The Well-Tempered Classifier: Some Elementary Properties of Temperature Scaling
Temperature scaling is a simple method that allows to control the uncertainty of probabilistic models. It is mostly used in two contexts: improving the calibration of classifiers and tuning the stochasticity of large language models (LLMs). In both c…
Authors: Pierre-Alex, re Mattei, Bruno Loureiro
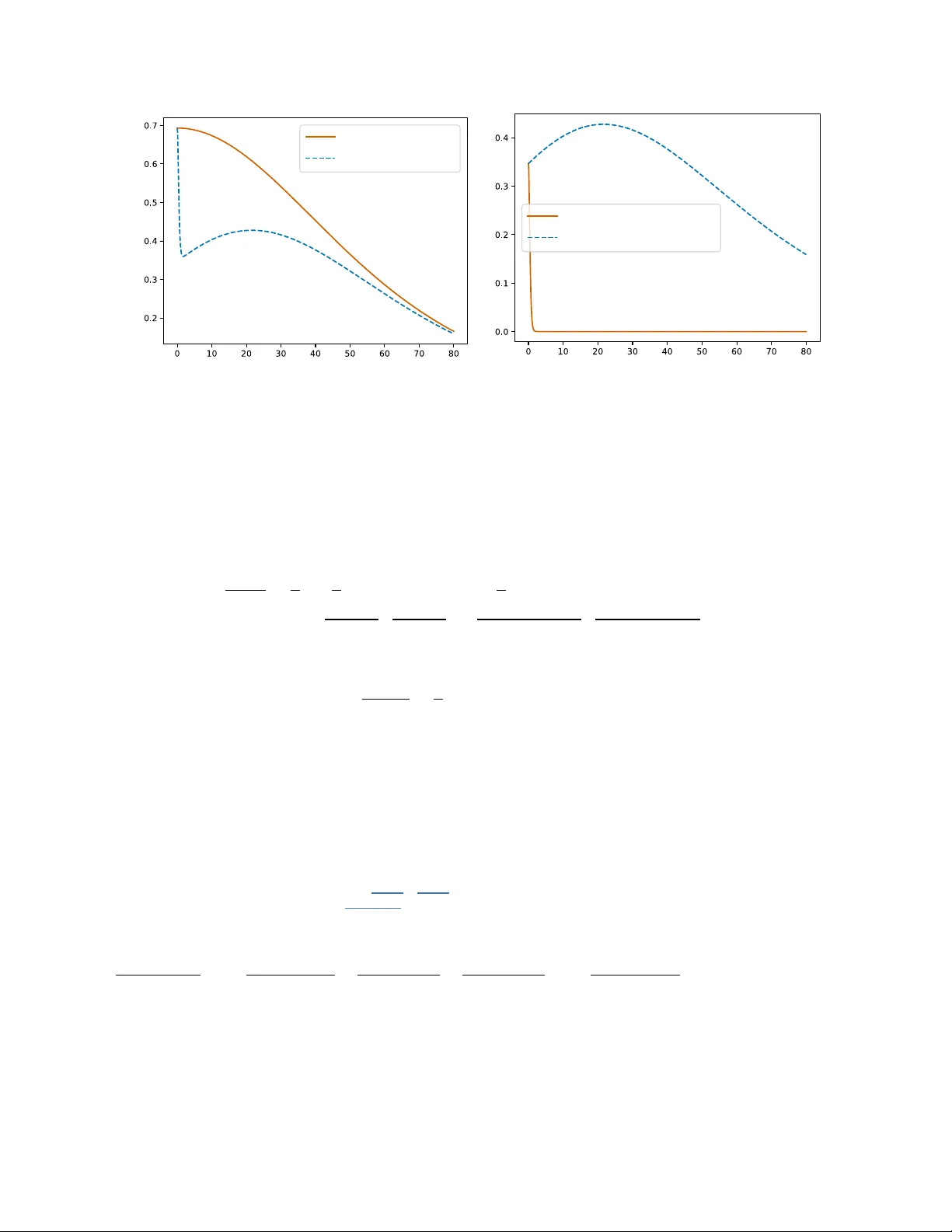
The W ell-T emp ered Classifier: Some Elemen tary Prop erties of T emp erature Scaling Pierre-Alexandre Mattei 1 and Bruno Loureiro 2 1 Univ ersité Côte d’Azur, Inria, CNRS, LJAD, F rance 2 Départemen t d’Informatique, École Normale Sup érieure - PSL, CNRS, F rance F ebruary 17, 2026 Abstract T emperature scaling is a simple method that allo ws to control the uncertaint y of probabilistic models. It is mostly used in tw o con texts: impro ving the calibration of classifiers and tuning the sto c hasticity of large language models (LLMs). In both cases, temp erature scaling is the most popular method for the job. Despite its p opularit y , a rigorous theoretical analysis of the properties of temp erature scaling has remained elusive. W e inv estigate here some of these prop erties. F or classification, w e show that increasing the temp erature increases the uncertain t y in the mo del in a v ery general sense (and in particular increases its entrop y). How ev er, for LLMs, we c hallenge the common claim that increasing temp erature increases div ersity . F urthermore, w e in tro duce tw o new c haracterisations of temp erature scaling. The first one is geometric: the temp ered mo del is sho wn to b e the information pro jection of the original mo del onto the set of models with a given en tropy . The second characterisation clarifies the role of temperature scaling as a submodel of more general linear scalers such as matrix scaling and Dirichlet calibration: we show that temp erature scaling is the only linear scaler that does not c hange the hard predictions of the model. 1 In tro duction Reliable uncertain ty quan tification in deep learning remains an op en problem, p oised b et ween strong theoretical limits ( F o ygel Barb er et al. , 2021 ) and a flurry of prop osed solutions (see e.g. Silv a Filho et al. , 2023 ; Angelop oulos et al. , 2023 ; Ulmer et al. , 2023 ; P apamarkou et al. , 2024 for presentations of the different paradigms at play). In a seminal pap er, Guo et al. ( 2017 ) adv o cated the use of an old and very simple uncertain ty quan tification metho d called temp er atur e sc aling . This technique emplo ys a single scalar parameter (the temp erature) to tune the confidence of a trained neural net work. In the complex landscap e of uncertaint y quantification, temp erature scaling imp osed itself as an immensely p opular metho d. Its use go es from calibrating models in industrial machine learning—it is implemented in the Scikit-learn library ( Pedregosa et al. , 2011 )—to con trolling inference in large language models (LLMs)—its use is perv asive in virtually all LLMs, and is explicitly mentioned in the technical rep orts of GPT-4 ( A chiam et al. , 2023 ), Gemini ( Gemini T eam , 2025 ), DeepSeek ( Liu et al. , 2024 ), and Mis tral ( Rastogi et al. , 2025 ). Often, other uncertaint y quantification tec hniques use temperature scaling as a building blo ck (e.g. Berta et al. , 2025a ; Gibbs et al. , 2025 ). In spite of this p opularit y , there is a surprising lack of theoretical in vestigations of temperature scaling. Exceptions include Clarté et al. ( 2023a ; b ), who studied in particular its asymptotic b eha viour under mo del missp ecification, Dabah and Tirer ( 2025 ) who lo ok ed at the interpla y b et ween temperature scaling and conformal prediction, and Berta et al. ( 2025b ), who studied in which cases it can (and cannot) b e optimal. This relative absence ma y b e due to the fact that the mo del is quite simple, and resembles man y well-studied mo dels in statistics, machine learning, and statistical physics. Nev ertheless, we b eliev e a thorough y et elemen tary inspection of temp erature scaling to be b oth timely and interesting. After reviewing and revisiting temp erature scaling in Section 2 (b oth for classification and LLMs), our main contributions are: 1 • In Section 3 , we show that for classification, increasing the temp erature has the exp ected effect of increasing the uncertaint y of the mo del. How ever, w e highlight that this may not b e the case for LLMs. • W e provide in Section 4 a geometric interpretation of temp erature scaling as an information pro jection: a temp ered model is the mo del closest to the original one that has the required level of en tropy . • An imp ortan t prop ert y of temp erature scaling is that it is ac cur acy-pr eserving: it do es not change the ordering of the classes. W e show in Section 5 that is actually a defining prop ert y , in the sense that it is the only accuracy-preserving linear scaler. Notation. V ectors are denoted by boldfaces. W e denote b y ∆ K = { π ∈ [0 , 1] K | π 1 + . . . + π K = 1 } the K -simplex and by H the Gibbs-Shannon entrop y of a discrete distribution. 2 What is temp erature scaling? W e start with a pretrained mo del f : X → R K where K is the num b er of classes — for instance, a neural net work trained on a classification problem. The output of this mo del are the logits, i.e. the softmax preactiv ations z = f ( x ) . Standard predictive probabilities are obtained by then applying a softmax lay er: p ( y | z ) = Categorical ( y | π ) = π y , (1) with π = Softmax ( z ) ∈ ∆ K , (2) where y ∈ { 1 , . . . , K } is the class lab el and Softmax ( z ) = e z 1 e z 1 + . . . + e z K , . . . , e z K e z 1 + . . . + e z K . (3) Here, we mean “mo del" in a v ery broad sense: while f could b e a standard classifier (with features x and lab el y ), it could also be, for instance, an autoregressiv e language mo del (in that case, x w ould b e the previous tok ens, y the next token(s), and K the size of the v o cabulary). Eac h π k ∈ [0 , 1] corresp onds to the probability that the mo del assigns to class k . Sometimes, one may not b e to o happ y with these probabilities. In particular, in the con text of classification tasks with neural net works, a widely rep orted issue is that these probabilities are generally ov erconfident, leading to p oor calibration ( Guo et al. , 2017 ; Minderer et al. , 2021 ) and difficult distillation ( Hinton et al. , 2015 ). F or LLMs, it is desirable to let users sharp en or smo othen these probabilities to give them control of the amoun t of sto c hasticit y of the generations, also referred to as “diversit y” in this context. T emp erature scaling is a simple and efficient metho d that allows us to slightly alter the probabilities in order to meet one of these goals. The idea is to m ultiply all logits b y a learnable parameter β > 0 , called the inverse temp er atur e in analogy to a Boltzmann-Gibbs distributions in statistical ph ysics. This leads to a new conditional distribution p β ( y | z ) = Categorical ( y | π β ) with π β = Softmax ( β z ) . (4) Since β is constrained to b e p ositiv e, the co efficien ts of β z are ordered in the same wa y as those of z . Th us, the hard predictions of p β will b e iden tical to the ones of the original mo del. In particular, this implies that temp erature scaling is ac cur acy-pr eserving: it do es not change the ac cur acy of the initial mo del. This feature w as already highligh ted by Guo et al. ( 2017 ), and is particularly relev ant for mo dern deep classifiers, which generally excel in terms of accuracy , but are often ov erconfident. As we will see in Section 5 , this is in fact a defining characteristic of temperature scaling. What if w e don’t hav e the logits? W e may not ha ve access to the logits z , but only to the class probabilities π . A natural idea is to replace the logits by the log-probabilities log π . Since the softmax is not in vertible, log π is not necessarily equal to z and there may b e a risk of loosing partial information when us ing 2 log π instead of z . F ortunately , this is not the case and the tw o approaches are equiv alen t. More precisely , as detailed in App endix A , Softmax ( β z ) = Softmax ( β log π ) = π β 1 π β 1 + . . . + π β K , . . . , π β K π β 1 + . . . + π β K ! . (5) Because of this equiv alence, some pap ers (e.g. Guo et al. , 2017 ) define temp erature scaling using the logits, and some using the log-probabilities (e.g. Berta et al. , 2025b ). Another simple wa y of write Equation ( 5 ) is p β ∝ p β . 2.1 Wh y is β called the in v erse temp erature? A temp ered softmax probabilistic classifier admits a natural interpretation in terms of a statistical physics problem in the canonical ensemble with K discrete states and in verse temp erature β , where each state k ∈ { 1 , . . . , K } has energy given by the (negativ e) logit E k = − z k . F rom this p ersp ectiv e, the temp ered categorical distribution is just the Boltzmann-Gibbs distribution of the system: p β ( y | z ) = e − β E y Z ( β , z ) , (6) where the denominator Z ( β , z ) = e β z 1 + . . . + e β z K . (7) is called the p artition function . Another equiv alent p oin t of view w ould be to see p β as an exp onential family distribution with sufficient statistic z y . The partition function has a few remark able y et elemen tary prop erties that will considerably simplify computations related to temp erature scaling. In particular, the deriv atives of its logarithm are related to the momen ts of the logit of a random label. Lemma 1. W e have d log Z ( β , z ) dβ = E y ∼ p β ( y | x ) [ z y ] , (8) d 2 log Z ( β , z ) dβ 2 = V ar y ∼ p β ( y | x ) ( z y ) . (9) V arian ts of Lemma 1 are standard results in statistical ph ysics (see e.g. Kardar , 2007 ) and in the theory of conditional exp onen tial families (see e.g. Domk e , 2020 ). W e giv e a proof in our sp ecific context in App endix B . These results will prov e useful to study the prop erties of the likelihoo d, that can b e written, for a single data p oin t, as log p β ( y | x ) = β z y − log Z ( β , z ) . (10) F rom the statistical physics persp ective, this is simply the free energy cost for the system to o ccup y state y . 2.2 Ho w to tune the temp erature? 2.2.1 Calibrating classifiers In the context of calibration, to tune β , it is customary to use a fresh set of lab elled data ( x 1 , y 1 ) . . . , ( x n , y n ) , called a c alibr ation set . Once the corresp onding predictions π 1 , . . . , π n ha ve bee n computed (this inv olves a forw ard pass through the neural net work), the inv erse temp erature is tuned by minimising the cross-entrop y loss (or equiv alen tly , maximising the log-lik eliho od) of the one-parameter mo del p β o ver the calibration set. This leads to the estimate ˆ β = argmin β > 0 L ( β ) , with L ( β ) = − 1 n n X i =1 log p β ( y i | x i ) . (11) 3 It is sensible to tune the temp erature using the cross-entrop y for several reasons. First, when n → ∞ , p β will con verge to the closest mo del (in terms of Kullbac k-Leibler divergence) to the true data-generating pro cess (see e.g. v an der V aart , 2000 , Example 2.25). Moreo ver, the cross-entrop y is a prop er scoring rule, whic h means that maximising it should lead to well-calibrated predictions ( Blasiok et al. , 2023 ). T ypically , cross-en tropy is also used for training the classifier. Emplo ying the same loss for training and calibration suggests an apparent parado x: since w e used the same loss for training and calibration, wh y was the initial mo del po orly calibrated? Classical statistical intuition suggests that one p ossible reason is that the original mo del, typically an ov erparametrised deep neural netw ork, w as likely sub ject to severe ov erfitting, whic h leads to ov erconfidence. On the other hand, temp erature scaling inv olv es fitting a one-p ar ameter mo del , whic h is unlikely to ov erfit. Ho wev er, modern netw orks can ov erfit without loosing in generalisation error, a phenomenon known as b enign overfitting . In particular, asymptotic results on high-dimensional logistic regression ha ve shown a non-monotonic b ehaviour of the calibration with o verparametrisation ( Bai et al. , 2021 ; Clarté et al. , 2023a ; c ), suggesting a more complex picture for the source of o verconfidence in ov erparametrised mo dels. Minimising the cross-en tropy o ver the calibration set is not a particularly difficult task, as we shall see b elo w. In terestingly , its gradient has a simple momen t-matching in terpretation for the cross-entrop y , and its Hessian can b e written as the v ariance of the logits of the original mo del. Prop osition 1. The function L is smo oth and c onvex. F or any β , its first and se c ond derivative satisfy d L ( β ) dβ = 1 β − 1 n n X i =1 log p β ( y i | x i ) | {z } cross-entrop y − − 1 n n X i =1 E y ∼ p β ( y | x i ) [log p β ( y | x i )] ! | {z } expected cross-entrop y , (12) d 2 L ( β ) dβ 2 = 1 n n X i =1 V ar y ∼ p β ( y | x i ) ( z iy ) . (13) If ther e exists at le ast one pr e diction not entir ely made of ties, i.e. if ther e exists i ∈ { 1 , . . . , n } , y , y ′ ∈ { 1 , . . . , K } such that z iy = z iy ′ , then L is strictly c onvex. Otherwise, if al l pr e dictions ar e ties, L is c onstant. If ther e is at le ast one misclassific ation in the c alibr ation set, then L has a unique minimiser. Otherwise, if the c alibr ation ac cur acy is one, L is strictly de cr e asing: in a sense, the optimal temp er atur e is thus zer o. The pro of is a straightforw ard consequence of Lemma 1 and is pro vided in App endix C . This result sho ws that, under very mild conditions, L will b e easy to optimise. The initial implementation of Guo et al. ( 2017 ) used L-BFGS ( Liu and No cedal , 1989 ) to minimise L but simpler algorithms like the bisection metho d (adv o cated by Berta et al. , 2025a ) are also go o d options. T emp erature scaling was recently implemen ted as an option of the CalibratedClassifierCV function, within the popular Scikit-learn library ( Pedregosa et al. , 2011 ), using an algorithm of Brent ( 1973 ) through the minimize_scalar function of Scipy ( Virtanen et al. , 2020 ). Giv en the simplicit y of the problem, an y w ell-tuned optimiser should b e able to find ˆ β efficien tly . The only p oten tially problematic case is the one of a classifier with zero classification error on the calibration set. This may happ en either b ecause the mo del has p erfectly learned a truly deterministic relationship b et ween x and y (in this case, the initial mo del was not c onfident enough and temp erature scaling will fix this by making the mo del fully deterministic), or, more realistically , because the calibration set w as to o small (whic h is cause for concern, b ecause temperature scaling will then artificially increase ov erconfidence). A s imple w ay to alleviate the latter is to add the constraint β ≤ 1 which implies that the temp ered model cannot b e more confident than the original one. Another option is to slightly regularise the optimisation problem: for instance, Berta et al. ( 2025a ) suggest using a form of Laplace smo othing. Equation ( 12 ) leads to an in teresting in terpretation of maxim um lik eliho o d as momen t-matching. Indeed, finding a ˆ β suc h that ∇L ( ˆ β ) = 0 means that the exp ected v alue of the cross-entrop y of the temp ered mo del, matc hes its actual observed v alue. This is related to the moment-matc hing in terpretation of maximum- lik eliho o d in exp onen tial families (see e.g. Domke , 2020 ). Although minimising the cross-entrop y is arguably the most p opular choice for tuning β , any other momen t-matching tec hnique can b e c hosen in principle. F or instance, we could imagine matc hing the accuracy instead of the cross-en tropy . This would b e equiv alent 4 to the exp e ctation c onsistency of Clarté et al. ( 2023b ), who, based on the observ ation that for the optimal classifier the exp ected accuracy should match the expected confidence, prop osed to find a ˆ β suc h that 1 n n X i =1 p ˆ β ( y i | x i ) = 1 n n X i =1 1 ( ˆ y ( x i ) = y i ) , (14) where ˆ y ( x ) = argmax y p β ( y | x ) is the hard lab el predictor. Note that since tempering do es not change the accuracy , the right-hand side is indep endent of β , and this condition can b e imp osed by optimising the difference ov er β > 0 as in temp erature scaling. Clarté et al. ( 2023b ) has shown that exp ectation consistency is comp etitiv e with minimising the cross-entrop y and has pro ven that it can outperform it in synthetic classification tasks. Other alternatives to maximum likelihoo d hav e b een explored. Mozafari et al. ( 2018 ) designed a loss function tailored for small calibration sets. Shen et al. ( 2024 ) used v ariational Ba yesian inference, in an LLM con text. 2.2.2 Calibrating language mo dels There are tw o differen t notions of calibration for LLMs. The first one, next token c alibr ation , is the simply the calibration of the autoregressiv e task of predicting the next token. The second one, semantic c alibr ation , refers to calibration of question-answering tasks. In general, language mo dels are somewhat well-calibrated for b oth tasks after their pretraining phase, but this calibration is jeopardised by b oth fine-tuning based on reinforcemen t learning and c hain-of-thought reasoning ( Nakkiran et al. , 2025 ). T emperature scaling has b een used to tac kle this lac k of calibration, typically using calibration data in a fashion similar to what we describ ed for classification ( Shen et al. , 2024 ; Xie et al. , 2024 ). 2.2.3 Man ual tuning for language mo dels In contrast with the calibration setting describ ed ab o ve, temperature scaling is most often used in language mo dels as a manual deco ding hyperparameter, rather than a parameter learned from labelled calibration data. In this con text, the temperature is typically exp osed to the user and adjusted heuristically to control the p erceiv ed diversit y of the generated text. Alternativ e techniques to con trol text diversit y are also used (e.g. nucleus sampling, Holtzman et al. , 2020 ). P eep erk orn et al. ( 2024 ) empirically show ed that changing the temp erature is v ery weakly correlated with text creativity . W e will see in Section 3 that temperature can ha ve coun ter-intuitiv e effects on LLMs. 2.3 Extensions of temp erature scaling 2.3.1 Linear scalers In their seminal pap er, Guo et al. ( 2017 ) also introduced a more general scaler called matrix sc aling , defined as ˜ p W , b ( y | x ) = Categorical ( y | Softmax ( Wz + b )) , (15) where W ∈ R K × K and b ∈ R K are trainable parameters. F or binary classification, matrix scaling reduces to Platt’s ( 1999 ) scaling, and in the general multiclass case, it is equiv alent to training a logistic regression mo del on top of the logits of the pretrained mo del. A similar mo del called Dirichlet c alibr ation was introduced b y Kull et al. ( 2019 ). Motiv ated by a generativ e p erspective (seeing the probabilities of the initial mo del as a mixture of Dirichlet distributions), they prop osed using log-probabilities instead of logits: ˇ p W , b ( y | x ) = Categorical ( y | Softmax ( W log π + b )) . (16) While more flexible than temp erature scaling, matrix scaling is generally trickier to fit on small calibration sets b ecause of its muc h larger n umber of parameters. Another issue is that it is possible that the calibrated mo del will predict different lab els than the original one, i.e. the mo de of ˜ p W , b ma y not b e the same as the one of p , whic h ma y lead to a drop in accuracy . Partly due to these issues, Guo et al. ( 2017 ) found temp erature scaling empirically superior to matrix scaling. Sev eral pap ers ha ve consequen tly prop osed specific 5 regularisation techniques to av oid ov erfitting, dating back to Platt ( 1999 ) who used a form of soft labelling (to alleviate the fact that he was training the scaler using the training set). More recently , Kull et al. ( 2019 ) and Berta et al. ( 2025b ) prop osed regularisation strategies tailored for matrix scaling. Their conclusions w ere that, when carefully regularised, it can b e competitive with temp erature scaling. 2.3.2 Nonlinear scalers A common limitation of temp erature/matrix scaling and Dirichlet calibration is that they are linear in the logits or log-probabilities of the initial mo del. A simple wa y to turn temp erature scaling into a nonlinear scaler is to use as temp erature the output of a neural net work. This idea has b een explored in sev eral works ( Tian et al. , 2020 ; T omani et al. , 2022 ; Jo y et al. , 2023 ). Another nonlinear extension of temp erature scaling is based on using a mixture of temp erature-scaled models ( Zhang et al. , 2020 ). 2.4 The history of temp erature scaling It seems that the first use of temperature scaling was b y Co x ( 1958 ), who used it as a simple parametric test of calibration for binary classifiers. His null h yp othesis w as β = 1 , which indeed implies p erfect calibration. Co x ( 1958 ) also men tioned that, when ˆ β > 1 , “ pr ob abilities show the right gener al p attern of variation, but do not vary enough ". On the other hand, when ˆ β ∈ (0 , 1) , “ pr ob abilities vary to o much ". Co x’s ( 1958 ) test and its v arian ts are still widely used in medical research ( Stev ens and P opp e , 2020 ). The use of a temperature parameter together with a softmax la yer is probably an old and common practice. It was particularly popularised b y Hinton et al. ( 2015 ). F or neural language mo dels, one of the early uses of a temp erature was in the influential blog p ost of Karpathy ( 2015 ) on the successes of recurrent neural nets. 3 Do es higher temp erature mean higher uncertain t y? The general motiv ation for tempering models is that it helps con trol their level of uncertain ty . In this section, w e in vestigate formalisations of this claim. W e choose and fix some input x ∈ X . A k ey motiv ating property of temp erature scaling, already men tioned b y Guo et al. ( 2017 ), is its limiting b eha viour. When β → 0 , p β ( y | x ) con verges to the uniform distributions o ver its supp ort. On the other hand, when β → ∞ , p β ( y | x ) con verges to a point mass at the maximum probabilit y class when p ( y | x ) is unimodal (for a pro of, see e.g. Girardin and Regnault , 2016 , Prop osition 1). Th us, by scaling the temp erature, we can in terp olate b et w een the most uncertain mo del (the uniform distribution), and the most certain one (the p oin t mass). W e will see that this interpolation happ ens monotonically in a fairly general sense. 3.1 En trop y is an increasing function of the temp erature The fact that β 7→ H ( p β ) decreases w as recently pro ven by Dabah and Tirer ( 2025 , Prop osition A.5) who sho wed that its deriv ative w as nonp ositive. W e revisit this result here and pro vide an alternative and shorter pro of, relying on the prop erties of the log-partition function (Lemma 1 ). This pro of, inspired by standard statistical physics computations, highligh ts that the en tropy is directly related to the v ariance of the logits. Prop osition 2. F or al l β > 0 , dH ( p β ( y | x )) dβ = − β V ar y ∼ p β ( y | x ) ( z y ) ≤ 0 . (17) As we saw in Prop osition 1 , the v ariance of the logits is also related to the second deriv ativ e of the lik eliho o d, and hence, to the Fisher information. Therefore, an in terpretation of this result is that the entr opy wil l vary faster when ther e is a lot of information in the c alibr ation set . While the (Shannon-Gibbs) entrop y is the most common uncertaint y measure in machine learning, man y others exist. W e will see that most reasonable measures of uncertain ty , temp erature scaling b eha v es monotonically . 6 3.2 Bey ond the Shannon-Gibbs entrop y: ma jorisation Ma jorisation is a strong measure of disp ersion for discrete distributions, orginally in tro duced in the influential b ook of H ardy et al. ( 1952 ). The notion has b een applied (in particular to deriv e new inequalities) in many subfields of applied mathematics ( Marshall et al. , 2011 ) or statistical ph ysics ( Sagaw a , 2022 ). There are man y different equiv alent definitions of ma jorisation (see e.g. Marshall et al. , 2011 , p.14), but a comp elling one is the following. Definition 1. Let π = ( π 1 , ..., π K ) and ρ = ( ρ 1 , ..., ρ K ) b e v ectors in R K . W e say that π ma jorises ρ , and denote it π ≺ ρ when, for all conv ex functions ϕ : R → R , K X k =1 ϕ ( π k ) ≤ K X k =1 ϕ ( ρ k ) . (18) Wh y is ma jorisation a go o d measure of disp ersion? It is instructive to lo ok at a few examples of conv ex functions. T aking ϕ ( π ) = π log π means that π ≺ ρ implies H ( π ) ≤ H ( ρ ) . This means that ma jorisation is a stronger measure of disp ersion than entrop y . Actually , π ≺ ρ also implies that π has a smaller Renyi entrop y than ρ , and the same result is true for man y generalisations and v ariants of en tropy (see e.g. K vålseth , 2022 ). It turns out that the effect of temp erature on ma jorisation has b een kno wn for a while. The follo wing result was originally deriv ed b y Marshall and Olkin ( 1965 ) to b ound the condition num b ers of some matrices, and is mentioned and prov en by Marshall et al. ( 2011 , p. 189). Dabah and Tirer ( 2025 , Theorem 4.1) pro ved the exact same result, but did not highlight its connection to ma jorisation theory . Theorem 3.1. L et π ∈ ∆ K . If 0 < β 1 < β 2 . Then, π β 1 ≺ π β 2 . (19) This result directly implies that β 7→ H ( p β ( y | x )) is a decreasing function, not only for the Shannon entrop y but for all other entropies that are w eaker than ma jorisation. F or instance, the function β 7→ max y log p β ( y | x ) is increasing. 3.3 The impact of temp erature on class prop ortions Altering the uncertaint y of the conditional distribution p β ( y | x ) for a fixed x is likely to ha ve an impact on the marginal distribution p β ( y ) , i.e. the class prop ortions. Let p ( x ) b e the distribution of the features. The class prop ortions can b e written p β ( y ) = Z p β ( y | x ) p ( x ) d x . (20) A direct consequence of Jensen’s inequality and Theorem 3.1 is that, when β 1 < β 2 , p β 2 ( y ) ma jorises p β 1 ( y ) . Th us, H ( p β ( y )) will also b e a decreasing function of β . Concretely , incr e asing the temp er atur e wil l make the class pr op ortions mor e spr e ad out . This b eha viour should b e k ept in mind in imbalanced scenarios, for which temp erature scaling is likely to “help” the minorit y classes. 3.4 F or language mo dels, increasing the temp erature can decrease the entrop y The previous results are fairly intuitiv e and grant that temp erature scaling behav es “as it should” for classification. Ho wev er, w e will see here that it can ha ve an unexp ected on language mo dels. Most state-of- the-art language mo dels are autoregressive mo dels of the form p ( x 1 , . . . , x T ) = p ( x 1 ) T − 1 Y t =1 p ( x t +1 | x t ) , (21) 7 AAAExHicjVRfaxNBEJ/UU2v9l+pLQYTFIIgP4XKxib4VFPFFqNC0hVpkb93EJXt/uL1riUE/i1/DL+CrvvoN9Fv428kFSTExC3c785uZ3+zM3F6cW+PKMPzZ2LgUXL5ydfPa1vUbN2/dbm7fOXRZVSg9UJnNiuNYOm1NqgelKa0+zgstk9jqo3j83NuPznThTJYelJNcnyZylJqhUbIElDXvix2xQ69pQhnlZEjRAxJUkqYEuqaCJLQKuwbuYJdk4ZfS6F2zFbbDJ1HU3xVhu9vrdsIuhF63Hz2LRKcd8mpRvfaz7cZXekvvkUmBMQFjCm4FPglmRyfUoRBZSzqlKbACkmG7pk+0hdgKXhoeEugY7xG0kxpNoXtOx9EKWSyeApGCHiIm4yoEZxNsr5jZo8u4p8zpzzbBHtdcCffkA9D/xc09143ztZQ0pKdcg+9yzoivTtUsFXfF8jz+VlWCYTYvgQ4bnpeq5zjrs+AYx7VLnqu3/2JPj3pd1b4V/V6jOl9LwpNZ5Wkh5Wyr6tln2PVacX5+Zq08vidj+njBa476LzbmmgtMcgpZYvd1p+w1j/LaOefTnNt37zH8c8gZd9vxeQykFFFT2l9iWcW2iHiWgwvI6tP47g3561g8y4t/4bil86solguHUbvTa/feRK293fq+btI9/Ase4U72aY9eodIBOv6FvtF3+hG8DGzggmrmutGoY+7Swgo+/wEVIvUW “Myopic” temperature scaling AAAEnXicjVPbbtNAEJ0UA6XcUvrIAxYREuLBchyawFslQOIBoSIlTaVSVWt3k67im9Y2KER8C6/wCXwKfwB/wZnBlkhFQjZKdvbMObN7ZrNhHpui9P0fra0rztVr17dv7Ny8dfvO3fbuvaMiq2ykR1EWZ/Y4VIWOTapHpSljfZxbrZIw1uNw9oLz4w/aFiZLh+U816eJmqZmYiJVAjpr7w11kmuryspqt4gU6kzP2h3f858GwWDf9b1ev9f1ewj6vUHwPHC7ni+jQ/U4zHZb3+k9nVNGEVWUkKaUSsQxKSrwOaEu+ZQDO6UFMIvISF7TZ9qBtgJLg6GAzvA7xeqkRlOsuWYh6gi7xPhaKF16BE0GnkXMu7mSr6Qyo6tqL6Qmn22OOaxrJUBLugD6P13D3FTHXkqa0DPxYOApF4TdRXWVSrrCJ3f/clWiQg6M43PkLeJIlE2fXdEU4p17qyT/U5iM8jqquRX92sAde0nkZtYxY0S55Kr67jPMeiMd35/ZaB/uyYw+XWI1aIw5FM8WN7lArDCz71RYjYpXH2U/LXtz956AnyPOpNuFnMcgSqFa0OGKzLpqywhXGV5C1p+GuzeRf8fyWV7+C8crbZ6iuzo4Crxu3+u/CzoH+/V73ab79JAe400O6IBew+kIHZ/TF/pK35wHzivnjfP2D3WrVWv2aGk449/VL/Ba T emp erature scaling AAAEj3icjVPbbtNAEJ0UA6XcGnjkxSJCQjxEjkMTeEGRAAneitQ0lUqFbHdTVrG91noNChEfwSt8CZ/SPyh/wZnBlkhFQjZKdvbMObN7ZrNxkerSBcF5a+uKd/Xa9e0bOzdv3b5zd7d977A0lU3UODGpsUdxVKpU52rstEvVUWFVlMWpmsSzl5yffFK21CY/cPNCnWTRWa6nOokcoMnr3FlTzD/sdoJu8DQMh3t+0O0P+r2gj2DQH4bPQ7/XDWR0qB77pt36Se/plAwlVFFGinJyiFOKqMTnmHoUUAHshBbALCIteUVfaQfaCiwFRgR0ht8zrI5rNMeaa5aiTrBLiq+F0qdH0BjwLGLezZd8JZUZXVV7ITX5bHPMcV0rA+roI9D/6Rrmpjr24mhKz8SDhqdCEHaX1FUq6Qqf3P/LlUOFAhjHp8hbxIkomz77oinFO/c2kvyFMBnldVJzK/q1gTv2ksnNrGOmiArJVfXdG8xqIx3fn95oH+7JjL5cYjVoijkWzxY3uUAcYWbfubAaFa8+y35K9ubuPQG/QGyk26WcRyPKoVrQ/orMumrLCFc5uISsPw13byr/juWzvPoXjlfaPEV/dXAYdnuD7uBd2Bnt1e91mx7QQ3qMNzmkEb2B07F0/Bt9px9e2xt6L7zRH+pWq9bcp6Xhvf0N0C3rEw== Entrop y AAAEpXicjVNNb9NAEJ0UA6V8pXDsxSJFIA6W49AEbpXgAAekIiVppbaK1u6mWPGX1mtQiTjwa7jCkZ/CP4B/wZvBlkhFQjZKdvbNe7P7ZrNhkcSl9f0frY0rztVr1zdvbN28dfvO3fb2vXGZVybSoyhPcnMUqlIncaZHNraJPiqMVmmY6MNw9oLzh++1KeM8G9qLQp+m6jyLp3GkLKBJe+d1xmntWp0W2ihbGe3unoTaqt1Ju+N7/tMgGOy5vtfr97p+D0G/NwieB27X82V0qB4H+XbrO53QGeUUUUUpacrIIk5IUYnPMXXJpwLYKc2BGUSx5DV9oi1oK7A0GAroDL/nWB3XaIY11yxFHWGXBF8DpUsPocnBM4h5N1fylVRmdFntudTks11gDutaKVBL74D+T9cw19WxF0tTeiYeYngqBGF3UV2lkq7wyd2/XFlUKIBxfIa8QRyJsumzK5pSvHNvleR/CpNRXkc1t6Jfa7hjL6nczCpmgqiQXFXffY5Zr6Xj+4vX2od7MqOPl1gNmmAOxbPBTc4RK8zsOxNWo+LVB9lPy97cvSfgF4hz6XYp54kRZVDN6WBJZlW1RYSrDC8hq0/D3ZvKv2PxLC//heOVNk/RXR6MA6/b9/pvg87+Xv1eN2mHHtBjvMkB7dMrOB2h45/pC32lb84j540zdMZ/qButWnOfFoYz+Q2gJ/Ml Inv erse temp erature ω Figure 1: Entropies of tw o temp ered versions of a toy language mo del. Standard temp erature scaling has the exp ected monotonic effect on entrop y , but is impractical for LLMs. The “m yopic" v ersion, widely used in practice, has a muc h less intuitiv e b eha viour. where x 1 , . . . , x T are tokens living in a finite vocabulary X . Standard temp erature scaling of the join t model is intractable in this case, since computing p β ( x 1 , . . . , x T ) ∝ p ( x 1 ) β T − 1 Y t =1 p ( x t +1 | x t ) β , (22) w ould inv olv e dealing with a normalising constant that is a sum o ver |X | T terms. A muc h simpler alternativ e, widely used in practice, is to apply temperature scaling independently to all deco ding steps, leading to the distribution p ′ β ( x 1 , . . . , x T ) = p β ( x 1 ) T − 1 Y t =1 p β ( x t +1 | x t ) , (23) called myopic temp er atur e sc aling in Shih et al. ( 2023 ). Of course, in general, there is no reason to exp ect that p β = p ′ β . Should this b e a source of concern? Shih et al. ( 2023 ) provide a tractable approximation of p β called long horizon temp er atur e sc aling and compare this approximation to p ′ β . Based on these exp erimen ts and on a toy example, they con vincingly argue that tuning the temp erature of the appro ximation of p β leads to a muc h better qualit y/diversit y trade-off than tuning the temp erature of p ′ β . While standard temp erature scaling p β has the predictable b eha viour describ ed previously (most reasonable measures of diversit y will increase as the temperature increase), we provide here a counter-example that highligh ts that the en tropy of p ′ β can b e nonmonotonic! Consider the simple toy autoregressiv e mo del on a binary vocabulary X = { 0 , 1 } p ( x 1 , x 2 ) = p ( x 1 ) p ( x 2 | x 1 ) , (24) with p ( x 1 ) = B ( x 1 | π ) and p ( x 2 | x 1 ) = B ( x 2 | ρ x 1 ) for some π , ρ 0 , ρ 1 ∈ (0 , 1) . Surprisingly , for some v alues of the parameters, β 7→ H ( p ′ β ) do es not alwa ys decrease. Indeed, Figure 3 shows that when π = 0 . 51 , ρ 0 = 0 . 01 , and ρ 1 = 0 . 51 , the entrop y of my opic temp erature scaling decreases when β small, but then starts to increase b efore finally decreasing again. Why is this the case? It is instructive to decomp ose the join t entrop y using the chain rule: H ( p ′ β ) = H ( p β ( x 1 )) + E p β ( x 1 ) [ H ( p β ( x 2 | x 1 ))] . (25) The entrop y of p β ( x 1 ) is decreasing so the monotonicity of the join t entrop y will mostly dep end on the conditional entrop y of x 2 giv en x 1 . When β b ecomes smaller it b ecomes more and more certain that x 1 = 0 . Ho wev er, the conditional en tropy of x 2 is m uch larger when x 1 = 0 than when x 1 = 1 , so there will b e a regime for which increasing β will incr e ase the entrop y . 8 AAAEtHicjVPbbtNAEJ0UA6XcUnjkxSJCQhWynKQ48FapPPBYpKatlESV7W7CKr5pbVO1Vv6Br0HiCX6DP4C/4MxgS6QiIRslO3vmnNk9s9kgi3ReuO6P1tYt6/adu9v3du4/ePjocXv3yUmeliZUwzCNUnMW+LmKdKKGhS4idZYZ5cdBpE6D+SHnTz8pk+s0OS6uMjWJ/Vmipzr0C0Dn7b1qLEVGZhZMKtdx93u9wetXrtP3+l23j8DrD3pve4tscd7uNHm7ydtN3u46rowO1eMo3W19pTFdUEohlRSTooQKxBH5lOMzoi65lAGbUAXMINKSV7SgHWhLsBQYPtA5fmdYjWo0wZpr5qIOsUuEr4HSphfQpOAZxLybLflSKjO6qnYlNflsV5iDulYMtKCPQP+na5ib6thLQVN6Ix40PGWCsLuwrlJKV/jk9l+uClTIgHF8gbxBHIqy6bMtmly8c299yf8UJqO8DmtuSb82cMdeYrmZdcwIUSa5sr77FLPaSMf3pzfah3syp+sbrAaNMAfi2eAmK8Q+ZvadCKtR8epS9lOyN3dvD/wMcSrdzuU8GlECVUVHKzLrqi0jXOX4BrL+NNy9qfw7ls/y7l84XmnzFO3VwUnP6XqO92G/c3BYv9dtekbP6SXe5IAO6D2cDtHxz/SFvtF3y7PGVmipP9StVq15SkvDSn4DIEf1og== p AAAEwnicjVNNb9NAEJ0UA6V8pXDkYhEhIYQs20mccKvUHjgWqWkrJSGy3U0wcWyzXoOKyV/hf3DnCnf+AfwL3g62RCoSslGyb9/Mm903mw2yOMqVbf9o7Fwzrt+4uXtr7/adu/fuN/cfnOZpIUMxCNM4leeBn4s4SsRARSoW55kU/iKIxVkwP9Txs/dC5lGanKjLTIwX/iyJplHoK1CTZr8ccZGhnAXj0rZ6fa/jdJ/bltvvtnsegO3artNdZpNyFAjlvx7lypfL5aTZQqzjur2uaVttr+3YbQCv3XNfuKZj2TxaVI3jdL/xhUZ0QSmFVNCCBCWkgGPyKcdnSA7ZlIEbUwlOAkUcF7SkPWgLZAlk+GDn+J1hNazYBGtdM2d1iF1ifCWUJj2BJkWeBNa7mRwvuLJm19UuuaY+2yXmoKq1AKvoDdj/6erMbXXai6Ip9dlDBE8ZM9pdWFUpuCv65OZfrhQqZOA0vkBcAoesrPtssiZn77q3Psd/cqZm9Tqscgv6tYU77WXBN7MpMwbKOFZUd59iFlvp9P1FW+2jezKnj1eyajbGHLBniZssgX3M2nfCWbVKrz7wfoL31t17hvwMOOVu53yeCCiBqqTjNZFN1VYZXeXkCrP5NLp7U/53rJ7l6F88Xmn9FM314NS1HM/yXnVaB4fVe92lR/SYnuJN9uiAXsLpAB3/TF/pG303joy3xjsj/5O606g0D2llGJ9+AxvY+/g= p ω ω AAAEvnicjVPLbtNAFL0pBkp5pbBkYxEhIYQsPxIn7CKVBctWatpKSVTZ7iS14pfGNrS18iP8CTu28Af8AfwFZy62RCoSMlEyZ869586cOxk/i8K8MM0frZ072t1793cf7D189PjJ0/b+s5M8LWUgRkEapfLM93IRhYkYFWERibNMCi/2I3HqLw5U/PSjkHmYJsfFdSamsTdPwlkYeAWo83a3mnCRsZz708o0+gO3a/XemoY96Dl9F8C0TdvqLSexV1wGXlQdLZfn7Q74rm33e7ppOK5jmQ6A6/Ttd7ZuGSaPDtXjMN1vfaEJXVBKAZUUk6CECuCIPMrxGZNFJmXgplSBk0AhxwUtaQ/aElkCGR7YBX7nWI1rNsFa1cxZHWCXCF8JpU6voEmRJ4HVbjrHS66s2HW1K66pznaN2a9rxWALugT7P12Tua1OeSloRgP2EMJTxoxyF9RVSu6KOrn+l6sCFTJwCl8gLoEDVjZ91lmTs3fVW4/jPzlTsWod1Lkl/drCnfIS881syoyAMo6V9d2nmMVWOnV/4Vb7qJ4s6OZWVsNGmH32LHGTFbCHWflOOKtRqdUn3k/w3qp7b5CfAafc7ZzPEwIlUFV0uCayqdoqo6oc32I2n0Z1b8b/jtWzvP8Xj1faPEV9PTixDcs13KNuZ3hQv9ddekEv6TXeZJ+G9AFOR+j4Z/pK3+i7NtRmWqylf1J3WrXmOa0M7eo3Kej6HA== Q AAAEtHicjVPbbtNAEJ0UA6XcUnjkxSJCQhWynKQ48FapPPBYpKatlESV7W7CKr5pbVO1Vv6Br0HiCX6DP4C/4MxgS6QiIRslO3vmnNk9s9kgi3ReuO6P1tYt6/adu9v3du4/ePjocXv3yUmeliZUwzCNUnMW+LmKdKKGhS4idZYZ5cdBpE6D+SHnTz8pk+s0OS6uMjWJ/Vmipzr0C0Dn7b1qLEVGZhZMKtdx93u9wetXrtP3+l23j8DrD3pve4tscd7uNHm7ydtN3u46rowO1eMo3W19pTFdUEohlRSTooQKxBH5lOMzoi65lAGbUAXMINKSV7SgHWhLsBQYPtA5fmdYjWo0wZpr5qIOsUuEr4HSphfQpOAZxLybLflSKjO6qnYlNflsV5iDulYMtKCPQP+na5ib6thLQVN6Ix40PGWCsLuwrlJKV/jk9l+uClTIgHF8gbxBHIqy6bMtmly8c299yf8UJqO8DmtuSb82cMdeYrmZdcwIUSa5sr77FLPaSMf3pzfah3syp+sbrAaNMAfi2eAmK8Q+ZvadCKtR8epS9lOyN3dvD/wMcSrdzuU8GlECVUVHKzLrqi0jXOX4BrL+NNy9qfw7ls/y7l84XmnzFO3VwUnP6XqO92G/c3BYv9dtekbP6SXe5IAO6D2cDtHxz/SFvtF3y7PGVmipP9StVq15SkvDSn4DIEf1og== p AAAEwnicjVNNb9NAEJ0UA6V8pXDkYhEhIYQs20mccKvUHjgWqWkrJSGy3U0wcWyzXoOKyV/hf3DnCnf+AfwL3g62RCoSslGyb9/Mm903mw2yOMqVbf9o7Fwzrt+4uXtr7/adu/fuN/cfnOZpIUMxCNM4leeBn4s4SsRARSoW55kU/iKIxVkwP9Txs/dC5lGanKjLTIwX/iyJplHoK1CTZr8ccZGhnAXj0rZ6fa/jdJ/bltvvtnsegO3artNdZpNyFAjlvx7lypfL5aTZQqzjur2uaVttr+3YbQCv3XNfuKZj2TxaVI3jdL/xhUZ0QSmFVNCCBCWkgGPyKcdnSA7ZlIEbUwlOAkUcF7SkPWgLZAlk+GDn+J1hNazYBGtdM2d1iF1ifCWUJj2BJkWeBNa7mRwvuLJm19UuuaY+2yXmoKq1AKvoDdj/6erMbXXai6Ip9dlDBE8ZM9pdWFUpuCv65OZfrhQqZOA0vkBcAoesrPtssiZn77q3Psd/cqZm9Tqscgv6tYU77WXBN7MpMwbKOFZUd59iFlvp9P1FW+2jezKnj1eyajbGHLBniZssgX3M2nfCWbVKrz7wfoL31t17hvwMOOVu53yeCCiBqqTjNZFN1VYZXeXkCrP5NLp7U/53rJ7l6F88Xmn9FM314NS1HM/yXnVaB4fVe92lR/SYnuJN9uiAXsLpAB3/TF/pG303joy3xjsj/5O606g0D2llGJ9+AxvY+/g= p ω ω AAAEvnicjVPLbtNAFL0pBkp5pbBkYxEhIYQsPxIn7CKVBctWatpKSVTZ7iS14pfGNrS18iP8CTu28Af8AfwFZy62RCoSMlEyZ869586cOxk/i8K8MM0frZ072t1793cf7D189PjJ0/b+s5M8LWUgRkEapfLM93IRhYkYFWERibNMCi/2I3HqLw5U/PSjkHmYJsfFdSamsTdPwlkYeAWo83a3mnCRsZz708o0+gO3a/XemoY96Dl9F8C0TdvqLSexV1wGXlQdLZfn7Q74rm33e7ppOK5jmQ6A6/Ttd7ZuGSaPDtXjMN1vfaEJXVBKAZUUk6CECuCIPMrxGZNFJmXgplSBk0AhxwUtaQ/aElkCGR7YBX7nWI1rNsFa1cxZHWCXCF8JpU6voEmRJ4HVbjrHS66s2HW1K66pznaN2a9rxWALugT7P12Tua1OeSloRgP2EMJTxoxyF9RVSu6KOrn+l6sCFTJwCl8gLoEDVjZ91lmTs3fVW4/jPzlTsWod1Lkl/drCnfIS881syoyAMo6V9d2nmMVWOnV/4Vb7qJ4s6OZWVsNGmH32LHGTFbCHWflOOKtRqdUn3k/w3qp7b5CfAafc7ZzPEwIlUFV0uCayqdoqo6oc32I2n0Z1b8b/jtWzvP8Xj1faPEV9PTixDcs13KNuZ3hQv9ddekEv6TXeZJ+G9AFOR+j4Z/pK3+i7NtRmWqylf1J3WrXmOa0M7eo3Kej6HA== Q AAAElnicjVPbbtNAEJ20Bkq5teUFiReLFAnxYDkOJPCCKhUEj0Fq2kqlINvdpKv4slrbVCXiP3ht/4JP4Q/gLzgz2BKpSMhGyc6eOWd2z2w2MokuSt//0VpZda5dv7F2c/3W7Tt3721sbu0XeWVjNYzzJLeHUVioRGdqWOoyUYfGqjCNEnUQTXY5f/BZ2ULn2V55btRxGo4zPdJxWAL6eBbaVGdjd9tsu5X5tNH2Pf9ZEPSfu77X7XU7fhdBr9sPXgZux/NltKkeg3yz9Z0+0AnlFFNFKSnKqEScUEgFPkfUIZ8MsGOaArOItOQVfaV1aCuwFBgh0Al+x1gd1WiGNdcsRB1jlwRfC6VLj6HJwbOIeTdX8pVUZnRe7anU5LOdY47qWinQkk6B/k/XMJfVsZeSRvRCPGh4MoKwu7iuUklX+OTuX65KVDDAOD5B3iKORdn02RVNId65t6HkfwqTUV7HNbeiX0u4Yy+p3MwiZoLISK6q7z7HrJbS8f3ppfbhnkzoyxVWgyaYI/FscZNTxCFm9p0Jq1Hx6kz2U7I3d+8p+AZxLt0u5DwaUQbVlAZzMouqzSJcZe8Ksvg03L2R/Dtmz/L6XzheafMU3fnBfuB1el7vfdDe2a3f6xo9pEf0BG+yTzv0Dk6H6Lilb3RBl84D55Xzxnn7h7rSqjX3aWY4g9/NXu1I w arming p up AAAEmnicjVNNb9NAEJ0UA6V8pXCEg0WKhDhYjgMJ3CrKAcSlSElbqVTIdjbpKrbXWtutSsQ/4Qr/gZ/CP4B/wZvBlkhFQjZKdvbNe7P7ZrNRnuii9P0frY0rztVr1zdvbN28dfvO3fb2vYPCVDZWo9gkxh5FYaESnalRqctEHeVWhWmUqMNotsf5wzNlC22yYXmRq5M0nGZ6ouOwBPSx3Y6NgXbq7uQ77ticA+r4nv8sCAbPXd/r9Xtdv4eg3xsELwO36/kyOlSPfbPd+k4faEyGYqooJUUZlYgTCqnA55i65FMO7ITmwCwiLXlFn2kL2gosBUYIdIbfKVbHNZphzTULUcfYJcHXQunSY2gMeBYx7+ZKvpLKjC6rPZeafLYLzFFdKwVa0inQ/+ka5ro69lLShF6IBw1PuSDsLq6rVNIVPrn7l6sSFXJgHI+Rt4hjUTZ9dkVTiHfubSj5n8JklNdxza3o1xru2EsqN7OKmSDKJVfVd28wq7V0fH96rX24JzP6dInVoAnmSDxb3OQccYiZfWfCalS8Opf9lOzN3XsKfo7YSLcLOY9GlEE1p/0lmVXVFhGuMryErD4Nd28i/47Fs7z+F45X2jxFd3lwEHjdvtd/H3R29+r3ukkP6BE9wZsc0C69gdMROn5GX+grfXMeOq+ct867P9SNVq25TwvDGf4GMJTuVg== co oling p do wn AAAE1nicjVNNbxMxEJ2UBUr5SuHIxSJBQkhEmw0kcKtUDkj0kEpNG6mtKq/jJG6865XXS1WickNc+S3c+CdwhBP8C8bDRiIVCXGUePxm3sy8cRxnWuUuDL9V1q4EV69dX7+xcfPW7Tt3q5v39nNTWCF7wmhj+zHPpVap7DnltOxnVvIk1vIgnmx7/8FbaXNl0j13nsnjhI9SNVSCO4ROqjtda06l8Admhqye1ZlJnWH1o4S7seB6untRZ0OjtTlT6Yi5sWRvCq1jLiZPd6TCOpaNpBnIXImTai1shM+iqPOchY1Wu9UMW2i0W53oZcSajZBWDcrVNZuVL3AEAzAgoIAEJKTg0NbAIcfPITQhhAyxY5giZtFS5JdwARvILTBKYgRHdIK/IzwdlmiKZ58zJ7bAKhq/FpkMHiHHYJxF21dj5C8os0cX5Z5STt/bOe5xmStB1MEY0f/xZpGr8rwWB0N4QRoUasoI8epEmaWgqfjO2V+qHGbIEPP2AP0WbUHM2ZwZcXLS7mfLyf+TIj3qz6KMLeDXCuq8loRuZlmkRisjX1HevcFdrsTz96dWquNnMoF3l6JmqMY9Js0Wb3KKNsfd604pasbypzOqJ6m2n94TjM/QNjTtnPpRaKXImkJ3gWdZtnnEZ9m7hCzvxk9vSP+O+V5e/QvHVzp7imyxsR81mu1GezeqbW2X73UdHsBDeIxvsgNb8BqV9nDin+ErfIcfQT94H3wIPv4JXauUnPswt4JPvwGT7Qa9 Pro jection of p onto Q follo wing the Kullback-Leibler geo desic Figure 2: T emp erature scaling as an information pro jection. In b oth cases, the initial mo del p is pro jected on to the set Q of distributions of constant entrop y h ⋆ = 0 . 9 . The blue arrow is the path of all tempered mo dels b etw een p and its pro jection p β ⋆ . This path can b e interpreted as the geo desic b et ween p and p β ⋆ . (L eft) The initial distribution p = (0 . 01 , 0 . 09 , 0 . 9) has a lo wer en tropy than h ⋆ , and is war med up tow ards p β ⋆ with β ⋆ ≈ 0 . 37 . (R ight) The initial distribution p = (0 . 4 , 0 . 35 , 0 . 25) has a higher entrop y than h ⋆ , and is co oled do wn tow ards p β ⋆ with β ⋆ ≈ 3 . 98 . This mechanism suggests that similar non-monotonic effects ma y arise whenev er early-tok en uncertaint y strongly conditions later-token en tropy . More details on this exp erimen t can b e found in App endix E . 4 A geometric in terpretation W e pro vide here geometric insigh ts ab out ho w changing the temp erature allo ws to trav el along the simplex. None of these results are new, but they were, to the b est of our knowledge, not discussed in this context. 4.1 T emp erature scaling as an information pro jection W e sa w in the previous section that temperature scaling allows to mov e from the initial mo del tow ards mo dels with higher or low er entrop y . There is a precise geometric interpretation of this fact, that we describe here. Again, we fix some input x ∈ X . The purp ose of temp erature scaling w as to alter the initial mo del p ( y | x ) to make it more or less uncertain, i.e. to increase or decrease its entrop y . A geometric approac h to this problem would be to select an entrop y level h ⋆ > 0 that we would lik e to reach, and find the distribution closest to p ( y | x ) that has this given en tropy . F or instance, if h ⋆ ≥ H ( p ) then we are lo oking for a model less confiden t than p . Considering the Kullbac k-Leibler divergence as a measure of closeness, this b ecomes the follo wing information pr oje ction problem: q ⋆ ( y | x ) ∈ argmin q ∈Q KL ( q ( y | x ) || p ( y | x )) , (26) where Q = { q s.t. H ( q ) = h ⋆ } . It turns out that the solution to this problem is exactly temp erature scaling. Theorem 4.1. If p ( y | x ) is unimo dal and has ful l supp ort, then the information pr oje ction pr oblem ( 26 ) has a unique solution q ⋆ , and ther e exists β ⋆ ≥ 0 such that q ⋆ ( y | x ) = p β ⋆ ( y | x ) . This result, illustrated on Figure 2 , means that we c an interpr et a temp er e d mo del as the closest mo del with the r e quir e d amount of unc ertainty . A version of this theorem dates back, at least, to Sgarro ( 1978 ). A recen t proof using Lagrange m ultipliers can b e found in Girardin and Regnault ( 2016 , Theorem 1), who also discuss what happ ens when there are several modes or when the distribution do es not hav e full supp ort. Theorem 4.1 is also a well-kno wn result in the statistical physics literature, where it is typically kno wn in terms of its dual form ulation (in the Lagrange sense). Indeed, recalling that in the statistical ph ysics p erspective of Section 2.1 p ( y | x ) is the Boltzmann-Gibbs distribution with energies E y and at temp erature β = 1 , op ening up the expression of the KL div ergence we can write: KL ( q ( y | x ) || p ( y | x )) = − H ( q ( y | x )) − E y ∼ q ( y | x ) [log p ( y | x )] = − H ( q ( y | x )) + E y ∼ q ( y | x ) [ E y ] + log Z (1 , z ) . (27) 9 Hence, minimising the KL ( q || p ) at fixed en tropy H ( q ) = h ⋆ is equiv alen t to maximising the entrop y H ( q ) at fixed “internal energy” E q [ E y ] = u ⋆ , which is precisely the original construction of the canonical ensem ble in Boltzmann ( 1885 ), later formalised by Gibbs ( 1902 ). Indeed, entrop y and energy are conjugate v ariables in thermo dynamics, with the linear relationship betw een them t ypically used as a definition for the inv erse- temp erature in equilibrium statistical physics. F rom this p ersp ectiv e, the assumption of unimo dalit y of p ( y | x ) in Theorem 4.1 is equiv alent to the existence of a unique ground state (i.e. unique minimal energy E y = − z y ). This connection b et ween information geometry and statistical physics w as pioneered by Ja ynes ( 1957 ). Note this result do es not hold under other metrics than the Kullbac k-Leibler divergence, and temperature scaling will generally not b e optimal. Girardin and Regnault ( 2016 , Prop osition 4) pro vide a similar result for the reverse Kullbac k-Leibler divergence. 4.2 T emp ering along geo desics What do es it mean, geometrically , to mo ve from one temp erature to another? A starting p oint is to notice that, for any 0 < β 1 < β < β 2 , p β ∝ p β = p αβ 1 +(1 − α ) β 2 = p α β 1 p 1 − α β 2 , (28) with α = ( β 2 − β ) / ( β 2 − β 1 ) ∈ (0 , 1) . This means that p β is the normalised geometric mean of p β 1 and p β 2 . Such normalised geometric means, sometimes called “pro ducts of exp ert”, “geometric mixtures”, or “logarithmic p ool”, hav e many in teresting prop erties (see e.g. Amari , 2007 ; Carv alho et al. , 2023 ). In particular, in information geometry , if w e see the family of discrete distributions as an exponential family , the curve β ∈ ( β 1 , β 2 ) 7→ p β is the geo desic from p β 1 to p β 2 (see, e.g. Amari , 2016 , Section 2.4). This means that moving from one temp erature to another will b e mo ving along a geo desic, as seen in Figure 2 . 5 T emp erature scaling is the only accuracy-preserving linear scaler W e prov e here another simple characterisation of temperature scaling, as the only linear scaler that does not alter “hard" mo del predictions. W e say that a scaler is ac cur acy-pr eserving when it do es not change the mo del predictions, i.e. when the argmax of the scaled predictions is the same as the one of the original predictions. Note that the argmax of a vector is defined as the set of indices that attain the max of the v ector (in particular it is not necessary a single lab el). Guo et al. ( 2017 ) attributed the superiority of temperature scaling ov er matrix scaling to its accuracy- preserving nature. This prop ert y was then further studied by Zhang et al. ( 2020 ), who coined the term “accuracy-preserving", and Rahimi et al. ( 2020 ), who b oth tried to design accuracy-preserving scalers that are more flexible than temp erature scaling. These w orks, as w ell as other accuracy-preserving scalers prop osed thereafter ( Esaki et al. , 2024 ; Zhang et al. , 2025 ), gain this additional flexibility b y making scalers nonlinear. Here, w e prov e that this nonlinearity is necessary: it is imp ossible for a line ar sc aler to b e b oth or der-pr eserving and mor e flexible than temp er atur e sc aling . Our main to ol will b e the following result, that characterises argmax-in v ariant linear functions. T o the b est of our kno wledge, this result has not app eared in the literature, and ma y b e of indep enden t interest. Theorem 5.1. L et W ∈ R K × K and b ∈ R K such that, for al l z ∈ R K we have argmax ( Wz + b ) = argmax ( z ) . (29) Then, ther e exist α ∈ R K , β > 0 , and γ ∈ R such that W = β I K + 1 K α T , and b = γ 1 K . (30) The pro of is a v ailable in App endix F . There are tw o different kinds of linear scalers: • the matrix s caling mo del ˜ p W , b , defined in Equation ( 15 ), whic h is linear in the logits, • the Dirichlet calibration mo del ˇ p W , b , defined in Equation ( 16 ), whic h is linear in the log-probabilities. While the tw o scalers are not formally equiv alen t, they b oth con tain temperature scaling as a submo del. The follo wing result sho ws that this is the only submo del that is accuracy-preserving in both cases. 10 Corollary 1. L et W ∈ R K × K and b ∈ R K such that ˜ p W , b (r esp e ctively ˇ p W , b ) is ac cur acy-pr eserving. Then, ther e exists β ≥ 0 such that ˜ p W , b = p β (r esp e ctively ˇ p W , b = p β ) . The pro of is a direct application of Theorem 5.1 , and is av ailable in App endix G . This result clarifies why attempts to design more expressive accuracy-preserving scalers must inevitably depart from linearity (at least when the initial mo del has a go od accuracy). Conv ersely , it explains why temp erature scaling often p erforms competitively despite its extreme simplicity: among all linear recalibrations, it already exhausts the av ailable degrees of freedom once accuracy is fixed. This result is therefore b oth an argumen t in fa vour of tempe rature scaling, and also one in fav our of nonlinear scalers. 6 Discussion W e revisited the elementary prop erties of temp erature scaling, and hop e that this w ork can serve as an in vitation to study this simple and p opular mo del. F or probabilistic classifiers, temp erature scaling b eha ves exactly as intended. Increasing the temp erature monotonically increases uncertaint y in the strong sense of ma jorisation. This justify its in terpretation as a principled uncertaint y con trol tuner. In contrast, w e sho wed that these guarantees do not extend automatically to autoregressiv e language mo dels as they are used in practice. This observ ation challenges the common assumption that temp erature acts as a reliable diversit y knob at the sequence level. Bey ond uncertaint y , our results also clarify the structural role of temp erature scaling among calibration metho ds: it is the only linear calibration metho d that preserves hard predictions. Consequently , any attempt to design more expressive accuracy-preserving scalers must necessarily rely on nonlinear transformations. One question that remains wide open is why do es temp er atur e sc aling p erforms so wel l? Berta et al. ( 2025b ) show ed that even in very simple cases, the optimal scaler is generally nonlinear, th us it is surprising to see a mo del that simple w ork that w ell. Another av enue of future research w ould b e to inv estigate the practical relev ance of our counter-example for real-life LLMs. Despite its theoretical nature, our w ork leads to t wo practical tak e-home messages: • F or LLMs, temp er atur e c an have c ounterintuive effe cts on the diversity, which ma y explains why other metho ds to play with text sto c hasticity are sometimes preferred ( Holtzman et al. , 2020 ), and is in line with the empirical findings of P eep erk orn et al. ( 2024 ). • T o c alibr ate very ac cur ate classifiers, temp er atur e sc aling should b e pr eferr e d to matrix sc aling and Dirichlet c alibr ation, since temp erature scaling is the only wa y to implemen t accuracy-preserv ation in to these mo dels. A c kno wledgemen ts BL was supported b y the F rench go vernmen t, managed by the National Research Agency (ANR), under the F rance 2030 programme with the reference “ANR-23-IACL-0008” and the Choose F rance - CNRS AI Rising T alents program. P AM was also supp orted by the F rench go vernmen t, through the F rance 2030 programme managed b y the ANR, with the reference n umber “ANR-23-IACL-0001”. References J. A chiam, S. A dler, S. Agarwal, L. Ah mad, I. Akk ay a, F. L. Aleman, D. Almeida, J. Altensc hmidt, S. Altman, S. Anadk at, et al. GPT-4 tec hnical rep ort. arXiv pr eprint arXiv:2303.08774 , 2023. S. Amari. Integration of stochastic mo dels b y minimizing α -div ergence. Neur al c omputation , 19(10):2780–2796, 2007. S. Amari. Information ge ometry and its applic ations , volume 194. Springer, 2016. 11 A. N. Angelop oulos, S. Bates, et al. Conformal prediction: A gentle in tro duction. F oundations and tr ends ® in machine le arning , 16(4):494–591, 2023. Y. Bai, S. Mei, H. W ang, and C. Xiong. Don’t just blame ov er-parametrization for o ver-confidence: Theoretical analysis of calibration in binary classification. In International c onfer enc e on machine le arning , pages 566–576. PMLR, 2021. E. Berta, D. Holzmüller, M. I. Jordan, and F. Bach. Rethinking early stopping: Refine, then calibrate. arXiv pr eprint arXiv:2501.19195 , 2025a. E. Berta, D. Holzmüller, M. I. Jordan, and F. Bach. Structured matrix scaling for multi-class calibration. arXiv pr eprint arXiv:2511.03685 , 2025b. J. Blasiok, P . Gopalan, L. Hu, and P . Nakkiran. When do es optimizing a proper loss yield calibration? A dvanc es in Neur al Information Pr o c essing Systems , 36:72071–72095, 2023. L. Boltzmann. Üb er die möglichk eit der begründung einer kinetischen gastheorie auf anziehende kräfte allein. A nnalen der Physik , 260(1):37–44, 1885. R. Brent. Algorithms for minimization without deriv atives. Pr entic e-Hal l, Englewo o d Cliffs NJ , 1973. L. M. Carv alho, D. A. M. Villela, F. C. Co elho, and L. S. Bastos. Bay esian Inference for the W eights in Logarithmic Pooling. Bayesian Analysis , 18(1):223 – 251, 2023. L. Clarté, B. Loureiro, F. Krzak ala, and L. Zdeb oro vá. On double-descent in uncertaint y quantification in o verparametrized mo dels. In International Confer enc e on Artificial Intel ligenc e and Statistics , pages 7089–7125. PMLR, 2023a. L. Clarté, B. Loureiro, F. Krzak ala, and L. Zdeb oro vá. Exp ectation consistency for calibration of neural net works. In Unc ertainty in Artificial Intel ligenc e , pages 443–453. PMLR, 2023b. L. Clarté, B. Loureiro, F. Krzak ala, and L. Zdeb oro vá. Theoretical c haracterization of uncertaint y in high-dimensional linear classification. Machine L e arning: Scienc e and T e chnolo gy , 4(2):025029, 2023c. D. R. Cox. T w o further applications of a mo del for binary regression. Biometrika , 45(3/4):562–565, 1958. L. Dabah and T. Tirer. On temp erature scaling and conformal prediction of deep classifiers. In International Confer enc e on Machine L e arning . PMLR, 2025. J. Domk e. Momen t-matching conditions for exp onential families with conditioning or hidden data. arXiv pr eprint arXiv:2001.09771 , 2020. Y. Esaki, A. Nak amura, K. Kaw ano, R. T okuhisa, and T. Kutsuna. A ccuracy-preserving calibration via statistical mo deling on probability simplex. In International Confer enc e on A rtificial Intel ligenc e and Statistics , pages 1666–1674. PMLR, 2024. R. F o ygel Barb er, E. J. Candes, A. Ramdas, and R. J. Tibshirani. The limits of distribution-free conditional predictiv e inference. Information and Infer enc e: A Journal of the IMA , 10(2):455–482, 2021. G. Gemini T eam. Gemini: a family of highly capable multimodal mo dels. arXiv pr eprint arXiv:2312.11805 , 2025. I. Gibbs, J. J. Cherian, and E. J. Candès. Conformal prediction with conditional guarantees. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , page 1100–1126, 2025. J. W. Gibbs. Elementary principles in statistic al me chanics: develop e d with esp e cial r efer enc e to the r ational foundations of thermo dynamics . C. Scribner’s sons, 1902. V. Girardin and P . Regnault. Escort distributions minimizing the kullbac k–leibler divergence for a large deviations principle and tests of en tropy lev el. A nnals of the Institute of Statistic al Mathematics , 68(2): 439–468, 2016. 12 C. Guo, G. Pleiss, Y. Sun, and K. Q. W einberger. On calibration of mo dern neural netw orks. In International c onfer enc e on machine le arning , pages 1321–1330. PMLR, 2017. G. H. Hardy , J. E. Littlewoo d, and G. Pólya. Ine qualities (2nd e dition) . Cam bridge Universit y Press, 1952. G. Hinton, O. Viny als, and J. Dean. Distilling the knowledge in a neural net work. NIPS 2014 De ep L e arning W orkshop, arXiv pr eprint arXiv:1503.02531 , 2015. A. Holtzman, J. Buys, L. Du, M. F orb es, and Y. Choi. The curious case of neural text degeneration. International Confer enc e on L e arning R epr esentations , 2020. E. T. Jaynes. Information theory and statistical mec hanics. Physic al r eview , 106(4):620, 1957. T. Joy , F. Pin to, S.-N. Lim, P . H. T orr, and P . K. Dok ania. Sample-dep enden t adaptive temperature scaling for impro ved calibration. In Pr o c e e dings of the AAAI Confer enc e on Artificial Intel ligenc e , volume 37, pages 14919–14926, 2023. M. Kardar. Statistic al Physics of Particles . Cam bridge Universit y Press, 2007. A. Karpath y . The unreasonable effectiv eness of recurrent neural netw orks. Blog p ost, https://karpathy. github.io/2015/05/21/rnn- effectiveness/ , 2015. M. Kull, M. Perello Nieto, M. Kängsepp, T. Silv a Filho, H. Song, and P . Flac h. Beyond temperature scaling: Obtaining w ell-calibrated m ulti-class probabilities with dirichlet calibration. A dvanc es in neur al information pr o c essing systems , 32, 2019. T. O. K vålseth. En tropies and their conca vity and Sc hur-conca vity conditions. IEEE A c c ess , 10:96006–96015, 2022. A. Liu, B. F eng, B. Xue, B. W ang, B. W u, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. DeepSeek-v3 tec hnical rep ort. arXiv pr eprint arXiv:2412.19437 , 2024. D. C. Liu and J. Nocedal. On the limited memory BF GS method for large scale optimization. Mathematic al pr o gr amming , 45(1):503–528, 1989. A. Marshall and I. Olkin. Norms and inequalities for condition num b ers. Pacific Journal of Mathematics , 15 (1):241–247, 1965. A. W. Marshall, I. Olkin, and B. Arnold. Ine qualities: The ory of Majorization and Its Applic ations . Springer, 2011. M. Minderer, J. Djolonga, R. Romijnders, F. Hubis, X. Zhai, N. Houlsb y , D. T ran, and M. Lucic. Revisiting the calibration of mo dern neural net works. A dvanc es in neur al information pr o c essing systems , 34:15682–15694, 2021. A. S. Mozafari, H. S. Gomes, W. Leão, S. Janny , and C. Gagné. A ttended temp erature scaling: a practical approac h for calibrating deep neural netw orks. arXiv pr eprint arXiv:1810.11586 , 2018. P . Nakkiran, A. Bradley , A. Goliński, E. Ndiay e, M. Kirchhof, and S. Williamson. T rained on tokens, calibrated on concepts: The emergence of semantic calibration in LLMs. arXiv pr eprint arXiv:2511.04869 , 2025. T. Papamark ou, M. Skoularidou, K. Palla, L. Aitchison, J. Arbel, D. Dunson, M. Filippone, V. F ortuin, P . Hennig, J. M. Hernández-Lobato, et al. Position: Ba yesian deep learning is needed in the age of large-scale AI. In International Confer enc e on Machine L e arning , pages 39556–39586. PMLR, 2024. F. Pedregosa, G. V aro quaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V. Dub ourg, J. V anderplas, A. Passos, D. Cournap eau, M. Bruc her, M. Perrot, and E. Duc hesnay . Scikit-learn: Machine learning in Python. Journal of Machine L e arning R ese ar ch , 12:2825–2830, 2011. 13 M. Peeperkorn, T. K ouw enho ven, D. Bro wn, and A. Jordanous. Is temperature the creativit y parameter of large language mo dels? In ICCC , 2024. J. Platt. Probabilistic outputs for supp ort vector mac hines and comparisons to regularized lik eliho o d methods. A dvanc es in lar ge mar gin classifiers , 10(3):61–74, 1999. A. Rahimi, A. Shaban, C.-A. Cheng, R. Hartley , and B. Boots. Intra order-preserving functions for calibration of multi-class neural net works. A dvanc es in neur al information pr o c essing systems , 33:13456–13467, 2020. A. Rastogi, A. Q. Jiang, A. Lo, G. Berrada, G. Lample, J. Rute, J. Barmentlo, K. Y adav, K. Khandelw al, K. R. Chandu, et al. Magistral. arXiv pr eprint arXiv:2506.10910 , 2025. T. Sagaw a. Entr opy, diver genc e, and majorization in classic al and quantum thermo dynamics . SpringerBriefs in Mathematical Physics, 2022. A. Sgarro. An informational div ergence geometry for sto c hastic matrices. Calc olo , 15(1):41–49, 1978. M. Shen, S. Das, K. Greenew ald, P . Sattigeri, G. W ornell, and S. Ghosh. Thermometer: T ow ards univ ersal calibration for large language mo dels. arXiv pr eprint arXiv:2403.08819 , 2024. A. Shih, D. Sadigh, and S. Ermon. Long horizon temp erature scaling. In International Confer enc e on Machine L e arning , pages 31422–31434. PMLR, 2023. T. Silv a Filho, H. Song, M. Perello-Nieto, R. Santos-Rodriguez, M. Kull, and P . Flac h. Classifier calibration: a survey on ho w to assess and improv e predicted class probabilities. Machine L e arning , 112(9):3211–3260, 2023. R. J. Stev ens and K. K. Poppe. V alidation of clinical prediction mo dels: what do es the “calibration slop e” really measure? Journal of clinic al epidemiolo gy , 118:93–99, 2020. J. Tian, W. Cheung, N. Glaser, Y.-C. Liu, and Z. Kira. Uno: Uncertaint y-aw are noisy-or multimodal fusion for unanticipated input degradation. In 2020 IEEE International Confer enc e on R ob otics and Automation (ICRA) , pages 5716–5723, 2020. doi: 10.1109/ICRA40945.2020.9197266. C. T omani, D. Cremers, and F. Buettner. P arameterized temp erature scaling for b oosting the expressive p o w er in post-ho c uncertaint y calibration. In Eur op e an c onfer enc e on c omputer vision , pages 555–569. Springer, 2022. D. Ulmer, C. Hardmeier, and J. F rellsen. Prior and p osterior netw orks: A survey on evidential deep learning metho ds for uncertain ty estimation. T r ansactions on Machine L e arning R ese ar ch , 2023. A. v an der V aart. Asymptotic statistics , v olume 3. Cambridge universit y press, 2000. P . Virtanen, R. Gommers, T. E. Oliphant, M. Hab erland, T. Reddy , D. Cournapeau, E. Burovski, P . P eterson, W. W eck esser, J. Bright, S. J. v an der W alt, M. Brett, J. Wilson, K. J. Millman, N. May orov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey , İ. Polat, Y. F eng, E. W. Mo ore, J. V anderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen, E. A. Quin tero, C. R. Harris, A. M. Archibald, A. H. Rib eiro, F. P edregosa, P . v an Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: F undamental Algorithms for Scientific Computing in Python. Natur e Metho ds , 17:261–272, 2020. doi: 10.1038/s41592- 019- 0686- 2. J. Xie, A. Chen, Y. Lee, E. Mitc hell, and C. Finn. Calibrating language mo dels with adaptiv e temp erature scaling. In Pr o c e e dings of the 2024 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pages 18128–18138, 2024. J. Zhang, B. Kailkh ura, and T. Y.-J. Han. Mix-n-match: Ensemble and comp ositional methods for uncertain ty calibration in deep learning. In International c onfer enc e on machine le arning , pages 11117–11128. PMLR, 2020. Y. Zhang, G. Batista, and S. S. Kanhere. Instance-wise monotonic calibration by constrained transformation. In Pr o c e e dings of the F orty-First Confer enc e on Unc ertainty in Artificial Intel ligenc e , 2025. 14 App endix A Pro of that using the logits and using the log-probabilities are equiv alen t With the notations of Section 2 , since π = Softmax ( z ) , w e find Softmax ( β log π ) = Softmax β z − log K X y =1 e z y ! 1 K !! (31) = Softmax ( β z ) , (32) using the fact that the Softmax is inv ariant to adding the same constant (here − β log ( e z 1 + . . . + e z K ) ) to all co ordinates. B Pro of of Le mma 1 (deriv ativ es of the log-partition function) The log-partition function is defined as log Z ( β , z ) = log K X y =1 e β z y ! . (33) Th us, its first deriv ative is d log Z ( β , z ) dβ = P K y =1 z y e β z y Z ( β , z ) = K X y =1 z y e β z y Z ( β , z ) | {z } p β ( y | x ) = E y ∼ p β ( y | x ) [ z y ] . (34) The second deriv ativ e can also b e seen as exp ectation, using the fact that d dβ p β ( y | x ) = d log p β ( y | x ) dβ p β ( y | x ) , d 2 log Z ( β , z ) dβ 2 = d dβ K X y =1 z k p β ( y | x ) = K X y =1 z k d log p β ( y | x ) dβ p β ( y | x ) = E z y d log p β ( y | x ) dβ . (35) No w, using the definition of p β ( y | x ) and Equation ( 34 ) yields d log p β ( y | x ) dβ = z y − d log Z ( β , z ) dβ = z y − E y ∼ p β ( y | x ) [ z y ] . (36) Plugging this back in Equation ( 35 ) finally leads to d 2 log Z ( β , z ) dβ 2 = E z y ( z y − E y ∼ p β ( y | x ) [ z y ]) = E y ∼ p β ( y | x ) [ z 2 y ] − E y ∼ p β ( y | x ) [ z y ] 2 = V ar y ∼ p β ( y | x ) ( z y ) . (37) C Pro of of Pr op osition 1 (prop erties of the lik eliho o d) The negative log-likelihoo d is equal to L ( β ) = − 1 n n X i =1 log p β ( y i | x i ) = − 1 n n X i =1 ( β z y i − log Z ( β , z i )) . (38) Th us, using Lemma 1 , we find d L ( β ) dβ = − 1 n n X i =1 z y − E y ∼ p β ( y | x ) [ z y ] . (39) 15 AAAEpXicjVNNb9NAEJ0UA6V8pXDsxSJFIA6W49AEbpXgAAekIiVppbaK1u6mWPGX1mtQiTjwa7jCkZ/CP4B/wZvBlkhFQjZKdvbNe7P7ZrNhkcSl9f0frY0rztVr1zdvbN28dfvO3fb2vXGZVybSoyhPcnMUqlIncaZHNraJPiqMVmmY6MNw9oLzh++1KeM8G9qLQp+m6jyLp3GkLKBJe+d1xmntWp0W2ihbGe3unoTaqt1Ju+N7/tMgGOy5vtfr97p+D0G/NwieB27X82V0qB4H+XbrO53QGeUUUUUpacrIIk5IUYnPMXXJpwLYKc2BGUSx5DV9oi1oK7A0GAroDL/nWB3XaIY11yxFHWGXBF8DpUsPocnBM4h5N1fylVRmdFntudTks11gDutaKVBL74D+T9cw19WxF0tTeiYeYngqBGF3UV2lkq7wyd2/XFlUKIBxfIa8QRyJsumzK5pSvHNvleR/CpNRXkc1t6Jfa7hjL6nczCpmgqiQXFXffY5Zr6Xj+4vX2od7MqOPl1gNmmAOxbPBTc4RK8zsOxNWo+LVB9lPy97cvSfgF4hz6XYp54kRZVDN6WBJZlW1RYSrDC8hq0/D3ZvKv2PxLC//heOVNk/RXR6MA6/b9/pvg87+Xv1eN2mHHtBjvMkB7dMrOB2h45/pC32lb84j540zdMZ/qButWnOfFoYz+Q2gJ/Ml Inv erse temp er at ur e ω AAAEj3icjVPbbtNAEJ0UA6XcGnjkxSJCQjxEjkMTeEGRAAneitQ0lUqFbHdTVrG91noNChEfwSt8CZ/SPyh/wZnBlkhFQjZKdvbMObN7ZrNxkerSBcF5a+uKd/Xa9e0bOzdv3b5zd7d977A0lU3UODGpsUdxVKpU52rstEvVUWFVlMWpmsSzl5yffFK21CY/cPNCnWTRWa6nOokcoMnr3FlTzD/sdoJu8DQMh3t+0O0P+r2gj2DQH4bPQ7/XDWR0qB77pt36Se/plAwlVFFGinJyiFOKqMTnmHoUUAHshBbALCIteUVfaQfaCiwFRgR0ht8zrI5rNMeaa5aiTrBLiq+F0qdH0BjwLGLezZd8JZUZXVV7ITX5bHPMcV0rA+roI9D/6Rrmpjr24mhKz8SDhqdCEHaX1FUq6Qqf3P/LlUOFAhjHp8hbxIkomz77oinFO/c2kvyFMBnldVJzK/q1gTv2ksnNrGOmiArJVfXdG8xqIx3fn95oH+7JjL5cYjVoijkWzxY3uUAcYWbfubAaFa8+y35K9ubuPQG/QGyk26WcRyPKoVrQ/orMumrLCFc5uISsPw13byr/juWzvPoXjlfaPEV/dXAYdnuD7uBd2Bnt1e91mx7QQ3qMNzmkEb2B07F0/Bt9px9e2xt6L7zRH+pWq9bcp6Xhvf0N0C3rEw== Entrop y AAAEoHicjVPLbtNAFL0pBkp5pUViw8ZqhFRYWI7TJmVXCRbZ0UpNW9FWlu1O2lH8kh/Q4vZn2MIP8Cn8AfwF515siVQkZKJk7px7zp05dzJ+Guq8sO0fraU7xt1795cfrDx89PjJ0/bq2kGelFmgRkESJtmR7+Uq1LEaFboI1VGaKS/yQ3XoT95y/vCjynKdxPvFVapOI+881mMdeAUgt/186Fape+KrwrvZuHQd89q8dLuv3HbHtuxNxxlsmbbV6/e6dg9Bvzdw3jhm17JldKgeu8lq6zud0BklFFBJESmKqUAckkc5PsfUJZtSYKdUAcsQackruqEVaEuwFBge0Al+z7E6rtEYa66ZizrALiG+GZQmvYQmAS9DzLuZki+lMqOzaldSk892hdmva0VAC7oA+j9dw1xUx14KGtO2eNDwlArC7oK6Sild4ZObf7kqUCEFxvEZ8hniQJRNn03R5OKde+tJ/qcwGeV1UHNL+rWAO/YSyc3MY4aIUsmV9d0nmNVCOr4/vdA+3JMJfb7FatAQsy+eM9xkhdjDzL5jYTUqXn2S/ZTszd17DX6KOJFu53IejSiGqqLdGZl51aYRrrJ/C5l/Gu7eWP4d02d59y8cr7R5iubs4MCxun2rv7fZ2dmq3+syvaB12sCbHNAODeF0hI5f0xf6St+MdWNovDf2/lCXWrXmGU0N48NvMSPwbw== H p ω ( x 2 | x 1 ) AAAEmnicjVPLbtNAFL0pBkp5pWUJC4sIqbCwbKdNyq4CFkVsipS0ldrKst1JseKX7HGhWP0TtvAPfAp/AH/BuRdbIhUJmSiZO+eec2fOnUyQx1GpbftHZ+WGcfPW7dU7a3fv3X/wsLu+cVBmVRGqcZjFWXEU+KWKo1SNdaRjdZQXyk+CWB0G09ecP7xQRRll6Uhf5uo08c/TaBKFvgbkdbt7Xp17J4HS/tXmJ8957nV7tmVvue5w27St/qDv2H0Eg/7QfemajmXL6FEz9rP1znc6oTPKKKSKElKUkkYck08lPsfkkE05sFOqgRWIIskruqI1aCuwFBg+0Cl+z7E6btAUa65ZijrELjG+BZQmPYMmA69AzLuZkq+kMqPzatdSk892iTloaiVANX0A+j9dy1xWx140TWhHPETwlAvC7sKmSiVd4ZObf7nSqJAD4/gM+QJxKMq2z6ZoSvHOvfUl/1OYjPI6bLgV/VrCHXtJ5GYWMWNEueSq5u4zzGopHd9ftNQ+3JMpfb7GatEYcyCeC9xkjdjHzL5TYbUqXn2U/ZTszd17AX6OOJNul3KeCFEKVU37czKLqs0iXGV0DVl8Gu7eRP4ds2d58y8cr7R9iub84MC1nIE1eL/V291u3usqPaantIk3OaRd2oPTMTp+QV/oK30znhivjLfGuz/UlU6jeUQzwxj9BsTr7m4= H p ω ( x 1 ) AAAEpXicjVNNb9NAEJ0UA6V8pXDsxSJFIA6W49AEbpXgAAekIiVppbaK1u6mWPGX1mtQiTjwa7jCkZ/CP4B/wZvBlkhFQjZKdvbNe7P7ZrNhkcSl9f0frY0rztVr1zdvbN28dfvO3fb2vXGZVybSoyhPcnMUqlIncaZHNraJPiqMVmmY6MNw9oLzh++1KeM8G9qLQp+m6jyLp3GkLKBJe+d1xmntWp0W2ihbGe3unoTaqt1Ju+N7/tMgGOy5vtfr97p+D0G/NwieB27X82V0qB4H+XbrO53QGeUUUUUpacrIIk5IUYnPMXXJpwLYKc2BGUSx5DV9oi1oK7A0GAroDL/nWB3XaIY11yxFHWGXBF8DpUsPocnBM4h5N1fylVRmdFntudTks11gDutaKVBL74D+T9cw19WxF0tTeiYeYngqBGF3UV2lkq7wyd2/XFlUKIBxfIa8QRyJsumzK5pSvHNvleR/CpNRXkc1t6Jfa7hjL6nczCpmgqiQXFXffY5Zr6Xj+4vX2od7MqOPl1gNmmAOxbPBTc4RK8zsOxNWo+LVB9lPy97cvSfgF4hz6XYp54kRZVDN6WBJZlW1RYSrDC8hq0/D3ZvKv2PxLC//heOVNk/RXR6MA6/b9/pvg87+Xv1eN2mHHtBjvMkB7dMrOB2h45/pC32lb84j540zdMZ/qButWnOfFoYz+Q2gJ/Ml Inv erse temp e rat u r e ω AAAEj3icjVPbbtNAEJ0UA6XcGnjkxSJCQjxEjkMTeEGRAAneitQ0lUqFbHdTVrG91noNChEfwSt8CZ/SPyh/wZnBlkhFQjZKdvbMObN7ZrNxkerSBcF5a+uKd/Xa9e0bOzdv3b5zd7d977A0lU3UODGpsUdxVKpU52rstEvVUWFVlMWpmsSzl5yffFK21CY/cPNCnWTRWa6nOokcoMnr3FlTzD/sdoJu8DQMh3t+0O0P+r2gj2DQH4bPQ7/XDWR0qB77pt36Se/plAwlVFFGinJyiFOKqMTnmHoUUAHshBbALCIteUVfaQfaCiwFRgR0ht8zrI5rNMeaa5aiTrBLiq+F0qdH0BjwLGLezZd8JZUZXVV7ITX5bHPMcV0rA+roI9D/6Rrmpjr24mhKz8SDhqdCEHaX1FUq6Qqf3P/LlUOFAhjHp8hbxIkomz77oinFO/c2kvyFMBnldVJzK/q1gTv2ksnNrGOmiArJVfXdG8xqIx3fn95oH+7JjL5cYjVoijkWzxY3uUAcYWbfubAaFa8+y35K9ubuPQG/QGyk26WcRyPKoVrQ/orMumrLCFc5uISsPw13byr/juWzvPoXjlfaPEV/dXAYdnuD7uBd2Bnt1e91mx7QQ3qMNzmkEb2B07F0/Bt9px9e2xt6L7zRH+pWq9bcp6Xhvf0N0C3rEw== Entrop y AAAEsnicjVPLbtNAFL0pBkp5pbBkM2qElCBh2U6awAKpEiy6bKWmrWgqy3YnZRS/5Ae0mP4CX8OGBfwHfwB/wZmLLZGKhEyUzJlz77kz507GT0OVF5b1o7V2w7h56/b6nY279+4/eNjefHSYJ2UWyHGQhEl27Hu5DFUsx4UqQnmcZtKL/FAe+bPXOn70Xma5SuKD4jKVp5F3HqupCrwClNvudu3nYpIqd+LLwuvtdlO3YnjVvXCdT+LCtcUrYfV6brtjmdbAcUbbwjL7w75t9QGG/ZHz0hG2afHoUD32ks3WV5rQGSUUUEkRSYqpAA7JoxyfE7LJohTcKVXgMiDFcUlXtAFtiSyJDA/sDL/nWJ3UbIy1rpmzOsAuIb4ZlIKeQpMgLwPWuwmOl1xZs4tqV1xTn+0Ss1/XisAW9A7s/3RN5qo67aWgKb1gDwqeUma0u6CuUnJX9MnFX64KVEjBaXyGeAYcsLLps2BNzt51bz2O/+RMzep1UOeW9GsFd9pLxDezLDMESjlW1nefYJYr6fT9qZX20T2Z0cdrWQ0bYvbZc4abrIA9zNp3zFmNSq8+8H6S99bde4b8FDjhbud8HgUUQ1XR3oLIsmrzjK5ycI1ZfhrdvSn/O+bP8uZfPF5p8xTFYnDomPbQHO4POjvb9Xtdpye0RV28yRHt0C6cjtHxz/SFvtF3Y2C8NTwj+JO61qo1j2luGOFvwQz1/Q== (1 → ω ω ) H ( p ω ( x 2 | x 1 = 0)) AAAErnicjVPLbtNAFL0pBkp5pWXJZkRASllYttMmZYFUCRZdFqlJKzWRZbuTdhS/5Ae0mP4AX8O2/Al/AH/BmYstkYqETJTMmXPvuTPnTsZPQ5UXlvWjtXbHuHvv/vqDjYePHj952t7cGuVJmQVyGCRhkp34Xi5DFcthoYpQnqSZ9CI/lMf+7J2OH3+UWa6S+Ki4SuUk8s5jNVWBV4By2y/HqXLHviw8cdBN3YrhdffSdb6IS9cWb4W9ve22O5Zp7TjOYFdYZq/fs60eQL83cN44wjYtHh2qx2Gy2bqhMZ1RQgGVFJGkmArgkDzK8TklmyxKwU2oApcBKY5LuqYNaEtkSWR4YGf4PcfqtGZjrHXNnNUBdgnxzaAU9AqaBHkZsN5NcLzkyppdVLvimvpsV5j9ulYEtqALsP/TNZmr6rSXgqa0xx4UPKXMaHdBXaXkruiTi79cFaiQgtP4DPEMOGBl02fBmpy96956HP/JmZrV66DOLenXCu60l4hvZllmCJRyrKzvPsEsV9Lp+1Mr7aN7MqPPt7IaNsTss+cMN1kBe5i175izGpVefeL9JO+tu/ca+Slwwt3O+TwKKIaqosMFkWXV5hld5egWs/w0untT/nfMn+X9v3i80uYpisVg5Jh23+x/2Ons79bvdZ2e0wvq4k0OaJ8O4HSIjn+lb3RD3w3LGBkTw/2TutaqNc9obhgXvwE2vvUn ω ω H ( p ω ( x 2 | x 1 = 1)) Figure 3: T erms in volv ed in the computation of the entrop y of the my opically scaled model. (L eft) The marginal and conditional en tropies of Equation 45 . (Right) The tw o terms of the decomp osition of Equation ( 46 ) . The source of nonmotonicit y is the term π β H ( p β ( x 2 | x 1 = 1) , that is the product of an increasing and a decreasing functions. No w, since log p β ( y | x i ) = β z y i − log Z ( β , z i ) , we can write z y i = (1 /β )( log p β ( y | x i ) + log Z ( β , z i )) , and plugging that in Equation ( 39 ), w e find d L ( β ) dβ = 1 β − 1 n n X i =1 log p β ( y i | x i ) | {z } cross-entrop y − − 1 n n X i =1 E y ∼ p β ( y | x i ) [log p β ( y | x i )] ! | {z } expected cross-entrop y . (40) The second deriv ativ e is a direct consequence of the second deriv ative of the log-partition (Lemma 1 ): d 2 L ( β ) dβ 2 = 1 n n X i =1 V ar y ∼ p β ( y | x i ) ( z y ) . (41) D Pro of of P rop osition 2 (monotonicity of the entrop y) The entrop y is equal to H ( p β ( y | x )) = − K X y =1 p β ( y | x ) log p β ( y | x ) = − K X y =1 p β ( y | x ) ( β z y − log Z ( β , z )) (42) = − β E y ∼ p β ( y | x ) [ z y ] | {z } d log Z ( β , z ) dβ (Lemma 1) + log Z ( β , z ) . (43) Th us, using Lemma 1 again, we find dH ( p β ( y | x )) dβ = − β d 2 log Z ( β , z ) dβ 2 − d log Z ( β , z ) dβ + d log Z ( β , z ) dβ = − β d 2 log Z ( β , z ) dβ 2 = − β V ar y ∼ p β ( y | x ) ( z y ) . (44) E More details on the to y language mo del In the context of Section 3.4 , the entrop y of the my opic mo del can b e decomp osed using the chain rule as H ( p ′ β ) = H ( p β ( x 1 )) + E p β ( x 1 ) [ H ( p β ( x 2 | x 1 ))] , (45) 16 where H ( p β ( x 1 )) is the marginal entrop y of the first tok en, that w e will denote H p β ( x 1 ) , and E p β ( x 1 ) [ H ( p β ( x 2 | x 1 ))] is the conditional entrop y , that we will denote H p β ( x 2 | x 1 ) . A ccording to Proposition 2 , H p β ( x 1 ) is decreasing. Since p ( x 1 ) = B ( x 1 | π ) and p ( x 2 | x 1 ) = B ( x 2 | ρ x 1 ) , the conditional entrop y can b e decomp osed as H p β ( x 1 ) = (1 − π β ) ↘ H ( p β ( x 2 | x 1 = 0)) ↘ + π β ↗ H ( p β ( x 2 | x 1 = 1)) ↘ . (46) The tw o entropies of the conditional distributions are decreasing (again, b ecause of Proposition 2 ). Ho wev er, since π = 0 . 55 , π β is an increasing function of β , which explains that the conditional entrop y can actually b e lo cally increasing. F Pro of of Theorem 5.1 (c haracterisation of linear accuracy-preserving functions) Theorem F.1. L et W ∈ R K × K and b ∈ R K such that, for al l z ∈ R K we have argmax ( Wz + b ) = argmax ( z ) . (47) Then, ther e exist α ∈ R K , β > 0 , and γ ∈ R such that W = β I K + 1 K α T , and b = γ 1 K . (48) Pr o of. The roadmap of the pro of go es as follows: first, w e will prov e that b has the desired form, then we will prov e that W has the desired form (b y studying separately the cases K = 2 and K ≥ 3 ). Finally , we will sho w that β > 0 . Applying Equation ( 47 ) to z = 0 leads to argmax ( b ) = argmax ( 0 K ) = { 1 , . . . , K } , therefore all co efficients of b need to b e equal, and thus there exists γ ∈ R such that b = γ 1 K . W e no w turn to W . The fact that b = γ 1 K implies that, for all z ∈ R K , argmax ( Wz + b ) = argmax ( Wz ) = argmax ( z ) , (49) whic h will be our main to ol to study the structure of W . W e b egin with the case K = 2 . Let W ∈ R 2 × 2 that verifies ( 49 ) , and let α 1 = w 21 , α 2 = w 12 , and β = w 11 − α 1 . The fact that argmax ( W1 2 ) = argmax ( 1 2 ) = { 1 , 2 } implies that w 11 + w 12 = w 21 + w 22 = ⇒ w 22 = w 11 + w 12 − w 21 = β + α 1 + α 2 − α 1 = β + α 2 . (50) Th us, W = β I K + 1 K α T . Let us no w treat the case K ≥ 3 . F or any j ∈ { 1 , . . . , K } , let us denote e j ∈ R K the v ector whose only nonzero co efficien t is the j th one, whic h is equal to 1 . Let W b e a matrix that satisfies ( 49 ) . Let i, j, k b e three distinct indices in { 1 , . . . , K } . Applying the condition to the vector e i + e j + e k leads to w ii + w ij + w ik = w j i + w j j + w j k = w ki + w kj + w kk , (51) and applying it to e i + e k leads to w ii + w ik = w ki + w kk . (52) Subtracting these equations implies that w ij = w kj . This means that, for eac h column j , all elemen ts but the diagonal one will hav e the same v alue, that we will denote α j . Let us now use condition ( 49 ) with the vector 1 K . This implies that w 11 + X j =1 α j = w 22 + X j =2 α j = . . . = w K K + X j = K α j . (53) Subtracting α 1 + . . . + α K from all terms leads then yields w 11 − α 1 = . . . = w K K − α K . (54) Let us denote this quantit y β . Putting the pieces together, we ha ve pro ven that W = β I K + 1 K α T . The only thing left to prov e is the p ositivit y of β . This follows from the fact that argmax ( W e 1 ) = argmax ( e 1 ) = { 1 } . Indeed, this implies that w 11 > w 21 i.e. that β + α 1 > α 1 , leading to β > 0 . 17 G Pro of of Corollary 1 (temp erature scaling is the only accuracy- preserving linear scaler) Corollary 2. L et W ∈ R K × K and b ∈ R K such that ˜ p W , b (r esp e ctively ˇ p W , b ) is ac cur acy-pr eserving. Then, ther e exists β ≥ 0 such that ˜ p W , b = p β (r esp e ctively ˇ p W , b = p β ) . Pr o of. Let us fo cus on matrix scaling (the pro of for Diric hlet calibration is es sen tially the same). Let W ∈ R K × K and b ∈ R K suc h that ˜ p W , b is accuracy-preserving. Because of Theorem 5.1 , there exist α ∈ R K , β > 0 , and γ ∈ R such that W = β I K + 1 K α T , and b = γ 1 K . Thus, for all z ∈ R K Softmax ( Wz + b ) = Softmax ( β z + ( α T z + γ ) 1 K ) = Softmax ( β z ) , (55) using the fact that the softmax is inv arian t to adding a v ector with iden tical co ordinates, therefore ˜ p W , b = p β . 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment