Catastrophic Forgetting Resilient One-Shot Incremental Federated Learning
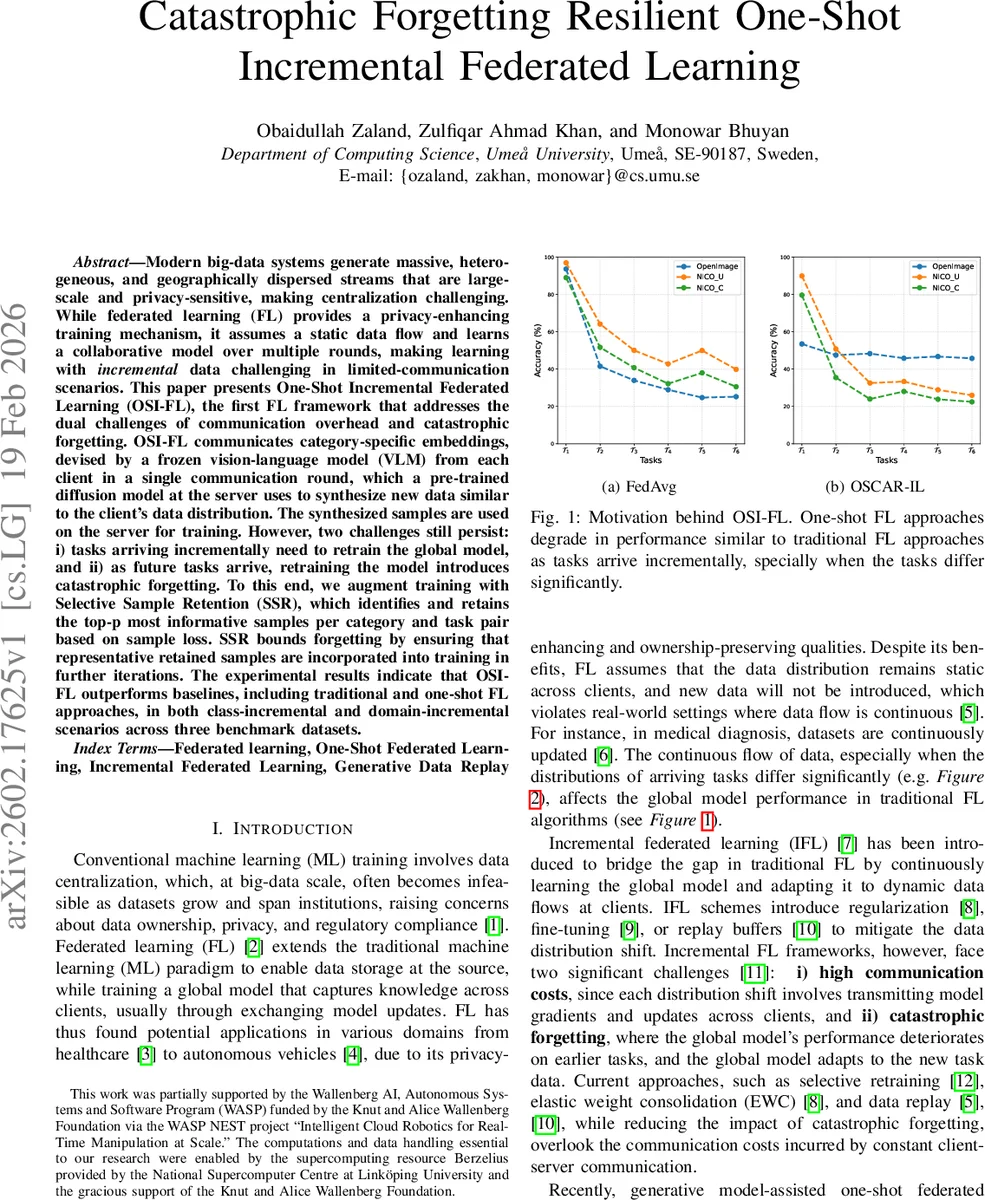
Modern big-data systems generate massive, heterogeneous, and geographically dispersed streams that are large-scale and privacy-sensitive, making centralization challenging. While federated learning (FL) provides a privacy-enhancing training mechanism, it assumes a static data flow and learns a collaborative model over multiple rounds, making learning with \textit{incremental} data challenging in limited-communication scenarios. This paper presents One-Shot Incremental Federated Learning (OSI-FL), the first FL framework that addresses the dual challenges of communication overhead and catastrophic forgetting. OSI-FL communicates category-specific embeddings, devised by a frozen vision-language model (VLM) from each client in a single communication round, which a pre-trained diffusion model at the server uses to synthesize new data similar to the client’s data distribution. The synthesized samples are used on the server for training. However, two challenges still persist: i) tasks arriving incrementally need to retrain the global model, and ii) as future tasks arrive, retraining the model introduces catastrophic forgetting. To this end, we augment training with Selective Sample Retention (SSR), which identifies and retains the top-p most informative samples per category and task pair based on sample loss. SSR bounds forgetting by ensuring that representative retained samples are incorporated into training in further iterations. The experimental results indicate that OSI-FL outperforms baselines, including traditional and one-shot FL approaches, in both class-incremental and domain-incremental scenarios across three benchmark datasets.
💡 Research Summary
The paper tackles two practical challenges of federated learning (FL) in real‑world, privacy‑sensitive big‑data environments: (1) the high communication cost incurred by repeated client‑server exchanges, and (2) catastrophic forgetting when data arrives incrementally. Existing incremental FL (IFL) methods mitigate forgetting with replay, regularization, or parameter isolation, but they still require many communication rounds. Conversely, recent one‑shot FL (OSFL) approaches reduce communication by synthesizing data at the server using a pre‑trained generative model, yet they assume a static dataset and fail under continual task arrival.
To bridge this gap, the authors propose One‑Shot Incremental Federated Learning (OSI‑FL), the first framework that combines one‑shot communication with incremental updates. The workflow is as follows:
-
Client‑side encoding – Each client uses a lightweight vision‑language model (GPT‑ViT for caption generation followed by CLIP text encoding) to produce a 512‑dimensional embedding for every image. For each class k in task t, the client averages the embeddings of all its images, yielding a class‑level vector µ_{c,t,k}. Only these class embeddings are transmitted once to the server, drastically shrinking the payload compared to full model parameters.
-
Server‑side data synthesis – The server hosts a pre‑trained classifier‑free diffusion model p_ϕ(x|µ). Conditioned on each received µ_{c,t,k}, the diffusion model generates a large set of synthetic images ˆD_{t,k}. Because CLIP embeddings align linearly with visual features, the generated data statistically mirrors the client’s true distribution, enabling effective central training without exposing raw data.
-
Incremental model update – When a new task t arrives, the global model θ_{t‑1} is fine‑tuned on the freshly synthesized dataset ˆD_t. To avoid catastrophic forgetting, the authors introduce Selective Sample Retention (SSR). For every class in the current task, they compute an importance score s_i = ‖∇θ ℓ(f_θ(x_i), y_i)‖² using the loss gradient of the previous model. The top‑p samples per class (those with highest s_i) are stored as exemplars E{t,k}. During subsequent updates, the training set consists of ˆD_t together with the retained exemplars from all earlier tasks. This replay strategy is both memory‑efficient (only p samples per class) and effective, as the gradient‑based criterion selects the most informative examples.
-
Efficiency considerations – Communication is reduced to a single round per client (only class embeddings). The server’s computational load is limited to one diffusion‑based generation phase per task and subsequent fine‑tuning on a modest replay buffer. Compared to traditional FL (multiple rounds of model exchange) and existing OSFL (which still need full‑task data at once), OSI‑FL achieves orders‑of‑magnitude lower bandwidth usage while preserving or improving accuracy.
Experimental evaluation is performed on three benchmarks: NICO Common, NICO Unique, and OpenImage. Both class‑incremental and domain‑incremental scenarios are tested. Baselines include FedAvg, FedProx, FedEWC, and the OSCAR one‑shot method. Results show that OSI‑FL consistently outperforms baselines by 3–7 % absolute accuracy, especially as the number of tasks grows. When SSR is disabled, performance on earlier tasks drops dramatically (up to 20 % loss), confirming the necessity of replay. With SSR, forgetting is limited to under 5 % across all tasks. Moreover, OSI‑FL requires only one communication round per client versus ≥10 rounds for conventional FL, and the server‑side training time is reduced by roughly 40 % due to the compact replay set.
Contributions:
- Introduces a one‑shot incremental FL paradigm that decouples communication from data volume via class‑level embeddings.
- Leverages a classifier‑free diffusion model to synthesize high‑fidelity data conditioned on lightweight embeddings, eliminating the need for raw client data.
- Proposes a gradient‑based selective sample retention mechanism that efficiently mitigates catastrophic forgetting without full replay.
Limitations and future work: The approach relies on the quality of the pre‑trained diffusion model; poor generative capacity could degrade performance. Current experiments focus on image data; extending to other modalities (text, time‑series) remains open. The authors suggest exploring asynchronous client participation, adaptive p‑selection, and automatic quality assessment of synthesized samples to further enhance robustness and scalability.
In summary, OSI‑FL offers a practical solution for privacy‑preserving, communication‑efficient, and forgetting‑resilient federated learning in environments where data streams continuously and heterogeneously across distributed clients.
Comments & Academic Discussion
Loading comments...
Leave a Comment