Support Recovery and $\ell_2$-Error Bound for Sparse Regression with Quadratic Measurements via Weakly-Convex-Concave Regularization
The recovery of unknown signals from quadratic measurements finds extensive applications in fields such as phase retrieval, power system state estimation, and unlabeled distance geometry. This paper investigates the finite sample properties of weakly…
Authors: Jun Fan, Jingyu Yang, Xinyu Zhang
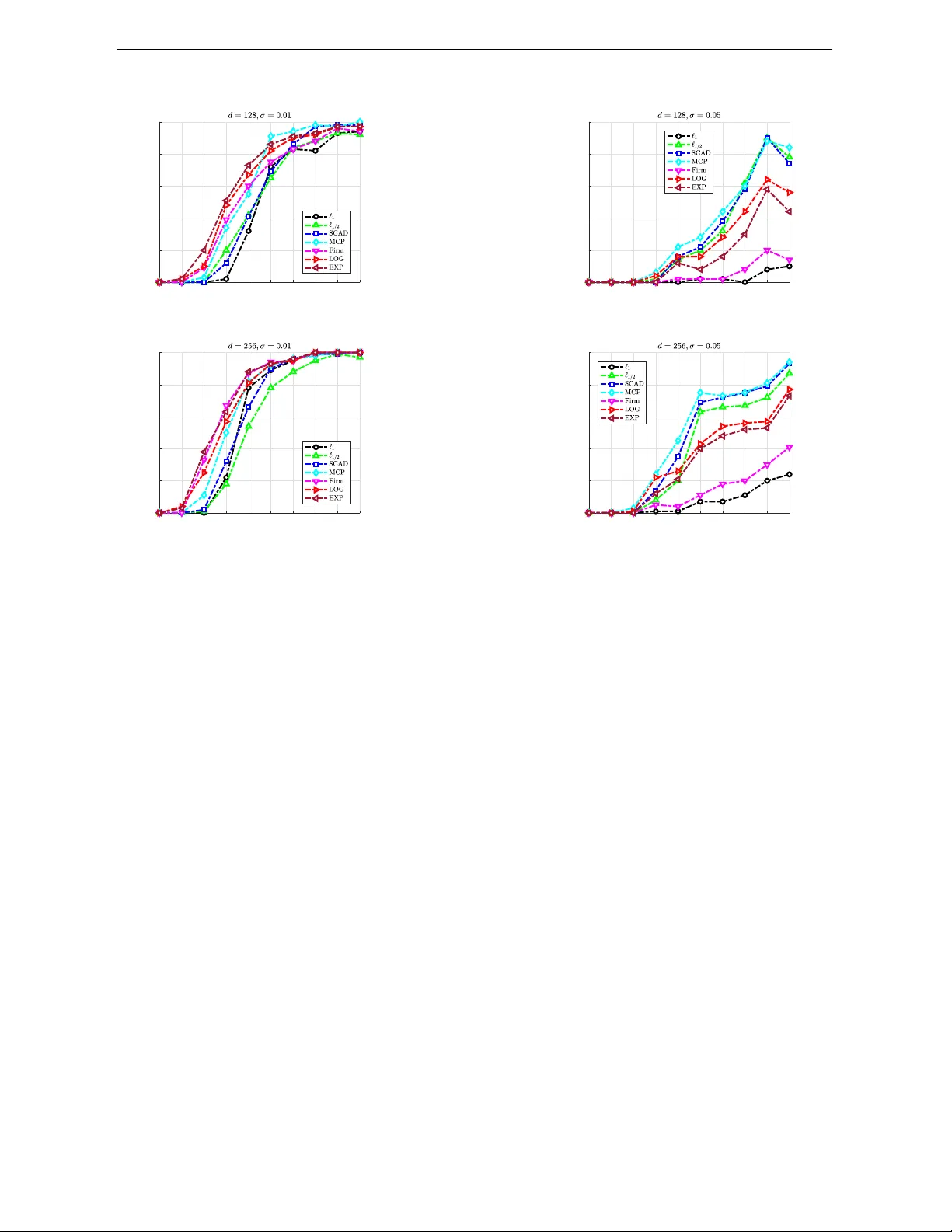
Supp ort Reco v ery and -Error Bound for Sparse Regression with Quadratic Measuremen ts via W eakly-Con v ex-Conca v e Regularization Jun F an, Jingyu Y ang, Xin yu Zhang Sc ho ol of Science, Heb ei Univ ersity of T ec hnolog and Liqun W ang ∗ Departmen t of Statistics, Universit y of Manitoba F ebruary 20, 2026 Abstract The reco v ery of unkno wn signals from quadratic measurements nds extensiv e applications in elds suc h as phase retriev al, p o w er system state estimation, and unlab eled distance geometry . This pap er inv estigates the nite sample prop erties of w eakly con v ex–conca ve regularized estimators in high-dimensional quadratic mea- suremen ts mo dels. By employing a w eakly conv ex–concav e p enalized least squares approac h, w e establish supp ort recov ery and -error b ounds for the lo cal minimizer. T o solve the corresp onding optimization problem, we adopt tw o pro ximal gradient strategies, where the pro ximal step is computed either in closed form or via a weigh ted appro ximation, dep ending on the regularization function. Numerical examples demonstrate the ecacy of the prop osed method. K eywor ds: Noncon vex statistics, Finite sample error bound, Consistency , Optimization algorithm. ∗ Corresp onding author: Liqun.W ang@umanitoba.ca. This work was supp orte d by the National Nat- ur al Scienc e F oundation of China under Gr ants 12571345 and 12271022; and the Natur al Scienc es and Engine ering R ese ar ch Council of Canada under Gr ant 4924-2023. 1 1 INTR ODUCTION 1 In tro duction W e consider the follo wing quadratic measuremen t regression mo del (1) where denotes the observ ed resp onse, is a symmetric design matrix, is the v ector of unkno wn parameters represen ting true signals, and is the random noise. Mo del ( 1 ) arises in numerous applications in physics, engineering, and data science, includ- ing phase retriev al ( Candes et al. 2015 ), generalized phase retriev al ( W ang & Xu 2019 ), the unassigned distance geometry problem ( Huang & Dokmanić 2021 ), and p o wer system state estimation ( W ang et al. 2019 ). Recen t y ears hav e witnessed a surge of in terests and metho dological dev elopmen ts for this mo del. Notable adv ances include Thaker et al. ( 2020 ), Huang et al. ( 2020 ), Chen & Ng ( 2022 ), and F an, Sun, Y an & Zhou ( 2025 ), who prop osed v arious algorithms and theoretical guaran tees of optimal solutions under v arious problem settings. It is w orth noting that when the design matrix can b e decomp osed as a outer pro duct of a real v ector , mo del ( 1 ) is referred to as real-v alued phase retriev al. In this case, it also represents a sp ecial case of the single index mo del, with index and square link function. Single index mo dels are widely used in statistics and econometrics ( Xu et al. 2022 , Y ang et al. 2024 ). In high-dimensional regime where is large or even exceeds , a common assumption is that the true signal is sparse, i.e., only a small num b er of its en tries are non-zero. This sparsit y assumption is crucial for ensuring identiabilit y and statistical eciency , leading to the problem of sparse regression with quadratic measuremen ts. Several studies ha ve explored this c hallenging problem. F or instance, F an et al. ( 2018 ) studied an - regularized least squares metho d, established a weak oracle prop erty and proposed a xed- 2 1 INTR ODUCTION p oin t iterativ e algorithm. Bolte et al. ( 2018 ) called the regularized least squares problem for mo del ( 1 ) quadratic in verse problem and proposed a Bregman proximal gradien t algorithm (PGA). Subsequently , Zhang et al. ( 2023 ) and Ding et al. ( 2025 ) developed Bregman PGA to solv e regularized problems including quadratic in v erse problem as a sp ecial case. While existing literature has primarily fo cused on algorithmic dev elopmen t for the regularized least squares formulation of quadratic in v erse problem (or model ( 1 )), the corresp onding statistical guaran tees remain relativ ely underexplored. More recently , Chen et al. ( 2025 ) emplo y ed the thresholded Wirtinger o w algorithm originally prop osed b y ( Cai et al. 2016 ) for sparse phase retriev al to solv e the regularized least squares problem for mo del ( 1 ). A sp ecial case of sparse quadratic mo del is sparse phase retriev al that attracted considerable atten tion ( Cai et al. 2016 , 2022 , Soltanolk otabi 2019 , Xia & Xu 2021 , Huang & Xu 2024 ). T o address sparse regression in linear mo dels, v arious other regularization techniques hav e b een dev elop ed, such as the p enalt y ( F rank & F riedman 1993 ), the SCAD ( F an & Li 2001 ), and the MCP ( Zhang 2010 ). It is well-kno wn that LASSO has constant deriv ativ e that induces p ersistent shrinkage and biased estimation( Zou 2006 ). In con trast, conca v e penalties (e.g., SCAD, MCP , and ) ha ve deriv atives that v anish for large co ecien ts, thereb y mitigating shrinkage bias and yielding nearly unbiased estimates. Ho w ev er, noncon vex p enalties in tro duces computational challenges. In particular, highly noncon v ex p enalties ma y cause n umerous lo cal minima, and the con vergence of rst-order algorithm (e.g., PGA) relies on fa v orable prop erties of the ob jectiv e function. One such prop ert y is w eak con vexit y , which is a key condition that generally ensures the pro ximal op erator is single-v alued ( W ang 2010 , Khanh et al. 2025 ), under standard tec hnical assump- tions. If this condition is violated, the pro ximal op erator ma y be multi-v alued, which poses a p oten tial risk that iterativ e algorithms could fail to con v erge to a meaningful solution. This c hallenge motiv ates the study of regularizers that balance statistical and computa- 3 1 INTR ODUCTION tional considerations. Loh & W ainwrigh t ( 2015 ) dev elop ed a general statistical analysis for a class of weakly conv ex regularized M-estimators and established nite sample error b ounds b et w een an y stationary p oin t of the p enalized estimator and the p opulation-optimal solution without regularization (i.e., the solution minimizing the exp ected p opulation risk). While their framew ork applies to a wide range of mo dels, including linear and generalized linear mo dels and graphical LASSO, it cannot b e directly applied to sparse quadratic mea- suremen t problems. The main diculty is that the least squares loss for this mo del leads to a highly nonconv ex quartic p olynomial that are computationally v ery c hallenging to minimize. In fact, as p oin ted out by Candes et al. ( 2015 ), it is already known that deter- mining whether a stationary p oin t of a quartic p olynomial is a lo cal minimizer is NP-hard. Moreo v er, Loh & W ainwrigh t ( 2015 ) imp osed an additional constrain t, whic h in tro duces an extra tuning parameter that must b e chosen carefully to ensure that the true v alue is a feasible p oint, thereby further increasing the diculty of solving the problem. W eakly con v ex regularization metho ds hav e also b een widely used in sparse signal recov ery ( Y ang et al. 2019 , K omuro et al. 2022 ) and linear in verse problems ( Sh uma ylov et al. 2024 , Goujon et al. 2024 , Ebner et al. 2025 ), but these w orks do not explicitly exploit concav e penalties. T o mitigate the abov e men tioned numerical issues, in this pap er, we prop ose a specic class of concav e p enalties that also satisfy w eak con v exity , termed W eakly-Con v ex-Conca ve P enalties (W CCP). The ma jor adv antage of this class is that it pro vides a exible framew ork for analyzing lo cal minimizers in sparse quadratic measuremen t problems, combining the statistical b enets of concavit y with the algorithmic guarantees of w eak conv exity . Sp ecically , in this pap er, w e study the regularization problem min (2) where is a tuning parameter that encourages sparsit y , and is a W CCP . As men tioned b efore, model ( 1 ) constitutes a sp ecial case of the single index mo del with a 4 1 INTR ODUCTION kno wn square link function. Therefore, the prop osed metho d ( 2 ) has potential applications for single index models. Our con tributions are threefold. First, w e bridge a notable gap in the literature b y providing the rst systematic statistical analysis of the WCCP-regularized estimator for the quadratic measuremen t model ( 1 ). W e establish rigorous supp ort recov ery guarantees and -error b ounds for its lo cal minimizer. w e deriv e the statistical prop erties of the W CCP-regularized estimator for the quadratic measuremen t mo del ( 1 ) and establish supp ort reco very and tigh t -error b ounds for the lo cal minimizer. Second, w e dev elop iterativ e algorithms tailored to dierent regularization functions that provide con v ergence guarantees. Third, w e demonstrate the eectiveness of our metho d, particularly in the context of sparse phase retriev al, and sho w that it p erforms comparable or b etter than the existing LASSO-based approac hes. The rest of this pap er is organized as follo ws. Section 2 presen ts the assumptions and statistical prop erties of the estimator. Section 3 in tro duces tw o iterativ e algorithms and pro vides a con v ergence analysis. Numerical experiments are presen ted in Section 4. T ech- nical lemmas and proofs are deferred to App endices A and B. Notation F or a v ector , let , , and denote its Euclidean, , and norms, resp ectively . Denote b y the th column of the identit y matrix . F or any matrix , denote max . The submatrix of with rows and columns indexed b y sets and is denoted . The sub v ector of indexed b y is denoted . The th standard basis vector in is denoted . F or a function , we denote its gradien t and Hessian b y and , resp ectively , and its sub dierential b y . Let b e the true parameter v alue, and denote supp 5 2 FINITE SAMPLE ST A TISTICAL RESUL TS . Dene the oracle regularized least square estimator as follows, arg min 2 Finite Sample Statistical Results In this section, w e deriv e the nite sample prop erties and consistency of the w eakly conv ex- conca v e estimator in the high-dimensional case where is large than . W e assume that ln with some constant and denote the n um b er of non-zero elements of the true signal b y . F ollowing literature ( Huang et al. 2008 , F an et al. 2018 ), w e assume that there exists constan ts suc h that min max (3) F urther regarding the observ ed response and design matrix, following F an et al. ( 2018 ), the data are assumed to b e standardized as and (4) F or the regularization function, noise and design matrix, we mak e the following assump- tions. Assumption 1. The r e gularization function is c o or dinate sep ar able: for some sc alar function which satises (i) The function is c onc ave on and ther e exists such that is c onvex. (ii) The function satises and for . 6 2 FINITE SAMPLE ST A TISTICAL RESUL TS (iii) F or , the function is non-de cr e asing and is non-incr e asing in . (iv) The function is dier entiable with derivative for al l , and sub dier en- tiable at , satisfying lim with . The function is lo c al ly Lipschitz c ontinuous in . Compared to the conditions of ( Loh & W ain wright 2017 , Loh 2017 ), Assumption 1 addition- ally requires the p enalt y function to b e conca v e and its deriv ative to b e lo cally Lipschitz con tin uous on the p ositiv e half-line. In fact, the condition used b y ( Loh & W ain wrigh t 2017 , Loh 2017 ) is relaxed enough to include the LASSO p enalt y . As mentioned earlier, conca v e penalties are kno wn to p ossess stronger v ariable selection capabilities. Therefore, w e explicitly emphasize the concavit y of the penalty function in our framework. Com- pared to a general concav e p enalt y , the imp osition of w eak con vexit y here constrains its degree of noncon v exity . As previously men tioned, this ensures the proximal mapping of the p enalt y function remains single-v alued, which is crucial for ac hieving superior algorithmic con v ergence. Combining the second order con tinuous dierentiabilit y of the loss and the assumption ab out the lo cally Lipsc hitz’s con tin uity of enables us to use the general- ized Hessian to verify that a stationary p oin t is a lo cal minimizer. In fact, many concav e p enalties, including SCAD and MCP , possess locally Lipsc hitz contin uous rst deriv ativ es on the p ositive half-line. Moreo v er, in addition to the well-kno wn SCAD and MCP regularizers, sev eral other com- monly used regularizers also satisfy the conditions in Assumption 1, we present a few examples b elo w. Example 1. Firm regularizer ( W o o dw orth & Chartrand 2016 ): where is regularization parameter and is a xed parameter. Assumption 1 holds 7 2 FINITE SAMPLE ST A TISTICAL RESUL TS with and . Example 2. LOG regularizer ( Lob o et al. 2007 ): log where is regularization parameter and is a xed parameter. Assumption 1 holds with and . Example 3. EXP regularizer ( Bradley et al. 1998 ): where is regularization parameter and is a xed parameter. Assumption 1 holds with and . Assumption 2. L et err ors b e indep endent and identic al ly distribute d Sub- Gaussian with varianc e pr oxy , and have zer o me an and p ositive varianc e . Assumption 3. F or any , ther e exist c onstants satisfying that T o establish the nite‑sample prop erties of our prop osed estimator, we rst analyze the oracle estimator , which is dened with prior knowledge of the true supp ort set. The follo wing theorem provides its non‑asymptotic consistency guaran tee. Theorem 1. Under mo del ( 1 ) and A ssumption 1-3, if , then wher e exp ln , ln and max . 8 2 FINITE SAMPLE ST A TISTICAL RESUL TS The condition is non‑restrictive, as the right‑hand side diminishes to near zero for an y practical and , meaning an y nite uniform b ound will automatically satisfy it. Theorem 1 shows that the estimation error of the oracle estimator is bounded by . Under the standard high‑dimensional scaling ln ln , one can choose suc h that , whic h ensures and thus the consistency of as . Building on this oracle result, a standard and necessary step for analyzing the high- dimensional estimator is to imp ose conditions on the design matrix to con trol its column correlations. Assumption 4. Ther e exists a c onstant such that wher e is the K r one cker pr o duct. The inequalities in Assumption 4 are similar to the partial orthogonality condition prop osed b y Huang et al. ( 2008 ) for linear mo dels, which was later extended to quadratic mo dels by F an et al. ( 2018 ). They can b e regarded as that the sub-matrix of corresp onding to and the other complemen tary matrix being orthogonal. Theorem 2. Under mo del ( 1 ) and A ssumption 1-4, supp ose ln (5) and max ln ln ln (6) If and ln (7) then ther e exists a lo c al minimizer of ( 2 ) such that 9 2 FINITE SAMPLE ST A TISTICAL RESUL TS (i) , (ii) min . Remark 1. The conditions in Theorem 2 dene a non‑asymptotic feasible region for the problem dimensions and the regularization parameter , within whic h the desired statistical guaran tees hold with explicit constan ts. F rom an asymptotic p ersp ectiv e ( , allo wing ), these conditions are naturally satised under standard sparsit y assumptions. The inequalities in ( 5 ) impose constrain ts on the scaling b etw een and . The rst in- equalit y , , implies . The remaining t wo inequalities inv olve terms that decay to zero as gro ws and are th us satised for suciently large . The admissible range for in ( 6 ) requires that the lo w er b ound (whic h dominates the noise) do es not exceed the upper bound (whic h preserv es the signal). Under the standard high‑dimensional scaling ln ln and the sparsit y condition , the lo w er bound is while the upp er b ound is . Hence, for large , the admissible in terv al for is non‑empt y . Moreov er, b y choosing to be of the same order as the lo w er b ound (which tends to zero), we ensure and . The upper bound is only needed to con trol the bias in the non‑asymptotic analysis and does not conict with asymptotically . The condition restricts the w eak con v exit y parameter of the p enalty function, ensuring that it does not dominate the curv ature of the loss function. F or t ypical w eakly con v ex p enalties (e.g., SCAD, MCP), is a xed constant. If , the righ t‑hand side gro ws un bounded, so a xed satises the inequality for large ; if remains b ounded, the condition imp oses a mild xed upp er b ound on . The inequalit y ( 7 ) inv olv es ln . Because as 10 3 OPTIMIZA TION ALGORITHM argued ab o v e, we ha ve as , which implies the estimation error b ound in Theorem 2 v anishes asymptotically . In summary , these conditions join tly describ e a regime where sparsit y grows slowly and dimension may grow exp onen tially with , a t ypical setting in high‑dimensional statistics. Therefore, all conditions in Theorem 2 are compatible with b oth nite‑sample guaran tees and asymptotic consistency . Remark 2. F or the sparse phase retriev al problem, Cai et al. ( 2016 ) considered parameter estimation of real-v alued signals b y minimizing the empirical loss function. Their results sho w that the estimator satises min ln as ln . In our result, when the regularization parameter satises ln ln , the error b ound simplies to ln under the assumption that ln ln , whic h sho ws that our estimator attains the kno wn optimal rate for sparse phase retriev al. Recen tly , Huang & Xu ( 2020 ) studied the estimation p erformance of the nonlinear Lasso of phase retriev al. Their results sho w that the estimator satises min . A ccording to Cai et al. ( 2009 ), the error satises ln with high probability as . In this case, the error bound simplies to ln . It is clear that the estimation error exceeds the estimation error b ound established in our w ork. 3 Optimization Algorithm In this section, w e discuss the n umerical computation of the problem to assess the p erfor- mance of the prop osed metho d. Since and are giv en, to simplify notation we denote , so that ( 2 ) is written as min (8) 11 3 OPTIMIZA TION ALGORITHM where and . Noting the term is smo oth and the term is w eakly conv ex-concav e, we emplo y the PGA to solv e the problem. The PGA is an established classical algorithm ( Beck 2017 ) and has been applied in v arious inv erse and optimization problems (e.g., Bolte et al. ( 2018 ), Soltanolkotabi ( 2019 ), Zhang et al. ( 2023 ), F an, Y an, Xiu & Liu ( 2025 )). The core component of PGA is the pro ximal op erator. Giv en a function , recall that the proximal op erator associated with is dened as prox arg min In particular, given a w eigh t vector T with for all , w e denote the pro ximal op erator of the w eighted -norm at by max min where the max and min op erations are p erformed comp onen t-wise. Note that this reduces to the classical soft thresholding op erator prox when for all . F or proximal op erators that does not admit a closed-form solution, we can adopt weigh ted algorithm based on the conca vity of the regularization function. This analysis yields tw o alternative xed-p oin t characterizations of the minimizers as fol- lo ws. Prop osition 1. Ther e exists a c onstant , for any , with sup and , such that for any minimizer of pr oblem ( 2 ) , it satises prox (9) and (10) 12 3 OPTIMIZA TION ALGORITHM wher e the th element of the ve ctor is dene d as max if if Her e is any p ositive numb er. These t wo characterizations pro vide the foundation for our algorithmic design. According to the relationship ( 9 ), the iterativ e sc heme for solving ( 2 ) is outlined in Algorithm 1. F or ( 10 ), the weigh t dep ends on the unknown optimal solution rendering the problem circular and not directly solv able. T o o v ercome this, w e adopt the classic framework of iterativ ely rew eigh ted algorithms ( Zou ( 2006 ), Bai et al. 2024 ). Within this framework, w e employ the Ma jorization-Minimization (MM) tec hnique. At eac h iteration, the regularization term is linearly appro ximated via its rst-order expansion, whic h constructs a surrogate function. This leads to a sequence of subproblems of the form min where is adaptiv ely up dated weigh ts computed from the curren t iterate . The next iterate is then updated according to the rule sp ecied in Algorithm 2, which stems from an approximate minimization step for this surrogate function. It is w orth noting that computing the step size is a crucial step, and its selection depends on the parameter , which is dicult to determine. T o address this, we emplo y the Armijo line searc h method ( 11 ). The existence of such a smallest and the admissible range for are established in Lemma 5 of App endix B. Ha ving established the step size selection strategy , w e no w turn to the con v ergence analysis of the algorithms. Prop osition 2. A ssume that is the se quenc e gener ate d by A lgorithm 1 or 2. Then the fol lowing c onclusions hold, 13 4 NUMERICAL EXPERIMENTS Algorithm 1 Require: Data , parameters Ensure: 1: Initialization: Cho ose a sp ectral initialization point and set 2: Computation: Compute pro x , where and is the smallest nonnegativ e integer suc h that: (11) 3: while max and do 4: Set , go bac k to Step 3 5: end while 6: Output: (i) and b oth ar e monotonic al ly de cr e asing. (ii) lim (iii) Every ac cumulation p oint of the se quenc e gener ate d by A lgorithm 1 satises the xe d-p oint e quation ( 9 ) , and that gener ate d by A lgorithm 2 satises ( 10 ) . 4 Numerical Exp erimen ts In this section, w e examine the nite sample p erformance of the prop osed metho d through n umerical simulations. All experiments are implemen ted in MA TLAB(R2023b) on a laptop with 32GB memory . The MA TLAB co de is av ailable at htt ps: //gi thub .co m/fj math /sp ar seQMR_WCCP . W e compares the p erformance of the SCAD, MCP , Firm, LOG, and EXP regularizers with the and regularizers. The initial p oint is obtained using the sparse sp ec- 14 4 NUMERICAL EXPERIMENTS Algorithm 2 Require: Data , parameters Ensure: 1: Initialization: Cho ose a sp ectral initialization point and set 2: W eight computation: T ake with max if and if 3: Up date: Compute , where and is the smallest nonnegative integer suc h that condition ( 11 ) holds 4: while max and do 5: Set , go bac k to Step 3 6: end while 7: Output: tral initialization metho d prop osed b y Chen et al. ( 2025 ). F or all regularization meth- o ds, the optimal step size is determined using the Armijo line search. The regulariza- tion parameter is c hosen according to the sc heme of Chen & Ng ( 2022 ), dened as ln , where the co ecien t is determined via cross-v alidation. The relative error in the exp erimen ts is computed as follo ws, Relerr min Exp erimen t 1. The sample size is , and the measuremen t matrix is taken to b e a symmetric matrix with Gaussian entries. The noise follo ws a sub-Gaussian distribution. The true signal is generated as a Gaussian random vector. This exp eriment compares the p erformance of WCCP-regularized with the and regularizers under v arying ratios. In the exp eriments, noise is added to the measurements . Regarding the signal dimension and sparsity level , w e consider t w o cases: and . F or and , the reco v ery of the unkno wn signal is considered 15 4 NUMERICAL EXPERIMENTS successful when the error is b elow and resp ectiv ely . The measurement ratios are set as , with eac h exp eriment run 100 times. The performance is ev aluated based on success rate and a verage relative error, with the latter is calculated only for successful trials. F urthermore, Supplementary T ables S1–S8 conrm that as approac hes 1, several WCCP regularizers—particularly SCAD and MCP—achiev e low er relativ e errors and higher stability than and , while b eing orders of magnitude faster. In contrast, Firm, LOG and EXP incur substantially higher computational costs. Ov erall, SCAD and MCP oer the best trade‑o betw een accuracy and eciency . Figure 1 illustrates the curv es of success rate as functions of the ratio . The results conrm that WCCP methods generally outp erform regularization and are comp etitive with . The SCAD and MCP p enalties achiev e the highest success rates, esp ecially as increases. Other W CCP members (Firm, LOG, and EXP) also exhibit strong p erformance, with LOG and EXP proving particularly robust across noise lev els. Detailed mean squared error and v ariance results for all measuremen t ratios are pro vided in App endix C (T ables 5- 12). These results sho w that as approac hes 1, our works exhibits sup erior relativ e-error p erformance. Therefore, our method is more stable in identifying the sparse supp ort. Exp erimen t 2. This exp eriment demonstrates the p erformance of WCCP-regularized metho d in the sparse phase retriev al problem. The proximal op erator of the EXP regular- izer is computationally exp ensiv e; therefore, Algorithm 2 is used to solv e the problem in this exp eriment. The sparse test signal is generated from the standard test image ”camera- man.tif ” (a v ailable in MA TLAB’s image processing to olbox) follo wing the w a v elet-based sparsication pro cedure Jagatap & Hegde ( 2018 ) and Shah & Hegde ( 2021 ). Our implemen- tation adapts the publicly av ailable co de from Shah & Hegde ( 2021 ): w e resize the image to 64×64 pixels, apply a 4-level Haar wa velet transform, and retain only the top of the co ecien ts b y magnitude. This diers from Shah & Hegde ( 2021 ) in b oth the test image 16 4 NUMERICAL EXPERIMENTS 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 n/d 0 0.2 0.4 0.6 0.8 1 Success rate 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 n/d 0 0.1 0.2 0.3 0.4 0.5 Success rate 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 n/d 0 0.2 0.4 0.6 0.8 1 Success rate 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 n/d 0 0.2 0.4 0.6 0.8 1 Success rate Figure 1 used and the sparsity criterion (p ercentage-based vs. xed coun t). In the exp erimen ts, noise is added to the measuremen ts. The comprehensive numerical exp eriments demonstrate the clear adv an tages of W CCP- regularized metho ds ov er traditional approac hes for sparse phase retriev al. As sho wn in T ables 1 and 3 , WCCP metho ds, particularly SCAD and MCP , consisten tly achiev e near- p erfect reconstruction (SSIM 0.9992) across all noise lev els and measurement ratios, while traditional and metho ds sho w signicant p erformance degradation, esp ecially under high noise conditions and lo w measuremen t ratios. Notably , MCP ac hiev es p er- fect reconstruction at measuremen t ratio , whereas requires to reac h comparable qualit y , demonstrating the sup erior sparse reco v ery capability of WCCP regularizers. In addition to enhanced reconstruction qualit y , WCCP metho ds oer substan tial compu- 17 A PR OOFS OF THEOREM 1 AND 2 tational adv antages. As evidenced in T ables 2 and 4 , SCAD and MCP complete recon- struction tasks in signican tly less time compared to regularization, while main taining sup erior accuracy . F or instance, at noise lev el , requires 139.08 seconds while SCAD and MCP complete in only 0.61 and 0.58 seconds resp ectively . These results con- rm that WCCP-regularized metho ds provide an ecient and robust framework for sparse signal recov ery , making them particularly suitable for practical applications requiring high- qualit y reconstruction under challenging conditions. (a) Original Image (256×256) Original resolution (b) Resized Image (64×64) Used in sparse phase retrieval experiments (c) Sparsified Image (64×64, 5% coeff.) Ground truth for SSIM evaluation Figure 2 A Pro ofs of Theorem 1 and 2 Without loss of generalit y , let and , and then denote F or con venience, we denote where . Since is lo cally Lipsc hitz con tin uous on , b y Rademac her’s theorem, the second deriv ative exists almost everywhere. F or any 18 A PR OOFS OF THEOREM 1 AND 2 T able 1: Structural Similarit y Index (SSIM) p erformance of sparse regularization metho ds at dierent noise lev els (measurement ratio ) Method Noise Level 0 1 L1 0.8142 (0.3295) 0.8410 (0.3246) 0.8020 (0.3508) 0.8805 (0.2901) 0.8416 (0.3238) 0.8825 (0.2848) 0.7733 (0.3554) SCAD 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) MCP 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9597 (0.1765) 0.9582 (0.1831) 0.9614 (0.1690) 0.9992 (0.0000) 0.9197 (0.2446) 0.9577 (0.1855) 0.9221 (0.2373) Firm 0.8787 (0.2960) 0.9564 (0.1912) 0.7615 (0.3731) 0.8071 (0.3422) 0.8418 (0.3231) 0.9206 (0.2424) 0.8782 (0.2956) LOG 0.9212 (0.2401) 0.9992 (0.0000) 0.9992 (0.0000) 0.9191 (0.2466) 0.9591 (0.1792) 0.9992 (0.0000) 0.9591 (0.1793) EXP 0.8353 (0.3372) 0.8310 (0.3453) 0.7186 (0.3931) 0.8468 (0.3129) 0.8371 (0.3337) 0.9122 (0.2675) 0.7116 (0.4023) T able 2: Computational time of sparse regularization metho ds at dieren t noise levels (measuremen t ratio ) Method Noise Level 0 1 L1 1.7725 1.9901 139.0842 1.9897 1.8820 1.9666 1.3740 SCAD 0.5458 0.6096 0.6105 0.5703 0.5774 0.5958 0.7209 MCP 0.5206 0.5516 0.5760 0.5341 0.5313 0.7673 0.6821 0.4745 0.5401 0.5185 0.5150 0.4807 0.4364 0.3899 Firm 0.6950 0.7791 0.7060 0.6844 0.6630 84.0347 0.5769 LOG 1.1945 1.3752 1.3729 1.1638 1.2105 1.3171 0.9131 EXP 1.1392 15.2622 1.1028 1.1917 1.1054 1.2542 0.8009 19 A PR OOFS OF THEOREM 1 AND 2 T able 3: Structural Similarity Index (SSIM) p erformance at dieren t measuremen t ratios (noise level ) Method Measurement Ratio 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 L1 0.1255 (0.0708) 0.4185 (0.2080) 0.6918 (0.3482) 0.8556 (0.2946) 0.8875 (0.2736) 0.8916 (0.2631) 0.9647 (0.1541) 0.9992 (0.0000) 0.9646 (0.1543) SCAD 0.4886 (0.0312) 0.6165 (0.0409) 0.9082 (0.1958) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) MCP 0.4614 (0.0298) 0.5978 (0.0347) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.2317 (0.1600) 0.6062 (0.0509) 0.9019 (0.2536) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) Firm 0.0820 (0.0823) 0.5535 (0.3544) 0.7897 (0.3724) 0.9112 (0.2708) 0.9287 (0.2172) 0.9648 (0.1535) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) LOG 0.2770 (0.1481) 0.5740 (0.1302) 0.8487 (0.2430) 0.9180 (0.2500) 0.9614 (0.1689) 0.9259 (0.2256) 0.9992 (0.0000) 0.9992 (0.0000) 0.9992 (0.0000) EXP 0.0564 (0.0198) 0.1998 (0.1355) 0.7809 (0.3571) 0.7959 (0.3620) 0.8439 (0.3187) 0.8873 (0.2733) 0.9292 (0.2156) 0.9992 (0.0000) 0.9992 (0.0000) T able 4: Computational time at dierent measuremen t ratios (noise level ) Method Measurement Ratio 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 L1 0.8037 1.5078 1.9668 1.9321 2.0649 2.0567 2.1940 2.3576 2.3357 SCAD 0.3875 0.4539 0.5693 0.5984 0.6111 0.6245 0.6540 0.6864 0.7105 MCP 0.3673 0.4219 0.5328 0.5630 0.5906 0.5945 0.6095 0.6428 0.6673 0.3269 0.3634 0.4327 0.4728 0.5130 0.5303 0.5673 0.5848 0.6059 Firm 0.4306 0.5050 0.6558 0.6647 0.6916 0.7159 0.7635 0.7762 0.8061 LOG 0.7325 0.8526 1.0285 1.1950 1.3259 1.4074 1.5055 1.5480 1.6134 EXP 0.7063 0.8373 1.0086 1.1550 1.2877 1.3680 1.4670 1.5155 1.5763 20 A PR OOFS OF THEOREM 1 AND 2 , the Clarke generalized second-order deriv ative of at is dened as co lim exists where co denotes the conv ex h ull (all conv ex com binations of the set). Moreov er, since is -weakly conv ex, its Clarke generalized second-order deriv ative satises The following lemma is analogous to Lemma 3.1 in F an, Sun, Y an & Zhou ( 2025 ) but uses a dieren t tail b ound for the noise term, whic h leads to a slightly dierent probabilit y lo w er b ound and a dierent constan t in the deviation inequalit y . Lemma 1. Under A ssumptions 2-4, if and it fol lows that exp ln wher e the event is dene d by sup ln Pr o of. The pro of follows the same structure as Lemma 3.1 in F an, Sun, Y an & Zhou ( 2025 ). The only dierence is our c hoice of the parameter when b ounding via Bernstein’s inequalit y . While F an, Sun, Y an & Zhou ( 2025 ) uses , w e take ln . This yields a dieren t tail probability and, under the condition , leads to the deviation inequalit y sup ln W e no w detail the mo died steps. By Assumption 2 and Lemma 1.12 of Rigollet & Hütter ( 2017 ), is sub‑exponential with parameter . Applying Bernstein’s inequalit y (Theorem 1.13 in Rigollet & Hütter ( 2017 )) with ln , we obtain ln exp ln 21 A PR OOFS OF THEOREM 1 AND 2 Since (due to the sub‑Gaussian prop erty), it follo ws that ln (12) The remaining argumen ts are identical to those in F an, Sun, Y an & Zhou ( 2025 ). In particular, with probability at least exp ln , sup ln ln Using , we hav e ln ln ln ln whic h implies ln ln . Consequently , sup ln ln This completes the proof. Pro of of Theorem 1 Without loss of generality , w e assume . Subsequen tly , it is easy to verify . Consider the lev el set . It is clear that inf inf Since is contin uous and the level set is compact, there exists at least one minimizer in the level set. Noting that condition (iv) of Assumption 1 implies that all sub-dieren tial and deriv atives of are b ounded in magnitude b y , we get (13) 22 A PR OOFS OF THEOREM 1 AND 2 A ccording to the denition of , for any , Then we get Com bining the inequality ( 13 ), w e obtain Under the even t , we get ln whic h yields that ln ln (14) 23 A PR OOFS OF THEOREM 1 AND 2 where max . Combing this and Lemma 1 , w e get the desired result. T o pro ve Theorem 2, w e also need the following lemma. Lemma 2. Dene max sup ln with ln ln . Under A ssumptions 2-4, it fol lows that Pr o of. Let . Then follo ws from the Lemma 14.27 of Bühlmann & V an De Geer ( 2011 ) that there exist v ectors with and suc h that Using this fact, w e obtain the follo wing inequalities max sup max sup max max max sup (15) Noting the fact that for any matrix and vectors , one can conclude from ( 4 ) that (16) for any . 24 A PR OOFS OF THEOREM 1 AND 2 F or the rst term of ( 15 ), we can apply the coun table subadditivit y of probabilit y , Bern- stein’s inequality , inequalit y ( 16 ) and to obtain, for an y , max max exp exp exp ln ln T aking , we drive max max F or the second term of ( 15 ), we can calculate that max sup max sup max sup sup (17) Com bing this, inequalities ( 12 ), ( 15 ) and ( 17 ), get the desired result. 25 A PR OOFS OF THEOREM 1 AND 2 Lemma 3. Under A ssumptions 2-4, it fol lows that wher e the event is dene d by max ln ln Pr o of. F rom Bernstein’s inequality , ( 16 ) and ( 3 ), w e can conclude that max exp exp exp ln By taking ln ln , we subsequently obtain max Then, we get the desired result. By combining the ideas from the pro ofs of Theorem 3.3 in Chen et al. ( 2013 ) and Theorem 2.4 in Bai et al. ( 2024 ), w e deriv e the following result. Lemma 4. Supp ose A ssumption 1 holds. L et b e a stationary p oint of Pr oblem ( 2 ) , i.e., If for any nonzer o ve ctor with for al l , min (18) then is a strict lo c al minimum of Pr oblem ( 2 ) . 26 A PR OOFS OF THEOREM 1 AND 2 Pro of of Theorem 2 A ccording to Theorem 1, we can obtain the existence of a estimator , and the error b ound betw een and is . Let be a vector with and . Firstly , w e prov e that is a stationary point of Problem ( 2 ), i.e., (19) By simple caiculation, w e hav e Since w e only need to prov e It suces to pro ve that (20) since . Noting w e get (21) W e rst estimate the upper b ound of the rst term on the righ t-hand side of the ab o v e inequalit y . Using again the fact that for an y matrix and 27 A PR OOFS OF THEOREM 1 AND 2 v ectors , we conclude from Hölder’s inequalit y , Assumption 4 and ( 3 ) that max max max max max max max (22) if the ev ent o ccurs. Here, the fth inequality relies on the b ounds and . The rst b ound follows from ( 14 ) under even t . The second is a consquence of conditions ( 7 ) and whic h together imply W e pro ceed to estimate the upp er b ound of the second term on the right-hand side of inequalit y ( 21 ). Notice that max max max 28 A PR OOFS OF THEOREM 1 AND 2 max sup max ln ln under the even t . Therefore, com bining the ab ov e inequalit y , inequalities ( 21 ) and ( 22 ), we get ln ln ln (23) under the even t . On the other hand, note that the left inequality of condition ( 7 ) results in ln ln (24) By the rst inequalit y of condition ( 5 ), w e get whic h together with the left inequalit y of condition ( 7 ) also leads to ln ln ln By simple calculation, w e get ln ln ln ln ln ln ln ln ln ln 29 A PR OOFS OF THEOREM 1 AND 2 where the last ineauality follo ws from the second inequality of condition ( 5 ). Com bing this and the inequality ( 24 ) enable us to get ln ln ln By simple calculation, w e get ln ln ln ln ln ln ln where the last ineauality follo ws from the second inequality of condition ( 6 ). Com bing this and the inequality ( 24 ) enable us to get ln ln Considering ln ln ln ln ln ln where rst inequality deriv es from (resulting in ln ) and ln ln ln and the last ineauality follo ws from the second inequalit y of condition ( 6 ). Combing this and the inequality ( 24 ) enable us to get ln By these inequalities, the denition of and inequality ( 23 ), we get ( 20 ) under the ev ent . Next, we prov e that is a lo cal minimizer if the even t o ccurs. Based on Lemma 4 , it suces to prov e that satises condition ( 18 ). Note that the conv exity of implies min for an y 30 A PR OOFS OF THEOREM 1 AND 2 and hence min On the other hand, a simple calculation yields that min min Therefore, it remains to pro v e that for an y nonzero v ector with for all , (25) W e no w pro ceed to pro ve this inequalit y . Since sup w e ha v e ln if the even t o ccurs. Notice that Com bining these tw o inequalities and Assumption 3, under the ev ent , we ha v e for an y 31 A PR OOFS OF THEOREM 1 AND 2 non-zero vector with for all , ln ln ln ln ln ln where the fth inequalit y follo ws from and . Com bing the ab o v e inequalit y and the condition and ( 6 ), w e get ( 25 ) under the ev en t . Ov erall, we prov e that is a lo cal minimizer under the even t . By Lemmas 1 , 2 and 2 , we complete the pro of. 32 B PR OOFS OF PROPOSITIONS 1 AND 2 B Pro ofs of Prop ositions 1 and 2 Pro of of Prop osition 1 Based on the similar pro of metho d to that of Theorem 5 in F an et al. ( 2018 ), it is easy to pro v e equation (3.6) and th us it is omitted. W e mainly pro v e equation (3.7). F or an y , dene the follo wing auxiliary function (1) where max if if It is clear that minimizing ( 3 ) with resp ect to is equiv alent to the follo wing minimization problem min (2) F or any , let and sup Then for an y and , we hav e max 33 B PR OOFS OF PROPOSITIONS 1 AND 2 where and for some . The rst inequality follo ws from the conca vity of , the second inequalit y follows from the upp er bound of and the third inequality follo ws from . Assuming arg min and arg min , then w e get hence arg min . It means that is also a minimizer of the problem ( 2 ) with . It is clear that problem ( 2 ) can b e solved using the soft-thresholding op erator , therefore w e can get ( 10 ). T o pro ve Prop osition 2 , we also need the follo wing lemma. Lemma 5. L et , sup wher e F or any , dene if [ log ] otherwise Then ( 11 ) holds, and ther e exists a nonne gative inte ger such that Pro of sketc h The pro of follows the same structure as that of Lemmas 8 and 9 in F an et al. ( 2018 ). The core function is iden tical. Although the regularizer considered here (a w eakly con vex concav e regularizer or a w eigh ted p enalt y) diers in form from the regularizer in F an et al. ( 2018 ), the argument relies only on the co ercivit y of the regularizer and the nonexpansiveness of the proximal op erator, b oth of whic h hold in our setting. Consequently , the entire line of reasoning applies directly , and detailed calculations are omitted. Pro of of Prop osition 2 Regarding Algorithm 1, based on the similar pro of metho d to that of Theorem S3.1 in F an et al. ( 2018 ), it is easy to prov e it and so is omitted. The 34 B PR OOFS OF PROPOSITIONS 1 AND 2 conclusion for Algorithm 2 is pro ved b elo w, where the pro of of (i) follo ws the approac h of Prop osition 3.2 in Bai et al. ( 2024 ). F or any , dene the follo wing auxiliary function (3) where max if if Notice that the iteration is equiv alent to arg min Hence the sequence is b ounded b ecause ev ery entry of is p ositiv e, and from Lemma 5 . Then there exists a positive constant suc h that sup . (i) F rom the conv avit y of for any , w e conclude that (4) where the second inequality follows from lim and . A dditionally , from the T a ylor expansion, it follows that (5) 35 B PR OOFS OF PROPOSITIONS 1 AND 2 Com bining ( 4 ) and ( 5 ), w e can get (6) F or eac h subproblem, staises the optimal condition whic h implies that there exists an v ector suc h that (7) where . Therefore, we obtain where the inequalit y follo ws from the con vexit y of and , and the last equalit y deriv es from ( 7 ). Com bining this and ( 6 ), w e get (8) 36 B PR OOFS OF PROPOSITIONS 1 AND 2 (ii) F rom the denition of and ( 8 ), we ha v e Hence, , whic h implies lim . (iii) Because and ha ve conv ergent subsequences, without loss of generality , as- sume that and as (9) and denote with max if if It is known that the iteration Then for an y , Com bing the contin uousness of the function and the limit ( 9 ), w e can obtain lim lim Based on the abov e inequality , we get arg min A ccording to the Prop osition 1, it means that is also satises Then, we complete the proof. 37 REFERENCES C A dditional n umerical results T able 5: MSE(SD) of relative error for and SCAD MCP Firm LOG EXP 0.1 MSE 1.091 (0.1414) 1.114 (0.1394) 1.091 (0.1646) 1.111 (0.1571) 1.152 (0.1743) 1.166 (0.1704) 1.187 (0.1779) 0.2 MSE 1.068 (0.1778) 1.108 (0.1568) 1.042 (0.1955) 1.03 (0.2445) 1.12 (0.3158) 1.133 (0.2951) 1.122 (0.349) 0.3 MSE 0.9705 (0.293) 1.052 (0.2643) 0.9269 (0.2784) 0.8665 (0.3783) 0.7603 (0.6056) 0.9416 (0.4998) 0.823 (0.5875) 0.4 MSE 0.5529 (0.5201) 0.7402 (0.4788) 0.6218 (0.407) 0.4724 (0.4664) 0.4097 (0.5788) 0.5031 (0.5934) 0.4627 (0.6022) 0.5 MSE 0.3079 (0.5235) 0.4849 (0.5386) 0.4257 (0.4788) 0.3526 (0.477) 0.2461 (0.4983) 0.2959 (0.5359) 0.2387 (0.4991) 0.6 MSE 0.05125 (0.2487) 0.2159 (0.4243) 0.2071 (0.3718) 0.06997 (0.2575) 0.04582 (0.2242) 0.08147 (0.2997) 0.04663 (0.2289) 0.7 MSE 0.07634 (0.302) 0.08627 (0.316) 0.1135 (0.3098) 0.05085 (0.2215) 0.07238 (0.2859) 0.07605 (0.3014) 0.05124 (0.2502) 0.8 MSE 0.01417 (0.1356) 0.008939 (0.08315) 0.02032 (0.141) 0.01137 (0.1108) 0.0005478 (0.0003627) 0.0003913 (0.0003058) 0.0004205 (0.0003104) 0.9 MSE 0.01311 (0.1256) 0.02341 (0.1631) 0.01126 (0.1101) 0.02173 (0.1514) 0.01205 (0.1157) 0.01312 (0.1279) 0.012 (0.1164) 1.0 MSE 0.0005213 (0.0002837) 0.0004813 (0.0008072) 0.008467 (0.08181) 0.0002522 (0.0001432) 0.0004765 (0.0002836) 0.0003329 (0.0002278) 0.0003577 (0.0002334) References Bai, L., Hu, Y., W ang, H. & Y ang, X. (2024), ‘A v oiding strict saddle p oin ts of noncon v ex regularized problems’, arXiv pr eprint . Bec k, A. (2017), First-or der metho ds in optimization , SIAM. Bolte, J., Sabach, S., T eb oulle, M. & V aisb ourd, Y. (2018), ‘First order metho ds b eyond con v exit y and lipsc hitz gradient con tinuit y with applications to quadratic in v erse prob- lems’, SIAM Journal on Optimization 28 (3), 2131–2151. Bradley , P . S., Mangasarian, O. L. & Street, W. N. (1998), ‘F eature selection via mathe- matical programming’, INFORMS Journal on Computing 10 (2), 209–217. Bühlmann, P . & V an De Geer, S. (2011), Statistics for high-dimensional data: metho ds, the ory and applic ations , Springer Science & Business Media. 38 REFERENCES REFERENCES T able 6: MSE(SD) of relative error for and SCAD MCP Firm LOG EXP 0.1 MSE 1.085 (0.1328) 1.106 (0.1324) 1.087 (0.1423) 1.101 (0.1628) 1.153 (0.1718) 1.16 (0.1624) 1.175 (0.1777) 0.2 MSE 1.049 (0.1958) 1.101 (0.1642) 1.021 (0.2048) 1.043 (0.2243) 1.094 (0.3356) 1.121 (0.2632) 1.13 (0.342) 0.3 MSE 0.8273 (0.3511) 0.9234 (0.3213) 0.8148 (0.3337) 0.7896 (0.3815) 0.6387 (0.593) 0.6949 (0.5856) 0.6682 (0.612) 0.4 MSE 0.6436 (0.5085) 0.8282 (0.4484) 0.6899 (0.395) 0.5693 (0.4823) 0.4613 (0.5924) 0.59 (0.5957) 0.5024 (0.607) 0.5 MSE 0.243 (0.4811) 0.509 (0.5236) 0.4271 (0.471) 0.2844 (0.4427) 0.2429 (0.4918) 0.2886 (0.5111) 0.205 (0.4681) 0.6 MSE 0.203 (0.4607) 0.2593 (0.493) 0.2211 (0.405) 0.1493 (0.3698) 0.174 (0.4275) 0.1916 (0.454) 0.1882 (0.4472) 0.7 MSE 0.02853 (0.1732) 0.07949 (0.2845) 0.08671 (0.2745) 0.02283 (0.1482) 0.02904 (0.1793) 0.03935 (0.211) 0.04164 (0.2227) 0.8 MSE 0.003159 (0.002873) 0.03442 (0.1868) 0.05568 (0.2171) 0.02166 (0.1408) 0.002817 (0.002608) 0.0135 (0.1145) 0.01544 (0.1327) 0.9 MSE 0.0153 (0.1272) 0.01504 (0.1357) 0.01208 (0.1083) 0.01222 (0.1099) 0.01495 (0.1276) 0.01413 (0.1258) 0.01482 (0.1317) 1.0 MSE 0.002603 (0.001302) 0.0154 (0.1383) 0.01241 (0.1108) 0.01251 (0.112) 0.01539 (0.1304) 0.01415 (0.1254) 0.001726 (0.0009298) T able 7: MSE(SD) of relative error for and SCAD MCP Firm LOG EXP 0.1 MSE 1.121 (0.06421) 1.143 (0.05974) 1.138 (0.09982) 1.144 (0.07845) 1.18 (0.1058) 1.231 (0.08987) 1.263 (0.1073) 0.2 MSE 1.103 (0.15) 1.147 (0.1259) 1.062 (0.2094) 1.049 (0.2355) 1.087 (0.3919) 1.165 (0.3045) 1.15 (0.377) 0.3 MSE 0.9678 (0.3185) 1.101 (0.2053) 0.8716 (0.3311) 0.866 (0.3872) 0.7233 (0.6405) 0.8856 (0.5504) 0.7427 (0.6431) 0.4 MSE 0.5304 (0.5944) 0.8253 (0.482) 0.5715 (0.497) 0.4767 (0.5222) 0.3911 (0.5887) 0.5146 (0.6151) 0.4587 (0.6179) 0.5 MSE 0.2341 (0.476) 0.4294 (0.534) 0.293 (0.4405) 0.1878 (0.4069) 0.1399 (0.3996) 0.2263 (0.4728) 0.1496 (0.4082) 0.6 MSE 0.1276 (0.3851) 0.1752 (0.4071) 0.1024 (0.3097) 0.08888 (0.3035) 0.07372 (0.2932) 0.08987 (0.3296) 0.08984 (0.329) 0.7 MSE 0.06553 (0.2857) 0.08276 (0.3045) 0.04321 (0.2121) 0.04276 (0.21) 0.06264 (0.2731) 0.06505 (0.2842) 0.05078 (0.2491) 0.8 MSE 0.0003446 (0.000144) 0.02425 (0.1695) 0.01038 (0.1022) 0.02158 (0.1507) 0.0003082 (0.0001376) 0.0002127 (0.0001035) 0.0002275 (0.0001077) 0.9 MSE 0.0002978 (0.0001248) 0.0001692 (0.0001473) 0.01013 (0.09999) 0.0001356 (6.212e-05) 0.0002639 (0.0001202) 0.0001809 (9.108e-05) 0.0001931 (9.303e-05) 1.0 MSE 0.0002786 (0.0001441) 0.0001873 (0.0002725) 0.0001275 (6.871e-05) 0.0001276 (7.027e-05) 0.0002492 (0.0001398) 0.0001706 (0.0001048) 0.0001842 (0.0001158) 39 REFERENCES REFERENCES T able 8: MSE(SD) of relative error for and SCAD MCP Firm LOG EXP 0.1 MSE 1.129 (0.07115) 1.151 (0.06742) 1.153 (0.07808) 1.175 (0.09573) 1.192 (0.1179) 1.245 (0.09804) 1.273 (0.1223) 0.2 MSE 1.12 (0.1201) 1.169 (0.09863) 1.114 (0.1472) 1.094 (0.2043) 1.221 (0.2625) 1.227 (0.2284) 1.219 (0.3407) 0.3 MSE 0.9922 (0.2916) 1.091 (0.2339) 0.9472 (0.2679) 0.9405 (0.3577) 0.8092 (0.6053) 0.95 (0.5133) 0.8946 (0.5978) 0.4 MSE 0.4294 (0.5732) 0.8253 (0.4619) 0.5233 (0.4976) 0.431 (0.5097) 0.3336 (0.5659) 0.4446 (0.6011) 0.3967 (0.6094) 0.5 MSE 0.2368 (0.4876) 0.5002 (0.5624) 0.2478 (0.4343) 0.1508 (0.3751) 0.1756 (0.4334) 0.2441 (0.4929) 0.2194 (0.4847) 0.6 MSE 0.05631 (0.2677) 0.1342 (0.3705) 0.1246 (0.3398) 0.05633 (0.2435) 0.06604 (0.2818) 0.07899 (0.3117) 0.06739 (0.29) 0.7 MSE 0.01509 (0.1325) 0.01446 (0.1328) 0.01168 (0.1076) 0.02301 (0.156) 0.01473 (0.1312) 0.02736 (0.1845) 0.01441 (0.132) 0.8 MSE 0.001777 (0.0008609) 0.01031 (0.09262) 0.01142 (0.106) 0.000823 (0.0004187) 0.001569 (0.0008123) 0.00113 (0.0006776) 0.00119 (0.0006817) 0.9 MSE 0.001553 (0.0006901) 0.0008882 (0.0005476) 0.01075 (0.09993) 0.000747 (0.0003353) 0.001367 (0.0006242) 0.0009917 (0.0004932) 0.001044 (0.0004984) 1.0 MSE 0.00136 (0.0005866) 0.0007221 (0.0004205) 0.0006343 (0.0002849) 0.0006249 (0.0002817) 0.0012 (0.0005614) 0.0008326 (0.0004163) 0.0008955 (0.0004457) T able 9: Mean Time (SD) for and SCAD MCP Firm LOG EXP 0.1 Time 0.03377 (0.01813) 0.1205 (0.09658) 0.01371 (0.007892) 0.01626 (0.01263) 0.1419 (0.09485) 0.3334 (0.1808) 0.55 (0.3274) 0.2 Time 0.02298 (0.007626) 0.05555 (0.02541) 0.003957 (0.00106) 0.005396 (0.009777) 0.06276 (0.03421) 0.08763 (0.01004) 0.2456 (0.1286) 0.3 Time 0.07842 (0.04432) 0.0535 (0.05498) 0.006069 (0.003454) 0.00785 (0.007068) 0.07034 (0.07559) 0.1158 (0.06931) 0.519 (0.3738) 0.4 Time 0.341 (0.1211) 0.1132 (0.08343) 0.02539 (0.01485) 0.04185 (0.04007) 0.1626 (0.1324) 0.2637 (0.2602) 1.015 (1.207) 0.5 Time 0.6451 (0.1132) 0.1928 (0.1897) 0.0556 (0.02597) 0.06179 (0.06821) 0.1708 (0.0657) 0.2991 (0.3289) 1.042 (1.746) 0.6 Time 0.5028 (0.1514) 0.1376 (0.1614) 0.05767 (0.02264) 0.05976 (0.02864) 0.1421 (0.04185) 0.1573 (0.2019) 0.3919 (0.93) 0.7 Time 0.3975 (0.1663) 0.1015 (0.1064) 0.07437 (0.07595) 0.08195 (0.1162) 0.1253 (0.03575) 0.1538 (0.2255) 0.3738 (1.007) 0.8 Time 0.3499 (0.1075) 0.09129 (0.03348) 0.07957 (0.03062) 0.07738 (0.03206) 0.142 (0.03733) 0.1259 (0.1176) 0.1909 (0.06753) 0.9 Time 0.3183 (0.1172) 0.0907 (0.03449) 0.09587 (0.1122) 0.1031 (0.1207) 0.1454 (0.02508) 0.1609 (0.2382) 0.2925 (0.9214) 1.0 Time 0.303 (0.05565) 0.1067 (0.0494) 0.1029 (0.0561) 0.1073 (0.0597) 0.1552 (0.03678) 0.1841 (0.2233) 0.1944 (0.06617) 40 REFERENCES REFERENCES T able 10: Mean Time (SD) for and SCAD MCP Firm LOG EXP 0.1 Time 0.01993 (0.01462) 0.07793 (0.06112) 0.00739 (0.00417) 0.008899 (0.005657) 0.08419 (0.06419) 0.1891 (0.09824) 0.2951 (0.1907) 0.2 Time 0.1336 (0.04051) 0.3351 (0.1643) 0.02581 (0.01689) 0.02901 (0.0108) 0.4944 (0.2485) 0.61 (0.1112) 1.245 (0.4835) 0.3 Time 0.3753 (0.1275) 0.2123 (0.1632) 0.0257 (0.01092) 0.04378 (0.08122) 0.302 (0.2415) 0.4586 (0.2208) 1.296 (1.137) 0.4 Time 0.6192 (0.1141) 0.1942 (0.1632) 0.03955 (0.02311) 0.04445 (0.0207) 0.191 (0.1407) 0.4549 (0.3075) 1.53 (1.698) 0.5 Time 0.6784 (0.1806) 0.1867 (0.179) 0.05155 (0.02586) 0.06454 (0.1035) 0.1413 (0.05757) 0.3199 (0.3196) 0.9733 (1.625) 0.6 Time 0.4605 (0.161) 0.1458 (0.1995) 0.04942 (0.02432) 0.05805 (0.06407) 0.1279 (0.04818) 0.2552 (0.2949) 1.105 (2.237) 0.7 Time 0.3264 (0.1112) 0.0944 (0.1296) 0.05519 (0.02142) 0.06366 (0.08287) 0.1171 (0.04002) 0.1778 (0.1704) 0.33 (0.7549) 0.8 Time 0.3621 (0.118) 0.1184 (0.1856) 0.0924 (0.08049) 0.09844 (0.07525) 0.1592 (0.04999) 0.1901 (0.1602) 0.3504 (1.017) 0.9 Time 0.3463 (0.1191) 0.1029 (0.05027) 0.1115 (0.1813) 0.1292 (0.215) 0.1702 (0.03466) 0.2192 (0.1908) 0.2837 (0.6244) 1.0 Time 0.3231 (0.1258) 0.09973 (0.035) 0.1363 (0.2276) 0.1741 (0.3248) 0.1673 (0.04315) 0.2882 (0.3655) 0.2437 (0.1679) T able 11: Mean Time (SD) for and SCAD MCP Firm LOG EXP 0.1 Time 0.05887 (0.01293) 0.2234 (0.08841) 0.01697 (0.005035) 0.01699 (0.004914) 0.1988 (0.09614) 0.3827 (0.07207) 0.6776 (0.1144) 0.2 Time 0.1291 (0.04144) 0.3178 (0.1516) 0.01979 (0.004716) 0.02326 (0.01892) 0.2496 (0.1418) 0.4005 (0.08792) 2.426 (1.495) 0.3 Time 0.7639 (0.2156) 0.289 (0.2028) 0.04582 (0.01895) 0.05365 (0.02381) 0.2879 (0.1784) 0.7338 (0.3489) 4.571 (3.882) 0.4 Time 1.514 (0.2979) 0.4177 (0.3474) 0.1032 (0.06255) 0.123 (0.1618) 0.3198 (0.1482) 0.7819 (0.6811) 4.638 (5.593) 0.5 Time 1.508 (0.4161) 0.3399 (0.3124) 0.1315 (0.05244) 0.1227 (0.03739) 0.291 (0.09094) 0.5467 (0.6743) 2.529 (4.824) 0.6 Time 3.892 (1.556) 1.135 (1.459) 0.5243 (0.1609) 0.5964 (0.9066) 1.018 (0.2602) 1.366 (1.971) 3.584 (9.087) 0.7 Time 2.256 (1.078) 0.6103 (0.5344) 0.4549 (0.08223) 0.4341 (0.0722) 0.7783 (0.1122) 0.9275 (1.521) 2.688 (9.078) 0.8 Time 1.738 (0.2359) 0.5042 (0.092) 0.5566 (0.7428) 0.5519 (0.7202) 0.7686 (0.1213) 0.702 (0.708) 1.018 (0.9496) 0.9 Time 1.576 (0.1965) 0.531 (0.1265) 0.7153 (0.9071) 0.73 (1.01) 0.7896 (0.1359) 1.044 (1.544) 0.9093 (0.4753) 1.0 Time 1.438 (0.183) 0.5723 (0.2167) 0.645 (0.6552) 0.6464 (0.5954) 0.7828 (0.09955) 0.8698 (0.9806) 0.9996 (0.9732) 41 REFERENCES REFERENCES T able 12: Mean Time (SD) for and SCAD MCP Firm LOG EXP 0.1 Time 0.06015 (0.01408) 0.2368 (0.08766) 0.01761 (0.004725) 0.01972 (0.01006) 0.2015 (0.08702) 0.3895 (0.06751) 0.6818 (0.07771) 0.2 Time 0.1358 (0.06205) 0.3425 (0.1847) 0.02148 (0.008248) 0.02143 (0.007374) 0.2777 (0.1744) 0.4298 (0.1278) 2.522 (1.414) 0.3 Time 0.859 (0.2789) 0.3643 (0.2975) 0.04648 (0.02163) 0.06987 (0.1505) 0.2603 (0.182) 0.7928 (0.3222) 5.155 (3.626) 0.4 Time 1.832 (0.2002) 0.484 (0.3226) 0.1184 (0.06135) 0.1091 (0.04349) 0.3176 (0.09057) 0.8818 (0.7331) 4.047 (5.325) 0.5 Time 1.812 (0.435) 0.3944 (0.3735) 0.1328 (0.04252) 0.1257 (0.03247) 0.2781 (0.08556) 0.6853 (0.7801) 2.898 (5.014) 0.6 Time 1.234 (0.4237) 0.3135 (0.3604) 0.1599 (0.04195) 0.1796 (0.2797) 0.2856 (0.06056) 0.4151 (0.5578) 1.49 (4.121) 0.7 Time 0.9523 (0.2734) 0.2349 (0.275) 0.1719 (0.0329) 0.1647 (0.03235) 0.2858 (0.06317) 0.3363 (0.3792) 0.654 (2.279) 0.8 Time 0.7881 (0.1328) 0.2051 (0.05422) 0.1973 (0.1323) 0.201 (0.1327) 0.2805 (0.04738) 0.3521 (0.2724) 0.4649 (0.4407) 0.9 Time 0.7322 (0.1035) 0.2063 (0.02253) 0.2012 (0.03551) 0.2529 (0.3343) 0.2927 (0.04338) 0.3249 (0.1853) 0.4405 (0.2648) 1.0 Time 0.6781 (0.0835) 0.2296 (0.05449) 0.2365 (0.1932) 0.2358 (0.1469) 0.3107 (0.05463) 0.4408 (0.4755) 0.4186 (0.06463) Cai, J.-F., Li, J., Lu, X. & Y ou, J. (2022), ‘Sparse signal recov ery from phaseless measure- men ts via hard thresholding pursuit’, A pplie d and Computational Harmonic A nalysis 56 , 367–390. Cai, T. T., Li, X. & Ma, Z. (2016), ‘Optimal rates of conv ergence for noisy sparse phase retriev al via thresholded wirtinger o w’, The A nnals of Statistics 44 (5), 2221–2251. Cai, T. T., Xu, G. & Zhang, J. (2009), ‘On recov ery of sparse signals via l1 minimization’, IEEE T r ansactions on Information The ory 55 (7), 3388–3397. Candes, E. J., Li, X. & Soltanolkotabi, M. (2015), ‘Phase retriev al via wirtinger o w: Theory and algorithms’, IEEE T r ansactions on Information The ory 61 (4), 1985–2007. Chen, J. & Ng, M. K. (2022), ‘Error b ound of empirical risk minimization for noisy standard and generalized phase retriev al problems’, arXiv pr eprint . Chen, J., Ng, M. K. & Liu, Z. (2025), ‘Solving quadratic systems with full-rank matrices using sparse or generativ e priors’, IEEE T r ansactions on Signal Pr o c essing . 42 REFERENCES REFERENCES Chen, X., Niu, L. & Y uan, Y. (2013), ‘Optimalit y conditions and a smo othing trust region newton metho d for nonlipsc hitz optimization’, SIAM Journal on Optimization 23 (3), 1528–1552. Ding, K., Li, J. & T oh, K.-C. (2025), ‘Nonconv ex sto c hastic bregman proximal gradi- en t method with application to deep learning’, Journal of Machine L e arning R ese ar ch 26 (39), 1–44. Ebner, A., Sc h w ab, M. & Haltmeier, M. (2025), ‘Error estimates for weakly conv ex frame-based regularization including learned lters’, SIAM Journal on Imaging Scienc es 18 (2), 822–850. F an, J., Kong, L., W ang, L. & Xiu, N. (2018), ‘V ariable selection in sparse regression with quadratic measurements’, Statistic a Sinic a 28 (3), 1157–1178. F an, J. & Li, R. (2001), ‘V ariable selection via nonconcav e p enalized likelihoo d and its oracle prop erties’, Journal of the A meric an statistic al A sso ciation 96 (456), 1348–1360. F an, J., Sun, J., Y an, A. & Zhou, S. (2025), ‘An oracle gradien t regularized newton metho d for quadratic measuremen ts regression’, A pplie d and Computational Harmonic A nalysis 78 , 101775. F an, J., Y an, A., Xiu, X. & Liu, W. (2025), ‘Robust sparse phase retriev al: Statistical guar- an tee, optimality theory and con vergen t algorithm’, arXiv pr eprint . F rank, L. E. & F riedman, J. H. (1993), ‘A statistical view of some chemometrics regression to ols’, T e chnometrics 35 (2), 109–135. Goujon, A., Neuma yer, S. & Unser, M. (2024), ‘Learning w eakly conv ex regularizers for con- v ergen t image-reconstruction algorithms’, SIAM Journal on Imaging Scienc es 17 (1), 91– 115. 43 REFERENCES REFERENCES Huang, J., Horo witz, J. L. & Ma, S. (2008), ‘Asymptotic prop erties of bridge estimators in sparse high-dimensional regression models’, The A nnals of Statistics 36 (2), 587–613. Huang, M. & Xu, Z. (2020), ‘The estimation p erformance of nonlinear least squares for phase retriev al’, IEEE T r ansactions on Information The ory 66 (12), 7967–7977. Huang, M. & Xu, Z. (2024), ‘Performance b ounds of the in tensity-based estimators for noisy phase retriev al’, Applie d and Computational Harmonic A nalysis 68 , 101584. Huang, S. & Dokmanić, I. (2021), ‘Reconstructing p oin t sets from distance distributions’, IEEE T r ansactions on Signal Pr o c essing 69 , 1811–1827. Huang, S., Gupta, S. & Dokmanić, I. (2020), ‘Solving complex quadratic systems with full-rank random matrices’, IEEE tr ansactions on Signal Pr o c essing 68 , 4782–4796. Jagatap, G. & Hegde, C. (2018), T ow ards sample-optimal metho ds for solving random quadratic equations with structure, in ‘2018 IEEE International Symposium on Informa- tion Theory (ISIT)’, pp. 2296–2300. Khanh, P . D., Mordukho vich, B. S., Phat, V. T. & T ran, D. B. (2025), ‘Inexact pro ximal metho ds for weakly con vex functions’, Journal of Glob al Optimization 91 (3), 611–646. K om uro, K., Y ukaw a, M. & Ca v alcan te, R. L. G. (2022), ‘Distributed sparse optimization with w eakly con vex regularizer: Consensus promoting and appro ximate moreau enhanced p enalties to w ards global optimalit y’, IEEE T r ansactions on Signal and Information Pr o- c essing over Networks 8 , 514–527. Lob o, M. S., F azel, M. & Bo yd, S. (2007), ‘P ortfolio optimization with linear and xed transaction costs’, A nnals of Op er ations R ese ar ch 152 , 341–365. Loh, P .-L. (2017), ‘Statistical consistency and asymptotic normalit y for high-dimensional robust m-estimators’, The A nnals of Statistics 45 (2), 866–896. 44 REFERENCES REFERENCES Loh, P .-L. & W ainwrigh t, M. J. (2015), ‘Regularized m-estimators with nonconv exity: Sta- tistical and algorithmic theory for lo cal optima’, The Journal of Machine L e arning R e- se ar ch 16 (1), 559–616. Loh, P .-L. & W ainwrigh t, M. J. (2017), ‘Supp ort recov ery without incoherence: A case for noncon v ex regularization’, The A nnals of Statistics 45 (6), 2455–2482. Rigollet, P . & Hütter, J.-C. (2017), High dimensional statistics. Lecture notes for course. Shah, V. & Hegde, C. (2021), ‘Sparse signal recov ery from mo dulo observ ations’, EURASIP Journal on A dvanc es in Signal Pr o c essing 2021 (1), 1–17. Sh uma ylo v, Z., Budd, J., Mukherjee, S. & Schönlieb, C.-B. (2024), ‘W eakly con vex regu- larisers for in v erse problems: Con vergence of critical p oin ts and primal-dual optimisa- tion’, arXiv pr eprint . Soltanolk otabi, M. (2019), ‘Structured signal reco v ery from quadratic measuremen ts: Breaking sample complexity barriers via noncon v ex optimization’, IEEE T r ansactions on Information The ory 65 (4), 2374–2400. Thak er, P . K., Dasarath y , G. & Nedić, A. (2020), ‘On the sample complexity and opti- mization landscape for quadratic feasibilit y problems’, IEEE International Symp osium on Information The ory (ISIT) pp. 1438–1443. W ang, G., Zhu, H., Giannakis, G. B. & Sun, J. (2019), ‘Robust p ow er system state estima- tion from rank-one measurements’, IEEE T r ansactions on Contr ol of Network Systems 6 (4), 1391–1403. W ang, X. (2010), ‘On c heb yshev functions and klee functions’, Journal of mathematic al analysis and applic ations 368 (1), 293–310. 45 REFERENCES REFERENCES W ang, Y. & Xu, Z. (2019), ‘Generalized phase retriev al: measurement num b er, matrix reco v ery and b ey ond’, A pplie d and Computational Harmonic A nalysis 47 (2), 423–446. W o o dworth, J. & Chartrand, R. (2016), ‘Compressed sensing reco v ery via nonconv ex shrinkage p enalties’, Inverse Pr oblems 32 (7), 075004. Xia, Y. & Xu, Z. (2021), ‘Sparse phase retriev al via phaselifto ’, IEEE T r ansactions on Signal Pr o c essing 69 , 2129–2143. Xu, W., W ang, H. J. & Li, D. (2022), ‘Extreme quantile estimation based on the tail single-index mo del’, Statistic a Sinic a 32 (2), 893–914. Y ang, C., Shen, X., Ma, H., Chen, B., Gu, Y. & So, H. C. (2019), ‘W eakly con v ex regu- larized robust sparse recov ery metho ds with theoretical guarantees’, IEEE T r ansactions on Signal Pr o c essing 67 (19), 5046–5061. Y ang, W., Shi, H., Guo, X. & Zou, C. (2024), ‘Robust group and simultaneous inferences for high-dimensional single index mo del’, A dvanc es in Neur al Information Pr o c essing Systems 37 , 65217–65259. Zhang, C.-H. (2010), ‘Nearly unbiased v ariable selection under minimax conca v e p enalty’, The A nnals of Statistics 38 (2), 894–942. Zhang, H., Zhang, L. & Y ang, H.-X. (2023), ‘Revisiting linearized bregman iterations under lipsc hitz-lik e con v exity condition’, Mathematics of Computation 92 (340), 779–803. Zou, H. (2006), ‘The adaptiv e lasso and its oracle prop erties’, Journal of the A meric an statistic al asso ciation 101 (476), 1418–1429. 46
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment