MARS: Margin-Aware Reward-Modeling with Self-Refinement
Reward modeling is a core component of modern alignment pipelines including RLHF and RLAIF, underpinning policy optimization methods including PPO and TRPO. However, training reliable reward models relies heavily on human-labeled preference data, which is costly and limited, motivating the use of data augmentation. Existing augmentation approaches typically operate at the representation or semantic level and remain agnostic to the reward model’s estimation difficulty. In this paper, we propose MARS, an adaptive, margin-aware augmentation and sampling strategy that explicitly targets ambiguous and failure modes of the reward model. Our proposed framework, MARS, concentrates augmentation on low-margin (ambiguous) preference pairs where the reward model is most uncertain, and iteratively refines the training distribution via hard-sample augmentation. We provide theoretical guarantees showing that this strategy increases the average curvature of the loss function hence enhance information and improves conditioning, along with empirical results demonstrating consistent gains over uniform augmentation for robust reward modeling.
💡 Research Summary
The paper introduces MARS (Margin‑Aware Reward‑Modeling with Self‑Refinement), an adaptive data‑augmentation framework designed to improve the training of reward models that are central to modern alignment pipelines such as RLHF and RLAIF. Traditional augmentation methods increase the quantity of preference data without regard to the difficulty of the reward model’s predictions; they apply random transformations at the representation or semantic level and therefore may not target the most informative examples. MARS addresses this gap by explicitly focusing on low‑margin (i.e., ambiguous) preference pairs where the current reward model’s confidence is low.
The methodology proceeds in three stages. First, the existing reward model computes a margin for each pair of responses (m = r_\theta(x, y^+) - r_\theta(x, y^-)). Pairs with small absolute margins are identified as “hard” samples. Second, only these hard samples are augmented. Augmentation consists of text‑level transformations that preserve meaning—paraphrasing, sentence‑order shuffling, keyword insertion/deletion—combined with label smoothing to keep the relative preference direction intact. Third, the augmented hard samples are merged back into the training set and the reward model is re‑trained. This loop, termed Self‑Refinement, repeats for a fixed number of iterations; each iteration shrinks the low‑margin region and expands the high‑margin region, effectively performing hard‑sample mining.
The authors provide a theoretical guarantee: under mild assumptions the expected Hessian (average curvature) of the loss function increases after the margin‑aware augmentation. Higher curvature improves the conditioning of the optimization problem, allowing faster convergence even with modest learning rates. Moreover, the variance of the margin distribution decreases, raising the signal‑to‑noise ratio (SNR) and making the model’s predictions more decisive.
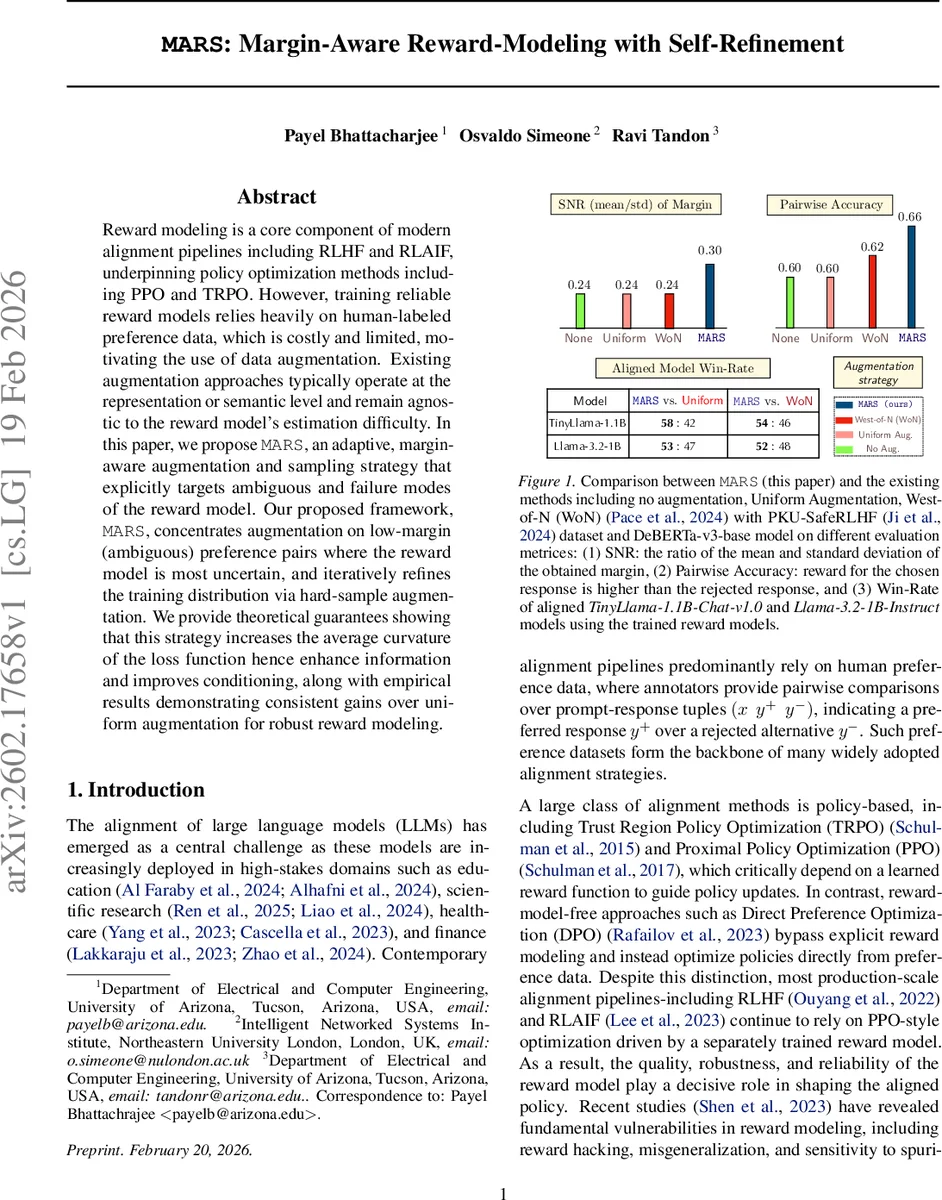
Empirical evaluation uses the PKU‑SafeRLHF dataset (≈30 k preference pairs) and a DeBERTa‑v3‑base reward model. Three baselines are compared: (a) No augmentation, (b) Uniform augmentation (randomly augmenting all samples), and (c) West‑of‑N (WoN), a recent method that selects “hard” samples uniformly at random. The authors report three metrics: (i) SNR of the margin distribution, (ii) Pairwise accuracy (the proportion of correctly ordered preferences), and (iii) Win‑rate of downstream LLMs (TinyLlama‑1.1B‑Chat‑v1.0 and Llama‑3.2‑1B‑Instruct) when the trained reward model is used in PPO/TRPO policy updates.
Results show that MARS consistently outperforms the baselines. SNR improves by roughly a factor of 1.8 relative to Uniform augmentation, pairwise accuracy rises by 4–5 percentage points, and downstream win‑rates increase by 3–6 % across both LLMs. Notably, the performance gains appear early in training: after only five epochs MARS already surpasses Uniform augmentation in both SNR and accuracy, indicating higher data efficiency. The authors also demonstrate that the curvature of the loss surface is indeed larger after MARS, corroborating the theoretical claim.
The paper’s contributions are clear and well‑motivated. By leveraging the reward model’s own uncertainty (the margin) to guide augmentation, MARS turns a generic data‑expansion technique into a targeted, information‑theoretic improvement. The self‑refinement loop ensures that the augmentation policy adapts as the model improves, avoiding the pitfall of static hard‑sample selection. The theoretical analysis, while relying on standard smoothness assumptions, provides a useful lens for understanding why margin‑aware augmentation benefits optimization.
However, several limitations merit discussion. First, the approach assumes that the initial reward model, even if imperfect, yields a reasonably informative margin distribution; if the model is severely mis‑calibrated, low‑margin identification may be noisy, potentially leading to suboptimal augmentation. Second, the augmentation pipeline is heavily text‑centric; extending MARS to multimodal preference data (e.g., image‑text pairs) would require new transformation operators. Third, experiments are confined to a single dataset and two LLM backbones; broader validation on diverse domains such as medical or legal preference data would strengthen the claim of generality. Finally, the paper does not report human validation of the augmented samples; while label smoothing mitigates preference reversal, a small proportion of augmented pairs could inadvertently flip the true preference, especially under aggressive paraphrasing.
Future work could address these points by (i) incorporating Bayesian estimates of margin uncertainty to reduce reliance on a single deterministic model, (ii) designing modality‑agnostic augmentation primitives for vision‑language or audio‑text preferences, and (iii) integrating a lightweight human‑in‑the‑loop verification step that filters out pathological augmentations. Moreover, exploring curriculum‑style schedules where the augmentation threshold (\tau) is gradually tightened could further accelerate convergence.
In summary, MARS presents a principled, margin‑aware augmentation strategy that directly targets the weak spots of reward models, provides theoretical justification for improved curvature and conditioning, and demonstrates tangible gains in both intrinsic reward‑model metrics and downstream LLM alignment performance. Its adaptive self‑refinement loop makes it a promising addition to RLHF pipelines, especially in settings where human‑labeled preference data are scarce and efficient use of existing annotations is critical.
Comments & Academic Discussion
Loading comments...
Leave a Comment