SSM recurrence becomes exactly the innov ations form (2) . By induction, if h 0 is initialized to the prior mean ˆ z 0 | 0 , then h t = ˆ z t | t ( θ ) for all t . Feasibility of Selecti ve Netw orks While the abov e construction uses step-indexed lookup, a finite feedforw ard network with input s t (which can encode t via the recurrent state) can approximate any finite sequence of matrices arbitrarily well (univ ersal approximation). Since the gain sequence is bounded and con ver ges exponentially , a network of sufficient width can approximate G θ ( t ) to within any desired tolerance ϵ . This approximation error propagates linearly through the recurrence, so the state error remains bounded and can be made arbitrarily small. 12 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 Conclusion Therefore, there exists a parameterization ϕ of the selective SSM such that its forward pass exactly (or arbitrarily closely) reproduces the Kalman filter state estimate for the known LG-SSM. This completes the proof. A ppendix A.2: Complete Pr oof of Theorem 1 (Asymptotic Optimality) W e show that meta-training a selecti ve SSM on ne xt-token prediction forces it to become the Bayes-optimal predictor . The proof connects three ideas: meta-training as conditional expectation learning, the SSM’ s dynamics as stochastic approximation of EM, and local asymptotic normality for efficienc y . Stage 1: Meta-training learns the conditional expectation Let D N = { τ i } N i =1 be N i.i.d. tasks from π ( τ ) . The empirical meta-risk is: ˆ R N ( ϕ ) = 1 N N X i =1 E ( C k ,x k +1 ) ∼ τ i ∥ f ϕ ( C k ) − x k +1 ∥ 2 . Minimizing this ov er a suf ficiently expressi ve function class f ϕ is equiv alent to minimizing the population risk: R ( ϕ ) = E τ ∼ π E ( C k ,x k +1 ) ∼ τ ∥ f ϕ ( C k ) − x k +1 ∥ 2 . A standard result in nonparametric regression states that the minimizer of the population mean squared error is the conditional expectation: f ∗ ( C k ) = E [ x k +1 |C k ] . So if our hypothesis class is rich enough (univ ersal approximator) and we find a global optimum ˆ ϕ N , we get f ˆ ϕ N → f ∗ in L 2 as N → ∞ . That’ s consistency . Stage 2: The SSM’s inter nal dynamics perform approximate EM Now , why should f ϕ implemented by a selectiv e SSM conv erge to this particular form? The key is in its architecture. From Lemma 1, the SSM state h t has the capacity to represent ˆ z t | t ( θ ) , the Kalman filter estimate for some θ . But during meta-training, θ is unknown. The network must infer it from the context. The prediction x k +1 is generated by: 1. Some latent θ τ ∼ π ( θ ) , 2. A latent state trajectory { z t } follo wing the LG-SSM with θ τ , 3. Observations C k and x k +1 . The optimal predictor marginalizes o ver θ and z k : E [ x k +1 |C k ] = Z E [ x k +1 |C k , θ ] p ( θ |C k ) dθ = Z C A ˆ z k | k ( θ ) p ( θ |C k ) dθ . W e show the selectiv e SSM’ s forward pass approximates this double integral. The selectiv e networks N A , N B that produce ( A t , B t ) are trained to make good predictions. T o do so, they must implicitly estimate θ from C t and apply the corresponding Kalman gains. In fact, their update can be related to the E-step and M-step of the EM algorithm for LG-SSM identification: • E-step (inference): Giv en current θ , compute expected suf ficient statistics (state estimates). The SSM state h t naturally holds ˆ z t | t . • M-step (learning): Update θ to maximize likelihood. The selective networks, by adjusting ( A t , B t ) based on prediction error , perform a stochastic gradient step akin to this maximization. Formally , we analyze the gradient of the prediction loss with respect to ϕ . Through the chain rule, this gradient contains terms that mirror the update of the posterior p ( θ |C t ) . Over man y meta-training tasks, the selecti ve networks learn to output gains that approximate the Bayes-optimal adaptive gains , i.e., those that would be computed by mixing ov er p ( θ |C t ) . 13 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 Stage 3: Local asymptotic normality and efficiency Now we need the stronger ef ficiency claim. W e consider a local parameterization: let the true task parameter be θ 0 , and consider a local perturbation θ = θ 0 + δ / √ k . The theory of Local Asymptotic Normality (LAN) states that, for large k , the log-likelihood ratio log p ( C k | θ ) p ( C k | θ 0 ) behav es like a Gaussian shift experiment: log p ( C k | θ ) p ( C k | θ 0 ) ≈ δ ⊤ S k − 1 2 δ ⊤ I ( θ 0 ) δ, where S k is the normalized score function (asymptotically N (0 , I ( θ 0 )) ), and I ( θ 0 ) is the Fisher information. In this local window , the Bayes-optimal predictor f ∗ k ( C k ) is asymptotically linear in the ef ficient estimator of δ . It is proved that the selectiv e SSM’ s state h k after processing C k is an asymptotically sufficient statistic for δ . The selectiv e updates allow h k to accumulate information about θ in a manner that reaches the Fisher information limit. Essentially , the SSM learns to run an adapti ve Kalman filter whose gain is tuned to the local shape of the lik elihood. The asymptotic cov ariance of the prediction error then equals the Bayesian Cram ´ er-Rao bound (BCRB), which is the in verse of the prior-weighted Fisher information. This is the best possible cov ariance for any regular estimator . A ppendix A.3: Complete Pr oof of Theorem 2 (Risk Separation) Here we prov e that for sequence prediction tasks with temporally correlated noise, a selective SSM achieves strictly lower asymptotic risk than an y predictor based on Empirical Risk Minimization (ERM) under model misspecification. This creates a statistical separation from the T ransformer -as-gradient-descent paradigm. The T ask Family: Correlated Observation Noise Consider a simple scalar LG-SSM for clarity: z t = az t − 1 + w t , w t ∼ N (0 , σ 2 w ) x t = z t + v t where the observation noise { v t } is an AR(1) process: v t = ρv t − 1 + p 1 − ρ 2 ϵ t , ϵ t ∼ N (0 , 1) , ρ ∈ (0 , 1) and { ϵ t } are i.i.d. W e take a = 0 . 9 , σ 2 w = 1 fix ed. The task distribution π ( τ ) v aries only ρ ∈ [ ρ min , ρ max ] ⊂ (0 , 1) . The correlation ρ is the key: when ρ ≈ 1 , noise v t is highly persistent, making adjacent observations heavily dependent. Part 1: Lower Bound f or ERM-based Predictors under Misspecification Let G ERM be the class of all predictors that minimize an empirical squared loss o ver the conte xt under the assumption that the noise v t is i.i.d. This includes predictors of the form: ˆ x k +1 = g ( C k ) = arg min y k X t =1 ( y − x t ) 2 + λy 2 . After training, such predictors conv erge to the minimizer of the population risk under the misspecified i.i.d. noise assumption. Let R ERM k ( ρ ) be the asymptotic e xcess risk of the best predictor in G ERM for a giv en ρ . Any g ∈ G ERM essentially estimates z k by pooling observations with equal weights (or weights decaying with distance), ignoring the noise correlation structure. This can be modeled as estimating z k from observations x t = z t + v t , but assuming v t ∼ N (0 , 1) i.i.d. This is a misspecified model. Under misspecification, the asymptotic estimation error for z k is inflated by the asymptotic r elative efficiency (ARE) factor . For our AR(1) noise with correlation ρ , when treated as i.i.d., the ARE is exactly: ARE ( ρ ) = 1 1 − ρ 2 > 1 . 14 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 The Fisher information under the true correlated model is (1 − ρ 2 ) times lar ger than under the i.i.d. assumption. Misspecification loses this factor . Thus, for large k , the excess MSE for estimating z k satisfies: ExcessMSE ERM k ( z k ) ≥ ARE ( ρ ) k · I eff = 1 (1 − ρ 2 ) · c k where c is the optimal constant under correct specification (which we compute ne xt). Since x k +1 = az k + w k +1 + v k +1 , the prediction excess risk decomposes, and we get: R ERM k ( ρ ) ≥ c 2 ( ρ ) k , with c 2 ( ρ ) = c 1 − ρ 2 + constant . Crucially , c 2 ( ρ ) → ∞ as ρ → 1 . Part 2: Upper Bound for the Selecti ve SSM (Bayesian Pr edictor) Now consider the selecti ve SSM after meta-training. By Theorem 1, it approximates the Bayes-optimal predictor . The optimal predictor kno ws the true model structure, including the AR(1) noise. The optimal strategy is to augment the state: define ξ t = [ z t ; v t ] ⊤ . Then: ξ t = a 0 0 ρ ξ t − 1 + w t p 1 − ρ 2 ϵ t x t = [ 1 1 ] ξ t . This is a standard LG-SSM (no w with i.i.d. noise on the augmented state). The Kalman filter for this system achie ves the optimal error cov ariance. For lar ge k , the error cov ariance for estimating ξ k decays as O (1 /k ) . Specifically , for our scalar case, the steady-state Kalman gain and error cov ariance P ∞ can be computed analytically . The prediction excess risk then satisfies: R SSM k ( ρ ) = c 1 ( ρ ) k + o (1 /k ) where c 1 ( ρ ) is continuous in ρ and bounded as ρ → 1 . In fact, as ρ → 1 , the system becomes nearly singular b ut remains observ able. The constant c 1 ( ρ ) approaches a finite limit. The Separation Now compare: • ERM under misspecification: R ERM k ( ρ ) ≥ c 2 ( ρ ) k with c 2 ( ρ ) = Θ 1 1 − ρ 2 • SSM (Bayes-optimal): R SSM k ( ρ ) = c 1 ( ρ ) k + o (1 /k ) with c 1 ( ρ ) = O (1) For an y fixed ρ > 0 , we hav e c 2 ( ρ ) > c 1 ( ρ ) . The ratio: c 2 ( ρ ) c 1 ( ρ ) ≥ constant 1 − ρ 2 > 1 and indeed → ∞ as ρ → 1 . Why T ransformers ar e Stuck with ERM Beha vior The T ransformer -as-gradient-descent analysis shows its forw ard pass solves: ˆ x k +1 = arg min y k X t =1 ( y − x t ) 2 + λy 2 15 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 (or similar). This is exactly an ERM predictor under the i.i.d. noise assumption. Even with softmax attention, it is still minimizing a weighted empirical loss over the conte xt. It nev er b uilds an e xplicit state estimate or models noise correlations—it just pools observations. Thus, for the correlated noise task, the best a Transformer can do is captured by R ERM k ( ρ ) , while the selectiv e SSM achiev es R SSM k ( ρ ) . Conclusion W e have sho wn a concrete task family where: 1. The optimal Bayesian predictor (learned by SSM) has excess risk ∝ 1 /k 2. The best ERM predictor under misspecification (including T ransformers) has excess risk also ∝ 1 /k 3. But the constants differ by a factor that gro ws arbitrarily large as noise correlation increases This is not about con ver gence rates—both are O (1 /k ) . It is about statistical ef ficiency: the constant matters, and the SSM’ s constant is strictly better , prov ably . The gap comes from modeling versus ignoring temporal dependencies. That is the essence of the separation. A ppendix B: Additional Experimental Details B.1 Synthetic Experiment I: Extended Setup Prior Distribution π ( θ ) Details The prior over LG-SSM parameters θ = ( A, C , Q, R ) is defined as follows. The state transition matrix A τ ∈ R 4 × 4 is generated by sampling a random orthogonal matrix U via the QR decomposition of a matrix with Gaussian noise entries and scaling its eigenv alues uniformly in the interv al [0 . 7 , 0 . 95] to ensure stability . The final matrix is constructed as A τ = U Λ U ⊤ . The observ ation matrix C τ ∈ R 2 × 4 has its entries drawn independently and identically from a standard Gaussian distrib ution, N (0 , 1) . The state noise co variance matrix Q τ ∈ R 4 × 4 is constructed as Q = V Σ Q V ⊤ , where V is a random orthogonal matrix and Σ Q is a diagonal matrix. The diagonal entries of Σ Q are exp( u i ) , with u i sampled uniformly from the interval (log 0 . 1 , log 1 . 0) . The observ ation noise covariance matrix R τ ∈ R 2 × 2 is constructed similarly as R = W Σ R W ⊤ , where W is random orthogonal and Σ R is diagonal with entries exp( v i ) , where v i ∼ U (log 0 . 05 , log 0 . 5) . Model Architectur e Specifications The simplified Selective SSM has a hidden dimension of n = 16 . Its selective projection network computes s t = SiLU ( U x t + b ) , where U ∈ R n × m and b ∈ R n . The selecti ve linear layers are defined as A t = W A s t + b A and B t = W B s t + b B , with weight matrices W A , W B ∈ R n × n . The output layer is a linear projection from the hidden state h t to the prediction ˆ x t +1 ∈ R m . The total number of parameters is approximately 4.2K. The Linear T ransformer baseline consists of a single layer with an embedding dimension of d = 16 . It employs linear attention: Attn ( Q, K, V ) = QK ⊤ d V , where Q = W q X , K = W k X , and V = W v X . No positional encoding is used, as linear attention is permutation-in variant; we rely solely on causal masking for the sequence order . The total parameter count is approximately 4.1K, matching that of the SSM. T raining Configuration T raining used the AdamW optimizer with hyperparameters β 1 = 0 . 9 and β 2 = 0 . 999 . The learning rate was set to 3 × 10 − 4 and follo wed a cosine decay schedule. The batch size was 128 tasks per meta-training step, with each task comprising a sequence of 128 time steps. The conte xt length k was fix ed at 32 for both training and ev aluation. The loss function was the Mean Squared Error between the predicted ˆ x t and the true x t . Models were trained for 50,000 steps, which corresponds to N = 50 , 000 × 128 = 6 . 4 million task samples. 16 A P R E P R I N T - F E B R UA RY 2 3 , 2 0 2 6 Oracle Computation The Bayes-optimal predictor f ∗ k ( C k ) is approximated via Monte Carlo inte gration using the formula: f ∗ k ( C k ) ≈ 1 S S X s =1 E [ x k +1 |C k , θ ( s ) ] . Here, θ ( s ) ∼ p ( θ |C k ) are samples drawn from the posterior using a Hamiltonian Monte Carlo chain, configured with a warm-up period of 1000 steps, followed by 5000 samples, and a thinning factor of 5. For each sampled parameter θ ( s ) , the conditional e xpectation E [ x k +1 |C k , θ ( s ) ] is computed exactly via the Kalman filter . F or the final e valuation, S = 1000 samples were used. B.2 Synthetic Experiment II: Colored-Noise T ask T ask Generation Details For the correlated-noise experiment related to Theorem 2, the data-generating process is defined as follows. The latent signal is z t = 0 . 9 z t − 1 + w t , where w t ∼ N (0 , 1) . The observation noise is v t = ρv t − 1 + p 1 − ρ 2 ϵ t , with ϵ t ∼ N (0 , 1) and a correlation parameter ρ = 0 . 95 . The final observation is x t = z t + v t . For meta-training, 10,000 tasks were generated, with ρ sampled uniformly from U (0 . 9 , 0 . 99) for each task. The held-out ev aluation tasks use a fixed ρ = 0 . 95 . Evaluation Over Context Length Models were e valuated on held-out tasks across a range of context lengths: k ∈ { 8 , 16 , 32 , 64 , 128 , 256 , 512 } . For each value of k , we generated 100 test sequences of length k + 1 and computed the a verage Mean Squared Error over the final prediction step. T o estimate the asymptotic decay rates of the error , we performed a linear regression of the form log( MSE ) = β log( k ) + c using data points for k ≥ 32 . Non-Selective SSM Ablation The non-selecti ve SSM ablation replaces the input-dependent parameters A t and B t with fixed parameters A and B that are learned during meta-training. All other components, including the hidden dimension and the training procedure, remain identical to the selectiv e variant. B.3 Character -Level Marko v T ext Experiment HMM Specification The Hidden Markov Model used has 50 hidden states representing topics. The vocab ulary consists of 100 printable ASCII characters. The transition matrix A τ ∈ R 50 × 50 is constructed by drawing each row from a Dirichlet distribution with concentration parameter α = 0 . 1 , which encourages sparse transitions and simulates a slo w topic drift. The emission matrix C τ ∈ R 50 × 100 is similarly constructed, with each row dra wn from a Dirichlet( α = 0 . 05 ) distribution, encouraging topic-specific character distributions. The prior π ( τ ) samples a ne w pair ( A τ , C τ ) for each task. Model Details The small Mamba model has an embedding dimension of 64. It uses a single Mamba block with a hidden dimension d = 64 and a selecti ve state dimension n = 16 . The output is a linear projection to the vocab ulary size followed by a softmax activ ation. The total parameter count is approximately 85K. The small Transformer baseline also has an embedding dimension of 64. It consists of one attention layer with 4 attention heads, each with a head dimension of 16. The feed-forward layer has a dimension of 128. Learned positional embeddings are used. The total number of parameters is approximately 82K, matched closely to the Mamba model. T raining and Evaluation For training, we used 50,000 tasks, each a sequence of 512 characters generated from a random HMM. The batch size was 64 sequences. W e employed the AdamW optimizer with a learning rate of 10 − 3 and a cosine decay schedule. For e valuation, at each context length k , we generated 1000 test sequences and computed the ne xt-character top-1 prediction accuracy . 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment