KLong: Training LLM Agent for Extremely Long-horizon Tasks
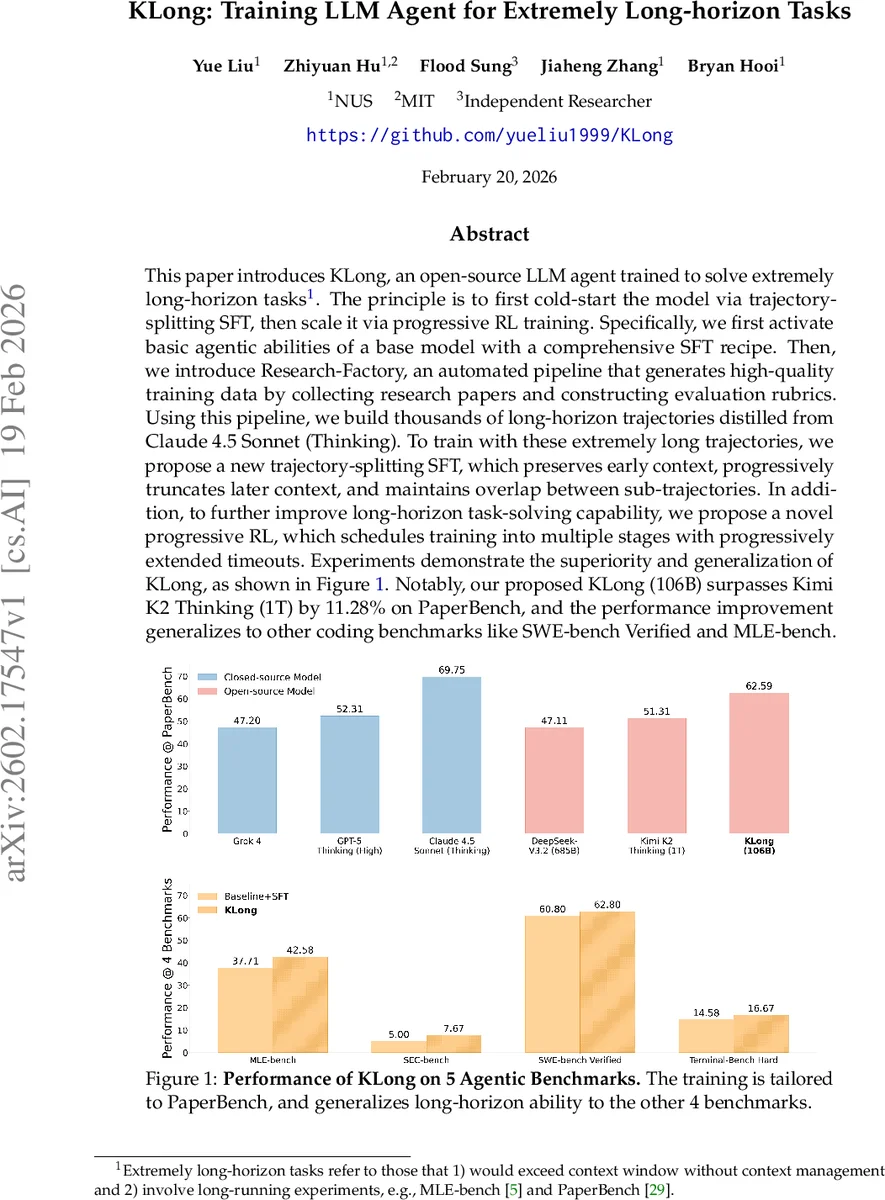
This paper introduces KLong, an open-source LLM agent trained to solve extremely long-horizon tasks. The principle is to first cold-start the model via trajectory-splitting SFT, then scale it via progressive RL training. Specifically, we first activate basic agentic abilities of a base model with a comprehensive SFT recipe. Then, we introduce Research-Factory, an automated pipeline that generates high-quality training data by collecting research papers and constructing evaluation rubrics. Using this pipeline, we build thousands of long-horizon trajectories distilled from Claude 4.5 Sonnet (Thinking). To train with these extremely long trajectories, we propose a new trajectory-splitting SFT, which preserves early context, progressively truncates later context, and maintains overlap between sub-trajectories. In addition, to further improve long-horizon task-solving capability, we propose a novel progressive RL, which schedules training into multiple stages with progressively extended timeouts. Experiments demonstrate the superiority and generalization of KLong, as shown in Figure 1. Notably, our proposed KLong (106B) surpasses Kimi K2 Thinking (1T) by 11.28% on PaperBench, and the performance improvement generalizes to other coding benchmarks like SWE-bench Verified and MLE-bench.
💡 Research Summary
The paper presents KLong, a 106‑billion‑parameter open‑source large language model (LLM) agent specifically designed to tackle “extremely long‑horizon” tasks—tasks that exceed the model’s context window and require thousands of interaction steps, such as reproducing research papers (PaperBench) or full‑scale machine‑learning engineering (MLE‑bench). The authors identify two fundamental obstacles for such tasks: (1) standard supervised fine‑tuning (SFT) cannot ingest trajectories that are longer than the maximum context length, and (2) reinforcement learning (RL) on these tasks suffers from extremely sparse rewards, high variance, and severe pipeline bottlenecks when using fixed timeouts.
To overcome (1), they introduce a novel trajectory‑splitting SFT. An original long trajectory τ = (s₁, a₁, …, s_N, a_N) is broken into overlapping sub‑trajectories τ⁽ⁱ⁾ of length L ≤ L_max. Each sub‑trajectory is prefixed with a fixed “paper‑reading” segment p that contains the task specification and early context, ensuring that essential information is always present. Overlap O between consecutive sub‑trajectories preserves continuity, allowing the model to learn long‑range dependencies while staying within its context window. Empirically, this technique raises the number of assistant turns from ~115 to ~733, demonstrating that the model can effectively learn to act over very long horizons.
For (2), the authors propose progressive RL. Instead of a single, prohibitively long timeout, they define a schedule of increasing timeouts T^(1) < T^(2) < … < T^(M). At stage m, rollouts are truncated at T^(m) and then further split using the same trajectory‑splitting method, yielding n·K^(m) sub‑trajectories per batch. PPO‑style updates are performed with a clipped objective, KL regularization, and advantage estimates computed across all sub‑trajectories. Crucially, they introduce partial rollouts and a priority‑based judge queue to avoid synchronous evaluation bottlenecks; unfinished rollouts are carried over to the next iteration, keeping compute resources fully utilized. This progressive schedule stabilizes learning, improves sample efficiency, and yields a 6.67 % performance boost over plain SFT.
Data generation is handled by the “Research‑Factory” pipeline. A search agent harvests recent papers from top conferences (ICML, NeurIPS, ICLR), filters them by quality and impact, converts PDFs to markdown, and records official code URLs in a blacklist to prevent cheating. An evaluation agent then automatically constructs a rubric tree for each paper by analyzing its content and official implementation. Using this pipeline, the authors create thousands of high‑quality prompts and, after quality filtering, distill long‑horizon trajectories from Claude 4.5 Sonnet (Thinking). The resulting dataset provides rich supervision for both SFT and RL stages.
Infrastructure optimizations are also described. A unified Kubernetes‑based sandbox supports >10 000 concurrent instances, manages >25 000 Docker images, and pre‑installs 80+ research‑related Python packages (e.g., PyTorch, TensorFlow). The rollout‑training pipeline mitigates the “pipeline imbalance” problem (where long tasks cause judges to become a bottleneck) by overlapping rollouts with evaluation and using an open‑source judge (gpt‑oss‑120b) during training to reduce cost and prevent benchmark hacking.
Experimental results show that KLong (106 B) outperforms the 1‑trillion‑parameter closed‑source Kimi K2 Thinking by 11.28 % on PaperBench (62.34 % vs. 51.06 %). Across five agentic benchmarks, KLong achieves the highest average score (62.59 %). It also generalizes to other coding benchmarks such as SWE‑bench Verified and MLE‑bench, where it surpasses existing open‑source baselines. Ablation studies confirm that trajectory‑splitting SFT is responsible for the dramatic increase in assistant turns, while progressive RL contributes the additional performance gain.
In summary, KLong demonstrates that with carefully engineered data pipelines, trajectory‑splitting supervision, and a staged progressive RL schedule, an LLM agent can acquire robust long‑horizon reasoning and tool‑use capabilities without needing an enormous model size. The work opens a path toward autonomous agents that can conduct full research reproducibility, complex software development, and multi‑day experimental workflows, bringing us closer to truly general-purpose AI assistants.
Comments & Academic Discussion
Loading comments...
Leave a Comment