Mixture-of-Experts under Finite-Rate Gating: Communication--Generalization Trade-offs
Mixture-of-Experts (MoE) architectures decompose prediction tasks into specialized expert sub-networks selected by a gating mechanism. This letter adopts a communication-theoretic view of MoE gating, modeling the gate as a stochastic channel operatin…
Authors: ** - A. Khalesi (Assistant Professor, Institut Polytechnique des Sciences Avancées, IPSA
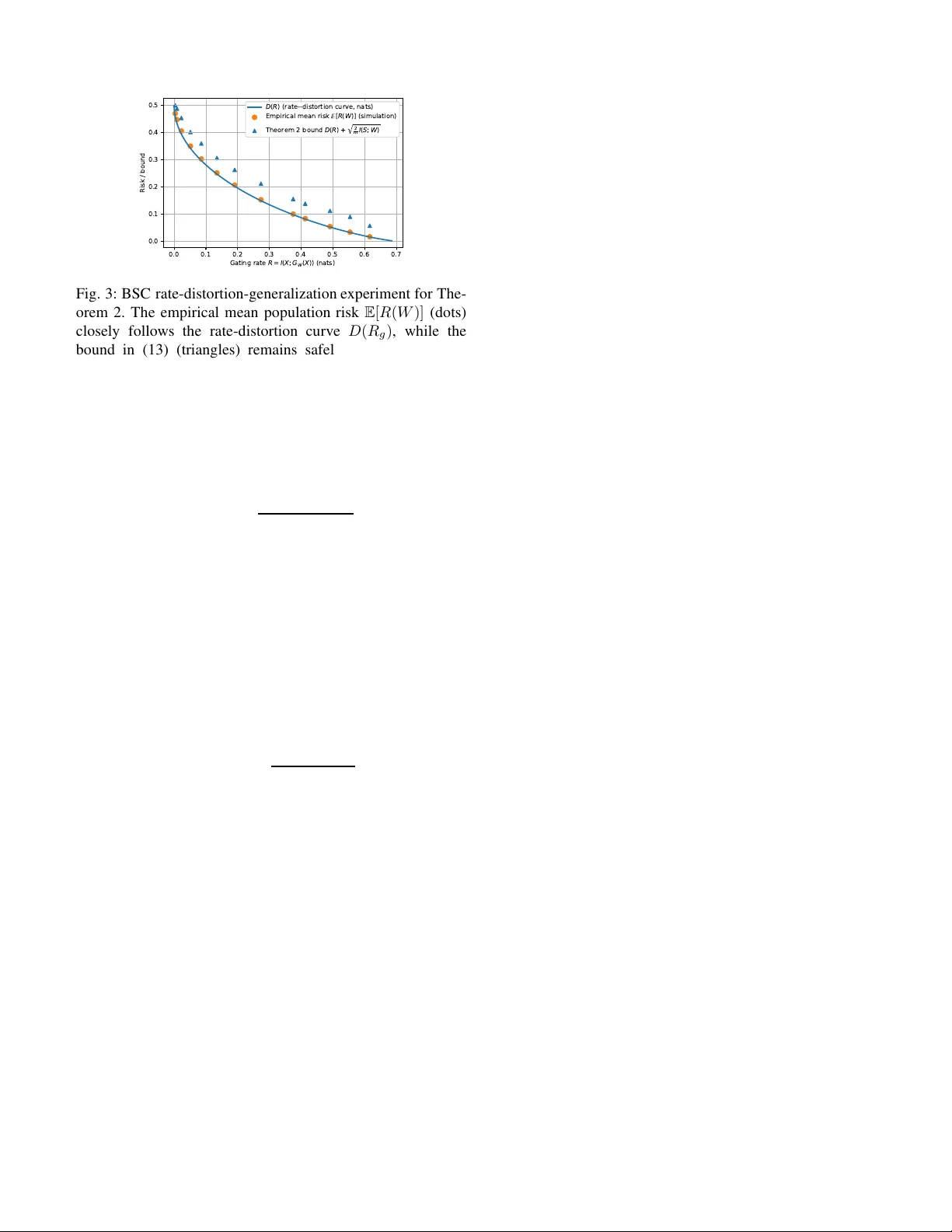
1 Mixture-of-Experts under Finite-Ra te Gating: Communication–Generaliz ation T rade-of fs Ali Khalesi and Mohammad Reza Deylam Salehi Abstract —Mixture-of-Experts (MoE) architectures decompose prediction tasks into specialized expert sub-networks selected by a gating mechanism. Th is letter adopts a communication- theoretic view of MoE gating, modeling the gate as a stochas- tic channel operating under a fi nite information rate. Within an i nform ation-theoretic l earning framework, we sp ecialize a mutual-information generalization b ound and d ev elop a rate- distortion characterization D ( R g ) of finit e-rate gating, where R g := I ( X ; T ) , yielding (under a standard empirical rate- distortion opt imality conditi on ) E [ R ( W )] ≤ D ( R g ) + δ m + p (2 /m ) I ( S ; W ) . The analysis yields capacity-aware limits for communication-constrained MoE systems, and numerical sim- ulations on synthetic mu lti-expert models empirically confirm the predicted trade-offs between gating rate, expressivity , and generalization. Index T erms —Mixture of Experts, Generalization Bound s, Communication T ra de-off, Rate-Distortion I . I N T R O D U C T I O N MoE models [1] , [2] combine multiple expert predictors via a gating network that assigns probabilistic weights or discrete routing d ecisions. Th is modu lar structure en ables specializa- tion, scalability , and sparse activ ation in large ar chitectures such as the Switch Transformer [3], where only a small subset of expe rts is active per inp ut. Despite their prac tical success, the theoretica l understan d ing of MoE systems—par ticularly generalizatio n under finite comm unication resour c e s—remains limited. Classical analyses [4] g av e Radem acher-based bound s that additively depend on the gate complexity and the sum of expert co mplexities, scalin g linearly with the num ber of experts. Mo re r ecently , Akretche et al. [5] introd uced loc a l differential priv acy (LDP) regu lar ization on the g ate, o btaining tighter P A C-Bayesian and Rademacher b ounds with logarith- mic de penden ce o n the number of experts. Howe ver , even in this setting, the gate is treated as a stochastic selector rath er than an informatio n-constra ined communication p rocess. The proposed communication -genera liza tion framework for MoE, beyond its th eoretical significance in distributed learn - ing, h as a natural interp r etation in ae r onautical and aerospace commun ication systems [6] , [7 ] . Moder n aircraft, satellites, and u nmann ed aerial vehicles (U A Vs) increasingly rely on distributed sensing and computatio n , wher e multiple o n board or remote mod ules act as experts pr ocessing heterogene ous sensor streams und er stringen t bandwid th, latency , and reli- ability constraints. The MoE gate parallels the routing log ic A. Khalesi is an Assistant Pr ofessor at Institut Polytec hnique des Science s A vancé es (IPSA) and LINCS Lab, Paris, France (ali.khal esi@ipsa .fr). M.R. Deylam Salehi is an IEEE member , Nice, France (reza.de ylam@ie ee.or g). in such system s—d eciding which local estimator or co ntrol unit sh o uld communicate with the flight computer o r ground segment. In this co ntext, the m utual-inf ormation rate co n- straints deriv ed here quantify the per f orman c e degrad ation (in estimation, n avigation, or control) induced by lim ited commun ication capacity , extending d ata-rate theo r ems [8], [9] to le a r ned, data-d riv en aerospace decision systems. Novelty a nd Contribution: From a commun ication- theoretic perspective, this work develops an explicit communica tion-generalization trade-off f or MoE models by reinterpr e ting the g ating mechanism a s a fin ite-capacity stochastic channel. W e quantif y the ga tin g p a thway by its mutual inform ation rate R g = I ( X ; T ) , wh ich limits how much inform ation about the input can reach the expe rt bank and thus con trols expressivity and statistical ro bustness. Build- ing on this v iew , we introd uce a rate - distortion for mulation of the gating p roblem and sh ow how the be st achievable prediction risk at a gi ven gatin g r ate is characterize d by a rate- distortion fun c tio n D ( R g ) , leading to the b ound E [ R ( W )] ≤ D ( R g ) + δ m + p (2 /m ) I ( S ; W ) , where R g enters throug h D ( R g ) . W e furthe r consider the pra ctically rele vant case where gate decisions are con ve yed over a physical link o f c apacity C ; when the g ate is train e d/regularized to operate near th is budget (so that I ( X ; T ) ≈ C ), the boun d specializes to D ( C ) , making the de p endenc e on C explicit, and connects MoE gating to classical n otions suc h as channel cap acity and data- rate limitations. While information -theor e tic g eneralization theory [10], [11], commun ication-limited learning [12 ] , [1 3], and recent MoE risk bounds [5 ] ar e well established, to the best o f our knowledge, while several works interpr et specializatio n an d routing through informa tio n-theor etic lenses, we ar e not aw are of prio r MoE risk b ounds in which th e ga te is modeled explicitly as a rate-limited c h annel and the achievable risk is expressed with the gating rate I ( X ; T ) app earing a s an explicit design parameter thro u gh a rate–distor tion function. Related in formatio n -theor e tic per spectiv es on spe c ialization and hier archical decision systems have also been studied , e.g., v ia m u tual-info rmation p rinciples an d on lin e learnin g in hierarchical arch itectures [14 ]–[16 ]. Our co ntribution is to place MoE arch itectures within a unified rate-distortio n and capacity framew ork, where the g ating rate I ( X ; T ) acts as a system-level commun ication constrain t ( which, in practice, is upper-boun ded by the av ailable link capacity ) shap ing both expressivity and gen eralization, and where pr iv ac y or com- pression m echanisms c an be interp reted as add itional noisy- channel lay ers. Th eoretical results are supported by num erical simulations on multi-expert MoE mo dels and on a bin ary 2 symmetric one - bit gating scenario, which em p irically illustrate the predicted trad e-offs between gating rate, sam ple size, and generalizatio n perfor mance. Organization : Section II formalizes MoE models as stochastic communicatio n systems. Section III app lies informa tio n-theo r etic generalization bo unds to MoE gating . Section IV in tr oduces a rate-d istortion formulatio n of th e gating mechanism and establishes a rate-distortion model combined with an inf o rmation- theoretic gen eralization term. Section V presents numerical simulations that em pirically validate the the oretical trade-offs, and Section VI concludes with perspectives for commun ication-aware Mo E desig n . I I . M O E A S A C O M M U N I C A T I O N S Y S T E M System Model: Let ( X, Y ) ∼ D denote a ran dom input– output pair, where X ∈ X ⊆ R d is a fe a ture vector and Y ∈ Y is the corr espondin g labe l. W e consid e r a Mixture- of-Exp erts (MoE) model w ith n experts indexed by [ n ] , { 1 , . . . , n } . Expert g ∈ [ n ] is a predictor h g ( · ; W g ) : X → b Y parameteriz e d by expert param eters W g (e.g., b Y = { 0 , 1 } f or classification or b Y = R for regression ). W e collect all expert parameters into the expert ba nk W exp , ( W 1 , . . . , W n ) . The gatin g network is parameterize d by W gate and maps an input x to a p robability vector g W gate ( x ) = ( g W gate , 1 ( x ) , . . . , g W gate ,n ( x )) ∈ ∆ n , wh ere ∆ n , { p ∈ R n + : P n i =1 p i = 1 } and g W gate ,g ( x ) de n otes the prob ability of routing x to exp e r t g . Given X = x , the ro uting rando m variable T ∈ [ n ] is sampled acco rding to P ( T = g | X = x ; W gate ) = g W gate ,g ( x ) for g ∈ [ n ] . Cond itioned on T = g , the model ou tputs ˆ Y = h T ( X ; W T ) , where W T denotes the parameters of the selected expert, i.e., W T = W g when T = g . W e denote the overall (po ssibly randomized ) model parameters by W , ( W gate , W exp ) . Unless stated otherwise, routing is applied p e r sample an d is con ditionally memo ryless: gi ven W and in puts { X j } m j =1 , the routing variables { T j } m j =1 are con - ditionally in depend ent with P ( T j | X j , W ) = P W gate ( T | X j ) for each j . Under this modeling, the gate defines a discrete memory less ch annel X → T with chan nel law P W gate ( T | X ) , whose output T selects one exper t fro m the bank (see Fig. 1) . Note tha t we de note the data-gen erating d istribution by D (not to be confused with th e rate–distortion fu nction D ( · ) in Section IV). Also through out, upp e rcase symbo ls d enote random variables (e.g. , X , Y , T , ˆ Y , W ), while lowercase letters denote realizations (e.g . , x, y , t ) and deterministic indices (e.g. , g ∈ [ n ] ). Learning Setup a nd Risk : Let S = { ( x j , y j ) } m j =1 ∼ D m denote a tr a ining sample of m i.i.d. inpu t–outpu t pairs, an d let W = ( W gate , W exp ) be the (po ssibly rando m ized) par ameters produ ced by a learn ing algor ithm trained on S . For a bounded loss functio n ℓ : Y × Y → [0 , 1] , the p o pulation and empirica l risks are defined as R ( W ) = E ( X,Y ) ∼D E T ∼ g W gate ( X ) ℓ ( h T ( X ; W T ) , Y ) , (1 ) R S ( W ) = 1 m m X j =1 E T ∼ g W gate ( x j ) ℓ ( h T ( x j ; W T ) , y j ) . (2) Here T ∼ P W gate ( · | X ) deno te s the stoch astic gate ou tput. Input X Gating P ( T | X ; W gate ) h 2 ,W 2 h 1 ,W 1 · · · h n,W n Output ˆ Y Expert Pool Fig. 1: Mo E system viewed as a finite-rate stochastic commu - nication link. The input feature vector X is processed by a gating module implementing a channel P ( T | X ; W gate ) that maps X to a ro uting index T ∈ [ n ] und e r an info rmation- rate constraint. The index selects an expert h g ( · ; W g ) n g =1 , yielding the predic tio n ˆ Y = h T ( X ; W T ) . Here I ( X ; T ) is the effective commun ication rate to th e expert bank , so the gate acts a s a constrained link that limits how much inform ation ab out X reaches the experts, sh a p ing expr essi vity and gen eralization. Communication-Constra ined Learning Objective From a comm unication- theoretic p erspective, the g ating mecha n ism constitutes the only pathway thro ugh which info rmation about the input X is co n veyed to th e exp e rt bank . W e quan tify this pathway b y the gating information rate , i.e., R g , I ( X ; T ) , which measures how much information abou t X can be transmitted thro ugh the routing de cision. In practice, R g may be limited either implicitly (e.g., by r egularization or noise) or explicitly by a physical c ommun ication link of finite capacity . The ob jec ti ve of interest is to minim ize the po pulation risk subject to a constrain t on the gatin g info rmation rate : min W R ( W ) subject to I ( X ; T ) ≤ ¯ R g , (3) or , equiv alently , under an exoge n ous capacity constrain t R g ≤ C . This formulation par a llels classical communication pro b- lems in wh ich expe c ted distortion is minimized sub ject to a rate constraint, with prediction loss playing the role of distortion 1 This is the stand a rd communicatio n objective of minimizing an ap plication-level distor tion (h ere, pr ediction loss) subject to an in formatio n-rate co n straint on th e message T . Section IV f o rmalizes this via a rate–distortio n fu n ction. I I I . I N F O R M AT I O N - T H E O R E T I C B O U N D A N D P RO O F W e adopt the framew ork of inf o rmation- theoretic lear ning theory [10], [11 ] , our contribution is the co mmunica tio n interpretatio n of the gating ran domn ess an d its integration with the r ate-distortion . I n particu la r, The following is a direct specialization of the mutual-in formatio n gener a lization b ound 1 Throughout, we use the term gatin g rate for the achie v ed mutual informa- tion R g = I ( X ; T ) , and we reserve the term capacity for an e xterna l uppe r bound on this rate (e.g., the Shannon capacity of a physica l link). 3 of Xu and Raginsky to the MoE pred iction r u le w ith internal stochastic gatin g . Let I ( S ; W ) denote the mutua l inf ormation between the training sam ple and th e lea r ned param eters. This quantity measures how mu ch the learned model de p ends o n the data and therefore controls its expected ge n eralization gap. Theorem 1 (Xu– Raginsky bound specialized to MoE) . As- sume ℓ ∈ [0 , 1] . Let W be the (p ossibly randomized) p a- rameters pr oduced by a learning alg orithm trained on sample S = { ( x j , y j ) } m j =1 ∼ D m . Then , for a n y sample size m ≥ 1 , the expected generalization g ap satisfies E [ R ( W )] − E [ R S ( W )] ≤ r 2 m I ( S ; W ) , (4) wher e I ( S ; W ) in (4 ) is the mutual information b etween the training sample a nd th e learned parameters 2 . The proof is given in Appendix A. Remark 1 (Comm unication interpretation ) . The boun d in Theor em 1 qu antifies th e estimation o r learning-alg o rithm compon e nt o f generalization thr ough I ( S ; W ) . Separately , the gating mechanism defines a co mmunicatio n channel X → T with rate I ( X ; T ) . Constraining this rate—e.g., via local differ ential privacy (LDP), wh er e each input is first random- ized by a local privac y mechanism, or via a rate-distortion objective—limits how much in formation the gate can transmit fr om the inp ut to the experts, ther eb y contr olling the model capacity . Th us, generalization is governed b y I ( S ; W ) , while expr e ssivity an d commu n ication depende nce are governed by I ( X ; T ) . The n ovelty of our framework is th at, althoug h th e mutual-in f ormation bound itself fo llows classical results, inter- preting the gating mechanism as a finite-rate c ommun ication channel and exp licitly link in g its com municatio n rate I ( X ; T ) to model expr e ssi v ity and generalization h as not ap peared in prior analyses of MoE. Remark 2 (O n estimating I ( X ; T ) and I ( S ; W ) in practice ) . F or discr ete r ou ting T ∈ [ n ] with ga te pr ob abilities g W gate , the gating rate a dmits th e computa ble form I ( X ; T ) = E h log g W gate ,T ( X ) π T i , π g , E [ g W gate ,g ( X )] , g ∈ [ n ] which can be appr oxima ted b y empirical averages over a held-ou t dataset or minib atches. F or high-dimen sional learned parameters, I ( S ; W ) is generally in tractable; in practice one may upper b ound or p r oxy it via P AC-Bayesian/compression- based estimates or va ria tio nal mutual-informa tion bo unds, using it as a design heuristic rather than a n exactly computed quantity [17]. I V . R A T E - D I S T O RT I O N F O R M U L AT I O N O F G AT I N G The gating mechanism can also b e interpreted throug h a rate-distortion lens. It m ust encode each input X into a discrete message of lim ited c o mmun ic a tion rate that still yields low pred iction loss. In th e MoE setting, th e rate-distortio n 2 Unless stated otherwise, all mutual information and entrop y quantit ies are measured in nat s , i.e., logari thms are nat ural ( ln ). Reference s to bi ts are pur ely informal; using base- 2 logari thms would simply resca le these quantities by a fac tor of l n 2 . index T correspon ds to the routing v ar iable T prod uced by the gating mechanism. A. Rate-Distortion Optimization The gating d esign problem can be posed as: min P ( T | X ) E ℓ ( h T ( X ; W T ) , Y ) , (5) s.t. I ( X ; T ) ≤ R g , where the expectation is over an ind ependen t ( X , Y ) ∼ D and T | X ∼ P ( ·| X ) . Classical Shannon rate–d isto r tion theory is an asymp totic statem ent: it characterizes the m inimum achiev ab le expec ted distortion when en coding lon g blocks of i.i.d. source samples with blockleng th L → ∞ un d er an av e r age rate constraint. In ou r setting, we assume ( X j , Y j ) are i.i.d. and the gate is memoryless across samples cond itio ned on ( X , W ) ; thus D ( R g ) is interprete d a s the single-letter distortion– rate fu n ction induced by the realized expert ban k W exp throug h th e per-sample selection T and the incurr ed loss ℓ ( h T ( X ; W T ) , Y ) ; the term δ m captures fin ite-sample/finite- optimization ef fects wh en training a rate-regularized g ate f rom data. The a b ove expresses the fu ndamen tal trade- off between commun ication rate and p r edictive p erform ance. Equiv alently , by in troduc in g a L agrang e multiplier λ > 0 , we can minimize L ( P ( T | X )) = E ℓ ( h T ( X ; W T ) , Y ) + λ I ( X ; T ) . (6) The co n strained problem (5 ) and its Lagr angian form (6) can be solved b y classical rate–d istortion iteratio n s (e.g., Blahu t- Arimoto) in settings where the distributions are tractable [1 8]. B. Rate-Distortion Function and Generalization Bo und W e d efine the rate–d istortion fun ction D ( R g ) , inf I ( X ; T ) ≤ R g E ℓ ( h T ( X ; W T ) , Y ) . (7) When W exp is lea r ned fr om S , D W exp ( R g ) is a random quantity; th rough out, D ( R g ) sho uld be interpreted condi- tionally on the realized bank W exp . As in classical rate– distortion theo ry , D ( R ) is non-incr easing in R . Through out, we v iew D ( R g ) as induced by a fixed expert bank W exp (i.e., D ( R g ) ≡ D W exp ( R g ) ), and the infim um ranges over all condition al la ws P ( T | X ) satisfying the rate constraint. Thu s, D ( R g ) is the best achievable prediction loss un der g ating rate R g . T h e following theorem co mbines rate–distortion an d generalizatio n principles. Theorem 2 (Rate-Distortion-Gen eralization Bound) . Let W = ( W gate , W exp ) de n ote the p arameters pr o duced by a learning algorithm tr ained on a sample S ∼ D m , and let T deno te the corr espo nding ( possibly stochastic) gating output. Defi ne the effective gating rate as R g := I ( X ; T ) . Assume mor eover that the e xpected empirical risk satisfies E [ R S ( W )] ≤ D ( R g ) + δ m , (8) for some no nnegative err or term δ m ≥ 0 (captu rin g opti- mization and empirica l-to-pop ulation mismatch for the rate- distortion objective a t rate R g ). Such a co n dition is satisfied, for example, wh en the gating parameters W gate ar e obtain ed 4 (for the r ea lized expert b ank W exp ) by app r oximately minimiz- ing the empirical rate-distortion Lagrangia n b L S ( W gate ; W exp ) , R S ( W gate , W exp ) + λ I ( X ; T ) , (9) for some λ > 0 , or equiva lently by solving the constrained empirical pr oblem in (5) . In this case, δ m captures the optimization sub-op timality and th e e mpirical-to-p opulatio n mismatch of the rate-distortion objective at r a te R g . Then the expected po pulation risk of th e lea rned MoE satisfies E [ R ( W )] ≤ D ( R g ) + δ m + r 2 m I ( S ; W ) . (10) The proof is given in Append ix B. It combines (8) with Theorem 1. Remark 3 (Generalizatio n trad e-off in MoE un der local priv acy) . Th eor em 1 pr ovides an explicit commun ication- generalizatio n f rontier for MoE systems. Su p pose that the gating mechan ism is designed thr o ugh an ǫ -LDP channe l, meaning tha t ea ch input X is passed th r ough a random- ized mechanism Q ( ·| X ) satisfyin g the per-sample p rivacy condition Q ( z | x ) ≤ e ǫ Q ( z | x ′ ) for all x, x ′ , z . F o r such locally priva te chann els, standard information b ound s (e.g., [19]) imply that there exists a con stant ζ > 0 (in nats) such that I ( X ; T ) ≤ ζ , ǫ 2 . Ther efor e, ǫ -LDP dir ectly limits the gatin g information rate R g = I ( X ; T ) an d hen ce constrains the a chievable r a te-distortion performan ce thr oug h D ( R g ) . In pa rticular , if R g ≤ ζ ǫ 2 , then b y Theo r em 2 we obtain E [ R ( W )] ≤ D ( ζ ǫ 2 ) + δ m + q 2 m I ( S ; W ) . Any further r edu ction of I ( S ; W ) due to p rivacy mechan isms d epends on the learning algorithm and is no t asserted her e. Remark 4 (Capacity-limited MoE gating) . S uppo se th at the gating dec isions T ar e conve yed over a physica l commun ica- tion link with per-sample Shanno n capa c ity C nats, so that the achieved gating rate R g , I ( X ; T ) ≤ C . Since D ( · ) is non -incr e asing, R g ≤ C implies D ( R g ) ≥ D ( C ) . Ther efo re , Theor em 2 h olds as stated with the achieved rate R g : E [ R ( W )] ≤ D ( R g ) + δ m + r 2 m I ( S ; W ) , R g ≤ C . (1 1) In particular , R g = I ( X ; T ) is the fundamen tal bo ttleneck: any privacy-preserving randomization that r ed uces mutual information necessarily increases the min imu m achievable distortion thr ou g h D ( R g ) . Mor e over , under a n e a r-satur ation design in wh ich I ( X ; T ) ≈ C (an d (8) holds at rate o f C ), we ha ve D ( R g ) ≈ D ( C ) , so the bound effectively specializes to E [ R ( W )] . D ( C ) + δ m + r 2 m I ( S ; W ) . (12) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 √ 2 I ( S ; W ) m (nats) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Generalization gap [ R − R S ] [ R − R S ] (simulation) y = √ 2 I ( S ; W ) m (upper bound) Fig. 2: MoE simulation for Th eorem 1. The e m pirical gen- eralization gap | E [ R − R S ] | incr eases with the in formation term p 2 I ( S ; W ) /m an d remains below th e theoretical upper bound , illustratin g the inf o-gen e r alization trade-off at the al- gorithm lev e l. V . N U M E R I C A L S I M U L A T I O N S W e next illustrate the applicability of Theorems 1 and 2 on two syn thetic experimen ts. I n th e first experiment (Fig. 2 ) , we consider a bin ary classification task gener ated by a true MoE model with r e al-valued Gaussian features. The tru e m o del has d = 3 inp u t dimension s and 10 experts. A bank of 30 candidate MoE models is drawn i.i.d. fro m the same prio r distribution. For each dataset of size m = 5 , we compu te th e empirical 0 – 1 r isk of every candidate model and use an α - mixture learning algorithm: with prob ability 1 − α th e learner samples a mo del u n iformly at rand om, and with probability α it selects the emp irical-risk minimizer . By sweeping α from 0 to 1 , we obtain a family of learn ing algo rithms with in creasing depend ence on the sample and hence increasing m utual infor- mation I ( S ; W ) , estimate d via I ( S ; W ) = H ( W ) − H ( W | S ) from the po ster ior q ( W | S ) . F or each α we estimate the generalizatio n g ap | E [ R ( W ) − R S ( W )] | by averaging over 100 datasets and a separate test set of size 100 0 . Fig. 2 plots th e empirical generalization g ap a s a fu n ction of the inform ation term p 2 I ( S ; W ) /m , togeth er with the theoretical lin e y = p 2 I ( S ; W ) /m . The po ints f orm an increasing curve that stays strictly below the diagonal, sho wing that the m u tual-info rmation bound o f Th eorem 1 is respected and captur e s the growth of th e generalization gap as the lea r ner becomes more data-dep endent. In the second exper im ent (Fig. 3), we use a b in ary sym- metric chan nel (BSC) setting that makes the rate-distortion structure explicit. W e let X ∼ B e rnoulli(1 / 2) and Y = X ⊕ Z , where Z ∼ Bernoulli( p true ) models n oise. A finite can d idate set { p r } of c r ossover pro babilities is fixed, and for each dataset of size m = 200 , we compute the log-likelihood of the o b served sample under e very c a n didate BSC ( p r ) , form a tempered po ster io r over indices, and sample a single ch annel index W . The resulting mode l has crossover prob ability p W , so its population risk is R ( W ) = p W , and its gating ra te is R g = I ( X ; T ) = ln 2 − h ( p W ) in nats, where h ( · ) deno tes the binary entropy fu nction (in nats). This toy channel can be vie wed as a one-b it gating scen ario, where the crossover probab ility p W measures how accurately the gate ro utes X to the appro priate expert, and the ra te R g = ln 2 − h ( p W ) 5 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Gating rate R = I ( X ; G W ( X )) (na(s) 0.0 0.1 0.2 0.3 0.4 0.5 Ris / bo)nd D ( R ) (ra(e--dis(or(ion c)rve, na(s) Empirical mean ris [ R ( W )] (sim)la(ion) Theorem 2 bo)nd D ( R ) + √ 2 m I ( S ; W ) Fig. 3: BSC rate-d istor tion-gen eralization experiment for The- orem 2. The empir ical mean population risk E [ R ( W )] (d o ts) closely fo llows th e rate-d istortion curve D ( R g ) , while the bound in (13) ( triangles) rem ains safely above, co nfirming the theoretica l trade-off between gating r ate and predictio n accuracy . represents the effecti ve communication r ate of this binary gating path . For each p true in a g rid, we ru n 400 Mon te Carlo datasets, estimate I ( S ; W ) v ia en tropies of the poster io r , an d ev aluate the boun d fro m Th e orem 2 as D ( R g ) + p (2 /m ) I ( S ; W ) , (13) where D ( R g ) is the BSC rate-distor tio n fu n ction in nats 3 . Fig. 3 shows the an alytical rate-d istor tion curve D ( R g ) , the empirical mean population risks E [ R ( W )] obtain ed from the simulation, a n d the correspondin g up per-bound values of Theorem 2. The empirical risks track D ( R g ) closely across a wide ran ge of gating rates, wh ile all simulated p oints lie comfor tably below the theo retical curve in ( 13), thus illus- trating the p redicted rate-distortio n-gene ralization trade- off. T o compleme n t the sy nthetic simu lations, we also provid e in th e Supplemen tary M aterial a small MNIST experim e nt based on a finite bank of pretrained CNN experts a n d a discrete selection r ule, wh ich enables emp irical estimatio n o f I ( S ; W ) and verification o f the term p 2 I ( S ; W ) /m . V I . C O N C L U S I O N This letter established an explicit in f ormation -theore tic connectio n b etween the commu nication rate of the gating mechanism and the gen eralization perform ance of Mixture- of-Exp erts mod e ls. By casting the gate as a fin ite-capacity stochastic chann el, we der iv ed mutua l- inform ation and r ate- distortion-g eneralization boun ds in wh ich the g ating r ate I ( X ; T ) ap p ears as an operational capacity measure shaping expressivity and statistical robustness. From a p ractical standpoin t, the an alysis ap plies to commun ication-co nstrained learning settings such as federated MoE, ed g e o r split infere nce, coded compu tin g, and d is- tributed aerospace systems, wh ere expert ro uting must o perate under strict band width or reliab ility co n straints [ 6 ], [7]. In such settings, the gating rate I ( X ; T ) acts as a n opera- tional comm unication rate (u pper-bound ed by the av a ilable link capacity) that governs statistical efficiency and mod el 3 Note that, in this BSC setting, D ( R g ) is a vaila ble in closed form and the rate term is ev aluate d analytic ally , so δ m is neg ligibl e in the plotte d bound. expressivity; in ae r ospace and autonomo us platf orms, it also captures trade-o ffs b etween commu n ication rate, inf erence accuracy , and con trol responsiveness, extending classical data- rate th eorems [8 ], [9] to mod e rn learn ed decision systems. Future work includes extend ing these results to dee p er a nd hierarchica l MoE architectures, dev e lo ping training proced ures that explicitly regular iz e I ( X ; T ) , and validating the theory on large-scale, b andwidth -limited dep loyments. While our analysis is single-letter and f o cuses o n memoryless per-sample routing , exten ding it to deep/hier archical MoE and to finite- blockleng th rou ting over noisy ph ysical links is non trivial; in such regimes, I ( X ; T ) and D ( R g ) shou ld be inter preted as design proxies and may be appro ximated via variational bound s or learned compr e ssion objec tives. R E F E R E N C E S [1] R. A. Jacobs et al. , “ Adapti ve m ixtures of local experts, ” Neural computat ion , v ol. 3, no. 1, pp. 79–87, 1991. [2] M. I. Jord an and R. A. Jacobs, “Hi erarchical mixtures of e xperts and the em algorit hm, ” Neural computati on , vol . 6, no. 2, pp. 181–214, 1994. [3] W . Fedus et al. , “Swi tch transformers: Scaling to tril lion parameter models with simple and effic ient sparsity , ” J. M.L. R esear ch , vol. 23, no. 120, pp. 1–39, 2022. [4] A. Azran and R. Meir , “Data depe ndent risk bounds for hierarchica l mixture of exp erts classifie rs, ” in Internat ional Confer ence on Compu- tationa l Learni ng Theory . Springer , 2004, pp. 427–441. [5] W . Akretche, F . LeBlanc, and M. Marcha nd, “T ighter risk bounds for mixtures of expe rts, ” arXiv preprint arX iv:2410.1039 7 , 2024 . [6] F . T oso and J. P . How , “Distrib uted estima tion and control for aerospace systems: A surve y of challenge s and opportuniti es, ” IEE E T rans. on Aer ospace and Elect ronic Systems , vol. 58, no. 6, pp. 4879–4902, 2022. [7] Y . Li et al. , “ A surv ey on inte llige nt unmanned aerial v ehicle commu- nicat ions: A reinforcement learni ng persp ecti ve, ” IEEE Com. Surv & T utorials , vol. 25, no. 1, pp. 473–510, 2023. [8] G. N. Nair and R. J. E v ans, “Stabiliz abili ty of stocha stic linea r systems with fini te fe edback da ta rates, ” SIAM Journal on Contr ol and Optimiza- tion , vol. 43, no. 2, pp. 413–436, 2013. [9] N. Martins and M. Dahleh, “Fund amental li mitati ons of performance in the presence of limited communic ation, ” IEE E T rans. on Auto. Contr ol , vol. 61, no. 12, pp. 4111–4126 , 2016. [10] A. Xu and M. Ragi nsky , “Informati on-theor etic analysis of genera liza- tion capab ility of lea rning algorithms, ” Advances in neur al informatio n pr ocessing systems , v ol. 30, 2017. [11] Y . Bu, S. Z ou, and V . V . V eera valli, “Ti ghteni ng mutual information- based bounds on gene raliz ation error , ” IEEE J . Sel. Areas info. , vol. 1, no. 1, pp. 121–130, Apr . 2020. [12] Y . Polyanskiy and Y . Wu , “Strong data-pro cessing inequaliti es and informati on contraction , ” F ound. & T rends in Comm. & Info. Theory , 2022. [13] O. Shamir , “Communicat ion-const rained learning: Funda mental li mits and algorit hms, ” in Conf . Learn. Theory , 2022. [14] H. Hihn, S. Gottwald, and D. A. Brau n, “ An information-the oretic on- line learni ng principle for specializ ation in hierarchic al decision-making systems, ” in IEEE Conf. Dec. and contr ol (CDC) . IEEE, 2019, pp. 3677–3684. [15] H. Hihn and D. A. Braun, “Hierarc hical ly structured task-agnosti c continu al learning, ” Machi ne Learni ng , vol. 112, no. 2, pp. 655–686, 2023. [16] ——, “Online continual lear ning through unsupe rvised mutual informa- tion maximizati on, ” Neur ocomputi ng , vol. 578, p. 127422, 2024. [17] M. I. Belghazi , A. Bara tin, S. Rajeshwar , S. Ozair , Y . Bengi o, A. Courville, and R. D. Hjelm, “Mut ual info rmation neural estimat ion, ” in Pr oceedings of the 35th International Confer ence on Mac hine Learn- ing (ICML) , 2018. [18] R. E. Blahut, An hypo thesis testing approac h to inf ormation the ory . Cornell Uni versity , 1972. [19] J. C. Duchi et al. , “Loca l pri v acy and statistic al m inimax rates. ” IEEE, 2013, pp. 429–438. 6 A P P E N D I X A P R O O F O F T H E O R E M 1 Pr oof. Th e training samp le is S = { ( X j , Y j ) } m j =1 ∼ D m (i.i.d.). A (possibly randomized ) learning algorithm takes S as input and outpu ts model param eters W = ( W gate , W exp ) , hence W is a ran dom variable wh ose law is induced by ( S, algorithm ic rando m ness ) . T o ev alua te the pop ulation risk, we additionally draw an indepen dent test examp le ( X , Y ) ∼ D that is independen t of S and indepe ndent of the a lgorithmic random ness. Gi ven W and the test input X , th e gate samples a routing index T ∼ g W gate ( X ) (i.e., P ( T = g | X , W ) = g W gate ,g ( X ) ) . All inf ormation quan tities below are with resp e ct to th is joint distribution of ( S, W, X , Y , T ) . Define the rando m loss on the test po int as L , ℓ h T ( X ; W T ) , Y ∈ [0 , 1] . (14) The bound edness L ∈ [0 , 1] h olds by assumption on ℓ . By the definition of the MoE po p ulation risk, R ( W ) = E [ L | W ] , where the condition al expectation is over the indepen dent test draw ( X , Y ) ∼ D an d over the internal gate randomn e ss T ∼ g W gate ( X ) . Similarly , the empirical risk is R S ( W ) = 1 m m X j =1 E h ℓ h T j ( X j ; W T j ) , Y j S, W i , where T j ∼ g W gate ( X j ) are the per-sample g ate variables (conditio nally i.i.d. given ( S, W ) under the m emoryless-g ating modeling ). T aking to tal expectatio n over ( S, W ) yield s the quantities appearing in th e th eorem statement: E [ R ( W )] an d E [ R S ( W )] . W e claim that, cond itioned on W , the loss L is independ ent of the training sample S : P ( L | W , S ) = P ( L | W ) . (15) Indeed , given W , • the test pair ( X , Y ) is drawn from D indepe n dently of S ; • the rou ting variable T is samp led from g W gate ( X ) using internal randomness that is also independe nt o f S (once W is fixed). Therefo re, the conditio nal law of L d epend s on S on ly thro ugh W , which is exactly (15). This is equi valent to the Markov chain S → W → L. (16) By the data-pro cessing ineq uality , equation (16) implies I ( S ; L ) ≤ I ( S ; W ) . (17) For bounded losses in [0 , 1] , Xu an d Raginsky sh ow (v ia their decoup lin g lemma) that E [ R ( W )] − E [ R S ( W )] ≤ r 2 m I ( S ; L ) . (18) (Here L is the single-sample test loss d efined in (14); see [1 0, Lemma 1 and Theore m 1].) Combining (18) with (17) yields E [ R ( W )] − E [ R S ( W )] ≤ r 2 m I ( S ; W ) , which is exactly (4 ). A P P E N D I X B P R O O F O F T H E O R E M 2 Pr oof. For any two rea l n umber s a, b , we have a = b + ( a − b ) ≤ b + | a − b | . Applyin g this with a = E [ R ( W )] and b = E [ R S ( W )] gives E [ R ( W )] ≤ E [ R S ( W )] + E [ R ( W )] − E [ R S ( W )] . (19) By assumption (8), the learned param eters satisfy E [ R S ( W )] ≤ D ( R g ) + δ m , (20) where R g , I ( X ; T ) is the achieved gating rate induced by the learned g ate and th e data distribution. Substituting (20) into (19) yields E [ R ( W )] ≤ D ( R g ) + δ m + E [ R ( W )] − E [ R S ( W )] . (2 1) Define the in stan taneous test loss o n an in depend ent test draw ( X , Y ) ∼ D and intern al g ate sam ple T ∼ g W gate ( X ) as L , ℓ h T ( X ; W T ) , Y ∈ [0 , 1] . (22) Exactly a s in the proof o f Theorem 1, we have the Markov chain S → W → L , hence I ( S ; L ) ≤ I ( S ; W ) . Applying the Xu–Rag insky deco u pling bound to this same L giv es E [ R ( W )] − E [ R S ( W )] ≤ r 2 m I ( S ; L ) ≤ r 2 m I ( S ; W ) . (23) Plugging (23) into (21) yields E [ R ( W )] ≤ D ( R g ) + δ m + r 2 m I ( S ; W ) , (24) which is the claim (10).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment