Online Single-Channel Audio-Based Sound Speed Estimation for Robust Multi-Channel Audio Control
Robust spatial audio control relies on accurate acoustic propagation models, yet environmental variations, especially changes in the speed of sound, cause systematic mismatches that degrade performance. Existing methods either assume known sound spee…
Authors: ** - 저자 정보가 논문 본문에 명시되지 않음 (원고에 포함되지 않음). **
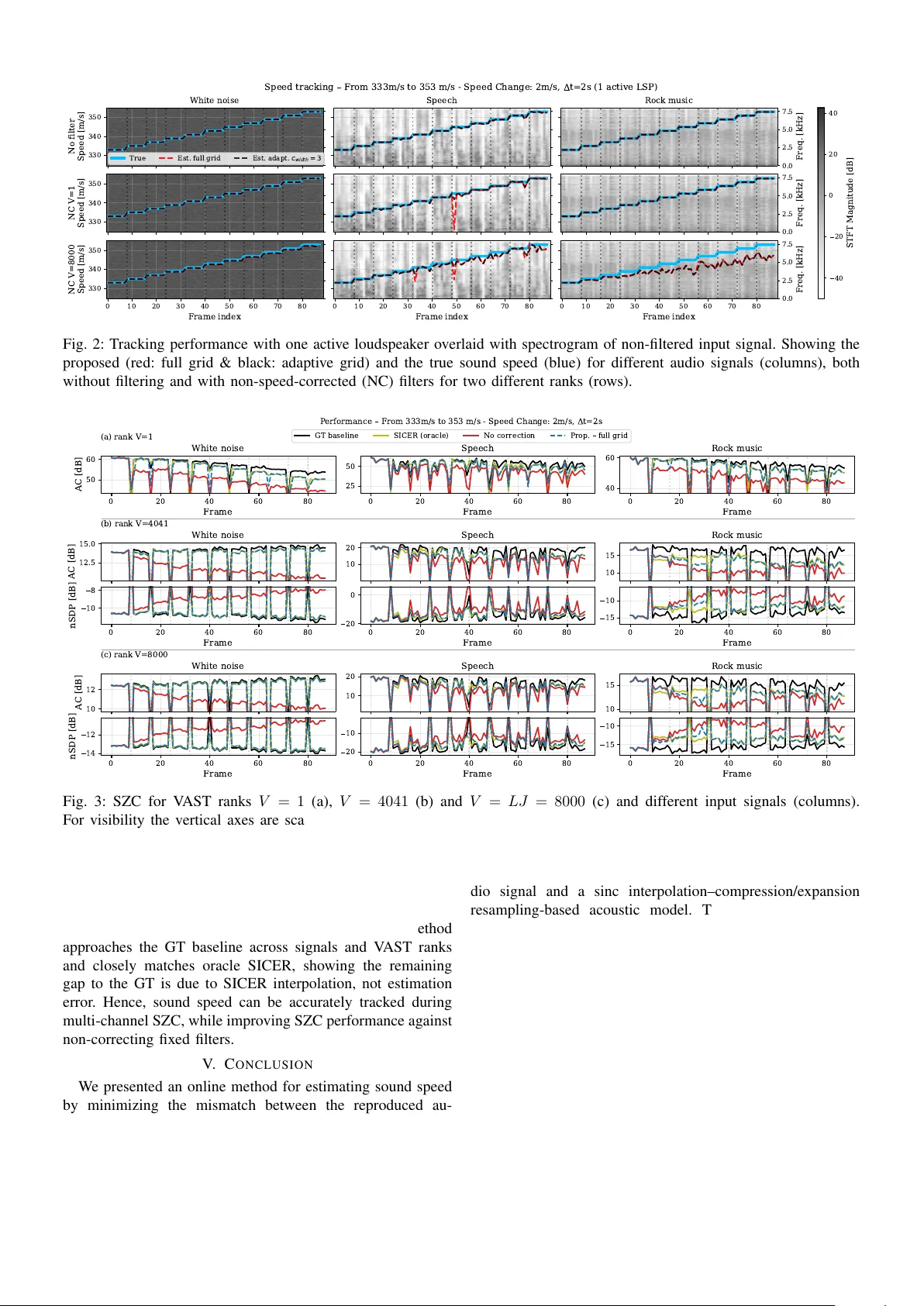
Online Single-Channel Audio-Based Sound Speed Estimation for Rob ust Multi-Channel Audio Control Andreas Jonas Fuglsig, Mads Græsbøll Christensen and Jesper Rindom Jensen Department of Electr onic Systems, Aalbor g University , 9220 Aalborg , Denmark Email: { ajf,mgc,jrj } @es.aau.dk Abstract —Robust spatial audio control relies on accurate acoustic propagation models, y et en vironmental variations, espe- cially changes in the speed of sound, cause systematic mismatches that degrade performance. Existing methods either assume known sound speed, require multiple microphones, or rely on separate calibration, making them impractical for systems with minimal sensing. W e propose an online sound speed estimator that operates during general multichannel audio playback and requir es only a single observation microphone. The method exploits the structured effect of sound speed on the r eproduced signal and estimates it by minimizing the mismatch between the measured audio and a parametric acoustic model. Simulations show accurate tracking of sound speed for diverse input signals and impro ved spatial control performance when the estimates are used to compensate propagation errors in a sound zone control framework. Index T erms —A udio-Based, T racking, Sound Speed, Estima- tion, Robust, Sound Zone Control, Single-channel, Multi-channel Spatial audio control techniques such as sound zone control (SZC), spatial activ e noise control (ANC), and immersiv e audio reproduction are increasingly deployed in practical sys- tems including personal audio de vices, cars, and smart en vi- ronments. These methods shape acoustic sound fields using multiple loudspeak ers to enhance desired audio in specific regions while suppressing it elsewhere. In practice, robust spatial audio control remains challenging because most methods rely on control filters computed offline from pre-measured acoustic impulse responses (IRs) that are assumed fixed during deployment. Howe ver , en vironmental changes such as listener movement, transducer drift, or temper - ature variations alter the IRs and degrade performance [1 – 4]. Among these f actors, variations in the speed of sound are particularly critical, as they introduce systematic delay and phase mismatches that sev erely affect spatial control [1, 5, 6]. Nev ertheless, only a few approaches address sound speed vari- ations [1, 5, 7–9]. Constraint-based IR reshaping [1], learned parametric propagation models [7], learned IR priors [9], and cov ariance-prior-based methods [8] have been proposed to im- prov e robustness. Howe ver , these approaches typically require repeated calibration, multiple microphones during deployment, or substantial pre-measured training data. Adaptiv e filtering and secondary path modeling can track acoustic changes online [10, 11], but require access to microphone signals at all control points, limiting applicability in minimally instru- mented systems. Recently , [5] proposed interpolation-based IR modeling using a Sinc Interpolation–Compression/Expansion Resampling (SICER) framework, which enables recomputa- tion of control filters at new sound speeds. Howe ver , this assumes that the sound speed is known or estimated separately , for example using temperature and humidity sensors. More broadly , classical sound speed estimation methods are often coupled with source localization and rely on multiple spatially distributed microphones [12–15], or require dedicated mea- surement procedures [16, 17], which is poorly suited for online adaptation in systems with limited sensing infrastructure. In this paper, we propose an online sound speed estimation method that operates during multichannel audio playback using only a single observation microphone, not necessarily placed at the control points. The method exploits the structured effect of sound speed v ariations on acoustic propagation, as described in [5], and estimates the sound speed directly from the reproduced audio signal without additional sensors. As an example application, the estimated sound speed is integrated into an SZC framework to compensate for prop- agation mismatches without modifying the underlying control architecture. The proposed approach enables practical, single- channel sound speed tracking for robust spatial audio control. I . F R A M E - B A S ED S I G NA L M O D E L W e consider a general frame-based multichannel audio system where a set of loudspeakers, L , is used to generate a desired sound field at a set of control-point microphones M . For example, in SZC the loudspeakers are used to create different sound zones with dif ferent desired sound fields, cf. Section III-A [18, 19]. W e denote by h m,l ∈ R K the IR from the l th loudspeaker to the m th microphone. Each loudspeaker is assumed to be equipped with a finite impulse response (FIR) filter, q l ∈ R J to control the reproduced sound field, e.g., an ANC or SZC filter . Then, for an input signal frame x [ τ ] = [ x [ τ N − N + 1] , . . . , x [ τ N ]] ∈ R N , the signal frame reproduced by all L loudspeakers at microphone m and frame index τ , is p m [ τ ] = X l ∈L h m,l ∗ y l [ τ ] = X l ∈L h m,l ∗ q l ∗ x [ τ ] ∈ R N . (1) where ∗ denotes conv olution, and y l [ τ ] ∈ R N is the l th loudspeaker output signal for frame τ . W e use overlap-add and buf fers for each con volution to avoid frame boundary errors[20], and let all signal frames have length N . W e assume K − 1 ≤ N and J − 1 ≤ N such that the con volution tail can be stored in a single frame b uf fer[4]. For a vector v ∈ R M containing time-consecutive samples of a signal, v [ n ] , we define a buf fering operator, Buff N K − 1 ( v ) , which e xtracts the last K − 1 elements of v and zero-pads to length N as Buff N K − 1 ( v ) ≜ [( v ) T M − ( K − 2): M , 0 , . . . , 0 | {z } N − ( K − 1) ] ∈ R N , (2) where ( v ) a : b ≜ [ v [ a ] , v [ a + 1] , . . . , v [ b ]] T . The reproduced signal from loudspeaker l at microphone m in frame τ is then p m,l [ τ ] = ( h m,l ∗ y l [ τ ]) 0: N − 1 + Buff N K − 1 ( h m,l ∗ y l [ τ − 1]) . (3) Similarly , we can express y l [ τ ] from x [ τ ] and q l . I I . O N L I N E S O U N D S P E E D E S T I M A T I O N W e first present our model for sound speed changes in the reproduced audio based on the SICER model for speed changes on IRs [5]. A. Modeling Sound Speed Effect on IRs & Signals Follo wing the SICER model in [5], an IR measured at sound speed c old , h ∈ R K , can be mapped to a ne w sound speed c new with IR, ˆ h ∈ R I ˆ h ( α ) = α S ( α ) h , α = c new c old (4) where S ( α ) ∈ R I × K is a sinc interpolation matrix with the i th row defined as s ( α ) i = [sinc ( α i ) , . . . , sinc ( αi − K + 1)] . Using this model and assuming a uniform temperature in the environment, the reproduced signal under a sound speed change becomes ˆ p ( α ) m [ τ ] = X l ∈L ˆ h ( α ) m,l ∗ y l [ τ ] 0: N − 1 + Buff N K − 1 ˆ h ( α ) m,l ∗ y l [ τ − 1] (5) W ith this model for audio reproduction under new sound speeds, we can now estimate the change in sound speed based on recordings of reproduced audio. B. Estimating Sound Speed W e now present our method for estimating the current sound speed, c new , online during audio playback. W e let m o be an observation microphone in the environment, where we assume the IR, h m 0 ,l , from each loudspeaker to the observ ation microphone is kno wn at a reference sound speed, c old , e.g., measured prior to audio playback. Letting p meas m [ τ ] be the signal measured at microphone m for frame τ , we can estimate the current sound speed by minimizing the error between the measured signal and the modeled reproduced signal under a sound speed change in (5), i.e., ˆ c new = arg min c new p meas m o [ τ ] − ˆ p ( α ) m o [ τ ] 2 2 . (6) The resulting single-parameter , non-con vex, nonlinear opti- mization problem can be readily solved numerically . This estimation is then performed frame-wise during playback. W e note that the cost function can be generalized to cover multiple microphones; howe ver , as we will see in Section IV, using a single microphone is already effecti ve. I I I . R O B U S T C O N T R O L W I T H S O U N D S P E E D C H A N G E S In this Section, we show our complete algorithm for sound speed estimation along with robust spatial audio control. As an example of a spatial audio control system, where filters depend on the IRs and thereby sound speed, we consider SZC. A. Sound Zone Control Backgr ound W e consider a SZC system as depicted in Fig. 1, where the goal is to find a set of loudspeaker control filters { q l } l ∈L , that creates a bright zone (BZ) with a desired sound field and a dark zone (DZ) with silence. When computing the filters prior to deployment, each of the control zones are equipped with a set of control microphones, i.e., M B and M D . For each of these control points, we assume the IRs from each of the loudspeak- ers are known at a reference sound speed, c old , and compute filters based on these. Consequently , the filters are only optimal for that specific sound speed. Furthermore, for simplicity and as is common in SZC filter design, we assume the input signal is x [ n ] = δ [ n ] , i.e., a deterministic spectrally white signal [18, 19]. The sound reproduced at the m th microphone in either the BZ or DZ microphones can then be expressed as the vector p m = P L l =1 h m,l ∗ q l = P L l =1 H m,l q l ∈ R K + J − 1 , where H ( s ) m,l is the con volution matrix containing the IR h m,l [18]. The reproduced sound field at all microphones in, e.g., the BZ is then p B = [ p 1 , . . . , p M B ] T = H B q ∈ R M B ( K + J − 1) . (7) Here H B = { H m,l } m ∈M B ,l ∈L and q = q T 1 , . . . , q T L T ∈ R LJ [18]. Letting d m ∈ R K + J − 1 be the desired signal at microphone m , defined according to a virtual source position, z , [18], we stack these into a desired signal vector for the BZ as d B = d T 1 , . . . , d T M B T ∈ R M B ( K + J − 1) . The desired signal for the DZ is silence, i.e., d D = 0 ∈ R M D ( K + J − 1) . 1) V AST Appr oach: The filters are derived by minimizing the weighted mean-squared error between the desired and reproduced signals ξ ( q ) = q T R B q + µ q T R D q − 2 q T r B + ∥ d B ∥ 2 2 , (8) where µ is a weighting parameter , r B = H T B d B , and R B = H B H T B and R D = H D H T D are the spatial covariance matrices corresponding to the BZ and DZ[19]. Using the V ariable-Span T rade-of f (V AST) approach[19], the solution is found via the eigenv alue decomposition of R − 1 D R B and yields a V -rank ( 1 ≤ V ≤ LJ ) approximation of q as q = V X v =1 u T v r B λ v + µ u v , (9) where λ 1 ≥ . . . ≥ λ V are the non-negati ve real-valued eigen values of R − 1 D R B and µ controls the weighting between BZ and DZ performance. For positi ve semi-definite R D , regularization can be applied as R ′ D = R D + γ I . W e can now Algorithm 1 Online Sound Speed Estimation using SICER 1: Input: c old , { h m,l } m ∈ m o ∪M B ∪M D ,l ∈L , c thresh 2: search range [ c min , c max ] , step size ∆ c , 3: Optional Input: Adaptiv e search range c width , ∆ c adapt 4: Initialization Compute { q l [1] } for c old , { y l [0] = 0 } , c filt = c old , 5: for τ = 1 , 2 , . . . do 6: Compute & play { y l [ τ ] } 7: Measure { p meas m [ τ ] } m ∈M O 8: if Adaptiv e search range & τ > 1 then 9: c min = max { ˆ c new [ τ − 1] − c width , c min } 10: c max = min { ˆ c new [ τ − 1] + c width , c max } 11: ∆ c = ∆ c adapt 12: end if 13: ˆ c new [ τ ] = arg min c new p meas m [ τ ] − ˆ p ( α ) m [ τ ] 2 2 s.t. α = c new c old , c new ∈ [ c min , c max ] with step size ∆ c 14: if | ˆ c new [ τ ] − c filt | ≥ c thresh then ▷ Update filters 15: ˆ α = ˆ c new [ τ ] c old 16: ˆ h ( ˆ α ) m,l = ˆ α S ( ˆ α ) h m,l , m ∈ M B ∪ M D , l ∈ L 17: Compute new filters { q l [ τ + 1] } from { ˆ h ( ˆ α ) m,l } 18: c filt = ˆ c new [ τ ] 19: end if 20: end for 0 1 2 3 4 X P osition (m) 0 1 2 3 4 Y P osition (m) Loudspeakers Ref . LSP , L8 Dark Zone Mics Bright Zone Mics Obs. Mic Fig. 1: Simulation setup for e v aluating online sound speed estimation and robust sound zone control performance. combine the SZC filter computation with our online sound speed estimation to a robust control algorithm. B. Sound Speed Estimation and Robust Contr ol Algorithm Algorithm 1 summarizes the proposed procedure with two main components: 1) online sound speed estimation and 2) updating the control filters when the speed change exceeds a giv en threshold c thresh based on SICER adjusted IRs [5]. Sound speed is estimated frame-wise using either a full grid search or an adaptiv e grid search around the previous estimate. I V . E X P E R I M E N TA L E V A L UA T I O N A. Simulation Setup T o ev aluate both tracking and robust SZC performance, we simulate a setup similar to [5, 21] with the RIR Generator T oolbox[22] and sample rate of 16 kHz. The setup has a square room of size 4 . 5 × 4 . 5 × 2 . 2 m, cf. Fig. 1, with a linear array of L = 16 loudspeakers spaced 6 cm apart, and a BZ and DZ each with M B = M D = 37 control microphones and 9 cm spacing. All transducers are placed at a height of 1 . 2 m. T o facilitate faster processing, we simulate a short re verberation time of RT 60 = 100 ms, giving an IR length of K = 800 . IRs are simulated with sound speeds ranging from 333 m/s to 353 m/s with 2 m/s steps, and the IRs at these steps are considered as the true ground truth (GT). The SZC filters are computed with length J = 500 , weighting µ = 1 , no regularization, and with loudspeaker l = 8 as reference desired source for the BZ. As observation microphone we use a point on the edge of the BZ. W e consider 22 s input signals with varying spectral con- tent: white noise, speech (four talkers from EARS[23]) and instrumental rock music (MUSAN[24]). The frame length is N = 4000 ( 250 ms) with no overlap. T o stress-test the method, sound speed is increased by 2 m/s (corresponding to approximately 1 . 7 ◦ C) every 8 frames by changing the GT propagation IR 1 . W e use a fixed search range of [326 , 360] m/s with step size 0 . 25 m/s, and adaptive search range width ± 3 m/s with step size 0 . 1 m/s. The filter update threshold is set to 1 m/s. B. T racking P erformance T o focus only on tracking performance, we first consider the simple case where only the reference loudspeaker is activ e, both when no filter is applied, i.e., ( q 8 = [1 , 0 , . . . , 0] ), and when applying a SZC filter but with no speed correction (NC), i.e., keeping it fixed across time. The results in Fig. 2 show accurate tracking for white noise and speech, and robust performance for music despite its more limited spectral diver - sity . T racking accuracy decreases when the input signal has low energy or reduced frequency content, e.g., around frames 32 , 50 and 78 for speech input. The adaptiv e search range improv es stability in such frames. Furthermore, applying full rank ( V = 8000 ) pre-filtering decreases performance slightly for speech and white noise but more sev erely for rock music. Overall, the proposed method reliably tracks sound speed using only a single observation microphone. C. Sound Zone Control P erformance W e next ev aluate the SZC performance of the proposed algorithm when all loudspeakers are activ e in terms of the acoustic separation between the zones and the reproduction error in the BZ. These are quantified, respectiv ely , by the acoustic contrast (A C) and normalized signal distortion power (nSDP), defined as A C [ τ ] = 10 log 10 M D M B ∥ p B [ τ ] ∥ 2 ∥ p D [ τ ] ∥ 2 , (10) nSDP [ τ ] = 10 log 10 ∥ d B [ τ ] − p B [ τ ] ∥ 2 ∥ d B [ τ ] ∥ 2 . (11) W e compare performance against fixed filters (no speed cor- rection) (lo wer baseline), filters computed with ground truth IRs (upper baseline) and oracle SICER[5]. Figure 3 sho ws the SZC performance for the dif ferent input signals and three V AST ranks. nSDP for rank V = 1 is omitted for brevity as it is close to 0 dB for all inputs and 1 Results from other speed changes can be found on our GitHub along with our code: https://github .com/afuglsAAU/EUSIPCO2026SoundSpeedEst 40 20 0 20 40 STFT Magnitude [dB] 0.0 2.5 5.0 7.5 Freq. [kHz] 0.0 2.5 5.0 7.5 Freq. [kHz] 0.0 2.5 5.0 7.5 Freq. [kHz] 330 340 350 No filter Speed [m/s] White noise Speech Rock music 330 340 350 NC V=1 Speed [m/s] 0 10 20 30 40 50 60 70 80 Frame index 330 340 350 NC V=8000 Speed [m/s] 0 10 20 30 40 50 60 70 80 Frame index 0 10 20 30 40 50 60 70 80 Frame index Speed tracking From 333m/s to 353 m/s - Speed Change: 2m/s, t=2s (1 active LSP) True Est. full grid E s t . a d a p t . c w i d t h = 3 Fig. 2: Tracking performance with one activ e loudspeaker ov erlaid with spectrogram of non-filtered input signal. Showing the proposed (red: full grid & black: adaptiv e grid) and the true sound speed (blue) for dif ferent audio signals (columns), both without filtering and with non-speed-corrected (NC) filters for two different ranks (rows). (a) rank V=1 0 20 40 60 80 Frame 50 60 AC [dB] White noise 0 20 40 60 80 Frame 25 50 Speech 0 20 40 60 80 Frame 40 60 Rock music (b) rank V=4041 12.5 15.0 AC [dB] White noise 10 20 Speech 10 15 Rock music 0 20 40 60 80 Frame 10 8 nSDP [dB] 0 20 40 60 80 Frame 20 0 0 20 40 60 80 Frame 15 10 (c) rank V=8000 10 12 AC [dB] White noise 10 20 Speech 10 15 Rock music 0 20 40 60 80 Frame 14 12 nSDP [dB] 0 20 40 60 80 Frame 20 10 0 20 40 60 80 Frame 15 10 P erformance From 333m/s to 353 m/s - Speed Change: 2m/s, t=2s GT baseline SICER (oracle) No correction Prop. full grid Fig. 3: SZC for V AST ranks V = 1 (a), V = 4041 (b) and V = LJ = 8000 (c) and different input signals (columns). For visibility the vertical axes are scaled according to performance between frames with speed changes. The proposed (blue dashed) is compared to uncorrected filters (red), oracle SICER (green) and GT performance (black). methods. W e note that the sharp changes are caused by the simulated step change in speed but in practice the change would be smooth. The results show the proposed method approaches the GT baseline across signals and V AST ranks and closely matches oracle SICER, showing the remaining gap to the GT is due to SICER interpolation, not estimation error . Hence, sound speed can be accurately tracked during multi-channel SZC, while impro ving SZC performance against non-correcting fixed filters. V . C O N C L U S I O N W e presented an online method for estimating sound speed by minimizing the mismatch between the reproduced au- dio signal and a sinc interpolation–compression/expansion resampling-based acoustic model. The approach estimates sound speed directly from the ongoing playback using only a single observation microphone, without additional sensors or dedicated calibration measurements. Simulation results demonstrated accurate tracking across different input signals and in the presence of spatial audio control filters. Integrat- ing the estimated sound speed into a sound zone control framew ork enabled compensation for propagation mismatches and improv ed performance compared to fixed-filter designs, ev en under exaggerated sound speed variations. Future work includes improving computational ef ficiency and validating the method using measured impulse responses. V I . R E F E R E N C E S [1] T . Betlehem, L. Krishnan, and P . T eal, “T emperature Robust Acti ve-Compensated Sound Field Reproduc- tion Using Impulse Response Shaping, ” in Pr oc. IEEE Int. Conf. Acoust., Speech Signal Pr ocess. , Apr . 2018, pp. 481–485. [2] M. B. Møller, J. K. Nielsen, E. Fernandez-Grande, and S. K. Olesen, “On the Influence of Transfer Function Noise on Sound Zone Control in a Room, ” IEEE/ACM T rans. Audio, Speech Lang. Pr ocess. , vol. 27, no. 9, pp. 1405–1418, 2019. [3] P . Coleman, P . J. B. Jackson, M. Olik, M. Møller, M. Olsen, and J. A. Pedersen, “ Acoustic contrast, planarity and robustness of sound zone methods using a circular loudspeaker array , ” J. Acoust. Soc. Amer . , vol. 135, no. 4, pp. 1929–1940, Apr . 2014. [4] S. S. Bhattacharjee, A. J. Fuglsig, F . Christensen, J. R. Jensen, and M. Græsbøll Christensen, “Robust Fixed- Filter Sound Zone Control with Audio-Based Position T racking, ” in Proc. IEEE Int. Conf. Acoust., Speech Signal Pr ocess. , Apr . 2025, pp. 1–5. [5] S. S. Bhattacharjee, J. R. Jensen, and M. G. Chris- tensen, “Sound Speed Perturbation Robust Audio: Im- pulse Response Correction and Sound Zone Con- trol, ” IEEE/A CM T rans. Audio, Speech Lang. Pr ocess. , vol. 33, pp. 2008–2020, 2025. [6] D. Caviedes Nozal, F . M. Heuchel, F . T . Agerkvist, and J. Brunskog, “The effect of atmospheric conditions on sound propagation and its impact on the outdoor sound field control, ” in INTER-NOISE and NOISE-CON Congr ess and Conference Pr oceedings , vol. 259, 2019, pp. 7211–7220. [7] F . M. Heuchel, D. Ca viedes-Nozal, J. Brunskog, F . T . Agerkvist, and E. Fernandez-Grande, “Large-scale out- door sound field control, ” J. Acoust. Soc. Amer . , vol. 148, no. 4, pp. 2392–2402, Oct. 2020. [8] J. Brunnstrom, M. B. Møller, J. Østergaard, T . van W aterschoot, M. Moonen, and F . Elvander , “Spatial cov ariance estimation for sound field reproduction us- ing kernel ridge regression, ” in Pr oc. Eur opean Signal Pr ocess. Conf. , Sep. 2025. [9] J. Zhang, L. Shi, M. G. Christensen, W . Zhang, L. Zhang, and J. Chen, “CGMM-Based Sound Zone Gen- eration Using Robust Pressure Matching W ith A TF Per- turbation Constraints, ” IEEE/A CM T rans. Audio, Speec h Lang. Pr ocess. , vol. 31, pp. 3331–3345, 2023. [10] M. Hu, L. Shi, H. Zou, M. G. Christensen, and J. Lu, “Sound zone control with fixed acoustic contrast and simultaneous tracking of acoustic transfer functions, ” J. Acoust. Soc. Amer . , vol. 153, no. 5, p. 2538, May 2023. [11] J. Zhang, J. Xie, D. Shi, W . Zhang, J. Chen, and J. Benesty , “An Alternating Mode Strategy for Adaptiv e Sound Field Control and Acoustic Path T racking, ” in Asia P acific Signal and Inf. Process. Asso. Annu. Sum- mit and Conf. , Oct. 2025, p. 422. [12] P . Annibale, J. Filos, P . A. Naylor, and R. Rabenstein, “TDO A-Based Speed of Sound Estimation for Air T em- perature and Room Geometry Inference, ” IEEE/A CM T rans. Audio, Speech Lang. Pr ocess. , vol. 21, no. 2, pp. 234–246, Feb . 2013. [13] A. Mahajan and M. W alworth, “3D position sensing using the differences in the time-of-flights from a wav e source to various recei vers, ” IEEE T rans. Robot. Autom. , vol. 17, no. 1, pp. 91–94, Feb . 2001. [14] J.-S. Hu, C.-Y . Chan, C.-K. W ang, M.-T . Lee, and C.-Y . Kuo, “Simultaneous Localization of a Mobile Robot and Multiple Sound Sources Using a Microphone Array, ” Adv . Robotics , vol. 25, no. 1-2, pp. 135–152, Jan. 2011. [15] C. Othmani, N. S. Dokhanchi, S. Merchel, A. V ogel, M. E. Altinsoy, and C. V oelker, “A revie w of the state- of-the-art approaches in detecting time-of-flight in room impulse responses, ” Sensors and Actuators A: Physical , vol. 374, Aug. 2024. [16] O. A. Godin, V . G. Irisov, and M. I. Charnotskii, “Passi ve acoustic measurements of wind velocity and sound speed in air, ” J. Acoust. Soc. Amer . , vol. 135, no. 2, EL68–EL74, Jan. 2014. [17] M. E. Anderson and G. E. T rahey , “The direct esti- mation of sound speed using pulse–echo ultrasound, ” J. Acoust. Soc. Amer . , v ol. 104, no. 5, pp. 3099–3106, Nov . 1998. [18] M. F . S. G ´ alvez, S. J. Elliott, and J. Cheer, “Time domain optimization of filters used in a loudspeaker array for personal audio, ” IEEE/ACM T rans. Audio, Speech Lang. Pr ocess. , vol. 23, no. 11, pp. 1869–1878, 2015. [19] T . Lee, J. K. Nielsen, J. R. Jensen, and M. G. Chris- tensen, “A unified approach to generating sound zones using variable span linear filters, ” in Proc. IEEE Int. Conf. Acoust., Speech Signal Pr ocess. , 2018, pp. 491– 495. [20] M. G. Christensen, Intr oduction to Audio Pr ocessing . Cham: Springer International Publishing, 2019. [21] T . Lee, L. Shi, J. K. Nielsen, and M. G. Christensen, “Fast Generation of Sound Zones Using V ariable Span T rade-Off Filters in the DFT-Domain, ” IEEE/A CM T rans. Audio, Speech Lang. Process. , vol. 29, pp. 363– 378, 2021. [22] E. A. Habets, Room impulse response generator , Oct. 2020. [23] J. Richter et al., “EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and dere- verberation, ” in ISCA Interspeech , 2024, pp. 4873– 4877. [24] D. Snyder, G. Chen, and D. Pove y, MUSAN: A Music, Speech, and Noise Corpus , arXiv:1510.08484v1, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment