Linear Convergence in Games with Delayed Feedback via Extra Prediction
Feedback delays are inevitable in real-world multi-agent learning. They are known to severely degrade performance, and the convergence rate under delayed feedback is still unclear, even for bilinear games. This paper derives the rate of linear conver…
Authors: ** *저자 정보가 논문 본문에 명시되어 있지 않아 확인할 수 없습니다.* **
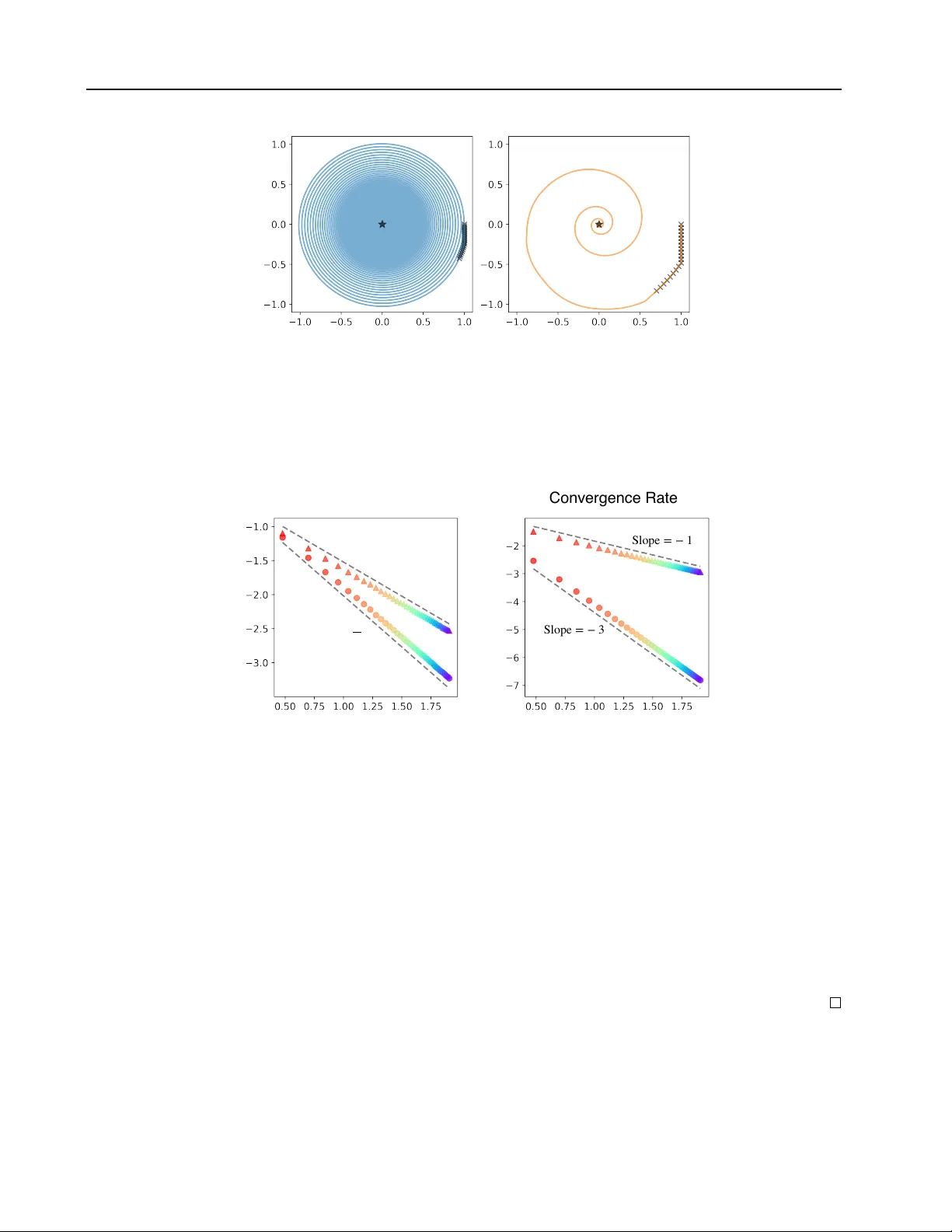
Linear Con ver gence in Games with Delayed F eedback via Extra Prediction Y uma Fujimoto 1 2 Kenshi Abe 1 Kaito Ariu 1 Abstract Feedback delays are inevitable in real-w orld multi-agent learning. They are kno wn to sev erely degrade performance, and the con ver gence rate under delayed feedback is still unclear , ev en for bilinear games. This paper deriv es the rate of linear con ver gence of W eighted Optimistic Gra- dient Descent-Ascent (WOGD A), which predicts future rew ards with extra optimism, in uncon- strained bilinear games. T o analyze the algorithm, we interpret it as an approximation of the Extra Proximal Point (EPP), which is updated based on farther future re wards than the classical Prox- imal Point (PP). Our theorems show that stan- dard optimism (predicting the next-step reward) achiev es linear conv ergence to the equilibrium at a rate exp( − Θ( t/m 5 )) after t iterations for delay m . Moreov er , employing e xtra optimism (pre- dicting farther future re ward) tolerates a larger step size and significantly accelerates the rate to exp( − Θ( t/ ( m 2 log m ))) . Our experiments also show accelerated conv ergence driv en by the ex- tra optimism and are qualitatively consistent with our theorems. In summary , this paper validates that extra optimism is a promising countermea- sure against performance de gradation caused by feedback delays. 1. Introduction Online learning aims for ef ficient sequential decision- making. T ypically , it assumes an ideal situation in which cur- rent strategies can be determined from all the past feedback. In real-world online learning scenarios, ho wev er , delays in feedback are generally inevitable. For instance, in online advertising, there is often a significant time lag between dis- playing an ad and observing a con version ( Chapelle , 2014 ; Y oshika wa & Imai , 2018 ; Y asui et al. , 2020 ). Similarly , in distributed learning, communication latency and asyn- 1 CyberAgent, T okyo, Japan 2 Soken Uni versity , Kana- gaw a, Japan. Correspondence to: Y uma Fujimoto < fuji- moto.yuma1991@gmail.com > . Pr eprint. F ebruary 20, 2026. chronous updates inherently introduce delays in gradient aggregation ( Agarwal & Duchi , 2011 ; McMahan & Streeter , 2014 ; Zheng et al. , 2017 ). Indeed, a considerable num- ber of papers on online learning are motiv ated by such feedback delays and report that delays amplify regret for full feedback ( W einberger & Ordentlich , 2002 ; Zinke vich et al. , 2009 ; Quanrud & Khashabi , 2015 ; Joulani et al. , 2016 ; Shamir & Szlak , 2017 ) and bandit feedback ( Neu et al. , 2010 ; Joulani et al. , 2013 ; Desautels et al. , 2014 ; Cesa-Bianchi et al. , 2016 ; V ernade et al. , 2017 ; Pike-Burk e et al. , 2018 ; Cesa-Bianchi et al. , 2018 ; Li et al. , 2019 ). Such feedback delays have also been of interest in multi- agent learning or learning in games ( Zhou et al. , 2017 ; Hsieh et al. , 2022 ) and are known to se verely de grade per- formance ( Fujimoto et al. , 2025a ). This is because good performance in multi-agent learning is based on each agent predicting their future reward, and feedback delays make this prediction more challenging. Indeed, Optimistic F ollow the Re gularized Leader (OFTRL), which is a predicti ve algo- rithm and enjoys O (1) -regret under instantaneous feedback, suffers from Ω( √ T ) -regret for the time horizon T . Even if we adopt a delay-correction mechanism called “W eighted” OFTRL (WOFTRL), the re gret scales as O ( m 2 ) , gro wing too large with delay m . Despite these prior studies, fundamental challenges remain in delayed feedback in multi-agent learning, especially about con vergence analysis in bilinear games, defined as max x ∈X min y ∈Y x T B y . (bilinear game) The prior study ( Fujimoto et al. , 2025a ) prov ed WOFTRL con verges to the equilibrium, called last-iterate con vergence (LIC), when X and Y are constrained to probability spaces. Howe ver , LIC in the unconstrained setting X = R d X and Y = R d Y under delayed feedback is not guaranteed. Fur- thermore, its con vergence rate is still unestablished. Finding this rate is vital for understanding how quickly agents can stabilize their strategies in applications, and thus con ver- gence rate is an attractiv e topic in the context of learning in games. Lastly , although the experiment in the prior research suggests that predicting the farther future than necessary to correcting the delays (called “extra prediction”) results in faster con ver gence, the v alidity of this extra prediction has yet to be established. 1 Linear Con vergence in Games with Delayed Feedback via Extra Prediction In this paper , we address these open problems in uncon- strained bilinear games. Our contrib utions are as follo ws. • W e establish the rate of linear conv ergence even with feedback delays. W e approximate our algorithm WOGD A by Extra Proximal Point (EPP), an exten- sion of classical Proximal Point (PP) to predict future rew ards. W e prov e that EPP linearly con ver ges and that the difference between WOGD A and EPP is suffi- ciently small by setting the step size appropriately . • W e demonstrate that extra prediction accelerates con vergence. W e find that extra prediction permits larger step sizes, and the underlying EPP con ver ges faster . Therefore, WOGD A with extra prediction achiev es much faster conv ergence at the scale of delay m . • Our theoretical results are also reproduced in ex- periments. Both the linear con vergence and the accel- eration by extra prediction are observed in e xperiments using both representati ve (Matching Pennies) and un- intended ( 5 × 5 random matrix) games. Unconstrained bilinear games: This study targets the class of unconstrained bilinear games. This class is closely related to min-max optimization, and conv ergence is an im- portant issue there. Also, unconstrained bilinear games are one of the minimum necessary configurations (zero-sum utility and Euclidean strategy space), including dif ficulties specific to multi-agent learning, and thus have the potential to dev elop into other various adv anced configurations, such as con vex-conca ve utility and constrained strategy space. Indeed, the celebrated study showing LIC in unconstrained bilinear games ( Daskalakis et al. , 2018 ) has been there- after applied to the constrained setting ( Mertikopoulos et al. , 2019 ). The linear con ver gence was first demonstrated in un- constrained bilinear games ( Mokhtari et al. , 2020 ) and later shown to hold in constrained saddle-point problems ( W ei et al. , 2021 ). Also, LIC in time-varying games was first prov en in unconstrained bilinear games ( Feng et al. , 2023 ) and later discussed for the constrained setting ( Feng et al. , 2024 ; Fujimoto et al. , 2025b ). T o summarize, unconstrained bilinear games serve as a touchstone for analyzing novel phenomena in learning in games. Analysis Based on PP method: Many algorithms in learn- ing in games are analyzed based on the PP method. Here, PP linearly con verges to equilibrium and thus is a powerful algorithm, but its applicability is limited because it uses the information on the next-step re ward (thus, implicit and coupled method). For e xample, in the unconstrained setting, PP is used to ev aluate predictiv e variant of gradient descent- ascent (GDA), i.e., optimistic GD A (OGDA) ( Mokhtari et al. , 2020 ). In the constrained setting, optimistic algo- rithms are analyzed using the next-step re ward ( Rakhlin & Sridharan , 2013 ; Syr gkanis et al. , 2015 ). A method that approximates this PP with arbitrary precision has been pro- posed ( Piliouras et al. , 2022 ; Ce vher et al. , 2023 ). Overall, the advantage of predicting the next step has been widely discussed, but this adv antage is still unexplained for predict- ing farther future than the next step. 2. Unconstrained Bilinear Game This study addresses bilinear game with unconstrained set- ting X = R d X and Y = R d Y . The solution of this bilinear game is gi ven by ( x ∗ , y ∗ ) such that B T x ∗ = 0 , B y ∗ = 0 . (1) For each time t ∈ { 1 , · · · , T } , each player determines their strategies as x t ∈ R d X and y t ∈ R d Y . Each game play returns the full feedback, where each player observes the gradient of their objective function, i.e., u t = B y t for X and v t = − B T x t for Y . 2.1. Delayed Feedback While standard online learning assumes instantaneous feed- back where each player can use all their strategies and re- ceiv e rewards up to time t to determine their ne xt strategy , this study addresses a realistic scenario in volving a fixed time delay of m steps in observing their rew ards. Formally , although player X should determine their next strate gy as a function x t +1 ( { x s } 0 ≤ s ≤ t , { u s } 0 ≤ s ≤ t ) in the standard set- ting, suppose that under delayed feedback with m ∈ N , the y should instead determine a function x t +1 ( { x s } 0 ≤ s ≤ t , { u s } 0 ≤ s ≤ t − m ) . (Delayed Feedback) 2.2. Notation and Assumption For con venience, we introduce the notations of z t = x t y t , w t = u t v t , (2) A = O B − B T O , ¯ A = O B B T O . (3) Here, z t and w t are the concatenation of the strategies and rew ards, respectively . A is the matrix such that w t = Az t holds. W e also defined ¯ A , which satisfies ¯ A T = ¯ A and A T A = ¯ A 2 . A T = − A , A T A = − A 2 = ¯ A 2 . (4) Follo wing the previous studies on linear con ver gence to the Nash equilibrium ( Mokhtari et al. , 2020 ), we also assume that B is a regular matrix. 2 Linear Con vergence in Games with Delayed Feedback via Extra Prediction Assumption 2.1 (Re gular Matrix Game) . Suppose that d X = d Y =: d and B is a regular matrix. This assumption is con venient for discussing se veral con ver- gence properties. First, because B has the inv erse matrix, the Nash equilibrium is uniquely giv en by x ∗ = y ∗ = 0 . Second, because B is a full-rank matrix, the skew- symmetric matrix A has only pure imaginary eigen values, denoted as ± iλ min , · · · , ± iλ max for some (0 < ) λ min ≤ · · · ≤ λ max . Thus, we can e v aluate 0 < λ min ∥ z ∥ ≤ ∥ Az ∥ ≤ λ max ∥ z ∥ , (5) for all z ∈ R 2 d \ { 0 } . W e note that we use ∥ · ∥ indicates the Euclidean norm ∥ · ∥ 2 throughout this paper . W e also define the ratio of the maximum and minimum eigen values as κ = λ max λ min ( > 1) . (6) Remark: Bilinear games can be e xtended to the follo wing alternativ e problem max x ∈ R d X min y ∈ R d Y x T B y + x T c ′ + c T y , (7) where c , c ′ ∈ R d are unobserv able v ectors. The equilibrium of this alternative problem is x ∗ = − ( B T ) − 1 c and y ∗ = − B − 1 c ′ . As similar to the study ( Daskalakis et al. , 2018 ), our algorithm is applicable to this alternati ve problem. Even though one might consider that x ∗ = y ∗ = 0 is tri vial equilibrium, this study , just for the simplicity of notation, chooses the special case of c = c ′ = 0 without loss of generality . 3. Algorithm In this work, we focus on W eighted Optimistic Gradient Descent-Ascent (WOGD A), which is the application of WOFTRL and WOMD algorithms ( Fujimoto et al. , 2025a ) to unconstrained bilinear games. (T echnically , WOGD A is obtained by replacing the constrained strategy domain with a Euclidean space and employing a Euclidean regularizer in WOFTRL and WOMD.) 3.1. WOGD A In the delayed feedback setting, the next strategy z t +1 should be determined by the delayed rew ards, i.e., w 1 , · · · , w t − m . W ith extra prediction length n ∈ N , the WOGD A giv es z t +1 as follows. ( ˆ z t +1 = ˆ z t + η w t +1 z t +1 = ˆ z t − m + ( n + m ) η w t − m . (W OGDA) Because the next strate gy z t +1 depends on ˆ z t − m (the first term) determined only by w 1 , · · · , w t − m and w t − m (sec- ond), WOGD A is executable e ven with feedback delays m . By using the following notation ∆ a t = a t +1 − a t , ( ∆ -notation) WOGD A is also written as ∆ z t = η Az t − m + ( n + m ) η A ∆ z t − m − 1 . (8) Connection to GDA and OGD A: If there is no delay ( m = 0 ), the WOGD A immediately reproduces the GDA ( n = 0 ) and OGD A ( n = 1 ) as z t +1 = z t + η Az t , (GD A) z t +1 = z t + η Az t + η A ( z t − z t − 1 ) . (OGD A) Interpr etation: Here, ˆ z t is a dummy v ariable and repre- sents the cumulati ve re wards until the current time t . Thus, the strategy z t +1 is giv en by the observable cumulati ve rew ards ˆ z t − m and weighting the latest re wards ( n + m ) times. Here, the weight m is interpreted as canceling out the delay , because depending on the delay length m , the number of observ able re wards is reduced by m in ˆ z t − m . On the other hand, the weight n is interpreted as predicting the future rew ard, because the cumulativ e of future rewards w t +1 , · · · , w t + n is e xtrapolated by the latest re ward w t − m . Therefore, when n = 1 , WOGDA predicts the next-step cumulativ e rew ard, called “next-step prediction”. When n > 1 , it predicts further future cumulati ve rew ards, called “extra prediction”. 4. Linear Con vergence of WOGD A This section presents the main theorems, sho wing the rate of linear con vergence of WOGD A. W e consider two cases: n = 1 (next-step prediction) and n = m/ 2 + 1 (extra prediction). Interestingly , depending on the difference of these n , the possible step size and con vergence rate change on the scale of m . W e skip the proofs of these main theorems until the later section, and see Appendix for the omitted full proofs. 4.1. Con vergence by Next-Step Prediction Follo wing the con ventional methodology , suppose n = 1 , where WOGDA predicts the reward at the next step, then we can provide the rate of linear con ver gence as follo ws. Theorem 4.1 (Linear Con ver gence by Next-Step Prediction) . Suppose n = 1 and η = 1 / (56( m + 1) 2 κ 2 λ max ) , then it holds ∥ z t ∥ ≤ exp − t cκ 6 ( m + 1) 5 ∥ ˜ z 0 ∥ , (9) 3 Linear Con vergence in Games with Delayed Feedback via Extra Prediction with some positive constant c ( > 0) . Her e, ∥ ˜ z 0 ∥ is defined as ∥ ˜ z 0 ∥ = max 0 ≤ s ≤ 4( m +1) ∥ z s ∥ . (10) Connection to Prior Research: Theorem 4.1 establishes a linear con vergence rate, guaranteeing e xponential con ver- gence to equilibrium, whereas this remained an open ques- tion in pre vious work ( Fujimoto et al. , 2025a ). Although our setting (unconstrained bilinear) differs to some extent from theirs (poly-matrix zero-sum), both approaches share the underlying mechanism (approximating the PP method) and the step size scaling ( η = O (1 /m 2 ) ). 4.2. Con vergence by Extra Prediction Beyond the con ventional methodology , suppose n = m/ 2 + 1 , where WOGD A extra-predicts the re ward beyond the ne xt step, then we can prov e accelerated linear conv ergence as follows. Theorem 4.2 (Linear Con vergence by Extra Prediction) . Suppose n = m/ 2 + 1 and η = 1 / (93( m + 1) 2 j 2 j − 1 κ 2 λ max ) with j = ⌊ log ( m + 1) ⌋ + 2 , then it holds ∥ z t ∥ ≤ exp − t cκ 6 ( m + 1) 2 (log( m + 1) + 2) ∥ ˜ z 0 ∥ , (11) with some positive constant c ( > 0) . Her e, ∥ ˜ z 0 ∥ is defined as ∥ ˜ z 0 ∥ = max 0 ≤ s ≤ 2( m +1)(log( m +1)+2) ∥ z s ∥ . (12) Accelerated con vergence by extra prediction: Compar - ing Theorem 4.1 with Theorem 4.2 , we see that the con- ver gence rate is quite accelerated from exp( − Θ( t/m 5 )) in next-step prediction to exp( − Θ( t/ ( m 2 log m ))) in extra prediction. W e also see that the step size increases from η = O (1 /m 2 ) in next-step prediction to η = O (1 / ( m log m )) in e xtra prediction. Since a lar ger step size is kno wn to desta- bilize con vergence in general, extra prediction enhances the stability of WOGD A. In conclusion, extra prediction is a strong countermeasure against feedback delays in both ac- celerated and stabilized con vergence, as later supported by rigorous proofs and experiments. 5. Proof of Theorems 4.1 and 4.2 T o prove Theorems 4.1 and 4.2 , we analyze the dynamics of WOGD A for all prediction lengths n ∈ N and step sizes 0 ≤ η ≤ O (1 / ( n + m )) . The proof proceeds as follows. In § 5.1 , we prov e that EPP , an implicit method approximating WOGD A, linearly conv erges. In § 5.2 , we ev aluate the ap- proximation error between WOGD A and EPP . In § 5.3 , we combine the con vergence term by EPP and the error term. 5.1. Analysis of EPP W e introduce EPP , an extension of the classical PP method. For an y z t , its EPP z † t +1 is determined as z † t +1 = z t + η Az t + nη A ( z † t +1 − z t ) . (EPP) Here, n ∈ R means the prediction length, corresponding to that in WOGD A . Connection to GDA and PP: This EPP linearly connects well-known algorithms, GD A ( n = 0 ) and PP ( n = 1 ) as z † t +1 = z t + η Az t , (GD A) z † t +1 = z t + η Az † t +1 . (PP) When n = 0 , EPP corresponds to GD A and updates its strategy based on the previous re ward Az t . When n = 1 , EPP corresponds to PP and is based on the next-step rew ard Az † t +1 . When n > 1 , EPP is based on the n -step future rew ard, meaning extra prediction. The dynamics of EPP satisfy the following lemma. Lemma 5.1 (Dynamics of EPP) . F or all n ∈ R , 0 ≤ η , and z t ∈ R 2 d , it holds ∥ z † t +1 ∥ 2 = z T t I + ( n − 1) 2 η 2 ¯ A 2 I + n 2 η 2 ¯ A 2 z t . (13) Fraction of matrices: Here, note that we abused the frac- tion notation of matrices for conv enience. This notation has no mathematical contradiction because the inv erse matrix of the denominator ( I + n 2 η 2 ¯ A 2 ) exists, and it is also com- mutativ e with the numerator ( I + ( n − 1) 2 η 2 ¯ A 2 ). W e will henceforth use this notation throughout this paper . Pr oof Sketch. First, EPP can be rewritten as ( I − nη A ) z † t +1 = ( I − ( n − 1) η A ) z t . (14) Since A is ske w-symmetric, the in verse matrix of I − nη A exists and is also commutativ e with I − ( n − 1) η A . There- fore, we obtain z † t +1 = I − ( n − 1) η A I − nη A z t . (15) which deriv es Eq. ( 13 ) . Here, note that by utilizing the properties of Eqs. ( 3 ) , the cross terms between x t and y t cancels out and only the squared terms (corresponding to ¯ A 2 ) remain. Since ¯ A has only positiv e eigen values, Lemma 5.1 immedi- ately implies linear con vergence as follo ws. Lemma 5.2 (Analysis of EPP) . F or all n ∈ R , 0 ≤ η ≤ 1 / ( nλ min ) , and z t ∈ R 2 d , it holds ∥ z † t +1 ∥ ≤ LCR EPP ( n ) ∥ z t ∥ , (16) LCR EPP ( n ) = 1 − 2 n − 1 2 η 2 λ 2 min + n 2 (2 n − 1) 2 η 4 λ 4 min . (Linear Con vergence Rate of EPP) 4 Linear Con vergence in Games with Delayed Feedback via Extra Prediction Pr oof. By Lemma 5.1 , we obtain ∥ z † t +1 ∥ 2 = z T t I + ( n − 1) 2 η 2 ¯ A 2 I + n 2 η 2 ¯ A 2 z t = 1 n 2 z T t ( n − 1) 2 I + ( n 2 − ( n − 1) 2 ) I I + n 2 η 2 ¯ A 2 z t ≤ 1 n 2 ( n − 1) 2 + n 2 − ( n − 1) 2 1 + n 2 η 2 λ 2 min ∥ z t ∥ 2 = 1 + ( n − 1) 2 η 2 λ 2 min 1 + n 2 η 2 λ 2 min ∥ z t ∥ 2 (17) ≤ LCR EPP ( n ) 2 ∥ z t ∥ 2 . (18) In the final inequality , we used that the inequality (holding for all 0 ≤ a ≤ b ≤ 1 ) 1 + a 1 + b ≤ 1 − ( b − a )(1 − b ) ≤ 1 − 1 2 ( b − a )(1 − b ) 2 . (19) for a = ( n − 1) 2 η 2 λ 2 min and b = n 2 η 2 λ 2 min . Interpr etation: Lemma 5.2 is interpreted as LCR EPP ( n ) = 1 − O ( nη 2 ) , meaning that EPP achiev es linear con ver gence under suf ficiently small step sizes. Furthermore, it also shows that a larger n leads to faster con vergence. Thus, if some external factor — just like delayed feedback — requires a small step size, EPP with extra prediction ( n > 1 ) outperforms that with ne xt-step prediction ( n = 1 , corresponding to classical PP). W e note that if no such factor exists, EPP no longer improves PP . Indeed, the tighter rate, i.e., Eq. ( 17 ) , sho ws that PP ( n = 1 ) con verges arbitrarily f ast in the limit of η → ∞ . 5.2. Evaluation of Error The difference between EPP (i.e., z † t +1 ) and WOGD A (i.e., z t +1 ) is ev aluated as follows. Lemma 5.3 (Dynamics of Error T erm) . F or all n ∈ N and 0 ≤ η , it holds ∥ z † t +1 − z t +1 ∥ 2 = ∆ 2 Z T t η 2 ¯ A 2 I + n 2 η 2 ¯ A 2 ∆ 2 Z t , (20) Z t = n m +1 X s =1 z t − s + m +1 X s =2 m +1 X r = s z t − r . (21) Pr oof. W e can directly obtain z † t +1 − z t +1 = { η Az t + nη A ( z † t +1 − z t ) } − { η Az t − m + ( n + m ) η A ∆ z t − m − 1 } = η A ( z † t +1 − z t +1 ) + η A { n ∆ z t + (∆ z t − 1 + · · · + ∆ z t − m ) − ( n + m )∆ z t − m − 1 } (22) = η A ( z † t +1 − z t +1 ) + η A ∆ 2 Z t . (23) Here, we remark that in Eq. ( 22 ) , the numbers of +∆ z and − ∆ z are balanced, it degenerates to a finite number of ∆ 2 z . By using the fraction notation of matrices, we can write z † t +1 − z t +1 = η A I − nη A ∆ 2 Z t , (24) leading to Eq. ( 20 ) by performing the same operation as the proof of Lemma 5.1 . Here, we note that ∥ z † t +1 − z t +1 ∥ is described as the finite number of ∆ 2 z s , which is ev aluated as suf ficiently small below . Lemma 5.4 (Evaluation of Error T erm) . F or all j, n ∈ N and 0 ≤ η ≤ 1 / (2( n + m ) λ max ) , it holds ∥ z † t +1 − z t +1 ∥ ≤ ER( j, n ) max 2 m ≤ s ≤ 2 j ( m +1) ∥ z t − s ∥ , (25) ER( j, n ) = 2(2 n + m )( m + 1) η 3 λ 3 max + 8( n + m ) j +1 η j +2 λ j +2 max + 2(2 n + m + 1)( n + m ) 2 j η 2 j +1 λ 2 j +1 max . (Error Rate) Pr oof Sketc h. By recursively substituting Eq. ( 8 ) j times, we obtain ∆ z t = j X k =1 ( n + m ) k − 1 η k A k z t − k ( m +1)+1 + ( n + m ) j η j A j ∆ z t − j ( m +1) . (26) ER( j, n ) is obtained by applying Eq. ( 26 ) to ∆ 2 Z t twice and upper-bounding all z t − s by max s z t − s . Here, the first term of ER( j, n ) corresponds to the product of the first terms of Eq. ( 26 ) . The second term of ER( j, n ) corresponds to the product of the first and second terms of Eq. ( 26 ) . The third term of ER( j, n ) corresponds to the product of the second terms of Eq. ( 26 ). 5.3. Combination of EPP and Error By combining the con vergence term by EPP and the error term, we can analyze WOGD A as follows. 5 Linear Con vergence in Games with Delayed Feedback via Extra Prediction Fig.1-1:Last-IterateConvergence n = 1 n = m / 2 + 1 η * = 10 − 1.95 η * = 10 − 1.66 ⟨ x t , c ⟩ ⟨ x t , c ⟩ ⟨ y t , c ⟩ A B F igure 1. Conv ergence in Matching Pennies with delayed feedback. W e set the delay as m = 10 and the initial state as ( x 0 , y 0 ) = ( c / 2 , 0 ) . In both panels, the solid lines are the trajectories on the plane of x t , c and y t , c . The black star markers are the Nash equilibria which satisfy x ∗ , c = y ∗ , c = 0 . In A , the extra-optimistic weight is set to the minimum necessary value, n = 1 . In B , it is to n = m/ 2 + 1 = 6 . The step size is respecti vely fine-tuned as η = 10 − 1 . 95 in A and η = 10 − 1 . 66 in B . The black cross marks indicate the first 20 steps of learning, which visualize that learning proceeds more quickly in B than in A . The trajectory also requires fewer cycles until con vergence in B than in A . Fig.2-1:LinearConvergence(MatchingPennies) Optimal Step Size C o n ve rg e n ce R a t e Slope = − 3 2 Slope = − 1 Slope = − 3 Slope = − 1 log 10 ( m + 1) log 10 ( m + 1) log 10 (1 − eLCR*) A B log 10 η * F igure 2. Optimal step size ( A ) and optimal linear con ver gence rate ( B ) in Matching Pennies. The circle and triangle markers indicate n = 1 (next-step prediction) and n = m/ 2 + 1 (extra prediction), respecti vely . W e consider the delays from m = 2 (red) to m = 80 (purple). In A , the horizontal and vertical axes indicate logarithmic delay log 10 ( m + 1) and logarithmic optimal step size log 10 η ∗ . The gray broken lines fit the circle markers with slope − 3 / 2 and the triangle markers with slope − 1 , respectiv ely . This means that the extra prediction admits a larger step size than the next-step prediction. In B , the vertical axis indicates logarithmic linear conv ergence rate log 10 (1 − eLCR ∗ ) . The gray broken lines fit the circle markers with slope − 3 and the triangle markers with slope − 1 , respectiv ely . This means that the extra prediction con verges f aster than the next-step prediction. Theorem 5.5 (Analysis of WOGD A) . F or all j, n ∈ N and 0 ≤ η ≤ 1 / (2( n + m ) λ max ) , we derive ∥ z t +1 ∥ ≤ LCR WOGD A ( j, n ) max 0 ≤ s ≤ 2 j ( m +1) ∥ z t − s ∥ , (27) LCR WOGD A ( j, n ) = LCR EPP ( n ) + ER( j, n ) . (Linear Con vergence Rate of W OGD A) Pr oof. Eq. ( 27 ) is obvious by the triangle inequality of ∥ z t +1 ∥ ≤ ∥ z † t +1 ∥ + ∥ z † t +1 − z t +1 ∥ , (28) with the results from Lemma 5.2 and Lemma 5.4 ∥ z † t +1 ∥ ≤ LCR EPP ( n ) ∥ z t ∥ , (29) ∥ z † t +1 − z t +1 ∥ ≤ ER( j, n ) max 2 m ≤ s ≤ 2 j ( m +1) ∥ z t − s ∥ . (30) Finally , Theorem 5.5 immediately derives Theorems 4.1 and 4.2 by setting the step size properly to cancel out the con vergence and error terms. The proof sketches are below . Pr oof Sketch of Theorem 4.1 . When n = 1 , WOGD A 6 Linear Con vergence in Games with Delayed Feedback via Extra Prediction Fig.2-1:LinearConvergence(MatchingPennies) Slope = − 3 2 Slope = − 1 Slope = − 3 Slope = − 1 log 10 ( m + 1) log 10 ( m + 1) log 10 η * A B Convergence Rate Optimal Step Size log 10 (1 − eLCR*) F igure 3. Optimal step size ( A ) and optimal linear con vergence rate ( B ) in 5 × 5 random matrix game. How to read the panels is the same as Figure 2 . The initial state is ( x 0 , y 0 ) = ( 1 , 0 ) . linearly con verges with the rate of LCR EPP (1) = 1 − O ( η 2 λ 2 min ) . On the other hand, it also di verges with the rate of ER( j, 1) = O ( m 2 η 3 λ 3 max ) . In order to can- cels out the terms of O ( η 2 λ 2 min ) with O ( m 2 η 3 λ 3 max ) , we should set the step size as η = O (1 / ( m 2 κ 2 λ max )) . When j ≥ 2 , the other terms can be ignored with this step size. Therefore, we set j = 2 at best and obtain the conv er- gence rate as LCR WOGD A (2 , 1) = 1 − O ( η 2 λ 2 min ) = exp( − Θ(1 / ( κ 6 m 4 ))) . This conv ergence rate scales down to exp( − Θ(1 / ( κ 6 m 5 ))) because the conv ergence delays O ( m ) times by the definition of Eq. ( 27 ). Pr oof Sketch of Theorem 4.2 . When n = m/ 2 + 1 , WOGD A linearly conv erges with the rate of LCR EPP ( m/ 2 + 1) = 1 − O ( mη 2 λ 2 min ) . On the other hand, it also diver ges by the eff ect of ER( j, n ) , and the leading term is O ( m 2 j +1 η 2 j +1 λ 2 j +1 max ) . In or- der to cancels out the terms of O ( mη 2 λ 2 min ) with O ( m 2 j +1 η 2 j +1 λ 2 j +1 max ) , we should set the step size as η = O (1 / ( m 2 j 2 j − 1 κ 2 λ max )) , immediately leading to the con vergence rate of LCR WOGD A ( j, m/ 2 + 1) = 1 − O ( mη 2 λ 2 min ) = exp( − Θ(1 / ( κ 6 m 1+ 2 2 j − 1 ))) . This rate scales down to exp( − Θ(1 / ( κ 6 j m 2+ 2 2 j − 1 ))) because the con vergence delays O ( j m ) times by the defini- tion of Eq. ( 27 ) . It takes the minimum v alue of exp( − Θ(1 / ( κ 6 m 2 log m ))) when j = O (log m ) . 6. Experiments This section numerically tests the performance of the WOGD A, based on the two measures of the optimal step size η ∗ and the estimated linear con vergence rate there eLCR ∗ . As far as we ha ve conducted, our experiments guarantee that if WOGD A con ver ges with a step size, it also con verges with smaller step sizes. Thus, a lar ger step size contributes not only to faster con vergence but also to the stability of con vergence. Experimental Setup: F or each delay m and prediction length n , we run WOGD A with 251 step sizes of η = 10 − 1 . 00 , 10 − 1 . 01 , · · · , 10 − 3 . 50 . W e stop the algorithm ei- ther 10 − 9 ≤ ∥ z ∥ t ≤ 10 9 or 10 4 ≤ t no longer holds. W e measure the estimated linear con ver gence rate eLCR by the final 100 steps of z t . Finally , the optimal step size η ∗ is one such that minimize eLCR , and the optimal estimated linear con vergence rate eLCR ∗ is the minimum eLCR . First, let us pick up Matching Pennies, whose payof f matrix is giv en by B = c ⊗ c , c := +1 − 1 . (Matching Pennies) Because this payoff matrix is not re gular, the Nash equilib- rium is not unique but all ( x ∗ , y ∗ ) such that x ∗ , c = y ∗ , c = 0 . W e should emplo y another measure for the distance from these equilibria as q x t , c 2 + y t , c 2 . Matching Pennies is out of our theoretical scope, b ut our algorithm remains applicable. Fast con vergence by Extra Prediction: W e consider Matching Pennies with the delay m = 10 . Figure 1 -A considers the minimum optimistic weight n = 1 (next- step prediction), while B considers the extra weight n = m/ 2 + 1 = 6 (extra prediction). In both A and B, we tuned the step size to the optimal one. W e see two merits to take the extra weight. One is that the optimal step size is lar ger in B than in A. Another is that con ver gence to the Nash equilibrium is quick without cycling too man y times. Scaling law: K eeping using Matching Pennies, we next see ho w the optimal step size and the linear con ver gence rate depend on the delay m . In Figure 2 -A, which compares the 7 Linear Con vergence in Games with Delayed Feedback via Extra Prediction optimal step size η ∗ between n = 1 (next-step prediction) and n = m/ 2 + 1 (extra prediction), we see that it shrinks with delay as η ∗ = O (1 /m 3 / 2 ) in n = 1 , but this shrinking becomes slower in n = m/ 2 + 1 as η ∗ = O (1 /m ) . On the other hand, Figure 2 compares the optimal linear con- ver gence rate eLCR ∗ , where we observe that con vergence slows down with delay in n = 1 as eLCR ∗ = 1 − O (1 /m 3 ) , but it is f aster in n = m/ 2 + 1 as eLCR ∗ = 1 − O (1 /m ) . Random-matrix game: Not only for Matching Pennies, but we also conduct e xperiments for a randomly-generated 5 × 5 matrix game, all of whose elements follo ws Gaus- sian distribution N (0 , 1) . Figure 3 observes that the same scaling law as in Matching Pennies holds. An interesting observation is that the scaling la w for n = 1 is disordered a little as if the con ver gence speed must be lower than in n = m/ 2 + 1 . W e see similar scaling law in all 10 random matrices generated independently . 7. Discussion Comparison between theory and experiment: Our the- oretical and experimental results share the qualitati ve con- sensus that extra prediction permits larger step sizes and accelerates conv ergence. W e remark that a quantitative gap remains between these theoretical and experimen- tal results. Regarding the next-step prediction, the op- timal step size is O (1 /m 2 ) in theory versus O (1 /m 3 / 2 ) in experiments, and the corresponding con vergence rate is exp( − Θ( t/m 5 )) in theory versus exp( − Θ( t/m 3 )) in experiments. Similarly , for the extra prediction, the opti- mal step size is O (1 / ( m log m )) in theory versus O (1 /m ) in experiment, and the corresponding conv ergence rate is exp( − Θ( t/ ( m 2 log m ))) in theory versus exp( − Θ( t/m )) in experiment. Bridging the gap between these theories and experiments is an open problem. Especially for the extra prediction, howe ver , the rate in theory could potentially be tightened to exp( − Θ( t/ ( m log m ))) by discov ering the L yapunov function and a voiding the bound using the max function in Eq. ( 25 ). Alternativ e algorithm that is memory complex: There is a way to force the e xisting algorithm OGD A to adapt to delayed feedback. Suppose m + 1 OGD A algorithms, labeled as OGD A 0 to OGD A m , in parallel, and the re ward at time t is assigned to OGD A t mo d ( m +1) . Although this parallelized algorithm trivially achiev es the linear conv er- gence rate of exp( − Θ( t/m )) by applying the pre vious pa- per ( Mokhtari et al. , 2020 ), it crucially suf fers from the mem- ory complexity of O ( m ) . Because this memory complexity is obviously incomparable to ours O (1) , we did not com- pare the parallelized algorithm with ours, but we not e that at least, WOGD A also achiev es the rate of exp( − Θ( t/m )) as well as the memory complexity of O (1) in our experiments. Robustness to stochastic and unknown delays: Al- though our algorithm assumes a fixed and known delay m ∈ N , we hypothesize that exact knowledge of m is not strictly required to enjo y the qualitati ve benefits of e xtra pre- diction. In real-world scenarios such as online advertising, feedback delays are often stochastic or unkno wn, but their time scale is thought to be easily observ able. As shown in the proof sketches in Theorems 4.1 and 4.2 , we ha ve discussed ho w the term contrib uting to conv ergence (i.e., LCR EPP ( n ) ) cancels out that contributing to diver gence (i.e., ER( j, n ) ), and this discussion is applicable to uncer- tainty in delays that does not affect the scale. Although a precise step size under unknown delays remains an open problem, this observ ation suggests that WOGD A could be robust to such uncertain delays. Conclusion: This paper has established the rate of linear con vergence in learning in games with feedback delays. The con vergence was prov en based on unconstrained bilinear games, complementary to LIC in past constrained settings. This linear rate is a strong contribution to agents quickly stabilizing their optimal strategies. Furthermore, we success- fully accelerated this con ver gence by introducing a novel mechanism that predicts the future re ward farther a way than the ne xt step. This study de veloped a strong countermeasure against delayed feedback in learning in games. Impact Statement This paper presents work whose goal is to advance the field of Learning in Games, Multi-Agent Learning, and Online Learning. There are man y potential societal consequences of our work, none which we feel must be specifically high- lighted here. References Agarwal, A. and Duchi, J. C. Distributed delayed stochastic optimization. In NeurIPS , 2011. Cesa-Bianchi, N., Gentile, C., Mansour , Y ., and Minora, A. Delay and cooperation in nonstochastic bandits. In COLT , 2016. Cesa-Bianchi, N., Gentile, C., and Mansour , Y . Nonstochas- tic bandits with composite anonymous feedback. In COLT , 2018. Cevher , V ., Piliouras, G., Sim, R., and Skoulakis, S. Min- max optimization made simple: Approximating the prox- imal point method via contraction maps. In SOSA , 2023. Chapelle, O. Modeling delayed feedback in display adv er- tising. In KDD , 2014. 8 Linear Con vergence in Games with Delayed Feedback via Extra Prediction Daskalakis, C., Ilyas, A., Syrgkanis, V ., and Zeng, H. T rain- ing gans with optimism. In ICLR , 2018. Desautels, T ., Krause, A., and Burdick, J. W . Paralleliz- ing exploration-e xploitation tradeoffs in gaussian process bandit optimization. J. Mac h. Learn. Res. , 15(1):3873– 3923, 2014. Feng, Y ., Fu, H., Hu, Q., Li, P ., Panageas, I., W ang, X., et al. On the last-iterate con ver gence in time-varying zero-sum games: Extra gradient succeeds where optimism fails. In NeurIPS , 2023. Feng, Y ., Li, P ., Panageas, I., and W ang, X. Last-iterate con- ver gence separation between e xtra-gradient and optimism in constrained periodic games. In U AI , 2024. Fujimoto, Y ., Abe, K., and Ariu, K. Learning from de- layed feedback in games via e xtra prediction. In NeurIPS , 2025a. Fujimoto, Y ., Ariu, K., and Abe, K. Synchronization in learning in periodic zero-sum games triggers di ver gence from nash equilibrium. In AAAI , 2025b. Hsieh, Y .-G., Iutzeler , F ., Malick, J., and Mertikopoulos, P . Multi-agent online optimization with delays: Asyn- chronicity , adapti vity , and optimism. Journal of Machine Learning Resear ch , 23(78):1–49, 2022. Joulani, P ., Gyorgy , A., and Szepesv ´ ari, C. Online learning under delayed feedback. In ICML , 2013. Joulani, P ., Gyorgy , A., and Szepesv ´ ari, C. Delay- tolerant online con ve x optimization: Unified analysis and adaptiv e-gradient algorithms. In AAAI , 2016. Li, B., Chen, T ., and Giannakis, G. B. Bandit online learning with unknown delays. In AIST A TS , 2019. McMahan, B. and Streeter , M. Delay-tolerant algorithms for asynchronous distributed online learning. In NeurIPS , 2014. Mertikopoulos, P ., Lecouat, B., Zenati, H., F oo, C.-S., Chan- drasekhar , V ., and Piliouras, G. Optimistic mirror descent in saddle-point problems: Going the extra (gradient) mile. In ICLR , 2019. Mokhtari, A., Ozdaglar , A., and Pattathil, S. A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach. In AIST A TS , 2020. Neu, G., Antos, A., Gy ¨ orgy , A., and Szepesv ´ ari, C. Online markov decision processes under bandit feedback. In NeurIPS , 2010. Pike-Burke, C., Agrawal, S., Szepesv ari, C., and Grune walder , S. Bandits with delayed, aggregated anony- mous feedback. In ICML , 2018. Piliouras, G., Sim, R., and Skoulakis, S. Beyond time- av erage con ver gence: Near-optimal uncoupled online learning via clairvo yant multiplicati ve weights update. In NeurIPS , 2022. Quanrud, K. and Khashabi, D. Online learning with adver - sarial delays. In NeurIPS , 2015. Rakhlin, S. and Sridharan, K. Optimization, learning, and games with predictable sequences. In NeurIPS , 2013. Shamir , O. and Szlak, L. Online learning with local permu- tations and delayed feedback. In ICML , 2017. Syrgkanis, V ., Agarwal, A., Luo, H., and Schapire, R. E. Fast conv ergence of regularized learning in games. In NeurIPS , 2015. V ernade, C., Capp ´ e, O., and Perchet, V . Stochastic bandit models for delayed con versions. In U AI , 2017. W ei, C.-Y ., Lee, C.-W ., Zhang, M., and Luo, H. Linear last-iterate con vergence in constrained saddle-point opti- mization. In ICLR , 2021. W einberger , M. J. and Ordentlich, E. On delayed prediction of individual sequences. IEEE T ransactions on Informa- tion Theory , 48(7):1959–1976, 2002. Y asui, S., Morishita, G., K omei, F ., and Shibata, M. A feedback shift correction in predicting conv ersion rates under delayed feedback. In WWW , 2020. Y oshikawa, Y . and Imai, Y . A nonparametric delayed feed- back model for con version rate prediction. arXiv pr eprint arXiv:1802.00255 , 2018. Zheng, S., Meng, Q., W ang, T ., Chen, W ., Y u, N., Ma, Z.-M., and Liu, T .-Y . Asynchronous stochastic gradient descent with delay compensation. In ICML , 2017. Zhou, Z., Mertikopoulos, P ., Bambos, N., Glynn, P . W ., and T omlin, C. Countering feedback delays in multi-agent learning. In NeurIPS , 2017. Zinke vich, M., Langford, J., and Smola, A. Slow learners are fast. In NeurIPS , 2009. 9 Linear Con vergence in Games with Delayed Feedback via Extra Prediction A ppendix A. Flowchart of the lemmas and theorems Lemma 5.1 Lemma 5.3 Lemma 5.2 Lemma 5.4 Theorem 5.5 Theorem 4.2 Theorem 4.1 Analysis of EPP Evaluation of Error Combination of EPP and Error §5.1: §5.3: §5.2: F igure 1. Flowchart of the lemmas and theorems. In § 5.1 , Lemma 5.1 captures the dynamics of EPP , and 5.2 analyzes them. In § 5.2 , Lemma 5.3 captures the dynamics of the error between WOGD A and EPP , and Lemma 5.4 analyzes them. In § 5.3 , Theorem 5.5 analyzes WOGD A by combining the conv ergence term by EPP and the error term. It leads to Theorem 4.1 , providing the rate of linear con ver gence by next-step prediction, and Theorem 4.2 , pro viding the rate of linear con vergence by extra prediction. B. Proof of Lemma 5.1 Pr oof. The dynamics of EPP are re written as ( I − nη A ) z † t +1 = ( I − ( n − 1) η A ) z t . (A1) Since A is ske w-symmetric matrix ( A T = − A ), I + α A has its in verse matrix for all α ∈ R . Furthermore, for all α, α ′ ∈ R , ( I + α A ) − 1 and ( I + α ′ A ) are commutativ e. Therefore, we obtain z † t +1 = ( I − nη A ) − 1 ( I − ( n − 1) η A ) z t = ( I − ( n − 1) η A )( I − nη A ) − 1 z t . (A2) Since the in verse matrix of the denominator exists and it can be commutati ve with the numerator , it is acceptable to ab use the following notation. z † t +1 = I − ( n − 1) η A I − nη A z t . (A3) Finally , we obtain ∥ z † t +1 ∥ 2 a = z T t I T − ( n − 1) η A T I T − nη A T I − ( n − 1) η A I − nη A z t (A4) b = z T t I + ( n − 1) η A I + nη A I − ( n − 1) η A I − nη A z t (A5) = z T t I − ( n − 1) 2 η 2 A 2 I − n 2 η 2 A 2 z t (A6) c = z T t I + ( n − 1) 2 η 2 ¯ A 2 I + n 2 η 2 ¯ A 2 z t . (A7) In (a), we used the transpose of Eq. ( A3 ). In (b), we used I T = I and A T = − A . In (c), we used A 2 = − ¯ A 2 . 10 Linear Con vergence in Games with Delayed Feedback via Extra Prediction C. Proof of Lemma 5.4 By substituting Eq. ( 8 ) recursiv ely j ∈ N times, we obtain ∆ z t = η Az t − m + ( n + m ) η A ∆ z t − m − 1 (A8) = η Az t − m + ( n + m ) η A ( η Az t − 2 m − 1 + ( n + m ) η A ∆ z t − 2 m − 2 ) (A9) = · · · = j X k =1 ( n + m ) k − 1 η k A k z t − k ( m +1)+1 + ( n + m ) j η j A j ∆ z t − j ( m +1) . (A10) Also, ∆ 2 z t is ev aluated as ∆ 2 z t a = j X k =1 ( n + m ) k − 1 η k A k ∆ z t − k ( m +1)+1 + ( n + m ) j η j A j ∆ 2 z t − j ( m +1) (A11) b = j X k =1 ( n + m ) k − 1 η k A k j X l =1 ( n + m ) l − 1 η l A l z t − ( k + l )( m +1)+2 + ( n + m ) j η j A j ∆ z t − ( k + j )( m +1)+1 ! (A12) + ( n + m ) j η j A j j X k =1 ( n + m ) k − 1 η k A k ∆ z t − ( j + k )( m +1)+1 + ( n + m ) j η j A j ∆ 2 z t − 2 j ( m +1) ! (A13) = j X k =1 j X l =1 ( n + m ) k + l − 2 η k + l A k + l z t − ( k + l )( m +1)+2 (A14) + 2 j X k =1 ( n + m ) j + k η j + k A j + k ∆ z t − ( j + k )( m +1)+1 + ( n + m ) 2 j η 2 j A 2 j ∆ 2 z t − 2 j ( m +1) . (A15) In (a) and (b), we applied Eq. ( A10 ) repeatedly . Suppose sufficiently small step size η ≤ 1 / (2( n + m ) λ max ) , then we obtain ∥ ∆ 2 Z t ∥ (A16) a ≤ n + m 2 ( m + 1) j X k =1 j X l =1 ( n + m ) k + l − 2 η k + l λ k + l max + 4( n + m ) j X k =1 ( n + m ) j + k − 1 η j + k λ j + k max + 2(2 n + m + 1)( n + m ) 2 j η 2 j λ 2 j max ! max 2 m ≤ s ≤ 2 j ( m +1) ∥ z t − s ∥ (A17) b = n + m 2 ( m + 1) η 2 λ 2 max 1 − ( n + m ) j η j λ j max 1 − ( n + m ) η λ max 2 + 4( n + m )( n + m ) j η j +1 λ j +1 max 1 − ( n + m ) j η j λ j max 1 − ( n + m ) η λ max + 2(2 n + m + 1)( n + m ) 2 j η 2 j λ 2 j max ! max 2 m ≤ s ≤ 2 j ( m +1) ∥ z t − s ∥ (A18) c ≤ 2(2 n + m )( m + 1) η 2 λ 2 max + 8( n + m ) j +1 η j +1 λ j +1 max + 2(2 n + m + 1)( n + m ) 2 j η 2 j λ 2 j max max 2 m ≤ s ≤ 2 j ( m +1) ∥ z t − s ∥ . (A19) 11 Linear Con vergence in Games with Delayed Feedback via Extra Prediction In (a), we upper-bounded A by λ max and also upper-bounded z t , ∆ z t , and ∆ 2 z t in ∆ 2 Z t as n m +1 X s =1 z t − s + m +1 X s =2 m +1 X r = s z t − r ≤ n m +1 X s =1 ∥ z t − s ∥ + m +1 X s =2 m +1 X r = s ∥ z t − r ∥ (A20) ≤ n + m 2 ( m + 1) max 1 ≤ s ≤ m +1 ∥ z t − s ∥ , (A21) n m +1 X s =1 ∆ z t − s + m +1 X s =2 m +1 X r = s ∆ z t − r = n ( z t − z t − ( m +1) ) + m +1 X s =2 ( z t − s +1 − z t − ( m +1) ) (A22) ≤ n ( ∥ z t ∥ + ∥ z t − ( m +1) ∥ ) + m +1 X s =2 ( ∥ z t − s +1 ∥ + ∥ z t − ( m +1) ∥ ) (A23) ≤ 2( n + m ) max 0 ≤ s ≤ m +1 ∥ z t − s ∥ , (A24) n m +1 X s =1 ∆ 2 z t − s + m +1 X s =2 m +1 X r = s ∆ 2 z t − r = n ( z t +1 − z t ) + ( z t − z t − m ) − ( n + m )( z t − m − z t − ( m +1) ) (A25) ≤ n ( ∥ z t +1 ∥ + ∥ z t ∥ ) + ( ∥ z t ∥ + ∥ z t − m ∥ ) + ( n + m )( ∥ z t − m ∥ + ∥ z t − ( m +1) ∥ ) (A26) ≤ 2(2 n + m + 1) max − 1 ≤ s ≤ m +1 ∥ z t − s ∥ . (A27) In (b), we summed up the geometric series. In (c), we used η ≤ 1 / (2( n + m ) λ max ) . Finally , by Lemma 5.3 ∥ z † t +1 − z t +1 ∥ 2 = ∆ 2 Z T t η 2 ¯ A 2 I + n 2 η 2 ¯ A 2 ∆ 2 Z t (A28) ≤ η 2 λ 2 max 1 + n 2 η 2 λ 2 max ∥ ∆ 2 Z t ∥ 2 (A29) ≤ η 2 λ 2 max ∥ ∆ 2 Z t ∥ 2 (A30) ≤ ER( j, n ) 2 ∥ ∆ 2 Z t ∥ 2 . (A31) D. Proof of Theorem 4.1 By substituting n = 1 and j = 2 , we obtain linear conv ergence rate as LCR WOGD A (2 , 1) = 1 − 1 2 η 2 λ 2 min + 1 2 η 4 λ 4 min + 2( m + 2)( m + 1) η 3 λ 3 max (A32) + 8( m + 1) 3 η 4 λ 4 max + 2( m + 3)( m + 1) 4 η 5 λ 5 max . (A33) For η = 1 / 56( m + 1) 2 κ 2 λ max , this con vergence rate is upper -bounded as LCR WOGD A (2 , 1) = 1 − 1 2 η 2 λ 2 min + 1 2 η 4 λ 4 min + 2( m + 2)( m + 1) η 3 λ 3 max (A34) + 8( m + 1) 3 η 4 λ 4 max + 2( m + 3)( m + 1) 4 η 5 λ 5 max (A35) ≤ 1 − 1 2 η 2 λ 2 min + 1 56 1 2 η 2 λ 2 min + 4 η 2 λ 2 min + 8 η 2 λ 2 min + 6 η 2 λ 2 min (A36) ≤ 1 − 1 6 η 2 λ 2 min (A37) = 1 − 1 6 · 56 2 κ 6 ( m + 1) 4 . (A38) 12 Linear Con vergence in Games with Delayed Feedback via Extra Prediction By the definition of Eq. ( 27 ), this immediately deriv es ∥ z t +1 ∥ ≤ 1 − 1 6 · 56 2 κ 6 ( m + 1) 4 max 0 ≤ s ≤ 4( m +1) ∥ z t − s ∥ (A39) ≤ exp − t 6 · 56 2 κ 6 ( m + 1) 4 max 0 ≤ s ≤ 4( m +1) ∥ z t − s ∥ . (A40) By applying this t times and defining ∥ ˜ z 0 ∥ = max 0 ≤ s ≤ 4( m +1) ∥ z s ∥ , we obtain ∥ z t ∥ ≤ exp − t 6 · 56 2 κ 6 ( m + 1) 4 × 1 4( m + 1) ∥ ˜ z 0 ∥ (A41) = exp − t 4 · 6 · 56 2 κ 6 ( m + 1) 5 ∥ ˜ z 0 ∥ . (A42) This results in Eq. ( 9 ) with positiv e constant c = 4 · 6 · 56 2 . E. Proof of Theorem 4.2 By substituting n = m/ 2 + 1 , we obtain linear con vergence rate as LCR WOGD A ( j, m 2 + 1) = 1 − 1 2 ( m + 1) η 2 λ 2 min + 1 2 m 2 + 1 2 ( m + 1) η 4 λ 4 min (A43) + 4( m + 1) 2 η 3 λ 3 max + 8 3 m 2 + 1 j +1 η j +2 λ j +2 max + 2 m 2 + 3 3 m 2 + 1 2 j η 2 j +1 λ 2 j +1 max . (A44) For η = 1 / (93( m + 1) 2 j 2 j − 1 κ 2 λ max ) , this con vergence rate is upper -bounded as LCR WOGD A ( j, m 2 + 1) = 1 − 1 2 ( m + 1) η 2 λ 2 min + 1 2 m 2 + 1 2 ( m + 1) η 4 λ 4 min + 4( m + 1) 2 η 3 λ 3 max (A45) + 8 3 m 2 + 1 j +1 η j +2 λ j +2 max + 2 (2 m + 3) 3 m 2 + 1 2 j η 2 j +1 λ 2 j +1 max (A46) ≤ 1 − 1 2 ( m + 1) η 2 λ 2 min + 1 62 1 2 ( m + 1) η 2 λ 2 min + 4( m + 1) η 2 λ 2 min (A47) + 8 3 m 2 + 1 η 2 λ 2 min + 2 (2 m + 3) η 2 λ 2 min (A48) ≤ 1 − 1 6 ( m + 1) η 2 λ 2 min (A49) = 1 − 1 6 · 93 2 κ 6 ( m + 1) 1+ 2 2 j − 1 . (A50) By substituting j = ⌊ log ( m + 1) ⌋ + 2 , we obtain LCR WOGD A ( ⌊ log( m + 1) ⌋ + 2 , m 2 + 1) ≤ 1 − 1 6 · 93 2 κ 6 ( m + 1) 1+ 2 2 ⌊ log( m +1) ⌋ +3 (A51) ≤ 1 − 1 6 · 93 2 κ 6 ( m + 1) 1+ 1 log( m +1) (A52) = 1 − 1 6 · 93 2 eκ 6 ( m + 1) . (A53) By the definition of Eq. ( 27 ), this immediately deriv es ∥ z t +1 ∥ ≤ 1 − 1 6 · 93 2 eκ 6 ( m + 1) max 0 ≤ s ≤ 2( ⌊ log( m +1) ⌋ +2)( m +1) ∥ z t − s ∥ . (A54) 13 Linear Con vergence in Games with Delayed Feedback via Extra Prediction By applying this t times and defining ∥ ˜ z 0 ∥ = max 0 ≤ s ≤ 2( m +1)(log( m +1)+2) ∥ z s ∥ , we obtain ∥ z t ∥ ≤ exp − t 6 · 93 2 eκ 6 ( m + 1) × 1 2( ⌊ log( m + 1) ⌋ + 2)( m + 1) ∥ ˜ z 0 ∥ (A55) ≤ exp − t 6 · 93 2 eκ 6 ( m + 1) × 1 2(log( m + 1) + 2)( m + 1) ∥ ˜ z 0 ∥ (A56) ≤ exp − t 2 · 6 · 93 2 eκ 6 ( m + 1) 2 (log( m + 1) + 2) ∥ ˜ z 0 ∥ . (A57) This results in Eq. ( 11 ) with positiv e constant c = 2 · 6 · 93 2 e . 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment