Multi-Channel Replay Speech Detection using Acoustic Maps
Replay attacks remain a critical vulnerability for automatic speaker verification systems, particularly in real-time voice assistant applications. In this work, we propose acoustic maps as a novel spatial feature representation for replay speech dete…
Authors: Michael Neri, Tuomas Virtanen
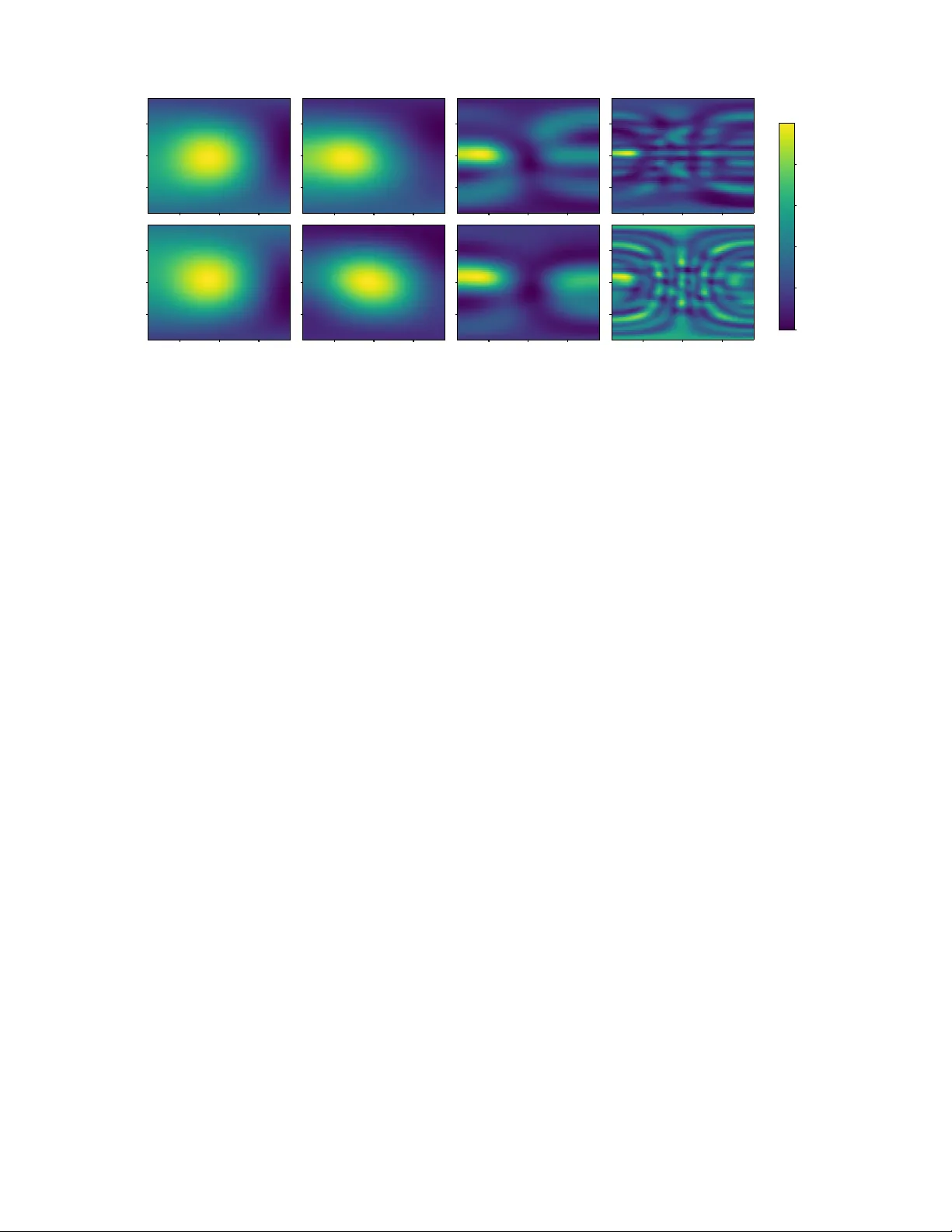
Multi-Channel Replay Speech Detection using Acoustic Maps Michael Neri , T uomas V irtanen F aculty of Information T ec hnology and Commmunication Sciences , T amper e University , T ampere, Finland { michael.neri, tuomas.virtanen } @tuni.fi Abstract —Replay attacks remain a critical vulnerability for automatic speaker verification systems, particularly in real-time voice assistant applications. In this work, we propose acoustic maps as a novel spatial feature repr esentation f or r eplay speech detection from multi-channel recordings. Derived from classical beamforming over discrete azimuth and elevation grids, acoustic maps encode dir ectional energy distrib utions that reflect physical differences between human speech radiation and loudspeaker - based replay . A lightweight con volutional neural network is designed to operate on this r epresentation, achieving competitive performance on the ReMASC dataset with approximately 6 k trainable parameters. Experimental results show that acoustic maps pr ovide a compact and physically interpretable feature space for replay attack detection across different devices and acoustic en vironments. Index T erms —Replay attack, Physical Access, Beamforming, Spatial A udio, V oice anti-spoofing, Acoustic maps. I . I N T RO D U C T I O N Recently , voice assistants (V As) ha ve become a central interface for human–machine interaction, exploiting speech as a biometric trait for user authentication and authorization [1]. In practical deployments, V As operate in real time to control Internet of things (IoT) devices and to transmit sensitive information, making timely and reliable spoofing detection a critical requirement. Ho wever , automatic speaker verification (ASV) systems remain vulnerable to a wide range of audio- based attacks [2]. Among these, logical access (LA) attacks manipulate speech content or speaker identity using text-to-speech (TTS) or voice conv ersion (VC) techniques, while compression- or quantization-induced artifacts can further obscure such ma- nipulations, leading to so-called deepfake (DF) attacks [2]. Physical access (P A) attacks, instead, aim to decei ve the ASV system at the microphone level [3]. In this setting, an adversary may either imitate the target speaker (impersonation attack) [1] or replay a previously captured recording using a loudspeaker (replay attack) [4]. In this work, we focus on replay attacks, as speech is inherently easy to capture in e veryday en vironments and can be replayed with minimal effort [5]. Moreover , existing ASV systems often struggle to reliably discriminate between genuine and replayed speech, ev en when using commodity off-the-shelf devices such as smartphones and loudspeakers [6], [7]. From a physical perspectiv e, genuine speech and replayed speech are generated by fundamentally dif ferent sound produc- tion mechanisms: human speech originates from a comple x vo- cal tract excitation, whereas replayed speech is emitted by an electro-acoustic transducer with its own frequency response, directivity , and radiation characteristics. These differences affect not only the spectral content of the signal but also its spatial propagation and interaction with the en vironment. In addition, the sound is emitted from a physical object, which can be either a human talker or a loudspeak er, so it does not originate from a single point but rather from a larger body with spatially distributed acoustic properties. Moti vated by this observ ation, we in vestigate whether acoustic maps, capturing spatial and multi-channel sound field information, can be le veraged to distinguish between genuine and replayed speech excerpts in real time. By analyzing ho w sound is spatially produced and recei ved across microphone arrays, we aim to assess whether these physical dif ferences can be reliably exploited for replay attack detection. The contributions of this work are as follows: • W e introduce acoustic maps derived from classical beam- forming as a spatial feature representation for replay speech detection, explicitly encoding directional en- ergy distributions that reflect dif ferences between human speech radiation and loudspeaker -based replay . • W e design a compact con volutional neural network tai- lored to acoustic maps, achieving competiti ve replay detection performance on the Realistic Replay Attack Microphone Array Speech (ReMASC) dataset with ap- proximately 6 k trainable parameters. • W e ev aluate the proposed approach under both en vironment-dependent and environment-independent conditions, analyzing robustness across dif ferent microphone arrays, beamformers, and unseen acoustic en vironments, and highlighting the strengths and limitations of spatial representations for replay detection. The work is organized as follo ws: Sec. II includes a litera- ture re view about replay speech detection, encompassing both traditional and learning-based approaches; Sec. III describes the nov el feature set and the con volutional neural network (CNN) used for detection; Sec IV illustrates the experimental results on real data and the comparison with prior works whereas Sec. V draws the conclusions. − 50 0 50 Genuine Elev ation (deg) Low (100-500 Hz) Mid (500-3000 Hz) High (3000-8000 Hz) Super-High (8000-22050 Hz) − 50 0 50 Azimuth (deg) − 50 0 50 Replay Elev ation (deg) − 50 0 50 Azimuth (deg) − 50 0 50 Azimuth (deg) − 50 0 50 Azimuth (deg) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 Fig. 1. Spatial distribution of acoustic maps from delay-and-sum beamformer across azimuth and ele vation angles for two utterances from the ReMASC dataset, recorded using de vice D3 with 6 microphones arranged in a hexagonal shape. The top row corresponds to the genuine sample 1264222.wav , and the bottom row to the replay sample 1380536001.wav from the same indoor en vironment and positions. Each column represents a distinct frequency band: Low ( 100–500 Hz), Mid ( 500–3000 Hz), High ( 3000–8000 Hz), and Super -High ( 8000–22050 Hz). The color scale indicates normalized acoustic intensity . I I . R E L A T E D W O R K S In the literature, se veral works hav e tried to mitigate the replay speech attack by providing single-channel speech datasets, such as RedDots [3], ASVSpoof2017 P A [8], ASVSpoof2019 [9] P A, and ASVSpoof2021 P A [2]. Build- ing upon these datasets, recent works in state-of-the-art (SO T A) focused on hand-crafted single-channel features with simple classifiers (such as CNNs and Gaussian mixture models (GMMs)) after a beamforming phase (TECC [10], CTECC [11], and ETECC [12]). Ho wev er, all these meth- ods suffer from generalization capabilities, i.e., changing the acoustic properties on the test set yields random guess predic- tions. Howe ver , for speech enhancement and separation tasks, microphone arrays are usually employed in ASV systems to exploit spatial information and improv e audio quality [13]. Moreov er, multi-channel data can be beneficial for detecting the replay detection for several reasons: (i) multi-channel recordings encompass audio spatial cues that can help the detection [4], [7], [14], and (ii) such spatial information cannot be easily counterfeited by an attacker , differently to single- channel data where temporal and frequency cues can be manipulated to fool an ASV system [15]. Despite these adv antages, progress in multi-channel replay detection has been limited by the lack of suitable datasets and models specifically designed to capture and exploit spatial information. T o date, ReMASC [7] remains the only publicly av ailable dataset providing real multi-channel recordings for replay attack detection, encompassing different microphone arrays, playback de vices, and acoustic en vironments. The base- line of this dataset was CQCC-GMM [7], which is a GMM classifier trained on constant-Q cepstral coef ficients (CQCCs). They also proposed a conv olutional recurrent neural network (CRNN) which acts as both a learnable and adaptive time- domain beamformer with a CRNN replay attack classifier [4]. In [6] a CRNN replay detector with a learnable time-frequency beamformed was proposed, achieving SOT A performance on ReMASC. T o partially alleviate this data scarcity , an acoustic simulation framework was recently proposed in [16] to gen- erate synthetic genuine and replay multi-channel recordings. I I I . A C O U S T I C M A P - B A S E D R E P L A Y D E T E C T O R In this section we describe how we compute the acoustic maps from a multi-channel recording using the delay-and-sum beamformer . Then, we describe the lightweight CNN, which is responsible for distinguishing between genuine and replay speeches, that is, if the sound is emitted from a real talker or a loudspeaker . A. Beamforming-based Acoustic Maps Let x ∈ R N × T s denote a multi-channel audio segment with T s samples recorded from N microphones. Each channel is first pre-processed using the short-time Fourier transform (STFT) with window length N FFT and hop size H : X i ( f , t ) = STFT { x i } , X ∈ C N × F × T , (1) where F is the number of frequency bins and T is the number of frames. The microphone geometry is encoded by P = { p 1 , . . . , p N } ⊂ R 3 , (2) where p i is the vector defining the position of the i -th microphone in the space. For computing the acoustic maps, we define a discrete spatial grid sampled from a set of azimuth ( Az ) and elev ation ( El ) angles as G = { ( α k , β l ) | α k ∈ Az , β l ∈ El } , (3) where α k and β l denote a single point of the grid with a fixed azimuth and elev ation angles, respecti vely . Specifically , the azimuth and ele vation angle sets are defined as uniformly sampled angular grids. The azimuth set Az consists of 91 discrete angles uniformly spanning the interval [ − 90 ◦ , 90 ◦ ] , while the elev ation set El consists of 41 discrete angles uniformly spanning the same interval. For each grid point ( α, β ) , the corresponding unit direction vector is u ( α, β ) = cos β cos α cos β sin α sin β , (4) and the plane-wa ve steering vector is a ( ω , α, β ) = exp − j ω c P u ( α, β ) ∈ C N , (5) where c = 343 m / s is the speed of sound, ω = 2 πf Hz denotes the angular frequenc y (rad/s) corresponding to a physical frequency f Hz , and j = √ − 1 . Using this steering vector , a narrowband pseudo-power response is computed for each ( f , t ) as M ( f , t, α, β ) = a ( f , α, β ) H X ( f , t ) 2 , (6) where X ( f , t ) is a vector consisting of all the pre-processed channels. T o obtain a more compact representation, the maps are time av eraged and the frequency bins are grouped into K disjoint bands, where each B m is a set consisting of frequency indices of the m -th band B k ⊆ { 1 , . . . , F } , (7) and the band- and time-a veraged acoustic map is computed as M m ( a, e ) = 1 | B m | T s X f ∈ B m T s X t =1 M ( f , t, α a , β e ) . (8) The final representation is a 3-D acoustic-map tensor M ∈ R K × A × E with A = | Az | = 91 as the number of azimuths and E = | El | = 41 as the number of elev ations, encoding sound radiation patterns. Moreov er, the acoustic map can encompass directional energy distributions that capture array- manifold structure, direct-path cues, and early reflections, all of which are informative for discriminating genuine and replayed signals. An example of the computed acoustic maps using delay-and-sum on genuine and replay recordings are depicted in Fig. 1. Although this subsection explained the computation using the delay-and-sum beamforming, acoustic maps are not tied to a specific spatial processing method and can also be computed using alternati ve approaches, such as minimum vari- ance distortionless response (MVDR) beamforming or steered response po wer with phase transform (SRP-PHA T), which are ev aluated in later experiments. B. Con volutional Neural Network Classifier The computed acoustic maps are then fed to a neural network that is responsible for classifying between genuine and replay recordings. Specifically , the proposed lightweight CNN operates on acoustic maps M ∈ R K × A × E . The ar- chitecture is designed to balance representational capacity and computational ef ficiency , making it suitable for data- limited and resource-constrained scenarios. The network is built around a repeated con volutional block composed of a depthwise separable 2D con volution operating ov er A and E dimensions, follo wed by batch normalization, an exponential linear unit (ELU) activ ation function [17], and (2 × 2) max pooling. Depthwise separable con volutions substantially re- duce the number of trainable parameters and computational cost compared to standard con volutions [18], while still cap- turing local spectro-temporal patterns in the acoustic maps. This block is applied three times with progressively increasing channel dimensionality and decreasing kernel size, namely ( K → 8 , k = 5) , (8 → 16 , k = 3) , and (16 → 32 , k = 3) , enabling hierarchical feature extraction with controlled model capacity . After these three blocks, a final depthwise separable 2D con volution with 32 input and output channels and kernel size 3 is applied, follo wed by batch normalization and ELU [17] ac- tiv ation, without further pooling. Early spatial downsampling in the repeated blocks reduces the resolution of intermediate representations, limiting sensiti vity to noise and fine-grained variations and improving generalization. The resulting feature maps are projected to 2 channels and flattened. The flattened representation is processed by a shallow fully connected classification head composed of a multilayer perceptron (MLP) with 110 neurons and 32 hidden units, followed by batch normalization and ELU [17] activ ation, and a final linear layer mapping to a 2 -dimensional output for the classification between genuine and replay classes. The projection to a low-dimensional embedding and the shallow classifier further constrain model capacity and mitigate ov erfitting. Overall, the architecture contains approximately 6000 train- able parameters and provides a compact yet effecti ve alter- nativ e to deeper or attention-based models for acoustic scene analysis. The deep neural network (DNN) has been trained with the categorical cross-entropy loss with sofmax nonlin- earity . In addiction, we employed MixUp augmentation [19] with α = 0 . 05 . I V . E X P E R I M E N T S A. Dataset ReMASC [7] is selected as it is the only publicly av ail- able dataset providing synchronized multi-channel recordings acquired with de vices featuring different numbers of mi- crophones and array geometries for this task. The dataset comprises recordings from four ASV microphone arrays, denoted as D1 , D2 , D3 , D4 , equipped with 2 , 4 , 6 , and 7 omnidirectional microphones, respectiv ely . D1 and D2 are linear microphone arrays, while D3 and D4 are arranged in a hexagonal configuration, with D4 additionally including a central microphone. In total, the dataset includes 9 , 240 genuine and 45 , 472 replay audio samples. Devices D1 , D2 , and D3 operate at a sampling rate of 44 . 1 kHz, while D4 records at 16 kHz. The bit depth is 16 bits for all devices except D3 , which uses 32 bits. ReMASC features speech from 55 speakers with di verse gender and v ocal characteristics, recorded across four dif ferent acoustic en vironments: an out- door scenario (En v-A), two enclosed spaces (En v-B and En v- C), and a moving vehicle (En v-D). Genuine speech is captured using two spoofing microphones and subsequently replayed through four playback de vices of varying quality , enabling the simulation of realistic replay attack scenarios under div erse acoustic conditions. T o assess the performance of our approach and directly compare with SO T A models, equal error rate (EER) metric is used following the same train-test split provided by the authors of the dataset [7]. A separate model is trained for each microphone array in the dataset. W e perform fiv e independent runs to compute the 95% mean confidence interv als. All four en vironments are present in the training and testing sets. Howe ver , we perform generalization capabilities to unseen en vironments later in the experiments, i.e., when one of the them is remov ed from the training set. B. Results The results in T able I shows that the proposed acoustic- map-based approach achiev es div erse performance across mi- crophone arrays. Detection accuracy is clearly influenced by the number of microphones and array geometry: arrays with more microphones ( D3 and D4 ) consistently yield lower EERs compared to D1 and D2 . This trend is expected, as larger arrays provide richer spatial sampling of the sound field, improving the reliability of directional energy cues encoded in the acoustic maps. Compared to learning-based multichannel baselines, the proposed method does not uniformly outperform state-of- the-art approaches; ho wever , from a model-comple xity per- spectiv e, the proposed approach is highly efficient in terms of number of learnable parameters: with approximately 6 k parameters, it is significantly lighter than M-ALRAD ( ≈ 300 k) and the ReMASC CRNN baseline ( ≈ 1 M). This supports the claim that acoustic maps, combined with a shallow CNN, of fer a fav orable trade-off between performance and computational cost. The results indicate that acoustic maps are informative for replay detection, but their ef fectiveness is constrained when spatial resolution is limited, as in small arrays. T ABLE I M I CR OP H O N E - W I S E C O MPA R IS O N O F E E R ( % ) W I T H R E MA S C BA S E L IN E . Methods D1 D2 D3 D4 NN-Single [4] 16 . 6 23 . 7 23 . 7 27 . 5 NN-Dummy Multichannel [4] 16 . 0 23 . 2 24 . 5 25 . 2 NN-Multichannel [4] 14 . 9 15 . 4 16 . 5 19 . 8 ALRAD [6] 5 . 5 ± 2 . 6 11 . 9 ± 2 . 2 19 . 5 ± 2 . 2 21 . 7 ± 2 . 1 M-ALRAD [6] 5 . 2 ± 1 . 2 10 . 0 ± 0 . 9 10 . 4 ± 2 . 1 14 . 2 ± 0 . 8 Acoustic maps 21 . 6 ± 1 . 0 19 . 9 ± 2 . 8 10 . 1 ± 2 . 8 19 . 7 ± 2 . 8 C. Analysis on the c hoice of beamformer As pre viously mentioned, different spatial processing meth- ods can be employed to compute the acoustic maps. W e stud- ied the performance of delay-and-sum beamforming, MVDR beamforming, and SRP-PHA T in T able II, which highlights the impact of the chosen method to generate acoustic maps on replay detection accuracy . Overall, the results indicate that the choice of spatial processing technique influences performance in a device- dependent manner . Delay-and-sum beamforming achieves competitiv e performance across all microphone arrays and provides a stable baseline, particularly for arrays with a lo wer number of microphones, e.g. D1 . MVDR beamforming yields comparable results and, in some cases, slightly improved performance (e.g., for D3 and D4 ), but may be more sensitiv e to estimation errors in the spatial covariance matrices, especially for short or noisy utterances. SRP-PHA T generally exhibits higher EERs, which may be attributed to its sensiti vity to re verberation and noise, potentially leading to less reliable spatial energy patterns for this task. These results suggest that while more adv anced spatial processing methods can be beneficial, simpler approaches such as delay-and-sum remain effecti ve and robust for generating acoustic maps in replay detection scenarios. T ABLE II E E R ( % ) C H AN G I N G T H E T Y PE O F B E A M FO R M E R F O R C O MP U T I NG T H E AC O U ST I C M A P S . Methods D1 D2 D3 D4 Delay-and-sum 21 . 6 ± 1 . 0 19 . 9 ± 2 . 8 10 . 1 ± 2 . 8 19 . 7 ± 2 . 8 MVDR 32 . 4 ± 1 . 3 20 . 6 ± 1 . 5 9 . 9 ± 2 . 7 17 . 6 ± 1 . 6 SRP-PHA T 31 . 4 ± 1 . 6 19 . 4 ± 2 . 5 12 . 5 ± 5 . 6 21 . 2 ± 2 . 2 Env A Env B Env C Env D 0 10 20 30 40 50 60 70 EER (%) Environmen t-dep enden t Env A Env B Env C Env D Environmen t-indep enden t D1 D2 D3 D4 Random Guess Fig. 2. Microphone-wise performance in both generalization scenarios. D. Analysis on gener alization As done in previous works [6], [11], we provide the performance of acoustic maps on ReMASC in a envir onment- dependent and -independent scenarios in T able III. Specifi- cally , in the envir onment-dependent setting, training data en- compasses all the en vironments, and the model is tested on the same en vironments. Differently , the en vironment-independent setting is designed to assess robustness to unseen conditions: the model is trained using data from three environments and ev aluated on the remaining fourth unseen en vironment. This procedure is repeated for each en vironment. In the en vironment-dependent setting , acoustic maps achie ve reasonable performance, although they do not consis- tently outperform handcrafted-feature-based methods such as TECC [10] or M-ALRAD [6]. This suggests that while spatial information is useful, it does not fully replace carefully designed spectral features under matched conditions. In the more challenging en vironment-independent setting, performance degradation is observed for all methods, includ- ing the proposed approach. Acoustic maps exhibit limited robustness to unseen environments, with EERs increasing sub- stantially , particularly for arrays with fewer microphones. This highlights a key limitation of the current representation: spatial patterns captured by acoustic maps remain sensitiv e to envi- ronmental changes such as room geometry and rev erberation. In addition, fixed frequenc y bands and static beamforming limit adaptability , particularly in unseen en vironments. This suggests that future improvements should focus on learning frequency-dependent or adaptiv e spatial representations to better capture replay-specific directivity cues. Nev ertheless, the results confirm that acoustic maps gener- alize at a le vel comparable to other multichannel approaches, despite using a fixed, non-adaptiv e spatial representation and a lightweight classifier . T ABLE III E E R S ( % ) F O R E N VI RO N M E NT - DE P E N DE N T V S . E N VI RO N M E NT - IN D E P EN D E N T S C EN AR I O S O N R E M A SC D A TAS E T . Methods En v-A En v-B ∗ En v-C En v-D En vironment-dependent CQCC-GMM [7] 13 . 5 17 . 4 21 . 3 22 . 1 ETECC [12] 15 . 1 33 . 8 14 . 1 10 . 4 CTECC [11] 13 . 0 26 . 8 9 . 9 10 . 1 TECC [10] 13 . 4 27 . 9 10 . 3 9 . 1 M-ALRAD [6] 8 . 1 ± 2 . 3 5 . 8 ± 2 . 4 7 . 5 ± 2 . 6 14 . 0 ± 2 . 0 Acoustic maps 13 . 9 ± 4 . 0 19 . 2 ± 9 . 5 11 . 9 ± 3 . 7 21 . 7 ± 2 . 2 En vironment-independent CQCC-GMM [7] 19 . 9 39 . 9 34 . 6 48 . 9 ETECC [12] 29 . 0 32 . 5 30 . 0 49 . 9 CTECC [11] 28 . 5 34 . 7 32 . 5 50 . 0 TECC [10] 26 . 8 35 . 4 31 . 8 50 . 0 M-ALRAD [6] 13 . 8 ± 2 . 8 20 . 3 ± 3 . 1 15 . 1 ± 5 . 5 24 . 2 ± 2 . 4 Acoustic maps 27 . 1 ± 7 . 1 41 . 6 ± 4 . 3 28 . 3 ± 7 . 4 43 . 2 ± 2 . 0 Env-B ∗ does not encompass D1 genuine utterances due to hardware fault during data collection. V . C O N C L U S I O N In this work, we proposed acoustic maps as a spatial feature representation for replay speech detection from multi- channel recordings. The proposed approach exploits classi- cal spatial processing to project multi-channel audio onto discrete azimuth and ele vation grids, encoding directional energy distributions that reflect physical differences between genuine human speech radiation and loudspeaker -based replay . Experimental results on the ReMASC dataset demonstrate that acoustic maps provide a compact and physically inter- pretable representation for replay detection, achieving com- petitiv e performance with a lightweight con volutional neural network containing approximately 6000 trainable parameters. At the same time, the results highlight limitations of the current formulation, particularly in en vironment-independent scenarios, where fixed frequency bands and static spatial processing reduce adaptability to unseen acoustic conditions. Future work will focus on the implementation of a learning- based frequency band selector to better capture directivity cues from multi-channel mixtures. R E F E R E N C E S [1] W . Huang, W . T ang, H. Jiang, J. Luo, and Y . Zhang, “Stop deceiving! an effecti ve defense scheme against voice impersonation attacks on smart devices, ” IEEE Internet of Things Journal , vol. 9, no. 7, pp. 5304–5314, 2022. [2] X. Liu, X. W ang, M. Sahidullah, J. Patino, H. Delgado, T . Kinnunen, M. T odisco, J. Y amagishi, N. Evans, A. Nautsch, and K. A. Lee, “ASVspoof 2021: T owards Spoofed and Deepfake Speech Detection in the W ild, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 31, pp. 2507–2522, 2023. [3] T . Kinnunen, M. Sahidullah, M. Falcone, L. Costantini, R. G. Hau- tam ¨ aki, D. Thomsen, A. Sarkar, Z. T an, H. Delgado, M. T odisco, N. Evans, V . Hautam ¨ aki, and K. A. Lee, “RedDots replayed: A ne w replay spoofing attack corpus for text-dependent speaker verification research, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2017. [4] Y . Gong, J. Y ang, and C. Poellabauer, “Detecting replay attacks using multi-channel audio: A neural network-based method, ” IEEE Signal Pr ocessing Letters , vol. 27, pp. 920–924, 2020. [5] K. Delac and M. Grgic, “ A survey of biometric recognition methods, ” in Pr oceedings. Elmar-2004. 46th International Symposium on Electronics in Marine , 2004. [6] M. Neri and T . V irtanen, “Multi-channel replay speech detection using an adapti ve learnable beamformer , ” IEEE Open J ournal of Signal Pr ocessing , pp. 1–7, 2025. [7] Y . Gong, J. Y ang, J. Huber , M. MacKnight, and C. Poellabauer, “Re- MASC: Realistic Replay Attack Corpus for V oice Controlled Systems, ” Interspeech , 2019. [8] T . Kinnunen, M. Sahidullah, H. Delgado, M. T odisco, N. Evans, J. Y a- magishi, and K. A. Lee, “The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection, ” in Interspeec h , 2017. [9] M. T odisco, X. W ang, V . V estman, M. Sahidullah, H. Delgado, A. Nautsch, J. Y amagishi, N. Evans, T . Kinnunen, and K. A. Lee, “ASVspoof 2019: Future horizons in spoofed and fake audio detection, ” in Interspeech , 2019. [10] H. K otta, A. T . Patil, R. Acharya, and H. A. Patil, “Subband Channel Selection using TEO for Replay Spoof Detection in V oice Assistants, ” in Asia-P acific Signal and Information Pr ocessing Association Annual Summit and Conference (APSIP A ASC) , 2020. [11] R. Acharya, H. Kotta, A. T . Patil, and H. A. Patil, “Cross-T eager Energy Cepstral Coefficients for Replay Spoof Detection on V oice Assistants, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2021, pp. 6364–6368. [12] A. T . Patil, R. Acharya, H. A. Patil, and R. C. Guido, “Improving the potential of enhanced teager energy cepstral coefficients (ETECC) for replay attack detection, ” Computer Speech & Language , vol. 72, p. 101281, 2022. [13] M. Omologo, M. Matassoni, and P . Sv aizer, “Speech recognition with microphone arrays, ” in Microphone arrays: signal pr ocessing techniques and applications . Springer , 2001, pp. 331–353. [14] M. Neri and T . V irtanen, “Impact of Microphone Array Mismatches to Learning-Based Replay Speech Detection, ” in 2025 33rd Eur opean Signal Pr ocessing Confer ence (EUSIPCO) , 2025. [15] L. Zhang, S. T an, J. Y ang, and Y . Chen, “V oicelive: A phoneme localiza- tion based li veness detection for voice authentication on smartphones, ” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , 2016, pp. 1080–1091. [16] M. Neri and T . V irtanen, “Acoustic Simulation Frame work for Multi- channel Replay Speech Detection, ” arXiv pr eprint arXiv:2509.14789 , 2025. [17] C. Djork-Arn ´ e, T . Unterthiner , and S. Hochreiter, “Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs), ” in International Conference on Learning Repr esentations (ICLR) , 2016. [18] M. Neri and M. Carli, “Low-Complexity Attention-Based Unsupervised Anomalous Sound Detection Exploiting Separable Conv olutions and Angular Loss, ” IEEE Sensors Letters , vol. 8, no. 11, pp. 1–4, 2024. [19] H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization, ” in ICLR , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment