SCENE OTA-FD: Self-Centering Noncoherent Estimator for Over-the-Air Federated Distillation
We propose SCENE (Self-Centering Noncoherent Estimator), a pilot-free and phase-invariant aggregation primitive for over-the-air federated distillation (OTA-FD). Each device maps its soft-label (class-probability) vector to nonnegative transmit energ…
Authors: ** - **H. Chen** (haochen@boisestate.edu) – Department of Electrical, Computer Engineering, Boise State University
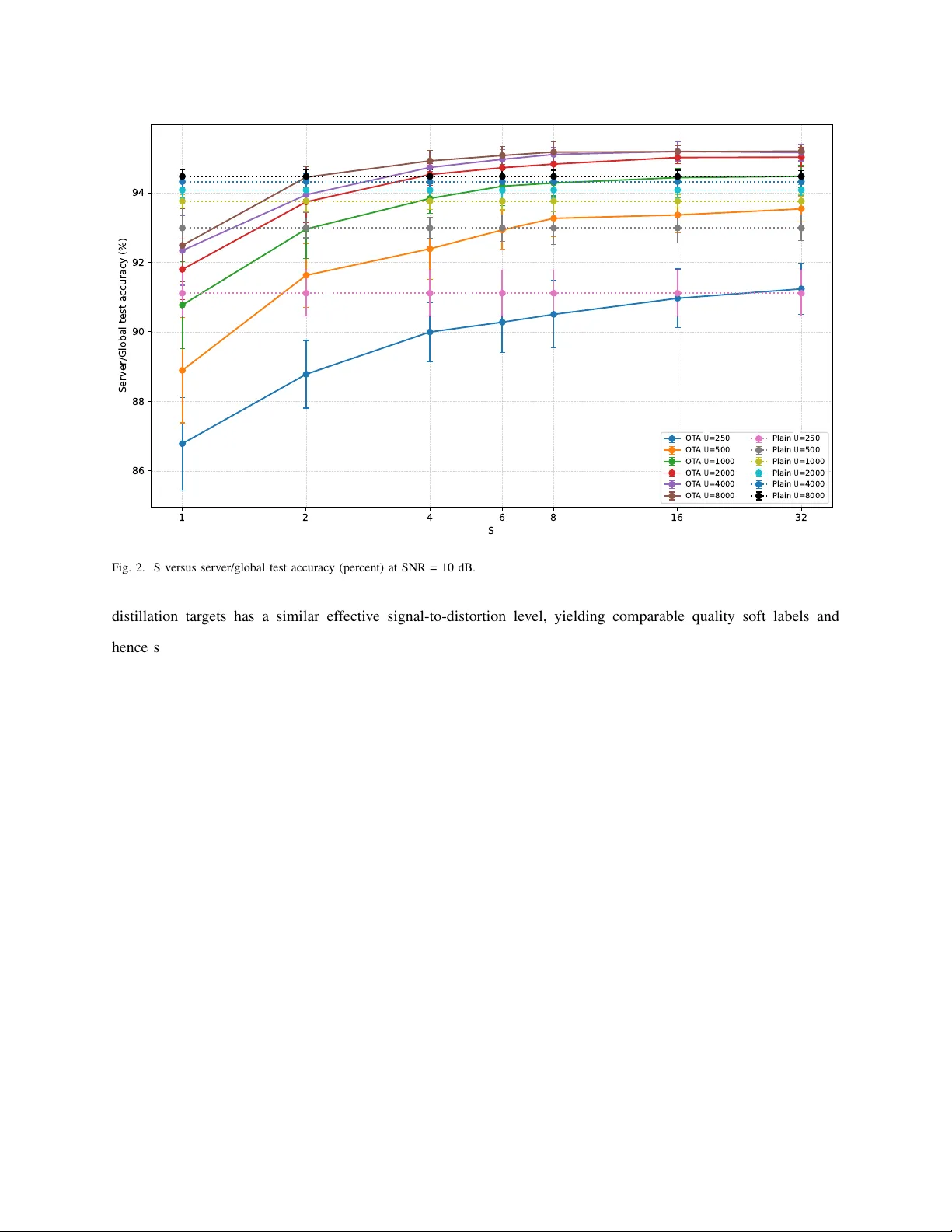
1 SCENE O T A-FD: Self-Centering Noncoherent Estimator for Ov er -the-Air Federated Distillation Hao Chen, Member , IEEE, and Zav areh Bozor gasl, Member , IEEE Abstract W e introduce a pilot-free, phase-inv ariant noncoherent aggregation primitiv e for over -the-air federated distillation (O T A–FD) called SCENE —Self-CEntering Noncoherent Estimator . De vices map soft-label v ectors to transmit ener gies with constant per-round power and constant-en v elope w aveforms (P APR ≈ 1 ). The parameter server (PS) forms a self-centering estimate that is unbiased in expectation and whose variance decays as O (1 / ( S M )) with the number of antennas M and repetitions S . W e further pro vide a β -cancelling ratio variant that remains pilot-free on the uplink, a con ver gence bound that mirrors coherent O T A–FD analyses, and a concise overhead comparison that clarifies when SCENE outperforms coherent designs under short coherence. W e target regimes with short coherence or hardware-simplicity constraints, where av oiding per -round CSI is a first-order design objective. SCENE instantiates this point in the design space: it trades a slightly larger constant in the O (1 / ( S M )) aggre gation variance for zer o uplink pilots , unbiasedness by design, and constant-en v elope transmission. When pilot overhead is non-negligible, the effecti ve mean-squared error can fav or SCENE despite its purely noncoherent processing. I . I N T R O D U C T I O N Over -the-air (OT A) learning aggregates distrib uted statistics in the air . In federated distillation (FD), exchanging soft labels instead of model parameters slashes communication costs. Most O T A–FD designs are coher ent , requiring per-round CSI and phase alignment with nontrivial pilot/feedback o verhead and sensiti vity to CFO/phase noise. This represents one point in a broader design space. W e analyze the opposite point: a fully noncoherent approach that discards instantaneous CSI altogether . The geometry of soft labels makes noncoher ent ener gy aggr e gation a natural fit: energies are nonne gati ve and additi ve; the tar get lies on the probability simplex. Our thesis is not that noncoherent is universally superior , but that under short coherence or strict device simplicity , the cost of e ven imperfect phase H. Chen (haochen@boisestate.edu) and Z. Bozor gasl (za varehbozor gasl@u.boisestate.edu) are with the Department of Electrical and Computer Engineering, Boise State Uni versity , Boise, ID 83712 USA. 2 acquisition outweighs its benefits. W e therefore prioritize an un biased estimator and hardware-friendly constant- en velope signaling, accepting a well-quantified variance as the trade-of f. This paper de velops SCENE (Self-CEntering Noncoherent Estimator), a pilot-free O T A–FD estimator built on mean-centering of recei ved ener gies. SCENE eliminates noise-ener gy bias and yields an unbiased estimate of the weighted soft-label av erage under coarse pathloss in version, with v ariance O (1 / ( S M )) . Lightweight renormalization makes the per-round output a valid soft label. Constant-en velope signaling enables efficient non-linear P As and materially lowers de vice energy per round versus coherent high-P APR schemes. a) Contributions.: • A truly noncoherent O T A mapping from soft labels to energy . • SCENE: a simple, unbiased, pilot-free noncoherent estimator for soft-label aggre gation with v ariance O (1 / ( S M )) . • A constant-power transmission scheme by design, making it highly suitable for power-ef ficient amplifiers and simpler hardware compared to high-P APR coherent schemes. • An analysis framew ork for comparing the MSE against coherent baselines to identify the regimes (e.g., high mobility) where our scheme is superior . I I . R E L A T E D W O R K A. Soft-Label F ederated Distillation Soft-label–based federated distillation (FD) exchanges predictions/logits instead of parameters, typically ev aluated on a public (unlabeled) dataset, enabling model heter ogeneity and reducing communication cost compared to parameter sharing. Foundational frameworks include FedMD [1], which introduced public-data logit sharing for heterogeneous models, and F edDF [2], which performs serv er-side ensemble distillation on unlabeled or generated data to fuse heterogeneous clients. DS-FL [3] formalized public-data distillation with the entr opy r eduction aver aging (ERA) rule that deliberately sharpens aggregated logits for faster conv ergence under non-IID data. A parallel line explores server capacity and split-style training via FedGKT [4], which alternates client-side small models with a large server model using bidirectional KD; this highlights that distillation can decouple edge compute from serv er capacity . When public data are unav ailable, F edGen [5] and related data-free KD approaches learn a generator at the server to synthesize queries for distillation, trading sample fidelity for pri vac y portability . Robust fusion under heterogeneity has been studied by FedBE [6], which casts aggregation as Bayesian model ensemble followed by distillation. Giv en that soft labels can still be large when K or the public batch is large, recent work targets communication shaping . CFD [7, 8] quantizes soft labels and applies delta coding with active query selection, showing orders-of-magnitude sa vings v ersus vanilla FD. V ery recent extensions like SCARLET [9] add soft-label caching across rounds combined with an enhanced ERA rule to avoid redundant retransmissions. These techniques are complementary to our transport-layer contribution: SCENE can aggregate soft labels over the air under any of 3 T ABLE I OT A AG G R E G AT I O N F O R L E A R N I N G : P O S I T I O N O F S C E N E V S . C L O S E S T L I N E S . W ork O T A T ype Pilots/CSI Aggregand Estimator Hu et al. [22] Coherent O T A–FD Per-round CSI logits beamforming + scaling Hu et al. [23] Coherent DP OT A–FD Per-round CSI logits DP + co-design T ransceiv er opt. [24] Coherent O T A–FD Per-round CSI logits MMSE transcei ver NCAirFL [15] Noncoh. AirFL No pilots gradients unbiased noncoh. detector FSK/PPM MV [16, 17] Noncoh. AirFL No pilots signs noncoh. ener gy SCENE (Proposed) Noncoh. O T A–FD No pilots probabilities/soft labels self-centering / ratio the above FD protocols. Surveys provide taxonomies and practical guidance. W e follo w the organization of [10] (FD surve y) and [11] (practical guide to KD in FL), as well as broader KD-in-FL surveys [12, 13]. For completeness, we note emerging security analyses sho wing that lo git poisoning is a meaningful threat model in FD [14], which our self-centering estimator mitigates partly via its e xplicit renormalization and projection options. B. Noncoher ent O T A for AirFL (gradients) vs. SCENE for FD (soft labels) What exists (gradients/parameters). There is a growing body of noncoher ent over -the-air learning for FL gradi- ents/parameters : (i) CSI-free noncoherent AirFL (“NCAirFL ”) with an unbiased ener gy-based detector that matches FedA vg con vergence up to constants [15]; (ii) noncoherent FSK/PPM majority-v ote (signSGD) schemes with theory and SDR demonstrations [16–18]; and (iii) formal comparisons of coherent vs. noncoherent O AC that quantify the mean-squared-error (MSE) crossover as a function of pilots and coherence [19]. See also tutorials/surveys for broader context on AirFL and AirComp [20, 21]. How SCENE differs (distillation/soft labels). SCENE targets federated distillation (FD), aggregating class- pr obability vectors q i ∈ ∆ K − 1 rather than real-valued gradients or signs. This changes the estimator design and bias handling: (i) the aggregand lies on the simplex, so we can exploit sum-to-one constraints and self-centering to cancel unkno wn of fsets; (ii) the nonne gativity of energies makes ener gy aggr egation well matched to the task; and (iii) modest side-information (long-term pathloss) suffices to debias lar ge-scale ef fects. O T A–FD (coherent designs). Recent O T A–FD works co-design transcei vers and learning under coher ent combin- ing (pilots/CSI per round), including VTC’24 designs and follow-ons that add differential pri vac y or optimize transceiv ers [22–24]. SCENE is complementary: it removes pilots entirely on the uplink and trades a small O (1 / ( S M )) variance for zero pilot cost, which is fa vorable when coherence is short. I I I . N O T A T I O N A N D A S S U M P T I O N S W e consider K classes and de vices i = 1 , . . . , N . Each device holds q i ∈ ∆ K − 1 = { q ∈ R K : q ≥ 0 , 1 ⊤ q = 1 } . Let nonnegati ve weights satisfy P i ω i = 1 . The desired global target is ¯ q = P i ω i q i . The uploading of updates 4 from edge de vices to the server is through a broadband multi-access channel. W e assume that the devices kno w the large-scale path-loss, β i > 0 , by a po wer control mechanism lik e physical uplink control channel (PUCCH) in Fifth Generation (5G) Ne w Radio (NR) [25]. During updates, devices transmit concurrently and are assumed to be symbol-synchronized using a synchronization channel (e.g., “timing advance” in L TE systems [26]) 1 . The PS uses M antennas and repeats each O T A b urst S times. W e introduce a global energy scale ρ > 0 broadcast by the PS each round. I V . N O N C O H E R E N T E N E R G Y A G G R E G A T I O N A N D S C E N E A. Measur ement Model a) Received signal and noncoher ent a ggr egation.: Each de vice maps class c to ener gy E i,c = η i q i,c , η i = ρ ω i β i , K X c =1 E i,c = η i , (1) and transmits over K orthogonal REs, repeated S times. W ith Rayleigh fading h i,s,m = √ β i g i,s,m , g i,s,m ∼ C N (0 , 1) . Path-loss follows a log-distance model, which can be expressed by β i ( d i ) ∝ d − α i [27–29], where α denotes the path-loss exponent and d i is the distance of the i -th edge device from the server . During repetition s ∈ { 1 , . . . , S } on receive antenna m ∈ { 1 , . . . , M } for class c , the comple x baseband sample at the PS is y c,s,m = X i h i,s,m p E i,c e j ϕ i,c,s,m + n c,s,m , (2) where E i,c ≥ 0 is the energy emitted by client i on class c , h i,s,m is the small-scale channel from client i to antenna m in repetition s with E [ | h i,s,m | 2 ] = β i , ϕ i,c,s,m is an unknown random phase U nif orm [0 , 2 π ) , and n c,s,m ∼ C N (0 , σ 2 N ) is A WGN independent of all other terms. Hence the per- ( s, m, c ) average SNR (signal po wer ov er noise po wer) is SNR ( s,m ) c = P i β i E i,c σ 2 N = ρ ¯ q c σ 2 N . The PS performs noncoher ent energy aggregation by summing magnitudes squared across the S M observations: Y c = S X s =1 M X m =1 y c,s,m 2 = S X s =1 M X m =1 X i h i,s,m p E i,c e j ϕ i,s,m 2 , (3) T aking e xpectations (cross terms v anish in e xpectation due to independence and random phases), E [ Y c ] = S X s =1 M X m =1 X i E | h i,s,m | 2 E i,c + S M σ 2 N = S M X i β i E i,c + S M σ 2 N , (4) Define m c = P i β i E i,c = ρ P i ω i q i,c = ρ ¯ q c and ν N the noise-energy term. 1 The robustness of synchronization scales with the bandwidth allocated to the sync channel. With a modern phase-locked loop, the synchronization error can be as small as 0 . 1 B − 1 s , where B s denotes the synchronization bandwidth. For L TE, a common choice is B s = 1 MHz , yielding a timing of fset on the order of 0 . 1 µ s [27] . 5 V . D E T E R M I N I N G ρ F O R S C E N E Per repetition total transmit energy across the K orthogonal REs is K X c =1 E i,c = η i = ρ ω i β i . (5) This identity holds whether the K REs are used in parallel or serialized in time; the mapping is energy per RE per trial. a) F easibility with a per-trial cap.: If client i has a per-trial (or per -round, per repetition) po wer/energy cap P i , feasibility is η i ≤ P i ⇐ ⇒ ρ ω i β i ≤ P i ⇐ ⇒ ρ ≤ β i P i ω i . (6) T aking the weakest user over the activ e set S t giv es the corr ect min– ρ rule for SCENE : ρ ∗ ,t = min i ∈S t β i P i ω i (SCENE / soft-label ener gies). (7) A. Min- ρ pr otocol (per r ound t ) 1) Client-side estimation. Each i ∈ S t forms a local estimate ρ t i . 2) Uplink r eport (control). Client i attaches the scalar ρ t i to its participation A CK (one number per client). 3) Server aggregation and br oadcast. The PS computes the conserv ativ e common scale ρ t min ≜ min i ∈S t ρ t i , (8) and broadcasts ρ t min to all i ∈ S t . 4) Usage in SCENE. Where ver ρ appears in SCENE’ s estimators/normalizers for round t , substitute ρ ← ρ t min . a) Why the minimum?: Using ρ t min guarantees that normalizations are safe for the weakest-SNR participant. It yields a single broadcast scalar and a voids per-client tuning. B. SCENE: Self-CEntering Noncoherent Estimator Let ¯ Y = 1 K P K j =1 Y j and set r c = a ( Y c − ¯ Y ) + 1 K , a = 1 S M ρ . (9) a) Remark 1 (What “pilot-fr ee” means).: SCENE is pilot-free on the uplink and per r ound : it requires no instantaneous CSI or phase alignment. De vices assume a slo w-varying pathloss estimate ˆ β i (via infrequent downlink RSRP/RSSI with reciprocity), updated on a slow timescale T slow spanning many coherence interv als. This amortized 6 ov erhead is decoupled from the per -round latency of coherent designs. The effect of mismatch β i = ˆ β i is quantified in §VI; ratio-normalization (§V -D) further remo ves common gain/offset factors. Theorem 1 (Unbiasedness and v ariance) . Assume: (A1) small-scale fading h i,m,s ∼ C N (0 , β i ) i.i.d. acr oss de vices i , antennas m = 1 , . . . , M , and repetitions s = 1 , . . . , S ; (A2) A WGN with per -RE noise-ener gy mean σ 2 N and finite variance v N ; (A3) devices use η i = ρ ω i /β i with P i ω i = 1 ; and (A4) ortho gonal REs acr oss classes c = 1 , . . . , K . Let r c be defined by (9) . Then E [ r c ] = ¯ q c ≜ X i ω i q i,c . Mor eover , with E i,c = η i q i,c and V sig ( c ) ≜ P i β 2 i E 2 i,c , one has the variance bound V ar( r c ) ≤ 2 S M ρ 2 V sig ( c ) + v N = 2 S M X i ω 2 i q 2 i,c + v N ρ 2 . (10) Hence V ar( r c ) = Θ 1 S M with constants depending on ( ω , ¯ q, ρ, σ 2 N ) . In our setting with independent REs per class and ener gy detection, V ar( Y j ) scales as S M and admits the usual decomposition V ar( Y j ) = 2 V sig ( j ) + v N (up to model constants), yielding the e xplicit upper bound V ar( r c ) ≤ K − 1 K · 1 S M ρ 2 max j 2 V sig ( j ) + v N . In the balanced case V ar( Y j ) ≡ V , the identity simplifies to V ar( r c ) = K − 1 K · V S M ρ 2 . C. Scalability and Resource Requir ements Our baseline maps K classes to K orthogonal REs per transmission. This is efficient for moderate K (e.g., 10 ≤ K ≤ 100 ) but burdensome for very large K . T wo standard compressions integrate cleanly with SCENE: T op- T logits. Let T ≪ K and q ( T ) i retain the T largest entries of q i followed by renormalization. Denote the tail mass δ i = 1 − P c ∈T i q i,c and ¯ δ = P i ω i δ i . Then the aggregation bias b = E [ q ( T ) ] − ¯ q satisfies ∥ b ∥ 1 ≤ 2 ¯ δ and hence ∥ b ∥ 2 ≤ √ 2 ¯ δ , while the noncoherent variance term scales as O 1 S M with K replaced by T in constants. Hashed binning (Count-Sketch). Choose B < T ≪ K buckets and H hash functions; transmit H B REs and reconstruct an unbiased estimator of ¯ q with collision noise that vanishes as B , H grow . This preserves unbiasedness and yields O 1 S M variance with constants depending on ( B , H ) . A full exploration is orthogonal to our focus; we use full K in experiments b ut note SCENE’ s primitive extends directly with resource cost ∝ T (or H B ) rather than K . Pr oof sk etch. Unbiasedness follows from E [ Y c ] = S M P i β i E i,c + S M σ 2 N = S M ρ ¯ q c + S M σ 2 N and E [ ¯ Y ] = S M σ 2 N + S M ρ K . Substituting a = 1 S M ρ in (9) cancels the noise offset and re-centers the mean to ¯ q c . For variance, write Y c = P m,s P i E i,c | h i,m,s | 2 + N m,s,c and use independence to obtain V ar( Y c ) = S M P i E 2 i,c V ar( | h i | 2 ) + 7 V ar( N ) = S M V sig ( c ) + v N since V ar( | h i | 2 ) = β 2 i for Rayleigh. Because r c uses Y c − ¯ Y and REs are independent across classes, the exact centering identity gives V ar( Y c − ¯ Y ) = (1 − 2 K )V ar( Y c ) + 1 K 2 P K j =1 V ar( Y j ) . W ith a = 1 S M ρ this yields (10). Finally , substituting η i = ρ ω i /β i turns V sig ( c ) into ρ 2 P i ω 2 i q 2 i,c , and inserting this into Y c together with the centering step produces the stated self-centering form in (9). Then E [ r c ] = ¯ q c and P c r c = 1 . Ignoring Cov( Y c , ¯ Y ) yields V ar[ r c ] = Θ(1 / ( S M )) . Algorithm 1 SCENE Aggregation for OT A–FD 1: Each device i : compute q ( k ) i ∈ ∆ K − 1 ; set η ( k ) i = ρ ω ( k ) i /β i . 2: T ransmit energies E ( k ) i,c = η ( k ) i q ( k ) i,c ov er K orthogonal REs, for S repetitions. 3: PS: measure total ener gies Y ( k ) c ov er all reps and M antennas. 4: Form the estimate b q ( k ) using the self-centering formula in Eq. (9). 5: Broadcast b q ( k ) ; devices compute local FD loss. D. Ratio-Normalized SCENE (pilot-free β cancellation) Add a single r eference RE per repetition with E i, ref = η i , and let R be its recei ved energy . Define ˜ q c = Y c R , ˆ q c = max { ˜ q c , 0 } P K d =1 max { ˜ q d , 0 } . (11) Ignoring thermal noise, E [ ˜ q c ] = P i ω i γ i q i,c ¯ γ , which cancels the common scale error . With noise, a first-order delta- method expansion around ( E [ Y c ] , E [ R ]) giv es E [ ˜ q c ] = P i ω i γ i q i,c ¯ γ + O 1 S M and V ar( ˜ q c ) = Θ 1 S M . Thus ratio- normalization removes uniform drift but does not correct heterogeneous γ i reweighting in (12). V I . B I A S - I N D U C E D D R I F T A N D C O N V E R G E N C E A. Bias-Induced Drift in F ederated Learning Proposition 1 (Bias under lar ge-scale mismatch) . Suppose de vices use ˆ β i and η i = ρ ω i / ˆ β i , and define γ i ≜ β i / ˆ β i and ¯ γ = P i ω i γ i . Then the self-center ed estimator satisfies E [ r c ] − ¯ q c = X i ω i ( γ i − 1) q i,c − 1 K . (12) In particular , if | γ i − 1 | ≤ δ for all i , then ∥ E [ r ] − ¯ q ∥ 2 ≤ δ q K − 1 K . Pr oof. With mismatch, E [ Y c ] = S M ρ P i ω i γ i q i,c + S M σ 2 N and E [ ¯ Y ] = S M ρ ¯ γ /K + S M σ 2 N . Plugging into (9) yields E [ r c ] = P i ω i γ i q i,c + (1 − ¯ γ ) /K . Subtract ¯ q c = P i ω i q i,c to obtain (12). The ℓ 2 bound follows from Cauchy–Schwarz and that P c ( q i,c − 1 /K ) = 0 with maximal norm p ( K − 1) /K on the simple x. 8 Our design philosophy deliberately prioritizes unbiasedness ov er minimum single-round MSE. This choice is motiv ated by the unique demands of iterati ve learning algorithms like FD. Lemma 1 (Bias-Induced Fixed-Point Shift) . Consider an FD update step driven by a loss function that penalizes the KL-diver gence between the model’ s output and the global average q ⋆ . If the ag gr e gator consistently r eturns a biased estimate ˆ q = q ⋆ + b (wher e b is a persistent bias vector), the stationary point of the learning process will be shifted. The final learned model θ ∗ will con ver ge to a solution that satisfies ∇L ( θ ∗ ) + γ J ( θ ∗ ) b = 0 , r epr esenting an O ( ∥ b ∥ ) deviation fr om the true optimum. An unbiased aggregator , by contrast, ensures that any error in a given round is zero-mean noise ( E [ ε ] = 0 ), which can be a veraged out over the course of training. It does not introduce a systematic drift. a) P athloss mismatch and a ratio-estimator variant.: If β i mismatch introduces scaling errors, periodic coarse calibration bounds the bias. Alternati vely , a pilot-free ratio estimator cancels unkno wn large-scale factors: let Y ( k ) c be receiv ed energy for class k on subchannel c , then ˜ q ( k ) c = Y ( k ) c P K d =1 Y ( k ) d , which cancels common β i factors; its bias is second-order in noise via a delta-method correction. B. Pr eservation of Dark Knowledge The bias in MSE-optimal estimators often manifests as a "shrinkage" effect, where the estimate is pulled tow ards the origin to dampen noise. This is particularly harmful for FD because it can systematically destroy dark knowledge . The small, non-maximal probabilities in a soft-label vector represent crucial information about class similarity . These low-ener gy signals are the most vulnerable to being mistaken for noise and suppressed by a shrinkage estimator . Our unbiased, noncoherent scheme does not perform such filtering. It faithfully transmits a noisy but complete version of the soft labels, preserving the faint-but-vital dark knowledge in expectation and trusting the learning algorithm to average out the zero-mean noise ov er time. V I I . C O M PA R AT I V E M S E A N D C RO S S OV E R A NA LY S I S Let T coh denote per -round pilot/feedback ov erhead (in REs) for coherent O T A–FD, and let the total round budget be B REs. A fair comparison holds B fixed. • Coherent O T A–FD: usable aggre gation REs ≈ B − T coh ; aggregation MSE scales as O 1 / M per RE but must be amortized over fewer repetitions. • SCENE: usable aggregation REs ≈ B with S ≈ B /K repetitions; aggre gation MSE = O (1 / ( S M )) without CSI ov erhead. A crossover occurs when T coh ≳ S , i.e., under short coherence or large M , SCENE in vests more wall-clock in av eraging rather than pilots. For large K , top- T logits or low-dimensional projections reduce REs while introducing 9 a controllable modeling bias that is reflected in our con ver gence term O ( λ 2 ∥ b ∥ 2 ) . A persistent bias b shifts the stationary point by ∆ θ ≈ − η λ ( ∇ 2 F ) − 1 Gb , magnitude O ( λ ∥ b ∥ ) . SCENE’ s zero bias thus preserves dark knowledge. Under L -smoothness and step η t = η 0 / √ t + 1 , min t 10 dB Y es SCENE None K S O (1 / ( S M )) ≈ 1 No Ratio–SCENE None K + 1 O (1 / ( S M )) ≈ 1 No I X . C O H E R E N T V S . N O N C O H E R E N T : A S I M P L E C R O S S OV E R M O D E L Assume a per-round RE budget B and K classes. Coherent O T A–FD requires P REs for pilots/feedback/CSI acquisition, so S coh = ( B − P ) /K usable repeats; SCENE uses S nc = B /K (no UL pilots). Suppose c coh and c nc are scheme-dependent MSE constants that absorb all non-asymptotic factors (e.g., estimator ef ficiency , noise enhancement, channel-estimation/beamforming errors for coherent OT A–FD, and phase-loss/energy-detection variance for noncoherent SCENE) beyond the common Θ(1 / ( M S )) averaging scaling. Therefore, the round-MSEs scale as c coh M S coh and c nc M S nc , respectiv ely . Hence, SCENE has lower MSE iff c nc B ≤ c coh B − P ⇐ ⇒ P ≥ 1 − c coh c nc B . (14) Empirically , c nc > c coh because noncoherent detection discards phase, but when P is a significant fraction of B (e.g., short coherence/high mobility), the increase in usable repeats can outweigh the constant gap. Indeed, SCENE buys itself extra av eraging repetitions by not paying the pilot tax. The threshold P threshold = 1 − c coh c nc B is the pilot-tax le vel abov e which coherent loses because it w astes too much of the round just acquiring CSI. SCENE in the Design Space of FL V ersus digital FD. State-of-the-art digital FD achie ves excellent bit-efficienc y via quantization and entropy coding. SCENE’ s motiv ation is different: one-shot analog superposition yields ultra-low latency and device simplicity (constant power , constant en velope), which is attractiv e at large scale. Our goal is not to beat digital in bits per label, but to furnish a rob ust analog primiti ve when latenc y and hardw are constraints dominate. V ersus hybrid coherent schemes. A middle ground is possible: infrequent pilots to capture partial coherent gain. This can reduce MSE constants but reintroduces broadcast pilot mechanisms, client-side phase tracking, and sensiti vity to oscillator drift. Residual phase/amplitude errors may elev ate the noise floor and, under persistent 11 miscalibration, introduce bias. SCENE deliberately a voids this complexity: it is unbiased by construction, insensitive to fast phase v ariation, and competitiv e whenev er the pilot fraction is non-negligible (short coherence or many users). X . S I M U L A T I O N R E S U LT S W e consider a federated distillation system with a single parameter server (PS) and sev eral edge de vices (clients). W e ev aluate on MNIST (60,000 train / 10,000 test, 10 classes). W e fix the number of clients to N = 100 and split the 60k training images into a shar ed unlabeled open set of size I o and a labeled private set of size I p (with I o + I p ≤ 60 , 000 ) [3]. W e fix the shared unlabeled open set to ha ve size I o = 20 , 000 and the labeled pri vate set to hav e size I p = 40 , 000 (so that I o + I p = 60 , 000 ) [3]. F or IID experiments, the priv ate set is shuffled and e venly partitioned so that each client holds I p / N labeled examples. All reported experimental results are av eraged over 20 independent trials. a) Model and tr aining.: W e use the MNIST CNN (similar to [3]) implemented in our codebase for both client and server models. The network consists of two 5 × 5 con volutional layers with 32 and 64 channels, respectiv ely , each followed by ReLU and 2 × 2 max pooling. The resulting feature map is flattened and passed through two fully-connected layers: 512 units with ReLU, followed by a 10-way linear classifier . The softmax is applied to con vert the outputs to probabilities. This architecture has 1 , 663 , 370 trainable parameters. U denotes the unlabeled budget, i.e., the number of unlabeled samples selected from the shared pool I o and used for one-shot distillation. For the one shot protocol, clients first perform supervised pretraining for a fixed number of local epochs on labeled data using mini-batch SGD (batch size 32, learning rate 0.005, momentum 0.9, weight decay 5 × 10 − 4 ). Next, the server runs a one-shot distillation stage: for each unlabeled budget U , clients provide class-probability predictions on the selected unlabeled subset, which are aggregated either over -the-air (O T A) or via a noise-free weighted a verage (Plain). The serv er then distills for a fix ed number of epochs using unlabeled mini-batches of size 32 and e valuates the global model after distillation. Distillation is carried out primarily at the serv er by K ullback- Leibler di vergence (KLD) as the loss function: once per round on the shared unlabeled batch, while clients do not perform additional local distillation epochs beyond their supervised updates. The client pretraining stage and the server distillation stage are both run for 20 epochs. b) W ir eless channel and path-loss.: For the O T A experiments, we simulate a broadband uplink with nonco- herent combining at the PS. Each client i experiences a large-scale gain β i = d − α i 10 X i / 10 , where d i is the distance from client i to the PS, drawn uniformly in the interval [5 , 50] meters, α = 3 . 5 is the path-loss exponent, and X i is a zero-mean Gaussian random variable with standard deviation 8 dB modeling lognormal shadowing. The resulting gains are normalized such that their empirical mean equals one. Per-de vice 12 power constraints are modeled by assigning each client a maximum transmit po wer uniformly dra wn from a fixed interval P i ∼ U [0 . 5 , 1 . 5] . ; all de vices employ the same mapping from soft-label probabilities to transmit energies, ensuring constant total transmit ener gy per de vice per round. Small-scale fading is modeled as independent Rayleigh fading across de vices, antennas, and repetitions. The PS is equipped with M antennas and each O T A burst is repeated S times, so that each class-energy measurement is av eraged o ver S M independent observ ations. The noise v ariance at the recei ver is chosen to realize a prescribed target signal-to-noise ratio (SNR) per resource element. Giv en the average recei ved signal energy implied by the soft-label energies and path-loss, the noise power is set so that the effecti ve per-resource-element SNR equals either 5 dB or 10 dB, depending on the scenario. Clients training and test accuracies are 100 percent and 92.18 percent, respectively . Clients train/test accuracies are reported before the O T A distillation stage (they are the local pretraining accuracies). Indeed, SNR affects the O T A aggregation/distillation performance, not the clients’ supervised pretraining metrics—so the client a verages remain the same across SNR sweeps. In our experiments, the Plain baseline aggregates client predictions by a noise-free, data-size–weighted arithmetic mean of the class-probability vectors on the simplex, i.e., it reflects ideal server-side av eraging without O T A impairments. c) SCENE aggr egation and operating points.: Devices map their soft-label vectors to nonne gativ e ener gies and transmit concurrently over K orthogonal resource elements. The PS aggregates the receiv ed magnitudes squared ov er S repetitions and M antennas and applies the SCENE self-centering estimator, followed by a light projection back onto the probability simplex (clipping and renormalization). In all cases, the learning-rate schedule, batch sizes, number of local epochs, and distillation protocol are kept fixed; only the aggre gation mechanism, SNR, and div ersity parameters ( S, M ) are v aried. Indeed, the server forms soft targets for distillation by aggregating client-predicted class probabilities over the wireless channel. For O T A aggre gation, each unlabeled sample can be transmitted multiple times, i.e., repeated S times, which effecti vely averages channel impairments across repetitions. Consequently , considering M = 1 , the total OT A communication/airtime cost scales with the product of the unlabeled batch size and the repetition factor , B ∝ U S . Under a fixed b udget B , there is an inherent trade-off: increasing the unlabeled batch size U improves cov erage/div ersity for knowledge transfer, whereas increasing the repetition factor S improves the reliability of the aggregated soft labels by reducing O T A-induced distortion. Empirically , as shown in Figures 1 and 2 this trade-off produces a clear “sweet spot” in ( U, S ) : allocating some budget to repetition can be strictly more effecti ve than spending the entire budget on sending a larger unlabeled batch only once. Intuitively , when S is too small, the O T A aggregation noise degrades the soft tar gets and limits distillation quality e ven if man y unlabeled samples are used. In contrast, a moderate number of repetitions substantially stabilizes the received soft labels and yields a marked accuracy improvement, often outperforming the “send-once” strategy 13 1 2 4 6 8 16 32 S 86 88 90 92 94 96 Server/Global test accuracy (%) OTA U=250 OTA U=500 OTA U=1000 OTA U=2000 OTA U=4000 OTA U=8000 Plain U=250 Plain U=500 Plain U=1000 Plain U=2000 Plain U=4000 Plain U=8000 Fig. 1. S versus server/global test accuracy (percent) at SNR = 5 dB. at the same total budget. Beyond this regime, howe ver , excessi ve repetition exhibits diminishing returns because the reduced U ev entually limits the diversity of unlabeled data, leading to saturation and, in some cases, a decline in performance. This beha vior is consistent across channel conditions: at lo wer SNR, as in Figure 1, the benefit of repetition is amplified (since O T A impairments are stronger), while at higher SNR, as in Figure 2, the optimum shifts slightly but remains in the moderate-repetition re gime. Overall, these results support the design principle that, for a fixed OT A budget, moderate r epetition is typically prefer able to a single transmission of a lar ger unlabeled batch , indicating a robust sweet-spot allocation that balances unlabeled coverage and O T A reliability . At this stage, we hypothesize that when O T A outperforms the ideal noise-free aggregation, it is because residual O T A perturbations can act as an implicit regularizer during distillation, improving the neural network’ s generaliza- tion. d) Why the S – M curves nearly coincide when S M is fixed.: The close overlap of the OT A curves in Figure 3 for different ( S , M ) pairs with the same product S M = 16 is consistent with the way O T A noise enters the aggregation in our implementation. In the code, M (the number of receiv e antennas/branches) provides spatial averaging of the O T A distortion, while S (the number of repeated transmissions) provides temporal averaging . Both mechanisms reduce the effecti ve variance of the aggregation error through averaging across approximately independent realizations. As a result, for fixed total div ersity order S M , the recei ved aggregate used to generate 14 1 2 4 6 8 16 32 S 86 88 90 92 94 Server/Global test accuracy (%) OT A K=250 OT A K=500 OT A K=1000 OT A K=2000 OT A K=4000 OT A K=8000 Plain K=250 Plain K=500 Plain K=1000 Plain K=2000 Plain K=4000 Plain K=8000 U U U U U U U U U U U U Fig. 2. S versus server/global test accuracy (percent) at SNR = 10 dB. distillation targets has a similar effecti ve signal-to-distortion level, yielding comparable quality soft labels and hence similar server test accurac y as a function of U . Residual gaps at small U can be attributed to finite-sample effects and non-idealities (e.g., mild dependence between repetitions/branches and nonlinearities from probability normalization), but o verall the observed in variance indicates that, in this regime, performance is primarily gov erned by the total aver aging budget S M rather than how it is split between repetitions and antennas. By exchanging soft labels (class-probability vectors) on a shared unlabeled batch instead of full model parameters or gradients, federated distillation reduces the uplink payload from model-size O ( P ) (with P parameters) to label- size O ( K ) (with K classes), yielding substantial communication savings and a representation that is naturally compatible with o ver -the-air aggregation. Moreover , it enables heterogeneous model architectures across clients and the server , since aggregation operates on predicted probability vectors rather than model parameters. X I . C O N C L U S I O N W e have proposed a simple, robust, and pilot-free noncoherent O T A aggregation scheme for Federated Distillation. By mapping soft-label vectors directly to transmit energies, our uplink is in variant to channel phase and CFO; combined with a practical self-centering estimator, this yields a pilot-fr ee implementation. The constant-en velope signaling (P APR ≈ 1 ) further makes the approach har dwar e-friendly for edge devices. Crucially , we prioritize unbiasedness o ver minimal single-round MSE. Whereas coherent LMMSE-style designs reduce v ariance via shrink- 15 250 500 1000 2000 4000 8000 K 91 92 93 94 95 Server/Global test accuracy (%) OT A (S=1, M=16) OT A (S=2, M=8) OT A (S=4, M=4) OT A (S=8, M=2) OT A (S=16, M=1) Plain U Fig. 3. different combinations of (S,M)=(1,16),(16,1),(2,8),(8,2),(4,4) for 100 clients, one-shot, average of 20 trials at SNR = 5 dB. age—risking systematic attenuation of the probability tail and the loss of “dark knowledge”—our estimator preserves the target distribution in expectation , aligning better with the needs of iterativ e learning and helping retain dark knowledge. Our analysis frames a fundamental trade-of f between CSI acquisition and bandwidth, identifying short- coherence/high-mobility and hardware-constrained regimes as key operating points where the proposed noncoherent design excels, deliv ering superior test accuracy versus wall-clock time despite a higher per -round MSE. R E F E R E N C E S [1] D. Li and J. W ang, “FedMD: Heterogenous federated learning via model distillation, ” in Pr oc. NeurIPS W orkshop on F ederated Learning for Data Privacy and Confidentiality , V ancouver , Canada, Dec. 2019, contributed talk. [Online]. A vailable: https://neurips.cc/virtual/2019/workshop/13202 [2] T . Lin, L. K ong, S. U. Stich, and M. Jaggi, “Ensemble distillation for rob ust model fusion in federated learning, ” in Adv . Neural Inf. Pr ocess. Syst. (NeurIPS) , 2020. [3] S. Itahara, T . Nishio, Y . Koda, M. Morikura, and K. Y amamoto, “Distillation-based semi-supervised federated learning for communication-efficient collaborati ve training with non-iid priv ate data, ” IEEE T rans. Mobile Comput. , vol. 22, no. 1, pp. 191–205, 2021. 16 [4] C. He, M. Annavaram, and S. A vestimehr , “Group knowledge transfer: Federated learning of large cnns at the edge, ” in Adv . Neural Inf. Pr ocess. Syst. (NeurIPS) , 2020. [5] Z. Zhu, J. Hong, and J. Zhou, “Data-free knowledge distillation for heterogeneous federated learning, ” in Pr oceedings of the 38th International Conference on Machine Learning (ICML) , ser . Proceedings of Machine Learning Research, vol. 139, 2021, pp. 12 878–12 889. [6] H.-Y . Chen and W .-L. Chao, “FedBE: Making bayesian model ensemble applicable to federated learning, ” in Pr oc. Int. Conf. Learn. Repr esent. (ICLR) , 2021, poster . [7] F . Sattler, A. Marban, R. Rischk e, and W . Samek, “Communication-efficient federated distillation, ” arXiv:2012.00632 , 2020. [8] ——, “CFD: Communication-ef ficient federated distillation via soft-label quantization and delta coding, ” IEEE T rans. Netw . Sci. Eng. , vol. 9, no. 4, pp. 2025–2038, 2021. [9] K. Azuma, T . Nishio, Y . Kitagawa, W . Nakano, and T . T animura, “Soft-label caching and sharpening for communication-efficient federated distillation, ” IEEE T rans. Mobile Comput. , 2026. [10] L. Li, J. Gou, B. Y u, L. Du, Z. Y i, and D. T ao, “Federated distillation: A survey , ” , 2024. [11] A. Mora, I. T enison, P . Bellavista, and I. Rish, “Kno wledge distillation for federated learning: a practical guide, ” , 2022. [12] Z. W u, S. Sun, Y . W ang, M. Liu, X. Jiang, R. Li, and B. Gao, “Knowledge distillation in federated edge learning: A survey , ” , 2023. [13] H. Salman, C. Zaki, N. Charara, S. Guehis, J.-F . Pradat-Peyre, and A. Nasser , “Knowledge distillation in federated learning: A comprehensi ve surve y , ” Discov . Comput. , 2025. [14] Y . T ang, Z. W u, B. Gao, T . W en, Y . W ang, and S. Sun, “Peak-controlled logits poisoning attack in federated distillation, ” Discov . Comput. , v ol. 28, no. 1, pp. 1–18, 2025. [15] H. W en, N. Michelusi, O. Simeone, and H. Xing, “NCAirFL: CSI-free o ver -the-air federated learning based on non-coherent detection, ” in Pr oc. IEEE Int. Conf. Commun. (ICC) . IEEE, 2025, pp. 3443–3448. [16] A. ¸ Sahin, B. Everette, and S. S. M. Hoque, “Over -the-air computation with DFT-spread OFDM for federated edge learning, ” in Pr oc. IEEE W ir eless Commun. Netw . Conf. (WCNC) . IEEE, 2022, pp. 1886–1891. [17] A. ¸ Sahin, “Distributed learning o ver a wireless network with non-coherent majority vote computation, ” IEEE T rans. on W ireless Commun. , vol. 22, no. 11, pp. 8020–8034, 2023. [18] A. Sahin, “ A demonstration of over -the-air computation for federated edge learning, ” in Pr oc. IEEE GLOBECOM W orkshops , 2022, pp. 1821–1827. [Online]. A vailable: https://arxi v .org/abs/2209.09954 [19] Y . Lee, J. Hwang, I.-H. Lee, H. Jung, and T . Q. Duong, “Performance comparison between coherent and non-coherent approaches for ov er-the-air computation, ” IEEE T rans. on V eh. T echnol. , vol. 73, no. 10, pp. 17 15 826–15 831, 2024. [20] J. Zhu, Y . Shi, Y . Zhou, C. Jiang, W . Chen, and K. B. Letaief, “Over-the-air federated learning and optimization, ” IEEE Internet Things J . , vol. 11, no. 10, pp. 16 996–17 020, 2024. [21] B. Xiao, X. Y u, W . Ni, X. W ang, and H. V . Poor , “Ov er-the-air federated learning: Status quo, open challenges, and future directions, ” Fundam. Res. , 2024. [22] Z. Hu, J. Y an, Y .-J. A. Zhang, J. Zhang, and K. B. Letaief, “Communication-learning co-design for o ver -the-air federated distillation, ” in Pr oc. IEEE V eh. T echnol. Conf. (VTC-Spring) , Singapore, 2024. [23] Z. Hu, J. Y an, and Y .-J. A. Zhang, “Communication-learning co-design for dif ferentially pri vate o ver -the-air federated learning with de vice sampling, ” IEEE T rans. on W ir eless Commun. , 2024. [24] Z. Hu, J. Y an, Y .-J. A. Zhang, J. Zhang, and K. B. Letaief, “Optimal transcei ver design in ov er-the-air federated distillation, ” , 2025. [25] E. Dahlman, S. Parkv all, and J. Skold, 5G NR: The ne xt gener ation wir eless access technology . Academic Press, 2020. [26] 3GPP Specifications, “T iming advance (T A) in L TE, ” http://4g5gworld.com/blog/timing- advance- ta- lte, 2010, accessed: Sep. 2010. [27] G. Zhu, Y . W ang, and K. Huang, “Broadband analog aggregation for low-latenc y federated edge learning, ” IEEE trans. on wireless commun. , vol. 19, no. 1, pp. 491–506, 2019. [28] Y . Dong, H. Hu, Q. Liu, T . Lv , Q. Chen, and J. Zhang, “Modeling and performance analysis of ov er-the-air computing in cellular iot networks, ” IEEE W ir eless Commun. Lett. , v ol. 13, no. 9, pp. 2332–2336, 2024. [29] O. A ygün, M. Kazemi, D. Gündüz, and T . M. Duman, “Over-the-air federated edge learning with hierarchical clustering, ” IEEE T rans. on W ir eless Commun. , 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment