Balanced Stochastic Block Model for Community Detection in Signed Networks
Community detection, discovering the underlying communities within a network from observed connections, is a fundamental problem in network analysis, yet it remains underexplored for signed networks. In signed networks, both edge connection patterns …
Authors: Yichao Chen, Weijing Tang, Ji Zhu
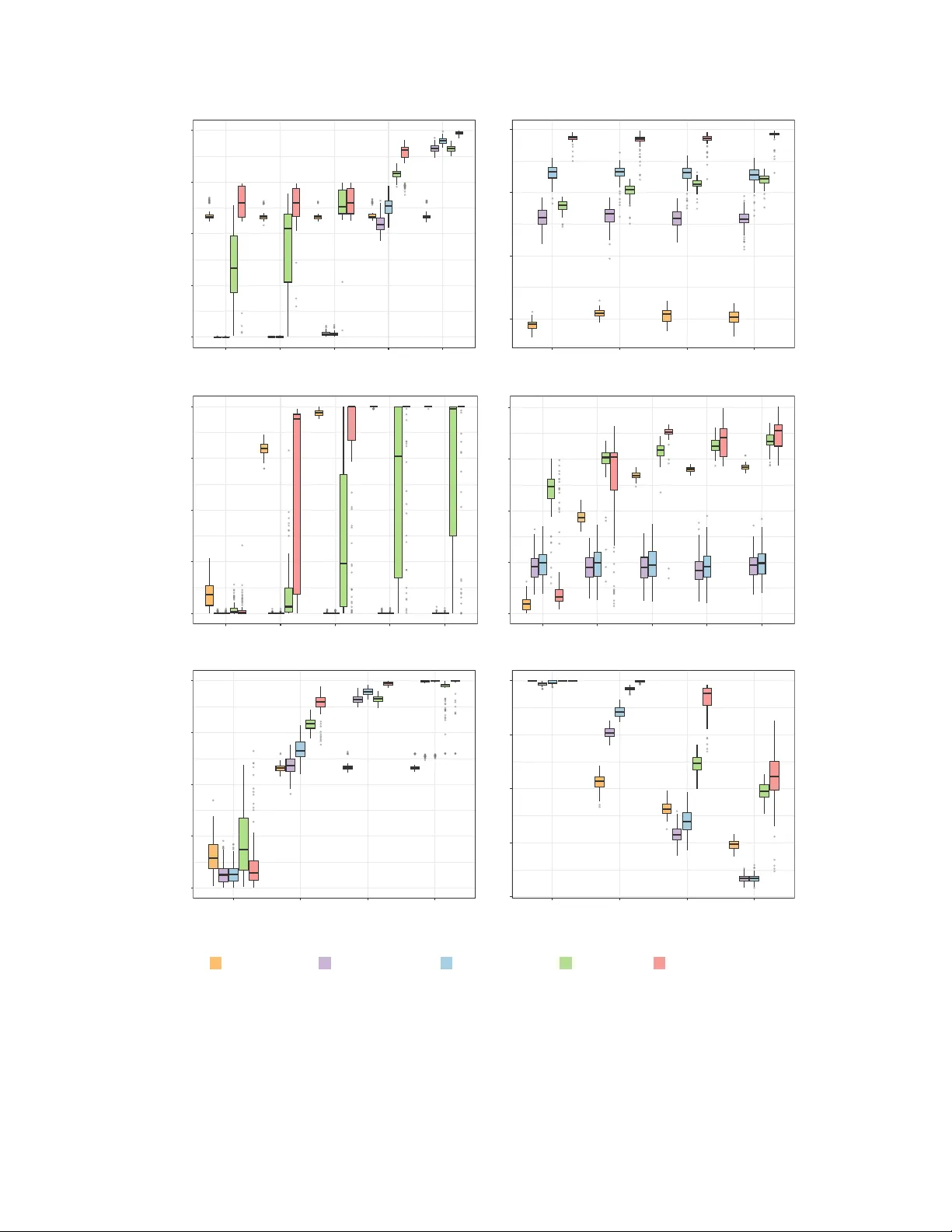
Balanced Sto c hastic Blo c k Mo del for Comm unit y Detection in Signed Net w orks Yic hao Chen ∗ Departmen t of Statistics, Univ ersit y of Mic higan W eijing T ang ∗ Departmen t of Statistics & Data Science, Carnegie Mellon Univ ersit y Ji Zh u Departmen t of Statistics, Univ ersit y of Mic higan Abstract Comm unity detection, disco vering the underlying communities within a net work from observ ed connections, is a fundamental problem in net w ork analysis, yet it re- mains underexplored for signe d networks . In signed net works, both edge connection patterns and edge signs are informativ e, and structural balance theory (e.g., triangles aligned with “the enem y of my enemy is my friend” and “the friend of my friend is my friend” are more prev alent) provides a global higher-order principle that guides com- m unity formation. W e prop ose a Balanced Sto c hastic Blo c k Mo del (BSBM), whic h incorp orates balance theory into the net work generating pro cess such that balanced triangles are more likely to o ccur. W e develop a fast profile pseudo-likelihoo d esti- mation algorithm with pro v able conv ergence and establish that our estimator achiev es strong consistency under weak er signal conditions than metho ds for the binary SBM that rely solely on edge connectivity . Extensiv e simulation studies and tw o real-world signed net works demonstrate strong empirical performance. 1 In tro duction In netw ork analysis, c ommunities are defined as clusters of nodes whose mem b ers share sim- ilar connection patterns with others. Comm unit y detection, discov ering such laten t clusters ∗ These authors contributed equally to this w ork. 1 from an observed netw ork, is a fundamental problem that has received extensive attention. Man y methods for comm unity detection are based on probabilistic net work mo dels, including the sto c hastic blo c k model (SBM) (Holland et al. 1983 ; No wicki et al. 2001 ), degree-corrected SBM (Karrer et al. 2011 ), latent factor mo del (Handcock et al. 2007 ; Hoff 2007 ), and mixed- mem b ership SBM for o verlapping comm unity detection (Airoldi et al. 2008 ). Other metho ds form ulate communit y detection as an optimization problem, whic h maximizes criteria that quan tify the strength of comm unit y structure or their sp ectral approximations, including nor- malized cuts (Shi et al. 2000 ), modularity (Newman et al. 2004 ; Newman 2006 ), and v arian ts of sp ectral clustering (Ng et al. 2001 ). These metho ds rely solely on the edge-connectivity information in binary net works for communit y detection. In man y applications, ho wev er, net works contain not only information ab out whether a connection exists but also the t yp e of the connection. In signe d networks , eac h edge tak es either a p ositive (e.g., friendship, trust, agreemen t, p ositive correlation) or negativ e (e.g., hostilit y , distrust, disagreemen t, negativ e correlation) sign. Suc h signed net w orks are common in diverse fields, examples include so cial netw ork (Heider 1946 ; Lesko v ec et al. 2010 ), in ternational relations (Doreian et al. 1996 ; Doreian et al. 2015 ; T ang et al. 2025 ), and biological netw ork (Vinay agam et al. 2014 ; Morabito et al. 2023 ). Incorp orating edge- sign information in signed net w orks allo ws for the iden tification of comm unity structures that are not captured by edge-connectivit y patterns alone. T o this end, n umerous algorithms ha ve b een prop osed for communit y detection in signed net works (Doreian et al. 1996 ; Bansal et al. 2004 ; Y ang et al. 2007 ; Chiang et al. 2012 ; Li et al. 2014 ; Kunegis et al. 2010 ), among which many extend classical criteria such as nor- malized cuts and mo dularit y that were originally designed for binary (unsigned) net works to incorp orate edge signs. These extensions aggregate lo cal pairwise sign signals in to a par- tition ob jective, where p ositiv e edges encourage placing the connected nodes in the same comm unity while negative edges encourage assigning them to different communities. Ho w- ev er, metho ds based on local pairwise information alone ov erlo oks a unique feature of signed net works: p ositiv e and negative edges interact through higher-order patterns. An imp ortan t theory in so cial psyc hology for understanding such interactions is structur al b alanc e the ory (Harary 1953 ). The theory c haracterizes signed triangles (e.g., three nodes connected to each other) as either b alanc e d if the pro duct of their three edge signs is p ositiv e, or unb alanc e d oth- erwise. In particular, balanced triangles are consistent with the prov erbs “the enem y of my enem y is m y friend” and “the friend of my friend is my friend”. The balance theory suggests that balanced triangles are more prev alent than un balanced ones in signed netw orks. This pattern has b een empirically observ ed in n umerous real-w orld signed netw orks, including so cial and biological netw orks (F acchetti et al. 2011 ; Allah yari et al. 2022 ; Aref et al. 2018 ). 2 Balance theory provides a global higher-order principle for communit y detection. Bey ond lo cal pairwise information, it suggests that comm unities should b e formed to minimize the o ccurrence of unbalanced triangles across the netw ork. T o incorp orate the structural bal- ance, one line of work uses lo w-rank matrix completion algorithms for communit y detection and sign prediction (Hsieh et al. 2012 ; Chiang et al. 2014 ). Ho wev er, they treat non-edges as missing entries and thereby rely solely on edge-sign information. Probabilistic mo del-based approac hes for signed net works, in con trast, ha ve b een less explored (V u et al. 2013 ; Chen et al. 2014 ; Jiang 2015 ; Zhang et al. 2022 ; Li et al. 2023 ; T ang et al. 2025 ; Pensky 2025 ). Among them, Jiang ( 2015 ) transformed a signed netw ork in to a t wo-la yer netw ork, where one lay er represents the presence of p ositiv e edges and the other represents the presence of negativ e edges. This approac h, ho wev er, ignores the m utual exclusivit y b et ween p ositive and negative edges on the same no de pair. V u et al. ( 2013 ) dev elop ed an exponential random net w ork mo del for discrete-v alued netw orks, which can b e applied to signed net works, and Li et al. ( 2023 ) prop osed a signed SBM, where each edge follows a multinomial distribution. More recently , P ensky ( 2025 ) prop osed a v arian t of the generalized random dot product graph mo del for signed netw orks. How ever, all of them do not incorp orate the balance theory for comm unity detection that is the fo cus of our w ork. Zhang et al. ( 2022 ) in tro duced a laten t space model for join t communit y and anomaly detection. Their metho d mo dels signed edges as ordinal v ariables in {− 1 , 0 , 1 } , in terpreting a non-edge as a neutral status b etw een positive and negativ e. Ho wev er, this assumption ma y not hold in practice, especially for large sparse net works. F or example, t wo individuals with opp osing political views may ha v e no observed connection not b ecause they hold neutral attitudes, but simply b ecause their so cial circles do not intersect. In comparison, T ang et al. ( 2025 ) treated signed edges as categorical v ariables with three lev els and introduced a sto c hastic notion of p opulation-level b alanc e . They established sufficient conditions under whic h signed net w ork generated from a broad class of laten t v ariable mo dels are inheren tly p opulation-lev el balanced. While their sufficien t condition offers insights that could guide comm unity detection, it remains unclear how p opulation-lev el balance can b e effectiv ely lev eraged to p erform comm unity detection. T o bridge this gap, w e develop a no vel probabilistic mo del-based metho d guided by balance theory for comm unity detection in signed netw orks, whic h in tegrates b oth the edge- connectivit y and edge-sign information. Our con tributions consist of three parts: 1. W e prop ose a balanced sto c hastic blo ck mo del (BSBM) for signed net works, whic h treats signed edges as categorical v ariables. Unlik e existing SBMs for signed net works, our mo del introduces a hierarchical meta-gr oup structure in the sign-generation process to incorp orate p opulation-level balance. Specifically , communities are mapp ed to one 3 of tw o meta-groups, where edges are more lik ely to b e negativ e b etw een meta-groups and p ositiv e within meta-groups. Therefore, negative edges tend to o ccur b et w een comm unities rather than within them. This hierarc hical design naturally incorp orates structural balance theory to guide communit y detection. 2. While the hierarchical design effectively incorp orates balance theory , it also makes the mo del estimation, already a w ell-known challenge in fitting blo ck mo dels, ev en more complicated. T o address this, w e dev elop a fast profile-pseudo lik eliho o d estimation metho d for the BSBM with a con v ergence guaran tee. Our metho d builds on the idea of decoupling no de mem b erships for ro ws and columns (W ang et al. Oct. 2021 ), but differs in several asp ects. In con trast to their binary SBM, the hierarc hical structure in the BSBM couples eac h comm unity with a higher-level meta-group, leading to a binary quadratic optimization subproblem without closed-form up dates. W e solv e this subproblem exactly when the num b er of comm unities is small and approximately via semi-definite programming when the num b er is large. 3. W e also establish the strong consistency of communit y membership estimation in sce- narios where strong consistency is not achiev able using edge-connection information alone. Note that in binary SBM, strong consistency requires a sufficien tly large gap b et w een the within- and b etw een-communit y connection probabilities. Our metho d can achiev e strong consistency under w eaker conditions on this gap b y lev eraging both edge-connectivit y and edge-sign information, provided that the latter offers sufficient separation b etw een comm unities. The rest of this pap er is organized as follows. Section 2 in tro duces our prop osed mo del and presen ts an illustrative example demonstrating the adv antage of incorporating edge-sign information. Section 3 pro vides the details of our estimation metho d and algorithm with a con vergence guaran tee. Section 4 establishes the strong consistency . Sections 5 and 6 demonstrate the p erformance of our metho d through extensive simulation studies and tw o real-w orld data applications. Section 7 concludes our work. 2 Balanced Sto c hastic Blo c k Mo del The sto c hastic blo ck model (SBM) is a canonical probabilistic framew ork for studying com- m unity detection. In this section, we in tro duce an SBM for signed net w orks and imp ose a structure to incorp orate the balance theory . Denote an undirected signed net work b y a symmetric adjacency matrix A = [ A ij ] 1 ≤ i,j ≤ n ∈ {− 1 , 0 , 1 } n × n , where A ij = 1 if there is a p ositive edge betw een node i and no de j , A ij = − 1 4 if there is a negativ e edge, and A ij = 0 if there is no edge. Assume there are K communities and let z = ( z 1 , · · · , z n ) ∈ [ K ] n denote the communit y mem b erships of n nodes, with z i i.i.d. dra wn from a categorical distribution Cat( π ) with probabilities π = ( π 1 , · · · , π K ) satisfying P K ℓ =1 π ℓ = 1. W e consider an SBM for signed netw orks, where edges are generated indep enden tly given the no de comm unity memberships. Sp ecifically , an edge b et ween no des i and j forms with probability P r ( | A ij | = 1 | z ) = P z i ,z j , (1) and, given that the edge exists, it is p ositiv e with probability P r ( A ij = 1 | | A ij | = 1 , z ) = Q z i ,z j . (2) Here, P = [ P ℓℓ ′ ] 1 ≤ ℓ,ℓ ′ ≤ K ∈ [0 , 1] K × K and Q = [ Q ℓℓ ′ ] 1 ≤ ℓ,ℓ ′ ≤ K ∈ [0 , 1] K × K are symmetric matrices. The entry P ℓℓ ′ sp ecifies the probabilit y of formation of an edge b et ween a no de in the communit y ℓ and a no de in the communit y ℓ ′ , while Q ℓℓ ′ sp ecifies the probability that such an edge is p ositive. This mo del form ulation is equiv alen t to mo deling each edge as a three-category m ultinomial v ariable as in Li et al. ( 2023 ), since a multinomial with three categories can b e parameterized b y tw o probabilities. Our formulation separates edge formation and sign assignment, whic h mak es it easier to interpret and incorp orate structural balance theory . W e imp ose additional structure on Q to incorporate p opulation-level b alanc e , a sto c hastic notion of balance theory that accoun ts for the noise in the observ ed data (T ang et al. 2025 ). A signed net work is said to be p opulation-level balanced if E ( A ij A j k A ki | | A ij A j k A ki | = 1) > 0 for an y three differen t no des 1 ≤ i, j, k ≤ n . In tuitively , this definition requires that, in exp ectation, triangles are more lik ely to ha ve a p ositiv e pro duct of edge signs. Recall that balanced triangles corresp ond to triangles with a p ositiv e pro duct, while unbalanced triangles ha v e a negativ e pro duct (see Figure 1 for illustration). Th us, p opulation-level balance suggests that balanced triangles are more prev alent than un balanced ones. F ollo wing Figure 1: The left tw o are balanced triangles and the right t wo are unbalanced triangles T ang et al. ( 2025 ), one sufficien t condition for achieving p opulation-level balance is latent- sp ac e sep ar ability , where the latent space can b e partitioned into tw o regions such that 5 edges connecting no des within the same region are more likely to ha v e p ositiv e signs, while edges across regions are more lik ely to hav e negative signs. Motiv ated by this insight, we parameterize the sign probabilit y matrix Q as P r ( A ij = 1 | | A ij | = 1 , z ) = Q z i z j = 1 + η z i z j ν ( z i ) ν ( z j ) 2 , (3) where η ℓℓ ′ = η ℓ ′ ℓ ∈ [0 , 1] for 1 ≤ ℓ, ℓ ′ ≤ K and ν : [ K ] → {− 1 , 1 } maps eac h communit y to one of tw o groups. The mapping ν ( · ) th us induces a hierarchical partition of K communities in to tw o meta-gr oups : G 1 = { ℓ ∈ [ K ] : ν ( ℓ ) = 1 } and G 2 = { ℓ ∈ [ K ] : ν ( ℓ ) = − 1 } . Under this structure, pairs of no des whose communities share the same meta-group lab el, i.e., ν ( ℓ ) ν ( ℓ ′ ) = 1, are more likely to hav e p ositive signs, whereas pairs across different meta-groups are more likely to hav e negative signs. W e refer to this structured SBM as the Balanc e d Sto chastic Blo ck Mo del (BSBM). The following prop osition formalizes that this hierarc hical structure induced by ν ( · ) guaran tees p opulation-level balance. Prop osition 1. F or A ∼ B S B M , E ( A ij A j k A ki | | A ij A j k A ki | = 1) > 0 for any 1 ≤ i < j < k ≤ n . The pro of of Prop osition 1 is in App endix. Our prop osed BSBM integrates balance theory in to the generation pro cess of signed net works, whic h leads to globally coheren t sign patterns. As a result, BSBM can reveal communit y structure when edge connectivity alone provides w eak signals. In particular, under BSBM, a negative edge b etw een t w o no des suggests that they likely b elong to different meta-groups, and hence to differen t communities. Figure 2 illustrates this effect: in the left panel, comm unities 1 and 2 are difficult to distinguish using only unsigned edge connectivit y information, whereas the right panel that incorp orates edge- sign information enables a clear separation b et w een them. Figure 2: The netw ork con tains three comm unities: no des lab eled 1 to 4, nodes lab eled 5 to 8, and no des lab eled 9 to 12. No des 1–4 and 9–12 b elong to meta-group G 1 , and no des 5–8 b elong to meta-group G 2 . L eft: Comm unity detection under a v anilla SBM using unsigned connectivit y (grey edges). R ight: Communit y detection under the BSBM using signed edges (p ositiv e in green and negative in red). 6 3 Maxim um Profile-Pseudo Lik eliho o d Estimation Fitting the lik eliho o d function of an SBM has b een kno wn as a non-trivial task, as maximizing the lik eliho o d for the observed data requires summing ov er all p ossible communit y lab el assignmen ts, which is an NP-hard problem in general. Sp ecifically , the lik eliho o d of complete data for ( A , z ) under BSBM is given b y L ( π , P , Q ; A , z ) = Y i ∈ [ n ] π z i Y 1 ≤ i P (0) ℓℓ ′ , Q (0) ℓℓ = Q (0) ℓℓ ′ = 1 2 , 1 ≤ ℓ = ℓ ′ ≤ 2 ) . Here, the initial column lab els e (0) assign an equal num b er of no des to each of the t wo comm unities and agree with the true comm unity lab els on γ m nodes per comm unity , for some γ ∈ (0 , 1 2 ) ∪ ( 1 2 , 1). W e assume that e (0) is sligh tly b etter than random guessing (i.e., γ = 1 / 2) and exclude the degenerate cases γ = 0 or γ = 1, whic h already corresp ond to p erfect lab eling up to p erm utation. The assumptions on the initial mo del parameters Ω (0) are mild. The initial within- comm unity edge probability is greater than the b etw een-communit y probability , the initial comm unity prop ortions are balanced, and the sign-probability matrix is not required to b e informativ e. Giv en the initial lab els e (0) and parameters Ω (0) , one outer iteration first computes the p osterior probabilities ˆ τ iℓ for i ∈ [ n ] , ℓ ∈ { 1 , 2 } using ( 5 ) and then up dates the column lab els follo wing ( 11 ). W e denote the estimated lab els after one outer iteration b y ˆ z ( e (0) , Ω (0) ). The follo wing theorem establishes the strong consistency of this one-step estimator. Theorem 2. Supp ose ( a (1+ c ) − b (1 − d )) 2 a (1+ c )+ b (1 − d ) ≥ C log n , ( a (1 − c ) − b (1+ d )) 2 a (1 − c )+ b (1+ d ) ≥ C log n , and ac + bd ≥ C log n hold for sufficiently lar ge c onstant C > 0 , then for any ϵ > 0 , ther e exists N > 0 such that for al l n ≥ N , P \ Ω (0) ∈P Ω ˆ z e (0) , Ω (0) = z ≥ 1 − ne − ( a (1+ c ) − b (1 − d ) − 4 ϵ ) 2 8( a (1+ c )+ b (1 − d )) + ne − ( a (1 − c ) − b (1+ d ) − 4 ϵ ) 2 8( a (1 − c )+ b (1+ d )) +(2 n 2 + 2 n ) e − (2 γ − 1) 2 ( a (1+ c ) − b (1 − d )) 2 16( a (1+ c )+ b (1 − d )) + e − (2 γ − 1) 2 ( a (1 − c ) − b (1+ d )) 2 16( a (1+ c )+ b (1 − d )) + e − (2 γ − 1) 2 ( ac + bd ) 8 , for any e (0) ∈ P γ E , wher e ˆ z = z denotes e quivalenc e up to a p ermutation of c ommunity lab els. The pro of of Theorem 2 is given in App endix. As n → ∞ , the b ound in Theorem 2 implies that the one-step estimator ˆ z is a strongly consistent estimate of comm unity lab els. Our result for strong consistency requires ( a (1+ c ) − b (1 − d )) 2 a (1+ c )+ b (1 − d ) ≥ C log n and ( a (1 − c ) − b (1+ d )) 2 a (1 − c )+ b (1+ d ) ≥ C log n . 13 Note that the probabilities of forming p ositiv e edges are a (1+ c ) n within communities and b (1 − d ) n b et w een comm unities, while those for negative edges are a (1 − c ) n within communities and b (1+ d ) n b et w een comm unities. Therefore, our result requires a sufficient gap b etw een the within- and b etw een-comm unity probabilities for b oth positive and negative edges, whic h shares the same order as the gap condition required for strong consistency in the binary SBM setting (W ang et al. Oct. 2021 ). Both conditions are necessary in our metho d, as the pseudo-lik eliho o d of the BSBM in volv es randomness from b oth edge formation and sign generation. In addition, w e require ac + bd ≥ C log n . When c = d , this simplifies to ( a + b ) c ≥ C log n , where a + b corresponds to the a verage no de degree (often denoted by λ n in the literature (Bick el et al. 2009 ; Zhao et al. 2012 )). In tuitively sp eaking, when the signal strength from the edge-sign distribution, reflected by the magnitude of c , is weak, a denser net work is needed to ensure that enough signed edges are observed. Conv ersely , when the signal from edge signs is sufficiently strong, i.e., c is of constan t order, the condition reduces to requiring λ n ≥ C log n , which aligns with the standard requirement λ n / log n → ∞ for strong consistency in SBMs. Notably , in this case, we do not require an y gap in the edge-formation probabilities b et ween and within comm unities, ev en when a = b , strong consistency can still b e ac hieved as long as the sign information provides sufficient signal (see further discussion in Remark 1 b elo w). Remark 1. If c ommunity dete ction r elies solely on e dge c onne ctivity p atterns, str ong c on- sistency under the binary SBM with two b alanc e d c ommunities r e quir es ( a − b ) 2 a + b ≥ C log n for a sufficiently lar ge c onstant C (Wang et al. Oct. 2021 ). This c ondition excludes the de gener ate c ase a = b , wher e within- and b etwe en-c ommunity e dge pr ob abilities ar e identic al and thus c ontain no c ommunity signal. Our r esult extends this b oundary by al lowing a = b . When a = b and c = d , our c onditions r e duc e to ac 2 ≥ C log n for a sufficiently lar ge c onstant C . In this setting, the pr oblem is e quivalent to fitting an SBM wher e e ach observe d e dge takes value 1 with pr ob ability (1 + c ) / 2 and − 1 with pr ob ability (1 − c ) / 2 , and e ach e dge is observe d indep endently with pr ob ability p = a/m . Note that when c is of c onstant or der, Mariadassou et al. ( 2020 ) shows that c onsistency for SBMs with missing data r e quir es the sampling pr ob ability to satisfy p ≫ log( n ) /n ; under this r e gime, our c ondition natur al ly holds. Our the ory gener alizes these r esults by establishing str ong c onsistency of the estimate d memb erships as long as pc 2 ≫ log( n ) /n . Next, we generalize our results to K equal-sized communities. Let m = n/K denote the num b er of no des in each communit y and the true communit y lab els b e z i = k for i ∈ I k = { ( k − 1) m + 1 , . . . , k m } . Without loss of generality , assume the edge probability 14 in ( 1 ) is P ℓℓ ′ = a m I ( ℓ = ℓ ′ ) + b m I ( ℓ = ℓ ′ ) , for 1 ≤ ℓ, ℓ ′ ≤ K, where no des are more likely to form edges within communities than b et ween them. Supp ose eac h comm unity maps to one of tw o meta-groups via ν ℓ = ( − 1) ℓ +1 for 1 ≤ ℓ ≤ K , and let η ℓℓ ′ = c · I ( ℓ = ℓ ′ ) + d · I ( ℓ = ℓ ′ ) with c, d ∈ [0 , 1] in ( 2 ). Then the edge-sign p robabilit y matrix Q takes (1 + c ) / 2 within communities and (1 − d ) / 2 or (1 + d ) / 2 b et ween comm unities. Similarly , w e assume the initial column lab els e (0) ∈ P γ E and the initial model parameters Ω (0) ∈ P Ω , where P γ E = ( e (0) ∈ [ K ] n : X i ∈ I k I e (0) i = k = γ k m, n X i =1 I e (0) i = k = m, γ k ∈ 1 2 , 1 , k ∈ [ K ] ) , and P Ω = ( Ω (0) = ( π (0) , P (0) , Q (0) ) : π (0) ℓ = 1 K , P (0) ℓℓ > P (0) ℓℓ ′ , Q (0) ℓℓ = Q (0) ℓℓ ′ = 1 2 , 1 ≤ ℓ = ℓ ′ ≤ K ) . The following corollary establishes the strong consistency of the one-step estimator. Corollary 2.1. Supp ose S 1 := ( a (1+ c ) − b (1 − d )) 2 ( a (1+ c )+ b (1 − d )) ≥ C log n , S 2 := ( a (1 − c ) − b (1+ d )) 2 ( a (1 − c )+ b (1+ d )) ≥ C log n , S 3 := ( a (1+ c ) − b (1+ d )) 2 ( a (1+ c )+ b (1+ d )) ≥ C log n , S 4 := ( a (1 − c ) − b (1 − d )) 2 ( a (1 − c )+ b (1 − d )) ≥ C log n , and S 5 := ac − bd ≥ C log n , for sufficiently lar ge c onstant C > 0 , then for any ϵ > 0 , ther e exists N > 0 such that for al l n ≥ N , P \ Ω (0) ∈P Ω n ˆ z e (0) , Ω (0) = z o ≥ 1 − n ( K − 1) " e − ( a (1+ c ) − b (1 − d ) − 4 ϵ ) 2 16( a (1+ c )+ b (1 − d )) + e − ( a (1 − c ) − b (1+ d ) − 4 ϵ ) 2 16( a (1 − c )+ b (1+ d )) + e − ( a (1+ c ) − b (1+ d ) − 4 ϵ ) 2 16( a (1+ c )+ b (1+ d )) + e − ( a (1 − c ) − b (1 − d ) − 4 ϵ ) 2 16( a (1 − c )+ b (1 − d )) # − (16 K − 8) n 2 K K X ℓ =1 K X ℓ ′ =1 5 X w =1 exp − S w 24 ( r ℓ + r ℓ ′ − 1) , for any e (0) ∈ P γ E , wher e ˆ z = z denotes e quivalenc e up to a p ermutation of c ommunity lab els. The pro of of Corollary 2.1 is pro vided in App endix, whic h is a natural extension of the pro of of Theorem 2 . Compared with Theorem 2 , we require additional conditions 15 ( a (1+ c ) − b (1+ d )) 2 a (1+ c )+ b (1+ d ) ≥ C log n and ( a (1 − c ) − b (1 − d )) 2 a (1 − c )+ b (1 − d ) ≥ C log n . These additional conditions arise from the presence of mixed en tries in the b et w een-communit y sign-probability matrix when K > 2. Sp ecifically , when K > 2, the off-diagonal en tries of the sign-probabilit y matrix Q can tak e either (1 − d ) / 2 or (1 + d ) / 2, while the diagonal en tries are (1 + c ) / 2. As a result, the probabilities of forming p ositive edges are a (1+ c ) n within communities, and b (1 − d ) n or b (1+ d ) n b e- t ween comm unities, while those for negativ e edges are a (1 − c ) n within comm unities, and b (1+ d ) n or b (1 − d ) n b et w een communities. This difference among b etw een-commun it y probabilities necessitates that the minimum separation b et ween within- and b et w een-communit y proba- bilities b e sufficiently large. F urthermore, when a = b = λ n , the condition ac − bd ≥ C log n simplifies to λ n ( c − d ) ≥ C log n . In addition to requiring the av erage no de degree λ ≫ log n , w e also need c > d strictly , i.e., the probabilities of forming positive edges are strictly higher within communities than b etw een them, since the latter may tak e v alue (1 + d ) / 2. 5 Sim ulation Studies 5.1 Sim ulation Setup W e compare our metho d with four baselines for communit y detection in signed netw orks, whic h differ in how they use edge signs and connectivity patterns. • The low-rank matrix completion (MC) metho d relies solely on e dge-sign informa- tion and do es not use e dge-c onne ctivity patterns for communit y detection. It treats zeros in the signed adjacency matrix as missing v alues and completes the matrix under a lo w-rank assumption using the observed edge signs (Chiang et al. 2014 ). Comm unity assignmen ts are obtained via sp ectral embedding follo wed b y k -means clustering. • The sp ectral clustering with p erturbation (SCP) (Amini et al. 2013 ) and profile- pseudo likelihoo d (PPL) (W ang et al. Oct. 2021 ) metho ds for binary net works detect comm unities based solely on e dge-c onne ctivity and ignore sign patterns. W e bi- narize the signed net w ork b y retaining only edge connectivit y information, i.e., treating | A | as a binary unsigned adjacency matrix. The former applies the SCP algorithm on the binary net w ork, while the latter fits an SBM for binary netw ork via PPL estimation. • The PPL-merge baseline partially preserves sign information b y merging negativ e edges with non-edges, i.e., setting − 1 entries to 0 in the adjacency matrix, and then fitting an SBM for the resulting binary netw ork via profile pseudo-lik eliho o d estimation. This baseline is motiv ated b y the assumption that negative edges tend to o ccur across comm unities. 16 W e generate signed netw orks from BSBM. The communit y mem b ership of eac h no de z i ∈ [ K ] is dra wn i.i.d. from a categorical distribution with probabilities π = ( π 1 , · · · , π K ). W e set balanced communities π k = 1 /K for k ∈ [ K ] in the main text and provide additional results for unbalanced communities in App endix A . Given comm unit y memberships, edges are formed indep enden tly with probabilities P z i z j , where P ℓℓ ′ = P bt + ( P in − P bt ) · I ( ℓ = ℓ ′ ) for 1 ≤ ℓ, ℓ ′ ≤ K with P in = 0 . 13 and P bt = 0 . 07 by default. Conditional on an edge betw een no des i and j , its sign is p ositiv e with probabilit y Q z i z j , where Q ℓℓ ′ = (1 + η ℓℓ ′ · ν ℓ · ν ℓ ′ ) / 2 for 1 ≤ ℓ, ℓ ′ ≤ K with η ℓℓ ′ randomly generated from the uniform distribution U ([0 , 1]), and ν ℓ = ( − 1) ℓ +1 b y default. W e set the num b er of no des n = 1 , 000 and the num b er of comm unities K = 3 unless otherwise stated. T o ev aluate comm unity detection p erformance, w e rep ort normalized m utual information (NMI) b etw een estimated and true communit y mem b erships. It ranges from 0 (indep enden t assignmen t) to 1 (perfect matc h); a higher v alue indicates a b etter comm unit y detection accuracy . W e rep ort results for 100 indep endently generated signed net w orks. In the following subsections, we in v estigate four settings that v ary (1) the signal from edge-connectivit y patterns, quan tified by the gap b et w een within- and b etw een-communit y connection probabilities P in − P bt ; (2) the meta-group size, i.e., the n um b er of communities mapp ed to the same meta-group; (3) the signal from edge-sign patterns, quantified by the magnitude of η ℓℓ ′ in Q ; and (4) the netw ork size n and the num b er of communities K . 5.2 V arying the Signal from Edge-Connectivit y Patterns In this setting, we in vestigate ho w the strength and direction of the edge-connectivity signal, quan tified b y the gap b et w een within- and b et ween-comm unity connection probabilities, affect the p erformance of the five metho ds. The b etw een-comm unit y probabilit y is fixed at P bt = 0 . 07, while the within-comm unit y probability P in v aries from 0 . 05 to 0 . 13. Figure 3 (a) shows that, as P in increases, the NMI scores of all metho ds except MC impro ve, which demonstrates improv ed detectability with a larger gap b etw een within- and b et w een-communit y probabilities. The p erformance of the MC metho d remains flat, as it relies solely on edge signs and ignores connectivity information. Across all v alues of P in , our prop osed metho d consistently outp erforms the others. Notably , when P in is close to P bt , corresp onding to an extremely w eak edge-connectivit y signal, the NMI scores of PPL and SCP drop to nearly zero, indicating their failure to recov er meaningful communities when relying only on connectivit y information. In con trast, our metho d, MC, and PPL-merge ac hieve substantially higher NMI scores in this c hallenging scenario b y effectiv ely lev eraging sign information. 17 In addition, when P in further decreases in to the disassortativ e regime ( P in = 0 . 05 < P bt ), the p erformance of PPL-merge drops. This is b ecause, in disassortativ e netw orks, negativ e edges tend to o ccur b et ween communities, while non-edges are more lik ely to app ear within communities. Merging these t wo t yp es of edges therefore conflates distinct patterns. These results demonstrate the imp ortance of appropriately incorporating edge-sign patterns, esp ecially when the signal from edge-connectivity patterns is w eak. 5.3 V arying the Meta-Group Size W e further in v estigate the p erformance of the fiv e metho ds when v arying the sign r atio in the v ector ν , which determines ho w man y communities share the same sign and th us b elong to the same meta-group. W e set the n um b er of communities K = 8 with equal communit y size. A sign ratio of 1:7, for example, corresp onds to the case where only the first entry of ν is − 1, and all remaining sev en en tries are 1, indicating one meta-group is sev en times larger than the other. A more balanced sign ratio 4:4 implies that communities are ev enly divided b et w een the t wo meta-groups. The within- and betw een-comm unit y probabilities P in and P bt are fixed at 0 . 15 and 0 . 06, resp ectiv ely . W e c ho ose a relativ ely high P in and a larger gap b et ween P in and P bt than the default v alues since the case with K = 8 is more c hallenging. As shown in Figure 3 (b), our metho d remains robust and consisten tly outp erforms the other methods across differen t sign ratios. 5.4 V arying the Signal from Edge-Sign P atterns In this setting, w e ev aluate the communit y detection p erformance of the fiv e metho ds under v arying strengths of the edge-sign signal. The entries of the edge-sign probability matrix Q are randomly generated from uniform distributions with differen t ranges to con trol the signal magnitude. Sp ecifically , η ℓ,ℓ ′ are uniformly sampled from fiv e differen t in terv als: U ([0 . 1 , 0 . 2]), U ([0 . 2 , 0 . 3]), U ([0 . 3 , 0 . 4]), U ([0 . 4 , 0 . 5]), and U ([0 . 5 , 0 . 6]), resp ectiv ely . Larger v alues corre- sp ond to stronger signals from edge-sign patterns. W e set P bt = 0 . 07 and P in = 0 . 1, slightly lo wer than the default v alue, to create a more challenging scenario where differences in p erformance across metho ds b ecome clearer. Figures 3 (c) and 3 (d) present the results for K = 2 and K = 3, resp ectively . In b oth cases, the performances of our method, MC, and PPL-merge impro v e as the magnitude of η ’s increases, which b enefits from stronger signals from edge signs. The p erformances of SCP and PPL, which only use edge-connectivit y information, remain almost identical. When K = 2, the structure of Q ensures that the edges within communit y are more lik ely to b e 18 0.00 0.25 0.50 0.75 1.00 0.05 0.07 0.09 0.11 0.13 V alue of Within−Community Edge Probability P in NMI (a) 0.25 0.50 0.75 1.00 1:7 2:6 3:5 4:4 Sign Ratio NMI (b) 0.00 0.25 0.50 0.75 1.00 Unif[0.1, 0.2] Unif[0.2, 0.3] Unif[0.3, 0.4] Unif[0.4, 0.5] Unif[0.5, 0.6] η NMI (c) 0.0 0.2 0.4 0.6 0.8 Unif[0.1, 0.2] Unif[0.2, 0.3] Unif[0.3, 0.4] Unif[0.4, 0.5] Unif[0.5, 0.6] η NMI (d) 0.00 0.25 0.50 0.75 1.00 100 500 1000 2000 Number of Nodes (n) NMI (e) 0.00 0.25 0.50 0.75 1.00 2 4 6 8 Number of Commnuties (K) NMI (f) MC (sign only) SCP (edge only) PPL (edge only) PPL−merge Our Method Figure 3: Comparisons of NMI scores across five methods under six sim ulation settings. P anels (a)-(f ), from top left to b ottom right, corresp ond to: (a) v arying within-communit y probabilities P in with fixed b etw een-communit y probabilities P bt = 0 . 07; (b) v arying the size of meta-groups; (c) v arying the magnitude of η ’s when K = 2; (d) v arying the magnitude of η ’s when K = 3; (e) v arying the num b er of no des n ; and (f ) v arying the n umber of comm unities K . 19 p ositiv e and the edges b et w een communities betw een are more likely to b e negativ e. In this scenario, methods that lev erage sign information significan tly outp erform those that do not. F or K = 3, when the v alues of η ’s are small, the probabilities of edge signs b etw een and within communities b ecome less distinguishable, which reduces the informativ eness of signs patterns. Consequen tly , the p erformance of our metho d decreases under weak sign signals. Ho wev er, as shown in Figure 3 (d), when the v alues exceed 0.3, our metho d ac hieves the b est p erformance among all fiv e metho ds. 5.5 V arying the Net work Size n and the Num b er of Comm unities K Finally , we study the impact of v arying the net work size and the num b er of communities. W e first fix K = 3 and v ary the num b er of no des from 100 to 2 , 000. As sho wn in Figure 3 (e), the p erformances of all metho ds improv e as n increases. Our metho d consistently outp erforms all baselines when n ≥ 500; and when n = 2 , 000, our metho d, SCP , PPL, and PPL- Merge all ac hiev e near-p erfect comm unit y recov ery . F or small net works with n = 100, the p erformance of our metho d declines b ecause it is sub ject to t w o sources of randomness arising from edge formation and sign generation, whereas the baselines rely on only one. The additional randomness in our metho d makes comm unit y recov ery more difficult giv en the limited netw ork size. Next, w e fix the netw ork size n = 1 , 000 and v ary the num b er of communities K ov er { 2 , 4 , 6 , 8 } . Figure 3 (f ) sho ws that NMI generally decreases as K increases, whic h is expected as the comm unity detection problem b ecomes more challenging. Nonetheless, our prop osed metho d consisten tly outp erforms all baselines across different v alues of K . When K = 2, all fiv e metho ds achiev e NMI scores close to 1. As K increases, the p erformances of SCP and PPL deteriorate substan tially , with NMI scores falling b elow 0 . 2 when K = 8. MC p erforms sligh tly b etter but still lags b ehind our metho d and PPL-merge. 6 Real-w orld Data Examples 6.1 In ternational Relation Net w ork W e apply our metho d to the Corr elates of War (CO W) dataset, whic h records v arious types of in ternational relations betw een coun tries, including w ars, alliances, and militarized in- terstate disputes (Izmirlioglu 2017 ). F ollo wing the pro cedures in T ang et al. ( 2025 ), we construct a signed international relations net work b y treating alliance records as p ositiv e 20 relationship and records of w ars or militarized disputes as negative relationship. W e fo cus on the p erio d from 1941 to 1943, corresp onding to the phase of W orld W ar I I after the U.S. en tered the conflict, during whic h the ma jor p ow ers largely maintained stable alliance structures. F or eac h pair of coun tries, w e aggregate records ov er this three-year p erio d. The sign of the edge is set to negativ e if the duration of negative relationship is longer than that of p ositive relationship and set to p ositive otherwise. Coun try pairs with no recorded inter- actions during this p erio d are assigned non-edge. The signed net work includes 52 countries, with 237 p ositiv e edges and 184 negative edges in total. W e assess the empirical evidence of structural balance theory in this signed netw ork using the hypothesis test prop osed b y F eng et al. ( 2022 ). The p-v alue is near 0, which provides strong evidence against the null h yp othesis of a balance-free net w ork, and motiv ates us to lev erage balance theory for com- m unity detection. W e adopt the net work cross-v alidation metho d (Li et al. 2020 ) and select the num b er of communities K = 8. Our metho d identifies eigh t comm unities that align closely with geop olitical structures during 1941–1943 (see Figure 4 for detailed assignments). Communit y 1 captures the core Axis p ow ers, and Communit y 2 includes their Eastern Europ ean allies. The Allied pow ers are divided into multiple communities: one centered on the United Kingdom and Commonw ealth nations (Comm unit y 3), another on the United States and its regional allies (Comm unit y 4), and a third including F rance, Spain, and Finland (Communit y 5). Latin American countries cluster together in Communit y 6, reflecting regional ties rather than direct military engagement. Neutral or less in v olved states, suc h as Switzerland, Swe- den, and several Middle Eastern countries, form Comm unity 8, partially due to their geop olit- ical distance from the primary conflict. Ov erall, our metho d effectively captures meaningful p olitical and geographical comm unit y structures. F or comparison, w e also apply PPL and PPL-merge to the same dataset. Both metho ds partially recov er geop olitical patterns but pro duce less coherent clusters than ours. De- tailed communit y assignments for b oth metho ds are rep orted in App endix B . Under PPL, Hungary , Bulgaria, and Romania are group ed with the Common wealth nations, which is inconsisten t with the fact that the former w ere Axis-aligned while the latter w ere Allied supp orters. In addition, the United Kingdom is group ed with P ortugal, Iran, T urkey , and Thailand, which app ears inconsisten t with historical records, as b oth Portugal and T urk ey main tained neutralit y most of the time. Under PPL-merge, Canada, F rance, China, and the Common wealth nations are group ed with Italy , whic h w as one of ma jor Axis p ow ers, while German y is group ed together with Greece, Y ugoslavia, Iran, and T urk ey , whic h w ere either neutral or opp osed to Axis expansion. 21 Japan Italy Germany 50 ° S 30 ° S 10 ° S 10 ° N 30 ° N 50 ° N 70 ° N 150 ° W 120 ° W 90 ° W 60 ° W 30 ° W 0 ° 30 ° E 60 ° E 90 ° E 120 ° E 150 ° E Longitude Latitude Community 1 2 3 4 5 6 7 8 Figure 4: W orld map showing eight communities identified by our metho d, with each color represen ting one communit y: (1) Germany , Italy , Japan; (2) Hungary , Bulgaria, Romania; (3) Canada, United Kingdom, Y ugosla via, Greece, Russia, Ethiopia, South Africa, China, Australia, New Zealand; (4) United States, Haiti, Nicaragua; (5) F rance, Spain, Finland; (6) Cuba, Dominican Republic, Mexico, Guatemala, Honduras, El Salv ador, Costa Rica, P anama, Colombia, V enezuela, Ecuador, P eru, Brazil, Bolivia, P aragua y , Chile, Argentina, Urugua y; (7) Portugal, T urk ey , Thailand; (8) Switzerland, Sweden, Iran, Iraq, Egypt, Saudi Arabia, Y emen Arab Republic, Afghanistan, Mongolia. Differen t colors represen t different comm unities. 6.2 Protein-Protein In teraction Net w ork W e further apply our metho d to a protein-protein in teraction (PPI) netw ork (Huttlin et al. 2021 ). In this netw ork, each protein is represented as a no de, and significant p ositive or negativ e correlations betw een protein expression levels define the existence of edges and their signs. W e use a significance threshold of 0.05 for the correlation p -v alues and remo ve no des with degrees less than 5, resulting in a net w ork with 1 , 109 no des, 5 , 163 p ositiv e edges, and 1 , 308 negativ e edges. Similarly , w e apply the hypothesis test prop osed by F eng et al. ( 2022 ) and find strong empirical evidence of balance theory in this signed netw ork ( p -v alue ≈ 0). The n um b er of communities is selected as 25 using the net w ork cross-v alidation metho d (Li et al. 2020 ). T o interpret our communit y detection results, we conduct an o ver-represen tation analy- ses (ORA) (Huang et al. 2009 ) to identify biological pathw ays enric hed within eac h detected comm unity . The predefined sets of proteins are obtained from the Molecular Signatures Database (MSigDB) (Lib erzon et al. 2015 ). Within each communit y , we use the hyperge- 22 ometric test to assess whether predefined sets of proteins are statistically ov er-represented compared to what would b e exp ected by chance. Multiple testing correction is applied via the Benjamini–Hoch b erg pro cedure to con trol the false discov ery rate. F or eac h comm unity , w e rep ort the path w ay with the smallest adjusted p-v alue. The results for our metho d are summarized in T able 3 in App endix B , where 23 out of 25 communities are significan tly asso ciated with biologically meaningful pathw ays (adjusted p-v alues < 0 . 05). Compared with the PPL metho d, whic h uses only edge-connectivity patterns, our metho d iden tifies communities with stronger biological interpretabilit y . Sp ecifically , Figure 5 com- pares the distributions of pr otein r atios obtained from the tw o metho ds. Here, the pr otein r atio ( M 1 / M 2 ) for a given comm unity represen ts the fraction of proteins ( M 1 ) annotated to the enriched pathw ay out of the total n umber of proteins in that communit y ( M 2 ). Higher ratios indicate more coherent and functionally homogeneous communities. As shown in Figure 5 , the comm unities iden tified by our metho d tend to ha ve larger protein ratios. F ur- thermore, for the 10 communities with protein ratios greater than 0.5 that share the same asso ciated path wa ys under b oth metho ds, Figure 6 compares their negativ e log-transformed adjusted p-v alues. Our metho d ac hiev es higher v alues in most comm unities, whic h indicates that it identifies pathw a ys with stronger statistical significance than those obtained using the PPL metho d. Finally , the comm unities obtained from the PPL metho d con tain a higher prop ortion of negative edges within comm unities (10% vs. 7%) and a lo wer prop ortion of neg- ativ e edges b et ween communities (26% vs. 28%), indicating w eaker alignment with balance theory compared to our metho d. 0.0 0.5 1.0 1.5 2.0 0.25 0.50 0.75 1.00 Protein Ratio Density Method Our Method PPL (edge only) Figure 5: Densit y plot comparing the distribution of protein ratios obtained from our metho d and the PPL method. The pr otein r atio ( M 1 / M 2 ) for a giv en comm unity represents the fraction of proteins ( M 1 ) annotated to the enric hed path wa y out of the total num b er of proteins in that comm unit y ( M 2 ). Higher ratios indicate more coheren t and functionally homogeneous communities. 23 cytoplasmic translation endomembrane system organization mitochondrial gene expression mitochondrial translation NADH dehydrogenase comple x assembly positive regulation of double−str and break repair via homologous recombination proteasome−mediated ubiquitin−dependent protein catabolic process regulation of RNA splicing ribosome biogenesis RNA splicing, via transesterification reactions with bulged adenosine as nucleophile 0 10 20 30 40 −log10(Adjusted P−V alues) Description Our Method PPL (edge only) Figure 6: Comparison of o ver-represen tation analysis results b etw een our metho d and the PPL metho d. Eac h bar represen ts − log 10 (adjusted p -v alue) for enric hed biological path wa y in a giv en comm unity . Higher v alues indicate stronger statistical significance of enric hment. 7 Conclusion W e ha ve prop osed a no vel balanced stochastic blo ck mo del (BSBM) for signed net works, whic h introduces a hierarchical organization of comm unities into t wo meta-groups to ac hiev e p opulation-lev el balance. The BSBM integrates balance theory in to its generative pro cess and leverages b oth edge-connectivity and edge-sign information for communit y detection. This design allo ws BSBM to uncov er meaningful communit y structures when edge connec- tivit y alone provides w eak signals, whic h has b een demonstrated b oth theoretically and n umerically . W e hav e also developed a fast maximum profile-pseudo likelihoo d estimation algorithm for fitting BSBM with conv ergence guarantee. F uture w ork may extend our BSBM to capture diverse heterogeneit y in real-w orld signed net works. One natural direction is to incorp orate no de degree heterogeneit y and ov erlapping comm unity memberships b y adapting ideas from the degree-corrected mixed mem b ership SBM. It is also of interest to extend BSBM to dynamic signed netw orks, where communit y mem b erships may ev olve o v er time. 24 References Airoldi, E. M., Blei, D., Fienberg, S., and Xing, E. (2008). “Mixed membership sto c hastic blo ck- mo dels”. In: A dvanc es in Neur al Information Pr o c essing Systems 21. Allah yari, N., Kargaran, A., Hosseiny , A., and Jafari, G. (2022). “The structure balance of gene-gene net works beyond pairwise interactions”. In: Plos one 17.3, e0258596. Amini, A. A., Chen, A., Bick el, P . J., and Levina, E. (2013). “Pseudo-lik eliho o d metho ds for comm unity detection in large sparse net works”. In: The Annals of Statistics 4, pp. 2097–2122. Aref, S. and Wilson, M. C. (2018). “Measuring partial balance in signed netw orks”. In: Journal of Complex Networks 6.4, pp. 566–595. Bansal, N., Blum, A., and Chawla, S. (2004). “Correlation clustering”. In: Machine L e arning 56, pp. 89–113. Bic kel, P . J. and Chen, A. (2009). “A nonparametric view of netw ork mo dels and Newman–Girv an and other modularities”. In: Pr o c e e dings of the National A c ademy of Scienc es 106.50, pp. 21068– 21073. Chen, Y., W ang, X., Y uan, B., and T ang, B. (2014). “Ov erlapping comm unit y detection in netw orks with p ositive and negativ e links”. In: Journal of Statistic al Me chanics: The ory and Exp eriment 2014.3, P03021. Chiang, K.-Y., Hsieh, C.-J., Natara jan, N., Dhillon, I. S., and T ew ari, A. (2014). “Prediction and clustering in signed netw orks: a lo cal to global p ersp ective”. In: The Journal of Machine L e arning R ese ar ch 15.1, pp. 1177–1213. Chiang, K.-Y., Whang, J. J., and Dhillon, I. S. (2012). “Scalable clustering of signed netw orks using balance normalized cut”. In: Pr o c e e dings of the 21st ACM International Confer enc e on Information and Know le dge Management , pp. 615–624. Doreian, P . and Mrv ar, A. (1996). “A partitioning approach to structural balance”. In: So cial networks 18.2, pp. 149–168. Doreian, P . and Mrv ar, A. (2015). “Structural balance and signed international relations”. In: Journal of So cial Structur e 16, p. 1. 25 F acc hetti, G., Iacono, G., and Altafini, C. (2011). “Computing global structural balance in large- scale signed so cial netw orks”. In: Pr o c e e dings of the National A c ademy of Scienc es 108.52, pp. 20953–20958. F eng, D., Altmey er, R., Stafford, D., Christakis, N. A., and Zhou, H. H. (2022). “T esting for balance in social netw orks”. In: Journal of the Americ an Statistic al Asso ciation 117.537, pp. 156–174. Go emans, M. X. and Williamson, D. P . (1995). “Improv ed appro ximation algorithms for maximum cut and satisfiability problems using semidefinite programming”. In: Journal of the A CM 42.6, pp. 1115–1145. Handco c k, M. S., Raftery , A. E., and T an trum, J. M. (2007). “Mo del-based clustering for so cial net works”. In: Journal of the R oyal Statistic al So ciety: Series A (Statistics in So ciety) 170.2, pp. 301–354. Harary , F. (1953). “On the notion of balance of a signed graph”. In: Michigan Mathematic al Journal 2.2, pp. 143–146. Heider, F. (1946). “A ttitudes and cognitive organization”. In: The Journal of Psycholo gy 21.1, pp. 107–112. Hoff, P . (2007). “Mo deling homophily and sto chastic equiv alence in symmetric relational data”. In: A dvanc es in Neur al Information Pr o c essing Systems 20. Holland, P . W., Laskey , K. B., and Leinhardt, S. (1983). “Sto chastic blo c kmo dels: First steps”. In: So cial Networks 5.2, pp. 109–137. Hsieh, C.-J., Chiang, K.-Y., and Dhillon, I. S. (2012). “Low rank mo deling of signed netw orks”. In: Pr o c e e dings of the 18th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , pp. 507–515. Huang, D. W., Sherman, B. T., and Lempic ki, R. A. (2009). “Bioinformatics enric hmen t tools: paths to ward the comprehensive functional analysis of large gene lists”. In: Nucleic acids r ese ar ch 37.1, pp. 1–13. Huttlin, E. L., Bruc kner, R. J., Na v arrete-Perea, J., Cannon, J. R., Baltier, K., Gebreab, F., Gygi, M. P ., Thorno ck, A., Zarraga, G., T am, S., et al. (2021). “Dual proteome-scale net works rev eal cell-sp ecific remodeling of the h uman interactome”. In: Cel l 184.11, pp. 3022–3040. 26 Izmirlioglu, A. (2017). “The Correlates of W ar Dataset”. In: Journal of World-Historic al Informa- tion . Jiang, J. Q. (2015). “Sto chastic blo c k mo del and exploratory analysis in signed net works”. In: Physic al R eview E 91.6, p. 062805. Karp, R. M. (1972). “Reducibility among Com binatorial Problems”. In: Complexity of Computer Computations . Springer US, pp. 85–103. Karrer, B. and Newman, M. E. (2011). “Sto chastic blo c kmo dels and communit y structure in net- w orks”. In: Physic al R eview E 83.1, p. 016107. Kunegis, J., Sc hmidt, S., Lommatzsc h, A., Lerner, J., De Luca, E. W., and Alba yrak, S. (2010). “Sp ectral analysis of signed graphs for clustering, prediction and visualization”. In: Pr o c e e dings of the 2010 SIAM International Confer enc e on Data Mining . SIAM, pp. 559–570. Lesk ov ec, J., Huttenlo cher, D., and Klein b erg, J. (2010). “Signed netw orks in so cial media”. In: Pr o c e e dings of the SIGCHI c onfer enc e on human factors in c omputing systems , pp. 1361–1370. Li, T., Levina, E., and Zhu, J. (2020). “Net work cross-v alidation by edge sampling”. In: Biometrika 107.2, pp. 257–276. Li, Y., Liu, J., and Liu, C. (2014). “A comparativ e analysis of ev olutionary and memetic algorithms for comm unity detection from signed social netw orks”. In: Soft Computing 18, pp. 329–348. Li, Y., Y ang, B., Zhao, X., Y ang, Z., and Chen, H. (2023). “SSBM: a signed sto chastic block mo del for multiple structure disco very in large-scale exploratory signed net works”. In: Know le dge- Base d Systems 259, p. 110068. Lib erzon, A., Birger, C., Thorv aldsd´ ottir, H., Ghandi, M., Mesiro v, J. P ., and T ama y o, P . (2015). “The molecular signatures database hallmark gene set collection”. In: Cel l systems 1.6, pp. 417– 425. Mariadassou, M. and T ab ouy , T. (2020). “Consistency and asymptotic normality of stochastic blo ck mo dels estimators from sampled data”. In: Ele ctr onic Journal of Statistics 14.2, pp. 3672–3704. doi : 10.1214/20- EJS1750 . url : https://doi.org/10.1214/20- EJS1750 . Morabito, S., Reese, F., Rahimzadeh, N., Miy oshi, E., and Swarup, V. (2023). “hdWGCNA identifies co-expression netw orks in high-dimensional transcriptomics data”. In: Cel l r ep orts metho ds 3.6. 27 Newman, M. E. (2006). “Mo dularity and communit y structure in net w orks”. In: Pr o c e e dings of the National A c ademy of Scienc es 103.23, pp. 8577–8582. Newman, M. E. and Girv an, M. (2004). “Finding and ev aluating comm unit y structure in net w orks”. In: Physic al R eview E 69.2, p. 026113. Ng, A., Jordan, M., and W eiss, Y. (2001). “On sp ectral clustering: Analysis and an algorithm”. In: A dvanc es in Neur al Information Pr o c essing Systems 14. No wicki, K. and Snijders, T. A. B. (2001). “Estimation and prediction for sto c hastic blo c kstruc- tures”. In: Journal of the Americ an Statistic al Asso ciation 96.455, pp. 1077–1087. P ensky , M. (2025). “Signed div erse multiplex netw orks: clustering and inference”. In: IEEE T r ans- actions on Information The ory . Shi, J. and Malik, J. (2000). “Normalized cuts and image segmentation”. In: IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e 22.8, pp. 888–905. T ang, W. and Zh u, J. (2025). “P opulation-lev el balance in signed netw orks”. In: Journal of the A meric an Statistic al Asso ciation 120.550, pp. 751–763. Vina yagam, A., Zirin, J., Ro esel, C., Hu, Y., Yilmazel, B., Samsono v a, A. A., Neum ¨ uller, R. A., Mohr, S. E., and P errimon, N. (2014). “Integrating protein-protein in teraction netw orks with phenot yp es rev eals signs of in teractions”. In: Natur e metho ds 11.1, pp. 94–99. V u, D. Q., Hunter, D. R., and Sch w einberger, M. (2013). “Mo del-based clustering of large netw orks”. In: The annals of applie d statistics 7.2, p. 1010. W ang, J., Zhang, J., Liu, B., Zhu, J., and Guo, J. (2021). “F ast Netw ork Comm unity Detection With Profile-Pseudo Likelihoo d Metho ds”. In: Journal of the A meric an Statistic al Asso ciation , pp. 1–14. Y ang, B., Cheung, W., and Liu, J. (2007). “Communit y mining from signed so cial netw orks”. In: IEEE T r ansactions on Know le dge and Data Engine ering 19.10, pp. 1333–1348. Zhang, H. and W ang, J. (2022). “Signed net work embedding with application to sim ultaneous detection of communities and anomalies”. In: arXiv pr eprint arXiv:2207.09324 . 28 Zhao, Y., Levina, E., and Zhu, J. (2012). “Consistency of comm unity detection in net works under degree-corrected sto chastic blo c k mo dels”. In: The Annals of Statistics 40.4, pp. 2266–2292. doi : 10.1214/12- AOS1036 . url : https://doi.org/10.1214/12- AOS1036 . 29 A Additional Sim ulation Results In this App endix, we pro vide additional sim ulation results for unbalanced comm unities. The sim ulation set-up is consistent with the main text, except for the choice of π . A.1 V arying the Signal from Edge-Sign patterns In this setting, w e ev aluate the communit y detection p erformance of the fiv e metho ds under v arying strengths of the edge-sign signal. The entries of the edge-sign probability matrix Q are randomly generated from uniform distributions with differen t ranges to con trol the signal magnitude. Sp ecifically , η ℓ,ℓ ′ are uniformly sampled from fiv e differen t in terv als: U ([0 . 1 , 0 . 2]), U ([0 . 2 , 0 . 3]), U ([0 . 3 , 0 . 4]), U ([0 . 4 , 0 . 5]), and U ([0 . 5 , 0 . 6]), resp ectiv ely . Larger v alues corre- sp ond to stronger signals from edge-sign patterns. W e set P bt = 0 . 07 and P in = 0 . 1, slightly lo wer than the default v alue, to create a more challenging scenario where differences in p erformance across metho ds b ecome clearer. Figures 7 and 8 presen t the results for K = 2 and K = 3, resp ectively . When K = 2, we set π = (0 . 3 , 0 . 7). When K = 3, w e set π = (0 . 2 , 0 . 3 , 0 . 5). In both cases, the p erformances of our metho d, MC, and PPL-merge impro v e as the magnitude of η ’s increases, whic h b enefits from stronger signals from edge signs. The p erformances of SCP and PPL, which only use edge-connectivit y information, remain almost identical. When K = 2, the structure of Q ensures that the edges within the communit y are more likely to b e p ositive and the edges b et w een the communit y are more lik ely to b e negativ e. In this scenario, metho ds that lev er- age sign information significan tly outp erform those that do not. F or K = 3, when the v alues of η ’s are small, the probabilities of edge signs b etw een and within communities b ecome less distinguishable, which reduces the informativ eness of signs patterns. Consequently , the p erformance of our metho d decreases under weak sign signals. How ever, as shown in Fig- ure 8 , when the v alues exceed 0.3, our metho d achiev es the b est p erformance among all fiv e metho ds. A.2 V arying the Net w ork Size n and the Num b er of Comm unities K In this setting, w e study the impact of v arying the net w ork size and the n um b er of commu- nities. W e set π = (0 . 2 , 0 . 3 , 0 . 5). W e first fix K = 3 and v ary the n umber of no des from 100 to 2 , 000. As sho wn in Figure 9 , the p erformances of all metho ds impro v e as n increases. Our method consisten tly outp erforms all baselines when n ≥ 500; and when n = 2 , 000, our metho d, SCP , PPL, and PPL-Merge all ac hieve near-p erfect comm unity reco v ery . F or 30 0.00 0.25 0.50 0.75 1.00 Unif[0.1, 0.2] Unif[0.2, 0.3] Unif[0.3, 0.4] Unif[0.4, 0.5] Unif[0.5, 0.6] η NMI Method MC (sign only) SCP (edge only) PPL (edge only) PPL−merge Our Method Figure 7: Comparisons of NMI scores across five metho ds under v arying magnitude of η ’s when K = 2 with π = (0 . 3 , 0 . 7) . 0.0 0.2 0.4 0.6 0.8 Unif[0.1, 0.2] Unif[0.2, 0.3] Unif[0.3, 0.4] Unif[0.4, 0.5] Unif[0.5, 0.6] η NMI Method MC (sign only) SCP (edge only) PPL (edge only) PPL−merge Our Method Figure 8: Comparisons of NMI scores across five metho ds under v arying magnitude of η ’s when K = 3 with π = (0 . 2 , 0 . 3 , 0 . 5) . 31 small netw orks with n = 100, the p erformance of our metho d declines b ecause it is sub ject to tw o sources of randomness arising from edge formation and sign generation, whereas the baselines rely on only one. The additional randomness in our metho d mak es comm unity reco very more difficult given the limited net w ork size. Next, w e fix the netw ork size n = 1 , 000 and v ary the num b er of communities K ov er { 2 , 4 , 6 , 8 } . W e set π as π = (0 . 3 , 0 . 7), π = (0 . 1 , 0 . 2 , 0 . 3 , 0 . 4), π = (0 . 05 , 0 . 15 , 0 . 15 , 0 . 2 , 0 . 2 , 0 . 25), π = (0 . 05 , 0 . 05 , 0 . 1 , 0 . 1 , 0 . 1 , 0 . 15 , 0 . 2 , 0 . 25), resp ectiv ely . Figure 10 sho ws that NMI generally decreases as K increases, which is exp ected as the communit y detection problem b ecomes more challenging. Nonetheless, our prop osed metho d consistently outp erforms all baselines across different v alues of K . When K = 2, all fiv e metho ds ac hieve NMI scores close to 1. As K increases, the p erformances of SCP and PPL deteriorate substantially , with NMI scores falling b elo w 0 . 2 when K = 8. MC p erforms sligh tly b etter but still lags b ehind our metho d and PPL-merge. 0.00 0.25 0.50 0.75 1.00 100 500 1000 2000 Number of Nodes (n) NMI Method MC (sign only) SCP (edge only) PPL (edge only) PPL−merge Our Method Figure 9: Comparisons of NMI scores across five methods under v arying num b er of no des n with π = (0 . 2 , 0 . 3 , 0 . 5) . 32 0.25 0.50 0.75 1.00 2 4 6 8 Number of Commnuties (K) NMI Method MC (sign only) SCP (edge only) PPL (edge only) PPL−merge Our Method Figure 10: Comparisons of NMI scores across fiv e metho ds under v arying n um b er of com- m unities K with π = (0 . 3 , 0 . 7), π = (0 . 1 , 0 . 2 , 0 . 3 , 0 . 4), π = (0 . 05 , 0 . 15 , 0 . 15 , 0 . 2 , 0 . 2 , 0 . 25), π = (0 . 05 , 0 . 05 , 0 . 1 , 0 . 1 , 0 . 1 , 0 . 15 , 0 . 2 , 0 . 25) resp ectively . . 33 B Additional Real Data Analyses Results B.1 In ternational Relation Net w ork The communit y detection results for in ternational relation netw ork using metho ds of PPL and PPL merge are shown in T able 1 and T able 2 . No. Comm unity 1 German y , Italy , Japan 2 Y ugoslavia, Greece, Russia, China 3 Canada, Hungary , Bulgaria, Romania, Ethiopia, South Africa, Aus- tralia, New Zealand 4 United States, Cuba, Haiti, Dominican Republic, Mexico, Guatemala, Honduras, El Salv ador, Nicaragua, Costa Rica, Panama, Bolivia 5 Colom bia, V enezuela, Ecuador, P eru, Brazil, Paragua y , Chile, Ar- gen tina, Uruguay 6 F rance, Spain, Finland 7 United Kingdom, Portugal, Iran, T urk ey , Thailand 8 Switzerland, Sweden, Iraq, Egypt, Saudi Arabia, Y emen Arab Repub- lic, Afghanistan, Mongolia T able 1: Eigh t Communities iden tified by PPL metho d B.2 Protein-Protein In teraction Net w ork The detailed results of o v er-representation analyses for our metho d and PPL method are pre- sen ted in T able 3 and 4 . The pr otein r atio ( M 1 / M 2 ) for a giv en communit y represents the fraction of proteins ( M 1 ) annotated to the enric hed path wa y out of the total num b er of pro- teins in that communit y ( M 2 ). The BgR atio ( M 3 / M 4 ) reflects the background distribution, where M 3 out of M 4 total proteins in the entire database are annotated with that pathw a y . The results of the following 10 comm unities are shown in Figure 5 in our main text: (1)RNA splicing, via transesterification reactions with bulged adenosine as nucleophile; (2)rib osome biogenesis; (3)regulation of RNA splicing; (4)proteasome-mediated ubiquitin-dep endent pro- tein catab olic pro cess; (5)p ositiv e regulation of double-strand break repair via homologous recom bination; (6)NADH dehydrogenase complex assembly; (7)mito chondrial translation; (8)mito c hondrial gene expression; (9)endomem brane system organization; (10)cytoplasmic translation. 34 No. Comm unity 1 German y , Hungary , Y ugosla via, Greece, Bulgaria, Romania, Iran, T urkey , Afghanistan, Japan 2 Russia, Mongolia 3 Canada, F rance, Switzerland, Italy , Finland, Sweden, Ethiopia, South Africa, Egypt, China, Thailand, Australia, New Zealand 4 (Empt y) 5 United States, Cuba, Haiti, Dominican Republic, Mexico, Guatemala, Honduras, El Salv ador, Nicaragua, Costa Rica, Panama, Colom bia, V enezuela, Ecuador, P eru, Brazil, Bolivia, P araguay , Chile, Argentina, Urugua y 6 (Empt y) 7 United Kingdom, Spain, Portugal 8 Iraq, Saudi Arabia, Y emen Arab Republic T able 2: Eigh t Communities iden tified by PPL-merge metho d 35 Cluster Description ProteinRatio BgRatio Adjusted P-V alue 1 regulation of mRNA splicing, via spliceosome 4/9 13/1012 2.80e-04 2 translational initiation 4/9 17/1012 7.47e-04 3 p ositiv e regulation of DNA biosynthetic pro- cess 8/35 11/1012 7.62e-08 4 mito c hondrial translation 27/29 94/1012 5.32e-26 5 resp onse to stimulus 155/268 441/1012 2.12e-05 6 p ositiv e regulation of double-strand break re- pair via homologous recombination 14/18 15/1012 1.55e-24 7 mito c hondrial gene expression 20/34 104/1012 4.37e-10 8 transp ort 25/43 218/1012 6.03e-05 9 RNA splicing, via transesterification reactions with bulged adenosine as nucleophile 24/26 57/1012 1.88e-28 10 regulation of RNA splicing 9/16 30/1012 1.55e-08 11 RNA splicing, via transesterification reactions with bulged adenosine as nucleophile 19/21 57/1012 2.26e-21 12 cell comm unication 33/63 290/1012 2.76e-02 13 mito c hondrial gene expression 29/33 104/1012 1.60e-24 14 proteasome-mediated ubiquitin-dep enden t protein catab olic pro cess 24/24 59/1012 2.08e-30 15 regulation of transcription initiation b y RNA p olymerase I I 25/63 28/1012 3.87e-27 16 rib osome biogenesis 34/51 96/1012 8.63e-23 17 transcription b y RNA p olymerase I I I 9/31 16/1012 3.46e-08 18 RNA biosyn thetic pro cess 31/37 351/1012 3.29e-07 19 cytoplasmic translation 36/44 55/1012 9.79e-42 20 NADH deh ydrogenase complex assembly 17/18 19/1012 1.26e-31 21 resp onse to growth factor 17/92 44/1012 3.63e-05 22 mito c hondrial translation 22/22 94/1012 1.08e-22 23 endomem brane system organization 5/6 30/1012 1.06e-05 T able 3: Ov er-represen tation analyses using our metho d. 36 Cluster Description GeneRatio BgRatio Adjusted P-V alue 1 cytoplasmic translation 11/17 55/1012 1.68e-08 2 translational initiation 4/9 17/1012 7.47e-04 3 p ositiv e regulation of DNA biosynthetic pro- cess 8/34 11/1012 5.91e-08 4 mito c hondrial gene expression 30/34 104/1012 2.43e-25 5 m ulticellular organismal pro cess 162/310 343/1012 5.35e-13 6 p ositiv e regulation of double-strand break re- pair via homologous recombination 14/17 15/1012 3.42e-25 7 mito c hondrial RNA metab olic pro cess 6/27 16/1012 4.18e-04 8 transp ort along microtubule 9/39 18/1012 1.27e-06 9 RNA splicing, via transesterification reactions with bulged adenosine as nucleophile 23/25 57/1012 3.50e-27 10 regulation of RNA splicing 9/9 30/1012 6.57e-13 11 RNA splicing, via transesterification reactions with bulged adenosine as nucleophile 19/23 57/1012 1.03e-19 12 G protein-coupled receptor signaling pathw ay 9/36 27/1012 5.30e-05 13 mito c hondrial translation 26/30 94/1012 7.49e-23 14 proteasome-mediated ubiquitin-dep enden t protein catab olic pro cess 19/19 59/1012 3.10e-23 15 regulation of DNA-templated transcription initiation 27/105 29/1012 1.49e-23 16 rib osome biogenesis 31/59 96/1012 6.07e-16 17 transcription b y RNA p olymerase I I I 10/33 16/1012 1.14e-09 18 rRNA pro cessing 12/33 63/1012 7.94e-05 19 cytoplasmic translation 21/31 55/1012 5.93e-19 20 NADH deh ydrogenase complex assembly 17/20 19/1012 7.96e-30 21 mitotic cell cycle phase transition 12/49 37/1012 2.33e-05 22 mito c hondrial translation 28/28 94/1012 1.31e-29 23 endomem brane system organization 5/6 30/1012 1.06e-05 T able 4: Ov er-represen tation analyses using PPL metho d. 37
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment