Harnessing Implicit Cooperation: A Multi-Agent Reinforcement Learning Approach Towards Decentralized Local Energy Markets
This paper proposes implicit cooperation, a framework enabling decentralized agents to approximate optimal coordination in local energy markets without explicit peer-to-peer communication. We formulate the problem as a decentralized partially observa…
Authors: Nelson Salazar-Pena, Alej, ra Tabares
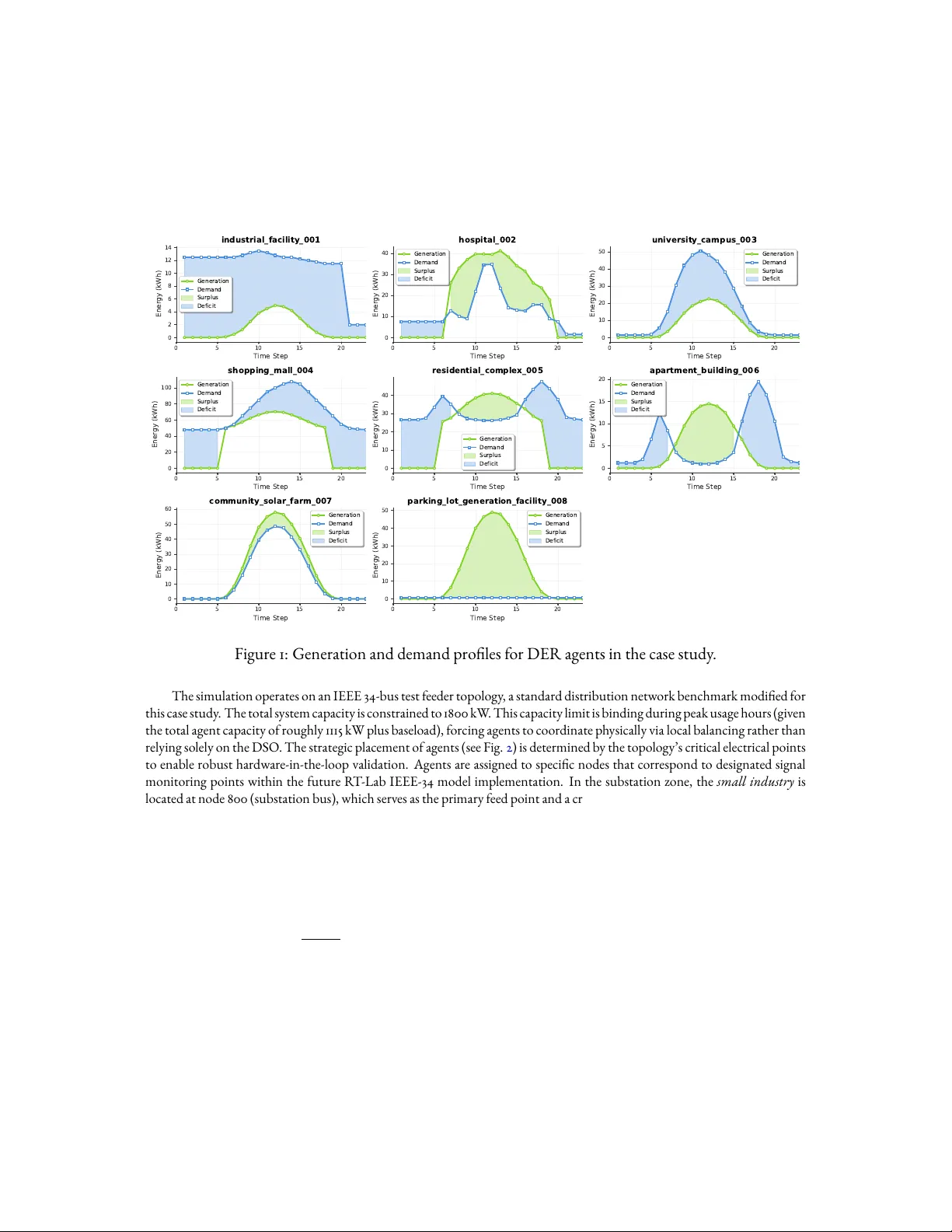
Harnessing Imp licit Cooperation: A Multi-Agent Reinf orc ement Learning Appro ach T o w ards De centralize d Local Energy M arkets Nelson Salazar-P eña a , Alejandra T abares b , and Andrés González-Manc era a, * a Department of M echanical Engineering, Univ ersidad de los Andes, 111711, Bogotá D . C., Colombia b Department of Industrial Engine ering, Universidad de los Andes, 111711, Bogotá D .C., Co lombia Abstract The rapid integration of distributed energy resourc es strains centralized management, nec essitating de- centralize d control paradigms that ensure ph ysical stability without compromising privacy . This p aper proposes impli cit cooper ati on , a framework enabling decentralize d agents to approximate optimal coor- dination in local energy markets without explicit pe er-to-peer communication. W e formulate the prob- lem as a de centralized partially observable Marko v decision problem that is solv ed through a multi-agent reinf orcement learning task in which agents use stigmergic signals (key perf ormance indic ators at the system lev el) to inf er and react to global states. Through a 3 × 3 f actorial design on an IEEE 34-node topology , we evaluate d thre e training paradigms (CTCE, CTDE, DTDE) and three algorithms (PPO, APPO , SAC). Results identify APPO-D TDE as the optimal c onguration, achieving a coordination score of 91.7% relativ e to the theoretical centralized benchmark (CTCE). Howev er, a c ritical trade-o emerges betw een ecienc y and stability: while the c entralized benchmark maximizes allocativ e eciency with a peer-to-peer trade ratio of 0.6, the fully decentralize d approach (DTDE) demonstrates superior ph ysical stability . Spe cically , DTDE re duces the v ariance of grid balanc e b y 31% c ompare d to h ybrid architectures, establishing a highly predictab le, import-biase d load prole that simplies grid regula- tion. Furthermore, topo logical analysis rev eals emergent sp atial clustering, where dec entralized agents self-organize into stable trading communities to minimize congestion penalties. While SAC ex celled in h ybrid settings, it failed in decentralized environments due to entropy-driv en instability . This research prov es that stigmergic signaling pro vides sucient conte xt for c omplex grid coordination, o ering a ro- bust, privac y-preserving alternative to e xpensive c entralized communic ation infrastructure. Keywor ds Implicit Cooperation, Multi-Agent Reinf orcement Learning, Dec entralized Energy M arkets, Distributed Energy Resources, Loc al Energy Markets * Corresponding author Email addresses: na.salazar10@uniandes.e du.co (Nelson Salazar-P eña ), a.tab aresp@uniandes.e du.co (Alejandra T abares ), angonzal@uniandes.e du.co (Andrés González-M ancera ) 1 1 Intr oduction 1.1 Mo tivation The energy landsc ape is undergoing a structural transf ormation, driv en by the decarbonization, digitalization, and decentraliza- tion [ 1 ]. This transition is characterize d b y the prolif eration of distributed energy resources (DERs), such as solar photov oltaics, battery storage systems, and electric vehicles, which are transforming passiv e consumers into active prosumers [ 1 ]. While this shift promises greater grid resilience and re duced carbon emissions, it fundamentally alters traditional grid management. The c entralized contro l paradigm, e ectiv e f or dispatching a limited number of large generators, fac es intractable compu- tational comple xity and single-point-of-failure risks when attempting to c oordinate thousands of geographically distributed, intermittent endpoints [ 2 ]. Consequently , local energy markets (LEMs) hav e emerged as an operational framework for man- aging this comp lexity , enabling the de centralized trading of energy and exibility servic es [ 3 ]. How ever, the succ essful implementation of LEMs faces the challenges of achieving computational scalability to manage multiple agents, data priv acy to protect agent autonom y , and the balance betwe en supply and demand in the grid [ 1 ]. T raditional solutions do not satisfy all three conditions simultaneously . F or examp le, centralized optimization fails in terms of scalability and privacy , while peer-to-peer (P2P) trading improves priv acy but fac es a scalability hurdle due to quadratic communication ov erhead [ 1 ]. 1.2 Pro bl em statement While the nec essity of dec entralized coordination is well-estab lished, current state-of-the-art approaches possess aws regard- ing their deployment in real-world energy systems. The primary problem is the reliance on centralized training as the default paradigm f or multi-agent learning in energy markets [ 4 ]. While algorithms like multi-agent deep deterministic polic y gradient (MADDPG) succ essfully demonstrate coordination in simulation, they do so by vio lating the privac y and decentralization constraints during the training phase. Centralized training requires a c entralized critic with ac cess to the glob al state including the private c ost functions, battery states, and preferenc es of all agents to guide the learning process [ 5 ]. Conv ersely , decentralize d training respects these privacy constraints but su ers from non-stationarity . As all agents learn simultaneously , the environment appears unpredictable to an y single agent, leading to learning instability and con vergenc e to suboptimal equilibria [ 6 ]. Furthermore, existing implicit c oordination models often rely solely on price signals, which can induce s ystemic instabilities such as price vo latility and load synchronization, threatening ph ysical grid security [ 7 ]. Consequently , there is a lack of a framework that enables fully decentralize d agents to learn stable, cooperativ e strategies for energy b alance without requiring c entralized training data or destabilizing price signals. 1.3 Research gap The main challenge addressed in this paper is achieving a balance between energy supply and demand in a de centralized grid through imp licit cooper ation , i.e., without relying on centralized dispatch or explicit communication. Unlike traditional cen- tralized c ontrol, which relies on a single entity making decisions about all resourc es or direct negotiation, imp licit cooperation requires that self-interested agents learn to work together while operating independently to achiev e s ystem-wide coherenc e through agents reacting to share d environmental signals [ 8 ]. This approach o ers a potential solution by de coupling decision- making while maintaining grid balanc e. Subsequently , in this work we establish the theoretical basis f or implicit cooperation, proposing it as a necessary coordination model f or LEMs where agents must c ollaborate to maintain grid balanc e without compromising priv acy or autonom y . This p aper builds upon our previous work [ 9 ], which introduces a simulation framew ork f or studying multi-agent in- teractions in LEMs and integrates modular market mechanisms with realistic ph ysical network constraints (e.g., energy ow , congestion), to test and v alidate the imp licit cooperation h ypothesis using learning agents. This implicit cooperation challenge imposes a set of constraints that distinguish it from traditional multi-agent c ontrol problems: • Communication c onstraints: Agents must coordinate their actions without exp licit, two-wa y communication. Co- ordination must emerge solely from the observation of shared environmental signals, such as agent reputation or grid congestion indic ators, to preserve privac y and scalability . • Conicting objectiv es: The s ystem is populated b y self-interested agents driv en to maximize their individual objectiv e function. The challenge is to design incentiv e structures and information fe edback loops that align individual objectiv es with the system-level goal of grid balance (supply-demand balance), enabling agents to learn strategies that balanc e both. 2 • Non-stationarity: The LEM environment is non-stationary be cause other agents are simultaneously learning and adapting. An optimal strategy for one agent depends on the strategies of others, creating a moving target problem where agents must adapt to changing opponent strategies while maintaining coordination. • Partial o bservability: Agents operate with limited information about the ov erall state of the system. They can observ e their o wn local state and some system-level signals, but they cannot dire ctly observe the states or strategies of other agents. This partial observ ability limits agents’ ability to understand the eects of their actions on the entire s ystem. • Continuous spaces: Unlike discrete action selection problems, energy market coordination requires continuous de- cisions about prices and quantities. Agents must learn policies in continuous action spac es, requiring sophistic ated polic y gradient methods and exploration strategies. • Uncertain ty and stochasticity: The system must acc ount f or various sourc es of uncertainty , including fore cast errors in generation and demand, stochastic market conditions, and technical constraints. Agents must learn robust strategies that perform w ell under uncertainty . 1.4 N ovel ty and contribution T o solv e this challenge, w e used multi-agent reinf orcement learning (MARL) as our main research method, and analyzed com- plementary studies that pro vide a deeper understanding of the coordination mechanisms: 1. T raining paradigms: How do dierent MARL training paradigms, specic ally centralized training with centralized ex ecution (CTCE), c entralized training with decentralized e xecution (CTDE), and de centralized training with dec en- tralized ex ecution (DTDE), a ect the emergence and stability of implicit cooperation. This study addresses the trade- o betw een coordination quality and deployment feasibility , e xploring whether c entralized training is nec essary for ee ctive coordination or whether fully de centralized learning can achiev e comparab le results. 2. Algorithm eectiv eness: Which MARL algorithms are most eectiv e f or learning cooperativ e strategies in dec en- tralized energy markets. This study explores algorithm-specic characteristics that promote or hinder coordination, providing guidanc e for algorithm selection in practical dep loyments. 3. Mec hanism design: How do system-level key performanc e indicators (KPIs) integrated into the observation space and reward function enable implicit c oordination. This study delv es into the mechanisms of implicit cooperation, understanding how inf ormation structure and incentive design c reate conditions f or coordination emergence. 4. Scalability and ro bustness: Ho w does implicit cooperation scale with inc reasing numbers of agents. This study addresses practical deplo yment c onsiderations, ensuring that coordination mechanisms work bey ond the experimental setup. This research proposes that the non-stationarity of fully dec entralized training (D TDE) can be resolv ed by engineering the observation space to include stigmergic environmental signals. Specic ally , we embedded system-level KPIs (e.g., social welf are, grid congestion levels, and reputation scores) directly into the local observ ations of agents to create a f eedback loop that functions as a surrogate for a centralized controller. This enables agents to internalize their impact on the grid and learn behaviors to b alance the grid implicitly . The contributions of this w ork are: • W e demonstrate that a decentralized implementation (DTDE), when enhanced with engineered observation spaces and rew ard shaping, c an approximate the performanc e of centralized training (CT CE/CTDE), thereby validating a privac y-preserving path for real-w orld deplo yment. • W e introduce and validate a mechanism for using reputation scores and system-lev el KPIs as c ontinuous state variab les. W e sho w how these non-price signals mitigate the synchronization risks of standard transactive energy models, allowing agents to learn stable lo ad-balancing policies that respect p hysic al grid constraints. • W e conduct a systematic evaluation of distinct training p aradigm and MARL algorithm congurations in a high- delity simulation invo lving medium-scale agents with continuous action spaces. This analysis identies the optimal algorithmic characteristics for f ostering emergent cooperation in c ompetitive energy markets. 1.5 P aper structure This paper provides a progression from the theoretical foundations of de centralized coordination to the computational vali- dation of the proposed implicit cooperation model. The remainder of the paper is structured as fo llows: Section 2 provides a review of the state-of-the-art in the evo lution of coordination in energy s ystems, analyzing the limitations of explicit contro l in 3 LEMs and the potential of MARL, establishing the specic gap regarding implicit cooperation and privac y . Section 3 details the methodology , cov ering the mathematical basis for modeling the constraints of scarce inf ormation sharing, the conceptual architecture of the implicit cooperation to inc orporate system-level KPIs into the observ ation sp ace and reward function to work as stigmergic signals, the the oretical analysis of the three training p aradigms (CTCE, CTDE, and D TDE), and the math- ematical formulations of the MARL algorithms, estab lishing the basis for their comp arison. Section 4 outlines the experimental setup, describing the framework conguration for the me dium-scale agents, the grid topology , and the market rules, and the specic metrics used to assess the solution spac e. Section 5 presents an analysis of the experimental outcomes, comp aring the ecac y of the training p aradigms in fostering coordination, ev aluating the robustness of the spe cic algorithms in continuous contro l tasks, and analyzing the emergent behaviors of the agents. This section provides the evidence f or the trade-os be- twe en coordination quality and deplo yment feasibility , validating whether fully decentralize d agents can indeed approximate the performanc e of centralized baselines through implicit mechanisms. Finally , Section 6 synthesizes the ndings to conclude the paper, summarizing the contributions regarding the viability of implicit cooperation, oering practical guidelines for the design of priv acy-preserving energy markets, and outlining future research directions for scaling these me chanisms to larger, more heterogeneous grid en vironments. 2 Literature r eview 2.1 Implicit cooperation and emerg ent coordination The evolution of power system control has been driv en b y the ph ysical transformation of the grid from a c entralized hierar- ch y to a distribute d network of autonomous DERs, which has fundamentally changed the contro l philosoph y of the electrical grid [ 1 , 10 ]. T raditional centralized contro l, although theoretically capab le of glob al optimization, faces intractable computa- tional c omplexity (limited sc alability) and c reates single points of f ailure when app lied to thousands of autonomous endpoints [ 2 , 11 ]. As a result, the research landscape has shifted toward decentralize d paradigms where control intelligence is distributed to the grid edge [ 12 ]. How ever, a key distinction must be made regarding how these decentralized agents coordinate: whether through explicit communic ation channels, inv olving direct negotiation and message passing, or imp licit c ommunication chan- nels, where coordination emerges from en vironmental observation. 2.1.1 A tax onomy of coordination: the limits of explicit con trol T o na vigate the LEM landsc ape, we adopt the structural tax onom y proposed b y [ 1 ], which classies strategies b ased on the decision-making and the architecture of information ow . The fundamental distinction lies betwe en direct contro l , where a central entity issues set-points, and i ndirect control , where prosumers retain autonom y [ 13 ]. In direct control and the paradigm of centralized bottleneck, a central controller aggregates data from all p articipating agents and computes global optimal set-points [ 12 ]. This is ex emplied by the model of coordination managed by the T rans- mission System Operator (TSO), where the central TSO retains full responsibility for v alidating and dispatching DER services, treating the Distribution System Operator (DSO) merely as a data provider [ 14 ]. While this o ers high controllability and theo- retical optimality , it is hindered by the curse of dimensionality [ 1 ]. As the number of DERs increases, the computational burden grows e xponentially , and the requirement to relay vast amounts of real-time data creates signicant priv acy vulnerabilities and communic ation bottlenecks [ 2 ]. Conv ersely , a DSO-managed model delegates validation and disp atch to the DSO, lev eraging local network knowledge but potentially creating conicts of interest regarding asset [ 14 ]. Hybrid models attempt to bridge this by assigning pre-qualic ation to the DSO and dispatch to the TSO . T o address these limitations, research has piv oted to indirect contro l, bifurcate d into mediated and bi latera l architec- tures. Mediated coordination relies on a hub-and-spoke topology where a c entral aggregator interfaces between the grid and prosumers [ 15 ]. Although this f acilitates v alue co-creation through global optimization (e.g., mixed-integer linear programming (MILP) or alternating direction method of multipliers (ADMM)), it retains a single point of f ailure and signicant privac y vul- nerabilities, as agents must disclose detailed load proles to the coordinator [ 13 ]. Furthermore, the computational burden of clearing comple x stochastic optimization problems creates a scalability bottleneck for real-time planning [ 16 ]. Bilateral c oor- dination, or peer-to-peer (P2P) trading, attempts to resolve this b y enab ling direct pairwise negotiation via technologies like blockchain [ 3 , 17 ]. These markets often emplo y sophisticated mechanisms such as double auctions or game-theoretic negotia- tion [ 18 ]. How ever, this introduces a sc alability w all since the c ommunication o verhead in a mesh netw ork grows quadratically with the number of participants [ 10 ]. Approaches relying on explicit pref erence matching often incur prohibitiv e negotiation latency , making them unsuitable f or the granular, intraday planning required b y thousands of assets [ 1 ]. 4 2.1.2 Price-only mec hanisms for implicit coor dination The architectural choice of a c ontrol s ystem denes the operational c apabilities and failure modes of a LEM. The literature de- lineates a spectrum ranging from fully centralized to fully decentralized (see T able 1 ), each presenting distinct trade-os between system-lev el optimality and agent-level autonom y . At one end of the spectrum lies the centralized contro l architecture, typically orchestrated by a central c ontroller [ 12 ]. In this p aradigm, the c entral contro ller aggregates data from all p articipating agents (e.g., generators, loads, and storage units) and computes glob al optimal set-points to minimize operational costs or maintain stability [ 12 ]. While this approach the oretically ensures global optimality and high c ontrollability , it is increasingly view ed as computationally intractable for large-sc ale systems inv olving high DER penetration [ 2 ]. Furthermore, centralize d architectures introduce a single point of failure. The compro- mise or malfunction of the c entral controller can c ascade into s ystem-wide c ollapse, and the c ommunication infrastructure required to rela y vast amounts of real-time data creates signicant bottlenecks and priv acy vulnerabilities [ 2 ]. Conv ersely , de centralized control paradigms distribute de cision-making authority to individual agents or local controllers [ 12 ]. This architecture aligns with the ph ysically distributed nature of DERs, enab ling agents to make decisions base d on local measurements (e.g., voltage, frequency) or local objectives [ 19 ]. The primary advantages of decentralization are enhanced re- silience as the system lacks a single point of f ailure, and plug-and-pla y scalability , which allows for the integration of new assets without redesigning the central control logic [ 2 , 19 ]. How ever, purely decentralize d decisions, if uncoordinate d, can lead to suboptimal global outc omes or localized imb alances [ 20 ]. P2P control represents a further evo lution of this autonom y , where agents act as peers without hierarchical relationships, f orming the technical b asis for direct energy trading [ 12 , 21 ]. Systematic reviews indicate a trend toward dec entralized coordination schemes in this domain [ 20 ]. Centralized opti- mization is increasingly viewed as practically inf easible due to data privac y conc erns and computational load. Decentralized approaches, often emplo ying game-the oretic or distributed optimization, are f av ored because they signicantly reduce com- ple xity and operational c osts, ev en if they yield theoretically sub-optimal resourc e allocations comp ared to a perfe ct centralized benchmark [ 20 ]. This real-w orld structural trend reinforc es the need f or scalable, lo w-communication coordination methods in LEMs. T o manage the de centralize d actions of prosumers within LEMs, c oordination strategies ha ve shifte d from direct ph ysical commands to market-based mechanisms that utilize economic signals. For instance, demand response represents the founda- tional lay er of this shift, incentivizing consumers to alter consumption patterns in response to price signals or reliability needs [ 11 ]. While e ective for peak shaving, incentiv e-based demand response f aces technical challenges in estab lishing accurate coun- terfactual b aselines for c onsumption, which can be strategically exp loited by p articipants [ 22 , 23 ]. T ransactiv e energy extends these princip les b y creating a dynamic equilibrium betw een supp ly and demand across the entire infrastructure, using prot as the key operational p arameter [ 24 ]. T ransactive energy empo wers prosumers to activ ely buy and sell energy , improving eciency and integrating intermittent renewab les [ 25 , 26 ]. P2P energy trading is the most decentralized manifestation of transactiv e energy , facilitating direct exchange betwe en agents [ 3 ]. These markets often emplo y sophisticated mechanisms such as double auctions, game-theoretic negotiation, or optimization-base d clearing [ 18 ]. How ever, these approaches predominantly rely on exp licit coordination: they require struc- tured, binding communication protoco ls (e.g., submitting formal bids and asks) and comple x market clearing processes [ 27 ]. This reliance on explicit negotiation creates signicant communic ation ov erhead, computational latency during clearing, and potential privac y concerns regarding the disclosure of prosumer pref erences [ 3 , 28 ]. T able 1: Comp arativ e analysis of control p aradigms for distributed energy resourc es (DERs). Paradigm Controll er Coordination Signal Key Adv antage Key Disadv antage Scalability Resilience Centralized control Single central contro ller Direct command and control signals Global optimization, high contro llability Single point of failure, high computational burden Low Low Decentralized c ontrol Individual agents Loc al measurements (voltage, frequency) No single point of failure, p lug-and-play cap ability Suboptimal global outc omes, system imbalance High High T ransactive energy Individual agents Economic signals (pric es, bids, asks) Fosters prosumer autonom y , economic eciency Communication infrastructure, potential for market po wer abuse High High 2.1.3 Theoretic al foundations: from exp licit negotiation to stigmergy The challenges of price-only signals necessitates a shift tow ard more robust forms of implicit c oordination, grounded in the conc ept of stigmergy . Stigmergy describes a mechanism of indirect coordination where an action taken by an agent leaves a trace in the environment, which subsequently stimulates the performanc e of a next action by the same or a dierent agent [ 29 , 30 , 31 ]. In the context of a LEM, the market platf orm itself functions as the stigmergic environment [ 31 ]. Agents do not need to communic ate directly (distributed topology) or report to a central c ontroller (c entralized topology). Instead, they interact with the shared en vironment. An agent’s action (such as injecting or withdrawing power) modies shared environmental variables. 5 These modications serve as environmental markers [ 30 , 32 ]. Other agents perceive these changes and adapt their policies acc ordingly [ 33 ]. This process allows for system-wide order to emerge from local rules, e ectively dec oupling the c omplexity of the system from the c omplexity of the individual agents [ 34 , 35 ]. The objective of this interaction is emergent coordination: the realization of a global property (such as supply-demand balanc e) that is not e xplicitly programmed into any single agent but arises from their colle ctive interactions [ 35 ]. Howev er, emergence is non-deterministic and not inherently benecial; without careful design, the aggregation of self-interested loc al rules can lead to grid instability [ 36 ]. Therefore, the research challenge shifts towards engineering emergence via quantitative, marker-base d stigmergy [ 30 , 37 ]. By embedding system-lev el KPIs into the local observation space of each agent, the environ- ment e ectively guides the learning process. Agents trained via MARL can learn to interpret these environmental markers as pre dictors of future rewards, leading to the emergenc e of cooperativ e policies even in the absenc e of e xplicit cooperation protoco ls [ 38 ]. 2.1.4 Emergen t coordination and the c halleng e of unintended beha viors The objectiv e of implicit cooperation is emergent coordination: the realization of a coherent global property such as supply- demand b alance that is not e xplicitly programme d into an y single agent but arises organically from their c ollectiv e interactions. This princip le suggests that for large-sc ale systems, it is neither f easible nor necessary to exp licitly orchestrate ev ery decision for every scenario . Instead, desirable system-wide beha viors can be induce d by designing the right set of local rules and in- formation structures [ 35 ]. Howev er, achieving benecial emergence requires navigating a comp lex landscape of coordination architectures, where the limitations of exp licit control highlight the nec essity for imp licit mechanisms. In mediated coordination architectures, where a central entity manages the system, the computational burden becomes prohibitiv e. [ 39 ] illustrates this through a stochastic optimization framework that bridges wholesale and local markets; while mathematically robust, the need to manage uncertainty via Monte Carlo simulations results in an explosion of scenarios, ren- dering the central optimization problem computationally intractable f or real-time, large-scale applications. Similarly , [ 40 ] high- light the latenc y issues inherent in Lagrangian dec omposition methods. While these iterative pricing mechanisms theoretically achieve c onv ergence, the communication delays re quired f or agents to compute and uplo ad responses, coup led with a privac y challenge where iterative ex changes ev entually rev eal private utility functions, make them ill-suited f or the granular responsiv e- ness required in modern grids. Dec entralizing contro l via bilateral c oordination (P2P) resolv es the single point of failure but introduc es sev ere c ommuni- cation ov erhead. [ 3 ] proposes a network-c onstrained P2P scheme that utilizes sensitivity coecients (v oltage sensitivity coe- cients and po wer transf er distribution f actors) to validate trades against grid p hysics. While this suc cessfully integrates ph ysical constraints, the requirement to validate every bilateral transaction creates a new computational bottleneck. Furthermore, the negotiation proc ess itself induces signicant latenc y . [ 41 ] demonstrates this in a game-the oretic model where buy ers and sellers engage in nested evolutionary and Stackelberg games. The time required for these iterative algorithms to conv erge to a stable strategy makes them impractical f or high-frequenc y , intraday planning. Ev en when mechanisms ev olve to include heteroge- neous preferenc es, as seen in [ 42 ], where agents trade based on attributes like reputation and location, the reliance on explicit matching algorithms retains a heavy c ommunication burden that mirrors the negotiation comp lexity . Consequently , the research challenge shifts from explicit orchestration to engineered implicit c oordination. Here, agents do not negotiate, they merely observ e and react. How ever, the literature c autions that undened emergenc e is non-deterministic and not inherently benecial. Without careful design, the aggregation of self-interested local rules can lead to grid instability . If thousands of agents react independently to a simple broadcast signal (like a low price) without c oordination logic, they may synchronize their actions creating a new emergent peak that destabilizes the netw ork [ 35 , 36 ]. T o mitigate this, the information structure of the environment must be designe d so that loc ally optimal actions align with global stability . [ 13 ] pro vides a breakthrough in this domain using MARL. Their framework demonstrates that b y training agents with marginal rewards (signals that quantify an individual’s specic c ontribution to the global state) agents can learn to desynchronize their beha viors. Through Q-learning, agents learn to interpret en vironmental markers not just as immediate incentiv es, but as predictors of c ollective system states, e ectiv ely learning to wait or curtail consumption v oluntarily when the grid is congeste d [ 38 ]. The frontier of this eld in volv es exp anding the observation sp ace bey ond simple price signals to include the rich, non-price attributes identied in explicit models. The p hysic al sensitivities identied b y [ 3 ] and the reputation and preferenc e metrics uti- lized by [ 42 ] must be transf ormed from validation tools into passiv e environmental signals. By embedding these system-level objectiv es into the local observation sp ace, the environment e ectively guides the learning process, allowing c omplex c oopera- tive po licies to emerge without the scalability constraints of direct c ommunication. 6 2.1.5 KPI-based coordination and the r ole of r eputation in energy markets A primary v ehicle for implementing quantitativ e stigmergy in LEMs is the use of KPIs and reputation metrics. The shift from exp licit negotiation to imp licit c oordination requires a specic mechanism to serve as the environmental signal. While price signals ha ve prov en unstable, reputation serves as a robust parameter that enc odes historical performance into an en vironmental marker [ 30 ]. By turning trustw orthiness into a tangible, data-b ased measure, reputation systems allow agents to coordinate implicitly , aligning with system goals not through direct commands but through the driv e for higher standing and the associated ec onomic advantages. In the conte xt of multi-agent systems, it is nec essary to distinguish reputation from trust. T rust is often dened as a subjec- tive, private belief formed through direct pairwise interaction [ 43 ]. While early models relied on subjectiv e recommendations (e.g., agents rating each other), this approach is vulnerab le to bias and c ollusion [ 44 ]. Conv ersely , reputation is a c ollective, public measure of an agent’s standing derived from observable historical performanc e [ 45 ]. For LEMs, a robust paradigm re- lies on quantitative, marker-base d coordination where reputation is a veriable fact calculate d from objective KPIs [ 30 ]. This approach aligns with research incorporating social netw ork topo logy , where factors like an agent’s relative electrical distance contribute to its reputation independent of dire ct feedb ack [ 45 ]. T o function as an e ective coordination signal, reputation must be quantie d through multi-f aceted metrics that cap- ture distinct dimensions of agent beha vior, spanning p hysic al reliability to cyber-security . For instance, the c ommitment score measures the reliability of an agent by tracking the deviation betw een cleared market schedules and actual pow er delivery [ 46 ]. Calculated as a mo ving average of these deviations, it provides a direct, historical record of ph ysical comp liance, determining whether a prosumer will actually deliver the e xibility they agreed. Furthermore, the trustability score safeguards against c om- promised nodes by utilizing anomaly detection on cyber-ph ysical data (such as communic ation packet metadata and power data) to assess the integrity of an agent [ 46 ]. Reputation can also be directly linked to grid constraints. For instance, a voltage impact score penalizes prosumers who contribute to loc al vo ltage rise while rewarding those who mitigate it, ee ctively internalizing grid ph ysics into social standing [ 47 ]. Similarly , system KPIs such as grid congestion levels serve as observab le signals [ 47 ]. Literature proposes holistic metrics like the resilience score [ 46 ], which aggregates the c ommitment and trustability sc ores, or the R360 sc ore, which integrates quality of service, def ense capabilities, and resourc e availability [ 48 ]. Once quantied, these scores transition from passive indicators to active control variables that close the loop in implicit coordination. In dec entralized P2P markets, they act as a lter for p artner selection, where agents prefer transacting with high- reputation peers to minimize risk [ 47 ]. This ee ctively marginalizes unreliable agents and prev ents a rac e to the bottom on price. Advanc ed models ev en propose reputation-adjusted pricing, where high-reputation agents rec eive pref erential rates, creating a direct ec onomic incentive f or grid-friendly behavior [ 49 ]. More critically for MARL applications, these metrics function as state variables that resolv e the non-stationarity of the environment. In a fully decentralized setting, other agents appear as part of the environment, making it unpredictable. By making reputation sc ores and system KPIs visible in the observation sp ace, agents c an learn to correlate these high-lev el signals with the probability of suc cessful trades or grid constraint vio lations, thereby making the en vironment more predictable. How ever, the relianc e on reputation introduces new vulnerabilities. The robustness of the system against strategic ma- nipulation remains a primary research challenge. The literature identies risks such as playboo k attacks, where agents build a high reputation through numerous lo w-value transactions only to exploit this trust for a massiv e defection on a high-value trade [ 50 , 51 ]. Simple moving-a verage metrics like the commitment score are vulnerable to this. Therefore, robust metric design must weight actions b y their impact and critic ality , not just their frequency . Furthermore, agents may engage in collusion to articially inate scores, or the system may su er from emergent c en- tralization, where a few agents dominate the market because high reputations lead to more interaction opportunities [ 50 ]. A resilient design must b alance eciency with div ersity , potentially b y incentivizing interaction with new or mid-tier agents to foster s ystem-wide resilience. Current analysis conrms that while reputation provides the necessary trust layer f or implicit coordination, naiv e imple- mentations are insucient. The gap in the state of the art lies in the lack of implicit c oordination models that specically address the real-time supply-demand balancing problem through stigmergic mechanisms. Existing approaches largely restrict reputation to a ltering mechanism for explicit trading or f ault detection, rather than using it as the primary environmental signal to drive c ooperative lo ad-balancing beha viors [ 24 ]. Furthermore, there is a lack of systematic c omparison regarding how dierent training paradigms (c entralized versus decentralized) aect the emergence of this implicit c ooperation when agents are driven b y these shared KPI signals. 7 2.2 MARL in energy sy stems The structural transf ormation driven by the dec entralization of modern po wer systems has rendered traditional centralized optimization paradigms insucient, primarily due to their inability to manage the stochasticity and scale of DERs eectiv ely [ 52 , 53 ]. As renewable energy penetration increases, the grid is evo lving from a passive distribution netw ork into an active ec osystem of prosumers, microgrids, and aggregators, necessitating robust LEMs that facilitate P2P and community-b ased trading [ 53 ]. In this c ontext, MARL has emerged as a critical c omputational framework. Unlike centralized optimization methods such as con vex optimization or dynamic programming, which struggle with the non-linear dynamics and computational bur- den of coordinating thousands of heterogeneous agents, MARL enables dec entralized agents to learn optimal po licies through interaction with the environment [ 53 ]. Howev er, the application of MARL in LEMs introduces comp lex challenges, particu- larly regarding coordination under uncertainty . The non-stationary nature of the environment, where the optimal strategy of one agent depends on the changing strategies of others, requires sop histicated learning p aradigms beyond simple independent learning [ 53 ]. Furthermore, the ph ysical c onstraints of the pow er grid and the privacy requirements of market particip ants im- pose sev ere limitations on inf ormation sharing, creating a need f or implicit cooperation models where coordination is achiev ed without direct c ommunication [ 54 ]. 2.2.1 Fr om independ ent learning to cen tralized training The application of RL to energy systems has evolv ed in parallel with the complexity of the grid itself. Early research predom- inantly utilized independent learning approaches, such as independent Q-learning [ 1 ]. In this paradigm, each agent (e.g., a home energy management system or a b attery c ontroller) views other agents merely as p art of the environment. While indepen- dent learning is computationally ecient and scales linearly with the number of agents, it fundamentally violates the Markov property required f or con vergenc e: as agents simultaneously update their policies to maximize local rew ards, the environment bec omes non-stationary from the perspective of an y single agent [ 53 ]. This non-stationarity leads to undesired behaviors where agents chase a moving target, leading to polic y oscillations. F or instance, if multiple prosumers learn to discharge batteries during a pric e spike, their collectiv e action may eliminate the ar- bitrage opportunity , in validating the policy they just learne d [ 53 ]. Furthermore, independent learners in partially observable environments often c onverge to suboptimal Nash equilibria that fail to achiev e glob al P areto optimality , potentially causing grid instability issues such as vo ltage oscillations [ 1 ]. M oreov er, in cooperativ e settings, determining which agent’s action con- tributed to a glob al reward (e.g., grid balance) is dicult without a me chanism to decouple individual c ontributions [ 53 ]. T o mitigate these instabilities without reverting to intractable centralized control, the research community has come to- gether around the CTDE p aradigm [ 55 ]. CTDE acknowledges the dual nature of the problem: training can occur with acc ess to global state inf ormation, while ex ecution must rely solely on local observ ations. This information is used to train a centralized critic, which then guides the updates of dec entralized actors that ex ecute using only local observations [ 6 ]. Prominent algorithms like MADDPG use a centralized c ritic to estimate Q-values b ased on the joint state and action spac e, stabilizing the learning proc ess for decentralize d actors [ 1 , 56 ]. MADDPG employs a centralize d critic that takes the joint action and state sp ace as input to estimate Q-v alues, while actors remain decentralized. Fundamentally , a centralized critic is a training-only neural nerwork capab le of acc essing the full global state and joint actions, and Q-values quantify the expecte d long-term return of taking a specic action in a given state. Studies hav e demonstrate d MADDPG’s e ectiveness in c ontinuous action spac es (crucial for energy bidding), showing it can atten community demand curves and reduc e costs more ee ctively than independent learners [ 5 ]. While MADDPG is o-policy (i.e., it updates its policy using stored data co llected by older versions of the agents or a completely dierent exploration strategy), multi-agent proximal policy optimization (MAPPO) applies the on-po licy PPO algorithm to multi-agent settings, requiring that an agent updates its current po licy based on the actions it takes while follo wing that same policy [ 57 ]. This dierence impacts con vergenc e. Recent comparativ e studies in industrial manufacturing and grid contro l suggest MAPPO often exhibits superior stability and h yperparameter robustness c ompared to MADDPG, particularly in high-dimensional environments where o-po licy learning can su er from distributional shift [ 58 ]. Similarly , v alue-decomposition methods like QMIX, which addresses the multi-agent credit assignment problem by break- ing down a global team reward into individual agent contributions, hav e become standard f or discrete c ontrol tasks. They function by decomposing the global team reward into individual agent utilities, ensuring that a maximization of local values leads to a maximization of the joint value [ 5 ]. How ever, the standard CTDE framew ork fac es challenges in LEMs regarding data privac y and scarc e inf ormation sharing. The requirement for a c entralized critic implies that during training, all agents must share their private states (e.g., battery levels, consumption patterns, cost functions) with a c entral learner [ 24 ]. This contradicts the privacy requirements of many 8 deregulated LEMs and the operational reality where agents ma y be competitiv e or owned b y distinct entities, nec essitating the exp loration of implicit cooperation models where ev en the training phase minimizes global inf ormation exchange [ 1 ]. 2.2.2 T raining paradigms for MA RL While CTDE is the pref erred choice in the literature review , a critical analysis reveals signicant limitations when applied to privac y-sensitive LEMs. The choic e of training paradigm dictates the inf ormation ow betwe en agents and constrains the type of c oordination (explicit versus implicit) that can be achiev ed. A systematic comp arison of the three primary paradigms rev eals the specic gap this research addresses: • CTCE: This paradigm treats the multi-agent problem as a single-agent problem with a joint action space. A central c on- troller (i.e., a single neural network) receiv es the full state c ontaining all private information of all agents and optimizes the joint policy (i.e., the action of each agent) [ 55 ]. While this serves as a theoretical upper bound for performanc e, its challenge for LEMs is due to the sc alability bottleneck (exponential growth as the number of agents inc rease) and pri- vac y violation since prosumers are increasingly un willing to share detailed usage data and cost functions with a c entral authority [ 55 ]. • CTDE: While solving the ex ecution-time communication problem, CTDE assumes rich information sharing during training. Agents possess individual actor neural networks that e xecute locally b ased on partial observations. How ever, during training, a centralized critic neural netw ork is utilized [ 6 ]. The requirement for a centralized c ritic implies that during the learning phase, all agents must share their priv ate observations (e.g., battery state, c onsumption pref erences, internal c ost functions) with a central learner [ 6 ]. How ever, the CTDE facilitates implicit cooperation by allowing the critic to train the actor how their local action contributes to the o verall reward. The actor learns to approximate the glob al value function using only loc al data. Howev er, for a LEM where agents ma y be competitiv e, sharing private observations f or a centralized critic is often pro hibitive [ 24 ]. • DTDE: This paradigm aligns best with the constraints of eectiv e training without global view assumptions [ 55 ]. In DTDE, agents update po licies b ased solely on their o wn tra jectories (observations, actions, and rewards). While this respects the dec entralized p artially observ able Marko v decision process (Dec-POMDP) constraints (i. e., limiting agents to local partial observations without acc ess to the true global state), it reintroduces the challenges of non-stationarity and coordination without communication [ 58 ]. The frontier of research lies here: developing mechanisms that allow DTDE agents to achiev e coordination comparab le to CTDE without the c entralized inf ormation requirements [ 1 ]. Rec ent work, such as [ 5 ], attempts to bridge CTDE and DTDE by sharing only strategic information rather than raw data, optimizing decision-making while enhancing privacy . This represents a move towards federate d or privacy- preserving MARL [ 59 ], but rigorous comp arisons in continuous LEMs remain limited. The Dec-POMDP framew ork is uniquely suited for LEMs because it explicitly accounts for the p artial observability caused by privac y constraints and distributed geograph y [ 53 ]. An agent knows its own load and battery state but cannot observe the internal state of other agents [ 60 ]. The global state (network vo ltage, total demand) is a result of joint actions but is not fully visible to an y single entity [ 61 ]. Solving Dec-POMDPs nec essitates the use of approximate solutions via MARL rather than ex act dynamic programming [ 61 ]. Rec ent works hav e e xplicitly modeled P2P trading as a Dec-POMDP , utilizing RL to appro ximate optimal policies in c ontinuous spaces where traditional heuristics f ail [ 62 ]. 2.2.3 Mec hanisms for implicit c ooperation in MARL In scarce inf ormation scenarios where explicit communic ation is restricted, MARL agents must coordinate via implicit coop- eration. This relies on agents learning to interpret en vironmental f eedbacks as coordination signals. The ph ysics of the grid and the economics of the market act as natural stigmergic media. Deviations in grid frequency or voltage act as implicit broadcast signals. A drop in fre quency signals all agents to increase generation or shed lo ad. MARL agents can learn to interpret these en- vironmental f eedb acks to c oordinate c orrective actions (e.g., vo ltage restoration) without explicit data e xchange [ 63 ]. Similarly , the clearing pric e in a LEM aggregates the preferenc es and scarcity of all agents. A high clearing pric e implicitly c ommunicates a state of high demand or low supply . Research demonstrates that MARL agents can learn to use price volatility as a coordi- nation signal, for examp le, inferring that a sharp price rise indicates a neighbor is discharging, prompting the agent to hold its own c apacity [ 64 ]. This mechanism allows agents to achieve lo ad balancing simp ly by reacting to the aggregate price signal [ 1 ]. Rec ent MARL research studies how self-interested agents in mixed-motiv e games like LEMs can learn reciproc al altruism. Agents may learn that unrestraine d gree d leads to market collapse or grid instability , and thus long-term penalties. Through repeated interaction, agents can disco ver sustainable strategies where they vo luntarily curtail consumption during peaks to 9 low er the clearing pric e f or everyone [ 5 ]. T o foster these beha viors, reward shaping is often emp loye d, modifying the agent’s reward function to include not just individual prot, but also a marginal contribution to the system or a global stability term [ 65 ]. This technique aligns individual greed with glob al w elfare, enab ling cooperativ e beha viors such as peak shaving to emerge from self-interested learning [ 66 , 67 ]. In the absence of direct communic ation, agents must c onstruct internal models of other agents. T echniques like deep implicit coordination graphs proposed in [ 68 ] allow agents to inf er the hidden states or future intentions of peers based on their observable actions [ 69 ]. For instanc e, an agent might infer that a competitor’s aggressive bidding implies a high state-of- charge, subsequently adjusting its own strategy to a void a pric e competition. This inferenc e allows agents to form a c onsensus about the system state b ased on local observations [ 54 ]. 2.2.4 Revie w of existing MA RL applications in LEMs The application of MARL to energy systems has expanded to address specic market structures and ph ysical constraints. Re- search in P2P markets has utilized consensus MARL to enable agents to develop trading strategies that conv erge to dynamic balanc e and vo ltage stability without central disp atch [ 70 ]. Other works utilize loc al strategy-driven MADDPG to harmo- nize individual building needs with c ommunity goals, e ectively reducing energy c osts and attening demand curves through shared strategic inf ormation [ 5 ]. F or microgrids, multi-agent twin dela ye d DDPG (MA TD3) has been used to optimize the bidding beha vior of energy storage units, oering better stability than standard MADDPG in market modeling [ 71 ]. Hier- archical approaches have also been proposed, where an upper-level agent (aggregator) learns to coordinate lower-lev el agents (households), although this often leans b ack towards centralize d control [ 72 ]. The literature distinguishes between agent sc ales, which impacts the learning formulation. While much research is f ocused on residential households, the me dium-scale agent represents a distinct and critical class of actors in LEMs. A me dium-scale agent refer to entities larger than a single residential household but smaller than utility-sc ale pow er plants, such as commercial buildings and industrial microgrids [ 73 , 74 , 75 , 76 ]. Unlike small households which are price-takers, medium-scale agents of- ten possess sucient capacity to be price-makers [ 73 ]. This introduces market power issues where the agent’s action directly impacts the state transition of the market price, reinforcing the non-stationary nature of the environment [ 77 ]. For instance, an aggregator contro lling a large eet of ele ctric vehicles can signicantly alter the clearing price b y withho lding or ooding the market. MARL is p articularly valuable here for learning strategic bidding behaviors that account for this price impact, optimizing the trade-o betwe en volume and pric e inuence [ 78 ]. F or medium-scale, c ontrol inherently inv olves continuous variables (power quantities and pric es) where an agent must decide how much energy to trade and at what price. Early approaches used deep Q-netw ork (DQN) with discretize d actions but results in the curse of dimensionality and loss of pre cision, leading to suboptimal market clearing [ 53 ]. In the industrial sector, MARL has be en applie d to optimize energy c onsumption in energy-intensive settings using POMDP frameworks [ 79 ]. For commercial buildings, MARL agents c ontrol HV AC and storage to minimize c osts under dynamic pricing. Notably , research comp aring MAPPO and MADDPG in these settings suggest that while MADDPG ex cels in continuous action manipulation, MAPPO often provides more robust conv ergence in c omplex, multi-modal environments [ 80 ]. Furthermore, medium-scale agents operate critical infrastructure with strict p h ysical limits. Safe (or constrained) MARL is a gro wing sub-eld where agents learn po licies that maximize reward while satisfying safety constraints. T echniques such as Saf e-MADDPG inc orporate barrier functions or Lagrangian multipliers into the loss function to enforc e constraints (e.g., voltage limits) during the learning process [ 81 ]. This is relevant for c oordination without explicit communication, ensuring that implicit c ooperation does not violate grid safety limits [ 82 ]. Rec ent research fa vors polic y gradient methods like MADDPG and soft actor-critic (SAC), which can output c ontinuous actions dire ctly [ 1 ]. Recent literature has provided comp arative analyses of algorithms f or c ontinuous energy prob lems. SAC is increasingly fa vored for its maximum entropy framework, which encourages exploration, a critic al feature for non-stationary LEMs where agents must constantly adapt to the changing policies of competitors [ 83 ]. SAC has been shown to outperform DDPG in robustness and sample ecienc y for microgrid energy management [ 84 ]. Despite the eorts of e xisting research, there is a lack of systematic c omparison of training p aradigms (CTCE, CTDE, DTDE) specically evaluated on their ability to foster coordination under scarce information constraints [ 58 ]. Most studies default to CTDE (e.g., MADDPG) without questioning the priv acy imp lications of sharing observations during training [ 53 ]. The trade-o betw een the optimality of CTDE and the privacy / scalability of DTDE remains under-e xplored [ 58 ]. Further- more, the majority of literature f ocuses either on micro-sc ale households or mac ro-scale TSO operations. The coordination of medium-scale agents via implicit cooperation is under-researched [ 1 ]. These agents possess market power, meaning their actions directly impact price formation, reinforcing the non-stationary nature of the environment and requiring specialized MARL formulations (e.g., Safe-MADDPG or c onstrained SAC) rather than generic P2P algorithms [ 77 , 85 ]. Moreo ver, while Dec- POMDPs are the the oretical standard for partial observability [ 53 ], applied research often simp lies the problem to discrete 10 action spac es or assumes full observability . There is a distinct need f or robust MARL algo rithms that act within a rigorous c on- tinuous Dec-POMDP formulation for intraday markets, specically addressing coordination without direct communication through implicit mechanisms rather than e xplicit message passing [ 60 ]. 2.3 T raining paradigms: theory and practice The transition from c entralized dispatch models tow ard decentralized grid operation and contro l introduces stochasticity and comp lexity that traditional optimization te chniques struggle to manage due to computational burdens and priv acy c onstraints [ 1 ]. Consequently , MARL has emerged as a framework f or enabling autonomous agents to learn optimal policies in these comp lex environments. How ever, the deployment of MARL in LEMs is constraine d by the architecture chosen for inf orma- tion sharing and de cision authority . This architectural choic e denes the system’s ability to balanc e the coordination of DERs for energy management considering the c omplexities of c omputational scalability , perf ormance optimality , and data privacy [ 86 , 87 ]. The literature outlines a range of training paradigms (CT CE, CTDE, and DTDE) each with dierent theoretical features and practic al trade-os concerning this challenges (se e T able 2 ). 2.3.1 CTCE: the theor etical benchmark f or optimality CTCE represents the classical top-down approach. In this p aradigm, a single, omniscient contro ller possesses a c omplete global view , gathering all private observations, rewards, and state information from every agent to solv e a glob al optimization problem [ 86 ]. In the conte xt of LEMs, CTCE serv es as the theoretical performance upper bound benchmark [ 86 ]. It is frequently implemented via MILP or single-agent RL to quantify the loss of ecienc y inherent in decentralized systems compare d to a central planner with perf ect information [ 86 , 88 ]. While CTCE is theoretic ally ideal for calculating the social welfare upper bound, the literature is unanimous in classifying it as non-viable f or real-world deplo yment due to three disqualifying failures [ 89 ]: • Computational intractability: The joint state-action spac e grows exponentially with the number of agents, known as the curse of dimensionality . This renders optimization computationally intractable f or all but small problems [ 1 ]. • Privacy vio lation: CTCE requires prosumers to surrender granular, high-resolution data such as internal consump- tion patterns, b attery states-of-charge, and e conomic utility functions to a central monopoly . This is an undesirable requirement in deregulated, priv acy-focuse d markets [ 90 ]. • Latency and infrastructure constraints: The entire s ystem’s reliability hinges on the continuous, a wless opera- tion of a single central controller [ 53 ]. This architecture is brittle and vulnerable to communic ation failures. Research indicates that fault prote ction in microgrids often requires reaction times of 3–5 ms; centralized c ontrollers relying on standard telemetry frequently f ail to meet these stringent limits, creating a risk for c ritical energy infrastructure [ 91 ]. 2.3.2 CTDE: the h ybrid standard for stability T o address the limitations of centralized ex ecution, the research community has come together around the CTDE as the cur- rent academic standard [ 92 ]. Exemp lied by algorithms like MADDPG and MA TD3, this paradigm distinguishes between a centralize d training phase and a decentralized e xecution p hase [ 86 ]. CTDE algorithms solv e the non-stationarity inherent in multi-agent learning by emplo ying a centralized c ritic during training [ 5 ]. This critic receiv es the joint observations and actions of all agents, eectiv ely making the environment stationary from its perspective. By observing the full global state, the critic can explicitly solv e the credit assignment problem, determin- ing exactly how agent’s action contributed to the global reward amidst the noise of other agents’ behaviors [ 86 ]. This allows dec entralized actors to learn coordinate d policies, as in [ 1 ], where agents implicitly desynchronize their load proles to a void price c ompetition in storage markets. How ever, the c entralized critic’s neural netw ork architecture typically has a xe d input layer dimension that is a function of the number of agents. If a new prosumer joins the LEM, or an e xisting agent lea ves, the input ve ctor size changes, rendering the trained model in valid. The system cannot adapt. Thus, it must be taken oine, the architecture re designed, and the entire system retrained from scratch [ 86 ]. Furthermore, the training assumes the existenc e of a high-delity simulator where global states (including private prosumer data) are av ailable. In privacy-sensitiv e residential scenarios, c onstructing such a centralize d training en vironment is often as unf easible as centralize d exe cution [ 86 , 93 ]. Thus, while CTDE so lves the ex ecution-time and single point of failure, it f ails to provide the plug-and-p lay scalability and privac y required for dynamic energy markets. 11 2.3.3 DTDE: the fr ontier of decen tralization The disqualication of c entralized p aradigms f orces the c onclusion that DTDE (also known as independent learning) is the viable architecture for sc alable, private, and robust LEMs [ 94 ]. In DTDE, agents learn and act based so lely on local data, ensuring linear scalability and data so vereignty [ 86 ]. Despite its architectural suitability , naiv e DTDE fails in practic e due to the non-stationarity problem. From the perspectiv e of any single agent, the en vironment is inco herent bec ause all other agents are simultane ously updating their po licies [ 86 ]. This violation of the Markov property leads to the cre dit assignment failure where an agent cannot distinguish whether a reward (e.g., a protable trade) was due to its own intelligent bid or simply random noise resulting from the simultaneous actions of others [ 86 ], and also to the a valanche ee ct where independent agents optimizing f or similar taris inevitably synchronize their behaviors. For ex ample, in residential energy management, independent learners often identify the same lo w-price interval and synchronize their b attery charging. This co llective action c reates a new maximum lo ad, impacting arbitrage opportunities and violating netw ork restrictions [ 1 , 95 ]. The f ailure of DTDE stems from a partially observ able en vironment where agents are b lind to the s ystemic consequenc es of their actions. T o saf eguard DTDE’s scalability , agents must coordinate. How ever, exp licit communication is disqualie d as it re-introduces high b andwidth costs and privac y risks [ 96 ]. The proposed so lution lies in imp licit c oordination, where MARL agents can coordinate through observation augmenta- tion [ 86 ]. This stigmergy allows f or a common frame of ref erence, eectiv ely resolving the non-stationarity of the environment. Instead of reacting to a chaotic, une xplained pric e signal, an agent perceiv es a correlated c ontext (e.g., high pric e and high con- gestion). This allo ws f or the emergence of cooperation (e.g., to reduce load when congestion is high) purely from local learning, bridging the gap betwe en the privacy of D TDE and the coordination of CTDE [ 86 ]. T able 2: T echnical tax onom y of MARL training paradigms in LEMs. Featur e CTCE CTDE DTDE Ref Architecture 1-to-N N-to-N (centralized c ritic) N-to-N (independent) [ 96 , 97 , 98 ] Information (T raining) Global state Global state (c entralized critic) Local observations [ 5 , 86 ] Information (Ex ecution) Global state Local observations Local observations [ 86 ] Coordination mechanism Centralized optimizer Centralized critic Independent learners [ 5 , 86 ] Strength Optimality P erformance Scalability [ 5 , 86 ] W eakness Curse of dimensionality Curse of dimensionality Non-stationarity [ 89 , 97 , 98 ] Optimality High Medium Low [ 94 , 99 ] Coordination High Medium Low [ 1 ] Communication ov erhead High Medium Low [ 94 , 99 ] Privacy preserv ation Low Medium High [ 53 , 92 , 93 , 100 ] Scalability Low Low High [ 1 , 53 , 89 , 93 ] Non-Stationarity Handling High Medium Low [ 5 , 89 , 101 ] T rade-o Computational comp lexity vs. optimality Privact vs. performance Non-stationarity vs. scalability - RL algorithms Single-agent DQN, PPO MADDPG, MAPPO, QMIX, MA TD3 IQL, IDDPG, IPPO, Hysteretic Q [ 1 , 6 , 5 , 86 ] Optimization model MILP ADMM Heuristics/Local contro l [ 102 , 103 ] Game theory model Stackelberg leader Hybrid DRL/EGT Independent agents [ 104 , 105 ] 2.4 MARL algorithms f or con tro l in continuous spaces As LEMs evolv e from c entralized, top-down dispatch models to P2P and community-based trading structures, the decision- making p aradigm has shifte d from static optimization to dynamic, sequential decision-making proc esses under uncertainty [ 57 ]. In this environment, MARL has become a computational framework that enables autonomous agents to learn optimal bidding and disp atch policies through interaction with the en vironment and with each other. Unlike discrete action sp aces, which simplify decision-making in nite options (e.g., load, unload, or hold), continuous contro l enables precise modulation of active pow er, pricing, and energy scheduling. This granularity is essential to meet the stringent balancing requirements of day-ahead and intraday markets, where deviations in pow er injection or withdrawal can lead to grid instabilities or vo ltage violations. 2.4.1 Comparative anal ysis between optimization, game theory , and RL T o justify the selection of MARL for modern LEMs, we rst analyze the limitations of traditional contro l paradigms, speci- cally optimization-b ased and game-theory models, which are the preferre d methods for po wer system analysis. A comp arative ov erview of these paradigms is presented in T able 3 . 12 Optimization-base d models, such as MILP or con vex optimization, hav e been the standard for dispatch problems. These models typically operate under the assumption of a central entity with perfect foresight and comp lete access to system infor- mation [ 3 ]. Their primary objectiv e is usually the maximization of social welf are or the minimization of total system costs, implicitly assuming that all market particip ants act cooperativ ely to achieve a global optimum [ 106 ]. How ever, this system optimum appro ach fails to capture the behavioral representation of deregulated markets, where p articipants are self-intereste d agents seeking to maximize their individual benets rather than system ecienc y [ 107 , 108 ]. From a modeling perspective, optimization approaches fac e scalability and delity challenges. Man y studies employ the copper plate assumption, which treats the network as having innite capacity , thus ignoring critical network constraints and leading to potentially unf easible disp atch decisions in congested networks [ 3 ]. Furthermore, the assumption of a perf ect f orecast regarding the demand and generation of renewable energy is becoming inc reasingly unsustainable. While stochastic or robust optimization c an mitigate this by inc orporating sets or scenarios of uncertainty , these extensions often result in computationally comp lex models that produce ov erly conserv ative solutions [ 106 , 109 ]. Fundamentally , they remain static solv ers since they do not allow agents to adapt their beha vior in real time to changing market policies or evo lving competitor strategies [ 3 ]. Game-theoretic models (e.g., Stackelberg games or Nash equilibrium analysis) address the strategic decit of pure opti- mization by exp licitly modeling the interactions between competitiv e agents. These approaches provide a theoretical b asis for understanding market dynamics and identifying stab le operating points where no agent has an incentiv e to deviate [ 41 ]. How- ever, they are often limite d by strong assumptions of perfect rationality and c omplete information, such as that agents possess accurate models of their competitors’ cost functions and c onstraints [ 41 ]. In privac y-preserving LEMs, such inf ormation is rarely available. More over, nding equilibria in c omplex, dynamic markets with continuous action sp aces presents a signi- cant dimensionality challenge. The computational comple xity of these models often renders them intractable for large-scale simulations or real-time control [ 41 ], limiting their utility to oine structural analysis rather than operational decision-making. MARL bridges the gap between these paradigms by facilitating dec entralized coordination without requiring explicit models of uncertainty or agent dynamics. Unlike robust optimization, which requires a pre dened set of uncertainties, MARL agents use a representation of uncertainty , integrating the stochastic nature of renewab le energy demand and generation directly into the hidden lay ers of the neural network through repeated interaction with the en vironment [ 86 ]. This enab les robust per- formanc e in the fac e of fore cast errors without the computational exp losion of scenario-b ased trees [ 86 ]. Furthermore, unlike the static nature of optimization, MARL is intrinsically designed to handle non-stationarity . In a multi-agent environment, the environment changes as other agents update their policies, constituting a violation of the Markov property that breaks standard single-agent learning [ 110 ]. MARL algorithms, particularly those emplo ying CTDE, address this problem by allowing agents to learn coordinate d strategies using global inf ormation during training, while ex ecuting base d so lely on loc al observ ations [ 111 ]. T able 3: Comp arativ e analysis of market modeling and control methods in LEMs. Featur e Optimization Mod els Game Theoretic M odels MARL Objectiv e System-optimal (e.g., global w elfare) Nash equilibrium Adaptiv e prot maximization Uncertainty handling Robust or stochastic Deterministic Belief state (experienc e-based) Market dynamics Static with perfect c ompetition Static equilibrium Non-stationary and emergent Scalability High (linear/ con vex) Low (c ombinatorial) High (observations and reward shaping) Limitation Requires perf ect foresight Computational intractability Non-stationarity and training stability 2.4.2 PPO PPO has become estab lished as a fundamental algorithm in RL applied to electrical s ystems. Introduc ed as a computationally more ecient alternativ e to trust region policy optimization, PPO simplies the optimization process while preserving the advantages of trust region methods, primarily the prevention of destructive policy updates that could destabilize the learning process. In the context of LEMs, where agents must manage non-stationary en vironments driven by uctuating renewable generation and dynamic pricing, the stability oere d by PPO is crucial [ 57 ]. PPO operates as an on-polic y gradient method, optimizing policy based directly on data colle cted by the current policy . Its main inno vation lies in the clipped surrogate obje ctive function, which limits the magnitude of polic y updates. This mech- anism is mathematically represented by a clipped ratio that limits the deviation of the new policy from the old one in a single update step [ 57 ]. This clipping mechanism acts as a regulator in energy applications. In power systems, the reward landscape is often highly non-conv ex and riddled with regions where a small policy change (e.g., a slight increase in power injection) c an trigger sev ere penalties due to c onstraint violations, such as line overlo ads or v oltage spikes. Standard polic y gradient meth- 13 ods risk po licy co llapse in these regions, whereas the PPO’s clipped objective function avoids such drastic changes, ensuring monotonically impro ved polic y [ 112 ]. The applic ation of PPO in LEM has demonstrated advantages o ver traditional optimization methods such as MILP , spe- cially when computational speed and adaptability are prioritized. Research indic ates that PPO-based contro llers c an achiev e near-optimal perf ormance in economic dispatch strategies while signic antly reducing the computational load associated with solving c omplex optimization problems at each time step . F or examp le, in home energy management systems integrating elec- tric vehicles and photov oltaic units, PPO has been shown to reduce daily energy costs by appro ximately 54% comp ared to con ventional scenarios, ee ctively learning comple x, nonlinear relationships betw een stochastic inputs and optimal contro l ac- tions without requiring an explicit model of the environment dynamics [ 113 ]. Furthermore, the eectiv eness of PPO extends to the presence of b attery energy storage systems in joint markets inv olving both spot energy trading and frequenc y regulation. In these scenarios, the agent must continuously decide how much cap acity to allocate to arbitrage versus regulation, a problem requiring continuous and precise monitoring. Research ha ve conrmed that PPO agents c an learn joint bidding strategies that signicantly outperf orm single-market strategies, thereby maximizing total prot under uncertain market c onditions [ 114 ]. A crucial comp arative advantage of the PPO is its stability during the training phase. Comp ared to o-policy algorithms such as DDPG or TD3, the PPO exhibits low er varianc e in reward conv ergence and a robust ability to mitigate power imbalanc es [ 62 ]. Nev ertheless, this conservativ e nature can lead to sensitivity in h yperparameter tuning. Comparativ e studies on pow er system sche duling hav e highlighted that the PPO ma y require signic antly higher penalty coecients to strictly enf orce po wer balanc e constraints c ompared to its o-polic y counterp arts [ 62 ]. Furthermore, as an on-po licy algorithm, PPO is generally less ecient in sampling, as it discards experience data after a polic y update. In a LEM context where high-delity simulations are computationally e xpensive, this ineciency c an become a bottleneck [ 112 ]. 2.4.3 Asynchr onous PPO As energy systems scale to include thousands of prosumers, the computational demands for training MARL agents inc rease exponentially . Asynchronous PPO (APPO) addresses the scalability limitations of standard PPO by decoupling the data col- lection process from the polic y optimization proc ess. This architecture is particularly relevant f or LEMs modele d like Dec- POMDP , where agents operate based on loc al observations and re quire ecient mechanisms to e xplore large state-action spaces [ 115 ]. APPO introduces a high-performance architecture that facilitates distributed learning. Unlike PPO, APPO allows mul- tiple agents to interact with their en vironment instances asynchronously , sending the co llected trajectories to a central learner. This asynchronous sampling introduces a degree of polic y lag because the behavior polic y can lag behind the target policy . T o corre ct this and ensure mathematical rigor, APPO employs importance sampling techniques, specically V -trace, which esti- mates the value function and corrects the policy gradient by weighting updates based on the likelihood ratio between policies [ 115 ]. In the c ontext of po wer systems, this architecture enables parallel simulation of diverse operating c onditions. Dierent workers can simultaneously simulate dierent days, weather p atterns, netw ork topologies, or agent c ongurations, signic antly reducing the clock time require d to train c omplex multi-agent policies [ 116 ]. This c apability has be en succ essfully applied to autonomous P2P trading in netw orked microgrids. By modeling the trading process as a partially observable Markov game, APPO agents w ere ab le to operate ee ctively in the c ompetitive environment, optimizing economic objectiv es while respecting transmission losses and network constraints [ 117 ]. The asynchronous nature of APPO is advantageous in this case, as it av oids the articial lock-step synchronization typically found in simulations, allowing agents to operate on slightly di erent timesc ales that reect the true heterogeneity of real-w orld prosumers [ 117 ]. 2.4.4 SAC SA C represents a paradigm shift in the continuous contro l of energy systems by incorporating the maximum entropy RL framework. Unlike PPO, which seeks to maximize only the expecte d cumulative reward, SA C optimizes a dual objectiv e: maximizing the expected reward plus the polic y entropy . This entropy term incentivizes the agent to exp lore the action spac e more deeply and prev ents the policy from prematurely c onv erging to deterministic and suboptimal behavior [ 118 ]. The dening feature of SA C is the entropy regularization term, where a temperature parameter dynamic ally controls the balanc e betw een exp loitation and exploration. In the conte xt of LEMs, this mechanism is v aluable for managing the multimodal nature of optimal strategies. For e xample, in a bidding scenario , multiple v alid pricing strategies c ould generate similar returns; a maximum entrop y policy learns a distribution across these strategies rather than narrowing do wn to a single point. This provides robustness against changes in the opponent’s strategy , as the agent maintains a portfo lio of potential optimal actions 14 [ 119 ]. Furthermore, as an o-po licy algorithm that uses a repla y buer, SA C is signicantly more sampling-ecient than PPO, making it preferab le for data-scarc e or slow simulation applic ations [ 120 ]. Theoretical stability in SA C is achiev ed through clipped double Q-learning, which mitigates the o verestimation bias c om- mon in value-b ased methods. This prevents the propagation of optimistic errors that c ould lead to aggressive and unsaf e bidding behavior, a crucial feature for energy disp atch problems [ 121 ]. In multi-agent environments, the maximum entrop y framew ork oers clear adv antages f or implicit c ooperation. In a Dec-POMDP LEM, the en vironment is inherently non-stationary bec ause other agents are learning simultaneously . A deterministic policy (such as those in DDPG) can be brittle; if neighbors slightly change their behavior, the optimal response could v ary drastically . SAC’s stochastic po licy smooths the interaction landscape, allowing the agent to maintain its perf ormance even when market dynamics drift [ 118 ]. In direct comparison with PPO , SAC typic ally demonstrates superior perf ormance in c omplex tasks re quiring signicant exp loration. For examp le, in building energy management tasks in vo lving HV A C contro l, SAC has achieve d greater energy savings and better c ompliance with thermal comf ort standards c ompared to PPO, as the entrop y term prev ents the agent from bec oming stuck in local optima [ 122 ]. Furthermore, in multi-microgrid sche duling, SAC has pro ven superior to PPO in terms of generalization and con vergence cap abilities f or reducing operating costs [ 123 ]. Howev er, the dra wback is that PPO can some- times achieve slightly low er nal operating costs in static environments due to its conservativ e and monotonous updates [ 24 ]. Therefore, the choice betw een PPO and SAC often depends on the specic constraints of the LEM. PPO is pref erred f or hard ph ysical security and stability , while SAC is preferre d for soft economic optimality , exploration, and robustness in highly dy- namic and competitiv e environments. T able 4 presents a summary comp arison of these algorithmic characteristics. T able 4: Comp arativ e analysis of PPO/ APPO and SA C for c ontinuous contro l in LEMS. F eature PPO / APPO SAC Ref P olicy type On-polic y O-polic y [ 57 , 118 ] Key feature Clip function Max entrop y [ 124 ] T rade-o Stability / Sample eciency Sample ecienc y / Stale data - Sample ecienc y Low (discards data after update) High (re-uses data via replay bu er) [ 57 ] Update mechanism Clipped surrogate objectiv e Actor-critic with entrop y regularization [ 57 ] Data sensitivity Robust to stale data Prone to stale data issues [ 125 ] V ariance/Bias Low bias / GAE ∗ -reduc ed variance Low v ariance / P otential o-policy bias [ 57 , 126 ] Strength Stability and monotonic improvement Exploration and samp le eciency [ 127 ] LEM Suitability Safety-c ritical contro l (e.g., voltage regulation) Dynamic pricing and competitiv e bidding [ 126 ] * GAE: Generalized advantage estimation. 2.5 Research gap and c ontribution opportunity A review of the state of the art reveals a disconnect betw een the operational requirements of future power grids and the cap a- bilities of existing coordination architectures. While the ph ysical imperative to integrate DERs is evident and the theoretical promise of dec entralized c ontrol is w ell established, the engineering challenge of achieving grid balance without relying on widespread communic ation or centralized authority remains an open problem. 2.5.1 Fail ure of coordination f or grid balance The primary research gap identied is the lack of a scalable, privacy-preserving mechanism for balancing supply and demand that is robust to the non-stationarity of decentralize d markets. Current approaches fail to resolve the coordination challenges of sc alability , privac y , and optimality , spe cically in the conte xt of the ph ysical grid b alance [ 1 , 10 ]. The dominant coordination strategies f or energy balancing rely on explicit c ommunication. Mediated architectures (aggregators) create single points of failure and privac y bottlenecks [ 15 ], while bilateral (P2P) architectures face a scalability obstacle due to the quadratic commu- nication ov erhead required for pairwise negotiation [ 1 , 10 ]. These methods solve the economic clearing problem, but they do not overc ome the engineering challenge of real-time ph ysical balancing for multiple agents, as negotiation latency ex ceeds the network dynamics timesc ales [ 20 ]. Existing attempts at implicit c oordination for energy balanc e rely primarily on dynamic pricing (transactiv e energy) as the sole control signal [ 128 ]. Howev er, the literature conrms that applying price signals to automated cyber-ph ysical systems induces system instabilities, specically the pric e/load volatility and the massive lo ad synchronization [ 129 , 130 ]. This rev eals a 15 critic al gap: no establishe d engineering framework exists for imp licit coordination that balances the electric al grid without in- ducing herd behavior. The eld lacks a non-price-b ased, stigmergic coordination mechanism capab le of guiding agent behavior tow ard physic al equilibrium without the instability of purely nancial signals. The engineering challenge is more acute for medium-scale agents (commercial buildings, industrial microgrids). Unlike small residential loads, these agents possess market po wer as their individual actions signicantly impact the state of the local grid and price f ormation [ 73 ]. Current literature f ocuses primarily on micro-sc ale (househo lds) or macro-sc ale (TSO) coordination, leaving a gap in understanding how medium-scale agents can implicitly contribute to energy balance without exploiting their market pow er to the detriment of grid stability [ 77 ]. While MARL is recognized as the appropriate computational method for modeling adaptive agents, its applic ation to the energy balanc e problem has presented methodological shortcomings regarding decentralization. Most applie d research in MARL is based on CTDE p aradigms (e.g., MADDPG) [ 1 ]. While these algorithms suc cessfully learn c oordination in simula- tion, they do so by b ypassing the privacy constraint, relying on a centralized critic that acc esses the global state (including the agent’s private data) during training [ 5 ]. This does not solv e the problem of true implicit cooperation; it simply shifts central- ization from exe cution to training. There is a clear lack of studies validating whether agents can learn to balanc e the network using DTDE, relying so lely on local observations and engineered en vironmental signals (KPIs) instead of global c ritics [ 6 ]. This research addresses these methodological and engineering shortc omings by proposing and validating a nov el implicit cooperation model f or energy balance in LEM. The w ork has the fo llowing three main contributions: • W e propose a mechanism that resolv es the coordina tion instability of price-b ased systems b y introducing multidimen- sional stigmergic signals. Instead of relying solely on price, the proposed model uses reputation scores and system-lev el KPIs (e.g., c ongestion indicators, social w elfare) as c ontinuous environmental variab les [ 30 ]. By integrating these met- rics into the agent’s observation space, w e design a fee dback loop where agents internalize their impact on the grid. This transf orms the problem from reacting to price to maintaining system health, enabling stable energy b alance as an emergent property of the system [ 35 ]. • This research provides a systematic assessment of implicit cooperation under strict constraints of scarce information sharing. By comparing the CTCE, CTDE, and DTDE p aradigms, we test the hypothesis that engineere d observation spac es (stigmergy) can replac e centralized critical ones. This validates whether fully de centralized agents can achiev e an energy balance comp arable to that of centralize d baselines, demonstrating the feasibility of the proposed engineered solution in priv acy-important markets [ 5 ]. • Leveraging the MARLEM simulation framew ork developed in [ 9 ], this research v alidates coordination in a ph ysically constraine d environment. It focuses specic ally on the medium-scale agent gap , studying how continuous contro l policies (learned using MARL f or exploration) can manage the b alance between maximizing individual benets and co llective grid b alance [ 64 ]. 3 M ethodol ogy The simulation framework detailed in this p aper is a comprehensiv e, open-source tool dev eloped for the analysis of LEMs within a MARL paradigm. A design principle of the framew ork is its implementation as a multi-agent en vironment conf orming to the Gymnasium standard. This adherence ensures comp atibility with an extensive range of state-of-the-art RL libraries and algorithms, thereby low ering the barrier to entry for researchers. By adopting this interfac e, the framework f acilitates reproducible experiments and allo ws f or the standardized benchmarking of new MARL strategies against established b aselines. T o model the challenges of decision-making under uncertainty and limited information inherent in dec entralized s ystems, the problem is formally structured as a Dec-POMDP . This formalization provides the mathematical foundation upon which the interactions betw een agents and their environment are built. The Dec-POMDP is dened by the tuple ⟨ I, S , A, P , R, Ω , O ⟩ , where I denotes the set of agents participating in the market, S the set of environment states, A the joint action space, P the state transition function, R the reward function, Ω the joint observation spac e, and O the observ ation function. Subindex i denotes the state, spac e, or function for agent i ∈ I . The comp lete Dec-POMDP formulation is detailed in [ 9 ]. In a realistic LEM en vironment, no single agent has access to the global environment state s ∈ S at an y giv en trading period t . Instead, agents re ceiv e local observations o i ∈ Ω i that are probabilistically correlated with the state but do not fully rev eal it. This partial observability necessitates that agents maintain a belief state (i.e., a probability distribution ov er possible global environment states); as is common in RL, neural networks are used to encode the history of observations into a hidden state that serves as a pro xy for the true state. T o facilitate learning in a partially observable environment, each agent i ∈ I receiv es a loc al observ ation v ector o i ∈ Ω i that constitutes a structure d subset of the glob al environment state. It provides a suciently rich signal for decision-making 16 without violating the princip les of decentralization and privac y . The observation v ector (see T able 5 ) includes: • Mark et signals: Pub licly a vailable information acc essible to an y market particip ant. This encomp asses the last clearing price and vo lume, anon ymized statistics regarding P2P versus DSO trading volumes, the prevailing DSO buy (feed-in tari) and sell (utility) prices, and the reputation score of each agent. These signals provide a common ground of information, re ducing uncertainty and allowing agents to f orm shared expectations about the market’s state. • Agent-specic signals: The agent’s private information, which remains unobserv able to other agents, thereby pre- serving privac y . This set of signals includes its current energy generation and demand forecasts, the state of charge (SoC) of its b attery , its cumulative prot, and its dynamic reputation sc ore. This private information is essential for the agent to tailor its strategy to its own specic circumstanc es and constraints. • Implicit cooperation KPIs: A selection of system-lev el KPIs, such as social welf are, grid congestion, and supply- demand imb alance, that augments the observ ation vector. These KPIs w ork as a shared public signal that provides all agents with a consistent representation of the overall market health, thereby allo wing them to learn the correlation betwe en their local actions and desirable glob al outcomes, ev en without direct communic ation. See Se ction 3.2 where a comp lete description of the KPIs is presented. The objective within this environment is to nd a joint policy π that maximizes the expected disc ounted sum of rewards R i , which in an LEM context typically correlates to net prot or utility . The comple xity of solving this Dec-POMDP lies in the fact that the optimal policy f or agent i depends on the policies of all other agents j ≠ i , which are evo lving simultaneously . This interdependenc e creates a non-stationary environment for the learning algorithm, reinforcing the need for the robust, specialized MARL algorithms supported by this framework to ensure stable con vergenc e in continuous, high-dimensional spac es. T able 5: Observation sp ace v ector f or the f ormulation of the LEM as a Dec-POMDP . Market Signals Agent-Specic Signals Implicit Cooperation KPIs 1. Current step 2. Time of day 3. Clearing price 4. Clearing volume 5. Grid balance 6. DSO buy volume 7. DSO sell volume 8. DSO total volume 9. P2P volume 10. DSO trade ratio 11. Net grid import 12. DSO buy price 13. DSO sell price 14. Mean local price 15. Price spread 16. Local price advantage 1. Energy generation 2. Energy demand 3. Cumulative demand satised 4. Cumulative demand deferred 5. Remaining demand 6. Cummulative supply satised 7. Cummulative supply deferred 8. Remaining supply 9. Mean prot 10. Reputation 11. Battery energy level 12. Battery SoC 13. Battery available charge 14. Battery available discharge 15. Battery cummulative charge 16. Battery cummulative discharge 1. Social welfare 2. Market liquidity 3. Mean bid-ask spread 4. Price volatility 5. Supply-demand imbalance 6. Grid congestion 7. Coordination score 8. Coordination convergenc e 9. DER self-consumption 10. Flexibility utilization 3.1 Implicit cooperation mod el The implicit cooperation model represents a fundamental departure from traditional centralized control and explicit negoti- ation paradigms. Building upon the MARLEM simulation framework establishe d in our previous work [ 9 ], which provided the ph ysical and market layers of the environment, this se ction details the spe cic algorithmic contributions designed to en- able coordination. Unlike explicit coordination mechanisms that require direct communic ation, centralized orchestration, or predened protoco ls where agents must share information about their intentions and cap abilities [ 30 ], implicit cooperation emerges naturally through the strategic design of inf ormation structures and incentiv e mechanisms. In our framework, agents learn to c oordinate their actions without e xplicit communic ation, relying instead on s ystem-level signals that reect the co llec- tive state of the market and grid. W e dene impli cit cooper ation in the context of decentralize d energy markets as the emergence of coordinated behaviors among self-intereste d agents that simultaneously satisfy individual economic objectives and c ollectiv e grid constraints. This is achieve d through the interaction of three components: shared information signals in the form of system-lev el KPIs that provide agents with information about market and grid health, incentive alignment via reward structures that link individual agent perf ormance to s ystem-level outc omes, and the dev elopment of comp lementary strategies through repeated interactions and learning. The motivation for this appro ach is grounded in the theory of emergent behavior in complex systems. In dec entralized systems, explicit coordination mechanisms fac e challenges including c ommunication overhead and latenc y , privacy conc erns regarding sensitiv e data, the risk of single points of failure, and inherent sc alability limitations [ 1 , 10 ]. Implicit cooperation addresses these challenges by enab ling c oordination through shared en vironmental signals rather than dire ct agent-to-agent communic ation, follo wing principles similar to quantitative, marker-b ased stigmergy in swarm intelligence [ 30 ]. 17 In this analogy , the market platf orm functions as the stigmergic medium [ 31 ], and an agent’s action leav es a trac e (e.g., congestion signal) in the environment, which subsequently stimulates the performanc e of a next action by other agents. The role of system-level KPIs is critical in this framework. These indicators serve as the pheromones that allow agents to infer the global state from local observations [ 30 ]. By including KPIs regarding market eciency , grid balanc e, and resource utilization in both the observation spac e and the reward function, agents can learn to associate their local actions with grid-level outcomes. This creates a f eedb ack loop where self-interested learning leads to the emergence of strategies that stabilize the grid, ee ctively dec oupling the comple xity of the system from the comple xity of the individual agents [ 35 ]. The implementation of implicit cooperation relies on tw o coup led mechanisms: an augmented observ ation spac e design and a multi-objectiv e reward function. While the complete mathematical derivation of the environment is detailed in [ 9 ], we focus here on the spe cic augmentations that drive cooperativ e behavior. The design of the observation space is fundamental to enabling implicit cooperation under the constraints of partial ob- servability . In a standard Dec-POMDP , an agent i typic ally observes only its local state. T o enable coordination without vio- lating privacy , we introduce an augmented observation spac e b Ω . Each agent rec eives a local observation o i ∈ b Ω i that includes not only its internal state (e.g., generation/ demand proles, battery SoC, prot) but also a comprehensiv e set of system-level signals. T o guide ec onomic strategy , the observation spac e includes dynamic market signals such as the clearing price, clearing vo lume, and the price spread. Crucially , agents also observ e the P2P trade ratio, dened as the proportion of P2P trades relative to the total trade volume. A high P2P trade ratio serves as a signal of market self-suciency , implicitly encouraging agents to prioritize the local lay er ov er the DSO. Simultaneously , grid state signals are injecte d to internalize ph ysical constraints. The grid balanc e ( B grid ) acts as a normal- ized indicator of the net energy position of the grid (se e ( 1 ), where G t is the energy generation, D t the energy demand, and E bought,t and E sold,t are the energy bought and sold for agent i at trading period t ), where positive values indicate a surplus and negative values a decit. A positive B grid indicates a generation surplus, while a negative value indicates a decit. This is com- plemented b y the grid congestion metric (see ( 2 ), where F is the power o w for each pow er line e ∈ ξ , C is the capacity at the grid edge, and ζ the mean congestion lev el), which represents the average c ongestion level across all netw ork edges normalized to [ 0 , 1 ] . Lo w congestion lev els are indicativ e of a system operating well within its ph ysical limits, enhancing reliability . These signals function as congestion indicators, warning agents of infrastructure stress directly without acc essing the topology data of the grid operator [ 32 ]. B grid = i ∈ I ( G i − D i + E bought,i − E sold,i ) (1) ¯ ζ = 1 | ξ | e ∈ ξ F e max ( C e ) (2) Finally , specic implicit cooperation KPIs are injecte d to guide high-lev el strategy . These KPIs are categorized to provide a multi-fac eted view of s ystem performanc e, and include KPIs f or economic ecienc y , grid stability , resource coordination, and coordination eectiv eness. The c omplete suite of implicit cooperation KPIs is described in more detail in [ 9 ]. By broadcast- ing these signals, the system conv erts global state information into local observables without revealing individual private data, thereby preserving priv acy while enabling system-a ware learning. The rew ard function is the primary driver of behavioral adaptation and is designed to b alance individual economic incen- tives with s ystem-level stability goals. As deriv ed in [ 9 ], the reward R i for agent i at trading period t is a c omposite function creating a hierarchic al incentive mechanism (se e ( 3 )). R i = R base,i · ( 1 + f coop · f contrib,i ) − γ DSO,i − γ UD,i (3) The base reward ( R base,i ) is a w eighted sum that represents the individual performanc e of the agent and ensures that agents learn ee ctive bidding strategies to trade on their own behalf. R base,i comprises an e conomic component which rew ards prot maximization relative to DSO prices and inc entivizes agents to learn eectiv e bidding strategies, a grid balanc e component which rew ards agents for actions that help re duce ov erall grid imb alance (i. e., buying during surp lus periods and selling during decit periods), a resourc e allocation component which enc ourages ecient utilization of availab le DER capacity , a trading component which inc entivizes succ essful transactions with a higher weight for P2P transactions to create a pref erence f or local coordination, and a stability c omponent which rewards behaviors that c ontribute to long-term market stability . The core c ontribution of this w ork regarding implicit cooperation is the cooperation bonus, represented b y the multi- plic ative term in vo lving the c ooperation factor f coop , which is c alculated from the w eighted sum of normalized system KPIs (including economic eciency , grid stability , and coordination eectiv eness). It acts as a multip licative bonus that scales the base reward. When the s ystem is health y (i.e., high social welf are and lo w c ongestion) all agents perceive higher potential re- wards. This creates a dynamic where agents are motivated to maintain a stable market environment in order to maximize their 18 own long-term utility [ 31 , 131 ]. T o prev ent reward exploitation, the cooperation bonus is modulate d by the contribution factor f contrib,i , which quanties agent i ’s spe cic individual impact on the s ystem health. f contrib,i is a weighted sum of the agent’s marginal contribution to reducing grid imbalanc e ( − 𝜕 | B grid | 𝜕 a i ), its contribution to price eciency , and its contribution to local trading v olume. This term ensures e ective credit assignment, a challenge in c ooperative MARL, by rew arding agents propor- tional to their positive impact on the co llective state. Finally , the structure includes a penalty mechanism, encouraging agents to prioritize P2P transactions and fostering a self-sucient local market. γ DSO,i is applied for trading with the DSO, scale d by the current grid imbalance, and γ UD,i is applied for the unmet demand. This creates a dual incentive: agents are discouraged from relying on the DSO, and this discouragement is amplied during critical imbalanc e periods, f orcing agents to seek local matching solutions. These mechanisms establish a c ontinuous f eedback loop of measurement, sharing, and adaptation. First, the system calcu- lates all KPIs b ased on the current market state and grid c onditions. These KPIs are then integrated into each agent’s augmented observation spac e, providing a shared signal about system health. Simultaneously , these KPIs determine the magnitude of the cooperation factor in the reward function. As agents exe cute actions to maximize this reward, they learn to associate specic behaviors (such as reducing load when the coordination score is low) with system-level outcomes. This fee dback loop enables agents to learn coordination strategies without explicit communication, as they can infer the impact of their actions on the co llective through the KPI signals. 3.2 Implicit cooperation KPIs The framework calculates a comprehensiv e suite of KPIs, categorize d to provide a multi-facete d view of system performanc e [ 9 ]. The fo llowing are the indicators used to measure: 1. Economic eciency KPIs: This set of metrics measures the market’s ability to create value and facilitate ecient price disc overy . • Social welfar e: The total ec onomic v alue of all trades, representing the sum of c onsumer and produc er surp lus. It serv es as the primary indic ator of overall market eciency . Note that p is the price and q the energy quantity . Social W elf are = trades p trade · q trade (4) • Mark et liquidity: The total volume of energy trade d, indicating market activity and depth. Liquidity = trades q trade (5) • A verage bid-ask spread: The av erage dierenc e between buy and sell order prices, measuring market eciency . Spread = E [ p ask ] − E [ p bid ] (6) • Price vo latility: The standard deviation of the clearing price ov er a time window , indicating market stability . 2. Grid stability KPIs: This set of metrics assesses the p hysical health and operational ecienc y of the electrical grid. • Supply-d emand imbalanc e: The net energy imbalanc e normalized b y grid capacity C grid , measuring how well supply and demand are balanc ed. A v alue near zero suggests stable operation that does not strain the wider grid. Imbalanc e = | Í q buy − Í q sell | C grid (7) • Grid gongestion: The av erage congestion lev el across all po wer lines e ∈ ξ as dened in ( 2 ), indic ating ph ysical stress on the infrastructure. Low congestion levels are indicativ e of a s ystem operating w ell within its ph ysical limits, enhancing reliability . • Grid balance: The overall energy balance of the grid, calculated as the dierenc e between total generation and consumption as in ( 1 ). 3. Resource coor dination KPIs: These metrics evaluate how e ectively DERs are utilized and c oordinated. 19 • DER self-consumption: The proportion of total energy transacted that oc curs in P2P trades as opposed to with the DSO. A high value is indicative of a self-sucient and ee ctive local market, reducing reliance on centralize d utilities. Self-Consumption = Í q P 2 P Í ( q P 2 P + q DSO ) (8) • Fle xibility utilization: The proportion of a vailable exible energy that is actively utilized in P2P trading. This metric measures how eectiv ely agents utilize their energy exibility resources (generation surplus, demand decit, and battery c apacity). Flexibility Utilization = Í q p 2 p Í q available (9) where Í q available is the total a vailab le exibility across all agents, c onsidering the sellable e xibility (surplus gen- eration plus battery discharge cap acity), and the buyable e xibility (decit demand plus b attery charge cap acity) at a given trading period t ∈ { 1 , . . . , τ } . 4. Coordination eectiv eness KPIs: These metrics measure the emergenc e and ee ctiveness of c oordination among agents. • Coordination score: A measure of coordination, reecting the market’s balanc e. A score approaching 1 indi- cates perf ect system balanc e. Coordination Score = 1 − Imbalanc e (10) • Coordination conv ergence: Measures the stability of trading vo lumes o ver a rec ent windo w , indicating if a stable, c oordinated pattern has emerged. It is calculated similarly to the pric e vo latility metric. 3.3 MARL algorithms: algorithm-specic characteristics 3.3.1 PPO As an on-polic y gradient method, PPO learns dire ctly from the data generated by the current policy . It was designe d to address the step size problem in polic y gradient methods: if a policy update is too large, the agent may mov e into a region of the parameter spac e that yields bad performance. Bec ause on-policy agents collect data based on their own behavior, a bad policy leads to bad data, c reating a terminal performance c ollapse from which the agent cannot rec over. The core inno vation of PPO is the clipped surrogate objective function, which enf orces a trust region to ensure that policy updates are incremental. For a dec entralized prosumer agent i , the objectiv e J CLIP ( θ i ) is dened in ( 11 ). J CLIP ( θ i ) = E t h min r t ( θ i ) b A t , clip ( r t ( θ i ) , 1 − ε, 1 + ε ) b A t i (11) r t ( θ i ) = π θ i ( a t | o t ) π θ old ( a t | o t ) (12) Where r t ( θ i ) is the probability ratio that measures how much more (or less) likely an action a t is under the new policy comp ared to the old , and θ i is the polic y parameters of agent i ∈ I . The term b A t is the advantage, which quanties how much better a spe cic action was comp ared to the a verage behavior. The operational logic of the clipping mechanism ( ε , typically 0.2) varies b ased on the nature of the experience: • P ositive adv antage ( b A t > 0 ) : If the action was good, the algorithm wants to increase r t . The min operator caps this increase at 1 + ε . This prevents the polic y from ov er-optimizing based on a single lucky market interaction, ensuring stability . • Negativ e adv antage ( b A t < 0 ): If the action was bad, the algorithm wants to decrease r t . The clipping prevents the prob ability from being driven to zero instantaneously , which would destro y the agent’s ability to explore better strategies in the future. 20 T o compute the advantage b A t , PPO utilizes the generalized advantage estimation. This mechanism reduc es the variance of the rewards rec eived from the LEM b y interpolating betw een immediate fee dback and long-term returns. In the context of implicit cooperation, PPO’s strength lies in this dampening e ect. In a multi-agent environment, the transition dynamics are non-stationary because other agents are learning simultaneously . If Agent A changes its bidding strategy drastically , Agent B’s environment changes. PPO’s conserv ative updates allow neighbors time to adapt to these shifts, facilitat- ing con vergenc e toward stable Nash e quilibria rather than the chaotic oscillations often observed in non-clipped methods. 3.3.2 APPO APPO addresses the computational bottlene ck of standard PPO in medium-scale simulations. In an LEM with a hundred agents, the time required to solv e market-clearing ph ysics can vary . Standard PPO is synchronous, meaning the learner must wait f or every agent to nish its simulation before updating. APPO decoup les actors (data colle ctors) from the learner (policy optimizer) in an actor-learner topology . Because c ollection and optimization happen in parallel, a policy lag occurs: the data might ha ve been co llected by a slightly older v ersion of the polic y ( π behavior ) than the one currently being updated ( π target ). Using this stale data introduces bias. APPO emplo ys V -trace to c orrect this discrep ancy mathematic ally . The V -trace target for value updates is dened in ( 13 ), where V target t is the c orrected v alue estimate that the learner aims to reach f or the state at time t , V ( s t ) is the current value function’s estimate of the state s t ∈ S , ψ is the discount factor which determinies how much the agent values future rewards versus immediate ones, ℓ is the length of the trajectory segment, c t + j is a trace-cutting coecient that contro ls how much the errors from future steps ae ct the current update, ρ t + k is the truncated importance sampling weight (being ¯ ρ a h yperparameter representing the clipping threshold to prev ent the importance weight from be coming too large), and δ t + k is the temporal dierenc e error. V target t = V ( s t ) + ℓ − 1 k = 0 ψ k © « k − 1 Ö j = 0 c t + j ª ® ¬ ρ t + k δ t + k (13) ρ t = min ¯ ρ, π target ( a t | o t ) π behavior ( a t | o t ) (14) The importance weight ρ t measures how much the current policy has drifted from the one that collecte d the data. If the drift is too high, the weights e ectively cut the trac e, forcing the learner to rely more on its current value estimates rather than the stale rewards. In our multi-agent c ontext, APPO provides experience diversity . Because dierent actors can interact with di erent in- stances of the energy grid simultaneously , the learner rec eives a bro ader range of sc enarios (e.g., varying generation levels across dierent simulate d days). This prevents the lock-step synchronization of strategies and encourages the dev elopment of decen- tralized policies that are robust to a wide v ariety of grid conditions. 3.3.3 SAC While PPO maximizes the expected return, SAC maximizes the expecte d return plus the entropy ( H ) of the policy . The objectiv e function is dened in ( 15 ), where α is the temperature parameter. J ( π ) = τ t = 0 E ( o t ,a t ) ∼ ρ π r ( o t , a t ) + α H ( π ( · | o t ) ) (15) Entropy is a measure of randomness. By maximizing it, SAC forc es the agent to remain as stochastic as possib le while still achieving the goal. This provides three critic al benets for LEM c oordination: • Robustness to non-stationarity: In a Dec-POMDP , deterministic policies are brittle. If a neighbor changes a bid- ding threshold, a deterministic po licy might suddenly f ail. A stochastic po licy learns a distribution of optimal actions, making it more resilient to the shifting behaviors of pe ers. • Discov ery of cooperative strategies: Coordinated lo ad shifting is dicult to disco ver bec ause it often requires a tem- porary local economic loss f or a global system benet. SA C’s mandated entropy prevents the agent from prematurely con verging to a selsh, suboptimal local minimum strategy . • Reparameterization for continuous contro l: T o optimize the stochastic polic y , SA C makes the sampled action a t a dierentiab le function of the policy parameters. This allows for the pre cise, continuous modulation of bid quantity and bid price bids ne eded for ne-grained grid b alancing. 21 SA C is an o-po licy algorithm, utilizing a rep lay bu er to store ev ery p ast interaction. This makes it more samp le-ecient than PPO . T o prevent agents bec ome ov erly optimistic about certain actions due to errors in the neural network, SAC maintains two independent Q-netw orks and uses the minimum of the tw o for its updates, ensuring that the coordination signals learned by the agents are grounde d in stable value estimates. 3.4 MARL training paradigms 3.4.1 CTCE CTCE represents the theoretic al upper bound f or coordination quality and serves as the primary benchmark for maximum achievab le perf ormance in this study . In this paradigm, the multi-agent problem is re duced to a single-agent prob lem with a high-dimensional joint action spac e. The architecture utilizes a single polic y network π θ that receiv es the global environment state S t . This global state provides a c omplete description of the en vironment, concatenating all private inf ormation from the grid. The po licy maps this global state directly to the joint action v ector a t , solving the optimization problem in a single f orward pass. The mathematical f ormulation assumes a joint policy that, while it may be factorized for implementation, remains glob ally conditione d (see ( 16 )). π θ ( a 1 ,t , . . . , a I,t | s t ) = I Ö i = 1 π θ,i ( a i,t | s t ) (16) The shared conditioning on S t enables the network to learn sophisticated c orrelations betwe en agent behaviors. The centralize d value function V ϕ ( s ) estimates the expected return b y c onsidering the aggregate system-level reward, thereb y directly optimizing for the glob al objective J CTCE ( θ ) dened as the expected disc ounted global return (see ( 17 )). J CTCE ( θ ) = E s ∼ ρ π , a ∼ π θ " T t = 0 I i = 1 ψ t R i ( s t , a t ) # (17) Because the c ontroller has comp lete visibility and authority , the training process is stationary; the environment dynamics are xe d, and there are no other independent learning entities to create non-stationarity . CTCE can achiev e P areto optimality by explicitly trading o the utility of one agent against another to satisfy s ystem constraints. How ever, CTCE serves strictly as a benchmark due to its vio lation of privacy and sc alability issues, as the search sp ace vo lume gro ws e xponentially with the number of agents. 3.4.2 CTDE The operating logic of CTDE relies on a h ybrid actor-critic architecture. During the training p hase, a centralized c ritic Q ϕ ( s, a ) is utilized. This critic has acc ess to the glob al state S t and the joint action ve ctor a t , allowing it to estimate the Q-value with a full perspectiv e of the system’s coupling. How ever, during the ex ecution phase, the critic is discarded, and each agent i retains an independent polic y netw ork π θ i ( a i | o i ) (decentralized actor) that maps only its loc al observ ation o i to an action a i . The gradient for updating the actor po licy θ i is compute d using the deterministic policy gradient theorem or its stochastic equiv alent. ∇ θ i J ( θ i ) = E s, a ∇ θ i log π θ i ( a i | o i ) Q ϕ ( s, a 1 ,t , . . . , a I,t ) (18) In ( 18 ), the c entralized critic evaluates the quality of agent i ’s action a i not b ased on local outcomes, which might be noisy due to the actions of pe ers, but in the conte xt of the global system state. This reso lves the non-stationarity prob lem during training: the critic exp licitly ac counts f or the shifting policies of all other agents π − i , ensuring that the adv antage signal remains stable. This informed signal allo ws the local actor to learn coordination strategies that can later be e xecuted autonomously . In our study , CTDE tests whether coordination strategies c an be explicitly taught via centralized guidanc e. How ever, it still presents a privac y hurdle during the training phase, as agents must share their experiences (observations, actions, and rewards) with the c entral critic, which may conict with data prote ction regulations in real-world LEMs. 3.4.3 DTDE In DTDE, the multi-agent system is treate d as a set of independent learners. Each agent i maintains its own actor π θ i ( a i | o i ) and its own independent critic V ϕ i ( o i ) or Q ϕ i ( o i , a i ) . Critically , the critic only has acc ess to the local observ ation o i and the agent’s own action a i , treating the actions of all other agents purely as part of the environment dynamics. The training objective for each agent is to maximize its own e xpected discounted return, as dene d in ( 19 ). 22 J DTDE ( θ i ) = E o i ,a i " τ t = 0 ψ t R i ( o i,t , a i,t ) # (19) The central theoretic al hurdle of DTDE is non-stationarity . In a Dec-POMDP , from the perspective of agent i , the envi- ronment transition function P i ee ctively absorbs the evo lving policies of all other agents π − i (see ( 20 )). P i ( s ′ | s, a i ) = a − i ∈ A − i P ( s ′ | s, a i , a − i ) Ö j ≠ i π j ( a j | o j ) (20) Because all agents update their policies π j simultaneously during training, P i bec omes time-variant. This violation of the Marko v property leads to learning instability , oscillations, and con vergence to suboptimal Nash e quilibria. Our contribution is to mitigate this non-stationarity through the augmente d observation space described in Section 3.1 . By injecting system-level KPIs into the local observation o i , the environment bec omes quasi-stationary . These KPIs provide a compresse d, privac y-preserving representation of the aggregate beha vior of the other agents. Instead of ne eding to know Agent B’s specic state, Agent A only nee ds to know the ph ysical impact of Agent B’s actions on the grid. 4 Experimental setup This case study is designed to test the implicit cooperation hypothesis under realistic conditions. Specically , it examines whether dec entralized agents can achiev e system-level c oordinationm such as maintaining supply-demand b alance, using only local observ ations augmented with stigmergic KPI signals, thereby b ypassing the ne ed f or centralized disp atch or exp licit com- munication. The scenario is evaluated across all combinations of the training p aradigms (CTCE, CTDE, DTDE) and MARL algorithms (PPO , APPO, SA C). The primary goal of this design is to quantitativ ely verify whether decentralize d agents, operating under the constraints of scarc e inf ormation (DTDE), can approximate the coordination quality of theoretic ally optimal centralized systems (CTCE). W e assess which continuous control algorithm (PPO , APPO , or SAC) best navigates the trade-o betw een exploration—essential for disco vering cooperative equilibria—and stability , which is c ritical f or maintaining ph ysical grid constraints in a non-stationary environment. By subjecting div erse algorithms to identical en vironmental c onditions (spe cically an heterogene ous agent pop- ulation and constrained IEEE 34-bus topology) we eliminate conf ounding variab les. This ensures that observed perf ormance dierenc es are attributab le so lely to the interaction between the training paradigm and the learning update rule. W e test the h ypothesis that system-level KPIs (e.g., the Grid Balanc e Index) injected into the observation spac e function as e ective proxies for c entralized coordination signals, allo wing agents to internalize the externalities of their actions. Detailed congurations and implementations for replic ating this case study can be f ound in the project’s dedicated GitHub repository ( https://github. com/ salazarna/ marlem ). 4.1 Case stud y conguration The experimental conguration enf orces interdependenc e through a diverse population of 8 DER agents with comp lementary generation and demand proles (se e Fig. 1 ). This heterogeneity ensures that c oordination is not just benecial but necessary for optimal system performanc e. The cap acity ranges (75–180 kW) and battery ratios are selecte d to ensure realistic penetration levels (40-60% of total lo ad) that provide meaningful impro vement potential without c ausing immediate grid instability . T able 6 details the spe cic conguration f or each agent, including their roles, capacities, and the behavioral logic underpinning their proles. T o ensure reproducibility , the environment c onguration is detailed in T able 7 . T able 6: Conguration of the agents f or the case study . Agent IEEE-34 Nod e C apacity (kW) Battery (k W) Battery Ratio Description Small Industry 840 180.0 108.0 0.6 Continuous demand with morning peak; relies on stored energy Community Hospital 890 170.0 85.0 0.5 High morning demand peak, transitioning to afternoon generation surplus University Campus 844 140.0 98.0 0.7 Bi-modal demand (morning/ afternoon peaks); moderate midday generation Shopping Mall 816 130.0 78.0 0.6 High afternoon/ evening demand; generation sink f or midday surplus Residential Complex 800 80.0 64.0 0.8 Dual-peak demand (morning/ evening); reliant on storage for ev ening ramp Apartment Building 830 75.0 52.5 0.7 Similar to residential complex; moderate generation cap ability Community Solar F arm 848 180.0 180.0 1.0 High midday generation, minimal demand; acts as exible provider P arking Lot 860 160.0 144.0 0.9 High midday generation; acts as exibility provider 23 Each agent is equipped with a b attery modeled with a 95% charge/ discharge ecienc y . T o preserve battery health and realism, the SoC is c onstrained betwe en 5% and 95% of nominal c apacity . These di ering battery ratios (0.5 to 1.0) create a heterogeneous landscape of market po wer, allo wing to analyze how agents with dierent storage c apabilities c ontribute to grid balanc e. 0 5 10 15 20 T ime Step 0 2 4 6 8 10 12 14 Ener gy (kWh) industrial_facility_001 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 10 20 30 40 Ener gy (kWh) hospital_002 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 10 20 30 40 50 Ener gy (kWh) university_campus_003 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 20 40 60 80 100 Ener gy (kWh) shopping_mall_004 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 10 20 30 40 Ener gy (kWh) residential_complex_005 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 5 10 15 20 Ener gy (kWh) apartment_building_006 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 10 20 30 40 50 60 Ener gy (kWh) community_solar_farm_007 Generation Demand Surplus Deficit 0 5 10 15 20 T ime Step 0 10 20 30 40 50 Ener gy (kWh) parking_lot_generation_facility_008 Generation Demand Surplus Deficit Agent Energy Profiles: Generation vs Demand Figure 1: Generation and demand proles f or DER agents in the case study . The simulation operates on an IEEE 34-bus test fe eder topology , a standard distribution network benchmark modied f or this case study . The total system cap acity is c onstrained to 1800 kW . This cap acity limit is binding during peak usage hours (given the total agent c apacity of roughly 1115 kW p lus baselo ad), forcing agents to coordinate ph ysically via local balancing rather than relying solely on the DSO . The strategic plac ement of agents (see Fig. 2 ) is determined by the topology’s critic al electric al points to enable robust hardw are-in-the-loop validation. Agents are assigned to specic nodes that c orrespond to designated signal monitoring points within the future R T -Lab IEEE-34 model implementation. In the substation zone, the small industry is located at node 800 (substation bus), which serv es as the primary f eed point and a critic al loc ation f or measuring grid entry / exit ows. The com munity hospital agent is positioned at node 890 (transformer secondary), a key measurement node f or assessing pow er quality and vo ltage regulation immediately downstream of the v oltage transf ormation. Deeper within the network, the shoppi ng mal l is situated at node 816, a ma jor fee der branch point sele cted to validate c oordination dynamics at critic al netw ork bifurcations. Finally , to test system stability across signicant ele ctrical distanc es, the com munity sola r f arm and parking lot are plac ed at netw ork extremities (node 860 and node 848 at the end of the rst lateral, respectiv ely) where v oltage support is most critic al and will be rigorously monitored during hardware-in-the-loop validation. The market layer is congured to incentivize local coordination ov er relianc e on the main grid. W e emp loy an av erage pricing mechanism ( p trade = p buy + p sell 2 ). This mechanism is selected to promote fair price discov ery and reduce the comple xity of strategic bidding. The market parameters include a price oor of 20 $/kWh and a ceiling of 600 $/kWh to encourage local trading over DSO arbitrage. P artner pref erences are enabled, allowing agents to learn and prioritize reliable peers. Crucially , the DSO price signals act as the boundary conditions for agent behavior. As illustrated in Fig. 3 , a distinct gap is maintained betwe en the feed-in tari (FIT) and the utility price. The FIT represents the revenue f or selling to the grid and it remains consistently lower than the utility price (peaking around 300 $/kWh). The utility price represents the cost to buy from the grid and it peaks signicantly during the day (reaching 600 $/MWh), c reating an economic penalty f or agents that fail to sourc e energy locally during peak demand. The gap betwe en these two curv es creates the P2P margin, where agents are economic ally incentivize d to trade with each other bec ause a seller c an earn more than the FIT , and a buy er can pay less than the utility price, 24 800 802 806 808 810 812 814 850 816 818 824 820 822 826 828 830 854 832 858 834 860 842 836 840 862 844 846 848 852 856 864 838 888 890 Grid Network T opology (IEEE34) Network Zones & Agents feeder1 feeder2 lateral1 lateral2 substation transfor mer Agents industrial_facility_001 hospital_002 university_campus_003 shopping_mall_004 residential_complex_005 apartment_building_006 community_solar_farm_007 parking_lot_generation_facility_008 Figure 2: The 34-node IEEE test f eeder as the grid netw ork f or the case study . provided they coordinate eectiv ely . DSO price proles are kept xed between experiments to ensure that DSO price signals remain consistent ac ross episodes, acting as a stable basis f or learning. 4.2 T raining conguration and experimen tal matrix T o systematically isolate the ee cts of information architecture and the learning update rule, w e used a 3 × 3 factorial design: the c ombination of the three training paradigms (CTCE, CTDE, DTDE) with the three MARL algorithms (PPO , APPO , SA C). The initial set of hyperp arameters of the MARL algorithms are specied in T able 8 . The training process is orchestrated using the MARLEM framework. T o optimize h yperparameters dynamic ally , we em- plo y P opulation-Based T raining (PBT) [ 132 ]. The proc ess initializes 10 tune samp les for each of the nine congurations, re- sulting in 90 concurrent trials. These trials evo lve independently: f or exploitation, PBT periodically clones the weights of the best-performing trials, while for exploration, the framework mutates the h yperparameters of lo w-performing trials to search the parameter spac e eciently . Although PBT modies specic learning rates during training, the initial settings are adapted to the mathematical requirements of each MARL algorithm to ensure a rigorous benchmark c omparison. Each conguration is trained for a total of 10 000 episodes, ensuring sucient interaction steps f or con vergenc e in the comp lex multi-agent en vironment. Model checkpoints are sa ve d ev ery 10 iterations, and the evaluation is perf ormed at each training iteration, with the duration automatically determined b y the framework to dene the appropriate number of evalua- tion episodes base d on the capacity of the evaluation w orkers. The training campaign is ex ecuted on a specialize d machine with a 12 c ore Ryzen 9 9900X processor, 128 GB R AM, R TX 4090 graphics card, Linux operating system with amd64 architecture, Ubuntu 24.04 distribution, and equippe d with CUD A 13. 25 0 5 10 15 20 T ime Step 0 100 200 300 400 500 600 P rice ($/kWh) DSO Pricing F eed-in T ariff Utility P rice Figure 3: F eed-in tari and utility price proles f or DSO agent in the case study . T able 7: Core simulation p arameters f or the case study . Parameter V alue Descrip tion Max steps 24 Episode length representing a full 24-hour cy cle (1 hour/ step) Grid topology IEEE 34-Bus Standard distribution network topo logy Grid cap acity 1800 kW T otal grid capacity Seed 42 Fixed random se ed for reproducibility Price range 20 - 600.0 Allowab le bid range, designed to be wider than DSO prices Quantity range 0 - 180 kWh Allowable trade size per order F orecast error 30% (max_error=0.3) Maximum random error app lied to agent fore casts to simulate uncertainty Async orders T rue Enables asynchronous order proc essing to simulate realistic market latency 4.3 E valuation metrics The assessment of imp licit cooperation relies on a multi-dimensional set of KPIs that capture the trade-os betw een e conomic eciency , grid stability , resource coordination, and agent autonom y (recall Se ction 3.2 ). The core measure of suc cess is the coordination score , dened as the c omplement of the normalized supp ly-demand im- balanc e (recall ( 10 )). A score approaching 1.0 indicates perf ect ph ysical equilibrium, directly v alidating the agents’ ability to synchronize generation and consumption without central dispatch. This is complemente d by the grid balanc e index ( B index ), which incorporates transmission losses and external grid relianc e to provide a holistic view of ph ysical stability . T o assess market self-suciency , w e utilize the P2P trade r atio , where a higher ratio indic ates succ essful local matching and reduc ed dependence on the DSO . Finally , social welf are quanties the total economic v alue generated, ensuring that ph ysical c oordination does not come at the e xpense of economic eciency . T o understand how coordination emerges, we analyze agent responsiveness , calculated as the correlation between system- level signals and agent actions over time. High positive responsiveness conrms that the engineered stigmergic signals are ee ctively guiding decision-making. Additionally , price volatility is monitored to ensure market stability , while DER self- consu mption tracks the eectiv eness of assets in providing exibility servic es. All stochastic processes within the simulation (e.g., noise injection‚ are controlled by a global seed (recall T able 7 ). This ensures that the environmental conditions are identical across all experimental runs, guaranteeing that an y observed variance in performanc e is due to the learning dynamics and not environmental randomness. T o assess the c omputational feasibility of the propose d framew ork, a c omplementary scalability test w as perf ormed along- side the c ore coordination experiments. In this specic analysis, the exact same simulation environment w as execute d for 1 26 T able 8: Initial h yperparameters of the MARL algorithm f or the case study . Hyperparameter PPO APPO SA C Learning rate 1e-5 1e-5 Actor: 1e-5, Critic: 1e-5 Disc ount factor ( ψ ) 0.99 0.99 0.99 Entrop y coecient 0.01 0.01 Dynamic Gradient clip 0.5 0.5 0.5 Clip P aram 0.2 N/ A N/ A GAE / V -trace GAE V -trace - Batch/Bu er size Minib atch: 128 - Buer Cap acity: 1 000 * For centralized paradigms (CTCE/CTDE), the target entropy is set to the negative sum of all action dimensions ( − sum Í dim ( A i ) ). For the decentralize d mode (DTDE), it corresponds to the negativ e dimension of the individual agent’s action space ( − dim ( A i ) )). 000 episodes per run, utilizing a re duce d PB T conguration with 1 tune sample. The analysis maintained the standard 3 × 3 experimental matrix while varying the number of agents across the set { 2 , 20 , 34 } . The upper limit of 34 agents is strictly im- posed b y the ph ysical node constraints of the IEEE 34-node test f eeder topology . For each training session, the total w all-clock training time w as recorded until con vergence is achieve d or until the comp letion of the 1 000 episodes (whichever c omes rst), providing a direct metric for comp aring the c omputational ov erhead of centralize d versus decentralize d p aradigms as the agent population scales. 5 Results and discussion This section presents a comprehensiv e analysis of the experimental results obtained from Section 4 , systematically comp aring the three training p aradigms (CTCE, CTDE, D TDE) and three MARL algorithms (PPO , APPO , SA C) to validate the implicit cooperation h ypothesis. By integrating the quantitative performanc e metrics with a qualitativ e analysis of algorithmic learning dynamics, we quantify the trade-os betw een coordination quality , stability , and computational scalability . 5.1 Experimental matrix: training paradigms and MARL algorithms T o rigorously evaluate the ecac y of implicit cooperation, we c onducted a factorial analysis of 9 distinct experimental cong- urations, dene d b y the intersection of three inf ormation architectures (training paradigms) and three learning update rules (MARL algorithms). The results, derived from mean episodic rewards over 10 000 training episodes and validated through a specic evaluation phase, reveal a distinct performance hierarch y (see T able 9 ). Since con vergenc e was achieved in all 9 experi- ments bef ore 300 training episodes, only these rst episodes are shown in Fig. 4 f or better visualization. This analysis identies how specic algorithmic mechanisms (such as entropy maximization, trust regions, and asynchronous updates) interact with the av ailable information to enab le or hinder coordination. 5.1.1 Analysis of the training p aradigms The training paradigm denes the boundaries of the observation space and the mechanism of policy updates, setting the the- oretical limits of coordination potential. CTCE congurations served as the theoretical benchmark for coordination quality . In this paradigm, agents are provide d with the full glob al state v ector during both training and ex ecution. As expected, the acc ess to perfect information allow ed agents to achieve the highest potential performance. The APPO-CT CE c onguration established the absolute ceiling for the system, achieving a peak episodic reward of 3272.1 and a mean of 3143.9 during the ev alu- ation p hase. SAC-CTCE also perf ormed robustly , maintaining a high mean rew ard of 3139.8 with a standard deviation of 93.4. The PPO-CTCE lagged slightly behind with an a verage of 3099.4. The high reward values reect optimal social welf are and 27 0 50 100 150 200 250 300 Episode 1000 500 0 500 1000 1500 2000 2500 3000 3500 Mean R ewar d (T rain) Mean Episode Reward (T rain) PPO CT CE PPO CTDE PPO DTDE APPO CT CE APPO CTDE APPO DTDE S A C CT CE S A C CTDE S A C DTDE (a) T rain. 0 50 100 150 200 250 300 Episode 1000 500 0 500 1000 1500 2000 2500 3000 3500 Mean R ewar d (Evaluation) Mean Episode Reward (Evaluation) PPO -CT CE PPO -CTDE PPO -DTDE APPO -CT CE APPO -CTDE APPO -DTDE S A C-CT CE S A C-CTDE S A C-DTDE (b) E valuation. Figure 4: Mean episode rew ard for ev aluating the 9 e xperiments ov er 10 000 training episodes. Only the rst 300 episodes are shown. T able 9: M ean episode reward f or evaluating the 9 e xperiments ov er 10 000 training episodes. CTCE CTDE DTDE PPO APPO SAC PPO APPO SA C PPO APPO SA C Min 2702,2 2641,2 2560,7 2618,9 2791 2730 989,7 991,6 -669,8 Mean 3099,4 3143,9 3139,8 3004,8 3096,5 3158,2 2742,5 2998 54,5 Std 44,8 97,9 93,4 49,1 64,6 42,5 431,5 431,4 215,8 Max 3123,3 3272,1 3189,7 3074,1 3181,4 3166,1 2935,2 3243,5 708,4 minimized grid imbalance. The c entralized controller succ essfully lev eraged the complete information vector to synchronize agent actions, thereby a voiding simultaneous peaks and e ectively managing grid c onstraints. CTDE emerged as a robust middle ground, eectiv ely distilling global c oordination insights into loc al policies. In this setup, a c entralized critic (ac cesse d only during training) guides local actors who must execute using only partial observ ations. The SAC-CTDE c onguration demonstrated exc eptional stability and performanc e, achieving a mean reward of 3158.2 and a maximum of 3166.1. Notably , its standard deviation w as the lowest among all congurations (42.5), signicantly low er than its CT CE counterp art (93.4). This indicates that the c entralized critic successfully guided the loc al actors to a highly stable cooperativ e equilibrium, eectiv ely smoothing the learning landsc ape. The perf ormance of SAC-CTDE eectiv ely matched the performanc e of SAC-CT CE. This validates that agents succ essfully internalized global objectiv es into their local polic y networks during the centralized training phase, learning to treat local stigmergic signals as reliable proxies for the global state. These results c onrm CTDE as a safe choic e for managed energy communities where oine c entralized training is permissib le. How ever, PPO-CTDE showe d a more marked degradation (mean reward of 3004.8), suggesting that on-policy algorithms struggle more to compress glob al value functions into local policies without the aid of entrop y maximization. DTDE provide d the most critical validation f or the proposed implicit cooperation model, though its suc cess was found to be highly algorithm-dependent. The most signicant nding of this study is the ex ceptional perf ormance of APPO-D TDE. It achieve d a maximum reward of 3243.5 and a conv erged mean of 2998. This peak performanc e is statistically comparab le to the APPO-CTCE benchmark (3272.1), a gap of only 8.3%. This proves that true implicit cooperation can emerge solely through stigmergic signaling (KPIs) in the observation space, without an y centralized components. In contrast, SAC-D TDE faile d to coordinate ee ctively , ending with a mean reward of 54.5 and frequently dipping into negative values (min -669.8). This may suggest the fragility of entropy-b ased maximization in fully non-stationary , decentralize d environments. Without a stabilizing central critic, the agents’ simultaneous pursuit of randomness creates a chaotic environment where no stable equilibrium can be f ound. PPO-DTDE show ed stable but suboptimal perf ormance (mean rew ard of 2742.5), struggling to reach the high-lev el equilibrium f ound by APPO . While it av oided the collapse of SA C, it demonstrated the limitations of conserv ative, on-polic y updates in a partially observ able environment. 28 5.1.2 Analysis of MA RL algorithms While the training p aradigm denes the information limits, the MARL algorithm determines how eectiv ely agents explore and exploit the a vailable polic y space. The results reveal distinct behavioral proles f or PPO, APPO, and SA C, driven b y their underlying mathematical f ormulations. PPO functioned as the reliab le baseline. Across all paradigms, PPO demonstrated c onsistent, albeit conservativ e, per- formanc e. PPO exhibited steady learning curv es in the early phases but p lateaued at lower rew ard levels than its o-polic y counterp arts. In the DTDE paradigm, it achiev ed 94.4% of its centralized benchmark. PPO’s on-policy nature and clipped objective function specically punish large policy updates. While this prevents the co llapse of the po licy , it hinders the aggressive e xploration needed to disc over c omplex cooperativ e strategies in a dynamic LEM. APPO emerged as the strictly dominant algorithm for decentralize d en vironments. APPO consistently achiev ed the high- est rewards across all paradigms. Its asynchronous architecture de couples data c ollection from po licy updates, generating a high-throughput stream of div erse experiences. This noise in data co llection acts as a regularizer, prev enting ov ertting to spe- cic peer behaviors. The key to APPO’s succ ess in DTDE is the V -trace correction. This mechanism allows the algorithm to utilize near-on-polic y data (i.e., e xperiences generated b y slightly older policies of peers) without the bias that destabilizes stan- dard PPO . This makes APPO uniquely robust to the non-stationarity of dec entralized learning, ee ctively treating the shifting behaviors of neighbors as en vironmental noise rather than adversarial disturb ances. APPO demonstrated superior scalability . SA C display ed a binary performanc e prole, exc elling in hybrid setups but co llapsing in pure decentralization. In CTCE and CTDE, SA C was highly eectiv e. SA C-CTDE achieved the most stable perf ormance of all 9 congurations (standard deviation of 42.5), validating that maximum entrop y is pow erful when stabilized by a centralize d critic. The entropy term encourages agents to e xplore diverse strategies, prev enting premature conv ergence to selsh local minima. In DTDE, SA C faile d catastrophic ally (gap of 73.7%). The theoretical reason is the lack of a common truth. In a fully dec entralized setting, if every agent maximizes entropy simultaneously , the environment becomes chaotic and unpredictable. Without a shared critic to ground the value function, the agents’ pursuit of randomness leads to a feedb ack loop of div ergence. PBT analysis reveals that while successful runs (CTDE) con verged to moderate learning rates (2.98 × 10 − 3 ), the f ailed DTDE runs oscillated, unable to nd a stable h yperparameter region. 5.1.3 P erformance of the e xperimental matrix PBT dynamically adjusted the hyperp arameters f or each conguration to maximize performance. T able 10 presents the nal h yperparameters obtained at the end of the training proc ess for the best performing trial of each c onguration. The h yperparameter analysis rev eals interesting adaptation p atterns. APPO-CTCE c onv erged to a signicantly higher learning rate (3.3 × 10 − 4 ) comp ared to its decentralized counterp arts, likely exploiting the stability provided b y the centralized state. Conv ersely , PPO-DTDE require d a very high entrop y coecient (0.24) and learning rate (4.4 × 10 − 3 ) to f orce exp loration in the dec entralized setting, although this aggressive tuning did not result in optimal perf ormance comp ared to APPO. T able 10: Final h yperparameters optimize d by PB T after 10 000 training episodes. CTCE CTDE DTDE PPO APPO SAC PPO APPO SAC PPO APPO SAC Learning Rate 9 . 2 × 10 − 6 3 . 3 × 10 − 4 4 . 6 × 10 − 3 9 . 2 × 10 − 6 1 . 2 × 10 − 5 2 . 9 × 10 − 3 4 . 4 × 10 − 3 3 . 7 × 10 − 5 1 . 0 × 10 − 3 Entrop y Coe 5.72 0.01 - 0.04 0.01 - 0.24 0.02 - 5.1.4 Discussion on the perf ormance gap in implicit cooperation The most signic ant nding from this 9-c onguration analysis is the negligible performanc e gap betwe en the best fully dec en- tralized conguration (APPO-DTDE) and the theoretical centralized upper bound (APPO-CTCE). Quantitatively , the best DTDE c onguration achiev ed a conv erged mean rew ard of 3243.5, which is 99.2% of the best CTCE benchmark of 3272.1. This result validates that implicit cooperation, when enabled by correct signal engineering (KPIs) and robust algorithms (APPO), renders centralized contro l redundant for this class of energy management problems. The implications for real-w orld deplo y- ment are relevant, as DSOs can achieve optimal grid balance without building expensive, privacy-in vasive centralized control infrastructure. Instead, the focus shifts to maintaining the integrity of the bro adcasted KPI signals. The quantitativ e analysis of maximum rewards rev eals distinct performance hierarchies that challenge con ventional as- sumptions about the cost of decentralization. For PPO and SAC, the results conrm the hypothesis that information restric- 29 tion leads to performance degradation, where PPO scales from CTCE (3123.3) down to DTDE (2935.2), and SA C drops from CTCE (3189.7) to 708.4 in DTDE. F or these algorithms, a c entralized training phase (CTDE) is essential to achieving near- optimal performanc e, as relying on pure decentralization (D TDE) incurs a tangible c ost that is manageable for PPO at a 6.0% loss but catastrophic f or SA C at a 77.8% loss. In contrast, APPO-DTDE matches the c entralized benchmark to within 1%, implying that true implicit cooperation is fully achievab le without an y centralized components. The superior performanc e of DTDE o ver CTDE f or APPO may stem from the eciency of parallel, asynchronous e xploration in the dec entralized setting, which av oids the potential bottlenecks or training instabilities of a centralized c ritic in the hybrid model. APPO is the strictly dominant algorithm, achieving the highest maximum rewards across all three paradigms: CTCE (3272.1), CTDE (3181.4), and DTDE (3243.5). Its suc cess is attributed to two key mechanisms: the decoup ling of data collec- tion from policy updates, which generates high-throughput experienc e that acts as a regularizer, and the use of V -trace targets which allow for near-on-policy data usage without introducing destabilizing bias. This makes it uniquely robust to the non- stationarity of the DTDE paradigm, allowing it to treat the shifting behaviors of pe ers as environmental noise. In dec entralized energy markets, throughput matters more than perf ect polic y alignment, and APPO’s ability to process vast amounts of slightly o-polic y data yields better results than strictly on-policy c onservatism or fragile entropy maximization. SA C displa ys a binary performanc e prole, proving ex cellent in CTCE and CTDE where a glob al critic stabilizes learning, but failing in DTDE. SAC is designed for maximum entropy , optimizing for both reward and po licy randomness f or e xplo- ration. In the comple x LEM landscape, The SAC may ha ve unco vere d nuanced behaviors, while PPO’s conservativ e trust region often trapped agents in suboptimal loc al minima. Howev er, pure entropy maximization is dangerous in fully dec en- tralized settings; without a common truth pro vided by a central critic, the drive for randomness exacerb ates non-stationarity and leads to a f eedb ack loop of div ergence. PPO , while functioning as a reliable b aseline, is often too slow to adapt to comp lex interactions, achieving only 94% of its benchmark performanc e in decentralized settings. Based on this analysis, specic algorithms are rec ommended for each paradigm to ensure maximum potential is reached. F or CTCE, APPO is the superior choic e due to its ability to exp lore massiv e joint state-action sp aces asynchronously , achieving the absolute highest reward of 3272.1. For CTDE, SA C is the optimal choic e as the centralized critic perf ectly complements its entropy maximization, resulting in the most stable learning curve with the low est standard deviation of 42.5. Finally , for DTDE, APPO is the dominant choice, closing the gap to the c entralized benchmark almost entirely (1%) while PPO and SA C struggle or fail. The ability of APPO-DTDE to match CTCE prov es that stigmergic signals in the observation spac e are sucient for agents to coordinate optimally , rendering the infrastructure costs and privacy risks of centralized control unnec essary for this class of LEMs. 5.2 System-l evel perf ormance: economic and grid metrics T o thoroughly validate the proposed implicit cooperation framework, it is necessary to go beyond abstract analysis of reward con vergenc e and evaluate the tangible ph ysical and ec onomic outcomes of the system. This subsection provides a rigorous analysis of s ystem-level perf ormance for the best c ongurations identied in the previous se ction: APPO-CTCE (benchmark), SA C-CTDE (standard), and APPO-DTDE (proposed solution). The analysis synthesizes detaile d simulation re cords, desc rip- tive statistics of market evolution, and topo logical analyses of emerging commercial networks to quantify trade-os between distributive ecienc y , network stability , and operational autonom y . 5.2.1 Economic eciency and mark et dynamics The economic performanc e of the LEM serves as the primary indicator of alloc ative eciency , reecting how eectiv ely the mechanism b alances local supply and demand while maximizing the aggregate v alue for all particip ants (see Fig. 5 ). The centralized benchmark (CTCE) demonstrated superior structural eciency , driv en b y its access to glob al information. The descriptiv e statistics reveal that CTCE generated an social w elfare of $33 023.2 per episode, with a standard deviation of $21 892.5. This high welf are value indicates a consistent ability to capture economic surpluses across varying demand proles. The structural eciency of CT CE is further evidenced b y its market liquidity; the conguration f acilitated an av erage trading vo lume of 237.9 kWh per step. In contrast, the CTDE paradigm achiev ed an av erage social welf are of $21 209.6, with a signicantly reduced market vo l- ume of 115.9 kWh. This re duction of appro ximately 35% in welf are and ov er 50% in v olume highlights the cost of p artial ob- servability during exe cution. Ev en though agents were trained centrally , the lack of real-time global information forc ed them to adopt more conservativ e bidding strategies to av oid penalties, resulting in a thinner market where only the most protable trades were e xecuted. Surprisingly , the fully decentralized DTDE conguration reported the highest mean Social W elfare of $44 544.9. How- ever, an analysis of the desc riptive statistics rev eals that this performance is highly vo latile and driven by price scarcity rather 30 0 5 10 15 20 T ime Step 0 100 200 300 400 500 Clearing P rice Clearing Price CT CE CTDE DTDE 0 5 10 15 20 T ime Step 0.0 0.2 0.4 0.6 0.8 P2P T rading R atio P2P T rading Ratio CT CE CTDE DTDE 0 5 10 15 20 T ime Step 0.0 0.2 0.4 0.6 0.8 Der Self Consumption Der Self Consumption CT CE CTDE DTDE 0 5 10 15 20 T ime Step 150 100 50 0 50 100 150 200 Grid Balance Grid Balance CT CE CTDE DTDE 0 5 10 15 20 T ime Step 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Coor dination Scor e Coordination Score CT CE CTDE DTDE 0 5 10 15 20 T ime Step 0 20000 40000 60000 80000 Social W elfar e Social W elfare CT CE CTDE DTDE T raining Mode Comparison: Environment Metrics Figure 5: Implicit cooperation KPIs and market dynamics f or the best congurations identied: APPO- CTCE, SA C-CTDE, and APPO-DTDE. than allocativ e eciency . The standard deviation for DTDE w elfare is $36 472.3 (nearly double that of CTCE) and its perfor- mance oor is virtually zero (a minimum of $0.8 vs CTCE’s $108.3). This extreme variance suggests that while DTDE agents can achieve unexpected prots, likely through sc arcity pricing during peak demand periods, they lack the consistency of the centralize d baseline. The high welfare gure is thus an artifact of inated producer surplus rather than a reection of optimal resource distribution. The market clearing price statistics further illuminate the c ost of unc ertainty inherent in decentralized systems. CTCE achieve d the lowest and most stable average market pric e of 110.7 $/kWh, with a standard deviation of $56.1. The maximum price observe d was $175.4, reecting a highly ecient market where supply consistently matches demand at the marginal cost of generation. CTDE maintained a competitive a verage price of 118.8 $/kWh, closely tracking the benchmark. This similarity suggests that the c entralized critic succ essfully taught agents to v alue energy c onsistently with the global optimum, even if they traded less vo lume. Lastly , DTDE exhibited e xtreme price volatility with a mean price was 253.9 $/kWh, more than double the benchmark, with a standard deviation of $174.2 and price spikes reaching 511.8 $/kWh. This price ination ree cts the risk premium of decentralization. Without a central coordinator to guarantee supply availability , decentralize d agents bid more aggressively to ensure that their c ritical energy nee ds are met, driving up the settlement price and imposing higher costs on consumers. 5.2.2 Grid stability: the bias-variance trad e-o While economic metrics measure incentiv es, grid stability metrics measure the ph ysical viability of the solution. The grid bal- ance should remain close to zero, indicating that local generation perfectly matches local demand. A statistical analysis of the temporal evo lution of grid b alance reveals a distinct trade-o betwe en bias (ac curacy of the mean) and variance (stability) across the paradigms. CTCE achieved near-perfect balance with a mean of -4.5 kWh and a moderate standard deviation of ± 57.4 kWh. The range of imbalanc e ([-136.5, 85.0]) is balanc ed around zero , c onrming that with perf ect inf ormation, the system c an eectiv ely 31 maintain the net load at zero with moderate uctuation. CTDE showe d a positive bias (mean of +46.5 kWh) with the highest instability (standard deviation of ± 93.5 kWh) of all p aradigms. The maximum imbalance reached 221.8 kWh (ex cess supply), indicating that agents trained with a central critic but ex ecuting locally struggle to predict the aggregate impact of their peers’ actions at night hours. This leads to overshooting behaviors where multip le agents simultaneously discharge to meet a perceiv ed decit, c ausing a grid surp lus. DTDE exhibited a negativ e bias (mean of -58.0 kWh) but with the lo west standard deviation ( ± 39.1 kWh) of all paradigms. Notably , the maximum grid b alance for DTDE was -0.0 kWh, implying that dec entralized agents learned a strictly import-biased strategy (i.e., they never net-export to the grid). While this results in a persistent decit (relianc e on the DSO), the low variance makes DTDE a highly predictable load for the grid operator. Unlike the erratic oscillations of CTDE, the consistent import bias of D TDE can be easily compensated f or by the DSO . 5.2.3 Resource utilization and autonom y The eciency with which DERs are utilized highlights the operational strategi es learned b y the agents and the degree of auton- om y achiev ed b y the microgrid. The P2P trading ratio measures the community’s autonom y , dene d as the proportion of total energy demand met through local trading versus imports from the DSO . Contrary to the assumption that dec entralization naturally f osters independence, the detaile d statistics show a nuanc ed hierarch y: CTCE achiev ed the highest mean ratio of 0.6, CTDE achieve d a mean ratio of 0.5, and DTDE achieve d the lowest mean ratio of 0.4. This hierarchy aligns with the coordination scores (CTCE 0.9 > DTDE 0.7). Without a global view , DTDE agents miss comp lex matching opportunities, satisfying only 40% of their needs locally and relying on the DSO for the remaining 60%. This corresponds dire ctly with the -58.0 kWh import bias observed in the grid b alance metrics. While DTDE agents prioritize local trading when possible, their limited visibility prev ents them from optimizing the matching process as eectiv ely as the centralize d controller. How ever, during nighttime hours, D TDE achieves high P2P trading ratios, suggesting that they use the energy stored in their batteries to provide these exibility services, which is c onsistent with the high clearing pric es during those same hours. The DER self-consumption eciency mirrors the trade ratios, dropping from 0.6 in CTCE to 0.4 in DTDE. This con- rms that implicit coordination, while eectiv e f or stability , operates at a lo wer eciency than centralized control. Similarly , the mean e xibility utilization was highest in CT CE (23.3%) comp ared to DTDE (9.0%). The c entralized controller actively cy cled batteries, whereas decentralized agents preferred to keep batteries charged f or se curity , utilizing them only when local signals strongly indicated a ne ed. 5.2.4 Emergen t trading relationships: network topo logy anal ysis T o exp lain the divergenc e in P2P ratios and market liquidity , we analyzed the emerging netw ork topologies visualized in Fig 6 . 110.3 kWh 75.1 kWh 189.5 kWh 249.0 kWh 343.5 kWh 0.0 kWh 361.3 kWh 112.3 kWh 481.8 kWh 276.5 kWh 759.6 kWh 306.6 kWh 1013.9 kWh 629.5 kWh 487.0 kWh 315.4 kWh dso apartment_building_006 community_solar_farm_007 hospital_002 industrial_facility_001 parking_lot_generation_facility_008 residential_complex_005 shopping_mall_004 Local Energy Mark et T rading Network Agent T ypes Buyers Sellers (a) CTCE. 187.9 kWh 2.5 kWh 478.9 kWh 113.3 kWh 713.3 kWh 895.7 kWh 390.5 kWh dso industrial_facility_001 university_campus_003 apartment_building_006 parking_lot_generation_facility_008 hospital_002 Local Energy Mark et T rading Network Agent T ypes Buyers Sellers (b) CTDE. 172.0 kWh 159.4 kWh 1051.8 kWh 9.7 kWh 0.0 kWh 506.9 kWh 727.0 kWh 328.4 kWh 67.1 kWh dso residential_complex_005 shopping_mall_004 parking_lot_generation_facility_008 apartment_building_006 hospital_002 Local Energy Mark et T rading Network Agent T ypes Buyers Sellers (c) DTDE. Figure 6: T rading network f or the case study . The blue circles represent buy ers, while the black circles represent sellers. The thickness of the edges indicates the magnitude of the energy ex changed betwe en the agents. The CTCE trading network exhibits a dense, highly connected topology . High-capacity agents, such as the c ommunity sola r Fa rm and s hopping mal l , act as central hubs with thick edges connecting them to virtually every other peer. The global visibility allows the central contro ller to identify and ex ecute long-distance arbitrage opportunities that are ph ysically feasib le but comple x to coordinate. This dense mesh explains the high P2P ratio (0.6) and market liquidity (237.9 kWh). The system ee ctively unlocks the full cap acity of the network. The CTDE network shows a thinning of connections. While the hub agents remain visible, the peripheral connections (P2P trades between smaller agents) are signicantly reduce d comp ared to CTCE. Although trained centrally , the local ex e- 32 cution creates uncertainty . Agents prioritize high-probability trades with major hubs and ignore riskier marginal trades with smaller peers. This structural thinning correlates with the drop in P2P ratio to 0.5. The D TDE network reveals a sparse, fragmented topology . The graph is characterized by distinct community clusters where trading is concentrated among electric al neighbors, with very few long-distanc e links trav ersing the network. This frag- mentation is an emergent response to the congestion penalty stigmergy . Without global visibility to ensure a clear p ath, decen- tralized agents learned to be risk-av erse, trading only with neighbors where the likelihood of c ausing c ongestion is low . This exp lains the counter-intuitiv e combination of high welf are but Low P2P ratio (0.4). Agents are highly protab le in their lo- cal clusters (due to high prices) but f ail to integrate the bro ader grid, leading to a relianc e on the DSO for balancing and the persistent import bias observe d in the grid metrics. 5.3 Scalability test The scalability of MARL is a c ritical factor f or real-world deplo yment in LEMs, where the number of p articipating agents c an vary signicantly . The results from the training time analysis, as illustrated in Fig. 7 , reveal distinct computational proles f or each algorithm-paradigm interse ction as the system scales from 2 to 34 agents. CT CE- APPO CT CE-PPO CT CE-S A C CTDE- APPO CTDE-PPO CTDE-S A C DTDE- APPO DTDE-PPO DTDE-S A C 2 20 34 Number of Agents 56 28 5 36 54 7 52 125 24 89 174 10 128 186 21 153 465 23 159 216 20 153 235 23 149 460 22 T raining T ime Heatmap 100 200 300 400 T ime (min) Scalability T est: T raining T ime Analysis Figure 7: Computational scalability matrix of MARL c ongurations for di erent numbers of agents. 5.3.1 Algorithmic training time prol es The results sho ws that SA C is the most computationally ecient algorithm in terms of wall-clock time to c onv ergence or limit. Across all paradigms, SAC consistently maintains the lowest training times, often by an order of magnitude. For instance, in the DTDE paradigm, SAC remains nearly constant at approximately 22–24 minutes regardless of the agent count. How ever, it is essential to contextualize this speed with the performance collapse previously noted in Section 5.1 ; the rapid training of SA C in DTDE likely reects an early failure to learn rather than ecient optimization. In contrast, in the CTDE p aradigm where SAC is highly eectiv e, it scales from 7 minutes (2 agents) to only 23 minutes (34 agents), demonstrating e xcellent samp le eciency and stability . 33 APPO demonstrates a highly robust and linear sc alability prole. In the DTDE paradigm, APPO’s training time remains remarkably stable, mo ving from 52 minutes with 2 agents to 149 minutes with 34 agents. This supports the claim that APPO is the strictly dominant choic e for scaling de centralized systems, as its as ynchronous nature allows it to proc ess high-throughput data eciently without the exponential time inc reases typically associated with increasing the joint action sp ace. PPO exhibits the poorest scalability , p articularly in the DTDE paradigm. PPO training time balloons from 125 minutes (2 agents) to 460 minutes (34 agents). This signicant computational burden is a direct result of its strictly on-policy nature and clipped objective function, which nec essitates more frequent and slo wer updates to maintain monotonic impro vement, rendering it less suitable f or high-dimensional multi-agent environments. 5.3.2 Impact of training paradigms on eciency The choic e of training p aradigm introduces di erent computational ov erheads. CTCE generally e xhibits higher training times for APPO (159 minutes at 34 agents) compare d to its decentralize d counterp art, likely due to the complexity of optimizing a massive joint state-action sp ace within a single contro ller. The CTDE paradigm serv es as a middle ground betw een APPO and PPO , but remains the optimal point for SA C. Ho w- ever, DTDE paired with APPO oers the best balance of performanc e and scalability . While PPO struggles with the moving target prob lem of DTDE (re quiring 460 minutes to reach the episode limit), APPO’s V -trace correction and asynchronous exp loration allow it to con verge in nearly one-third of that time (149 minutes) while achieving near-optimal social welf are 5.3.3 Summary of computational perf ormance SA C is the primary rec ommendation f or h ybrid (CTDE) setups where rapid iteration and high stability are require d, provided a centralized critic c an be imp lemented to maintain its 99.3% perf ormance retention and stab le learning dynamics. APPO is the most viable candidate for large-scale, fully decentralize d deployment (DTDE), as it maintains consistent training throughput and achiev es paradigm in variance, matching centralize d performanc e even as the number of agents increases. Conv ersely , PPO remains a computationally expensive and conservativ e baseline that, while reliable, may become prohibitively slow and fail to disco ver global optima in markets with a high density of agents. 6 Conclusion and futur e work The transition toward a dec entralized energy grid nec essitates contro l paradigms that can manage the explosion of DERs with- out suc cumbing to the c omputational bottlenecks and privacy conc erns inherent in c entralized dispatch. This article aime d to validate that implicit c ooperation, enabled b y MARL and stigmergic signaling, allows de centralized agents to appro ximate the optimal behavior of a c entral controller without the nee d for exp licit P2P communication. Through a rigorous 3 × 3 f actorial experimental design and a comp lementary scalability test, w e demonstrated that dec en- tralized agents, when provided with appropriate system-level KPIs in their observation space, can achiev e 91.7% of the coordi- nation quality of a theoretical centralized benchmark while scaling linearly with the system size. This nding fundamentally challenges the prevailing assumption that complex grid management requires heavy , centralized communication infrastructure, unlocking a new path way f or privacy-preserving, sc alable LEMs. This research adv ances the state-of-the-art in dec entralized energy management through f our distinct and substantial con- tributions. First, it provides a systematic ev aluation of implicit c ooperation, marking the rst study to isolate and c ompare the ee cts of training paradigms (CTCE, CTDE, D TDE) and MARL algorithms (PPO, APPO, SAC) on the emergence of co- ordination in energy markets. By testing all nine c ongurations under identical ph ysical c onstraints using the realistic IEEE 34-node topology , this w ork has quantie d the c ost of dec entralization in terms of economic welf are and grid b alance. Sec ond, the study o ers a theoretical validation of stigmergy in LEMs, f ormalizing a c oordination me chanism where global system states are compressed into sc alar KPI signals and broadcast to local agents. These results prove that an augmented observation sp ace is sucient for agents to reconstruct the nec essary global context to make cooperativ e decisions, ee ctively solving the partial observability prob lem without direct communic ation or model sharing. Third, through benchmarking and scalability analysis, a performanc e matrix was generated to balance optimality with feasibility . APPO-D TDE was identied as the best congura- tion f or scalability , matching the centralize d benchmark’s reward con vergenc e (achieving 3243.5 comp ared to the benchmark’s 3272.1) while maintaining robust performanc e. Finally , this research estab lishes operational design guidelines f or real-world implementation, distinguishing betwe en distributive eciency and netw ork predictability , in order to oer network operators a range of architectural options b ased on specic priorities of stability versus ecienc y . 34 The e xperimental camp aign pro vided information that has changed our understanding of how MARL can be applied to cyber-ph ysical energy systems. As e xpected, CTCE established the performance ceiling. It achiev ed the highest P2P trad- ing ratios (0.6) and near-perfe ct grid balance (mean of -4.5 kWh). How ever, its super-linear computational scaling renders it unsuitable f or large-sc ale, real-time control. While CTDE is often the standard f or multi-agent systems, our results rev eal that while it retained ec onomic eciency , it exhibited the highest p hysic al instability (grid balanc e standard deviation of ± 93.5 kWh). Agents trained with a c entral critic but e xecuting locally struggled to predict the aggregate actions of their peers, leading to dangerous oscillation and overshooting behaviors. On the contrary , fully decentralized learning did not result in a co llapse of coordination. With the APPO algorithm, the performanc e gap to the centralized benchmark was 8.3%. Crucially , D TDE exhibited the lowest varianc e in grid b alance ( ± 39.1 kWh). While it operated with a persistent import bias (mean of -58.0 kWh), this grid balanc e makes it a highly predictable and saf e load prole for the DSO . In terms of algorithmic suitability , APPO emerged as the strictly dominant algorithm f or dec entralized environments. Its V -trace correction mechanism allow ed it to robustly handle the non-stationarity of independent learners, enabling it to c onverge to c ooperative equilibria that standard PPO missed. While SA C f ailed in fully de centralized settings due to entropy-driv en instability (gap of 73.7%), it ex celled in the CTDE paradigm. The centralized critic ee ctively channeled SAC’s exploration, resulting in the most stab le and sample-ecient policies for managed microgrids. PPO pro vided a saf e but suboptimal b aseline. It avoide d failure but consistently underperformed in terms of total social welf are and required exc essive computational time in dec entralized settings (over 460 minutes f or 34 agents). The study conrms that coordination is an emergent property of the reward structure. By incorporating a cooperation factor into the reward function, agents naturally learned complementary strategies purely to maximize their long-term e xpected returns. The trading network analysis revealed that this resulte d in spatial clustering, where agents preferentially traded with electrical neighbors to minimize c ongestion penalties, ee ctively self-organizing the grid into stable nanogrids without exp licit topologic al maps. Implicit cooperation improv es DER management b y dec oupling the comple xity of de cision-making from the c omplexity of communic ation. It enab les agents to autonomously resolv e the conict betwe en individual prot maximization and co llec- tive grid stability , as simulation results sho wed that Dec entralized agents sacrice d short-term arbitrage opportunities when the network equilibrium signal indicated critical stress. Through emergent P2P trading, the system achieved local self-c onsumption rates of up to 62% in c entralized congurations and maintained a robust 36.6% in fully decentralized setups, signicantly re- ducing relianc e on the external transmission grid c ompared to non-cooperativ e baselines. Furthermore, the s ystem maintained the net grid b alance within tight bounds purely through dec entralized reactions to pric e and balanc e signals; specically , the dec entralized approach (DTDE) achieve d the most stable ph ysical prole, minimizing the variance of grid injections and thus reducing the regulation burden on the DSO. These benets were achieved without exp licit c ommunication, v alidating that stigmergic signaling is a sucient coordination me chanism for pow er systems. The ndings ha ve relevant implications f or the design, polic y , and deplo yment of future energy s ystems. LEMs operators do not nee d to in vest in expensiv e, high-b andwidth P2P communication netw orks. A reliable broadc ast channel that publishes system-lev el KPIs is sucient to induc e optimal beha vior. The inationary welf are observ ed in DTDE suggests that sc arcity prices are a feature that acts as a signal to curtail demand during periods of stress. Regulators should incentivize the inclusion of a c ooperation f actor in automate d trading agents. T aris and settlement mechanisms should be structure d not just on v olume, but on the correlation of an asset’s beha vior with the grid’s needs. In terms of implementation recommendations, it is suggested to use APPO-DTDE f or competitiv e markets where scala- bility and privacy are priorities. It oers maximum privac y , linear scalability , and ph ysical stability , although it sacric es some distributive eciency . Conversely , SA C-CTDE is recommended for cooperativ e mic rogrids where eciency is a priority . It maximizes economic eciency and better manages comp lex arbitrage strategies (higher P2P ratio), provided that c entralized oine training is feasib le and the network can to lerate greater variance. While this study establishes a rigorous basis f or implicit cooperation, there are sev eral av enues that merit further study to bridge the gap betwe en this cooperation and its large-scale implementation. One primary direction inv olv es expanding the simulation from the current 8-34 agent scale to 100+ agents with highly stochastic user proles to test the limits of stigmergic signal saturation. Additionally , it is necessary to research the impact of signal latency , p acket loss, or adv erse signal injection on the stability of c ooperative equilibrium, with future w ork aimed at quantifying the c ritical latenc y threshold bey ond which implicit coordination co llapses. Finally , validating the simulation results using hardware-in-the-loop setups is crucial to assess how implicit c ooperation handles the ph ysics of v oltage support and frequency dynamics, which were abstracted in the current pow er ow model. 35 Ref erences [1] F. Charbonnier, T . Morstyn, M. D. M cCulloch, Scalab le multi-agent reinforc ement learning for distributed c ontrol of residential energy exibility , Applied Energy 314 (2022) 118825. doi:10.1016/j.apenergy.2022.118825 . [2] A. Aoun, M. Adda, A. Ilinca, M. Ghandour, H. Ibrahim, Centralized vs. Decentralize d Ele ctric Grid Resilience Analysis Using Leontief’s Input–Output M odel, Energies 17 (6) (2024) 1321. doi:10.3390/en17061321 . [3] J. Guerrero, A. C. Chapman, G. V erbic, Decentralize d P2P Energy T rading Under Network Constraints in a Low- V oltage Netw ork, IEEE T ransactions on Smart Grid 10 (5) (2019) 5163–5173. doi:10.1109/TSG.2018.2878445 . [4] R. May , P . Huang, A multi-agent reinforcement learning appro ach f or in vestigating and optimising pe er-to-peer pro- sumer energy markets, Applied Energy 334 (2023) 120705. doi:10.1016/j.apenergy.2023.120705 . [5] P . W ilk, N. W ang, J. Li, Multi-Agent Reinf orcement Learning for Smart Community Energy Management, Energies 17 (20) (2024) 5211. doi:10.3390/en17205211 . [6] M. A. Hady , S. Hu, M. Pratama, Z. Cao, R. Kowalc zyk, Multi-agent reinf orcement learning for resources allocation optimization: A survey , Articial Intelligence Review 58 (11) (2025) 354. doi:10.1007/s10462- 025- 11340- 5 . [7] J. Liang, H. Miao, K. Li, J. T an, X. W ang, R. Luo, Y . Jiang, A Review of Multi-Agent Reinforcement Learning Algo- rithms, Electronics 14 (4) (2025) 820. doi:10.3390/electronics14040820 . [8] D . J. Moore, A T ax onomy of Hierarchical Multi-Agent Systems: Design P atterns, Coordination Mechanisms, and In- dustrial Applic ations (Aug. 2025). , doi:10.48550/arXiv.2508.12683 . [9] N. Salazar-P eña, A. T abares, A. González-M ancera, M arlem: A multi-agent reinforc ement learning simulation frame- work for imp licit cooperation in de centralized loc al energy markets, SSRN (Nov . 2025). doi:http://dx.doi.org/ 10.2139/ssrn.5705203 . [10] Z. Guo, B. Qin, Z. Guan, Y . W ang, H. Zheng, Q . Wu, A High-Ecienc y and Incentiv e-Compatible P eer-to-P eer Energy T rading Mechanism, IEEE T ransactions on Smart Grid 15 (1) (2024) 1075–1088. doi:10.1109/TSG.2023.3266809 . [11] N. T . Mbungu, R. M. Naidoo , R. C. Bansal, V . V ahidinasab , Overview of the Optimal Smart Energy Coordination f or Microgrid App lications, IEEE Access 7 (2019) 163063–163084. doi:10.1109/ACCESS.2019.2951459 . [12] H. Nshuti, Centralized and Dec entralize Control of Microgrids. [13] F. Charbonnier, T . Morstyn, M. D . McCulloch, Coordination of resourc es at the edge of the ele ctricity grid: Systematic review and taxonom y , Applied Energy 318 (2022) 119188. doi:10.1016/j.apenergy.2022.119188 . [14] A. G. Givisiez, K. Petrou, L. F. Ochoa, A Review on TSO-DSO Coordination Models and Solution T echniques, Electric P ow er Systems Research 189 (2020) 106659. doi:10.1016/j.epsr.2020.106659 . [15] M. Shae-khah, A. S. Ga zafroudi (Eds.), T rading in Loc al Energy Markets and Energy Communities: Concepts, Struc- tures and T echnologies, V ol. 93 of Lecture Notes in Energy , Springer International Publishing, Cham, 2023. doi: 10.1007/978- 3- 031- 21402- 8 . [16] S. Anand, Stable and Sc alable Day-Ahead Clearing Prices f or Electricity Markets. [17] I. Azim, N. Al Khafaf, M. Khorasany , R. Razzaghi, M. Jalili, W p2.7 and 2.8 techno-ec onomic modelling (existing and future): T ask 1: Literature review , T echnic al report, Centre for New Energy T echno logies (C4NET), monash Univ ersity and RMIT University (F ebruary 2024). [18] P . Raghoo, K. Shah, Bridging theory and practice in peer-to-peer energy trading: Market mechanisms and techno- logical innovations, En vironmental Research: Infrastructure and Sustainability 5 (1) (2025) 012001. doi:10.1088/ 2634- 4505/adac8a . [19] A. Kantamneni, L. E. Brown, G. P arker, W . W . W eav er, Survey of multi-agent systems f or microgrid control, Engineering Applic ations of Articial Intelligence 45 (2015) 192–203. doi:10.1016/j.engappai.2015.07.005 . [20] T . Alazemi, M. Darwish, M. Radi, TSO/DSO Coordination for RES Integration: A Systematic Literature Review, Energies 15 (19) (2022) 7312. doi:10.3390/en15197312 . [21] S. Zheng, Y . Zhou, Chapter 8 - peer-to-peer energy trading with advanc ed pricing and decision-making mechanisms , in: Y . Zhou, J. Y ang, G. Zhang, P . D. Lund (Eds.), Advances in Digitalization and Machine Learning for Inte- grated Building- T ransportation Energy Systems, Elsevier, 2024, pp. 133–158. doi:https://doi.org/10.1016/ B978- 0- 443- 13177- 6.00013- 8 . URL https://www.sciencedirect.com/science/article/pii/B9780443131776000138 36 [22] A. P apav asiliou, H. Hindi, D. Greene, M arket-based contro l mechanisms for ele ctric pow er demand response, in: 49th IEEE Conferenc e on Decision and Contro l (CDC), IEEE, Atlanta, GA, USA, 2010, pp. 1891–1898. doi:10.1109/ CDC.2010.5717572 . [23] B. Satchidanandan, M. Roo zbehani, M. A. Dahleh, A T wo-Stage M echanism for Demand Response M arkets, IEEE Control Systems Letters 7 (2023) 49–54. doi:10.1109/LCSYS.2022.3186654 . [24] S. Khaskheli, A. An vari-Moghaddam, Energy T rading in Local Energy M arkets: A Comprehensiv e Review of Mod- els, Solution Strategies, and Machine Learning Approaches, Applied Scienc es 14 (24) (2024) 11510. doi:10.3390/ app142411510 . [25] Q . Huang, W . Amin, K. Umer, H. B. Gooi, F. Y . S. Eddy , M. Afzal, M. Shahzadi, A. A. Khan, S. A. Ahmad, A review of transactive energy systems: Concept and implementation, Energy Reports 7 (2021) 7804–7824. doi:10.1016/j. egyr.2021.05.037 . [26] H. Zhou, B. Li, X. Zong, D. Chen, T ransactiv e energy system: Concept, conguration, and mechanism, Frontiers in Energy Research 10 (2023) 1057106. doi:10.3389/fenrg.2022.1057106 . [27] N. W ang, Z. Liu, P . Heijnen, M. W arnier, A peer-to-peer market mechanism incorporating multi-energy coup ling and cooperativ e behaviors, Applie d Energy 311 (2022) 118572. doi:10.1016/j.apenergy.2022.118572 . [28] E. Anderson, T . Cau, Implicit c ollusion and individual market po wer in electricity markets, European Journal of Oper- ational Research 211 (2) (2011) 403–414. doi:10.1016/j.ejor.2010.12.016 . [29] S. Frey , A. Diaconescu, D. Menga, I. Demeure, A Generic Ho lonic Control Architecture f or Heterogeneous Multiscale and Multiobjectiv e Smart Microgrids, A CM T ransactions on Autonomous and Adaptiv e Systems 10 (2) (2015) 1–21. doi:10.1145/2700326 . [30] R. Schubotz, T . Spieldenner, M. Chelli, stigld: Stigmergic coordination in linked systems , Mathematics 10 (7) (2022). doi:10.3390/math10071041 . URL https://www.mdpi.com/2227- 7390/10/7/1041 [31] R. De Nico la, L. Di Stef ano, O . In verso , Multi-agent systems with virtual stigmergy , Science of Computer Programming 187 (2020) 102345. doi:10.1016/j.scico.2019.102345 . [32] W . Deng, J. Xu, H. Zhao , An Improve d Ant Colon y Optimization Algorithm Based on Hybrid Strategies for Scheduling Problem, IEEE Ac cess 7 (2019) 20281–20292. doi:10.1109/ACCESS.2019.2897580 . [33] C. Ziras, Integration of distributed energy resources on distribution and transmission s ystems, Phd thesis, T echnical University of Denmark (2019). [34] J. Sauter, R. Matthews, H. P arunak, S. Brueckner, Demonstration of Digital Pheromone Swarming Control of Multi- ple Unmanne d Air V ehicles, in: Infotech@Aerosp ace, American Institute of Aeronautics and Astronautics, Arlington, Virginia, 2005. doi:10.2514/6.2005- 7046 . [35] D . Roca, D . Nemiro vsky , M. Nemirovsky , R. Milito, M. V alero, Emergent Behaviors in the Internet of Things: The Ultimate Ultra-Large-Scale System, IEEE Mic ro 36 (6) (2016) 36–44. doi:10.1109/MM.2016.102 . [36] C. Binder, J.-A. Gross, C. Neureiter, G. Lastro, Investigating Emergent Behavior cause d b y Electric V ehicles in the Smart Grid using Co-Simulation, in: 2019 14th Annual Conferenc e System of Systems Engineering (SoSE), IEEE, Anchorage, AK, USA, 2019, pp. 230–235. doi:10.1109/SYSOSE.2019.8753861 . [37] M. Debe, H. R. Hasan, K. Salah, I. Y aqoob, R. Jay araman, Blockchain-Based Energy T rading in Electric V ehicles Us- ing an Auctioning and Reputation Scheme, IEEE Access 9 (2021) 165542–165556. doi:10.1109/ACCESS.2021. 3133958 . [38] R. V erborgh, A. Dimou, A. Hogan, C. d’ Amato, I. Tiddi, A. Bröring, S. May er, F. Ongenae, R. T ommasini, M. Alam (Eds.), The Semantic W eb: ESW C 2021 Satellite Ev ents: Virtual E vent, June 6–10, 2021, Revised Selected P apers, V ol. 12739 of Le cture Notes in Computer Scienc e, Springer International Publishing, Cham, 2021. doi:10.1007/ 978- 3- 030- 80418- 3 . [39] F. Lezama, J. Soares, P . Hernandez-Leal, M. Kaisers, T . Pinto, Z. V ale, Local Energy Markets: P aving the P ath T ow ard Fully T ransactive Energy Systems, IEEE T ransactions on P ow er Systems 34 (5) (2019) 4081–4088. doi:10.1109/ TPWRS.2018.2833959 . [40] G. T saousoglou, J. S. Giraldo, N. G. Paterakis, Market Me chanisms for Local Electricity Markets: A review of models, solution c oncepts and algorithmic techniques, Renewab le and Sustainable Energy Reviews 156 (2022) 111890. doi: 10.1016/j.rser.2021.111890 . 37 [41] A. P audel, K. Chaudhari, C. Long, H. B. Gooi, P eer-to-P eer Energy T rading in a Prosumer-Based Community Mi- crogrid: A Game- Theoretic Model, IEEE T ransactions on Industrial Electronics 66 (8) (2019) 6087–6097. doi: 10.1109/TIE.2018.2874578 . [42] S. T alari, M. Khorasan y , R. Razzaghi, W . Ketter, A. S. Gazafroudi, Mechanism design for dec entralized peer-to-peer energy trading considering heterogeneous preferences, Sustainable Cities and Society 87 (2022) 104182. doi:10.1016/ j.scs.2022.104182 . [43] S. D. Ramchurn, D. Huynh, N. R. Jennings, T rust in multi-agent systems, The Knowledge Engineering Review 19 (1) (2004) 1–25. doi:10.1017/S0269888904000116 . [44] Y . W ang, J. V assileva, T rust and reputation model in peer-to-peer networks, in: Procee dings Third International Con- ferenc e on P eer-to-P eer Computing (P2P2003), IEEE Comput. Soc, Linkoping, Sweden, 2003, pp. 150–157. doi: 10.1109/PTP.2003.1231515 . [45] J. M. Pujol, R. Sangesa, J. Delgado, Extracting reputation in multi agent systems by means of social network topology , in: Proce edings of the First International Joint Conferenc e on Autonomous Agents and Multiagent Systems, AAMAS ’02, A CM, Bologna, Italy , 2002, pp. 467–474. doi:10.1145/544741.544854 . [46] V . J. Nair, P . Srivastav a, V . V enkataramanan, P . S. Sarker, A. Srivastav a, L. D. Marinovici, J. Zha, C. Irwin, P . Mit- tal, J. Williams, J. Kumar, H. V . Poor, A. M. Annaswam y , Resilience of the electric grid through trustable IoT - coordinate d assets, Procee dings of the National Academ y of Scienc es 122 (8) (2025) e2413967121. doi:10.1073/pnas. 2413967121 . [47] C. Y ap a, C. De Alwis, M. Liyanage, J. Ekanayake, Utilization of a b lockchainized reputation management service f or per- formanc e enhanc ement of Smart Grid 2.0 app lications, Journal of Industrial Inf ormation Integration 39 (2024) 100580. doi:10.1016/j.jii.2024.100580 . [48] L. Sang, H. Hexmoor, Reputation-Based Consensus for Blockchain T echno logy in Smart Grid, International Journal of Network Se curity & Its Applications 14 (4) (2022) 15–37. doi:10.5121/ijnsa.2022.14402 . [49] C. Y apa, C. De Alwis, U. Wijewardhana, M. Liyanage, Utilization of a Blockchain-Based Reputation Management System for Energy T rading in Smart Grid 2.0, in: 2023 IEEE Latin-American Conference on Communications (LA T - INCOM), IEEE, P anama City , P anama, 2023, pp. 1–6. doi:10.1109/LATINCOM59467.2023.10361893 . [50] G. Jøsang, Challenges for Robust T rust and Reputation Systems. [51] A. Raza, E. Badidi, M. Hayajneh, E. Barka, O. E. Harrouss, Blockchain-Based Reputation and T rust Management for Smart Grids, Healthcare, and T ransportation: A Review , IEEE Acc ess 12 (2024) 196887–196913. doi:10.1109/ ACCESS.2024.3521428 . [52] M. Sanayha, P . V ateekul, M odel-Based Approach on Multi-Agent Deep Reinforcement Learning W ith Multiple Clus- ters f or P eer- T o-P eer Energy T rading, IEEE Access 10 (2022) 127882–127893. doi:10.1109/ACCESS.2022.3224460 . [53] S. Keren, C. Essay eh, S. V . Albrecht, T . M ortsyn, Multi-Agent Reinforc ement Learning f or Energy Netw orks: Compu- tational Challenges, Progress and Open Problems. [54] D . Li, N. Lou, Z. Xu, B. Zhang, G. F an, Ecient Communication in Multi-Agent Reinforcement Learning with Im- plicit Consensus Generation. [55] C. Amato, An Initial Introduction to Cooperative Multi-Agent Reinforc ement Learning (May 2025). arXiv:2405. 06161 , doi:10.48550/arXiv.2405.06161 . [56] R. Low e, Y . Wu, A. T amar, J. Harb, P . Abbeel, I. Mordatch, Multi-Agent Actor-Critic for Mixed Cooperative- Competitive En vironments (Mar. 2020). , doi:10.48550/arXiv.1706.02275 . [57] J. Schulman, F. W olski, P . Dhariw al, A. Radf ord, O. Klimov , Proximal P olicy Optimization Algorithms (Aug. 2017). arXiv:1707.06347 , doi:10.48550/arXiv.1707.06347 . [58] S. Ahilan, P . Da yan, Feudal Multi-Agent Hierarchies for Cooperativ e Reinf orcement Learning (Jan. 2019). arXiv: 1901.08492 , doi:10.48550/arXiv.1901.08492 . [59] G. W en, J. Fu, P . Dai, J. Zhou, D TDE: A new c ooperative multi-agent reinforc ement learning framework, The Innova- tion 2 (4) (2021) 100162. doi:10.1016/j.xinn.2021.100162 . [60] M. Lauri, J. P ajarinen, J. P eters, Multi-agent activ e inf ormation gathering in discrete and c ontinuous-state dec entralized POMDPs by polic y grap h impro vement, Autonomous Agents and Multi-Agent Systems 34 (2) (2020) 42. doi:10. 1007/s10458- 020- 09467- 6 . 38 [61] C. Amato , G. Chow dhary , A. Geramifard, N. K. Ure, M. J. Kochenderf er, Dec entralized c ontrol of partially observable Marko v decision processes, in: 52nd IEEE Conference on Decision and Control, IEEE, Firenze, 2013, pp. 2398–2405. doi:10.1109/CDC.2013.6760239 . [62] C. Lou, Z. Jin, W . T ang, G. Geng, J. Y ang, L. Zhang, LLM-Enhanc ed Multi-Agent Reinf orcement Learning with Expert W orkow f or Real- Time P2P Energy T rading (Nov . 2025). , doi:10.48550/arXiv.2507. 14995 . [63] D . Wu, D. Kalathil, M. Begovic, L. Xie, Deep Reinforcement Learning-BasedRobust Protection in DER-Rich Distri- bution Grids (Jun. 2021). , doi:10.48550/arXiv.2003.02422 . [64] D . Zhu, B. Y ang, Y . Liu, Z. W ang, K. Ma, X. Guan, Energy Management Based on Multi-Agent Deep Reinforcement Learning for A Multi-Energy Industrial P ark, App lied Energy 311 (2022) 118636. , doi:10.1016/ j.apenergy.2022.118636 . [65] S. Stein, A. Chapman, Y . Du, B. Kooh y , V . Y azdanpanah, P . Y o lum, Proce edings of the Sec ond International W orkshop on Citizen-Centric Multiagent Systems 2024 (C-MAS 2024) (2024). doi:10.6084/M9.FIGSHARE.25743057.V1 . [66] T . Phan, Emergence and Resilience in Multi-Agent Reinf orcement Learning. [67] P . Mannion, S. Devlin, J. Duggan, E. Howley , Reward shaping for knowledge-b ased multi-objective multi-agent rein- forc ement learning, The Knowledge Engineering Review 33 (2018) e23. doi:10.1017/S0269888918000292 . [68] S. Li, J. K. Gupta, P . M orales, R. Allen, M. J. Kochenderf er, Deep Imp licit Coordination Graphs for Multi-agent Rein- forc ement Learning (Feb . 2021). , doi:10.48550/arXiv.2006.11438 . [69] H. W ang, B. Chen, T . Zhang, B. W ang, Learning to Communicate Through Implicit Communication Channels (F eb. 2025). , doi:10.48550/arXiv.2411.01553 . [70] C. F eng, DECENTR ALIZED INTEGR A TION OF DISTRIBUTED ENERGY RESOURCES INTO ENERGY MARKETS WITH PHYSICAL CONSTR AINTS. [71] T . W olgast, A. Nieße, Appro ximating Energy Market Clearing and Bidding With Model-Based Reinforc ement Learn- ing, IEEE Acc ess 12 (2024) 145106–145117. doi:10.1109/ACCESS.2024.3472480 . [72] H. Zhang, M. Montazeri, P . Heer, K. Kok, N. G. Paterakis, Arbitrage T actics in the Local M arkets via Hierarchical Multi-agent Reinforc ement Learning (Jul. 2025). , doi:10.48550/arXiv.2507.16479 . [73] J. Lu, Z. Xie, H. Xu, J. Liu, Optimizing Joint Bidding and Incentivizing Strategy for Price-M aker Lo ad Aggregators Based on Multi- T ask Multi-Agent Deep Reinf orcement Learning, IEEE Acc ess 12 (2024) 163988–164001. doi:10. 1109/ACCESS.2024.3491189 . [74] L. Qiu, Multi-Agent Reinforcement Learning f or Coordinated Smart rid and Building Energy Management Ac ross Urban Communities. [75] K. Guo, N. E ckhert, K. Chhajer, L. Abeykoon, L. Schell, AutoGrid AI: Deep Reinf orcement Learning Framework f or Autonomous Microgrid M anagement (Sep. 2025). , doi:10.48550/arXiv.2509.03666 . [76] Z. Feng, J. An, M. Han, X. Ji, X. Zhang, C. W ang, X. Liu, L. Kang, Oce building energy consumption fore cast: Adap- tive long short term memory networks driven by improve d beluga whale optimization algorithm, Journal of Building Engineering 91 (2024) 109612. doi:10.1016/j.jobe.2024.109612 . [77] J. Li, M. Motoki, B. Zhang, Strategic and Fair Aggregator Interactions in Energy Markets: Mutli-agent Dynamics and Quasiconc ave Games (Oct. 2024). , doi:10.48550/arXiv.2410.11296 . [78] E. Eusébio, J. A. M. Sousa, M. V entim Neves, Impacts of Energy Market Prices V ariation in Aggregator’s P ortfo lio, in: L. M. Camarinha-Matos, A. J. Falcão , N. V af aei, S. Najdi (E ds.), T echnologic al Innovation f or Cyber-Ph ysical Systems, V ol. 470, Springer International Pub lishing, Cham, 2016, pp. 437–445. doi:10.1007/978- 3- 319- 31165- 4_41 . [79] A. Bash yal, T . Boroukhian, P . V eerachanchai, M. Naransukh, H. Wicaksono , Multi-agent deep reinforc ement learning base d demand response and energy management for hea vy industries with discrete manuf acturing systems, Applied Energy 392 (2025) 125990. doi:10.1016/j.apenergy.2025.125990 . [80] Y . Gao, X. Yuan, S. W ang, L. Chen, Z. Zhang, T . W ang, Flash-Attention-Enhanced Multi-Agent Deep Deterministic P olicy Gradient for Mobile Edge Computing in Digital T win-P owered Internet of Things, Mathematics 13 (13) (2025) 2164. doi:10.3390/math13132164 . 39 [81] J. Källström, Reinf orcement Learning f or Improv ed Utility of Simulation-Based T raining, V o l. 2351 of Linköping Studies in Scienc e and T echnology. Dissertations, Linköping Univ ersity Electronic Press, Linköping, 2023. doi:10.3384/ 9789180753678 . [82] C. Mylonas, E. V arvarigos, G. T saousoglou, Safe Bottom-Up Flexibility Provision from Distributed Energy Resources (Apr. 2025). , doi:10.48550/arXiv.2504.20529 . [83] D . Zhu, B. Y ang, Y . Liu, Z. W ang, K. Ma, X. Guan, Energy Management Based on Multi-Agent Deep Reinforcement Learning for A Multi-Energy Industrial P ark, App lied Energy 311 (2022) 118636. , doi:10.1016/ j.apenergy.2022.118636 . [84] D . D. Sharma, R. C. Bansal, Department of Electrical Engine ering, MJP Rohilkhnad University , Bareilly, Electrical Engineering Department, University of Sharjah, Sharjah, United Arab Emirates, Department of Electrical, Electron- ics & Computer Engineering, University of Pretoria, Pretoria, South Africa, LSTM-SAC reinforc ement learning base d resilient energy trading f or networke d microgrid system, AIMS Electronics and Electric al Engineering 9 (2) (2025) 165–191. doi:10.3934/electreng.2025009 . [85] N. Azizan Ruhi, K. Dvijotham, N. Chen, A. Wierman, Opportunities for Price Manipulation by Aggregators in Elec- tricity Markets, IEEE T ransactions on Smart Grid 9 (6) (2018) 5687–5698. doi:10.1109/TSG.2017.2694043 . [86] F. Charbonnier, B. P eng, J. Vienne, E. Stai, T . Morstyn, M. McCulloch, Centralised rehearsal of decentralise d cooper- ation: Multi-agent reinf orcement learning for the sc alable coordination of residential energy exibility , Applied Energy 377 (2025) 124406. doi:10.1016/j.apenergy.2024.124406 . [87] D . Qiu, J. W ang, Z. Dong, Y . W ang, G. Strbac, Mean-Field Multi-Agent Reinforcement Learning for P eer-to-P eer Multi-Energy T rading, IEEE T ransactions on P ow er Systems 38 (5) (2023) 4853–4866. doi:10.1109/TPWRS.2022. 3217922 . [88] L. V elvis, Hybrid Multi-Agent Reinf orcement Learning for Lo w-Carbon Dispatch in Renewable Energy V alleys. [89] T . Qi, S. Chen, J. Zhang, A Generativ e Model Enhanced Multi-Agent Reinforc ement Learning M ethod f or Electric V ehicle Charging Navigation. [90] M.-Q . Dao, J. S. Berrio , V . Frémont, M. Shan, E. Héry , S. W orrall, Practical Collaborativ e P erception: A Framework for Asynchronous and Multi-Agent 3D Object Detection, IEEE T ransactions on Intelligent T ransportation Systems 25 (9) (2024) 12163–12175. doi:10.1109/TITS.2024.3371177 . [91] D . Muyizere, L. K. Letting, B. B. Mun ya zikwiye, E ects of Communic ation Signal Delay on the P ower Grid: A Review, Electronics 11 (6) (2022) 874. doi:10.3390/electronics11060874 . [92] T . Ikeda, T . Shibuya, Centralized T raining with Decentralized Execution Reinforcement Learning for Cooperative Multi-agent Systems with Communication Delay , in: 2022 61st Annual Conferenc e of the Society of Instrument and Control Engineers (SICE), IEEE, Kumamoto, Jap an, 2022, pp. 135–140. doi:10.23919/SICE56594.2022. 9905866 . [93] H. Y ang, J. Chen, M. Siew , T . Lorido-Botran, C. Joe- W ong, LLM-P ow ered Decentralize d Generativ e Agents with Adap- tive Hierarchical Kno wledge Graph for Cooperative Planning (Feb . 2025). , doi:10.48550/ arXiv.2502.05453 . [94] D . Hu, Z. Li, Z. Y e, Y . P eng, W . Xi, T . Cai, Multi-agent graph reinforcement learning f or dec entralized V olt- V AR c ontrol in pow er distribution systems, International Journal of Electrical P ow er & Energy Systems 155 (2024) 109531. doi: 10.1016/j.ijepes.2023.109531 . [95] M. H. Rothkopf, Thirteen Reasons Wh y the Vickrey-Clarke-Grov es Process Is Not Practical, Operations Research 55 (2) (2007) 191–197. doi:10.1287/opre.1070.0384 . [96] D . Qiu, Y . Y e, D . P apadaskalopoulos, G. Strb ac, Scalable coordinated management of peer-to-peer energy trading: A multi-cluster deep reinforc ement learning approach, Applied Energy 292 (2021) 116940. doi:10.1016/j.apenergy. 2021.116940 . [97] R. Musca, E. Riva Sanseverino, P eer-to-P eer Distributed Algorithms for Wide-Area Monitoring and Control in P ower Systems, Energies 18 (15) (2025) 3972. doi:10.3390/en18153972 . [98] S. Gronauer, K. Diepold, Multi-agent deep reinf orcement learning: A surv ey , Articial Intelligence Review 55 (2) (2022) 895–943. doi:10.1007/s10462- 021- 09996- w . 40 [99] E. Y e, R. T ao, N. Jaques, An Ecient Open W orld En vironment f or Multi-Agent Social Learning (Aug. 2025). arXiv: 2508.15679 , doi:10.48550/arXiv.2508.15679 . [100] R. Donatus, K. T er, O.-O . Ajayi, D . Udekwe, Multi-Agent Reinforc ement Learning in Intelligent T ransportation Sys- tems: A Comprehensive Surv ey (Aug. 2025). , doi:10.48550/arXiv.2508.20315 . [101] P . Y adav , A. Mishra, S. Kim, A Comprehensive Survey on Multi-Agent Reinf orcement Learning for Conne cted and Automated V ehicles, Sensors 23 (10) (2023) 4710. doi:10.3390/s23104710 . [102] V . Dvorkin, J. Kazempour, L. Baringo , P . Pinson, A Consensus-ADMM Approach f or Strategic Generation Inv estment in Electricity M arkets (Oct. 2018). , doi:10.48550/arXiv.1711.04620 . [103] R. H. Wuijts, M. van den Akker, M. van den Broek, New ecient ADMM algorithm f or the Unit Commitment Prob- lem (Nov . 2023). , doi:10.48550/arXiv.2311.13438 . [104] T . Gao , S. W ang, X. Geng, L. Zhang, M. Jing, T . Yu, J. Yu, A Stackelberg Game Pricing for Blockchain-Based Industrial Internet of Things Data M arket, in: 2025 28th International Conferenc e on Computer Supported Cooperative W ork in Design (CSCWD), IEEE, Compiegne, France, 2025, pp . 1776–1781. doi:10.1109/CSCWD64889.2025.11033563 . [105] L. Cheng, P . Huang, M. Zhang, R. Y ang, Y . W ang, Optimizing Electricity Markets Through Game- Theoretical Methods: Strategic and P olic y Imp lications for P ower Purchasing and Generation Enterprises, M athematics 13 (3) (2025) 373. doi: 10.3390/math13030373 . [106] J. Guerrero, D. Gebbran, S. Mhanna, A. C. Chapman, G. V erbič, T owards a transactive energy system for integration of distributed energy resources: Home energy management, distributed optimal power ow , and peer-to-peer energy trading, Renewab le and Sustainable Energy Reviews 132 (2020) 110000. doi:10.1016/j.rser.2020.110000 . [107] A. Baringo, L. Baringo , J. M. Arroy o, Da y-Ahead Self-Scheduling of a Virtual P ower Plant in Energy and Reserv e Elec- tricity Markets Under Uncertainty , IEEE T ransactions on P ower Systems 34 (3) (2019) 1881–1894. doi:10.1109/ TPWRS.2018.2883753 . [108] C. Ghenai, L. A. Husein, M. Al Nahlawi, A. K. Hamid, M. Bettayeb , Recent trends of digital twin technologies in the energy sector: A comprehensiv e review , Sustainable Energy T echno logies and Assessments 54 (2022) 102837. doi: 10.1016/j.seta.2022.102837 . [109] J. Guerrero, B. Sok, A. C. Chapman, G. V erbič, Electrical-distanc e driven peer-to-peer energy trading in a low-vo ltage network, App lied Energy 287 (2021) 116598. doi:10.1016/j.apenergy.2021.116598 . [110] N. Harder, R. Qussous, A. W eidlich, Fit f or purpose: Modeling wholesale electricity markets realistic ally with multi- agent deep reinf orcement learning, Energy and AI 14 (2023) 100295. doi:10.1016/j.egyai.2023.100295 . [111] N. Harder, A. W eidlich, P . Staudt, Finding individual strategies f or storage units in ele ctricity market models using deep reinforc ement learning, Energy Informatics 6 (S1) (2023) 41. doi:10.1186/s42162- 023- 00293- 0 . [112] A. Rizki, A. T ouil, A. Echchatbi, R. Oucheikh, M. Ahlaqqach, A Reinforc ement Learning-Based Proximal P ol- icy Optimization Approach to Solve the Ec onomic Dispatch Problem, in: The 1st International Conferenc e on Smart Management in Industrial and Logistics Engineering (SMILE 2025), MDPI, 2025, p . 24. doi:10.3390/ engproc2025097024 . [113] M. Alonso, H. Amaris, D. Martin, A. de la Esc alera, Pro ximal po licy optimization f or energy management of ele ctric vehicles and p v storage units , Energies 16 (15) (2023). doi:10.3390/en16155689 . URL https://www.mdpi.com/1996- 1073/16/15/5689 [114] M. Anw ar, C. W ang, F. de Nijs, H. W ang, Pro ximal P olicy Optimization Based Reinforc ement Learning for Joint Bid- ding in Energy and Frequenc y Regulation Markets, in: 2022 IEEE P ow er & Energy Society General M eeting (PESGM), 2022, pp. 1–5. , doi:10.1109/PESGM48719.2022.9917082 . [115] A. C. Rigby , M. W agner, D . M. Mikkelson, B. Lindley , A Reinforc ement Learning Approach to Augment Con ventional PID Control in Nuclear P ow er Plant T ransient Operation. [116] S. Hasheminasab, A. Lotfy , M. Alzayed, H. Chaoui, A Proximal Po licy Optimization-Based Controller for Enhanced P ow er Sharing in Microgrids, IEEE Acc ess 13 (2025) 162391–162405. doi:10.1109/ACCESS.2025.3610451 . [117] M. Foroughi, S. M aharjan, Y . Zhang, F. Eliassen, Autonomous P eer-to-P eer Energy T rading in Networked Mic rogrids: A Distributed Deep Reinforc ement Learning Approach, in: 2023 IEEE PES Conference on Innovativ e Smart Grid T echno logies - Middle East (ISGT Middle East), IEEE, Abu Dhabi, United Arab Emirates, 2023, pp. 1–5. doi:10. 1109/ISGTMiddleEast56437.2023.10078444 . 41 [118] T . Haarnoja, A. Zhou, P . Abbeel, S. Levine, Soft Actor-Critic: O-P olicy M aximum Entropy Deep Reinf orcement Learning with a Stochastic Actor (Aug. 2018). , doi:10.48550/arXiv.1801.01290 . [119] T . Li, W . Cui, N. Cui, Soft Actor-Critic Algorithm-Based Energy Management Strategy f or Plug-In Hybrid Electric V ehicle, W orld Electric V ehicle Journal 13 (10) (2022) 193. doi:10.3390/wevj13100193 . [120] K. Cheruiyot, N. Kiprotich, V . Kungurtsev , K. Mugo, V . M wirigi, M. Ngesa, A Survey of Multi Agent Reinforc ement Learning: Federate d Learning and Cooperativ e and Nonc ooperative Decentralized Regimes (Jul. 2025). arXiv:2507. 06278 , doi:10.48550/arXiv.2507.06278 . [121] C.-H. Chao, C. Feng, W .-F. Sun, C.-K. Lee, S. See, C.- Y . Lee, Maximum Entrop y Reinforc ement Learning via Energy- Based Normalizing Flow (Oct. 2024). , doi:10.48550/arXiv.2405.13629 . [122] H. Sun, Y . Hu, J. Luo, Q. Guo, J. Zhao , Enhancing HV AC Control Systems Using a Steady Soft Actor–Critic Deep Reinforc ement Learning Approach, Buildings 15 (4) (2025) 644. doi:10.3390/buildings15040644 . [123] J. Gao , Y . Li, B. W ang, H. Wu, Multi-Microgrid Co llaborative Optimization Scheduling Using an Improv ed Multi- Agent Soft Actor-Critic Algorithm, Energies 16 (7) (2023) 3248. doi:10.3390/en16073248 . [124] C. Liu, D . Li, Multi-agent Pro ximal P olicy Optimization via Non-xe d V alue Clipping, in: 2023 IEEE 12th Data Driven Control and Learning Systems Conferenc e (DDCLS), IEEE, Xiangtan, China, 2023, pp. 1684–1688. doi:10.1109/ DDCLS58216.2023.10167264 . [125] P . Sun, W . Zhou, H. Li, Attentiv e Experienc e Replay, Proceedings of the AAAI Conference on Articial Intelligenc e 34 (04) (2020) 5900–5907. doi:10.1609/aaai.v34i04.6049 . [126] B. De Mo l, D . Barbieri, J. Vieb ahn, D . Grossi, Centrally Coordinated Multi-Agent Reinforc ement Learning for P ow er Grid T opology Control, in: Procee dings of the 16th ACM International Conferenc e on Future and Sustainable Energy Systems, A CM, Rotterdam Netherlands, 2025, pp. 460–475. doi:10.1145/3679240.3734602 . [127] H. Xu, Q. Fang, C. Hu, Y . Hu, Q. Yin, MIR A: Model-Based Imagined Rollouts Augmentation for Non-Stationarity in Multi-Agent Systems, Mathematics 10 (17) (2022) 3059. doi:10.3390/math10173059 . [128] T . Ramachandran, K. Dvijotham, K. Kalsi, Integration of wholesale and retail electricity markets: Modeling and stability analysis, T ech. Rep . PNNL-26469, 1812546 (Apr. 2017). doi:10.2172/1812546 . [129] D . Holmberg, M. Burns, S. Bushby , A. Gopstein, T . McDermott, Y . T ang, Q. Huang, A. Pratt, M. Ruth, F. Ding, Y . Bichpuriya, N. Rajagopal, M. Ilic, R. Jaddivada, H. Neema, NIST transactive energy modeling and simulation chal- lenge phase II nal report, T ech. Rep . NIST SP 1900-603, National Institute of Standards and T echnology , Gaithersburg, MD (Ma y 2019). doi:10.6028/NIST.SP.1900- 603 . [130] E. B. T . T chuisseu, D. Gomila, D. Brunner, P . Colet, Ee cts of dynamic-demand-control applianc es on the power grid frequenc y , Physic al Review E 96 (2) (2017) 022302. doi:10.1103/PhysRevE.96.022302 . [131] D . Schraudner, Stigmergic Multi-Agent Systems in the Semantic W eb of Things, 2021, pp. 218–229. doi:10.1007/ 978- 3- 030- 80418- 3_34 . [132] M. Jaderberg, V . Dalibard, S. Osindero, W . M. Czarne cki, J. Donahue, A. Ra zavi, O . Vin yals, T . Green, I. Dunning, K. Simon yan, C. F ernando, K. Kavukcuoglu, P opulation based training of neural networks (2017). arXiv:1711. 09846 . URL 42
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment